
Abstract
The rock mass is one of the key parameters in engineering design. Accurate rock mass classification is also essential to ensure operational safety. Over the past decades, various models have been proposed to evaluate and predict rock mass. Among these models, artificial intelligence (AI) based models are becoming more popular due to their outstanding prediction results and generalization ability for multiinfluential factors. In order to develop an easy-to-use rock mass classification model, support vector machine (SVM) techniques are adopted as the basic prediction tools, and three types of optimization algorithms, i.e., particle swarm optimization (PSO), genetic algorithm (GA) and grey wolf optimization (GWO), are implemented to improve the prediction classification and optimize the hyper-parameters. A database was assembled, consisting of 80 sets of real engineering data, involving four influencing factors. The three combined models are compared in accuracy, precision, recall, F1 value and computational time. The results reveal that among three models, the GWO-SVC-based model shows the best classification performance by training. The accuracy of training and testing sets of GWO-SVC are 90.6250% (58/64) and 93.7500% (15/16), respectively. For Grades I, II, III, IV and V, the precision value is 1, 0.93, 0.90, 0.92, 0.83, the recall value is 1, 1, 0.93, 0.73, 0.83, and the F1 value is 1, 0.96, 0.92, 0.81, 0.83, respectively. Sensitivity analysis is performed to understand the influence of input parameters on rock mass classification. It shows that the sensitive factor in rock mass quality is the RQD. Finally, the GWO-SVC is employed to assess the quality of rocks from the southeastern ore body of the Chambishi copper mine. Overall, the current study demonstrates the potential of using artificial intelligence methods in rock mass assessment, rendering far better results than the previous reports.
Similar content being viewed by others

Introduction
The rock mass is a concrete manifestation of the non-linear coupling of multiple factors in complex rock systems, which is directly related to the selection of construction design parameters and overall safety. The accurate assessment of rock mass quality reflects the physical and mechanical properties of the rock mass and provides reliable bases for engineering stability analysis, disaster prediction, prevention and control1. Therefore, it is necessary to develop appropriate methods to predict and evaluate the quality of rock mass2.
Numerous studies have been performed for the assessment of rock mass quality. For instance, Terzaghi’s rock-load classification scheme can be considered as the first empirical rock mass classification system3. Thereafter, various other evaluation methods have also been proposed based on different engineering practices. For example, the classical single-index grading methods, such as the Protodyakonov coefficient f grading method, the tensile strength Rt gradin g method, the compressive strength Rc grading method4, Deer's RQD grading method5, and the elastic wave velocity Vp method6. In addition, there are grading methods with juxtaposition of indicators such as Chinese engineering rock grading standard (BQ method)7. With the development of systems engineering, the influence of multiple factors is considered in the assessment of rock quality. Bieniawski et al. have utilized the sum-difference method to integrate different factors and construct an RMR rock grading system8. Similarly, Barton et al. have employed the product method to establish the rock tunneling index (Q) grading system9. Naithani et al. used a Q-system for tunnel rock quality grading, which supported the choice of support method10. Subsequently, several other rock classification systems were built on this basis. For example, Laubscher combined RMR values and adjustment parameters for different factors under mining conditions to build MRMR systems11. The M-RMR system as developed by Unal is also based on the RMR system and includes additional features for the characterization of weak, stratifified, anisotropic and clay bearing rock masses12. As the study progresses, the utilization of fuzzy theory has significantly improved the generalization performance and accuracy of classification methods2. Daftaribesheli constructed the M-SMR system using the mamdani fuzzy algorithm and the SMR system, which quantifies the fuzziness in the rock system13. Chen et al. have proposed a classification method for the quality of surrounding rocks based on hierarchical analysis and fuzzy Delphi method14. Zhou et al. have improved the classification distinction by the grey clustering method, which enhanced the applicability of the classification method and improved the positive assessment rate of rock mass quality15. Hu et al. have established the RS-TOPSIS model and applied it for the mass classification of rock masses in underground engineering16. Zhou et al. have effectively combined experimental expertise and multidimensionality of rock masses by improving RES and the uncertainty cloud theory to obtain a novel assessment method, which does tendentious evaluation17. Nowadays, big data and artificial intelligence are developed rapidly and neural network models, based on prior knowledge, are proposed and applied in the geotechnical fields. Feng and Wang have described a novel approach to predict probable rock bursts in underground openings based on learning and adaptive recognition of neural networks18. Alimoradi et al. learned Tunnel Seismic Prediction (TSP-203) data by ANN model. The trained ANN successfully predicted the poorer geological regions in the tunnel19. Klose et al. learned six seismic features by Self-Organizing Mapping (SOM) model to describe the complex relationship between geological conditions and seismic parameters. The results show that the trained SOM model can predict the geological conditions well from the seismic monitoring data20. Jalalifar et al. used the fuzzyneural inference system and predicted RMR-value. They used three types of fuzzy-neural networks and showed that the subtractive clustering method is more efficient in predicting RMR-value21. Rad et al. successfully implemented the prediction of the RMR system output values by coupling the Chaos-ANFIS model22. More pertinent work about rock mass classification prediction using AI methods is tabulated in Table 1.
These studies have improved the theory and methods of rock mass grading to a certain extent. For instance, the traditional single-indicator or multi-indicator comprehensive evaluation method is easy to operate, but the way is idealized and does not match with the actual complex rock system. The majority of models are unpopular and have been restricted to specific geological environments or countries. On the other hand, the selection of factor levels and weights in the fuzzy mathematical theory is a challenging task and different models may result in different classification results, limiting the generalization performance of the proposed model. And third, the mining of relevant data is difficult when AI-based methods are used to assess rock mass quality, limiting the accuracy of the proposed model. At the same time, traditional methods such as neural networks are less capable of learning small sample data, and the trained models are prone to extreme cases such as poor accuracy or overfitting. Hence, based on a large number of rock mass classification results, it is necessary to organize existing cases, establish a rock mass quality database and train an efficient rock mass classification model based on a small sample classification algorithm.
Zheng et al. established a small database containing 80 sets of tunnel rock samples and conducted a study on tunnel rock mass classification based on the SVM algorithm, which verified the excellent small sample learning ability of the SVM algorithm30. It has many attractive properties such as a strong mathematical foundation, few tuning parameters, fast classification and high generalization capability. The success of SVM relies on the selection of key parameters (c, g). In general, the machine learning models, without combining optimisation algorithms, are inefficient31. The traditional SVMs are often paired with the traversal method, such as the grid search (GS) method, to perform optimal computations. The traversal method is computationally intensive and renders low accuracy. Fayed propose a new method to prune the data by removing those data points that have a very small chance of becoming support vectors to ensure shorter search time and the acquisition of globally optimal parameters32. A disadvantage of the methods is that they are highly sensitive to the initial parameters. If they are far from the global optimal solution, they often converge to a local optimal solution33.
Recently, heuristic algorithm have been widely used and considered to have a big chance to converge to the global optimum34. Ren and Bai too offered twin methodologies for constraint refinement in SVM: particle swarm optimization PSO-SVM and GA-SVM35. Zhou et al. coupled the GA algorithm and PSO algorithm for parameter selection to reduce the parameter finding time and improve the accuracy36. Hussein used the simulated annealing (SA) algorithm to find the parameters of the SVM and validated it using data from the UCI machine learning repository, experimentally verifying that the accuracy of the SA-SVM algorithm is greater than that of the SVM algorithm37. Li established GA-SVR model, PSO-SVR model, and salp swarm algorithm SSA-SVR model, and used the models to predict fber-reinforced CPB strength, and the study showed that the heuristic algorithm can capture the hyperparameters of SVR model better than the grid search algorithm38. In geotechnical engineering, Arsalan et al. developed an SVR model to successfully obtain dynamic RQD values of rock mass during tunnel excavation39. Li uses the uckoo search algorithm-improved support vector machine method is applied to slope stability analysis and parameter inversion, which proves the advantages of hybrid heuristic algorithm in parameter optimization40. The above study proves that the SVM algorithm meets the needs of small sample rock mass classification. The heuristic algorithm can better balance the state of global search and local search and effectively escape from local optimum. The combination of heuristic algorithm and SVM can better exploit the advantages of SVM algorithm. Meanwhile to the best knowledge of the authors, currently, the application of heuristic algorithm combined with SVM in improving the performance of machine learning models for rock mass classification has not been reported.
This paper will focus on the development and application of support vector machine in rock mass classification, and try to study the heuristic algorithms in the support vector machine parameter optimization, algorithm improvement of the application, and MATLAB as a programming platform, to achieve the method. The main work of this study is as follows:
-
In this study, we collected 80 groups of rock mass quality datasets from different studies to build a database to improve the problem of small and single-source data sets in previous studies.
-
The support vector machine (SVM) models are utilized as the main classification tools combined with three optimization algorithms, i.e. GA, PSO, grey wolf optimization (GWO) to find key SVM parameters (c, g). Meanwhile, cross-validations are employed to examine the classification capability of different models.
-
Five mathematical indices, i.e. accuracy, precision, recall, F1 value, and computational time, are used to assess the classification performance. The sensitivity analysis is implemented to understand the sensitivity of each input parameter on rock mass quality grade.
-
Finally, the trained model is used for rock mass quality grading of the southeast ore body of the Chambishi copper mine.
Support vector machines and heuristic algorithms
Support vector machines (SVM)
Support vector classification model (SVC)
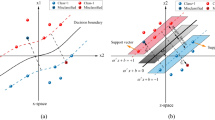
SVM is a statistical learning method based on Vapnik–Chervonenkis theory (VC) and structural risk minimization principle of the statistical learning theory41. SVM mainly learns, classifies and predicts the small datasets. SVM can map data that are not linearly classifiable in low-dimensional space to high-dimensional space by kernel functions. Then, the mapped data are classified and regressed. SVM possess strong generalization ability and can find a superior balance between complex non-linear mapping relations of limited data and generalization ability. The traditional support vector classification (SVC) is a typical binary classification model. The principle of the model is shown in Fig. 1. The mathematical theory can be given as42:

