
Abstract
Purpose
This study aims to explore the contribution of differentially expressed programmed cell death genes (DEPCDGs) to the heterogeneity of serous ovarian cancer (SOC) through single-cell RNA sequencing (scRNA-seq) and assess their potential as predictors for clinical prognosis.
Methods
SOC scRNA-seq data were extracted from the Gene Expression Omnibus database, and the principal component analysis was used for cell clustering. Bulk RNA-seq data were employed to analyze SOC-associated immune cell subsets key genes. CIBERSORT and single-sample gene set enrichment analysis (ssGSEA) were utilized to calculate immune cell scores. Prognostic models and nomograms were developed through univariate and multivariate Cox analyses.
Results
Our analysis revealed that 48 DEPCDGs are significantly correlated with apoptotic signaling and oxidative stress pathways and identified seven key DEPCDGs (CASP3, GADD45B, GNA15, GZMB, IL1B, ISG20, and RHOB) through survival analysis. Furthermore, eight distinct cell subtypes were characterized using scRNA-seq. It was found that G protein subunit alpha 15 (GNA15) exhibited low expression across these subtypes and a strong association with immune cells. Based on the DEGs identified by the GNA15 high- and low-expression groups, a prognostic model comprising eight genes with significant prognostic value was constructed, effectively predicting patient overall survival. Additionally, a nomogram incorporating the RS signature, age, grade, and stage was developed and validated using two large SOC datasets.
Conclusion
GNA15 emerged as an independent and excellent prognostic marker for SOC patients. This study provides valuable insights into the prognostic potential of DEPCDGs in SOC, presenting new avenues for personalized treatment strategies.
Similar content being viewed by others


Introduction
Ovarian cancer (OC) is a prevalent gynecologic malignancy that affects the female reproductive system. Serous ovarian cancer (SOC) is the most common subtype, accounting for approximately 70–80% of all cases OC. SOC is characterized by high mortality and the rising number of cases each year, posing a significant threat to women’s well-being [1]. Despite significant advancements in debulking surgery and chemotherapy treatments, the overall survival rate of SOC remains suboptimal, with only approximately 30% of patients surviving beyond five years [2]. The tumor heterogeneity of SOC patients presents a significant challenge for predicting overall survival and treatment efficacy. Traditional prognostic indicators have included pathological types and stages, the presence of residual disease after debulking surgery, serum markers like CA125 and HE4, and imaging indicators such as ultrasound [3]. However, these predictors no longer meet the clinical requirements of precision medicine in managing SOC. Therefore, it is imperative to expedite the development of efficacious prognostic markers and novel treatment targets to enhance the survival rates of SOC.
Programmed cell death (PCD) is a genetically regulated process of cellular demise that serves a vital function in maintaining homeostasis [4]. Extensive research has focused on PCD in malignancies, revealing its significance in the development and dissemination of malignant cells [5]. Studies have shown that PCD, such as ferroptosis, necroptosis, and pyroptosis, are closely associated with OC’s occurrence, progression, and therapeutic potential [6]. However, intra-tumoral heterogeneity remains a significant challenge in the context of ovarian cancer [7, 8], with implications for cancer progression and survival rates [9, 10]. Therefore, investigating how PCD contributes to the heterogeneity of SOC is essential for providing precise treatment guidance and improving overall survival rates.
The advent of single-cell RNA sequencing (scRNA-seq) has revolutionized the study of tumoral heterogeneity in OC. It has facilitated the identification of critical factors and cellular subpopulations involved in tumor progression [11,12,13]. By enhancing our understanding of tumoral heterogeneity, scRNA-seq offers novel perspectives on cancer biology [14]. Liu et al. utilized scRNA-seq to identify four M2 tumor-associated macrophage (TAM)-associated genes that possess predictive significance in OC patients [15]. Similarly, Tan et al. utilized scRNA-seq to reveal dynamic alterations occurring in the immunological milieu of bladder cancer and establish a predictive model [16]. Moreover, scRNA-seq has led to the discovery of new malignant cell populations associated with unfavorable prognostic outcomes in OC [17]. Additionally, Yu et al. [18] identified flavin-containing monooxygenase 2 as a novel cancer-associated fibroblast-derived biomarker for predicting the course of OC. However, despite these advancements, a comprehensive study of the relationship between PCD and tumor heterogeneity in SOC still needs to be conducted. The detailed mechanism of PCD in SOC’s heterogeneity remains thinly investigated.
In this study, we identified 48 differentially expressed programmed cell death-related genes (DEPCDGs) associated with apoptotic signaling and oxidative stress pathways. We further identified seven key DEPCDGs (CASP3, GADD45B, GNA15, GZMB, IL1B, ISG20, and RHOB) with prognostic significance through survival analysis. We identified eight distinct cell subtypes corresponding to 13 clusters using scRNA-seq on SOC tumor tissue samples. Interestingly, G protein subunit alpha 15 (GNA15) exhibited low expression across these single-cell subtypes and was strongly associated with immune cells in the RNA-seq data. To further investigate GNA15, we conducted a single-gene bioinformatics analysis and constructed a prognostic model. This model displayed promising predictive ability in both the TCGA and GEO cohorts, establishing GNA15 as a valuable autonomous prognostic determinant for SOC patients. Overall, our scRNA-seq investigation offers crucial insights into the complex tumoral heterogeneity of SOC, shedding light on potential avenues for developing novel therapeutic strategies.
Materials and methods
Data preparation
We collected 375 tumor tissues samples (TCGA-OV) (Homo sapiens) from the University of California Santa Cruz Xena (UCSC Xena, https://xenabrowser.net/datapages/) [19], ensuring all selected samples had complete survival data. These samples provided transcriptome sequencing data with fragments per kilobase million (FPKM) expression values, along with relevant clinical information, such as age, histologic grade, and clinical stage (Table S1). Additionally, we sourced 88 healthy ovarian tissue samples (Homo sapiens) from the Genotype-Tissue Expression database (GTEx, https://gtexportal.org/home/) [20]. These samples provided the transcriptome sequencing FPKM expression profile and count matrix. In addition, we downloaded the RNA-seq dataset GSE63885 [21] from the Gene Expression Omnibus database(GEO, https://www.ncbi.nlm.nih.gov/geo/) through the “GEOquery” R package [22]. This dataset was derived from the GPL570 [HG-U133_Plus_2] Affymetrix Human Genome U133 Plus 2.0 Array, which focuses on Homo sapiens and comprises a total of 75 ovary tumor samples after removing missing survival data. We further downloaded scRNA-seq data GSE184880 from the GEO database [23], which was derived from the platform GPL24676 Illumina NovaSeq 6000 (Homo sapiens) and contained seven SOC samples without treatment and five control samples. The inclusion and exclusion criteria of this study were defined as follows: (1) The inclusion criteria: ① Patients diagnosed and treated for SOC initially, excluding those with recurrent SOC; ② Complete clinical and pathological data. (2) The exclusion criteria: ① Excluded patients with incomplete pathologica or clinical data; ② Patients with incomplete follow-up time, other causes of death and unknown death status; ③ Patients with multiple tumors and non-primary tumors.
