
Abstract
We study the statistical mechanics of a one-dimensional log gas or \(\beta \)-ensemble with general potential and arbitrary \(\beta \), the inverse of temperature, according to the method we introduced for two-dimensional Coulomb gases in Sandier and Serfaty (Ann Probab, 2014). Such ensembles correspond to random matrix models in some particular cases. The formal limit \(\beta =\infty \) corresponds to “weighted Fekete sets” and is also treated. We introduce a one-dimensional version of the “renormalized energy” of Sandier and Serfaty (Commun Math Phys 313(3):635–743, 2012), measuring the total logarithmic interaction of an infinite set of points on the real line in a uniform neutralizing background. We show that this energy is minimized when the points are on a lattice. By a suitable splitting of the Hamiltonian we connect the full statistical mechanics problem to this renormalized energy \(W\), and this allows us to obtain new results on the distribution of the points at the microscopic scale: in particular we show that configurations whose \(W\) is above a certain threshold (which tends to \(\min W\) as \(\beta \rightarrow \infty \)) have exponentially small probability. This shows that the configurations have increasing order and crystallize as the temperature goes to zero.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In [36] we studied the statistical mechanics of a 2D classical Coulomb gas (or two-dimensional plasma) via the tool of the “renormalized energy” \(W\) introduced in [35], a particular case of which is the Ginibre ensemble in random matrix theory.
In this paper we are interested in doing the analogue in one dimension, i.e. first defining a “renormalized energy” for points on the real line, and applying this tool to the study of the classical log gases or \(\beta \)-ensembles, i.e. to probability laws of the form
where \({Z}_{n}^{\beta }\) is the associated partition function, i.e. a normalizing factor such that \({\mathbb {P}_{n}^{\beta }}\) is a probability, and
Here the \(x_i\)’s belong to \(\mathbb {R}\), \(\beta >0\) is a parameter corresponding to (the inverse of) a temperature, and \(V\) is a relatively arbitrary potential, satisfying some growth conditions. For a general presentation, we refer to the textbook [23]. Minimizers of \({{w}_{n}}\) are also called “weighted Fekete sets” and arise in interpolation, cf. [34].
There is an abundant literature on the random matrix aspects of this problem (the connection was first pointed out by Wigner and Dyson [21, 44]), which is the main motivation for studying log gases. Indeed, for the quadratic potential \(V(x)=x^2/2\), particular cases of \(\beta \) correspond to the most famous random matrix ensembles: for \(\beta =1\) the law \({\mathbb {P}_{n}^{\beta }}\) is the law of eigenvalues of matrices of the Gaussian Orthogonal Ensemble (GOE), while for \(\beta =2\) it corresponds to the Gaussian Unitary Ensemble (GUE), for general reference see [2, 23, 30]. For \(V(x)\) still quadratic, general \(\beta \)’s have been shown to correspond to tri-diagonal random matrix ensembles, cf. [1, 20]. This observation allowed Valkó and Virág [43] to derive the sine-\(\beta \) processes as the local spacing distributions of these ensembles. When \(\beta =2\) and \(V(x)\) is more general, the model corresponds (up to minor modification) to other determinantal processes called orthogonal polynomial ensembles (see e.g. [25] for a review).
The study of \({\mathbb {P}_{n}^{\beta }}\) via the random matrix aspect is generally based on explicit formulas for correlation functions and local statistics, obtained via orthogonal polynomials, as pioneered by Gaudin, Mehta, Dyson, cf. [18, 19, 30]. We are interested here in the more general setting of general \(\beta \) and \(V\), with equilibrium measures for the empirical distribution of the eigenvalues whose support can have several connected components, also called the “multi-cut regime” as opposed to the “one-cut regime.” One class of recent results in this direction are those of Borot-Guionnet and Shcherbina who prove in particular partition functions expansions in the case of the one-cut regime with general \(V\) [10, 38] or the case of the multi-cut regime with analytic \(V\) [11, 39] (see references therein for prior results). Another class is those on universality (i.e. independence with respect to \(V\)) of local eigenvalue statistics, obtained for \(V\in C^4 \) by Bourgade-Erdös-Yau [12, 13], for \(V\) analytic in [40], and for \(V\in C^{31}\) in [8].
The results and the method here are counterparts of those obtained in [36] for \(x_1, \dots , x_n\) belonging to \(\mathbb {R}^2\), in other words the two-dimensional Coulomb gas (this corresponds for \(V\) quadratic and \(\beta =2\) to the Ginibre ensemble of non-hermitian Gaussian random matrices). The study in [36] relied on relating the Hamiltonian \({{w}_{n}}\) to a Coulomb “renormalized energy” \(W\) introduced in [35] in the context of Ginzburg-Landau vortices. This relied crucially on the fact that the logarithm is the Coulomb kernel in two dimensions, or in other words the fundamental solution to the Laplacian. When looking at the situation in one dimension, i.e. the present situation of the 1D log-gas, the logarithmic kernel is no longer the Coulomb kernel, and it is not a priori clear that anything similar to the study in two dimensions can work. Note that the 1D Coulomb gas, corresponding to \({\mathbb {P}_{n}^{\beta }}\) where the logarithmic interaction is replaced by the 1D Coulomb kernel \(|x|\), has been studied, notably by Lenard [28, 29], Brascamp-Lieb [15], Aizenman-Martin [4]. The situation there is rendered again more accessible by the Coulomb nature of the interaction and its less singular character. In particular [15] prove crystallization (i.e. that the points tend to arrange along a regular lattice) in the limit of a small temperature, we will get a similar result for the log-gas.
The starting point of our study is that even though the logarithmic kernel is not Coulombic in dimension 1, we can view the particles on the real line as embedded into the two-dimensional plane and interacting as Coulomb charges there. This provides a way of defining an analogue of the “renormalized energy” of [35] in the one-dimensional setting, still called \(W\), which goes “via” the two-dimensional plane and is a way of computing the \(L^2\) norm of the Stieltjes transform, cf. Remark 1.1 below.
Once this is accomplished, we connect in the same manner as [36] the Hamiltonian \({{w}_{n}}\) to the renormalized energy \(W\) via a “splitting formula” (cf. Lemma 1.10 below), and we obtain the counterparts results to [36], valid with our relatively weak assumptions on \(V\):
-
a next-order expansion of the partition function in terms of \(n\) and \(\beta \), cf. Theorem 6.
-
the proof that the minimum of \(W\) is achieved by the one-dimensional regular lattice \(\mathbb {Z}\), called the “clock distribution” in the context of orthogonal polynomial ensembles [42]. This is in contrast with the dimension 2 where the identification of minimizers of \(W\) is still open (but conjectured to be “Abrikosov” triangular lattices).
-
the proof that ground states of \({{w}_{n}}\), or “weighted Fekete sets”, converge to minimizers of \(W\) and hence to crystalline states, cf. Theorem 5.
-
A large deviations type result which shows that events with high \(W\) become less and less likely as \(\beta \rightarrow \infty \), proving in particular the crystallization as the temperature tends to \(0\).
Our renormalized energy \(W\), which serves to prove the crystallization, also appears (like its two-dimensional version) to be a measurement of “order” of a configuration at the microscopic scale \(1/n\). This is more precisely quantified in [26]. What we show here is that there is more and more order (or rigidity) in the log gas, as the temperature gets small. Of course, as already mentioned, it is known that eigenvalues of random matrices, even of general Wigner matrices, should be regularly spaced, and [12, 13] showed that this could be extended to general \(V\)’s. Our results approach this question sort of orthogonally, by exhibiting a unique number which measures the average rigidity. (Note that in [9] the second author and Borodin used \(W\) as a way of quantifying the order of random point processes, in particular those arising as local limits in random matrix theory.)
Crystallization was already known in some particular or related settings. One is the case where \(V\) is quadratic, for which the \(\beta \rightarrow \infty \) limits of the eigenvalues—in other words the weighted Fekete points—are also zeroes of Hermite polynomials, which are known to have the clock distribution (see e.g. [5]). The second is the case of the \(\beta \)-Hermite ensemble [43].
Our study here differs technically from the two-dimensional one in two ways: the first one is in the definition of \(W\) by embedding the problem into the plane, as already mentioned. The second one is more subtle: in both settings a crucial ingredient in the analysis is to reduce the evaluation of the interactions to an extensive quantity (instead of sums of pairwise Coulomb interactions); that quantity is essentially the \(L^2\) norm of the electric field generated by the Coulomb charges, or equivalently of the Stieljes transform of the point distribution. Test-configurations can be built and their energy evaluated by “copying and pasting”, provided a cut-off procedure is devised: it consists essentially in taking a given electric field and making it vanish on the boundary of a given box while not changing its energy too much. In physical terms, this corresponds to screening the field. The point is that screening is much easier in two dimensions than in one dimension, because in two dimensions there is more geometric flexibility to move charges around. We found that in fact, in dimension 1, not all configurations with finite energy can be effectively screened. However, we also found that generic “good” configurations can be, and this suffices for our purposes. The screening construction, which is different from the two-dimensional one, is one of the main difficulties here, and forms a large part of the paper.
The rest of the introduction is organized as follows: We begin by introducing the equilibrium measure (i.e. the minimizer of the mean-field limiting Hamiltonian) and known facts concerning it, in the next two sections we describe the central objects in our analysis, i.e. the marked electric field process and the renormalized energy \(W\). Then we state the results which connect \({{w}_{n}}\) to \(W\): the “splitting formula”, and the Gamma-convergence lower and upper bounds. Finally, in Sect. 1.5 we state our main results about Fekete points and the 1D Coulomb gas.
1.1 The spectral and equilibrium measures and our assumptions
The Hamiltonian (1.2) is written in the mean-field scaling. The limiting “mean-field” limiting energy (also called Voiculescu’s noncommutative entropy in the context of random matrices, cf. e.g. [2] and references therein) is
it is well known (cf. [34]) that it has a unique minimizer, called the (Frostman) equilibrium measure, which we will denote \({\mu _{0}}\). It is not hard to prove that the “spectral measure” (so-called in the context of random matrices) \(\nu _n = \frac{1}{n} \sum _{i=1}^n \delta _{x_i}\) converges to \({\mu _{0}}\). The sense of convergence usually proven is
For example, for the case of the GUE i.e. when \(V(x)=|x|^2\) and \(\beta =1\), the correspond distribution \({\mu _{0}}\) is simply Wigner’s “semi-circle law” \(\rho (x)=\frac{1}{2\pi }\sqrt{4-x^2}\mathbf {1}_{|x|<2}\), cf. [30, 44]. A stronger result was proven in [7] for all \(\beta \) (cf. [2] for the case of general \(V\)): it estimates the large deviations from this convergence and shows that \({\mathcal {F}}\) is the appropriate rate function. The result can be written:
Theorem 1
(Ben Arous–Guionnet [7]) Let \(\beta >0\), and denote by \({\tilde{\mathbb {P}}_{n}^{\beta }}\) the image of the law (1.1) by the map \((x_1,\dots ,x_n)\mapsto \nu _n\), where \(\nu _n=\frac{1}{n}\sum _{i=1}^n \delta _{x_i}\). Then for any subset \(A\) of the set of probability measures on \(\mathbb {R}\) (endowed with the topology of weak convergence), we have
where \(\widetilde{\mathcal {F}}=\frac{\beta }{2}( {\mathcal {F}}- \min {\mathcal {F}})\).
The Central Limit Theorem for (macroscopic) fluctuations from the law \({\mu _{0}}\) was proved by Johansson [24].
Let us now state a few facts that we will need about the equilibrium measure \({\mu _{0}}\), for which we refer to [34]: \({\mu _{0}}\) is characterized by the fact that there exists a constant \(c\) (depending on \(V\)) such that
where for any \(\mu \), \(U^\mu \) is the potential generated by \(\mu \), defined by
We also define
where \(c\) is the constant in (1.5). From the above we know that \(\zeta \ge 0\) in \(\mathbb {R}\) and \(\zeta = 0\) in \({\Sigma }:=\text {Supp}({\mu _{0}})\). We will make the assumption that \(\mu _0\) has a density \(m_0\) with respect to the Lebesgue measure, as well as the following additional assumptions:
The assumption (1.8) ensures (see [34]) that (1.3) has a minimizer, and that its support \({\Sigma }\) is compact. Assumptions (1.9)–(1.11) are needed for the construction in Sect. 3.3. They could certainly be relaxed but are meant to include at least the model case of \({\mu _{0}}=\rho \), Wigner’s semi-circle law. Assumption (1.12) is a supplementary assumption on the growth of \(V\) at infinity, needed for the case with temperature. It only requires a very mild growth of \(V/2- \log |x|\), i.e. slightly more than (1.8).
1.2 The marked electric field process
Theorem 1 describes the asymptotics of \({\mathbb {P}_{n}^{\beta }}\) as \(n\rightarrow +\infty \) in terms of the spectral measure \(\nu _n = \frac{1}{n} \sum _{i=1}^n \delta _{x_i}\). Our results will rather use an object which retains information at the microscopic scale: the marked electric field process.
More precisely, given any configuration \({\mathbf {x}}= (x_1, \dots , x_n)\), we let \(\nu _n= \sum _{i=1}^n \delta _{x_i}\) and \(\nu _n' = \sum _{i=1}^n\delta _{x_i'}\) where the primes denote blown-up quantities (\(x'=nx\)). We set \({m_0}'(nx) = {m_0}(x)\), and we denote by \({\delta _{\mathbb {R}}}\) denotes the measure of length on \(\mathbb {R}\) seen as embedded in \(\mathbb {R}^2\), that is
for any smooth compactly supported test function \(\varphi \) in \(\mathbb {R}^2\). The configuration \({\mathbf {x}}\) generates (at the blown-up scale) an electric field via
where \(H_n'\) is understood to be the only solution of the equation which decays at infinity, which is obtained by convoling the right-hand side with \(-\log |x|\). We will sometimes write it as \( H_n' = - 2\pi \Delta ^{-1} \left( \nu _n' - {m_0}' {\delta _{\mathbb {R}}}\right) = -\log *\left( \nu _n' - {m_0}' {\delta _{\mathbb {R}}}\right) \). Here We note that from (1.13), \({E}_{\nu _n}\) satisfies the relation
supplemented with the fact that \(E_{\nu _n}\) is a gradient.
Remark 1.1
When considering the Stieljes transform of a (say compactly supported) measure \(\mu \) on \(\mathbb {R}\),
one observes that
Thus the electric field \(E=-\nabla \log *\mu \) of the type we introduced is very similar to the Stieltjes transform, in particular they have the same norm. We note however that it seems much easier to take limits in the sense of distributions—what we will need to do—in (1.14) than in Stieltjes transforms.
The field \({E}_{\nu _n}\) belongs to \( L^p_\mathrm{loc}(\mathbb {R}^2,\mathbb {R}^2) \) for any \(p\in [1,2)\). Choosing once and for all such a \(p\), we define \(X:= \Sigma \times L^p_\mathrm{loc}(\mathbb {R}^2,\mathbb {R}^2) \) the space of “marked” electric fields, where the mark \(x\in \Sigma \) corresponds to the point where we will center the blow-up. We denote by \(\mathcal {P}(X)\) the space of probability measures on \(X\) endowed with the Borel \(\sigma \)-algebra, where the topology is the usual one on \(\mathbb {R}\) and the topology of weak convergence on \(L^p_\mathrm{loc}\).