Schematic illustration of the SVC classification algorithm.
Suppose there are n-dimensional sample vectors in a region, then there is \(w^{T} \cdot x + b = 0\) hyperplane, which divides the sample into two categories. The hyperplanes may exist in different forms and the one that satisfies the minimum distance between two types of samples is called the optimal hyperplane. The above condition can be given as Eq. (1):
where \(w^{T}\) represents the weight vector, b denotes the bias of sample fitting deviation and \(y_{i} \in \left\{ { - 1,\left. 1 \right\}} \right.\).
Figure 1 shows that the sum of two types of sample distances from the hyperplane is 2/||w|| and the hyperplane margin is equal to 2/||w||. Also, any training tuples that fall on hyperplanes H1 or H2, i.e., the sides defining the margin, are the support vectors, as shown in Fig. 1. Thus, the problem is the maximization of margin by minimizing the ||w||/2 value, which is a convex quadratic programming (QP) problem and can be solved with the help of Lagrangian operators.
where: \(\alpha_{i} > 0\) is Lagrange coefficient. In order to simplify the prediction calculation, the original problem is transformed into a mathematical dual problem by solving the partial differential of \(w\), \(b\) with the above formula.
The constraints of the above equation can be given as:
When \(\alpha_{i}^{*}\) is the optimal solution of the equation, then the optimal weight vector can be given as: \(w^{*} = \sum\limits_{i = 1}^{k} {\alpha_{i}^{*} y_{i} x_{i} }\).
A unique solution under the given constraints exists when the problem satisfies \(\alpha_{i} [y_{i} (w^{T} \cdot x_{i} + b) - 1] = 0\). The optimal classification plane function can be obtained by solving the question described as Eq. (5), where sgn() is a symbolic function.
The relaxation variable \(\xi_{i} \ge 0\) is introduced in the case of linear indistinguishability of the corresponding samples so that the maximum number of misclassified samples at the maximum classification interval can be satisfied under the given condition, as shown in Fig. 1. Then, Eq. (1) can be rewritten as:
The penalty variable C is inserted in the constraint.
For non-linear classification, the kernel function can map the sample data to \(K(x_{i} ,x_{j} )\) high-dimensional space and, then, the problem of finding optimal hyperplane in the new space is simplified. Hence, the non-linear classification is realized. The Gaussian radial basis (RBF) is one of the mapping functions and, after selecting the kernel function, the problem can be given as Eq. (8):
where \(K(x_{i} ,x_{j} ){ = }\exp \left( { - g\left\| {x_{i} - x_{j} } \right\|^{2} } \right)\). The corresponding classification function can be given as Eq. (9):
SVC multi-classifier
In practice, the simple binary classification problems are less applicable and the rock mass classification is a typical multiclassification problem. Traditional SVC often utilizes a one-against-rest classification method in multiclassification problems. The basic principle is that each classification and remaining classifications form a binary calculation, and the n classifications build n sets of sub-classifiers. This multi-classification method utilizes the basic principle of SVC to achieve multi-classification, but the one-against-rest classification may bring too large non-distinguishable regions, resulting in an inferior generalization model, as shown in Fig. 2a. Therefore, the current study adopts the one-against-one classification method, as shown in Fig. 2b, which reduces the non-separable regions and enhances the generalization ability of the proposed model43,44.

