
Abstract
Background
Climate fluctuations during the Pleistocene and mountain uplift are vital driving forces affecting geographic distribution. Here, we ask how an annual plant responded to the Pleistocene glacial cycles.
Methods
In this study, we analyzed the population demographic history of the annual herb Swertia tetraptera Maxim (Gentianaceae) endemic to Qinghai-Tibetan Plateau (QTP). A total of 301 individuals from 35 populations of S. tetraptera were analyzed based on two maternally inherited chloroplast fragments (trnL-trnF and trnS-trnG). Phylogeographic analysis was combined with species distribution modeling to detect the genetic variations in S. tetraptera.
Results
The genetic diversity of S. tetraptera was high, likely due to its wide natural range, high proportion of endemic haplotypes and evolutionary history. Fifty-four haplotypes were identified in S. tetraptera. Only a few haplotypes were widespread (Hap_4, Hap_1, Hap_3), which were dispersed throughout the present geographical range of S. tetraptera, while many haplotypes were confined to single populations. The cpDNA dataset showed that phylogeographic structuring was lacking across the distribution range of S. tetraptera. Analyses of molecular variance showed that most genetic variation was found within populations (70.51%). In addition, the relationships of the haplotypes were almost completely unresolved by phylogenetic reconstruction. Both mismatch distribution analysis and neutrality tests showed a recent expansion across the distribution range of S. tetraptera. The MaxEnt analysis showed that S. tetraptera had a narrow distribution range during the Last Glacial Maximum (LGM) and a wide distribution range during the current time, with predictions into the future showing the distribution range of S. tetraptera expanding.
Conclusion
Our study implies that the current geographic and genetic distribution of S. tetraptera is likely to have been shaped by Quaternary periods. Multiple microrefugia of S. tetraptera existed during Quaternary glaciations. Rapid intraspecific diversification and hybridization and/or introgression may have played a vital role in shaping the current distribution patterns of S. tetraptera. The distribution range of S. tetraptera appeared to have experienced contraction during the LGM; in the future, when the global climate becomes warmer with rising carbon dioxide levels, the distribution of S. tetraptera will expand.
Similar content being viewed by others


Introduction
The Qinghai-Tibetan Plateau (QTP), which covers approximately 2.5 × 106 km2 or one-quarter of China, is the world’s largest and highest plateau, with an average altitude of 4500 m above sea level [1]. In the lower Cretaceous, the uplift of the QTP was caused by the collision of the Indian Plate with the Eurasian Plate [2]. Large changes have taken place in the biota of the QTP and its neighboring mountains due to the alteration in topography and local climate. Numerous species have become extinct [3, 4]. However, the southern edge of the QTP and the Hengduan Mountains region has been labeled a biodiversity hotspot [5]. In addition, a new and young biota has developed on the plateau [6, 7]. Among alpine seed plant species, 34% are endemic to the QTP [8], whereas only 2.9% of the genera are endemic [6]. Where this young alpine flora originated and how the plateau uplift and climatic fluctuations during the Quaternary glacial period have influenced their differentiation, evolution, and dispersal are the subject of continuing debate.
Using the phylogeographic method [9], the phylogeographic history of some species on the QTP and its adjacent areas has been explored recently [10,11,12,13,14,15,16,17,18,19,20,21,22]. However, most of these species were trees or perennial herbs, and only a few studies have concentrated on annual taxa [23, 24], and it has been established that the genetic diversity of plant species is affected by life-history traits [25]. Compared with long-lived trees, annuals, with their specific life-history characteristics, may show different levels and structuring of genetic variation. The high selfing rate [26], low mutation rate [27] and short generation time are the main characteristics of annuals that could influence the level and structure of diversity. Furthermore, the failure to reproduce due to adverse conditions in a particular year may have a strong impact on the demography of a population of annuals, and as a result, annual species may be expected to experience more bottlenecks. Research on such species is therefore necessary to increase our understanding of how Quaternary climate changes have affected the range distributions and intraspecific divergence of alpine plants on the QTP.
The history of a species in space as well as time can be revealed by phylogeography [28], however, until recently, geographical and ecological information have mostly been invoked descriptively during tree interpretation [29]. One way to integrate these data more objectively is with ecological niche models (ENMs), which use collection localities and Geographic Information System (GIS) maps of environmental data to develop spatial predictions of a species’ historical and current range [29, 30] This technique has to be widely used in Europe and North America phylogeography [30, 31], but rarely used in Qinghai-Tibetan Plateau phylogeography.
Swertia tetraptera, belonging to the genus Swertia in the Gentianaceae, is an annual herb endemic to the QTP. The main distribution of S. tetraptera is in Qinghai, Gansu, and Sichuan Provinces, occurring primarily in moist hillsides and shrub locations with an elevation of 2,000–5,000 m. The main characteristic that distinguishes S. tetraptera from other Swertia plants is its heteromorphic flowers, that is, every plant has two kinds of flowers: normal ‘open-pollinated’ flowers and ‘closed’ or cleistogamous flowers. As an endemic species of the QTP, S. tetraptera formed within its strong uplift (approximately 3.97 Ma) [32]. Therefore, this species is an indispensable part of the study of the influence of the QTP uplift on the distribution pattern of modern plants. To date, only a few studies of S. tetraptera based on molecular biology have been reported [33, 34]. Yang et al. (2011) [32] clarified the phylogeography of S. tetraptera based on only one chloroplast DNA (cpDNA) fragment. However, this previous study did not concentrate on phylogeographic structure or deep evolutionary history.
In the current study, 301 individuals from 35 populations of S. tetraptera were collected from the entire geographic distribution in the high-altitude QTP and adjacent areas. To characterize the population histories of this species, two chloroplast DNA (cpDNA) markers were used to detect genetic variations. The aims were (1) to explore the genetic structure and diversity level of S. tetraptera in the Qinghai-Tibetan Plateau; (2) to identify the evolutionary history of S. tetraptera; and (3) to infer on the reasons for the existing geographic distribution patterns of S. tetraptera.
Results
cpDNA variations and haplotype distributions
Two chloroplast gene fragments (trnL-trnF and trnS-trnG) were applied to analyze 301 individuals from 35 populations of S. tetraptera. The total length of the fragments was 1215 bp, and the lengths of the trnL-trnF and trnS-trnG regions were 761 and 454 bp, respectively, which included 22 mutation sites (Supplementary Table S1). Due to the uniparental inheritance of cpDNA, the two chloroplast gene fragments were combined in the subsequent population genetic analysis.
The distribution of the observed haplotypes in each population is indicated in Table 1; Fig. 1. In total, 54 haplotypes were detected in S. tetraptera. The main feature of the 54-haplotype distribution was the absence of clear geographic structuring. The most common haplotype, Hap_4, was found in 24 of the 35 populations and made up 23.92% of the total sample. Haplotypes, such as Hap_1, Hap_3, Hap_6, Hap_7, Hap_13 and Hap_53, were also common and were present in 12.96%, 8.64%, 5.32%, 6.31%, 4.32% and 3.32% of the individuals, respectively (Fig. 1; Table 1). The remaining haplotypes were divided into two classes: (i) rare but widely distributed (Hap_5, Hap_8, Hap_9, Hap_10, Hap_11, Hap_12, Hap_13, Hap_14, Hap_15, Hap_19, Hap_21, Hap_22, Hap_24, Hap_26, Hap_29, Hap_30, Hap_31, Hap_32, Hap_34, Hap_35, Hap_36, Hap_38, Hap_42, Hap_44 and Hap_54) and (ii) population-specific (Hap_17, Hap_18, Hap_20, Hap_23, Hap_25, Hap_27, Hap_28, Hap_33, Hap_37, Hap_39, Hap_40, Hap_41, Hap_43, Hap_45, Hap_47, Hap_48, Hap_49, Hap_50, Hap_51 and Hap_52).

