
Abstract
In this paper, we address the preconditioned iterative solution of the saddle-point linear systems arising from the (regularized) Interior Point method applied to linear and quadratic convex programming problems, typically of large scale. Starting from the well-studied Constraint Preconditioner, we review a number of inexact variants with the aim to reduce the computational cost of the preconditioner application within the Krylov subspace solver of choice. In all cases we illustrate a spectral analysis showing the conditions under which a good clustering of the eigenvalues of the preconditioned matrix can be obtained, which foreshadows (at least in case PCG/MINRES Krylov solvers are used), a fast convergence of the iterative method. Results on a set of large size optimization problems confirm that the Inexact variants of the Constraint Preconditioner can yield efficient solution methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In this paper, we consider linear and convex quadratic programming (LP and QP) problems of the following form:
where \(c,x \in {\mathbb {R}}^n\), \(b \in {\mathbb {R}}^m\), \(A \in {\mathbb {R}}^{m\times n}\). For quadratic programming problems we assume that \(Q \succeq 0 \in {\mathbb {R}}^{n \times n}\), while for linear programming we have \(Q=0\). The problem (1.1) is often referred to as the primal form of the quadratic programming problem; the dual form of the problem is given by
where \(z \in {\mathbb {R}}^n\), \(y \in {\mathbb {R}}^m\). Problems of linear or quadratic programming form are fundamental problems in optimization, and arise in a wide range of scientific applications.
A variety of optimization methods exist for solving the problem (1.1). Two popular and successful approaches are interior point methods (IPMs) and proximal methods of multipliers (PMMs). Within an IPM, a Lagrangian is constructed involving the objective function and the equality constraints of (1.1), to which a logarithmic barrier function is then added in place of the inequality constraints. Hence, a logarithmic barrier sub-problem is solved at each iteration of the algorithm (see [36] for a survey on IPMs). The key feature of a PMM is that, at each iteration, one seeks the minimum of the problem (1.1) as stated, but one adds to the objective function a penalty term involving the norm of the difference between x and the previously computed estimate. Then, an augmented Lagrangian method is applied to approximately solve each such sub-problem (see [55, 63] for a review of proximal point methods, and [16, 41, 61, 62] for a review of augmented Lagrangian methods).
Upon applying either naive IPM or IP-PMM, the vast majority of the computational effort arises from the solution of the resulting linear systems of equations at each IP–PMM iteration. These linear equations can be tackled in the form of an augmented system, or the reduced normal equations: we focus much of our attention on the augmented system, as unless Q has some convenient structure it is highly undesirable to form the normal equations or apply the resulting matrix within a solver. Within the linear algebra community, direct methods are popular for solving such systems due to their generalizability, however if the matrix system becomes sufficiently large the storage and/or operation costs can rapidly become excessive, depending on the computer architecture used. The application of iterative methods, for instance those based around Krylov subspace methods such as the Conjugate Gradient method (CG) [42] or MINRES [54], is an attractive alternative, but if one cannot construct suitable preconditioners which can be applied within such solvers then convergence can be prohibitively slow, and indeed it is possible that convergence is not achieved at all. The development of powerful preconditioners is therefore crucial.
A range of general preconditioners have been proposed for augmented systems arising from optimization problems, see [14, 17, 24, 29, 53, 66] for instance. However, as is the case within the field of preconditioning in general, these are typically sensitive to changes in structure of the matrices involved, and can have substantial memory requirements. Preconditioners have also been successfully devised for specific classes of programming problems solved using similar optimization methods: applications include those arising from multicommodity network flow problems [22], stochastic programming problems [21], formulations within which the constraint matrix has primal block-angular structure [23], and PDE-constrained optimization problems [56, 57], or various applications [26]. However, such preconditioners exploit particular structures arising from specific applications; unless there exists such a structure which hints as to the appropriate way to develop a solver, the design of bespoke preconditioners remains a challenge. We finally remark that also selection of a proper stopping criterion for the inner linear solver is crucial to devise an efficient outer–inner iteration (see [74] for a recent study).
The block structure of the linear system we will address is the well-known saddle-point system:
where G is an \({\mathbb {R}}^{n \times n}\) SPD matrix, while \(A \in {\mathbb {R}}^{m \times n }\) rectangular matrix with full row rank, as usually \(m < n\). The exact constraint preconditioner (CP) is defined as
Application of \(M^{-1}\) to a vector, required at each iteration of a Krylov solver, rests on the efficient computation of the square-root free Cholesky factorization of the negative Schur complement of D in M,
which allows for the following factorization:
The aim of this paper is to review the block preconditioners proposed mainly for solving system (1.3) with focus on the approximate construction (or factorization) of the Schur complement matrix, a key issue for the development of efficient iterative solver.
This paper is structured as follows. In Sect. 2 we describe the structure of a linear system to be solved at each IP iteration in the case of Quadratic (Linear) and Non Linear problems. In Sect. 3 we recall the main properties of the exact constraint preconditioner (see e.g. [44]), whereas in Sects. 4, 5 and 6 we describe three variants of this approach, to make the cost of the preconditioner application affordable also when addressing large size problems. Namely, in Sect. 4 we describe the Inexact Constraint Preconditioner obtained by sparsifying matrix A [12, 13], in Sect. 5 we approximate directly the Schur complement matrix \(A D^{-1} A^T\) by neglecting small terms in \(D^{-1}\) as proposed in [11]; in Sect. 6 we review an approach which considers application of the exact CP at selected IP iterations while simply updating it (by a BFGS-like formula) in the subsequent iterations [8]. Some numerical results are shown in Sect. 7 and, finally, in Sect. 8 we give some concluding remarks.
Notation: Given an arbitrary square (or rectangular) matrix A, then \(\lambda _{\max }(A)\) and \(\lambda _{\min }(A)\) (or \(\sigma _{\max }(A)\) and \(\sigma _{\min }(A)\)) denote the largest and smallest eigenvalues (or singular values) of the matrix A, respectively. In all the following sections we will indicate with the symbol H the coefficient matrix, with M the preconditioner in its “direct” form (i.e. \(M \approx H\)) and with P the inverse preconditioner (satisfying \(P \approx H^{-1}\)).
2 Linear algebra in interior point methods
Interior point methods for linear, quadratic and nonlinear optimization differ obviously in many details but they rely on the same linear algebra kernel. We discuss briefly two cases of quadratic and nonlinear programming, following the presentation in [14].
2.1 Quadratic programming
Consider the convex quadratic programming problem
where \(Q \in {\mathbb {R}}^{n \times n}\) is positive semidefinite matrix, \(A \in {\mathbb {R}}^{m \times n}\) is the full rank matrix of linear constraints and vectors x, c and b have appropriate dimensions. The usual transformation in interior point methods consists in replacing inequality constraints with the logarithmic barriers to get
where \(\mu \ge 0 \) is a barrier parameter. The Lagrangian associated with this problem has the form:
and the conditions for a stationary point write
where \( X^{-1} = {{\,\mathrm{diag}\,}}\{ x_1^{-1}, x_2^{-1}, \ldots , x_n^{-1} \}. \) Having denoted
where \( S = {{\,\mathrm{diag}\,}}\{ s_1, s_2, \ldots , s_n \} \) and \( e = (1, 1, \ldots , 1)^T\), the first order optimality conditions (for the barrier problem) are:
Interior point algorithm for quadratic programming [72] applies Newton method to solve this system of nonlinear equations and gradually reduces the barrier parameter \(\mu \) to guarantee the convergence to the optimal solution of the original problem. The Newton direction is obtained by solving the system of linear equations:
where
By elimination of
from the second equation we get the symmetric indefinite augmented system of linear equations
where \(\Theta _1 = X S^{-1}\) is a diagonal scaling matrix. By eliminating \(\Delta x\) from the first equation we can reduce (2.3) further to the form of normal equations
For a generic large and sparse matrix Q it is generally inefficient to form explicitly the normal equation matrix \(H_{NE}\) so that this kind of problems are usually tackled in their augmented form (2.3).
