
Abstract
Background
Machine learning has many attractive theoretic properties, specifically, the ability to handle non predefined relations. Additionally, studies have validated the clinical utility of mpMRI for the detection and localization of CSPCa (Gleason score ≥ 3 + 4). In this study, we sought to develop and compare machine-learning models incorporating mpMRI parameters with traditional logistic regression analysis for prediction of PCa (Gleason score ≥ 3 + 3) and CSPCa on initial biopsy.
Methods
A total of 688 patients with no prior prostate cancer diagnosis and tPSA ≤ 50 ng/ml, who underwent mpMRI and prostate biopsy were included between 2016 and 2020. We used four supervised machine-learning algorithms in a hypothesis-free manner to build models to predict PCa and CSPCa. The machine-learning models were compared to the logistic regression analysis using AUC, calibration plot, and decision curve analysis.
Results
The artificial neural network (ANN), support vector machine (SVM), and random forest (RF) yielded similar diagnostic accuracy with logistic regression, while classification and regression tree (CART, AUC = 0.834 and 0.867) had significantly lower diagnostic accuracy than logistic regression (AUC = 0.894 and 0.917) in prediction of PCa and CSPCa (all P < 0.05). However, the CART illustrated best calibration for PCa (SSR = 0.027) and CSPCa (SSR = 0.033). The ANN, SVM, RF, and LR for PCa had higher net benefit than CART across the threshold probabilities above 5%, and the five models for CSPCa displayed similar net benefit across the threshold probabilities below 40%. The RF (53% and 57%, respectively) and SVM (52% and 55%, respectively) for PCa and CSPCa spared more unnecessary biopsies than logistic regression (35% and 47%, respectively) at 95% sensitivity for detection of CSPCa.
Conclusion
Machine-learning models (SVM and RF) yielded similar diagnostic accuracy and net benefit, while spared more biopsies at 95% sensitivity for detection of CSPCa, compared with logistic regression. However, no method achieved desired performance. All methods should continue to be explored and used in complementary ways.
Similar content being viewed by others

Background
Prostate cancer (PCa) is the most common malignancy of the male reproductive system, with over one million cases and 358 989 deaths in 2018 [1, 2]. Prostate-specific antigen (PSA) testing, introduced in the 1990s, not only increased the incidence of clinically insignificant PCa (CSPCa, defined as Gleason score ≥ 3 + 4), but also led to an increased number of unnecessary biopsies. This is particularly the case in a PSA gray zone, at which 65–70% of men have a negative biopsy result [3]. In our study, the PCa and CSPCa were detected in 23% and 17%, 27% and 18%, 53% and 47%, 68% and 66%, 73% and 68%, and 93% and 93% of the men with serum total PSA (tPSA) in the range of ≤ 10 ng/ml, 10–20 ng/ml, 20–30 ng/ml, 30–40 ng/ml, 40–50 ng/ml, and > 50 ng/ml, respectively. Therefore, the major challenge is to identify CSPCa among cases with serum tPSA ≤ 50 ng/ml at an early stage.
Studies have validated the clinical utility of multiparametric resonance imaging (mpMRI) in the detection and localization of International Society of Urological Pathology grade ≥ 2 cancers [4, 5]. Additionally, predictive models have the potential to improve diagnostic accuracy to influence disease trajectory and reduce healthcare costs [6, 7]. To reduce unnecessary biopsy and overdiagnosis, a dozen of nomograms have been used to help diagnose PCa and/or CSPCa, including PCPT-RC [8], STHLM3 [9], ERSPC-RC [10], and CRCC-PC [11], which are based on standard statistical technique of logistic regression (LR).
Over the past decade, we have entered the era of big data, and major advancements have emerged in the fields of statistics, artificial intelligence technology and urological medicine [12, 13]. Machine learning-assisted models have been proposed as a supplement or alternative for standard statistical techniques, including artificial neural network (ANN), support vector machine (SVM), classification and regression tree (CART), and random forest (RF). Machine learning has many attractive theoretic characteristics, specifically, the ability to deal with non-predefined relations such as nonlinear effects and/or interactions, at the cost of reducing interpretability and explanation, especially for complex nonlinear models [14, 15]. However, model validation helps to discover domain-relevant models with better generalization ability, and further implies better interpretability. These new algorithms incorporating mpMRI parameters may help improve the diagnosis of CSPCa [16, 17], but available data is limited.
