
Abstract
There are several parameters that highly influence material quality and printed shape in laser Directed Energy Deposition (L-DED) operations. These parameters are usually defined for an optimal combination of energy input (laser power, scanning speed) and material feed rate, providing ideal bead geometry and layer height to the printing setup. However, during printing, layer height can vary. Such variation affects the upcoming layers by changing the printing distance, inducing printing to occur in a defocus zone then cumulatively increasing shape deviation. In order to address such issue, this paper proposes a novel intelligent hybrid method for in-process estimating the printing distance (\(Z_s\)) from melt pool images acquired during L-DED. The proposed hybrid method uses transfer learning to combine pre-trained Convolutional Neural Network (CNN) and Support Vector Regression (SVR) for an accurate yet computationally fast methodology. A dataset with 2,700 melt pool images was generated from the deposition of lines, at 60 different values of \(Z_s\), and used for training. The best hybrid algorithm trained performed with a Mean Average Error (MAE) of 0.266 and a Mean Absolute Percentage Error (MAPE) of \(6.7\%\). The deployment of this algorithm in an application dataset allowed the printing distance to be estimated and the final part geometry to be inferred from the data.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Most of the processes for 3D printing components are standardized through the international standard ISO/ASTM F52900 [1], which classifies all Additive Manufacturing (AM) processes into seven. One such process is Directed Energy Deposition (DED), which prints 3D shapes by fusing the feedstock (wire/powder) when applying a highly focused thermal source (laser/electrical beam/arc) through a deposition nozzle [1]. It lays down adjacent lines, building layers, which are stacked to obtain a 3D shape. Due to its principle, DED is capable of producing and repairing metal-alloy components in complex geometries, whilst also being competitive in part customization [2], which makes the processes highly attractive for the aerospace industry [3], amongst many others.
Conventional slicing software consider a constant layer height and it uses that value as the Z-axis increment for generating the CNC program, which contains the scanning path and the parameters defined for the entire 3D construction. Laser DED (L-DED) processes are mainly driven by three parameters: laser power, feed speed and mass flow rate [4]. To obtain consistency in a build, these parameters should be optimized and remain constant throughout a 3D building shape [5, 6]. However, some of those parameters may have to be adjusted back to the set value, as they usually vary on the fly. Therefore, monitoring and controlling strategies are needed [7] and have been explored lately on the monitoring of powder flow [8, 9]; thermal activity [10]; and melt pool characteristics [11, 12], etc.
The deposition occurs by means of the melt pool and is related with all those fundamental parameters governing the L-DED process [13], so it is reasonable to expect that its state represents a great portion of the quality of the built part. Monitoring performed in real time using machine learning (ML) algorithms and neural networks (NN) present a model-free monitoring approach, which is suitable for complex systems that require a multi-physical modelling involving a great number of variables. Such monitoring may provide information on both the fault being monitored [14,15,16] and its specific intensity.
Recently, there has been some research inclined towards an establishment of melt pool monitoring through imaging [17, 18] with the aid of artificial intelligence methods [7, 15]. They can also be linked to the rapid growth and improvement of image processing techniques, especially those using modern ML techniques, such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN). As the use of CNN and RNN require a vast amount of data in order to be effectively trained, the use of transfer learning [19], in which a pre-trained CNN is used to generalize the data input, has been increasingly adopted.
One of the most important variables to be monitored and controlled in the process is the layer height, which is a result of the heat distribution throughout the 3D geometry [20] and the material fed at the melt pool. Likewise, the scanning strategy is also a parameter that can affect the layer height as it influences the heat distribution and solidification process during printing, also affecting the temperature distribution in the melt pool and the resulting microstructure of the solidified metal [21]. As the heat distribution varies during printing from the first layer on, the z-axis increment between layers must suffer adjustments from the initial set value for the first layer.
Besides, when producing large blocks and bulk regions, the center of the geometry tends to cool down slower than its borders and edges, resulting in locally higher layer. On the corners and borders, a balling or rounding effect on the edges and corners can result in local shorter layers [21]. Therefore, as the 3D part grows, that match is fundamental to assure a good 3D part quality [9]. To evolve the L-DED processes, it is imperative to monitor and detect unexpected changes in \(Z_s\) and use this data in a feedback loop to adjust Z-axis increment [4, 20].