A, map of China, indicating the Qinghai-Tibetan Plateau (Green) and the distribution range of Swertia tetraptera. B, map of the 35 sampled populations of Swertia tetraptera and the distribution of cpDNA haplotypes in the species. Pie charts show the proportions of haplotypes within each population. The codes of populations are the same as in Table 1. (Note: The background map is taken from an open-access dataset, Integration dataset of Tibet Plateau boundary. National Tibetan Plateau Data Center. Zhang, Y. (2019). Integration dataset of Tibet Plateau boundary. National Tibetan Plateau Data Center. https://doi.org/10.11888/Geogra.tpdc.270099. https://cstr.cn/18406.11.Geogra.tpdc.270099.)
Genetic diversity and structure
Unbiased haplotype diversity (Hd) within the 35 populations ranged from 0.182 to 0.982, and nucleotide diversity (π) ranged from 0.00015 to 0.00362 (Table 1). The NQ (Nangqian, Qinghai) population had the highest haplotype diversity (0.981), and the DB (Diebu, Gansu) population had the highest nucleotide diversity (0.00362). The total gene diversity (HT) was estimated to be 0.912, and the average gene diversity within populations (HS) was 0.768. The values of NST and GST were 0.158 and 0.315, respectively. No phylogeographic signal in the haplotype distribution was detected by means of a standard phylogeographic analysis because NST was non-significantly larger than GST. AMOVA suggested that most of the genetic variation was found within populations (70.51%) as opposed to between populations (29.49%) (Table 2).
Phylogenetic relationships
The maximum likelihood and Bayesian methods were used to reconstruct phylogenetic trees for the 54 cpDNA haplotypes in S. tetraptera. There was a little difference in the topological structures of the phylogenetic trees obtained by the two methods (Fig. 2, Figure S1). Phylogenetic tree obtained from BI method showed that all 54 cpDNA haplotypes in S. tetraptera formed two clades (A and B) (Fig. 2), while phylogenetic tree obtained from ML method demonstrated that all 54 cpDNA haplotypes in S. tetraptera formed three clades (A, B and C) (Figure S1). However, haplotypes in different populations mixed in both phylogenetic trees and did not cluster in separate branches according to population. That is, haplotypes lack a distinct geographic distribution structure and disperse into different clades (Figs. 2 and 3). Then, these shallow divergent cpDNA haplotypes were subjected to a MJ network. In the cpDNA network, haplotypes with high distribution frequency (e.g., Hap_4, Hap_1, and Hap_3) were located in the central positions of individual networks, while population-specific haplotypes with low frequency generally occupied network tips (Fig. 3). Divergence between adjacent cpDNA haplotypes was even shallower and was usually distinguished by one mutation step (Fig. 3).

Phylogenetic tree for 54 cpDNA haplotypes using Bayesian inference (BI) method. Posterior probabilities are shown above the branches. A and B represent two different branches

MP median-joining network of the 54 cpDNA haplotypes. Circle size is proportional to haplotype frequencies and the red dot represent missing haplotypes. Each color denotes one population of S. tetraptera. The numbers on the branches indicate the number of steps separating adjacent haplotypes
Population dynamics history and divergence time
DnaSP software was used to test the neutrality of all populations based on the chloroplast data of S. tetraptera. The results showed that Tajima’s D was − 0.12975 (P < 0.001) and Fu’s Fs was − 1.28549 (P < 0.001); that is, all were significantly negative values, and the observed mismatch distribution analysis results were single-peak curves (Fig. 4). The results of mismatch distribution analysis were verified by Arlequin software, and the SSD and HRI values were positive and non-significant (SSD = 0.04703, P > 0.05; HRI = 0.004, P > 0.05). The results indicated that the distribution area or quantity of S. tetraptera in its current distribution area had experienced a recent expansion.

Mismatch distribution of Swertia tetraptera in the overall populations based on cpDNA dataset
Species distribution modeling
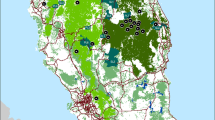
MaxEnt predicted the distributions of S. tetraptera during three time periods, LGM (LGM-CCSM4, ~ 21Kya), current (1960–1990), and future (2070s-RCP8.5, 2061–2080), based on selected predictor variables (Fig. 5). The AUC value of the test data was 0.987 (Figure S2), which showed that the prediction result of the model for the potential suitable areas of S. tetraptera were very good, and the reliability was relatively high. The environmental variables used to fit the models in S. tetraptera were BIO02(Mean Diurnal Range), BIO03(Isothermally (BIO02/BIO07) (100)), BIO04(Temperature seasonality (Standard deviation×100)), BIO10(Mean Temperature of Warmest Quarter), BIO11(Mean Temperature of Coldest Quarter), BIO14 (Precipitation of Driest Month), BIO15(Precipitation Seasonality), BIO18 (Precipitation of Warmest Quarter) (Table S2). The model for the present scenario properly predicted the known distribution range of S. tetraptera, assigning high probabilities of occurrence mainly to the Qinghai and Gansu, and dispersed distribution in northwest Sichuan and northeast Xizang (Fig. 6A). The LGM model estimated a shift of the distribution range towards the southern of Qinghai-Tibetan Plateau in response to LGM climates (Fig. 6B). The future scenarios for the distribution of S. tetraptera showed a general pattern of expansion of its distribution range when compared to the present (Fig. 6C, Table S3).

Predicted distribution of S. tetraptera based on Present (A), LGM (B) and Future (C) bioclimatic data. The highest probability of occurrence was shown in red color, while the lowest probability of occurrence was shown in green color. (Note: The background map is taken from an open-access dataset, Integration dataset of Tibet Plateau boundary. National Tibetan Plateau Data Center. Zhang, Y. (2019). Integration dataset of Tibet Plateau boundary. National Tibetan Plateau Data Center. https://doi.org/10.11888/Geogra.tpdc.270099. https://cstr.cn/18406.11.Geogra.tpdc.270099.)

Changes in the distribution of suitable habitats of S. tetraptera. The green area indicates that the distribution area of S. tetraptera expands in the later period compared with the previous period; the blue area indicates that the distribution area shrinks compared with the previous period; the gray area indicates that there is no distribution in both periods; and the yellow area indicates that there is potential distribution of S. tetraptera in both periods. (Note: The background map is taken from an open-access dataset, Integration dataset of Tibet Plateau boundary. National Tibetan Plateau Data Center. Zhang, Y. (2019). Integration dataset of Tibet Plateau boundary. National Tibetan Plateau Data Center. https://doi.org/10.11888/Geogra.tpdc.270099. https://cstr.cn/18406.11.Geogra.tpdc.270099.)
Changes in the distribution of suitable habitats and refuge speculation
In this study, all models built for comparison were tested for regularized multipliers under different conditions (from 0.1 to 2.0), and the ones with good models were finally selected as predictions (AUC = 0.980, RM = 0.1, FC = LQ). Taking the fitness index value 0.0612 as the threshold value for the existence and distribution of S. tetraptera in each period, the potential distribution changes of S. tetraptera from LGM to current and from current to future were calculated (Fig. 5). The green area indicates that the distribution area of S. tetraptera expands in the later period compared with the previous period; the blue area indicates that the distribution area shrinks compared with the previous period; the gray area indicates that there is no distribution in both periods; and the yellow area indicates that there is potential distribution of S. tetraptera in both periods.
