
Abstract
Additive manufacturing (AM) has emerged as a commonly utilized technique in the manufacturing process of a wide range of materials. Recent advances in AM technology provide precise control over processing parameters, enabling the creation of complex geometries and enhancing the quality of the final product. Moreover, Machine Learning (ML) has become widely used to make systems work better by using materials and processes more intelligently and controlling their resulting properties. In industrial settings, implementing ML not only reduces the lead time of manufacturing processes but also enhances the quality and properties of produced parts through optimization of process parameters. Also, ML techniques have facilitated the advancement of cyber manufacturing in AM systems, thereby revolutionizing Industry 4.0. The current review explores the application of ML techniques across different aspects of AM including material and technology selection, optimization and control of process parameters, defect detection, and evaluation of properties results in the printed objects, as well as integration with Industry 4.0 paradigms. The progressive phases of utilizing ML in the context of AM, including data gathering, data preparation, feature engineering, model selection, training, and validation, have been discussed. Finally, certain challenges associated with the use of ML in the AM and some of the best-practice solutions have been presented.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Additive manufacturing (AM) technologies, particularly in the process of manufacturing polymer and polymer-based composite components, are introducing a significant shift in production paradigms as an important element of the Industrial Revolution 4.0, currently extending their application to a variety of industrial sectors [1,2,3,4,5,6,7]. The term “additive” refers to the notion of adding materials (usually in sequential layers) to obtain the three-dimensional geometry of final products, as opposed to conventional technologies which mainly involve forming and subtracting materials [8, 9]. AM brings several advantages, such as the ability to produce complex geometries that would be difficult or impossible to achieve with conventional techniques. It would also reduce production time, minimize material waste, and enhance cost efficiency [10].
However, AM faces challenges due to inherent variations in manufacturing conditions and process parameters, where, for example, even small fluctuations in process parameters can significantly affect the energy input and result in microstructural defects. Fortunately, Machine Learning (ML) methods have emerged as a promising solution, offering great potential for determining the complexity of the combined effects of process parameters on the final performance of AMed parts [11]. The utilization of ML techniques has significantly increased in recent years owing to the large amounts of available data, advancement in computational technology, and emerging advanced ML algorithms and tools [12]. ML has been applied in AM for several purposes, such as optimizing input parameters, analyzing dimensional accuracy, detecting defects during manufacturing, and predicting material properties [9].
ML models can be trained using different types of data in AM, aimed to address various problems concerning different AM phases from process design and conception, preprocessing, process optimization and operation control, quality control, and smart manufacturing [1, 13]. For instance, such approaches would be used to design and realize innovative microstructural architecture, intelligent optimization part features such as density and topology optimization [14], detect and control various defects [15] and residual stress distribution [16, 17], and improve manufacturability [18] and operational performance within the AM process. Eventually, these efforts ensure greater efficiency, quality, and customization of process output, addressing many of the current AM challenges.
This paper explores the application of ML in polymer additive manufacturing, focusing on addressing challenges across various stages of the AM process. Section “Polymer additive manufacturing technologies” provides an overview of key polymer AM technologies, setting the stage by highlighting their capabilities and challenges. Section “Machine learning” covers the fundamentals of ML, including data collection, preprocessing, feature engineering, model selection, and validation, within the context of polymer AM. These foundational sections lead to section “Application of machine learning in polymer additive manufacturing”, which discusses specific ML applications in design, process optimization, quality control, and smart manufacturing. Finally, section “Challenges associated with using ML in AM” examines challenges such as overfitting, data acquisition, computational cost, and standardization, offering insights into current limitations and future directions for ML in AM.
Polymer additive manufacturing technologies
Originally introduced as a rapid prototyping technique, the use of AM has become increasingly widespread for a wide variety of applications, offering particular advantages in product development, efficient production, and innovative manufacturing [10] by providing unique capabilities in the manufacturability of complex geometries, optimizing mechanical performance, and sustainability of material processes. Despite these advancements, the application of polymer AM parts confronts several critical challenges, including the inherent mechanical limitations of the polymers used, a lack of comprehensive understanding of the interplay between the part architecture and mechanical properties, and the suboptimal matching of part design to its functional requirements [2, 19,20,21,22].
Polymers are dominant materials in industrial AM applications, accounting for around 51% of all materials used in the various AM technologies [23]. They are available in a variety of forms, including thermoplastic filaments, powders, and reactive resins, usable in different AM processes. Correspondingly, each material has inherent capabilities and limitations in terms of process design and final properties, which should be considered in material and technology selection and conception.
As depicted in Table 1, AM technologies have been classified into seven categories according to the Standard Terminology for AM Technologies (ISO/ASTM 52900: 2021) [24], including Binder Jetting (BJT), Directed Energy Deposition (DED), Material Extrusion (MEX), Material Jetting (MJT), Powder Bed Fusion (PBF), Sheet Lamination (SHL) and Vat Photopolymerization (VPP). Each of these technologies presents unique advantages and challenges [6, 25]. Moreover, multi-step processes combine various technologies to leverage the strengths of each, as required for achieving the desired design [26]. Similarly, hybrid manufacturing processes combining additive manufacturing and subtractive methods can offer high efficiency, improved surface finishing, and dimensional accuracy, further reducing manufacturing time and costs by minimizing material waste within a single setup [27]. These attributes underscore AMs pivotal role in advancing sustainable and efficient production paradigms. Table 1 provides a summary of categories and the most common subcategories of polymer AM techniques [28].
Among these, MEX, VPP, and MJT are the most widely used polymer-based AM technologies [28]. For instance, stereolithography (SLA), a VPP technology, has been the first AM technology to be commercialized since the 1980s [29]. SLA along with its variants such as masked projection technologies (e.g. LCD masked stereolithography, digital light processing (DLP), and continuous digital light processing (cDLP)), have gained a large share of industrial applications [30,31,32]. In this regard, it has been reported that photopolymers, which are used in VPP and MJT technologies, account for around 50% of AM market share [33].
Prototyping can still be considered the most important application for AM. Fused Filament Fabrication (FFF), also known as Fused Deposition Modeling (FDM™), is a MEX technology that can be considered one of the simplest and most attractive processes currently available for the AM [19, 34], and has gained wide applications, notably for prototyping and producing functional parts of thermoplastics polymer components with low melting points and composites [35, 36].
Selective laser sintering (SLS), a PBF technology, is another widely used AM technology of polymer materials. This technology, besides promising advantages in the fabrication of highly isotropic parts with complex geometries without support structures, is still limited to polymers with large enough sintering window, such as polyamide 11 and 12 (PA-11 and PA-12), Polystyrene (PS), thermoplastic Polyurethane (TPU) and thermoplastic elastomers [37]. Nevertheless, huge advantages in the fabrication of biocompatible porous components made this technology a great choice for biomedical applications [38].
The use of pure polymer AMed parts has traditionally been mainly limited to conceptual prototyping. This is primarily due to their inherent limitations in mechanical performance. As shown in Fig. 1, mechanical properties are one of the main concerns in AM research. These research efforts have led to the emergence of innovative processes and materials for the production of functional advanced polymer components.

Keyword co-occurrence analysis for additive manufacturing as reported by Zheng et al. [39], indicating the importance of the mechanical properties of AMed parts
Conversely, AM technologies of polymer composites have undergone significant advancements over time, with researchers investigating and exploring novel materials to address the inherent limits of pure polymer materials. These technologies have the ability to greatly enhance industrial manufacturing by providing excellent functionality and mechanical performance. Nevertheless, the limitation of printable materials, that may meet the design requirements of AM technologies, remains a key challenge for broader industrial applications of high-performance composites. Indeed, the manufacturing rate of AM for composites and its capacity to produce consistent results are typically lower compared to traditional materials [40]. However, there is a growing interest in transitioning from rapid prototyping to mass production of functional parts. With this transition, new materials could also be developed by the synthesis of new matrix materials, which can provide excellent mechanical properties. Therefore, further research is needed to explore more suitable materials and applications for AM polymer composites [13].
Multi-material AM offers a wide range of possibilities for the design and manufacture of functional components. For example, the ability to create components with spatially varying properties makes them suitable candidates to produce functionally graded materials (FGMs). However, the co-processing of two or more raw materials poses more complex requirements in terms of process design, optimization, and control [41, 42].
In the optimization of AM processes, various final properties can be defined as optimization targets at different scales, indicating the multiphysics and multiscale nature of these studies [40, 43,44,45]. Accordingly, personalized material architecture can be designed and realized utilizing AM technologies, providing application-oriented features in terms of mechanical and physicochemical properties in different scales. For instance, bioinspired AM architectures have been introduced to ensure the biocompatibility of components, from the molecular to the macroscopic scale [46]. This includes molecular lever cytotoxicity, morphological miscibility, and microstructure porosity, as well as FGM structures, extending to the macroscopic scale by the coherence of the thermal expansion coefficient and of the overall mechanical behavior of the component [46,47,48,49,50,51,52,53,54].
The optimization of process parameters should be addressed in the overall context of the Process-Structure-Properties-Performance (PSPP) relationship as a key area of research in AM materials science [55,56,57,58,59,60,61,62,63]. The structure of a material refers to its internal architecture, which can be studied at different scales from the nano-(molecular or atomic level) to the macro-scale (visible features such as layers or fiber alignments) [55, 64]. Microstructure is directly influenced by the manufacturing process and sequentially determines material properties as well as overall mechanical anisotropy and geometrical accuracy due to architectural properties and residual stress distribution in the final part.
Physics-informed approaches rely on constitutive equations that describe the underlying physical phenomena of AM processes, structures, and properties. However, they are limited by high computational costs and the need to calibrate input parameters. On the other hand, data-driven models use ML and statistical analysis to predict AM results without explicit physical equations. These models can efficiently process large data sets to uncover patterns and correlations. However, they can suffer from a lack of interpretability and the need for extensive data for training. Kouraytem et al. [65] suggest that both physics-driven and data-driven models have their place in advancing the understanding of PSPP relationships in AM. Physics-driven models provide detailed insights into the mechanisms involved, while data-driven models offer scalability and efficiency in exploring the effects of processing parameters on final part properties.
For instance, vat photopolymerization processes comprise in-situ photochemical reactions that provoke various phenomena including shrinkage (resulting in residual stresses and or deformation), thermal and chemical composition evolution, solute redistribution and segregations. Such phenomena would also influence the resin characteristics (namely critical energy Ec and depth of penetration Dp) during the process. Similarly, extrusion-based processes (such as FFF) involve thermal evolutions including crystallization and diffusion, determining layer adhesion conditions, and the eventual performance of the component [66, 67]. In general, layer-by-layer fabrication is the common approach in most AM technologies, despite some exceptions such as volumetric [68, 69] or multiaxial approaches [70]. Hence, the sequence of material addition (through deposition, curing, sintering, etc.) within the layers, as well as the stacking orientation of the layers, have a decisive effect on the stress distribution and the final microstructure of the AMed part [71,72,73]. These process parameters need to be considered alongside material variables and desired properties. In particular, composite materials and multi-material additive manufacturing would require case-specific optimization of process parameters.
During the AM processes, several parameters can affect the process and final properties of components. As illustrated in Fig. 2, One can categorize these parameters into material, process, machine, and environment parameters. These parameters have different effects on the evolution of material during the process. For example, during the FFF process, different process parameters affect the thermal treatment of the deposited material during solidification, the effective contact and formation of the adhesion interface, and, consequently, the eventual mechanical behavior and geometrical stability of AMed parts [74, 75]. Similarly, within the SLS process, laser energy density has a determinative role alongside powder properties, chamber temperature, and even atmosphere composition. It is therefore necessary to study the combined influence of these parameters and to establish adequate strategies to enhance the microstructure of the final product [75,76,77,78].

An overview of additive manufacturing parameters
As an example, Özen et al. [79] have studied the microstructure and mechanical properties of PETG FFF samples under different layer thicknesses and deposition overlaps. These results indicate the influence of the deposition strategy on the effective adhesion between the deposited filaments and the reduction of intra-layer porosity, which ultimately has a critical effect on the overall performance of the AMed components.
From another point of view, the slicing direction of component design (i.e. building orientation) under consistent deposition patterns can be investigated. As an example, Chacón et al. [80] characterized the effect of construction orientation, layer thickness, and feed rate on the mechanical performance of PLA samples produced by the FFF process. This study shows that PLA samples exhibit significant anisotropy, and that edge-oriented samples and flat configurations exhibit higher stiffness and ultimate tensile and flexural strengths. On the other hand, the mechanical properties of upright-oriented samples are enhanced by increasing layer thickness and decreasing feed rate. However, these variations were not significantly evident in edge and flat orientations, except in the case of low layer thickness. It’s worth mentioning that the research employed a response surface methodology for tensile and flexural strengths, analyzed using Statgraphics Centurion XVII software. An analysis of variance (ANOVA) was performed to assess the significance of factors such as construction orientation, feed rate, and layer thickness [80].