Identification and enrichment analysis of DEPCDGs
Initially, we collected 268 programmed cell death genes (PCD genes) from existing literature sources [24, 25]. Using scRNA-seq datasets, we identified 3,000 cell Differential genes (cellDiffgenes) intersecting with PCD genes to obtain our target gene. Subsequently, we obtained a combined dataset by emerging OC samples from TCGA databases with healthy ovarian samples from GTEx databases using the “ComBat” R package [26]. We successfully identified differentially expressed programmed cell death genes (DEPCDGs) in SOC by analyzing these target genes in the combined dataset using the “limma” R package [27] (p < 0.05 and | logFC (Fold Change) |> 1). Among the DEPCDGs, those with a p-value less than 0.05 and logFC more than 1 were classified as up-regulated. Conversely, DEPCDGs with a p-value less than 0.05 and logFC less than -1 were categorized as down-regulated. The “heatmap” and “ggplot2” R packages were employed to generate visual representations of heat and volcano maps.
Gene Ontology (GO) [28] is a commonly used approach in conducting comprehensive investigations of functional enrichment studies. This method encompasses the examination of cell composition (CC), biological process (BP), and molecular function (MF). Similarly, the Kyoto Encyclopedia of Genes and Genomes (KEGG) [29] is an extensively utilized database encompassing comprehensive data on genomes, biological processes, diseases, and pharmaceuticals. To analyze the functional characteristics and pathway enrichment of the DEPCDGs, we performed GO and KEGG analyses using the “ClusterProfler” R package [30] and graphically represented using the “ggplot2” R package. For statistical significance, we defined enrichment as a function or pathway term with a false discovery rate (FDR) less than 0.25 and a p-value less than 0.05. The p-value adjustment used the Benjamini-Hochberg (BH) approach [31].
Identification of key DEPCDGs based on survival analysis
We performed survival analysis on DEPCDGs utilizing the “survival” R package [32] and identified key prognostic genes with statistical significance (p < 0.05). These key prognostic genes were then selected as key DEPCDGs for further analysis.
Expression of key DEPCDGs on scRNA-seq data
We imported raw data from SOC samples in the scRNA-seq dataset utilizing the “Seurat” R package (version 4.0) [33] and created Seurat objects for subsequent analysis. We applied gene < 200 or > 3,000 filtration conditions to remove low-quality cells [34]. The proportion of mitochondrial genes in relation to the total genetic material can indicate cellular homeostasis. Cells with mitochondrial gene content > 10% were excluded from further analysis due to potential stress. Consequently, we obtained a final set of 3,555 cells for subsequent analysis.
The scRNA-seq data was normalized using the LogNormalize method. We identified cellDiffgenes in individual cells after controlling for the relationship between average expression and dispersion. Next, we employed Principal Component Analysis (PCA) to decentralize all genes and cluster all cells. Subsequently, we displayed the resulting cell subclusters utilizing Uniform Manifold Approximation and Projection (UMAP) [35]. The cell type of each cluster was determined by referencing the Human Primary Cell Atlas (HPCA) dataset using the singleR method [36].
Evaluation of immune cell infiltration
CIBERSORT (https://cibersortx.stanford.edu/) is a computational tool that employs linear support vector regression to deconvolute the transcriptome expression matrix. Its purpose is to estimate the composition and number of immune cells within a mixture of cells [37]. We utilized the CIBERSORT algorithm to determine the fraction of 22 immune cell types, exploring the association between key DEPCDGs and the immunological microenvironment. The relative abundance of immune cells in a dataset sample can be calculated using single-sample gene set enrichment analysis (ssGSEA) [38]. The immune cell enrichment scores of combined datasets were assessed by using ssGSEA with the “GSVA” R package. This analysis was performed based on the relative abundance of each immunocyte infiltrate in every sample. Samples with a p-value less than 0.05 were filtered and included in the output. Finally, the correlation analysis results between key DEPCDGs and infiltrating immune cells in combined datasets were visually represented using the “pheatmap” R package. The core genes for further analysis were selected based on the most relevant key DEPCDGs.
Difference and enrichment analysis of core gene
Within the TCGA-OV dataset, SOC patients were classified into high- and low-expression groups by utilizing the median value of the core gene. Differential analysis was performed using the “limma” R package to identify the differentially expressed genes (DEGs) with statistical significance (p < 0.05 and | logFC |> 1). To determine the biologically significant pathways mediated by the hub gene, we performed GO and KEGG enrichment analyses using the “ClusterProfiler” R package [39] and visualized using the “ggplot2” R package.
In order to evaluate the contribution of DEGs to the phenotype, we employed Gene Set Enrichment Analysis (GSEA) [40]. GSEA is a computational methodology in which genes in a predetermined genetic set are analyzed within the gene list ordered by phenotypic correlation. We performed enrichment analysis on all DEGs with high and low phenotype correlations in both groups using the “clusterProfiler” R package. The parameters employed for GSEA were as follows: a seed value of 2020 was utilized for random number generation, 10,000 computations were performed, and each gene set contained a minimum of 10 genes and a maximum of 500 genes. Enrichment analysis was conducted using the “c2.cp.v7.2.symbols.gmt” gene set obtained from the Molecular Signatures Database (MSigDB) [41] via the GSEA method. We defined statistically significant enrichment as a pathway or function term with an FDR less than 0.25 and a p-value less than 0.05. The p-value correction was conducted using the BH method.
Construction and evaluation of a prognosis model based on core gene
DEGs identified from hub gene grouping were selected as candidate genes. To investigate their prognostic value for SOC, we assess the correlation between these candidate genes and survival outcomes via univariate Cox regression analysis using “survival” and “forestplot” R packages. Based on the DEGs with noteworthy prognostic value (p < 0.05), we conducted multivariate Cox regression analysis to calculate regression coefficients and develop a risk model. This model enabled us to assign a risk score (RS) to each tumor sample using the following formula,
Where N denotes the number of genes, coef(k) represents the multivariate Cox regression coefficient, and x(k) represents the expression value of each gene.
