
Abstract
Pathogenic bacteria present a major threat to human health, causing various infections and illnesses, and in some cases, even death. The accurate identification of these bacteria is crucial, but it can be challenging due to the similarities between different species and genera. This is where automated classification using convolutional neural network (CNN) models can help, as it can provide more accurate, authentic, and standardized results.In this study, we aimed to create a larger and balanced dataset by image patching and applied different variations of CNN models, including training from scratch, fine-tuning, and weight adjustment, and data augmentation through random rotation, reflection, and translation. The results showed that the best results were achieved through augmentation and fine-tuning of deep models. We also modified existing architectures, such as InceptionV3 and MobileNetV2, to better capture complex features. The robustness of the proposed ensemble model was evaluated using two data splits (7:2:1 and 6:2:2) to see how performance changed as the training data was increased from 10 to 20%. In both cases, the model exhibited exceptional performance. For the 7:2:1 split, the model achieved an accuracy of 99.91%, F-Score of 98.95%, precision of 98.98%, recall of 98.96%, and MCC of 98.92%. For the 6:2:2 split, the model yielded an accuracy of 99.94%, F-Score of 99.28%, precision of 99.31%, recall of 98.96%, and MCC of 99.26%. This demonstrates that automatic classification using the ensemble model can be a valuable tool for diagnostic staff and microbiologists in accurately identifying pathogenic bacteria, which in turn can help control epidemics and minimize their social and economic impact.
Similar content being viewed by others


Introduction
Bacteria are ubiquitous in our environment, living on and within us as well as in the atmosphere. Some bacteria are harmless and coexist with other species like animals and birds, while others can cause disease in humans. Approximately 1500 different pathogens are responsible for causing illnesses in humans, including tuberculosis, cholera, pneumonia, diarrhea, plague, and typhoid [1]. These pathogens are not only responsible for significant outbreaks but also cause billions of dollars in economic losses worldwide and disrupt businesses [2].
Accurate and rapid identification of bacterial genera and species is critical in preventing the spread of diseases, especially contagious ones. The current study concentrates on 24 bacterial pathogens, with a focus on the five pathogens (Enterococcus faecium, Acinetobacter baumannii, Pseudomonas aeruginosa, Staphylococcus aureus, and Neisseria gonorrhoeae) that instantly need new therapeutics by the World Health Organization [3]. The DIBaS dataset [4] used in this research includes all of these pathogens. Automated identification of these pathogens using computational approaches is becoming increasingly important. The advent of deep Convolutional Neural Network (CNN) models has the potential to greatly aid in the quick diagnosis, prevention, and treatment of illnesses.
Traditional laboratory techniques for bacterial identification are time-consuming and require expert knowledge and experience. Two key features can help with bacterial recognition: shape and colony structure. Bacterial shape is a distinctive feature that can be identified in an image, but it is difficult to classify bacteria solely based on shape as bacteira can have similar forms or structures. Colony structure, including the shape and size of colonies, is another important characteristic in terms of unique structures and spatial arrangements. However, some bacterial species have morphologically dissimilar cells and can have different forms and sizes, making classification based on shape and colony structure challenging. As a result, specialists may require additional examination using additional microbiological features.
Deep learning models like AlexNet [5], GoogleNet [6], SqueezNet [7], MobileNetV2 [8], and InceptionV3 [9], large-size databases like ImageNet [10], and effective regularization methods “dropout” [11], show improved performance, prediction accuracy, and excellent generalizability to resolve complex computer vision, biological and medical tasks [12]. The benefit of Convolution network’s for image classification is that the network automatically identifies essential features without any human intervention.
However, training deep models with large features on small datasets can result in overfitting. Transfer learning (TL) is a solution to this problem, using the knowledge gained from solving a specific task to solve a different but related problem. The method is effective when combined with augmentation, rigorous hyper-parameter optimization, and appropriate fine-tuning policies. Moreover, deep learning models possess varying architectures, layers, and convolutions, which enable them to learn distinct features from the data. This diversity of features can be leveraged through ensemble learning, a successful approach in computer vision, to integrate distinctive features from different models and achieve consistent and improved predictive performance.