The structural analysis and simulation of AMed techniques involve using computational models to predict the mechanical behavior and structural integrity of the designed parts under various loading conditions [3, 64, 81]. Advanced simulation tools, for example using finite element analysis (FEA), are employed to assess stress distribution, deformation, and failure modes. This ensures that the designs are not only manufacturable but also meet the required performance criteria [82]. Within the work of Guessasma et al. [83], the anisotropy of FFF AMed ABS polymer parts under different building orientations has been investigated through X-ray micro-tomography and FEA. Moreover, Khadilkar et al. [84] work is another instance representing a case study in the use of the Convolutional Neural Networks (CNN) deep learning approach to predict the stress distribution in AMed parts.
Emerging design approaches for the innovative optimization of AM processes would result in satisfying a variety of design criteria, including mechanical performance, geometric precision, and aesthetic properties while taking into account application-specific properties such as biocompatibility and applicability under severe conditions, and finally manufacturing cost-effectiveness and sustainability. For example, the generative design (GD) approach uses algorithm-driven processes to generate design alternatives based on specified goals, constraints, parameters, and material choices [14]. It leverages artificial intelligence and computational methods to explore a vast design space, presenting designers with optimized solutions that meet predefined criteria in order to take full advantage of AM capabilities [14, 85, 86].
For instance, Li et al. [87] introduced a multidisciplinary topology optimization (TO) framework for AM regarding PSPP relationships. TO is described as a method that iteratively optimizes material distribution within a given design space, subject to constraints, to achieve designs that meet predefined objectives, such as minimal mass or maximal stiffness. The experimental evaluations have been conducted on an SLS process using PA-12 powder. The proposed workflow involves mapping functions of PSPP relationships through a data-driven approach and optimizing process parameters and structural topology using a gradient-based algorithm. The study showcases the efficacy of this method by implementing three case-specific optimizations, resulting in significant enhancements in lightweight performance as compared to traditional optimization methods.
Furthermore, another study by Barbieri and Muzzupappa [88] focused on the design and optimization of two components of a Formula Student race car - a rocker arm and a brake pedal - to evaluate and compare the potential and limitations of GD and TO tools with the objectives of reducing weight and improving stiffness. The analysis indicates that GD generally outperforms TO in producing more optimized solutions with significant reductions in weight and improvements in mechanical performance. This advantage is attributed to the ability of GD to explore a wider design space without the limitations imposed by a predefined initial design space, as is the case with TO.
Machine learning
ML is a subfield of artificial intelligence that focuses on the development of algorithms enabling computers to learn from data and make predictions based on learned patterns. ML models can enhance their performance over time by adjusting their algorithms or adding new data [89]. Generally, ML can be defined as algorithms “allowing computers to solve problems without being specifically programmed to do so” [90]. For instance, in the context of polymers AM, ML techniques are instrumental in optimizing process parameters, improving material properties, and predicting potential defects. The following sections provide an overview of a typical ML project, followed by detailed discussions on the application of ML methods in various sectors of AM. Finally, the paper considers the challenges associated with utilizing ML in AM projects.
General overview of a machine learning project
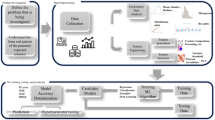
In order to describe the application of an ML project, it is crucial to outline a roadmap of interconnected steps forming the fundamental workflow known as the end-to-end ML process. This approach is of utmost importance as it sets the foundation for the model’s efficacy in subsequent phases, including prediction, validation, and overall accuracy evaluation. A general ML project’s workflow is shown in Fig. 3. The very first step is to comprehend and define the problem and objective of the ML project. In the context of polymer AM, this could involve optimizing the process parameters such as extrusion temperature to prevent warping [91], predicting the final performance features such as tensile strength of printed parts [92, 93], or identifying defects during the printing process [94, 95]. This guarantees that the model leads to findings that are relevant and replicable in both research and industrial settings.
Following the problem definition, the iterative and dynamic journey begins with data collection and data preprocessing, where raw data is gathered from various stages of the AM process and prepared for analysis. This raw data may include input characteristics, such as G-code and input process parameters, output characteristics, such as geometrical accuracy, microstructure, and mechanical characteristics of final parts, and in-process sensor data. Analyzing and visualizing this data provides insights that guide the implementation of the ML model, helping to understand the complex relationships between process parameters and final product structure, properties and performance.
Feature engineering is a critical step where specific characteristics, such as layer adhesion quality or surface roughness, are selected or engineered to enhance the model’s predictive performance. For example, in polymer AM, features might include cooling rates or infill patterns, which are known to significantly impact the mechanical properties of the printed components. Once features are selected, the dataset is divided into training and testing sets. For instance, training sets might include historical data from past production runs, while testing sets could consist of newly produced parts. The model selection and training phases are crucial, where various algorithms—such as neural networks or decision trees—are trained on this data to detect patterns that relate to the desired output, such as minimizing print defects or maximizing strength. After training, models are evaluated using the testing data to assess their performance and generalization ability. For instance, an ML model trained to optimize layer thickness might be tested on a new batch of prints to see if it can accurately predict the optimal settings for achieving desired material properties.
Finally, the ML process includes hyperparameter tuning, deployment, monitoring, and maintenance. For AM applications, this could involve adjusting model parameters to better align with changes in material batches or machine settings, integrating the model into the manufacturing workflow to provide real-time optimization recommendations, and ensuring the model adapts over time as new data is collected. The end-to-end ML process in polymer AM thus encapsulates the journey from raw data to valuable insights that drive informed decisions, improving the efficiency and quality of the manufacturing process. Successful implementation requires collaboration between data scientists, engineers, and domain experts who understand the intricacies of both ML and AM technologies.

Workflow of an end-to-end ML project
Data collection
In applied science, data is generally collected from two main sources: laboratory experiments and computational simulations such as FEA and density functional theory (DFT) [63]. In this step, the authenticity and origin of the collected data significantly impact the quality of the ML model [11]. Within AM, the data collection process involves a wide range of data types, and different sensors and monitoring devices are employed for this purpose. Particularly, the data collected can be categorized into several phases, including but not limited to process parameters, in-situ monitoring data, and post-process evaluation metrics.
Process parameters refer to the input variables that can be controlled or adjusted during the AM process, such as layer thickness, print speed, energy input (e.g., laser power in laser-based AM techniques), and material flow rate. In polymer AM, these parameters are critical as they directly influence the quality and characteristics of the final printed component, including its mechanical properties and surface finish. For example, variations in layer thickness or print speed can lead to defects such as voids or poor layer adhesion, which in turn affect the mechanical performance of the part. Data on these parameters is crucial for training ML models to predict and optimize outcomes, such as improving the tensile strength or reducing the porosity of the printed polymer parts.
In-situ monitoring data is collected in real-time during the AM process using a variety of sensors and monitoring equipment. This data is invaluable for developing ML models that can predict and correct defects as they occur. For example, thermal imaging captures temperature distributions across the printed part, which is essential for understanding and controlling thermal gradients that may cause warping or residual stresses in polymers [96, 97]. Acoustic emissions can provide early warning of defects such as cracks or delamination [98], while optical coherence tomography offers detailed insights into layer-by-layer build quality [99]. Collecting and analyzing this data allows for real-time adjustments to process parameters, thereby enhancing the overall quality and consistency of the AM process.
After the AM process, a series of experimental evaluations are conducted to assess the quality and properties of the printed components. These evaluations include mechanical testing (e.g., tensile and fatigue behavior, fracture toughness, creep, and hardness), which are critical for determining whether the printed part meets the required specifications for its intended application. Surface roughness measurements are particularly important in polymer AM, as surface finish can significantly impact the part’s performance, especially in applications requiring high precision or specific aesthetic qualities. Rheological and physicochemical evaluations provide further insights into the material properties, such as viscosity and chemical stability, which are essential for ensuring that the printed parts maintain their integrity under various environmental conditions.
Collecting this comprehensive dataset is essential for validating the predictions made by ML models and ensuring that the AMed components meet the desired specifications and performance criteria. The utilization of this data enables the training of ML models to optimize process parameters, detect defects in real-time and predict the final properties of the printed components.
Data preprocessing
Data preprocessing is a crucial step in the lifecycle of an ML project, particularly within the context of polymer AM. This step involves preparing the raw data collected during the AM process to ensure that it is in a suitable format for training ML models. The objective is to enhance the model’s ability to learn effectively and efficiently by providing it with clean, consistent, and meaningful data.
In polymer AM, preprocessing tasks include data cleaning, where noise, errors, and inconsistencies in sensor data (e.g., temperature fluctuations or material flow variations) are corrected or removed. Handling missing values and outliers is also critical; for instance, gaps in thermal imaging data [96, 97] or unexpected spikes in acoustic emissions [98] need to be addressed to avoid misleading the model during training.
Encoding categorical variables such as different polymer types into a numerical format is another important step, allowing the ML model to process these variables effectively. Data scaling or normalization ensures that all input features, such as print speed and layer thickness, are on a comparable scale, which is particularly important in AM where varying units and scales are common.
Exploratory Data Analysis (EDA) is used to identify existing patterns and correlations in the data, such as the relationship between print speed and surface roughness or between layer height and tensile strength. In polymer AM, EDA helps in understanding complex interactions between process parameters and final part properties, guiding the selection of relevant features for the ML model [100, 101].
A rule of thumb when dealing with data in the collection and analysis step is to consider the “7 Vs” of big data, which are Value, Volume, Variety, Velocity, Veracity, Visualization, and Variability (Fig. 4). In polymer AM, the Value lies in the predictive insights ML can provide, Volume refers to the vast amounts of data generated during AM processes, and Variety reflects the diverse types of data (e.g., thermal images, mechanical properties). Velocity is critical in real-time monitoring and control, while Veracity involves ensuring data accuracy and reliability. Visualization tools help in understanding complex data patterns, and Variability accounts for the changing conditions in AM processes, such as variations in material properties or environmental conditions.

Big data characteristics known as the ‘7 Vs’
Feature engineering
Feature engineering is the process of using domain knowledge to create new features from existing data that make ML algorithms work better. It’s about transforming raw data into features that better represent the underlying problem for the predictive models, resulting in improved model accuracy on unseen data. Features are, in short, input variables that an ML model uses to train itself to make predictions. The type of features a model uses depends on the problem at hand. In AM problems, features fall into three categories: numerical features which encompass a range of process parameters (e.g., scan speed, temperature, pressure, etc.). [102,103,104], categorical features (e.g., material type, infill pattern, layer strategy, etc.) [105, 106], and time-series features (e.g., sensor readings, vibration data, acoustic emissions, cooling rates, etc.) [15, 107, 108].
Features can be selected manually or automatically using statistical techniques such as filter methods, wrapper methods, and embedded methods. However, automatic feature selection has disadvantages, including adding complexity to the ML model through redundant values. The primary statistical methods employed in filter methods are Pearson correlation, Spearman correlation, and variance threshold [109]. Their goal is to reduce the feature space by eliminating intercorrelated and semi-constant features. This enhances performance by reducing unnecessary complexity that may cause overfitting in the training model and decreasing computing time.
After completing feature development, filtering, and selection, one can do further EDA to comprehend the data’s properties, the desired attributes, and the features [100, 101]. EDA can provide valuable insights into any outliers and incorrect data or features that need to be removed before starting the training and testing of the dataset for ML models.
Model selection
After preparing input data and features, the next step is selecting an appropriate ML algorithm. There are different approaches to categorizing ML algorithms. ML algorithms are generally categorized into three broad classes: supervised learning, unsupervised learning, and reinforcement learning [110]. Figure 5 presents a few popular ML techniques for each category [111]. Figure 5 presents a few popular ML techniques within each category, illustrating their applicability to various tasks in polymers AM.

Examples of popular ML methods of Supervised, Unsupervised, and reinforced learning
Supervised learning
In supervised learning, the model is trained on a labeled dataset to learn the relationship between input variables and their corresponding outputs, enabling it to predict results on new data. The model’s performance is assessed by comparing its predictions on a test dataset with the actual outcomes. Later, cross-validation techniques are used for performance evaluation. The main objective of a regression-based ML model is to minimize the difference (error) between the predicted output and the actual data, thereby identifying a model that accurately correlates inputs and outputs. The most commonly used supervised learning algorithms are Deep Neural Network (DNN), Support Vector Machines (SVM), Random Forests (RF), Bayesian Networks (BN), and Decision Trees (DT) [10].
Supervised learning techniques mostly apply to classification and regression tasks. Regression tasks aim at predicting numerical or quantitative results such as the properties of AMed parts, including compressive strength [112, 113], surface roughness [114], tensile properties [115], and hardness [116]. The process parameters were used as model inputs in these examples [28].
Classification tasks aim at defining decision boundaries between known classes based on patterns learned from the input training data. Tools based on classification models are frequently employed for real-time or in situ surveillance of AM processes, encompassing the identification of defects, detection of process irregularities, and prediction of product quality. These tasks often involve training ML models using images [28].
Unsupervised learning
Unsupervised learning, on the other hand, applies to discovering patterns, clustering, and dimensionality reduction tasks and works with unlabeled data. Unsupervised learning algorithms learn entirely on their own and extract the features of input data, then categorize them into separated clusters. Therefore, these models are typically used to uncover hidden or unknown relationships within the data. K-means clustering, Hidden Markov models, Gaussian Mixture models, Autoencoder, and Generative Adversarial Networks (GAN) are among the most widely used unsupervised learning methods [10].
