
Abstract
Noise and interference are the two most common and basic problems in wireless communication systems. The noise in wireless communication channels has the characteristics of randomness and impulsivity, so the performance of adaptive filtering algorithms based on geometric algebra (GA) and second-order statistics is greatly reduced in the wireless communication systems. In order to improve the performance of adaptive filtering algorithms in wireless communication systems, this paper proposes two novel GA-based adaptive filtering algorithms, which are deduced from the robust algorithms based on the minimum error entropy (MEE) criterion and the joint criterion (MSEMEE) of the MEE and the mean square error (MSE) with the help of GA theory. The noise interference in wireless communication is modeled by \(\alpha\)-stable distribution which is in good agreement with the actual data in this paper. Simulation results show that for the mean square deviation (MSD) learning curve, the GA-based MEE (GA-MEE) algorithm has faster convergence rate and better steady-state accuracy compared to the GA-based maximum correntropy criterion algorithm (GA-MCC) under the same generalized signal-to-noise ratio (GSNR). The GA-MEE algorithm reduces the convergence rate, but improves the steady-state accuracy by 10–15 dB compared to the adaptive filtering algorithms based on GA and second-order statistics. For GA-based MSEMEE (GA-MSEMEE) algorithm, when GA-MSEMEE and the adaptive filtering algorithms based on GA and second-order statistics keep the same convergence rate, its steady-state accuracy is improved by 10–15 dB, and when GA-MSEMEE and GA-MEE maintain approximately steady-state accuracy, its convergence rate is improved by nearly 100 iterations. In addition, when the algorithms are applied to noise cancellation, the average recovery error of the two proposed algorithms is 7 points lower than that of other GA-based adaptive filtering algorithms. The results validate the effectiveness and superiority of the GA-MEE and GA-MSEMEE algorithms in the \(\alpha\)-stable noise environment, providing new methods to deal with multi-channel interference in wireless networks.
Similar content being viewed by others
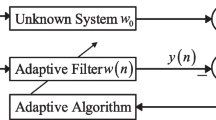

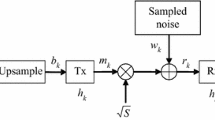
1 Introduction
The rapid development of modern communication technology provides more advanced communication technology for the construction of the Internet of things [1, 2]. As multimedia communication technology becomes more mature, data information transfer is faster, anti-interference ability is stronger, and data is more secure. The process of wireless communication is to transform the required information, including text, voice, video, etc., into digital signal [3, 4] under the packaging and conversion of baseband. Then, the digital signal is converted into waveform in the RF modulation center, transmitted in the antenna after power amplifier and filter, and logistics distribution is carried out in the base station [5, 6]. After reaching the destination antenna, the filter extracts the original wave again, and then the wave is demodulated and decoded into the original information form. In the process of wireless communication, the influence of noise in the channels needs to be considered. Filter, as a frequency selection and interference elimination device, can be said to be the channel of any information transmission, which is the key link of the mobile communication industry chain [7,8,9].
Compared with the traditional filter, the adaptive filter has stronger adaptability and better filtering performance. Adaptive filters have a strong effect on signal processing, such as adaptive beamforming [10], acoustic echo cancelation [11, 12] and channel equalization [13]. As the core of adaptive filters, adaptive filter algorithms are the key to the development of filters. Among them, mean square error (MSE) has been the typical criterion of adaptive filtering algorithms. Owing to its simple structure and rapid convergence, the LMS algorithm has been applied in many fields [14,15,16]. Nevertheless, the performance of the LMS algorithm is not optimal, one problem is that the algorithm is vulnerable to the input signal, the other problem is the contradiction between step size and steady-state error. Subsequently, the NLMS algorithm was proposed to solve these problems by normalizing the power of the input signal [17]. However, when signals are disturbed by abnormal values such as impulse noise, the performance of the LMS-type algorithm will be seriously degraded. Therefore, some robustness criteria have been proposed and successfully applied to adaptive filtering algorithms to deal with adaptive signal under impulsive noise, such as adaptive wireless channel tracking [18] and blind source decomposition [19]. Some typical robustness criteria include maximum correntropy criterion (MCC) [20, 21], minimum error entropy (MEE) [22, 23] and generalized MCC [24]. They are insensitive to large outliers, which can effectively deal with impulse noise interference.
However, the current adaptive filtering algorithms only can be used for one-dimensional signals processing. It is worth noting that combined with geometric algebra, these algorithms can be extended to higher dimensions, so that the correlation of each dimension can be considered in the process of analyzing problems, and the performance of algorithms can be effectively improved.
Geometric algebra (GA) gives an effective computing framework for multi-dimensional signal processing [25, 26]. GA has a wide range of applications, such as image processing [27, 28], multi-dimensional signal processing [29, 30] and computer vision [31, 32]. Combined with this framework, Lopes et al. [33] devised the GA-LMS algorithm and analyzed the feasibility of the algorithm. After that, Al-Nuaimi et al. [34] further exploited the potential of the algorithm, which is applied for point cloud registration. However, the LMS algorithm extended to the GA space still has some limitations, such as its poor performance in non-Gaussian environment. Wang et al. [35] deduced and proposed the GA-MCC algorithm, analyzing its performance in \(\alpha\)-stable noise. The results show that GA-MCC has good robustness, but there is still room for improvement in its convergence rate. Due to the superiority of MEE criterion over MCC criterion, the GA-MEE and GA-MSEMEE algorithms are proposed in this paper to improve the effectiveness of existing GA adaptive filtering algorithms and expand the scope of application.
Our contributions are as follows. Firstly, according to the GA theory, the multi-dimensional problem is transformed into mathematical description, represented by multivectors. Secondly, the algorithms based on the MEE and MSEMEE are deduced in GA space. The original MEE and MSEMEE algorithms can be used for higher dimensional signal processing with the help of GA theory; finally, some experiments validate the effectiveness and robustness of the GA-MEE and GA-MSEMEE algorithms.
