
Abstract
The present research aims to build a unique ensemble model based on a high-resolution groundwater potentiality model (GPM) by merging the random forest (RF) meta classifier-based stacking ensemble machine learning method with high-resolution groundwater conditioning factors in the Bisha watershed, Saudi Arabia. Using high-resolution satellite images and other secondary sources, twenty-one parameters were derived in this study. SVM, ANN, and LR meta-classifiers were used to create the new stacking ensemble machine learning method. RF meta classifiers were used to create the new stacking ensemble machine learning algorithm. Each of these three models was compared to the ensemble model separately. The GPMs were then confirmed using ROC curves, such as the empirical ROC and the binormal ROC, both parametric and non-parametric. Sensitivity analyses of GPM parameters were carried out using an RF-based approach. Predictions were made using six hybrid algorithms and a new hybrid model for the very high (1835–2149 km2) and high groundwater potential (3335–4585 km2) regions. The stacking model (ROCe-AUC: 0.856; ROCb-AUC: 0.921) beat other models based on ROC's area under the curve (AUC). GPM sensitivity study indicated that NDMI, NDVI, slope, distance to water bodies, and flow accumulation were the most sensitive parameters. This work will aid in improving the effectiveness of GPMs in developing sustainable groundwater management plans by utilizing DEM-derived parameters.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Groundwater is a valuable resource in all parts of the world. In dry and semi-arid locations where there are no rivers or other sources of surface water, groundwater is the primary supply of water for agricultural and human activities. The quest for additional groundwater resources is a major concern in these places, particularly in locations where water demand is gradually increasing over time (Falkenmark et al. 2019). Therefore, suitable water resource management is highly necessary. Due to limited water supplies and rising uncertainties induced by climate change, water management in the Kingdom of Saudi Arabia (KSA) is experiencing significant problems. Exploiting deep aquifers for subterranean water depletes supplies that took decades or centuries to develop and on which the current annual rainfall has little direct influence (Mahmoud et al. 2014). An estimated 158.47 billion m3 of rainfall occurs on the nation each year (Al-Rashed and Sherif 2000). In KSA's biggest single alluvial reservoir, the total capacity in alluvial deposits is estimated to be 84 billion m3 (Abdulrazzak 1995). While the entire amount of groundwater removed from Saudi Arabia's deep aquifers during the previous two decades is estimated to be about 254.5 billion m3, it was pumped from Saudi Arabia to meet the demands of the agriculture sector's development (Al-Rashed and Sherif 2000). While the recharging of deep aquifers has been restricted to 41.04 billion m3 during the previous two decades (Al-Rashed and Sherif 2000). By the year 2000, the agriculture sector in Saudi Arabia consumed around 20 billion m3/year of water (Al-Rashed and Sherif 2000). Demands of water in Agricultural accounted for 83–90% of overall water demands from 1990 to 2009 (Chowdhury and Al-Zahrani 2015). To meet the water conservation policy, KSA implemented a plan to minimise agricultural water needs by adopting advanced irrigation techniques, which resulted in a 2.5 percent yearly decrease in water use for agricultural reasons between 2004 and 2009 (MoEP 2014). Because of the scarcity of water and the possibility for an expansion in the area under agriculture, Demarcating groundwater potential zones for agricultural growth is critical (Zhang et al. 2018a; Mahato and Pal 2019; Zhu and Abdelkareem 2021).
The first step in protecting ecosystems from groundwater discharge is identifying the groundwater discharge, the locations where groundwater discharge occurs, and the support that groundwater discharge provides for down-gradient ecosystems (e.g., fluvial ecosystems) (Zhang et al. 2018a; Mahato and Pal 2019; Zhu and Abdelkareem 2021). Such determinations are typically only possible by field investigation because different types (and an unknown number) of groundwater discharge sources are commonly intermingled in the subsurface near their point of connection with surface water (e.g., seeps and springs) (Yu and Michael 2019; Bierkens and Wada 2019). Field mapping of these forms of groundwater outflow is doable in some instances (Arabameri et al. 2019b; Díaz-Alcaide and Martínez-Santos 2019). Such approaches are often expensive to apply and require substantial ground truth knowledge prior to deployment. Therefore, it is impracticable across broad geographical scales and in difficult-to-reach areas. Remote sensing, geospatial modeling, and machine learning have all been employed in these cases to map remote sites where groundwater discharge occurs, with varying degrees of effectiveness (Mahato and Pal 2019; Das et al. 2019; Mallick and Rudra 2021; Vellaikannu et al. 2021; Zhu and Abdelkareem 2021). As computer processing capacity develops and remote sensing data becomes more readily accessible, these methods garner greater attention for broad applications in hydrology.
The aim of geospatial modeling, in particular, is to use a procedure for setting out the models and a suitable choice of geospatial algorithms to help decision-makers and other stakeholders decide the most optimal and beneficial option (Nagpal et al. 2019; van Eeuwijk et al. 2019; Pal et al. 2020a; Malik and Bhagwat 2021; Forootan and Seyedi 2021; Phong et al. 2021). Over the years, various methods such as multi-criteria decision analysis (MCDA), the statistical index (SI) (Mandal and Mandal 2018), logistic regression (LR) (Mandal and Mandal 2018; Zhang et al. 2018a),evidential belief function (EBF)(Chen et al. 2018b), probability-frequency ratio (FR) (Lee and Dan 2005; Chen et al. 2017b), certainty factors (CF) (Dou et al. 2014; Chen et al. 2016; Hong et al. 2016a), weight of evidence (WoE) (Xu et al. 2012; Xie et al. 2017), index of entropy (IoE) (Jaafari et al. 2014; Tien Bui et al. 2018) have been used to generate GPM in various regions. A review of past research demonstrates that, although the models used to provide decent results, utilizing them as standalone has drawbacks (Boori et al. 2019; Mahato and Pal 2019; Das et al. 2019; Pradhan et al. 2019; Mallick and Rudra 2021; Mosavi et al. 2021; Chen et al. 2021a). Furthermore, approaches like the multi-criteria index may give helpful information for selecting appropriate locations for managed aquifer recharge (MAR) (He et al. 2012; Kazakis et al. 2020).
ANN (Tien Bui et al. 2016; Chen et al. 2017a), neuro-fuzzy (Tien Bui et al. 2012), decision trees (Tien Bui et al. 2014; Hong et al. 2015), and support vector machines (Trigila et al. 2015; Hong et al. 2016a, b; Chen et al. 2018a, b) are examples of machine learning models that have been developed to address complex issues and have been applied to a variety of groundwater research (Ghimire et al. 2019; Qadir et al. 2019; Hamdani and Baali 2019; Hoque et al. 2020; Malik and Bhagwat 2021). They have shown promising predictive capabilities for groundwater potentiality prediction and are often used as benchmarks to evaluate new approaches (Pal and Sarda 2021a). Lee et al. (2018) show that the ANN technique is beneficial for producing GPM investigations. Emamgholizadeh et al. (2014) employed two machine learning approaches to estimate groundwater levels: ANN and ANFIS. According to their findings, the ANFIS model performs well in prediction and may be applied in similar investigations. There is still no broad consensus on which strategy is superior since learning algorithms with a single or straightforward hypothesis space have difficulty satisfying all case scenarios as the data they use changes (Tien Bui et al. 2018; Truong et al. 2018).
However, these efficient instances contain significant flaws that restrict the efficacy of individual algorithms in terms of prediction (Luo et al. 2017). Individual learning methods may overlook the best-fit function or actual distribution of the sample set from the hypothesis space, for example, since training data for GPM is generally insufficient (Stamatopoulos et al. 2015; Crosta et al. 2003). As a result, researchers created ensemble-learning algorithms for GPM, including Adaboost (Nguyen et al. 2020), Bagging (Iqbal et al. 2021), random subspace (Elbeltagi et al. 2021), and rotating forest (Mallick et al. 2021), to increase the prediction accuracy of a single classifier (Singha et al. 2020). These ensemble-learning strategies are homogenous because they often mix the same classifier to create an aggregated model. Consequently, the flaws of a single classifier may compound, which is undesirable for the outcome (Regmi et al. 2010).