We may now naturally associate to each configuration \({\mathbf {x}}= (x_1, \dots , x_n)\) a “marked electric field distribution” \(P_{\nu _n}\) via the map

i.e. \(P_{\nu _n} \) is the push-forward of the normalized Lebesgue measure on \({\Sigma }\) by \(x \mapsto (x, {E}_{\nu _n} ({n}x+\cdot )).\) Another way of saying is that each \(P_{\nu _n} (x, \cdot )\) is equal to a Dirac at the electric field generated by \({\mathbf {x}}\), after centering at the point \(x\). We stress that \(P_{\nu _n}\) has nothing to do with \({\mathbb {P}_{n}^{\beta }}\), and is strictly an encoding of a particular configuration \((x_1,\dots ,x_n)\).
The nice feature is that, assuming a suitable bound on \({{w}_{n}}(x_1, \dots , x_n)\), the sequence \(\{P_{\nu _n}\}_n\) will be proven to be tight as \(n\rightarrow \infty \), and thus to converge to an element \(P\) of \(\mathcal {P}(X)\). From the point of view of analysis, \(P\) may be seen as a family \(\{P^x\}_{x\in {\Sigma }}\)—the disintegration of \(P\)—each \(P^x\) being a probability density describing the possible blow-up limits of the electric field when the blow-up center is near \(x\). It is similar to the Young measure on micropatterns of [3].
When \((x_1, \dots , x_n)\) is random then \(P\) also is and, from a probabilistic point of view, \(P\) is an electric field process, or to be more precise an electric field distribution process.
The limiting \(P\) will be concentrated on vector fields which are obtained by taking limits in (1.14) (after centering at \(x\)), which will be elements of the following classes:
Definition 1.2
Let \(m\) be a positive number. A vector field \({E}\) in \(\mathbb {R}^2\) is said to belong to the admissible class \(\mathcal {A}_m \) if it is a gradient and
where \(\nu \) has the form
and
One should understand the class \(\mathcal {A}_m\) as corresponding to infinite configurations on the real line with density of points \(m\). The distribution of points on the real line, seen as positive Dirac charges, is compensated by a background charge \(m{\delta _{\mathbb {R}}}\) which is also concentrated on the real line.
The properties satisfied by \(P= \lim _{n\rightarrow \infty } P_{\nu _n}\) may now be summarized in the following definition:
Definition 1.3
(admissible probabilities) We say \(P\in \mathcal {P}(X)\) is admissible if
-
The first marginal of \(P\) is the normalized Lebesgue measure on \({\Sigma }\).
-
It holds for \(P\)-a.e. \((x, E)\) that \({E}\in \mathcal {A}_{m_0(x)}\).
-
\(P\) is \(T_{\lambda (x)}\)-invariant.
Here \(T_{\lambda (x)}\)-invariant is a strengthening of translation-invariance, related to the marking:
Definition 1.4
(\(T_{\lambda (x)}\) -invariance) We say a probability measure \(P\) on \({\Sigma }\times L^p_\mathrm{loc}(\mathbb {R}^2,\mathbb {R}^2)\) is \(T_{\lambda (x)}\)-invariant if \(P\) is invariant by \((x,{E})\mapsto \left( x,{E}(\lambda (x)+\cdot )\right) \), for any \(\lambda (x)\) of class \(C^1\) from \({\Sigma }\) to \(\mathbb {R}\).
Note that from such an admissible electric field process \(P\), and since \({E}\in \mathcal {A}_{m_0(x)}\) implies that \({E}\) solves (1.17), one can immediately get a (marked) point process by taking the push-forward of \(P(x, {E}) \) by \({E}\mapsto \frac{1}{2\pi } \mathrm {div} \ {E}+ m_0(x) \delta _\mathbb {R}\). This process remembers only the point locations, not the electric field they generate, but we will show (Lemma 1.7) that the two are equivalent.
1.3 The renormalized energy
In Theorem 1, large deviations (at speed \(n^{2}\)) from the equilibrium measure \(\mu _0\) of the spectral measure \(\nu _n\) were described with the rate function based on the energy \({\mathcal {F}}(\mu )\). Our statements concern the next order behavior, and if we try to put them in parallel to Theorem 1, the electric field distribution replaces the spectral measure as the central object, while the renormalized energy \(W\) that we describe in this section replaces \({\mathcal {F}}\).
First we define the renormalized energy of an electric field \({E}\). It is adapted from [35] which considered distribution of charges in the plane, by simply “embedding” the real line into the plane. As above we denote points in \(\mathbb {R}\) by the letter \(x\) and points in the plane by \(z=(x,y)\).
Definition 1.5
Let \(m\) be a nonnegative number. For any bounded function \(\chi \) and any \({E}\) satisfying a relation of the form (1.17)–(1.18), we let
and the renormalized energy \(W\) is defined by
where \(\{\chi _R\}_{R>0}\) is a family of cut-off functions satisfying
for some \(C\) independent of \(R\).
After this work was completed, a slightly different definition of renormalized energy was proposed in [33] for points in dimensions \(d\ge 2\). A version for dimension one can also be written down, cf. [32] and this allows to retrieve our results with a few simplifications in the proof, more precisely it suppresses the need for Proposition 2.1.
Remark 1.6
While \(W\) in 2D can be viewed as a “renormalized” way of computing \(\Vert H\Vert _{H^1(\mathbb {R}^2)}\), in 1D it amounts rather to a renormalized computation of \(\Vert H\Vert _{H^{1/2}(\mathbb {R})}\) (where \(H^s\) denote the fractional Sobolev spaces). In other words, because the logarithmic kernel is not Coulombic in one-dimension, the associated energy is non-local (and the associated operator is the fractional Laplacian \(\Delta ^{1/2}\)). Augmenting the dimension by 1 allows to make it local and Coulombic again. This well-known harmonic extension idea seems to be attributed to [31].
As in the two dimensional case, we have the following properties:
-
The value of \(W\) does not depend on \(\{\chi _{R}\}_R\) as long as it satisfies (1.22).
-
\(W\) is insensitive to compact perturbations of the configuration.
-
Scaling: it is easy to check that if \({E}\) belongs to \(\mathcal {A}_m\) then \({E}':=\frac{1}{m} {E}(\cdot / m)\) belongs to \(\mathcal {A}_1 \) and
$$\begin{aligned} W({E})= m \left( W({E}') - \pi \log m\right) , \end{aligned}$$(1.23)so one may reduce to studying \(W\) on \(\mathcal {A}_1\).
-
If \({E}\in \mathcal A_m\) then in the neighborhood of \(p\in \Lambda \) we have \(\mathrm {div} \ {E}= 2\pi (\delta _p - m{\delta _{\mathbb {R}}})\), \(\mathrm{curl}{E}= 0\), thus we have near \(p\) the decomposition \({E}(x) = - \nabla \log |x-p| + f(x)\) where \(f\) is smooth, and it easily follows that the limit (1.20) exists. It also follows that \({E}\) belongs to \(L^p_\mathrm{loc}\) for any \(p<2\), as stated above.
In the case where (1.18) is satisfied, then there exists at most on \({E}\) satisfying (1.17) and such that \(W({E}) <+\infty \). This is the content of the next lemma, and is in contrast with the \(2\)-dimensional case—when the support of \(\nu \) is not constrained to lie on the real line and where the definition of \(W\) is modified accordingly—where (1.17) and \(W({E})<+\infty \) only determine \({E}\) up to constant (see Lemma 3.3 in [36]). The following lemma is proved in the appendix.
Lemma 1.7
Let \({E}\in \mathcal {A}_m\) be such that \(W({E})<+\infty \). Then any other \({E}'\) satisfying (1.17)–(1.18) with the same \(\nu \) and \(W({E}')<+\infty \), is such that \({E}'={E}\). In other words, \(W\) only depends on the points.
By simple considerations similar to [36, Section 1.2] this makes \(W\) a measurable function of the bounded Radon measure \(\nu \).
The following lemma is proven in [9], see also [16], and shows that there is an explicit formula for \(W\) in terms of the points when the configuration is assumed to have some periodicity. Here we can reduce to \(m=1\) by scaling, as seen above.
Lemma 1.8
In the case \(m=1\) and when the set of points \(\Lambda \) is periodic with respect to some lattice \( N\mathbb {Z}\), then it can be viewed as a set of \(N\) points \(a_1,\dots , a_N\) over the torus \({\mathbb {T}}_N := \mathbb {R}/(N\mathbb {Z})\). In this case, by Lemma 1.7 there exists a unique \({E}\) satisfying (1.17) and for which \(W({E})<+\infty \). It is periodic and equal to \({E}_{\{a_i\}}= \nabla H\), where \(H\) is the solution on \({\mathbb {T}}_N\) to \(-\Delta H = 2\pi (\sum _i\delta _{a_i} - {\delta _{\mathbb {R}}})\), and we have the explicit formula:
As in the two-dimensional case, we can prove that \(\min _{\mathcal {A}_m}\) is achieved, but contrarily to the two-dimensional case, the value of the minimum can be explicitly computed: we will prove the following
Theorem 2
\(\min _{{\mathcal {A}_{m}}} W= - \pi m \log (2\pi m) \) and this minimum is achieved by the perfect lattice i.e. \(\Lambda = \frac{1}{m} \mathbb {Z}\).
We recall that in dimension 2, it was conjectured in [35] but not proven, that the minimum value is achieved at the triangular lattice with angles \(60^\circ \) (which is shown to achieve the minimum among all lattices), also called the Abrikosov lattice in the context of superconductivity.
The proof of Theorem 2 relies on showing that a minimizer can be approximated by configurations which are periodic with period \(N \rightarrow \infty \) (this result itself relies on the screening construction mentioned at the beginning), and then using a convexity argument to find the minimizer among periodic configurations with a fixed period via (1.24).
The minimizer of \(W\) over the class \(\mathcal {A}_m\) is not unique, because as already mentioned it suffices to perturb the points of the lattice \(m\mathbb {Z}\) in a compact set only, and this leaves \(W\) unchanged. However, it is proven by Leblé in [26] that \(W\), once averaged with respect to a translation-invariant probability measures, has a unique minimizer. We now describe more precisely this averaging of \(W\) and Leblé’s result.
We may extend \(W\) into a function on electric field (or point) processes, as follows: given any \(m>0\), we define
over stationary probability measures on \({L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) concentrated on the class \(\mathcal {A}_m\). Leblé proves that \(\overline{W}\) achieves a unique minimum of value \(\min _{\mathcal {A}_m} W\), and the unique minimizer is \(P_{\frac{1}{m}\mathbb {Z}}\), defined as the electric field process associated (via Lemma 1.8) to the point configurations \(u+\frac{1}{m}\mathbb {Z}\) where \(u\) is uniform in \([0,\frac{1}{m}]\). In other words, to each \(u \in [0,\frac{1}{m}]\) we associate the unique (by Lemma 1.7) periodic electric field \(E_{u+ \frac{1}{m} \mathbb {Z}}\) such that \(\mathrm {div} \ E= 2\pi ( \sum _{p\in \mathbb {Z}} \delta _{u+\frac{1}{m} p} - m \delta _\mathbb {R})\), and define \(P_{\frac{1}{m}\mathbb {Z}}\) as the push-forward of the normalized Lebesgue measure on \([0,\frac{1}{m}]\) by \(u \mapsto E_{u+\frac{1}{m}\mathbb {Z}}\).
Leblé’s proof is quantitative: he shows the estimate
for \(\varphi \in C^1_c(\mathbb {R}\times \mathbb {R})\), where \(\rho _{2}\) is the two-point correlation function of the point process associated to \(P\) (i.e. given by the push-forward of \(P\) by \(P\mapsto \frac{1}{2\pi } \mathrm {div} \ P + m \delta _\mathbb {R}\)) and \(\rho _{2, \mathbb {Z}}\) is the two-point correlation function associated to the point process \(u + \frac{1}{m}\mathbb {Z}\) where \(u\) follows a uniform law on \([0,\frac{1}{m}]\).
We will also need a version of \(W\) for marked electric field processes, in fact it is the one that will play the role of the rate function in our results. For each \(P\in \mathcal {P}(X)\), we let
In view of Theorem 2 and the definition of admissible, the minimum of \(\widetilde{W}\) can be guessed to be
From [26], this minimum is uniquely achieved (here the assumption of translation-invariance made in the definition of admissible is the crucial point):
Corollary 1.9
[26] The unique minimizer of \(\widetilde{W}\) on \(\mathcal P(X)\) is
where \(P_{\frac{1}{m}\mathbb {Z}}\) has just been defined.
1.4 Link between \({{w}_{n}}\) and \(W\)
We are now ready to state the two basic results which link the energies \({{w}_{n}}\) and \(W\). In the language of Gamma-convergenceFootnote 1 these results establish in essence that the second term in the development of \({{w}_{n}}\) by Gamma-convergence is \(\widetilde{W}\) (the first term being \({\mathcal {F}}\)). The consequences for the asymptotics of minimizers of \({{w}_{n}}\) and \({\mathbb {P}_{n}^{\beta }}\) will be stated in the next subsection.
We begin with the following splitting formula which is the starting point to establish this link, and which is proved in the appendix.
Lemma 1.10
(Splitting formula) For any \(n\), any \(x_1, \dots , x_n \in \mathbb {R}\) the following holds
where \(H_n'\) is as in (1.13), \(W\) as in (1.20), and \(\zeta \) as in (1.7).
We may then define
and also
and we thus have the following rewriting of \({{w}_{n}}\):

This allows to separate orders in the limit \(n \rightarrow \infty \) since one of the main outputs of our analysis is that \({{F}_{n}}(\nu )\) is of order \(1\).
We next state some preliminary results which connect directly \(F_n\) and \(\widetilde{W}\). The first result is a lower bound corresponding to the lower-bound part in the definition of Gamma-convergence. We will systematically abuse notation by writing \((x_1, \dots , x_n)\) instead of \((x_{1,n}, \dots , x_{n,n})\) and \(\nu _n= \sum _{i=1}^n \delta _{x_i}\) instead of \(\nu _n= \sum _{i=1}^n \delta _{x_{i,n}}\).
Theorem 3
(Lower bound) Let the potential \(V\) satisfy assumptions (1.8), (1.11). Let \(\nu _n= \sum _{i=1}^n \delta _{x_i}\) be a sequence such that \( \widehat{F_n}(\nu _n) \le C\), and let \(P_{\nu _n}\) be associated via (1.16).
Then any subsequence of \(\{P_{\nu _n}\}_n\) has a convergent subsequence converging as \(n\rightarrow \infty \) to an admissible probability measure \(P\in \mathcal {P}(X)\) and
The second result corresponds to the upper-bound part in the definition of Gamma-convergence, with an added precision needed for statements in the finite temperature case.
Theorem 4
(Upper bound construction) Let the potential \(V\) satisfy assumptions (1.8)–(1.11). Assume \(P\in \mathcal {P}(X) \) is admissible.
Then, for any \(\eta > 0\), there exists \(\delta >0\) and for any \(n\) a subset \(A_n\subset \mathbb {R}^n\) such that \(|A_n|\ge n!(\delta /n)^n\) and for every sequence \(\{\nu _n= \sum _{i=1}^n \delta _{y_i}\}_n\) with \((y_1,\dots ,y_n)\in A_n\) the following holds.
-
(i)
We have the upper bound
$$\begin{aligned} \limsup _{n \rightarrow \infty }\widehat{F_n} (\nu _n) \le \widetilde{W}(P) +\eta . \end{aligned}$$(1.33) -
(ii)
There exists \(\{{E}_n\}_n\) in \(L^p_\mathrm{loc}(\mathbb {R}^2,\mathbb {R}^2)\) such that \(\mathrm {div} \ {E}_n = 2\pi ( \nu _n' -{m_0}'{\delta _{\mathbb {R}}})\) and such that the image \(P_n\) of \(dx_{|{\Sigma }}/|{\Sigma }|\) by the map \(x\mapsto \left( x,{E}_n(n x+\cdot )\right) \) is such that
$$\begin{aligned} \limsup _{n \rightarrow \infty } \text {dist}\ (P_n,P) \le \eta , \end{aligned}$$(1.34)where \(\text {dist}\ \) is a distance which metrizes the topology of weak convergence on \(\mathcal {P}(X)\).