From LGM to current, the distribution area of S. tetraptera in eastern and central of Qinghai-Tibetan Plateau has contracted, while the distribution area in few regions of southern Qinghai-Tibetan Plateau has expanded (Fig. 5A; Table 3). From current to future, its distribution area has expanded in platform of Qinghai-Tibetan Plateau (Fig. 5B; Table 3), while its distribution area has shank in eastern edge of Qinghai-Tibetan Plateau. As can be seen from Fig. 5A and B, the distribution of S. tetraptera overlapped in some platform, eastern edge and southeast of Qinghai-Tibetan Plateau before and after LGM. Therefore, these areas may be the potential refuges of S. tetraptera during the LGM.
Discussion
Genetic diversity of S. tetraptera
In this study, based on the combined chloroplast fragment, we found that at the species level, the Hd (haplotype diversity) and π (nucleotide diversity) of S. tetraptera were 0.908 and 0.0257, respectively. According to statistics, these values were higher than those of other herbaceous plants on the QTP, such as Rhodiola chrysanthemifolia (Hd = 0.411, π = 0.0025) [35], Notopterygium incisum (Hd = 0.75, π = 0.00086) [22], and Meconopsis integrifolia (Hd = 0.8064, π = 0.000144) [36]. Although the different studies used different molecular markers and the environment, biological characteristics and evolutionary history of the different species are not completely the same, and the biological significance of such indirect comparisons still needs further study, such comparisons can intuitively indicate the degree of genetic diversity of S. tetraptera. The high level of genetic diversity in S. tetraptera may have been caused by the following. First, there is a strong correlation between plant genetic diversity and the geographical distribution of species [37,38,39]. Species with a wide natural range usually contain more genetic diversity. Although S. tetraptera is an annual herb, it has a wide distribution range and is widely distributed in Qinghai, Gansu, Sichuan and the Tibetan Plateau, China. It can thus be predicted that S. tetraptera should have a high level of genetic diversity. This is consistent with the genetic diversity parameters obtained from our analysis of 35 populations. Second, the proportion of endemic haplotypes was high in the populations of S. tetraptera, which may have correspondingly increased the level of diversity within populations. Third, the high genetic diversity of S. tetraptera may be related to its evolutionary history. According to a previous study, Swertia originated in the early Miocene of the Tertiary (29.60 Ma), and the differentiation of S. tetraptera was completed in the late Pliocene of the Tertiary (3.97 Ma) (data are presented in the Supplementary Figure S3). Therefore, prior to the Quaternary ice age, S. tetraptera may have been widely distributed in the QTP, which may be one of the reasons for its high genetic diversity. In addition, the uplift of the QTP, Himalayan, Hengduan, and Qinling mountains and the inland dry period during the mid-Tertiary led to the differentiation of plants along the direction of adaptation to alpine dry conditions. During the evolution process, S. tetraptera experienced different climatic changes and accumulated more genetic diversity under different environmental conditions for its survival by adapting to various environmental pressures.
Genetic structure of S. tetraptera
In general, the chloroplast data (GST=0.315, FST=0.2949) indicated a low degree of differentiation among populations of S. tetraptera. This may be caused by sufficiently strong gene flow between populations [40, 41]. However, a large number of endemic haplotypes were detected in S. tetraptera and which were endemic to most populations, suggesting that gene flow between populations was limited. Although the mechanisms of pollen and seed dispersal in this species are not well understood, a previous study showed that outcrossing and self-crossing existed simultaneously in S. tetraptera [33]. However, for populations that grow in extreme environments, where pollen is scarce, self-pollination is especially important to ensure reproduction, which can be confirmed by the special flowers (normal ‘open-pollinated’ flowers and ‘closed’ or cleistogamous flowers). Therefore, effective gene flow was not responsible for the low level of differentiation between populations in S. tetraptera. Thus, rapid intraspecific diversification was one of the reasons for the low degree of differentiation among populations of S. tetraptera. Of course, it is possible that other factors, such as hybridization and/or introgression, contributed to the low level of differentiation between populations in S. tetraptera, but we do not currently know whether this phenomenon exists in this species. According to our long-term observations in the field, it was found that the distribution of S. tetraptera and Halenia elliptica was sympatric. When plant spacing between sympatric species is less than 10 cm, geographical opportunities for hybridization and/or gene introgression between them are provided. Therefore, considering the genetic structure of the population and the close relationship between S. tetraptera and H. elliptica, as indicated in previous studies [42,43,44,45,46,47,48], it is inferred that there may be hybridization and/or gene introgression between S. tetraptera and its sympatric species H. elliptica.
A large number of private haplotypes existed in the current populations of S. tetraptera, and a small number of widely distributed haplotypes with high frequency occurred among populations, which might reduce the degree of differentiation between populations to some extent. In addition, limited mutation sites were detected in many haplotypes, and adjacent haplotypes were separated by a limited number of mutation steps. Due to the limited number of mutation sites of haplotypes generated by cpDNA fragments, clear results were not obtained when constructing ML and BI phylogenetic relationship trees. The low mean nucleotide diversity among populations further confirmed that the differentiation of the chloroplast haplotypes of this species was shallow. Therefore, the lack of phylogeographic structure in S. tetraptera might be the consequence of the low occurrence frequency, scattered distribution and shallow differentiation of the endemic haplotypes, which was similar to Saxifraga sinomontana [49], Rhodiola chrysanthemifolia [35], R. alsia [16], Stellera chamaejasme [50], and Potentilla glabra [21].
Glacial refugia of S. tetraptera
Ice refugium is the concentration of plants to escape from the harsh climate of ice age, and also the starting point of population redistribution after ice age [51]. Compared with redispersal populations, the evolutionary history of plant populations in refugium is able to accumulate rich genetic diversity. However, the dispersal from refugium is often accompanied by genetic drift or founder effect, and haplotype polymorphism or gene polymorphism decreases with the increase of population dispersal distance. Therefore, the level of genetic diversity can be used as an important basis to infer the specific location of shelters [52]. A summarization of the QTP alpine species investigated to date shows that the ‘‘contraction/recolonization’’ hypothesis, ‘‘platform refugia/local expansion’’ hypothesis and ‘‘microrefugia’’ hypothesis are the three main phylogeographic patterns of plant species on the QTP during the Quaternary glaciations [50, 53]. In this study, many private haplotypes were dispersed across the distribution range of S. tetraptera, and populations with high genetic diversity demonstrated an even distribution. Moreover, ancestral (Hap_4) and unique haplotypes appeared in the same population (Table 1; Fig. 1). All these results strongly suggest the existence of multiple microrefugia of S. tetraptera in the QTP. This result was also supported by the ENM. The distribution of S. tetraptera overlapped in the eastern, southeast and southwest Qinghai, southern and north Gansu, and southwest of Sichuan before and after LGM. Therefore, these areas may be the potential refuges of S. tetraptera during the LGM. At the LGM, the range of S. tetraptera showed a dispersed distribution in the QTP (Fig. 6B). In fact, taking into consideration the topological heterogeneity of the QTP and rejecting the claim that there was no unified ice sheet on the QTP during the ice age [54], it was likely that suitable microenvironments existed for cold-tolerant herbs [35] to survive glaciations in situ. However, both mismatch distribution analysis and neutrality tests showed a recent expansion across the distribution range of S. tetraptera. As mentioned above, combining the present genetic structure of S. tetraptera with the low dispersal ability of seeds provided evidence of extensive horizontal range expansion across the distribution range of S. tetraptera. Therefore, the discovered expansion signal possibly represents demographic expansion or altitudinal migration in response to repeated glacier advances and retreats, which was also detected in R. chrysanthemifolia [35], Potentilla fruticosa [55] and P. glabra [21]. As a result, we inferred that S. tetraptera had a continuous distribution in the QTP region before the Quaternary glaciations and had some widespread haplotypes (such as Hap_4 and Hap_3) across its distribution range. After the repeated advance and retreat of the glaciers during the Quaternary, the distribution range of S. tetraptera may have fragmented into isolated patches, ultimately facilitating in situ allopatric divergence. Since then, affected by bottleneck effects caused by Quaternary glaciations, the number of individuals in S. tetraptera population decreased dramatically, and only a few individuals remained, the new population developed from these individuals retained only part of the ancestral population genotype (Hap_4 and Hap_3). Finally, S. tetraptera has lost some of the ancient genetic structure to some degree, producing a large number of unique haplotypes, which eventually formed the existing genetic structure.