Computer-aided techniques are efficient tools for the classification of bacterial species. During the early days of the research image processing techniques like morphological and geometric properties were applied for bacterial classification. However, recently newly devised machine and deep learning methods are being used in this area of research. Zielinski et al. [4] propose a deep learning approach for bacterial colony classification using Convolutional Neural Networks (CNNs). They provide an open-source image dataset for various bacterial species and use the CNNs for feature extraction. The classification is performed using two traditional machine learning algorithms, Random Forest and Support Vector Machines (SVM). The authors report an impressive accuracy of 97.24% with their proposed approach. However, the limitations of the study include the lack of external testing data to evaluate the generalizability of the design. In recent years different researches have applied DIBaS dataset for training their models. Khalifa et al. [13] developed a deep neural network approach for the classification of bacterial colonies. They used the DIBaS dataset, consisting of 660 images of 33 classes of bacteria, for their study. To overcome the limitation of limited data, the authors applied data augmentation techniques to increase the number of images. The proposed approach was evaluated using a split of 80% of the data for training and 20% for testing, resulting in an accuracy of 98.22%. Muhammed Talo [14] proposed an automated approach for bacterial colony classification by fine-tuning a pre-trained ResNet-50 model on the DIBaS dataset. The study achieved a classification accuracy of 99.12% but used an imbalanced dataset with varying number of images in each class. Additionally, the study did not employ augmentation techniques or perform hyperparameter optimization. Another research by Rujichan et al. [15] proposed a deep learning solution for bacterial colony classification by fine-tuning a MobileNetV2 model. The authors utilized color masking for data preparation and applied various data augmentation techniques to increase the number of training images. The study reported an accuracy of 95.09% for the classification of bacterial colonies. Abd Elaziz et al. [16] applied a novel approach for feature extraction in bacterial colony classification. They used fractional-order orthogonal moments to extract fine features from the images. The authors tested their method on 660 images from the DIBaS dataset and achieved an accuracy of 98.68%. In the study by Gallardo et al. [17], the authors employed a fine-tuned MobileNetV2 model and utilized data augmentation techniques to perform bacterial colony classification. The research was based on the DIBaS dataset, which consisted of imbalanced classes of images. Despite this, the authors were able to achieve an accuracy of 94.22% in their classification results. Satoto et al. [18] proposed an automated classification model for bacterial colonies based on a Convolutional Neural Network (CNN). The study focused on a subset of four classes from the DIBaS dataset and applied data augmentation techniques to increase the diversity of the training data. The model achieved a classification accuracy of 98.59%.
In recent years, the use of deep learning models in the field of bacterial specie classification has increased. However, many of these studies are limited by the small amount of available training data and the absence of testing data to assess the generalizability of the models. Most previous approaches also neglected crucial techniques such as image patching, ensemble learning, data augmentation, and hyperparameter tuning, which have the potential to further enhance the performance of these models. Table 1 gives us an overview of previous approaches presented in the literature.
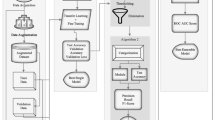
The gap in the existing studies that motivated this research is the need for a more robust and accurate classification model for bacterial species. This is particularly important in the classification of pathogenic bacteria, as incorrect classification could have serious implications for public health. To address this gap, this research presents an extensive and balanced dataset prepared by segmenting high-scale images using image patching, and each class of the dataset now consists of 320 images. The bacterial images are trained using a combination of transfer learning, fine-tuning, hyper-parameter tuning, and augmentation strategies applied on pre-trained models. The research also introduces a deep model, which combines the distinctive features of InceptionV3 and MobileNetV2, using an ensemble learning technique, as illustrated in Fig. 1.
Our research contribution can be summarized as follows:
-
(1)
An extensive and balanced dataset was prepared through image patching.
-
(2)
An ensemble learning design combining InceptionV3 and MobileNetV2 architectures with additional dense layers and a dropout layer was proposed.
-
(3)
The research blended transfer learning, fine-tuning, hyper-parameter tuning, and augmentation in one design.
-
(4)
The focus of the research was specifically on the classification of pathogenic bacteria.
-
(5)
Two data splits were applied to evaluate the robustness of the ensemble model with increased training data from 10 to 20%.

Various phases of our proposed method
Materials and methods
In our study, we used two state-of-the-art deep learning architectures, MobileNetV2 and InceptionV3, to classify bacterial colonies based on their gram-stain images. The architectural differences between MobileNetV2 and InceptionV3 allow them to capture distinct features from the data. MobileNetV2 focuses on efficiently capturing spatial details using depthwise separable convolutions, making it effective at capturing fine-grained features and patterns [8]. In contrast, InceptionV3 utilizes factorized inception blocks to gather a wide range of feature patterns at varying scales [9].