The rest of this paper is arranged as follows. Section 2 classifies and systematically reviews the existing studies on adaptive filtering algorithms. Section 3 briefly reviews the basic theory of geometric algebra and the traditional MEE and MSEMEE adaptive filtering algorithms, and gives the derivation process of the GA-MEE and GA-MSEMEE algorithms. The Experimental analysis of the two novel algorithms in \(\alpha\)-stable noise environment is provided in Sect. 4. Section 5 concludes this paper.
2 Related works
As an important branch of information processing, adaptive filtering algorithms have obtained great research results in real and complex domains, especially in signal processing in non-Gaussian environment. Previously, Professor J.C. and his team proposed to use the error signal of Renyi entropy instead of the MSE. Minimum error entropy is capable of getting better error distribution according to [36]. Although MEE criterion can obtain high accuracy, it does not take the mean factor into account, while the characteristics of MSE are just opposite to that of MEE. In this regard, B. Chen et al. [36] proposed a joint criterion building up a connection between MSE and MEE by adding the weight. In addition, recent studies have shown that MEE criterion is superior to MCC criterion and can be used for adaptive filtering [23] and Kalman filtering [22]. Therefore, G. Wang et al. [37] improved the MEE criterion and proposed the recursive MEE algorithm. In the complex domain, Horowitz et al. [16] proposed and verified the performance advantages of complex LMS algorithm. Qiu et al. [38] recently proposed Fractional-order complex correntropy algorithm for signal processing in \(\alpha\)-stable environment. These mature real and complex adaptive filtering algorithms are widely used in various fields [10,11,12, 39]. However, the real adaptive filtering algorithms cannot consider the internal relationship of the signals of each dimension, and the complex filtering algorithms need to convert multi-dimensional signals into complex signals for processing, respectively. Similarly, it cannot well describe the correlation between multi-dimensional signals, which will cause some performance loss and application limitations.
Quaternion, as an extension of real and complex domains, was first proposed by Hamilton and applied to the field of attitude control. Took et al. [40] successfully expressed multi-dimensional signals in meteorology in the form of quaternion, and proposed the quaternion least mean square (QLMS) and the augmented quaternion least mean square (AQLMS) algorithms. The research of the QLMS and AQLMS algorithms provides a theoretical basis for the development of quaternion adaptive filtering algorithms. The quaternion distributed filtering, the widely linear quaternion recursive total least squares, the widely linear power QLMS and the reduced-complexity widely linear QLMS algorithms are proposed one after another [41,42,43,44]. However, these algorithms are more suitable for Gaussian signals in linear systems. In order to make the quaternion adaptive filtering algorithms better used in signal processing in nonlinear channels and improve the universality of the algorithms, Paul et al. [45] further proposed quaternion kernel adaptive filtering algorithm via gradient definition and Hilbert space. The introduction of quaternion tool paves the way for the research of adaptive filtering algorithms for 3D and 4D signals. However, the quaternion-based adaptive filtering algorithms cannot be used in higher dimensional signal processing, and the quaternion-based methods will produce a lot of data redundancy and huge complexity.
Since geometric algebra can provide an ideal mathematical framework for the expression and modeling of multi-dimensional signals, some scholars have applied GA to adaptive filtering [46], feature extraction [26] and image processing [47]. GA-based adaptive filtering algorithms have attracted more and more scholars’ attention. Lopes and Al-Nuaimi et al. [33, 34] deduced the updating rules of the GA-LMS algorithm by using geometric algebra and applied them to 6DOF point cloud registration. Since the GA-LMS algorithm cannot achieve a good trade-off between the convergence rate and the steady-state error, Wang et al. [48, 49] proposed GA-based least-mean Kurtosis (GA-LMK) and GA-based normalized least mean square (GA-NLMS) adaptive filtering algorithms successively to make up for the deficiency of the GA-LMS algorithm. And then, in order to reduce the computational complexity of the GA-LMK algorithm, He et al. [50] continued to deduce and propose the GA-based least-mean fourth (GA-LMF) and least-mean mixed-norm (GA-LMMN) adaptive filtering algorithms. In order to further improve the performance of GA-based adaptive filtering algorithms in non-Gaussian environment, Wang et al. [35] theoretically deduced geometric algebraic correlation (GAC) and proposed an adaptive filtering algorithm (GA-MCC) based on the maximum GAC criterion.
Most of these existing GA-based adaptive filtering algorithms are mainly to improve the performance of the filters in Gaussian environment. For non-Gaussian noise, especially the noise interference similar to that in wireless communication channels, the performance of this kind of algorithms will be greatly reduced. How to optimize the existing GA-based adaptive filtering algorithms and improve their performance in non-Gaussian environment is a problem worth studying. Compared with MCC criterion, the MEE criterion and the joint criterion (MSEMEE) have more advantages in non-Gaussian environment. Hence, this paper extends these two criteria to the GA space and proposes novel GA-based robust algorithms. The \(\alpha\)-stable distribution fits very well with the actual data, and is consistent with multichannel interference in wireless networks and backscatter echoes in radar systems. Therefore, the use of \(\alpha\)-stable distribution to simulate non-Gaussian noise has more general significance.
3 Methods
3.1 Basic theory
Geometric Algebra contains all geometric operators and permits specification of constructions in a coordinate-free manner [47]. Compared with several particular cases of vector and matrix algebras, complex numbers and quaternions, using geometric algebra can deal with higher dimensional signals.
Assuming that an orthogonal basis of \(\mathbb {R}_{n}\) is \(\left\{ e_{1}, e_{2}, \cdots , e_{n}\right\}\), the basis of \(\mathbb {G}_{n}\) can be generated by multiplying the n basis elements (plus the scalar 1) via geometric product. The geometric product of two basis elements is non-commutative, its property is defined as:
Given \(n= p + q\), the expression of the operation rule of orthonormal basis is:
Thus, the basis of \(G_n\) is:
The core product in GA space is geometric product. The expression of the geometric product of vector a and b is:
in which \(a \cdot b\) represents the inner product, which is commutative, \(a \wedge b\) denotes the outer product, which is not commutative. According to their properties, the following expression can be obtained:
Suppose A is a general multivector in \(\mathbb {G}_{n}\), the basic element of \(\mathbb {G}_{n}\) can be defined as:
which is made up of its s-vector part \(\langle \cdot \rangle _{s}\).