2.2 Special cases. linear programming, separable problems
Simplified versions of (2.3) are obtained for linear programming by simply setting \(Q \equiv 0\), thus obtaining
This problem is usually solved by resorting to the normal equation system which now reads
Differently from the quadratic case, the normal equation matrix can be explicitly formed. As \(H_{NE}\) is symmetric positive definite, the system \(H_{NE} \Delta y = \mathbf{b}_{LP}\) can be solved by the Preconditioned Conjugate Gradient (PCG) iterative method. However, as it is observed by many authors, the condition number of \(H_{NE}\) grows rapidly as the Interior Point method approaches the solution to the optimization problem, and finding suitable preconditioners for this problem is currently under research. This topic will be discussed in Sect. 5.
Separable problems are characterized by the fact that Q is a diagonal matrix and hence easily invertible. As in the linear case, \(H_{NE}\) can be formed allowing to address the normal equation system.
2.3 Nonlinear programming
Consider the convex nonlinear optimization problem
where \(x \in {\mathbb {R}}^{n}\), and \(f: {\mathbb {R}}^n \mapsto {\mathbb {R}}\) and \(g: {\mathbb {R}}^n \mapsto {\mathbb {R}}^m\) are convex, twice differentiable. Having replaced inequality constraints with an equality \( g(x) + z = 0\), where \(z \in {\mathbb {R}}^m\) is a nonnegative slack variable, we can formulate the associated barrier problem
and write the Lagrangian for it
The conditions for a stationary point write
where \(Z^{-1} = {{\,\mathrm{diag}\,}}\{ z_1^{-1}, z_2^{-1}, \cdots ,z_m^{-1} \}\). The first order optimality conditions (for the barrier problem) have thus the following form
where \(Y = {{\,\mathrm{diag}\,}}\{ y_1, y_2, \cdots ,y_m \}\). Interior point algorithm for nonlinear programming [72] applies Newton method to solve this system of equations and gradually reduces the barrier parameter \(\mu \) to guarantee the convergence to the optimal solution of the original problem. The Newton direction is obtained by solving the system of linear equations:
where
Using the third equation we eliminate
from the second equation and get
The matrix involved in this set of linear equations is symmetric and indefinite. For convex optimization problem (when f and g are convex), the matrix Q is positive semidefinite and if f is strictly convex, Q is positive definite and the matrix in (2.7) is quasidefinite. Similarly to the case of quadratic programming by eliminating \(\Delta x\) from the first equation we can reduce this system further to the form of normal equations
The two systems (2.3) and (2.7) have many similarities. The main difference is that in (2.3) only the diagonal scaling matrix \(\Theta _1\) changes from iteration to iteration, while in the case of nonlinear programming not only the matrix \(\Theta _2 = Z^{-1} Y\) but also the matrices Q(x, y) and A(x) in (2.7) change in every iteration. Both these systems are indefinite. However, to avoid the need of using \(2 \times 2\) pivots in their factorization we transform them to quasidefinite ones by the use of primal and dual regularization [1]. Our analysis in the following sections is concerned with the quadratic optimization problems, and hence A and Q are constant matrices. However, the major conclusions can be generalized to the nonlinear optimization case.
3 Exact constraint preconditioner
In this section we shall discuss the properties of the preconditioned matrices involved in (2.3). For ease of the presentation we shall focus on the quadratic programming case with linear equality constraints hence we will assume that \(\Theta _2^{-1} = 0\) (we also drop the subscript in \(\Theta _1\)). In [14] these results are extended to the nonlinear programming case.
Due to the presence of matrix \(\Theta ^{-1}\), the augmented system
is very ill-conditioned. Indeed, some elements of \(\Theta \) tend to zero while others tend to infinity as the optimal solution of the problem is approached. The performance of any iterative method critically depends on the quality of the preconditioner in this case.
Block-type preconditioners are widely used in linear systems obtained from a discretization of PDEs [10, 15, 34, 58, 73]. The preconditioners for the augmented system have also been used in the context of linear programming [33, 53] and in the context of nonlinear programming [29, 44, 47, 48, 64]. As was shown in [53], the preconditioners for indefinite augmented system offer more freedom than those for the normal equations. Moreover, the factorization of the augmented system is sometimes much easier than that of the normal equations [2] (this is the case, for example, when A contains dense columns). Hence even in the case of linear programming (in which normal equations is a viable approach) augmented system offers important advantages. For quadratic and nonlinear programming the use of the augmented system is a must and so we deal with the augmented system preconditioners in this paper. On the other hand, we realize that for some specially structured problems such as multicommodity network flows, very efficient preconditioners for the normal equations [22, 43] can also be designed.
3.1 Spectral analysis
We consider the augmented system
CPs for matrix H have the following form:
where D is some symmetric approximation to G. Any preconditioner of this type can be regarded as the coefficient matrix of a Karush-Kuhn-Tucker (KKT) system associated with an optimization problem with the same constraints as the original problem, thus motivating the name of the preconditioner. We note that D should be chosen so that M is nonsingular and is “easier to factorize” than H; furthermore, it must involve \(\Theta \) in order to capture the key numerical properties of H. A common choice is
a different approach consists in implicitly defining D by using a factorization of the form \(M=U C U^T\), where U and C are specially chosen matrices [28]. Here we consider (3.4), which is SPD. The spectral properties of the preconditioned matrix \(M^{-1}H\) and the application of CG with preconditioner M to the KKT linear system have been deeply investigated. For the sake of completeness, in the next theorem we summarize some theoretical results about CPs, given in e.g. [8, 14, 44, 47].
Theorem 3.1
Let \(Z \in {\mathbb {R}}^{n \times (n-m)}\) be a matrix whose columns span the nullspace of A. Assume also that D is SPD. The following properties hold.
-
1.
\(M^{-1} H\) has an eigenvalue at 1 with multiplicity 2m.
-
2.
The remaining \(n-m\) eigenvalues of \(M^{-1} H\) are defined by the generalized eigenvalue problem
$$\begin{aligned} Z^T G Z w = \lambda Z^T D Z w. \end{aligned}$$(3.5) -
3.
The eigenvalues, \(\lambda \), of (3.5) satisfy
$$\begin{aligned} \lambda _{min} (D^{-1} G) \le \lambda \le \lambda _{max} (D^{-1} G). \end{aligned}$$(3.6) -
4.
If CG is applied to system (3.2) with preconditioner M and starting guess \(u_0 = [\, x_0^T \; y_0^T \,]^T\) such that \(A x_0 = c\), then the corresponding iterates \(x_j\) are the same as the ones generated by CG applied to
$$\begin{aligned} (Z^T G Z) x = Z^T (b - G x_0), \end{aligned}$$(3.7)with preconditioner \(Z^T D Z\). Thus, the component \(x^*\) of the solution \(u^*\) of system (3.2) is obtained in at most \(n-m\) iterations and the following inequality holds:
$$\begin{aligned} \Vert x_j - x^* \Vert \le 2 \sqrt{\kappa } \left( \frac{\sqrt{\kappa }-1}{\sqrt{\kappa } + 1} \right) ^j \Vert x_0 - x^* \Vert , \quad j=1,\ldots ,n-m, \end{aligned}$$where \(\kappa = \kappa ( (Z^T D Z)^{-1} Z^T G Z )\).
-
5.
