
Abstract
Background
Porcine reproductive and respiratory syndrome virus (PRRSV) is a macrophage-tropic arterivirus with extremely high genetic and pathogenic heterogeneity that causes significant economic losses in the swine industry worldwide. PRRSV can be divided into two species [PRRSV1 (European) and PRRSV2 (North American)] and is usually diagnosed and genetically differentiated into several lineages based on the ORF5 gene, which constitutes only 5% of the whole genome. This study was conducted to achieve nonselective amplification and whole-genome sequencing (WGS) based on a simplified sequence-independent, single-primer amplification (SISPA) technique with next-generation sequencing (NGS), and to genetically characterize Korean PRRSV field isolates at the whole genome level.
Methods
The SISPA-NGS method coupled with a bioinformatics pipeline was utilized to retrieve full length PRRSV genomes of 19 representative Korean PRRSV strains by de novo assembly. Phylogenetic analysis, analysis of the insertion and deletion (INDEL) pattern of nonstructural protein 2 (NSP2), and recombination analysis were conducted.
Results
Nineteen complete PRRSV genomes were obtained with a high depth of coverage by the SISPA-NGS method. Korean PRRSV1 belonged to the Korean-specific subtype 1A and vaccine-related subtype 1C lineages, showing no evidence of recombination and divergent genetic heterogeneity with conserved NSP2 deletion patterns. Among Korean PRRSV2 isolates, modified live vaccine (MLV)-related lineage 5 viruses, lineage 1 viruses, and nation-specific Korean lineages (KOR A, B and C) could be identified. The NSP2 deletion pattern of the Korean lineages was consistent with that of the MN-184 strain (lineage 1), which indicates the common ancestor and independent evolution of Korean lineages. Multiple recombination signals were detected from Korean-lineage strains isolated in the 2010s, suggesting natural interlineage recombination between circulating KOR C and MLV strains. Interestingly, the Korean strain GGYC45 was identified as a recombinant KOR C and MLV strain harboring the KOR B ORF5 gene and might be the ancestor of currently circulating KOR B strains. Additionally, two novel lineage 1 recombinants of NADC30-like and NADC34-like viruses were detected.
Conclusion
Genome-wide analysis of Korean PRRSV isolates retrieved by the SISPA-NGS method and de novo assembly, revealed complex evolution and recombination in the field. Therefore, continuous surveillance of PRRSV at the whole genome level should be conducted, and new vaccine strategies for more efficient control of the virus are needed.
Similar content being viewed by others


Background
Porcine reproductive and respiratory syndrome (PRRS) is one of the most important epidemic diseases affecting the global pig industry and was first identified in the United States in 1987 [1]. The economic impact of the disease in the United States, the pork industry of which accounts for approximately 60% of global pig production, has been estimated at $664 million annually [2, 3]. The causative agent, porcine reproductive and respiratory virus (PRRSV), is an enveloped, single-stranded positive-sense RNA virus with a genome that is approximately 15 kb in length and encodes a 5′ untranslated region (UTR), at least 11 open reading frames (ORFs), a 3′ UTR and a 3′-poly(A) tail [4, 5]. PRRSV is classified into two genotypes, namely, PRRSV1 (EU-type, prototype strain Lelystad virus) and PRRSV2 (NA-type, prototype strain VR-2332 virus), which share only approximately 60% similarity at the nucleotide level [6, 7].
The mutation rate of RNA viruses is high due to the lack of 3′–5′ exonuclease proofreading ability of RNA-dependent RNA polymerase (RdRp), and the calculated rate of nucleotide substitutions in PRRSV is the highest reported for an RNA virus [8, 9]. Among the structural genes of PRRSV, the ORF5 gene encodes the major viral envelope protein GP5, which plays an important role in viral assembly, infectivity and neutralizing antibody induction [10,11,12]. As ORF5 exhibits high genetic diversity, it is widely used for phylogenetic analysis [13]. Based on the genetic relationships among ORF5 sequences, PRRSV2 is divided into nine lineages, lineage 1 to lineage 9 (L1 to L9), and PRRSV1 is divided into four subtypes, subtype 1 to subtype 4 (sub1 to sub4) [14,15,16].
In South Korea, PRRSV2 was first detected in the mid-1980s [17], while PRRSV1 was first detected in 2005 and has since spread rapidly [18, 19]. PRRSV1 has been recognized as highly prevalent in Korea and is classified into subgroups A (sub1A), B (sub1B) and C (sub1C) of subtype 1 (Pan-European PRRSV1), with the majority of isolates belonging to sub1A [14, 20]. PRRSV2 has been spreading across the nation for decades, and its genetic diversity has continued to increase through independent evolution, forming unique nation-specific clades designated lineages K and A (LKA), B (LKB) or C (LKC), which are distinct from prevalent global PRRSV strains and commercially modified live vaccine (MLV) strains [14, 21].
Although PRRSV ORF5 has been a very useful tool that has provided insight into the epidemiology of PRRSV, it accounts for only 5% of the whole genome. Thus, whole-genome sequencing (WGS) studies are urgently needed to provide a more complete picture of the virus and obtain identify the remaining 95% of genomic information for prediction of genetic variations [22, 23]. Indeed, based on the whole-genome information of PRRSV strains, studies have identified recombination between two wild-type PRRSV strains [21, 24, 25], between wild-type PRRSV and a MLV strain [26,27,28] and between MLV strains [29]. RNA recombination has been experimentally suggested to occur in vitro and in vivo in two different strains of PRRSV [30, 31]. It not only results in the generation of novel PRRSV genotypes but is also associated with increases in virulence [32]. Additionally, WGS of PRRSV enabled the analysis of insertion and deletion (INDEL) patterns within the genome. Deletion is often observed in PRRSVs. For example, nonstructural protein 2 (NSP2), which is the largest PRRSV protein, can tolerate amino acid (aa) deletions and foreign gene insertions [33], and it has been reported to be linked to certain patterns, such as a 131-aa discontinuous deletion in NSP2 of MN184- or NADC30-like PRRSV [34], a 100-aa continuous deletion in NSP2 of NADC34-like PRRSV [35], and a 30-aa discontinuous deletion in NSP2 of a highly pathogenic PRRSV strain in China [36].
Since high-throughput next-generation sequencing (NGS) became available in 2005 (Roche 454 FLX platform), NGS technology has become an essential tool for nearly all fields of biological research [37]. However, NGS is not yet in routine use for veterinary testing, and recent studies have attempted to utilize NGS technology for PRRSV WGS based on several different methods and sequencing platforms [23, 38, 39]. Sequence-independent, single-primer amplification (SISPA) is a random priming method that allows the enrichment of the viral genome in only a few steps [40, 41]. The value of the high sensitivity of NGS combined with target-independent genome amplification has been proven via the identification of novel viruses from various samples in previous studies [42,43,44,45]. However, to the authors’ knowledge, NGS utilizing the SISPA method (SISPA-NGS) has not been tested or applied in PRRSV.
As the majority of PRRSV genomic sequences submitted to GenBank were contributed by the United States and China [46], the two leading pig-raising countries, the need to identify the prevalent features and genetic variation of unique Korean strains at the whole-genome level has increased [47]. Thus, the purpose of this study was to establish and assess the SISPA-NGS method with the Illumina iSeq 100 platform for PRRSV WGS and to characterize genomic features at the whole-genome level by sequencing archived Korean PRRSV strains.