Clustering tasks involve the process of categorizing input data that share common characteristics. Clustering ML methods have been used for real-time monitoring of AM processes for defect detection, failure mode detection, and process monitoring.
Dimensionality reduction involves reducing the input features or data dimensionality while keeping as much variation or information as possible. Topics linked to polymer AM may involve several input variables, although not all of them have an equal amount of influence on the parameter under investigation. Dimensionality reduction approaches can improve model efficiency by selecting the most significant input features. These methods have been utilized to explore the relationships between process parameters and properties [28]. Some examples of unsupervised learning algorithms in the AM field are K-means clustering, self-organizing maps, and restricted Boltzmann.
Reinforcement learning
Reinforcement learning (RL) involves combining training and testing datasets to maximize overall reward by interacting with the environment. In contrast to supervised learning, where algorithms are trained by the correct outputs for given inputs, RL algorithms operate on a system of rewards and punishments to encourage positive behaviors and discourage negative ones. The most commonly used RL algorithms include Dataset Aggregation (dAgger), Q-learning, Deep Q Network (DQN), State-Action-Reward-State-Action (SARSA), and Monte-Carlo learning [10].
Reinforcement learning algorithms typically use the concepts of exploration and exploitation. Exploitation involves selecting actions that yield the highest rewards, while exploration involves trying new actions. By combining these strategies, the model can gradually improve its understanding of the environment, identify actions that result in positive rewards, and ultimately reach optimal solutions [117]. Some examples of reinforcement learning algorithms are Q-learning [118], temporal difference [119], and deep adversarial networks [120].
In polymer AM, RL can be employed for real-time optimization of process parameters, which directly impacts the quality of printed objects and the efficiency of the AM process. For instance, RL algorithms can be used to optimize the deposition trajectory in FFF processes, with specific goals such as minimizing process time while maintaining or improving the mechanical properties of the printed part [111].
Another example is the application of RL in the adaptive control of the printing process. For instance, RL can be used to monitor and adjust the print parameters in real-time to compensate for variations in material properties or environmental conditions, such as temperature fluctuations or humidity changes. This capability is particularly beneficial in polymer AM, where such variations can lead to defects like warping, delamination, or inconsistent surface finish. By continuously learning from the production environment, RL algorithms can ensure that the printing process remains within optimal parameters, reducing the likelihood of defects and improving overall yield.
Selecting the appropriate RL algorithm for a polymer AM application depends on various factors, including the nature of the problem, the size of the training set, the type of available data, and the computational resources [10, 121]. For example, Q-learning and Deep Q Networks (DQN) are often preferred for their ability to handle large state-action spaces, which are common in complex AM processes where multiple parameters need to be optimized simultaneously. On the other hand, SARSA might be more suitable for environments where safety or risk mitigation is critical, as it tends to be more conservative in its learning approach.
Model validation
One of the final phases of an ML project is model validation. This process ensures that the model is effective, reliable, and suitable for deployment. Model validation employs methods such as cross-validation to evaluate a model’s performance on unseen data. Cross-validation techniques are commonly employed to evaluate the model’s performance on unseen data, providing an estimate of its generalization ability. This step is particularly important in polymer AM, where process variability can introduce noise and affect the consistency of the printed parts. By systematically partitioning the dataset and performing repeated training and validation cycles, cross-validation minimizes the risk of overfitting and ensures that the model remains accurate across different production scenarios.
Following successful validation, the focus shifts to optimizing the model’s performance through hyperparameter tuning. This involves refining the model’s parameters to achieve an optimal balance between accuracy, interpretability, and computational efficiency. In polymer AM, where real-time predictions might be required for process control, hyperparameter optimization ensures that the model is not only accurate but also operationally viable within the constraints of the manufacturing environment.
Once optimized, the model is deployed for real-world application, where continuous monitoring is essential. This ongoing validation phase includes the periodic assessment of the model’s predictions against actual outcomes, ensuring that it adapts to any changes in material properties, process parameters, or environmental conditions. In the dynamic environment of polymer AM, this adaptability is crucial for maintaining the model’s relevance and effectiveness over time.
Application of machine learning in polymer additive manufacturing
Several approaches in classifications of different applications of ML techniques in AM technologies have been investigated in the literature. For instance, Jiang [111] discussed different ML methods applied to seven categories of AM techniques: material extrusion, powder bed fusion, material jetting, binder jetting, directed energy deposition, VAT photopolymerization, and sheet lamination. Then, he summarized the literature in three categories based on their target objectives: dimensional accuracy analysis, manufacturing defect detection, and property prediction. This categorization provides a guideline for researchers to review previous works and opt for suitable ML methods related to the specific aim at hand. However, he explained that considering the objective in itself does not provide an appropriate approach to choosing a proper ML technique since there are many other factors in play. For instance, in the context of optimizing process parameter problems, the application of previously utilized ML techniques would be rendered ineffective by the introduction of an additional process parameter as an input feature. Consequently, the incorporation of supplementary training data or the adoption of an alternative ML algorithm would lead to enhanced accuracy.
Similarly, Baumann et al. [89] have classified literature that applied ML technologies to AM contexts into five categories: selection or optimization of process parameters, adaption or optimization of the model (structure, topology, surface), process monitoring and control utilizing various monitoring technologies, general discussions and recommendations for utilizing ML in the context of AM, especially in the prospect applications such as Industry 4.0.
The application of ML in polymer AM spans multiple domains, from design and process optimization to quality control and smart manufacturing. Each of these domains contributes to the overarching goal of creating intelligent, adaptive manufacturing systems capable of producing high-quality, cost-effective products with minimal human intervention. Our current approach aims to synthesize several applications of ML into a comprehensive framework that addresses the main aspects of AM processes. The first section (section Design) examines how ML techniques can be employed in the design and conception phase, selecting materials and AM technologies. This also involves using large datasets to identify optimal combinations of part geometry, materials, and technologies that yield optimized designs with superior performance and efficiency.
The following section explores the application of ML models in optimizing and controlling the AM process parameters. These models offer significant potential in identifying the optimal settings of process parameters to achieve desired design goals. In addition, they are helpful in controlling the AM process, permitting the detection of anomalies in processing conditions and the identification of potential defects. Such anomalies may stem from a variety of sources, including environmental disruptions or equipment malfunctions.
From a more profound perspective, these ML-based methods can serve as a promising complement to traditional analytical and numerical methods for modeling the physical and chemical phenomena associated with the AM processes. Integrating physical theories into ML models leads to the development of physics-informed ML models. Such models are particularly beneficial in leading the AM process toward the production of materials with customized microstructures and architectures.
AMed components quality control constitutes another major area of ML applications. Besides investigating process parameters’ effects on microstructural evolutions, automatic early fault detection systems represent an important field of research for the use of ML models in AM. Through the application of ML algorithms, potential defects can be automatically identified in real time during the AM process, providing immediate corrective measures. Moreover, ML approaches present huge advantages in material inspection and post-process analysis of the mechanical performance and physical properties of the final parts, ensuring they meet the required specifications.
Finally, our approach takes into account the integration of the AM process within Industry 4.0 paradigms, including the Internet of Things (IoT) and smart manufacturing. By implementing ML model-based AM systems connected to a wider network of manufacturing processes, unprecedented levels of automation and efficiency can be achieved. This integration facilitates the real-time exchange of data between different stages of the manufacturing process, from design to final product, optimizing the entire production chain.
Design
The design phase involves conceptualizing the AM process plan according to the design requirements and constraints. This would include defining the required properties of the final product and the constraints in terms of part manufacturability, efficiency, and sustainability of the process, as well as selecting materials and appropriate AM process technologies for the desired objectives. In addition, the part geometry could be optimized according to the performance requirements of the final product, and the process could be modeled and optimized in terms of shape deviations, thermal gradients, and stress distributions, as well as energy consumption and material waste, mainly through analytical and numerical approaches. It should be mentioned that the inherent features of the process, such as the layer-wise nature of most AM processes, require several considerations for optimizing the process design.
Depending on the process nature and requirements, different aspects can be considered in the design for AM processes, including manufacturability studies, geometrical optimizations, preprocessing such as slicing acceleration, material, process and machine parameters, and cloud service platform, security, and sustainability [117].
According to Sbrugnera Sotomayor et al. [122], within the Design for Additive Manufacturing (DfAM) framework, a holistic workflow is essential, incorporating various design optimization strategies such as TO, lattice infill optimization, and GD. The study highlights the critical stages of the DfAM process, which include product planning, design optimization, manufacturing optimization, and product validation, underlining the importance of a guided, comprehensive approach to efficiently manage the design process. Specifically, it underscores the significance of leveraging optimization strategies early in the design phase to maximize the capabilities of AM, such as achieving complex, lightweight, and high-performance parts. Moreover, the paper emphasizes the potential of integrating ML techniques to enhance the DfAM workflow, suggesting that ML can significantly streamline and improve the design efficiency in manufacturing by facilitating smarter decision-making and reducing the number of design evaluations required. This integration of optimization strategies and ML in the DfAM process is crucial for overcoming traditional manufacturing limitations and fully exploiting the unique advantages offered by AM technologies.
In another work conducted by J. Jiang et al. [9], an ML-integrated DfAM framework has been introduced, addressing process-structure-properties PSP relationships, which is capable of modeling input-output relationships in both directions. This is achieved by employing DNNs for point data and CNNs for distributions and image data. Unlike traditional methods that require complex surrogate models and cannot reverse the PSP relationships, this framework utilizes ML to establish these relationships in any direction using additive manufacturing data. As demonstrated in a case study, the authors designed a customized ankle brace with tunable mechanical performance, demonstrating customized stiffness through the application of the proposed ML framework. The case study results are compared to a traditional methodology result using surrogate models (Gaussian process regression models), demonstrating that the ML-integrated design approach not only matches but sometimes surpasses the accuracy and efficiency of conventional methods. However, the article suggests that further research is needed to fully extend the models and methods to the broader PSP domain, noting that the proposed framework primarily examines structure-property and property-structure relationships.
In another study, Lee et al. [123] introduced an ML-based optimization approach for designing lattice structures’ beam elements using Bézier curves, a method initially utilized in computer graphics. This research focused on body-centered lattice structures, employing high-order Bézier curves for modeling beam element shapes to explore a more extensive and flexible design space. The process involves predicting the relative density and modulus of the lattice structure through FEA and homogenization, with initial data sourced from randomly generated Bézier curve control points. Subsequently, two deep neural networks (NNs) were trained to predict the relative density and relative Young’s modulus based on the shape of the Bézier curve. A hybrid approach combining neural network and genetic optimization (NN-GO) was then applied to generate new beam element shapes, aiming to create innovative material structures. The optimized designs were compared with two conventional models: a cylindrical beam with a single geometric parameter (radius) and a graded-density beam parameterized by two variables (the radii of the cross-section at the midpoint and ends of the beam element). The study also explores the advantages of the combined NN-GO approach over a simple genetic optimization method in accelerating the design process. Finally, the research validates the optimized BC structure through additive manufacturing and compression experiments, demonstrating the effectiveness of the proposed ML algorithm in optimizing the shape and mechanical properties of lattice structures.
Wang et al. [124] introduced a novel approach to generating innovative structural designs by integrating topology optimization and deep learning techniques, specifically through the use of Boundary Equilibrium Generative Adversarial Networks (BEGAN). This method aims to overcome the challenges of automatically generating innovative and optimal structures that enhance the intelligence of structural design, shorten the design cycle, and improve the design quality. The paper proposes a framework that uses topology optimization to generate a diverse set of optimized structural models, which serve as a training dataset for a deep learning model. The BEGAN algorithm is then applied to generate a large number of innovative structural designs. The application of the framework is demonstrated through two engineering case studies: the base plate of a cast steel support joint and a cross joint. These cases show how the method can intelligently generate designs with improved mechanical performance and material efficiency. The generated structures are evaluated in terms of innovation, aesthetics, machinability, and mechanical performance. In addition, the feasibility of manufacturing the optimized designs through 3D reconstruction and additive manufacturing techniques is demonstrated, highlighting the practical applicability of the proposed method.
Gu et al. [125] explored an innovative bioinspired approach to designing hierarchical composite materials. To discover high-performance materials, a CNN augmented with a self-learning algorithm was trained on a database of hundreds of thousands of FEA structures, resulting in the creation of microstructural patterns that enhance both the toughness and strength of materials.
The designs generated by the ML model were realized through a multi-material PolyJet AM process and subjected to tensile testing, validating the effectiveness of the ML approach in producing materials with improved mechanical properties. This approach is highlighted as an alternative method of coarse-graining, which analyzes and designs materials without relying on full microstructural data.
An often underexplored yet critical aspect of applying machine learning in additive manufacturing is the selection of polymers. The choice of polymer material significantly influences the mechanical properties, durability, and overall performance of the final product. Machine learning models can be employed to analyze vast datasets comprising different polymer characteristics, environmental conditions, and intended use-cases to recommend the most suitable materials for specific applications. This capability not only streamlines the material selection process but also enables the customization of polymers tailored to specific performance requirements, such as improved strength, flexibility, or thermal resistance.