The schematic illustration of the SVC multi-classification algorithm (a, b).
Heuristic optimization algorithm
In general, the SVM algorithm alone is inefficient. Hence, the optimized algorithms, such as Genetic Algorithm (GA) and Particle Swarm Optimisation Algorithm (PSO), were applied by some researchers to optimize the initial parameters of machine learning models and the increase in both predictive accuracy and convergence、speed of the constructed machine learning models after combining optimization algorithms has been demonstrated45. Grey wolf optimiser (GWO) is one of the latest heuristic algorithms. This new optimization method has shown a great result in optimizing problems and has successfully beaten the well-known methods such as the PSO in engineering design problems46. Therefore, this study uses three heuristic algorithms to optimize the SVM algorithm to explore the classification ability of different combinations of algorithms.
Optimization of SVC parameters using metaheuristic algorithms requires the construction of fitness functions to achieve optimal parameter selection. In SVM, classification accuracy (AR) and mean square error (MSE) are often used as fitness functions; AR or 1/AR is often used as a fitness function for classification models, and MSE is often used as a fitness function for prediction models47.
Genetic algorithms (GA)
At the University of Michigan, John and Bagley first proposed the genetic algorithm (GA), an optimization algorithm based on genetics and evolution theory48. GA is widely used in the field of optimization and optimal solutions. The core idea in GA is to utilize relevant information generated in the evolutionary history of a population to guide the search for results, leading to simplified application and excellent robustness49. The algorithm encodes the dataset, i.e., the population, and utilizes genetic operators to cyclically perform selection, crossover and mutation operations to generate new individuals, and constructs and calculates a reasonable fitness function for the selection of new populations to generate individuals, which satisfy the end conditions. Herein, the key parameters (c, g) in SVM are optimized using the genetic algorithm, as given below Table 2.
The fitness function of the classification problem is:
where Tn = The number of accurate classifications in the training and test sets; and M = Total number of samples in the training and test sets.
Particle swarm optimization (PSO)
Eberhart and Kennedy proposed the principle of bird flocks foraging in 199550. This theory evolved into an optimization algorithm for group intelligence. PSO is often used in the optimization of algorithms through cooperation and competition between particles in a population. PSO renders efficient parallel search capabilities, tracks in real-time, and adjusts the search methods in real-time. PSO optimizes the SVM in a similar way to GA using the following algorithmic steps, as given below Table 3. The PSO algorithm optimizes the fitness function of the SVC algorithm in the same way as Eq. (10).
Grey wolf optimizer (GWO)
The gray wolf algorithm was proposed by Mirjalili et al. in51. The algorithm mimics wolf hunting hierarchy and works on simple computational principles and few control parameters. Mirjalili et al. have compared GWO with PSO, GSA, DE, EP and ES based on 29 well-known test functions, showing the promise of GWO51. The optimization process is given below Table 4. The fitness function of the classification problem is47:
where ARtr = classification accuracy of training sets in the training process; and ARva = classification accuracy of validating sets.
Database description and SVC-based model development
Rock mass quality characterization factors
The selection of input parameters is the first step in building an assessment model for rock mass quality using the AI models. Santos et al. applied a technique of multivariate statistics, the factor analysis, to select a set of variables commonly used in rock mass classifications. The most important variables for describing the rock mass quality were kept in the model, and the removal of less important variables was justified. Studies have demonstrated that several factors affect the rock mass quality, such as rock strength, integrity of the rock mass and rock environment (including the groundwater seepage)52. Therefore, firstly, in this paper, we refer to the three major variables in the literature and select rock saturated compressive strength (Rc), etc. as rock strength characterization parameters, RQD value and rock mass integrity factor (Kv) as rock discontinuities' characteristics, unit roadway water inflow (ω/(L(min 10 m)−1)) as the characterization parameter of groundwater. The input parameters should reflect the characteristics of rock strength, degree of rock fragmentation, degree of structural surface development of rock body, and weakening effect of groundwater on rock body. Meanwhile, the above four parameters are used as the input parameters of the model.
Database creation and analysis
Artificial intelligence can establish non-linear relationships between multiple factors by learning from a large dataset. Therefore, the samples used as a training set must be representative of all the categories. Currently, many case data for rock mass classification are documented in the literature. Thus, mining the results of previous studies can yield a large number of valid samples. Furthermore, the model accuracy can be improved by expanding the sample size.
Herein, we investigate and analyze the relevant work throughout the past years. The available data were filtered to obtain 80 sets of tagged data, which were assembled into the database for SVC model training (Table 5). All data were obtained from the available literature. It contains rock samples from different geographical areas and engineering types in China. For example, the sample sources include power station underground works, tunnel envelope, roadway envelope, etc. The established database satisfies the model training requirements. The samples are divided into two parts, where 64 groups are randomly selected as a training set and the remaining 16 groups are set as a testing set. The better training samples were determined after several random training sessions. The markers of the training and prediction samples are shown in Table 5.
Most of the rock mass grades in Table 5 are based on traditional rock mass classification methods. The different rock mass quality is qualitatively described as the following Table 61.
Then, the numerical analysis was performed on input parameters in the database and the analysis results are shown in Table 7. The single-factor analysis results of each input parameter are shown in Fig. 3. Figure 3 contains line box plots and violin plots for each factor, where the line box plots reflect the data interval, interquartile range and median data for each indicator, and the violin plots highlight the distribution of dataset. As shown in Fig. 3, the median value of each indicator is not in the center of the data box, which indicates the asymmetrical data distribution. At the same time, we conducted a correlation analysis of the factors in the dataset, and the correlation matrix is shown in Fig. 4. Figure 4 shows that the p-values of each factor and rock mass quality grade are all greater than 0.5. Among them, Rc, RQD, and Kv show a negative correlation trend with rock mass quality grade, indicating that the larger the three parameters are the lower the grade is, the better the rock mass quality is. On the contrary, ω showed a positive correlation. In general, the selected factors showed a good correlation with rock mass quality. Moreover, the density deviation of ω distribution is large, which indicates the specificity of sample data. In general, the sample set constructed in this paper meets the model training requirements.

The database violin diagram.