The directions \(p_j\) and the residuals \(r_j\) generated by applying CG with preconditioner M to system (3.2), with the same starting guess as in item 4, take the following form:
$$\begin{aligned} p_j = \left[ \begin{array}{c} Z {\bar{p}}_{j,1} \\ p_{j,2} \end{array} \right] , \quad r_j = \left[ \begin{array}{c} r_{j,1} \\ 0 \end{array} \right] , \end{aligned}$$(3.8)where \({\bar{p}}_{j,1}\) and \(r_{j,1}\) are the direction and the residual, respectively, at the j-th iteration of CG applied to (3.7) with preconditioner \(Z^T D Z\), and
$$\begin{aligned} p_j^T H p_i = {\bar{p}}_{j,1} ^T Z^T G Z {\bar{p}}_{i,1} . \end{aligned}$$(3.9)
From the previous theorem it follows that the preconditioned matrix has 2m unit eigenvalues independently of the particular choice of D; on the other hand, properties 2 and 3 show that the better D approximates G, the more the remaining \(n-m\) eigenvalues of \(M^{-1} H\) are clustered around 1. Furthermore, the application of CG to the KKT system (3.2) with preconditioner M is closely related to the application of CG to system (3.7) with preconditioner \(Z^T D Z\). We note that property 4 does not guarantee that \(y_j = y^*\) after at most \(n-m\) iterations; actually, a breakdown may occur at the \((n-m+1)\)-st iteration. However, this is a “lucky breakdown”, in the sense that \(y^*\) can be easily obtained starting from the last computed approximation of it, as shown in [47]. More generally, since it may happen that the 2-norm of the PCG residual may not decrease as fast as the H-norm of the PCG error, a suitable scaling of the KKT system matrix can be used to prevent this situation [64]. We mention that other constraint-preconditioned Krylov solvers, such as MINRES, SYMMLQ and GMRES have been analyzed and implemented in [27].
Remark 3.2
The excellent spectral properties of the constraint-preconditioned matrix and the possibility of employing a suitable Conjugate Gradient method makes this preconditioner a natural choice for solving the IP linear systems. However, we note that the effectiveness of CPs may be hidden by the computational cost for the factorization of their Schur complements, thus reducing the efficiency of the overall IP procedure. Sects. 4, 5 and 6 will be devoted to address this issue. In particular we will focus on
-
1.
Constructing an inexact-constraint preconditioner, thus allowing a sparser L-factor for the Normal Equation matrix \(A D^{-1} A^T\).
-
2.
Dropping small elements in \(D^{-1}\), in this way producing a far sparser Schur complement matrix.
-
3.
Avoiding factorization of the Schur complement matrix at each IP iteration by modifying, with a low rank matrix, the preconditioner computed at one of the previous iterations.
4 Inexact jacobian constraint preconditioner
We consider the preconditioning of the KKT system \(H u = d\) by the inexact Jacobian constraint preconditioner \(M_{IJ}\), where
Once again we will consider D as a diagonal approximation of G and \({\tilde{A}}\) a sparsification of A in order to have a sparse matrix \({\tilde{A}} D^{-1} {\tilde{A}}^T\) which is needed at each application of the preconditioner \(M_{IJ}\). The eigenvalue distribution of \(M_{IJ}^{-1} H\) has been investigated in [12, 13].
Following [12] we define \(E = A - {\tilde{A}}, \, {{\,\mathrm{rank}\,}}(E) = p\). Here \({\tilde{\sigma }}_1\) is the smallest singular value of \(\tilde{A} D^{-1/2}\). We introduce two error terms:
which measure the errors of the approximations to the (1, 1) block and to the matrix of the constraints, respectively. The distance \(|\epsilon |\) of the complex eigenvalues from one with \(\epsilon = \lambda -1\), will be bounded in terms of these two quantities.
Theorem 4.1
Assume A and \(\tilde{A}\) have maximum rank. If the eigenvector is of the form \((0, y)^T\) then the eigenvalues of \(M_{IJ}^{-1}H\) are either one (with multiplicity at least \(m-p\)) or possibly complex and bounded by \(|\epsilon | \le e_A\). The eigenvalues corresponding to eigenvectors of the form \((x,y)^T\) with \(x \ne 0\) are
-
1.
equal to one (with multiplicity at least \(m-p\)), or
-
2.
real positive and bounded by
$$\begin{aligned} {{ \lambda _{\min }(D^{-1/2}QD^{-1/2}) \le \lambda \le \lambda _{\max }(D^{-1/2}QD^{-1/2})}}, \ or \end{aligned}$$ -
3.
complex, satisfying
$$\begin{aligned} | \epsilon _R|\le & {} e_Q + e_A \end{aligned}$$(4.3)$$\begin{aligned} | \epsilon _I|\le & {} e_Q + e_A, \end{aligned}$$(4.4)where \(\epsilon = \epsilon _R + \mathrm{i} \epsilon _I\).
The efficiency of the inexact Jacobian constraint preconditioner rely on (1) the clustering of the eigenvalues around one, stated by Theorem 4.1, and (2) by the ability to exactly (and economically) factorize \({\tilde{A}} D^{-1} {\tilde{A}}^T =: L D_0 L^T\).
5 An inexact normal equations preconditioner
Following [11] we consider the following augmented system after regularization.
In (5.1) two positive and decreasing sequences \(\rho _k\) and \(\delta _k\) have been introduced in order to obtain a regularized interior point method. In the sequel we will assume that both \(\rho _k\) and \(\delta _k\) are \(O(\mu _k)\) i.e. go to zero as the barrier parameter.
We remind the important feature of the matrix \(\Theta _k\): as the method approaches an optimal solution, the positive diagonal matrix has some entries that (numerically) grow like \(\mu _k^{-1}\), while others approach zero. By observing the matrix in (5.1), we can immediately see the benefits of using regularization in IPMs. On one hand, the dual regularization parameter \(\delta _k\) ensures that the system matrix in (5.1) is invertible, even if A is rank-deficient. On the other hand, the primal regularization parameter \(\rho _k\) controls the worst-case conditioning of the (1, 1) block of (5.1), improving the numerical stability of the method (and hence its robustness). We refer the reader to [1, 59, 60] for a review of the benefits of regularization in the context of IPMs.
The normal equations, at a generic step k of the Interior Point method, read as follows:
In order to employ preconditioned MINRES or CG to solve (5.1) or (5.2) respectively, we must find an approximation for the coefficient matrix in (5.2). To do so, we employ a symmetric and positive definite block-diagonal preconditioner for the saddle-point system (5.1), involving approximations for the negative of the (1,1) block, as well as the Schur complement \(H_{NE}\). See [45, 51, 68] for motivation of such saddle-point preconditioners. In light of this, we approximate Q in the (1,1) block by its diagonal, i.e. \(\tilde{Q} = \text {diag}(Q)\) and define the diagonal matrix \({\tilde{G}}_k\) as
Then, we define the diagonal matrix \(E_k\) with entries (dropping the index k in \(E_k\) and \({\tilde{G}}_k\))
where \(i \in \{1,\ldots ,n\}\), \(C_{k}\) is a constant, and we construct the normal equations approximation \(M_{NE} = L_M L_M^T\), by computing the (exact) Cholesky factorization of
The dropping threshold in (5.4) guarantees that a coefficient in the diagonal matrix \((\Theta ^{-1} + \tilde{Q}+ \rho _kI_n)^{-1}\) is set to zero only if it is below a constant times the barrier parameter \(\mu _k\). As a consequence fewer outer products of columns of A contribute to the normal equations, and the resulting preconditioner \(M_{NE}\) is expected to be more sparse than \(H_{NE}\). This choice is also crucial to guarantee that the eigenvalues of the preconditioned normal equations matrix are independent of \(\mu \). Before discussing the role of the constant \(C_{k}\), let us first address the preconditioning of the augmented system matrix in (5.1). The matrix \(M_{NE}\) acts as a preconditioner for CG applied to the normal equations. In order to construct a preconditioner for the augmented system matrix in (5.1), we employ a block-diagonal preconditioner of the form:
with \({\tilde{G}}_k\) and \(M_{NE}\) defined in (5.3) and in (5.5), respectively. Note that MINRES requires a symmetric positive definite preconditioner and hence many other block preconditioners for (5.1) are not applicable.