Actually, any multivector can be decomposed according to [51]:
In the operation of geometric algebra, the main properties used are as follows:
-
(1)
Scalar product: \(A^{*} B=\langle A B\rangle _{0}\)
-
(2)
Cyclic reordering: \(\langle A B \cdots C\rangle =\langle B \cdots C A\rangle\)
-
(3)
Clifford reverse: \(\tilde{A} \triangleq \sum _{s=0}^{n}(-1)^{s(s-1) / 2}\langle A\rangle _{s}\)
-
(4)
Magnitude: \(|A| \triangleq \sqrt{A^{*} \tilde{A}}=\sqrt{\sum _{s}\left| \langle A\rangle _{s}\right| ^{2}}\)
3.2 The related adaptive filtering algorithms
3.2.1 The MEE algorithm
Professor J.C. and his research team proposed to replace MSE with the error signal of Renyi entropy in the training of supervised adaptive systems; this method uses a nonparametric estimator-Parzen window to estimate the probability density of a random variable directly from the sample points.
The Renyi entropy of the error sample is defined as:
where \(\alpha\) is the order of entropy, and \(\alpha >0\), \(V_{\alpha }\left( e_{k}\right)\) is information potential. when \(\alpha \rightarrow 1\), Renyi entropy is equivalent to Shannon entropy. In addition, to keep the orientation consistent with the LMS algorithm (minimization), select \(\alpha <1\). In this case, the minimum error entropy can be converted into minimizing the information potential.
Hence, for the traditional minimum error entropy (MEE) algorithm, its core expressions are:
3.2.2 The MSEMEE algorithm
The mean square error standard has good sensitivity. The minimum error entropy has a good error distribution, especially in the case of high-order statistics. Therefore, based on these two methods, a new performance index is proposed, which combines the advantages of each method to realize the synchronization effectiveness of sensitivity and error distribution.
The core expressions of the LMS algorithm are:
While the MSEMEE algorithm is the mixed of square power of LMS and information potential of MEE. Then the MSEMEE cost function is:
in which \(\eta\) is the mixing parameter and \(\eta \in [0,1]\).
Then the corresponding gradient algorithm is:
3.3 Problem formulation of adaptive filtering
Regarding the linear filtering model, its formulation involves the input signal of length L \(u(n)=\left[ U_{n},U_{n-1},\cdots ,U_{n-L+1}\right] ^{T}\), the system vector to be estimated \(w_{o}=\left[ W_{o 1},W_{o 2},\cdots ,W_{o L}\right] ^{T}\), the weight vector \(w(n)=\left[ W_{1}(n),W_{2}(n),\cdots ,W_{L}(n)\right] ^{T}\) and the desired signal d(n):
In this research, we give some assumptions as follows:
-
(A1)
The multivector valued components of the input signal u(n) are zero-mean white Gaussian processes with variance \(\sigma _{\mathrm {s}}^{2}\).
-
(A2)
The multivector valued components of the additive noise are described by \(\alpha\)-stable processes. \(\alpha\)-stable distribution is a family of four parameter distributions, which can be represented by S (\(\alpha , \beta , \gamma , \sigma\)), in which \(\alpha\) denotes the characteristic index, which describes the tail of the distribution; \(\beta\) denotes the skewness, \(\gamma\) denotes the dispersion coefficient, \(\sigma\) denotes the distribution position.
-
(A3)
The noise \(v_{n}\), the initial weight vector \(w_{o}\), the input signal u(n) and the weight error vector \(\Delta w_{n}\) are uncorrelated.
3.4 The proposed GA-MEE algorithm
In this part, we deduce the GA-MEE algorithm with the help of GA theory [35]. In traditional algorithms, the cost function of MEE is expressed by information potential. When \(\alpha \in (0,1)\), the minimum error entropy is equal to minimize the cost function. The GA-MEE cost function can be obtained by rewriting formula (9) in the GA form.
in which \(E(i)=D(i)-\hat{D}(i), \hat{D}(i)=u_{i}^{H} w_{i-1}\), L denotes the length of the sliding window, \(k_{\sigma }(x)\) denotes the Gaussian kernel defined as \(k_{\sigma }(x)=\exp \left( -\frac{x^{2}}{\sigma ^{2}}\right)\), where \(\sigma\) is the kernel size.
Our algorithms keep the same direction as the LMS algorithm, which is opposite to that of the steepest-descent rule [48], yielding the adaptive rule based on GA:
where B denotes a multivectors matrix. Choosing different B, we will get various types of adaptive filtering algorithm [48]. let B be the identity matrix here.
The derivative term \(\partial _{w} J\left( w_{i-1}\right)\) in (10) can be calculated as:
where \(|E(i)-E(l)|^{2}\) is given by
According to formula (8), the differential operator \(\partial _{w}\) can be expressed in another form. Thus, we obtain the new expression of \(\partial _{w}\):
in which \(\partial _{w,k}\) is the common derivative from standard calculus and only relates to blade \(k, \left\{ \gamma _{k}\right\}\) is the basis of \(\mathbb {G}_{n}\).