In this study, only the effects of climate change on the distribution range, population structure and population dynamics of S. tetraptera were analyzed, while the natural geographical barriers such as mountains and rivers and human activities could also affect the evolution and dispersal of S. tetraptera, which were not involved in this study. Therefore, we should continue to study the differentiation pathway and evolutionary mechanism of S. tetraptera in the future, so as to provide a more comprehensive and richer theoretical basis for the utilization and protection of this species.
Conclusion
Our study indicates that the current geographic and genetic distribution of S. tetraptera is likely to have been shaped by Quaternary periods. Multiple microrefugia of S. tetraptera existed during Quaternary glaciations. Rapid intraspecific diversification and hybridization and/or introgression may have played a vital role in shaping the current distribution patterns of S. tetraptera. The distribution range of S. tetraptera appeared to have experienced contraction during the LGM; in the future, when the global climate becomes warmer with rising carbon dioxide, the distribution of S. tetraptera will expand.
Materials and methods
Population sampling
During the summers of 2008 and 2009, we collected samples throughout the range of S. tetraptera. Fresh leaves were collected from 35 populations, and with few exceptions, 4–12 individuals that were at least 50 m apart from each other were sampled from each population (Table 1; Fig. 1). We measured the longitude, latitude and altitude of each collection location using an Etrex Global Positioning System device (Garmin). In total, 301 individuals were sampled, and leaves were dried with silica gel.
DNA extraction, amplification and sequencing
Total genomic DNA was extracted from silica gel-dried leaves using the modified CTAB method [56] and used as a template in the polymerase chain reaction (PCR). Preliminary universal primer scans of chloroplast DNA genomes were performed on 10 individuals from 10 different populations using 5 pairs of primers. Primers a and f of Taberlet et al. (1991) [57] were used to amplify the trnT-trnF region and sequenced with primers a, c and f. The other four regions, psbB-psbH, rpl20–5′rps12, trnS-trnG and psbA-trnH, were amplified and sequenced using primers described in Hamilton (1999) [58]. The primers used to amplify trnS-trnG showed different sequences within the 10 individuals tested and were used thereafter for the large-scale survey of haplotype variation within S. tetraptera. PCR was performed in a 25 µL volume containing 10–40 ng plant DNA, 50 mM Tris-HCl, 1.5 mM MgCl2, 250 µg/mL BSA, 0.5 mM dNTPs, 2 µM of each primer, and 1 unit of Taq polymerase. Initial template denaturation was programmed at 95 °C for 5 min, followed by 35 cycles of 94 °C for 1 min, 52 °C for 1 min, and 72 °C for 1 min plus a final extension of 72 °C for 7 min. The BioDev Gel Extraction System B Kit (BioDev-Tech) was used to purify all successfully amplified DNA fragments. The PCR primers trnS and trnG were adopted to perform sequencing reactions using the ABI Prism Bigdye™ Terminator Cycle Sequencing Ready Reaction Kit. All trnL-trnF sequences of S. tetraptera used in this study were obtained from Yang et al. (2011) [33].
Proofreading and alignment of DNA and data analysis
We used BioEdit v 7.0.9.0 [59] software for manual proofreading and examining the variable sites. Then, we used MEGA v 7.0 [60] software to eliminate low-quality sequences, and we only used high-quality sequences for subsequent analysis. Sequence Matrix 1.8 was used to combine the trnL-trnF and trnS-trnG gene segments, and the combined cpDNA gene segment was used to carry out the subsequent analysis.
Genetic variation and genetic structure analysis
We used the program ARLEQUIN version 3.5.2 [61] to calculate the unbiased genetic diversity (Hd) and nucleotide diversity (π) indices for each population. Differentiations among populations and within populations were calculated by analysis of molecular variance (AMOVA) using ARLEQUIN version 3.5.2.
The program PERMUT was used to calculate the total gene diversity (HT), average gene diversity within populations (HS), coefficient of genetic variation over all populations (GST) and equivalent coefficient taking into account sequence similarities between haplotypes (NST) [62]. A comparison was made between GST and NST using a permutation test with 1000 permutations. The phylogeographic structure appears when the NST value is significantly larger than the GST value.
Phylogenetic analysis
We used DnaSP v5.10 to identify haplotypes of the cpDNA genes. Haplotype distribution was visualized by GenGIS [63]. The program Popart 1.7 [64] (available at http://popart.otago.ac.nz/index.shtml) was used to construct the haplotype network based on Median joining network [65].
In this study, a phylogenetic tree was constructed based on Bayesian inference (BI) [66] and maximum likelihood (ML) [67] using Gentiana straminea (HM598090 for trnS-trnG intergenic spacer and HM598120 for trnL-trnF intergenic spacer) and Gentiana crassicaulis (DQ398745 for trnS-trnG intergenic spacer and KT907776 for trnL-trnF intergenic spacer) as the outgroup. MAFFT 7.205 software was used to compare the cpDNA sequences and remove the irregular sequences at both ends [68]. Before building the BI tree, PAUP and MrModeltest were jointly run through MrMTgui. The Akaike information criterion (AIC) results showed that the best model for BI analysis was GTR + I + G, with a random tree as the starting tree. Starting with four Markov chains, namely, three hot chains and one cold chain, one tree was saved every 100 generations, and 9,000,000 generations were calculated in total, after which the first 25% preheated (burn-in) trees were discarded, and the remaining trees were used to calculate the Bayesian posterior probability (PP) of the consistent trees and of each branch. PAUP 4.0b10 software was used to construct the ML tree and bootstrap support (BS) was used to evaluate the reliability of each branch of ML phylogenetic tree [69].
Demographic history
Mismatch distribution and neutral tests for the existing populations of S. tetraptera were conducted with DnaSP ver. 5.10 [70] software. If the result of mismatch distribution is unimodal, it indicates that the population may have experienced recent expansion. If it is multiple peaks, it means that the population size is relatively stable and in individual equilibrium for a long time [71]. For the neutral test, two infinite mutation-site model indices, Tajima’s D and Fu’s Fs [72,73,74], were selected to predict the nature of sequence evolution and possible population history dynamics. Negative values of the two indices indicate that the population may have undergone recent expansion or selective sweep. Positive values of the two indices indicate that populations may have been geographically isolated for a long time and that mutation differences between populations were accumulated or controlled by balanced selection [70, 74]. Arlequin ver. 3.5.2 [61] was used to test the results of mismatch distribution analysis, among which sum of square deviation (SSD) and Harpending’s raggdeness index (HRI) were used to test whether to accept the hypothesis of recent rapid population expansion.