As we will show in the sequel, following the developments in [60], forcing the regularization variables \(\delta _k,\ \rho _k\) to decrease at the same rate as \(\mu _k\) is numerically beneficial, will provide the spectrum of the preconditioned normal equations to be independent of \(\mu _k\); a very desirable property for preconditioned systems arising from IPMs.
5.1 Spectral analysis. LP or separable QP cases
In this section we provide a spectral analysis of the preconditioned normal equations in the LP or separable QP case, assuming that (5.5) is used as the preconditioner. Although this is a specialized setting, we may make use of the following result in our analysis of the augmented system arising from the general QP case.
Let us define this normal equations matrix \(\tilde{H}_{NE}\), using the definition of \({\tilde{G}}_k\) (5.3), as
The following Theorem provides lower and upper bounds on the eigenvalues of \(M_{NE}^{-1} \tilde{H}_{NE}\), at an arbitrary iteration k of Algorithm IP–PMM.
Theorem 5.1
There are \(m-r\) eigenvalues of \(M_{NE}^{-1} \tilde{H}_{NE}\) at one, where r is the column rank of \(A^T\), corresponding to linearly independent vectors belonging to the nullspace of \(A^T\). The remaining eigenvalues are bounded as
Proof
The eigenvalues of \(M_{NE}^{-1} \tilde{H}_{NE}\) must satisfy
Multiplying (5.8) on the left by \(u^T\) and setting \(z = A^T u\) yields
For every vector u in the nullspace of \(A^T\) we have \(z = 0\) and \(\lambda = 1\). The fact that both \(E_k\) and \(\tilde{G}_k - E_k \succeq 0\) (from the definition of \(E_k\)) implies the lower bound. To prove the upper bound we first observe that, in view of (5.4), \(\lambda _{\max } (\tilde{G}_k-E_k) \le C_{k} \mu _k\); then
\(\square \)
Remark 1
Following the discussion in the end of the previous section, we know that \(\dfrac{\mu _k}{\delta _k} = O(1)\), since IP–PMM forces \(\delta _k\) to decrease at the same rate as \(\mu _k\). Combining this with the result of Theorem 5.1 implies that the condition number of the preconditioned normal equations is asymptotically independent of \(\mu _k\).
Remark 2
In the LP case (\( Q = 0\)), or the separable QP case (Q diagonal), Theorem 5.1 characterizes the eigenvalues of the preconditioned matrix within the CG method.
5.1.1 BFGS-like low-rank update of the \({M_{NE}}\) preconditioner
Given a rectangular (tall) matrix \(V \in {\mathbb {R}}^{m \times p} \) with maximum column rank, it is possible to define a generalized block-tuned preconditioner M satisfying the property
so that the columns of V become eigenvectors of the preconditioned matrix corresponding to the eigenvalue \(\nu \). A way to construct M (or its explicit inverse) is suggested by the BFGS-based preconditioners used e.g. in [7] for accelerating Newton linear systems or analyzed in [50] for general sequences of linear systems, that is
We notice that BFGS-like updates for sequences of linear systems have also been investigated e.g. in [31, 38].
Note also that if the columns of V would be chosen as e.g. the p exact rightmost eigenvectors of \(M_{NE}^{-1} \tilde{H}_{NE}\) (corresponding to the p largest eigenvalues) then all the other eigenpairs,
of the new preconditioned matrix \(M^{-1} \tilde{H}_{NE}\) would remain unchanged (nonexpansion of the spectrum of \(M^{-1} \tilde{H}_{NE}\), see [39]).
Usually columns of V are chosen as the (approximate) eigenvectors of \(M_{NE}^{-1} \tilde{H}_{NE}\) corresponding to the smallest eigenvalues of this matrix [6, 65]. However, this choice would not produce a significant reduction in the condition number of the preconditioned matrix as the spectral analysis of Theorem 5.1 suggests a possible clustering of smallest eigenvalues around 1. We choose instead, as the columns of V, the rightmost eigenvectors of \(M_{NE}^{-1} \tilde{H}_{NE}\), approximated with low accuracy by the function eigs of MATLAB. The \(\nu \) value must be selected to satisfy \(\lambda _{\min }(M_{NE}^{-1}\tilde{H}_{NE}) < \nu \ll \lambda _{\max }(M_{NE}^{-1}\tilde{H}_{NE})\). We choose \(\nu = 10\), to ensure that this new eigenvalue lies in the interior of the spectral interval, and the column size of V as \(p = 10\). This last choice is driven by experimental evidence that in most cases there are a small number of large outliers in \(M_{NE}^{-1}\tilde{H}_{NE}\). A larger value of p would (unnecessarily) increase the cost of applying the preconditioner.
Finally, by computing approximately the rightmost eigenvectors, we would expect a slight perturbation of \(\lambda _1, \ldots , \lambda _{m-p}\), depending on the accuracy of this approximation. For a detailed perturbation analysis see e.g. [70].
Updating a given preconditioner and reusing it, in the framework of solution of sequences of linear systems, have been analyzed in various papers. Among the others we quote [71] in which an adaptive automated procedure is devised for determining whether to use a direct or iterative solver, whether to reinitialize or update the preconditioner, and how many updates to apply. In [69] the update involves an inexact LU factorization of a given matrix in the sequence, [46] in the context of slightly varying coefficient matrices in the sequence (which is not the case in IP optimization). More related to the Interior Point iteration are [3, 4] where the \(LDL^T\) factorization of the saddle point matrix is updated at each IP iteration, and cheap approximations of the initial Schur complement matrix are provided.
5.2 Spectral analysis. QP case
In the MINRES solution of QP instances the system matrix is
while the preconditioner is
The following Theorem will characterize the eigenvalues of \(M_{AS}^{-1} H_{AS}\) in terms of the extremal eigenvalues of the preconditioned (1,1) block of (5.1), \({\tilde{F}}_k^{-1} F_k\), and of \(M_{NE}^{-1} \tilde{H}_{NE}\) as described by Theorem 5.1. We will work with (symmetric positive definite) similarity transformations of these matrices defined as
and set
Hence, an arbitrary element of the in the range of the Rayleigh Quotient of these matrices is represented as:
Similarly, an arbitrary element of \(q(M_{NE})\) is denoted by
Observe that \(\alpha _{F} \le 1 \le \beta _{F}\) as
Theorem 5.2
Let k be an arbitrary iteration of IP–PMM. Then, the eigenvalues of \(M_{AS}^{-1} H_{AS}\) lie in the union of the following intervals:
Proof
The proof of this theorem, following an idea in [5], can be found in [11]. \(\square \)
Remark 5.3
It is well known that a pessimistic bound on the convergence rate of MINRES can be obtained if the sizes of \(I_-\) and \(I_+\) are roughly the same [40]. In our case, as usually \(\beta _F \ll \beta _{NE}\), we can assume that the length of both intervals is roughly \(\sqrt{\beta _{NE}}\). As a heuristic we may therefore use [30, Theorem 4.14], which predicts the reduction of the residual in the \(M_{AS}^{-1}\)-norm in the case where both intervals have exactly equal length. This then implies that
where
6 Multiple BFGS-like updates of the constraint preconditioner
In order to avoid the factorization (1.5) at a certain IP iteration k, we construct a preconditioner for the KKT system at that iteration by updating a CP computed at an iteration \(i < k\). We extend to KKT systems and CPs the preconditioner updating technique for SPD matrices presented in [39], which in turn exploits ideas from [52, 67].
Let us consider, as before,
and
with \(S_1 \in {\mathbb {R}}^{n \times q}\) such that
We first define a preconditioner for H by applying a BFGS-like rank-2q update to \(M\):
which is well defined because \(S^T MS = S_1^T D S_1\) and \(S^T H S = S_1^T G S_1\). By using the Sherman-Morrison-Woodbury inversion formula, we get the inverse of \(M_{upd}\):
which is analogous to the BFGS update discussed in [39] for SPD matrices.