Similarly, given \(\hat{D}(i)=u_{i}^{H} w_{i-1}\), then \(\hat{D}(i)\) can be expanded as follows according to (8):
Since \(u_{i}\) and \(w_{i-1}\) are arrays with M multivector entries, they can be decomposed as follows by employing (8),
and
Plugging (21) and (22) back into (20),
in which
Thus, the derivative term \(\partial _{w}|E(i)-E(l)|^{2}\) in (17) can be calculated as:
According to (19), each term of equation (25) can be expanded:
in which
According to (24), the parts \(\hat{d}_{i, A}\) and \(\hat{d}_{l, A}\) in formula (27) can be expressed as:
From (27), \(\partial _{w, D} \hat{d}_{i, A}\) and \(\partial _{w, D} \hat{d}_{l, A}\) need to be calculated, according to (28), \(\partial _{w, D} \hat{d}_{i, A}\) can be unfolded as:
in the same way,
Plugging (27), (29) and (30) into (26) yields
in the same way,
and
Plugging (31), (32) and (33) into (25) yields the following expression:
Finally, plugging (34) into (17), the gradient expression can be written as:
Then, plugging (35) into (16), we can obtain the GA-MEE updating rule:
in which \(\upmu\) denotes the step size.
3.5 The proposed GA-MSEMEE algorithm
In the same way, according to GA theory, we can obtain the GA-MSEMEE cost function as follows by rewriting formula (12) in the GA form.
where \(\eta\) is the mixing parameter and \(\eta \in [0,1]\).
When we replace the mathematical expectation of the preceding and subsequent terms of equation (37) with instantaneous value and sample average, respectively, \(\partial _{w} J\left( w_{i-1}\right)\) can be expressed as:
The former term of formula (38) is equivalent to GA-LMS algorithm, and the latter term of formula (38) is to seek deviation guide to information potential. In order to keep the whole direction consistent (minimized), select \(\alpha \in (0,1)\). According to (32), \(\partial _{w}|E(i)|^{2}\) is:
According to (15) and (35), \(\partial _{w} V_{\alpha }\left( e_{i}\right)\) is:
Plugging (39) and (40) into (38), we can obtain the GA-MSEMEE updating rule:
in which \(\mu\) denotes the step size, \(\eta\) denotes the mixing parameter and \(\eta \in [0,1]\).
4 Results and discussion
This section carries out some experiments, analyzing the performance of the two novel algorithms in \(\alpha\)-stable noise environment. First of all, in order to know how to select appropriate adjustable parameters for the GA-MEE and GA-MSEMEE algorithms, the experimental part analyzes the influence of these parameters (the kernel width \(\sigma\), the order of entropy \(\alpha\) and weight coefficient \(\eta\)) on the mean-square deviation (MSD) learning curves in detail. Secondly, the GA-MEE and GA-MSEMEE algorithms are compared with other GA-based algorithms to verify their superiority. Finally, the algorithms are applied to multi-dimensional signal denoising in \(\alpha\)-stable noise environment.
All MSD learning curves and the experimental data are averaged 50 independent runs. In this paper, initial weight vector \(\omega _{0}\) denotes a \(5 \times 1\) multivector, and the length of the sliding window is \(L = 8\). The input signal and noise are shown in A1 and A2, \(\alpha\)-stable distribution is given by S (1.5, 0, 1, 0) in the experiment. In addition, we use the generalized signal-to-noise ratio (\(\text {GSNR}=10 \log \left( \sigma _{s}^{2} / \gamma _{v}\right)\)) to describe the relationship between the input signal and noise, \(\sigma _{s}^{2}\) is the variance of input signal multivector, \(\gamma _{v}\) is the dispersion coefficient of noise.
4.1 The performance of GA-MEE and GA-MSEMEE algorithms under different parameters
Herein, we discuss the effect of the parameters \(\sigma , \eta\) and \(\alpha\) on the performance of the two novel algorithms for 4-dimension signals. The performance of the two novel algorithms is estimated by the MSD, \(\text {MSD}=\mathbb {E}\left\{ \left\| w_{0}-w(n)\right\| _{2}^{2}\right\}\). According to equation (36) and (41), the GA-MEE algorithm mainly involves the parameters \(\sigma\) and \(\alpha\), and the GA-MSEMEE algorithm mainly involves the parameters \(\sigma , \eta\) and \(\alpha\). In the following experiments, we select \(\mu _{\text {GA-MEE}}=\mu _{\text {GA-MSEMEE}}=0.5\) and \(\text {GSNR}=0\) dB for the GA-MEE and GA-MSEMEE algorithms.
4.1.1 GA-MEE algorithm
This section selects different parameters \(\sigma\) and \(\alpha\), then calculates the MSD of the GA-MEE algorithm under different parameters. Table 1 displays the steady-state MSDs under different parameters (\(\sigma\) and \(\alpha\)) of the GA-MEE algorithm.
To further instinctively analyze the effect of kernel width and order of entropy on the GA-MEE algorithm, the steady-state MSD taken as a function of kernel width and order of entropy is plotted in Fig. 1 for various values of the kernel width \(\sigma\) and the order of entropy \(\alpha\).
The tendency of steady-state values in respect of kernel width and order of entropy is clearly highlighted in Fig. 1. It can be obtained from Table 1 and the 3-dimensional diagram that the steady-state MSD is smaller with both larger values of \(\sigma\) and \(\alpha\).
Figure 2 demonstrates the instantaneous MSDs of the GA-MEE under various parameters. The GA-MEE1, GA-MEE2, GA-MEE3, GA-MEE4, and GA-MEE5 denote [\(\alpha =0.3, \sigma =50\)], [\(\alpha =0.5, \sigma =60\)], [\(\alpha =0.6, \sigma =70\)], [\(\alpha =0.7, \sigma =90\)] and [\(\alpha =0.8, \sigma =100\)], respectively. Since increasing two parameters at the same time leads to the decrease in steady-state value and slow convergence rate, it is difficult to determine the role of a single parameter in the performance of the GA-MEE. Therefore, it is necessary to use the method of controlling variables.

The steady-state MSD is taken as a function of kernel width and order of entropy

The instantaneous MSDs of the GA-MEE under various parameters

The instantaneous MSDs of the GA-MEE under different \(\sigma\)

The instantaneous MSDs of the GA-MEE under different \(\alpha\)

The steady-state MSD is taken as a function of kernel width and weight coefficient
Different parameter \(\sigma\): The value of parameter \(\alpha\) is setting as 0.6, and the values of parameter \(\sigma\) are setting as 50, 60, 70, 90, 100, respectively. Figure 3 shows the instantaneous MSDs of the GA-MEE under various \(\sigma\). It can be seen from Fig. 3, as kernel width increases, the steady-state MSD decreases and convergence rate increases. But when the parameter \(\sigma\) exceeds a certain value, the convergence rate decreases gradually. So, the selection of \(\sigma\) should balance the steady-state MSD and convergence rate. In this group of experiments, its convergence rate is the best when \(\sigma =70\).