Some studies have reported the estimation/measurement of the layer height in-situ, and for this purpose, usually multi-cameras, and other electromagnetic sensors have been applied [22,23,24]. However, when it comes to measuring printing distance in-process to infer on the layer height for real-time applications, only one study has been reported [24]. By using vision-based inspection on a combination of three digital cameras, the authors were able to measure the distance between the bottom of the nozzle and the plan of the melt pool with great accuracy [24]. However, the setup for such measurement requires fine alignment and high-cost instruments. Such solution may not always be as feasible to reproduce in industrial and academic environments as the one proposed in the present work, which suggests the use of coaxial IR cameras previously installed in the machine. Progress has also been made in multi-physical modelling to correlate the deviation in printing distance [25, 26], with success in repairing uneven surfaces. Yet, such control is not done online, but by post-processing the data when repairing surfaces.
Despite various intentions in regard of real time monitoring of the melt pool using CNNs, efforts to minimize its processing time, whilst maintaining geometry accuracy, are lacking [27]. Therefore, this study proposes a novel hybrid artificial intelligent method to quickly identify with accuracy and low computational cost the printing distance. This method was designed to combine the best out of pre-trained CNN and SVR, using solely processed melt pool images from the process as training data. The proposed methodology provides an efficient and accurate way of monitoring the printing distance, being the stepping stone for online feedback control of the Z-axis increment during printing operation for better quality produced parts.
2 Theoretical correlation between printing distance deviation and layer height
Fundamentally, in L-DED processes a laser beam is focused at the printing surface, generating a melt pool. To maximize the process efficiency, both powder flow and laser beam focuses must be exactly at the printing surface. The higher the energy delivered, the deeper the melt pool tends to be and the longer the time of exposure, the wider the melt pool area. In addition, when both focus, powder and laser, matches exactly at the printing plan, the resulting deposition tends to be at its best.
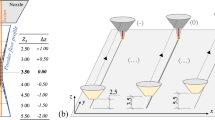
However, it often happens that such match is not maintained, throughout the process, because the height of the layers (h) changes during stacking. The Z-axis increment must equal the overall height of the previous deposited layer in order to keep the deposition in focus. If just a constant Z-axis increment is used in the G-code for the entire 3D building, the printing distance and laser beam focus tend to diverge. This difference may be acceptable in prints with few layers, but as the number of stacked layers increases, the divergence grows and the efficiency of the process drops to unacceptable levels. Powder catchment, delivered power, melt pool depth and area decrease, and layer height may shrink. All those outcomes induce defects and affect the material mechanical properties and its 3D geometry as a whole [25]. Therefore, to improve the process results, the Z-axis increment must be adjusted, according to each layer height, in order to avoid printing out of focus. Figure 1 summarizes the focus conditions during printing.

Schematics for a deposition nozzle and focus conditions during printing as in b positive defocus, c in focus, and d negative defocus
Figure 1a shows the focal point(\(Z_{s,0}\)) from both powder jet and laser beam. When the printing distance (\(Z_s\)) coincides with the laser focal point (\(Z_s = Z_{s,0}\)), the deposition is considered ’in focus’ (see Fig. 1c). That is the situation at the first layer, or when the actual layer height (h) is equal to the Z-axis increment (\(d_z\)). Thus, there are two cases in which the deposition can be defocused: when the printing distance is greater than the focal distance, in positive defocus (\(Z_s>Z_{s,0}\), see Fig. 1b) and when it is lesser than the focal distance, in negative defocus (\(Z_s<Z_{s,0}\), see Fig. 1d).

Schematics for defocused printing
With the increase in loss of focus, both the layer height and the following layer geometries and material quality are affected, leading to a printed part with overall cumulative deviations. The process must prevent this effect from happening. At the present research, several depositions were conducted at the 3 defined focal zones, so the predicted printing distance (\(\hat{Z}_s\)) could be estimated. Based on that predicted value, a correction factor (\(\Delta z\)) can be seen in Fig. 2 and is defined in Eq. 1.
Using the correction factor, a Z-axis increment correction factor in instant ’i’ (\(\hat{Z}_{add,i}\)) can be predicted according to Eq. 2.
in which dz is the programmed Z-axis increment and \(\Delta \hat{z}_i\) is the predicted correction factor in instant ’i’.

Schematics on the a printing distance (\(Z_s\)) and correction factor (\(\Delta z\)), and b experimental setup
All in all, in L-DED via powder feeders’ systems, keeping the printing on focus is a challenge - as the bead geometry is highly influenced by the heat transfer mechanisms and the melt pool shape and solidification. So, as the layer height is highly dependent on many printing parameters, as well as on scanning strategies, part geometry, etc. real-time monitoring and estimation of the printing distance can be used to correct z-axis displacement for each layer and maintain the expected printing outcome and quality.
3 Experimental setup
In this study, a 5-axis DED machine model M250 (SN 006) from BeAM with a CNC SIEMENS SINUMERIK 840D sI (Version V4.7) was used. Equipped with the BeAM Vx10 nozzle with 0.8 mm spot size, both powder and laser beam are focused at \(Z_{s,0} = 3.5~mm\) from the nozzle. In this system, a coaxial Basler ACA2000-50GM-NIR camera (pixel size of \(30.25~\mu m^2\)) was calibrated to match the focal and laser power focus.