Materials and methods
Cell culture and virus propagation
A total of 19 representative Korean PRRSV isolates that have been most prevalent in the last two decades [48] and two reference strains, namely, VR-2332 (GenBank: AY150164) and JA142 (GenBank: AY424271), were cultured in MARC-145 cells or primary porcine alveolar macrophages (PAMs) in RPMI-1640 medium containing 10% fetal bovine serum and 1% antibiotic–antimycotic at 37 °C in a humid 5% CO2 atmosphere. The virus stock was prepared via three consecutive freeze/thaw cycles of the infected cells when approximately 90% of the infected cells showed a cytopathic effect (CPE). The virus-containing cell lysate was clarified by centrifugation at 4000 rpm for 30 min at 4 °C. The clarified samples were filtered through a 0.22-µm-pore-size filter and collected in a sterile container. The collected viruses were kept at − 80 °C until use.
Virus concentration and RNA preparation
Before applying NGS to the Korean PRRSV strains, we compared PRRSV cDNA preparation procedures using a cell-cultured reference strain (VR-2332) [see Additional file 1]. A total of 8 cDNA preparation methods were tested (designated method 1–method 8). The virus-cultured cell supernatant (method 1 ~ method 4) and concentrated supernatant (method 5–method 8) were used to determine the effect of the PRRSV concentration method. Virus concentration/ultrafiltration was performed with 15 ml of clarified sample by centrifugation at 4000 rpm and 4 °C until all the samples were filtered utilizing a VivaSpin®20 unit with a 300,000 Da molecular weight cutoff (MWCO) (Vivascience) as previously described [49]. Viral RNA was extracted using a QIAamp Viral RNA Mini Kit (Qiagen) according to the manufacturer’s instructions. The extracted RNA was treated with a DNase Max Kit (Qiagen) and purified with Agencourt RNA Clean XP beads (Beckman Coulter) following the manufacturer’s instructions. Purified RNA was examined with a NanoDrop spectrophotometer and a Qubit 2.0 fluorometer using a Qubit RNA BR Assay Kit. Real-time reverse transcription-polymerase chain reaction (RT–qPCR) was performed for the quantification of viral RNA using the Prime-Q PCV2 PRRSV Detection Kit (Genet Bio, Daejeon, South Korea). The prepared RNAs were stored at − 80 °C until use.
cDNA preparation and next-generation sequencing
Different combinations of simple random hexamer cDNA synthesis (RH), RNA fragmentation (RF), and SISPA techniques for generating double-stranded (ds) cDNA were tested: methods 1 and 5, RH; methods 2 and 6, RF + RH; methods 3 and 7, SISPA; and methods 4 and 8; RF + SISPA [see Additional file 1] [38, 40, 43, 50]. For RF, 100 ng of the prepared RNA was fragmented using a NEBNext Magnesium RNA Fragmentation Module (NEB) with a 2 min incubation time, and fragmented RNA was purified using the GeneJet RNA Cleanup and Concentration Micro Kit following the manufacturer’s instructions. A 100-ng sample of fragmented or nonfragmented RNA was used for conduct reverse transcription (SuperScript IV First-Stand Synthesis System, Invitrogen) with random hexamers provided in the kit (methods 1, 2, 5, and 6) or with the SISPA primer (K-6 N) (methods 3, 4, 7, and 8). The synthesized first-strand cDNA was subsequently treated with 1 µl of RNase H for 30 min at 37 °C. For the RH and RF + RH methods, 21 µl of first-strand cDNA was incubated at room temperature (RT) for 30 min in the presence of 1 µl of 10 mM dNTPs, 1 µl of Klenow fragment, 1 µl of E. coli DNA ligase (NEB), 5 µl of 10 × E. coli ligation buffer (NEB) and 21 µl of DEPC-treated water (final volume 50 µl). For the SISPA and RF + SISPA methods, 21 µl of first-strand cDNA, 1 µl of 100 pmol of SISPA primer (K-6N), 1 µl of 10 mM dNTPs, 1 µl of Klenow fragment, 5 µl of 10 × Klenow reaction buffer (NEB) and 21 µl of DEPC-treated water (final volume 50 µl) were mixed and incubated at RT for 30 min. After conversion to ds cDNA by the Klenow reaction, the products were purified using Agencourt AMPure XP beads (Beckman Coulter). For methods including SISPA, 5 µl of the ds cDNA was used as template for PCR amplification in a final reaction volume of 50 µl, which contained 1 × Platinum SuperFi II Green PCR Master Mix (Thermo Fisher) and 10 µM SISPA primer (K). PCR cycling was performed as follows: 98 °C for 30 s, followed by 35 cycles of 98 °C for 10 s, 60 °C for 10 s, and 72 °C for 30 s, with a final extension at 72 °C for 5 min. The PCR products were purified with Agencourt AMPure XP beads (Beckman Coulter). The final ds cDNA products were quantified using a Qubit dsDNA HS Assay Kit (Invitrogen).
One hundred nanograms of the prepared ds-cDNA and the Nextera DNA Flex Library Prep Kit were used to generate multiplexed paired-end sequencing libraries according to the manufacturer’s instructions. The prepared sequencing libraries were analyzed with a High Sensitivity DNA Chip on a Bioanalyzer (Agilent Technologies). A barcoded multiplexed library pooled with 3% PhiX (positive control) was sequenced on the Illumina iSeq 100 platform (2 × 150 bp).
Bioinformatics
The adaptor and index sequences of the reads were trimmed, and low-quality sequences were filtered out using AfterQC version 0.9.6 [51]. The filtered reads were mapped to the VR-2332 reference genome (AY150564) and the host genome (AQIB01) using Minimap2 [52] version 2.17 with the following command modifications of the default parameters: -k 7 for virus and -k 14 for host. Read coverage was calculated using QualiMap version 2.2.1 [53]. Host-unmapped reads were extracted using SAMtools [54] and subsequently used for de novo assembly by SPAdes version 3.14.1 with the -meta command [55]. The generated contigs were subjected to BLAST analysis to identify the longest PRRSV-matching contig. The longest contigs that were close to the genome size of VR-2332 (15,451 bp) were used for quality assessment of the genome assembly with Quast version 5.0.2 [56]. Reference sequences and assembled contigs were aligned using Lasergene software (DNASTAR Inc.) to assess the ability to sequence the 5′ and 3′UTRs.
WGS of Korean PRRSV isolates
Subsequently, a total of 20 PRRSV strains that were isolated and archived in our laboratory were sequenced via the established SISPA-NGS procedure (method_7) with a maximum of 6 samples per sequencing batch. Among these strains, the WGS of JA142 (AY424271), CBNU0495 (KY434183) and D40 (KY434184) was performed as a resequencing analysis of the known genome to confirm the fidelity of the established procedure, and the other Korean PRRSV strains were sequenced for novel genome assembly. For data analysis, filtering of the raw data and de novo assembly were conducted as described above. Newly obtained Korean PRRSV whole genome sequences were submitted to GenBank under accession numbers MW847781 and MZ287313–MZ287330. To determine the cutoff Cq value for successful WGS, the Prime-Q PCV2 PRRSV Detection Kit (GeNet Bio Inc., Daejun, Korea) was used to extract RNAs according to the manufacturer’s instructions.