Meanwhile, the studied locations differ geographically in terms of GW potentiality forecast. Diverse places have different geo-environmental characteristics, and homogenous ensemble-learning approaches for GPM ignore such differences (Hong et al. 2016b; Pham et al. 2017). In several sectors, heterogeneous ensemble-learning approaches that combine several single classifiers have exhibited significant nonlinear representation (Mirchooli et al. 2019; Rizeei et al. 2019; Roy and Saha 2019; Nhu et al. 2020; Pal and Sarda 2021b). Heterogeneous ensemble learning is more resilient and generalizable than homogeneous ensemble learning because it can harness the benefits of diverse groundwater potentiality models. Furthermore, the challenge of model selection for GPM may be mitigated to some degree using heterogeneous ensemble-learning approaches, which can preserve heterogeneity using any base classifier. Despite this, there is little research on using heterogeneous ensemble-learning approaches in GPM. It is essential to look into new ensemble modeling methodologies for groundwater potentiality assessment. Ensemble modeling is the simultaneous analysis of multiple (not necessarily optimized) models to look for regularities and patterns in the output from these different models that might give insights into how well they might predict possible future events (Forkuor et al. 2017; Chen et al. 2018a; Zhang et al. 2018b; Abdulkadir et al. 2019; Arabameri et al. 2019a).
In this study, we carried out GWP mapping in the Bisha watershed in Saudi Arabia for the first time using a stacking ensemble technique based on multiple machine learning algorithms. The approach is divided into two levels: the heterogeneous base learners at the bottom and the meta-learner at the top. It is worth noting that the benefits of stacking have been studied in various fields. According to Wang et al. (2011), the stacking-based credit scoring model had better predictive performance than base learners in average accuracy and error. Another study found that the ANN with stacking outperformed both the single ANN and the combination of ANNs employing the averaging technique in flood frequency analysis (Shu and Burn 2004). Three machine learning algorithms, namely SVM, ANN, and LR, were chosen as candidate base learners and RF as meta-classifiers of the stacking ensemble technique to estimate the spatial groundwater potential. The following three advancements for GWP modeling are presented in our study:
(1) For GWP, we used three heterogeneous ensemble-learning approaches. We adopted the RF approach over other machine learning and ensemble machine learning methods because of its superior performance (Talukdar et al. 2020). (2) We used both parametric and non-parametric ROC curves for the first time to validate the models. (3) The specifics of heterogeneous ensemble-learning techniques and result evaluation are presented in this paper. According to our literature analysis, heterogeneous ensemble-learning is still seldom applied in GPM, and many studies only used basic heterogeneous ensemble-learning algorithms. We used the aforesaid basic heterogeneous approaches as well as one meta heterogeneous way of stacking and blending for GPM in this investigation.
Materials and methodology
Study area
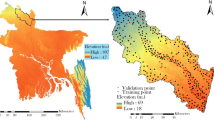
The Bisha watershed covers an area of 21,260 km2 and is bordered by Yemen. The Bisha watershed is located north of the equator between 17°59′27.588ʺ and 20°49′13.958ʺ north, and east of the Greenwich meridian between 41°49′50.825ʺ and 43°11′20.254ʺ east (Fig. 1). It features a varied scenery, including highlands, high mountains (between 2000 and 3000 m above sea level), plateaus, and Wadiyan. Additionally, it encompasses a sizable portion of the desert to the north and east, all the way to Bisha. The elevation ranges from 950 to 2980 m above sea level, with a mean of 1655 m. The climate of the region varies substantially by terrain and season. The climate varies considerably between semi-arid regions in the south and desert regions in the north. The average temperature over the last 30 years has fluctuated between 12 and 44 °C. Annual rainfall averages 245 mm. Rainfall in excess of 200 mm per year is restricted to a 20–30 km broad crest zone. As a result, eastward and northward Wadi flow rapidly reduces downstream, and deposition exceeds erosion at the plateau's eastern margin. The highland of the watershed is bordered by forests and Juniperus procera, which are home to a variety of indigenous and rare flora and wildlife.

The study area, Bisha Watershed
Materials
We prepared 21 parameters at the spatial scale for GWP modeling. We derived 14 parameters (among 21) from a high-resolution digital elevation model (DEM). In the present study, we used ALOS PALSAR DEM, having a spatial resolution of 12.5 m. We obtained it from the EarthData website, NASA (“https://asf.alaska.edu/data-sets/derived-data-sets/alos-palsar-rtc/alos-palsar-radiometric-terrain-correction/”). The sentinel-2 MSI satellite image has been obtained from the website of the United States Geological Survey- Earth Explorer (“https://earthexplorer.usgs.gov/”). On the other hand, rainfall data was collected from 16 meteorological stations of Saudi Arabia (the “Ministry of Environment, Water, and Agriculture (MEWA), Saudi Arabia”). A geological map has been obtained from the Survey of Saudi Arabia. Distance to water bodies and the urban center has been generated by integrating the maps provided by DIVA-GIS and field survey.
Groundwater potentiality inventory
The initial part was identifying the spring and non-spring locations and creating the appropriate inventory map. A random selection of non-spring locations was made using the Create Random Points feature in the Data Management Tools on the ArcGIS platform. Spring locations were obtained from land records, field surveys, and the Hydrological Data Management System. There were 50 springs and 50 non-spring places found. In addition, based on prior relevant research, twenty-four groundwater spring-associated variables were initially chosen in this phase (Mahato and Pal 2019; Das et al. 2019; Mallick and Rudra 2021; Vellaikannu et al. 2021; Zhu and Abdelkareem 2021). All groundwater and non-groundwater data have been separated into 80 (80):20 (20 points) training and testing datasets by arbitrary separation (Mallick and Rudra 2021).
Rationale and preparation of groundwater potentiality conditioning factors
When groundwater springs are present, it is believed that the slope, elevation, and aspect all have a role. Elevation has a significant impact on the local circumstances of the terrain that influence groundwater distribution (Arabameri et al. 2019b). Groundwater reservoirs often follow the gradient of height and tend to gather beneath the low-elevated terrain areas, which is why they are called "altitude reservoirs” (Chen et al. 2021b) (Fig. 2a). The landscape slope was chosen as an additional explanatory variable because of its link with the hydrologic processes that govern the direction of runoff and the infiltration capacity of the landscape (Sarkar et al. 2001; Arabameri et al. 2019b) (Fig. 2b). The slope length (LS) is a combination of the slope gradient (S) and the slope length (L) (Moore and Burch 1986). In general, a low value of LS indicates a greater likelihood of a productive groundwater aquifer. The length of the slope is a measure of the extent of ground cover (Fig. 2c). TRI is another morphological parameter that is extensively employed in groundwater assessments to quantify the relative elevation of a target cell concerning its neighboring cell. The TRI index ranges from 0 to 1, where high values indicate a well-drained surface and low values indicate a poorly drained surface (2d). Flow across a surface is affected by the profile curvature, which runs parallel to its maximum slope and is proportional to the acceleration or deceleration of the flow (Ginesta Torcivia et al. 2020). In contrast, planform curvature is perpendicular to the direction of the maximum slope and influences the convergence and divergence of flow across a surface, respectively (Costache and Tien Bui, 2020) (Fig. 2e, f). To generate potential groundwater maps, it was necessary to include the variable aspect as an essential explanatory variable. This variable is related to evapotranspiration because it indicates the direction of water flow, which has an effect on groundwater recharge and storage (Fig. 2g).

DEM derived topographic parameters, such as a elevation, b slope, c LS Factor, d TRI, e plan curvature, f profile curvature, g aspect
Once the TPI is calculated as the ratio of the target pixel elevation to the average elevation of the surrounding area, a positive value (Ridge) indicates a cell above the surrounding pixels concerning the target pixel. The negative value (Valley) reflects the sites at a lower elevation than the neighboring cells in the neighbourhood (Fig. 3a). Besides illustrating the curvature of a slope, CI also depicts the convergence or divergence of a cell, with positive values indicating diverging pixels and negative values indicating converging pixels. The minimal convergence suggests that there is a significant amount of groundwater available. The CI index oscillates between the extremes of maximum divergence (100) and maximum convergence (− 100) (Fig. 3b). When applied to hydrologic processes, TWI quantifies the influence of topography and, hence, on infiltration and recharge (Meles et al. 2020a). By examining the connection between the topographic index surface and reference data, it is possible to determine the correctness of a topographic index concerning grid spacing and terrain roughness (Meles et al. 2020a; Shit et al. 2020) (Fig. 3c). Stream power is the rate at which flowing water expends energy over a certain period. The Stream Power Index (SPI), sometimes known as the compound index (SPI), assesses stream power in geographic information systems (Chen et al. 2021b). SPI values below certain thresholds are related to a low erosion rate by runoff, allowing sufficient time for precipitation to percolate underground (Fig. 3d). Although there are other approaches for determining flow direction in grids, the most straightforward way to explain the flow direction is to consider the direction in which water and silt would flow out of that cell (Burrough and Mcdonnell 1998) (Fig. 3e). When water and slope materials gather, it impacts how they are distributed and where they prefer to collect (Pack et al. 1999) (Fig. 3f, g).