Remark 1.11
Theorem 4 is only a partial converse to Theorem 3 because the constructed \({E}_n\) need not be a gradient, hence in general \({E}_n\ne {E}_{\nu _n}\).
A direct consequence of Theorem 4 (by choosing \(\eta =1/k\) and applying a diagonal extraction argument) is
Corollary 1.12
Under the same hypothesis as Theorem 4 there exists a sequence \(\{\nu _n= \sum _{i=1}^n \delta _{x_i}\}_n\) such that
Moreover there exists a sequence \(\{{E}_n\}_n\) in \(L^p_\mathrm{loc}(\mathbb {R}^2,\mathbb {R}^2)\) such that \(\mathrm {div} \ {E}_n = 2\pi (\nu _n' -{m_0}'{\delta _{\mathbb {R}}})\) and such that defining \(P_n\) as in (1.16), with \({E}_n\) replacing \({E}_{\nu _n}\), we have \(P_n\rightarrow P\) as \(n \rightarrow \infty \).
1.5 Main results
Theorems 3 and 4 have straightforward and not-so straightforward consequences which form our main results.
Theorem 5
(Microscopic behavior of weighted Fekete sets) Let the potential \(V\) satisfy assumptions (1.8)–(1.11). If \((x_1,\dots , x_n)\) minimizes \(w_n\) for every \(n\) and \(\nu _n=\sum _{i=1}^n \delta _{x_i}\), then \(P_{\nu _n}\) as defined in (1.16) converges as \(n\rightarrow \infty \) to
and
Proof
This follows from the comparison of Theorem 3 and Corollary 1.12, together with (1.30): For minimizers, (1.32) and (1.35) must be equalities. Moreover we must have \(\lim _n( F_n(\nu _n) - \widehat{F_n} (\nu _n)) = 0\)—that is \( \lim _{n\rightarrow \infty }\sum _{i=1}^n \zeta (x_i) = 0\)—and \(P\) must minimize \(\widetilde{W}\), hence be equal to \(P_0\) in view of Corollary 1.9. By uniqueness of the limit, the statement is true without extraction of a subsequence. \(\square \)
It can be expected that \(\zeta \) (which is positive exactly in the complement of \({\Sigma }\)) controls the distance to \({\Sigma }\) to some power. One can show this under suitable assumptions on \(V\) by observing that \(U^{\mu _0}\) as in (1.5) is the solution to a fractional obstacle problem and using the results in [17].
We next turn to the situation with temperature. The estimates on \(w_n\) that we just obtained first allow to deduce, as announced, a next order asymptotic expansion of the partition function, which becomes sharp as \(\beta \rightarrow \infty \).
Theorem 6
Let \(V\) satisfy assumptions (1.8)–(1.12). There exist functions \(f_1, f_2\) depending only on \(V\), such that for any \(\beta _0>0 \) and any \( \beta \ge \beta _0\), and for \(n\) larger than some \(n_0\) depending on \(\beta _0\), we have
with \(f_1,f_2\) bounded in \([\beta _0,+\infty )\) and
Remark 1.13
In fact we prove that the statement holds with \(f_2(\beta )=\frac{\min \widetilde{W}}{2} + \frac{C}{\beta }\) for any \(C>\log |{\Sigma }|\).
As mentioned above, this result can be compared to the expansions known in the literature, which can also be obtained as soon as a Central Limit Theorem is proven for general enough \(V\)’s, cf. [10, 11, 24, 38, 39]. These previous results generally assume more regularity on \(V\) though. It is also not obvious to check that the formulas agree when \(\beta \rightarrow \infty \) (for which \(\min \widetilde{W}\) is completely explicit, cf. (1.27)) because the coefficients in these prior works are in principle computable but in quite an indirect manner.
Our method also allows to give a statement on the thermal states themselves (the complete statement in the paper can be phrased as a next order large deviations type estimate, to be compared to Theorem 1).
Theorem 7
Let \(V\) satisfy (1.8)–(1.12). There exists \(C_\beta >0\) such that \(\lim _{\beta \rightarrow \infty }C_\beta =0\) and such that the following holds. If \(\beta >0\) is finite, the law of \(P_{\nu _n}\), i.e. the push-forward of \({\mathbb {P}_{n}^{\beta }}\) by \(i_n\) defined in (1.15) converges weakly, up to extraction, to a probability measure \(\widetilde{\mathbb {P}^\beta }\) in \(\mathcal {P}(\mathcal {P}(X))\) concentrated on admissible probabilities; and for \(\widetilde{\mathbb {P}^\beta }\)-almost every \(P\) it holds that
The first statement in the result is the existence of a limiting random electric field process, hence equivalently, via projecting by \((x, {E}) \mapsto \frac{1}{2\pi } \mathrm {div} \ {E}+ m_0(x){\delta _{\mathbb {R}}}\), of a limiting random point process. The second statement allows to quantify the average distance to the crystalline state as \(\beta \) gets large, using (1.25):
Corollary 1.14
Let \(P \in \mathcal {P}(X)\) be admissible, and let us write its disintegration \(P= \{ P^x\}_{x\in {\Sigma }} \) where \(x\)-a.e. in \(\Sigma \), \(P^x\) is a probability measure on \({L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) concentrated on \(\mathcal {A}_{m_0(x)}\). Let \(\rho _2^x\) be the two-point correlation function of the point process given as the push forward of \(P^x\) by \(E \mapsto \frac{1}{2\pi } \mathrm {div} \ E +m_0(x) \delta _\mathbb {R}\). Let \(\rho _{2, \frac{1}{m}\mathbb {Z}}\) be the two-point correlation function associated to \(P_{\frac{1}{m}\mathbb {Z}}\) as above. Then, for any \(\widetilde{\mathbb {P}^\beta }\) obtained by Theorem 7, it holds for \(\widetilde{\mathbb {P}^\beta }\)-almost every \(P\) and any smooth compactly supported \(\varphi \) that

where \(C_\varphi \) depends only on \(\varphi \), and \(C_\beta \) is as in Theorem 7.
Since \(C_\beta \rightarrow 0\), our results can thus be seen as a result of crystallization as \(\beta \rightarrow \infty \). We believe that when \(\beta \) is finite a complete large deviations principle should hold with a rate function involving both \(\widetilde{W}\) and a relative entropy term, whose weight decreases as \(\beta \rightarrow \infty \). This is work in progress [27].
Finally, let us mention that our method yields estimates on the probability of some rare events, typically the probability that the number of points in a microscopic interval deviates from the number given by \({\mu _{0}}\). We present them below, even though stronger results are obtained in [12, 13]. The results below follow easily from the estimate (provided by Theorem 6) that \(\widehat{{{F}_{n}}}\le C\) except on a set of small probability.
Theorem 8
Let \(V\) satisfy assumptions (1.8)–(1.12). There exists a universal constant \(R_0>0\) and \(c,C>0\) depending only on \(V\) such that: For any \(\beta _0>0\), any \(\beta \ge \beta _0\), any \(n\) large enough depending on \(\beta _0\), for any \(x_1,\ldots ,x_n\in \mathbb {R}\), any \(R>R_0\), any interval \(I\subset \mathbb {R}\) of length \(R/n\), and any \(\eta >0\), letting \(\nu _n=\sum _{i=1}^n \delta _{x_i}\), we have the following:
where \(W^{-1,q}(I)\) is the dual of the Sobolev space \(W^{1,q'}_0(I)\), with \(1/q+ 1/q'=1\), in particular \(W^{-1,1}\) is the dual of Lipschitz functions; and
Note that in these results \(R\) can be taken to depend on \(n\).
(1.38) tells us that the density of eigenvalues is correctly approximated by the limiting law \({\mu _{0}}\) at all small scales bigger than \(C n^{-1/2}\) for some \(C\). However this in fact should hold at all scales with \(R\gg 1\), cf. [12, 13, 22]. (1.40) serves to control the probability that points are outside \({\Sigma }\) (since \(\{\zeta >0\}= {\Sigma }^c\)).
The rest of the paper is organized as follows. In Sect. 2 we prove Theorem 3, in Sect. 3 we prove Theorem 4. In Sect. 4 we prove the remaining theorems. In the appendix we prove Lemmas 1.7 and 1.10, as well as the main screening result Proposition 3.1.
2 Lower bound
In this section we prove Theorem 3.
2.1 Preliminaries: a mass displacement result
In this subsection, we state the analogue in 1D of Proposition 4.9 in [35], a result we will need later. The proposition below asserts that, even though the energy density \(\frac{1}{2}|{E}|^2 + \pi \log \eta \sum _p \delta _p\) associated to \(W\) is not bounded below, there exists a replacement \(g\) which is. The sense in which \(g\) is a replacement for the energy density of \(W\) (specified in the statement of the proposition) is what is needed to make the energy density of \(W\) effectively behave as if it were bounded from below.
The density \(g\) is obtained by displacing the negative part of the energy-density into the positive part. The proof is identical to that of [35] once the one-dimensional setting has been embedded into the two-dimensional one as stated. What follows will be applied to \(\nu _n'\), i.e. the measure in blown-up coordinates.
Proposition 2.1
Assume \((\nu ,{E})\) are such that \(\nu = 2\pi \sum _{p\in \Lambda } \delta _p\) for some finite subset \(\Lambda \) of \(\mathbb {R}\), \(\mathrm {div} \ {E}= 2\pi (\nu - a(x){\delta _{\mathbb {R}}})\), for some \(a\in L^\infty (\mathbb {R})\), and \({E}\) is a gradient.
Then, given \(0<\rho <\rho _0\), where \(\rho _0\) is universal, there exists a measure density \(g\) in \(\mathbb {R}^2\) such that
-
(i)
There exists a family of disjoint closed balls \(\mathcal {B}_\rho \) centered on the real line, covering \(\text {Supp}(\nu )\), such that the sum of the radii of the balls in \(\mathcal {B}_\rho \) intersected with any segment of \(\mathbb {R}\) of length \(1\) is bounded by \(\rho \) and such that
$$\begin{aligned} g\ge - C (\Vert a\Vert _{L^\infty }+1) + \frac{1}{4} |{E}|^2\mathbf {1}_{ \mathbb {R}^2 \setminus \mathcal {B}_\rho }\quad \text {in} \ \mathbb {R}^2, \end{aligned}$$(2.1)where \(C\) depends only on \(\rho \).
-
(ii)
$$\begin{aligned} g = \frac{1}{2}|{E}|^2 \text { in the complement of } \ \mathbb {R}\times [-1,1]. \end{aligned}$$
-
(iii)
For any function \(\chi \) compactly supported in \(\mathbb {R}\) we have, letting \(\bar{\chi }(x,y) = \chi (x)\),
$$\begin{aligned} \left| W({E},\chi ) - \int \bar{\chi }\,dg\right| \le C N (\log N + \Vert a\Vert _\infty )\Vert \nabla \chi \Vert _\infty , \end{aligned}$$(2.2)where \(N=\#\{p\in \Lambda \mid B(p,\lambda )\cap \text {Supp}(\nabla \bar{\chi })\ne \varnothing \}\) and \(\lambda \) depends only on \(\rho \). (Here \(\#A\) denotes the cardinality of \(A\)).
Proposition 4.9 of [35] of which the above proposition is a restatement, was stated for a fixed universal \(\rho _0\), but we may use instead in its proof any \(0<\rho <\rho _0\), which makes the constant \(C\) above depend on \(\rho \). Another fact which is true from the proof of [35, Proposition 4.9] but not stated in the proposition itself is that in fact \(g = \frac{1}{2}|{E}|^2\) outside \(\cup _p B(p,r)\) for some constant \(r>0\) depending only on \(\rho \), and if \(\rho \) is taken small enough, then we may take \(r=1\), which yields item ii) of Proposition 2.1.
The next lemma shows that a control on \(W\) implies a corresponding control on \(\int g\) and of \(\int |{E}|^2\) away from the real axis, growing only like \(R\).
Lemma 2.2
Assume that \(G\subset \mathcal A_1\) is such that, writing \(\nu = \frac{1}{2\pi } \mathrm {div} \ {E}+ {\delta _{\mathbb {R}}}\),
hold uniformly w.r.t. \({E}\in G\). Then for any \({E}\in G\), for every \(R\) large enough depending on \(G\), we have
and denoting by \(g\) the result of applying Proposition 2.1 to \({E}\) for some fixed value \(\rho <1/8\), we have
where \(\chi _R\) satisfies (1.22), \(C_1\) depends only on \(G\) and \(C\) is a universal constant.
Proof
We denote by \(C_1\) any constant depending only on \(G\), and by \(C\) any universal constant. From (2.3), (2.4) we have for any \({E}\in G\) that \(\nu (I_R) \le C_1 R\) and \(W({E}, \chi _R) \le C_1 R\) if \(R\) is large enough depending on \(G\). Thus, applying (2.2) we have
which, in view of the fact that \(\chi _R=1\) in \(I_{R-1}\) and \(g\) is positive outside \(\mathbb {R}\times [-1, 1]\) and bounded below by a constant otherwise, yields that for every \(R\) large enough,
This in turn implies—using (2.1) and the fact that \(\frac{1}{2}|{E}|^2 = g\) outside \(\mathbb {R}\times [-1,1]\)—the first (unsufficient) control
Since the sum of the radii of the balls in \(\mathcal {B}_\rho \) intersected with any segment of \(\mathbb {R}\) of length \(1\) bounded by \(\rho <1/8 \), we deduce by a mean value argument with respect to the variable \(x\) that there exists \(t \in [0,1]\) such that
Using now a mean value argument with respect to \(y\), we deduce from (2.8) the existence of \(y_R \in [1, 1+ \sqrt{R}] \) such that
Next, we integrate \(\mathrm {div} \ {E}= 2\pi (\nu - {\delta _{\mathbb {R}}})\) on the square \([-\frac{R}{2}-t, \frac{R}{2}+t]\times [-y_R, y_R]\). We find using the symmetry property of Corollary 5.1 that
Using the Cauchy-Schwarz inequality and (2.9)–(2.10), this leads for \(R\) large enough to
and then—since \(\nu (I_R) \ge \nu (I_{R-t/2})\)—to
To prove the same upper bound for \(R-\nu (I_R)\) we proceed in the same way, but using a mean value argument to find some \(t\in (-1,0)\) instead of \((0,1)\) such that (2.9) holds, and then (2.10) also. We deduce as above that (2.11) holds and conclude by noting that since \(t\in (-1,0)\) we have \(\nu (I_R) \le \nu (I_{R-t/2})\). This establishes (2.5).
We may bootstrap this information: Indeed (2.5) implies in particular that \(\nu (I_R)- \nu (I_{R-1}) \le C_1 R^{3/4} \log R\) and thus we deduce from (2.2) that (2.7) holds:
Then since \(W({E}, \chi _R)/R\rightarrow W({E})\) as \(R\rightarrow \infty \) uniformly w.r.t. \({E}\in G\) and since \(g\) is both bounded from below by a universal constant and equal to \(\frac{1}{2}|{E}|^2\) outside \(\mathbb {R}\times [-1,1]\), we deduce (2.6), for \(R\) large enough depending on \(G\). \(\square \)
Definition 2.3
Assume \(\nu _n = \sum _{i=1}^n\delta _{x_i}\). Letting \(\nu '_n = \sum _{i=1}^n\delta _{x_i'}\) be the measure in blown-up coordinates, i.e. \(x_i' = n x_i\), and \({E}_{\nu _n} = - \nabla H'_n\), where \(H'_n\) is defined by (1.13), we denote by \(g_{\nu _n}\) the result of applying Proposition 2.1 to \((\nu '_n,{E}_{\nu _n})\).
