
Abstract
Laser-based directed energy deposition (L-DED) is a rising field in the arena of metal additive manufacturing and has extensive applications in aerospace, medical, and rapid prototyping. The process parameters, such as laser power, scanning speed, and layer thickness, play an important role in controlling and affecting the properties of DED fabricated parts. Nevertheless, both experimental and simulation methods have shown constraints and limited ability to generate accurate and efficient computational predictions on the correlations between the process parameters and the final part quality. In this paper, two data-driven machine learning algorithms, Extreme Gradient Boosting (XGBoost) and Random Forest (RF), were applied to predict the tensile behaviors including yield strength, ultimate tensile strength, and elongation (%) of the stainless steel 316L parts by DED. The results suggest that both models successfully predicted the tensile properties of the fabricated parts. The performance of the proposed methods was evaluated and compared with the Ridge Regression by the root mean squared error (RMSE), relative error (RE), and coefficient of determination (R2). XGBoost outperformed both Ridge Regression and Random Forest in terms of prediction accuracy.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Additive manufacturing (AM), also called 3D printing, is a manufacturing technique where an object is created by adding material layer upon layer directly from 3D model data. AM has revolutionized the way of creating lighter, stronger parts, and complex systems as it eliminates traditional manufacturing-process design restrictions. Directed energy deposition (DED) is a flexible type of AM process in which a focused heat source is used to melt the feedstock material and build up three-dimensional objects in a manner similar to the extrusion-based processes [1]. Holding the advantages of metallurgical bonding, controllable heat input, minimal stress and distortion, and comparable mechanical properties with traditional means, DED is now popular for effectively repairing and refurbishing defective and damaged high-tech components, e.g., turbine blades [1].
One of the major challenges in DED is the unrepeatable material properties and unpredictable microstructure. The quality of the deposited layers highly depends on the dynamic processes during material deposition, including energy absorption, melting, mass transfer, and rapid solidification. Better part quality and accuracies can be achieved by altering process parameters, such as laser power and scanning speed, but the effect mechanism is not documented. To achieve compact and reliable deposited layers and to optimize the processing parameters, the process-structure–property (PSP) relationship needs to be fully understood. Over the past decades, both experiment-based methods and simulations are performed to investigate PSP relationships in DED. Finite element analysis (FEA) is commonly applied to model the mechanical behavior of printed parts. Using cohesive elements to model bonded interfaces is an advantage of FEA, but it is difficult to determine the boundary conditions at the bonded interface [2]. Recently, researchers attempted to combine physics-based hybrid models and artificial neural network to predict the mechanical properties of the printed parts, but these models faced difficulties in achieving better prediction due to the requirement of huge sets of data [3]. Conducting experiments and high-fidelity simulations for DED are either time-consuming or expensive, and there is a critical need for an effective and efficient tool for property prediction with data analysis and data mining. Machine learning (ML), being a subset of artificial intelligence (AI), has been proved to be a useful tool in modeling and simulation in AM [4].
This paper aims to build and evaluate data-driven predictive modeling with machine learning on the quality of DED printed parts. This work addresses the challenges arising from both experimentation and modeling methods. The experimentation section includes the design of the specimen, fabrication, strength behaviors testing, and data collection. In predictive modeling, the ML model is trained by the training data, and then, the prediction is compared with the test data to analyze the accuracy of the prediction. The rest of the paper is organized as follows. In Sect. 2, the previous research works are summarized. Section 3 describes the methodology, including the theory of the machine learning algorithms, material selection, and detailed experimentation. In Sect. 4, we discussed and explained the results obtained using ML. In Sect. 5, we concluded with an explanation of the result and the future recommendation.
2 Related work
Enriched literature is available on data-driven models on various AM process parameters. Zhang et al. [5] developed a data-driven predictive model using extreme gradient boosting (XGBoost) and long short-term memory (LSTM) to estimate the melt pool temperature during DED with high accuracy. They also introduced a data-driven predictive modeling approach to estimate the tensile strength of polymers fabricated by the cooperative 3D printing process. The authors used ensemble learning to combine multiple learning algorithms including Lasso, Support Vector Regression, and XGBoost, and compared the results with Ridge Regression. They claimed that the ensemble learning method outperformed the linear regression model.
Li et al. [6] presented an ensemble learning-based approach to surface roughness prediction in fused deposition modeling processes. To improve computational efficiency and to avoid overfitting, a subset (40) of the features was selected based on feature importance. The ensemble learning algorithm combined six different machine learning algorithms, including Random Forest (RF), Adaptive Boosting (AdaBoost), Classification & Regression Tree (CART), Support Vector Regression (SVR), and Random Vector Functional Link (RVFL) network. The authors claimed that the performance of the ensemble approach outperforms the individual base learners based on RMSE and RE. Scime et al. [7] worked on Inconel 718 material for flaw formation in laser-based powder bed fusion (PBF) using bag of words (BoW) and scale invariant feature transform (SIFT) method. The prediction of thermal history and microhardness in the DED process were experimentally validated by a computational thermo-fluid dynamics (CtFD) model by Wolff et al. [8]. Both mentioned works demonstrated that the proposed inexpensive and well-tested computational frameworks can generate a large amount of high-quality prediction data, including temperature field, velocity field, melt pool dimensions, dilution, heating and cooling rates, solidification parameters, and microhardness. Several other algorithms have been proposed and applied in data-driven modeling in AM processes, including Ensembled Learning, Taguchi, and Discriminant Analysis, as summarized in Table 1.