Phylogenetic analysis
A total of 69 representative PRRSV strains were obtained from the GenBank database, including all the Korean strains that were available in the database as of November 2020 [see Additional file 2]. All the sequences were aligned using Clustal Omega, including the 19 newly obtained whole-genome sequences from this study [57]. Phylogenetic trees of the complete genome and ORF5 were constructed by using RAxML-NG [58] with 1,000 bootstrap replicates and the GTRGAMMA nucleotide substitution model. The constructed trees were visualized and edited using FigTree software [59].
NSP2 polymorphic pattern analysis
To identify the various INDEL patterns of NSP2, all the complete sequences described above were split and aligned with the Lelystad virus (PRRSV1) or VR-2332 (PRRSV2) as a reference using Clustal Omega. The alignment was split to obtain NSP2 sequences based on the reference annotation and realigned based on aa sequences by using Clustal Omega. The aligned aa sequences were then converted to a nucleotide alignment with PAL2NAL software to obtain an accurate alignment as previously described [46, 60]. The INDEL patterns of NSP2 at the aa level were visualized using the NCBI Multiple Sequence Alignment (MSA) tool.
SimPlot and recombination analysis
To detect recombination events among the Korean strains, nine lineage representative strains (Amervac, KNU07, CBNU0495, RespPRRS_MLV, NADC30, NADC34, K07-2273, JB15-N-PJ10-GN and KU-N1606) were selected based on time inferences and previous reports of the epidemiological status of PRRSV in Korea [14, 18,19,20,21, 47, 61, 62]. After the alignment of whole-genome sequences, the representative strains listed above were queried as recombinant parental strains and analyzed with SimPlot version 3.5.1 [63] with a window size of 500 bp and a step size of 20 bp to identify potential recombination events and breakpoints. Subsequently, the sequences were analyzed using RDP v4.9.6 [64], and recombination events were indicated when seven methods reported positive recombination signals (RDP, GENECONV, BootScan, Maxchi, Chimaera, SiScan, and 3Seq). The final recombination events were determined after taking into consideration both the SimPlot and RDP results.
Results
Comparison of cDNA preparation methods
All the methods resulted in nearly 100% mapping to the reference, but the methods that included the SISPA protocol showed 100% coverage with greater depth than the other methods and generated fewer low-quality reads than the methods using random hexamers for ds cDNA construction [see Additional file 3]. Although complete or near-complete virus genome sequences could be obtained by de novo assembly by all the methods [see Additional file 4], only assembly via method_7 (virus concentration + SISPA) allowed the full sequences of the 5′ and 3′ UTRs of the virus to be retrieved [see Additional file 5].
PRRSV WGS with the SISPA-NGS method
To obtain the whole-genome sequences of all the Korean PRRSV strains and reference strains, the ds-cDNAs of all the virus stocks were constructed using the SISPA-NGS method (method_7) and sequenced on the iSeq100 platform (Table 1). The assembled sequences of the JA142, D40 and CBNU0495 strains, which were used as resequencing controls, showed highly consistent nucleotide identity with the corresponding reference sequence (99.87% to 99.97%) [see Additional file 6] (Table S4). The whole-genome sequences of all the viral stocks were successfully assembled without any gaps, allowing the recovery of complete or near-complete genome sequences, while the average contig read depth differed according to the Cq values of the stocks (Table 1). The read depth of the PRRSV genomic sequences decreased as the Cq value decreased, and the approximate cutoff Cq value for whole-genome assembly was 18.96 (Fig. 1).

Correlation between contig coverage and virus Cq value for de novo assembly. Different colors indicate each batch of sequencing conducted on the iSeq 100 platform
Phylogenetics and NSP2 INDEL patterns of Korean PRRSV1
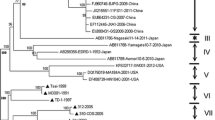
Phylogenetic trees were constructed based on the ORF5, whole-genome and NSP2 nucleotide sequences of the Korean PRRSV strains to identify genetic characteristics at the level of each gene or genome (Fig. 2). Among seven Korean PRRSV1 isolates, six isolates could be grouped into PRRSV1 sub1A, which formed a unique branch, separate from those of PRRSV1 strains from other countries, at the ORF5 and whole-genome levels. One Korean PRRSV1 isolate was close to strain SHE and the Amervac vaccine strain at the ORF5 and whole-genome levels and was included in the PRRSV1 sub1C group (Fig. 2). At the NSP2 level, Korean PRRSV1 showed the same phylogenetic pattern observed at the ORF5 and whole-genome levels. However, NSP2 INDEL pattern analysis revealed that all the Korean PRRSV1 sub1A isolates showed a unique 19-aa deletion (aa positions 361–379 in the Lelystad virus), and one strain, CBNU0495, showed an additional 11-aa deletion (aa positions 280–290) (Fig. 3a and Additional file 7).

Midpoint-rooted phylogenetic tree of a ORF5 and b the whole-genome sequences of Korean isolates and representative reference strains. Korean isolates newly sequenced in this study are indicated in bold. Lineages of PRRSV1 and PRRSV2 are color-coded and include lineages 1 (blue), 5 (red), KOR A (teal), KOR B (lime), KOR C (orange), sub1A (purple), and sub1C (aqua). Trees were generated by RAxML-NG with 1,000 bootstrap replicates using the GTRGAMMA nucleotide substitution model

Schematic diagram of multiple alignments of NSP2 amino acid sequences relative to a the Lelystad virus (PRRSV1) and b VR-2332 (PRRSV2). The illustration on the top represents the organization of the PRRSV NSP2 protein, featuring a putative cysteine domain (PL2) between two hypervariable (HV) regions. The trees on the left were generated and color-coded based on NSP2 nucleotide sequences, as indicated in Fig. 2. Multiple sequence alignments (MSAs) were generated by using the NCBI MSA tool version 1.18, with coloration based on the BLOSUM62 matrix. Detailed MSAs of the PRRSV1 and PRRSV2 isolates are illustrated in Additional files 7 and 8, respectively
Phylogenetic analysis and NSP2 INDEL patterns of Korean PRRSV2
With regard to PRRSV2, all the Korean PRRSV2 isolates could be divided by ORF5 lineage classification into lineage 5, lineage 1 and Korean-specific clusters (LKA, LKB, and LKC) (Fig. 2a). The Korean strains classified into lineage 5 were related to the RespPRRS_MLV strain at the ORF5 and NSP2 levels and at the whole-genome level, indicating that they are MLV-like viruses. Two strains from lineage 5 showed different patterns from the other MLV-like strains. Strain JB15-N-M8 showed a unique 150-aa deletion (aa position; 615–764 in VR-2332) in the hypervariable (HV) region of NSP2. Strain KU-N1202, which was previously reported as a recombinant strain [21], exhibited an ORF5 phylogeny close to that of MLV strains. However, at the whole-genome and NSP2 levels, the strain was clustered into the Korean lineage group (Figs. 2, 3b and Additional file 8).
The Korean strains within lineage 1 could be divided into two groups at the ORF5 and whole-genome levels by phylogenetic analysis; one group (JB15-NP31-GB, JB15-N-PJ73-GN, and KU-N1702 strain) was close to the highly pathogenic NADC30 strain, and the other group (JBNU-19-N01 and JBNU-20-N01 strain) was relatively close to the NADC31 or NADC34 strain (Fig. 2). However, all the Korean lineage 1 strains in both groups were close to NADC30 in the NSP2 phylogenetic analysis. The NSP2 aa structures of both groups showed the same deletion pattern of 111-aa (aa positions 323–433 in VR-2332), 1-aa (aa position 485), and 19-aa (aa positions 501–519) deletions (“111 + 1 + 19”) in the HV region of NSP2, which was consistent with the findings for the NADC30 strain (Fig. 3b and Additional file 8).