It is easy to see that the previous rank-2q update allows the preconditioned matrix to have at least q eigenvalues equal to 1 by directly verifying that
We also prove most important property of \(M_{upd}\) i.e. that the rank-2q update (6.4) (or, equivalently, (6.5)) produces a CP. To this aim, define
where \(L_S\) is the lower triangular Cholesky factor of the matrix \(S^T H S\).
Theorem 6.1
The matrix \(M_{upd}\) given in (6.4) is a CP for the matrix H in (3.2).
Proof
We show that the update (6.4) involves only the (1, 1) block of \(M\) and that \(M_{upd}\) is nonsingular; hence the thesis holds. Let us split \({\mathscr {S}}\) into two blocks:
From (6.3) it follows that \(A {\mathscr {S}}_1 = 0\). Then,
where
Likewise, we have
where
It follows that
In order to prove that \(M_{upd}\) is nonsingular, we consider a matrix \(Z \in {\mathbb {R}}^{n \times (n-m)}\) whose columns span the nullspace of A and prove that \(Z^T (D+ \Gamma -\Phi ) Z\) is SPD (see, e.g., [25]). We observe that
where we set
Then, by using the Sherman-Morrison-Woodbury formula, we have
which implies that \(D_{upd}\) is SPD. This concludes the proof. \(\square \)
The unit eigenvalues of the preconditioned matrix \(P_{upd}H \), in view of Theorem 3.1, are those of
where \(Z \in {\mathbb {R}}^{n \times (n-m)}\) spans the nullspace of A.
Following [8] the following results on the eigenvalue distribution of \(P_{upd}H \) can be proved:
Theorem 6.2
Let \(P_{upd}\) be the matrix in (6.5). Then \(P_{upd} H\) has an eigenvalue at 1 with multiplicity at least \(2m+q\).
The next theorem shows that the nonunit extremal eigenvalues of \(D_{upd}^{-1} G\) are bounded by the extremal eigenvalues of \(D^{-1} G\). Thus, by Theorem 3.1, we expect the application of \(P_{upd}\) to H to yield better spectral properties than the application of \(P\).
Theorem 6.3
Let \(D_{upd}\) be as in (6.9), then any eigenvalue of \(D_{upd}^{-1} G\) satisfies
Proof
See [8]. \(\square \)
We defer a discussion on the choice of columns of matrix S in Sect. 7.3.
7 Numerical results
Extensive numerical results regarding all the proposed inexact block preconditioners can be found in [8, 11,12,13]. We will briefly report some examples in which the advantages for the proposed inexact CP variants are evident. The problems we will consider, whose characteristics are reported in Table 1, are taken from the CUTEst [37] collection or they are modifications of them.
7.1 Inexact jacobian
In the definition of preconditioner \(M_{IJ}\) we used the following dropping rule to determine matrix E:
where with \(A_j\) we denote the jth column of A.
In other words, we drop an element from matrix A if it is below a prescribed tolerance and outside a fixed band. The first requirement prevents \(\Vert E\Vert \) from becoming too large with consequent going away of the eigenvalues from the unity (see the bounds in Theorem 4.1). The second requirement attempts to control the fill-in of \(A A^T\) and hence of its Cholesky factor L.
The following results refer to the runs on an Intel Xeon PC 2.80 GHz with 2 GB RAM of a pure FORTRAN version of the HOPDM code [35], with the g77 compiler and the -O4 option. We solved the SQP2500_2 problem using both the exact CP (with PCG as the inner solver) and with the Inexact Jacobian Constraint Preconditioner (IJCP – in combination with QMRs [32]).
The results are reported in Table 2 which shows the impressive gain in terms of CPU time provided by the inexact preconditioner. The number of inner iterations are (clearly) larger using IJCP, however the extreme sparsity of the preconditioner reduces considerably the cost of a single iteration.
To show how the drop and nband values may affect the distribution of the eigenvalues of \(M_{IJ}^{-1}H\), we have plotted in Fig. 1 all the eigenvalues of the preconditioned matrix on the complex plane. In the “no-drop” case (exact constraint preconditioner), the eigenvalues are all real (the ones are \(4007 > 2m = 4000\), as expected). With \(E \ne 0\), the number of unit eigenvalues is smaller but still remains important. Increasing the drop parameter, also \(|\epsilon |\) increases, but the real part of eigenvalues still remains bounded away from zero.

Distribution of the eigenvalues of \(M_{IJ}^{-1} H\) in the complex plane for problem sqp2500_2 with different combinations of the parameters \(\mathtt{nband, drop}\)
This is also shown in Table 3, where we report the number of unit eigenvalues, the maximum distance from the unity (\(|\epsilon |\), see Theorem 4.1), and the smallest real part of all the eigenvalues.
7.2 Inexact NE preconditioner
The experiments reported in this Section were conducted on a PC with a 2.2GHz Intel Core i7 processor (hexa-core), 16GB RAM The MATLAB version used was R2019a. We set the tolerance for the PCG/MINRES relative residual to \(10^{-4}\) and 100 (300) the maximum number of PCG (MINRES) iterations.
7.2.1 Low-rank updates and dynamic refinement
At each IP iteration we check the number of non-zeros of the preconditioner used in the previous iteration. If this number exceeds some predefined constant (depending on the number of constraints m), we perform certain low-rank updates to the preconditioner, to ensure that its quality is improved, without having to use very much memory. In such a case, the following tasks are performed as sketched in Algorithm LRU-0. Then, at every Krylov iteration, the computation of the preconditioned residual \(\hat{r} = M^{-1} r\) requires the steps outlined in Algorithm LRU-1.


In our implementation, the first step of Algorithm LRU-0 is performed using the restarted Lanczos method through the inbuilt MATLAB function eigs, requesting 1-digit accurate eigenpairs. We finally remark that a good approximation of the largest eigenvalues of the preconditioned matrix could be extracted for free [9] during the iterative solution of the correction linear system and used them to accelerate the predictor linear system by the low-rank correction. This approach, would save on the cost of computing eigenpairs but would provide acceleration in the second linear system only.
The quality of both preconditioners in (5.6) and (5.5) depends heavily on the quality of the approximation of the normal equations. If the Krylov method converged fast in the previous IP–PMM iteration (compared to the maximum allowed number of Krylov iterations), while requiring a substantial amount of memory, then the preconditioner quality is lowered (i.e. \(C_{k+1} > C_{k}\)). Similarly, if the Krylov method converged slowly, the preconditioner quality is increased (i.e. \(C_{k} > C_{k+1}\)). If the number of non-zeros of the preconditioner is more than a predefined large constant (depending on the available memory), and the preconditioner is still not good enough, we further increase the preconditioner’s quality (i.e. we decrease \(C_{k}\)), but at a very slow rate. This behavior is observed in practice very close to the IP convergence especially on large scale problems.
To show the efficiency of this variant we first present in Table 4 the results of the \(M_{NE}\) preconditioner for the LP-NUG-20 and LP-NUG-30 problems.
From this table we can see that the \(M_{NE}\) preconditioner (plus low-rank correction) is able to keep very low the number of inner iterations in both problems. Note that the largest instance can not be solved by an exact Constraint Preconditioner. In order to clarify the benefit of the low-rank (LR) updates in Table 5 we report the results in solving these linear systems with the low-rank strategy and different accuracy/number of eigenpairs (LR(\(p, \texttt {tol}\)) meaning that we approximate p eigenpairs with eigs with a tolerance tol). The best choice, using \(p=10\) and 0.1 accuracy, improves the \(M_{NE}\) preconditioner both in terms of linear iterations and total CPU time.
To summarize the comparison of the two approaches, we include Fig. 2. It contains the performance profiles of the two methods, over the 26 largest linear programming problems of the QAPLIB, Kennington, Mittelmann, and Netlib libraries, for which at least one of the two methods was terminated successfully. In particular, in Fig. 2a we present the performance profiles with respect to time, while in Fig. 2b we show the performance profiles with respect to the number of IPM iterations. IP–PMM with factorization is represented by the green line (consisting of triangles), while IP–PMM with PCG is represented by the blue line (consisting of stars).