Different parameter \(\alpha\): The value of parameter \(\sigma\) is setting as 70, and the values of parameter \(\alpha\) are setting as 0.3, 0.5, 0.6, 0.7, 0.8, respectively. Figure 4 demonstrates the instantaneous MSDs of the GA-MEE under various \(\alpha\). the steady-state MSD increases with the increase in the order of entropy \(\alpha\), and the convergence rate decreases obviously. So, the selection of \(\alpha\) should balance the steady-state MSD and convergence rate.
4.1.2 GA-MSEMEE algorithm
From the experimental part of the GA-MEE algorithm, it is concluded that the greater the parameter \(\alpha\), the slower the convergence rate. In order to study the influence of parameters on the GA-MSEMEE algorithm, this section selects different parameters \(\sigma\) and \(\eta\), to analyze the performance of the GA-MSEMEE when \(\alpha =0.8\). Table 2 displays the steady-state MSDs under different parameters (\(\sigma\) and \(\eta\)) of the GA-MSEMEE algorithm.
To further instinctively analyze the effect of kernel width and weight coefficient on the GA-MSEMEE algorithm, the steady-state MSD taken as a function of kernel width and weight coefficient is plotted in Fig. 5 for various values of kernel width \(\sigma\) and weight coefficient \(\eta\).
Figure 5 clearly shows the tendency of steady-state MSD in relation to kernel width and weight coefficient. It is shown as Table 2 and 3-dimensional diagram that the steady-state value is smaller as \(\sigma\) becomes larger. However, from the numerical point of view, the influence of the weight coefficient \(\eta\) on MSD is not obvious.
Figure 6 shows the MSD learning curves of the GA-MSEMEE under various parameters, in which GA-MSEMEE1, GA-MSEMEE2, GA-MSEMEE3, GA-MSEMEE4, and GA-MSEMEE5 denote [\(\eta =9 \times 10^{-6}, \sigma =50\)], [\(\eta =8.5 \times 10^{-6}, \sigma =60\)], [\(\eta =8 \times 10^{-6}, \sigma =70\)], [\(\eta =7.5 \times 10^{-6}, \sigma =90\)] and [\(\eta =7 \times 10^{-6}, \sigma =100\)], respectively. Since it is difficult to determine the role of a single parameter in the performance of the GA-MSEMEE, it is necessary to use the method of controlling variables.
Different parameter \(\sigma\): The value of parameter \(\eta\) is setting as \(8.5 \times 10^{-6}\), and the values of parameter \(\sigma\) are setting as 50, 60, 70, 90, 100, respectively. Figure 7 shows the instantaneous MSDs of the GA-MSEMEE under various \(\sigma\). It is concluded from Fig. 7 that as the kernel width becomes more larger, the steady-state MSD and convergence rate decrease gradually. Comprehensively considering the above two indicators, GA-MSEMEE has better performance when \(\sigma =70\) in this group of experiments.

The instantaneous MSDs of the GA-MSEMEE under various parameters

The instantaneous MSDs of the GA-MSEMEE under different \(\sigma\)

The instantaneous MSDs of the GA-MSEMEE under different \(\eta\)

The instantaneous MSDs of different algorithms. a GSNR = 0 dB; b GSNR = −1 dB
Different parameter \(\eta\): The value of parameter \(\sigma\) is setting as 70. Since the values of parameters \(\eta\) are similar in Table 2, it is difficult to see the impact of these parameters on the MSDs of the GA-MSEMEE. Thus, we set the parameters \(\eta\) at large intervals, which are: \(7 \times 10^{-6}, 7 \times 10^{-5}, 7 \times 10^{-4}, 8 \times 10^{-4}\) and \(9 \times 10^{-4}\). Figure 8 shows the instantaneous MSDs of the GA-MSEMEE under different \(\eta\). As \(\eta\) increases by ten times, the convergence rate becomes faster, the steady-state MSD gradually increases, and the robustness of the algorithm becomes worse. Therefore, the selection of weight coefficient should comprehensively compare the performance of three aspects. In this group of experiments, GA-MSEMEE has the best performance when \(\eta =7 \times 10^{-5}\).
4.2 Comparison of different GA-based algorithms
In this part, we contrast the MSD learning curves of the two novel algorithms to that of GA-LMS [33], GA-NLMS [49], GA-MCC [35] algorithms under different GSNR. Their parameters are set as follows: \(\mu _{\text {G A-LMS}}=8 \times 10^{-4}, \mu _{\text {G A-NLMS}}=0.8, \mu _{\text {GA-MCC}}=0.5(\sigma =40), \mu _{\text {GA-MEE}}=0.5(\alpha =0.1, \sigma =90), \mu _{\text {GA-MSEMEE}}=0.5(\alpha =0.1, \sigma =300, \eta =0.0006)\), trying to make the convergence rate of each algorithm consistent. Figure 9 demonstrates the instantaneous MSDs of different algorithms.
As can be seen from Fig. 9, compared with GA-MCC, the GA-MEE has better steady-state MSD and convergence rate, but its convergence rate slows down significantly with the decrease in GSNR. Compared with GA-based LMS-type algorithms, the GA-MEE has better steady-state MSD and robustness, but GA-MEE needs more iterations to converge. The improved GA-MSEMEE algorithm solves this problem to a certain extent. The GA-MSEMEE always maintains superior convergence rate, good steady-state MSD and robustness under different GSNR.
4.3 Application and multi-dimensional signal analysis
In this part, the two novel algorithms are applied to signal denoising. In order to test their superiority in \(\alpha\)-stable noise environment, we performed the following experiments.