Model and data collection are the most challenging aspects in data-driven modeling for DED because there are multiple parameters and a non-linear relationship existed between input variables and outputs. In addition, data collection in DED is either expensive or extremely complicated and lengthy, or even both. Therefore, the data size to construct models for DED prediction is always relatively smaller and overfitting may occur in fitting predictive modeling. Few techniques can be used to reduce overfitting, e.g., random sampling, regularization, averaging across multiple models, and data randomization. As an open-source and fast algorithm, XGBoost is a widely recognized machine learning algorithm and a very popular choice by data scientists [17]. XGBoost uses a gradient descent algorithm to minimize the loss when adding new models and is suitable for data mining challenges and tabular data types [18, 19]. RF regression is a supervised learning technique that uses ensemble learning to construct a group of decision trees from the bootstrap samples of a training data set [20]. It is a bagging technique that contains several decision trees on different subsets of the given dataset and takes the average to increase the accuracy of the prediction. Since boosting and bagging methods perform the random sampling and averaging across multiple models, also they have regularization in their objective functions, both two ML algorithms are suitable matches for better prediction for the data which is non-linear and relatively smaller in size. Other challenges during data-driven modeling for DED include preprocessing and hyperparameter tuning. Special measures are needed to ensure the data quality in preprocessing. The hyperparameter, number of trees, shrinking rate, observation nodes, and depth of trees are required to be tuned accordingly to achieve a higher prediction accuracy.
3 Methodology
3.1 Predictive modeling
3.1.1 Extreme gradient boosting (XGBoost)
In XGBoost, after each iteration, a decision tree is added to the ensemble with the weights added from the error of the previous learner added to the model. From the mistakes/errors of the previous model, the weak learners are trained to improve the performance of the ensemble learner to function as a single strong learner. The purpose of building XGBoost is to appraise up all the computational advantages of boosting. XGBoost is an advanced implementation of gradient boosted models (GBM) because GBM builds trees in series, while XGBoost follows parallel mechanism.
Tree building
The main concept of the tree building is to predict the residuals from the prediction and test data. At every iteration, a new tree is built and then the residuals are recomputed. Tree building process keeps going until the model can fit the data well. A tree in XGBoost with a total of \(J\) leave can be expressed in Eq. (1) [5].
Here, parameters \(\Theta ={\{{R}_{j},{\gamma }_{j}\}}_{1}^{J}\) where \({\gamma }_{j}\) is the constant assigned to the disjoint region \({R}_{j}\). The boosted tree model can be expressed by the sum of all trees, as shown in Eq. (2), where \(M\) represents the number of trees.
Loss function
In the forward stagewise procedure, the objective function that needs to be optimized at each step can be expressed as Eq. (3) where \({{\nu}}\) is the shrinkage factor while \({{\varepsilon}}\) and \({{\lambda}}\) are the regularization parameters to reduce overfitting.
The first part of the objective function, \(\sum_{{{i}}=1}^{{{n}}}{{L}}\left({{{y}}}_{{{i}}},{{{f}}}_{{{m}}-1}\left({{{x}}}_{{{i}}}\right)+{{\nu}}\cdot {{T}}\left({{x}};{{{\Theta}}}_{{{m}}}\right)\right)\) measures the loss for using \({{{f}}}_{{{m}}}\left({{{x}}}_{{{i}}}\right)\) to predict \({y}_{i}\). The prediction \({{{f}}}_{{{m}}}\left({{{x}}}_{{{i}}}\right)\) in XGBoost is combined by the prediction from previous trees \({{{f}}}_{{{m}}-1}\left({{{x}}}_{{{i}}}\right)\) and the scaled approximation from the m-th tree \({{\nu}}\cdot {{T}}\left({{x}};{{{\Theta}}}_{{{m}}}\right)\). The second part of the objective function, \({{\varepsilon}}\cdot {{J}}+{{\lambda}}\cdot \sum_{{{j}}=1}^{{{J}}}{{{{\gamma}}}_{{{j}}{{m}}}}^{2}\), defines the complexity of the tree \({{T}}\left({{x}};{{{\Theta}}}_{{{m}}}\right)\) and perform regularization to reduce overfitting.
Split
XGBoost trees use binary splitting. And the split point selection starts with searching the point where the gain is maximum. During the tree pruning process, a gain function is calculated with Eq. (4).
where \({G}_{L}\), \({H}_{L}\), \({G}_{R}\), and \({H}_{R}\) represent the sum of \({g}_{i}\) and \({h}_{i}\) at the left and right branch after splitting, respectively. \({g}_{i}\) and \({h}_{i}\) are the first and second derivatives of \({{L}}\left({{{y}}}_{{{i}}}, {{{f}}}_{{{m}}-1}\left({{{x}}}_{{{i}}}\right)\right)\). To make the optimal split at each node, the branch with the maximum value of gain is selected. \({{\gamma}}\) is a constant assigned as a tuning factor. This is used as a stopping criterion in pruning. Pruning also works as the regularization to reduce the overfitting. If the gain function value \({{G}}\) is higher than the \({{\gamma}},\) then the leaves are not pruned and don’t check the parent node. If the gain function value \({{G}}\) is smaller than \({{\gamma}},\) then it prunes the node.