Species distribution modeling
Data description
Species occurrence data
A total of 97 samples were collected in this study between 1960 and 2020, covering the known distribution areas of S.tetraptera. The geographic distribution data of S.tetraptera were obtained mainly by the following methods: (1) field investigation (for detailed information, see Table 1); (2) the network data, including the China digital plant herbarium (http://www.cvh.org.cn/), China plants subject database (http://www.plant.csdb.cn/) and Global Biodiversity Information Facility (https://www.gbif.org/). (3) Literature review, including Chinese and English journals, flora of China, flora of local areas, investigation reports of nature reserves, etc. We selected the reasonable sampling sites according to the following principles: First, only one record of the duplicate site data was retained, and the distance between the two sampling sites was more than 10 km. Second, the sampling points must have accurate latitude and longitude information (distribution points that had place name no geographic coordinate information were removed) to ensure the accuracy of geography. Third, to reduce the overfitting of model predictions due to species distribution clusters, spatial auto-correlation analysis was performed using the Perl script-based GUI ENMTools v1.4.4 (http://www.ENMTools.com) and followed the selection and elimination criteria provided by previous researchers [75,76,77,78] (http://www.ENMTools.com). Finally, 83 records of species occurrence data were obtained for analysis (Supplementary Table S4).
Environmental data
In this study, nineteen bioclimatic variables in the global circulation model of the Community Climate System Model (CCSM4) for the period of 1970‒2000 were obtained from the WorldClim dataset, with a resolution of 30 arcseconds or approximately 1 km2 per pixel [79]. To estimate the potential distributions of S. tetraptera in the past and the future, the climatic scenarios of the LGM (Last Glacial Maximum, approximately 22,000 years ago, with a resolution of 2.5 arcminutes or approximately 5 km2 per pixel); 2070s (average for 2061–2080, with a resolution of 30 arcseconds or approximately 1 km2 per pixel), were used for the modelling. For future climate scenarios, we used one future climate projection, CCSM4 from CMIP5 [80] that were downloaded from the World Climate Database version 1.4. Representative concentration pathways (RCPs) for maximum (8.5 W/m2) emission hypothesis over the period 2070 were selected for further projections. The RCPs reflect potential radiative forcing by 2100 compared with the pre-industrial values of + 8.5 W/m2 which is more pessimistic and reflects high emission levels of greenhouse gases [79]. To facilitate the spatial analysis within Qinghai-Tibetan Plateau, all variables (past, present and future) that were selected for modelling were resampled to 2.5 arcminutes (approximately 5 km2) by using the spatial analysis tools in ArcGIS 10.6 (ESRI Inc, California, USA) [81, 82]. The layers were processed using a system with identical projection (WGS84), cell size, and extent, cropped to the region of interest, and converted into .asc format using Spatial Analyst and Conversion tools in ArcGIS 10.5 (ArcGIS, 2016).
MaxEnt model processing
At present, maximum entropy (MaxEnt) modelling is one of the most popular distribution models [83, 84], which was used to predict the species potential distribution based on current geographic locations and associated environmental variables and provide a spatial representation of habitat suitability on a scale from 0 (lowest suitability) to 1 (highest suitability). We used the MaxEnt model to predict the past, current and future potential distribution of S. tetraptera in the Qinghai-Tibetan Plateau. The main factors affecting the MaxEnt modelling results include highly multicollinear bioclimatic variables, regularization parameters and feature classes. Herein, we address this issue in two main ways. First, for the 19 climate variables, the “cor” function in R was used to remove the highly correlated variables and retain with Pearson statistic values < 0.85 [85, 86], which can reduce data redundancy and improve prediction accuracy. Second, we used the Kuenm package (https://github.com/marlonecobos/kuenm) to optimize the regularization multiplier and feature class parameters in the R version 3.6.3 software (Supplementary Model_calibration.PDF). AICc values indicate how well models fit the data while penalizing complexity to favor simple models [38]. Therefore, for S. tetraptera, 1160 candidate models were created using the kuenm package to test candidate solutions for each of the environmental variables, all possible combinations of the feature types (linear = l, quadratic = q, product = p, threshold = t, and hinge = h), and regularization multiplier settings (0.1–2.0 at intervals of 0.1) [79, 87]. Finally, using the kuenm and AICc values (the class with the lowest delta AICc was preferred), the best set of candidate solutions that feature combination (FC), including L and Q, and the regularization multiplier, set to 0.1, was chosen [88]. Based on the above optimized parameters, MaxEnt v3.4 was used to build current niche model. The 83-occurrence data of S. tetraptera and eight environmental variables are imported into MaxEnt v3.4 [89] for calculation, and the result is logistic output [82, 90,91,92]. For evaluation of the predictive performance of the model, 75% of the data was used for training, and the remaining 25% was used to evaluate the performance of the model [93,94,95]. The model was set to be run repeatedly for 10 times, the maximum background point and the number of iterations were set to 10,000 and 5000 respectively, and the rest parameters were set to the default values [88, 96, 97]. The model trained with current climate data was projected on past and future climate data to determine potential distributions in the LGM and 2070s. Average output (based on ten replicates) was used for further analyses. The MaxEnt results were validated using the threshold-independent area under the curve (AUC) of receiver operating characteristics (ROC) [98,99,100]. Jackknife analyses were performed to assess the importance of the variables [101]. The output of the model is a continuous probabilistic layer, ranging from 0 to 1. Areas with higher values imply more favorable conditions for the species growth [25]. We selected the maximum test sensitivity plus specificity logistic threshold as a threshold or “cutoff” value for each scenario, which is very robust with all types of data [102]. The threshold is equal to 0.0612 for S. tetraptera. And then, habitat suitability was divided into four classes based on nature breaks through ArcGIS with 0.0612 as a threshold: unsuitability (0-0.0612), low suitability (0.0612–0.3741), moderate suitability (0.3741–0.6871), and high suitability (0.6871-1).
For the three ENMs, ensemble models were averaged prior to conversion to a binary model. The final ensemble ENMs were converted to a binary model by classifying values greater than (or equal to) 0.5 to a value of 1 and those lower to a value of 0 [103]. This model represented the predicted binary distribution of S. tetraptera. To measure the predicted distribution changes for S. tetraptera, the binary ENMs were projected to Qinghai-Tibetan Plateau projection in ArcGIS 10.5 using SDMtoolbox v2.2 [104]. The Last Glacial Maximum and Present ENMs, present and future ENMs were then subtracted from each other, and areas of contraction, expansion and stability were calculated, generating a map displaying the intensity of contraction, expansion, and stability throughout its distribution area of the species. Combined with the three periods of suitable distribution overlapping area, the refugium of S. tetraptera was inferred [53, 78].
Data Availability
All data generated or analyzed during this study are included in this published article and its supplementary information files. The datasets generated and/or analyzed during the current study are available in the GenBank repository (the accession numbers of trnL-trnF are OQ354846-OQ354860 https://www.ncbi.nlm.nih.gov/nuccore/OQ354846, https://www.ncbi.nlm.nih.gov/nuccore/OQ354860), and the accession numbers of trnS-trnG are OQ377134-OQ377201, https://www.ncbi.nlm.nih.gov/nuccore/OQ377134, https://www.ncbi.nlm.nih.gov/nuccore/OQ377201).
References
Zhang YL, Li B, Zheng D. A discussion on the boundary and area of the Tibetan Plateau in China. Geogr Res. 2002;21:1–10.
Zheng D, Yao TD. Progress in research on formation and evolution of Tibetan Plateau with its envir onment and resource effects. Chin Basic Sci. 2004;2:15–21.
Huang W, Ji H. Discovery of Hipparion of fauna in Xizang. Chin Sci Bull. 1979;24:885–5.
Spicer RA, Harris NBW, Widdowson M, et al. Constant elevation of southern Tibet over the past 15 million years. Nature. 2003;421:622–4.