As one can observe, IP–PMM with factorization was able to solve only 84.6% of these problems, due to excessive memory requirements (namely, problems LP-OSA-60, LP-PDS-100, RAIL4284, LP-NUG-30 were not solved due to insufficient memory). As expected, however, it converges in fewer iterations for most problems that are solved successfully by both methods. Moreover, IP–PMM with PCG is able to solve every problem that is successfully solved by IP–PMM with factorization. Furthermore, it manages to do so requiring significantly less time, which can be observed in Fig. 2a. Notice that we restrict the comparison to only large-scale problems, since this is the case of interest.

Performance profiles for large-scale linear programming problems
Finally, with regards to convex quadratic problems, the IP–PMM method with MINRES as the inner iterative solver and \(M_{AS}\) as the preconditioner was able to solve more than \(99\%\) of the Maros–Mészáros test set [49], which is comprised of 127 convex quadratic programming problems. See [11] for details.
7.3 Low-rank update of an exact CP
To experimentally analyze this CP variant, we first focus on the choice of the matrix S needed for building \(P_{upd}\) for the k-th KKT system in the sequence under consideration, by suggesting a number of choices:
BFGS-P. k-th iteration is obtained by setting its columns equal to the he first q H-orthonormal directions constructed during the PCG solution of IP step \(k-1\). Since we have experimentally verified that the PCG directions can rapidly lose the property of being mutually \(H_{k-1}\)-orthogonal when \(H_{k-1}\) is highly ill conditioned, we perform a selective reorthogonalization of the directions forming S, during their computation. More precisely, \(p_i\) is \(H_{k-1}\)-reorthogonalized against \(p_l\), with \(l < i\), whenever needed. We now present a different choice of S, which deserves a detailed explanation.
BFGS-C. Matrix S used to build \(P_{upd}\) for the KKT system at the k-th iteration is obtained by setting its columns equal to the first q H-orthonormal directions constructed during the PCG solution of the current IP step k. The suffix -C in BFGS-C refers to the fact that PCG directions from the current system are used to define S. As for BFGS-P, a selective \(H_k\)-reorthogonalization of the directions is performed in the first q PCG iterations.
It is easy to show [8] that in exact arithmetic the BFGS-C procedure is equivalent to PCG with preconditioner \(P\). Thus, BFGS-C may appear completely useless. Nevertheless, it is useful in finite-precision arithmetic. Freezing the preconditioner \(P\) computed at a certain IP iteration and using it in subsequent IP iterations yields directions which rapidly and dramatically lose orthogonality. BFGS-C appears to mitigate this behavior, improving the performance of PCG.
In order to illustrate this situation, we discuss some numerical results obtained with one of the 35 KKT systems arising in the solution, by an IP procedure, of the CVXQP3 convex QP problem, with dimensions \(n = 20000\) and \(m = 15000\) (see Sect. 7 for the details).
We considered PCG with the following preconditioning procedures:
-
BFGS-C with \(q=50\) and seed CP recomputed every 6 IP iteration;
-
CP recomputed from scratch every sixth IP iteration and frozen in the subsequent five iterations (henceforth this is referred to as FIXED preconditioning procedure).
In order to make a fair comparison, we performed a selective reorthogonalization of the first 50 directions during the execution of PCG with FIXED preconditioning. We also run PCG with FIXED preconditioning without any reorthogonalization. We focus on the KKT system at the 24-th IP iteration, hence the seed preconditioner comes from the 19-th IP iteration.

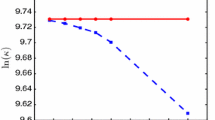
CVXQP3 test problem, KKT system at the 24-th IP iteration: normalized scalar products (7.1) for BFGS-C and FIXED (the latter with and without orthogonalization) and \(l=50\).
Figure 3 shows the normalized scalar products
for BFGS-C and both versions of the FIXED procedure. In the latter case, we observe a quick loss of orthogonality with respect to the first q directions, even when the reorthogonalization procedure is applied. Conversely, BFGS-C appears to better preserve orthogonality. As a consequence, the number of PCG iterations corresponding to BFGS-C is smaller than in the other cases (122 iterations for BFGS-C vs 176 and 196 for FIXED with and without reorthogonalization, respectively).
Applying the FIXED preconditioning approach with a selective reorthogonalization of each PCG direction with respect to the first 50 ones we achieved a worst PCG behavior than the one obtained with the BFGS-C strategy. This observation led us to consider a further preconditioning procedure.
DOUBLE. We apply q PCG iterations to the current system \(H_k u = d_k\) by using a CP, say \(P_{upd}^{(0)}\), built with the BFGS-P procedure, i.e., by updating a seed preconditioner \(P\) with the first q normalized PCG directions obtained at the \((k-1)\)-st IP iteration. Then we restart PCG from the last computed iterate \(u_q\), with the following preconditioner:
where \(S^C\) contains the normalized directions computed in the first q PCG iterations. As for the previous preconditioning procedures, a selective reorthogonalization is applied to the PCG directions used to build \(P_{upd}^{(0)}\) and to those used for \(P_{upd}\).
The sequences of KKT systems have been obtained by running the Fortran 95 PRQP code, which implements an infeasible inexact potential reduction IP method [18, 20, 25] using as the tolerances on the relative duality gap and the relative infeasibilities \(10^{-6}\) and \(10^{-7}\), respectively. Within PRQP, the PCG iterations have been stopped as soon as
where \(\tau _1\) depends on the duality gap value at the current IP iteration (see [19] for the details). A maximum number of 600 PCG iterations has been considered. The preconditioning procedures FIXED, BFGS-P, BFGS-C and DOUBLE have been applied with different values of s and q, while the PCG solver has been also applied with the CP recomputed from scratch for each KKT system (RECOM).
The code has been implemented in Fortran 95 and run on an Intel Core i7 CPU (2.67 GHz) with 6 GB RAM and 8 MB cache. The factorization of the Schur complement has been performed by the MA57 routine from HSL Mathematical Software Library (http://www.hsl.rl.ac.uk).
In Table 6 we report some results concerning the application of the preconditioning procedures, including the FIXED one, to CVXQP3N: the cumulative number of PCG iterations (PGC iters), the relevant CPU times (in seconds), namely: for the factorization of the Schur complement (Tf-Schur), for the application of the seed preconditioner \(P\) within PCG (Ta-seed), for the preconditioner updates and the reorthogonalization steps (Tupd), and the total times (Ttot).

Problem CVXQP3N, KKT system at IP iteration #24: PCG convergence profile for the different updates and with \(s=8\) and \(q_{\max } = 50\). The seed preconditioner comes from the IP iteration #17
The factorization of the Schur complement is rather expensive, and the recomputation of the CP from scratch produces by far the largest execution time, even if it yields a much smaller number of PCG iterations than the other preconditioning procedures. Furthermore, the updating procedures generally produce a significant reduction of the number of iterations with respect to the FIXED one, and hence smaller execution times. BFGS-C and DOUBLE turn out to be the most efficient procedures.
The PCG convergence histories for the KKT systems at the 24-th IP iteration, with the updating procedures and the FIXED ones for \(s=8\) and \(q_{max}=50\), clearly show how each procedure compares with the others in terms of PCG iterations (see Fig. 4): the best preconditioning procedure is DOUBLE, followed by BFGS-P, BFGS-C and then FIXED. This is a general behavior, although sporadic failures have been observed with BFGS-P and DOUBLE in cases where BFGS-C and FIXED work.
8 Concluding remarks
We have presented three inexact variants of the Constraint Preconditioner for solving Convex Linear and Quadratic Programming Problems of very large size. Any of these procedures aims at reducing the complexity of the exact factorization of the CP, often prohibitive for realistic problems. We list below the pros and cons of these approaches to help driving the reader to the best choice for the problem at hand.