Process parameters and operation
ML models excel at navigating the complex, non-linear dynamics characteristic of AM processes, offering an enhanced parameter optimization approach with reduced reliance on trial-and-error methods. Diverse ML techniques have been employed in order to facilitate the identification and optimization of AM process parameters, including Artificial Neural Networks (ANN), Genetic Algorithms (GA), Principal Component Analysis (PCA), SVM, and Support Vector Regression (SVR) [89].
Data-driven ML models are becoming powerful tools for predicting complex, non-linear relationships between AM parameters, offering a promising alternative to conventional Design of Experiment (DOE) strategies. DOE relies on extensive trial and error to identify critical response behaviors, which can often be time-consuming and costly [126]. In contrast, ML models utilize historical data to streamline the optimization of process parameters, thereby enhancing the final properties in accordance with design aims.
By integrating principles of physics into machine learning algorithms, Physics-Informed Machine Learning (PIML) models provide a more detailed analysis of the relationships between process-structure-property-performance (PSPP) within AM processes [127]. This approach not only makes machine learning models more interpretable by aligning them with physical laws but also enhances their accuracy and predictive capabilities. For instance, Inyang-Udoh and Mishra [128] introduce a physics-based Recurrent Neural Network (RNN) model to optimize inkjet 3D printing processes, effectively demonstrating the balance between data-driven flexibility and the physical accuracy required for robust model performance. Building on the integration of physics-informed models, the application of machine learning in optimizing specific process parameters can further enhance the efficiency and precision of polymer additive manufacturing.
Correspondingly, process parameters would be optimized for different targeted design features. For example, biological properties such as biocompatibility and cytotoxicity can be improved through enhancing process conditions and optimizing process parameters, which are crucial for biomedical applications. Moreover, the material evolutions during the AM process are directly influenced by process parameter settings, which eventually determine the final attributes of the AMed component. When it comes to bioprinting, adjusting process conditions can be a delicate and challenging task since they have a direct impact on the cells and sensitive biomaterial. As an example, Xu et al. [129] aimed to improve cell viability in stereolithography (DLP)-based bioprinting processes, specifically addressing the challenges posed by ultraviolet (UV) irradiation on cells during bioprinting. They employed an ensemble learning model that incorporates neural networks, ridge regression, K-nearest neighbors (KNN), and RF algorithms. This model is used to predict cell viability across different bioprinting parameters, including UV intensity, UV exposure time, gelatin methacrylate (GelMA) concentration, and layer thickness. Also, using the random forest algorithm, the study quantified the significance of each bioprinting parameter on cell viability, and the performance of the predictive model was evaluated using metrics such as the coefficient of determination (R²), relative error (RE), and root mean square error (RMSE).
As process parameters significantly influence the final properties of AMed components, machine learning models provide a sophisticated approach to monitoring and controlling these parameters in real-time, ensuring consistency and quality across different production cycles.
In another study, Bonatti et al. [130], presented a DL approach to enhancing quality control in extrusion-based bioprinting (EBB). This research focused on developing a robust DL-based control loop designed to automate the optimization of process parameters and monitor the process in real-time. The core of the study is the implementation of a CNN model designed to predict the outcome of the bioprinting process based on video data collected during printing. A comprehensive dataset was compiled by recording the EBB process with a high-resolution webcam, covering various printing parameters like setup (mechanical or pneumatic extrusion), material color, layer height, and infill density. The collected data underwent preprocessing before being used to train and validate the CNN, focusing on controlling overfitting and optimizing the network’s prediction speed. This model is capable of classifying the print quality into categories such as good, under-extrusion, and over-extrusion, thus facilitating real-time adjustments to the printing parameters to ensure optimal results. Integrating the DL model with a mathematical model of the EBB process, the study showcases a quality control loop capable of real-time monitoring of the printing process. This loop can identify prints with errors early on to save material and time, and it automatically optimizes printing parameters for subsequent prints.
Zhang et al. [131] presented a comprehensive study on modeling the PSPP relationships within the FFF process using a DL approach based on Long Short-Term Memory (LSTM) networks for predicting the tensile strength of final parts. The study proposed a novel approach by integrating in-process sensing data (temperature and vibration) with process parameters and material properties into an LSTM-based predictive model to enhance the accuracy and reliability of tensile strength prediction. This model significantly outperformed traditional ML methods, such as SVR and RF, in predicting the tensile strength of printed parts. Layer-wise Relevance Propagation (LRP) has been employed to quantify the influence of each process parameter on the model’s predictions, comparing the relative importance of different factors affecting tensile strength. This analysis highlighted the substantial impact of layer height, among other parameters, on the final part quality.
In addition to optimizing process parameters, machine learning can play a pivotal role in linking these parameters to the in-service performance of the final products. By predicting how variations in processing conditions—such as temperature, pressure, and cooling rates—affect long-term performance attributes like fatigue resistance, wear, and environmental stability, ML models help in designing more robust and reliable AMed components. Moreover, the contribution of machine learning to the recyclability of products is increasingly relevant. By analyzing the degradation of polymer properties through multiple cycles of reuse and predicting the remaining lifecycle of recycled materials, ML models aid in developing sustainable manufacturing practices that align with circular economy principles.
Fault detection and quality control
Predictive control based on ML models presents promising potential for automated manufacturing systems. By dynamically adjusting process parameters in real-time, the system can respond to variations in material behavior and environmental conditions, ensuring optimal results. However, the formation of certain defects may not be directly caused by process parameters. ML models would contribute to several early fault detection techniques in order to monitor and control the part quality during the process. Process monitoring serves as the basis for implementing closed-loop process controls, a pivotal operational mode for several AM systems. Prem et al. [132] summarized the most important monitoring techniques of the AM process as follows: Acoustic Emission Monitoring, Temperature Monitoring (regarding both material and environmental conditions), Camera-based Monitoring, Spectroscopy (for the analysis of plasma emissions from lasers), Infrared Imaging (for the assessment of heat distribution), Layer-by-Layer Imaging (incorporating X-ray/CT scanning for Non-destructive Evaluations (NDEs)), Process Parameter Monitoring, Machine Vision, Ultrasonic Monitoring (for in situ NDE, facilitating the detection of internal defects), Force/Vibration Sensing, Gas and Particle Monitoring, and Electromagnetic Sensing (utilizing eddy currents).
For example, Wasmer et al. [98] explored the potential of using acoustic emission (AE) with an RL model for real-time and in situ quality monitoring in AM processes. The use of AE for capturing subsurface dynamics during AM processes offers significant advantages over surface-based monitoring techniques, such as temperature measurements or high-resolution imaging. The RL model demonstrates the ability to classify the quality of AM parts based on their unique acoustic signatures, achieving classification accuracy that indicates the method’s high potential for real-time quality monitoring. The paper highlights the cost-effectiveness and reliability of using AE for detecting various physical phenomena associated with the AM process. The RL model’s self-learning capabilities suggest that this approach can reduce the need for extensive training datasets and adapt to new manufacturing conditions.
ML-based approaches not only augment the system’s adaptability to real-time data but also significantly improve the accuracy and efficiency of fault detection mechanisms. Notable contributions in this domain include several methodologies such as ANN, Decision Trees, KNN, Principal Component Analysis (PCA), and SVM [89].
For instance, Erik Westphal and Hermann Seitz [133], employed a CNN-based approach to enhance quality control in the SLS process, to automate the detection of powder bed defects, They presented an innovative use of complex transfer learning methods to classify powder bed defects in the SLS process, utilizing a relatively small dataset. They employed pre-trained CNN models, specifically VGG16 and Xception, with adaptations for defect classification in SLS images. The performance of the CNN models was thoroughly evaluated using metrics such as accuracy, precision, recall (sensitivity), F1-score, and the area under the receiver operating characteristic (ROC) curve (AUC).
Similarly, Klamert et al. [134], propose a real-time, in-situ quality control system utilizing CNNs specialized to detect curling defects during the SLS process. The DL model is used to analyze infrared thermography recordings of the SLS process employing an infrared camera to capture temperature distributions on the powder bed surface. This allows for a detailed analysis of the thermal patterns associated with different process conditions. The VGG-16 network underwent iterative training using a binary cross-entropy cost function, Adam optimizer, and specific hyperparameters. The network demonstrated exceptional performance, with an accuracy of 99.1% and an F1 score of 97.2% during the training phase with artificially induced defects. Gradient-weighted Class Activation Mapping (Grad-CAM) was used to visualize and interpret the model’s predictions, highlighting areas of importance related to curling defects. Finally, the use of a VGG16 CNN architecture achieves an average curling failure detection accuracy of 98.54%.
In another study, Ogunsanya et al. [135], presented an innovative approach to improving the inkjet 3D printing (IJP) process through the application of image analysis and machine learning. The study focused on addressing the variability in droplet formation during the printing process, which can significantly impact the final product quality. The research introduces a novel vision-based technique for in-situ monitoring of droplet formation. A drop watcher camera is utilized to capture a sequence of videos from which droplet attributes such as size, velocity, aspect ratio, and presence of satellites are analyzed. The study employed an ML model, specifically a backpropagation neural network (BPNN), to classify droplets into distinct modes based on their observed attributes. The BPNN demonstrated a high classification accuracy of 90%, indicating the model’s effectiveness in identifying droplet formation patterns.
Lu et al. [136] developed a DL-based real-time defect detection and closed-loop control system for AM processing of carbon fiber reinforced polymer (CFRP) composites (Fig. 6). They developed a robot-based AM system equipped with an integrated DL model for in-situ defect detection. Evaluating the performance of different deep learning algorithms (Faster R-CNN, SSD, and YOLOv4) in detecting CFRP defects, specifically misalignments and abrasions, YOLOv4 stands out for its optimal balance of detection accuracy and efficiency. The severity of the defects can be quantified using the DL-based model combined with geometric analysis. The system used real-time imaging to identify defects and automatically adjust process parameters (layer thickness, filament feed rate, printing speed, and path design) to mitigate or eliminate these defects.

The software architecture of the robot-based AM system within the work of Lu et al. [136]
Smart manufacturing
The fourth industrial revolution, known as Industry 4.0, is characterized by the integration of advanced manufacturing techniques with intelligent technologies to create smart factories [137]. These factories are capable of autonomously managing manufacturing processes, optimizing production workflows, and customizing products on demand through the digital interconnection of machines, systems, and processes. This interconnectedness facilitates enhanced real-time data exchange and decision-making, which is crucial for achieving the efficiency and adaptability required in modern manufacturing environments.
In the context of polymer AM, the evolution towards smart manufacturing is the culmination of advancements in design optimization, process parameter control, and quality assurance—all of which are heavily influenced by ML techniques. The previous sections have demonstrated how ML contributes to optimizing the design of AMed components, fine-tuning process parameters for improved material properties, and enhancing fault detection and quality control systems. These applications are foundational to the development of smart manufacturing systems, where ML enables a higher level of automation and precision.
ML techniques play a pivotal role in smart manufacturing by enabling predictive maintenance, adaptive process control, and real-time quality monitoring. For instance, the integration of ML with in-situ monitoring technologies allows for continuous assessment of AM processes, enabling immediate adjustments to process parameters based on real-time data. This capability is essential for maintaining the consistency and quality of AMed products, particularly when dealing with complex geometries and material compositions that are typical in polymer AM.
Moreover, ML-driven cost estimation models are crucial in optimizing resource allocation and financial planning within cybermanufacturing frameworks. For example, Chan et al. [138] explored an ML framework for cost estimation in the context of additive manufacturing, employing data analytics within a cybermanufacturing system. This system integrates manufacturing software and hardware tools via an information infrastructure, accessible as services in cyberspace. In this framework, the manufacturing cost of new jobs is predicted by comparing it with similar past jobs. ML algorithms, including Dynamic Clustering, Least Absolute Shrinkage and Selection Operator (LASSO), and Elastic Net Regression (ENR), are applied to feature vectors representing job characteristics to estimate costs effectively. This approach enables more accurate financial planning and resource allocation, which are critical for maintaining competitiveness in a rapidly evolving manufacturing landscape.
As smart manufacturing systems become increasingly reliant on interconnected networks and cyber-physical systems, ensuring the security of AM operations is paramount. ML techniques such as K-Nearest Neighbors (KNN), Random Forest (RF), and Decision Trees (DT) are employed to detect and mitigate cyber-physical attacks and intrusions. These techniques are vital for safeguarding the integrity of manufacturing infrastructures, preventing disruptions that could compromise product quality or lead to significant financial losses.
Despite the significant advancements in applying ML to smart manufacturing, several challenges remain. Issues such as data quality, model interpretability, and the need for multidisciplinary expertise must be addressed to fully realize the potential of ML in this domain. Future research should focus on enhancing the integration between ML and AM technologies, particularly in developing standards and fostering cross-disciplinary collaboration. This will be crucial for driving innovation in manufacturing processes, materials, and design strategies within the Industry 4.0 framework. The following section will explore some of these critical challenges in greater detail, including the difficulties in data acquisition, managing computational costs, and the complexities of model validation and standardization.