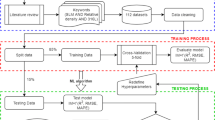
The flowchart for the XGBoost modeling is shown in Fig. 1, which includes two main phases: (1) the training phase, where the data is loaded into the model and the algorithm is trained to create the right output, and (2) the testing phase, where a set of observations is used to evaluate the performance of the model. In the training phase, the hyperparameters need to be tuned according to the data and the problem type. The n number of trees are built where the objective values are minimized, the residuals are computed consequent, and weight is given to the errors of the previous models for the new model to learn. In this study, the training data is selected from tensile test and the split function is used to separate the test data from the training data.

Flowchart of XGBoost
3.1.2 Random forest
In Random Forest, for a given predictor, a response is created by a decision tree, where the branch denotes the outcome of the test and the leaves are the responses as the predictions. The tree is regarded as the regression tree if the response is continuous. Since tensile properties are continuous values, the regression model is performed for prediction.
For a given training data D, expressed as Eq. (5), with N samples from the original training data set, for, i = 1 to N [16].
At each node, m number of variables and random split called feature bagging is selected. The data is partitioned by M number of regions, as shown in Eq. (6), where Rm is the region and ϒm is a constant.
The splitting at node is performed to minimize the sum of the squares. The best \({\widehat{S}}_{m}\) as shown in Eq. (7) is the average of \({y}_{i}\) in region \({R}_{m}\).
We suppose a splitting variable k and split points n, and the pair of the half planes are defined as Eqs. (8) and (9).
The objective function L to solve the splitting variables and split points can be expressed in Eq. (10).
For any random values of k and n, the inner minimizations are solved by Eqs. (11) and (12).
The stopping criterion is satisfied when the number of responses in \({D}_{i}\) falls under the threshold. The number estimators or trees we have selected is 500 and 1000; a prediction at a new point x is made by average of all the regression trees, as shown in Eq. (13). Bootstrap or bagging generates b number of new training data set \({D}_{i}\) and \({V}_{t}\) is the bootstrapped tree in Eq. (13). The flowchart of the Random Forest model is shown in Fig. 2.

Flowchart of Random Forest
3.2 Data collection
3.2.1 Material selection
Commercial gas atomized 316 Stainless Steel L (SS 316L) powder (size: 45 ~ 105 micron) is used in this study because it has higher creep, higher tensile strength properties, and is widely used for durable and high-stress situations [21]. Low carbon steel (LCS) is used as the substrate. The chemical composition of SS 316L and LCS is shown in Table 2.
3.2.2 Specimen design
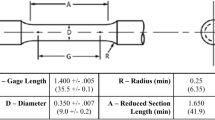
Dog bone specimen is designed according to the ASTM standard [22]. To reduce the printing time and associated expenses, the standard dimensions are scaled down to length, width, and height to 82.5 mm, 9.50 mm, and 3 mm, respectively, as shown in Fig. 3 [23]. The layer thickness is 0.54 mm with totally five layers.

Schematic diagram of AMBIT™ laser-based DED hybrid system
3.2.3 Design of experiment
Four process variables were selected in this work. The input of laser power was selected between 600 and 1000 W with 100 W interval, and the scanning speed was changed from 8 to 12 mm/s. Powder feed rate (5 g/mm), laser spot diameter (2 mm), nozzle gas rate (9 L/min), shield gas rate (12 L/min), and carrier gas rate (5 L/min) are constant for all the experiments.
In this study, full experimental design is applied based on two operator-controlled input parameters: laser power (W) and scanning speed (mm/s). Each of these two factors had 5 levels. Thereby, a total of 52 = 25 dog bone specimens had been printed using 25 different distinct sets of parameters, as shown in Table 3.
3.2.4 Dog bone specimen fabrication
The experiments were performed with a customized powder-based DED system (AMBIT™ core DED, Hybrid Manufacturing Technology, TX, USA). The system consists of an inert gas supply, a system chamber including the X–Y axes motion table, the deposition head and the lens system, powder hoppers, AMBIT core, operator control, a chiller, and a fume extractor, as shown in Fig. 3 from [23]. SS 316L powders are delivered to the deposition head with delivery gas (argon); the powder feeding rate is controlled with the rotational disk in the hoppers. Inert gas is supplied to the system’s chamber to avoid oxidation during the print. The path of the deposition head is generated by Autodesk Fusion 360 and controlled by the AMBIT™ core.
In DED, a subsequent layer is typically deposited in a different orientation than the previous layer. Common scan patterns from layer to layer are usually multiples of 30°, 45°, and 90° [1]. Layer orientations can also be randomized between layers. In this setup, the first and fifth layers are at 0°, the second layer at 45°, the third layer at 135°, and the fourth layer at 45°. The scanning pattern at different layers is shown in Table 4 [23]. The variation in printing orientation from layer to layer eliminates preferential grain growth, which otherwise makes the properties anisotropic and reduces residual stresses [1]. The printing directions are demonstrated in Fig. 4.