2.2 Proof of Theorem 3
We start with a result that shows how \(\widehat{F_n}\) controls the fluctuation \(\nu _n - n\mu _0\).
Lemma 2.4
Let \(\nu _n=\sum _{i=1}^n \delta _{x_i}\). For any interval \(I\) of width \(R\) (possibly depending on \(n\)) and any \(1<q<2\), we have
Here \(W^{-1,q}\) is the dual of the Sobolev space \(W^{1,q'}_0\) with \(1/q+1/q'=1\).
Proof
In [36, Lemma 5.1], we have the following statement
The proof is based on [41] which works in our one-dimensional context as well, thus the proof can be reproduced without change. It is immediate to deduce the result. \(\square \)
We now turn to bounding from below \(\widehat{F_n}\). The proof is the same as in [36, Sec. 6], itself following the method of [35] based on the ergodic theorem. We just state the main ingredients.
Let \(\{\nu _n\}_n\) and \(P_{\nu _n}\) be as in the statement of Theorem 5. We need to prove that any subsequence of \(\{P_{\nu _n}\}_n\) has a convergent subsequence and that the limit \(P\) is admissible and (1.32) holds. Note that the fact that the first marginal of \(P\) is \(dx_{|{\Sigma }}/|{\Sigma }|\) follows from the fact that, by definition, this is true of \(P_{\nu _n}\).
We thus take a subsequence of \(\{P_{\nu _n}\}\) (which we don’t relabel), which satisfies \(\widehat{{{F}_{n}}}(\nu _n)\le C \). This implies that \(\nu _n\) is of the form \(\sum _{i=1}^n \delta _{x_{i,n}}\). We let \({E}_n\) denote the electric field and \({{g}_{n}}\) the measures associated to \({{\nu }_{n}}\) as in Definition 2.3. As usual, \({{\nu }_{n}}'= \sum _{i=1}^n \delta _{ n x_{i,n}}\).
A useful consequence of \(\widehat{{{F}_{n}}}({{\nu }_{n}})\le C \) is that, using Lemma 2.4, we have
We then set up the framework of Section 6.1 in [36] for obtaining lower bounds on two-scale energies. We let \(G = {\Sigma }\) and \(X= \mathcal {M}_+\times {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\times \mathcal {M}\), where \(p\in (1,2)\), where \(\mathcal {M}_+\) denotes the set of positive Radon measures on \(\mathbb {R}^2\) and \(\mathcal {M}\) the set of those which are bounded below by the constant \(-C_V:= -C (\Vert {m_0}\Vert _\infty +1)\) of Proposition 2.1, both equipped with the topology of weak convergence.
For \(\lambda \in \mathbb {R}\) and abusing notation we let \(\theta _\lambda \) denote both the translation \(x\mapsto x+\lambda \) and the action
Accordingly the action \(T^n\) on \({\Sigma }\times X\) is defined for \(\lambda \in \mathbb {R}\) by
Then we let \(\chi \) be a smooth nonnegative cut-off function with integral \(1\) and support in \([-1,1]\) and define
Finally we let,

We have the following relation between \({\mathbf {F}}_n\) and \(\widehat{{{F}_{n}}}\), as \(n\rightarrow +\infty \) (see [36, Sec. 6]):
The hypotheses in Section 6.1 of [36] are satisfied and applying the abstract result, Theorem 6 of [36], we conclude that letting \(Q_n\) denote the push-forward of the normalized Lebesgue measure on \({\Sigma }\) by the map \(x\mapsto (x,\theta _{ n x} ({{\nu }_{n}}', {{{E}}_{n}},{{g}_{n}}))\), and \(Q = \lim _n Q_n,\) we have
and, \(Q\)-a.e. \(({E},\nu )\in \mathcal A_{{m_0}(x)}\).
Now we let \(P_n\) (resp. \(P\)) be the marginal of \(Q_n\) (resp. \(Q\)) with respect to the variables \((x,{E})\). Then the first marginal of \(P\) is the normalized Lebesgue measure on \(E\) and \(P\)-a.e. we have \({E}\in \mathcal A_{{m_0}(x)}\), in particular
Integrating with respect to \(P\) and noting that since only \(x\) appears on the right-hand side we may replace \(P\) by its first marginal there, we find, in view of (1.27) that the lower bound (1.32) holds.
3 Upper bound
In this section we prove Theorem 4. The construction consists of the following.
First we state our main screening result, whose proof is given in the appendix, on which the proof of Theorem 4 is based, and which is the main difference with the two-dimensional situation. It allows to truncate electric fields to allow all sorts of cutting and pastings necessary for the construction. However, for the truncation process to have good properties, an extra hypothesis [see (3.1)] needs to be satisfied.
The second step consists in selecting a finite set of vector fields \(J_1, \dots , J_{N}\) (\(N\) will depend on \(\varepsilon \)) such that the marginal of the probability \(P(x,{E})\) with respect to \({E}\) is well-approximated by measures supported on the orbits of the \(J_i\)’s under translations. This is possible because \(P\) is assumed to be \(T_{\lambda (x)}\)-invariant. It is during this approximation process that we manage to select the \(J_i\)’s as belonging to a part of the support of \(P\) of almost full measure for which the extra assumption (3.1) holds and the screening can be performed.
Third, we work in blown-up coordinates and split the region \({\Sigma }'\) (of order \(n\) size) into many intervals, and then select the proportion of the intervals that corresponds to the relative weight that the orbit of each \(J_i \) carries in the approximation of \(P\). In these rectangles we paste a (translated) copy of (the screened version of) \(J_i\) at the appropriate scale (approximating the density \({m_0}'\) by a piecewise constant one and controlling errors).
To conclude the proof of Theorem 4, we collect all of the estimates on the constructed vector field to show that its energy \({{w}_{n}}\) is bounded above in terms of \(\widetilde{W}\) and that the probability measures associated to the construction have remained close to \(P\).
In what follows we use the notation \(\theta _\lambda {E}(x,y) = {E}(x+\lambda ,y)\) for the translates of \({E}\), and \(\sigma _m{E}(x,y) = m {E}(m x, my)\) for the dilates of \({E}\).
3.1 The main screening result
This result says that starting from an electric field with finite \(W\) which also satisfies some appropriate decay property away from the real axis, we may truncate it in a strip of width \(R\), keep it unchanged in a slightly narrower rectangle around the real axis, and use the layer between the two strips to transition to a vector field which is tangent to the boundary, while paying only a negligible energy cost in the transition layer as \(R\rightarrow \infty \). The new electric field \(E_R\) thus constructed can then be extended outside of the strip by other vector fields satisfying the same condition of being tangent to the boundary of the strip. Because the divergence of a vector field which is discontinuous across an interface is equal (in the sense of distributions) to the jump of the normal derivative across the interface, pasting two such vector fields together will not create any divergence along the boundary interface. We will thus be able to construct vector fields that still satisfy globally equations of the form (1.17), the only loss being that they may no longer be gradients. However, this can be overcome by projecting them later onto gradients (in the \(L^2\) sense), and since the \(L^2\) projection decreases the \(L^2\) norm, this operation can only decrease the energy, while keeping the relation (1.17) unchanged.
Proposition 3.1
Let \(I_R=[-R/2,R/2]\), let \(\chi _R\) satisfy (1.22).
Assume \(G\subset \mathcal A_1\) is such that there exists \(C>0\) such that for any \( {E}\in G\) and writing \( \nu = \frac{1}{2\pi } \mathrm {div} \ {E}+ {\delta _{\mathbb {R}}}\) we have (2.3), (2.4) and

and such that moreover all the convergences are uniform w.r.t. \({E}\in G\).
Then for every \(0<\varepsilon <1\), there exists \(R_0>0\) such that if \(R>R_0\) with \(R\in \mathbb {N}\), then for every \({E}\in G\) there exists a vector field \({E}_R\in L^p_{loc}( I_R \times \mathbb {R}, \mathbb {R}^2)\) such that the following holds:
-
(i)
\({E}_R \cdot \vec {\nu } =0\) on \(\partial {I}_R\times \mathbb {R}\), where \(\vec {\nu }\) denotes the outer unit normal.
-
(ii)
There is a discrete subset \(\Lambda \subset I_R\) such that
$$\begin{aligned} \mathrm {div} \ {E}_R = 2\pi \left( \sum _{p\in \Lambda }\delta _p - \delta _\mathbb {R}\right) \quad \text {in} \ I_R\times \mathbb {R}. \end{aligned}$$ -
(iii)
\({E}_R(x,y) = {E}(x,y)\) for \(x \in [- R/2+\varepsilon R, R/2-\varepsilon R]\).
-
(iv)
$$\begin{aligned} \frac{W({E}_R,\mathbf {1}_{I_R\times \mathbb {R}})}{R} \le W({E})+ C\varepsilon . \end{aligned}$$(3.2)
Remark 3.2
The assumption (3.1) is a supplementary assumption which allows to perform the screening but which is not necessarily satisfied for all \({E}\in \mathcal {A}_m\), even those satisfying \(W({E})<+\infty \). We believe a counter example could be constructed as follows: let \(z_k = (2^k,0)\) and
Then
hence

where \(C_0\) is independent of \(k\). Therefore \({E}= \nabla U\) violates (3.1). On the other hand, because the strength of each charge in the sum defining \(\mu \) is negligible compared to the distance from the next charge, it is possible to approximate \(\mu \) by a measure of the type \(\nu - {\delta _{\mathbb {R}}}\), where \(\nu = \sum _{p\in \Lambda } \delta _p\). Letting \({E}= 2\pi \nabla \Delta ^{-1} (\nu -{\delta _{\mathbb {R}}})\) would then yield a counter-example.
We have not been able to show that screening is always possible without assuming (3.1). However we will see in Lemma 3.6 that this assumption is satisfied “generically” i.e. for a large set of vector-fields in the support of any invariant probability measure, and this will suffice for our purposes.
3.2 Abstract preliminaries
We repeat here the definitions of distances that we used in [36]. First we choose distances which metrize the topologies of \({L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) and \({\mathcal {B}}(X)\), the set of finite Borel measures on \(X={\Sigma }\times {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\). For \({E}_1,{E}_2\in {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) we let
and on \(X\) we use the product of the Euclidean distance on \({\Sigma }\) and \(d_p\), which we denote \(d_X\). On \({\mathcal {B}}(X)\) we define a distance by choosing a sequence of bounded continuous functions \(\{\varphi _k\}_k\) which is dense in \(C_b(X)\) and we let, for any \(\mu _1,\mu _2\in {\mathcal {B}}(X)\),
where we have used the notation \(\langle \varphi ,\mu \rangle = \int \varphi \,d\mu \).
We will use the following general facts, whose proofs are in [36, Sec. 7.1].
Lemma 3.3
For any \(\varepsilon >0\) there exists \(\eta _0>0\) such that if \(P,Q\in {\mathcal {B}}(X)\) and \(\Vert P-Q\Vert <\eta _0\), then \(d(P,Q)<\varepsilon \). Here \(\Vert P-Q\Vert \) denotes the total variation of the signed measure \(P-Q\), i.e. the supremum of \(\langle \varphi ,P-Q\rangle \) over measurable functions \(\varphi \) such that \(|\varphi |\le 1\).
In particular, if \(P = \sum _{i=1}^\infty \alpha _i\delta _{x_i}\) and \(Q = \sum _{i=1}^\infty \beta _i\delta _{x_i}\) with \(\sum _i|\alpha _i - \beta _i| <\eta _0\), then \(d_{{\mathcal {B}}}(P,Q)<\varepsilon \).
Lemma 3.4
Let \(K\subset X\) be compact. For any \(\varepsilon >0\) there exists \(\eta _1>0\) such that if \(x\in K, y\in X\) and \(d_X(x,y)<\eta _1\) then \(d_{{\mathcal {B}}}(\delta _x, \delta _y)<\varepsilon \).
Lemma 3.5
Let \(0<\varepsilon <1\). If \(\mu \) is a probability measure on a set \(A\) and \(f,g:A\rightarrow X\) are measurable and such that \(d_{{\mathcal {B}}}(\delta _{f(x)}, \delta _{g(x)})<\varepsilon \) for every \(x\in A\), then
where \(\#\) denotes the push-forward of a measure.
The next lemma shows how, given a translation-invariant probability measure \(\tilde{P}\) on \({L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\), one can select a good subset \(G_\varepsilon \) and vector fields \(J_i\) of \({L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) to approximate it. It is essentially borrowed from [36] except it contains in addition the argument that ensures that we may choose \(G_\varepsilon \) to satisfy the assumption (3.1) needed for the screening.
Lemma 3.6
Let \(\tilde{P}\) be a translation invariant measure on \(X\) such that, \(\tilde{P}\)-a.e., \({E}\) is in \(\mathcal A_1\) and satisfies \(W({E})<+\infty \). Then, for any \(\varepsilon >0\) there exists a compact \(G_\varepsilon \subset {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) such that
-
(i)
Letting \(0<\eta _0\) be as in Lemma 3.3 we have
$$\begin{aligned} \tilde{P}({\Sigma }\times {G_\varepsilon }^c) <\min ({\eta _0}^2,\eta _0 \varepsilon ). \end{aligned}$$(3.3) -
(ii)
The convergence (1.21) is uniform with respect to \({E}\in G_\varepsilon \).
-
(iii)
Writing \(\mathrm {div} \ {E}= 2\pi (\nu _{E}-{\delta _{\mathbb {R}}})\), both \(W({E})\) and \(\nu _{E}(I_R)/R\) are bounded uniformly with respect to \({E}\in G_\varepsilon \) and \(R>1\).
-
(iv)
Uniformly with respect to \({E}\in G_\varepsilon \) we have
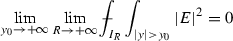 (3.4)
(3.4)Moreover, (3.3) implies that for any \(R>1\) there exists a compact subset \(H_\varepsilon \subset G_\varepsilon \) such that
-
(v)
For every \({E}\in H_\varepsilon \), there exists \({\Gamma ({E})}\subset I_{{\overline{m}}R}\) such that
$$\begin{aligned} |{\Gamma ({E})}|< C {R} \eta _0 \quad \mathrm{and}\quad \lambda \notin {\Gamma ({E})}\implies \theta _\lambda {E}\in G_\varepsilon . \end{aligned}$$(3.5) -
(vi)
We have
$$\begin{aligned}&d_{{\mathcal {B}}}(\bar{P},P') < C \varepsilon ({|\mathrm {log }\ \varepsilon |}+1),\quad \text {where} \nonumber \\&P' = \int _{{\Sigma }\times H_\varepsilon }\frac{1}{{m_0}(x)|I_{R}|} \int _{{{m_0}(x)}I_{R}\setminus {\Gamma ({E})}} \delta _x\otimes \delta _{\sigma _{{m_0}(x)}\theta _\lambda {E}}\,d\lambda \,d\tilde{P}(x,{E})\nonumber \\&\bar{P} = \int _{{\Sigma }\times {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}} \delta _x \otimes \delta _{ \sigma _{{m_0}(x)}{E}} \, d\tilde{P} (x,{E}). \end{aligned}$$(3.6) -
(vii)
$$\begin{aligned} \tilde{P}( {\Sigma }\times {H_\varepsilon }^c) < \min (\eta _0, \varepsilon ). \end{aligned}$$
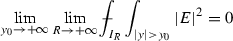
Finally, there exists a partition of \(H_\varepsilon \) into \(\cup _{i=1}^{N_\varepsilon } H_\varepsilon ^i\) satisfying \(\mathrm{diam}\ (H_\varepsilon ^i) <\eta _3\), where \(\eta _3\) is such that
and there exists for all \(i\), \({E}_i \in H_\varepsilon ^i\) such that
Proof
The lemma is almost identical to Lemma 7.6 in [36], except for item iv). The proof in [36] is as follows: First one proves that there exists \(G_\varepsilon \) satisfying items ii) and iii) with \(\tilde{P}({\Sigma }\times {G_\varepsilon }^c)\) arbitrarily small, in particular one can choose it so that (3.3) is satisfied. Then one deduces from (3.3) the existence, for any \(R>1\), of a compact subset \(H_\varepsilon \subset G_\varepsilon \) satisfying the remaining properties. The only difference here is that we must check that there exists \(G_\varepsilon \) with \(\tilde{P}({\Sigma }\times {G_\varepsilon }^c)\) arbitrarily small satisfying not only items ii) and iii), but iv) as well. Then, the proof of the existence \(H_\varepsilon \subset G_\varepsilon \) satisfying the remaining properties is exactly as in [36].