Stainless steel 316 L powder from Höganäs (particle size distribution ranging from 45 to \(105~\mu m\)) was printed on a stainless steel 316 plate (\(160x160~mm^2\)). All prints were carried out with 350 W laser power, 2000 mm/min travel speed, 6.5 g/min mass flow rate, and carrier, central and secondary gases at the rate of 3 L/min, 3 L/min and 6L/min, respectively.
-
Training and validation: In the first stage of the present work, the melt pool characteristics during deposition of single lines 270 mm long were investigated under different printing distances (\(Z_s\) ranging from 2.50 mm to 5.50 mm, with 0.05 mm increment between sets), as presented in Fig. 3. From these tests, the images from the melt pool and the known printing distance for each set were the main outputs used to train the algorithm.
-
Case study: Following the lines setup, thick walls (12 mm thickness x 35 mm long with 35 layer height) were built with five different programmed layer heights (0.26 mm, 0.27 mm, 0.28 mm, 0.29 mm, and 0.30 mm) to induce defocus printing at different levels. The scanning strategy used in this geometry was zigzag with distance between adjacent lines in XY equal to 0.55 mm.
For all printings, images from the melt pool were acquired at 50 fps (frames per second) by the Basler Pylon V.6.3.0 Camera Software Suite TM for Windows. The training dataset is composed by 27000 images and each set of labels contains approximately 670 images. As part of our commitment to open science, all training data is freely available at our online repository. To allow each image to be spatially located at the testing stage, axis position data was acquired at 50 Hz and synchronized to the image acquisition based on matching timestamps. The acquired images were processed by the proposed hybrid machine learning model, depicted in the following section.
4 Hybrid Machine Learning Model
In order to correlate the images acquired by the camera and the printing distance, a supervised Hybrid Machine Learning Model (HMLM) is proposed. The images from the melt pool were processed and used as the input data to the HMLM, and the printing distance in which the images were captured are the labels (output) for the training and evaluation stage. Although traditional techniques for image binarization can be used to obtain the features (inputs) for the model, those techniques have shown to poorly represent the melt pool region from the image when the camera loses its focus. In that regard, the use of CNN to create features and predict outputs is a well-established alternative [19, 28].
Due to the amount of data required to effectively train a CNN [29], it is proposed to use the transfer learning technique [18]. In transfer learning, a CNN is pre-trained in a very large dataset of images uncorrelated to the images under study. This pre-trained CNN is then used to generalize the images under study, creating intermediate features that represent the images and can be used as inputs to a machine learning regression model which predicts the distance between the deposition head and the melt pool plan, considered as the printing distance.

Pipeline architecture for this work
The flowchart for model training and validation and deployment is illustrated in Fig. 4. All melt pool images were acquired online by the melt pool monitoring system. Sample images of the melt pool from the line experiment were used to train and validate the algorithm, in which the defined labels (printing distance) were addressed for each dataset.
The training and validation of the HMLM flows as follows: features were extracted from each image by the use of a pre-trained CNN; the features were then reduced with Principal Component Analysis (PCA) without losing significant information from the process; the dataset was separated between training (\(80\%\)) and testing (\(20\%\)) datasets using a train test split function; the training dataset was used to re-train the model and then, the model used the remaining testing dataset to predict the output. An error assessment was performed on the prediction results for each model tested. Subsequently, all data were evaluated under different machine learning regressors so the best HMLM could be determined.
A comparison using 5-fold cross validation was used to elect the best combination of regressors between SVR, Random Forest and Gradient Boosting Regressor, tested with the features extracted by the pre trained CNN. The regressor with the best metrics with the default parameters was selected for hyperparameter optimization through grid search. The best hybrid machine learning model was selected and used to run melt pool images and predict outcomes for data acquired during the printing of the case study geometry.
4.1 Convolutional Neural Network (CNN)
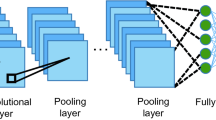
CNN are a specialization of Artificial Neural Networks (ANN) that are particularly suited to perform image processing. The advent of Residual Neural Networks (RNNs), such as ResNet in Fig. 5, was a technological breakthrough that made possible the use of CNNs due to a data forwarding architecture, in which the results of a previous deposited layer are considered for the next layer [30]. This has empirically shown to speed up convergence and diminish the errors in image classification tasks.