Our data analysis identified seven prognosis-related feature genes: CD3E, CD2, IL2RG, FCGBP, RARRES1, UBD, VSIG4, and STAB1. Subsequently, the patients were classified into high- and low-risk groups according to the median of the RS. To evaluate the predictive effectiveness of our risk model, we employed several methods: the Risk Triptych, time-dependent receiver operator characteristic (time-ROC) curve analysis [42], Kaplan–Meier (K-M) curve analysis [43], and decision curve analysis (DCA).
Construction and evaluation of a nomogram based on the risk score
In order to determine the potential independence of the prognostic factor, we assess the correlation between survival outcomes and variables such as RS, age, stage, and grade via univariate Cox regression using the “survival” and “forestplot” R packages. Furthermore, we explored independent influencing factors through multivariate Cox regression and visualized them in forest plots. A nomogram was ultimately constructed utilizing the RS and clinical characteristics in order to forecast the prognosis of SOC. The performance of this nomogram was subsequently assessed through the use of the Calibration curve and ROC curve.
Statistical analysis
We performed statistical analysis in this study using RStudio (version 4.2). The Kruskal–Wallis test was employed to compare groups consisting of three or more, while the Wilcoxon rank sum test was utilized for the comparison of two groups. Spearman’s method was employed for correlation analysis. The “survival” R package was employed to conduct univariate and multivariate Cox analyses. Additionally, survival differences were displayed using K-M survival curves. The Log-rank test was employed to evaluate the extent of the disparity in survival durations among the various groups of patients. All statistical tests were conducted with bilateral p-values, and a significance level of p < 0.05 was employed.
Results
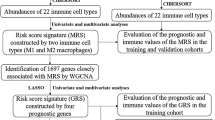
Workflow chart
In order to provide a clearer understanding of the research process, we presented the workflow of our study in Fig. 1.

Flow chart for the comprehensive analysis of DEPCDGs. DEPCDGs, differentially expressed programmed cell death genes
Identification and pathway enrichment analysis of DEPCDGs
We identified a total of 97 PCD-related cellDiffgenes by intersecting 3,000 cellDiffgenes from the scRNA-seq dataset with 268 PCD genes from existing literature sources. Moreover, the 171 genes are uniquely associated with the PCD gene set, which were not present among the cellDiffgenes., hinting at their potential involvement in specific PCD pathways relevant to ovarian cancer (Fig. 2A). A combined dataset was obtained by emerging OC samples from TCGA databases with healthy ovarian samples from GTEx databases. We identified 48 DEPCDGs by performing differential analysis on the expression of PCD-related cellDiffgenes in the combined dataset using the “limma” R package ( |logFC|> 1 and p < 0.05). Among them, 18 genes were up-regulated ( logFC > 1 and p < 0.05), and 30 genes were down-regulated ( logFC < -1 and p < 0.05). The volcano plot visualized these DEPCDGs (Fig. 2). The differential expression of DEPCDGs between various sample groups in combined datasets was analyzed. The results of this analysis were visualized using a heatmap plot generated by the “pheatmap” R package (Fig. 2C).

Identification and pathway enrichment analysis of DEPCDGs. A Venn diagram displaying the overlap genes between cell Diff genes and PCD genes (3,000 PCD genes shown in red, 268 cellDiffgenes shown in blue, and 97 PCD-related cellDiffgenes overlap between both sets). B The volcano plot of DEPCDGs in combined datasets. C Clustered heatmap of DEPCDGs in combined datasets. D GO enrichment analysis of DEPCDGs (FDR < 0.05). E KEGG enrichment analysis of DEPCDGs (FDR < 0.05). Blue represents the normal group; orange represents the tumor group. DEPCDGs, differentially expressed programmed cell death genes; PCD, programmed cell death; GO, Gene Ontology; KEGG, Kyoto Encyclopedia of Genes and Genomes; FDR, false discovery rate
Forty-eight DEPCDGs were analyzed by GO and KEGG pathway enrichment analysis (Table 1). GO analysis revealed enrichment of DEPCDGs in pathways such as extrinsic apoptotic signaling pathway, cellular response to chemical stress, regulation of extrinsic apoptotic signaling pathway, response to oxidative stress, and regulation of apoptotic signaling pathway (Fig. 2D). In the KEGG pathway analysis, several enriched pathways of DEPCDGs were identified, including legionellosis, proteoglycans in cancer, and salmonella infection (Fig. 2E).
Identification of key DEPCDGs based on survival analysis
We conducted survival analysis on 48 DEPCDGs in the TCGA-OV group and identified seven key DEPCDGs with prognostic significance in SOC (p < 0.05). These genes were the third comparative assessment of techniques of protein structure prediction (CASP3), growth arrest and DNA-damage-inducible protein 45 beta (GADD45B), GNA15, Granzyme B (GZMB), cytokine interleukin-1β (IL1B), Interferon-stimulated gene 20 (ISG20), and RhoB (RHOB) (p < 0.05) (Fig. 3A-G). The differential expression of these seven genes in the combined dataset shown in Fig. 3H, with GASP3, GNA15, GZMB, and IL1B strongly expressed in the tumor group, while GADD45B, ISG20, and RHOB were lowly expressed (p < 0.001). Additionally, correlation analysis revealed that GNA15 and IL1B were relatively highly correlated (Fig. 3I). These findings suggest the potential prognostic significance of these key DEPCDGs in SOC.

Identification of key DEPCDGs based on survival analysis. A-G Kaplan–Meier survival curves of seven key DEPCDGs in TCGA-OV: CASP3 (A), GADD45B (B), GNA15 (C), GZMB (D), IL1B (E), ISG20 (F), RHOB (G). H Group comparison boxplot of seven key DEPCDGs. I Correlational analysis of seven key DEPCDGs. Red represents positive correlation, blue represents negative correlation. *, p < 0.05; **, p < 0.01; ***, p < 0.001; DEPCDGs, differentially expressed programmed cell death genes; TCGA-OV, The Cancer Genome Atlas—Ovarian Cancer; CASP3, the third comparative assessment of techniques of protein structure prediction; GADD45B, growth arrest and DNA-damage-inducible protein 45 beta; GNA15, G protein subunit alpha 15; GZMB, Granzyme B, IL1B, cytokine interleukin-1β; ISG20, Interferon-stimulated gene 20; RHOB, RhoB
Expression of key DEPCDGs on scRNA-seq data
In our study, RNA sequencing was performed on single cells from seven ovarian cancer samples. To ensure the overall quality of single-cell data, we implemented filtering conditions to eliminate low-quality cells and batch effects. Specifically, we set the filtering condition as follows: the number of RNA features (nFeature_RNA) had to be between 200 and 3,000, and the percentage of mitochondrial genes (percent.mito) had to be below 20%. Through this filtering process, we successfully identified and retained a total of 3,555 high-quality cells.
