
Abstract
Background
Individual response to medications varies significantly among different populations, and great progress in understanding the molecular basis of drug action has been made in the past 50 years. The field of pharmacogenomics seeks to elucidate inherited differences in drug disposition and effects. While we know that different populations and ethnic groups are genetically heterogeneous, we have not found any pharmacogenomics information regarding minority groups, such as the Tajik ethnic group in northwest China.
Results
We genotyped 85 Very Important Pharmacogene (VIP) variants selected from PharmGKB in 100 unrelated, healthy Tajiks from the Xinjiang Uygur Autonomous Region and compared our data with HapMap data from four major populations around the world: Han Chinese (CHB), Japanese in Tokyo (JPT), Utah Residents with Northern and Western European Ancestry (CEU), and Yorubia in Ibadan, Nigeria (YRI). We found that Tajiks differed from CHB, JPT and YRI in 30, 32, and 32 of the selected VIP genotypes respectively (p < 0.005), while differences between Tajiks and CEU were found in only 6 of the genotypes (p < 0.005). Haplotype analysis also demonstrated differences between the Tajiks and the other four populations.
Conclusion
Our results contribute to the pharmacogenomics database of the Tajik ethnic group and provide a theoretical basis for safer drug administration that may be useful for diagnosing and treating disease in this population.
Similar content being viewed by others


Background
To date, pharmacogenomic studies have focused on candidate genes involved in drug pharmacokinetics or pharmacodynamics. Many of these genes contain functional polymorphisms that are obvious pharmacological choices for investigation in appropriate clinical populations [1],[2]. For some drugs, genetic information is important to avoid drug toxicity and to optimize response [2],[3]. Pharmacogenomic studies are rapidly elucidating the inherited nature of differences in drug disposition and effects, thereby enhancing drug discovery and providing a stronger scientific basis for optimizing drug therapy on an individual basis [4].
Tajiks are an ethnic group with a worldwide population of 15 to 20 million; they live mostly in Tajikistan, Afghanistan, Uzbekistan, and the Xinjiang Uygur Autonomous Region [4]. According to the 2010 census, approximately 51,000 Tajiks live in China, mostly in the Tashkurgan Tajik Autonomous County, which is located in the eastern part of the Pamir Plateau.
The Pharmacogenetics and Pharmacogenomics Knowledge Base (PharmGKB: http://www.pharmgkb.org) is devoted to disseminating primary data and knowledge in pharmacogenetics and pharmacogenomics and has annotated genes that are important for drug response. This information is presented in the form of Very Important Pharmacogene (VIP) summaries, pathway diagrams, and curated literature [5]. It currently contains information for more than 3000 drugs, 3000 diseases, and 26,000 genes with genotyped variants [4].
We systematically genotyped 85 VIP variants selected from PharmGKB VIP in 100 Tajiks from Xinjiang [6]. We compared genotype frequencies and haplotype construction with those in Han Chinese (CHB), Japanese in Tokyo (JPT), Utah Residents with Northern and Western European Ancestry (CEU), and Yorubia in Ibadan, Nigeria (YRI). Our goals were to identify differences and determine their extent and provide a theoretical basis for safer drug administration and better therapeutic treatment in the Tajik population.
Methods
Ethics statement
All participants recruited and genotyped in the present study had at least three generations of paternal ancestry in their ethnic group, and each subject provided written informed consent. The Ethics Committees of Xinjiang University and Northwest University approved the use of human samples in this study.
Study participants
We recruited a random sample of 100 healthy, unrelated Tajiks (50 males and 50 females) from Tashkurgan Tajik Autonomous County between July and October 2010 using detailed recruitment and exclusion criteria. All of the chosen subjects were Tajik Chinese living in the Xinjiang Uygur Autonomous Region.