-
Inexact Jacobian. This preconditioner is suggested when the coefficients in the matrix of constraint display variation of magnitudes and/or the matrix displays some band structure. Solvers like PCG or MINRES can not be used, and theoretical convergence estimates are problematic due to the presence of complex eigenvalues in the preconditioned matrix.
-
Inexact NE preconditioner. This is a promising variant which drives the sparsity of the of the Cholesky factor of the (approximate) Schur complement matrix by means of a sequence, \(\{C_k\}\). At each IP iteration k, \(C_k\) is defined dynamically as a function of the fill-in and the number of iterations at previous iteration \(k-1\). Krylov solvers such as PCG (Linear and Quadratic separable Problems) or MINRES (Quadratic Problems) are allowed.
-
Low Rank updates of an exact CP. This method can be employed whenever the exact CP factorization is expensive but applicable. It reduces considerably the main cost of the overall algorithm, which is the factorization of the Schur complement. The PCG is allowed also for the augmented system since updated CPs are still CPs (see Theorem 3.1).
References
Altman, A., Gondzio, J.: Regularized symmetric indefinite systems in interior point methods for linear and quadratic optimization. Optim. Methods Softw. 11–12, 275–302 (1999)
Andersen, E.D., Gondzio, J., Mészáros, C., Xu, X.: Implementation of interior point methods for large scale linear programming. In: Terlaky, T. (ed.) Interior Point Methods in Mathematical Programming, pp. 189–252. Kluwer Academic Publishers, Dordrecht (1996)
Bellavia, S., De Simone, V., di Serafino, D., Morini, B.: Updating constraint preconditioners for KKT systems in quadratic programming via low-rank corrections. SIAM J. Optim. 25, 1787–1808 (2015)
Bellavia, S., De Simone, V., di Serafino, D., Morini, B.: On the update of constraint preconditioners for regularized KKT systems. Comput. Optim. Appl. 65, 339–360 (2016)
Bergamaschi, L.: On the eigenvalue distribution of constraint-preconditioned symmetric saddle point matrices. Numer. Lin. Alg. Appl. 19, 754–772 (2012)
Bergamaschi, L.: A survey of low-rank updates of preconditioners for sequences of symmetric linear systems. Algorithms 13, 100 (2020)
Bergamaschi, L., Bru, R., Martínez, A.: Low-rank update of preconditioners for the inexact Newton method with SPD jacobian. Math. Comput. Model. 54, 1863–1873 (2011)
Bergamaschi, L., De Simone, V., di Serafino, D., Martínez, A.: BFGS-like updates of constraint preconditioners for sequences of KKT linear systems. Numer. Lin. Alg. Appl. 25, 1–19 (2018). (e2144)
Bergamaschi, L., Facca, E., Martínez, A., Putti, M.: Spectral preconditioners for the efficient numerical solution of a continuous branched transport model. J. Comput. Appl. Math. 254, 259–270 (2019)
Bergamaschi, L., Ferronato, M., Gambolati, G.: Mixed constraint preconditioners for the solution to FE coupled consolidation equations. J. Comput. Phys. 227, 9885–9897 (2008)
Bergamaschi, L., Gondzio, J., Martínez, A., Pearson, J., Pougkakiotis, S.: A new preconditioning approach for an interior point-proximal method of multipliers for linear and convex quadratic programming. Numer. Linear Algebr. Appl. 28, e2361 (2021)
Bergamaschi, L., Gondzio, J., Venturin, M., Zilli, G.: Inexact constraint preconditioners for linear systems arising in interior point methods. Comput. Optim. Appl. 36, 137–147 (2007)
Bergamaschi, L., Gondzio, J., Venturin, M., Zilli, G.: Erratum to: Inexact constraint preconditioners for linear systems arising in interior point methods. Comput. Optim. Appl. 49, 401–406 (2011)
Bergamaschi, L., Gondzio, J., Zilli, G.: Preconditioning indefinite systems in interior point methods for optimization. Comput. Optim. Appl. 28, 149–171 (2004)
Bergamaschi, L., Martínez, A.: RMCP: Relaxed mixed constraint preconditioners for saddle point linear systems arising in geomechanics. Comp. Methods App. Mech. Engrg. 221–222, 54–62 (2012)
Bertsekas, P.D.: Constrained Optimization and Lagrange Multiplier Methods. Athena Scientific, Nashua (1996)
Bocanegra, S., Campos, F., Oliveira, A.R.L.: Using a hybrid preconditioner for solving large-scale linear systems arising from interior point methods. Comput. Optim. Appl. 36, 149–164 (2007)
Cafieri, S., D’Apuzzo, M., De Simone, V., di Serafino, D.: On the iterative solution of KKT systems in potential reduction software for large-scale quadratic problems. Comput. Optim. Appl. 38, 27–45 (2007)
Cafieri, S., D’Apuzzo, M., De Simone, V., di Serafino, D.: Stopping criteria for inner iterations in inexact potential reduction methods: a computational study. Comput. Opim. Appl. 36, 165–193 (2007)
Cafieri, S., D’Apuzzo, M., De Simone, V., di Serafino, D., Toraldo, G.: Convergence analysis of an inexact potential reduction method for convex quadratic programming. J. Optim. Theory Appl. 135, 355–366 (2007)
Cao, Y., Laird, C.D., Zavala, V.M.: Clustering-based preconditioning for stochastic programs. Comput. Optim. Appl. 64, 379–406 (2016)
Castro, J.: A specialized interior-point algorithm for multicommodity network flows. SIAM J. Optim. 10, 852–877 (2000)
Castro, J., Cuesta, J.: Quadratic regularizations in an interior-point method for primal block-angular problems. Math. Program. 130, 415–455 (2011)
Chai, J.-S., Toh, K.-C.: Preconditioning and iterative solution of symmetric indefinite linear systems arising from interior point methods for linear programming. Comput. Optim. Appl. 36, 221–247 (2007)
D’Apuzzo, M., De Simone, V., di Serafino, D.: On mutual impact of numerical linear algebra and large-scale optimization with focus on interior point methods. Comput. Optim. Appl. 45, 283–310 (2010)
De Simone, V., di Serafino, D., Gondzio, J., Pougkakiotis, S., Viola, M.: Sparse approximations with interior point methods (2021). arXiv:2102.13608
di Serafino, D., Orban, D.: Constraint-preconditioned krylov solvers for regularized saddle-point systems. SIAM J. Sci. Comput. 43, A1001–A1026 (2021)
Dollar, H., Wathen, A.: Approximate factorization constraint preconditioners for saddle-point matrices. SIAM J. Sci. Comput. 27, 1555–1572 (2006)
Durazzi, C., Ruggiero, V.: Indefinitely preconditioned conjugate gradient method for large sparse equality and inequality constrained quadratic problems. Numer. Lin. Alg. Appl. 10, 673–688 (2003)
Elman, H.C., Silvester, D.J., Wathen, A.J.: Finite Elements and Fast Iterative Solvers: with Applications in Incompressible Fluid Dynamics. Numerical Mathematics and Scientific Computation, Oxford University Press, 2nd ed. (2014)
Fisher, M., Gratton, S., Gürol, S., Trémolet, Y., Vasseur, X.: Low rank updates in preconditioning the saddle point systems arising from data assimilation problems. Optim. Meth. Softw. 33, 45–69 (2018)
Freund, R.W., Nachtigal, N.M.: Software for simplified Lanczos and QMR algorithms. Appl. Numer. Math. 19, 319–341 (1995)
Gill, P.E., Murray, W., Ponceleon, D.B., Saunders, M.A.: Preconditioners for indefinite systems arising in optimization. SIAM J. Matrix Anal. Appl. 13, 292–311 (1992)
Golub, G.H., Wathen, A.J.: An iteration for indefinite systems and its application to the Navier-Stokes equations. SIAM J. Sci. Comput. 19, 530–539 (1998)