Myers N, Mittermeier RA, da Mittermeier CG. Fonseca GAB& Kent J. Biodiversity hotspots for conservation priorities. Nature. 2000;403:853–8.
Wu SG, Yang YP, Fei Y. On the flora of the alpine region in the Qinghai-Xizang Plateau. Acta Bot Yunnan. 1995;17:233–25.
Qiu ZD, Li CK. Evolution of chinese mammalian faunal regions and elevation of the Qinghai-Xizang (Tibet) Plateau. Sci China Ser D. 2005;48(1):246–1258.
Fan ZX, Liu SY, Liu Y, Zhang XY, Yue BS. How quaternary geologic and climatic events in the southeastern margin of the Tibetan Plateau influence the genetic structure of small mammals: inferences from phylogeography of two rodents, Neodon irene and Apodemus latronum. Genetica. 2011;139:339–51.
Avise JC, Nelson WS, Bowen BW, Walker D. Phylogeography of colonially nesting seabirds, with special reference to global matrilineal patterns in the sooty tern (Sterna fuscata). Mol Ecol. 2000;9:1783–92.
Petit RJ, Pineau E, Demesure B, Bacilieri R, Ducousso A, Kremer A. Chloroplast DNA footprints of postglacial recolonization by oaks. Proc Natl Acad Sci. 1997;94:9996–10001.
Abbott RJ, Brochmann C. History and evolution of the arctic flora: in the footsteps of Eric Hulten. Mol Ecol. 2003;12:299–313.
Hewitt GM. Genetic consequences of climatic oscillations in the Quaternary. Philos T R Soc B. 2004;359:183–95.
Petit RJ, Hampe A, Cheddadi R. Climate changes and tree phylogeography in the Mediterranean. Taxon. 2005;54:877–85.
Soltis DE, Morris AB, McLachlan JS, Manos PS, Soltis PS. Comparative phylogeography of unglaciated eastern North America. Mol Ecol. 2006;15:4261–93.
Zhang Q, Chiang TY, George M, Liu JQ, Abbott RJ. Phylogeography of the Qinghai-Tibetan Plateau endemic Juniperus przewalskii (Cupressaceae) inferred from chloroplast DNA sequence variation. Mol Ecol. 2005;14:3513–24.
Gao QB, Zhang DJ, Duan YZ, Zhang FQ, Li YH, Fu PC, Chen SL. Intraspecific divergences of Rhodiola alsia (Crassulaceae) based on plastid DNA and internal transcribed spacer fragments. Bot J Linn Soc. 2012;168:204–15.
Meng LH, Yang R, Abbott RJ, Miehe G, Hu TH, Liu JQ. Mitochondrial and chloroplast phylogeography of Picea crassifolia Kom. (Pinaceae) in the Qinghai-Tibetan Plateau and adjacent highlands. Mol Ecol. 2007;16:4128–37.
Yuan QJ, Zhang ZY, Peng H, Ge S. Chloroplast phylogeography of Dipentodon (Dipentodontaceae) in southwest China and northern Vietnam. Mol Ecol. 2008;17:1054–65.
Zheng W, Wang LY, Meng LH, Liu JQ. Genetic variation in the endangered anisodus tanguticus (Solanaceae), an alpine perennial endemic to the Qinghai-Tibetan Plateau. Genetica. 2008;132:123–9.
Wang L, Abbott RJ, Zheng W, Chen P, Wang YJ, Liu JQ. History and evolution of alpine plants endemic to the Qinghai-Tibetan Plateau: Aconitum gymnandrum (Ranunculaceae). Mol Ecol. 2009a;18:709–21.
Wang LY, Ikeda H, Liu TL, Wang YJ, Liu JQ. Repeated range expansion and glacial endurance of Potentilla glabra (Rosaceae) in the Qinghai-Tibetan Plateau. J Integr Plant Biol. 2009b;51:698–706.
Shahzad K, Jia Y, Chen F-L, Zeb U, Li Z-H. Effects of Mountain Uplift and climatic oscillations on Phylogeography and Species Divergence in four endangered notopterygium herbs. Front Plant Sci. 2017;8:e01929.
Chen SY, Wu GL, Zhang DJ, Gao QB. Molecular phylogeography of alpine plant Metagentiana striata (Gentianaceae). J Syst Evol. 2008a;46:573–85.
Chen SY, Wu GL, Zhang DJ, Gao QB. Potential refugium on the Qinghai-Tibet Plateau revealed by the chloroplast DNA phylogeography of the alpine species Metagentiana striata (Gentianaceae). Bot J Linn Soc. 2008b;157:125–40.
Hamrick JL, Godt MJW. Effects of life history traits on genetic diversity in plant species. Philos Trans R Soc Lond B Biol Sci. 1996;351:1291–8.
Barrett SCH, Harder LD, Worley AC. The comparative biology of pollination and mating in flowering plants. Philos T Roy Soc B. 1996;351:1271–80.
Linhart YB. Variation in woody plants: molecular markers, evolutionary processes and conservation biology. In: Jain SM, Minocha SC, editors. Molecular Biology of Woody plants. Dordrecht: Kluwer Academic; 2000. pp. 341–74.
Avise JC. Phylogeography: retrospect and prospect. J Biogeogr. 2009;36:3–15.
Richards CL, Carstens BC, Knowles LL. Distribution modeling and statistical phylogeography: an integrative framework for generating and testing alternative biogeographic hypotheses. J Biogeogr. 2007;34:1833–45.
Hugall A, Moritz C, Moussalli A, Stanisic J. Reconciling paleodistribution models and comparative phylogeography in the wet tropics rainforest land snail Gnarosophia bellendenkerensis. PNAS. 2002;99:6112–7.
Marske KA, Leschen RAB, Barker GM, Buckley TR. Phylogeography and ecological niche modelling implicate coastal refugia and trans-alpine dispersal of a New Zealand fungus beetle. Mol Ecol. 2009;18:5126–42.
Yang LC, Zhou GY, Chen GC. Genetic diversity and population structure of Swertia tetraptera (Gentianaceae), an endemic species of Qinghai-Tibetan Plateau. Biochem Syst Ecol. 2011;39(4–6):302–8.
Yang LC, Li JJ, Zhou GY. Comparative chloroplast genome analyses of 23 species in Swertia L. (Gentianaceae) with implications for its phylogeny. Front Genet. 2022;13:895146.
Yang LC, Zhou GY, Li CL, Song WZ, Chen GC. Potential refugia in Qinghai-Tibetan Plateau revealed by the phylogeography study of Swertia tetraptera (Gentianaceae). Pol J Ecol. 2011;59(4):753–64.
Gao QB, Zhang FQ, Xing R, Gornall RJ, Fu PC, Li Y, Gengji ZM, Chen SL. Phylogeographic study revealed microrefugia for an endemic species on the Qinghai-Tibetan Plateau: Rhodiola chrysanthemifolia (Crassulaceae). Plant Syst Evol. 2016;302(9):1179–93.
Guo JL, Zhang XY, Zhang JW, Li ZM, Sun WG, Zhang YH. Genetic diversity of Meconopsis integrifolia (Maxim.) Franch. In the East Himalaya–Hengduan Mountains inferred from fluorescent amplified fragment length polymorphism analysis. Biochem Syst Ecol. 2016;69:67–75.
Hamrick JL, Godt MJW, Murawski DA, Loveless MD. Correlations between species traits and allozyme diversity: implications for conservation biology. In: Falk DA, Holsinger KE, editors. Genetics and Conservation of Rare plants. New York: Oxford University Press; 1991. pp. 75–86.