Polymerase chain reaction (PCR) and DNA sequencing
We successfully genotyped 85 VIP variants in 37 pharmacogenomic genes in 100 participants. Genomic DNA from whole blood was isolated using the GoldMag® nanoparticles method according to the manufacturer’s protocol, and DNA concentration was measured by spectrometry (DU530 UV/VIS spectrophotometer, Beckman Instruments, Fullerton, CA, USA). We designed primers for amplification and extension reactions using Sequenom MassARRAY Assay Design 3.0 Software [6] and used a Sequenom MassARRAY RS1000 to genotype the single nucleotide polymorphisms (SNPs) using the protocol recommended by the manufacturer. Sequenom Typer 4.0 Software was used for data management and analysis [6],[7].
Data analysis
Statistical analyses were performed using Microsoft Excel (Redmond, WA, USA) and SPSS 16.0 statistical package (SPSS, Chicago, IL, USA). All p values in this study were two-sided, and p ≤ 0.005 after Bonferroni correction was considered the statistical significance threshold [8]. We calculated and compared the genotype frequencies of Tajiks and four other populations (CHB, JPT, CEU, and YRI) using chi-squared tests [9]. We used the Haploview software package (version 4.2) for analysis of linkage disequilibrium (LD), haplotype construction, and genetic associations at polymorphic loci [10]-[12]. Our method excluded SNPs with minor allele frequency < 0.001 for SNPs with lower frequencies that have little power to detect LD. We also ignored SNPs with Hardy-Weinberg equilibrium (HWE) p values < 0.001 for their small probability that their deviation from HWE could be explained by chance. The D’ values on the square is a measure of the LD extent for each pair of SNPs, squares in red without D’ values indicate the two sites are in complete LD (D’ = 1). We constructed haplotypes using the common sites of the selected SNPs and sites downloaded from HapMap for the VDR gene and derived the haplotype frequencies in all five populations.
Results
We successfully sequenced 85 VIP pharmacogenomic variant genotypes from 100 Tajiks. The PCR primers used for the selected variants are listed in Additional file 1. Table 1 lists the basic characteristics of the selected variants, including gene name, chromosome number and position, and their allele frequencies in Tajiks.
Table 2 lists the genotype frequencies in Tajiks and identifies significant variants in Tajiks compared with the other four populations (p < 0.005), all variant data are shown in Additional file 2. We also categorized the genes into different families and phases related to pharmacogenomics, the statistically significant values are shown in red (p < 0.05). We found that Tajiks differed from CHB, JPT, and YRI in 30, 32, and 32 selected VIP genotypes, respectively. These genes encode phase I drug metabolic enzymes (VCORC1, MTHFR, and CYP3A5), a phase II drug metabolic enzymes (COMT), and transporters, channel proteins, and receptors (e.g., ADRB1, KCNH2, and VDR, respectively). However, the difference between Tajiks and CEU was much smaller; just six SNP genotypes were different, and these were randomly distributed on genes such as CYP2C9, which encodes a phase I enzyme. For genes such as ADH1B and PTGS2, we observed differences between Tajiks and the other four populations.
We counted the variants in each family, excluding those that belonged to none of the families or were not significantly different between Tajiks and the other four populations. The remaining 71 sites belonged to 26 genes in 12 families (Table 3). We found that the difference between Tajiks and CEU existed in only one site in the nuclear receptor family and 0 site in adrenergic receptors family respectively. However, in the nuclear receptor family, Tajiks differed from CHB, JPT, and YRI in 66.7%, 75%, and 33.3% of selected sites, respectively. In the adrenergic receptor family, Tajiks differed from CHB, JPT, and YRI in 60%, 40%, and 40% of selected sites, respectively. For genes in ATP-binding cassette (ABC) transporters, Tajiks differed from YRI in 66.7% of the selected sites, but there was no difference between Tajiks and CHB, JPT, CEU.