The database correlation matrix.
SVC-based model development
In underground projects, such as mining and tunneling, the safety of production and control of construction cost are highly dependent on the quality of rock mass58. Therefore, we must classify the rock mass according to the project needs. To ensure a smooth project, different rock mass quality classes correspond to different construction methods and support measures. Several factors reflect the quality of rock masses in actual projects. Therefore, the researchers refer to different grading criteria and factors when building the rock mass quality assessment models, leading to a poor generalization of the results. Moreover, the continuous work on new models resulted in a lot of duplication research and bad utilization of the existing data.
Therefore, the current study establishes the SVC classification model of rock mass by a large number of prior cases. We expect to replace the complex and repetitive modeling, and classification work by optimized SVC with artificial intelligence algorithms in engineering practice. It is worth emphasizing that the prediction results will become more accurate with the continuous use of the proposed SVC model. The implementation processes of the traditional rock mass classification model and AI classification model are compared in Fig. 5. The process represented by the yellow arrows in Fig. 5 is the steps of rock mass classification using conventional methods. First, the rock mass quality characterization factors are determined by the actual conditions. Secondly, obtain the grade interval of each factor. Third, the values of each factor are obtained. Fourth, obtain the rock mass quality grade by a classification model. The process represented by the blue arrow in Fig. 5 is the step of rock mass classification using SVC methods. When using the SVC model, the rock mass quality grade is obtained by simply inputting the values of the characterization parameters into the trained model. It is worth emphasizing that the complex process needs to be repeated each time the traditional method is used. In contrast, it is much easier to use SVC classification. As the model continues to be used, its accuracy and generalization capabilities are continuously improved.

The prediction case flow chart.
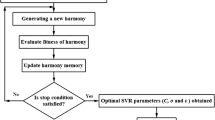
The optimized SVC model for rock mass classification is established based on SVC theory and database. The model is built and trained using the MATLAB software and the main part is based on the SVM algorithm using the LIBSVM toolbox59,60. Herein, the heuristic algorithms, such as GA, PSO and GWO, are utilized to optimize SVC, reduce prediction error, and improve computing efficiency and generalization ability. By comparing the classification performance of three algorithms, the heuristic algorithm with SVC, which renders a better optimization effect, is selected to construct the rock mass classification model. The model training input metrics are the rock mass quality characterization parameters, as identified in “Rock mass quality characterization factors”. The output index is the rock mass quality grade. The optimized SVC model comparison and construction process are shown in Fig. 6.

The research architecture for the proposed SVM-based approach with GWO, GA and PSO optimization method.
Cross-validation is a useful method for assessing the model robustness and generalization. It can avoid overfitting the model when the samples are small. In this study, we use the fivefold cross-validation, where we divide the training set into five samples, one for training and four for testing. This process is operated five times, and the average classification accuracy is the model accuracy. A general display of fivefold cross-validation is shown in Fig. 7. In this figure, P1, P2, P3, P4 and P5 represent the prediction results of the corresponding fold, respectively.

A schematic diagram of fivefold cross-validation.
Results and discussion
SVC- based model classification performance
For the multi-classification problem, two main parameters affect the SVC classification effect, i.e., the error penalty parameter (c) and the kernel function parameter (g). The role of penalty parameter c is to adjust the learning confidence range and empirical risk ratio in a defined data subspace, rendering better generalization. The optimal c differs in different data subspaces. The kernel function parameter g mainly influences the complexity of the degree of distribution of sample data in high-dimensional space. The three models are trained and tested according to the database and the optimization ability of three heuristics is evaluated based on the test results. The performance classification metrics in the multi-classification model, such as accuracy, precision, recall, F1 value and model operation time consumption, are used to evaluate the model. Among them, accuracy is a direct response to the model prediction performance. The model computation time reflects the ease of model running. The rest of the metrics reflect the classification ability of the model itself. The initial process of self-organization-based heuristic optimization-seeking algorithm is stochastic, which means that the combinatorial model first obtains a certain key parameter value and search it within the fitness criterion to obtain the optimal parameter. The combined rock mass classification model was subjected to the training parameter settings.
-
(1)
GA-SVC: Set the maximum number of iterations of the genetic algorithm to 100, set the maximum number of populations to 20, and set both c and g to [0, 100] for the merit search range. The mutations are performed to alter the binary code from 0 to 1 or vice versa. Hence, the rate of mutation is set at 0.05 and the crossover probability is 0.9.
-
(2)
PSO-SVC: Set the number of search groups to 20 and the maximum number of iterations to 100; set the search range of both c and g to [1, 100]; and set the personal factor c1 to 1.5 and the social factor c2 to 1.5.
-
(3)
GWO-SVC: The number of wolf packs is set to 20, the maximum number of iterations is 100, and the range of key parameter penalty coefficient c and the kernel parameter coefficient g are both searched in the range of [1, 100].
The current study normalizes the training data to eliminate the effect of dimension. The parametric search is conducted using the processed data and the model is validated using a fivefold-cross-validation of training samples to determine the SVC key parameters c and g. According to the previous studies, the choice of RBF kernel function can lead to better model training results. One should note that different kernel function choices are available in the LIBSVM tool.
GA, PSO and GWO optimization selected the key parameters of SVC. The results reveal that the genetic algorithm determines Optimal c = 4.734 and Optimal g = 3.7127; the particle swarm algorithm determines Optimal c = 62 and Optimal g = 0.5501, and the gray wolf algorithm determines Optimal c = 22.1397 and Optimal g = 2.8339. The SVC models were trained using the resulting optimal parameters and the results of three combined models for database classification are shown in Figs. 8, 9, and 10 and Table 8. The box in the figure represents the real rock mass quality grade, the red-colored dot represents the model prediction grade, the left side of the black-colored vertical line presents the prediction result of the training set, and the right side shows the prediction result of the test set. The results demonstrate that the three heuristic algorithms possess different abilities to optimize SVC. In terms of training set validation accuracy, all three combined models are more than 80% accurate and render superior performance. Among them, the GWO-SVC algorithm results in optimal performance with 90.6250% (58/64) accuracy of the training set prediction, followed by PSO-SVC with 87.5000% (54/64) accuracy of the training set prediction and GA-SVC with 82.8125% (53/64) accuracy of the training set prediction. This shows that all three models can achieve the rock mass classification function with reasonable accuracy and reliability through training. The training results of GWO-SVC algorithm with the current training set outperform the other two optimization-seeking algorithms. The trained model was used to test the classification of 16 datasets and the classification results are presented in the right-hand panels (Figs. 8, 9, 10). The GWO-SVC rendered the highest model classification accuracy (93.7500%, 15/16), whereas both PSO-SVC and GA-SVC exhibited similar performance, i.e., 81.2500% (13/16) and 81.2500% (13/16), respectively. The rock mass classification is such a multi-classification problem that the model's ability to classify different categories should be assessed while considering the accuracy. Herein, the precision, recall and F1 values are calculated for different grades (I–V) of the three models. By analyzing and comparing the classification capabilities of different grades of the model, it is possible to determine that which type of rock mass level lacks training at this stage, providing guidance for further model optimization. Figures 11, 12 and 13 show the discrimination accuracy, recall, and F1 values for each category of three combined models, respectively. Figure 11 and 12 show that the three combined algorithms differ in their ability to classify different grades. The classification accuracy rate of all three optimization algorithms for Grade I rock samples is 1. The recall rate of PSO-SVC and GWO-SVC is 1, whereas the recall of GA-SVC is 0.6. At this stage, it indicates that the PSO-SVC and GWO-SVC judge all Grade I samples correctly and, instead of misclassification, the GA-SVC exhibits under-classification. Under-classification means that all samples of Grade I are not found. The classification precision of all three optimization algorithms for Grade I rock samples is 1. The recall of PSO-SVC and GWO-SVC is 1, while the recall of GA-SVC is 0.6. At this point, it means that PSO-SVC and GWO-SVC judge all the samples of Grade I correctly, and GA-SVC does not misclassification, but there is under- classification. Therefore, the order of classification ability of Grade I samples is PSO-SVC = GWO-SVC > GA-SVC. For the Grade II rock samples, all three algorithms correctly identified the real Grade II rock samples. However, there are different degrees of misclassification. Misclassification means that samples of other grades are divided into Grade II. Therefore, the order of classification ability of Grade II samples is GWO-SVC > PSO-SVC > GA-SVC. For the Grade III rock samples, all three algorithms suffer from both under-classification and misclassification. From the precision and recall viewpoints, Grade III classification ability can be given as GWO-SVC > PSO-SVC > GA-SVC. The precision and recall of PSO-SVC and GA-SVC in Grade IV were the same, i.e., 0.89 and 0.53, and GWO-SVC were 0.92 and 0.73, respectively. Therefore, the order of classification ability of Grade IV samples is GWO-SVC > PSO-SVC = GA-SVC. The precision and recall rates of PSO-SVC and GA-SVC for Grade V samples are the same, i.e., 1 and 0.83, respectively, confirming that both algorithms do not exhibit misclassification. However, under-classification of Grade V samples still exists. The precision and recall of GWO-SVC were both 0.83, indicating partial under-classification and misclassification. Therefore, the order of classification ability of Grade V samples is GWO-SVC > PSO-SVC = GA-SVC. Combined with the F1 values in Fig. 13, the F1 values of Grades I, II, III and V of the three algorithms are better than the Grade IV, indicating the inferior classification ability of the given algorithms for Grade IV samples. The poor quality of Grade IV samples cannot sufficiently train the model and results in inferior classification ability. The F1 value of PSO-SVC and GWO-SVC for Grade I samples is found to be 1, indicating the absence of misclassification and under-classification. In summary, the classification ability of three algorithms on different grades can be ranked as: GWO-SVC > PSO-SVC > GA-SVC.