The Korean strains that could be clearly classified into three distinct Korean-specific clusters (LKA, B and C) by ORF5 phylogenetic analysis were merged into one large branch with two subbranches by whole-genome and NSP2 phylogenetic analysis, indicating that they shared a potential common ancestor or showed recombination (Figs. 2, 3b). Interestingly, whole-genome phylogenetic analysis demonstrated that the strains that were isolated before 2015 formed one subbranch, and those that were isolated after 2015 formed the other subbranch (Fig. 2b). All the Korean lineage strains shared a common “111 + 1 + 19” deletion pattern in the HV region, which was exactly the same pattern observed for the NADC30 strain or K07-2273 strain (Fig. 3b and Additional file 8).
Recombination analysis of Korean PRRSV2
As a few Korean PRRSV2 isolates showed the possibility of recombination in the ORF5, whole-genome and NSP2 phylogenetic analyses, SimPlot software was utilized to determine potential recombination events and breakpoints by querying the potential parental strains based on the corresponding time inferences and impacts [see Additional file 9]. Strains RespPRRS_MLV (L5), NADC30 (L1), NADC34 (L1), KU-N1606 (LKA), 2015-N-PJ10-GN (LKB) and K07-2273 (LKC) were selected as potential parents of other Korean strains. Subsequent genetic recombination analysis performed with seven methods in RDP4 software indicated recombination signals in 8 Korean PRRSV strains (Table 2, Fig. 4, and Additional file 10).

Recombination detection in Korean isolates. The x-axis indicates the genomic position, and the y-axis indicates the pairwise identity between the major parent and minor parent (yellow), between the major parent and the recombinant strain (green), or between the minor parent and the recombinant strain (purple). The range of recombination is shaded in red
The K07-2273 strain (LKC, isolated in 2007) was the major parent of all the recombinant strains isolated before 2016. All of these recombinants showed the vaccine strain RespPRRS_MLV as the minor parent, with recombination hotspots ranging from NSP8 and NSP12. Additionally, these recombinant strains possessed different ORF5 lineage phylogenies (GGYC45; LKB, GBGJ22; LKA, and KU-N1202 and JB15-N-PJ4-GN; L5) from their major parent strain, K07-2273 (LKC) (Fig. 2), indicating that the KLC lineage might have been responsible for the emergence of nation-specific Korean lineages through recombination with the MLV strain after vaccine introduction in Korea in the early 2010s.
After 2016, since the LKB and LKC strains emerged, the KNU-1901 and KNU-1902 strains showed recombination signals with KU-N1606 (LKA) as the major strain and K07-2273 (LKC) as the minor strain, with the recombination regions ranging from ORF3 to ORF7. Among lineage 1 strains, the JBNU-19-N01 and JBNU-20-N01 strains showed recombination signals with NADC30 as the major strain and NADC34 as the minor strain, with recombination regions of NSP2 and NSP10 (Table 2). No potential recombination event or breakpoint was detected in the PRRSV1 isolates.
Discussion
The epidemiology of PRRSV has been investigated largely by sequencing the ORF5 gene and classifying virus lineages based on ORF5 phylogenetic analysis since the ORF5 lineage classification system was established [15, 16]. However, due to the error-prone nature of PRRSV RdRp and frequent recombination among field strains or vaccine strains, an urgent need for WGS and genome-based analysis has been demonstrated recently. In Korea, ORF5 sequencing has been used in most diagnostic laboratories and has identified PRRSV outbreaks and the emergence of Korean nation-specific lineages [14, 18,19,20, 62, 65]. However, the origin and genetic characteristics of these novel lineages remain unclear due to the limited available whole-genome information, as only 12 PRRSV whole-genome sequences are available in the GenBank database. Furthermore, recent reports of recombinant strains in Korea indicate that ORF5 sequencing is no longer sufficient for the complete identification or classification of PRRSV isolates [21, 47, 61, 66]. Thus, the purposes of this study were to establish a WGS method for retrieving PRRSV whole-genome sequences and to analyze the PRRSV genetic diversity in Korea at the whole-genome level.
WGS provides an unsurpassed level of genetic information. In this study, we compared cDNA preparation methods using random hexamers with or without RNA fragmentation and SISPA with or without RNA fragmentation [see Additional file 1]. SISPA is a random priming method that allows the enrichment of a viral genome in only a few steps, which is very useful for obtaining genome sequences from RNA viruses or complex clinical samples, as no prior sequence information is needed [43]. As expected, more virus reads could be generated from samples using SISPA than by using non-SISPA methods [see Additional file 3], resulting in the retrieval of complete genome sequences with a higher depth of coverage [see Additional files 4 and 5]. Moreover, we applied a 300,000 Da MWCO membrane to concentrate PRRSV particles from the cell-cultured supernatant as previously described [49], resulting in a higher initial virus titer, shown as a lower Cq value [see Additional file 3]. Such virus filtration or concentration protocols are common methods for capturing and sequencing unknown virus pools from samples with large volumes, such as ocean water samples [67, 68]. With the advantages mentioned above, the established SISPA-NGS method coupled with virus concentration in this study enabled the successful WGS of cell-cultured PRRSV isolates without prior sequence information (Table 1 and Additional file 6). However, the detection limit based on the Cq value (18.96) was lower than that indicated in a previous report that used the MiSeq platform (20.6 ~ 23.6) [38] (Fig. 1). This might have been due to the reduced data output of the iSeq100 platform, which allows smaller batch sizes than higher-throughput sequencers, such as the MiSeq system [69], resulting in a less sufficient depth of coverage for de novo assembly. It will be necessary to test the established NGS method with clinical samples and other sequencers in the future.
The Korean PRRSV strains newly sequenced in this study were classified into distinct lineages by the ORF5 lineage classification system as previously reported in Korea [14, 48]: subtype 1A, subtype 1C, lineage 1, lineage 5, lineage KOR A (LKA), KOR B (LKB), and KOR C (LKC) (Fig. 2a). With regard to PRRSV1 (EU type), phylogenetic analysis of the whole genome showed that Korean PRRSV subtype 1A viruses are highly divergent from viruses identified from other countries and share a low level of identity with each other (Fig. 2b), which is consistent with previous studies [18, 19]. As PRRSV1 continued to become increasingly prevalent and to impose an enormous economic burden in Korea, two PRRSV1 MLVs [Unistrain PRRS (Amervac) and Porcilis PRRS)] were introduced in Korea in 2014 [66]. A vaccine-like strain (subtype 1C) isolated in this study (strain JB15-E-M17-JB) shares > 99% nucleotide homology with the Unistrain PRRS or SHE strain at the whole-genome level (Fig. 2b). PRRSV1 subtype 1A strains isolated in Korea after 2015 (JB15-E-P47-GB, CBNU0495, and JBNU-19-E01 strains) are highly divergent from those isolated before 2015 (KNU-07, E38, and D40 strains) at the whole-genome level (Fig. 2b). As NSP2 INDEL pattern analysis indicated a consistent 19-aa deletion among PRRSV1 subtype 1A strains (Fig. 3a and Additional file 7) and no recombination signal was detected among PRRSV1 strains, it is suspected that increased independent evolution of Korean PRRSV1 subtype 1A is ongoing in the field. Indeed, a recent study in Korea revealed that PRRSV1 MLV vaccination increased viral genetic heterogeneity and the emergence of new glycosylation sites among Korean subtype 1A viruses when comparisons were conducted before and after vaccine adoption in the field [66]. Continuous surveillance of the dynamics of PRRSV1 evolution in Korea should be further performed at the whole-genome level.