Of course, by intersecting sets, it is equivalent to prove that (ii), (iii), and (iv) can be satisfied simultaneously or separately, on a set of measure arbitrarily close to full. The proof in [36] shows that this is possible for (ii) or (iii), it remains to check it for (iv). For this we consider \(G_n = \{{E}\mid W({E})<n\}\). Then \(G_n\) is a translation-invariant set since \(W\) is a translation-invariant function, and therefore by the multiparameter ergodic theorem (as in [6]), and since \(\tilde{P}\) is translation-invariant, we have
where \(\chi _R = \mathbf {1}_{I_R}*\mathbf {1}_{[-1,1]}\). Then, using Lemma 2.2 and using the fact that the \(g\) there was defined in Proposition 2.1 hence is equal to \(\frac{1}{2}|{E}|^2\) on \(\mathbb {R}\times \{|y|>1\}\) we deduce from (2.7) and the fact that \(g\) is bounded below by a constant independent of \({E}\) that
holds for every \({E}\in G_n\) with \(n\ge 1\).
It follows that for every fixed \(n\ge 1\) the family of functions
decreases to \(0\) on \({\Sigma }\times G_n\) as \(y_0 \rightarrow +\infty \), and is dominated by the bounded, hence \(\tilde{P}\)-integrable, function \(\varphi _1\). Lebesgue’s theorem then implies that their integrals on \({\Sigma }\times G_n\) converge to \(0\), hence in view of (3.9) that
tends to \(0\) as \(y_0\rightarrow +\infty \). Fatou’s lemma then implies that (3.4) holds for \(\tilde{P}\)-almost every \((x,{E})\in {\Sigma }\times G_n\).
Since \(W({E})<+\infty \) holds for \(\tilde{P}\)-a.e. \((x,{E})\), we know that \(\tilde{P}({\Sigma }\times G_n)\rightarrow 1\) as \(n\rightarrow +\infty \) therefore the measure of \({\Sigma }\times G_n\) can be made arbitrarily close to \(1\), and then Egoroff’s theorem implies that by restricting \(G_n\) we can in addition require the convergence in (3.4) to be uniform. \(\square \)
3.3 Construction
In what follows \({\Sigma }' = n {\Sigma }\), \({m_0}'(x) = {m_0}(x/n)\): we work in blown-up coordinates. In view of assumption (1.9), we may assume without loss of generality that \({\Sigma }\) is made of one closed interval \([a, b ]\) (it is then immediate to generalize the construction to the case of a finite union of intervals). In that case \({\Sigma }'=[na,nb ]\). Let \({\underline{m}}>0\) be a small parameter. For any integer \(n\) we choose real numbers \(a_n\) and \(b_n\) (depending on \({\underline{m}}\)) as follows: Let \(a_n\) be the smallest number and \(b_n \) the largest such that
where \(q_\varepsilon \) is an integer, to be chosen later, and \(\gamma \) is the constant in (1.10). By (3.10) and assumption (1.9), we are sure to have \({m_0}'\ge {\underline{m}}\) in \({\Sigma }'_{{\underline{m}}}:=[a_n, b_n]\). This fact also ensures that
We also denote \({\Sigma }_{{\overline{m}}} :=\frac{1}{n}{\Sigma }'_{{\overline{m}}}\).
Let \(P\) be a probability on \({\Sigma }\times {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) which is as in the statement of Theorem 4. Our goal is to construct a vector field \({E}_n\) whose \(W\) energy is close to \(\int W\, dP\) and such that the associated \(P_n\) (defined as the push-forward of the normalized Lebesgue measure on \({\Sigma }\) by \(x \mapsto \left( x, {E}( nx + \cdot )\right) \)) well approximates \(P\).
In \([na, a_n]\) and \([b_n, nb]\), we approximate \({m_0}'(x)\,dx\) by a sum of Dirac masses at points appropriately spaced, and build an associated \({E}_n\), whose contribution to the energy will shown to be negligible as \({\overline{m}}\rightarrow 0\). We leave this part for the end.
For now we turn to \([a_n, b_n]\), where we will do a more sophisticated construction, approaching \(P\) via Lemma 3.6 and using Proposition 3.1. The idea of the construction is to split the interval \([a_n, b_n]\) into intervals of width \(\sim q_\varepsilon R_\varepsilon \), where \(q_\varepsilon \) is an integer and \(R_\varepsilon \) a number, both chosen large enough, and then paste in each of these intervals a large number of copies of the (rescaled) truncations of the \(J_i\)’s provided by Proposition 3.1, in a proportion following that of \(P\).
- Step 1: Reduction to a density bounded below. We have
Moreover, since the first marginal of \(P\) is the normalized Lebesgue measure on \({\Sigma }\) and since \(|{\Sigma }_{\underline{m}}|\simeq |{\Sigma }|\) as \({\underline{m}}\rightarrow 0\), we have
where \(\bar{P}\) is defined by
Clearly \(\tilde{P}\) is \(T_{\lambda (x)}\)-invariant since \(P\) is, and in particular it is translation-invariant. In addition, for \(\tilde{P}\)-a.e. \((x, {E})\), we have \({m_0}(x)\in [{\underline{m}}, {\overline{m}}]\), a situation similar to [36] where the density was assumed to be bounded below.
- Step 2: Choice of the parameters. Let \(0<\varepsilon <1\). We define the compact set \(G_\varepsilon \subset {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) to be given by Lemma 3.6. Then, from Proposition 3.1 applied to \(G_\varepsilon \), there exists \(R_0>0\) such that for any integer \(R>R_0\), and any \({E}\in G_\varepsilon \), there exists a truncation (in the sense of items i), ii), iii) of Proposition 3.1) \({E}_R\) satisfying (3.2). Applying Lemma 3.4 on the compact set \(\{\sigma _m {E}: m\in [{\underline{m}},{\overline{m}}], {E}\in G_\varepsilon \}\), there exists \(\eta _1>0\) such that
Then we define \(R_\varepsilon \) to be such that \({\underline{m}}R_\varepsilon > R_0\) and such that for any \({E},{E}'\in {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\),
Going back to Lemma 3.6, we deduce the existence of \(H_\varepsilon \subset G_\varepsilon \), of \(N_\varepsilon \in \mathbb {N}\) and of \(\{{E}_i\}_{1\le i\le N_\varepsilon }\) satisfying (3.5), (3.6), (3.7) and (3.8), with \(R\) replaced by \(R_\varepsilon \).
Finally, we choose \(q_\varepsilon \in \mathbb {N}\) sufficiently large so that
- Step 3: construction in \([a_n,b_n]\). We start by splitting this interval into subintervals with integer “charge”. This is done by induction by letting \(t_0=a_n\) and, \(t_k\) being given, letting \(t_{k+1}\) be the smallest \(t\ge t_k +q_\varepsilon R_\varepsilon \) such that \(\int _{t_{k-1}}^{t_k} {m_0}'(x)\, dx \in q_\varepsilon \mathbb {N}\). By (3.13) there exists \(K\in \mathbb {N}\) such that \(t_K=b_n\), and
Since \({m_0}'\ge {\underline{m}}\) in \([a_n,b_n]\), it is clear that \(t_k- (q_\varepsilon R_\varepsilon +t_{k-1}) \le q_\varepsilon {\underline{m}}^{-1}\). To summarize and letting \(I_k= [t_{k-1}, t_k]\), we thus have
In each \(I_k\) we will paste \(n_{i,k}\) copies of a rescaled version of \({E}_i\), where
\([\cdot ] \) denoting the integer part of a number. Because the first marginal of \(\tilde{P}\) is the normalized Lebesgue measure on \({\Sigma }_{\underline{m}}\) and since \([a_n,b_n]\subset {\Sigma }_{\underline{m}}\subset [a,b]\), and \(\cup _k I_k = [a_n,b_n]\), we have that
and therefore \(\sum _{i=1}^{N_\varepsilon } n_{i,k} \le q_\varepsilon .\) Also, using in particular (3.19),
We divide \(I_k \) into \(q_\varepsilon \) subintervals with disjoint interiors, all having the same width \(\in [R_\varepsilon , R_\varepsilon +{\underline{m}}^{-1}]\). Then for each \(1\le i\le N_\varepsilon \) we let \(\mathcal {I}_{i,k}\) denote a family consisting of \(n_{i,k}\) of these intervals. This doesn’t necessarily exhaust \(I_k\) since \( \sum _{i=1}^{N_\varepsilon }n_{i,k} \le q_\varepsilon \) so we let \(n_{0,k}= q_\varepsilon - \sum _{i=1}^{N_\varepsilon } n_{i,k}\).
We define \(m_k\) to be the average of \({m_0}'\) over \(I_k\). From (3.21) we have \(m_k |I_k|\in q_\varepsilon \mathbb {N}\) hence for each \(I\in \mathcal I_{i,k}\) we have \(R :=|m_k I|\in \mathbb {N}\), and \(R \in [m_k R_\varepsilon , m_k (R_\varepsilon + {\underline{m}}^{-1})]\). We then apply Proposition 3.1 in \(I_R\) to the vector field \({E}_i\), which yields a “truncated” vector field \({E}_{i,I}\) defined in \(I_R\), where \(R = |m_k I|\). If \(I\in \mathcal {I}_{0,k}\) we apply the same procedure with an arbitrary current \({E}_0\in \mathcal {A}_1\) fixed with respect to all the parameters of the construction.
We then set
on each interval \(I\in \mathcal {I}_{i,k}\), where \(x_I\) is the center of \(I\). The next step is to rectify the weight in \({E}_n^{(1)}\). For this we let \(\mathcal R_k\) be the square \(I_k\times (-|I_k|/2, |I_k|/2)\) and let \(H_k\) be the solution to
From Lemma 5.2 applied with \(\varphi \) and \(m_0\) equal to zero, and using the fact that \({m_0}\) is assumed to belong to \( C^{0,\frac{1}{2}}\), we have for any \(q \in [1,4]\),
We then define
Using Lemma 5.4 and (3.22) we deduce using (3.21) that
where \(o_n(1)\) tends to zero as \(n\rightarrow \infty \) and depends on \(\varepsilon , {\underline{m}}>0\) but not the interval \(I_k\) we are considering. Summing (3.22) for \(1\le k\le K\) and in view of (3.20) we find that for any \(q\in [1,4]\)
On the other hand, in view of the construction and the result of Proposition 3.1 we have
Then, following the exact same arguments as in [36, Sec. 7] which we do not reproduce here (the only difference is that the rescaling factors \(\sqrt{n}\) there should be replaced by \(n\)), thanks to (3.18)–(3.17)–(3.19) we find that we can choose \(C_1\) in (3.19) such that
where
and stands for \(P^{(6)}\) in [36, Sec. 7]. Also, and again as in [36], since (3.24) holds, and from Lemma 3.4, we may replace \({E}_n^{(1)} \) with \({E}_n\) at a negligible cost, more precisely for any large enough \(n\) we have
where
- Step 3: construction in \([b_n, nb]\). The construction in \([na,a_n]\) is exactly the same hence will be omitted. We claim that there exists \({E}_n\) defined in \([b_n,nb] \times \mathbb {R}\) such that
and
where \(C\) may depend on \(\gamma , {\overline{m}}\) and \(\varepsilon \). To prove this claim, let \(s_0=b_n\) and for every \(l\ge 1\), let \(s_l\) be the smallest \(s\ge s_{l-1}\) such that \(\int _{s_{l-1}}^{s_l} {m_0}'(x)\, dx=1\). Since (3.12) holds, this terminates at some \(s_L= nb\) with \(L= \int _{b_n}^{nb}{m_0}'\le {\overline{m}}|nb-b_n|\). We then set \(x_l\) to be the middle of \([s_{l-1}, s_l]\). We let \(u_l\) be the solution in the square \(\mathcal {R}_l:=[s_{l-1}, s_{l}] \times [-\frac{1}{2}(s_l- s_{l-1}), \frac{1}{2}(s_l-s_{l-1})]\)
This equation is solvable since, by construction of the \(s_l\)’s, the right-hand side has zero integral. Then for each \(l\) we let \({E}_n=-\nabla u_l\) in \(\mathcal {R}_l\), and let \({E}_n = 0\) in \([b_n,nb]\times \mathbb {R}\setminus \cup _l \mathcal R_l\). Clearly \({E}_n\) satisfies (3.28).
To estimate the energy of \(u_l\) we let \(u_l = v_l+w_l\) where, letting  ,
,
From Lemma 5.2 and Lemma 5.3 we find, choosing for instance \(q=4\) so that \(q\in [1,4]\) and \(q'<2\),
and
From (1.10) and Lemma 5.4, since \({E}_n= - (\nabla v_l + \nabla w_l)\) in \(\mathcal {R}_l\), we have
Using (1.11),
Replacing in (3.30) and letting \(q=4\) we deduce that
Then, summing with respect to \(l\)—using the fact that from (3.14) we have \(\sum _l |s_{l+1} - s_l| \le C n {\overline{m}}(1+ o_n(1))\), the fact that the integral over \([s_{l-1}, s_l]\) of \({m_0}'\) is \(1\) and that from (1.10) we have \((s_l - s_{l-1})\le n^{\frac{1}{3}}\)—we find
since \({m_0}' - {m_0}'\log {m_0}'\) is bounded by a constant depending only on \({m_0}\) and using (3.14). This proves (3.29)
- Step 4: conclusion. Once the construction of \({E}_n\) is completed, the proof of Theorem 4 is essentially identical to that of [36, Proposition 4.1], which is its 2-dimensional equivalent, except that the scaling factor \({\sqrt{n}}\) there must be replaced by \(n\). We only sketch the proof below and refer to the specific part of [36] for the details.
