
Abstract
Over the past two decades, hyperspectral imaging has become popular for non-destructive assessment of food quality, safety, and crop monitoring. Imaging delivers spatial information to complement the spectral information provided by spectroscopy. The key challenge with hyperspectral image data is the high dimensionality. Each image captures hundreds of wavelength bands. Reducing the number of wavelengths to an optimal subset is essential for speed and robustness due to the high multicollinearity between bands. However, there is yet to be a consensus on the best methods to find optimal subsets of wavelengths to predict attributes of samples. A systematic review procedure was developed and applied to review published research on hyperspectral imaging and wavelength selection. The review population included studies from all disciplines retrieved from the Scopus database that provided empirical results from hyperspectral images and applied wavelength selection. We found that 799 studies satisfied the defined inclusion criteria and investigated trends in their study design, wavelength selection, and machine learning techniques. For further analysis, we considered a subset of 71 studies published in English that incorporated spatial/texture features to understand how previous works combined spatial features with wavelength selection. This review ranks the wavelength selection techniques from each study to generate a table of the comparative performance of each selection method. Based on these findings, we suggest that future studies include spatial feature extraction methods to improve the predictive performance and compare them to a broader range of wavelength selection techniques, especially when proposing novel methods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Hyperspectral imaging is emerging as one of the most popular non-destructive approaches for assessing food quality, and safety [1, 2]. Hyperspectral imaging performs digital imaging from spatial information augmented with spectral information based on spectroscopy. Exceeding the predictive performance of digital RGB imaging and human visual examination [3], spectral and spatial information captured in hyperspectral images allows for highly accurate sensory and chemical attribute prediction. This technology has enabled applications such as predicting the soluble solid content of kiwifruit [4] and classifying brands of Cheddar cheeses [5].
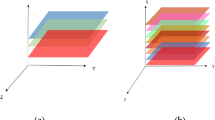
Hyperspectral images capture hundreds of contiguous narrow wavelengths, typically only a few nanometers wide, compared with the 5-50 broad bands captured by multispectral sensors. The captured images consider the spatial context of the samples, which is not possible with single point sampling of spectroscopy [6]. Figure 1 illustrates the differences between these modalities.
Using multivariate analysis, important information can be extracted from the observed reflectance images to predict attributes of the target sample [7]. Multivariate analysis establishes statistical or mathematical relationships between samples and their chemical attributes [8]. Predicting continuous measurements is a regression problem (e.g., total soluble solids of fruits [9]), whereas assigning a discrete class to each observation is a classification problem (e.g., identifying the geographical origin [2]). Most hyperspectral imaging studies in food science typically regress a target variable or classify a sample [10] based on the rich spatial and spectral information delivered by hyperspectral sensors.

Comparison of RGB channel digital imaging (left) to hyperspectral imaging (middle) and spectroscopy (right). Hyperspectral images capture hundreds of wavelength channels across the electromagnetic spectrum
High dimensionality is the main challenge when analyzing hyperspectral data. Many applications of hyperspectral sensors require low-cost real-time (online) decision-making, such as sensors for unmanned aerial vehicles (UAVs) [11], assessment of food safety on processing lines [12], and guided surgery [13]. The high cost and low acquisition speed of hyperspectral sensors render these applications infeasible. High dimensionality also leads to models that overfit redundant features or noise [14], a phenomenon known as the Hughes phenomenon [15]. Dimensionality reduction is a way to address all three of these issues.
Two methods exist for dimensionality reduction: projection-based methods and wavelength (feature) selection. Projection-based methods require capturing all the wavelengths, whereas wavelength selection reduces the required wavelengths. Based on the selected wavelengths, multispectral sensors can be designed that are cheaper, faster, and more robust than the original hyperspectral sensors [3]. Wavelength selection is essential for rapid and robust models [7, 16]. However, there is no consensus regarding which wavelength selection techniques provide the best predictive performance, as the results vary among studies [1, 6, 7, 17,18,19,20].
Previous reviews on hyperspectral imaging have comprehensively assessed the applications of hyperspectral imaging and spectroscopy in individual disciplines. For food science applications, reviews have surveyed applications in muscle foods [3, 12, 20, 21], seafood [22, 23], fruits [6, 9, 24], or plant foods and vegetation [19, 25]. Other reviews have also investigated methods for making sense of hyperspectral image data, such as data mining [10], machine learning techniques [26], and deep learning [8]. Previous reviews have only discussed a small set of feature selection methods and have not covered all commonly used methods [2, 10, 12, 19, 20, 24, 25, 27,28,29]. Our review comprehensively surveys wavelength selection techniques across all applications of hyperspectral imaging that apply wavelength selection to provide a detailed answer to the best and most common wavelength selection methods.
Hyperspectral imaging is unique compared with other spectroscopic techniques because the images produced include the spatial context of each pixel. Spatial features are an element of hyperspectral image analysis that is often disregarded in studies. Data fusion refers to how different feature modalities are combined. Selecting the best data fusion method is vital for maximizing the benefits of including spatial information. Although models based on spectral information are often sufficient for high classification or prediction accuracy, including spatial data has been shown to further increase the predictive performance [26, 30]. Previously published reviews discussed the importance of considering both spectral and spatial features to improve the reliability and prediction accuracy of models [22]. However, a review has yet to explore the best practices for considering both the spectral and spatial features. Our study comprehensively reviews spectral and spatial feature selection techniques in hyperspectral imaging across disciplines to inform the use of spatial features in future investigations.
This review provides a complementary guide to discipline-specific reviews by making the following contributions:
-
A comprehensive review of the best and most common wavelength selection techniques for hyperspectral imaging applications.
-
A comprehensive review of previous studies incorporating spatial features from optimal wavelengths.
-
An overview of the typical sample sizes and targeted wavelength ranges of hyperspectral imaging studies using wavelength selection.
Methods
Systematic reviews are essential to quantify the usefulness of techniques and practices across all studies in a research area. This systematic review followed the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) framework developed by David Moher [31] to survey hyperspectral imaging research that applied wavelength selection techniques to reduce dimensionality and the subset of studies that investigated spatial features. PRISMA reviews consist of four steps: identification, screening, eligibility, and inclusion criteria. This section describes the methodology followed in each step.
Research questions and conceptual framework
This study examined research related to wavelength selection for hyperspectral images by following the PRISMA framework on publications retrieved from the Scopus database. The first stage of research questions focuses on three areas: application area, study design, and methods (i.e., feature selection and learning). We also included an extended second stage of questions for the subset of studies that extracted spatial features. This study answers the following research questions:
Standard hyperspectral study design (Section 2.2)
- RQ 1:
-
How many samples are acquired in hyperspectral imaging studies?
- RQ 2:
-
What wavelength ranges are most common for hyperspectral image analysis?
Feature selection and learning (Section 2.3)
- RQ 3:
-
What are the most common wavelength selection algorithms?
- RQ 4:
-
Which wavelength selection algorithms provide the best predictive performance?
- RQ 5:
-
Which learning algorithms are most common after wavelength selection?
Spatial features (Section 2.4)
- RQ 6:
-
What are the most common spatial features, and what parameters are used to extract these features?
- RQ 7:
-
How are spectral and spatial features combined for learning models?
- RQ 8:
-
How do studies select representative images to extract spatial features?
- RQ 9:
-
Does combining spectral and spatial features improve the predictive performance, and which type of feature performs best individually?
Selection criteria and search strategy
The Scopus database was the primary source of publications. Scopus provides a wide selection of studies with more coverage than other academic databases such as Web of Science [32]. Scopus integrates more sources, particularly conference proceedings, and is still manually curated, unlike Google Scholar.Footnote 1 Our search included abstracts because not all publications mentioned wavelength selection within the title or keywords. We searched the titles, keywords, and abstracts of publications in the Scopus database using the following search string:
(( “hyperspectral imaging” OR“spectroscopic imaging” OR “chemical imaging” OR “imaging spectroscopy” ) AND( “wavelength” OR “waveband” OR “wave band” OR “wave length” ) AND ( “selection” OR “selected” ))
While the search string included multiple synonyms for hyperspectral imaging and wavelength selection, this does not have the effect of excluding studies missing “wavelength selection”, meaning that the search results may include unwanted studies. Studies were manually included and excluded based on the criteria listed in Table 1. The analysis was limited to a subset of hyperspectral imaging studies with wavelength selection to reduce the dimensionality. We did not exclude studies based on language (e.g., English, Chinese, and French) or year of publication. We only excluded studies based on publication type (e.g., conference or peer-reviewed journal) if the publication lacked a full methodology (e.g., published abstracts).
Study selection process
The initial search stage of the literature review returned 1063 studies. The articles were retrieved on the 14th of October 2021. Our review was then updated with 166 more recent studies on the 13th of December 2022, resulting in a total of 1229 studies. The selection criteria defined in Table 1 were applied to reduce the total number of studies. Figure 2 shows a flowchart of the study’s selection process. Duplicate studies (n = 2) and conference announcements (n = 2) were excluded resulting in 1,225 records screened. Next, we set aside 17 reviews before screening the full-text results, leaving 1208 publications. Reviews were excluded because they did not provide empirical results comparing wavelength selection methods or follow a methodology to analyze the images.

Study selection process flow chart. This details the database search, the screening process and the number of studies included for two parts of the review
The selection criteria addressed hyperspectral imaging, wavelength selection, and empirical results. This study defined hyperspectral imaging as acquiring images with a hyperspectral sensor capturing at least 90 wavelengths. Hyperspectral imaging is commonly defined in the literature as 100 wavelengths or more. We applied leniency to include studies that initially captured over 100 wavelengths but removed noisy bands during their analysis, reducing the total number of wavelengths to between 90 and 100.
The second criterion is wavelength selection, which is defined as algorithm-based feature selection to select a subset of optimal wavelengths without limiting the size (such as restricting the search to a single band or pair of bands). These distinctions excluded studies that could perform a brute-force search of all wavelength combinations to select wavelengths. We excluded non-algorithmic and expert knowledge-based wavelength selection methods, such as manually selected band ratios. However, we included methods in which humans needed to manually interpret charts to select wavelengths (e.g., principal component plots or derivative curves).
The final criterion was empirical results: each study required a transparent methodology incorporating selected wavelengths with machine learning or other statistical methods for hyperspectral image analysis. Each study was required to provide clear experimental results. This criterion excluded studies proposing novel hyperspectral systems or sensors without experimentation and studies with very few details available to answer our research questions.
We screened the full texts of 1208 publications selected to establish which studies met our inclusion criteria (Table 1). As the lack of details in the abstract was not an exclusion criterion, all the studies required full-text screening. In this stage, 395 studies were eliminated. Of the eliminated studies, 156 did not apply an appropriate wavelength selection technique, while 100 did not investigate hyperspectral images. Finally, 14 studies were inaccessible to the researchers and associates. We contacted the original authors of 13 studies through ResearchGate.Footnote 2 Fourteen of the 16 originally inaccessible did not respond in time for this publication. The first stage of this review included 799 studies. A complete list of these publications is available in the Supplementary Material of this manuscript.
The second stage of this review included 62 English studies that extracted spatial features from hyperspectral images to answer the spatial feature research questions defined in Section 1.1. The entire study population (n = 799) and the subset that utilized spatial features (n = 71) were the two groups of studies investigated.
Encoding of the studies
A single reviewer manually checked whether each study met our inclusion criteria and recorded all relevant information in a Google form.Footnote 3 The reviewer then completed multiple passes, checking one attribute at a time across all the studies to check the information collected, and our inclusion criteria were applied consistently. Google Translate was sufficient to extract information from non-English studies during the first stage of the review. The second stage was limited to studies written in English to avoid misrepresentation of information due to incorrect translations. The data collection process was manual, as some studies were not readable using automation tools.
The language, year of publication, and broad application area (e.g., meat science or medical imaging) of each study were collected for demographic and application area analyses. The wavelength range and sample size were collected from each study to answer the hyperspectral study design research questions. The effective wavelength ranges were collected after the authors discarded noisy bands (if applicable) of all hyperspectral systems investigated. The sample size was recorded as the number of unique objects imaged in the study after the outlying samples were excluded (if applicable).
The collected publications contained over 200 wavelength selection techniques and learning algorithms. From each study, we collected a comma-separated list of the techniques for wavelength selection and machine learning and an ordered list of the best wavelength selection methods based on their performance. Performance was defined as the accuracy of predicting the class or continuous measurement of interest. The performance of the sets of optimal wavelengths was determined based on the prediction set (testing set) accuracy of the best learning model for this subset. When there was a tie, the validation set followed by the calibration set accuracy acted as the tiebreaker. The methods were ranked based on their performance on the prediction set when one method clearly outperformed a subset of the others. If no method decisively outperformed the others, or if there was no comparison between multiple methods, we recorded the best method as inconclusive. Many studies have applied only a single wavelength selection method. In this case, the best method was recorded as only one.
The results were tabulated with Python scripts, ranking which wavelength selection methods performed better based on the number of comparisons with other methods. We only included wavelength selection techniques applied in seven or more studies, and binned all others into the Other category. For example, if one study applied genetic algorithms (GA), successive projections algorithm (SPA), and regression coefficients (RC) to select an optimal subset, and they were ranked as such, we recorded three comparisons: GA outperformed SPA, GA outperformed RC, and SPA outperformed RC.
We tabulated the number of studies that utilized each learning algorithm using Python scripts based on the collected comma-separated lists. Many studies have tested multiple variants of the same family of algorithms, such as random forests and decision trees. For more valuable insights, we counted the number of studies as a measure of popularity rather than the number of occurrences of each algorithm, meaning a study comparing two versions of support vector machines counted as a single observation.