In this study, we sought to develop and evaluate of multiple supervised machine-learning models based on age, PSA derivates, prostate volume, and mpMRI parameters to predict PCa and CSPCa. Additionally, we compare our models with conventional LR analysis to evaluate whether there were improvements in the diagnostic ability, using the same variables and population.
Methods
Study populations
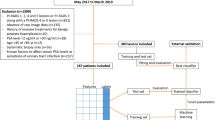
This retrospective study was approved by the Institutional Ethics Review Board, and a waiver of informed consent was obtained. Between April 2016 and March 2020, prostate biopsy and mpMRI examination was done among 903 consecutive patients without a prior prostate biopsy. The 25 patients diagnosed with other types of tumors, 94 patients with incomplete data, and 96 patients with tPSA > 50 ng/ml were excluded leaving 688 cases available for analysis.
Data collection
The clinical variables including the age at prostate biopsy, serum tPSA and free PSA (fPSA) level, reports of mpMRI examination, and results of prostate biopsy were extracted from clinical records. Prostate volume was measured using mpMRI examination, the ratio of fPSA (f/t PSA) was measured by dividing the (fPSA) by the tPSA, and the PSA density (PSAD) was calculated by dividing the tPSA by the prostate volume. All mpMRI examination were performed using the 3.0-T MRI system with a pelvic phased-array coil, complaint with European Society of Urology Radiology guidelines. The scan protocol for all patients included T2-weighted imaging, diffusion-weighted imaging, and dynamic contrast-enhanced imaging. The prostate mpMRI images were interpreted by two experienced genitourinary radiologists with at least three years of prostate mpMRI experience. The mpMRI results were divided into groups according to the reports: “negative”, “equivocal”, and “suspicious” for the presence of PCa (MRI-PCa), seminal vesicle invasion (MRI-SVI), lymph node invasion (MRI-LNI) according to the mpMRI reports.
All patients underwent transrectal ultrasound-guided systematic12-point biopsy according to the same protocol by three surgeons. If suspected malignant nodules by mpMRI and/or ultrasound, additional 1–5 needles were performed in regions with cognitive MRI-ultrasound fusion and/or abnormal ultrasound echoes. Biopsy cores were analyzed according to the standards of International Society of Urological Pathology.
Machine learning-assisted methods
Four types of supervised machine learning-based methods (ANN, SVM, CART, and RF) were applied in this study. Nine variables comprising age, PSA derivates (tPSA, f/tPSA, and PSAD), prostate volume, mpMRI results (MRI-PCa, MRI-SVI, and MRI-LNI), and results of prostate biopsy were used to develop the PCa and CSPCa prediction models. Age of patients, PSA derivates, and prostate volume were normalized [(value − minimum value)/(maximum value − minimum value)] to fall in between 0 and 1, and entered as continuous variables. The mpMRI parameters were entered as dummy variables, and biopsy results were entered as binary variables.
The machine learning models were fit using the packages in R (version 3.6.2). The ANN is based on biological neural networks and composed of interconnected groups of artificial neurons [15]. And it was trained using the function of “Std_Backpropagation” in the package of “RSNNS”, and used three hyperparameters: size, learnFuncParams, and maxit. The three hyperparameters for ANN are c(3,3), 0.05 and 100 in the PCa model, and c(4,2), 0,05, and 100 in the CSPCa model. The SVM model is a machine learning model that finds an optimal boundary between the possible outputs. It was trained using the package of “e1071”, used a radical kernel and consisted of three hyperparameters: degree, cost, and gamma. The three hyperparameters for SVM are 3, 1, and 0.005 in the PCa model, and 3, 2 and 0.005 in the CSPCa model. The CART is based on the recursive partitioning method and belongs to a family of nonparametric regression methods. It was trained with the package of “rpart” and used three hyperparameters: minsplit, minbucket, and complexity parameter cp. The three hyperparameters for CART are 15, 5, and 0.01 in the PCa model, and 10, 3 and 0.01 in the CSPCa model. The RF is an ensemble learning method which that generating multiple decision trees and forming a “forest” to jointly determine output class [18]. The RF model was trained with using the package of “randomForest” in R, and used two hyperparameters: ntree, and mtry in this study. The two hyperparameters for RF are 500 and 2 in the PCa and CSPCa models.