The test vector-field \({E}_n\) has now been defined on all \([na,nb]\times \mathbb {R}\). It is extended by \(0\) outside, and is easily seen to satisfy the relation \(\mathrm {div} \ {E}_n= 2\pi (\nu _n'-{m_0}')\) for \(\nu _n'= \sum _{i=1} \delta _{x'_i}\), a sum of Dirac masses on the real line. Combining (3.29) with (3.23), (3.25) and (3.8), we have
Letting \(n\rightarrow \infty \) and then \({\underline{m}}\rightarrow 0\), we see that the error term on the right-hand side can be made arbitrarily small, say smaller than \(C\varepsilon \). On the other hand, the reasoning of [36], Step 2 in Paragraph 7.4, shows that
so that taking \(n\) larger if necessary we obtain
Then arguing as in Paragraph 7.4, Step 3 of [36], letting \((x_1,\ldots , x_n)\) be the rescalings to the original scale of the points \(x_i'\) i.e. \(x_i = x_i'/n\), we have for \(n\) large enough
Also letting \(P_n\) be the push-forward of \(\frac{1}{|{\Sigma }|} dx\mid _{\Sigma }\) by the map \(x \mapsto (x, {E}_n(nx + \cdot ))\), it is easy to see that \(d_{\mathcal {B}}(P'', P_n) < C {\underline{m}}\). In view of (3.15) and (3.27), and taking \({\underline{m}}\) small enough, for any given \(\varepsilon >0\), we can achieve
This proves that items i) and ii) of Theorem 4 are satisfied by \((x_1,\dots ,x_n)\) and \({E}_n\). Then, the perturbation argument of Paragraph 7.4, Step 4 in [36] shows that there exists \(\delta >0\) and for each \(n\) a subset \(A_n\subset \mathbb {R}^n\) such that \(|A_n|\ge n!(\delta /n)^n\) and such that for every \((y_1,\dots ,y_n)\in A_n\) there exists a corresponding \({E}_n\) satisfying (1.33) and (1.34). This concludes the proof of Theorem 4.
4 Proof of Theorems 2, 6, 7 and 8
4.1 Proof of Theorem 2
By scaling [cf. (1.23)], we reduce to \(m=1\). The result relies on the fact that there exists a minimizing sequence for \(\min _{{\mathcal {A}_{1}}} W\) consisting of periodic vector-fields:
Proposition 4.1
There exists a sequence \(\{{E}_R\}_{R \in \mathbb {N}}\) in \({\mathcal {A}_{1}}\) such that each \({E}_R\) is \(2R\)-periodic (with respect to the \(x\) variable) and
Proof
The result of Proposition 4.1 is a consequence of Proposition 3.1.
First, applying Theorem 5, there exists a translation-invariant measure \(P\) on \({\Sigma }\times {L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) such that \(P\)-a.e. \((x,{E})\) is such that \({E}\) minimizes \(W\) over \(\mathcal {A}_{{m_0}(x)}\). Then, taking the push-forward of \(P\) under \((x,{E})\mapsto \sigma _{1/{m_0}(x)} {E}\), we obtain a probability \(Q\) on \({L^{p}_{\mathrm{loc}(\mathbb {R}^{2},\mathbb {R}^{2})}}\) such that \(Q\)-a.e. \({E}\) minimizes \(W\) over \(\mathcal A_1\).
Applying Lemma 3.6 to \(Q\), we find that \(Q\)-a.e. \({E}\) is such that \({E}\in \mathcal {A}_1\), such that (3.1) holds, and such that \(W({E}) = \min _{\mathcal {A}_1} W\). Choosing such an \({E}_0\) and applying Proposition 3.1 to \(G=\{{E}_0\}\), we find that for any given \(\varepsilon >0\) and any integer \(R\) large enough depending on \(\varepsilon \), there exists \({E}_R\) defined on \(I_R\times \mathbb {R}\) such that \({E}_R \cdot \vec {\nu }=0\) on \(\partial ( I_R\times \mathbb {R}) \) and \( W({E}_R,\mathbf {1}_{ I_R\times \mathbb {R}})< R(W({E}_0)+\varepsilon )\). This \({E}_R\) can be extended periodically by letting \({E}_R(x+kR,y) = {E}_R(x,y)\) for any \(k\in \mathbb {Z}\).
From the condition \({E}_R \cdot \vec {\nu }=0\) on \(\partial ( I_R\times \mathbb {R})\) we find that, letting \(\Lambda \subset I_R\) be the locations of the Dirac masses in \(\mathrm {div} \ {E}_R\), we have \(\mathrm {div} \ {E}_R = 2\pi \left( \sum _{p\in \Lambda _R} \delta _p - \delta _\mathbb {R}\right) \), where \(\Lambda _R = \Lambda + R\mathbb {Z}\). Moreover
There remains to make \({E}_R \) a gradient. Following the proof of Corollary 4.4 of [35] we let \(\tilde{{E}}_R = {E}_R + {{\nabla }^{\perp }}f_R\) in \({I}_R\times \mathbb {R}\) where \(f_R\) solves \(-\Delta f_R= \mathrm{curl}{E}_R\) in \({I}_R\times \mathbb {R}\) and \(f_R=0\) on \(\partial ({I}_R\times \mathbb {R}) \). Then, \(\mathrm {div} \ \tilde{{E}}_R= \mathrm {div} \ {E}_R \) and \(\mathrm{curl}\tilde{{E}}_R= 0\) in \(\bar{I}_R\). We can thus find \(H_R\) such that \(\tilde{{E}}_R= \nabla H_R\) in \({I}_R\times \mathbb {R}\). It also satisfies \(\nabla H_R \cdot \vec {\nu }=\tilde{{E}}_R \cdot \vec {\nu } = {E}_R \cdot \vec { \nu } + {{\nabla }^{\perp }}f_R \cdot \vec {\nu }=0 \) on \(\partial ({I}_R\times \mathbb {R}) \). We may then extend \(H_R\) to a periodic function by even reflection, and take the final \(\bar{{E}}_R\) to be \(\nabla H_R\). This procedure can only decrease the energy (arguing again as in [35, 36]): we have \(W(\tilde{{E}}_R, \mathbf {1}_{{I}_R\times \mathbb {R}})\le W({E}_R, \mathbf {1}_{{I}_R\times \mathbb {R}} )\) since
It can be checked that the last two terms on the right-hand side converge as \(\eta \rightarrow 0\) to the integrals over \({I}_R\times \mathbb {R}\). Also integrating by parts, using the Jacobian structure and the boundary data, we have \( \int _{{I}_R\times \mathbb {R}} \nabla H_R \cdot {{\nabla }^{\perp }}f_R =0 \). Therefore, letting \(\eta \rightarrow 0\) in the above yields
We deduce that \(W(\bar{{E}}_R) \le W({E}_R) \le \min _{\mathcal {A}_1} W+C\varepsilon \), with \(\bar{{E}}_R\) a \(2R\)-periodic (with respect to the variable \(x\)) test vector field belonging to \(\mathcal {A}_1\). The result follows by a standard diagonal argument. \(\square \)
The following proposition could be proven as in [35], however we omit the proof here.
Proposition 4.2
\(W: L^p_{loc}(\mathbb {R}^2, \mathbb {R}^2) \rightarrow \mathbb {R}\cup \{+\infty \} \), \(1<p<2\), is a Borel function. \(\inf _{\mathcal {A}_1} W\) is achieved and is finite.
The result of Theorem 2 will follow from Proposition 4.1 combined with the following
Proposition 4.3
(Minimization in the periodic case) Let \(a_1,\ldots , a_N\) be any points in \([0,N]\) and \({E}_{\{a_i\}}\) be the corresponding periodic vector field, as in Lemma 1.8. Then
where \({E}_{\mathbb {Z}} \) is the electric field associated to the perfect lattice \(\mathbb {Z}\).
Proof
The proof relies on a convexity argument. First, \(W({E}_{\mathbb {Z}})\) is immediately computed via (1.24), taking \(N=1\).
Let us now consider arbitrary points \(a_1,\dots , a_N\) in \([0,N]\), and assume \(a_1<\dots <a_N\). Let us also denote \(u_{1,i}= a_{i+1}-a_i \), with the convention \(a_{ N+1}=a_1+ N \). We have \(\sum _{i=1}^N u_{1,i}= N\). Similarly, let \(u_{p,i}= a_{i+p}-a_{i}\), with the convention \(a_{N+l}=a_l+N\). We have \(\sum _{i=1}^N u_{p,i}= p N\). By periodicity of \(\sin \), we may view the points \(a_i\) as living on the circle \(\mathbb {R}/(N\mathbb {Z})\). When adding the terms in \(a_i-a_j\) in the sum of (1.24), we can split it according to the difference \(p=j-i\) but modulo \(N\). This way, there remains
where \([\cdot ]\) denotes the integer part. But the function \(\log |2\sin x|\) is stricly concave on \([0,\pi ]\). It follows that
with equality if and only if all the \(u_{p,i}\) are equal. Inserting into (4.1) we obtain
On the other hand, if we take for the \(a_i\)’s the points of the lattice \( \mathbb {Z}\) viewing them as \(N\)-periodic, we have \(u_{p,i}= p\) for all \(p, i\), so if we compute \(W({E}_{\mathbb {Z}})\) using (4.1), we find
This is the right-hand side of (4.2), so (4.2) proves that \(W({E}_{\{a_i\}}) \ge W({E}_{\mathbb {Z}})\) with equality if and only if all the \(u_{p,i}\) are equal, which one can easily check implies that \(\{a_i\}=\mathbb {Z}\). \(\square \)
Combining with Proposition 4.1, this proves Theorem 2.
4.2 Proof of Theorems 6 and 7
We may cancel out all leading order terms and rewrite the probability law (1.1) as
where
A consequence of Theorem 4 is, recalling (1.27):
Corollary 4.4
(Lower bound part of Theorem 6) For any \(\beta >0\) there exists \(C_\beta >0\) such that \(\lim _{\beta \rightarrow \infty } C_\beta =0\) and
Proof
It is exactly the same as in [36, Corollary 4.7] but just letting
\(\square \)
For the upper bound part of Theorem 6, we start with the following lemma, which has the same proof as in [36, Lemma 3.5].
Lemma 4.5
Letting \(\nu _n\) stand for \(\sum _{i=1}^n \delta _{x_i}\) we have, for any constant \(\alpha >0\) and uniformly w.r.t. \(\beta \ge \beta _0>0\),
Then, exactly as in [36], we integrate (4.3) (recall that \(\nu \) stands for \(\sum _i \delta _{x_i}\)). We find,
hence
We deduce, since \(\widehat{F}_n(\nu ) = {{F}_{n}}(\nu ) - 2\sum _i\zeta (x_i)\), that
The result then follows as in [36] from the above lemma and the lower bound of Theorem 3 which implies that \(\liminf _n\inf \inf \widehat{F}_n\ge \min \widetilde{W}.\)
The proof of Theorem 7 is identical to [36] once Theorems 3 and 4 are known, except for the replacement of the scaling \({\sqrt{n}}\) by \(n\) and \(|A_n|\ge n! (\pi \delta ^2/n)^n\) by \(|A_n|\ge n! (\pi \delta /n)^n\).
4.3 Proof of Theorem 8
The proof relies on the following proposition, whose proof is much shorter than in [36], due to the simpler nature of the one-dimensional geometry.
Proposition 4.6
Let \(\nu _n=\sum _{i=1}^n \delta _{x_i}\), and \(g_{\nu _n}\) be as in Definition 2.3. For any \(R>1\), for any \(x_0\in \mathbb {R}\), denoting
we have
where \(c>0\) and \(C\) depend only on \(V\).Footnote 2
Proof
Two cases can happen: either \(D(x_0,R) \ge 0\) or \(D(x_0, R) \le 0\).
We start with the first case. Let us choose \(\tau =\min \left( 2, 1+\frac{D(x_0,R)}{2R\Vert {m_0}\Vert _{L^\infty }} \right) \) and denote \(T= \{r \in [R, \tau R], B_r(x_0') \cap \mathcal {B}_\rho = \varnothing \}\), where \(\mathcal {B}_\rho \) is as in Proposition 2.1. By construction of \(\mathcal {B}_\rho \) and since \(\rho <\frac{1}{2}\), we have \(|T|\ge \frac{1}{2}(\tau -1) R\). We then follow the method of “integrating over circles” introduced in [37]: let \(\mathcal {C} \) denote \(\{x \in B_{\tau R}(x_0')\backslash B_R(x_0'), |x-x_0'|\notin T\}\).
For any \(r \in T\), since \(\partial B_r(x_0')\) does not intersect \(Supp (\nu _n')\), we have
by assumption and by choice of \(\tau \). Moreover, for any \(r \in T\), we have, by Cauchy-Schwarz,
Integrating over \(T\), using \(|T|\ge \frac{1}{2}(\tau -1) R\), we have
and thus
for some \(c>0\) depending only on \(\Vert {m_0}\Vert _{L^\infty } \) hence on \(V\). Inserting into (2.1), we are led to
The case \(D(x_0, R) \le 0\) is essentially analogous. \(\square \)
We also need
Lemma 4.7
For any \(\nu _n=\sum _{i=1}^n \delta _{x_i}\), we have
where \(\widehat{{{F}_{n}}}\) is as in (1.30) and \(g_{\nu _n}\) is the result of applying Proposition 2.1 to \(\nu _n\).
Proof
This follows from (2.2) applied to \(\chi _{R}\), where \(\chi _{R}\) is as in (1.22). If \(R\) is large enough then \(\#\{p\in \text {Supp}(\nu )\mid B(p,C)\cap \text {Supp}(\nabla \bar{\chi })\ne \varnothing \} = 0\) and therefore (2.2) reads
Letting \(R\rightarrow +\infty \) yields \(W({E}_{\nu _n},\mathbf {1}_{\mathbb {R}^2}) = \int \,dg_{\nu _n}\) and the result, in view of (1.29). \(\square \)
We now proceed to the proof of Theorem 8, starting with (1.38). If \(R>R_0\) and \(|D(x_0',R)|\ge \eta R\) then from Proposition 4.6 and using the fact—from Proposition 2.1—that \(g_{\nu _n}\) is positive outside \(\cup _{i=1}^n B(x_i',C)\) and that \(g_{\nu _n}\ge -C\) everywhere, we deduce from (4.11) and (1.29), (1.30) that
Inserting into (4.3) we find
Then, using the lower bound (4.5) and Lemma 4.5 we deduce that if \(\beta \ge \beta _0\) and \(n\) is large enough depending on \(\beta _0\) then
where \(c, C>0\) depend only on \(V\). Thus (1.38) is established.
We next turn to (1.40). Arguing as above, from (4.11) we have \({{F}_{n}}(\nu _n) \ge - C + 2 \int \zeta \,d\nu _n.\) Splitting \(2\int \zeta \, d\nu _n \) as \(\int \zeta \, d\nu _n+\int \zeta \, d\nu _n\), inserting into (4.3) and using (4.5) we are led to
where \(C\) depends only on \(V\). Then, using Lemma 4.5 we deduce (1.40).
We finish with (1.39). Inserting the result of Lemma 2.4 into (4.3), we have, if \(I\) is an interval of width \(R/n\)
Arguing as before and rearranging terms yields (1.39).
This concludes the proof of Theorem 8.
Notes
A sequence of functionals \(\{f_n\}_n\) Gamma-converges to \(f\) if (i) for any sequence \(x_n\rightarrow x\), \(\liminf _n f_n(x_n)\ge f(x)\) and (ii) for any \(x\) there exists a sequence \(x_n\rightarrow x\) such that \(f(x) = \lim _n f_n(x_n)\). See [14] for an introduction to the subject.
The condition \(R>1\) could be replaced by \(R>R_0\) for any \(R_0>0\) at the expense of a constant \(c\) depending on \(R_0\).