The denoising results of 4-dimensional signal with different algorithms. a GA-LMS; b GA-NLMS; c GA-MCC; d GA-MEE; e GA-MSEMEE

The average 4-dimensional signal recovery errors of different algorithms

The denoising results of 8-dimensional signal with different algorithms. a GA-MEE; b GA-MSEMEE
Figure 10 demonstrates the denoising results of 4-dimension signal with GA-LMS, GA-NLMS, GA-MCC, GA-MEE and GA-MSEMEE when GSNR = 0 dB. Their parameters are set as follows: \(\mu _{\text {GA-LMS}}=7 \times 10^{-7}, \mu _{\text {GA-NLMS}}=7 \times 10^{-4}, \mu _{\text {GA-MCC}}=0.5(\sigma =200), \mu _{\text {GA-MEE}}=0.5(\alpha =0.8, \sigma =300), \mu _{\text {GA-MSEMEE}}=0.5(\alpha =0.1, \sigma =300, \eta =2 \times 10^{-6})\). As shown in Fig. 10, the GA-LMS, GA-NLMS and GA-MCC algorithms all need an adaptive process at the beginning of denoising, which the proposed algorithms do not need. Figure 11 shows the average 4-dimensional signal recovery errors of different algorithms with different GSNR. The recovery error of 4-dimensional signal is described by \(\left\| u^{\prime }-u\right\| _{2}^{2}\), which represents the norm square of the difference between the denoised signal and the clean signal.
What is more, it is worth noting that the two novel algorithms can be applied to higher dimensional signal processing. Figure 12 demonstrates the denoising results of 8-dimensional signal with GA-MEE and GA-MSEMEE when GSNR = 0 dB.
4.4 Computational Complexity
The running time of different algorithms for 4-dimensional and 8-dimensional signal denoising is shown in Table 3. The experiments are carried out via MATLAB with Intel (R) Core (TM) i7-6500U 2.50GHz CPU and 4 GB memory.
Table 3 shows that the proposed algorithms in this paper have higher computational complexity. The reason for the higher computational complexity of GA-MEE algorithm is that it involves the calculation of minimum error entropy, which includes exponential operation of different error signals. The computational complexity of GA-MSEMEE is the highest, mainly because GA-MSEMEE algorithm is acquired by fusing MSE and MEE through a weight coefficient.
5 Conclusions
Two novel GA-based algorithms GA-MEE and GA-MSEMEE are proposed, which are deduced from the MEE criterion and the joint criterion, respectively, combined with GA theory. The GA-MEE and GA-MSEMEE algorithms show strong robustness and high precision for high-order signal processing in \(\alpha\)-stable noise environment. However, although the GA-MEE shows more robustness than other algorithms, its convergence rate and sensitivity are low. The GA-MSEMEE can effectively compensate for the lack of the GA-MEE. The experiments demonstrate that the GA-MSEMEE achieves a good balance between robustness and convergence rate.
Due to the high accuracy and sensitivity of the GA-MSEMEE, the algorithm can also be applied to more aspects, such as signal prediction, which can be further studied. Moreover, how to reduce the computational complexity is also a major direction of further research.
Availability of data and materials
The datasets used and analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- GA:
-
Geometric algebra
- MEE:
-
Minimum error entropy
- MSE:
-
Mean square error
- MSEMEE:
-
A joint criterion of mean square error and minimum error entropy
- LMS:
-
Least mean square
- NLMS:
-
Normalized least mean square
- MCC:
-
Maximum correntropy criterion
- QLMS:
-
Quaternion least mean square
- AQLMS:
-
Augmented quaternion least mean square
- MSD:
-
Mean-square deviation
- GSNR:
-
Generalized signal-to-noise ratio
References
H. Gao, Y. Zhang, H. Miao, Sdtioa: modeling the timed privacy requirements of iot service composition: a user interaction perspective for automatic transformation from bpel to timed automata, in ACM/Springer Mobile Networks and Applications (MONET) (2021). pp. 1–26. https://doi.org/10.1007/s11036-021-01846-x
R.J.D. Barroso, Collaborative learning-based industrial iot api recommendation for software-defined devices: the implicit knowledge discovery perspective. IEEE Trans Emerg. Top. Comput. Intell. (2020). https://doi.org/10.1109/TETCI.2020.3023155
H. Long, W. Xiang, Y. Zhang, Y. Liu, W. Wang, Secrecy capacity enhancement with distributed precoding in multirelay wiretap systems. IEEE Trans. Inf. Forensics Secur. 8(1), 229–238 (2013). https://doi.org/10.1109/TIFS.2012.2229988
W. Xiang, C. Zhu, C.K. Siew, Y. Xu, M. Liu, Forward error correction-based 2-d layered multiple description coding for error-resilient h.264 svc video transmission. IEEE Trans. Circuits Syst. Video Technol. 19(12), 1730–1738 (2009). https://doi.org/10.1109/TCSVT.2009.2022787
Y. Huang, H. Xu, H. Gao, X. Ma, W. Hussain, Ssur: an approach to optimizing virtual machine allocation strategy based on user requirements for cloud data center. IEEE Trans. Green Commun. Netw. 5(2), 670–681 (2021). https://doi.org/10.1109/TGCN.2021.3067374
X. Ma, H. Xu, H. Gao, M. Bian, Real-time multiple-workflow scheduling in cloud environments. IEEE Trans. Netw. Serv. Manag. 18(4), 4002–4018 (2021). https://doi.org/10.1109/TNSM.2021.3125395