We performed LD analysis using Haploview to define blocks and haplotypes. Using the common sites of our study and those from HapMap in the VDR gene, we identified two LD blocks in Tajiks, JPT, and CEU and one LD block in CHB and YRI (Figure 1). The block identified in all five populations spans 0.4 kb and consists of two complete LD markers (rs1540339 and rs2239179) with a D’ value equal to 1. The block identified in Tajiks, JPT, and CEU spans 0.9 kb and also consists of two complete LD markers (rs7975232 and rs1544410) with a D’ value equal to 1.

Linkage disequilibrium (LD) analysis of VDR in five populations. LD is displayed by standard color schemes, with bright red for very strong LD (LOD > 2, D’ = 1), light red (LOD > 2, D’ < 1) and blue (LOD < 2, D’ = 1) for intermediate LD, and white (LOD < 2, D’ < 1) for no LD. A. Tajiks, B. CHB, C. JPT, D. CEU, E. YRI.
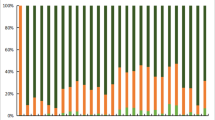
Haplotype analysis results are shown in Figure 2. For the common block comprised of rs1540339 and rs2239179, three kinds of haplotypes were identified in all five populations, but they differed in frequency. Three colors of bars indicate the three kinds of haplotypes. The highest and lowest frequencies of haplotype “AA” were found in JPT (73.8%) and YRI (20.0%). The highest and lowest frequencies of haplotype “GG” were observed in CEU (47.0%) and JPT (22.1%). The highest and lowest frequencies of haplotype “GA” were found in YRI (50.4%) and JPT (4.1%). The haplotype constitutions and frequencies show that there are relatively minimal differences between Tajik and CEU, CHB, and JPT, whereas the differences between YRI and the other four populations seem obvious. These findings are in accordance with the results shown in Table 3.

Haplotype analysis results of rs1540339 and rs2239179 in VDR .
Discussion
With the rapid development of pharmacogenetics, serious attention has been given to interethnic and interracial differences in drug responses [13]. Here, we genotyped 85 variants related to pharmacogenomics in the Tajik ethnic group for the first time and compared the results with other ethnic populations around the world. We found that 30, 32, 32, and 6 VIP variants differed from CHB, JPT, YRI, and CEU respectively (p < 0.005). These findings corroborate the current opinion that polymorphisms with varying frequencies occur among different populations.
Vitamin D receptor (VDR) is a gene whose function has been widely reported. Epithelial cells convert the primary circulating form of vitamin D to its active form, which binds VDR to regulate a variety of genes that keep cellular proliferation and differentiation within normal ranges to prevent malignant transformation [14]. That is to say, the active form of vitamin D can induce apoptosis and prevent angiogenesis by binding VDR, which reduces the survival potential of malignant cells. Studies have demonstrated that rs10735810 and rs1544410 SNPs in VDR might modulate the risk of breast, skin, and prostate cancers, as well as other forms [15],[16]. An Italian study reported that GA and AA rs1544410 genotypes were associated with decreased cutaneous malignant melanoma (CMM) risk (odds ratio = 0.78 and 0.75, respectively) compared with the GG genotype [16]. A study in Japan found that head and neck squamous cell carcinoma patients with the TT rs10735810 genotype was associated with poor progression-free survival compared with CC or CT genotype patients (log-rank test, p = 0.0004; adjusted hazard ratio, 3.03; 95% confidence interval, 1.62 to 5.67; p = 0.001), and the A-T-G (rs11568820-rs10735810-rs7976091) haplotype showed a significant association with a higher progression rate (p = 0.02). [14] We found that the GA and AA genotype frequencies of rs1544410 in Tajiks were as much as 52% and 8% respectively, which is different from those in CHB and JPT (data not shown), suggesting that Tajiks may have decreased susceptibility to CMM.