Statistical analysis
All data cleaning and analyses were conducted using R statistical software (Version 3.6.2). Diagnostic accuracy of the models was evaluated using the area under the ROC curve (AUC). The 95% confidence interval (CI) and comparisons of AUCs were determined using the method of DeLong et al. [19]. Performance characteristics of the models were examined by calibration plots. Calibration was assessed by grouping men in the validation cohort into delices (each of size 20 or 21), and then comparing the mean of predicated probabilities and the observed proportions. The sum squares of the residuals (SSR) was used to assess the deviation of calibration plots from the 45° line [20]. The clinical utility of the models was evaluated with a decision-curve analysis.
Results
Patient characteristics
A total of 688 cases were included in this study. The patients (480, 70%) biopsied before December 31, 2018 were used as training cohort, and the remaining patients (208, 30%) were used as validation cohort. Table 1 summarized the patient characteristics stratified by pathological results. PCa patients displayed higher age (70 vs 66 years, P < 0.001), tPSA (20.8 vs 10.5 ng/ml, P < 0.001), and PSAD (0.46 vs 0.18, P < 0.001), while lower f/tPSA (0.11 vs 0.15, P < 0.001) and prostate volume (38 vs 58 ml, P < 0.001) compared with no-PCa (Table 1). Additionally, the proportions for suspicious presence of PCa (73% vs 22%), SVI (31% vs 0.7%), and LNI (10% vs 0%) by mpMRI examination were higher among PCa patients than no-PCa (Table 1). The CSPCa patients displayed similar pattern with no-CSPCa patients (Table 1).
Comparison of predictive accuracy between machine-learning models
In our study, four machine-learning models based on age, PSA derivates, prostate volume, and mpMRI parameters were developed to predict initial biopsy results. Among these machine-learning assisted models for PCa and CSPCa, the SVM (AUC = 0.903 for PCa and AUC = 0.925 for CSPCa), RF (AUC = 0.897 for PCa and AUC = 0.916 for CSPCa), LR (AUC = 0.894 for PCa and AUC = 0.917 for CSPCa), and ANN (AUC = 0.891 for PCa and AUC = 0.911 for CSPCa) models outperformed CART (AUC = 0.834 for PCa and AUC = 0.867 for CSPCa) model in diagnostic accuracy (all P < 0.05); Whilst the pairwise comparison of AUCs were insignificant amongst ANN, SVM, RF, and LR models for PCa and CSPCa, respectively (each P > 0.05) (Fig. 1).

Receive operating characteristic (ROC) curves of machine-learning and logistic regression models for predicting prostate cancer (PCa) and clinically significant prostate cancer (CSPCa) in the validation cohort. a PCa: Gleason score ≥ 3 + 3; b CSPCa: Gleason score ≥ 3 + 4. Abbreviations ANN artificial neural network, SVM support vector machine, CART classification and regression tree, RF random forest, LR logistic regression
Regarding PCa models, the calibration plot of predicated probabilities against observed proportion of PCa indicated excellent concordance in CART model (SSR = 0.027), followed by SVM (SSR = 0.049), LR (SSR = 0.063), ANN (SSR = 0.091), and RF (SSR = 0.125) (Fig. 2a). For CSPCa models, the calibration plot of CART also had good agreement between the predicated probability and observed ratio of CSPCa on biopsy (SSR = 0.033), followed by LR (SSR = 0.046), ANN (SSR = 0.065), RF (SSR = 0.082), and SVM (SSR = 0.142) models (Fig. 2b).