GA-SVC: predicted sample vs. actual sample.

PSO-SVC: predicted sample vs. actual sample.

GWO-SVC: predicted sample vs. actual sample.

Classification precision.

Classification recall.

Classification F1 value.
The operation speed reflects the algorithm's optimization ability and a faster operation speed renders optimal performance in training large-sized samples. Herein, the computational speed of GA-SVC, PSO-SVC and GWO-SVC for 100 iterations was found to be 6.03 s, 4.30 s and 1.54 s, respectively. These results reveal that the GWO-SVC model has an advantage in training and prediction time consumption. We have analyzed the accuracy, precision, recall, F1 value and computational time consumption of the three models in detail. Overall, the GWO-SVC rendered the best classification performance, followed by PSO-SVC and GA-SVC.
Sensitivity analysis
For exploring and comparing the sensitivity of diferent infuenced factors on rock mass quality, in this section, the cosine amplitude method was employed38 . Each input variable and one output variable were transformed into a single column matrix. Thus, five single column matrixes were obtained as Eq. (12).
where the length of each single column matrix is equal to the number of all datasets and then the sensitivity of diferent infuenced factors on rock mass quality can be calculated as Eq. (13)
According to the results (Fig. 14), it can be observed that the most sensitive factor is RQD and Kv, the RQD is more important. This result is reasonable because the degree of rock fragmentation also plays a large part in the traditional classification method. Finally, the sensitivity of diferent parameters on rock mass quality can be sorted in descending order as: RQD, Kv, ω, Rc.