The gene alcohol dehydrogenase 1B (ADH1B) produces a key protein for alcohol metabolism that determines blood acetaldehyde concentrations after drinking [17]. This member of the alcohol dehydrogenase family also metabolizes a wide variety of substrates besides ethanol, including retinol, other aliphatic alcohols, hydroxysteroids, and lipid peroxidation products. The minor allele “A” of rs1229984 encodes a super-active allozyme that is reportedly associated with lower rates of alcohol dependence in numerous association studies, and its frequency varies widely across different populations. It is 69% (19-91%) in normal Asian normal populations, 5.5% (1-43%) in normal European populations, and just 3% (2-7%) in normal Mexican populations [18]. Other studies have shown that rs1229984 may influence alcohol consumption behavior and is associated with upper aerodigestive (UADT) cancers [19]-[24]. A genome-wide association study found that the “A” allele of rs1229984 was associated with decreased UADT risk (p = 7 × 10-9) [19]. The data in our study is in accordance with previous findings; we found that the “A” allele frequency of rs1544410 in Tajiks was 29.5%, which was significantly different (p < 0.05) from 76.67%, 73.86%, 0%, and 0% in CHB, JPT, CEU, and YRI respectively, suggesting that Tajiks have an intermediate susceptibility to UADT cancer.
The catechol-o-methyltransferase gene (COMT) is responsible for eliminating dopamine from the synaptic cleft in the prefrontal cortex (PFC) [25]. Variations in the COMT gene exert complex effects on susceptibility to depression through various intermediate phenotypes, such as impulsivity and executive function [26]. The common functional COMT polymorphism rs4680 has been shown to affect enzyme activity and, consequently, intrasynaptic dopamine content. The “G” allele is associated with 40% higher enzymatic activity in the human brain compared to the “A” allele, leading to more efficient elimination of dopamine from the synaptic cleft; therefore, the GG genotype is associated with reduced synaptic dopamine in the PFC, and in turn, more active striatal dopamine neurotransmission [25],[27]-[29]. A study in northern Italy reported an association between the GG genotype and the risks of Alzheimer’s disease (AD) and its precursor, mild cognitive impairment (MCI) [30]. The GG genotype frequency in our study was just 24% in Tajiks, compared with 51.2%, 50%, and 46% in CHB, JPT, and YRI respectively (p < 0.05). This suggests that Tajiks may be less vulnerable to diseases related to dopamine content, including AD and MCI.
Our study also found significant differences in genotype frequencies between Tajiks and other populations in genes such as DRD2 and F5. Polymorphisms in these genes have been shown to be associated with dyskinesia induced by levodopa therapy in Parkinson’s disease patients and coronary artery disease, respectively [31],[32].
The Tajiks speak a western Indo-Iranian language and their presence in China dates to the 10th-century Muslim invasion, suggesting they are descendants of eastern Indo-Iranian speakers [33]. This may explain the smaller differences between Tajiks and CEU compared to other three populations we investigated.
However, intrinsic limitations still exist in our study. Our sample size is relatively not big enough, thus further investigation related to pharmacogenomics gene polymorphisms in a larger Tajik population is necessary to ascertain the results obtained in the current study.
Conclusions
These results provide the first pharmacogenomics information in Tajiks and illustrate the difference of selected genes between Tajiks and four other populations. Present-day China is a nation with 56 distinct ethnic groups. Our study provides a theoretical basis for safer drug administration and better therapeutic treatments in this unique population, and may also be applied in the diagnosis and prognosis of specific diseases in Tajiks.
Authors’ information
Jiayi Zhang and Tianbo Jin joint first authors.
Additional files
References
Roden DM, Altman RB, Benowitz NL, Flockhart DA, Giacomini KM, Johnson JA, Krauss RM, McLeod HL, Ratain MJ, Relling MV, Ring HZ, Shuldiner AR, Weinshilboum RM, Weiss ST: Pharmacogenomics: challenges and opportunities. Ann Intern Med. 2006, 145: 749-757. 10.7326/0003-4819-145-10-200611210-00007.