DEM derived topographic and hydrologic parameters, such as a TPI, b convergence index, c TWI, d SPI, e flow direction, f flow accumulation, g topographic features
The NDVI has a significant impact on the incidence of groundwater springs. They are primarily used to characterize the state of the surface vegetation, which impacts recharge rates and the availability of groundwater, both of which are necessary for the formation of vegetation communities (Fig. 4a). Dykes, shears, fractures, and other linear or curved structures on the surface topography are examples of lineaments. Lineaments play an essential part in the penetration process via rock weaknesses in hard rock terrain (Fig. 4b). The NDMI can detect wet or moist places in the landscape. However, soil moisture and groundwater cannot be separated. The wet/moisture pixels indicate those areas where water may resist for an extended period, commonly towards the end of a rainy event. Because water cannot resist uplands, the study also revealed moisture pixels in flat and valley regions, enabling more significant time for precipitation to sink into the subsurface; moreover, it highlights waterlogged places (Fig. 4c). Rainfall is a critical element in determining the variability of groundwater recharge and storage and calculating the groundwater potential. Annual continuous rainfall data was gathered from a network of 16 meteorological stations in and around the research area from 1976 to 2017. The kriging technique was used to plot the annual rainfall. Annual rainfall varies from 342 mm in the south and south-west to approximately 8.5 mm in the east (Fig. 4d). Because it influences the moisture content of soil and rock on the slope and the infiltration rate, distance from rivers has a significant impact on groundwater springs (Fig. 4e). Because the presence of urban area might create local hydrological and erosion difficulties while indirectly affecting the groundwater table, its distance from urban areas is thought to impact groundwater springs. As a consequence of the removal of geological formations and the disruption of the surface during the building phase, an urban area may affect the quantity of soil moisture and the infiltration rate (Fig. 4f). The infiltration capacity and porosity are governed by GG, which changes the particular groundwater storage. There are forty GG kinds in the research field. Some notable characteristics include sandstone and siltstone, intrusive plutonic rock, orthoamphibolite, andesite and dacite, andesitic volcaniclastic rocks, granodiorite, and granite suite (Fig. 4g).

The conditional parameters for GPM, such as a NDVI, b lineament density, c NDMI, d Rainfall, e distance to waterbody, f distance to urban, g geological structure
Multicollinearity test for groundwater potentiality variables
In this work, multicollinearity analysis assessed the relationship between the groundwater affecting elements and the groundwater itself. When there is a strong link between two or more predictor variables in a multiple regression model, this is called multicollinearity in statistics (Islam et al. 2021). To find multicollinearity among influencing variables in this research, the tolerance (TOL) and variance inflation factor (VIF) was utilized with each other. “Let \(X = \{ X_{1} ,X_{2} ,....,X_{N} )\) signify a particular independent variable set, and \(R_{j}^{2}\) denote the coefficient of determination when the jth independent variable \(X_{j}\) is regressed on all the other predictor variables in the model, as shown in the following example”. The following is the formula for calculating the VIF value:
When the VIF value is divided by the TOL value, the degree of linear correlation between the two independent variables, it is recommended that if the VIF value is over ten or the TOL value is less than 0.1, the related factors be eliminated from the landslide prediction models because of multicollinearity (Talukdar et al. 2021).
Developing stacking ensemble machine learning algorithm
Wolpert (1992) was the first to introduce the stacking ensemble approach. Stacking, unlike other existing ensemble learning approaches, use meta-learning to integrate many types of algorithms. The outputs of numerous base learners (level-0) are merged by the meta-learner in the stacking structure, which has two levels: level-0 and level-1 (level-1). Figure 5 depicts a basic drawing of the stacking structure used in this work. SVM, ANN, and LR were in charge of the basic learners. GPM frequently use these machine learning techniques. In the case of the meta-learner, RF was used in accordance with prior study recommendations.

Stacking-based ensemble frameworks for groundwater potentiality modeling. SVM support vector machine, ANN artificial neural network, LR logistic regression, RF random forest”
Level-0: Application of base classifiers
ANN
Behavioral trends are used in the artificial neural network to provide a basis for modelling processes. It has three layers: input, covered, and output, as well as processing units such as neurons that are organised in several layers (Moghaddam et al. 2019). The attachment weights bind the neurons of previous layers to those of subsequent layers. The output of the middle layer (hidden layer) is fed into the next layer as data. The input layer receives the data, while the final layer produces the ANN model's final output. The input data is received and sent by the middle layers to the related nodes in the subsequent layers. The secret neurons use the weighted number of inputs to generate the intermediate output. The activation functions are used in the ANN model to compute the hidden and output neurons' outputs. It uses the bias values, as well as the weighted number of the neuron's inputs, to set the output. The preparation of the network structure and the modification of the weights of links are the two main stages of the ANN modelling process. According to the literature review, the backpropagation training algorithm is widely used in a variety of areas, including water engineering (Fan et al. 2017). The performance of the ANN model is first obtained as the ANN model's response. The error between measured and predicted values is reduced at the next step to determine the model's weights. Where the output differs from the observed value, the weights and biases are adjusted to reduce the error values. However, since the backpropagation algorithm has a poor convergence rate, meta-heuristic optimization algorithms were used in this analysis to solve this flaw.
SVM
Vapnik (2013)presents the SVM, a widely used machine learning tool, as well as a collection of linear predictor functions that have been used to solve problems of function determination. In the SVM model, the kernel mathematical machine function was used for data transformation. A hyper-plane was generated using the training datasets after the individual SVM datasets were translated to high dimensional feature space (Choi et al. 2020).The best linear hyper-plane was used to differentiate the real output space. It is often used to divide data into two categories, such as low groundwater potential (0) and high groundwater potential (1). Several experiments have shown that, for groundwater potential models chosen as benchmarks kernel function, the RBF is overweight among various kernel functions (Tehrany et al. 2014). Due to the versatility of the radial base kernel to address different dimensions of the data set and its better capacity for generalisation, flood susceptibility was primarily modelled (Chen et al. 2021b). Modeling with SVM is generally limited because of its difficulties in recording essential parameters (Choubin et al. 2019).
LR
Logistic regression is a multivariate analytic model that predicts the presence or absence of an attribute or result based on the values of a collection of predictor variables. The term "logistic regression" refers to a kind of multivariate regression in which a dependent variable is linked to many independent variables (Tu 1996). Groundwater occurrences rely on several geo-hydrological independent variables, and the dependent variable is a binary variable representing the presence or absence of groundwater. The logistic regression technique is used for maximum likelihood estimate after turning the dependent variable (groundwater) into a logit variable (Ayalew and Yamagishi 2005). The advantages of logistic regression include that the variables do not have to have a normal distribution; they may be continuous, discrete, or a mix of both (Tu 1996). The ratios for each independent variable in the multivariate analysis model may be predicted using logistic regression coefficients. In multi-regression analysis, the factors must be numerical, and the variables must have a normal distribution. The dependent variable, which denotes the presence or absence of a groundwater, should be entered as 1 or 0, and the model applies sound to groundwater potentiality analysis in this research (Pradhan and Lee 2010).
Level-1: Application of meta classifier
RF
Breiman et al. (2017) established the random forest as an ensemble learning approach for generating numerous decision trees from distinct data subsets and voting on the findings of multiple decision trees to produce the random forest output. The random forest has a substantial body of research that shows it is tolerant to outliers and noise, unlikely to over-fit, and has good prediction accuracy and stability.
The basic idea behind random forest is to train many unconnected decision tree models. Each decision tree produces a different prediction regarding the sample's categorization (for classification algorithm). The sample classification mode is the outcome. To reduce model variance, the random forest's performance may be enhanced by creating unrelated training sets. Sample training is used to create different training sets of classifications, which are then merged to create the random forest model.
Ensemble procedure
After all of the base learning algorithms have been developed, the stacking approach is used to combine them into a larger framework. Assume that the initial dataset D contains examples \(d_{i} = (x_{i} - y_{i} )\), where \(x_{i}\) denotes groundwater conditioning variables and \(y_{i}\) denotes classifications (groundwater or non-groundwater). \(i \in [1,N]\), where N is the total number of data points in the modelling dataset. \(L_{t} (t = 1,2,3)\) is the abbreviation for base learning algorithms including SVM, ANN, and LR. To begin, the dataset D is periodically split into two distinct subsets: one is used to train base learning algorithms to produce level-0 classifiers, denoted by \(h_{t}\), and the other is used to construct level-0 classifiers.