References
Akemann, G., Baik, J.P.: The Oxford Handbook of Random Matrix Theory. Oxford University Press, Di Francesco (2011)
Anderson, G.W., Guionnet, A., Zeitouni, O.: An Introduction to Random Matrices. Cambridge University Press, Cambridge (2010)
Alberti, G., Müller, S.: A new approach to variational problems with multiple scales. Commun. Pure Appl. Math. 54(7), 761–825 (2001)
Aizenman, M., Martin, P.: Structure of Gibbs states of one dimensional Coulomb systems. Commun. Math. Phys. 78, 99–116 (1980)
Avila, A., Last, Y., Simon, B.: Bulk universality and clock spacing of zeros for ergodic Jacobi matrices with absolutely continuous spectrum. Anal. PDE 3(1), 81–108 (2010)
Becker, M.E.: Multiparameter groups of measure-preserving transformations: a simple proof of Wiener’s ergodic theorem. Ann. Probab. 9(3), 504–509 (1981)
Ben Arous, G., Guionnet, A.: Large deviations for Wigner’s law and Voiculescu’s non-commutative entropy. Probab. Theory Related Fields 108(4), 517–542 (1997)
Bekerman, F., Figalli, A., Guionnet, A.: Transport maps for \(\beta \)-matrix models and universality. arXiv:1311.2315 (2013)
Borodin, A., Serfaty, S.: Renormalized energy concentration in random matrices. Commun. Math. Phys. 320(1), 199–244 (2013)
Borot, G., Guionnet, A.: Asymptotic expansion of \(\beta \) matrix models in the one-cut regime. Commun. Math. Phys. 317(2), 447–483 (2013)
Borot, G., Guionnet, A.: Asymptotic expansion of \(\beta \) matrix models in the multi-cut regime. Commun. Math. Phys. 317(2), 447–483 (2013)
Bourgade, P., Erdös, L., Yau, H.-T.: Universality of general \(\beta \)-ensembles. Duke Math. J. 163(6), 1127–1190 (2014)
Bourgade, P., Erdös, L., Yau, H.T.: Bulk Universality of general \(\beta \)-ensembles with non-convex potential. J. Math. Phys. 53(9), 095221, 19 (2012)
Braides, A.: \(\Gamma \)-Convergence for Beginners. Oxford University Press, Oxford (2002)
Brascamp, H.J., Lieb, E.H.: Functional Integration and its Applications. Clarendon Press, Oxford (1975)
Brauchart, J.S., Hardin, D.P., Saff, E.B.: Discrete energy asymptotics on a Riemannian circle. Uniform Distrib. Theory 7(2), 77–108 (2012)
Caffarelli, L.A., Roquejoffre, J.-M., Sire, Y.: Variational problems for free boundaries for the fractional Laplacian. J. Eur. Math. Soc. 12(5), 1151–1179 (2010)
Deift, P.: Orthogonal polynomials and random matrices: a Riemann–Hilbert approach. In: Courant Lecture Notes in Mathematics. AMS, Providence (1999)
Deift, P., Gioev, D.: Random matrix theory: invariant ensembles and universality. In: Courant Lecture Notes in Mathematics. AMS, Providence (2009)
Dumitriu, I., Edelman, A.: Matrix models for beta ensembles. J. Math. Phys. 43, 5830–5847 (2002)
Dyson, F.: Statistical theory of the energy levels of a complex system. Part I. J. Math. Phys. 3, 140–156 (1962). Part II, ibid. 157–165; Part III, ibid. 166–175
Erdös, L., Schlein, B., Yau, H.T.: Semicircle law on short scales and delocalization of eigenvectors for Wigner random matrices. Ann. Probab. 37(3), 815–852 (2009)
Forrester, P.J.: Log-gases and random matrices. In: London Mathematical Society Monographs Series, vol. 34. Princeton University Press, Princeton (2010)
Johansson, K.: On fluctuations of eigenvalues of random Hermitian matrices. Duke Math. J. 91(1), 151–204 (1998)
König, W.: Orthogonal polynomial ensembles in probability theory. Probab. Surv. 2, 385–447 (2005)
Leblé, T.: A Uniqueness result for minimizers of the 1D log-gas renormalized energy. arXiv:1408.2283
Leblé, T., Serfaty, S.: Large Deviation Principle for Empirical Fields of Log and Riesz Gases (in preparation)
Lenard, A.: Exact statistical mechanics of a one-dimensional system with Coulomb forces. J. Math. Phys. 2, 682–693 (1961)
Lenard, A.: Exact statistical mechanics of a one-dimensional system with Coulomb forces. III. Statistics of the electric field. J. Math. Phys. 4, 533–543 (1963)
Mehta, M.L.: Random Matrices, 3rd edn. Elsevier/Academic Press, Amsterdam (2004)
Molchanov, S.A., Ostrovski, E.: Symmetric stable processes as traces of degenerate diffusion processes. Theory Probab. Appl. 14, 128–131 (1969)
Petrache, M., Serfaty, S.: Next order asymptotics and renormalized energy for Riesz interactions. arXiv:1409.7534
Rougerie, N., Serfaty, S.: Higher dimensional Coulomb gases and renormalized energy functionals. Commun. Pure Appl. Math. (to appear, 2014)
Saff, E., Totik, V.: Logarithmic Potentials with External Fields. Springer, Springer (1997)
Sandier, E., Serfaty, S.: From the Ginzburg–Landau model to vortex lattice problems. Commun. Math. Phys. 313(3), 635–743 (2012)
Sandier, E., Serfaty, S.: 2D Coulomb gases and the renormalized energy. Ann. Probab. (to appear, 2014)
Sandier, E., Serfaty, S.: Global minimizers for the Ginzburg–Landau functional below the first critical magnetic Field. Annales Inst. H. Poincaré, Anal. non linéaire 17(1), 119–145 (2000)
Shcherbina, M.: Orthogonal and symplectic matrix models: universality and other properties. Commun. Math. Phys. 307(3), 761–790 (2011)
Shcherbina, M.: Fluctuations of linear eigenvalue statistics of \(\beta \) matrix models in the multi-cut regime. J. Stat. Phys. 151(6), 1004–1034 (2013)
Shcherbina, M.: Change of variables as a method to study general \(\beta \)-models: bulk universality. arXiv:1310.7835
Serfaty, S., Tice, I.: Lorentz space estimates for the Coulombian renormalized energy. Commun. Contemp. Math. 14(4), 1250027, 23 (2012)
Simon, B.: The Christoffel–Darboux kernel. In: Perspectives in PDE, Harmonic Analysis and Applications, a volume in honor of V.G. Maz’ya’s 70th birthday. Proceedings of Symposia in Pure Mathematics, vol. 79, pp. 295–335 (2008)
Valkó, B., Virág, B.: Continuum limits of random matrices and the Brownian carousel. Invent. Math. 177(3), 463–508 (2009)
Wigner, E.: Characteristic vectors of bordered matrices with infinite dimensions. Ann. Math. 62, 548–564 (1955)
Acknowledgments
We are grateful to Alexei Borodin, Gérard Ben Arous, Amir Dembo, Percy Deift, Nicolas Fournier, Alice Guionnet and Offer Zeitouni for their interest and helpful discussions. We also thank the anonymous referees for their many useful comments. E. S. was supported by the Institut Universitaire de France and S. S. by a EURYI award.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
1.1 Proof of Lemma 1.7
Assume \({E}\) and \({E}'\) belong to \(\mathcal A_m\) and satisfy (1.17) with the same \(\nu \). Then \(f = {E}- {E}'\) is divergence-free and curl-free, hence can be seen, identifying \(\mathbb {R}^2\) and \(\mathbb {C}\), as an entire holomorphic function \(\sum _{n=0}^\infty a_n z^n\). If we assume that \(W({E})\) and \(W({E}')\) are finite, then it follows from [41], Corollary 1.2 that the growth of the \(L^1\) norms of \({E}\) and \({E}'\) is no worse than \(R^{3/2}{\sqrt{\log R}}\) hence there exists \(C>0\) such that for any \(R>2\) we have \(\Vert f\Vert _{L^1(B_R)}\le C R^{3/2} {\sqrt{\log R}}\). But by Cauchy’s formula we have, for any \(R>0\) and \(t\in [R, R+1]\)
It follows with the above that \(|a_n|\le CR^{3/2} {\sqrt{\log R}} R^{-n-1}\) which implies, letting \(R \rightarrow \infty \) that \(a_n=0\) for any \(n \ge 1\), thus \(f\) is a constant. This constant must then be zero since both \({E}\) and \({E}'\) are square integrable on the infinite strips \([a,b]\times [1,+\infty ]\).
We note that Lemma 1.7 implies in particular
Corollary 5.1
Under the same assumptions, if \(S(x,y) = (x,-y)\) then \({E}\circ S = S\circ {E}\).
Indeed, it is easy to check that \({E}' = S\circ {E}\circ S\) satisfies (1.17) with the same \(\nu \) as \({E}\), and obviously \(W({E}')<+\infty \), hence \({E}' ={E}\).
1.2 Proof of the splitting formula (Lemma 1.10)
Let \(\nu _n = \sum _{i=1}^n \delta _{x_i}\). First, letting \(\triangle \) denote the diagonal of \(\mathbb {R}\times \mathbb {R}\), we may rewrite \({{w}_{n}}\) as
Splitting \(\nu _n\) as \(n {\mu _{0}}+ \nu _n - n{\mu _{0}}\) and using the fact that \({\mu _{0}}\times \mu _0(\triangle ) = 0\), we obtain
Since \(U^{{\mu _{0}}} + \frac{V}{2}= c + \zeta \) and since \(\nu _n\) and \(n {\mu _{0}}\) have same mass \(n\), we have
using the fact that \(\zeta =0\) on the support of \({\mu _{0}}\).
In addition, we have that
where we define \(H_n= - 2\pi \Delta ^{-1}\left( \sum _{i=1}^n \delta _{x_i} -n{\mu _{0}}\right) \). Indeed, the integral might as well be written as over \(\mathbb {R}^2 \times \mathbb {R}^2 \backslash \triangle \) with the diagonal in \(\mathbb {R}^2 \times \mathbb {R}^2\); and then the identity is proven in [36, Section 2]. Combining all the above we find
But, changing variables, we have
and by adding \(\pi n\log \eta \) on both sides and letting \(\eta \rightarrow 0\) we deduce that \(W(\nabla H_n, \mathbf {1}_{\mathbb {R}^2})= W(-\nabla H_n', \mathbf {1}_{\mathbb {R}^2} ) - \pi n \log n\). Together with (5.2) this proves the lemma.
1.3 Proof of the screening result Proposition 3.1
Proposition 3.1 is the main hurdle in the analysis of the 1D log gas, and is specific to the one dimensional case. Our main task is to suitably truncate a field \({E}\) on a vertical strip \(I_R\times \mathbb {R}\) so that it can be pasted to other fields, or repeated to yield a periodic field. The constraints are that we wish the modification to be localized near the boundary of the strip, and the value of the renormalized energy not to increase much. We also need this truncation procedure to be done for a (compact) set of fields all at once, with uniform estimates over this set.
1.3.1 Some preliminary construction lemmas
The following lemmas serve to estimate the energy of explicit vector fields on boxes, which will be later combined to build the test vector fields in the transition strips we use for the screening. They are adaptations of [35] and rely on elliptic equations estimates.
Lemma 5.2
Let \(\mathcal {K} \) be the square \([-\frac{L}{2}, \frac{L}{2}]^2\). Let \( \varphi \in L^2 (\partial \mathcal {K})\) and \(a\in L^\infty ([-\frac{L}{2}, \frac{L}{2}])\) be such that \(\int _{-\frac{L}{2}}^{\frac{L}{2}} a(x) \, dx = - \int _{\partial \mathcal {K}} \varphi \). Then, \(a_0\) being the average of \(a\) over \([-\frac{L}{2},\frac{L}{2}]\), the solution (well defined up to an additive constant) to
satisfies for every \(q \in [1, 4]\)
Proof
We write the solution \(u\) of (5.3) as \(u=u_1+ u_2+u_3\) where
where \(\bar{\varphi }\) is equal to \(0\) on the vertical sides of the square and to \(\frac{a_0}{2L}\) on both horizontal sides;
and
The solution of (5.4) is (up to a constant) \(u_1(x,y)= \frac{a_0}{2}|y|\). Hence
For \(u_2\), we observe that \(\Vert (a-a_0)\delta _{\mathbb {R}}\Vert _{ W^{-1,q}(\mathcal {K}) }\) is controlled, for any \(q<\infty \), by \(\Vert a-a_0\Vert _{L^\infty ([-\frac{L}{2}, \frac{L}{2}])}\). Therefore, using elliptic regularity for (5.5), \(\Vert \nabla u_2\Vert _{L^q(\mathcal {K})}\) is controlled by \(\Vert a-a_0\Vert _{L^\infty ([-\frac{L}{2}, \frac{L}{2}])}\) and a scaling argument shows that for any \(q<\infty \)
Finally, in the proof of Lemma 4.16 of [35] it is shown that for any \(q\in [1,4]\)
Combining (5.6), (5.7) and (5.8), we obtain the result. \(\square \)
Lemma 5.3
Let \(m\) be a positive constant and let \(\mathcal {K}\) be a square of center \(0\), and sidelength \(1/m\). Then the solution to
satisfies
where \(C\) is universal, and for every \(1\le q<2\)
where \(C_q\) depends only on \(q\).
Proof
By scaling we can reduce to the case of \(m=1\). Then, it suffices to observe that \(f(z)= - \log |z|+S(z)\) with \(S\in W^{1,\infty }(\mathcal {K} )\) and scale back. \(\square \)
We note that \(W\) as defined in (1.20) still makes sense for vector fields satisfying \(\mathrm {div} \ {E}= 2\pi (\sum \delta _{x_i}-m)\) which are not necessary gradients, as long as \( {E}\) is a gradient in \(\cup B(x_i, \eta _0) \) for some \(\eta _0>0\). This is the notion we will use repeatedly below.
Lemma 5.4
Let \({E}_1\) and \({E}_2\) be two vector fields defined in a rectangle \(\mathcal {R}\) of the plane which is symmetric with respect to the real axis, and satisfying
and \(\mathrm{curl}{E}_1\) and \(\mathrm{curl}{E}_2\) vanish near the \(x_i\)’s, for some distinct points \(x_i \in \mathbb {R}\) and some bounded functions on the real line, \(a_1\) and \(a_2\). Then, for \(q<2\) and \(q'\) its conjugate exponent, we have \({E}_1\in L^q(\mathcal {R})\) and \({E}_2\in L^{q'}(\mathcal {R})\) and
where \(W\) is still defined as in (1.20).
Proof
We have
By Hölder’s inequality we have
The result easily follows. \(\square \)
1.3.2 Proof of Proposition 3.1
We start from a given electric field \(E\) in \(\mathbb {R}\) and restrict it to the strip \([-R/2,R/2] \times \mathbb {R}\). The steps of the screening then go as follows:
-
as a preliminary, we show that with the assumptions placed on the electric field, it decays fast enough away from the real axis.
-
By a mean value argument, we find a good substrip \([-t, t]\times \mathbb {R}\) on the boundary of which the \(L^2\) norm of \(E\) is not too large. This is possible because the energy \(W(E)\) which we control is “morally” equivalent (via the use of the mass displaced density \(g\)) to a control on
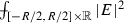 . We also want the strip to be only slightly narrower, i.e. \(R-t\) small with respect to \(R\).
. We also want the strip to be only slightly narrower, i.e. \(R-t\) small with respect to \(R\). -
We keep the vector field unchanged in \([-t,t] \times [-y_R, y_R]\) unchanged and define a new vector field \(E_R\) in the transition strip \((I_R\backslash I_{2t}) \times \mathbb {R}\), as well as in the parts far from the real axis: \([-R/2,R/2]\times ((-\infty ,-y_R]\cup [y_R, +\infty ))\). The new vector field has to satisfy a relation of the form (1.17) but not necessarily be a gradient, and it has to have the same normal component as \(E\) on the boundary of \([-t,t]\times \mathbb {R}\) so as not to create any new divergence there. This new vector field is constructed by splitting the region in which it needs to be defined into suitable rectangles and semi-infinite strips (cf. Fig. 1), and constructing it separately in each piece while keeping again the normal components on each interface continuous (so as again not to any create divergence). The construction in each piece is done thanks to the preliminary Lemmas 5.2 and 5.3 which provide at the same time the appropriate vector fields and estimates on their energy.