3D printed SS 316L Dog bone specimens by L-DED process
3.2.5 Dog bone specimen processing
Electric discharge machining (EDM) was used to subtract the dog bones from the substrate. Each specimen was first separated with the substrate with a vertical bandsaw. Then each specimen was cut from its substrate with the height of 2 mm with a wire EDM machine (VG plus series, EXCETEC Technologies Co. Ltd, Taiwan). A brass wire with a small diameter of 0.23 mm cut the narrow width of 2 mm from the original specimen. The workpiece moved steadily around the wire so that it can have an accurate tool path. Numerical control was used during cutting to maintain the precision of the motion. During cutting, the wire continuously moved between a supply and take in reels of wire to maintain the constant diameter of the electrode. Dielectric fluid was constantly flushed to wash away all the debris.
3.2.6 Tensile testing
The tensile test was performed on a universal testing machine (AGS-X, Shimadzu Co., Kyoto, Japan) with a 10 KN capacity load cell to evaluate the tensile properties according to ASMT E8. The gauge length was 12.5 mm, and the test speed was 1.5 mm/min. Stress and strain are calculated from the recorded tensile loads and extensions. In the beginning, the cross-sectional area of each dog bone specimen is measured. Then, the specimen is mounted to both clamps of the machine tightly to avoid distortion while the load is applied. The plastic deformation is visible during the testing. The graph is originated from the Trapezium software connected to the universal testing machine. The final data set is provided by the software to calculate the tensile strengths. The overall experimentation workflow starting from generating CAD files to the final state of the specimens after tensile testing is shown step by step in Fig. 5.

Workflow of the experimentation of the Dog bone specimens by DED
The average value of the yield strength, ultimate tensile strength, and elongation (%) of the DED fabricated SS 316L parts are compared with the similar properties of raw SS 316L (ASTM: A240). The result in Table 5 showed that the printed parts have mechanical properties similar to those of raw material. The mechanical properties of DED fabricated SS316 L is close to the ASTM standard values [22]. The average yield strength improved 50%, and ultimate tensile strength improved 8.06% but elongation (%) is 19% less than the ASTM standard. The fabricated parts behaved less ductile than the raw material but possess more strength compared to the raw ones. The decrease in ductility might have been caused by the internal porosities inside the printed part induced by the inert gas, or by the pores that existed in the original powders.
4 Results and discussion
4.1 Effects of process variables on material strength behaviors
Laser powder determines the amount of energy absorbed by the melt pool and also controls the powder efficiency in DED [24]. Typically, with higher laser power, heat increases causing more powder to melt in the melt pool, hence increases the thickness of the specimen [25]. The effects of laser power on materials’ tensile behavior are shown in Fig. 6 for scanning speed of 11 mm/sec. Yield strength (YS, MPa) has a descending trendline with the increase of the laser power, whereas ultimate tensile strength (UTS, MPa) and elongation (%) have an ascending trendline with the increase of laser power. All three curves dropped down at the maximum laser power of 1000 W. UTS and elongation are maximum at 900 (W) at 11 mm/sec scanning speed. Lower laser power induces higher un-melted particles in the layers and on the surface which is also responsible for shrinkage. So, the graph tends to rise with the rise of power but with higher laser power, there are higher chances of gas porosity which also means there is a higher thermal gradient. It induces higher residual stress which degrades the mechanical properties. This explains the fall of all the graphs at the maximum laser power.

Yield strength (MPa), ultimate tensile strength (MPa), and elongation (%) VS. a Laser power (W), b energy density (J/mm.2), and c layer height (mm), respectively, for 11 mm/sec scanning speed
Energy density is defined as the amount of energy absorbed by the powder and substrate during melting per unit area [26]. Energy density can be calculated by Eq. (14):
where P is the laser power (W or J/s), \({{v}}\) is the scanning speed (mm/sec) of the operating tool, and \({{D}}\) is the diameter (mm) of the laser spot. In our work, P = [600, 1000], \({{v}}\) = [8, 12], and \({{D}}\) = 2 mm (constant). As energy density is a combination of laser power and scanning speed, the graph showed a similar trend as laser power, as shown in Fig. 6b.
Laser scanning speed directly affects the part shape and dimensional accuracy [27]. Changes in the scanning speed cause variations in the bead size because of different deposition amount at a constant powder feed rate [27]. The higher the laser scanning speed, the better the tensile behavior but the trend goes down after a certain point [28]. With the rise of the scanning speed, the granular bainite decreases which improves the grain boundary area. Thus, the dislocation density increases but with higher speed; the grain bainite size decreases due to very poor bonding between the deposition layers causing the fall of the tensile strength [28]. The specimens are sorted into five groups based on different scanning speeds, and the graphs are plotted as the scanning speed of each group against the three other process parameters to exhibit the tensile behaviors of the specimens of a particular scanning speed group.
Both geometrical accuracies and mechanical properties of the printed parts are affected by the layer thickness, also referred as vertical resolution [26]. The average layer thickness for each specimen is calculated and considered one of the affecting parameters. The effects of layer thickness on materials’ tensile behavior are shown in Fig. 6c. Layer thickness (mm) has a similar effect on YS, elongation (%), and UTS like the other two process parameters. It has been proved that scanning speed, laser power, and powder feed rate control bead height, bead width, and penetration [27]. The result suggests that the bead height could not be maintained constant during the printing process. With the increase of scanning speed, bead height decreased and increased with the increase of powder feed rate. Laser power did not affect the height much compared to scanning speed and powder feed rate.