Building block of a ResNet. From [31]
Another CNN architecture is a Densely Connected Convolutional Neural Network (DenseNet). This CNN strategy connects the result of a previously layer to all the subsequent layers and has been shown to outperform all the other CNN architectures while using fewer trainable parameters [31]. L-DED monitoring research using DenseNets for coaxial image processing has also been conducted with promising results by Jolliffe and Cadima (2016) [32]. In the context of this research, three pre-trained versions of the DenseNet were used, with those being DenseNet121, DenseNet169 and DenseNet201 [32]. Those specific versions were used due to implementation availability and availability of the trained weights, as well as computational feasibility since no training on a large dataset is required.
Pre-trained CNNs are capable of representing general image data. Different implementations of ResNet and DenseNet, with various numbers of layers, were used to generate intermediate features of the higher-level HMLM. These features were then used to train different machine learning regression models to predict the printing distance of a particular image. All the explored CNN models with the respective layer quantities were: ResNet50, ResNet101, ResNet152, DenseNet121, DenseNet169 and DenseNet201.
4.2 Machine Learning Regressors
The use of pre-trained CNN reduces the amount of input data from 640x800 (512000) pixels to at most 2048 features. Principal Component Analysis (PCA) is a well-established model reduction tool that was performed to further speed up the model training [32]. The number of principal components chosen varies with the CNN used, and are selected to guarantee that at least \(97.5\%\) of the data variability is represented in those components. The features processed after PCA are then used as input in the ML regressors to predict the final output. The regressors used were eXtreme Gradient Boosting (XGBoost), Random Forest (RF) and Support Vector Regressor (SVR).
Both XGBoost and RF are ensemble algorithms based on decision trees, that show great performance for prediction [33]. A decision tree subdivides the data based in similarity scores, in which every new iteration tests every possible split and decides for the split that provides the most information, i.e. the split in which the similarity score is the minimum.
The RF algorithm utilizes multiple different decision trees, in a bagging strategy, each based on a random split of the initial dataset [34]. The XGBoost is a scalable ensemble algorithm based on a boosting strategy, that combines random decision trees, generated in a similar way as in the RF algorithm, in a sequential order.
SVR is a machine learning algorithm that uses an \(\epsilon \) insensitive loss function as penalization in an optimization [35], i.e errors that are smaller than \(\epsilon \) are ignored. The intention is to minimize \(\epsilon \), finding the hyperplane that best represents the regression task. SVR is known to be used with nonlinear and high-order relationships between features and the target. In that case, it is usually used with kernels that are capable of transforming the high-order and nonlinear relations into linear ones, that are suitable for the minimization of \(\epsilon \). The kernel used in this paper is the Radial Basis Function Kernel (RBF) [35].
Hyperparameters will also be optimized through a grid search, which consists of an exhaustive execution of all the possible combinations and selection of the one with the best results. The parameters and their respective sets of values are exhibited in Table 1.
4.3 Model Validation & Error assessment
In order to evaluate the error in the presented regression task, three metrics were explored: R-Squared (\(R^{2}\)), Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE). \(R^{2}\) is the coefficient of determination, which represents how well the model represents the dataset (Eq. 3). Although usually its values are constrained between 0 and 1, very poor model fitting could cause the index to have negative values. The closer \(R^{2}\) is to 1, the better is the model fit.
in which n is the number of datapoints on the dataset, \(Z_{s,i}\) is the actual target value, \(\hat{Z}_{s,i}\) is the predicted target value, and \(\bar{Z_s}\) is the average of the target values.
On the other hand, MAE directly represents the error between regression predictions and the actual target value included in the dataset (Eq. 4). The error is then averaged in the number of datapoints. The smaller the MAE, the better the model.
in which n is the number of datapoints on the dataset, \(Z_{s,i}\) is the actual target value and \(\hat{Z}_{s,i}\) is the predicted target value.
It is important to note, however, that the MAE does not include the average of the target value in its calculation. Therefore, the higher the target average, the higher the expected MAE can be. This problem can be tackled with the MAPE metric, that normalizes the values with respect to the average. With a slight modification to Eq. 4, it is defined as:
in which n is the number of data points on the dataset, \(Z_{s,i}\) is the actual target value and \(\hat{Z}_{s,i}\) is the predicted target value.
All the models were trained and tested with a 0.2 train test split, in which \(20\%\) of the dataset is randomly separated to be used as a validation dataset.
To validate the model and select the one that better generalizes the data using the aforementioned metrics, a K-fold cross validation technique will be used. For this study, the chosen value of K is 5. This technique involves dividing the dataset in K parts, and performing K times the training and evaluation step. Before performing these operations, the dataset is randomized to avoid having data points that are unknown to the model being used to assess the performance.