Following data normalization and gene centralization, we performed PCA dimensionality reduction by extracting the top 3, 000 cellDiffgenes at the single-cell level. To identify distinct groups of cells with similar gene expression profiles, we employed the top 50 principal components for clustering. This clustering analysis yielded 13 independent clusters, which were subsequently visualized using UMAP (Fig. 4A).

Expression of key DEPCDGs on scRNA-seq data. A UMAP plot of 13 cell clusters with similar gene expression profiles. B UMAP plot of eight cell subtypes. C Heatmap of key DEPCDGs’ expression level in eight cell subtypes. D-J UMAP plots of key DEPCDGs’ expression level in eight cell subtypes. GZMB (D), IL1B (E), ISG20 (F), CASP3 (G), GADD45B (H), GNA15 (I), RHOB (J). K-Q Violin diagrams of key DEPCDGs’ expression level in eight cell subtypes. GZMB (K), IL1B (L), ISG20 (M), CASP3 (N), GADD45B (O), GNA15 (P), RHOB (Q). Red represents low expression; yellow represents high expression. DEPCDGs, differentially expressed programmed cell death genes; UMAP, uniform manifold approximation and projection; CASP3, the third comparative assessment of techniques of protein structure prediction; GADD45B, growth arrest and DNA-damage-inducible protein 45 beta; GNA15, G protein subunit alpha 15; GZMB, Granzyme B, IL1B, cytokine interleukin-1β; ISG20, Interferon-stimulated gene 20; RHOB, RhoB
Using the HPCA data to identify cell type of each cluster, we found eight cell subtypes after annotating, including intermediate monocytes, myeloid dendritic cells (mDCs), NK cells, plasmablasts, progenitor cells, switched memory B cells, Tregs, and Vdelta2 gamma-delta (Vδ2 gδ) T cells (Fig. 4B). Expression levels of seven key DEPCDGs in various cell types visually showed by the UMAP (Fig. 4D-J). Our findings revealed that GADD45B exhibited a high expression level in intermediate monocytes, GZMB was highly expressed in NK cells, and IL1B showed significant expression in intermediate monocytes. Interestingly, GNA15 displayed low expression across all cell subtypes. These results were further validated by the violin diagram (Fig. 4K-Q) and heatmap (Fig. 4C).
Immune cell infiltration in the transcriptome and its correlation with key DEPCDGs
In order to examine the relationship between key DEPCDGs and immune infiltration in the transcriptome, we conducted an analysis of immune cell infiltrates in the combined datasets utilizing CIBERSOFT and ssGSEA methods. The CIBERSORT algorithm analyzed immune infiltrates abundance of Tregs, gδT cells, NK cells activated, monocytes, dendritic cells resting, dendritic cells activated, and B cells memory. The results revealed that the tumor group exhibited higher immune infiltration levels of Tregs, gδT cells, dendritic cells resting, and dendritic cells activated compared to the normal group. Additionally, the infiltration abundance of monocytes displayed a statistically significant decrease in the tumor group (Fig. 5A, p < 0.001). Using the ssGSEA algorithm, we analyzed immune infiltrates’ abundance of gδT cells, plasmacytoid dendritic cells, NK cells, Tregs, monocytes, activated B cells, activated dendritic cells, immature B cells, and immature dendritic cells. The results indicated that gδT cells, NK cells, Tregs, monocytes, and activated dendritic cells exhibited higher immune infiltration levels in the tumor group compared to the normal group (Fig. 5C, p < 0.01). We screened out GNA15 as a core DEPCDG in SOC, as it showed a strong correlation with dendritic cells resting in the CIBERSORT algorithm (R = 0.35), none of the other genes were highly correlated with cells (Fig. 5B). Similarly, GNA15 demonstrated a high correlation with all identified immune cell subtypes in the ssGSEA algorithm(all R ≥ 0.58) (Fig. 5D). Specific high correlation results were shown in Fig. 5E-H, where GNA15 exhibited a correlation with activated dendritic cells (R = 0.80, p < 0.001, Fig. 5E), monocytes (R = 0.70, p < 0.001, Fig. 5F), NK cells (R = 0.73, p < 0.001, Fig. 5G), and Tregs (R = 0.82, p < 0.001, Fig. 5H).

Immune infiltration analysis in combined datasets. A Group comparison chart of immune cell infiltration analysis in combined datasets by the CIBERSOFT method. B Heatmap of the relationship between key DEPCDGs and specific immune cell subtypes calculated by the CIBERSOFT method. C Group comparison chart of immune cell infiltration analysis in combined datasets by the ssGSEA method. D Heatmap of the relationship between key DEPCDGs and specific immune cell subtypes by the ssGSEA method. E–H Correlation analysis between GNA15 and specific immune cell subtypes (activated dendritic cell (E), monocyte (F), NK cell (G), Tregs (H)). Red represents the tumor group; blue represents the normal group. *, p < 0.05; **, p < 0.01; ***, p < 0.001; DEPCDGs, differentially expressed programmed cell death genes; ssGSEA, single-sample gene set enrichment analysis; GNA15, G protein subunit alpha 15
Analysis of variance and functional enrichment based on GNA15
Based on our analysis results, we specifically focused on the core gene GNA15 for single-gene bioinformatics analysis. The HGSOC patients were categorized into high- and low-expression groups using the median value of the GNA15 in the TCGA-OV dataset. Through differential analysis, we identified 5 down-regulated DEGs and 180 up-regulated DEGs (|logFC|> 1, p < 0.05) (Fig. 6A). To gain insights into biological pathways modulated by GNA15, we conducted GO and KEGG enrichment analyses on these DEGs. The GO enrichment analysis revealed a predominant involvement of DEGs in leukocyte-mediated immunity, B cell-mediated immunity, antigen-binding pathways, and other relevant pathways (Fig. 6B). Meanwhile, the KEGG enrichment analysis discovered that DEGs enrichment in pathways associated with staphylococcus aureus infection, phagosome, and other related pathways (Fig. 6C). Additionally, we employed GSEA analysis to investigate the implications of GNA15 expression further (Table 2). The results of our study indicate a significant association between the high expression of GNA15 and B cell receptor signaling pathway, T cell receptor signaling pathway, and Toll-like receptor signaling pathway (Fig. 6D-F). Conversely, low expression of GNA15 was enriched in the ribosome, spliceosome, and RNA polymerase pathways (Fig. 6G-I).