With regard to PRRSV2, vaccine variants of Ingelvac MLV (RespPRRS_MLV) with high nucleotide homology (> 95%) and a consistent NSP2 INDEL pattern were confirmed, except that the JB15-N-M8 strain had a unique 150-aa deletion in the HV region (Figs. 2b, 3b and Additional file 8). In lineage 1, NADC30-like strains (sublineage 1.8) that have emerged since 2015 in Korea [14] and non-NADC30-like strains that were closely related to the ISU30 strain at the whole-genome level were detected based on whole-genome phylogenetic analysis (Fig. 2b). These non-NADC30-like viruses (strains JBNU-19-N01 and JBNU-20-N01) were first isolated in Korea in 2017 [48] and were classified into sublineage 1.6 (close to strain NADC31) based on ORF5 (Fig. 2a). However, these viruses were confirmed to be recombinants of NADC30 and NADC34 through RDP and SimPlot analyses (Table 2 and Additional file 9). The NADC34-like (or RFLP 1–7-4) lineage, which emerged in the United States in 2014, is a highly pathogenic cluster of lineage 1 that causes dramatic abortion ‘storms’ in sow herds and high mortality among piglets [35]. It was subsequently detected in China beginning in 2017 [70], and some Chinese NADC34-like strains were confirmed to be recombinants of NADC34 as the major parent and NADC30 or ISU30 as the minor parent, with recombination in the NSP2 or ORF4-5 region [71]. Likewise, the lineage 1 recombinants identified in this study showed recombination involving NADC34 as the major parent and NADC30 as the minor parent, with recombination signals in the NSP2 and NSP10 regions (Table 2 and Additional file 9). Although it is not clear whether the observed recombination occurred among Korean field isolates or the recombinant strains were initially imported from outside of the country, lineage 1 viruses have been confirmed to be spreading extensively in Korea since 2017 [48]. Thus, the clinical manifestations and continual surveillance of these lineage 1 recombinants should be further assessed and monitored.
Recombination is a pervasive phenomenon among PRRSV isolates and is an important strategy for the generation of viral genetic diversity as a result of increased virulence and/or the generation of novel genotypes [30, 32, 72,73,74]. As variants of PRRSV2, Korean lineages (LKA, B and C) have been found to be prevalent in Korean swine herds, but the origin of these nation-specific lineages is currently unknown [14, 48]. Considering the epidemiology of PRRSV2 in Korea, it is suspected that genomic recombination between the LKC and Ingelvac MLV (RespPRRS_MLV) strains might have been involved in the generation of LKB (Fig. 5). Following the first identification of PRRSV2 in Korea in the 1980s [17], the Ingelvac MLV was commercialized in Korea in 1996 [75]. LKA and LKC have been isolated from Korean swine herds since 2003 and 2005, respectively [62, 75]. A study that investigated ORF5 sequences collected from 2003 to 2016 indicated that LKB was first detected in samples collected since 2014 [14]. In this study, multiple recombination signals were detected among Korean lineages, with K07-2273 (LKC) as the major parent and Ingelvac MLV as the minor parent of the strains isolated in the early 2010s (Table 2 and Fig. 4). The analysis of NSP2 INDEL patterns suggested that the Korean lineages originated from the same parents, as identical discontinuous 131-aa deletion patterns were identified in the HV region of NSP2 (Fig. 3b and Additional file 8), which is a well-established pattern in NADC30-like or MN184-like viruses [34, 76]. Among the recombinants identified among the isolates from the early 2010s, the GGYC45 strain (isolated in 2010) is suspected to be the ancestor of current LKB strains, as it is the earliest strain that possesses the ORF5 gene of LKB, since LKB strains emerged in 2014. Given that Korean PRRSV2 evolved independently with genetic heterogeneity in antigenic regions of structural proteins [61], recombination between the Korean-specific lineage (LKC) and the MLV strain in NSP regions, together with evolution in the structural protein regions that resulted in the LKB-like ORF5 gene, might have induced the emergence of a novel sublineage. Although more evidence should be collected and analyzed, it is well known that the extensive use of live-attenuated vaccines contributes to the increased PRRSV genetic diversity in the field [77, 78], and several studies have reported PRRSV2 recombinants involving MLVs [79, 80]. Since multiple lineages of PRRSV2, including MLV variants, Korean lineages and imported lineage 1 viruses are circulating in Korea [48], there is a potential risk of recombination between different lineages. Further research on PRRSV evolution followed by continuous surveillance at the whole-genome level in Korea is needed.

Schematic diagrams of PRRSV2 epidemiology in Korean pig herds. The top illustration shows the timeline of PRRSV2 epidemiology in Korea based on previous reports. The bottom illustration indicates the spreading of each lineage and recombination event
Conclusions
In summary, we established NGS using the SISPA protocol for successful WGS of PRRSV field isolates. Genomic sequence analysis revealed continuous independent evolution of PRRSV1 and evidence of multiple recombination events between PRRSV2 MLV variants and Korean lineages that are prevalent in Korea. Additionally, potential recombinant NADC30-like and NADC34-like strains could be detected in this study. As Korea is an isolated country with very tight borders, the independent evolutionary dynamics observed in Korea could contribute to the general knowledge of PRRSV evolution. Our study highlights the importance of continued monitoring of PRRSV and new vaccine strategies for more efficient control of the virus.
Availability of data and materials
All data generated or analyzed during this study are included in this published article (and its supplementary information files).
Abbreviations
- PRRSV:
-
Porcine reproductive and respiratory syndrome virus
- SISPA:
-
Sequence-independent, single-primer amplification
- NGS:
-
Next-generation sequencing
- UTR:
-
Untranslated region
- RdRp:
-
RNA-dependent RNA polymerase
- ORF:
-
Open reading frame
- NSP:
-
Nonstructural protein
- INDEL:
-
Insertion and deletion
- MLV:
-
Modified live vaccine
- WGS:
-
Whole-genome sequencing
- PAM:
-
Porcine alveolar macrophage
- CPE:
-
Cytopathic effect
- RH:
-
Random hexamer
- RF:
-
RNA fragmentation
- RT:
-
Room temperature
References
Keffaber K. Reproduction failure of unknown etiology. Am Assoc Swine Pract Newsl. 1989;1:1–9.
Holtkamp DJ, Kliebenstein JB, Neumann E, Zimmerman JJ, Rotto H, Yoder TK, Wang C, Yeske P, Mowrer CL, Haley CA. Assessment of the economic impact of porcine reproductive and respiratory syndrome virus on United States pork producers. J Swine Health Prod. 2013;21:72.
Neumann EJ, Kliebenstein JB, Johnson CD, Mabry JW, Bush EJ, Seitzinger AH, Green AL, Zimmerman JJ. Assessment of the economic impact of porcine reproductive and respiratory syndrome on swine production in the United States. J Am Vet Med Assoc. 2005;227:385–92.