Challenges associated with using ML in AM
This section discusses the primary challenges related to the application of ML models in additive manufacturing, with a focus on polymer AM. The challenges addressed include overfitting and underfitting, data acquisition techniques, dataset size, computational cost, standardization, and the integration of physics-informed models.
Overfitting and underfitting
Poor predictive performance by ML models is often a result of overfitting or underfitting [12]. Overfitting occurs when a model learns the specific details and noise in the training data to an extent that hinders its performance on new, unseen data. This is particularly problematic in AM, where the variability in process conditions and material properties can lead to a model that performs well on a specific dataset but fails to generalize to broader applications. For instance, an overfitted model might accurately predict the mechanical properties of parts produced under controlled conditions but could fail when applied to a different batch of materials or slightly altered process parameters. Conversely, underfitting occurs when a model is too simplistic to capture the underlying patterns in the data. In polymer AM, this might happen if the model fails to account for the complex relationships between multiple process parameters, such as temperature, layer thickness, and cooling rates, leading to inaccurate predictions across both the training and test datasets. Underfitting results in a model that does not adequately capture the intricate details of the AM process, leading to suboptimal recommendations for process adjustments.
To mitigate these issues, cross-validation is frequently employed as a method to assess the model’s generalization capabilities by evaluating its performance on multiple subsets of the data. Regularization techniques, which involve adding a penalty to the model’s cost function, are also commonly used to prevent overfitting by discouraging the model from becoming too complex. In the context of polymer AM, regularization can be particularly useful in ensuring that the model remains generalizable across different production runs with varying materials and process conditions.
Feature selection and engineering are other critical strategies in combating overfitting in polymer AM. Given the multitude of process parameters that influence the quality of the final parts, careful selection of the most relevant features is essential. For example, instead of using raw temperature data, engineered features such as average layer temperature or thermal gradient could be more informative and less prone to capturing irrelevant noise. This targeted approach helps the model focus on the most significant factors affecting part quality, thereby improving its predictive accuracy and robustness [28].
Data acquisition techniques
The performance of ML algorithms in polymer AM is heavily dependent on the quality and reliability of the data collected from various sensors during the manufacturing process. Effective data acquisition techniques are therefore critical to ensure that the data fed into the ML models offers valuable insights and accurately represents the process conditions [117].
In polymer AM, sensors are deployed to monitor key parameters such as temperature, pressure, material flow, and surface quality in real-time. However, each in-situ monitoring method comes with its own set of limitations, which can affect the quality of the data collected. For instance, thermal imaging sensors may suffer from accuracy issues due to emissivity variations in different polymer materials, while optical coherence tomography may struggle with capturing high-resolution data at the speed required for real-time monitoring. These limitations highlight the importance of selecting the most appropriate sensors based on a solid understanding of the specific characteristics that need to be captured for the ML model to be effective.
Moreover, the complexity of polymer AM processes demands that sensors not only capture the data accurately but also at a resolution and frequency that aligns with the rapid pace of the manufacturing process. This requires careful consideration of the trade-offs between sensor performance, data fidelity, and the practical constraints of integrating these sensors into the manufacturing line [139,140,141]. For instance, while high-resolution sensors may offer more detailed data, they can also generate large volumes of data that require substantial computational resources to process. Consequently, there is a need for advanced image processing techniques and data reduction strategies that can extract meaningful features from raw sensor data without compromising the integrity of the information.
Dataset size
One of the significant challenges in developing ML models for polymer AM is acquiring a sufficiently large and diverse dataset. The size and quality of the dataset are critical factors that directly impact the performance of the ML model, particularly in complex and variable processes such as AM. In polymer AM, the high costs associated with collecting extensive training data often limit the availability of large datasets. For instance, gathering data from in-situ monitoring systems across multiple production runs, with varying materials and process parameters, can be prohibitively expensive. This challenge is compounded by the fact that the effectiveness of an ML model is often proportional to the size of the dataset, particularly when the model must learn from a large number of input features [127].
To address the challenge of limited datasets, generative models, such as autoencoders, can be employed for data augmentation [12, 142, 143]. These techniques artificially enlarge the dataset by generating new data points that closely resemble the original training data. For example, a variational autoencoder (VAE) can be used to create synthetic data that mimics the statistical properties of the real dataset, thereby enhancing the diversity and volume of training data available for model development [144]. However, excessive reliance on data augmentation poses risks, such as overfitting, where the ML model may become too attuned to the augmented data and fail to generalize well to real-world scenarios. It is crucial that the augmented data accurately reflects the variability and complexity of the actual manufacturing process, ensuring that the ML model remains robust and reliable. Ultimately, while data augmentation offers a valuable tool for addressing the challenge of limited dataset sizes, it must be used judiciously, with careful consideration of its potential impact on model performance. Complementary strategies, such as active learning and transfer learning, may also be employed to make the most of the available data while minimizing the risk of overfitting.
Computational cost
While data-driven numerical simulations employing ML approaches are often more computationally efficient than traditional physics-based simulations, training large datasets in the context of polymer AM can still be computationally intensive and time-consuming. This challenge is particularly evident during in-situ monitoring, a critical phase in the application of ML to AM, where immediate, real-time data acquisition and analysis are required.
In polymer AM, in-situ monitoring includes various tasks such as layer thickness measurement [145], powder bed quality assessment [146], temperature distribution monitoring [147], part geometry measurement [148], and atmosphere composition monitoring [146]. For instance, real-time monitoring of each layer’s thickness is essential for ensuring uniformity and adherence to design specifications. However, processing high-resolution images or sensor data for each layer can significantly increase computational costs. This is exacerbated when high-frequency data collection is necessary to capture rapid changes in the manufacturing environment.
To address the high computational costs associated with real-time data processing, one potential solution is to integrate domain knowledge and physical laws into the ML models [149]. By incorporating these principles, the complexity of the models can be reduced, which in turn decreases the time and computational resources required for training. For example, leveraging known relationships between temperature gradients and material properties can help streamline the data processing pipeline, enabling more efficient feature extraction and model training.
Additionally, techniques such as model simplification, where less complex models are used without significantly compromising accuracy, and the use of advanced algorithms that are optimized for speed and efficiency, can further mitigate computational costs. For example, employing lightweight neural network architectures or optimizing existing algorithms to take advantage of parallel processing capabilities can enhance computational efficiency.
Furthermore, the use of cloud computing and distributed computing resources offers another avenue for managing computational costs. By distributing the computational load across multiple servers or using scalable cloud-based solutions, the time required for training large datasets can be significantly reduced, making real-time analysis more feasible.
Standardization
A significant obstacle in the effective application of ML within polymer AM is the lack of standardization across various aspects of the field. This encompasses material properties, design principles, manufacturing processes, post-processing procedures, testing methods, and quality assurance measures. The absence of standardized practices impedes the full realization of ML’s potential, as it hinders the creation of a cohesive framework necessary for the sharing and validation of ML models within the research community. Despite the growing number of researchers working on novel materials and AM methods, there is a notable lack of a unified, easily accessible database that includes a comprehensive range of materials, printing methods, and associated data. Furthermore, although numerous criteria are used to evaluate the quality of AM-produced parts, there is a conspicuous absence of formally established measurement standards for such assessments [127]. This lack of standardization poses significant challenges for the integration of ML into AM, as consistent, high-quality data is a prerequisite for effective ML model training and deployment. To effectively implement ML in polymer AM, standardization is essential in several key areas:
Data standardization
ML algorithms require large volumes of data for training and validation. Standardization of data formats, quality metrics, and collection methodologies across AM processes ensures that the data used is consistent, reliable, and suitable for ML applications. This encompasses data from sensors, process parameters, material properties, and post-process evaluations. For example, standardizing the way temperature data is recorded across different AM systems can facilitate more accurate comparisons and model training, thereby enhancing the robustness of ML applications in AM.
Process consistency
Standardizing AM processes is critical for generating consistent datasets that ML algorithms can effectively learn from. This includes standardizing machine settings, layer deposition techniques, and post-processing methods. Process consistency leads to more predictable outcomes, which are essential for the development of reliable ML models. In polymer AM, for instance, standardizing the extrusion temperature and print speed across different machines can help ensure that the data generated is comparable, thereby improving the model’s ability to generalize across different AM systems.
Quality assurance and control
ML can be leveraged to predict and optimize the quality of AM-produced parts, but this requires standardized criteria for quality assurance and control. Standards for defect detection, dimensional accuracy, and material properties are crucial for training ML models to distinguish between acceptable and unacceptable outcomes. Additionally, a standardized vocabulary for labeling categorical data, such as defect types, is essential for creating training datasets that are both consistent and comprehensive. This standardization facilitates the development of ML models that are better equipped to ensure consistent part quality across different production environments.
Interoperability
For ML applications to be broadly effective across different AM platforms and technologies, standardization of machine interfaces, communication protocols, and data exchange formats is necessary. Interoperability ensures that ML algorithms can be deployed across various AM systems without requiring extensive customization. In polymer AM, this might involve standardizing the communication protocols between different AM machines and the ML systems that monitor and control them, thereby enabling seamless integration and data exchange.
Safety and compliance
ML models can play a crucial role in ensuring that AM processes and products meet safety and regulatory standards. Standardizing safety requirements and compliance criteria allows ML algorithms to be trained to monitor adherence to these standards throughout the manufacturing process. This is particularly important in regulated industries, such as medical device manufacturing, where ensuring compliance with safety standards is not only critical for product quality but also for regulatory approval.
Physics-informed models
Conventional ML methods typically uncover statistical correlations between input and output data, often without considering the underlying physical laws and principles governing the processes involved. This can result in models that lack a physical basis for the conclusions they reach, limiting their generalizability and applicability across different conditions and materials. For instance, in PolyJet technology, ML models may use droplet deposition patterns as inputs without fully accounting for the complex fluid dynamics and physical relationships that govern droplet formation, distribution, and solidification. Such an approach may overlook critical factors, including the viscosity of the photopolymer material, the droplet ejection mechanism, and environmental conditions, all of which are essential for accurately predicting the final product’s resolution and mechanical properties.
This disconnect between data-driven models and physical reality can lead to ML models that perform well under specific conditions but fail to generalize across different materials or adapt to variations in printing parameters. For example, a model trained on a specific polymer might predict mechanical properties effectively for that material but could struggle when applied to a polymer with different viscosity or curing characteristics. This limitation underscores the need for models that not only capture statistical correlations but also respect the fundamental principles of polymer behavior and the dynamics inherent in the AM process, such as the jetting dynamics in PolyJet printing [150].
To address these limitations, an emerging approach is to integrate ML models with physics-informed models and experimental data. Physics-informed models incorporate physical laws and constraints directly into the ML framework, enabling the model to make predictions that are not only statistically robust but also physically plausible. By embedding the principles of mechanics, thermodynamics, fluid dynamics, and material science into the ML model, it becomes possible to more accurately predict outcomes across a wider range of conditions and materials [127].
In polymer AM, physics-informed models can bridge the gap between the capabilities of ML models and the fundamental principles governing AM processes. For example, in the context of FFF, incorporating the principles of heat transfer and material flow into the ML model can significantly improve its ability to predict warping, layer adhesion, and mechanical properties of the printed parts under varying process conditions [151]. Similarly, in material jetting, a physics-informed ML model might include fluid dynamics equations that account for droplet coalescence and solidification, leading to more accurate predictions of surface finish and dimensional accuracy [152].
However, the integration of physical modeling with ML is not without challenges. Physical models often rely on assumptions, simplifications, and approximations that can limit their accuracy. For example, a model that assumes a constant material viscosity might fail to account for temperature-dependent changes in viscosity, leading to inaccuracies in the predictions. Therefore, while physics-informed models offer a promising pathway to enhance the robustness and generalizability of ML in AM, careful consideration must be given to the limitations and assumptions of the physical models employed.
Summary and conclusion
Machine Learning has been recognized as a viable solution to address crucial challenges within Additive Manufacturing. It has significantly impacted various aspects of AM, such as Design, defect detection, process monitoring, modeling, and control. Therefore, ML holds immense potential to evolve into a pivotal solution for the entire domain of AM, offering advancements in optimization, efficiency, and quality control throughout the manufacturing process.
This review explores the integration of Machine Learning into Additive Manufacturing across various domains. It provides an overview of different ML algorithms currently employed and how they relate to enhancing the different sectors of the AM process including AM design, process parameters optimization, defect detection, and smart manufacturing. Finally, this review addresses several challenges such as acquiring datasets, overfitting, and standardization that hinder the widespread implementation of ML in AM currently.
Data availability
The authors declare that the data and the materials of this study are available within the article.