Calibration plot of observed vs predicted rick of prostate cancer (PCa) and clinically significant prostate cancer (CSPCa) using machine-learning and logistic regression models in the validation cohort. a: PCa: Gleason score ≥ 3 + 3; b CSPCa: Gleason score ≥ 3 + 4. Abbreviations ANN artificial neural network, SVM support vector machine, CART classification and regression tree, RF random forest, LR logistic regression
Impact of machine learning-assisted models on biopsies avoided
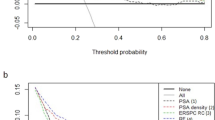
To further assess potential clinical benefit of the machine learning-assisted models, we performed DCA using the predicated risk in the validation cohort. It was observed that the ANN, SVM, RF, and LR models for PCa had higher net benefit than CART model across the threshold probabilities above 5%, and the five models for CSPCa displayed similar net benefit across the threshold probabilities below 40% (Fig. 3).

Decision curve analysis (DCA) of machine-learning and logistic regression models for predicting prostate cancer (PCa) and clinically significant prostate cancer (CSPCa) in the validation cohort. a PCa: Gleason score ≥ 3 + 3; b CSPCa: Gleason score ≥ 3 + 4. Abbreviations ANN artificial neural network, SVM support vector machine, CART classification and regression tree, RF random forest, LR logistic regression
Clinical consequences of using machine learning-assisted models at given sensitivity, including the number of biopsies that could be spared and the number of PCa by Gleason score that would be missed were displayed in Table 2. Using the SVM (74/143, 52%) and RF (76/143, 53%) models for PCa, significantly more unnecessary biopsies would be spared at 95% sensitivity for detection of CSPCa, compared with using ANN (53/143, 37%) and LR (50/143, 35%) models (all P < 0.05) (Table 2). Additionally, RF (81/143, 57%), SVM (79/143, 55%), and ANN (76/143, 53%) models for CSPCa spared more unnecessary biopsies than LR (67/143, 47%) model at 95% sensitivity (Table 2). At 95% sensitivity for detection of CSPCa, the RF and SVM models for CSPCa spared more unnecessary biopsies than the corresponding models for PCa (Table 2). However, the differences were insignificant (P = 0.688 for RF model, and P = 0.686 for SVM model).
Discussion
In our study, we developed, validated, and compared the machine learning-assisted models with LR analysis to predict PCa and CSPCa among patients with serum tPSA ≤ 50 ng/ml, using the same variables and population. The ANN, SVM, and RF models yielded similar diagnostic accuracy and net benefit with LR, and CART had lower diagnostic accuracy than LR in prediction of PCa and CSPCa. However, the CART model illustrated best calibration for PCa and CSPCa. And the SVM and RF models for PCa and CSPCa spared more biopsies than LR at 95% sensitivity for detection of CSPCa.
PCa was detected in 20% of the subjects with serum tPSA in the gray zone (4–10 ng/ml) in our study (data not shown). This was similar with the PCa detection rates of the same group of patients in Singapore (21%) [21], Japan (20%) [22], and Korea (20%) [23], while lower than that in Cleveland Clinic (40%) and Durham VA hospital (43%) [24]. This may suggest that the relationship between PCa risk and PSA level varies between Asian and Western populations, and it is essential to establish area-based risk prediction models. Our study revealed that the rates of PCa and CSPCa increased with tPSA, and CSPCa were detected in 279/301 (93%) of the men with serum tPSA > 50 ng/ml. Therefore, we recommended all cases with tPSA > 50 ng/ml to undergo prostate biopsy, and developed machine learning-assisted models to predict PCa and CSPCa among patients with tPSA ≤ 50 ng/ml (in accordance with ERSPC-RC) [10].