These architectural variances lead to differences in the types of features learned by each model. MobileNetV2 excels at capturing intricate textures, edges, and local patterns, while InceptionV3 excels at capturing more global features, such as object shapes or larger contextual information [8, 9]. By combining the outputs of these models in the ensemble, we leverage their complementary learned features. The ensemble model benefits from the diverse representations captured by each model, resulting in improved performance by capturing a broader range of discriminative features from the bacterial colony images.
A CNN model for merging features of pre-trained models with the help of ensemble learning is given in the Fig. 2. The presented design comprises of the following steps: (i) Segmenting a large-scale image into patches (ii) Image resizing (iii) Dataset splitting (iv) Data augmentation (iv) Embedding pre-trained MobileNetV2 and InceptionV3 models to the framework (v) Adding Dense layers to these models (vi) Merging features of these models using addition layer (vii) Adding some dropout and dense layers and eventually applying classification on the suggested ensemble design.
Algorithm 1 portrays the pseudocode of the suggested deep ensemble design. Initially, large scale gram-stained bacterial images are segmented into smaller patches. These segmented images are then resized to meet the input size requirement of the deep learning models. The resized images are then split into train, validation, and test datasets, and data augmentation techniques are applied to produce an augmented dataset. Two pre-trained deep models, MobileNetV2 and InceptionV3, are embedded into the ensemble model and dense layers are added before merging their features. Finally, dropout and dense layers are added to further enhance the quality of the model, and then classification is performed to obtain the class labels of the 24 categories of pathogenic bacterial images as output.

Flowchart of different stages of our deep ensemble model

Dataset details and augmentation
In our research, we utilied the DIBaS dataset [4] that comprises of annotated, high resolution, and microscopic images from thirty three species of bacteria. Out of these, 24 pathogenic species are selected, which are present in various environment’s and cause different diseases [22]. Each strain consists of 20 images of a specific class. Various augmentation techniques (random vertical translation, horizontal reflection, and translation) are applied to produce an augmented dataset. For experimentation, we divide the dataset into 3 sets, i.e., train, validation, and test data, with split ratio’s of 7:2:1 and 6:2:2.
Patch extraction and data preprocessing
The High dimensional images (2040 x 1536) consume a subsequent amount of memory. So, we segment each image into 16 patches of dimension i.e. (512 x 383), as shown in Fig. 3. Hence, now we have 320 bacterial images relating to each category. The patches with a white background and no significant information are removed. In the research, we have assessed different deep learning models. Each model’s input size is different like InceptionV3 has an input image size of 299-by-299, and MobileNetV2 has dimensions of 224-by-224. So, the images need to be further adjusted to meet the input requirement of the models.

Original Image of size 2040x1536 and its Patches of 512 x 383
Hyper-parameters tuning
We evaluated the effect of different hyper-parameter optimizations on the model performance, such as the learning rate, batch size, and epochs. In addition to the proposed model, we also assessed five CNN models and implemented fine-tuning using different parameters like learning rate, batch size, and number of epochs, etc. Table 2 shows the details of hyper-parameters utilized to optimize these models during the training phase.
Convolution neural networks
The motivation for using Convolutional Neural Network (CNN) models in computer vision tasks is due to their ability to handle large amounts of data and learn and extract meaningful features from images automatically that improve the accuracy of predictions. Unlike traditional machine learning models that require hand-crafted features, CNNs can learn hierarchical representations of images that capture complex relationships between pixels. They normally consists of three components: convolution, pooling, and dense layers. During a convolution operation, various filters are applied to extract features (feature map) from the image, by which their spatial information can be conserved. The pooling method is also known as subsampling, which is used to decrease the dimensionality of feature maps and also to pick the most vital feature from the convolution process. Dense layers, also known as fully connected layers, play a crucial role in making final predictions by mapping high-level features from convolution and pooling layers to output classes or labels. They are responsible for capturing complex relationships and patterns in the data to provide accurate predictions.
The training of CNN’s starts from the first input layer and goes up till the final layer. The error is back-propagated from the last classification layer to the initial convolutional layer. If n is a neuron in layer h, which recieves input from a neuron m of layer \({h-1}\),the sum input \(In_{n}^{h}\) can be computed as follows:
where \(b_{n}\) and \(W_{nm}^{h}\) are the bias term and weight vector of the \(h^{th}\) layer respectively.The output of the \(h^{th}\) layer can be computed by the ReLU function as:
The connections in the fully connected and convolution layers utilize Eqs. 1 and 2 to calculate the inputs/outputs. For more details on working of CNNs, the researchers may refer to [23]. In this section, we will discuss two popular CNN models, MobileNet and InceptionNet, and their motivations.