The dataset test window (\(80\%\) training and \(20\%\) testing) is then fed to the algorithm and the following charts are computed:
-
An error chart is drawn. It displays the ideal reference, all the predicted points and an average prediction for measurement label;
-
A MAE bar plot after windowing the dataset to each label represents the MAE for each different z-offset tested;
-
The MAE for the label is also displayed as a reference.
5 Results and discussion
5.1 Training and Validation: line geometry
From the training dataset, the original number of features was reduced through PCA, as presented in Table 2. The CNN with better performance in reducing features were the DenseNet121, Densenet169 and Densenet201, whose feature reduction amount to \(95.4 \%\), \(94.8 \%\) and \(97.5\%\), respectively. Thus, the network that needs the least number of components to represent \(97.5\%\) of the dataset variance is the DenseNet121, followed closely by DenseNet169. All ResNets presented performance in feature reduction below \(83\%\).
As both architectures present at least one CNN with a good possibility of very low processing time per image, all were tested together with the different regressors. The results from the regressor performance are compiled in Table 3. SVR, RF and XGBoost were evaluated as regression models, after feature reduction by PCA, in terms of MAE and \(R^{2}\).
One can see in Table 3 that the best performance for regressor, in combination with both ResNet or DenseNet models of CNN, is SVR. Therefore, a hyperparameter tuning was performed through grid search on the regularization parameter (C), kernel RBF, with results displayed in Table 4. The execution time was also provided for some additional considerations regarding the feasibility of the model.
As one can see in Table 4, the best performance was obtained when pre-training the model DenseNet169 with SVR as the output regressor, represented by a \(R^2 = 0.849\) and \(MAE = 0.266\). Figure 6 presents the complete regression plot from all the CNN/SVR. Detail on the best pair can be seen in Fig. 7.
It is important to emphasize that the MAE does not arbitrarily vary with the change in printing distance labeled. MAE does present a reduction when the system operates in focus, indicating that when the printing occurs close to the focus (Zone 0), the model can be more assertive in predicting the printing distance from the melt pool images. As a common point, all the models on average predicted a higher MAE for distances below the focal point (Zone -), and a lower MAE for values above the focal point (Zone +). All in all, the MAE for this dataset is 0.266 and it represents a MAPE of \(6.7\%\).

Complete regression plot in: a ResNet50 + SVR (C=1), b ResNet101, SVR(C=5), c ResNet151, SVR(C=5), d DenseNet121, SVR(C=5), e DenseNet169, SVR(C=1) and d DenseNet201, SVR(C=5)

Regression plot from training dataset by DenseNet169 + SVR (\(C=1\)) models and discrete error plot for each defined \(Z_s\) label
Another important point to discuss are the processing times for the developed algorithms. In order to achieve a real time process control, the processing pipeline must be able to quickly deliver the response, to then be used by other control mechanisms which would in turn adjust process parameters, increasing the part quality and thus many valuable properties. Table 5 presents the time for each step of the image processing, considering the total time for image processing (T) as a sum of the feature extraction, PCA and SVR time to predict the printing distance, and the overall process frequency by each CNN tested.
In Table 5, the feature reduction has clearly affected the processing time for processing each image. DenseNet121 has the best processing time (0.023s) per image, this model provides a lower MAE of 0.302 and a \(R^2\) of 0.806. On the other hand, DenseNet169 presents a combination of high feature reduction, a very low processing time per image (0.027s), whilst providing the model with the best metrics: MAE (0.266) and \(R^2\) (0.849).

Predicted printing distance, \(\hat{Z}_s (mm)\), during printing and final geometry of thick walls for buildings with programmed layer height, dz, of a 0.26 mm and b 0.31 mm
The processing frequencies were achieved using a general-purpose personal computer. It is important to stress that, depending on the real time requirements of the application, multiple ways of reducing the processing time can be explored. Some ways of decreasing the process time are to use a faster environment for the model (low level languages) or a more powerful computer to perform the operations, to integrate dedicated and optimized hardware (GPU and FPGAs), etc.
Although all the final processing frequencies are inferior to the acquisition of images rate (50 Hz), trying to feed the CNC with corrective actions at the same rate represents a risk for loosing printing quality. In this regard, the authors believe that the current model can provide real time information as a feedback to control the DED process online.
Thus, due to its high performance, the pre-trained model used to predict the printing distance was DenseNet169 with SVR (C=1).
5.2 Case study: thick walls geometry
Figure 8 reveals the presence of accumulative error into the printing distance for the thick walls built with 0.26 and 0.31 mm layer height. When printing this geometry with \(dz=0.31~mm\), the predicted printing distance shows a larger proportion of the data at the Zone +, indicating a severe loss of printing focus (see Fig. 8b). This is likely a result of a mismatch between actual layer height and programmed layer height, indicating defocus printing occurrence. The opposite occurs when majority of the signal is within the printing focus Zone 0, as shown in the part printed with \(dz=0.26~mm\) (see Fig. 8a).