Single-gene bioinformatic analysis of GNA15. A Volcano plot of DEGs in high and low GNA15 expression groups in TCGA-OV. B GO enrichment analysis of DEGs n high and low GNA15 expression groups in TCGA-OV. c KEGG enrichment analysis of DEGs n high and low GNA15 expression groups in TCGA-OV. D-F GSEA analysis of high GNA15 expression group. B cell receptor signal transduction (D), T cell receptor signaling pathway (E), TOLL-like receptor signaling pathway (F). G-I GSEA analysis of low GNA15 expression group. RNA polymerase (G), spliceosome (H), ribosome (I). GNA15, G protein subunit alpha 15; DEGs, differentially expressed genes; TCGA-OV, The Cancer Genome Atlas—Ovarian Cancer; KEGG, Kyoto Encyclopedia of Genes and Genomes; GSEA, gene set enrichment analysis
Construction and evaluation of a prognostic model based on GNA15
A predictive model was created utilizing the core gene GNA15. Initially, a univariate Cox regression analysis was performed on DEGs between high and low GNA15 expression. Our results revealed 11 genes with significant prognostic value (p < 0.05) in SOC (Fig. 7A). Subsequently, we performed multivariate Cox regression analysis on these 11 genes to construct the predictive model consisting of eight genes: CD3E, CD2, IL2RG, FCGBP, RARRES1, UBD, VSIG4, and STAB1 (Fig. 7B). We categorized patients into high- and low-risk groups based on the RS median. The Risk Triptych showed the strong predictive capacity of the model in both TCGA-OV and GSE63885 datasets (Fig. 7D-E, H-I). Furthermore, the K-M survival curve indicated that the high-risk group had worse prognoses compared to the low-risk group in both TCGA-OV and GSE63885 datasets (p < 0.0001, p = 0.048) (Fig. 7C, G). The timeROC curve showed the RS’s strong predictive ability for overall survival (OS) in SOC patients, with AUCs of 0.690, 0.694, and 0.713 for 1-year, 3-year, and 5-year respectively (Fig. 7F). Finally, the DCA confirmed the substantial predictive ability of the RS signature (Fig. 7J).

Construction evaluation of a predictive model based on GNA15. A Univariate Cox regression analysis of DEGs in the TCGA-OV dataset. B Multivariate Cox regression analysis of DEGs in the TCGA-OV dataset. C The K-M survival curve analysis of prognostic models in the TCGA-OV dataset (p < 0.001). D Distribution of SOC patients with different RS in the TCGA-OV dataset. E Survival status analysis of SOC patients with different RS in TCGA-OV dataset. F timeROC analysis of 1-, 3- and 5-year in the TCGA-OV dataset. G The K-M survival curve analysis of the prognostic model in the GSE63885 dataset (p < 0.05). H Distribution of patients with various RS in the GSE63885 dataset. I Survival status analysis of patients with various RS in the GSE63885 dataset. J DCA curve of the RS’ prediction power in the TCGA-OV dataset. Red represents the high-risk group; blue represents the low-risk group. GNA15, G protein subunit alpha 15; DEGs, differentially expressed genes; TCGA-OV, The Cancer Genome Atlas—Ovarian Cancer; SOC, serous ovarian cancer; K-M, Kaplan–Meier; ROC, receiver operator characteristic; DCA, decision curve analysis
Construction of a nomogram prediction model based on RS
We conducted a comprehensive analysis to determine whether RS could used as an independent prognostic factor. Firstly, a univariate Cox regression analysis was performed to assess the relationship between RS, age, stage, grade, and OS. The forest plots revealed that age and RS are significantly related to OS (Fig. 8A). Further analysis was undertaken using multivariate Cox regression, considering the aforementioned variables. Remarkably, both RS and age emerged as independent prognostic factors for predicting patients’ OS without relying on other clinical features (Fig. 8B). Subsequently, we constructed a nomogram model that incorporates RS along with three other clinical features for forecasting SOC patient outcomes (Fig. 8C). The good predictive power of this model was demonstrated by the Calibration curve (Fig. 8D). Moreover, the ROC curve analysis of the nomogram displayed its precise predictive ability for OS of SOC patients, with AUC values of 0.670, 0.650, and 0.653 for the 1-year, 3-year, and 5-year OS predictions, respectively (Fig. 8E).

Construction of a nomogram prediction model based on RS. A Univariate Cox regression analysis of RS and clinical features in the TCGA-OV dataset. B Multivariate Cox regression analysis of RS and clinical features in the TCGA-OV dataset. C Nomogram prediction model included stage, grade, age, and RS. D Calibration curve of the nomogram’s prognostic prediction. E ROC curve of the nomogram’s prognostic prediction. RS, risk score; TCGA-OV, The Cancer Genome Atlas—Ovarian Cancer; ROC, receiver operator characteristic
Discussion
SOC is an aggressive neoplasm of the reproductive system. Despite improvements in therapy, the high intra-tumor heterogeneity makes improving the overall survival rate challenging. scRNA-Seq technologies have been widely recognized for their ability to examine tumor heterogeneity through the evaluation of gene expression at the individual cell level [44]. Several studies have focused on developing accurate and sensitive predictive models for SOC prognosis, incorporating immune genes, serum biomarkers, and other factors [45,46,47]. However, to enhance the validity and reliability of these models, it is imperative to take into account the heterogeneity of tumor samples. PCD is a fundamental process for cellular self-repair and regulation, and its dysregulation contributes to malignant tumor development and metastasis [5]. PCD-related genes are critical in SOC [48]. In this study, we employed a combination of scRNA-Seq and bulk RNA-Seq techniques to examine tumor heterogeneity and investigate the involvement of PCD in the progression of SOC. To the best of our understanding, this bioinformatics analysis is the initial demonstration of the role of PCD and tumor heterogeneity on the prognosis of SOC using scRNA-Seq, and we establish prognostic signatures based on core DEPCDGs.