Sensitivity analysis of different factors on rock mass quality.
Model verification
Validation case: chambishi copper mine
Chambishi copper mine is a major mining project of the China Nonferrous Metals Group in Zambia. The copper mine is located in the central part of the Zambian copper belt, which is on the northern edge of the Chambishi Basin. The currently developed artificial intelligence model is mainly applied to the southeast orebody of the Chambishi copper mine. The southeast ore body is located about 7 km to the southeast of the main mining area, which is 6 km long (from east to west) and 5 km wide (from north to south) with an area of 30 km2. The ore body is laminated and exists in a set of shallowly metamorphosed muddy and sandy slates. The overall orientation of the ore body is north-west, which is basically consistent with the folded tectonic axis. The ore body trends to the north-east with a dip angle of 5°–55°, where the dip angle of ore body is 0°–30°. The morphology of some sections of the ore body has changed due to geological process, however, the ore body is stable along the strike and trend extension. The southeastern part of the Chambishi copper mine is the testing site of the National Key Research and Development Program of China under the project titled "Theory and Technology of Spatiotemporal Synergistically and Continuously Mining in a Multi-mining area of Deep Large Ore Section". The rock mass quality assessment of the Southeastern mine is a critical step to ensure the progress of several key technologies and the safety of industrial sites during the later stages of the project.
Rock mass classification based GWO-SVC model
The current study evaluated the classification ability of three combined models and identified that the GWO-SVC exhibits the optimal classification ability. Herein, the GWO-SVC model is used to evaluate the rock mass quality in different areas of the southeastern ore zone of the Chambishi copper mine. During the assessment of rock mass quality, the following input parameters are determined, i.e., rock saturated compressive strength (Rc), RQD value, integrity factor of the rock mass (Kv), and unit roadway water inflow (ω). The investigators have conducted on-site surveys of the hanging wall and footwall, and characterized the rocks from the exposed southern and northern mining areas to ensure the accuracy of rock mass classification of the southeastern ore body. The accurate field values of RQD, Kv, and ω of the rock mass were obtained through on-site borehole sampling, wave velocity testing and water seepage analysis. The mechanical strength testing capability in Zambia is insufficient. Therefore, we have transported the ore and rock specimens from each sampling area of the Southeastern ore body to the China to obtain comprehensive and reliable physical and mechanical parameters. The index parameters of each region are shown in Table 9.
Furthermore, GWO-SVC is used to predict the quality classification of typical rock masses in Southeastern orebody and the prediction results are shown in Table 10. The results reveal that the rock mass quality of the hanging and foot wall of the southeastern ore body in the south and north mining areas of the Chambishi copper mine is similar. The rock mass strength of the hanging wall and footwall in the southern mining area is better than the northern mining area, whereas the rock mass integrity of the southern mining area is weaker than the northern mining area. The orebody slate quality in the southern and northern mining areas is identified as Grade III and Grade II, which indicates that the quality of the same ore body exhibits little variation due to different rock-forming conditions and environments. Except for the slate of the orebody and flint-bearing banded dolomite in the southern mining area, which were wet, the rest of the samples are dry and less influenced by the groundwater. Overall, except for the slate of the orebody and flint-bearing banded dolomite in the southern mining area, which are evaluated as Grade III samples, the remaining samples belong to Grade II and the results reflect that the overall rock mass quality of the ore body in the southeastern region of the mine is highly stable and safe. Meanwhile, this study also applied traditional Rock Mass Rating (RMR) to classify the rock masses in the field and the classification results are shown in Table 10. The results obtained from RMR are consistent with the GWO-SVC results, further confirming the accuracy of GWO-SVC model.
Limitation
By utilizing SVC as the predominant strategy to predict the rock mass quality, satisfactory prediction accuracies are procured. However, there are still some drawbacks and limitations that need to be improved in future work. Firstly, the scale of data used to establish the evaluation models is still small and only 80 groups of samples are collected. The combined model can learn more valid information when there are more samples from different sources in the dataset. Therefore, the dataset of the model should be further increased. Secondly, deeply analyzing rock characterization parameters is significant for rock mass classification. Thirdly, more advanced metaheuristic algorithms are worthwhile to be combined with SVC prediction models to improve the classification accuracy. For instance, the extreme gradient boosting61, are not investigated and compared in this study.
Conclusions
The classification of rock mass is an important parameter for the design of underground engineering sites. The rock mass quality prediction and evaluation are always influenced by many factors. The relationship between these factors and the rock mass quality is elusive in different regions. Therefore it is difficult to grade the rock mass quality in different regions by some traditional method. AI-based techniques can simulate sophisticated relationships between influential factors and output targets compared to the conventional methods. In this study, we built a dataset containing 80 sets of samples, each containing four rock mass quality characterization parameters. To classify the rock masses, the SVC algorithm is used in this paper. Then, three types of optimal algorithms are combined with SVC to optimize the hyper-parameters. As a result, it is found that GWO-SVC obtains the most comprehensive classification performance. The accuracy of training and testing sets of GWO-SVC are 90.6250% (58/64) and 93.7500% (15/16), respectively. For Grades I, II, III, IV and V, the precision value is 1, 0.93, 0.90, 0.92, 0.83, the recall value is 1, 1, 0.93, 0.73, 0.83, and the F1 value is 1, 0.96, 0.92, 0.81, 0.83, respectively. According to the sensitivity analysis results, the RQD and Kv plays the most important role in influencing the rock mass quality. Finally, the GWO-SVC model, with optimal classification ability, is selected to classify the rock mass quality of the exposed area of southeastern ore body of the Chambishi copper mine in Zambia. The results reveal excellent consistency between GWO-SVC and RMR grading models, verifying the validity of GWO-SVC model for application in the field of rock mass.Therefore, the GWO-SVC rock mass classification model has good potential for application in the geotechnical field. After training with more data, the GWO-SVC model can become a powerful tool for engineering designers.