Pre-trained architectures
Different pre-trained models were utilized in our research, including MobileNetV2 and InceptionV3. These models are pre-trained on the ImageNet dataset, which consists of a vast collection of images across multiple classes. The pre-training process enables these models to learn generic features from the ImageNet dataset [10], which can then be fine-tuned for our specific task of classifying pathogenic bacteria. The following sub-sections provide a detailed description of these pre-trained models and their architectures.
AlexNet
The AlexNet was the victorious model in the 2012 ImageNet competition, primarily utilized for image classification. It is an expanded and deeper version of LeNet that includes the fundamental components of CNNs and serves as the basis for other deep learning architectures. While preserving the original design, it has added features such as LRN, dropout, and ReLU. The key finding from the study was that the model’s impressive performance was largely due to its depth, although this came at the cost of increased computational demands during training, which were made feasible through the use of GPUs. The model consists of 5 convolutional and 3 fully connected layers, as illustrated in the Fig. 4.

AlexNet architecture
SqueezeNet
The Squeeznet model was developed by researchers from Stanford, Berkeley, and DeepScale with the aim of creating a smaller CNN with fewer parameters that would consume less memory and could be efficiently transmitted over a computer network. The foundation of this deep learning architecture is the fire module, which consists of a convolution layer with 1x1 filters that feed into an expand layer that has both 1x1 and 3x3 convolution filters, as depicted in the Fig. 5.

SqueezeNet fire module
GoogleNet
Google introduced the inception structure called GoogLeNet, which was the best performer at the 2014 ImageNet competition. While constructing a Convolution Network you have to pick 1 x 1, 3 x 3, 5 x 5, convolution layer, or pooling layer. The GoogleNet has them all in its inception module. It makes architecture complicated but works remarkably well.
MobileNetV2
MobileNetV2 is a computationally efficient CNN model that is well-suited for mobile and embedded systems. Its design focuses on reducing the number of parameters, computations, and memory usage while still achieving good performance on image classification tasks. This makes it ideal for deployment on resource-constrained devices such as smartphones, which have limited computational resources. MobileNetV2 is quite similar to MobileNetV1, which offers a depthwise separable convolutional layer that reduces the size and complexity of the model. It also includes a useful module with an inverted residual block with bottlenecking features. It has a drastically lesser parameter than the initial MobileNetV1 design [24]. Figure 1 illustrates the MobileNetV2 block.
InceptionV3
InceptionNet is a flexible and scalable CNN model that is designed for a wide range of computer vision tasks. It features an Inception module that allows for multiple parallel convolutions of different kernel sizes, which can extract features from an image at multiple scales. This makes InceptionNet well-suited for tasks such as object detection, semantic segmentation, and image classification. Additionally, its scalability makes it possible to adapt the model to different data sets and computational resources. Like MobileNetV2, it strikes a balance between accuracy and computational cost, making it a good choice for our study. The inceptionV3 model is an updated form of inceptionV2 that attains excellent results on image recognition challenges by removing 5 \(\times\) 5 convolutions and including preferably two more 3 \(\times\) 3 convolution layers. The model restricts overfitting and tend to achieve label smoothing. It also factorizes a 7 \(\times\) 7 convolution layer and combines different CNN layers after normalization, rendering greater accuracy with limited computation complexity, as shown in Fig. 6.

InceptionV3 Module
Ensemble classification
These CNN’s are non-linear architectures that learn complex relations from input data through stochastic optimizations and error back-propagation, which makes them very responsive to weight initializations and the noise present in the dataset. Ensemble learning resolves these issues by training several models and joining their predictions or features. In this technique, model shortages are balanced by the predictions of the other architectures. Merged predictions produce better results than any single model [25]. Ensemble learning techniques reduce variance error, enhance performance, and generalizability of models.
Performace metrics
To evaluate the performance of the different deep models in comparison to the proposed methodology, multiple performance measures are employed, including precision, recall, F-Score, and Matthews Correlation Coefficient (MCC), in addition to accuracy. This comprehensive set of metrics provides a more complete assessment of the model’s effectiveness, as accuracy alone may not sufficiently capture its performance [26].