We recorded details from a subset of studies that extracted spatial features for the final research questions related to spatial features using a separate Google form. We recorded a list of the extracted spatial features, the parameters of these feature extractors, the performance of spectral features compared to spatial features, the performance of data fusion compared to individual models, how representative feature images were selected to extract spatial features, and how spectral-spatial features were fused. We recorded whether the data fusion models outperformed the individual models as yes, no, or inconclusive. The best individual set of features was recorded as spectral features, spatial features, not compared individually, or inconclusive. Both were determined based on the accuracy on the prediction set of the best model.
All studies required details regarding wavelength selection techniques to meet our inclusion criteria. Not all the other attributes collected were compulsory. For each research question, we ignored studies in which the related attributes of interest were not stated or unclear. Only studies investigating spatial features were gathered to answer the spatial feature research questions. Since the information gathered is essential for the reproducibility of each study, missing data could indicate lower publication quality.
A spreadsheet stored the information collected by this review and generated simple statistics (e.g., counts). Python scripts extracted other information required to answer questions (e.g., comparisons of methods and the wavelength range graph) and were used to generate tables and figures. The Python libraries required were PandasFootnote 4 for reading the data,Footnote 5 and MatplotlibFootnote 6 for creating figures.
Biases in this study
This review may introduce bias by including several studies from prevalent authors or research groups. Some research groups may follow the same methodology for multiple hyperspectral imaging applications. This imbalance may skew the conclusions on which wavelength selection, learning algorithms, camera models, and other attributes of interest are the most popular for hyperspectral imaging applications.
No methods explored the causes of heterogeneity among the study results because each study acquired different datasets, and no control groups were available. No method assessed the risk of bias due to missing results, the robustness of results, or the certainty of the body of evidence for an outcome. There is a significant imbalance in the occurrence of many wavelength selection techniques. Some wavelength selection techniques have been utilized in a small set of studies (e.g., LASSO [33]), and others have been consistently applied across hundreds of studies (i.e., SPA [34], and CARS [35]). We limited the analysis to methods applied in more than five studies to reduce the impact of less common techniques.
Results
The initial search returned 1229 publications. After applying the selection criteria, 799 publications were selected as relevant and analyzed, as described in the following subsections. Although all 799 studies informed the conclusions of this review, not all were cited here. The complete list of included and excluded studies with the reason for their exclusion is available in the Supplementary Material.
Demographic characteristics of research studies

Number of studies included in this review between 2000 and 2022. The number of studies increases over time. There has been a decline in recent years due to the COVID-19 pandemic limiting research
The reviewed studies included 734 journal articles and 65 conference papers based on the classification provided by Scopus. Of the total 799 studies, the publication language included 646 studies in English, 149 in Chinese, and four published in other languages (German, Spanish, French, and Persian). An analysis of publications per year showed an increase in hyperspectral imaging studies with wavelength selection (Figure 3). This increase is likely due to the increased accessibility of affordable hyperspectral sensors. The COVID-19 pandemic may have restricted access to research laboratories, causing a slight decline in research outputs since 2020.
Standard hyperspectral study design
Sample sizes
The first aspect of designing a hyperspectral imaging study examined in this review is the number of samples required (RQ 1). It is essential to ensure that each study has an adequate number of samples for training the models and a representative set of unseen samples for validation. To compare the sample sizes across the population of hyperspectral imaging studies included in this review, we must define a single sample. The number of images cannot represent the sample sizes because some may contain multiple samples (e.g., multiple maize kernels or grains of rice). The number of subjects purchased or retrieved may not be reliable since researchers can obtain measurements from multiple subsamples (e.g., measuring the tenderness of broiler breast fillets [36]). Therefore, we determined the number of samples as the number of individual samples of interest with the corresponding reference values or classes.
The box and whisker plot shown in Fig. 4 summarizes this data on a logarithmic scale due to the skew in observations; the median number of samples was 180, with the middle 50% between 105 and 300 samples. The mean was 424.04 samples, and the maximum and minimum were 19,000 and 1, respectively, indicating a clear skew in the data due to outliers. Some studies had as few samples as a single image, such as studies using the Indian pines dataset [37, 38] for land use classification. Studies with thousands of samples typically investigated low-cost, easy-to-image subjects, such as oats, maize kernels, or other types of seeds [39,40,41,42,43,44]. The study with the second highest number of samples (15,000) collected multiple years of data to detect diseases affecting grape cultivars [43].

Number of samples (log scale) encountered in hyperspectral studies that applied wavelength selection. The median number of samples was 180, with the middle 50% between 105 and 300 samples. The log scale was required for the outliers, which included one study using a single image and another using 19,000 samples
Some studies acquired images of the same subjects across multiple timestamps to see how damage symptoms developed over time [45] or to compare before and after treatment [46, 47]. Sampling like this increases the number of observations and sample variation. However, this is possible only when there is no destructive analysis to retrieve the ground-truth reference values from a sample. In these studies, we counted the number of imaged samples rather than the number of unique samples. The chemical analysis of samples is often destructive. Depending on the amount of material required for this analysis, measuring multiple attributes of each sample may not always be possible [48,49,50].
For classification, a single sample could be subdivided into regions with multiple classes, such as those for detecting white stripping on chicken fillets [51], where multiple affected areas were visible from a single sample. Another example is where multiple defective and unaffected regions are visible in the same image. Researchers studying the spectral response of damage to fruit samples typically defined multiple regions of interest for the damaged and unaffected areas [52, 53]. In conclusion, most studies captured between 105 and 300 samples, but the differences in methodologies between study types made recording the sample sizes difficult.
Wavelength ranges
The second aspect of the study design investigated in this review is how to select a suitable wavelength range to capture hyperspectral images (RQ 2). Figure 5 shows the wavelength ranges studied in the 681 studies that clearly indicated their sensor range. Based on the sensors available on the market, the three most common ranges were visible/near-infrared (VIS/NIR: 400–1000 nm), near-infrared (NIR: 900–1700 nm), and shortwave infrared (SWIR: 900–2500 nm). The specific range of interest depends on the application. For example, predicting the attributes of samples correlated with moisture is more suitable in an infrared range where water absorbs more light, but where pigments are correlated with the target attribute, a sensor focusing on visible light is more appropriate.
Most studies focused on one of these ranges, and only 50 investigated multiple ranges. When researchers combine multiple sensors (to examine the spectral features over a more extensive wavelength range), the authors extracted the mean spectra from each sensor and concatenated the vectors to form a single contiguous spectral vector that represented the sample. The researchers then fitted a model to the selected wavelengths from the combined spectra. No study in this review extracted extended pixel-wise spectra by combining data from multiple sensors because they could not find corresponding pixels between sensors.

Histogram of the number of studies investigating each wavelength range
Figure 5 shows a spike around 900–1000 nm in the wavelength range of interest due to the overlap between VIS/NIR and other sensors. The VIS/NIR range was the most common due to the accessibility of these sensors [54], and the lower cost of the detector coatings for this wavelength range [7]. There is no significant difference in the choice of sensors based on the sample type between these different ranges. The proportion number of studies looking at the SWIR and VIS/NIR is approximately the same for meat products as for fruit and vegetable-related studies, as shown by the lines on the plot.
Feature selection and machine learning
Wavelength selection
Previous reviews of wavelength selection techniques have divided the field into three categories based on how the methods find optimal features [29]. These categories are filter, embedded, and wrapper methods. Filter methods apply a threshold to a feature importance score to select the best wavelengths. Examples of filter methods include regression coefficients and variable importance in projection (VIP). Embedded methods integrate learning and feature selection, such as LASSO regression [33] and decision trees. Wrapper methods are the most popular category, and they operate by iteratively updating the wavelength subsets and fitting models to evaluate the performance. Wrapper methods include successive projection algorithms (SPA) [34] and genetic algorithms [55]. We also propose a fourth category of techniques, manual selection methods, in which an algorithm provides an output that is interpretable by experts to select the key wavelengths. Principal component analysis loading plots are an example of this type of method. Researchers typically determine points at the peaks/troughs of a plot as the important wavelengths.
We extend this categorization to two other categories of wavelength selection methods: concatenated and interval-based methods. Concatenated methods string multiple selection algorithms together to select important features from previously selected subsets, and interval-based methods select an informative interval of wavelengths, often of a manually determined width. Concatenated methods can combine the advantages of multiple algorithms, such as UVE and SPA. UVE has problems with multicollinearity, and SPA may select uninformative variables. UVE-SPA first removes uninformative wavelengths and SPA removes variables with the least multicollinearity [16]. In Table 2, we have categorized the most popular wavelength selection techniques into these categories and cited recent English studies that employed each technique (RQ 3).
Tables 3 provide an exhaustive comparison of wavelength selection techniques applied in the area against each other (RQ 4). These tables present the number of studies in which the selected method (rows) outperformed the comparison method (columns). Where the table reads “Only one”, it counts the number of studies where the comparison method was the only wavelength selection method. The “Inconclusive” row presents the number of studies that applied the wavelength selection technique, where the ranking of each method was unclear. Finally, the “Not compared” row provides the number of studies using the method that did not compare it to the other methods. From these tables, we find that there is a clear set of common methods: successive projections algorithm (SPA) [34], competitive adaptive reweighted sampling (CARS) [35], regression coefficients (RC) [60], and principal component analysis (PCA) loadings. Among these techniques, CARS was most often the best method. CARS performed better than SPA in 50 of 76 comparisons, where one was better than the other.
Researchers in 122 studies manually examined the peaks and troughs in the PCA loadings plot to select the key wavelengths. 79 studies applied this as the only wavelength selection technique, compared with 59 studies that compared it with other methods. PCA loadings outperformed SPA in four out of 14 comparisons, CARS in one out of 6 comparisons, and regression coefficients in three out of seven comparisons, where one method was better. PCA loadings are among the worst-performing techniques despite being among the most popular methods.
The most common and consistent methods found in this review were the CARS and SPA methods. The concatenated methods and variable importance in projection (VIP) are the only comparison methods in which the CARS algorithm did not perform well. Concatenated and interval-based methods, UVE and CARS outperformed SPA, whereas SPA performed well in all other comparisons. Regression Coefficients were the sole wavelength selection method used in 89 studies, and in 57 studies where researchers compared it to others, it did not perform well. The performance of regression coefficients is demonstrated by comparisons with genetic algorithms (best in two out of seven comparisons), CARS (best in five out of 16 comparisons), and SPA (best in 11 out of 30 comparisons). Regression coefficients, as with PCA loadings, is a simple feature selection method, making it more popular than novel methods that are not available in standard libraries for different programming languages or built into commercial software.
For the two concatenated methods utilized in more than five studies, there were very few comparisons with the other techniques. Studies that included these methods often compared them to other concatenated methods [129, 130]. CARS-SPA and UVE-SPA performed well but were only applied in 20 and 15 studies, respectively. CARS-SPA had the highest performance, outperforming SPA in ten out of 15 comparisons and an equal performance against CARS (better in eight out of 16 comparisons). UVE-SPA similarly performed well but underperformed other concatenated approaches, such as CARS-SPA (best in two out of five comparisons). UVE-SPA was outperformed by CARS and UVE individually (best in two out of nine and one out of seven comparisons, respectively).
The most common interval-based approaches encountered are interval-partial least squares (iPLS) [89], interval-VISSA (iVISSA) [103], Synergy interval partial least squares (siPLS) [123], and interval random frog (iRF) [105] were often compared to each other. These methods divide the full spectrum into equidistant partitions and fit regression models to the intervals [91]. There were not enough comparisons of these methods to conclude which interval-based method was the best, and their performance against single-feature methods was generally poor.
Many studies have proposed a novel wavelength selection method and compared it to a small set of the most common approaches while claiming superior performance. Comparisons with a broader range of techniques over multiple datasets are required to benchmark their performance. Since five or fewer studies applied each of these methods, we grouped them methods into the “other” column of Table 3. To the best of our knowledge, no standardized benchmark datasets are available for wavelength selection.
Other popular methods for wavelength selection include genetic algorithms [55], random frog [70], uninformative variable elimination [67], and variable importance in projection [60]. Genetic algorithms performed well, but it is not easy to compare to this algorithm because many hyperparameters must be manually set.
Machine learning methods
The final step in model creation is to fit the model to the selected wavelengths. Here, we list the most common machine learning and statistical models applied to the selected wavelengths (RQ 5). Partial least squares (PLS) is the most common learning algorithm for analyzing hyperspectral data after wavelength selection. A total of 470 studies chose a variant of PLS. The most common variants are partial least squares regression (PLSR) for regression and partial least squares discriminant analysis (PLS-DA) for classification. Previous reviews have reported the high utilization of PLSR and PLS-DA [131]. Instead of directly operating on the variables, PLS extracts a set of latent variables with the best predictive performance [21]. Seventy-four studies applied a more straightforward multiple linear regression (MLR) that fits a simple linear equation to the observed data. MLR struggles with high multicollinearity between wavelengths [132], which makes prior wavelength selection important. The advantage of MLR is the interpretability of the results, whereas the meaning of the latent variables or principle components is unclear. The second most common algorithm was support vector machines (SVM) [133] in 333 studies, the most common variants of which were least squares support vector machines (LS-SVM) and support vector regression (SVR).