Our study identified 48 DEPCDGs contributing to the heterogeneity of SOC by performing differential analysis using TCGA-OV and GTEx datasets. Through GO analysis, we determined enrichment pathways for these DEPCDGs, including the extrinsic apoptotic signaling pathway, cellular response to chemical stress, regulation of the extrinsic apoptotic signaling pathway, response to oxidative stress, and regulation of the apoptotic signaling pathway. Additionally, the KEGG analysis revealed enrichment pathways, such as legionellosis, proteoglycans in cancer, and salmonella infection. In small intestinal neuroendocrine neoplasia, GNA15 inhibits cell proliferation and promotes apoptosis through the NFκB and Akt signaling pathways [49]. LINC02474 inhibits apoptosis by impeding GZMB expression in colorectal cancer [50]. Moreover, proteoglycans have been found to play a significant role in cancer progression by influencing cancer cell aggressiveness, angiogenesis, and stromal microenvironment [51]. These studies provide support for the validity of the current study.
Among the genes studied, GNA15 exhibited consistently low expression across all eight cell subtypes and strongly correlated with immune cell subtypes. GNA15 is a member of the GNA gene family, which is crucial in regulating cell proliferation and apoptosis. It is expressed in highly specific cell types, such as hematopoietic [52] and epithelial cells [53], during certain stages of differentiation. GNA15 has been identified as highly expressed in small intestinal neuroendocrine neoplasia [49] and pancreatic ductal adenocarcinoma [54], correlating with poor survival. It is worth noting that prior research has yet to explore the specific role of GNA15 in the SOC tumorigenesis and progression mechanism. We predict that GNA15 is involved in the development and advancement of SOC, serving as a potential theoretical foundation for SOC treatment and prognosis.
The comparative analysis conducted on groups exhibiting contrasting levels of GNA15 expression demonstrated that a total of 180 genes showed up-regulation, whereas a mere 5 genes displayed down-regulation. We investigated the role of GNA15 in various biological pathways through GO and KEGG analyses. GO analysis revealed the involvement of GNA15 in leukocyte and B cell-mediated immunity, as well as antigen-binding pathways. Meanwhile, KEGG analysis identified staphylococcus aureus infection, phagosome, and other biological processes. These findings underscore the diverse functions of GNA15 in various cellular pathways. Furthermore, GSEA analysis demonstrated a significant correlation between high expression of GNA15 and the activation of T-cell receptor and B-cell receptor signaling pathways. In contrast, low expression is correlated with ribosome and spliceosome pathways, which indicates that GNA15 is engaged in the regulation of cellular processes associated with immunological signaling and protein synthesis. Moreover, a study by Zeng et al. [55] highlighted that the carcinogenic role of miR-211-5p mediated by GNA15, which modifies the immune function of the tumor microenvironment extrinsically while also impacting the intracellular processes of pyroptosis and glycolysis in melanoma cells. Additionally, the expression levels of GNA15 have been implicated in the effectiveness of anti-tumor chemotherapeutic medicines [56]. Overall, these findings underscore the multifaceted functions of GNA15 in tumor cellular processes. Further investigation into the role of GNA15 in these pathways can enhance our understanding of cellular mechanisms and contribute to the development of novel treatments.
To evaluate the predictive capability of GNA15, we constructed a prognostic model incorporating eight genes (CD3E, CD2, IL2RG, FCGBP, RARRES1, UBD, VSIG4, and STAB1), which were identified as DEGs in the GNA15 high- and low-expression groups. This model demonstrated predictive solid ability in the TCGA-OV and GSE63885 datasets, confirming that the resulting RS signature can be an independent prognostic factor for SOC. These findings suggest that GNA15 holds promising potential in forecasting overall survival in SOC patients, indicating its crucial role in PCD for heterogeneity of SOC. For instance, Innamorati et al. [54] conducted pancreatic ductal adenocarcinoma (PDAC), Zanini et al. [49] focused on small intestinal neuroendocrine neoplasia, and Li et al. [57] investigated acute myeloid leukemia. These studies provide valuable insights into the role of GNA15 in identifying and predicting the progression and prognosis of these malignancies. These studies align with our findings and further support the idea that GNA15 is involved in diverse malignancies. The relationship between increased expression of GNA15, early relapse, and poor survival in SOC may be attributed to the induction of a stem cell-like phenotype in human ovarian cancer cells through the downregulation of AKT activity. Additionally, GNA15 facilitates cellular signaling and migratory properties in transformed cells. Moreover, high expression of GNA15 is linked to the heterogeneity and prognosis of SOC. These findings suggest that GNA15 holds promise in predictive and prognostic analyses of SOC.
Despite offering valuable insights, this study has several limitations that warrant attention. Firstly, the exclusion criteria applied to patient selection enhance the quality and integrity of the data, thereby stabilizing and consistent results while ensuring the accuracy, reliability, and repeatability of the findings. However, this approach may also introduce sample selection bias, potentially limiting the generalizability of our conclusions. Secondly, our study does not statistically compare the clinical efficacy of our nomogram with any previously developed and validated models. This comparison is crucial for establishing the relative performance and potential advantages of our approach. Thirdly, the data analyzed in this study were exclusively derived from public databases, including TCGA, GTEx, and GEO, without incorporating raw data from our own investigations. This reliance on secondary data sources may affect the direct applicability of our findings to other datasets or clinical scenarios.
Conclusion
In conclusion, our research demonstrates the potent prognostic value of GNA15 for the overall survival of SOC patients. We have developed a novel single-cell prognostic model for SOC, shedding new light on the progression of this disease. Our study highlights the critical role of GNA15 in predictive analysis. Performing an in-depth analysis of gene patterns in SOC can further enhance our understanding of the disease’s etiology, prognosis, and treatment options. Future research in this area should focus on investigating the potential implications of GNA15 and related genes in the context of SOC. By doing so, we can make significant strides in advancing our knowledge of this complex disease and potentially identifying new therapeutic targets. In conclusion, we emphasize the significance of investigating the processes of carcinogenesis using the methodology of single-cell genomics, as it has the potential to yield vital insights into the underlying mechanisms of SOC formation.
Availability of data and materials
No datasets were generated or analysed during the current study.
References
Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2022. CA Cancer J Clin. 2022;72(1):7–33.
Siegel RL, Miller KD, Wagle NS, Jemal A. Cancer statistics, 2023. CA Cancer J Clin. 2023;73(1):17–48.
Kobayashi Y, Banno K, Aoki D. Current status and future directions of ovarian cancer prognostic models. J Gynecol Oncol. 2021;32(2):e34.