By considering precision, recall, F-Score, and MCC in conjunction with accuracy, we gain insights into different aspects of the model’s predictive capabilities, such as its ability to correctly identify positive instances (precision), capture all relevant positive instances (recall), achieve a balance between precision and recall (F-Score), and provide an overall correlation measure (MCC). Together, these performance measures offer a comprehensive evaluation of the deep models’ effectiveness in the context of the proposed methodology. The computation of these metrics involves the following equations, where TP represents true positives, TN represents true negatives, FP represents false positives, and FN represents false negatives:
Model training strategies
In the Results section, various experimental Strategies were adopted to demonstrate the effects of fine-tuning and augmentation on deep learning models with and without pre-trained weights from the ImageNet dataset. These strategies are as follows:
Training from the beginning
In this approach, deep models are trained from scratch on the target dataset without applying any parameter-tuning or utilizing any previously learned weights from the ImageNet dataset.
Parameter-tuning without pre-trained weights
In this strategy, various parameters such as learning rate, batch size, etc., of deep models are tuned on the target dataset without utilizing any previously learned weights from the ImageNet dataset.
Fine-tuned with pre-trained weights when all layers unfrozen
In this technique, deep models are fine-tuned on the target dataset using previously learned weights from the ImageNet dataset. However, the weights of the layers are not frozen, and they are updated during the training process.
Augmented and fine-tuned with pre-trained weights when all layers are unfrozen
In this strategy, deep learning models are fine-tuned on the target dataset, and various augmentation techniques are applied to increase the size of the training data. The models utilize previously learned weights from the ImageNet dataset, and the weights are updated as the models learn during training.
Results
Initially, we analyze the performance of the CNN models in four different scenarios. When the deep learning models are: (i) trained from scratch (ii) Parameter-tuning without pre-trained weights (iii) fine-tuned with pre-trained weights when all layers un-frozen, and (iv) augmented and fine-tuned with pre-trained weights when all layers are unfrozen. For every approach, the outcomes of loss and accuracy of models are shown in Tables 3 and 4. By looking at it, we can infer the following conclusions:
-
(1)
The results depicit that shallow models produce substantially better results than deeper models for stratergy (i) and (ii) for small-size dataset like DIBaS. Specially in case of (ii) we can see that only tuning model parameters like learning-rate, batch size etc. without any pre-trained weights from ImageNet show significant better results in shallower models as compared to deeper models because these deeper models need substaintially larger number of parameters to train as compared to shallow models, as reflected by the results in Tables 3 and 4.
-
(2)
Applying fine-tuning on a pre-trained model is a highly efficient transfer learning approach for image classification tasks. The results show improvement in the accuracy of all CNN models fine-tuned on the primary dataset.
-
(3)
Augmentation is extremely beneficial for enriching a design’s performance, notably when the dataset is inadequate. The deep learning designs, together with traditional augmentation procedures, can help in achieving excellent results. The results display that the strategies where augmentation was applied show a 1–6% enhancement in test accuracy, and the reduction in loss ranges from 19 to 91% over prior fine-tuned deep models without augmentation.
-
(4)
The two best-performing models, MobileNetV2 and InceptionV3, were selected for feature fusion in our ensemble model I. The results showed that these models produced a test accuracy of 97.79% and 97.92% and a minimum loss of 0.0212 and 0.0446, respectively.
-
(5)
The proposed ensemble model I and II, with a split ratio of 7:2:1, produces a validation accuracy and loss of 99.41% and 0.0275, respectively, for model I; and 97.14% and 0.0953, respectively, for model II. The test results for model I include an accuracy of 99.91%, F-Score of 98.95%, precision of 98.98%, recall of 98.96%, and MCC of 98.92%. For model II, the test results are an accuracy of 99.79%, F-Score of 97.52%, precision of 97.60%, recall of 97.53%, and MCC of 97.44%.
-
(6)
Similarly, the ensemble model I and II, with a split ratio of 6:2:2, produces a validation accuracy and loss of 98.96% and 0.0284, respectively, for model I; and 97.72% and 0.3087, respectively, for model II. The test results for model I include an accuracy of 99.94%, F-Score of 99.28%, precision of 99.31%, recall of 98.96%, and MCC of 99.26%. For model II, the test results are an accuracy of 99.85%, F-Score of 98.24%, precision of 98.30%, recall of 98.24%, and MCC of 98.18%.
-
(7)
These results indicate that both ensemble models I and II demonstrate significant improvements over their respective base models, InceptionV3 and MobileNetV3 for model I, and GoogleNet and SqueezeNet for model II. The performance enhancements are consistently observed across the different evaluation metrics, highlighting the effectiveness of the ensemble approach.
Furthermore, we investigated the performance of ensemble model I on the test dataset, focusing on two different aspects: i) classification of bacteria from similar genera, and ii) classification of bacteria from dissimilar genera. Based on the confusion matrices shown in Figs. 7 and 8, we draw the following conclusions:
-
(1)
There are 8 misclassification’s in Model I with 10% test data and only 9 misclassification’s for model with 20% test data.