Nybom H. Comparison of different nuclear DNA markers for estimating intraspecific genetic diversity in plants. Mol Ecol. 2004;13:1143–55.
Aguinagalde I, Hampe A, Martin JP, Duminil J, Petit RJ. Effects of life history traits and species distribution on genetic structure at maternally inherited markers in european trees and shrubs. J Biogeogr. 2005;32:329–39.
Oliver C, Hollingsworth PM, Gornall RJ. Chloroplast DNA phylogeography of the arctic-montane species Saxifraga hirculus (Saxifragaceae). Heredity. 2006;96:222–31.
Brochmann C, Gabrielsen TM, Nordal I, Landvik JY, Elven R. Glacial survival or tabula rasa? The history of the North Atlantic biota revisited. Taxon. 2003;52:417–50.
Shi GR. Cluster analysis for embryological characters of 12 species in Gentianaceae. J Huaibei Coal Indus Teach Colle. 2004;25(2):51–5.
Struwe L, Albert VA, Gentianaceae. Systematics and natural history. New York: Cambridge University Press; 2002. p. 242.
Von Hagen KB, Kadereit JW. Phylogeny and flower evolution of the Swertiinae (Gentianaceae-Gentianeae): Homoplasy and the principle of variable proportions. Syst Bot. 2002;27:548–72.
Chassot P, Nemomissa S, Yuan YM, Kupfer P. High paraphyly of Swertia L. (Gentianaceae) in the Gentianella-lineage as revealed by nuclear and chloroplast DNA sequence variation. Plant Syst Evol. 2001;229(1–2):1–21.
Favre A, Yuan YM, Küpfer P, Alvarez N. Phylogeny of subtribe Gentianinae (Gentianaceae): biogeographic inferences despite limitations in temporal calibration points. Taxon. 2010;59(6):1701–11.
Xi HC, Sun Y, Xue CY. Molecular phylogeny of Swertiinae (Gentianaceae-Gentianeae) based on sequence data of ITS and matK. Plant Divers Res. 2014;36(2):145–56.
Cao Q, Xu LH, Wang JL, Zhang FQ, Chen SL. Molecular phylogeny of subtribe swertiinae. Bull Bot Res. 2021;41(3):408–18.
Li Y, Gao QB, Gengji ZM, Jia LK, Wang ZH, Chen SL. Rapid Intraspecific diversification of the Alpine Species Saxifraga sinomontana (Saxifragaceae) in the Qinghai-Tibetan Plateau and Himalayas. Front Genet. 2018;9:381.
Zhang YH, Volis S, Sun H. Chloroplast phylogeny and phylogeography of stellera chamaejasme on the Qinghai-Tibet Plateau and in adjacent regions. Mol Phylogenet Evol. 2010;57(3):1162–72.
Tzedakis PC, Lawson IT, Frogley MR, Hewitt GM, Preece RC. Buffered tree population changes in a quaternary refugium: evolutionary implications. Science. 2002;297(5589):2044–7.
Sommer RS, Zachos FE. Fossil evidence and phylogeography of temperate species: ‘glacial refugia’ and post-glacial recolonization[J]. J Biogeogr. 2009;36(11):2013–20.
Jose VS, Nameer PO. The expanding distribution of the indian Peafowl (Pavo cristatus) as an indicator of changing climate in Kerala, southern India: a modelling study using MaxEnt. Ecol Indic. 2020;110:105930.
Qiu YX, Fu CX, Comes HP. Plant molecular phylogeography in China and adjacent regions: tracing the genetic imprints of quaternary climate and environmental change in the world’s most diverse temperate flora. Mol Phylogenet Evol. 2011;59(1):225–44.
Li C, Shimono A, Shen HH, Tang YH. Phylogeography of Potentilla fruticosa, an alpine shrub on the Qinghai-Tibetan Platea. J Plant Ecol. 2010;3:9–15.
Murray MG, Thompson WF. Rapid isolation of high molecular weight plant DNA. 1980; Pp.4320–4325. Nucleic Acids Research.
Taberlet P, Gielly L, Pautou G, Bouvet J. Universal primers for amplification of 3 noncoding regions of Chloroplast DNA. Plant Mol Biol. 1991;17:1105–9.
Hamilton MB. Four primer pairs for the amplification of chloroplast intergenic regions with intraspecific variation. Mol Ecol. 1999;8:521–3.
Hall TA, BioEdit:. A user-friendly Biological sequence alignment editor and analysis program for Windows 95/98/NT. Nucleic acids symp ser. 1999; 41: 95–8.
Kumar S, Nei M, Dudley J, Tamura K. MEGA: a biologist-centric software for evolutionary analysis of DNA and protein sequences. Brief Bioinform. 2008;9(4):299–306.
Excoffier L, Lischer HEL. Arlequin suite ver 3.5, a New Series of Programs to perform Population Genetics analyses under Linux and Windows. Mol Ecol Resour. 2010;10:564–7.
Pons O, Petit RJ. Measuring and testing genetic differentiation with ordered versus unordered alleles. Genetics. 1996;144:1237–45.
Parks DH, Mankowski T, Zangooei S, Porter MS, Armanini DG, Baird DJ, Langille MGI, Beiko RG. GenGIS 2: geospatial analysis of traditional and genetic biodiversity, with new gradient algorithms and an extensible plugin framework. PLoS ONE. 2013;8:7. e69885.
Leigh J, Bryant D. popart: full-feature software for haplotype network construction. Methods Ecol Evol. 2015;6:1110–6.
Bandelt HJ, Forster P. Röhl A.Median-joining networks for inferring intraspecific phylogenies. Mol Biol Evol. 1999;16(1):37–48.
Ronquist F, Huelsenbeck JP. MrBayes 3: bayesian phylogenetic inference under mixed models. Bioinformatics. 2003;19:1572–4.
Hall GB, DNA Sequences. Comparison of the Accuracies of several phylogenetic methods using protein and. Mol Biol Evol. 2005;22(3):792–802.
Katoh K, Misawa K, Kuma K, Miyata T. MAFFT: a novel method for rapid multiple sequence alignment based on fast Fourier transform. Nucleic Acids Res. 2002;30:3059–66.
Swofford DL. PAUP*: phylogenetic analysis using parsimony (and other methods), version 4.0 Beta. Sunderland: Sinauer; 2002.
Librado P, Rozas J. DnaSP v5: a software for comprehensive analysis of DNA polymorphism data. Bioinformatics. 2009;25:1451–2.
Rogers AR, Harpending H. Population growth makes waves in the distribution of pairwise genetic differences. Molec Biol Evol. 1992;9:552–69.
Simonsen KL, Churchill GA, Aquadro CF. Properties of statistical tests of neutrality for DNA polymorphism data. Genetics. 1995;141:413–29.
Fu YX, Li WH. Statistical tests of neutrality of mutations. Genetics. 1993;133:693–709.
Tajima F. Statistical method for testing the neutral mutation hypothesis by DNA polymorphism. Genetics. 1989;123:585–95.
Warren DL, Glor RE, Turelli M. Environmental niche equivalency versus conservatism: quantitative approaches to niche evolution. Evolution. 2008;62(11):2868–83.
Warren DL, Glor RE, Turelli M, ENMTools. A toolbox for com-parative studies of environmental niche models. Ecography. 2010;33(3):607–11.
Walls BJ, Stigall AL. A Field-based analysis of the accu-racy of niche models applied to the Fossil record. Paleontol Res. 2012; 2012(6): 1–12.
Liu T, Liu HY, Tong JB, Yang YX. Habitat suitability of neotenic net-winged beetles (Coleoptera: Lycidae) in China using combined ecological models, with implications for biological conservation. Divers Distrib. 2022;28:2806–23.