Peng F, Liao M, Qin R, Zhu S, Peng C, Fu L, et al. Regulated cell death (RCD) in cancer: key pathways and targeted therapies. Signal Transduct Target Ther. 2022;7(1):286.
Su Z, Yang Z, Xu Y, Chen Y, Yu Q. Apoptosis, autophagy, necroptosis, and cancer metastasis. Mol Cancer. 2015;14:1–14.
Ye Y, Dai Q, Qi H. A novel defined pyroptosis-related gene signature for predicting the prognosis of ovarian cancer. Cell death discovery. 2021;7(1):71.
Vos JR, Fakkert IE, de Hullu JA, van Altena AM, Sie AS, Ouchene H, et al. Universal tumor DNA BRCA1/2 testing of ovarian cancer: prescreening PARPi treatment and genetic predisposition. J Natl Cancer Inst. 2020;112(2):161–9.
Ihlow J, Monjé N, Hoffmann I, Bischoff P, Sinn BV, Schmitt WD, et al. Low expression of RGS2 promotes poor prognosis in high-grade serous ovarian cancer. Cancers (Basel). 2022;14(19):4620.
Marusyk A, Almendro V, Polyak K. Intra-tumour heterogeneity: a looking glass for cancer? Nat Rev Cancer. 2012;12(5):323–34.
Izar B, Tirosh I, Stover EH, Wakiro I, Cuoco MS, Alter I, et al. A single-cell landscape of high-grade serous ovarian cancer. Nat Med. 2020;26(8):1271–9.
Zhao H, Gao Y, Miao J, Chen S, Li J, Li Z, et al. Single-cell RNA-seq highlights a specific carcinoembryonic cluster in ovarian cancer. Cell Death Dis. 2021;12(11):1–11.
Lim B, Lin Y, Navin N. Advancing cancer research and medicine with single-cell genomics. Cancer Cell. 2020;37(4):456–70.
Guruprasad P, Lee YG, Kim KH, Ruella M. The current landscape of single-cell transcriptomics for cancer immunotherapy. J Exp Med. 2021;218(1): e20201574.
Andrews TS, Hemberg M. Identifying cell populations with scRNASeq. Mol Aspects Med. 2018;59:114–22.
Liu C, Zhang Y, Li X, Wang D. Ovarian cancer-specific dysregulated genes with prognostic significance: scRNA-Seq with bulk RNA-Seq data and experimental validation. Ann N Y Acad Sci. 2022;1512(1):154–73.
Tan Z, Chen X, Zuo J, Fu S, Wang H, Wang J. Comprehensive analysis of scRNA-Seq and bulk RNA-Seq reveals dynamic changes in the tumor immune microenvironment of bladder cancer and establishes a prognostic model. J Transl Med. 2023;21(1):1–20.
Sumitani N, Ishida K, Sawada K, Kimura T, Kaneda Y, Nimura K. Identification of malignant cell populations associated with poor prognosis in high-grade serous ovarian cancer using single-cell RNA sequencing. Cancers (Basel). 2022;14(15):3580.
Yu S, Yang R, Xu T, Li X, Wu S, Zhang J. Cancer-associated fibroblasts-derived FMO2 as a biomarker of macrophage infiltration and prognosis in epithelial ovarian cancer. Gynecol Oncol. 2022;167(2):342–53.
Zhu J, Sanborn JZ, Benz S, Szeto C, Hsu F, Kuhn RM, et al. The UCSC cancer genomics browser. Nat Methods. 2009;6(4):239–40.
Lonsdale J, Thomas J, Salvatore M, Phillips R, Lo E, Shad S, et al. The genotype-tissue expression (GTEx) project. Nat Genet. 2013;45(6):580–5.
Lisowska KM, Olbryt M, Student S, Kujawa KA, Cortez AJ, Simek K, et al. Unsupervised analysis reveals two molecular subgroups of serous ovarian cancer with distinct gene expression profiles and survival. J Cancer Res Clin Oncol. 2016;142(6):1239–52.
Stelzer G, Rosen N, Plaschkes I, Zimmerman S, Twik M, Fishilevich S, et al. The GeneCards suite: from gene data mining to disease genome sequence analyses. Curr Protoc Bioinformatics. 2016;54(1):1.30. 1-1.30. 33.
Xu J, Fang Y, Chen K, Li S, Tang S, Ren Y, et al. Single-cell RNA sequencing reveals the tissue architecture in human high-grade serous ovarian cancer. Clin Cancer Res. 2022;28(16):3590–602.
Shu J, Yang L, Wei W, Zhang L. Identification of programmed cell death-related gene signature and associated regulatory axis in cerebral ischemia/reperfusion injury. Front Genet. 2022;13: 934154.
Zhang G, Fan W, Wang H, Wen J, Tan J, Xue M, et al. Non-apoptotic programmed cell death-related gene signature correlates with stemness and immune status and predicts the responsiveness of transarterial chemoembolization in hepatocellular carcinoma. Frontiers in Cell and Developmental Biology. 2022;10: 844013.
Chin L, Hahn WC, Getz G, Meyerson M. Making sense of cancer genomic data. Genes Dev. 2011;25(6):534–55.
Ritchie ME, Phipson B, Wu D, Hu Y, Law CW, Shi W, et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015;43(7):e47–e47.
Mi H, Muruganujan A, Ebert D, Huang X, Thomas PD. PANTHER version 14: more genomes, a new PANTHER GO-slim and improvements in enrichment analysis tools. Nucleic Acids Res. 2019;47(D1):D419–26.
Kanehisa M, Goto S. KEGG: kyoto encyclopedia of genes and genomes. Nucleic Acids Res. 2000;28(1):27–30.
Yu G, Wang L-G, Han Y, He Q-Y. clusterProfiler: an R package for comparing biological themes among gene clusters. OMICS. 2012;16(5):284–7.
Benjamini Y, Hochberg Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J Roy Stat Soc: Ser B (Methodol). 1995;57(1):289–300.
Therneau TM, Grambsch PM. The cox model. In: Modeling survival data: extending the cox model. Statistics for biology and health. New York: Springer; 2000. https://doi.org/10.1007/978-1-4757-3294-8_3.
Hao Y, Hao S, Andersen-Nissen E, Mauck WM III, Zheng S, Butler A, et al. Integrated analysis of multimodal single-cell data. Cell. 2021;184(13):3573-3587.e29.