The remaining examples are being utilized to train classifiers to generate predictions \(Zit\):
These level-0 classifier outputs, along with their actual classifications, form a new dataset \(D^{\prime} = ((Zit,Zit,....,Zit),y_{i} )\), which is subsequently given to level-1 to train the meta-learner (RF). As a consequence, RF can put together the classification results of basic learners to come up with a final prediction for new cases:
The initial ensemble model, known as the SVM–ANN–LR, was built using three single candidate algorithms and the stacking approach. The optimum parameters for whole stacking model have been presented in Table 1.
Validation of the models
All model-based predictions, including GPM, require measuring the performance of a modeling method. In the literature, several performance metrics have been effectively utilized. The most widely-used measurements for GPM AUC of ROC curves were employed to evaluate the algorithms' performances in this research. The ROC graphs the plot of sensitivity (true positive rate) versus 1-specificity (false positive rate) with varying thresholds (Nahayo et al. 2019). The AUC value, or area under this curve, is a regularly used metric for evaluating model performance. The AUC value for random is 0.5, whereas the value for perfect conformance is 1. When the AUC is less than 0.5, the model is non-informative or fits the data worse than a random model. In the present study, we employed two types of ROC curve, such as parametric and non-parameteric ROC curves for the validation.
Sensitivity analysis
The mean decreases in the Gini and the mean decreases in accuracy were measured. These two measures are widely utilized because they may choose criteria and rank things. Calculating essential variables of landslide conditioning factors for the current research region was accomplished using the mean decrease accuracy (MDA) and mean decrease gini (MDG) techniques of the RF algorithm, respectively. The two approaches described above are pretty popular, and they have been extensively employed in a variety of research to determine the significance of various factors. MDA and MDG techniques were used in the RF algorithm to compute error since they were discovered during the OOB calculation error and participation of the relevant variable inside the homogeneity of the trees.
Results and analysis
Computation of multicolinearity analysis
In this work, VIF and Tolerances (TOL) were used to assess multicollinearity amongst independent variables. Multicollinearity problems can arise if there are high correlations between the independent variables. A VIF score of over ten and a tolerance value of 0.2 suggest a multicollinearity concern. In the present study, 21 parameters have been generated for GPM. After applying colinartity technique, it has been found that all parameters have VIF score < 5, except elevation (VIF: 68.94) and TRI (VIF: 60.544) (Table 2). Therefore, these two parameters could not be used for modelling; otherwise it would generate lower accurate results. Then, we decided to exclude TRI from the parameters list; again colinearity technique has been applied. The VIF and tolerance values of all factors were determined to be less than 5 and higher than 0.8, respectively (Table 3). As a result, the factors were incorporated into the model. The following are the outcomes of the current study's multicolinearity analysis:
Developing stacking based robust GW potentiality models
In this work, a stacking-based ensemble model for GPM was established. However, before employing the stacking-based ensemble model, we used ANN, SVM, and LR to investigate their performance and compare it to the stacking model. GPMs in stretch form were created after adopting all four models. The GPMs were then categorised into five categories: very high, high, moderate, low, and very low GPMs.
An advanced hybrid method like SVM, ANN, LR, or stacking was used to create the groundwater potentiality models shown in Fig. 6. According to the classifications illustrated in Fig. 6, there are five levels of groundwater potential: very high, high, moderate, low, and very low. Figure 6 also illustrates that most of these zones are extensive and coincide with the expected pattern of groundwater potentiality based on previous studies. Parallel to the drainage path of the watershed, the very high and very high potential groundwater zone flows northwest-northward. Low groundwater potential zones predominate in the south and southeast.

Groundwater potentiality models using a SVM, b ANN, c LR, and d stacking
It was discovered that around 1850km2-2149km2 and 3644km2-4585km2 of the basin's total area had "very low" and "low" potential for groundwater, respectively, with this model (Table 3). Overall, the most significant proportion of the area was assessed to have a high groundwater potential. According to all models, there are many potential areas for water harvesting in the catchment region. However, the most representative model must be explained since the region's size varies. There is much variability in the studies, which may be because the models are based on different data sets, including application, resolution, and assumptions of raster layer attributes.
Validation of the models
The GPMs based on GPS data were validated using the empirical and binormal ROC AUC. SVM has an AUC of 0.831 and 0.906; ANN has an AUC of 0.841 and 0.911; LR has an AUC of 0.819 and 0.903, while stacking has an AUC of 0.858 and 0.921 (see Fig. 7a–d). According to both ROC curves, stacking was the outperformed model, accompanied by ANN, SVM, and LR. However, the ROC curves show that the stacking outperforms all other models under investigation. All models with AUCs greater than or equal to 0.8 could be regarded as successful. Results showed that single models have performed well, but the accuracy level is relatively lower than stacking ensemble model. Therefore, it can be stated that stacking model outperformed other single models.

Empirical and binormal ROC curves were used to validate the hybrid models, a SVM, b ANN, c LR, and d stacking
Sensitivity analysis
Because of the complicated mathematical relationship between historical trends in the amount of groundwater and the variables that trigger those trends, it is impossible to determine the exact region in which a significant and significant quantity of groundwater will be available for commercial use by developing advanced hybrid algorithms for mapping groundwater potential zones. No factors are included in either model why groundwater potential is diminishing in a particular location. Unless the impact of these elements on the frequency of landslides can be quantified, how can management strategies be devised and put into action?
If the impact of these variables on groundwater potential cannot be established, how will management strategies be devised and implemented? Reducing the frequency of groundwater decline may be achieved by identifying characteristics associated with prospective zones for groundwater. As a result, it is critical to identify the most influential factors. To determine how important each conditioning variable is to the RF modeling process, the MDG and MDA have been used (Hollister et al. 2016). In the GWP modeling, all elements except TRI were included (based on MDG and MDA), but the most relevant ones were the NDMI, NDVI, slope, distance to water bodies, and flow accumulation (based on MDG and MDA) (Fig. 8). It was difficult to determine the relative importance of 14 different factors using just TPI, aspect, and TRI as a criterion (Fig. 8).

Analyses of sensitivity for the best model (AND model) using a MDA and b MDG
Discussion
Water consumption has grown dramatically in the last decade due to fast population expansion, particularly in arid and semi-arid regions (Rahmati et al. 2016). Groundwater is the primary water supply for life in the vast majority of the study region, which includes dry and semi-arid areas (Mousavi et al. 2017). Groundwater planning and management are essential in this area. Hydrogeologists, engineers, and decision-makers need specific fundamental tools for managing groundwater. GPM can be used as a basic groundwater management technique (Yousefi et al. 2020).
GPM results from lithology, tectonics, terrain, vegetation, rainfall, and hydrology are present and accessible in the environment. In this study, many types of data were employed as input datasets (Kumar et al. 2021). Research-based on DEMs yields more accurate and essential findings. Different DEMs provide different outcomes; for example, the ALOS DEM with a spatial resolution of 12.5 m produces relevant and excellent results compared to the ASTER and SRTM DEMs with 30 m. The authors used a combination of geomorphology, geology, and hydrology characteristics to determine the spatial groundwater potential. Considering the argument issue, spatial analysis is the study's primary focus on choosing the best performing technique and models for GPMs. VIF and tolerance tests have been performed on geo-environmental parameters (elevation, aspect, slope, lithology, rainfall, land use/land cover, drainage density, soil type, distance to fault, distance to road, distance to river, NDVI, TPI, TWI, and SPI) (Singha et al. 2020). They have proven to be the most effective for groundwater storage.
Based on prior research, it has been discovered that numerous factors on groundwater potential are primarily site-specific and hence cannot be directly generalized to other areas. In the Ningtiaota area of China, Bui et al. (2019) revealed that elevation was the most influencing variable on groundwater potential, while in the Chilgazi region of Iran, TWI and distance from rivers were the most relevant variables Bui et al. (2019). Nguyen et al. (2020) revealed that elevation and rainfall are the most and least essential environmental parameters, respectively, in the DakNong Province of Vietnam. In contrast, Oikonomidis et al. (2015) found that rainfall was the most crucial variable influencing groundwater potential in the Greek region of Thessaly. Singh et al. (2019) conducted a national-scale groundwater potential mapping project in New Zealand and found that lithology was the most relevant variable to employ. (Tolche 2020) and Mallick et al. (2021) have all reported different variable rankings for different regions around the world, showing that The significance of variables for determining groundwater potential varies based on the study area's geo-environmental and topo-hydrological characteristics.