4.2 Prediction results
YS, UTS, and Elongation (%) were collected from the tensile testing and they were considered three separate outputs array (Y0) . Four process parameters, including laser power, scanning speed, layer height, and energy density, are considered the input array (X0). The modeling process starts from calling the built-in functions from a machine learning library, loading the data, and defining the input array (X0) and the output array (Y0). The group 4 with scanning speed 11 mm/sec was selected as the testing data and rest of the groups as training data. Then, the hyperparameter metrics were created as the param_grid. The last step is to call the prediction function and define the performance evaluation metrics.
In the modeling, Scikit-learn was used as the library and the PyCharm 2020.2 version was used as a writing module. Both XGBoost and Random Forest have built-in functions in Scikit-learn library. Hyperparameter tuning was completed using RandomizedSearch cross-validation for both of the models and XGRegressor() and RandomForestRegressor() as the main fitting function were called from the sk.learn_model selection. The predictions are fitted against the laser power of the data as all the 5 groups have same set of laser power for each sample in Table 3. The model fitted to the data by XGBoost and Random Forest is shown in Fig. 7a-f, respectively. Both the models were run five times for each of tensile properties and the means of the results obtained at every laser power for all the 5 runs were plotted finally against that laser power. Smaller residuals are observed in a few points which is a good indicator of the performance accuracy of the model. To get a clearer idea of the accuracy, performance evaluation is performed on the predicted and test data.

The predicted and test data for a yield strength (MPa) by XGBoost, b yield strength (MPa) by RF, c ultimate tensile strength (MPa) by XGBoost, d ultimate tensile strength (MPa) by RF, e elongation (%) by XGBoost, and f elongation (%) by RF against laser power (600 \(\sim\) 1000 W) of the test data
4.3 Performance evaluation
As mentioned before, performance evaluation is an indicator of the model’s accuracy and precision of predicting the output. For regression modeling, root mean square error, coefficient of determination, and relative error are suitable statistical metrics for this purpose. RMSE has been a standard statistical metric to measure the model performance. The RMSE can be calculated with Eq. (15). It is assumed that there is a n number of samples and unbiased errors in the prediction and test data. A smaller RMSE value indicates better performance of the model.
Relative error (RE), shown in Eq. (16), is the ratio of absolute error and the real measurement taken. This is used to explain how accurate the prediction was compared to the real value.
where \({\widehat{{{y}}}}_{{{l}}}\) = predicted values, yi = observed values, and \({\overrightarrow{{{y}}}}_{{{i}}}\) = mean of the observed values.
The coefficient of determination (R2), shown in Eq. (17), explains how much of the data has fitted the regression model. Usually, closer the value to 1 indicates that the model has fitted the data well but not always a higher value is a good indication of the better-fitted model.
where \({\widehat{{{y}}}}_{{{l}}}\) = predicted values, yi = observed values, and \({\overrightarrow{{{y}}}}_{{{i}}}\)= mean of the observed value.
4.3.1 XGBoost and RF performance evaluation
The performance evaluation metrics of our XGBoost and RF models are computed using the sk.learn_metrics. For RMSE, we called mean_sqaure_error function from the library and took the square of it, and the coefficient of determination r2_score is called directly from the respective library. The relative error calculation is manually imported to the metrics.
The RMSEs obtained for the three outputs are summarized in Table 6, indicating the aggregated means of the deviation of the predicted values from the test data. For XGBoost, the deviation in RMSE is highest for UTS (12.22) and lowest for elongation (%) (3.22). The coefficient of determination (R2) indicates how well the model fits the training data. The results show that the XGBoost model fitted 76% of the YS data, 72% of the UTS data, and 85% of the elongation (%) data. Similarly, the deviation in RMSE is highest for UTS (20.01) and lowest for the elongation (%) (4.28) for RF. And this model fitted 69% of the YS data, 61% of the UTS data, and 78% of the elongation (%) data. The results of relative errors suggest that the relative uncertainty of the prediction to the actual values for YS, UTS, and elongation is 2.81%, 3.23%, and 0.89%, respectively, for XGBoost. And for RF, the values for YS, UTS, and elongation are 3.65%, 3.9%, and 2.09%, respectively, indicating that the XGBoost model outperformed the Random Forest in prediction.
To quantify the uncertainties associated with the prediction, a 95% confidence interval or vertical \(\pm\) 2σ bars (σ = Standard deviation) has been used and 95% of the predicted data from all the runs fell into \(\pm\) 2σ limit. Therefore, confidence in prediction has been represented using vertical \(\pm\) 2σ bars. In Fig. 7a and b, yield strength of group 4 data has been predicted by XGBoost and RF model, respectively. Both the graphs followed the trend and the fluctuations of the data. Both the models predicted the yield strength of the maximum laser power higher than the test data. This might have been caused by the higher yield strength values for this particular laser power in the training set. Moreover, the gap between the RMSE values from both models is comparatively smaller. In the case of UTS prediction in both Fig. 7c and d, both the graphs have similar trend and fluctuations (XGBoost and RF, respectively). The RMSEs obtained by the two models (XGBoost 12.22 & RF 20.01) are higher than the other two tensile properties because the fluctuations in the training data of UTS are comparatively higher. From the graphs in Fig. 7c and d and the RMSE values, it is evident that XGBoost handled the fluctuations of the UTS data better than RF. The UTS values from test data for 900 W and 1000 W fell inside the confidence interval of the predicted data for XGBoost and the gap of the RMSE values is comparatively higher. In the case of elongation (%), due to less fluctuation in the training data, both the models performed better to predict the elongation (%) with higher accuracy. In Fig. 7e, the test data for 600 W and 1000 W fell into the confidence interval of the predicted data by XGBoost. In Fig. 7e and f, both the models XGBoost and RF followed the trend and fluctuations of the test data very well.