A growing body of literatures have validated the clinical utility of mpMRI in the detection and localization of CSPCa [4]. However, as far as we know, the knowledge about the performance of risk prediction models incorporating mpMRI parameters is limited. We developed machine learning-assisted models based on age, PSA derivates, prostate volume, and mpMRI parameters in our study. The digital rectal examination and transrectal ultrasound were excluded as risk factors because of potential interobserver variability in its assessment [3, 25]. The ANN, SVM, RF and LR models (AUC = 0.891–0.903 for PCa, and AUC = 0.911–0.925 for CSPCa) incorporating mpMRI parameters developed in our study outperformed CRCC-PC (AUC = 0.80 for PCa, and AUC = 0.83 for CSPCa) and MRI-ERSPC-RC (AUC = 0.85 for CSPCa). This may suggest that the combination of mpMRI parameters including MRI-PCa, MRI-SVI, and MRI-LNI could improve the diagnostic accuracy of prediction model for PCa and CSPCa. The mpMRI parameters included in our models were extracted from the reports of mpMRI examination and were somewhat subjective. Some study showed that mpMRI radiomics features significantly associated with PCa aggressiveness on the histopathological and genomic levels [26, 27]. And addition of mpMRI radiomics may enhance the objectivity and diagnostic accuracy of prediction model.
For prediction of PCa, ANN has become (alongside LR) one of the fastest growing and most effective machine-learning algorithms [15]. Theoretically, ANN has considerable advantages over traditional statistical approaches, which automatically allow no explicit distributional assumptions, arbitrary nonlinear associations, and possible interactions. A systematic review including 28 studies showed that ANN outperformed regression in 10 (36%) cases, ANN and regression tied in 14 (50%) cases, and regression wined in the remaining 4 (14%) cases [14]. In our study, ANN displayed similar diagnostic accuracy and net benefit for prediction of PCa and CSPCa with LR. Based on the available data, ANN does not have significantly advantages in clinical practice compared with LR, and should not replace traditional LR for the classification of medical data.
Another three machine-learning algorithms (SVM, CART, and RF) were developed to predict PCa and CSPCa in our study. Some studies showed that RF algorithms outperformed LR model in the fields of identifying peripheral artery disease and mortality risk [28], predicting clinical outcomes after robot-assisted radical prostatectomy [29], and predicting clinical outcomes of large vessel occlusion before mechanical thrombectomy [30]. The RF and SVM showed similar diagnostic accuracy with LR model in prediction of PCa and CSPCa in our study, while spared more unnecessary biopsies than LR model at given sensitivity of 98% or 95% (Table 2). Above all, our study did not have enough power to draw conclusion that ANN, SVM, CART and RF models outperformed traditional LR analysis in diagnostic of CSPCa. Now we are entering the era of big data, in which complete patient data including macro-level physiology and behavior, laboratory and imaging studies, and “-omic” data, are becoming more readily available. Machine learning may become an indispensable tool to handle the complex data [6]. Further validation is required.
Conclusions
Our study developed and compared machine-learning models with LR analysis to predict PCa and CSPCa. The SVM and RF models yielded similar diagnostic accuracy and net benefit with LR, while spared more unnecessary prostate biopsies than LR model at 95% sensitivity for detection of CSPCa. CART model illustrated best calibration for the prediction of PCa and CSPCa. Our study did not have sufficient power to draw conclusion that machine-learning models outperformed traditional LR analysis in prediction of PCa and CSPCa. All methods should continue to be used and explored in complementary ways.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Abbreviations
- PCa:
-
Prostate cancer
- CSPCa:
-
Clinically significant prostate cancer
- PSA:
-
Prostate-specific antigen
- tPSA:
-
Total prostate-specific antigen
- LR:
-
Logistic regression
- ANN:
-
Artificial neural network
- SVM:
-
Support vector machine
- CART:
-
Classification and regression tree
- RF:
-
Random forest
- mpMRI:
-
Multiparametric magnetic resonance imaging
- f/t PSA:
-
Free/total prostate-specific antigen
- SVI:
-
Seminal vesicle invasion
- LNI:
-
Lymph node invasion
- DCA:
-
Decision curve analysis
- AUC:
-
Area under the curve
- CI:
-
Confidence interval
- SSR:
-
Sum squares of the residuals
References
Ferlay J, Soerjomataram I, Dikshit R, Eser S, Mathers C, Rebelo M, et al. Cancer incidence and mortality worldwide: sources, methods and major patterns in GLOBOCAN 2012. Int J Cancer. 2015;136(5):E359–86.