Weinshilboum R: Inheritance and drug response. N Engl J Med. 2003, 348: 529-537. 10.1056/NEJMra020021.
Evans WE, McLeod HL: Pharmacogenomics-drug disposition, drug targets, and side effects. N Engl J Med. 2003, 348: 538-549. 10.1056/NEJMra020526.
Evans WE, Relling MV: Pharmacogenomics: translating functional genomics into rational therapeutics. Science. 1999, 286: 487-491. 10.1126/science.286.5439.487.
Sangkuhl K, Berlin DS, Altman RB, Klein TE: PharmGKB: understanding the effects of individual genetic variants. Drug Metab Rev. 2008, 40: 539-551. 10.1080/03602530802413338.
Gabriel S, Ziaugra L, Tabbaa D: SNP genotyping using the Sequenom MassARRAY iPLEX platform. Curr Protoc Hum Genet. 2009, Chapter 2: Unit 2 12-
Thomas RK, Baker AC, Debiasi RM, Winckler W, Laframboise T, Lin WM, Wang M, Feng W, Zander T, MacConaill L, Lee JC, Nicoletti R, Hatton C, Goyette M, Girard L, Majmudar K, Ziaugra L, Wong KK, Gabriel S, Beroukhim R, Peyton M, Barretina J, Dutt A, Emery C, Greulich H, Shah K, Sasaki H, Gazdar A, Minna J, Armstrong SA, et al: High-throughput oncogene mutation profiling in human cancer. Nat Genet. 2007, 39: 347-351. 10.1038/ng1975.
Song MK, Lin FC, Ward SE, Fine JP: Composite variables: when and how. Nurs Res. 2012, 62: 45-49. 10.1097/NNR.0b013e3182741948.
Adamec C: Example of the use of the nonparametric test. Test X2 for comparison of 2 independent examples. Cesk Zdrav. 1964, 12: 613-619.
Barrett JC, Fry B, Maller J, Daly MJ: Haploview: analysis and visualization of LD and haplotype maps. Bioinformatics. 2005, 21: 263-265. 10.1093/bioinformatics/bth457.
Shi YY, He L: SHEsis, a powerful software platform for analyses of linkage disequilibrium, haplotype construction, and genetic association at polymorphism loci. Cell Res. 2005, 15: 97-98. 10.1038/sj.cr.7290286.
Hawley ME, Kidd KK: HAPLO: a program using the EM algorithm to estimate the frequencies of multi-site haplotypes. J Hered. 1995, 86: 409-411.
Zand N, Tajik N, Moghaddam AS, Milanian I: Genetic polymorphisms of cytochrome P450 enzymes 2C9 and 2C19 in a healthy Iranian population. Clin Exp Pharmacol Physiol. 2007, 34: 102-105. 10.1111/j.1440-1681.2007.04538.x.
Hama T, Norizoe C, Suga H, Mimura T, Kato T, Moriyama H, Urashima M: Prognostic significance of vitamin D receptor polymorphisms in head and neck squamous cell carcinoma. PLoS One. 2011, 6: e29634-10.1371/journal.pone.0029634.
Raimondi S, Johansson H, Maisonneuve P, Gandini S: Review and meta-analysis on vitamin D receptor polymorphisms and cancer risk. Carcinogenesis. 2009, 30: 1170-1180. 10.1093/carcin/bgp103.
Gandini S, Raimondi S, Gnagnarella P, Dore JF, Maisonneuve P, Testori A: Vitamin D and skin cancer: a meta-analysis. Eur J Cancer. 2009, 45: 634-641. 10.1016/j.ejca.2008.10.003.
Gianfagna F, De Feo E, van Duijn CM, Ricciardi G, Boccia S: A systematic review of meta-analyses on gene polymorphisms and gastric cancer risk. Curr Genomics. 2008, 9: 361-374. 10.2174/138920208785699544.