The present study constructed a novel ensemble model based high resolution groundwater potentiality model (GPM) by integrating random forest (RF) meta classiffier based stacking ensemble machine learning algorithm with high resolution groundwater conditioning parameters in Bisha watershed, Saudi Arabia. In the present research, twenty-one parameters were generated from high resolution satellite images and other secondary sources. The novel stacking ensemble machine learning algorithm has been developed by integrating three base-classifiers, such as artificial neural network (ANN), support vector machine (SVM), and logistic regression (LR) with RF meta-classifiers. The resulting AUC under the respective ROC (empirical and binormal) is 0.831 and 0.906 for SVM, 0.841 and 0.911 for ANN, 0.819 and 0.903 for LR, and 0.858 and 0.921 for stacking (see Fig. 7a–d). Based on the both ROC curves, stacking appeared as the best model, followed by ANN, SVM, and LR. As a result, the unique hybrid model performed better and can be applied to further domains. Although, if all possible parameters are combined, a better degree of precision can be reached. Our findings indicate that GW management in the study area region should focus their efforts on developing GW exploitation and agricultural operations in areas adjacent to wadies. As a result of the increased natural recharge, these areas offer a greater GW potential.
The imperative to employ ensemble learning techniques to minimize over-fitting was entirely salient in our study since the effective training efficiency of single models such as ANN, SVM, LR, and RF decreased to a relatively poor validation performance, indicating that the training performance had been over-fitted (Avand et al. 2020). When it comes to performance, while the models achieved different ranks (i.e., performance) during the training and validation phases, it was discovered that the ensemble models significantly improved the predictive ability of the single models using the ROC method (), which was used as the primary performance metric. When the single models (ANN, SVM, and LR) were combined with a single ensemble learning approach (RF) inside the stacking framework, the predictive ability of the hybrid model increased by 3.37 percent, 1.9 percent, and 4.52 percent, respectively, according to the results. The previous study has shown that model performance may be enhanced by employing the ensemble modeling technique. This is consistent with our modeling results (DeSimone et al. 2020; Feizizadeh et al. 2021; Fadhillah et al. 2021).
Ensemble modeling methods have been demonstrated to be successful in recent research; however, when applied to various situations in different locations of the globe, these strategies performed differently (Sachdeva and Kumar 2021). Using Rotation Forest and Bagging, Islam et al. (2021) found that the Reduced Pruning Error Tree (RPET) technique outperformed MultiBoost and Random Subspace (RSS) in the prediction of flood. Pal et al. 2020b) used the RSS ensemble learning approach for habitat quality prediction and found an enhanced model performance. This is also true for groundwater potentiality prediction studies using ensemble approaches (Golkarian et al. 2018; Chen et al. 2019; Vafaeinejad and Mahmoudi Jam 2021). These findings lead us to conclude that the performance of diverse predictive models obtained from different machine learning and ensemble learning approaches may be significantly affected by local variability. This, it seems, necessitates additional modeling work across areas to provide reliable forecast models.
According to the findings of this research, the new ensemble model described here is a powerful tool for modeling complex natural processes. To improve GWPM accuracy, various factors should be studied in the future. First and foremost, the consequences of restricting or expanding the region from which non-well sites are selected to locations where wells are situated or to areas outside the distribution of wells should be thoroughly examined. Since a second consideration, the traditional 80:20 ratio of datasets used for both testing and training has to be reexamined, as it may be contributing to problems. A comparison of the hybrid ensemble model to other ensemble models and deep learning to forecast groundwater sites should be performed to uncover any hidden impacts of the selection techniques used to choose features.
Conclusion
In the current study, a novel hybrid stacking model has been developed in which ANN, SVM, and LR were used as base classifiers, and RF was used as a meta-classifier for the generation of a groundwater potential map for the Bisha watershed, Saudi Arabia. The findings of the RF-based hybrid ensemble model are more accurate than the results of the three individual models. The study's findings also show that morphological characteristics, such as NDMI, NDVI, slope, flow accumulation, SPI, distance to the river, elevation, and aspect, substantially impact prediction performance. A few limitations should be highlighted despite the positive performance of the established models of groundwater spring potential. Several factors may affect the effectiveness of models, including the quality and amount of data and incorrectly identifying non-spring locations. In addition, fine-tuning the stacking framework's structural parameters is a computationally taxing undertaking that may need some prior user knowledge. Future work might be focused on providing a technique that automatically adjusts the structural parameters or on implementing an alternative evolutionary algorithm that requires fewer parameters to be adjusted as a direction. A future objective may be to deploy the approach in a location with a variety of geo-environmental circumstances to gauge its efficacy. In light of the fact that the environment and all of its inhabitants rely on groundwater resources, discovering the geographical patterns of its occurrence is critical to effective water resources management initiatives. Overall, the RF-based feature selection approach proposed in this research was determined to be essential for evaluating the potential of groundwater springs. As a result of its adoption, more accurate and dependable models were created at a lower cost. The findings of this research will be helpful to local governments and government agencies in developing future water resource management strategies since they identify possible groundwater spring locations.
Availability of data and materials
“The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request”.
References
Abdulkadir TS, Muhammad RUM, Wan Yusof K, et al (2019) Quantitative analysis of soil erosion causative factors for susceptibility assessment in a complex watershed. http://www.editorialmanager.com/cogenteng 6:. https://doi.org/10.1080/23311916.2019.1594506
Abdulrazzak MJ (1995) Water supplies versus demand in Countries of Arabian Peninsula. J Water Resour Plan Manag 121:227–234. https://doi.org/10.1061/(ASCE)0733-9496(1995)121:3(227)
Al-Rashed MF, Sherif MM (2000) (2000) Water Resources in the GCC Countries: an overview. Water Resour Manag 141(14):59–75. https://doi.org/10.1023/A:1008127027743
Arabameri A, Pradhan B, Lombardo L (2019a) Comparative assessment using boosted regression trees, binary logistic regression, frequency ratio and numerical risk factor for gully erosion susceptibility modelling. CATENA 183:104223. https://doi.org/10.1016/J.CATENA.2019.104223
Arabameri A, Rezaei K, Cerda A et al (2019b) GIS-based groundwater potential mapping in Shahroud plain, Iran. A comparison among statistical (bivariate and multivariate), data mining and MCDM approaches. Sci Total Environ 658:160–177. https://doi.org/10.1016/j.scitotenv.2018.12.115
Avand M, Janizadeh S, Tien Bui D, et al (2020) A tree-based intelligence ensemble approach for spatial prediction of potential groundwater. 13:1408–1429. https://doi.org/10.1080/17538947.2020.1718785
Ayalew L, Yamagishi H (2005) The application of GIS-based logistic regression for landslide susceptibility mapping in the Kakuda-Yahiko Mountains, Central Japan. Geomorphology 65:15–31. https://doi.org/10.1016/J.GEOMORPH.2004.06.010
Bierkens MFP, Wada Y (2019) Non-renewable groundwater use and groundwater depletion: a review. Environ Res Lett 14:63002. https://doi.org/10.1088/1748-9326/ab1a5f