Various studies applied variants of artificial neural network (ANN) architectures, such as backpropagation neural networks (BPNN) [134], extreme learning machines (ELM) [135], stacked autoencoders (SAE), and convolutional neural networks (CNN) [136]. These machine learning approaches apply a series of processing layers to extract higher-level features and are often referred to as deep learning approaches. Non-linear methods such as ANNs and SVMs are valuable for modelling complex relationships between dependent and independent variables. These non-linear approaches have a higher computational complexity [10]. Only a few studies have applied deep learning to hyperspectral imaging for food applications because of the time and cost requirements for gathering large datasets with corresponding reference (ground-truth) measurements [8]. Few studies (n = 20) have combined convolutional neural networks with wavelength selection despite their popularity in computer vision outside hyperspectral imaging, but these techniques have become more common since 2022 [57, 137,138,139]. Due to the challenges of big data and small sample sizes, CNN approaches typically apply one-dimensional filters to the spectral response rather than two- or three-dimensional filters to the hyperspectral image. Table 4 displays the counts for each learning algorithm found by this study.
Decision trees were found in 67 studies, including variants such as random forests and classification and regression trees (CART). K-nearest neighbors (KNN) is a simple method for classifying samples based on their distance from other labelled samples. Because of the number of neighborhood comparisons required, KNN becomes more computationally expensive with larger datasets. Projection methods such as linear discriminant analysis (LDA) and principal component analysis (PCA) distinguish classes within data by projecting the remaining wavelengths onto new axes to maximize variance and class separability. Principal component regression (PCR) is applied instead of PCA for regression analysis. Fifty-three studies utilized LDA compared with 26 studies that chose PCA instead. Of the 799 studies surveyed, 77 compared learning algorithms that did not fit these categories.
Spatial features
Spatial descriptors (image texture descriptors) provide information about the spatial arrangement of pixels, whereas spectral information describes how light interacts with samples. As discussed earlier, many reviews acknowledged that including spatial features as independent modelling variables helps to improve the predictive performance of models [22]. Spatial information includes statistical features that summarize the distribution of intensities, such as statistical moments, and higher-order spatial descriptors (statistics) describe the distribution of groups of pixels, such as pairs for grey-level co-occurrence matrices. Spatial features may also include local neighborhood operations, such as local binary patterns (LBP) [140], or shape features describing the shape of the regions of interest. This section describes the different techniques for extracting spatial features from hyperspectral images (RQ 6), approaches to select feature images (RQ 8), the predictive performance of models incorporating spatial features (RQ 9), and how studies combine spatial features with spectral features (RQ 7).
Spatial features descriptors
A total of 71 out of the 799 studies selected for review included spatial features and wavelength selection for hyperspectral image analysis. Table 5 provides a breakdown of these studies, answering RQ 6. The most popular spatial features were the grey-level co-occurrence matrices (GLCM) texture descriptors found in 41 out of 71 studies. GLCM descriptors (also known as Haralick features) describe the two-dimensional feature image by creating a matrix of the probability of joint occurrences of pixel grey level values at a given angle (\(\theta\)) and distance (d) [202].
Haralick et al. [202, 203] described 14 features to summarize GLCM matrices into texture descriptors. Studies such as Clausi [204] and Soh and Tsatsoulis [205] further extended this set of features. The five most common features encountered were: contrast/inertia moment (n = 38), energy/uniformity/angular second moment (n = 38), correlation (n = 36), homogeneity/inverse difference moment (n = 35), and entropy (n = 19). Four studies investigated features beyond this set of five core features [171, 178, 184, 194], but two did not provide sufficient information on the extracted features. One of the earliest studies combining spatial features with wavelength selection [194] extracted 22 GLCM features, including multiple methods for selecting the feature image. However, these studies did not examine the effectiveness of each feature.
The main parameters of the GLCM are the angle and distance used to measure pixel correlation. Typically, studies chose four angles 0°, 45°, 90°, and 135° describing the relationships diagonally, vertically, and horizontally to create GLCM matrices. Different angles and distances create different matrices. Eleven studies averaged the descriptors over the four orientations to produce a rotation-invariant descriptor. Many studies did not state whether they averaged over multiple angles (n = 16), did not average over angles (n = 8), or only employed a single angle (n = 5). For the distance parameter, the typical approach is to create matrices based on a one-pixel distance. Few studies have examined a broader range of distances, such as one to ten pixels [201] or one to five pixels [164, 190]. Because we can fix the distance between the samples and sensors in controlled environments, a single distance should be sufficient. Future studies should be conducted using multiple distances to determine the best effect.
The second most popular spatial feature extraction method was the grey-level gradient co-occurrence matrix (GLGCM) [206] (n = 11). Similar to GLCM, GLGCM captures second-order statistics about the spatial image content by describing the grey-level gradients of the images. The GLGCM matrix represents the relative frequency of occurrence between a pixel with a given grey value and gradient. The data fusion model outperformed the single modality models for all studies extracting GLGCM features that compared fusion models to individual models (n = 10). GLGCM has a much larger set of features than GLCM, describing the dominance and distribution of gradients and the entropy, average, standard deviation, asymmetry, and nonuniformity of both the pixel gradients and grey level. The popularity of GLCM and GLGCM was consistent with previous reviews [1, 14].
Another spatial feature extraction approach is local binary patterns (LBP) [169, 175, 182] where each pixel was compared to its horizontal, vertical, and diagonal neighbors to give an eight-digit binary code [140]. Each position in the binary code describes whether the neighboring pixel value is larger (1) or smaller (0) than the target pixel. There were mixed results from the LBP features for hyperspectral images. One study extracted LBP features from RGB images to classify freezer-burnt salmon with no data fusion and found that the spectral-based model performed better for discriminating classes [175]. Another study found that GLGCM and GLCM significantly outperformed LBP without data fusion [169].
GLCM, GLGCM, and LBP provide second-order statistics based on the relationships between pixel pairs [207]. SSome studies have extracted first-order statistics, such as histogram descriptors, based on the histogram of intensities in the feature image. Histogram statistics summarize the grey value distribution of the image without considering the spatial interactions between pixels. The most common features extracted from these grey-level histograms are mean, uniformity, entropy, standard deviation, and third-moment (skewness) [186, 195, 208], as well as kurtosis, energy, smoothness, contrast, consistency, and roughness [141, 149, 154, 178, 180]. One study applied feature selection to the precomputed spatial features and found that the selection algorithm did not select histogram-based features for beef tenderness forecasting [182]. Other studies found that histogram statistics improved the model accuracy more than GLCM features [178] or shape descriptors [186]. The GLCM features significantly outperformed histogram statistics in another study [51].
Five studies investigated Gabor filters for extracting spatial features from hyperspectral images [146, 165, 170, 182, 191]. Gabor filters, which are linear filters used for texture analysis, apply convolutions with kernels generated by combining the Gaussian and sinusoidal terms. The results are often averaged over multiple angles to obtain rotationally invariant descriptors [146, 165].
Prior to 2020, only one study extracted spatial features with a convolutional neural network (CNN) [153]. This CNN architecture utilized two branches: one extracted spectral features with a one-dimensional CNN and the second extracted spatial features with a two-dimensional CNN. The model concatenated the extracted feature vectors for classification into a single feature vector. Feature importance was evaluated using the weights learned by the CNN in the first layer to select the optimal wavelengths. Since then, more advanced two-dimensional CNN architectures have been used to utilize the spatial information within images [84, 143]. One study applied the YOLOv3 algorithm [209], a popular object detection algorithm, to detect defects on apples [139].
The final common spatial feature extraction approaches accounted for were morphological/shape features. These approaches described the contour of the region of interest encompassing the sample with shape features. Shape features require only the ROI mask of the sample. The typical features extracted were the area, perimeter, major- and minor-axis lengths, and eccentricity. The studies that extracted shape features had good results for discriminating the varieties of seeds [197] and black beans [181] because of the correlation between shape and variety. The accuracy of the models trained on spectral features in both cases outperformed spatial features, and the data fusion model further improved the results. Other studies have applied edge detection algorithms to detect cracks and morphological features to detect scattered egg yolk [142].
Other less frequently used spatial features extracted include grey-level run-length matrix analysis [183], wide line detectors [146, 191], and wavelet-based transformations, such as Discrete Wavelet Transform (DWT) [96, 192], and Discrete cosine transformation [172].
Selecting feature images
Each feature extraction approach requires an image to form the basis of spatial feature descriptors. The most common methods extract features from the principal component (PC) score images of a full hyperspectral image or pre-selected wavelengths. Selecting the optimal wavelengths before extracting spatial features is less computationally intensive. Preselecting optimal wavelengths assumes that wavelengths with important spectral information also carry important spatial information. Selecting the optimal wavelengths before extracting the spatial features was employed in 48 studies. Another approach is to extract spatial features from each wavelength within the hyperspectral images and then apply feature selection to reduce the features to a set of optimal features from a reduced number of bands (post-selected). Two studies directly selected bands with important spatial features by extracting them from all wavelengths [146, 188]. Other studies have applied feature selection to select informative features from a selected or full feature set [144, 165, 173, 191].
Twenty-five studies selected PC score images as feature images. Although extracting texture descriptors across the entire spectrum is possible, this increases the computational complexity, making it infeasible in real-time systems. A single study utilised spatial features from all available wavelengths without feature selection [177], and five studies created either RGB images from the hyperspectral sensor or captured RGB images from a secondary camera [84, 142, 166, 175, 201]. The selected feature images are listed in the feature image column of Table 5.
Data fusion
There are three levels of data fusion for combining features from different feature spaces [210]. Pixel-level fusion integrates multiple modalities as co-registered inputs into a single feature extraction model, feature-level fusion combines features after extracting characteristic features, and decision-level fusion combines multiple model outputs after fitting models to the extracted features. Almost all studies that considered spatial features combined spectral and spatial features with feature-level fusion, with some CNN-based models integrating spectral-spatial information at the pixel level [84, 139]. They first extracted features from the images to combine spectral and spatial features before fitting the models to the fused feature vector. It is possible to apply decision-level fusion by training independent models on the spectral and spatial features and then using a meta-model to the decisions of the separate models. Models trained after feature-level fusion can incorporate interactions between individual features, which decision-level fusion models cannot. Feature-level fusion avoids the computational burden of high-dimensional feature extraction in pixel-level fusion.
Pixel-level fusion is feasible when data from two hyperspectral sensors with different wavelength ranges are fused. All the studies that merged data from multiple sensors extracted the mean spectra from each sensor’s ROI and combined them into a single spectrum for modelling, which would also be considered feature-level fusion. However, regions of interest could be registered together to combine multiple wavelength ranges for each pixel.
Mean normalization is often applied to features of different modalities (spectral and various types of spatial descriptors) to overcome problems caused by disparities between features [154, 165, 171, 180, 183, 185, 189]. Normalization rescales each feature in the training set (calibration) by its mean and standard deviation, giving all features a comparable magnitude.
Performance
Thirty-seven studies that included spatial features within their feature sets found that the predictive performance of models trained on spectral features alone outperformed those trained solely on spatial features (Table 5). Only five studies discovered that spatial characteristics were more helpful for predicting attributes than spectral features, and 29 studies failed to compare the two approaches in a way that allowed us to determine which model was the most effective. However, the selected model also affected the results. The performance metric that we used was the accuracy of the best model. When combining spectral and spatial features, we found that most studies (n = 40) performed better by combining spectral and spatial features than by using spatial or spectral features individually. The individual model outperformed the data fusion model in six studies. Finally, 25 studies did not compare the individual models to the spectral-spatial fusion models.
In these outlying studies, spatial features tended to be more appropriate for the problem because they corresponded to clearly visible texture indicators. For example, pork marbling can be detected using a wide-line detector to predict intramuscular fat [146]. Other studies related to pork meat assessment found that Gabor and GLGCM features outperformed spectral features for prediction of the total volatile base nitrogen content (TVB-N) [165] and freshness prediction [187], respectively. For the classification of tea varieties [167] and prediction of the water content of tea leaves [196], the GLCM features outperformed the spectral features. These studies showed that spatial features could be more valuable than spectral features of hyperspectral images in predicting the attributes of interest.
Studies have likely found worse performance from data fusion models because they did not include spatial features correlated with the prediction variable. One study observed a significant drop in performance between the calibration set and the prediction set for classifying maize seed quality, possibly indicating that the model was overfitting to the data [154]. Overfitting occurs when the model identifies trends in the calibration set that are less prevalent in the prediction dataset. Another study reported a similar predictive performance between spectral and data fusion models for predicting the tenderness of salmon [190]. GLCM features did not help predict chilling injury classes of green jujubes [162]. In these studies, the spatial features may have been inappropriate for the particular problem, or the wavelengths selected based on the spectral data may have been unsuitable.
Discussion
This review systematically surveyed studies that applied wavelength selection to hyperspectral imaging and found that food quality and safety accounted for most of the applications. Popular subjects included pork, apples, maize kernels, wheat, and potatoes, and common attributes of interest included moisture content, variety, and adulteration.
Standard hyperspectral study design
Surveying the number of samples in each study showed that hyperspectral imaging studies utilized significantly fewer samples than other machine learning applications in computer vision. The main reason for this is the cost and time required to acquire sample images. Due to the lower accessibility of sensors, it is not possible to use crowd-source training data such as popular RGB image datasets [211]. Condensing each sample to a single mean reflectance spectrum reduces spatial dimensionality at the cost of losing potentially useful spatial information. While deep learning has become the most popular approach for many computer vision tasks, typical datasets for deep learning, such as object detection or image classification datasets, often have millions of annotated RGB images. With more cost-effective hyperspectral sensors, researchers can create larger hyperspectral imaging datasets and apply deep learning models that reduce the feature set to find reliable trends with fewer observations.