Gondzio, J.: HOPDM (version 2.12) – a fast LP solver based on a primal-dual interior point method. Eur. J. Oper. Res. 85, 221–225 (1995)
Gondzio, J.: Interior point methods 25 years later. Eur. J. Oper. Res. 218, 587–601 (2013)
Gould, N.I.M., Orban, D., Toint, P.L.: Cutest: a constrained and unconstrained testing environment with safe threads for mathematical optimization. Comput. Optim. Appl. 60, 545–557 (2015)
Gratton, S., Mercier, S., Tardieu, N., Vasseur, X.: Limited memory preconditioners for symmetric indefinite problems with application to structural mechanics. Numer. Linear Algebra Appl. 23, 865–887 (2016)
Gratton, S., Sartenaer, A., Tshimanga, J.: On a class of limited memory preconditioners for large scale linear systems with multiple right-hand sides. SIAM J. Optim. 21, 912–935 (2011)
Greenbaum, A.: Iterative Methods for Solving Linear Systems. Society for Industrial and Applied Mathematics (1997). https://doi.org/10.1137/1.9781611970937
Hestenes, M.R.: Multiplier and gradient methods. J. Optim. Theory Appl. 4, 303–320 (1969)
Hestenes, M.R., Stiefel, E.: Methods of conjugate gradients for solving linear systems. J. Res. Natl. Bur. Stand. 49, 409–436 (1952)
Júdice, J.J., Patricio, J., Portugal, L.F., Resende, M.G.C., Veiga, G.: A study of preconditioners for network interior point methods. Comput. Optim. Appl. 24, 5–35 (2003)
Keller, C., Gould, N.I.M., Wathen, A.J.: Constraint preconditioning for indefinite linear systems. SIAM J. Matrix Anal. Appl. 21, 1300–1317 (2000)
Kuznetsov, Y.A.: Efficient iterative solvers for elliptic finite element problems on nonmatching grids. Russ. J. Numer. Anal. Math. Model. 10, 187–211 (1995)
Loghin, D., Ruiz, D., Touhami, A.: Adaptive preconditioners for nonlinear systems of equations. J. Comput. Appl. Math. 189, 362–374 (2006)
Lukšan, L., Vlček, J.: Indefinitely preconditioned inexact Newton method for large sparse equality constrained nonlinear programming problems. Numer. Lin. Alg. Appl. 5, 219–247 (1998)
Lukšan, L., Vlček, J.: Interior point method for nonlinear nonconvex optimization. Tech. Report 836, Institute of Computer Science, Academy of Sciences of the Czech Republic, 18207 Prague, Czech Republic (2001)
Maros, I., Mészáros, C.: A repository of convex quadratic programming problems. Optim. Methods Softw. 11, 671–681 (1999)
Martínez, A.: Tuned preconditioners for the eigensolution of large SPD matrices arising in engineering problems. Numer. Lin. Alg. Appl. 23, 427–443 (2016)
Murphy, M.F., Golub, G.H., Wathen, A.J.: A note on preconditioning for indefinite linear systems. SIAM J. Sci. Comput. 21, 1969–1972 (2000)
Nash, S.G., Nocedal, J.: A numerical study of the limited memory BFGS method and the truncated-Newton method for large scale optimization. SIAM J. Optim. 1, 358–372 (1991)
Oliveira, A.R.L., Sorensen, D.C.: A new class of preconditioners for large-scale linear systems from interior point methods for linear programming. Linear Algebra Appl. 394, 1–24 (2005)
Paige, C.C., Saunders, M.A.: Solution of sparse indefinite systems of linear equations. SIAM J. Numer. Anal. 12, 617–629 (1975)
Parikh, N., Boyd, S.: Proximal algorithms. Found. Trends Optim. 3, 123–231 (2014)
Pearson, J.W., Gondzio, J.: Fast interior point solution of quadratic programming problems arising from PDE-constrained optimization. Numer. Math. 137, 959–999 (2017)
Pearson, J.W., Porcelli, M., Stoll, M.: Interior point methods and preconditioning for PDE-constrained optimization problems involving sparsity terms. Numer. Linear Algebra Appl. 27, e2276 (2019)
Perugia, I., Simoncini, V.: Block-diagonal and indefinite symmetric preconditioners for mixed finite elements formulations. Numer. Lin. Alg. Appl. 7, 585–616 (2000)
Pougkakiotis, S., Gondzio, J.: Dynamic non-diagonal regularization in interior point methods for linear and convex quadratic programming. J. Optim. Theory Appl. 181, 905–945 (2019)
Pougkakiotis, S., Gondzio, J.: An interior point-proximal method of multipliers for convex quadratic programming. Comput. Optim. Appl. 78, 307–351 (2021)
Powell, M.J.D.: A method for nonlinear constraints in minimization problems. In: Fletcher, R. (ed.) Optimization, pp. 283–298. Academic Press, New York, NY (1969)
Rockafellar, R.T.: Augmented Lagrangians and applications of the proximal point algorithm in convex programming. Math. Oper. Res. 1, 97–116 (1976)
Rockafellar, R.T.: Monotone operators and the proximal point algorithm. SIAM J. Control. Optim. 14, 877–898 (1976)
Rozlozník, M., Simoncini, V.: Krylov subspace methods for saddle point problems with indefinite preconditioning. SIAM J. Matrix Anal. Appl. 24, 368–391 (2002)
Saad, Y., Yeung, M., Erhel, J., Guyomarc’h, F.: A deflated version of the conjugate gradient algorithm. SIAM J. Sci. Comput. 21, 1909–1926 (2000). Iterative methods for solving systems of algebraic equations (Copper Mountain, CO, 1998)
Schenk, O., Wächter, A., Weiser, M.: Inertia-revealing preconditioning for large-scale nonconvex constrained optimization. Comput. Optim. Appl. 31, 939–960 (2008)
Schnabel, R.B.: Quasi–Newton methods using multiple secant equations. Tech. Report CU-CS-247- CU-CS-247-83, Department of Computer Sciences, University of Colorado, Boulder, CO (1983)
Silvester, D., Wathen, A.: Fast iterative solution of stabilized Stokes systems, Part II: Using general block preconditioners. SIAM J. Numer. Anal. 31, 1352–1367 (1994)
Tebbens, J.D., T\(\mathring{{\rm u}}\)ma, M.: Efficient preconditioning of sequences of nonsymmetric linear systems, SIAM J. Sci. Comput. 29, 1918 – 1941 (2007)
Tshimanga, J.: On a class of limited memory preconditioners for large scale linear nonlinear least-squares problems (with application to variational ocean data assimilation), PhD thesis, Facultés Universitaires Notre Dame de la Paix, Namur (2007)
Wang, W., O’Leary, D.P.: Adaptive use of iterative methods in predictor-corrector interior point methods for linear programming. Numer. Algorithms 25, 387–406 (2000)
Wright, S.J.: Primal-Dual Interior-Point Methods. SIAM, Philadelphia (1997)
Zanetti, F., Bergamaschi, L.: Scalable block preconditioners for linearized Navier-Stokes equations at high Reynolds number. Algorithms 13, 199 (2020)
Zanetti, F., Gondzio, J.: A new stopping criterion for Krylov solvers applied in Interior Point methods, arXiv:2106.16090 [math.OC]
Acknowledgements
L. Bergamaschi was supported by the INdAM-GNCS Project (Year 2020): Optimization and advanced linear algebra for PDE-discretized problems. We wish to thank the two anonymous reviewers whose comments helped improve the quality of the manuscript.
Funding
Open access funding provided by Universitá degli Studi di Padova within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zilli, G., Bergamaschi, L. Block preconditioners for linear systems in interior point methods for convex constrained optimization. Ann Univ Ferrara 68, 337–368 (2022). https://doi.org/10.1007/s11565-022-00422-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11565-022-00422-9
Keywords
- Interior point method
- Preconditioned conjugate gradient
- MINRES
- Preconditioning
- Saddle-point linear system
- Normal equations
- BFGS update
- Constraint preconditioner