Boori MS, Choudhary K, Kupriyanov A (2019) Mapping of groundwater potential zone based on remote sensing and GIS techniques: a case study of Kalmykia, Russia. Opt Mem Neural Networks 28:36–49. https://doi.org/10.3103/S1060992X1901003X
Breiman L, Friedman JH, Olshen RA, Stone CJ (2017) Classification and regression trees. CRC Press
Bui DT, Shirzadi A, Chapi K et al (2019) A hybrid computational intelligence approach to groundwater spring potential mapping. Water 11:2013. https://doi.org/10.3390/W11102013
Burrough PA, Mcdonnell RA (1998) Principles of Geographical Information Systems
Chen W, Li W, Chai H et al (2016) GIS-based landslide susceptibility mapping using analytical hierarchy process (AHP) and certainty factor (CF) models for the Baozhong region of Baoji City, China. Environ Earth Sci 75:1–14. https://doi.org/10.1007/s12665-015-4795-7
Chen C-W, Chen H, Wei L-W et al (2017a) Evaluating the susceptibility of landslide landforms in Japan using slope stability analysis: a case study of the 2016 Kumamoto earthquake. Landslides 14:1793–1801. https://doi.org/10.1007/s10346-017-0872-1
Chen W, Pourghasemi HR, Kornejady A, Zhang N (2017b) Landslide spatial modeling: Introducing new ensembles of ANN, MaxEnt, and SVM machine learning techniques. Geoderma 305:314–327. https://doi.org/10.1016/j.geoderma.2017.06.020
Chen W, Li H, Hou E et al (2018a) GIS-based groundwater potential analysis using novel ensemble weights-of-evidence with logistic regression and functional tree models. Sci Total Environ 634:853–867. https://doi.org/10.1016/J.SCITOTENV.2018.04.055
Chen W, Pourghasemi HR, Naghibi SA (2018b) Prioritization of landslide conditioning factors and its spatial modeling in Shangnan County, China using GIS-based data mining algorithms. Bull Eng Geol Environ 77:611–629. https://doi.org/10.1007/s10064-017-1004-9
Chen W, Tsangaratos P, Ilia I et al (2019) Groundwater spring potential mapping using population-based evolutionary algorithms and data mining methods. Sci Total Environ 684:31–49. https://doi.org/10.1016/J.SCITOTENV.2019.05.312
Chen J, Kuang X, Lancia M et al (2021a) Analysis of the groundwater flow system in a high-altitude headwater region under rapid climate warming: Lhasa River Basin, Tibetan Plateau. J Hydrol Reg Stud 36:100871. https://doi.org/10.1016/j.ejrh.2021.100871
Choi C, Kim J, Han H et al (2020) Development of water level prediction models using machine learning in wetlands: a case study of Upo wetland in South Korea. Water (switzerland). https://doi.org/10.3390/W12010093
Choubin B, Moradi E, Golshan M et al (2019) An ensemble prediction of flood susceptibility using multivariate discriminant analysis, classification and regression trees, and support vector machines. Sci Total Environ 651:2087–2096. https://doi.org/10.1016/j.scitotenv.2018.10.064
Chowdhury S, Al-Zahrani M (2015) Characterizing water resources and trends of sector wise water consumptions in Saudi Arabia. J King Saud Univ Eng Sci 27:68–82. https://doi.org/10.1016/J.JKSUES.2013.02.002
Costache R, Tien Bui D (2020) Identification of areas prone to flash-flood phenomena using multiple-criteria decision-making, bivariate statistics, machine learning and their ensembles. Sci Total Environ 712:136492. https://doi.org/10.1016/J.SCITOTENV.2019.136492
Crosta GB, Imposimato S, Roddeman DG (2003) Numerical modelling of large landslides stability and runout. Nat Hazards Earth Syst Sci 3:523–538. https://doi.org/10.5194/nhess-3-523-2003
Das B, Pal SC, Malik S, Chakrabortty R (2019) Modeling groundwater potential zones of Puruliya district, West Bengal, India using remote sensing and GIS techniques. Geol Ecol Landscapes 3:223–237. https://doi.org/10.1080/24749508.2018.1555740
DeSimone LA, Pope JP, Ransom KM (2020) Machine-learning models to map pH and redox conditions in groundwater in a layered aquifer system, Northern Atlantic Coastal Plain, eastern USA. J Hydrol Reg Stud 30:100697. https://doi.org/10.1016/J.EJRH.2020.100697
Díaz-Alcaide S, Martínez-Santos P (2019) Review: advances in groundwater potential mapping. Hydrogeol J 27:2307–2324. https://doi.org/10.1007/s10040-019-02001-3
Dou J, Oguchi T, Hayakawa SY et al (2014) GIS-Based Landslide Susceptibility Mapping Using a Certainty Factor Model and Its Validation in the Chuetsu Area, Central Japan. Landslide Science for a Safer Geoenvironment. Springer International Publishing, Cham, pp 419–424
Elbeltagi A, Pande CB, Kouadri S, Islam ARMT (2021) Applications of various data-driven models for the prediction of groundwater quality index in the Akot basin, Maharashtra, India. Environ Sci Pollut Res 2021:1–15. https://doi.org/10.1007/S11356-021-17064-7
Emamgholizadeh S, Moslemi K, Karami G (2014) Prediction the Groundwater Level of Bastam Plain (Iran) by Artificial Neural Network (ANN) and Adaptive Neuro-Fuzzy Inference System (ANFIS). Water Resour Manag Int J Publ Eur Water Resour Assoc 28:5433–5446. https://doi.org/10.1007/S11269-014-0810-0
Fadhillah MF, Lee S, Lee CW, Park YC (2021) Application of Support Vector Regression and Metaheuristic Optimization Algorithms for Groundwater Potential Mapping in Gangneung-si South Korea. Remote Sens 13:1196. https://doi.org/10.3390/RS13061196
Falkenmark M, Lindh G, Tanner RG et al (2019) Water for a starving world. Water a Starv World. https://doi.org/10.4324/9780429267260
Fan C, Myint SW, Kaplan S et al (2017) Understanding the Impact of Urbanization on Surface Urban Heat Islands—a Longitudinal Analysis of the Oasis Effect in Subtropical Desert Cities. Remote Sens 672(9):672
Feizizadeh B, Omarzadeh D, Kazemi Garajeh M, et al (2021) Machine learning data-driven approaches for land use/cover mapping and trend analysis using Google Earth Engine. https://doi.org/10.1080/09640568.2021.2001317
Forkuor G, Hounkpatin OKL, Welp G, Thiel M (2017) High resolution mapping of soil properties using remote sensing variables in South-Western Burkina Faso: a comparison of machine learning and multiple linear regression models. PLoS ONE 12:e0170478. https://doi.org/10.1371/JOURNAL.PONE.0170478
Forootan E, Seyedi F (2021) GIS-based multi-criteria decision making and entropy approaches for groundwater potential zones delineation. Earth Sci Inform 14:333–347. https://doi.org/10.1007/s12145-021-00576-8
Ghimire M, Chapagain PS, Shrestha S (2019) Mapping of groundwater spring potential zone using geospatial techniques in the Central Nepal Himalayas: a case example of Melamchi-Larke area. J Earth Syst Sci 128:1–24. https://doi.org/10.1007/s12040-018-1048-7
Ginesta Torcivia CE, Ríos López NN (2020) Preliminary Morphometric Analysis: Río Talacasto Basin, Central Precordillera of San Juan, Argentina. pp 158–168
Golkarian A, Naghibi SA, Kalantar B, Pradhan B (2018) Groundwater potential mapping using C5.0, random forest, and multivariate adaptive regression spline models in GIS. Environ Monit Assess 190:1–16. https://doi.org/10.1007/S10661-018-6507-8
Hamdani N, Baali A (2019) Height Above Nearest Drainage (HAND) model coupled with lineament mapping for delineating groundwater potential areas (GPA). Groundw Sustain Dev 9:100256. https://doi.org/10.1016/j.gsd.2019.100256
He J, Ma J, Zhang P et al (2012) Groundwater recharge environments and hydrogeochemical evolution in the Jiuquan Basin, Northwest China. Appl Geochemistry 27:866–878. https://doi.org/10.1016/J.APGEOCHEM.2012.01.014
Hollister JW, Milstead WB, Kreakie BJ (2016) Modeling lake trophic state: a random forest approach. Ecosphere 7:e01321. https://doi.org/10.1002/ECS2.1321
Hong H, Pradhan B, Xu C, Tien Bui D (2015) Spatial prediction of landslide hazard at the Yihuang area (China) using two-class kernel logistic regression, alternating decision tree and support vector machines. CATENA 133:266–281. https://doi.org/10.1016/j.catena.2015.05.019
Hong H, Pourghasemi HR, Pourtaghi ZS (2016a) Landslide susceptibility assessment in Lianhua County (China): a comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomorphology 259:105–118. https://doi.org/10.1016/j.geomorph.2016.02.012
Hong H, Pourghasemi HR, Pourtaghi ZS et al (2016b) Landslide susceptibility assessment in Lianhua County (China): a comparison between a random forest data mining technique and bivariate and multivariate statistical models. Geomo 259:105–118. https://doi.org/10.1016/J.GEOMORPH.2016.02.012