Abbreviations
- AM:
-
Additive Manufacturing
- ML:
-
Machine Learning
- BJT:
-
Binder Jetting
- DED:
-
Directed Energy Deposition
- MEX:
-
Material Extrusion
- MJT:
-
Material Jetting
- PBF:
-
Powder Bed Fusion
- SHL:
-
Sheet Lamination
- VPP:
-
Vat Photopolymerization
- ISO:
-
International Organization for Standardization
- ASTM:
-
American Society for Testing and Materials
- FFF:
-
Fused Filament Fabrication
- DIW:
-
Direct Ink Writing
- SLA:
-
Stereolithography
- DLP:
-
Digital Light Processing
- CLIP:
-
Continuous Liquid Interface Production
- 2PP:
-
Two-photon Polymerization
- SLS:
-
Selective Laser Sintering
- MJF:
-
Multi-Jet Fusion
- DOD:
-
Drop-On-Demand
- NPJ:
-
Nanoparticle Jetting
- LPD:
-
Laser Polymer Deposition
- LOM:
-
Laminated Object Manufacturing
- SDL:
-
Selective Deposition Lamination
- cDLP:
-
Continuous Digital Light Processing
- TPU:
-
Thermoplastic Polyurethane
- FDM:
-
Fused Deposition Modeling
- PA-11:
-
Polyamide 11
- PA-12:
-
Polyamide 12
- PS:
-
Polystyrene
- FEA:
-
Finite Element Analysis
- CNN:
-
Convolutional Neural Networks
- GD:
-
Generative Design
- TO:
-
Topology Optimization
- BEGAN:
-
Boundary Equilibrium Generative Adversarial Networks
- FGM:
-
Functionally Graded Material
- DfAM:
-
Design for Additive Manufacturing
- ANOVA:
-
Analysis of Variance
- R²:
-
Coefficient of Determination
- RE:
-
Relative Error
- RMSE:
-
Root Mean Square Error
- PCA:
-
Principal Component Analysis
- SVM:
-
Support Vector Machines
- SVR:
-
Support Vector Regression
- DNN:
-
Deep Neural Network
- RF:
-
Random Forest
- BN:
-
Bayesian Networks
- DT:
-
Decision Trees
- GAN:
-
Generative Adversarial Networks
- RL:
-
Reinforcement Learning
- dAgger:
-
Dataset Aggregation
- DQN:
-
Deep Q Network
- SARSA:
-
State-Action-Reward-State-Action
- LRP:
-
Layer-wise Relevance Propagation
- IJP:
-
Inkjet 3D Printing
- BPNN:
-
Backpropagation Neural Network
- EBB:
-
Extrusion-Based Bioprinting
- CFRP:
-
Carbon Fiber Reinforced Polymer
- IoT:
-
Internet of Things
- LASSO:
-
Least Absolute Shrinkage and Selection Operator
- ENR:
-
Elastic Net Regression
- KNN:
-
K-Nearest Neighbors
- PIML:
-
Physics-Informed Machine Learning
- VAE:
-
Variational Autoencoder
- SHL:
-
Sheet Lamination
- X-ray/CT:
-
X-ray/Computed Tomography
- FFF:
-
Fused Filament Fabrication
- RNN:
-
Recurrent Neural Network
- DLP:
-
Digital Light Processing
References
Dilberoglu UM, Gharehpapagh B, Yaman U, Dolen M (2017) The role of additive manufacturing in the era of industry 4.0. Procedia Manuf 11:545–554
Saleh Alghamdi S, John S, Roy Choudhury N, Dutta NK (Feb 28 2021) Additive Manufacturing of Polymer materials: Progress, Promise and challenges. Polym (Basel) 13(5). https://doi.org/10.3390/polym13050753
Bikas H, Stavropoulos P, Chryssolouris G (2015) Additive manufacturing methods and modelling approaches: a critical review. Int J Adv Manuf Technol 83:1–4. https://doi.org/10.1007/s00170-015-7576-2
Sun C, Wang Y, McMurtrey MD, Jerred ND, Liou F, Li J (2021) Additive manufacturing for energy: a review. Appl Energy 282. https://doi.org/10.1016/j.apenergy.2020.116041
Ngo TD, Kashani A, Imbalzano G, Nguyen KTQ, Hui D (2018) Additive manufacturing (3D printing): a review of materials, methods, applications and challenges. Compos Part B: Eng 143:172–196. https://doi.org/10.1016/j.compositesb.2018.02.012
Leung Y-S, Kwok T-H, Li X, Yang Y, Wang CCL, Chen Y (2019) Challenges and Status on Design and Computation for emerging additive Manufacturing technologies. J Comput Inf Sci Eng 19(2). https://doi.org/10.1115/1.4041913
Revilla-León M, Özcan M (2017) Additive Manufacturing technologies used for 3D Metal Printing in Dentistry. Curr Oral Health Rep 4(3):201–208. https://doi.org/10.1007/s40496-017-0152-0
Jiang J, Xu X, Stringer J (2018) Support structures for additive manufacturing: a review. J Manuf Mater Process 2(4):64
Jiang J, Xiong Y, Zhang Z, Rosen DW (2020) Machine learning integrated design for additive manufacturing. J Intell Manuf 33(4):1073–1086. https://doi.org/10.1007/s10845-020-01715-6
Xames MD, Torsha FK, Sarwar F (2022) A systematic literature review on recent trends of machine learning applications in additive manufacturing. J Intell Manuf 34(6):2529–2555. https://doi.org/10.1007/s10845-022-01957-6
Raza A, Deen KM, Jaafreh R, Hamad K, Haider A, Haider W (2022) Incorporation of machine learning in additive manufacturing: a review. Int J Adv Manuf Technol 122:3–4. https://doi.org/10.1007/s00170-022-09916-4
Qi X, Chen G, Li Y, Cheng X, Li C Applying Neural-Network-Based Machine Learning to Additive Manufacturing: Current Applications, Challenges, and Future Perspectives, Engineering, vol. 5, no. 4, pp. 721–729, 2019/08/01/ 2019, doi: https: https://doi.org/10.1016/j.eng.2019.04.012
Singh S, Ramakrishna S, Singh R (2017) Material issues in additive manufacturing: a review. J Manuf Process 25:185–200. https://doi.org/10.1016/j.jmapro.2016.11.006
Oh S, Jung Y, Kim S, Lee I, Kang N (2019) Deep generative design: integration of topology optimization and generative models. J Mech Des 141(11):111405
Zhao Y, Ren H, Zhang Y, Wang C, Long Y Layer-wise multi-defect detection for laser powder bed fusion using deep learning algorithm with visual explanation. Opt Laser Technol, 174, p. 110648, 2024/07/01/ 2024,https://doi.org/10.1016/j.optlastec.2024.110648
Szost BA et al (2016) A comparative study of additive manufacturing techniques: residual stress and microstructural analysis of CLAD and WAAM printed Ti–6Al–4V components. Mater Design 89:559–567
Srivastava S, Garg RK, Sharma VS, Sachdeva A (2021) Measurement and mitigation of residual stress in wire-arc additive manufacturing: a review of macro-scale continuum modelling approach. Arch Comput Methods Eng 28(5):3491–3515
Hegab HA (2016) Design for additive manufacturing of composite materials and potential alloys: a review. Manuf Rev 3. https://doi.org/10.1051/mfreview/2016010
Mohamed OA, Masood SH, Bhowmik JL Optimization of fused deposition modeling process parameters: a review of current research and future prospects. Adv Manuf, 3, 1, pp. 42–53, 2015/03/01 2015, https://doi.org/10.1007/s40436-014-0097-7
González-Henríquez CM, Sarabia-Vallejos MA, Rodríguez Hernandez J (2019) Antimicrobial polymers for additive manufacturing. Int J Mol Sci 20(5):1210
Kulkarni P, Marsan A, Dutta D (2000) A review of process planning techniques in layered manufacturing. Rapid Prototyp J 6(1):18–35. https://doi.org/10.1108/13552540010309859
Ahmadifar M, Benfriha K, Shirinbayan M, Tcharkhtchi A (2021) Additive Manufacturing of Polymer-based composites using fused filament fabrication (FFF): a review. Appl Compos Mater 28(5):1335–1380
Dantas F, Couling K, Gibbons GJ Long-fibre reinforced polymer composites by 3D printing: influence of nature of reinforcement and processing parameters on mechanical performance, Functional Composite Materials, vol. 1, no. 1, p. 7, 2020/09/21 2020, https://doi.org/10.1186/s42252-020-00010-0
S. International Organization for and, International A ISO/ASTM 52900: 2021 Additive manufacturing -- General principles -- Terminology, 2021 2021. [Online]. Available: https: http://www.iso.org/standard/74541.html
Herzberger J, Sirrine JM, Williams CB, Long TE (2019) Polymer Design for 3D Printing elastomers: recent advances in structure, Properties, and Printing. Prog Polym Sci 97. https://doi.org/10.1016/j.progpolymsci.2019.101144
Qin J et al (2022) Research and application of machine learning for additive manufacturing. Additive Manuf 52. https://doi.org/10.1016/j.addma.2022.102691
Zhu Z, Dhokia VG, Nassehi A, Newman ST A review of hybrid manufacturing processes – state of the art and future perspectives. Int J Comput Integr Manuf, 26, 7, pp. 596–615, 2013/07/01 2013, https://doi.org/10.1080/0951192X.2012.749530
Nasrin T, Pourkamali-Anaraki F, Peterson AM (2023) Application of machine learning in polymer additive manufacturing: a review. J Polym Sci. https://doi.org/10.1002/pol.20230649
Schmidleithner C, Kalaskar DM (2018) Stereolithography, IntechOpen
Jacobs PF (1995) Stereolithography and other RP&M technologies: from rapid prototyping to rapid tooling. Society of Manufacturing Engineers
Huang J, Qin Q, Wang J (2020) A Review of Stereolithography: Processes and Systems, Processes, vol. 8, no. 9, https://doi.org/10.3390/pr8091138
Zirak N, Shirinbayan M, Benfriha K, Deligant M, Tcharkhtchi A (2022) Stereolithography of (meth) acrylate-based photocurable resin: thermal and mechanical properties. J Appl Polym Sci 139(22):52248
Ligon SC, Liska R, Stampfl J, Gurr M, Mülhaupt R Polymers for 3D Printing and customized Additive Manufacturing. Chem Rev, 117, 15, pp. 10212–10290, 2017/08/09 2017, https://doi.org/10.1021/acs.chemrev.7b00074
Rodrı´guez JF, Thomas JP, Renaud JE (2003) Design of fused-deposition ABS components for stiffness and strength. J Mech Des 125(3):545–551. https://doi.org/10.1115/1.1582499
Boumedine A, Benfriha K, Ahmadifar M, Lecheb S, M. SHIRINBAYAN, and, Tcharkhtchi A (2021) Geometric accuracy and mechanical behavior of polymer-based Composite Curved tubes produced by Fused Filament Fabrication (FFF),
Benfriha K, Ahmadifar M, Shirinbayan M, Tcharkhtchi A (2021) Effect of process parameters on thermal and mechanical properties of polymer-based composites using fused filament fabrication, Polymer Composites, vol. 42, no. 11, pp. 6025–6037, doi: https: https://doi.org/10.1002/pc.26282
Schmid M, Amado A, Wegener K (2015) Polymer powders for selective laser sintering (SLS), in AIP Conference proceedings, vol. 1664, no. 1: AIP Publishing
Awad A, Fina F, Goyanes A, Gaisford S, Basit AW (Aug 30 2020) 3D printing: principles and pharmaceutical applications of selective laser sintering. Int J Pharm 586:119594. https://doi.org/10.1016/j.ijpharm.2020.119594
Zheng Y, Zhang W, Baca Lopez DM, Ahmad R (Jun 12 2021) Scientometric Analysis and Systematic Review of Multi-material Additive Manufacturing of Polymers. Polym (Basel) 13(12). https://doi.org/10.3390/polym13121957