This review also concludes that VIS/NIR range sensors are the most common for hyperspectral imaging applications with wavelength selection. VIS/NIR sensors are cheaper and provide adequate information for most studies. Future studies should consult prior works to determine which wavelength range suits their application.
Feature selection and machine learning
Wavelength selection
Given the current state of the literature, determining which feature selection technique yields the best wavelengths remains highly application dependent. Many confounding factors affected the accuracy of the models. Studies that have evaluated multiple wavelength selection methods and multiple classifiers may have one wavelength selection technique that performs best with one classifier and another performing best with a different classifier. Each study may differ in the implementation of each algorithm, experimental conditions, and datasets. The specific implementation may differ for methods with multiple hyperparameters, such as genetic algorithms, which require a fixed population size, genetic operator probability, number of generations, and a fitness function.
Many studies have proposed novel methods to select features but have not comprehensively compared the most common wavelength selection methods. We suggest that future studies compare the most common related methods to provide a more accurate benchmark for new feature selection methods on a particular dataset. The best-performing and most popular methods are the SPA, CARS, and genetic algorithm methods.
This review does not consider the number of wavelengths selected by each method. UVE often uses hundreds of wavelengths with high multicollinearity. Creating multispectral models for real-time analysis of hundreds of influential bands is not feasible. We also did not consider the differences between the interval-based and individual-feature approaches. Creating a multispectral model from a small subset of features may benefit from informative intervals instead of informative narrow wavelengths because some spectral features are visible over several adjacent wavelengths.
Machine learning
Our review concluded that there are fewer regression or classification methods than wavelength selection techniques. The most common methods are based on Support Vector Machines (SVM) or Partial Least Squares (PLS). We did not compare the effectiveness of these machine learning algorithms. This review attempts to gauge their popularity in literature. Partial least squares, decision trees, and multiple linear regression methods are explainable approaches compared to neural network approaches but are limited in extracting features. Wavelength selection for hyperspectral imaging studies follows the process of first extracting features from sample images, applying feature selection, and applying a regression or classification algorithm. This process limits the search space of models and contradicts the integrated approach of deep learning, where a model learns to extract meaningful features and applies regression or classification. This review found no algorithm combining feature extraction, selection, and regression (or classification) steps. The only similar example we found was the two-branch CNN approach by Liu et al., which extracted spectral and spatial features independently [153].
Spatial features
Our review found that GLCM and GLGCM were the most common methods for extracting spatial features. These handcrafted features require high levels of domain knowledge and may only be beneficial for certain problems. GLCM and GLGCM improved the accuracy of the learning algorithms in studies that incorporated them. Features learned by deep learning methods have dominated image classification of RGB images over the last decade [212]. Learning spatial features is complicated when considering the high number of channels in hyperspectral imaging (extensive fea- ture space), small sample sizes, and simultaneous challenge of selecting important wavelengths to enable online (real-time) applications.
The number of spatial features available exacerbates the high dimensionality of wavelength selection. GLCM alone has 14 standard texture descriptors per angle, distance, and wavelength. The feature space can quickly grow to extremely high dimensions with many combinations. Many studies have limited the feature image set to the selected wavelengths. Experimenting with enough features almost guarantees that at least one will correlate with the reference attributes in the training set, but this trend may not apply to the validation data.
Very few studies have selected important spatial features independent of the spectral features. Huang et al. [188] showed that the spatial features can be plotted over the entire wavelength range to form a continuous curve, similar to the standard approach to mean reflectance. Other types of features also share a high correlation between adjacent wavelengths. Many studies have extracted spatial features from the Principal Component score images and spectral features using wavelength selection. However, generating a PC score image requires a complete set of wavelength bands. All wavelengths would be needed to extract spatial features making wavelength reduction redundant and creating a lower-cost multispectral system impossible. The most common approach is to pre-select wavelengths based on the spectral features.
Most studies have revealed that spectral features are superior to spatial descriptors for the classification or prediction of attributes. Models incorporating both spectral and spatial data had higher predictive performance than individual features alone.
The two main limitations of studies investigating spatial features are that they assume that wavelengths with the most meaningful spectral information also have the most meaningful spatial information. In most cases, the set of available spatial features is limited to a set selected by the authors. More work is needed to create flexible feature selection techniques and test them on larger sets of spatial features.
Limitations
Due to the restrictions of our inclusion criteria used in this review, such as only including studies with wavelength selection, some aspects of the studies investigated in this review may not represent all hyperspectral imaging research. We did not compare spatial feature extraction methods for hyperspectral imaging rather than wavelength selection.
Studies may also have been missing from this review. They were either unavailable on Scopus, or the search string did not retrieve them. We mitigated this as much as possible by searching titles, keywords, and abstracts for multiple synonyms of “wavelength” and “selection”. However, we found some relevant studies that did not mention these keywords in their abstracts. Searching for an acronym for each wavelength selection technique is not feasible.
Conclusion
This review included 799 hyperspectral imaging studies from Scopus from the 1229 studies collected. This review excluded studies that did not investigate hyperspectral imaging and wavelength selection or did not provide a transparent methodology and experimentation results. We analyzed these studies to understand the methods for feature selection, machine learning, and spectral-spatial feature fusion.
Regarding the design of wavelength selection studies, this review found that hyper- spectral image analysis studies tended to have only a small number of samples, with the studies included in this review having a median sample size of 180. We investigated the wavelength ranges for studies that applied wavelength selection and found three commonly investigated regions of the electromagnetic spectrum: namely, 400–1000 nm, 900–1700 nm, and 900–2500 nm.
Many studies have applied an extensive range of wavelength selection algorithms. Although the comparative performance of the wavelength selection techniques is not an objective of most studies in hyperspectral imaging, we recommend that future work should apply a range of different techniques rather than just a single technique. We recommend the popular SPA, CARS, and genetic algorithms wavelength selection methods as benchmarks for future wavelength selection studies. Concatenated methods, such as CARS-SPA and UVE-CARS tend to provide features that lead to more accurate models. However, the number of studies that applied each of these techniques is not high enough to conclude whether they are better than other techniques. Any newly introduced wavelength selection method should be compared to a wide range of best-performing methods because there is no clear best selection method for all applications. The most common learning algorithms were partial least squares, support vector machines, and artificial neural networks. These wavelength selection and modelling steps were not integrated into the same solution because combining feature reduction with feature extraction and learning remains challenging.
This review found that spectral features were more informative than spatial features in most studies employing spatial features, whereas combining both feature types increased predictive performance. Spectral and spatial features are typically extracted independently and fused using feature-level fusion. The most common method is to select wavelengths with important spectral information and extract spatial features from each selected wavelength. GLCM features were the most common texture descriptor combined with wavelength selection and were applied in more than half of the studies that considered spatial features.
There is a need for more flexible feature selection and extraction methods, further investigation of spatial features, and publicly available large-scale hyperspectral image datasets. Flexibility can arise from flexible intervals of wavelengths or more flexible methods for extracting informative spatial features independent of spectral features.
Change history
27 September 2023
A Correction to this paper has been published: https://doi.org/10.1007/s11694-023-02148-4
References
J. Ma, D.-W. Sun, H. Pu, J.-H. Cheng, Q. Wei, Advanced techniques for hyperspectral imaging in the food industry: principles and recent applications. Annu. Rev. Food Sci. Technol. 10(1), 197–220 (2019). https://doi.org/10.1146/annurev-food-032818-121155
L. Feng, B. Wu, S. Zhu, Y. He, C. Zhang, Application of visible/infrared spectroscopy and hyperspectral imaging with machine learning techniques for identifying food varieties and geographical origins. Front. Nutr. (2021). https://doi.org/10.3389/fnut.2021.680357
A.Y. Khaled, C.A. Parrish, A. Adedeji, Emerging nondestructive approaches for meat quality and safety evaluation–a review. Compr. Rev. Food Sci. Food Saf. 20(4), 3438–3463 (2021). https://doi.org/10.1111/1541-4337.12781
L. Xu, X. Wang, H. Chen, B. Xin, Y. He, P. Huang, Predicting internal parameters of kiwifruit at different storage periods based on hyperspectral imaging technology. J. Food Meas. Charact. 16(5), 3910–3925 (2022). https://doi.org/10.1007/s11694-022-01477-0
T. Lei, X.-H. Lin, D.-W. Sun, Rapid classification of commercial cheddar cheeses from different brands using PLSDA, LDA and SPA–LDA models built by hyperspectral data. J. Food Meas. Charact. 13(4), 3119–3129 (2019). https://doi.org/10.1007/s11694-019-00234-0
Y. He, Q. Xiao, X. Bai, L. Zhou, F. Liu, C. Zhang, Recent progress of nondestructive techniques for fruits damage inspection: a review. Crit. Rev. Food Sci. Nutr. 62(20), 1–19 (2021). https://doi.org/10.1080/10408398.2021.1885342
M. Kamruzzaman, D.-W. Sun, Introduction to hyperspectral imaging technology, in Computer Vision Technology for Food Quality Evaluation, 2nd edn., ed. by D.W. Sun (Academic Press, London, 2016), pp.111–139
L. Zhou, C. Zhang, F. Liu, Z. Qiu, Y. He, Application of deep learning in food: a review. Compr. Rev. Food Sci. Food Saf. 18(6), 1793–1811 (2019). https://doi.org/10.1111/1541-4337.12492
J.-L. Li, D.-W. Sun, J.-H. Cheng, Recent advances in nondestructive analytical techniques for determining the total soluble solids in fruits: a review. Compr. Rev. Food Sci. Food Saf. 15(5), 897–911 (2016). https://doi.org/10.1111/1541-4337.12217
Q. Dai, D.-W. Sun, Z. Xiong, J.-H. Cheng, X.-A. Zeng, Recent advances in data mining techniques and their applications in hyperspectral image processing for the food industry. Compr. Rev. Food Sci. Food Saf. 13(5), 891–905 (2014). https://doi.org/10.1111/1541-4337.12088