-
(2)
The Model I exhibitions exceptional result for similar and dissimilar genera.
-
(3)
Additionally, for 10% test data, there are 6 misclassifications for different genera and 2 misclassifications for the same genera. For 20% test data, there are 6 misclassifications for different genera and 3 misclassifications for the same genera.
These findings provide valuable insights into the performance of ensemble model I when classifying bacteria from similar and dissimilar genera.

Confusion matrix of ensemble learning model for 10% test data

Confusion matrix of ensemble learning model for 20% test data
Overfitting can be an important matter, specially with small datasets. The model may achieve excellent accuracy, but when analyzed for unseen real-life examples, it may not generalize well for new examples. So, a vital issue to examine if there is overfitting or the design has generalized well for examples provided during training of the model. We access it by estimating the gap within validation and training curves, wider the gap among them higher the overfitting.

Model Performance Curves for train and validation accuracy (blue, black dotted lines) and train and validation loss (orange, black dotted lines) of Deep Ensemble model, for the Classification of Bacterial pathogens using DIBaS dataset
Figure 9 depicts that the validation and training curves either overlap or move alongside each other without any significant gap, which shows that the model has generalized accurately without any overfitting.
A comparison against previous works on bacterial colony classification
In order to provide a comprehensive comparison between our ensemble model and other state-of-the-art classifiers, we conducted additional experiments using a common dataset consisting of 660 images representing 33 bacterial classes. This ensures that the number of bacterial species is consistent across all models, eliminating any potential bias caused by variations in class distribution. To ensure a fair evaluation, we adopted the same train, validation, and test split as utilized in our proposed model. Furthermore, we carefully fine-tuned the compared models based on the specified experimental settings provided by the authors. This included factors such as the number of epochs, batch size, learning rate, and any additional dense or dropout layers added to the model. By following this approach, we aim to provide a comprehensive and unbiased comparison between our ensemble model and the other classifiers, enabling a more accurate assessment of their respective performances. While assessing the performance indicators in Table 5, the suggested ensemble models display better results for all the performace metrics applied for assissing the model performance.
Discussion
Deep and machine learning procedures are generating outstanding results in the area of pathogen classification [27], bacterial identification [4], COVID19 [25]. They can help in the immediate and reliable diagnosis of diseases.
Our study reveals that transfer learning can significantly improve current modes of identification of bacterial images while also independently yielding exceptional results for small datasets. Researches [28] reveal that transfer learning can generate outstanding performance, especially for small datasets [29].
Fine-tuning helps models to converge quicker and acquires refine and insightful features that capture intricate image details [30], as is visible in our approach. It is also effective and efficient technique for diverse classification tasks in the biological domain [31].
Image patching preserves important local details that would otherwise be lost due to down-scaling [30]. Researches have elaborated that image patching help increase dataset size [32] and preserve essential local image details [30].
We also applied augmentation to our model, which produced excellent results as compared to other models. Studies show that augmentation boosts performance and generates a generalized model without overfitting [29].
In our ensemble learning approach, we utilized both MobileNetV2 and InceptionV3, where MobileNetV2 is an improvement of Resnet’s residual block and faster than MobileNetV1 due to its efficient design [33]. Additionally, InceptionV3 demonstrated remarkable performance in skin cancer diagnosis and applied factorized inception blocks for the accumulation of low-level to high-level feature patterns through smaller and larger convolutions [34]. The combination of these unique features learned by the two models resulted in improved performance compared to using a single model, as the diverse architecture and layers allowed them to learn distinctive features, providing a more comprehensive understanding of the data. Our work shows that suggest that ensemble models acquire beneficial features and generate better performance than individual models, as in Tables 3 and 4. Ensemble models have achieved excellent results in image classification tasks in multiple fields like radiology images [35], and histopathology images [36].
Current improvements in computer-vision are usually dependent on extensive, annotated data, which are not conveniently accessible in the biological field. Hence, our proposed model can be extremely helpful for environments where the dataset is limited and may continue to be especially beneficial in the days to come for the automatic diagnosis of disease-causing bacteria.