Hijmans RJ, Cameron SE, Parra JL, Jones PG, Jarvis A. Very high resolution interpolated climate surfaces for global land areas. Int J Climatol. 2005;25(15):1965–78.
Pachauri RK, Allen MR, Barros VR, Broome J, Cramer W, Christ R, Church JA, Clarke L, Dahe QD, Dasqupta P, Dubash NK, Edenhofer O, Elgizouli I, Field CB, Forster P, Friedlingstein P, Fuglestvedt J, Gomez-Echeverri L, Hallegatte S, van Ypersele J-P. Climate change 2014 synthesis report. contribution of working groups I, II, and III to the fifth assessment report of the Intergovernmental Panel on Climate Change. IPCC. 2014.
Wei YQ, Zhang L, Wang JN, Wang WW, Niyati N, Guo YL, Wang XF. Chinese caterpillar fungus (Ophiocordyceps sinensis) in China: current distribution, trading, and futures under climate change and overexploitation. Sci Total Environ. 2021;755:142548.
Phillips SJ, Anderson RP, Schapire RE. Maximum entropy modeling of species geographic distributions. Ecol Modell. 2006;190:231–59.
Phillips SJ, Anderson RP, Schapire RE. Maximum entropy modeling of species geographic distributions. Ecol Model. 2006;190:231–59.
Phillips D, Albrecht A. Effects of inhomogeneity on the causal entropic prediction of Lambda. Phys Rev D. 2011;84:123530.
Elith J, Graham CH, Anderson PR, Dudík M, Ferrier S, Guisan A, Hijmans JR, Huettmann F, Leathwick RJ, Lehmann A, Li J, Lohmann GL, Loiselle AB, Manion G, Moritz C, Nakamura M, Nakazawa Y, Overton MCM, Townsend Peterson J, Zimmermann A. Novel methods improve prediction of species’ distributions from occurrence data. Ecography. 2006;29:129–51.
Dormann CF, Elith J, Bacher S, Buchmann C, Carl G, Carré G, et al. Collinearity: a review of methods to deal with it and a simulation study evaluating their performance. Ecography. 2013;36(1):27–46.
Merow C, Smith MJ, Silander JA. A practical guide to MaxEnt for modeling species’ distributions: what it does, and why inputs and settings matter. Ecography. 2013;36(10):1058–69.
Cobos ME, Peterson AT, Barve N, Osorio-Olvera L. Kuenm: an R package for detailed development of ecological niche models using Maxent. PeerJ. 2019;7:e6281.
Morales NS, Fernández IC, Baca-González V. MaxEnt’s parameter configuration and small samples: are we paying attention to recommendations? A systematic review. PeerJ. 2017;145:e3093.
Shi N, Naudiyal N, Wang J, Gaire NP, Wu Y, Wei Y, He J, Wang C. Assessing the impact of Climate Change on potential distribution of Meconopsis punicea and its influence on Ecosystem Services Supply in the Southeastern Margin of Qinghai-Tibet Plateau. Front Plant Sci. 2022;12:3338.
Yuan Y, Tang X, Liu M, Liu X, Tao J. Species distribution models of the Spartina alterniflora Loisel in its origin and Invasive Country reveal an ecological Niche Shift. Front Plant Sci. 2021;12:2159.
Zhang HH, Sun X, Zhang GS, Zhang XK, Miao YJ, Zhang M, Feng Z, Zeng R, Pei J, Huang LF. Potential global distribution of the Habitat of Endangered Gentiana rhodantha Franch: predictions based on MaxEnt Ecological Niche modeling. Sustainability. 2023;15:631.
Vintsek L, Klichowska Ewelina, Nowak A, Nobis M. Genetic differentiation, demographic history and distribution models of high alpine endemic vicariants outline the response of species to predicted climate changes in a central asian biodiversity hotspot. Ecol Indic. 2022;144:109419.
Jose S, Nameer PO. The expanding distribution of the indian Peafowl (Pavo cristatus) as an indicator of changing climate in Kerala, southern India: a modelling study using MaxEnt. Ecol Indic. 2020;110:105930.
Luo T, Yan SS, Xiao N, Zhou JJ, Wang XL, Chen WC, Deng HQ, Zhang BW, Zhou J. Phylogenetic analysis of combined mitochondrial genome and 32 nuclear genes provides key insights into molecular systematics and historical biogeography of asian warty newts of the genus Paramesotriton (Caudata: Salamandridae). Zool Res. 2022;43(5):787–804.
Elith J, Phillips SJ, Hastie T, Dudík M, Chee YE, Yates CJ. A statistical explanation of MaxEnt for ecologists. Divers Distrib. 2011;17(1):43–57.
Radosavljevic A, Anderson RP. Making better maxent models of species distributions: complexity, overfitting and evaluation. J Biogeogr. 2014;41:629–43.
Guisan A, Thuiller W. Predicting species distribution: offering more than simple habitat models. Ecol Lett. 2005;8(9):993–1009.
Allouche O, Tsoar A, Kadmon R. Assessing the accuracy of species distribution models: prevalence, kappa and the true skill statistic (TSS). J Appl Ecol. 2006;43:1223–32.
Peterson AT, Papeş M, Soberón J. Rethinking receiver operating characteristic analysis applications in ecological niche modeling. Ecol Model. 2008;213(1):63–72.
Pearce J, Ferrier S. Evaluating the predictive performance of habitat models developed using logistic regression. Ecol Modell. 2000;133:225–45.
Poirazidis K, Bontzorlos V, Xofis P, Zakkak S, Xirouchakis S, Grigoriadou E, Kechagioglou S, Gasteratos I, Alivizatos H, Panagiotopoulou M. Bioclimatic and environmental suitability models for capercaillie (Tetrao urogallus) conservation: identification of optimal and marginal areas in Rodopi Mountain-Range National Park (Northern Greece). Glob Ecol Conserv. 2019;17:e00526.
Brown JL, Yoder AD. Shifting ranges and conservation challenges for lemurs in the face of climate change. Ecol Evol. 2015;5:1131–42.
Brown JL. SDMtoolbox: a python-based GIS toolkit for landscape genetic, biogeographic and species distribution model analyses. Methods Ecol Evol. 2014;5:694–700.
Acknowledgements
We thank Hechun Liu, Xueli Zhou for material collection and experiment assistance. We also thank Shasha Yan for providing assistance with data processing.
Funding
This research was funded by the Second Tibetan Plateau Scientific Expedition and Research Program (No.2019QZKK1003) and Key deployment project of Chinese Academy of Sciences (No. ZDRW-ZS-2020). The funders were not involved in the study design, data collection, and analysis, decision to publish, or manuscript preparation.
Author information
Authors and Affiliations
Contributions
YL conceived and designed the research, performed the experiments, data analyses and wrote the article. ZG revised the article. All authors read and approved the final article. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The authors declared that experimental research works on the plants described in this paper comply with institutional, national and international guidelines. Field studies were conducted in accordance with local legislation and get permissions from provincial department of forest and grass of Gansu, Qinghai and Sichuan province. All samples were identified by Professor Guoying Zhou. Voucher specimens of all populations were deposited at the herbarium of the Qinghai-Tibetan Plateau Museum of Biology (QTPMB) with the voucher numbers QH20081311-QH20081345.
Consent for publication
Not applicable.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Yang, L., Zhou, G. Phylogeography and ecological niche modeling implicate multiple microrefugia of Swertia tetraptera during quaternary glaciations. BMC Plant Biol 23, 450 (2023). https://doi.org/10.1186/s12870-023-04471-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12870-023-04471-w