J. Zhang, T. Cheng, W. Guo, X. Xu, H. Qiao, Y. Xie, X. Ma, Leaf area index estimation model for UAV image hyperspectral data based on wavelength variable selection and machine learning methods. Plant Methods (2021). https://doi.org/10.1186/s13007-021-00750-5
J.-H. Cheng, B. Nicolai, D.-W. Sun, Hyperspectral imaging with multivariate analysis for technological parameters prediction and classification of muscle foods: a review. Meat Sci. 123, 182–191 (2017). https://doi.org/10.1016/j.meatsci.2016.09.017
G. Lu, D. Wang, X. Qin, L. Halig, S. Muller, H. Zhang, A. Chen, B.W. Pogue, Z.G. Chen, B. Fei, Framework for hyperspectral image processing and quantification for cancer detection during animal tumor surgery. J. Biomed. Opt. 20(12), 126012–126012 (2015). https://doi.org/10.1117/1.JBO.20.12.126012
G. Özdoğan, X. Lin, D.-W. Sun, Rapid and noninvasive sensory analyses of food products by hyperspectral imaging: Recent application developments. Trends Food Sci. Technol. 111(2), 151–165 (2021). https://doi.org/10.1016/j.tifs.2021.02.044
G. Hughes, On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 14(1), 55–63 (1968). https://doi.org/10.1109/TIT.1968.1054102
D. Wu, D.-W. Sun, Advanced applications of hyperspectral imaging technology for food quality and safety analysis and assessment: a review—part I: fundamentals. Innov. Food Sci. Emerg. Technol. 19, 1–14 (2013). https://doi.org/10.1016/j.ifset.2013.04.014
X. Lin, J.-L. Xu, D.-W. Sun, Evaluating drying feature differences between ginger slices and splits during microwave-vacuum drying by hyperspectral imaging technique. Food Chem. (2020). https://doi.org/10.1016/j.foodchem.2020.127407
J.-H. Cheng, J.H. Qu, D.-W. Sun, X.A. Zeng, Visible/near-infrared hyperspectral imaging prediction of textural firmness of grass carp (Ctenopharyngodon idella) as affected by frozen storage. Food Res. Int. 56, 190–198 (2014). https://doi.org/10.1016/j.foodres.2013.12.009
A. Hennessy, K. Clarke, M. Lewis, Hyperspectral classification of plants: a review of waveband selection generalisability. Remote Sens. (2020). https://doi.org/10.3390/RS12010113
H. Pu, M. Kamruzzaman, D.-W. Sun, Selection of feature wavelengths for developing multispectral imaging systems for quality, safety and authenticity of muscle foods-a review. Trends Food Sci. Technol. 45(1), 86–104 (2015). https://doi.org/10.1016/j.tifs.2015.05.006
T.-T. Pan, D.-W. Sun, J.-H. Cheng, H. Pu, Regression algorithms in hyperspectral data analysis for meat quality detection and evaluation. Compr. Rev. Food Sci. Food Saf. 15(3), 529–541 (2016). https://doi.org/10.1111/1541-4337.12191
J.-H. Cheng, D.-W. Sun, Hyperspectral imaging as an effective tool for quality analysis and control of fish and other seafoods: current research and potential applications. Trends Food Sci. Technol. 37(2), 78–91 (2014). https://doi.org/10.1016/j.tifs.2014.03.006
S. Ghidini, M.O. Varrà, E. Zanardi, Approaching authenticity issues in fish and seafood products by qualitative spectroscopy and chemometrics. Molecules 24(9), 1812 (2019)
H. Wang, J. Peng, C. Xie, Y. Bao, Y. He, Fruit quality evaluation using spectroscopy technology: a review. Sensors (Switzerland) 15(5), 11889–11927 (2015). https://doi.org/10.3390/s150511889
W.-H. Su, D.-W. Sun, Multispectral imaging for plant food quality analysis and visualization. Compr. Rev. Food Sci. Food Saf. 17(1), 220–239 (2018). https://doi.org/10.1111/1541-4337.12317
D. Saha, A. Manickavasagan, Machine learning techniques for analysis of hyperspectral images to determine quality of food products: a review. Current Res. Food Sci. 4, 28–44 (2021). https://doi.org/10.1016/j.crfs.2021.01.002
K. Wang, H. Pu, D.-W. Sun, Emerging spectroscopic and spectral imaging techniques for the rapid detection of microorganisms: an overview. Compr. Rev. Food Sci. Food Saf. 17(2), 256–273 (2018). https://doi.org/10.1111/1541-4337.12323
D. Liu, D.-W. Sun, X.-A. Zeng, Recent advances in wavelength selection techniques for hyperspectral image processing in the food industry. Food Bioprocess Technol. 7(2), 307–323 (2014). https://doi.org/10.1007/s11947-013-1193-6
T. Mehmood, K.H. Liland, L. Snipen, S. Sæbø, A review of variable selection methods in partial least squares regression. Chemom. Intell. Lab. Syst. 118, 62–69 (2012). https://doi.org/10.1016/j.chemolab.2012.07.010
J.-H. Cheng, D.-W. Sun, Data fusion and hyperspectral imaging in tandem with least squares-support vector machine for prediction of sensory quality index scores of fish fillet. LWT 63(2), 892–898 (2015). https://doi.org/10.1016/j.lwt.2015.04.039
M.J. Page, D. Moher, P.M. Bossuyt, I. Boutron, T.C. Hoffmann, C.D. Mulrow, L. Shamseer, J.M. Tetzlaff, E.A. Akl, S.E. Brennan, R. Chou, J. Glanville, J.M. Grimshaw, A. Hróbjartsson, M.M. Lalu, T. Li, E.W. Loder, E. Mayo-Wilson, S. McDonald, L.A. McGuinness, L.A. Stewart, J. Thomas, A.C. Tricco, V.A. Welch, P. Whiting, J.E. McKenzie, Prisma 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ (2021). https://doi.org/10.1136/bmj.n160
M.E. Falagas, E.I. Pitsouni, G.A. Malietzis, G. Pappas, Comparison of pubmed, scopus, web of science, and google scholar: strengths and weaknesses. FASEB J. 22(2), 338–342 (2008). https://doi.org/10.1096/fj.07-9492LSF
R. Tibshirani, Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 58(1), 267–288 (1996)
M.C.U. Araújo, T.C.B. Saldanha, R.K.H. Galvão, T. Yoneyama, H.C. Chame, V. Visani, The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 57(2), 65–73 (2001). https://doi.org/10.1016/S0169-7439(01)00119-8
H. Li, Y. Liang, Q. Xu, D. Cao, Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 648(1), 77–84 (2009). https://doi.org/10.1016/j.aca.2009.06.046
H. Jiang, S.-C. Yoon, H. Zhuang, W. Wang, K.C. Lawrence, Y. Yang, Tenderness classification of fresh broiler breast fillets using visible and near-infrared hyperspectral imaging. Meat Sci. 139, 82–90 (2018). https://doi.org/10.1016/j.meatsci.2018.01.013
Q. Li, F.K. Kit Wong, T. Fung, Comparison feature selection methods for subtropical vegetation classification with hyperspectral data. International Geoscience and Remote Sensing Symposium (IGARSS) 3693–3696 (2019). https://doi.org/10.1109/IGARSS.2019.8898541
J. Tschannerl, J. Ren, J. Zabalza, S. Marshall, Segmented autoencoders for unsupervised embedded hyperspectral band selection. Proceedings - European Workshop on Visual Information Processing, EUVIP 2018-November (2019). https://doi.org/10.1109/EUVIP.2018.8611643
J. Zhang, L. Dai, F. Cheng, Classification of frozen corn seeds using hyperspectral Vis/NIR reflectance imaging. Molecules (2019). https://doi.org/10.3390/molecules24010149
Y. Zhao, S. Zhu, C. Zhang, X. Feng, L. Feng, Y. He, Application of hyperspectral imaging and chemometrics for variety classification of maize seeds. RSC Adv. 8(3), 1337–1345 (2018). https://doi.org/10.1039/c7ra05954j
S. Zhu, L. Zhou, P. Gao, Y. Bao, Y. He, L. Feng, Near-infrared hyperspectral imaging combined with deep learning to identify cotton seed varieties. Molecules (2019). https://doi.org/10.3390/molecules24183268
N. Wu, Y. Zhang, R. Na, C. Mi, S. Zhu, Y. He, C. Zhang, Variety identification of oat seeds using hyperspectral imaging: Investigating the representation ability of deep convolutional neural network. RSC Adv. 9(22), 12635–12644 (2019). https://doi.org/10.1039/c8ra10335f
Z. Gao, L.R. Khot, R.A. Naidu, Q. Zhang, Early detection of grapevine leafroll disease in a red-berried wine grape cultivar using hyperspectral imaging. Comput. Electron. Agric. (2020). https://doi.org/10.1016/j.compag.2020.105807
S.R. Delwiche, I.T. Rodriguez, S.R. Rausch, R.A. Graybosch, Estimating percentages of fusarium-damaged kernels in hard wheat by near-infrared hyperspectral imaging. J. Cereal Sci. 87, 18–24 (2019). https://doi.org/10.1016/j.jcs.2019.02.008
B.-H. Zhang, W.-Q. Huang, J.-B. Li, C.-J. Zhao, C.-L. Liu, D.-F. Huang, L. Gong, Detection of slight bruises on apples based on hyperspectral imaging and MNF transform. Spectrosc. Spectral Anal. 34(5), 1367–1372 (2014). https://doi.org/10.3964/j.issn.1000-0593(2014)05-1367-06
D.F. Barbin, D.-W. Sun, C. Su, NIR hyperspectral imaging as non-destructive evaluation tool for the recognition of fresh and frozen-thawed porcine longissimus dorsi muscles. Innov. Food Sci. Emerg. Technol. 18, 226–236 (2013). https://doi.org/10.1016/j.ifset.2012.12.011
C.Q. Xie, X.L. Li, P.C. Nie, Y. He, Application of time series hyperspectral imaging (TS-HSI) for determining water content within tea leaves during drying. Trans. ASABE 56(6), 1431–1440 (2013). https://doi.org/10.13031/trans.56.10243
J. Long, J. Yang, J. Peng, L. Pan, K. Tu, Detection of moisture and carotenoid content in carrot slices during hot air drying based on multispectral imaging equipment with selected wavelengths. Int. J. Food Eng. 17(9), 727–735 (2021). https://doi.org/10.1515/ijfe-2021-0127
A. Iqbal, D.-W. Sun, P. Allen, Prediction of moisture, color and pH in cooked, pre-sliced turkey hams by NIR hyperspectral imaging system. J. Food Eng. 117(1), 42–51 (2013). https://doi.org/10.1016/j.jfoodeng.2013.02.001
S. Wang, A.K. Das, J. Pang, P. Liang, Artificial intelligence empowered multispectral vision based system for non-contact monitoring of large yellow croaker (Larimichthys crocea) fillets. Foods (2021). https://doi.org/10.3390/foods10061161
H. Jiang, S.-C. Yoon, H. Zhuang, W. Wang, Y. Li, Y. Yang, Integration of spectral and textural features of visible and near-infrared hyperspectral imaging for differentiating between normal and white striping broiler breast meat. Spectrochim. Acta Part A 213, 118–126 (2019). https://doi.org/10.1016/j.saa.2019.01.052
H. Wang, R. Hu, M. Zhang, Z. Zhai, R. Zhang, Identification of tomatoes with early decay using visible and near infrared hyperspectral imaging and image-spectrum merging technique. J. Food Process Eng. (2021). https://doi.org/10.1111/jfpe.13654
W. Tan, L. Sun, F. Yang, W. Che, D. Ye, D. Zhang, B. Zou, The feasibility of early detection and grading of apple bruises using hyperspectral imaging: Early detection and grading of apple bruises. J. Chemom. 32(10), 3067 (2018). https://doi.org/10.1002/cem.3067
C.-H. Feng, Y. Makino, M. Yoshimura, F.J. Rodríguez-Pulido, Real-time prediction of pre-cooked japanese sausage color with different storage days using hyperspectral imaging. J. Sci. Food Agric. 98(7), 2564–2572 (2018). https://doi.org/10.1002/jsfa.8746
D.E. Goldberg, J.H. Holland, Genetic algorithms and machine learning. Mach. Learn. 3(2), 95–99 (1988). https://doi.org/10.1023/A:1022602019183
H.-J. He, Y. Chen, G. Li, Y. Wang, X. Ou, J. Guo, Hyperspectral imaging combined with chemometrics for rapid detection of talcum powder adulterated in wheat flour. Food Control (2023). https://doi.org/10.1016/j.foodcont.2022.109378
R. Qiu, Y. Zhao, D. Kong, N. Wu, Y. He, Development and comparison of classification models on Vis-NIR hyperspectral imaging spectra for qualitative detection of the Staphylococcus aureus in fresh chicken breast. Spectrochim. Acta A285, 121838 (2023)
X. Li, M. Cai, M. Li, X. Wei, Z. Liu, J. Wang, K. Jia, Y. Han, Combining Vis-NIR and NIR hyperspectral imaging techniques with a data fusion strategy for the rapid qualitative evaluation of multiple qualities in chicken. Food Control (2023). https://doi.org/10.1016/j.foodcont.2022.109416
Y. Li, Y. Yin, H. Yu, Y. Yuan, Fast detection of water loss and hardness for cucumber using hyperspectral imaging technology. J. Food Meas. Charact. 16(1), 76–84 (2022). https://doi.org/10.1007/s11694-021-01130-2
S. Wold, M. Sjöström, L. Eriksson, PLS-regression: a basic tool of chemometrics. Chemom. Intell. Lab. Syst. 58, 109–130 (2001)
Y. Wang, H. He, S. Jiang et al., Nondestructive determination of IMP content in chilled chicken based on hyperspectral data combined with chemometrics. Int. J. Agric. Biol. Eng. 15(1), 277–284 (2022). https://doi.org/10.25165/j.ijabe.20221501.6612
Z. Yuan, Y. Ye, L. Wei, X. Yang, C. Huang, Study on the optimization of hyperspectral characteristic bands combined with monitoring and visualization of pepper leaf spad value. Sensors (2022). https://doi.org/10.3390/s22010183
Q. Thien Pham, N.-S. Liou, The development of on-line surface defect detection system for jujubes based on hyperspectral images. Comput. Electron. Agric. (2022). https://doi.org/10.1016/j.compag.2022.106743