Quan Z et al (2015) Additive manufacturing of multi-directional preforms for composites: opportunities and challenges. Mater Today 18(9):503–512. https://doi.org/10.1016/j.mattod.2015.05.001
Nohut S, Schwentenwein M (2022) Vat photopolymerization Additive Manufacturing of functionally graded materials: a review. J Manuf Mater Process 6(1). https://doi.org/10.3390/jmmp6010017
Kirihara S (2021) Stereolithographic additive manufacturing of ceramic components with functionally modulated structures. Open Ceram 5. https://doi.org/10.1016/j.oceram.2021.100068
Müller FJ, Fenton OS (2022) Additive Manufacturing approaches toward the fabrication of Biomaterials. Adv Mater Interfaces 9(7). https://doi.org/10.1002/admi.202100670
Wu H et al (2020) Recent developments in polymers/polymer nanocomposites for additive manufacturing. Prog Mater Sci 111. https://doi.org/10.1016/j.pmatsci.2020.100638
Yaragatti N, Patnaik A (2021) A review on additive manufacturing of polymers composites. Mater Today: Proc 44:4150–4157. https://doi.org/10.1016/j.matpr.2020.10.490
Zheng Y (2019) Fabrication on bioinspired surfaces. in Bioinspired Des Mater Surf, pp. 99–146
Abbasi N, Hamlet S, Love RM, Nguyen N-T (2020) Porous scaffolds for bone regeneration. J Science: Adv Mater Devices 5(1):1–9. https://doi.org/10.1016/j.jsamd.2020.01.007
Alifui-Segbaya F (2019) Biomedical photopolymers in 3D printing. Rapid Prototyp J 26(2):437–444. https://doi.org/10.1108/rpj-10-2018-0268
Carve M, Wlodkowic D (2018) 3D-Printed Chips: Compatibility of Additive Manufacturing Photopolymeric Substrata with Biological Applications, Micromachines, vol. 9, no. 2, https://doi.org/10.3390/mi9020091
Capuana E, Lopresti F, Ceraulo M, La Carrubba V (Mar 14 2022) Poly-l-Lactic acid (PLLA)-Based biomaterials for Regenerative Medicine: a review on Processing and Applications. Polym (Basel) 14(6). https://doi.org/10.3390/polym14061153
Derby B (Nov 16 2012) Printing and prototyping of tissues and scaffolds. Science 338(6109):921–926. https://doi.org/10.1126/science.1226340
Garcia A, Cabanas MV, Pena J, Sanchez-Salcedo S (2021) Design of 3D Scaffolds for Hard Tissue Engineering: From Apatites to Silicon Mesoporous Materials, Pharmaceutics, vol. 13, no. 11, Nov 22 https://doi.org/10.3390/pharmaceutics13111981
Ionov L (2018) 4D Biofabrication: Materials, Methods, and Applications, Adv Healthc Mater, vol. 7, no. 17, p. e1800412, Sep https://doi.org/10.1002/adhm.201800412
Javaid M, Haleem A (Jul-Sep 2019) Current status and applications of additive manufacturing in dentistry: a literature-based review. J Oral Biol Craniofac Res 9(3):179–185. https://doi.org/10.1016/j.jobcr.2019.04.004
Piedra-Cascon W, Krishnamurthy VR, Att W, Revilla-Leon M (Jun 2021) 3D printing parameters, supporting structures, slicing, and post-processing procedures of vat-polymerization additive manufacturing technologies: a narrative review. J Dent 109:103630. https://doi.org/10.1016/j.jdent.2021.103630
Choi J-W, Kim H-C, Wicker R (2011) Multi-material stereolithography. J Mater Process Technol 211(3):318–328. https://doi.org/10.1016/j.jmatprotec.2010.10.003
Goh GD, Yap YL, Agarwala S, Yeong WY (2019) Recent progress in Additive Manufacturing of Fiber Reinforced Polymer Composite. Adv Mater Technol 4(1). https://doi.org/10.1002/admt.201800271
K P, M. M, and, P SP (2020) Technologies in additive manufacturing for fiber reinforced composite materials: a review. Curr Opin Chem Eng 28:51–59. https://doi.org/10.1016/j.coche.2020.01.001
Niendorf K, Raeymaekers B (2021) Additive Manufacturing of Polymer Matrix Composite materials with Aligned or Organized Filler Material: a review. Adv Eng Mater 23(4). https://doi.org/10.1002/adem.202001002
Shaukat U, Rossegger E, Schlogl S (Jun 16 2022) A review of multi-material 3D Printing of functional materials via vat photopolymerization. Polym (Basel) 14(12). https://doi.org/10.3390/polym14122449
Wang Y, Zhou Y, Lin L, Corker J, Fan M (2020) Overview of 3D additive manufacturing (AM) and corresponding AM composites. Compos Part A: Appl Sci Manufac 139. https://doi.org/10.1016/j.compositesa.2020.106114
Steuben J, Van Bossuyt DL, Turner C (2015) Design for fused filament fabrication additive manufacturing, in International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, vol. 57113: American Society of Mechanical Engineers, p. V004T05A050
Agrawal A, Choudhary A (2016) Perspective: materials informatics and big data: realization of the fourth paradigm of science in materials science. APL Mater 4(5). https://doi.org/10.1063/1.4946894
Liu G, Xiong Y, Rosen DW (2022) Multidisciplinary design optimization in design for additive manufacturing. J Comput Des Eng 9(1):128–143. https://doi.org/10.1093/jcde/qwab073
Kouraytem N, Li X, Tan W, Kappes B, Spear AD (2021) Modeling process–structure–property relationships in metal additive manufacturing: a review on physics-driven versus data-driven approaches. J Physics: Mater 4(3):032002
Kallel A et al (2019) Study of Bonding formation between the filaments of PLA in FFF process. Int Polym Proc 34(4):434–444. https://doi.org/10.3139/217.3718
Ahmadifar M, Benfriha K, Shirinbayan M (2023) Thermal, Tensile and Fatigue Behaviors of the PA6, Short Carbon Fiber-Reinforced PA6, and Continuous Glass Fiber-Reinforced PA6 Materials in Fused Filament Fabrication (FFF), Polymers, vol. 15, no. 3, p. 507, [Online]. Available: https: http://www.mdpi.com/2073-4360/15/3/507
Kelly BE, Bhattacharya I, Heidari H, Shusteff M, Spadaccini CM, Taylor HK Volumetric additive manufacturing via tomographic reconstruction, Science, vol. 363, no. 6431, pp. 1075–1079, Mar 8 2019, https://doi.org/10.1126/science.aau7114
De Beer MP, Van Der Laan HL, Cole MA, Whelan RJ, Burns MA, Scott TF (2019) Rapid, continuous additive manufacturing by volumetric polymerization inhibition patterning. Sci Adv 5(1):eaau8723
Isa MA, Lazoglu I (2019) Five-axis additive manufacturing of freeform models through buildup of transition layers. J Manuf Syst 50:69–80
Shakeria Z, Benfriha K, Zirak N, Shirinbayan M (2021) Optimization of FFF Processing parameters to improve geometrical accuracy and mechanical behavior of polyamide 6 using Grey Relational Analysis (GRA),
Solomon IJ, Sevvel P, Gunasekaran J (2021) A review on the various processing parameters in FDM. Mater Today: Proc 37:509–514. https://doi.org/10.1016/j.matpr.2020.05.484
Yuan S, Li S, Zhu J, Tang Y (2021) Additive manufacturing of polymeric composites from material processing to structural design. Compos Part B: Eng 219. https://doi.org/10.1016/j.compositesb.2021.108903
Kaur G, Singari RM, Kumar H (2022) A review of fused filament fabrication (FFF): process parameters and their impact on the tribological behavior of polymers (ABS). Mater Today: Proc 51:854–860
Mutyala RS et al (2022) Effect of FFF process parameters on mechanical strength of CFR-PEEK outputs. Int J Interact Des Manuf (IJIDeM) 16(4):1385–1396
Pulipaka A, Gide KM, Beheshti A, Bagheri ZS (2023) Effect of 3D printing process parameters on surface and mechanical properties of FFF-printed PEEK. J Manuf Process 85:368–386
Guzzi EA, Tibbitt MW (2020) Additive Manufacturing of Precision Biomaterials, Adv Mater, vol. 32, no. 13, p. e1901994, Apr https://doi.org/10.1002/adma.201901994
Chen Y, Li W, Zhang C, Wu Z, Liu J (2020) Recent Developments of Biomaterials for Additive Manufacturing of Bone Scaffolds, Adv Healthc Mater, p. e2000724, Aug 2 https://doi.org/10.1002/adhm.202000724
Özen A, Abali BE, Völlmecke C, Gerstel J, Auhl D (2021) Exploring the role of manufacturing parameters on microstructure and mechanical properties in fused deposition modeling (FDM) using PETG. Appl Compos Mater 28(6):1799–1828
Chacón JM, Caminero MA, García-Plaza E, Núñez PJ (2017) Additive manufacturing of PLA structures using fused deposition modelling: Effect of process parameters on mechanical properties and their optimal selection. Mater Design 124:143–157. https://doi.org/10.1016/j.matdes.2017.03.065
Appuhamillage GA, Chartrain N, Meenakshisundaram V, Feller KD, Williams CB, Long TE (2019) 110th anniversary: vat photopolymerization-based Additive Manufacturing: current trends and future directions in materials design. Ind Eng Chem Res 58(33):15109–15118. https://doi.org/10.1021/acs.iecr.9b02679
Li L (2003) Modeling of bond formation in FDM process, in 31st NAMRC Conf.,(2003), pp. 613–620
Guessasma S, Belhabib S, Nouri H, Hassana OB (2016) Anisotropic damage inferred to 3D printed polymers using fused deposition modelling and subject to severe compression. Eur Polymer J 85:324–340
Khadilkar A, Wang J, Rai R (2019) Deep learning–based stress prediction for bottom-up SLA 3D printing process. Int J Adv Manuf Technol 102:5–8. https://doi.org/10.1007/s00170-019-03363-4
Ntintakis I, Stavroulakis GE, Sfakianakis G, Fiotodimitrakis N (2022) Utilizing Generative Design for Additive Manufacturing, in Recent Advances in Manufacturing Processes and Systems: Select Proceedings of RAM 2021: Springer, pp. 977–989
Gromat T, Gardan J, Saifouni O, Makke A, Recho N (2023) Generative design for additive manufacturing of polymeric auxetic materials produced by fused filament fabrication. Int J Interact Des Manuf (IJIDeM) 17(6):2943–2955
Li S, Yuan S, Zhu J, Zhang W, Zhang H, Li J Multidisciplinary topology optimization incorporating process-structure-property-performance relationship of additive manufacturing. Struct Multidisciplinary Optim, 63, 5, pp. 2141–2157, 2021/05/01 2021, https://doi.org/10.1007/s00158-021-02856-9
Barbieri L, Muzzupappa M (2022) Performance-driven engineering design approaches based on generative design and topology optimization tools: a comparative study. Appl Sci 12(4):2106
Baumann FW, Sekulla A, Hassler M, Himpel B, Pfeil M (2018) Trends of machine learning in additive manufacturing. Int J Rapid Manuf 7(4):310–336
Samuel AL Some studies in machine learning using the game of Checkers. IBM J Res Dev 3, 3, pp. 210–229, July 1959 1959.