4.3.2 Statistical analysis: ridge regression
Ridge Regression (RR) is a suitable choice for data set with multicollinearity. If there is a possibility of multicollinearity, the variance of the least square estimates gets too large to be closer to the true value though the estimates are unbiased [29]. In Ridge Regression, standardization of both dependable and independent variables is a must. Standardization is the statistical process of rescaling the mean and the standard deviation to 0 and 1, respectively. Ridge Regression is calculated on the standardized variable. But the final regression co-efficient is estimated, they are adjusted back to the original scale. The data was first standardized by using MinMaxScaler() function called from sklearn.preprocessing. The train and test data kept same for the comparison purpose. For the three tensile strength behavior, the predicted and test values of the three tensile properties are shown in Fig. 8.

The predicted and test data for a yield strength (MPa), b elongation (%), c ultimate tensile strength (MPa) by Ridge Regression
The performance evaluation metrics for Ridge Regression are summarized in Table 7. The RMSE values obtained for the three outputs meant a deviation of the predicted values from the test data. Similar to XGBoost, the deviation for RR is highest for UTS (33.5) and lowest for elongation (%) (4.51). The RR model did not fit the data well. The coefficients of the determination value are − 59% of the YS data, − 51% of the UTS data, and − 68% of the elongation (%) data. It clearly indicated that the regression line is forced to move through the data points. The relative uncertainty of the prediction to the actual values for YS, UTS, and elongation is 2.07%, 4.01%, and 1.85%, respectively. The overall performance accuracy of the model is good but it didn’t surpass either of the machine learning models. Unlike the two ML models, it failed to follow the trend of the test data.
The results suggest that XGBoost is a better choice for mechanical behavior prediction. One of the possible reasons is that XGBoost first prunes the tree with a score called the “similarity score” before starting the prediction [30]. It considers the gain function value of a node as the difference between the similarity score of the node and the similarity score of the children node. If the gain from a node is found to be minimal, then it just stops constructing the tree to a greater depth which controls overfitting to a great extent. On the other hand, Random Forest tends to overfit the data if the majority of the trees in the forest are provided with similar samples. XGBoost can handle imbalanced data better than Random Forest. XGBoost tends to put the highest significance to the functional space while reducing the loss function when Random Forest puts maximum importance on the hyperparameter optimization. The basic mechanism which makes XGBoost faster is that the weights are calculated as the ratio of the square of the sum of the residuals to the sum of the number of residuals and the regularization factor, whereas for Ridge Regression, it is the sum of the squared residuals in the denominator. Therefore, in the case of XGBoost, the sum of the residuals first neutralizes the negative values which reduces the overall values of residual. On the other hand, the squared values of the residuals in Ridge Regression are always non-negative which increases the values of residuals for Ridge Regression compared to XGBoost.
4.4 Limitations
For XGBoost and Random Forest which are capable to fit the small size of tabular data, the data size in this study is smaller for the model to train. It can be expected that with the larger data size, the prediction accuracy can be increased. The experimentation includes three extensive experimental works, e.g., fabrication, preparation of the final specimens by EDM, and finally the tensile testing. Fabrication by the L-DED machine is time-consuming and expensive. Due to time and facility constraints due to COVID 19, EDM facilities were not available to the users. For future work, more experiments are recommended to perform to improve the performance accuracy of the model.
DED process is prone to rough surface finish and internal porosity [1, 31]. The stress–strain curves obtained are similar but not identical between any two specimens. Such variation of tensile properties possibly resulted due to the variation in the layer thickness [26], which was caused by the surface and internal defects of the fabricated specimens. According to Zheng et al. [32], the internal defects were observed in 316 stainless steel specimens fabricated by the L-DED process and these defects can be divided mainly into two kinds: gas porosity and lack-of-fusion porosity. The final specimens are cut from the original one with the substrate by EDM. The final thickness was preset to 2 mm for all the specimens, but the cutting process faced difficulties due to defects of the specimens. Therefore, the thickness could not be maintained constant to 2 mm for all the groups, and after manual surface finishing, the final layer height ranged from 0.79 to 1.83 mm with an average of 1.51 mm. This might have been caused by coarser microstructure formed on the final layer due to decrease in cooling rate caused by thermal accumulation with the increasing deposition height [33]. It was observed that the first two groups with higher energy density due to their lower scanning speeds 8 mm/sec and 9 mm/sec had more constant layer thickness and was closer to 2 mm, while the deviation from 2 mm and the more variation in the layer height was observed in the rest of the groups as well. It can be concluded that with higher energy density which means lower scanning speed, there are fewer defects like entrapped gas porosity and un-melted particles found in the specimen. In the minimum scanning speed, the particles get more time to get melted. Therefore, the surface gets smoother which means less postprocessing and less changes in the overall quality of the parts [34]. It was observed just after the printing that with higher laser power, the powder efficiency increased. Although the higher powder efficiency is responsible for the higher thickness of the original specimen, it is evident that it could not control the un-melted particles in the melt pool. Moreover, higher laser power causes decrease in the height stability of the multi-layered specimen [35], which might have caused the decline of the tensile strength at the maximum laser power in this study.