Thus, by using the methodology proposed in this paper, it is also more feasible and faster to evaluate the best layer height to build a part at the initial design of experiments (DoE), saving time and resources in part handling and initial shape analysis. The correspondent final part geometry is also plotted in Fig. 8 as qualitative reference.
Starting at the borders and edges, where the melt pool tends to cool down faster, the printing defocusing can rise to a level that affects the overall part geometry. In early stages, with the quicker solidification of the melt pool, less material tends to be added, affecting the layer height first at the borders of the building. Following, when less material is captured at the melt pool, local layer height tends to decrease, provoking shape deviation to begin at the edges and start to move along the edge as the defocus printing areas increase. This behavior is shown in Fig. 8b, where there is a small area of Zone 0, in green-yellow, surrounded at the risen edges of Zone +, in orange-red.
To summarize, from the final part geometry, the higher the \(\Delta z\) throughout the printing, the higher the shape deviation at the final part. The best edges and shape geometry were obtained at the print with \(dz=0.26~mm\), as already indicated with the results from Fig. 8, whilst the lower quality shape geometry was obtained at the print with \(dz=0.31~mm\). These results suggests that the methodology proposed in this paper can support online inspection of printing geometry quality through printing defocusing quantification.
6 Conclusions
The present study proposes a novel hybrid machine learning model for estimating printing distance in L-DED operations. To support the study, three focal zones were defined: Zone 0 for printing in focus, Zone - and Zone + for printing out of focus when \(h>dz\) and \(h<dz\), respectively.
The results from the training and validation stage indicated that the model DenseNet169, with SVR regularization parameter \(C=1\), presents a combination of high feature reduction and low processing time per image (0.027s). This model provides the best metrics: MAE\(=0.266\) and \(R^2=0.849\), leading to an average target error of \(6.7\%\). Using this model, images are processed with high accuracy at the rate of 36.47 Hz, which is inferior to the acquisition of images rate (50 Hz); however, it is still reasonable to support feedback-control as the CNC machine is not actualized in the same rate.
Plots of predicted printing distance against spatial position shows variation at borders/edges, highly affecting the geometry from the building with \(dz=0.31\) mm. When compiling the results for the case study, it is possible to infer that \(dz=0.26\) mm is the closest value to the layer height from the printing, mitigating defocus regions, thus leading to better final geometry with less shape deviation.
Overall, understanding how the printing distance influences the quality during printing of stacked layers has shown to be imperative to high geometric accuracy in L-DED. Another outcome of the presented methodology is to aid the build of parts and the definition of parameters at the pre-build stage, so the layer height can be chosen to provide a mostly in focus deposition. This would prevent excessive shape deviation, reinforcing the importance of having a method that can estimate the printing distance changes in-situ.
Data Availability
The data collected has been made available to support future research and training of algorithms and is available at http://github.com/henriquenunez/nir-ded-dataset
References
52910:2018(E) I (2018) Additive Manufacturing – Design – Requirements, Guidelines and Recommendations, 1st edn., pp. 1–15. ISO/ASTM International, 100 Barr Harbor Drive, PO Box C700, West Conshohocken, PA 19428-2959. United States
Blakey-Milner B, Gradl P, Snedden G, Brooks M, Pitot J, Lopez E, Leary M, Berto F, du Plessis A (2021) Metal additive manufacturing in aerospace: A review. Mater Des 209, 110008. https://doi.org/10.1016/j.matdes.2021.110008
Liu R, Wang Z, Sparks T, Liou F, Newkirk J (2017) Aerospace applications of laser additive manufacturing. In: Brandt M (ed.) Laser Additive Manufacturing. Woodhead Publishing Series in Electronic and Optical Materials, pp. 351–371. Woodhead Publishing, Cambridge, MA, USA. https://doi.org/10.1016/B978-0-08-100433-3.00013-0
Freeman FSHB, Thomas B, Chechik L, Todd I (2022) Multi-faceted monitoring of powder flow rate variability in directed energy deposition. Additive Manufacturing Letters 2, 100024. https://doi.org/10.1016/j.addlet.2021.100024