M. Shiddiq, H. Herman, D.S. Arief, E. Fitra, I.R. Husein, S.A. Ningsih, Wavelength selection of multispectral imaging for oil palm fresh fruit ripeness classification. Appl. Opt. 61(17), 5289–5298 (2022). https://doi.org/10.1364/AO.450384
B. Li, F. Zhang, Y. Liu, H. Yin, J. Zou, A. Ou-yang, Quantitative study on impact damage of yellow peach based on hyperspectral image information combined with spectral information. J. Mol. Struct. (2023). https://doi.org/10.1016/j.molstruc.2022.134176
S. Sharma, K.C. Sumesh, P. Sirisomboon, Rapid ripening stage classification and dry matter prediction of durian pulp using a pushbroom near infrared hyperspectral imaging system. Meas. J. Int. Meas. Confeder. (2022). https://doi.org/10.1016/j.measurement.2021.110464
V. Centner, D.-L. Massart, O.E. Noord, S. Jong, B.M. Vandeginste, C. Sterna, Elimination of uninformative variables for multivariate calibration. Anal. Chem. 68(21), 3851–3858 (1996). https://doi.org/10.1021/ac960321m
B. Li, F. Zhang, Y. Liu, H. Yin, J. Zou, A. Ou-Yang, Quantitative study of impact damage on yellow peaches based on reflectance, absorbance and kubelka-munk spectral data. RSC Adv. 12(43), 28152–28170 (2022). https://doi.org/10.1039/d2ra04635k
P. Xu, Y. Zhang, Q. Tan, K. Xu, W. Sun, J. Xing, R. Yang, Vigor identification of maize seeds by using hyperspectral imaging combined with multivariate data analysis. Infrared Phys. Technol. (2022). https://doi.org/10.1016/j.infrared.2022.104361
H.-D. Li, Q.-S. Xu, Y.-Z. Liang, Random frog: an efficient reversible jump Markov chain Monte Carlo-like approach for variable selection with applications to gene selection and disease classification. Anal. Chim. Acta 740, 20–26 (2012). https://doi.org/10.1016/j.aca.2012.06.031
C. Liu, Z. Chu, S. Weng, G. Zhu, K. Han, Z. Zhang, L. Huang, Z. Zhu, S. Zheng, Fusion of electronic nose and hyperspectral imaging for mutton freshness detection using input-modified convolution neural network. Food Chem. (2022). https://doi.org/10.1016/j.foodchem.2022.132651
T. Cheng, P. Li, J. Ma, X. Tian, N. Zhong, Identification of four chicken breeds by hyperspectral imaging combined with chemometrics. Processes (2022). https://doi.org/10.3390/pr10081484
G. Xuan, C. Gao, Y. Shao, Spectral and image analysis of hyperspectral data for internal and external quality assessment of peach fruit. Spectrochim. Acta Part A (2022). https://doi.org/10.1016/j.saa.2022.121016
M. Kamruzzaman, D. Kalita, M.T. Ahmed, G. ElMasry, Y. Makino, Effect of variable selection algorithms on model performance for predicting moisture content in biological materials using spectral data. Anal. Chim.Acta (2022). https://doi.org/10.1016/j.aca.2021.339390
H. Song, S.-R. Yoon, Y.-M. Dang, J.-S. Yang, I.M. Hwang, J.-H. Ha, Nondestructive classification of soft rot disease in napa cabbage using hyperspectral imaging analysis. Sci. Rep. (2022). https://doi.org/10.1038/s41598-022-19169-6
RMd. Saleh, B. Kulig, A. Arefi, O. Hensel, B. Sturm, Prediction of total carotenoids, color, and moisture content of carrot slices during hot air drying using non-invasive hyperspectral imaging technique. J. Food Process. Preserv. (2022). https://doi.org/10.1111/jfpp.16460
R. Yuan, G. Liu, J. He, G. Wan, N. Fan, Y. Li, Y. Sun, Classification of lingwu long jujube internal bruise over time based on visible near-infrared hyperspectral imaging combined with partial least squares-discriminant analysis. Comput. Electron. Agric. (2021). https://doi.org/10.1016/j.compag.2021.106043
M. Gabrielli, V. LançSon-Verdier, P. Picouet, C. Maury, Hyperspectral imaging to characterize table grapes. Chemosensors (2021). https://doi.org/10.3390/chemosensors9040071
T. Wu, J. Yu, J. Lu, X. Zou, W. Zhang, Research on inversion model of cultivated soil moisture content based on hyperspectral imaging analysis. Agriculture (Switzerland) 10(7), 1–14 (2020). https://doi.org/10.3390/agriculture10070292
Y.-H. Yun, W.-T. Wang, B.-C. Deng, G.-B. Lai, X.-B. Liu, D.-B. Ren, Y.-Z. Liang, W. Fan, Q.-S. Xu, Using variable combination population analysis for variable selection in multivariate calibration. Anal. Chim. Acta 862, 14–23 (2015). https://doi.org/10.1016/j.aca.2014.12.048
L. Shi, L. Li, F. Zhang, Y. Lin, Nondestructive detection of panax notoginseng saponins by using hyperspectral imaging. Int. J. Food Sci. Technol. 57(7), 4537–4546 (2022). https://doi.org/10.1111/ijfs.15790
Z. Guo, J. Zhang, C. Ma, X. Yin, Y. Guo, X. Sun, C. Jin, Application of visible-near-infrared hyperspectral imaging technology coupled with wavelength selection algorithm for rapid determination of moisture content of soybean seeds. J. Food Compos. Anal. (2023). https://doi.org/10.1016/j.jfca.2022.105048
P. Zhang, H. Ji, H. Wang, Y. Liu, X. Zhang, C. Ren, Quantitative evaluation of impact damage to apples using NIR hyperspectral imaging. Int. J. Food Prop. 24(1), 457–470 (2021). https://doi.org/10.1080/10942912.2021.1900240
J. Onmankhong, T. Ma, T. Inagaki, P. Sirisomboon, S. Tsuchikawa, Cognitive spectroscopy for the classification of rice varieties: a comparison of machine learning and deep learning approaches in analysing long-wave near-infrared hyperspectral images of brown and milled samples. Infrared Phys. Technol. (2022). https://doi.org/10.1016/j.infrared.2022.104100
J. Wang, L. Yan, F. Wang, S. Qi, SVM classification method of waxy corn seeds with different vitality levels based on hyperspectral imaging. J. Sens. (2022). https://doi.org/10.1155/2022/4379317
Y.-H. Yun, W.-T. Wang, M.-L. Tan, Y.-Z. Liang, H.-D. Li, D.-S. Cao, H.-M. Lu, Q.-S. Xu, A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration. Anal. Chim. Acta 807, 36–43 (2014). https://doi.org/10.1016/j.aca.2013.11.032
D. Saha, T. Senthilkumar, S. Sharma, C.B. Singh, A. Manickavasagan, Application of near-infrared hyperspectral imaging coupled with chemometrics for rapid and non-destructive prediction of protein content in single chickpea seed. J. Food Compos. Anal. (2023). https://doi.org/10.1016/j.jfca.2022.104938
Z. Sun, H. Pan, M. Zuo, J. Li, L. Liang, C.-T. Ho, X. Zou, Non-destructive assessment of equivalent umami concentrations in salmon using hyperspectral imaging technology combined with multivariate algorithms. Spectrochim. Acta Part A (2023). https://doi.org/10.1016/j.saa.2022.121890
L. Nørregard, A. Saudland, J. Wagner, J.P. Nielsen, L. Munck, S.B. Engelsen, Interval partial least-squares regression (iPLS): a comparative chemometric study with an example from near-infrared spectroscopy. Appl. Spectrosc. 54(3), 413–419 (2000). https://doi.org/10.1366/0003702001949500
J. Florián-Huamán, J.P. Cruz-Tirado, D. FernandesBarbin, R. Siche, Detection of nutshells in cumin powder using NIR hyperspectral imaging and chemometrics tools. J. Food Compos. Anal. (2022). https://doi.org/10.1016/j.jfca.2022.104407
A. López-Maestresalas, C. Lopez-Molina, G.A. Oliva-Lobo, C. Jarén, J.I. Galarreta, C.M. Peraza-Alemán, S. Arazuri, Evaluation of near-infrared hyperspectral imaging for the assessment of potato processing aptitude. Front. Nutr. (2022). https://doi.org/10.3389/fnut.2022.999877
G. Kim, H. Lee, I. Baek, B.-K. Cho, M.S. Kim, Quantitative detection of benzoyl peroxide in wheat flour using line-scan short-wave infrared hyperspectral imaging. Sens. Actuators B (2022). https://doi.org/10.1016/j.snb.2021.130997
B. Wang, J. He, S. Zhang, L. Li, Nondestructive prediction and visualization of total flavonoids content in Cerasus humilis fruit during storage periods based on hyperspectral imaging technique. J. Food Process. Eng. (2021). https://doi.org/10.1111/jfpe.13807
M.M.A. Chaudhry, M.L. Amodio, J.M. Amigo, M.L.V. Chiara, F. Babellahi, G. Colelli, Feasibility study for the surface prediction and mapping of phytonutrients in minimally processed rocket leaves (Diplotaxis tenuifolia) during storage by hyperspectral imaging. Comput. Electron. Agric. (2020). https://doi.org/10.1016/j.compag.2020.105575
X. Ye, S. Abe, S. Zhang, Estimation and mapping of nitrogen content in apple trees at leaf and canopy levels using hyperspectral imaging. Precision Agric. 21(1), 198–225 (2020). https://doi.org/10.1007/s11119-019-09661-x
K. Song, S.-H. Wang, D. Yang, T.-Y. Shi, Combination of spectral and image information from hyperspectral imaging for the prediction and visualization of the total volatile basic nitrogen content in cooked beef. J. Food Meas. Charact. 15(5), 4006–4020 (2021). https://doi.org/10.1007/s11694-021-00983-x
H. Jiang, Y. Hu, X. Jiang, H. Zhou, Maturity stage discrimination of Camellia oleifera fruit using visible and near-infrared hyperspectral imaging. Molecules (2022). https://doi.org/10.3390/molecules27196318
D. Fu, Q. Wang, M. Ma, Nondestructive detection of egg freshness fusion index during storage based on hyperspectral imaging. ACM Int. Conf. Proc. Ser. (2020). https://doi.org/10.1145/3453187.3453379
X. Zheng, Y. Li, W. Wei, Y. Peng, Detection of adulteration with duck meat in minced lamb meat by using visible near-infrared hyperspectral imaging. Meat Sci. 149, 55–62 (2019). https://doi.org/10.1016/j.meatsci.2018.11.005
A.M. Rady, D.E. Guyer, I.R. Donis-González, W. Kirk, N.J. Watson, A comparison of different optical instruments and machine learning techniques to identify sprouting activity in potatoes during storage. J. Food Meas. Charact. 14(6), 3565–3579 (2020). https://doi.org/10.1007/s11694-020-00590-2
N. Ekramirad, A.Y. Khaled, L.E. Doyle, J.R. Loeb, K.D. Donohue, R.T. Villanueva, A.A. Adedeji, Nondestructive detection of codling moth infestation in apples using pixel-based NIR hyperspectral imaging with machine learning and feature selection. Foods (2022). https://doi.org/10.3390/foods11010008
I. Baek, C. Mo, C. Eggleton, S.A. Gadsden, B.-K. Cho, J. Qin, D.E. Chan, M.S. Kim, Determination of spectral resolutions for multispectral detection of apple bruises using visible/near-infrared hyperspectral reflectance imaging. Front. Plant Sci. (2022). https://doi.org/10.3389/fpls.2022.963591
B.-C. Deng, Y.-H. Yun, P. Ma, C.-C. Lin, D.-B. Ren, Y.-Z. Liang, A new method for wavelength interval selection that intelligently optimizes the locations, widths and combinations of the intervals. Analyst 140, 1876–1885 (2015). https://doi.org/10.1039/C4AN02123A
J. Hao, F. Dong, Y. Li, S. Wang, J. Cui, Z. Zhang, K. Wu, Investigation of the data fusion of spectral and textural data from hyperspectral imaging for the near geographical origin discrimination of wolfberries using 2D-CNN algorithms. Infrared Phys. Technol. (2022). https://doi.org/10.1016/j.infrared.2022.104286
Y.H. Yun, H.D. Li, L.R. Wood, W. Fan, J.J. Wang, D.S. Cao, Q.S. Xu, Y.Z. Liang, An efficient method of wavelength interval selection based on random frog for multivariate spectral calibration. Spectrochim. Acta Part A. 111, 31–6 (2013). https://doi.org/10.1016/j.saa.2013.03.083
I. Noda, Recent advancement in the field of two-dimensional correlation spectroscopy. J. Mol. Struct. (2008). https://doi.org/10.1016/j.molstruc.2007.11.038
H. Jiang, X. Jiang, Y. Ru, Q. Chen, J. Wang, L. Xu, H. Zhou, Detection and visualization of soybean protein powder in ground beef using visible and near-infrared hyperspectral imaging. Infrared Phys. Technol. (2022). https://doi.org/10.1016/j.infrared.2022.104401
H. Jiang, X. Jiang, Y. Ru, Q. Chen, X. Li, L. Xu, H. Zhou, M. Shi, Rapid and non-destructive detection of natural mildew degree of postharvest camellia oleifera fruit based on hyperspectral imaging. Infrared Phys. Technol. (2022). https://doi.org/10.1016/j.infrared.2022.104169
W. Cai, Y. Li, X. Shao, A variable selection method based on uninformative variable elimination for multivariate calibration of near-infrared spectra. Chemom. Intell. Lab. Syst. 90(2), 188–194 (2008). https://doi.org/10.1016/j.chemolab.2007.10.001
B. Sturm, S. Raut, B. Kulig, J. Münsterer, K. Kammhuber, O. Hensel, S.O.J. Crichton, In-process investigation of the dynamics in drying behavior and quality development of hops using visual and environmental sensors combined with chemometrics. Comput. Electron. Agric. 175, 96 (2020). https://doi.org/10.1016/j.compag.2020.105547
X. Wei, J. He, S. Zheng, D. Ye, Modeling for SSC and firmness detection of persimmon based on NIR hyperspectral imaging by sample partitioning and variables selection. Infrared Phys. Technol. (2020). https://doi.org/10.1016/j.infrared.2019.103099
B. Li, Z. Han, Q. Wang, A. Yang, Y. Liu, Detection of skin defects in loquats based on grayscale features combined with reflectance, absorbance, and kubelka-munk spectra. J. Chemometr. (2022). https://doi.org/10.1002/cem.3449