5 Conclusion
DED has been a popular choice for aerospace, defense, biomedical, and automotive industries for a decade. However, the process control is still manually operated. Applying AI optimization to the process parameters can reduce material waste and complexities of repetitive experimental work and to develop autonomous feed control for the DED process to print parts on industrial scale. The goal of this study is to employ machine learning to predict the tensile behavior of SS 316L printed using laser-based DED process. The motivation behind our current work is to examine the tensile properties of the printed specimens by the L-DED process, and at the same time, to be able to predict the tensile behavior of the fabricated parts without performing a series of laborious experiments. The results from the tensile testing provided outstanding insights, which exhibited better mechanical properties of the printed parts compared to raw SS 316L. A total of 25 experiments have been performed with three sets of data, and XGBoost and Random Forest have been selected because of their capability to predict with smaller tabular data. From this study, it can be concluded that (1) the yield strength and ultimate tensile strength of the printed SS 316 L were better than the raw materials and (2) XGBoost outperformed both Random Forest and Ridge Regression in terms of evaluation metrics.
There are a few challenges and difficulties in data-driven modeling for AM process prediction. The prospects and forthcoming investigation of this study will focus on the following issues.
-
The effects of thermal behavior and solidification on print quality are not considered in our study. Due to the varied laser power and additive layer nature of the process, the specimen experienced complex thermal cycles in the different locations of the built. Thermal behaviors can add a great deal to the prediction quality of the model.
-
A traversed molten pool formed by the finely focused laser beam causes a higher cooling rate and solidification. These complex thermal behaviors are responsible for microstructure complexity due to which the consistency of the tensile properties might have suffered. Therefore, the microstructure can be used as one of the outcomes along with the tensile properties to establish the correlation among them.
-
The inconsistency of the tensile properties of different groups also affected the learning curve of the model during training. Therefore, multicollinearity should be avoided during data collection.
-
To improve the model’s accuracy, different parameters should be considered along with the current ones in terms of F score to find out the optimum combination of parameters affecting the results. Based on feature importance, more experiments should be performed while modeling to examine whether the model performs better with and without the most important factors.
Availability of data and materials
Not available for publication.
Code availability
Not available for publication.
References
Gibson I, Rosen D, Stucker B (2015). Additive manufacturing technologies. https://doi.org/10.1007/978-1-4939-2113-3
Garg A, Bhattacharya A (2017) An insight to the failure of FDM parts under tensile loading: finite element analysis and experimental study. Int J Mech Sci 120:225–236. https://doi.org/10.1016/j.ijmecsci.2016.11.032
Hayes BJ, Martin BW, Welk B et al (2017) Predicting tensile properties of ti-6al-4v produced via directed energy deposition. Acta Mater 133:120–133. https://doi.org/10.1016/j.actamat.2017.05.025
Meng L, McWilliams B, Jarosinski W et al (2020) Machine learning in additive manufacturing: a review. JOM 72:2363–2377. https://doi.org/10.1007/s11837-020-04155-y
Zhang Z, Liu Z, Wu D (2021) Prediction of melt pool temperature in directed energy deposition using machine learning. Addit Manuf 37:101692. https://doi.org/10.1016/j.addma.2020.101692
Li Z, Zhang Z, Shi J, Wu D (2019) Prediction of surface roughness in extrusion-based additive manufacturing with machine learning. Robot Comput-Integr Manuf 57:488–495. https://doi.org/10.1016/j.rcim.2019.01.004
Scime L, Beuth J (2019) Using machine learning to identify in-situ melt pool signatures indicative of flaw formation in a laser powder bed fusion additive manufacturing process. Addit Manuf 25:151–165. https://doi.org/10.1016/j.addma.2018.11.010
Wolff SJ, Gan Z, Lin S et al (2019) Experimentally validated predictions of thermal history and microhardness in laser-deposited Inconel 718 on Carbon Steel. Addit Manuf 27:540–551. https://doi.org/10.1016/j.addma.2019.03.019
Zhang Z, Poudel L, Sha Z et al (2019) Data-driven predictive modeling of tensile behavior of parts fabricated by Cooperative 3D printing. J Comput Inf Sci Eng. https://doi.org/10.1115/1.4045290
Caiazzo F, Caggiano A (2018) Laser direct metal deposition of 2024 al alloy: trace geometry prediction via machine learning. Materials 11:444. https://doi.org/10.3390/ma11030444
Khanzadeh M, Chowdhury S, Marufuzzaman M et al (2018) Porosity prediction: supervised-learning of thermal history for direct laser deposition. J Manuf Syst 47:69–82. https://doi.org/10.1016/j.jmsy.2018.04.001
de La Batut B, Fergani O, Brotan V et al (2017) Analytical and numerical temperature prediction in direct metal deposition of ti6al4v. J Manuf Mater Process 1:3. https://doi.org/10.3390/jmmp1010003