H. Gao, C. Liu, Y. Yin, Y. Xu, Y. Li, A hybrid approach to trust node assessment and management for vanets cooperative data communication: Historical interaction perspective. IEEE Intell. Transp. Syst. Trans. (2021). https://doi.org/10.1109/TITS.2021.3129458
G. Wang, W. Xiang, J. Yuan, Outage performance for compute-and-forward in generalized multi-way relay channels. IEEE Commun. Lett. 16(12), 2099–2102 (2012). https://doi.org/10.1109/LCOMM.2012.112012.122273
L. Zhang, W. Xiang, X. Tang, An efficient bit-detecting protocol for continuous tag recognition in mobile rfid systems. IEEE Trans. Mob. Comput. 17(3), 503–516 (2018). https://doi.org/10.1109/TMC.2017.2735411
E.V. Kuhn, C.A. Pitz, M.V. Matsuo, K.J. Bakri, J. Benesty, A Kronecker product clms algorithm for adaptive beamforming. Digit. Signal Process. 111, 102968–102975 (2021). https://doi.org/10.1016/j.dsp.2021.102968
S.H. Pauline, D. Samiappan, R. Kumar, A. Anand, A. Kar, Variable tap-length non-parametric variable step-size nlms adaptive filtering algorithm for acoustic echo cancellation. Appl. Acoust. 159, 107074–107082 (2020). https://doi.org/10.1016/j.apacoust.2019.107074
R. Pogula, T.K. Kumar, F. Albu, Robust sparse normalized lmat algorithms for adaptive system identification under impulsive noise environments. Circuits Syst. Signal Process. 38, 5103–5134 (2019). https://doi.org/10.1007/s00034-019-01111-3
R. Arablouei, K. Dogangay, Low-complexity adaptive decision-feedback equalization of mimo channels. Signal Process. 92(6), 1515–1524 (2012). https://doi.org/10.1016/j.sigpro.2011.12.012
B. Widrow, J.M. McCool, M.G. Larimore, C.R. Johnson, Stationary and nonstationary learning characteristics of the lms adaptive filter. Proc. IEEE 64(8), 1151–1162 (1976). https://doi.org/10.1109/PROC.1976.10286
T. Moon, Session ta8a3: adaptive signal processing: theory and applications, in 2010 Conference Record of the Forty Fourth Asilomar Conference on Signals, Systems and Computers (2010). pp. 976–978. https://doi.org/10.1109/ACSSC.2010.5757544
L. Horowitz, K. Senne, Performance advantage of complex lms for controlling narrow-band adaptive arrays. IEEE Trans. Circuits Syst. 28(6), 562–576 (1981). https://doi.org/10.1109/TCS.1981.1085024
K. Elangovan, Comparative study on the channel estimation for ofdm system using lms, nlms and rls algorithms, in International Conference on Pattern Recognition, Informatics and Medical Engineering (PRIME-2012) (2012), pp. 359–363. https://doi.org/10.1109/ICPRIME.2012.6208372
Y. Xue, X. Zhu, The minimum error entropy based robust wireless channel tracking in impulsive noise. IEEE Commun. Lett. 6(6), 228–230 (2002). https://doi.org/10.1109/LCOMM.2002.1010863
K.E. Hild, D. Erdogmus, J.C. Príncipe, Blind source separation using Renyi’s mutual information. IEEE Signal Process. Lett. 8(6), 174–176 (2001). https://doi.org/10.1109/97.923043
H. Radmanesh, M. Hajiabadi, Recursive maximum correntropy learning algorithm with adaptive kernel size. IEEE Trans. Circuits Syst. II: Express Briefs 65(7), 958–962 (2018). https://doi.org/10.1109/TCSII.2017.2778038
G. Wang, R. Xue, J. Wang, A distributed maximum correntropy Kalman filter. Signal Process. 160, 247–251 (2019). https://doi.org/10.1016/j.sigpro.2019.02.030
B. Chen, L. Dang, Y. Gu, N. Zheng, J.C. Príncipe, Minimum error entropy Kalman filter. IEEE Trans. Syst. Man Cybernet. Syst. 51(9), 5819–5829 (2021). https://doi.org/10.1109/TSMC.2019.2957269
Z. Li, L. Xing, B. Chen, Adaptive filtering with quantized minimum error entropy criterion. Signal Process. 172, 107534–107542 (2020). https://doi.org/10.1016/j.sigpro.2020.107534
B. Chen, L. Xing, H. Zhao, N. Zheng, J.C. Príncipe, Generalized correntropy for robust adaptive filtering. IEEE Trans. Signal Process. 64(13), 3376–3387 (2016). https://doi.org/10.1109/TSP.2016.2539127
H. Su, Z. Bo, Conformal geometric algebra based band selection and classification for hyperspectral imagery, in 2016 8th Workshop on Hyperspectral Image and Signal Processing: Evolution in Remote Sensing (WHISPERS) (2016). pp. 1–4. https://doi.org/10.1109/WHISPERS.2016.8071661
M.T. Pham, T. Yoshikawa, T. Furuhashi, K. Tachibana, Robust feature extractions from geometric data using geometric algebra, in 2009 IEEE International Conference on Systems, Man and Cybernetics (2009). pp. 529–533. https://doi.org/10.1109/ICSMC.2009.5346869
R. Wang, M. Shen, W. Cao, Multivector sparse representation for multispectral images using geometric algebra. IEEE Access 7, 12755–12767 (2019). https://doi.org/10.1109/ACCESS.2019.2892822
R. Wang, K. Wang, W. Cao, X. Wang, Geometric algebra in signal and image processing: a survey. IEEE Access 7, 156315–156325 (2019). https://doi.org/10.1109/ACCESS.2019.2948615
R. Wang, M. Shen, T. Wang, W. Cao, L1-norm minimization for multi-dimensional signals based on geometric algebra. Adv. Appl. Cliff. Algebras 29(2), 1–18 (2019). https://doi.org/10.1007/s00006-019-0950-7
M. Shen, R. Wang, W. Cao, Joint sparse representation model for multi-channel image based on reduced geometric algebra. IEEE Access 6, 24213–24223 (2018). https://doi.org/10.1109/ACCESS.2018.2819691
F. Brackx, N.D. Schepper, F. Sommen, The Clifford–Fourier transform. J. Fourier Anal. Appl. 6(6), 668–681 (2005). https://doi.org/10.1007/s00041-005-4079-9