International Agency for Research on Cancer: GLOBAL CANCER OBSERVATORY. 2018. http://gco.iarc.fr/. Cited 15 July 2020.
Van Neste L, Hendriks RJ, Dijkstra S, Trooskens G, Cornel EB, Jannink SA, et al. Detection of high-grade prostate cancer using a urinary molecular biomarker-based risk score. Eur Urol. 2016;70(5):740–8.
Bratan F, Niaf E, Melodelima C, Chesnais AL, Souchon R, Mege-Lechevallier F, et al. Influence of imaging and histological factors on prostate cancer detection and localisation on multiparametric MRI: a prospective study. Eur Radiol. 2013;23(7):2019–29.
Le JD, Tan N, Shkolyar E, Lu DY, Kwan L, Marks LS, et al. Multifocality and prostate cancer detection by multiparametric magnetic resonance imaging: correlation with whole-mount histopathology. Eur Urol. 2015;67(3):569–76.
Obermeyer Z, Emanuel EJ. Predicting the future—big data, machine learning, and clinical medicine. N Engl J Med. 2016;375(13):1216–9.
Wong NC, Lam C, Patterson L, Shayegan B. Use of machine learning to predict early biochemical recurrence after robot-assisted prostatectomy. BJU Int. 2019;123(1):51–7.
Thompson IM, Ankerst DP, Chi C, Goodman PJ, Tangen CM, Lucia MS, et al. Assessing prostate cancer risk: results from the Prostate Cancer Prevention Trial. J Natl Cancer Inst. 2006;98(8):529–34.
Gronberg H, Adolfsson J, Aly M, Nordstrom T, Wiklund P, Brandberg Y, et al. Prostate cancer screening in men aged 50–69 years (STHLM3): a prospective population-based diagnostic study. Lancet Oncol. 2015;16(16):1667–76.
Roobol MJ, Verbeek JFM, van der Kwast T, Kümmerlin IP, Kweldam CF, van Leenders GJLH. Improving the Rotterdam European randomized study of screening for prostate cancer risk calculator for initial prostate biopsy by incorporating the 2014 International Society of Urological Pathology Gleason Grading and Cribriform growth. Eur Urol. 2017;72(1):45–51.
Chen R, Xie L, Xue W, Ye Z, Ma L, Gao X, et al. Development and external multicenter validation of Chinese Prostate Cancer Consortium prostate cancer risk calculator for initial prostate biopsy. Urol Oncol. 2016;34(9):e4161–7.
Checcucci E, De Cillis S, Granato S, Chang P, Afyouni AS, Okhunov Z. Applications of neural networks in urology: a systematic review. Curr Opin Urol. 2020;30(6):788–807.
Checcucci E, Autorino R, Cacciamani GE, Amparore D, De Cillis S, Piana A, et al. Artificial intelligence and neural networks in urology: current clinical applications. Minerva Urol Nefrol. 2020;72(1):49–57.
Sargent DJ. Comparison of artificial neural networks with other statistical approaches: results from medical data sets. Cancer. 2001;91(8 Suppl):1636–42.
Hu X, Cammann H, Meyer H-A, Miller K, Jung K, Stephan C. Artificial neural networks and prostate cancer—tools for diagnosis and management. Nat Rev Urol. 2013;10(3):174–82.
Alberts AR, Roobol MJ, Verbeek JFM, Schoots IG, Chiu PK, Osses DF, et al. Prediction of high-grade prostate cancer following multiparametric magnetic resonance imaging: improving the Rotterdam European randomized study of screening for prostate cancer risk calculators. Eur Urol. 2019;75(2):310–8.
Liu C, Liu SL, Wang ZX, Yu K, Feng CX, Ke Z, et al. Using the prostate imaging reporting and data system version 2 (PI-RIDS v2) to detect prostate cancer can prevent unnecessary biopsies and invasive treatment. Asian J Androl. 2018;20(5):459–64.
Liaw A, Wiener M. Classification and regression by RandomForest. Forest. 2001;23:18–22.
DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. 1988;44(3):837–45.
Kawakami S, Numao N, Okubo Y, Koga F, Yamamoto S, Saito K, et al. Development, validation, and head-to-head comparison of logistic regression-based nomograms and artificial neural network models predicting prostate cancer on initial extended biopsy. Eur Urol. 2008;54(3):601–11.
Lee A, Chia SJ. Contemporary outcomes in the detection of prostate cancer using transrectal ultrasound-guided 12-core biopsy in Singaporean men with elevated prostate specific antigen and/or abnormal digital rectal examination. Asian J Urol. 2015;2(4):187–93.
Matsumoto K, Satoh T, Egawa S, Shimura S, Kuwao S, Baba S. Efficacy and morbidity of transrectal ultrasound-guided 12-core biopsy for detection of prostate cancer in Japanese men. Int J Urol. 2005;12(4):353–60.
Seo HK, Chung MK, Ryu SB, Lee KH. Detection rate of prostate cancer according to prostate-specific antigen and digital rectal examination in Korean men: a nationwide multicenter study. Urology. 2007;70(6):1109–12.
Vickers AJ, Cronin AM, Roobol MJ, Hugosson J, Jones JS, Kattan MW, et al. The relationship between prostate-specific antigen and prostate cancer risk: the Prostate Biopsy Collaborative Group. Clin Cancer Res. 2010;16(17):4374–81.
Smeenge M, Barentsz J, Cosgrove D, de la Rosette J, de Reijke T, Eggener S, et al. Role of transrectal ultrasonography (TRUS) in focal therapy of prostate cancer: report from a Consensus Panel. BJU Int. 2012;110(7):942–8.
Hectors SJ, Cherny M, Yadav KK, Beksaç AT, Thulasidass H, Lewis S, et al. Radiomics features measured with multiparametric magnetic resonance imaging predict prostate cancer aggressiveness. J Urol. 2019;202(3):498–505.
Chaddad A, Niazi T, Probst S, Bladou F, Anidjar M, Bahoric B. Predicting Gleason score of prostate cancer patients using radiomic analysis. Front Oncol. 2018;8:630.
Ross EG, Shah NH, Dalman RL, Nead KT, Cooke JP, Leeper NJ. The use of machine learning for the identification of peripheral artery disease and future mortality risk. J Vasc Surg. 2016;64(5):1515-22.e3.
Hung AJ, Chen J, Che Z, Nilanon T, Jarc A, Titus M, et al. Utilizing machine learning and automated performance metrics to evaluate robot-assisted radical prostatectomy performance and predict outcomes. J Endourol. 2018;32(5):438–44.
Nishi H, Oishi N, Ishii A, Ono I, Ogura T, Sunohara T, et al. Predicting clinical outcomes of large vessel occlusion before mechanical thrombectomy using machine learning. Stroke. 2019;50(9):2379–88.
Acknowledgements
Not applicable.
Funding
The research was supported by the Henan Medical Science and Technology Project [Grant No. LHGJ20190181 (X.P.Z) and LHGJ20200334 (S.B.Y)].
Author information
Authors and Affiliations
Contributions
X. P. Z., and S. B. Y. conceptualized, designed and supervised the study. J. T., B. D., Y. F. F., H. P. D., H. T. D., J. S. C., G. D. H, and W. G. Q. coordinated and participated data collection. S. B. Y., and J. T. carried out the statistical analysis and drafted the manuscript. X. P. Z., and B. D. provided guidance on the data analysis. X. P. Z., J. T., B. D., and Y. F. F. revised the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval
All methods carried out were in accordance with relevant guidelines and regulations of Ethics Committee of the First Affiliated Hospital of Zhengzhou University, and a waiver of informed consent was approved from the Ethics Committee of the First Affiliated Hospital of Zhengzhou University.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Yu, S., Tao, J., Dong, B. et al. Development and head-to-head comparison of machine-learning models to identify patients requiring prostate biopsy. BMC Urol 21, 80 (2021). https://doi.org/10.1186/s12894-021-00849-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12894-021-00849-w