Li D, Zhao H, Gelernter J: Strong association of the alcohol dehydrogenase 1B gene (ADH1B) with alcohol dependence and alcohol-induced medical diseases. Biol Psychiatry. 2011, 70: 504-512. 10.1016/j.biopsych.2011.02.024.
McKay JD, Truong T, Gaborieau V, Chabrier A, Chuang SC, Byrnes G, Zaridze D, Shangina O, Szeszenia-Dabrowska N, Lissowska J, Rudnai P, Fabianova E, Bucur A, Bencko V, Holcatova I, Janout V, Foretova L, Lagiou P, Trichopoulos D, Benhamou S, Bouchardy C, Ahrens W, Merletti F, Richiardi L, Talamini R, Barzan L, Kjaerheim K, Macfarlane GJ, Macfarlane TV, Simonato L, et al: A genome-wide association study of upper aerodigestive tract cancers conducted within the INHANCE consortium. PLoS Genet. 2011, 7: e1001333-10.1371/journal.pgen.1001333.
Macgregor S, Lind PA, Bucholz KK, Hansell NK, Madden PA, Richter MM, Montgomery GW, Martin NG, Heath AC, Whitfield JB: Associations of ADH and ALDH2 gene variation with self report alcohol reactions, consumption and dependence: an integrated analysis. Hum Mol Genet. 2009, 18: 580-593. 10.1093/hmg/ddn372.
Tolstrup JS, Nordestgaard BG, Rasmussen S, Tybjaerg-Hansen A, Gronbaek M: Alcoholism and alcohol drinking habits predicted from alcohol dehydrogenase genes. Pharmacogenomics J. 2008, 8: 220-227. 10.1038/sj.tpj.6500471.
Zuccolo L, Fitz-Simon N, Gray R, Ring SM, Sayal K, Smith GD, Lewis SJ: A non-synonymous variant in ADH1B is strongly associated with prenatal alcohol use in a European sample of pregnant women. Hum Mol Genet. 2009, 18: 4457-4466. 10.1093/hmg/ddp388.
Luo X, Kranzler HR, Zuo L, Wang S, Schork NJ, Gelernter J: Diplotype trend regression analysis of the ADH gene cluster and the ALDH2 gene: multiple significant associations with alcohol dependence. Am J Hum Genet. 2006, 78: 973-987. 10.1086/504113.
Hashibe M, McKay JD, Curado MP, Oliveira JC, Koifman S, Koifman R, Zaridze D, Shangina O, Wünsch-Filho V, Eluf-Neto J, Levi JE, Matos E, Lagiou P, Lagiou A, Benhamou S, Bouchardy C, Szeszenia-Dabrowska N, Menezes A, Dall'Agnol MM, Merletti F, Richiardi L, Fernandez L, Lence J, Talamini R, Barzan L, Mates D, Mates IN, Kjaerheim K, Macfarlane GJ, Macfarlane TV, et al: Multiple ADH genes are associated with upper aerodigestive cancers. Nat Genet. 2008, 40: 707-709. 10.1038/ng.151.
Chen J, Lipska BK, Halim N, Ma QD, Matsumoto M, Melhem S, Kolachana BS, Hyde TM, Herman MM, Apud J, Egan MF, Kleinman JE, Weinberger DR: Functional analysis of genetic variation in catechol-O-methyltransferase (COMT): effects on mRNA, protein, and enzyme activity in postmortem human brain. Am J Hum Genet. 2004, 75: 807-821. 10.1086/425589.
Pap D, Gonda X, Molnar E, Lazary J, Benko A, Downey D, Thomas E, Chase D, Toth ZG, Mekli K, Platt H, Payton A, Elliott R, Anderson IM, Deakin JF, Bagdy G, Juhasz G: Genetic variants in the catechol-o-methyltransferase gene are associated with impulsivity and executive function: Relevance for major depression. Am J Med Genet B Neuropsychiatr Genet. 2012, 159B: 928-940. 10.1002/ajmg.b.32098.