Hoque MA-A, Pradhan B, Ahmed N (2020) Assessing drought vulnerability using geospatial techniques in northwestern part of Bangladesh. Sci Total Environ 705:135957. https://doi.org/10.1016/j.scitotenv.2019.135957
Iqbal N, Khan AN, Rizwan A et al (2021) Groundwater level prediction model using correlation and difference mechanisms based on boreholes data for sustainable hydraulic resource management. IEEE Access 9:96092–96113. https://doi.org/10.1109/ACCESS.2021.3094735
Islam ARMT, Saha A, Ghose B et al (2021) Landslide susceptibility modeling in a complex mountainous region of Sikkim Himalaya using new hybrid data mining approach. Geocarto Int. https://doi.org/10.1080/10106049.2021.2009920
Jaafari A, Najafi A, Pourghasemi HR et al (2014) GIS-based frequency ratio and index of entropy models for landslide susceptibility assessment in the Caspian forest, northern Iran. Int J Environ Sci Technol 11:909–926. https://doi.org/10.1007/s13762-013-0464-0
Kazakis N, Matiatos I, Ntona MM et al (2020) Origin, implications and management strategies for nitrate pollution in surface and ground waters of Anthemountas basin based on a δ15N-NO3− and δ18O-NO3− isotope approach. Sci Total Environ 724:138211. https://doi.org/10.1016/J.SCITOTENV.2020.138211
Kumar R, Dwivedi SB, Gaur S, et al (2021) A comparative study of machine learning and Fuzzy-AHP technique to groundwater potential mapping in the data-scarce region. CG 155:104855. https://doi.org/10.1016/J.CAGEO.2021.104855
Lee S, Dan NT (2005) Probabilistic landslide susceptibility mapping in the Lai Chau province of Vietnam: focus on the relationship between tectonic fractures and landslides. Environ Geol 48:778–787. https://doi.org/10.1007/s00254-005-0019-x
Lee S, Hong SM, Jung HS (2018) GIS-based groundwater potential mapping using artificial neural network and support vector machine models: the case of Boryeong city in Korea. Geocarto Int 33(8):847–861
Luo X, Kwok KL, Liu Y, Jiao J (2017) A Permanent Multilevel Monitoring and Sampling System in the Coastal Groundwater Mixing Zones. Groundwater 55:577–587. https://doi.org/10.1111/gwat.12510
Mahato S, Pal S (2019) Groundwater Potential Mapping in a Rural River Basin by Union (OR) and Intersection (AND) of Four Multi-criteria Decision-Making Models. Nat Resour Res 28:523–545. https://doi.org/10.1007/s11053-018-9404-5
Mahmoud SH, Alazba AA, AM T (2014) Identification of potential sites for groundwater recharge Using a GIS-based decision support system in Jazan Region-Saudi Arabia. Water Resour Manag 2810(28):3319–3340. https://doi.org/10.1007/S11269-014-0681-4
Malik A, Bhagwat A (2021) Modelling groundwater level fluctuations in urban areas using artificial neural network. Groundw Sustain Dev 12:100484. https://doi.org/10.1016/j.gsd.2020.100484
Mallick, S. K., & Rudra S (2021) Analysis of Groundwater Potentiality Zones of Siliguri Urban Agglomeration Using GIS-Based Fuzzy-AHP Approach
Mallick J, Talukdar S, Alsubih M, et al (2021) Proposing receiver operating characteristic-based sensitivity analysis with introducing swarm optimized ensemble learning algorithms for groundwater potentiality modelling in Asir region, Saudi Arabia. 1–28. https://doi.org/10.1080/10106049.2021.1878291
Mandal S, Mandal K (2018) Modeling and mapping landslide susceptibility zones using GIS based multivariate binary logistic regression (LR) model in the Rorachu river basin of eastern Sikkim Himalaya, India. Model Earth Syst Environ 4:69–88. https://doi.org/10.1007/s40808-018-0426-0
Meles MB, Younger SE, Jackson CR et al (2020a) Wetness index based on landscape position and topography (WILT): modifying TWI to reflect landscape position. J Environ Manag 255:109863. https://doi.org/10.1016/J.JENVMAN.2019.109863
Mirchooli F, Motevalli A, Pourghasemi HR et al (2019) How do data-mining models consider arsenic contamination in sediments and variables importance? Environ Monit Assess. https://doi.org/10.1007/S10661-019-7979-X
Moghaddam HK, Moghaddam HK, Kivi ZR et al (2019) Developing comparative mathematic models, BN and ANN for forecasting of groundwater levels. Groundw Sustain Dev 9:100237. https://doi.org/10.1016/J.GSD.2019.100237
MoEP (2014) Wastewater. Environmental statistics bulletin – various years. Ministry of environmental protection of the People’s Republic of China, Beijing, China (2013–2014). Available at: http://www.sviva.gov.il/English/env_topics/Wastewater/Pages/default.aspx
Moore ID, Burch GJ (1986) Physical basis of the length-slope factor in the universal soil loss equation. Soil Sci Soc Am J 50:1294–1298. https://doi.org/10.2136/SSSAJ1986.03615995005000050042X
Mosavi A, Sajedi Hosseini F, Choubin B et al (2021) Ensemble boosting and bagging based machine learning models for groundwater potential prediction. Water Resour Manag 35:23–37. https://doi.org/10.1007/s11269-020-02704-3
Mousavi SM, Golkarian A, Naghibi SA et al (2017) GIS-based groundwater spring potential mapping using data mining boosted regression tree and probabilistic frequency ratio models in Iran. AIMS Geosci 191(3):91–115. https://doi.org/10.3934/GEOSCI.2017.1.91
Nagpal S, Mueller C, Aijazi A, Reinhart CF (2019) A methodology for auto-calibrating urban building energy models using surrogate modeling techniques. J Build Perform Simul 12:1–16. https://doi.org/10.1080/19401493.2018.1457722
Nahayo L, Kalisa E, Maniragaba A, Nshimiyimana FX (2019) Comparison of analytical hierarchy process and certain factor models in landslide susceptibility mapping in Rwanda. Model Earth Syst Environ 5:885–895. https://doi.org/10.1007/S40808-019-00575-1
Nguyen PT, Ha DH, Jaafari A et al (2020) Groundwater Potential Mapping Combining Artificial Neural Network and Real AdaBoost Ensemble Technique: The DakNong Province Case-study, Vietnam. Int J Environ Res Public Heal 17:2473. https://doi.org/10.3390/IJERPH17072473
Nhu VH, Ngo PTT, Pham TD et al (2020) A new hybrid firefly–PSO Optimized random subspace tree intelligence for torrential rainfall-induced flash flood susceptible mapping. Remote Sens 12:2688. https://doi.org/10.3390/RS12172688
Oikonomidis D, Dimogianni S, Kazakis N, Voudouris K (2015) A GIS/Remote Sensing-based methodology for groundwater potentiality assessment in Tirnavos area, Greece. J Hydrol 525:197–208. https://doi.org/10.1016/J.JHYDROL.2015.03.056
Pack R, Tarboton D, Goodwin C (1999) SINMAP 2.0 - A Stability Index Approach to Terrain Stability Hazard Mapping, User’s Manual. Civ Environ Eng Fac Publ
Pal S, Sarda R (2021a) Measuring the degree of hydrological variability of riparian wetland using hydrological attributes integration (HAI) histogram comparison approach (HCA) and range of variability approach (RVA). Ecol Indic 120:106966. https://doi.org/10.1016/j.ecolind.2020.106966
Pal S, Kundu S, Mahato S (2020a) Groundwater potential zones for sustainable management plans in a river basin of India and Bangladesh. J Clean Prod 257:120311. https://doi.org/10.1016/j.jclepro.2020.120311
Pal S, Talukdar S, Ghosh R (2020b) Damming effect on habitat quality of riparian corridor. Ecol Indic 114:106300. https://doi.org/10.1016/J.ECOLIND.2020.106300
Pham BT, Tien Bui D, Prakash I, Dholakia MB (2017) Hybrid integration of Multilayer Perceptron Neural Networks and machine learning ensembles for landslide susceptibility assessment at Himalayan area (India) using GIS. CATENA 149:52–63. https://doi.org/10.1016/J.CATENA.2016.09.007
Phong TV, Pham BT, Trinh PT, Ly HB, Vu QH, Ho LS, Le HV, Phong LH, Avand M, Prakash I (2021) Groundwater potential mapping using gis-based hybrid artificial intelligence methods. Groundwater 59(5):745–760
Pradhan B, Lee S (2010) Delineation of landslide hazard areas on Penang Island, Malaysia, by using frequency ratio, logistic regression, and artificial neural network models. Environ Earth Sci 60:1037–1054. https://doi.org/10.1007/S12665-009-0245-8
Pradhan S, Kumar S, Kumar Y, Sharma HC (2019) Assessment of groundwater utilization status and prediction of water table depth using different heuristic models in an Indian interbasin. Soft Comput 23:10261–10285. https://doi.org/10.1007/s00500-018-3580-4
Qadir A, Mallick TM, Abir IA et al (2019) Morphometric analysis of song watershed: a GIS approach. Indian J Ecol 46:475–480
Rahmati O, Pourghasemi HR, Melesse AM (2016) Application of GIS-based data driven random forest and maximum entropy models for groundwater potential mapping: a case study at Mehran Region. Iran CATENA 137:360–372. https://doi.org/10.1016/J.CATENA.2015.10.010