Conclusion
The work presents a classification technique for pathogenic bacteria, which leverages the advantages of ensemble learning, image patching, transfer learning, fine-tuning, and data augmentation. Ensemble learning integrates diverse features from different models and addresses their weaknesses. Image patching preserves local details and increases the dataset size. Fine-tuning allows for quick convergence and acquisition of domain-related features. Transfer learning solves the problem of limited training data. Data augmentation increases the diversity of the data and improves the generalization ability of the models, reducing the risk of overfitting. For the 6:2:2 split, the proposed ensemble model I achieved an accuracy of 99.94%, F-Score of 99.28%, precision of 99.31%, recall of 98.96%, and MCC of 99.26%. These results are significantly better than those of any of the fine-tuned models, demonstrating the efficacy of the proposed approach. In conclusion, the suggested model can aid diagnostic staff and microbiologists in the accurate identification of pathogenic bacteria, which can help control pandemics and mitigate the socioeconomic impact on society.
Availability of data and materials
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Franconi R, Illiano E, Paolini F, Massa S, Venuti A, Demurtas OC. Rapid and low-cost tools derived from plants to face emerging/re-emerging infectious diseases and bioterrorism agents. In: Defence Against Bioterrorism, 2018;123–139. Springer
Bintsis T. Foodborne pathogens. AIMS Microbiol. 2017;3(3):529.
Tacconelli E, Carrara E, Savoldi A, Harbarth S, Mendelson M, Monnet DL, Pulcini C, Kahlmeter G, Kluytmans J, Carmeli Y, et al. Discovery, research, and development of new antibiotics: the who priority list of antibiotic-resistant bacteria and tuberculosis. Lancet Infect Dis. 2018;18(3):318–27. https://doi.org/10.1016/S1473-3099(17)30753-3.
Ahmad F, Farooq A, Khan MU. Deep learning model for pathogen classification using feature fusion and data augmentation. Current Bioinformatics. 2021;16(3):466-483.
Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, 2012;1097–1105.
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, Erhan D, Vanhoucke V, Rabinovich A. Going deeper with convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015; 1–9.
Iandola FN, Han S, Moskewicz MW, Ashraf K, Dally WJ, Keutzer K. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size. arXiv preprint arXiv:1602.07360 2016. https://doi.org/10.48550/arXiv.1602.07360
Sandler M, Howard A, Zhu M, Zhmoginov A, Chen L-C. Mobilenetv2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018; 4510–4520.
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z. Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016; 2818–2826.
Deng J, Dong W, Socher R, Li L-J, Li K, Fei-Fei L. Imagenet: A large-scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. https://doi.org/10.1109/CVPR.2009.5206848. IEEE; 2009. p. 248–255
Sermanet P, Frome A, Real E. Attention for fine-grained categorization. arXiv preprint arXiv:1412.7054 2014. https://doi.org/10.48550/arXiv.1412.7054
Dawud AM, Yurtkan K, Oztoprak H. Application of deep learning in neuroradiology: brain haemorrhage classification using transfer learning. Comput Intell Neurosci. 2019;20:19. https://doi.org/10.1155/2019/4629859.
Khalifa NEM, Taha MHN, Hassanien AE, Hemedan AA. Deep bacteria: robust deep learning data augmentation design for limited bacterial colony dataset. Int J Reason-based Intell Syst. 2019;11(3):256–64.
Talo M. An automated deep learning approach for bacterial image classification. arXiv preprint arXiv:1912.08765 2019. https://doi.org/10.48550/arXiv.1912.08765
Rujichan C, Vongserewattana N, Phasukkit P. Bacteria classification using image processing and deep convolutional neural network. In: 2019 12th biomedical engineering international conference (BMEiCON). https://doi.org/10.1109/BMEiCON47515.2019.8990270. IEEE; 2019. p. 1–4.
Abd Elaziz M, Hosny KM, Hemedan AA, Darwish MM. Improved recognition of bacterial species using novel fractional-order orthogonal descriptors. Appl Soft Comput. 2020;95:106504. https://doi.org/10.1016/j.asoc.2020.106504.
Gallardo-García R, Jarquín-Rodríguez A, Beltrán-Martínez B, Martínez R. Deep learning for fast identification of bacterial strains in resource constrained devices. Aplicaciones Científicas y Tecnológicas de las Ciencias Computacionales, 2020; 67–78.
Satoto BD, Utoyo MI, Rulaningtyas R, Koendhori EB. An auto contrast custom convolutional neural network to identifying gram-negative bacteria. In: 2020 International conference on computer engineering, network, and intelligent multimedia (CENIM). https://doi.org/10.1109/CENIM51130.2020.9297964. IEEE; 2020. p. 70–75.