-
We check that \(y_R\) can be chosen so that the energy of all the combined vector fields does not exceed the original energy in the strip plus a negligible error.
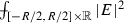 . We also want the strip to be only slightly narrower, i.e.
. We also want the strip to be only slightly narrower, i.e. First we note that, in view of (3.1), if we assume \(G\subset \mathcal A_1\) satisfies the hypothesis of Proposition 3.1 and \(0<\varepsilon <1\), then there exists \(y_0>0\) and \(R_0>0\) such that for all \({E}\in G\), we have
This motivates the following lemma in which we show an explicit decay of these vector fields away from the real axis.

The splitting of the strip \(I_R\times \mathbb {R}\) into subdomains \(D_0\), \(D_\pm \), \(D_e^\pm \), \(D_1\), \(D_\infty \) and the boundary data next to each portion of the boundary between the regions
Lemma 5.5
Let \({E}\in \mathcal A_1\) satisfy (5.13), where \(0<\varepsilon <1\). Then, denoting \(z=(x,y)\), if \(|y|> \max (2y_0,R_0) \), we have
where \(C\) is universal.
Proof
Each of the coordinates of \({E}\) is harmonic in the half plane \(\mathbb {R}^2_+ = \{y> 0\}\) since \(\mathrm {div} \ {E}=\mathrm{curl}{E}=0\) there. Therefore \(|{E}|^2 \) is sub-harmonic. Thus, if \(B(z, |y|/2)\subset \mathbb {R}^2_+\) then by the maximum principle we have

If \(y>2y_0\), then \(B(z, |y|/2)\subset [x- \frac{|y|}{2}, x+ \frac{|y|}{2}] \times [y_0,+\infty ) \subset [-|x|-|y|, |x|+|y|] \times [y_0,+\infty ).\) Thus in view of (5.13), if \(|x|+|y|> R_0/2\) we have
and the result follows, by symmetry with respect to the \(x\)-axis. \(\square \)
The next result is about finding the “good” boundary of a slightly narrower substrip via a mean-value argument.
Lemma 5.6
Let \(G\) satisfy the assumptions of Proposition 3.1. Then for any \({E}\in G\), any \(0<\varepsilon <1/2\) and any \(R\) large enough depending on \(G\), \(\varepsilon \), we may find \(t \in [\frac{R}{2}- \varepsilon R, \frac{R}{2}- \frac{1}{2}\varepsilon R]\) such that
where \(C\) depends only on \(G\), and
uniformly in \(G\).
Proof
Take \({E}\in G\) and apply Proposition 2.1 to \({E}\) for some fixed \(0<\rho < 1/8\). We obtain a density \(g\) and balls \({\mathcal {B}}_\rho \). Now, using (2.7) in Lemma 2.2 together with the bound (2.4), we deduce that if \(R\) is large enough depending on \(G\) then for any \({E}\in G\) and denoting \(g\) the result of applying Proposition 2.1 to \({E}\) we have
where \(C\) depends only on \(G\) and we have used the fact that \(g\ge -C\) everywhere and \(g\ge 0\) on the set \(\{|y|>1\}\). Then by using the fact that the radii of the balls in \({\mathcal {B}}_\rho \) which intersect any given interval of length \(1\) is bounded by \(1/8\) we deduce that if \(R\) is also large enough depending on \(\varepsilon \), the measure of the set \(A\) of \(x\in [R/2-\varepsilon R,R/2-\varepsilon R/2]\) such that \(\{x,-x\}\times \mathbb {R}\) does not intersect \({\mathcal {B}}_\rho \) is bounded below by \(\varepsilon R/4\). This and (5.16) implies that the set \(T\) of \(t\in A\) such that \(\int _\mathbb {R}\left( g(t,y)+g(-t,y)\right) \,dy < C/\varepsilon \) has measure at least \(\varepsilon R/8\) if \(C\) is chosen large enough depending on \(G\), and (2.1) and the fact that \(g = \frac{1}{2}|{E}|^2\) outside \(\mathbb {R}\times [-1,1]\) imply that (5.14) holds for \(t\in T\). Thus
For (5.15) we argue as in [35], Lemma 4.14. We let \(\chi :[0,+\infty )\rightarrow \mathbb {R}\) be a monotonic function with compact support and let \(\bar{\chi }(x,y) = \chi (|x|)\). First we note that for any Radon measure \(\mu \) in \(\mathbb {R}^2\) we have
This implies straightforwardly using the definition of \(W({E},\chi )\) that
On the other hand, by (2.2) and applying Lemma 2.2, (2.5), if \(\chi '\) is supported in \([x,y]\subset [R/2, R]\), then the right-hand side is bounded by \( C(|x-y|+ R^{3/4} \log ^2 R) \Vert \chi '\Vert _\infty \) for any \(R\) large enough depending on \(G\). Given now any \(\rho :\mathbb {R}_+\rightarrow \mathbb {R}\) supported in \([x,y]\subset [R/2, R]\) we may consider the positive and negative parts \(\rho _+\) and \(\rho _-\), and their primitives \(\chi _+\) and \(\chi _-\) with compact support, which are monotonic. Applying the above to \(\chi _+\) and \(\chi _-\) we find
Since this is true for any \(\rho \) supported in \([R-2\varepsilon R,R-\varepsilon R]\), it follows by duality that
Then we divide \([R-2\varepsilon R, R-\varepsilon R]\) into, say, \([{\sqrt{R}}]\) intervals \(I_1,\dots , I_{[{\sqrt{R}}]}\) so that their length is equivalent to \(\varepsilon {\sqrt{R}}\) for large \(R\). Then, for large enough \(R\), on each such interval (5.18) implies that
Therefore the set of \(u\in I_k\) such that \(|W({E}, \mathbf {1}_{ I_{u} \times \mathbb {R}} ) - g( I_{u} \times \mathbb {R}) |\le 8 C R^{3/4} \log ^2 R \) has measure at least \(7|I_k|/8\). Since this is true on each \(I_k\), and since \(\cup _k I_k = [R-2\varepsilon R, R-\varepsilon R]\), letting \(u=2t\) the set of \(t \in [R/2-\varepsilon R,R/2-\varepsilon R/2]\) such that \(|W({E}, \mathbf {1}_{ I_{2t} \times \mathbb {R}} ) - g(I_{2t}\times \mathbb {R}) |\le 8 C R^{3/4} \log ^2 R\) has measure at least \(7\varepsilon R/16\). Together with (5.17), this implies the existence of \(t\in [R/2-\varepsilon R,R/2-\varepsilon R/2]\) such that both (5.14) and (5.15) hold. \(\square \)
We now prove Proposition 3.1. Let \(G\) satisfy its hypothesis and choose \(0<\varepsilon <1\), and \({E}\in G\). Applying Lemma 5.6 we find that if \(R\) is large enough depending on \(G\), \(\varepsilon \), then there exists \(t\in [R/2-\varepsilon R,R/2-\varepsilon R/2]\) such that (5.14) and (5.15) hold. For any such integer \(R\in \mathbb {N}\) we may also choose \(y_R\) such that
Finally we choose \(s>t \) such that \(s-t \in [y_R, y_R +1] \) and \(\frac{R}{2}-s \in \mathbb {N},\) and start constructing the vector field \({E}_R\).
- Step 1: splitting the strip. We split the strip \(I_R=[-\frac{R}{2}, \frac{R}{2}]\times \mathbb {R}\) into several rectangles and strips (see figure below): let
First we let \({E}_R={E}\) in \(D_0\), \({E}_R=0\) in \(D_\infty \) and below we are going to define \({E}_R\) on each of the other sets.
Recall that from Corollary 5.1 we have that \({E}(x,y)\) is the reflection of \({E}(x,-y)\) with respect to the line \(\{y=0\}\). We denote by \(\varphi _+\) the trace \({E}\cdot \vec {\nu }\) on the right-hand side of \(D_0\) where \(\vec {\nu }\) is the outward-pointing normal to \(D_0\), \(\varphi _-\) the same on the left-hand side, \(\varphi _h\) the trace on the upper side of \(D_0\) (which by symmetry of the problem with respect to the real axis is equal to that on the lower side). From (5.14) and the Cauchy-Schwarz inequality, we have
and from Lemma 5.5 and (5.19) we have
In addition, integrating the relation \(\mathrm {div} \ {E}= 2\pi (\sum _{p\in \Lambda } \delta _p-\delta _\mathbb {R})\) over \(D_0\) gives
- Step 2: defining \({E}_R\) in \(D_+\). We first define \(\varphi _0 := {E}_R\cdot \vec {\nu }\) on the boundary \(\partial D_+\), where \(\vec {\nu }\) is the outward normal to \(D_+\). For a certain constant \(\varphi _h^+\) to be chosen later we let
Then, inside \(D_+\), we let \({E}_R = {E}_1+{E}_2\), where
Here, \(n_+\) is an integer and \(m_+\) a real number which are defined by
and for \(1\le i\le n_+\) we have let
Note that the above equations do not yield a uniquely defined \({E}_1\) and \({E}_2\). For (5.24) to make sense we need \(n_+\ge 0\) while for (5.25) to have a solution we need to have
which we take as the definition of \(\varphi _h^+\). The fact that \(n_+\ge 0\) follows for \(R\) large enough depending on \(\varepsilon \) from the fact that \(s-t \ge \varepsilon ^3 R\) and (5.20), (5.21).
- Step 3: Estimating the energy of \({E}_R\) in \(D_+\), \(D_-\). To compute the renormalized energy \(W({E}_R, \mathbf {1}_{D_+})\) we need to define \({E}_1\) and \({E}_2\) more precisely. For \({E}_1\) let us consider \(n_+\) identical squares \(\{K_i\}_{i=1}^{n_+}\) with sidelength \(\frac{s-t }{n_+} = \frac{1}{m_+} \), sides parallel to the axes and such that \(K_i\) is centered at \(x_i\). We define \({E}_1\) restricted to \(K_i\) by applying Lemma 5.3 with \(m = m_+\) and taking \({E}_1=-\nabla f\), while outside \(\cup _i K_i\) we let \({E}_1 = 0\). Since from Lemma 5.3 we have \({{E}_1}_{|K_i}\cdot \vec {\nu } = 0\) on \(\partial K_i\), it holds that \(\mathrm {div} \ {E}_1 = \sum _i \mathrm {div} \ {{E}_1}_{|K_i}\) and therefore (5.24) is satisfied by \({E}_1\). On the other hand, still from Lemma 5.3 we obtain by summing the bounds (5.9) and (5.10) on the \(n_+\) rectangles
and
We define \({E}_2\) by applying Lemma 5.2 in \(D_+\), hence with \(L = s-t\), with the boundary data \(\varphi _0\) and constant weight \(m = 2\pi (m_+-1)\). From (5.23) and (5.27) the hypothesis \(\int m(x) \, dx = - \int _{\partial D_+} \varphi \) is satisfied and applying the lemma yields
Using Lemma 5.4 we have, recalling that \({E}_R :={E}_1+{E}_2\) in \(D_+\) and using (5.28), (5.29), (5.30):
for any \(1<q<2\) such that the conjugate exponent \(q'\) is less then \(4\). Now, from (5.26), using (5.20), (5.21), (5.19) and the fact that \(y_R\le s-t\le y_R+1\) we deduce that
and thus for \(R\) large enough depending on \(\varepsilon \), since \(s-t\simeq y_R\) for large \(R\) and using (5.19) again as well as \(\varepsilon <1\),
Moreover, from (5.26), (5.27) and (5.21) we find
Then, in view of (5.23), (5.20),
Now we fix for instance \(q = 3/2\), so that \(q' = 3\) and combining the above with (5.31), (5.33) we find that for \(R\) large enough depending on \(\varepsilon \), and denoting by \(C_\varepsilon \) a positive constant depending on \(\varepsilon \) but independent of \(R\),
Thus for \(R\) large enough depending on \(\varepsilon \) we find that
An almost symmetric computation yields the same bound for \(W({E}_R, \mathbf {1}_{D_-})\). It suffices to let
and carry on the proof with minuses instead of pluses. The fact that \(n_-\) is an integer follows from the identity (5.22), the fact that \(2s\) is an integer and the fact that \(\nu ([-t,t])\in \mathbb {N}\). Moreover the definition of \(n_-\) implies that
hence \(n_-\) is positive if \(R\) is large enough and (5.32) holds for \(n_-\) as well. The rest of the proof is unchanged.
- Step 4: defining \({E}_R\) over \(D_1\). We need only consider the intersection of \(D_1\) with the upper half-plane (and then extend by reflection). We let \(\varphi _0\) be equal to \(-\varphi _h^-\), \(-\varphi _h\), \(-\varphi _h^+\), respectively, on the intersection of \(\partial D_1\) with \(\partial D_-\), \(\partial D_0\), \(\partial D_+\), respectively. On the remaining three sides of \(\partial D_1\) we let \(\varphi _0 = 0\). From (5.27) and its equivalent for \(n_-\) and the fact that \(n_\pm = (s-t)m_\pm \) we have
and then (5.26), (5.36) imply that the integral of \(\varphi _0\) is zero.
Thus there exists a harmonic function \(u\) in \(D_1\) with normal derivative \(\varphi _0\) on \(\partial D_1\), we let \({E}_R = \nabla u\) on \(D_1\). Using (5.34)—which holds for \(\varphi _h^-\) as well—and (5.21) we have
hence
Then standard elliptic estimates yield as in Lemma 5.2 that
where we have concluded by (5.19).
- Step 5: defining \({E}_R\) over \(D_e^+\). The construction will be entirely parallel in \(D_e^-\). We note that \(D_e^+\) is an infinite strip of width \(R/2- s\) and we have chosen \(s\) so that this quantity is an integer. We can thus split this strip into exactly \(R/2-s\) strips of width \(1\). On each of these strips we define \({E}_R\) to be equal to \(0\) for \(|y|\ge \frac{1}{2}\) and for \(|y|\le \frac{1}{2}\) (i.e. in a square of sidelength \(1\)) we choose it to be \(\nabla f\) where \(f\) is given by Lemma 5.3 applied with \(m=1\). Since \({E}_R \cdot \vec { \nu } = 0\) on the boundary of each of these squares, no divergence is created at the interfaces, and the resulting \({E}_R\) satisfies \(\mathrm {div} \ {E}_R = 2\pi (\sum _{p \in \Lambda }\delta _p - \delta _\mathbb {R})\). In addition in view of (5.10) the cost in energy is equal to a constant times the number of strips, that is
- Conclusion. We have now defined \({E}_R\) over the whole strip \({I}_R\times \mathbb {R}\). It satisfies items ii) and iii). The main point is again that as long as \({E}\cdot \vec { \nu }\) is continuous across an interface it creates no singular divergence there. Combining (5.39) with (5.15), (5.35) and (5.38), \({E}_R\) also satisfies (3.2). This concludes the proof of Proposition 3.1.
Rights and permissions
About this article

Cite this article
Sandier, E., Serfaty, S. 1D log gases and the renormalized energy: crystallization at vanishing temperature. Probab. Theory Relat. Fields 162, 795–846 (2015). https://doi.org/10.1007/s00440-014-0585-5
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00440-014-0585-5