Regmi NR, Giardino JR, Vitek JD (2010) Modeling susceptibility to landslides using the weight of evidence approach: Western Colorado, USA. Geomorphology 115:172–187. https://doi.org/10.1016/J.GEOMORPH.2009.10.002
Rizeei HM, Pradhan B, Saharkhiz MA, Lee S (2019) Groundwater aquifer potential modeling using an ensemble multi-adoptive boosting logistic regression technique. J Hydrol. https://doi.org/10.1016/J.JHYDROL.2019.124172
Roy J, Saha S (2019) Landslide susceptibility mapping using knowledge driven statistical models in Darjeeling District, West Bengal, India. Geoenviron Disasters 6:1–18. https://doi.org/10.1186/S40677-019-0126-8/FIGURES/7
Sachdeva S, Kumar B (2021) Comparison of gradient boosted decision trees and random forest for groundwater potential mapping in Dholpur (Rajasthan), India. Stoch Environ Res Risk Assess 35:287–306. https://doi.org/10.1007/S00477-020-01891-0
Sarkar BC, Deota BS, Raju PLN, Jugran DK (2001) A Geographic Information System approach to evaluation of groundwater potentiality of Shamri micro-watershed in the Shimla Taluk, Himachal Pradesh. J Indian Soc Remote Sens 29:151–164. https://doi.org/10.1007/BF02989927
Shit PK, Bhunia GS, Pourghasemi HR (2020) Gully erosion susceptibility mapping based on bayesian weight of evidence. Gully Erosion Studies from India and Surrounding Regions. Springer, Cham, pp 133–146
Shu C, Burn DH (2004) Artificial neural network ensembles and their application in pooled flood frequency analysis. Water Resour Res 40:1821. https://doi.org/10.1029/2003WR002816
Singha P, Das P, Talukdar S, Pal S (2020) Modeling livelihood vulnerability in erosion and flooding induced river island in Ganges riparian corridor. India Ecol Indic 119:106825. https://doi.org/10.1016/J.ECOLIND.2020.106825
Singh SK, Zeddies M, Shankar U, Griffiths GA (2019) Potential groundwater recharge zones within New Zealand. Geosci Front 10(3):1065–1072
Stamatopoulos CA, Di B (2015) Analytical and approximate expressions predicting post-failure landslide displacement using the multi-block model and energy methods. Landslides 12:1207–1213. https://doi.org/10.1007/s10346-015-0638-6
Talukdar S, Singha P, Mahato S et al (2020) Land-Use Land-cover classification by machine learning classifiers for satellite observations—a review. Remote Sens 12:1135. https://doi.org/10.3390/RS12071135
Talukdar S, Eibek KU, Akhter S et al (2021) Modeling fragmentation probability of land-use and land-cover using the bagging, random forest and random subspace in the Teesta River Basin, Bangladesh. Ecol Indic 126:107612. https://doi.org/10.1016/j.ecolind.2021.107612
Tehrany MS, Pradhan B, Jebur MN (2014) Flood susceptibility mapping using a novel ensemble weights-of-evidence and support vector machine models in GIS. J Hydrol 512:332–343. https://doi.org/10.1016/J.JHYDROL.2014.03.008
Tien Bui D, Pradhan B, Lofman O et al (2012) Landslide susceptibility mapping at Hoa Binh province (Vietnam) using an adaptive neuro-fuzzy inference system and GIS. Comput Geosci 45:199–211. https://doi.org/10.1016/j.cageo.2011.10.031
Tien Bui D, Pradhan B, Nampak H et al (2016) Hybrid artificial intelligence approach based on neural fuzzy inference model and metaheuristic optimization for flood susceptibilitgy modeling in a high-frequency tropical cyclone area using GIS. J Hydrol 540:317–330. https://doi.org/10.1016/j.jhydrol.2016.06.027
Tien Bui D, Shahabi H, Shirzadi A et al (2018) Landslide detection and susceptibility mapping by AIRSAR data using support vector machine and index of entropy models in Cameron Highlands. Malaysia Remote Sens 10:1527. https://doi.org/10.3390/rs10101527
Tien Bui D, Ho TC, Revhaug I, et al (2014) Landslide Susceptibility Mapping Along the National Road 32 of Vietnam Using GIS-Based J48 Decision Tree Classifier and Its Ensembles. pp 303–317
Tolche AD (2020) Groundwater potential mapping using geospatial techniques: a case study of Dhungeta-Ramis sub-basin, Ethiopia 5:65–80. https://doi.org/10.1080/24749508.2020.1728882
Trigila A, Iadanza C, Esposito C, Scarascia-Mugnozza G (2015) Comparison of Logistic Regression and Random Forests techniques for shallow landslide susceptibility assessment in Giampilieri (NE Sicily, Italy). Geomorphology 249:119–136. https://doi.org/10.1016/j.geomorph.2015.06.001
Truong XL, Mitamura M, Kono Y, Raghavan V, Yonezawa G, Truong XQ, Do TH, Tien Bui D, Lee S (2018) Enhancing prediction performance of landslide susceptibility model using hybrid machine learning approach of bagging ensemble and logistic model tree. Appl Sci 8(7):1046
Tu JV (1996) Advantages and disadvantages of using artificial neural networks versus logistic regression for predicting medical outcomes. J Clin Epidemiol 49:1225–1231. https://doi.org/10.1016/S0895-4356(96)00002-9
Vafaeinejad A, Mahmoudi Jam S (2021) Using particle swarm optimization algorithm and geospatial information system for potential evaluating of groundwater (case study: Mehran, Iran). Arab J Geosci. https://doi.org/10.1007/S12517-021-07475-8
van Eeuwijk FA, Bustos-Korts D, Millet EJ et al (2019) Modelling strategies for assessing and increasing the effectiveness of new phenotyping techniques in plant breeding. Plant Sci 282:23–39. https://doi.org/10.1016/j.plantsci.2018.06.018
Vapnik VN (2013) The Nature of Statistical Learning Theory. Nat Stat Learn Theory. https://doi.org/10.1007/978-1-4757-3264-1
Vellaikannu A, Palaniraj U, Karthikeyan S et al (2021) Identification of groundwater potential zones using geospatial approach in Sivagangai district. South India Arab J Geosci 14:8. https://doi.org/10.1007/s12517-020-06316-4
Wang G, Hao J, Ma J, Jiang H (2011) A comparative assessment of ensemble learning for credit scoring. Expert Syst Appl 38:223–230. https://doi.org/10.1016/J.ESWA.2010.06.048
Wolpert DH (1992) Stacked generalization. Neural Netw 5:241–259. https://doi.org/10.1016/S0893-6080(05)80023-1
Xie Z, Chen G, Meng X et al (2017) A comparative study of landslide susceptibility mapping using weight of evidence, logistic regression and support vector machine and evaluated by SBAS-InSAR monitoring: Zhouqu to Wudu segment in Bailong River Basin, China. Environ Earth Sci 76:1–19. https://doi.org/10.1007/s12665-017-6640-7
Xu C, Xu X, Lee YH et al (2012) The 2010 Yushu earthquake triggered landslide hazard mapping using GIS and weight of evidence modeling. Environ Earth Sci 66:1603–1616. https://doi.org/10.1007/s12665-012-1624-0
Yousefi S, Sadhasivam N, Pourghasemi HR et al (2020) Groundwater spring potential assessment using new ensemble data mining techniques. Meas J Int Meas Confed. https://doi.org/10.1016/J.MEASUREMENT.2020.107652
Yu X, Michael HA (2019) Offshore Pumping Impacts Onshore Groundwater Resources and Land Subsidence. Geophys Res Lett 46:2553–2562. https://doi.org/10.1029/2019GL081910
Zhang T, Han L, Chen W, Shahabi H (2018a) Hybrid integration approach of entropy with logistic regression and support vector machine for landslide susceptibility modeling. Entropy 20:884. https://doi.org/10.3390/e20110884
Zhang T, Han L, Chen W, Shahabi H (2018b) Hybrid integration approach of entropy with logistic regression and support vector machine for landslide susceptibility modeling. Entropy 20:884. https://doi.org/10.3390/E20110884
Zhu Q, Abdelkareem M (2021) Mapping groundwater potential zones using a knowledge-driven approach and GIS analysis. Water 13:579. https://doi.org/10.3390/w13050579
Acknowledgements
The authors extend their appreciation to the deputyship for research & innovation, Ministry of education in Saudi Arabia for funding this research work through the project number IFP-KKU-2020/13.
Funding
Funding for this research was given under award numbers IFP-KKU-2020/13 by the deputyship for research & innovation, Ministry of education in Saudi Arabia.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no competing interests. No potential conflict of interest was reported by the authors.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mallick, J., Talukdar, S. & Ahmed, M. Combining high resolution input and stacking ensemble machine learning algorithms for developing robust groundwater potentiality models in Bisha watershed, Saudi Arabia. Appl Water Sci 12, 77 (2022). https://doi.org/10.1007/s13201-022-01599-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-022-01599-2