References
Liu, K., Liu, B. & Fang, Y. An intelligent model based on statistical learning theory for engineering rock mass classification. Bull. Eng. Geol. Environ. 78, 4533–4548. https://doi.org/10.1007/s10064-018-1419-y (2019).
Shi, S. S., Li, S. C., Li, L. P., Zhou, Z. Q. & Wang, J. Advance optimized classification and application of surrounding rock based on fuzzy analytic hierarchy process and tunnel seismic prediction. Autom. Constr. 37, 217–222. https://doi.org/10.1016/j.autcon.2013.08.019 (2014).
Yang, B., Mitelman, A., Elmo, D. & Stead, D. Why the future of rock mass classification systems requires revisiting their empirical past. Q. J. Eng. Geol. Hydrogeol. https://doi.org/10.1144/qjegh2021-039 (2021).
Gao, Y., Gao, F. & Zhou, K. Evaluation model of surrounding rock stability based on fuzzy rock engineering systems (RES)-connection cloud. Bull. Eng. Geol. Environ. 79, 3221–3230. https://doi.org/10.1007/s10064-020-01744-8 (2020).
Azimian, A. A new method for improving the RQD determination of rock core in borehole. Rock Mech. Rock Eng. 49, 1559–1566. https://doi.org/10.1007/s00603-015-0789-8 (2016).
Nourani, M. H., Moghadder, M. T. & Safari, M. Classification and assessment of rock mass parameters in Choghart iron mine using P-wave velocity. J. Rock Mech. Geotech. Eng. 9, 318–328. https://doi.org/10.1016/j.jrmge.2016.11.006 (2017).
Xue, Y., Kong, F., Li, S., Zhang, L. & Gong, H. Using indirect testing methods to quickly acquire the rock strength and rock mass classification in tunnel engineering. Int. J. Geomech. 20, 05020001. https://doi.org/10.1061/(ASCE)GM.1943-5622.0001633 (2020).
Bieniawski, Z. T. Engineering classification of jointed rock masses. S. Afr. Inst. Civil. Eng. 15, 1–10 (1973).
Barton, N. R. Some new Q-value correlations to assist in site characterisation and tunnel design. Int. J. Rock Mech. Min. Sci. 39, 185–216. https://doi.org/10.1016/S1365-1609(02)00011-4 (2002).
Naithani, A. K. Rock mass classification and support design using the q-system. J. Geol. Soc. India. 94, 443–443. https://doi.org/10.1007/s12594-019-1336-0 (2019).
Laubscher, D. H. Geomechanics classification of jointed rock masses: Mining applications. Trans. Inst. Min. Metall. A 86, A1–A8 (1977).
Unal, E. Modifified rock mass classifification: M-RMR system. In: Milestones in rock engineering. The Bieniawski Jubilee Collection, Rotterdam, 203–223 (1996).
Daftaribesheli, A., Ataei, M. & Sereshki, F. Assessment of rock slope stability using the fuzzy slope mass rating (FSMR) system. Appl. Soft. Comput. 11, 4465–4473 (2011).
Liu, Y. C. & Chen, C. S. A new approach for application of rock mass classification on rock slope stability assessment. Eng. Geol. 89, 129–143. https://doi.org/10.1016/j.enggeo.2006.09.017 (2007).
Zhou, S., Pei, Q. & Ding, X. Application of grey evaluation model based on classification degree and weight of classification of index to rock mass quality evaluation of underground engineering. Chin. J. Rock Mech. Eng. Geol. 35, 3671–3679 (2016).
Hu, J. H., Shang, J. L. & Lei, T. Rock mass quality evaluation of underground engineering based on RS-TOPSIS method. J. Cent. South Univ. 43, 4412–4419 (2012).
Zhou, T., Hu, J. & Kunag, Y. Rock mass quality evaluation method and application based on fuzzy RES-multidimensional cloud model. Trans. Nonferrous Met. Soc. China. 29, 1771–1780 (2019).
Feng, X. T. & Wang, L. N. Rockburst prediction based on neural networks. Trans. Nonferrous Met. Soc. 4, 7–14 (1994).
Alimoradi, A., Moradzadeh, A., Naderi, R., Salehi, M. Z. & Etemadi, A. Prediction of geological hazardous zones in front of a tunnel face using TSP-203 and artificial neural networks. Tunn. Undergr. Space Technol. 23, 711–717. https://doi.org/10.1016/j.tust.2008.01.001 (2008).
Klose, C. D., Loew, S., Giese, R. & Borm, G. Spatial predictions of geological rock mass properties based on in-situ interpretations of multi-dimensional seismic data. Eng. Geol. 93, 99–116. https://doi.org/10.1016/j.enggeo.2007.06.001 (2007).
Jalalifar, H., Mojedifar, S., Sahebi, A. A. & Nezamabadi-Pour, H. Application of the adaptive neuro-fuzzy inference system for prediction of a rock engineering classification system. Comput. Geotech. 38, 783–790. https://doi.org/10.1016/j.compgeo.2011.04.005 (2011).
Rad, H. N., Jalali, Z. & Jalalifar, H. Prediction of rock mass rating system based on continuous functions using Chaos–ANFIS model. Int. J. Rock Mech. Min. Sci. 73, 1–9. https://doi.org/10.1016/j.ijrmms.2014.10.004 (2015).
Liu, B. et al. Prediction of rock mass parameters in the TBM tunnel based on BP neural network integrated simulated annealing algorithm. Tunn. Undergr. Space Technol. 95, 103103. https://doi.org/10.1016/j.tust.2019.103103 (2020).
Liu, B. et al. Improved support vector regression models for predicting rock mass parameters using tunnel boring machine driving data. Tunn. Undergr. Space Technol. 91, 102958. https://doi.org/10.1016/j.tust.2019.04.014 (2019).
Mutlu, B., Sezer, E. A. & Nefeslioglu, H. A. A defuzzification-free hierarchical fuzzy system (DF-HFS): Rock mass rating prediction. Fuzzy Sets Syst. 307, 50–66. https://doi.org/10.1016/j.fss.2016.01.001 (2017).
Hou, S. K., Liu, Y. R., Li, C. Y. & Qin, P. X. Dynamic prediction of rock mass classification in the tunnel construction process based on random forest algorithm and tbm in situ operation parameters. IOP Conf. Ser. Earth Environ. Sci. 570, 052056 (2020).
Barzegar, R. et al. Comparative evaluation of artificial intelligence models for prediction of uniaxial compressive strength of travertine rocks, case study: Azarshahr area, nw iran. Model. Earth Syst. Environ. 2, 76. https://doi.org/10.1007/s40808-016-0132-8 (2016).
Asheghi, R., Shahri, A. A. & Zak, M. K. Prediction of uniaxial compressive strength of different quarried rocks using metaheuristic algorithm. Arab. J. Sci. Eng. 44(10), 8645–8659. https://doi.org/10.1007/s13369-019-04046-8 (2019).
Jalalifar, H., Mojedifar, S., Sahebi, A. A. & Nezamabadi-Pour, H. Application of the adaptive neuro-fuzzy inference system for prediction of a rock engineering classification system. Comput. Geotech. 38(6), 783–790. https://doi.org/10.1016/j.compgeo.2011.04.005 (2011).
Zheng, S., Jiang, A. N., Yang, X. R. & Luo, G. C. A new reliability rock mass classification method based on least squares support vector machine optimized by bacterial foraging optimization algorithm. Adv. Civ. Eng. 1, 1–13. https://doi.org/10.1155/2020/3897215 (2020).
Guo, H. et al. A new technique to predict fly-rock in bench blasting based on an ensemble of support vector regression and GLMNET. Eng. Comput. 37, 421–435. https://doi.org/10.1007/s00366-019-00833-x (2021).
Fayed, H. A. & Atiya, A. F. Speed up grid-search for parameter selection of support vector machines. Appl. Soft. Comput. 80, 202–210. https://doi.org/10.1016/j.asoc.2019.03.037 (2019).