Nasip ÖF, Zengin K. Deep learning based bacteria classification. In: 2018 2nd international symposium on multidisciplinary studies and innovative technologies (ISMSIT). IEEE; 2018. p. 1–5.
Mohamed BA, Afify HM. Automated classification of bacterial images extracted from digital microscope via bag of words model. In: 2018 9th Cairo international biomedical engineering conference (CIBEC). IEEE; 2018. p. 86–89.
Patel S. Bacterial colony classification using atrous convolution with transfer learning. Ann Rom Soc Cell Biol. 2021;25:1428–41.
Ahmad F, Farooq A, Khan MU. Deep learning model for pathogen classification using feature fusion and data augmentation. Curr Bioinform. 2021;16(3):466–83.
Mitchell TM. Machine learning, volume 1 of 1. McGraw-Hill Science/Engineering/-Math; 1997.
Sandler, Mark, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. "Mobilenetv2: Inverted residuals and linear bottlenecks." In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4510-4520. 2018.
Alsabban WH, Ahmad F, Al-Laith A, Kabrah SM, Boghdadi MA, Masud F. Deep Dense Model for Classification of Covid-19 in X-ray Images. International Journal of Computer Science and Network Security. 2022:429-442
Maxwell A, Li R, Yang B, Weng H, Ou A, Hong H, Zhou Z, Gong P, Zhang C. Deep learning architectures for multi-label classification of intelligent health risk prediction. BMC Bioinform. 2017;18:121–31.
Ahmad F, Ghani Khan MU, Tahir A, Tipu MY, Rabbani M, Shabbir MZ. Two phase feature-ranking for new soil dataset for Coxiella burnetii persistence and classification using machine learning models. Scientific Reports. 2023;13(1):29
Wang Y, Guan Q, Lao I, Wang L, Wu Y, Li D, Ji Q, Wang Y, Zhu Y, Lu H, et al. Using deep convolutional neural networks for multi-classification of thyroid tumor by histopathology: a large-scale pilot study. Ann Transl Med. 2019;7(18):468.
Han D, Liu Q, Fan W. A new image classification method using CNN transfer learning and web data augmentation. Expert Syst Appl. 2018;95:43–56. https://doi.org/10.1016/j.eswa.2017.11.028.
Yosinski J, Clune J, Bengio Y, Lipson H. How transferable are features in deep neural networks? In: Advances in neural information processing systems, 2014; 3320–3328.
Shin H-C, Roth HR, Gao M, Lu L, Xu Z, Nogues I, Yao J, Mollura D, Summers RM. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans Med Imaging. 2016;35(5):1285–98.
Takahashi R, Matsubara T, Uehara K. Data augmentation using random image cropping and patching for deep CNNs. IEEE Trans Circuits Syst Video Technol. 2019;30(9):2917–2931.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016; 770–778.
Esteva A, Kuprel B, Novoa RA, Ko J, Swetter SM, Blau HM, Thrun S. Dermatologist-level classification of skin cancer with deep neural networks. Nature. 2017;542(7639):115–8.
Livieris IE, Kanavos A, Tampakas V, Pintelas P. An ensemble SSl algorithm for efficient chest X-ray image classification. J Imaging. 2018;4(7):95.
Li C, Xue D, Kong F, Hu Z, Chen H, Yao Y, Sun H, Zhang L, Zhang J, Jiang T, et al. Cervical histopathology image classification using ensembled transfer learning. In: International conference on information technologies in biomedicine. Springer; 2019. p. 26–37
Acknowledgements
We thank Chair of Microbiology of the Jagiellonian University in Krakow, Poland for providing us the providing us the bacteria images dataset.
Funding
There is no funding source for this work.
Author information
Authors and Affiliations
Contributions
FAR for Fareed Ahmad, AT for Ahsen Tahir, UGK for Usman Ghani, FM for Farhan Masud. Outlined the deep ensemble design: FAR, UGK. Formulated and planned the experiments: FAR, and UGK. Conducted the experiments: FAR. Interpreted the outcomes: FAR, and UGK. Drafted the article: FAR, and AT. Reviewed the article: FAR,AT, and FM.
Corresponding author
Ethics declarations
Ethical approval and consent to participate
Not applicable
Human and animal rights
Not applicable
Consent for publication
Not applicable
Competing interests
The authors have no competing interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Ahmad, F., Khan, M.U.G., Tahir, A. et al. Deep ensemble approach for pathogen classification in large-scale images using patch-based training and hyper-parameter optimization. BMC Bioinformatics 24, 273 (2023). https://doi.org/10.1186/s12859-023-05398-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-023-05398-7