Murtaugh MP, Stadejek T, Abrahante JE, Lam TT. Leung FC-C: The ever-expanding diversity of porcine reproductive and respiratory syndrome virus. Virus Res. 2010;154:18–30.
Johnson CR, Griggs TF, Gnanandarajah J, Murtaugh MP. Novel structural protein in porcine reproductive and respiratory syndrome virus encoded by an alternative ORF5 present in all arteriviruses. J Gen Virol. 2011;92:1107.
Adams MJ, Lefkowitz EJ, King AM, Harrach B, Harrison RL, Knowles NJ, Kropinski AM, Krupovic M, Kuhn JH, Mushegian AR. Changes to taxonomy and the International Code of Virus Classification and Nomenclature ratified by the International Committee on Taxonomy of Viruses (2017). Adv Virol. 2017;162:2505–38.
Nelsen CJ, Murtaugh MP, Faaberg KS. Porcine reproductive and respiratory syndrome virus comparison: divergent evolution on two continents. J Virol. 1999;73:270–80.
Forsberg R. Divergence time of porcine reproductive and respiratory syndrome virus subtypes. Mol Biol Evol. 2005;22:2131–4.
Hanada K, Suzuki Y, Nakane T, Hirose O, Gojobori T. The origin and evolution of porcine reproductive and respiratory syndrome viruses. Mol Biol Evol. 2005;22:1024–31.
Pirzadeh B, Gagnon CA, Dea S. Genomic and antigenic variations of porcine reproductive and respiratory syndrome virus major envelope GP5 glycoprotein. Can J Vet Res. 1998;62:170.
Wissink E, Kroese M, Van Wijk H, Rijsewijk F, Meulenberg J, Rottier P. Envelope protein requirements for the assembly of infectious virions of porcine reproductive and respiratory syndrome virus. J Virol. 2005;79:12495–506.
Delisle B, Gagnon CA, Lambert M-È, D’Allaire S. Porcine reproductive and respiratory syndrome virus diversity of Eastern Canada swine herds in a large sequence dataset reveals two hypervariable regions under positive selection. Infect Genet Evol. 2012;12:1111–9.
Gao J-C, Xiong J-Y, Ye C, Chang X-B, Guo J-C, Jiang C-G, Zhang G-H, Tian Z-J, Cai X-H, Tong G-Z. Genotypic and geographical distribution of porcine reproductive and respiratory syndrome viruses in mainland China in 1996–2016. Vet Microbiol. 2017;208:164–72.
Kang H, Yu JE, Shin J-E, Kang A, Kim W-I, Lee C, Lee J, Cho I-S, Choe S-E, Cha S-H. Geographic distribution and molecular analysis of porcine reproductive and respiratory syndrome viruses circulating in swine farms in the Republic of Korea between 2013 and 2016. BMC Vet Res. 2018;14:160.
Shi M, Lam TT-Y, Hon C-C, Hui RK-H, Faaberg KS, Wennblom T, Murtaugh MP, Stadejek T, Leung FC-C. Molecular epidemiology of PRRSV: a phylogenetic perspective. Virus Res. 2010;154:7–17.
Shi M, Lam TT-Y, Hon C-C, Murtaugh MP, Davies PR, Hui RK-H, Li J, Wong LT-W, Yip C-W, Jiang J-W. Phylogeny-based evolutionary, demographical, and geographical dissection of North American type 2 porcine reproductive and respiratory syndrome viruses. J Virol. 2010;84:8700–11.
Shin J, Kang Y, Kim Y, Yeom S, Kweon C, Lee W, Jean Y, Hwang E, Rhee J, An S. Sero-epidemiological studies on porcine reproductive and respiratory syndrome in Korea-(1)-Detection of indirect fluorescent antibodies. RDA J Agric Sci (Korea Republic). 1993;35:572–6.
Kim J-Y, Lee S-Y, Sur J-H, Lyoo YS. Serological and genetic characterization of the European strain of the porcine reproductive and respiratory syndrome virus isolated in Korea. Korean J Vet Res. 2006;46:363–70.
Nam E, Park C-K, Kim S-H, Joo Y-S, Yeo S-G, Lee C. Complete genomic characterization of a European type 1 porcine reproductive and respiratory syndrome virus isolate in Korea. Adv Virol. 2009;154:629–38.
Kim S-H, Roh I-S, Choi E-J, Lee C, Lee C-H, Lee K-H, Lee K-K, Song Y-K, Lee O-S, Park C-K. A molecular analysis of European porcine reproductive and respiratory syndrome virus isolated in South Korea. Vet Microbiol. 2010;143:394–400.
Kwon T, Yoo SJ, Park JW, Kang SC, Park C-K, Lyoo YS. Genomic characteristics and pathogenicity of natural recombinant porcine reproductive and respiratory syndrome virus 2 harboring genes of a Korean field strain and VR-2332-like strain. Virology. 2019;530:89–98.
Slatko BE, Gardner AF, Ausubel FM. Overview of next-generation sequencing technologies. Curr Protoc Mol Biol. 2018;122:e59.
Tan S, Dvorak CM, Murtaugh MP. Rapid, unbiased PRRSV strain detection using MinION direct RNA sequencing and bioinformatics tools. Viruses. 2019;11:1132.
Franzo G, Cecchinato M, Martini M, Ceglie L, Gigli A, Drigo M. Observation of high recombination occurrence of porcine reproductive and respiratory syndrome virus in field condition. Virus Res. 2014;194:159–66.
Zhao K, Ye C, Chang X-B, Jiang C-G, Wang S-J, Cai X-H, Tong G-Z, Tian Z-J, Shi M, An T-Q. Importation and recombination are responsible for the latest emergence of highly pathogenic porcine reproductive and respiratory syndrome virus in China. J Virol. 2015;89:10712–6.
Bian T, Sun Y, Hao M, Zhou L, Ge X, Guo X, Han J, Yang H. A recombinant type 2 porcine reproductive and respiratory syndrome virus between NADC30-like and a MLV-like: genetic characterization and pathogenicity for piglets. Infect Genet Evol. 2017;54:279–86.
Wang A, Chen Q, Wang L, Madson D, Harmon K, Gauger P, Zhang J, Li G. Recombination between vaccine and field strains of porcine reproductive and respiratory syndrome virus. Emerg Infect Dis. 2019;25:2335.
Zhou L, Kang R, Yu J, Xie B, Chen C, Li X, Xie J, Ye Y, Xiao L, Zhang J. Genetic characterization and pathogenicity of a novel recombined porcine reproductive and respiratory syndrome virus 2 among Nadc30-like, Jxa1-like, and Mlv-like strains. Viruses. 2018;10:551.
Eclercy J, Renson P, Lebret A, Hirchaud E, Normand V, Andraud M, Paboeuf F, Blanchard Y, Rose N, Bourry O. A field recombinant strain derived from two type 1 porcine reproductive and respiratory syndrome virus (PRRSV-1) modified live vaccines shows increased viremia and transmission in SPF pigs. Viruses. 2019;11:296.
Liu D, Zhou R, Zhang J, Zhou L, Jiang Q, Guo X, Ge X, Yang H. Recombination analyses between two strains of porcine reproductive and respiratory syndrome virus in vivo. Virus Res. 2011;155:473–86.
Yuan S, Nelsen CJ, Murtaugh MP, Schmitt BJ, Faaberg KS. Recombination between North American strains of porcine reproductive and respiratory syndrome virus. Virus Res. 1999;61:87–98.