Mathias, M. A. & Mohamed, C. Optimizing resources in model selection for support vector machine. Pattern Recogn. 40(3), 953–963. https://doi.org/10.1016/j.patcog.2006.06.012 (2007).
Alam, M. S., Sultana, N. & Hossain, S. Bayesian optimization algorithm based support vector regression analysis for estimation of shear capacity of frp reinforcedconcrete members. Appl. Soft. Comput. 105, 107281. https://doi.org/10.1016/j.asoc.2021.107281 (2021).
Ren, Y. & Bai, G. C. Determination of optimal SVM parameters by using GA/PSO. J. Comput. 5, 1160–1168 (2010).
Zhou, X., Li, Z., Dai, Z. & Zou, X. QSAR modeling of peptide biological activity by coupling support vector machine with particle swarm optimization algorithm and genetic algorithm. J. Mol. Graph. 29, 188–196. https://doi.org/10.1016/j.jmgm.2010.06.002 (2010).
Said, A. & Hussein, H. I. Imbalanced data classification using support vector machine based on simulated annealing for enhancing penalty parameter. Period. Eng. Nat. Sci. 9, 1030–1037 (2021).
Li, E., Zhou, J., Shi, X., Armaghani, D. J. & Huang, P. Developing a hybrid model of salp swarm algorithm-based support vector machine to predict the strength of fiber-reinforced cemented paste backfill. Eng. Comput. 37(3), 3519–3540. https://doi.org/10.1007/s00366-020-01014-x (2020).
Mahmoodzadeh, A., Mohammadi, M., Ali, H., Abdulhamid, S. N. & Noori, M. G. Dynamic prediction models of rock quality designation in tunneling projects. Transp. Geotech. 27, 100497. https://doi.org/10.1016/j.trgeo.2020.100497 (2021).
Li, F. & Zhang, H. Stability evaluation of rock slope in hydraulic engineering based on improved support vector machine algorithm. Complexity 2021, 1–13. https://doi.org/10.1155/2021/8516525 (2021).
Jayadeva, S. C., Sanjit, S. B. & Siddarth, S. Learning a hyperplane classifier by minimizing an exact bound on the VC dimesion. Neurocomputing 171, 1610–1616. https://doi.org/10.1016/j.neucom.2015.06.065 (2016).
Nie, F., Zhu, W. & Li, X. Decision tree SVM: An extension of linear SVM for non-linear classification. Neurocomputing 401, 153–159. https://doi.org/10.1016/j.neucom.2019.10.051 (2020).
Wang, Y. F., Hong, L. C. & Cai, M. F. Tunnel rock quality ranks based on support vector machine. Chin. J. Eng. 31, 1357–1362 (2009).
Lu, S. et al. Identification of impact location by using fiber Bragg grating based onwavelet transform and support vector classifiers. Chin. J. Lasers 41(03), 137–143 (2014).
Khalifah, H. A., Glover, P. & Lorinczi, P. Permeability prediction and diagenesis in tight carbonates using machine learning techniques. Mar. Pet. Geol. 112, 104096. https://doi.org/10.1016/j.marpetgeo.2019.104096 (2019).
Hatta, N. M., Zain, A. M., Sallehuddin, R., Shayfull, Z. & Yusoff, Y. Recent studies on optimisation method of grey wolf optimiser (gwo): A review (2014–2017). Artif. Intell. Rev. 52, 2651–2683. https://doi.org/10.1007/s10462-018-9634-2 (2018).
Deng, S., Wang, X., Zhu, Y., Lv, F. & Wang, J. Hybrid grey wolf optimization algorithm-based support vector machine for groutability prediction of fractured rock mass. J. Comput. Civil. Eng. 33(2), 040180651–040180659. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000814 (2019).
Majdi, A. & Beiki, M. Applying evolutionary optimization algorithms for improving fuzzy C-mean clustering performance to predict the deformation modulus of rock mass. Int. J. Rock Mech. Min. Sci. 113, 172–182. https://doi.org/10.1016/j.ijrmms.2018.10.030 (2019).
Duma, M. & Twala, B. Sparseness reduction in collaborative filtering using a nearest neighbour artificial immune system with genetic algorithms. Expert Syst. Appl. 132, 110–125. https://doi.org/10.1016/j.eswa.2019.04.034 (2019).
Fattahi, H. Application of improved support vector regression model for prediction of deformation modulus of a rock mass. Eng. Comput. 32, 567–580. https://doi.org/10.1007/s00366-016-0433-6 (2016).
Mirjalili, S., Mirjalili, S. M. & Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 (2014).
Santos, A., Lana, M. S. & Pereira, T. M. Rock mass classification by multivariate statistical techniques and artificial intelligence. Geotech. Geol. Eng. 12, 1–22. https://doi.org/10.1007/s10706-020-01635-5 (2020).
Hu, J. H. & Ai, Z. H. Extension evaluation model of rock mass quality for underground mine based on optimal combination weighting. Gold Sci. Technol. 25, 39–45 (2017).
Yang, Z. & Liu, H. Artificial neural network model for the stability classification of adjoining rock of underground construction. Adv. Eng. Sci. 3, 66–72 (1999).
Li, J., Wang, M. W., Xu, P. & Xu, P. C. Classification of stability of surrounding rock using cloud model. Chin. J. Geotech. Eng. 36, 83–87 (2014).
Liu, A. H., Su, L., Zhu, X. B. & Zhao, G. Y. Rock quality evaluation based on distance discriminant analysis and fuzzy mathematic method. J. Mining Saf. Eng. 28, 462–467 (2011).
Huang, R. D., Zhao, Z. F., Li, P. & Zhang, X. J. Based on entropy weight method and extenics tunnel’s quality evaluation of surrounding rock. Highway Eng. 37, 139–143 (2012).
Bakhtavar, E. & Yousefi, S. Assessment of workplace accident risks in underground collieries by integrating a multi-goal cause-and-effect analysis method with MCDM sensitivity analysis. Stoch. Environ. Res. Risk Assess. 32(12), 3317–3332. https://doi.org/10.1007/s00477-018-1618-x (2018).
Zhou, J., Huang, S., Wang, M. Z. & Qiu, Y. G. Performance evaluation of hybrid GA-SVM and GWO-SVM models to predict earthquake-induced liquefaction potential of soil: A multi-dataset investigation. Eng. Comput. 2, 1–19. https://doi.org/10.1007/s00366-021-01418-3 (2021).
Seref, O., Razzaghi, T. & Xanthopoulos, P. Weighted relaxed support vector machines. Ann. Oper. Res. 249, 1–37. https://doi.org/10.1007/s10479-014-1711-6 (2017).
Ding, Z. et al. Computational intelligence model for estimating intensity of blast-induced ground vibration in a mine based on imperialist competitive and extreme gradient boosting algorithms. Nat. Resour. Res. 29, 751–769. https://doi.org/10.1007/s11053-019-09548-8 (2020).
Acknowledgements
This work was supported by the National Key Research and Development Program of China [Grant Number 2017YFC0602901]; and the National Natural Science Foundation of China [Grant Number 41672298]; and the Fundamental Research Funds for the Central Universities of Central South University [Grant Number 2021zzts0274]; and the Support by the Open Sharing Fund for the Large-scale Instruments and Equipments of Central South University [Grant Number CSUZC202134].
Author information
Authors and Affiliations
Contributions
J.H. designed the studies; T.Z. performed experiments, analyzed the data, and wrote the manuscript; M.G. received training data; S.M. provided the Chambishi mine case; P.H., D.Y. supervised the project. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hu, J., Zhou, T., Ma, S. et al. Rock mass classification prediction model using heuristic algorithms and support vector machines: a case study of Chambishi copper mine. Sci Rep 12, 928 (2022). https://doi.org/10.1038/s41598-022-05027-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-05027-y
- Springer Nature Limited