B.-C. Deng, Y.-H. Yun, Y.-Z. Liang, L.-z Yi, A novel variable selection approach that iteratively optimizes variable space using weighted binary matrix sampling. Analyst 139, 4836–4845 (2014). https://doi.org/10.1039/C4AN00730A
L. Fu, J. Sun, S. Wang, M. Xu, K. Yao, X. Zhou, Nondestructive evaluation of Zn content in rape leaves using MSSAE and hyperspectral imaging. Spectrochim. Acta Part A (2022). https://doi.org/10.1016/j.saa.2022.121641
Y. Wang, Y. Zhang, Y. Yuan, Y. Zhao, J. Nie, T. Nan, L. Huang, J. Yang, Nutrient content prediction and geographical origin identification of red raspberry fruits by combining hyperspectral imaging with chemometrics. Front. Nutr. (2022). https://doi.org/10.3389/fnut.2022.980095
T. An, S. Yu, W. Huang, G. Li, X. Tian, S. Fan, C. Dong, C. Zhao, Robustness and accuracy evaluation of moisture prediction model for black tea withering process using hyperspectral imaging. Spectrochim. Acta Part A (2022). https://doi.org/10.1016/j.saa.2021.120791
C.X. Garzon-Lopez, E. Lasso, Species classification in a tropical alpine ecosystem using UAV-borne RGB and hyperspectral imagery. Drones 4(4), 1–18 (2020). https://doi.org/10.3390/drones4040069
S. Chang, U. Lee, J.-B. Kim, Y.D. Jo, Application of 3D-volumetric analysis and hyperspectral imaging systems for investigation of heterosis and cytoplasmic effects in pepper. Sci. Horticult. (2022). https://doi.org/10.1016/j.scienta.2022.111150
I. Guyon, J. Weston, S. Barnhill, V. Vapnik, Gene selection for cancer classification using support vector machines. Mach. Learn. 46(1), 389–422 (2002). https://doi.org/10.1023/A:1012487302797
A. Viinikka, P. Hurskainen, S. Keski-Saari, S. Kivinen, T. Tanhuanpää, J. Mäyrä, L. Poikolainen, P. Vihervaara, T. Kumpula, Detecting European aspen (Populus tremula, L.) in boreal forests using airborne hyperspectral and airborne laser scanning data. Remote Sens. (2020). https://doi.org/10.3390/RS12162610
J. Mohite, S. Sawant, R. Agarwal, A. Pandit, S. Pappula, Detection of crop water stress in maize using drone based hyperspectral imaging. Int. Geosci. Remote Sens. Symp. (IGARSS) 2022–July, 5957–5960 (2022). https://doi.org/10.1109/IGARSS46834.2022.9884686
A.U.G. Sankararao, P. Rajalakshmi, S. Kaliamoorthy, S. Choudhary, Water stress detection in pearl millet canopy with selected wavebands using UAV based hyperspectral imaging and machine learning. 2022 IEEE Sensors Applications Symposium (SAS), Sundsvall, Sweden, 1–6 (2022) https://doi.org/10.1109/SAS54819.2022.9881337
L. Munck, J.P. Nielsen, B. Møller, S. Jacobsen, I. Søndergaard, S.B. Engelsen, L. Nørgaard, R. Bro, Exploring the phenotypic expression of a regulatory proteome-altering gene by spectroscopy and chemometrics. Anal. Chim. Acta 446(1–2), 171–186 (2001)
J. Shi, W. Chen, X. Zou, Y. Xu, X. Huang, Y. Zhu, T. Shen, Detection of triterpene acids distribution in loquat (Eriobotrya japonica) leaf using hyperspectral imaging. Spectrochimica Acta - Part A: Molecular and Biomolecular Spectroscopy 188, 436–442 (2018). https://doi.org/10.1016/j.saa.2017.07.023
A. Hassanzadeh, F. Zhang, J. Van Aardt, S.P. Murphy, S.J. Pethybridge, Broadacre crop yield estimation using imaging spectroscopy from unmanned aerial systems (UAS): A field-based case study with snap bean. Remote Sensing 13(16) (2021). https://doi.org/10.3390/rs13163241
E. Bonah, X. Huang, J.H. Aheto, R. Yi, S. Yu, H. Tu, Comparison of variable selection algorithms on Vis-NIR hyperspectral imaging spectra for quantitative monitoring and visualization of bacterial foodborne pathogens in fresh pork muscles. Infrared Physics and Technology 107 (2020). https://doi.org/10.1016/j.infrared.2020.103327
W. Liu, S. Zeng, G. Wu, H. Li, F. Chen, Rice seed purity identification technology using hyperspectral image with lasso logistic regression model. Sensors 21(13) (2021). https://doi.org/10.3390/s21134384
N.H. Samrat, J.B. Johnson, S. White, M. Naiker, P. Brown, A rapid non-destructive hyperspectral imaging data model for the prediction of pungent constituents in dried ginger. Foods 11(5) (2022). https://doi.org/10.3390/foods11050649
Q. Wang, Y. Liu, Q. Xu, J. Feng, H. Yu, Identification of mildew degrees in honeysuckle using hyperspectral imaging combined with variable selection. Journal of Food Measurement and Characterization 13(3), 2157–2166 (2019). https://doi.org/10.1007/s11694-019-00136-1
Q. Wang, Y. Liu, X. Gao, A. Xie, H. Yu, Potential of hyperspectral imaging for nondestructive determination of chlorogenic acid content in flos lonicerae. Journal of Food Measurement and Characterization 13(4), 2603–2612 (2019). https://doi.org/10.1007/s11694-019-00180-x
D. Wu, D.-W. Sun, Advanced applications of hyperspectral imaging technology for food quality and safety analysis and assessment: A review - part ii: Applications. Innov. Food Sci. Emerg. Technol. 19, 15–28 (2013). https://doi.org/10.1016/j.ifset.2013.04.016
D. Wu, S. Wang, N. Wang, P. Nie, Y. He, D.-W. Sun, J. Yao, Application of time series hyperspectral imaging (TS-HSI) for determining water distribution within beef and spectral kinetic analysis during dehydration. Food Bioprocess Technol. 6(11), 2943–2958 (2013). https://doi.org/10.1007/s11947-012-0928-0
C. Cortes, V. Vapnik, Support-vector networks. Machine Learning 20(3 N - 1573-0565), 273–297 (1995) https://doi.org/10.1007/BF00994018
D.E. Rumelhart, G.E. Hinton, R.J. Williams, Learning representations by back-propagating errors. Nature 323(6088), 533–536 (1986). https://doi.org/10.1038/323533a0
G.-B. Huang, Q.-Y. Zhu, C.-K. Siew, Extreme learning machine: theory and applications. Neurocomputing 70(1), 489–501 (2006).
I.J. Goodfellow, Y. Bengio, A. Courville, Deep Learning. MIT Press, Cambridge, MA, USA (2016). http://www.deeplearningbook.org
Y. Wang, F. Xiong, Y. Zhang, S. Wang, Y. Yuan, C. Lu, J. Nie, T. Nan, B. Yang, L. Huang, J. Yang, Application of hyperspectral imaging assisted with integrated deep learning approaches in identifying geographical origins and predicting nutrient contents of coix seeds. Food Chemistry 404 (2023). https://doi.org/10.1016/j.foodchem.2022.134503
B. Jin, H. Qi, L. Jia, Q. Tang, L. Gao, Z. Li, G. Zhao, Determination of viability and vigor of naturally-aged rice seeds using hyperspectral imaging with machine learning. Infrared Physics and Technology 122 (2022). https://doi.org/10.1016/j.infrared.2022.104097
Q. Pang, W. Huang, S. Fan, Q. Zhou, Z. Wang, X. Tian, Detection of early bruises on apples using hyperspectral imaging combining with YOLOv3 deep learning algorithm. Journal of Food Process Engineering 45(2) (2022). https://doi.org/10.1111/jfpe.13952
T. Ojala, M. Pietikäinen, D. Harwood, A comparative study of texture measures with classification based on featured distributions. Pattern Recogn. 29(1), 51–59 (1996). https://doi.org/10.1016/0031-3203(95)00067-4
Z. Wang, W. Huang, X. Tian, Y. Long, L. Li, S. Fan, Rapid and non-destructive classification of new and aged maize seeds using hyperspectral image and chemometric methods. Frontiers in Plant Science 13 (2022). https://doi.org/10.3389/fpls.2022.849495
K. Yao, J. Sun, C. Chen, M. Xu, X. Zhou, Y. Cao, Y. Tian, Non-destructive detection of egg qualities based on hyperspectral imaging. Journal of Food Engineering 325 (2022). https://doi.org/10.1016/j.jfoodeng.2022.111024
R.D. Logan, B. Scherrer, J. Senecal, N.S. Walton, A. Peerlinck, J.W. Sheppard, J.A. Shaw, Assessing produce freshness using hyperspectral imaging and machine learning. Journal of Applied Remote Sensing 15(3) (2021). https://doi.org/10.1117/1.JRS.15.034505
S. Feng, Y. Cao, T. Xu, F. Yu, D. Zhao, G. Zhang, Rice leaf blast classification method based on fused features and one-dimensional deep convolutional neural network. Remote Sensing 13(16) (2021). https://doi.org/10.3390/rs13163207
S. Weng, B. Guo, Y. Du, M. Wang, P. Tang, J. Zhao, Feasibility of authenticating mutton geographical origin and breed via hyperspectral imaging with effective variables of multiple features. Food Anal. Methods 14(4), 834–844 (2021). https://doi.org/10.1007/s12161-020-01940-y
C.T. Kucha, L. Liu, M. Ngadi, C. Gariépy, Assessment of intramuscular fat quality in pork using hyperspectral imaging. Food Engineering Reviews 13(1), 274–289 (2021). https://doi.org/10.1007/s12393-020-09246-9
M.K. Behera, K.M.S. Kishore, S. Chakravarty, Classification of soil and prediction of total nitrogen content present in soil by using hyperspectral imaging. Lecture Notes in Networks and Systems 202 LNNS, 337–345 (2021). https://doi.org/10.1007/978-981-16-0695-3_33
C. Wang, S. Wang, X. He, L. Wu, Y. Li, J. Guo, Combination of spectra and texture data of hyperspectral imaging for prediction and visualization of palmitic acid and oleic acid contents in lamb meat. Meat Science 169 (2020). https://doi.org/10.1016/j.meatsci.2020.108194
H. Zhang, S. Zhang, Y. Chen, W. Luo, Y. Huang, D. Tao, B. Zhan, X. Liu, Non-destructive determination of fat and moisture contents in salmon (salmo salar) fillets using near-infrared hyperspectral imaging coupled with spectral and textural features. Journal of Food Composition and Analysis 92 (2020). https://doi.org/10.1016/j.jfca.2020.103567
D. Zhang, G. Chen, H. Zhang, N. Jin, C. Gu, S. Weng, Q. Wang, Y. Chen, Integration of spectroscopy and image for identifying fusarium damage in wheat kernels. Spectrochimica Acta - Part A: Molecular and Biomolecular Spectroscopy 236 (2020). https://doi.org/10.1016/j.saa.2020.118344
J.H. Aheto, X. Huang, X. Tian, Y. Ren, B. Ernest, E.A. Alenyorege, C. Dai, T. Hongyang, Z. Xiaorui, P. Wang, Multi-sensor integration approach based on hyperspectral imaging and electronic nose for quantitation of fat and peroxide value of pork meat. Anal. Bioanal. Chem. 412(5), 1169–1179 (2020). https://doi.org/10.1007/s00216-019-02345-5
H. Lin, Z. Wang, W. Ahmad, Z. Man, Y. Duan, Identification of rice storage time based on colorimetric sensor array combined hyperspectral imaging technology. Journal of Stored Products Research 85 (2020). https://doi.org/10.1016/j.jspr.2019.101523
Y. Liu, S. Zhou, W. Han, W. Liu, Z. Qiu, C. Li, Convolutional neural network for hyperspectral data analysis and effective wavelengths selection. Anal. Chim. Acta 1086, 46–54 (2019). https://doi.org/10.1016/j.aca.2019.08.026
C. Xia, S. Yang, M. Huang, Q. Zhu, Y. Guo, J. Qin, Maize seed classification using hyperspectral image coupled with multi-linear discriminant analysis. Infrared Physics and Technology 103 (2019). https://doi.org/10.1016/j.infrared.2019.103077
S. Jia, H. Li, X. Wu, Q. Li, Laboratory-based hyperspectral image analysis for the classification of soil texture. Journal of Applied Remote Sensing 13(4) (2019). https://doi.org/10.1117/1.JRS.13.046508
D. Tao, Z. Wang, G. Li, L. Xie, Sex determination of silkworm pupae using Vis-NIR hyperspectral imaging combined with chemometrics. Spectrochimica Acta - Part A: Molecular and Biomolecular Spectroscopy 208, 7–12 (2019). https://doi.org/10.1016/j.saa.2018.09.049
K. Tan, R. Wang, M. Li, Z. Gong, Discriminating soybean seed varieties using hyperspectral imaging and machine learning. Journal of Computational Methods in Sciences and Engineering 19(4), 1001–1015 (2019). https://doi.org/10.3233/JCM-193562
D. Tao, Z. Wang, G. Li, L. Xie, Simultaneous species and sex identification of silkworm pupae using hyperspectral imaging technology. Spectrosc. Lett. 51(8), 446–452 (2018). https://doi.org/10.1080/00387010.2018.1503602
Y. Wang, X. Hu, Z. Hou, J. Ning, Z. Zhang, Discrimination of nitrogen fertilizer levels of tea plant (camellia sinensis) based on hyperspectral imaging. J. Sci. Food Agric. 98(12), 4659–4664 (2018). https://doi.org/10.1002/jsfa.8996
J. Lu, M. Zhou, Y. Gao, H. Jiang, Using hyperspectral imaging to discriminate yellow leaf curl disease in tomato leaves. Precision Agric. 19(3), 379–394 (2018). https://doi.org/10.1007/s11119-017-9524-7
Y. Sun, K. Wei, Q. Liu, L. Pan, K. Tu, Classification and discrimination of different fungal diseases of three infection levels on peaches using hyperspectral reflectance imaging analysis. Sensors (Switzerland) 18(4) (2018). https://doi.org/10.3390/s18041295
H. Lu, X. Yu, L. Zhou, Y. He, Selection of spectral resolution and scanning speed for detecting green jujubes chilling injury based on hyperspectral reflectance imaging. Applied Sciences (Switzerland) 8(4) (2018). https://doi.org/10.3390/app8040523