Liu J, Zhou X, Zhai J, Li B, Wei C, Dai A, Yang X, Luo M. Emergence of a novel highly pathogenic porcine reproductive and respiratory syndrome virus in China. Transbound Emerg Dis. 2017;64:2059–74.
Fang Y, Kim D-Y, Ropp S, Steen P, Christopher-Hennings J, Nelson EA, Rowland RR. Heterogeneity in Nsp2 of European-like porcine reproductive and respiratory syndrome viruses isolated in the United States. Virus Res. 2004;100:229–35.
Brockmeier SL, Loving CL, Vorwald AC, Kehrli ME Jr, Baker RB, Nicholson TL, Lager KM, Miller LC, Faaberg KS. Genomic sequence and virulence comparison of four Type 2 porcine reproductive and respiratory syndrome virus strains. Virus Res. 2012;169:212–21.
van Geelen AG, Anderson TK, Lager KM, Das PB, Otis NJ, Montiel NA, Miller LC, Kulshreshtha V, Buckley AC, Brockmeier SL. Porcine reproductive and respiratory disease virus: Evolution and recombination yields distinct ORF5 RFLP 1-7-4 viruses with individual pathogenicity. Virology. 2018;513:168–79.
Tong G-Z, Zhou Y-J, Hao X-F, Tian Z-J, An T-Q, Qiu H-J. Highly pathogenic porcine reproductive and respiratory syndrome, China. Emerg Infect Dis. 2007;13:1434.
Metzker ML. Sequencing technologies—the next generation. Nat Rev Genet. 2010;11:31–46.
Zhang J, Zheng Y, Xia X-Q, Chen Q, Bade SA, Yoon K-J, Harmon KM, Gauger PC, Main RG, Li G. High-throughput whole genome sequencing of porcine reproductive and respiratory syndrome virus from cell culture materials and clinical specimens using next-generation sequencing technology. J Vet Diagn Invest. 2017;29:41–50.
Kvisgaard LK, Hjulsager CK, Fahnøe U, Breum SØ, Ait-Ali T, Larsen LE. A fast and robust method for full genome sequencing of Porcine Reproductive and Respiratory Syndrome Virus (PRRSV) Type 1 and Type 2. J Virol Methods. 2013;193:697–705.
Djikeng A, Halpin R, Kuzmickas R, DePasse J, Feldblyum J, Sengamalay N, Afonso C, Zhang X, Anderson NG, Ghedin E. Viral genome sequencing by random priming methods. BMC Genomics. 2008;9:1–9.
Reyes GR, Kim JP. Sequence-independent, single-primer amplification (SISPA) of complex DNA populations. Mol Cell Probes. 1991;5:473–81.
Blomström A-L, Widén F, Hammer A-S, Belák S, Berg M. Detection of a novel astrovirus in brain tissue of mink suffering from shaking mink syndrome by use of viral metagenomics. J Clin Microbiol. 2010;48:4392–6.
Chrzastek K, Lee D, Smith D, Sharma P, Suarez DL, Pantin-Jackwood M, Kapczynski DR. Use of sequence-independent, single-primer-amplification (SISPA) for rapid detection, identification, and characterization of avian RNA viruses. Virology. 2017;509:159–66.
Victoria JG, Kapoor A, Li L, Blinkova O, Slikas B, Wang C, Naeem A, Zaidi S, Delwart E. Metagenomic analyses of viruses in stool samples from children with acute flaccid paralysis. J Virol. 2009;83:4642–51.
Worobey M, Watts TD, McKay RA, Suchard MA, Granade T, Teuwen DE, Koblin BA, Heneine W, Lemey P, Jaffe HW. 1970s and ‘Patient 0’ HIV-1 genomes illuminate early HIV/AIDS history in North America. Nature. 2016;539:98–101.
Yu F, Yan Y, Shi M, Liu H-Z, Zhang H-L, Yang Y-B, Huang X-Y, Gauger PC, Zhang J, Zhang Y-H. Phylogenetics, genomic recombination, and NSP2 polymorphic patterns of porcine reproductive and respiratory syndrome virus in China and the United States in 2014–2018. J Virol. 2020;94:e01813-e1819.
Park J, Choi S, Jeon JH, Lee K-W, Lee C. Novel lineage 1 recombinants of porcine reproductive and respiratory syndrome virus isolated from vaccinated herds: genome sequences and cytokine production profiles. Adv Virol. 2020;165:2259–77.
Kim S-C, Jeong C-G, Park G-S, Park J-Y, Jeoung H-Y, Shin G-E, Ko M-K, Kim S-H, Lee K-K, Kim W-I. Temporal lineage dynamics of the ORF5 gene of porcine reproductive and respiratory syndrome virus in Korea in 2014–2019. Arch Virol. 2021;166:2803–15.
Hu J, Ni Y, Dryman BA, Meng X, Zhang C. Purification of porcine reproductive and respiratory syndrome virus from cell culture using ultrafiltration and heparin affinity chromatography. J Chromatogr A. 2010;1217:3489–93.
Van Dijk EL, Jaszczyszyn Y, Thermes C. Library preparation methods for next-generation sequencing: tone down the bias. Exp Cell Res. 2014;322:12–20.
Chen S, Huang T, Zhou Y, Han Y, Xu M, Gu J. AfterQC: automatic filtering, trimming, error removing and quality control for fastq data. BMC Bioinform. 2017;18:91–100.
Li H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics. 2018;34:3094–100.
Okonechnikov K, Conesa A, García-Alcalde F. Qualimap 2: advanced multi-sample quality control for high-throughput sequencing data. Bioinformatics. 2016;32:292–4.
Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, Marth G, Abecasis G, Durbin R. The sequence alignment/map format and SAMtools. Bioinformatics. 2009;25:2078–9.
Bankevich A, Nurk S, Antipov D, Gurevich AA, Dvorkin M, Kulikov AS, Lesin VM, Nikolenko SI, Pham S, Prjibelski AD. SPAdes: a new genome assembly algorithm and its applications to single-cell sequencing. J Comput Biol. 2012;19:455–77.
Gurevich A, Saveliev V, Vyahhi N, Tesler G. QUAST: quality assessment tool for genome assemblies. Bioinformatics. 2013;29:1072–5.
Sievers F, Wilm A, Dineen D, Gibson TJ, Karplus K, Li W, Lopez R, McWilliam H, Remmert M, Söding J. Fast, scalable generation of high-quality protein multiple sequence alignments using Clustal Omega. Mol Syst Biol. 2011;7:539.
Kozlov AM, Darriba D, Flouri T, Morel B, Stamatakis A. RAxML-NG: a fast, scalable and user-friendly tool for maximum likelihood phylogenetic inference. Bioinformatics. 2019;35:4453–5.
Rambaut A, Drummond A: FigTree version 1.4. 0. 2012.
Suyama M, Torrents D, Bork P. PAL2NAL: robust conversion of protein sequence alignments into the corresponding codon alignments. Nucleic Acids Res. 2006;34:W609–12.
Kwon T, Yoo SJ, Sunwoo SY, Lee D-U, Sang HJ, Park JW, Park C-K, Lyoo YS. Independent evolution of porcine reproductive and respiratory syndrome virus 2 with genetic heterogeneity in antigenic regions of structural proteins in Korea. Adv Virol. 2019;164:213–24.