Meyer-Lindenberg A, Kohn PD, Kolachana B, Kippenhan S, McInerney-Leo A, Nussbaum R, Weinberger DR, Berman KF: Midbrain dopamine and prefrontal function in humans: interaction and modulation by COMT genotype. Nat Neurosci. 2005, 8: 594-596. 10.1038/nn1438.
Bilder RM, Volavka J, Lachman HM, Grace AA: The catechol-O-methyltransferase polymorphism: relations to the tonic-phasic dopamine hypothesis and neuropsychiatric phenotypes. Neuropsychopharmacology. 2004, 29: 1943-1961. 10.1038/sj.npp.1300542.
Tunbridge EM, Harrison PJ, Weinberger DR: Catechol-o-methyltransferase, cognition, and psychosis: Val158Met and beyond. Biol Psychiatry. 2006, 60: 141-151. 10.1016/j.biopsych.2005.10.024.
Lanni C, Garbin G, Lisa A, Biundo F, Ranzenigo A, Sinforiani E, Cuzzoni G, Govoni S, Ranzani GN, Racchi M: Influence of COMT Val158Met polymorphism on Alzheimer’s disease and mild cognitive impairment in Italian patients. J Alzheimers Dis. 2012, 32: 919-926.
Tang W, Schwienbacher C, Lopez LM, Ben-Shlomo Y, Oudot-Mellakh T, Johnson AD, Samani NJ, Basu S, G gele M, Davies G, Lowe GD, Tregouet DA, Tan A, Pankow JS, Tenesa A, Levy D, Volpato CB, Rumley A, Gow AJ, Minelli C, Yarnell JW, Porteous DJ, Starr JM, Gallacher J, Boerwinkle E, Visscher PM, Pramstaller PP, Cushman M, Emilsson V, Plump AS, et al: Genetic associations for activated partial thromboplastin time and prothrombin time, their gene expression profiles, and risk of coronary artery disease. Am J Hum Genet. 2012, 91: 152-162. 10.1016/j.ajhg.2012.05.009.
Rieck M, Schumacher-Schuh AF, Altmann V, Francisconi CL, Fagundes PT, Monte TL, Callegari-Jacques SM, Rieder CR, Hutz MH: DRD2 haplotype is associated with dyskinesia induced by levodopa therapy in Parkinson’s disease patients. Pharmacogenomics. 2012, 13: 1701-1710. 10.2217/pgs.12.149.
Heyer E, Balaresque P, Jobling MA, Quintana-Murci L, Chaix R, Segurel L, Aldashev A, Hegay T: Genetic diversity and the emergence of ethnic groups in Central Asia. BMC Genet. 2009, 10: 49-10.1186/1471-2156-10-49.
Acknowledgments
This work was supported by the National 863 High-Technology Research and Development Program (No. 2012AA02A519).
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests. No conflict of interest exits in the submission of this manuscript, and manuscript is approved by all authors for publication. I would like to declare on behalf of my co-authors that the work described was original research that has not been published previously, and not under consideration for publication elsewhere, in whole or in part. All the authors listed have approved the manuscript that is enclosed.
Authors’ contributions
JZ and TJ designed the study, carried out the molecular genetic studies, and participated in the statistical analysis and drafted the manuscript. ZY and XL participated in molecular genetic studies and statistical analysis. TG and HG participated in the design of the study and performed the statistical analysis. YC conceived of the study, and participated in its design and coordination and helped to draft the manuscript. CC conceived of the study, and participated in its design and coordination, and funded the study. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article

{kind=link}
{kind=link}
Cite this article
Zhang, J., Jin, T., Yunus, Z. et al. Genetic polymorphisms of VIP variants in the Tajik ethnic group of northwest China. BMC Genet 15, 102 (2014). https://doi.org/10.1186/s12863-014-0102-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12863-014-0102-y