D. Tao, X. Li, X. Wu, S.J. Maybank, General tensor discriminant analysis and Gabor features for gait recognition. IEEE Trans. Pattern Anal. Mach. Intell. 29(10), 1700–1715 (2007). https://doi.org/10.1109/TPAMI.2007.1096
W.B. Lopes, A. Al-Nuaimi, C.G. Lopes, Geometric-algebra lms adaptive filter and its application to rotation estimation. IEEE Signal Process. Lett. 23(6), 858–862 (2016). https://doi.org/10.1109/LSP.2016.2558461
A. Al-Nuaimi, E. Steinbach, W.B. Lopes, C.G. Lopes, 6dof point cloud alignment using geometric algebra-based adaptive filtering, in 2016 IEEE Winter Conference on Applications of Computer Vision (WACV) (2016). pp. 1–9. https://doi.org/10.1109/WACV.2016.7477642
W. Wang, H. Zhao, X. Zeng, Geometric algebra correntropy: definition and application to robust adaptive filtering. IEEE Trans. Circuits Syst. II Express Briefs 67(6), 1164–1168 (2020). https://doi.org/10.1109/TCSII.2019.2931507
B. Chen, J. Hu, H. Li, Z. Sun, A joint stochastic gradient algorithm and its application to system identification with rbf networks, in 2006 6th World Congress on Intelligent Control and Automation, vol. 1 (2006). pp. 1754–1758. https://doi.org/10.1109/WCICA.2006.1712654
G. Wang, B. Peng, Z. Feng, X. Yang, N. Wang, Adaptive filtering based on recursive minimum error entropy criterion. Signal Process. 179, 107836–107841 (2021). https://doi.org/10.1016/j.sigpro.2020.107836
C. Qiu, Z. Dong, W. Yan, G. Qian, Fractional-order complex correntropy algorithm for adaptive filtering in stable environment. Electron. Lett. 57(21), 813–815 (2021). https://doi.org/10.1049/ell2.12271
E.P. Jayakumar, P.S. Sathidevi, An integrated acoustic echo and noise cancellation system using cross-band adaptive filters and wavelet thresholding of multitaper spectrum. Appl. Acoust. 141, 9–18 (2018). https://doi.org/10.1016/j.apacoust.2018.05.029
G. Wang, R. Xue, Comments on “the quaternion lms algorithm for adaptive filtering of hypercomplex processes’’. IEEE Trans. Signal Process. 67(7), 1957–1958 (2019). https://doi.org/10.1109/TSP.2019.2897967
C.C. Took, C. Jahanchahi, D.P. Mandic, A unifying framework for the analysis of quaternion valued adaptive filters, in 2011 Conference Record of the Forty Fifth Asilomar Conference on Signals, Systems and Computers (ASILOMAR) (2011). pp. 1771–1774. https://doi.org/10.1109/ACSSC.2011.6190325
R.G. Rahmati, A. Khalili, A. Rastegarnia, H. Mohammadi, An adaptive incremental algorithm for distributed filtering of hypercomplex processes. Am. J. Signal Process. 5(2A), 9–15 (2015). https://doi.org/10.5923/s.ajsp.201501.02
T. Thanthawaritthisai, F. Tobar, A.G. Constantinides, D.P. Mandic, The widely linear quaternion recursive total least squares, in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2015). pp. 3357–3361. https://doi.org/10.1109/ICASSP.2015.7178593
F.G.A. Neto, V.H. Nascimento, A novel reduced-complexity widely linear qlms algorithm, in 2011 IEEE Statistical Signal Processing Workshop (SSP) (2011). pp. 81–84. https://doi.org/10.1109/SSP.2011.5967831
T.K. Paul, T. Ogunfunmi, A kernel adaptive algorithm for quaternion-valued inputs. IEEE Trans. Neural Netw. Learn. Syst. 26(10), 2422–2439 (2015). https://doi.org/10.1109/TNNLS.2014.2383912
W.B. Lopes, C.G. Lopes, Geometric-algebra adaptive filters. IEEE Trans. Signal Process. 67(14), 3649–3662 (2019). https://doi.org/10.1109/TSP.2019.2916028
R. Wang, M. Shen, X. Wang, W. Cao, Rga-cnns: convolutional neural networks based on reduced geometric algebra. Sci. China. Inf. Sci. 64(2), 129101–129103 (2021). https://doi.org/10.1007/s11432-018-1513-5
R. Wang, Y. He, C. Huang, X. Wang, W. Cao, A novel least-mean kurtosis adaptive filtering algorithm based on geometric algebra. IEEE Access 7(99), 78298–78310 (2019). https://doi.org/10.1109/ACCESS.2019.2922343
R. Wang, M. Liang, Y. He, X. Wang, W. Cao, A normalized adaptive filtering algorithm based on geometric algebra. IEEE Access 8, 92861–92874 (2020). https://doi.org/10.1109/ACCESS.2020.2994230
Y. He, R. Wang, X. Wang, J. Zhou, Y. Yan, Novel adaptive filtering algorithms based on higher-order statistics and geometric algebra. IEEE Access 8, 73767–73779 (2020). https://doi.org/10.1109/ACCESS.2020.2988521
D. Hestenes, G. Sobczyk, J.S. Marsh, Clifford algebra to geometric calculus. A unified language for mathematics and physics. Am. J. Phys. 53(5), 510–511 (1985). https://doi.org/10.1119/1.14223
Acknowledgements
Not applicable.
Funding
This work was supported by the National Natural Science Foundation of China under Grants 61771299, 61771322.
Author information
Authors and Affiliations
Contributions
RW proposed the new idea of the paper and participated in the outage performance analysis. YW performed the simulations and drafted the paper. YL and WC conceived of the study, and participated in its design and coordination and helped to draft the manuscript. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, R., Wang, Y., Li, Y. et al. Research on geometric algebra-based robust adaptive filtering algorithms in wireless communication systems. J Wireless Com Network 2022, 38 (2022). https://doi.org/10.1186/s13638-022-02100-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13638-022-02100-y