Brion DA, Shen M, Pattinson SW (2022) Automated recognition and correction of warp deformation in extrusion additive manufacturing. Additive Manuf 56:102838
Nasrin T, Pourali M, Pourkamali-Anaraki F, Peterson AM Active learning for prediction of tensile properties for material extrusion additive manufacturing, Scientific Reports, vol. 13, no. 1, p. 11460, 2023/07/15 2023, https://doi.org/10.1038/s41598-023-38527-6
Jayasudha M, Elangovan M, Mahdal M, Priyadarshini J (2022) Accurate Estimation of Tensile Strength of 3D Printed Parts Using Machine Learning Algorithms, Processes, vol. 10, no. 6, p. 1158, [Online]. Available: https: http://www.mdpi.com/2227-9717/10/6/1158
Farhan Khan M et al (2021) Real-time defect detection in 3D printing using machine learning, Materials Today: Proceedings, vol. 42, pp. 521–528, /01/01/ 2021, doi: https: https://doi.org/10.1016/j.matpr.2020.10.482
Zhang Z, Fidan I, Allen M Detection of Material Extrusion In-Process Failures via Deep Learning, Inventions, vol. 5, no. 3, p. 25, 2020. [Online]. Available: https: http://www.mdpi.com/2411-5134/5/3/25
Mantecón R, Rufo-Martín C, Castellanos R, Diaz-Alvarez J (2022) Experimental assessment of thermal gradients and layout effects on the mechanical performance of components manufactured by fused deposition modeling. Rapid Prototyp J 28(8):1598–1608. https://doi.org/10.1108/RPJ-12-2021-0329
Zhang J, Meng F, Ferraris E Temperature gradient at the nozzle outlet in material extrusion additive manufacturing with thermoplastic filament. Additive Manuf, 73, p. 103660, 2023/07/05/ 2023, doi: https: https://doi.org/10.1016/j.addma.2023.103660
Wasmer K, Le-Quang T, Meylan B, Shevchik SA In situ Quality Monitoring in AM using Acoustic Emission: a reinforcement learning Approach. J Mater Eng Perform, 28, 2, pp. 666–672, 2019/02/01 2019, https://doi.org/10.1007/s11665-018-3690-2
Maloca PM et al 3D printing of the choroidal vessels and tumours based on optical coherence tomography, Acta Ophthalmologica, vol. 97, no. 2, pp. e313-e316, 2019, doi: https: https://doi.org/10.1111/aos.13637
Milo T, Somech A (2020) Automating Exploratory Data Analysis via Machine Learning: An Overview, presented at the Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, [Online]. Available: https://doi.org/10.1145/3318464.3383126
Cheung S, Elbadawi M, Awad A, Abdalla Y, Gaisford S, Basit A Human in the Loop: Accelerating Pharmaceutical SLS 3D Printing Through Active Machine Learning, Available at SSRN 4570617
Park HS, Nguyen DS, Le-Hong T, Van Tran X Machine learning-based optimization of process parameters in selective laser melting for biomedical applications. J Intell Manuf, 33, 6, pp. 1843–1858, 2022/08/01 2022, https://doi.org/10.1007/s10845-021-01773-4
Zhang M et al High cycle fatigue life prediction of laser additive manufactured stainless steel: a machine learning approach. Int J Fatigue, 128, p. 105194, 2019/11/01/ 2019, doi: https: https://doi.org/10.1016/j.ijfatigue.2019.105194
Cao L, Li J, Hu J, Liu H, Wu Y, Zhou Q Optimization of surface roughness and dimensional accuracy in LPBF additive manufacturing. Opt Laser Technol, 142, p. 107246, 2021/10/01/ 2021, doi: https: https://doi.org/10.1016/j.optlastec.2021.107246
Chen H et al Shape characterization and depth recognition of metal cracks based on laser infrared thermography and machine learning. Expert Syst Appl, 238, p. 122083, 2024/03/15/ 2024, doi: https: https://doi.org/10.1016/j.eswa.2023.122083
Gabbett C et al Quantitative analysis of printed nanostructured networks using high-resolution 3D FIB-SEM nanotomography, Nature Communications, vol. 15, no. 1, p. 278, 2024/01/04 2024, https://doi.org/10.1038/s41467-023-44450-1
Herzog T, Brandt M, Trinchi A, Sola A, Hagenlocher C, Molotnikov A (2024) Defect detection by multi-axis infrared process monitoring of laser beam directed energy deposition. Sci Rep 14(1):3861. https://doi.org/10.1038/s41598-024-53931-2. /02/16 2024
Peng J, Liu B, Li W, Liaw PK, Li J, Fang Q Data-driven investigation of microstructure and surface integrity in additively manufactured multi-principal-element alloys. J Alloys Compd, 937, p. 168431, 2023/03/15/ 2023, doi: https: https://doi.org/10.1016/j.jallcom.2022.168431
Zhou H, Wang X, Zhu R (2022) Feature selection based on mutual information with correlation coefficient. Appl Intell 52(5):5457–5474
Jordan MI, Mitchell TM (2015) Machine learning: Trends, perspectives, and prospects. Science 349(6245):255–260
Jiang J (2023) A survey of machine learning in additive manufacturing technologies. Int J Comput Integr Manuf 36(9):1258–1280. https://doi.org/10.1080/0951192x.2023.2177740
Agarwal R, Singh J, Gupta V (2022) Predicting the compressive strength of additively manufactured PLA-based orthopedic bone screws: a machine learning framework. Polym Compos 43(8):5663–5674
Izadgoshasb H, Kandiri A, Shakor P, Laghi V, Gasparini G (2021) Predicting compressive strength of 3D printed mortar in structural members using machine learning. Appl Sci 11(22):10826
Li Z, Zhang Z, Shi J, Wu D (2019) Prediction of surface roughness in extrusion-based additive manufacturing with machine learning. Robot Comput Integr Manuf 57:488–495. https://doi.org/10.1016/j.rcim.2019.01.004
Baturynska I Application of machine learning techniques to predict the Mechanical properties of Polyamide 2200 (PA12) in Additive Manufacturing, Applied Sciences, vol. 9, no. 6, p. 1060, 2019. [Online]. Available: https: http://www.mdpi.com/2076-3417/9/6/1060
Veeman D, Sudharsan S, Surendhar GJ, Shanmugam R, Guo L Machine learning model for predicting the hardness of additively manufactured acrylonitrile butadiene styrene. Mater Today Commun, 35, p. 106147, 2023/06/01/ 2023, doi: https: https://doi.org/10.1016/j.mtcomm.2023.106147
Goh GD, Sing SL, Yeong WY (2020) A review on machine learning in 3D printing: applications, potential, and challenges. Artif Intell Rev 54(1):63–94. https://doi.org/10.1007/s10462-020-09876-9
Dharmadhikari S, Menon N, Basak A (2023) A reinforcement learning approach for process parameter optimization in additive manufacturing. Additive Manuf 71:103556
Hansen N, Wang X, Su H (2022) Temporal difference learning for model predictive control, arXiv preprint arXiv: 2203.04955,
Wang X, Banthia N, Yoo D-Y (2024) Reinforcement bond performance in 3D concrete printing: explainable ensemble learning augmented by deep generative adversarial networks. Autom Constr 158:105164
Zimmerling C, Poppe C, Stein O, Kärger L Optimisation of manufacturing process parameters for variable component geometries using reinforcement learning. Mater Design, 214, p. 110423, 2022/02/01/ 2022, doi: https: https://doi.org/10.1016/j.matdes.2022.110423
Sbrugnera Sotomayor NA, Caiazzo F, Alfieri V (2021) Enhancing design for additive manufacturing workflow: optimization, design and simulation tools. Appl Sci 11(14):6628
Lee S, Zhang Z, Gu GX (2022) Generative machine learning algorithm for lattice structures with superior mechanical properties. Mater Horiz 9(3):952–960
Wang Y, Du W, Wang H, Zhao Y (2021) Intelligent Generation Method of Innovative Structures Based on Topology Optimization and Deep Learning, Materials, vol. 14, no. 24, p. 7680, [Online]. Available: https: http://www.mdpi.com/1996-1944/14/24/7680
Gu GX, Chen C-T, Richmond DJ, Buehler MJ (2018) Bioinspired hierarchical composite design using machine learning: simulation, additive manufacturing, and experiment. Mater Horiz 5(5):939–945. https://doi.org/10.1039/C8MH00653A
Shakeri Z, Benfriha K, Zirak N, Shirinbayan M Mechanical strength and shape accuracy optimization of polyamide FFF parts using grey relational analysis, Scientific Reports, vol. 12, no. 1, p. 13142, 2022/07/30 2022, https://doi.org/10.1038/s41598-022-17302-z
Parsazadeh M, Sharma S, Dahotre N (2023) Towards the next generation of machine learning models in additive manufacturing: a review of process dependent material evolution. Prog Mater Sci 135. https://doi.org/10.1016/j.pmatsci.2023.101102
Inyang-Udoh U, Mishra S A Learning-based Approach to Modeling and Control of Inkjet 3D Printing, in 2020 American Control Conference (ACC), 1–3 July 2020 2020, pp. 460–466, https://doi.org/10.23919/ACC45564.2020.9147313
Xu H et al Prediction of cell viability in dynamic optical projection stereolithography-based bioprinting using machine learning. J Intell Manuf, 33, 4, pp. 995–1005, 2022/04/01 2022, https://doi.org/10.1007/s10845-020-01708-5
Bonatti AF, Vozzi G, Chua CK, Maria CD (2022) A Deep Learning Quality Control Loop of the Extrusion-based Bioprinting Process, IJB, vol. 8, no. 4, https://doi.org/10.18063/ijb.v8i4.620
Zhang J, Wang P, Gao RX (2019) Deep learning-based tensile strength prediction in fused deposition modeling. Comput Ind 107:11–21. https://doi.org/10.1016/j.compind.2019.01.011. 05/01/ 2019, doi: https
Prem PR, Sanker AP, Sebastian S, Kaliyavaradhan SK (2023) A review on application of acoustic emission testing during additive manufacturing. J Nondestr Eval 42(4):96
Westphal E, Seitz H A machine learning method for defect detection and visualization in selective laser sintering based on convolutional neural networks, Additive Manufacturing, vol. 41, p. 101965, 2021/05/01/ 2021, doi: https: https://doi.org/10.1016/j.addma.2021.101965
Klamert V, Schmid-Kietreiber M, Bublin M A deep learning approach for real time process monitoring and curling defect detection in selective laser sintering by infrared thermography and convolutional neural networks. Procedia CIRP, 111, pp. 317–320, 2022/01/01/ 2022, doi: https: https://doi.org/10.1016/j.procir.2022.08.030
Ogunsanya M, Isichei J, Parupelli SK, Desai S, Cai Y In-situ droplet monitoring of Inkjet 3D Printing process using image analysis and machine learning models. Procedia Manuf, 53, pp. 427–434, 2021/01/01/ 2021, doi: https: https://doi.org/10.1016/j.promfg.2021.06.045
Lu L, Hou J, Yuan S, Yao X, Li Y, Zhu J Deep learning-assisted real-time defect detection and closed-loop adjustment for additive manufacturing of continuous fiber-reinforced polymer composites, Robotics and Computer-Integrated Manufacturing, vol. 79, p. 102431, 2023/02/01/ 2023, doi: https: https://doi.org/10.1016/j.rcim.2022.102431
Ghodsian N et al MSOA: A modular service-oriented architecture to integrate mobile manipulators as cyber-physical systems, Journal of Intelligent Manufacturing, 2024/05/13 2024, https://doi.org/10.1007/s10845-024-02404-4
Chan SL, Lu Y, Wang Y (2018) Data-driven cost estimation for additive manufacturing in cybermanufacturing. J Manuf Syst 46:115–126. https://doi.org/10.1016/j.jmsy.2017.12.001. /01/01/ 2018, doi: https
Hossain MS, Taheri H (2020) In situ process monitoring for Additive Manufacturing through Acoustic techniques. J Mater Eng Perform 29(10):6249–6262. https://doi.org/10.1007/s11665-020-05125-w. /10/01 2020
AbouelNour Y, Gupta N In-situ monitoring of sub-surface and internal defects in additive manufacturing: a review. Mater Design, 222, p. 111063, 2022/10/01/ 2022, doi: https: https://doi.org/10.1016/j.matdes.2022.111063
Colosimo BM, Grasso M (2020) In-situ monitoring in L-PBF: opportunities and challenges. Procedia CIRP 94:388–391. https://doi.org/10.1016/j.procir.2020.09.151. 01/01/ 2020, doi: https
Zhao X, Imandoust A, Khanzadeh M, Imani F, Bian L (2021) Automated anomaly detection of laser-based additive manufacturing using melt pool sparse representation and unsupervised learning, in 2021 International Solid Freeform Fabrication Symposium, University of Texas at Austin
Tan Y et al (2019) An Encoder-Decoder Based Approach for Anomaly Detection with Application in Additive Manufacturing, in 18th IEEE International Conference On Machine Learning And Applications (ICMLA), 16–19 Dec. 2019 2019, pp. 1008–1015, https://doi.org/10.1109/ICMLA.2019.00171
Ghayoomi Mohammadi M, Mahmoud D, Elbestawi M On the application of machine learning for defect detection in L-PBF additive manufacturing. Opt Laser Technol, 143, p. 107338, 2021/11/01/ 2021, doi: https: //https://doi.org/10.1016/j.optlastec.2021.107338
Liu C et al Toward online layer-wise surface morphology measurement in additive manufacturing using a deep learning-based approach. J Intell Manuf, 34, 6, pp. 2673–2689, 2023/08/01 2023, https://doi.org/10.1007/s10845-022-01933-0
Mahmoud D, Magolon M, Boer J, Elbestawi M, Mohammadi MG (2021) Applications of machine learning in process monitoring and controls of L-PBF additive manufacturing: a review. Appl Sci 11(24):11910
Chen J et al (2023) Accelerating Thermal simulations in Additive Manufacturing by Training Physics-informed neural networks with randomly synthesized data. J Comput Inf Sci Eng 24(1). https://doi.org/10.1115/1.4062852
Li Z et al (2018) In situ 3D monitoring of geometric signatures in the powder-bed-fusion additive manufacturing process via vision sensing methods, Sensors, vol. 18, no. 4, p. 1180
Nagarajan HPN et al (2018) Knowledge-based design of Artificial Neural Network Topology for Additive Manufacturing Process Modeling: a New Approach and Case Study for fused deposition modeling. J Mech Des 141(2). https://doi.org/10.1115/1.4042084
Babu SS, Mourad A-HI, Harib KH, Vijayavenkataraman S Recent developments in the application of machine-learning towards accelerated predictive multiscale design and additive manufacturing. Virtual Phys Prototyp, 18, 1, p. e2141653, 2023/01/01 2023, https://doi.org/10.1080/17452759.2022.2141653
Kapusuzoglu B, Mahadevan S Physics-Informed and Hybrid Machine Learning in Additive Manufacturing: Application to Fused Filament Fabrication, JOM, vol. 72, no. 12, pp. 4695–4705, 2020/12/01 2020, https://doi.org/10.1007/s11837-020-04438-4
Kwon SW, Kim JS, Lee HM, Lee JS Physics-added neural networks: an image-based deep learning for material printing system. Additive Manuf, 73, p. 103668, 2023/07/05/ 2023, doi: https: https://doi.org/10.1016/j.addma.2023.103668
Funding
Open access funding provided by Arts et Metiers Institute of Technology.
Author information
Authors and Affiliations
Contributions
M. Shirinbayan, K. Benfriha, N. Bahlouli, J. Fitoussi: construct the idea. M. Shirinbayan, M.H. Nikooharf, M. Arabkoohi, N. Bahlouli, J. Fitoussi K. Benfriha: analyzed results, draft manuscript preparation, and wrote the paper. M. Shirinbayan, M.H. Nikooharf, M. Arabkoohi, N. Bahlouli, J. Fitoussi K. Benfriha: corrected the English and the paper format.
Corresponding author
Ethics declarations
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nikooharf, M.H., Shirinbayan, M., Arabkoohi, M. et al. Machine learning in polymer additive manufacturing: a review. Int J Mater Form 17, 52 (2024). https://doi.org/10.1007/s12289-024-01854-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12289-024-01854-8