Kim H, Nguyen V, Kim I, Park J, Park S, Rho S, Han J, Park B. Epidemiologic and phylogenetic characteristics of porcine reproductive and respiratory syndrome viruses in conventional swine farms of Jeju Island as a candidate region for PRRSV eradication. Transbound Emerg Dis. 2012;59:62–71.
Lole KS, Bollinger RC, Paranjape RS, Gadkari D, Kulkarni SS, Novak NG, Ingersoll R, Sheppard HW, Ray SC. Full-length human immunodeficiency virus type 1 genomes from subtype C-infected seroconverters in India, with evidence of intersubtype recombination. J Virol. 1999;73:152–60.
Martin D, Murrell B, Golden M, Khoosal A, Muhire B. RDP4: detection and analysis of recombination patterns in virus genomes. Virus Evol. 2015;1:vev003.
Lee C, Kim H, Kang B, Yeom M, Han S, Moon H, Park S, Kim H, Song D, Park B. Prevalence and phylogenetic analysis of the isolated type I porcine reproductive and respiratory syndrome virus from 2007 to 2008 in Korea. Virus Genes. 2010;40:225–30.
Kwon T, Yoo SJ, Lee D-U, Sunwoo SY, Sang HJ, Park JW, Kim M-H, Park C-K, Lyoo YS. Differential evolution of antigenic regions of porcine reproductive and respiratory syndrome virus 1 before and after vaccine introduction. Virus Res. 2019;260:12–9.
Kim Y, Van Bonn W, Aw TG, Rose JB. Aquarium viromes: viromes of human-managed aquatic systems. Front Microbiol. 2017;8:1231.
Beaulaurier J, Luo E, Eppley JM, Den Uyl P, Dai X, Burger A, Turner DJ, Pendelton M, Juul S, Harrington E. Assembly-free single-molecule sequencing recovers complete virus genomes from natural microbial communities. Genome Res. 2020;30:437–46.
Colman RE, Mace A, Seifert M, Hetzel J, Mshaiel H, Suresh A, Lemmer D, Engelthaler DM, Catanzaro DG, Young AG. Whole-genome and targeted sequencing of drug-resistant Mycobacterium tuberculosis on the iSeq100 and MiSeq: a performance, ease-of-use, and cost evaluation. PLoS Med. 2019;16:e1002794.
Zhang H-L, Zhang W-L, Xiang L-R, Leng C-L, Tian Z-J, Tang Y-D, Cai X-H. Emergence of novel porcine reproductive and respiratory syndrome viruses (ORF5 RFLP 1-7-4 viruses) in China. Vet Microbiol. 2018;222:105–8.
Xu H, Song S, Zhao J, Leng C, Fu J, Li C, Tang Y, Xiang L, Peng J, Wang Q. A potential endemic strain in China: NADC34-like porcine reproductive and respiratory syndrome virus. Transbound Emerg Dis. 2020;67:1730–8.
Chen N, Yu X, Wang L, Wu J, Zhou Z, Ni J, Li X, Zhai X, Tian K. Two natural recombinant highly pathogenic porcine reproductive and respiratory syndrome viruses with different pathogenicities. Virus Genes. 2013;46:473–8.
Li B, Fang L, Xu Z, Liu S, Gao J, Jiang Y, Chen H, Xiao S. Recombination in vaccine and circulating strains of porcine reproductive and respiratory syndrome viruses. Emerg Infect Dis. 2009;15:2032.
Lu WH, Tun HM, Sun BL, Mo J, Zhou QF, Deng YX, Xie QM, Bi YZ. Leung FC-C, Ma JY: Re-emerging of porcine respiratory and reproductive syndrome virus (lineage 3) and increased pathogenicity after genomic recombination with vaccine variant. Vet Microbiol. 2015;175:332–40.
Cha S-H, Choi E-J, Park J-H, Yoon S-R, Song J-Y, Kwon J-H, Song H-J, Yoon K-J. Molecular characterization of recent Korean porcine reproductive and respiratory syndrome (PRRS) viruses and comparison to other Asian PRRS viruses. Vet Microbiol. 2006;117:248–57.
Zhou L, Wang Z, Ding Y, Ge X, Guo X, Yang H. NADC30-like strain of porcine reproductive and respiratory syndrome virus, China. Emerg Infect Dis. 2015;21:2256.
Zhou L, Yang X, Tian Y, Yin S, Geng G, Ge X, Guo X, Yang H. Genetic diversity analysis of genotype 2 porcine reproductive and respiratory syndrome viruses emerging in recent years in China. BioMed Res Int. 2014;2014:1–13.
Zhou L, Kang R, Ji G, Tian Y, Ge M, Xie B, Yang X, Wang H. Molecular characterization and recombination analysis of porcine reproductive and respiratory syndrome virus emerged in southwestern China during 2012–2016. Virus Genes. 2018;54:98–110.
Zhao H, Han Q, Zhang L, Zhang Z, Wu Y, Shen H, Jiang P. Emergence of mosaic recombinant strains potentially associated with vaccine JXA1-R and predominant circulating strains of porcine reproductive and respiratory syndrome virus in different provinces of China. Virol J. 2017;14:1–10.
Zhang Z, Qu X, Zhang H, Tang X, Bian T, Sun Y, Zhou M, Ren F, Wu P. Evolutionary and recombination analysis of porcine reproductive and respiratory syndrome isolates in China. Virus Genes. 2020;56:354–60.
Acknowledgements
Not applicable.
Funding
This study was supported by a Grant (Z-1543069-2017-20-1) from the Animal and Plant Quarantine Agency (QIA) and Bio & Medical Technology Development Program (2021M3E5E6019133) of the National Research Foundation of Korea.
Author information
Authors and Affiliations
Contributions
SCK and WIK conceived the study. HYG, GES, MKK, SHK and KKL performed sample collection. SCK, CGJ and GSP carried out the experiments. SCK, SHM and HSC analyzed the data. SCK drafted the manuscript. All authors have read and approved the final version of the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Additional file 1
. Workflow of the comparison of eight methods of cDNA preparation for NGS.
Additional file 2
. Representative PRRSV strains used in this study.
Additional file 3
. FASTQ quality control and mapping assessment of eight optimized cDNA preparation methods.
Additional file 4
. De novo assembly assessment by QUAST with contigs aligned to the reference genome.
Additional file 5
. Multiple sequence alignment of the reference genome and contigs generated from eight methods of cDNA preparation showing the 5′ and 3′UTRs.
Additional file 6
. BLAST results of newly assembled PRRSV whole-genome sequences.
Additional file 7
. Multiple sequence alignment of PRRSV1 NSP2.
Additional file 8
. Multiple sequence alignment of PRRSV2 NSP2, with the “111 + 1 + 19” deletions indicated with black dashed-line boxes.
Additional file 9
. SimPlot analysis querying potential major parent strains against Korean PRRSV isolates.
Additional file 10
. P value of seven methods (RDP, GENECONV, BootScan, Maxchi, Chimaera, SiScan, and 3Seq) applied in RDP4 software.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Kim, SC., Moon, SH., Jeong, CG. et al. Whole-genome sequencing and genetic characteristics of representative porcine reproductive and respiratory syndrome virus (PRRSV) isolates in Korea. Virol J 19, 66 (2022). https://doi.org/10.1186/s12985-022-01790-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12985-022-01790-6