J. Xiong, R. Lin, R. Bu, Z. Liu, Z. Yang, L. Yu, A micro-damage detection method of litchi fruit using hyperspectral imaging technology. Sensors (Switzerland) 18(3) (2018). https://doi.org/10.3390/s18030700
B. Jia, W. Wang, S.-C. Yoon, H. Zhuang, Y.-F. Li, Using a combination of spectral and textural data to measure water-holding capacity in fresh chicken breast fillets. Applied Sciences (Switzerland) 8(3) (2018). https://doi.org/10.3390/app8030343
T. Guo, M. Huang, Q. Zhu, Y. Guo, J. Qin, Hyperspectral image-based multi-feature integration for TVB-N measurement in pork. J. Food Eng. 218, 61–68 (2018). https://doi.org/10.1016/j.jfoodeng.2017.09.003
R. Khodabakhshian, B. Emadi, Application of Vis/SNIR hyperspectral imaging in ripeness classification of pear. Int. J. Food Prop. 20, 3149–3163 (2018). https://doi.org/10.1080/10942912.2017.1354022
J. Ning, J. Sun, S. Li, M. Sheng, Z. Zhang, Classification of five chinese tea categories with different fermentation degrees using visible and near-infrared hyperspectral imaging. Int. J. Food Prop. 20, 1515–1522 (2017). https://doi.org/10.1080/10942912.2016.1233115
H. Zhu, B. Chu, C. Zhang, F. Liu, L. Jiang, Y. He, Hyperspectral imaging for presymptomatic detection of tobacco disease with successive projections algorithm and machine-learning classifiers. Scientific Reports 7(1) (2017). https://doi.org/10.1038/s41598-017-04501-2
H.-H. Wang, S.-L. Zhang, K. Li, S.-S. Cheng, M.-Q. Tan, X.-H. Tao, X. Zhang, Non-destructive detection of ready-to-eat sea cucumber freshness based on hyperspectral imaging. Spectroscopy and Spectral Analysis 37(11), 3632–3640 (2017). https://doi.org/10.3964/j.issn.1000-0593(2017)11-3632-09
S. Zeng, L. Chen, L. Jiang, C. Gao, Hyperspectral imaging technique based on Geodesic K-medoids clustering and Gabor wavelets for pork quality evaluation. International Journal of Wavelets, Multiresolution and Information Processing 15(6) (2017). https://doi.org/10.1142/S0219691317500667
Y. Fan, T. Wang, Z. Qiu, J. Peng, C. Zhang, Y. He, Fast detection of striped stem-borer (chilo suppressalis walker) infested rice seedling based on visible/near-infrared hyperspectral imaging system. Sensors (Switzerland) 17(11) (2017). https://doi.org/10.3390/s17112470
D. Yang, D. He, A. Lu, D. Ren, J. Wang, Combination of spectral and textural information of hyperspectral imaging for the prediction of the moisture content and storage time of cooked beef. Infrared Physics and Technology 83, 206–216 (2017). https://doi.org/10.1016/j.infrared.2017.05.005
J.-H. Cheng, D.-W. Sun, Q. Wei, Enhancing visible and near-infrared hyperspectral imaging prediction of TVB-N level for fish fillet freshness evaluation by filtering optimal variables. Food Anal. Methods 10(6), 1888–1898 (2017). https://doi.org/10.1007/s12161-016-0742-9
J. Ma, D.-W. Sun, H. Pu, Model improvement for predicting moisture content (MC) in pork longissimus dorsi muscles under diverse processing conditions by hyperspectral imaging. J. Food Eng. 196, 65–72 (2017). https://doi.org/10.1016/j.jfoodeng.2016.10.016
J.-L. Xu, D.-W. Sun, Identification of freezer burn on frozen salmon surface using hyperspectral imaging and computer vision combined with machine learning algorithm [identification de la brûlure de congélation sur la surface du saumon congelé en utilisant l’imagerie hyperspectrale et la vision par ordinateur combinée avec l’algorithme d”’apprentissage automatique]. International Journal of Refrigeration 74, 149–162 (2017). https://doi.org/10.1016/j.ijrefrig.2016.10.014
Zhao, Y.R., Yu, K.Q., Feng, C., Cen, H.Y., He, Y.: Early detection of aphid (Myzus persicae) infestation on chinese cabbage by hyperspectral imaging and feature extraction. Transactions of the ASABE 60(4), 1045–1051 (2017) https://doi.org/10.13031/trans.11886
S. Fan, B. Zhang, J. Li, C. Liu, W. Huang, X. Tian, Prediction of soluble solids content of apple using the combination of spectra and textural features of hyperspectral reflectance imaging data. Postharvest Biol. Technol. 121, 51–61 (2016). https://doi.org/10.1016/j.postharvbio.2016.07.007
H. Ma, H.-Y. Ji, W.S. Lee, Identification of the citrus greening disease using spectral and textural features based on hyperspectral imaging. Spectroscopy and Spectral Analysis 36(7), 2344–2350 (2016). https://doi.org/10.3964/j.issn.1000-0593(2016)07-2344-07
U. Khulal, J. Zhao, W. Hu, Q. Chen, Nondestructive quantifying total volatile basic nitrogen (TVB-N) content in chicken using hyperspectral imaging (HSI) technique combined with different data dimension reduction algorithms. Food Chem. 197, 1191–1199 (2016). https://doi.org/10.1016/j.foodchem.2015.11.084
M. Huang, C. He, Q. Zhu, J. Qin, Maize seed variety classification using the integration of spectral and image features combined with feature transformation based on hyperspectral imaging. Applied Sciences (Switzerland) 6(6) (2016). https://doi.org/10.3390/app6060183
J. Sun, S. Jiang, H. Mao, X. Wu, Q. Li, Classification of black beans using visible and near infrared hyperspectral imaging. Int. J. Food Prop. 19(8), 1687–1695 (2016). https://doi.org/10.1080/10942912.2015.1055760
G.K. Naganathan, K. Cluff, A. Samal, C.R. Calkins, D.D. Jones, R.L. Wehling, J. Subbiah, Identification and validation of key wavelengths for on-line beef tenderness forecasting. Trans. ASABE 59(3), 769–783 (2016). https://doi.org/10.13031/trans.59.11034
L. Wang, D.-W. Sun, H. Pu, Z. Zhu, Application of hyperspectral imaging to discriminate the variety of maize seeds. Food Anal. Methods 9(1), 225–234 (2016). https://doi.org/10.1007/s12161-015-0160-4
C. Xie, Y. Shao, X. Li, Y. He, Detection of early blight and late blight diseases on tomato leaves using hyperspectral imaging. Scientific Reports 5 (2015). https://doi.org/10.1038/srep16564
Z. Xiong, D.-W. Sun, H. Pu, Z. Zhu, M. Luo, Combination of spectra and texture data of hyperspectral imaging for differentiating between free-range and broiler chicken meats. LWT 60(2), 649–655 (2015). https://doi.org/10.1016/j.lwt.2014.10.021
Y. Cao, C. Zhang, Q. Chen, Y. Li, S. Qi, L. Tian, Y. Ren, Identification of species and geographical strains of sitophilus oryzae and sitophilus zeamais using the visible/near-infrared hyperspectral imaging technique. Pest Manag. Sci. 71(8), 1113–1121 (2015). https://doi.org/10.1002/ps.3893
J. Ma, H. Pu, D.-W. Sun, W. Gao, J.-H. Qu, K.-Y. Ma, Application of Vis-NIR hyperspectral imaging in classification between fresh and frozen-thawed pork longissimus dorsi muscles. Int. J. Refrig. 50, 10–18 (2015). https://doi.org/10.1016/j.ijrefrig.2014.10.024
M. Huang, Y. Ma, Y. Li, Q. Zhu, G. Huang, P. Bu, Hyperspectral image-based feature integration for insect-damaged hawthorn detection. Anal. Methods 6(19), 7793–7800 (2014). https://doi.org/10.1039/c4ay01246a
D. Liu, H. Pu, D.-W. Sun, L. Wang, X.-A. Zeng, Combination of spectra and texture data of hyperspectral imaging for prediction of pH in salted meat. Food Chem. 160, 330–337 (2014). https://doi.org/10.1016/j.foodchem.2014.03.096
H.-J. He, D. Wu, D.-W. Sun, Potential of hyperspectral imaging combined with chemometric analysis for assessing and visualising tenderness distribution in raw farmed salmon fillets. J. Food Eng. 126, 156–164 (2014). https://doi.org/10.1016/j.jfoodeng.2013.11.015
H. Huang, L. Liu, M.O. Ngadi, C. Gariépy, S.O. Prasher, Near-infrared spectral image analysis of pork marbling based on Gabor filter and wide line detector techniques. Appl. Spectrosc. 68(3), 332–339 (2014). https://doi.org/10.1366/13-07242
H. Pu, D.-W. Sun, J. Ma, D. Liu, J.-H. Cheng, Using wavelet textural features of visible and near infrared hyperspectral image to differentiate between fresh and frozen–thawed pork. Food Bioprocess Technol. 7(11), 3088–3099 (2014). https://doi.org/10.1007/s11947-014-1330-x
X. Wei, F. Liu, Z. Qiu, Y. Shao, Y. He, Ripeness classification of astringent persimmon using hyperspectral imaging technique. Food Bioprocess Technol. 7(5), 1371–1380 (2014). https://doi.org/10.1007/s11947-013-1164-y
D. Wu, D.-W. Sun, Y. He, Novel non-invasive distribution measurement of texture profile analysis (TPA) in salmon fillet by using visible and near infrared hyperspectral imaging. Food Chem. 145, 417–426 (2014). https://doi.org/10.1016/j.foodchem.2013.08.063
Q. Chen, Y. Zhang, J. Zhao, Z. Hui, Nondestructive measurement of total volatile basic nitrogen (TVB-N) content in salted pork in jelly using a hyperspectral imaging technique combined with efficient hypercube processing algorithms. Anal. Methods 5(22), 6382–6388 (2013). https://doi.org/10.1039/c3ay40436f
H. Yong-Guang, C. Pei-Pei, L. Ping-Ping, Determination of water content in de-enzyming green tea leaves based on hyper-spectral imaging. Inf. Technol. J. 12(22), 6729–6734 (2013). https://doi.org/10.3923/itj.2013.6729.6734
J. Gao, X. Li, F. Zhu, Y. He, Application of hyperspectral imaging technology to discriminate different geographical origins of Jatropha curcas, L. seeds. Comput. Electron. Agric. 99, 186–193 (2013). https://doi.org/10.1016/j.compag.2013.09.011
X. Zhang, F. Liu, Y. He, X. Li, Application of hyperspectral imaging and chemometric calibrations for variety discrimination of maize seeds. Sensors (Switzerland) 12(12), 17234–17246 (2012). https://doi.org/10.3390/s121217234
Y. Tian, T. Li, L. Zhang, X. Zhang, Diagnosis method of cucumber downy mildew with NIR hyperspectral imaging. Proceedings of SPIE - The International Society for Optical Engineering 8002 (2011). https://doi.org/10.1117/12.901527
R. Gosselin, D. Rodrigue, C. Duchesne, A hyperspectral imaging sensor for on-line quality control of extruded polymer composite products. Comput. Chem. Eng. 35(2), 296–306 (2011). https://doi.org/10.1016/j.compchemeng.2010.07.020
G. ElMasry, N. Wang, A. ElSayed, M. Ngadi, Hyperspectral imaging for nondestructive determination of some quality attributes for strawberry. J. Food Eng. 81(1), 98–107 (2007). https://doi.org/10.1016/j.jfoodeng.2006.10.016
R.M. Haralick, Statistical and structural approaches to texture. Proc. IEEE 67(5), 786–804 (1979). https://doi.org/10.1109/PROC.1979.11328
R.M. Haralick, K. Shanmugam, I. Dinstein, Textural features for image classification. IEEE Trans. Syst. Man Cybern. SMC–3(6), 610–621 (1973). https://doi.org/10.1109/TSMC.1973.4309314
D.A. Clausi, An analysis of co-occurrence texture statistics as a function of grey level quantization. Can. J. Remote. Sens. 28(1), 45–62 (2002). https://doi.org/10.5589/m02-004
L.-K. Soh, C. Tsatsoulis, Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote Sens. 37(2), 780–795 (1999). https://doi.org/10.1109/36.752194
S.W.-C. Lam, Texture feature extraction using gray level gradient based co-occurence matrices. In: 1996 IEEE International Conference on Systems, Man and Cybernetics. Information Intelligence and Systems (Cat. No.96CH35929), vol. 1, pp. 267–2711 (1996). https://doi.org/10.1109/ICSMC.1996.569778
A. Ramola, A.K. Shakya, D. Van Pham, Study of statistical methods for texture analysis and their modern evolutions. Engineering Reports 2(4), 12149 (2020). https://doi.org/10.1002/eng2.12149
X. Chu, R. Li, H. Wei, H. Liu, Y. Mu, H. Jiang, Z. Ma, Determination of total flavonoid and polysaccharide content in anoectochilus formosanus in response to different light qualities using hyperspectral imaging. Infrared Physics and Technology 122 (2022). https://doi.org/10.1016/j.infrared.2022.104098
J. Redmon, A. Farhadi, YOLOv3: An Incremental Improvement. (2018). arxiv:1804.02767
C. Pohl, J.L. Van Genderen, Review article multisensor image fusion in remote sensing: concepts, methods and applications. Int. J. Remote Sens. 19(5), 823–854 (1998)
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, L. Fei-Fei, Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 (2009). https://doi.org/10.1109/CVPR.2009.5206848
J. Chai, H. Zeng, A. Li, E.W.T. Ngai, Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Machine Learning with Applications 6(2021). https://doi.org/10.1016/j.mlwa.2021.100134
Acknowledgements
Not applicable.
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions
Author information
Authors and Affiliations
Corresponding author
Additional information
Original article has been corrected to update affiliation.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Rogers, M., Blanc-Talon, J., Urschler, M. et al. Wavelength and texture feature selection for hyperspectral imaging: a systematic literature review. Food Measure 17, 6039–6064 (2023). https://doi.org/10.1007/s11694-023-02044-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11694-023-02044-x