Hansel A, Mori M, Fujishima M et al (2016) Study on consistently optimum deposition conditions of typical metal material using additive/subtractive hybrid machine tool. Procedia CIRP 46:579–582. https://doi.org/10.1016/j.procir.2016.04.113
Nag S, Zhang Y, Karnati S et al (2021) Probabilistic machine learning assisted feature-based qualification of DED TI64. JOM 73:3064–3081. https://doi.org/10.1007/s11837-021-04770-3
Garg A, Tai K (2014) An ensemble approach of machine learning in evaluation of mechanical property of the rapid prototyping fabricated prototype. Appl Mech Mater 575:493–496. https://doi.org/10.4028/www.scientific.net/amm.575.493
Wu D, Wei Y, Terpenny J (2018) Predictive modelling of surface roughness in fused deposition modelling using data fusion. Int J Prod Res 57:3992–4006. https://doi.org/10.1080/00207543.2018.1505058
Chen T, Guestrin C (2016) XGBoost. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/2939672.2939785
Feng J, Yu Y, Zhou Z-H (2018) Multi-layered gradient boosting decision trees. In: arXiv.org. https://arxiv.org/abs/1806.00007v1. Accessed 18 Feb 2022
Natekin A, Knoll A (2013) Gradient boosting machines, a tutorial. Front Neurorobot. https://doi.org/10.3389/fnbot.2013.00021
Breiman L (2001) Mach Learn 45:5–32. https://doi.org/10.1023/a:1010933404324
Montemor MF, Simões A, Ferreira MGS, Belo MDC (1999) The role of Mo in the chemical composition and semiconductive behaviour of oxide films formed on Stainless Steels. Corros Sci 41:17–34. https://doi.org/10.1016/s0010-938x(98)00126-7
Standard, A. S. T. M. (2012). ISO/ASTM 52900: 2015 Additive Manufacturing - General Principles - Terminology. https://doi.org/10.1520/f3177-15
Era IZ, Liu Z (2021) Effect of process parameters on tensile properties of SS 316 prepared by directional energy deposition. Procedia CIRP 103:115–121. https://doi.org/10.1016/j.procir.2021.10.018
Padmanaban G, Balasubramanian V (2010) Optimization of laser beam welding process parameters to attain maximum tensile strength in AZ31B magnesium alloy. Opt Laser Technol 42:1253–1260. https://doi.org/10.1016/j.optlastec.2010.03.019
Khalil Y, Kowalski A, Hopkinson N (2016) Influence of laser power on tensile properties and material characteristics of laser-sintered UHMWPE. Manuf Rev 3:15. https://doi.org/10.1051/mfreview/2016015
Shim D-S, Baek G-Y, Seo J-S et al (2016) Effect of layer thickness setting on deposition characteristics in direct energy deposition (DED) process. Opt Laser Technol 86:69–78. https://doi.org/10.1016/j.optlastec.2016.07.001
Woo Y-Y, Han S-W, Oh I-Y et al (2019) Control of directed energy deposition process to obtain equal-height rectangular corner. Int J Precis Eng Manuf 20:2129–2139. https://doi.org/10.1007/s12541-019-00226-6
Suiyuan Chen RW (2017) Effect of scanning speed on microstructure and properties of 12crni2re alloy steel prepared by laser additive manufacturing. In: Web of Proceedings - Francis Academic Press
McDonald GC (2009) Ridge regression. In: Wiley Interdisciplinary Reviews. https://wires.onlinelibrary.wiley.comhttps://doi.org/10.1002/wics.14. Accessed 18 Feb 2022
Shikhar (2019) The recent queen of ML Algorithms: XGBoost, and it’s future. In: Medium. https://medium.com/analytics-vidhya/the-recent-queen-of-ai-algos-xgboost-and-its-future-22d6df3cd206. Accessed 18 Feb 2022
Shamsaei N, Yadollahi A, Bian L, Thompson SM (2015) An overview of direct laser deposition for additive manufacturing; part II: Mechanical behavior, process parameter optimization and Control. Addit Manuf 8:12–35. https://doi.org/10.1016/j.addma.2015.07.002
Zheng B, Haley JC, Yang N et al (2019) On the evolution of microstructure and defect control in 316l SS components fabricated via directed energy deposition. Mater Sci Eng, A 764:138243. https://doi.org/10.1016/j.msea.2019.138243
Ghanavati R, Naffakh-Moosavy H, Moradi M (2021) Additive manufacturing of thin-walled SS316L-IN718 functionally graded materials by direct laser metal deposition. J Market Res 15:2673–2685. https://doi.org/10.1016/j.jmrt.2021.09.061
Moradi M, Hasani A, Pourmand Z, Lawrence J (2021) Direct laser metal deposition additive manufacturing of Inconel 718 superalloy: statistical modelling and optimization by design of experiments. Opt Laser Technol 144:107380. https://doi.org/10.1016/j.optlastec.2021.107380
Moradi M, Ashoori A, Hasani A (2020) Additive manufacturing of stellite 6 superalloy by direct laser metal deposition – part 1: effects of laser power and focal plane position. Opt Laser Technol 131:106328. https://doi.org/10.1016/j.optlastec.2020.106328
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethics approval
The authors declare the article was constructed respecting all ethical conditions of publication.
Consent to participate
All authors participated in the preparation of the article. Therefore, the authors allow their names in the article.
Consent for publication
The authors allow for publication.
Competing interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Era, I.Z., Grandhi, M. & Liu, Z. Prediction of mechanical behaviors of L-DED fabricated SS 316L parts via machine learning. Int J Adv Manuf Technol 121, 2445–2459 (2022). https://doi.org/10.1007/s00170-022-09509-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-022-09509-1