Ribeiro KSB, Núñez HHL, Jones JB, Coates P, Coelho RT (2021) A novel melt pool mapping technique towards the online monitoring of directed energy deposition operations. Procedia Manufacturing 53, 576–584. https://doi.org/10.1016/j.promfg.2021.06.058. 49th SME North American Manufacturing Research Conference (NAMRC 49, 2021)
Mi J, Zhang Y, Li H, Shen S, Yang Y, Song C, Zhou X, Duan Y, Lu J, Mai H (2022) In situ image processing for process parameter-build quality dependency of plasma transferred arc additive manufacturing. J Intell Manuf 34:683–693. https://doi.org/10.1007/s10845-021-01820-0
Zhang Y, Shen S, Li H, Hu Y (2022) Review of in situ and real-time monitoring of metal additive manufacturing based on image processing. The International Journal of Advanced Manufacturing Technology 123:1–20. https://doi.org/10.1007/s00170-022-10178-3
Whiting J, Springer A, Sciammarella F (2018) Real-time acoustic emission monitoring of powder mass flow rate for directed energy deposition. Addit Manuf 23:312–318. https://doi.org/10.1016/j.addma.2018.08.015
Haley JC, Zheng B, Bertoli US, Dupuy AD, Schoenung JM, Lavernia EJ (2019) Working distance passive stability in laser directed energy deposition additive manufacturing. Materials & Design 161:86–94. https://doi.org/10.1016/j.matdes.2018.11.021
Yan Z, Liu W, Tang Z, Liu X, Zhang N, Li M, Zhang H (2018) Review on thermal analysis in laser-based additive manufacturing. Optics & Laser Technology 106:427–441. https://doi.org/10.1016/j.optlastec.2018.04.034
Ocylok S, Alexeev E, Mann S, Weisheit A, Wissenbach K, Kelbassa I (2014) Correlations of melt pool geometry and process parameters during laser metal deposition by coaxial process monitoring. Physics Procedia 56, 228–238. https://doi.org/10.1016/j.phpro.2014.08.167. 8th International Conference on Laser Assisted Net Shape Engineering LANE 2014
Sampson R, Lancaster R, Sutcliffe M, Carswell D, Hauser C, Barras J (2020) An improved methodology of melt pool monitoring of direct energy deposition processes. Opt Laser Technol 127, 106194. https://doi.org/10.1016/j.optlastec.2020.106194
Jeon I, Yang L, Ryu K, Sohn H (2021) Online melt pool depth estimation during directed energy deposition using coaxial infrared camera, laser line scanner, and artificial neural network. Addit Manuf 47, 102295. https://doi.org/10.1016/j.addma.2021.102295
Sestito GS, Venter GS, Ribeiro KSB, Rodrigues AR, da Silva MM (2022) In-process chatter detection in micro-milling using acoustic emission via machine learning classifiers. The International Journal of Advanced Manufacturing Technology 120(11):7293–7303. https://doi.org/10.1007/s00170-022-09209-w
Era IZ, Grandhi M, Liu Z (2022) Prediction of mechanical behaviors of l-ded fabricated ss 316l parts via machine learning. The International Journal of Advanced Manufacturing Technology 121:2445–2459. https://doi.org/10.1007/s00170-022-09509-1
Gajbhiye RV, Rojas JGM, Waghmare PR, Qureshi AJ (2022) In situ image processing for process parameter-build quality dependency of plasma transferred arc additive manufacturing. The International Journal of Advanced Manufacturing Technology 119:7557–7577. https://doi.org/10.1007/s00170-021-08643-6
Jeon I, Yang L, Ryu K, Sohn H (2021) Online melt pool depth estimation during directed energy deposition using coaxial infrared camera, laser line scanner, and artificial neural network. Addit Manuf 47, 102295. https://doi.org/10.1016/j.addma.2021.102295
Yuan J, Liu H, Liu W, Wang F, Peng S (2022) A method for melt pool state monitoring in laser-based direct energy deposition based on densenet. Measurement 195, 111146. https://doi.org/10.1016/j.measurement.2022.111146
Westphal E, Seitz H (2021) A machine learning method for defect detection and visualization in selective laser sintering based on convolutional neural networks. Addit Manuf 41, 101965. https://doi.org/10.1016/j.addma.2021.101965
Montazeri M, Nassar AR, Stutzman CB, Rao P (2019) Heterogeneous sensor-based condition monitoring in directed energy deposition. Addit Manuf 30, 100916. https://doi.org/10.1016/j.addma.2019.100916
Ribeiro KSB, Mariani FE, Coelho RT (2020) A study of different deposition strategies in direct energy deposition (ded) processes. Procedia Manufacturing 48, 663–670. https://doi.org/10.1016/j.promfg.2020.05.158. 48th SME North American Manufacturing Research Conference, NAMRC 48
Garmendia I, Pujana J, Lamikiz A, Madarieta M, Leunda J (2019) Structured light-based height control for laser metal deposition. J Manuf Process 42:20–27. https://doi.org/10.1016/j.jmapro.2019.04.018