Etherington GJ, Soranzo N, Mohammed S, Haerty W, Davey RP, Palma FD. A Galaxy-based training resource for single-cell RNA-sequencing quality control and analyses. GigaScience. 2019;8(12):giz144.
Becht E, McInnes L, Healy J, Dutertre C-A, Kwok IW, Ng LG, et al. Dimensionality reduction for visualizing single-cell data using UMAP. Nat Biotechnol. 2019;37(1):38–44.
Huang Q, Liu Y, Du Y, Garmire LX. Evaluation of cell type annotation R packages on single-cell RNA-seq data. Genomics Proteomics Bioinformatics. 2021;19(2):267–81.
Newman AM, Liu CL, Green MR, Gentles AJ, Feng W, Xu Y, et al. Robust enumeration of cell subsets from tissue expression profiles. Nat Methods. 2015;12(5):453–7.
Xiao B, Liu L, Li A, Xiang C, Wang P, Li H, et al. Identification and verification of immune-related gene prognostic signature based on ssGSEA for osteosarcoma. Front Oncol. 2020;10: 607622.
Wu T, Hu E, Xu S, Chen M, Guo P, Dai Z, et al. clusterProfiler 4.0: A universal enrichment tool for interpreting omics data. The Innovation. 2021;2(3):100141.
Subramanian A, Tamayo P, Mootha VK, Mukherjee S, Ebert BL, Gillette MA, et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc Natl Acad Sci. 2005;102(43):15545–50.
Liberzon A, Birger C, Thorvaldsdóttir H, Ghandi M, Mesirov JP, Tamayo P. The molecular signatures database (MSigDB) hallmark gene set collection. Cell Syst. 2015;1(6):417–25.
Dai S, Xu S, Ye Y, Ding K. Identification of an immune-related gene signature to improve prognosis prediction in colorectal cancer patients. Front Genet. 2020;11: 607009.
Győrffy B. Survival analysis across the entire transcriptome identifies biomarkers with the highest prognostic power in breast cancer. Comput Struct Biotechnol J. 2021;19:4101–9.
Davis-Marcisak EF, Sherman TD, Orugunta P, Stein-O’Brien GL, Puram SV, Roussos Torres ET, et al. Differential variation analysis enables detection of tumor heterogeneity using single-cell RNA-sequencing data. Cancer Res. 2019;79(19):5102–12.
Martins FC, Couturier D-L, De Santiago I, Sauer CM, Vias M, Angelova M, et al. Clonal somatic copy number altered driver events inform drug sensitivity in high-grade serous ovarian cancer. Nat Commun. 2022;13(1):1–14.
Kim M, Chen C, Wang P, Mulvey JJ, Yang Y, Wun C, et al. Detection of ovarian cancer via the spectral fingerprinting of quantum-defect-modified carbon nanotubes in serum by machine learning. Nature Biomedical Engineering. 2022;6(3):267–75.
Pawar A, Chowdhury OR, Chauhan R, Talole S, Bhattacharjee A. Identification of key gene signatures for the overall survival of ovarian cancer. J Ovarian Res. 2022;15(1):1–13.
Lian X, Liu B, Wang C, Wang S, Zhuang Y, Li X. Assessing of programmed cell death gene signature for predicting ovarian cancer prognosis and treatment response. Front Endocrinol (Lausanne). 2023;14:1182776.
Zanini S, Giovinazzo F, Alaimo D, Lawrence B, Pfragner R, Bassi C, et al. GNA15 expression in small intestinal neuroendocrine neoplasia: functional and signalling pathway analyses. Cell Signal. 2015;27(5):899–907.
Du T, Gao Q, Zhao Y, Gao J, Li J, Wang L, et al. Long Non-coding RNA LINC02474 Affects Metastasis and Apoptosis of Colorectal Cancer by Inhibiting the Expression of GZMB. Front Oncol. 2021;11:651796.
Dituri F, Gigante G, Scialpi R, Mancarella S, Fabregat I, Giannelli G. Proteoglycans in cancer: friends or enemies? A special focus on hepatocellular carcinoma. Cancers (Basel). 2022;14(8):1902.
Wilkie TM, Scherle PA, Strathmann MP, Slepak VZ, Simon MI. Characterization of G-protein alpha subunits in the Gq class: expression in murine tissues and in stromal and hematopoietic cell lines. Proc Natl Acad Sci U S A. 1991;88(22):10049–53.
Giannone F, Malpeli G, Lisi V, Grasso S, Shukla P, Ramarli D, et al. The puzzling uniqueness of the heterotrimeric G15 protein and its potential beyond hematopoiesis. J Mol Endocrinol. 2010;44(5):259–69.
Innamorati G, Wilkie TM, Malpeli G, Paiella S, Grasso S, Rusev B, et al. Gα15 in early onset of pancreatic ductal adenocarcinoma. Sci Rep. 2021;11:14922.
Zeng B, Chen Y, Chen H, Zhao Q, Sun Z, Liu D, et al. Exosomal miR-211–5p regulates glucose metabolism, pyroptosis, and immune microenvironment of melanoma through GNA15. Pharmacol Res. 2023;188:106660.
Li M, Ding W, Wang Y, Ma Y, Du F. Development and validation of a gene signature for pancreatic cancer: based on inflammatory response–related genes. Environ Sci Pollut Res Int. 2022;30(7):1–13.
Li M, Liu Y, Liu Y, Yang L, Xu Y, Wang W, et al. Downregulation of GNA15 inhibits cell proliferation via P38 MAPK pathway and correlates with prognosis of adult acute myeloid leukemia with normal karyotype. Front Oncol. 2021;11:3490.
Acknowledgements
The authors thank the researchers who uploaded sequencing data to the public databases.
Funding
This work was supported by the Natural Science Foundation of Fujian Province (Nos. 2020J01937, 2021J01243), Joint Funds for the Innovation of Science and Technology, Fujian province (No. 2023Y9020).
Author information
Authors and Affiliations
Contributions
FZ contributed conceptualization, methodology, software, data curation, visualization, writing-original draft preparation, funding acquisition. YG contributed methodology, formal analysis, validation, writing-original draft preparation. LH helped methodology, software, formal analysis, validation, writing-review & editing, funding acquisition. All authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
All methods were carried out in accordance with relevant guidelines and regulations (declaration of Helsinki).
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Zhan, F., Guo, Y. & He, L. A novel defined programmed cell death related gene signature for predicting the prognosis of serous ovarian cancer. J Ovarian Res 17, 92 (2024). https://doi.org/10.1186/s13048-024-01419-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13048-024-01419-y