Binega E, Yang L, Sohn H, Cheng JCP (2022) Online geometry monitoring during directed energy deposition additive manufacturing using laser line scanning. Precis Eng 73:104–114. https://doi.org/10.1016/j.precisioneng.2021.09.005
Hsu H-W, Lo Y-L, Lee M-H (2019) Vision-based inspection system for cladding height measurement in direct energy deposition (ded). Addit Manuf 27:372–378. https://doi.org/10.1016/j.addma.2019.03.017
Wang S, Zhu L, Dun Y, Yang Z, Fuh JYH, Yan W (2021) Multi-physics modeling of direct energy deposition process of thin-walled structures: defect analysis. Comput Mech 67:1229–1242. https://doi.org/10.1007/s00466-021-01992-9
Pant P, Chatterjee D, Nandi T, Samanta SK, Lohar AK, Changdar A (2019) Statistical modelling and optimization of clad characteristics in laser metal deposition of austenitic stainless steel. J Braz Soc Mech Sci Eng 283. https://doi.org/10.1007/s40430-019-1784-x
Tang Z-J, Liu W-W, Wang Y-W, Saleheen KM, Liu Z-C, Peng S-T, Zhang Z, Zhang H-C (2020) A review on in situ monitoring technology for directed energy deposition of metals. The International Journal of Advanced Manufacturing Technology 108(11):3437–3463. https://doi.org/10.1007/s00170-020-05569-3
Jamnikar ND, Liu S, Brice C, Zhang X (2022) In-process comprehensive prediction of bead geometry for laser wire-feed ded system using molten pool sensing data and multi-modality cnn. The International Journal of Advanced Manufacturing Technology 121(1):903–917. https://doi.org/10.1007/s00170-022-09248-3
de Geus-Moussault SRA, Buis M, Koelman HJ (2021) A convolutional neural network developed to predict speed using operational data, 246–264. Proceedings of the 20th International Conference on Computer and IT Applications in the Maritime Industries, COMPIT’21
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770–778. https://doi.org/10.1109/CVPR.2016.90
Huang G, Liu Z, Weinberger KQ (2017) Densely connected convolutional networks. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 4700–4708. https://doi.org/10.48550/ARXIV.1608.06993
Jolliffe IT, Cadima J (2016) Principal component analysis: a review and recent developments. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 374(2065), 20150202. https://doi.org/10.1098/rsta.2015.0202
Kavzoglu T, Teke A (2022) Predictive performances of ensemble machine learning algorithms in landslide susceptibility mapping using random forest, extreme gradient boosting (xgboost) and natural gradient boosting (ngboost). Arab J Sci Eng 47(6):7367–7385. https://doi.org/10.1007/s13369-022-06560-8
Breiman L (2001) Random forests. Mach Learn 45(1):5–32. https://doi.org/10.1023/A:1010933404324
Song L, Huang W, Han X, Mazumder J (2017) Real-time composition monitoring using support vector regression of laser-induced plasma for laser additive manufacturing. IEEE Trans Industr Electron 64(1):633–642. https://doi.org/10.1109/TIE.2016.2608318
Acknowledgements
This work was fully supported by grants #2016/ \(11309-0\), #\(2019/00343-1\) and #\(2020/03119-2\), São Paulo Research Foundation (FAPESP). The authors are grateful to the Center for Advanced Vehicular Systems (CAVS) – Mississippi State University (MSU), Starkville, MS, USA; Joseph Young, Joel Austin, and CAVS’s members for the support given during the experimental phase of this study. All experiments were conducted at the CAVS, in collaboration with the Laboratory for Advanced Processes and Sustainability (LAPRAS) – University of São Paulo (USP), São Carlos, SP, Brazil.
Funding
São Paulo Research Foundation (FAPESP) Research grant #\(2016/11309-0\), #\(2019/00343-1\) and #\(2020/03119-2\). Open Access funding provided by University of Turku (UTU) including Turku University Central Hospital.
Author information
Authors and Affiliations
Contributions
Kandice S. B. Ribeiro contributed to the study conceptualization, methodology, investigation. Henrique H. L. Nunez worked on the software and Giuliana S. Venter aided the conceptualization and methodology. Data curation and the writing of the original draft were performed by Kandice S. B. Ribeiro, Henrique H. L. Nunez and Giuliana S. Venter. Haley Doude contribution were related to the research resources, and reviewing and editing the final draft with Reginaldo T. Coelho, who has also contributed with the supervision of the present research. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest/Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ribeiro, K.S.B., Núñez, H.H.L., Venter, G.S. et al. A hybrid machine learning model for in-process estimation of printing distance in laser Directed Energy Deposition. Int J Adv Manuf Technol 127, 3183–3194 (2023). https://doi.org/10.1007/s00170-023-11582-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-023-11582-z