
Abstract
We introduce a family of ‘spatial’ random cycle Huang–Yang–Luttinger (HYL)-type models in which the counter-term only affects cycles longer than some cut-off that diverges in the thermodynamic limit. Here, spatial refers to the Poisson reference process of random cycle weights. We derive large deviation principles and explicit pressure expressions for these models, and use the zeroes of the rate functions to study Bose–Einstein condensation. The main focus is a large deviation analysis for the diverging counter term where we identify three different regimes depending on the scale of divergence with respect to the main large deviation scale. Our analysis derives explicit bounds in critical regimes using the Poisson nature of the random cycle distributions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Since London’s proposal [19] that the super-fluid phase-transition in \(\mathrm{He}^4 \) is an example of Bose–Einstein condensation (BEC), it has been of interest to know how, in theory, interaction potentials affect the condensation of bosons. London himself conjectured that the momentum-space condensation of bosons is enhanced by spatial repulsion between particles. To address this question, Huang, Yang and Luttinger [17] introduced a model (HYL) of a bosons with a hard-sphere repulsion which displays enhanced condensation. The Hamiltonian for that model is given in terms of the energy occupation counts (number of particles occupying an eigenstate), and this version has been studied by the Dublin group in the early 1990s [23, 24]. In particular, they show that the density of zero-momentum condensation (ground state energy) in momentum space is a function of the interaction parameters, that is, the mean field parameter and the parameter of the negative counter term in the Hamiltonian.
In this paper, we study a corresponding model of spatial cycles with HYL-type interaction, and we analyse the condensation of parts of the system into ‘infinitely long cycles’. The model is given by so-called bosonic cycle counts \(\varvec{\lambda }_\Lambda =(\varvec{\lambda }_k)_{k\in {\mathbb {N}}} \) where \( |\Lambda |\varvec{\lambda }_k \) denotes the number of cycles of length k in finite volume \( \Lambda \Subset {\mathbb {R}}^d \). Each cycle of length k is a closed continuous path with time horizon \( [0,k\beta ] \) and describes k bosons. The bosonic cycle counts are random numbers, and their probability weights are obtained from a spatial marked Poisson point process, see [1, 5]. For the spatial cycle version of the HYL model, one needs only the cycle counts, and the detailed geometric structures of the cycles do not enter the equation. The Hamiltonian of the spatial cycle HYL model in \( \Lambda \Subset {\mathbb {R}}^d \) with interaction parameter \( a>b\ge 0 \) and chemical potential \( \mu \in {\mathbb {R}}\) is defined as
where \( (m_\Lambda )_{\Lambda \Subset {\mathbb {R}}^d} \) is a sequence with \( m_\Lambda \rightarrow \infty \) and \( \frac{m_\Lambda }{|\Lambda |}\rightarrow \kappa \in [0,\infty ] \) as \( \Lambda \uparrow {\mathbb {R}}^d \) and where \(\varvec{\lambda }_\Lambda \) is a sequence of positive numbers ensuring the expression on the right-hand side is finite, e.g. terminating sequences or sequences with finite particle density \( \sum _{k=1}^\infty k\varvec{\lambda }_k \). Here, \( \alpha <0 \) is the chemical potential of the reference process which gives the bosonic cycle count weights for the ideal Bose gas (no interaction), see Sect. 1.1. The Hamiltonian enhances the probability that the particle density, \( \sum _{k\in {\mathbb {N}}} k\varvec{\lambda }_k \), is concentrated on fewer cycle types. The sequence \( m_\Lambda \) pushes the counter terms to infinitely long cycles and the parameter \( \kappa \) governs how these infinitely long cycles are approached. The most interesting case is when the \( m_\Lambda \) is of order of the thermodynamic scale, the volume \( \Lambda \). Our results below are different for the three possible regimes where either \( \kappa =0, \kappa \in (0,\infty ) \), or \( \kappa =\infty \). The case \( \kappa =0 \) is special, see results in Sect. 2 below. If one takes all possible counter terms in the Hamiltonian (1.1), that is, if \( m_\Lambda =1 \) for all \( \Lambda \Subset {\mathbb {R}}^d \), then for \(a\equiv b \) the ground state of the Hamiltonian is degenerate as all particles would accumulate in cycles of a given but arbitrary length. The analysis of this degeneracy is currently investigated in [2] where all counter terms are considered. Choosing \( \kappa =0 \) excludes this degeneracy and allows cycles to emerge whose length grows slower than the thermodynamic scale, see Sect. 2 for the regime when there are two minimisers manifesting a first-order transition into condensation of ’infinitely long cycles’.
Our main results is a representation of the thermodynamic limit of the pressure via a large deviation principle for the pair empirical particle density \( {\varvec{M}}_\Lambda =(\sum _{k=1}^{m_\Lambda -1} k\varvec{\lambda }_k,\sum _{k\ge m_\Lambda } k\varvec{\lambda }_k) \), see Theorem 2.2. Both the rate function and the pressure depend on the parameter \( \kappa \in [0,\infty ] \) characterising the scale on which the counter term cycle lengths grow to infinity. The pressure is given as a variational problem (2.3) over \( {\mathbb {R}}^2 \), equal to the representation given in [23, 24], where now the second entry refers to the density of particles in ‘infinitely long cycles’. We obtain all the zeroes for the rate functions for all parameter regimes and identify critical parameter with two distinct zeroes, see Theorem 2.5. We emphasise here that in statistical mechanics of interacting particles BEC and particles in infinite cycles are independent notions, and their conjectured equivalence is subject to a proof which until today exists only for the ideal Bose gas and various mean-field models. We hope in future work to address this equivalency.
This analysis provides the pressure representation along with the phase transition (BEC) as well as the density of ‘infinitely long cycles’ in the phase transition regime as a function of the chemical potential and the interaction parameter \( a>b\). The relevant parameters are the chemical potential \( \mu \) in the Hamiltonian (1.1) and the net chemical potential is \( \mu +\alpha \), and we have some control on the temperature (\(\beta \)) dependence in Theorem 2.7 leading to phase diagrams in the \( (\mu -\beta ) \)—plane, see Fig. 1. Finally, we compare the density of ‘infinitely long cycle’ given by the zeroes of the rate functions in Corollary 2.10 with density order parameter defined as the double limit, thermodynamic limit for the density in cycles of length above a lower followed by taking the lower bound to infinity, see Theorem 2.11. We find that the densities are equal as long as \( \kappa \in [0,\infty ) \), whereas for \( \kappa =\infty \), the counter terms diverge too quickly to infinity to lead to any non-vanishing density of ‘infinitely long cycles’, see Remark 2.12.
In previous study of the momentum-space model, the relevant occupation number is the lowest index opposite to our spatial cycle model; For example, in [23], the authors need a technical constraint for the counter term up to an index growing to infinity slower than the volume. This technical gap has been closed in [24] where all the counter term indices are incorporated. However, in those cases for the momentum-space model, the higher indices are not relevant for the zero-momentum condensation, whereas for our model, the precise asymptotic of counter terms towards ’infinitely long cycles’ plays a crucial role. A similar model has been studied successfully in [12]. The interpretation of ‘infinitely long cycles’ as the Bose–Einstein condensate goes back to Feynman [13] and has been proved for mean-field models in [21]. The work of Feynman [13] also leads to various work on random permutations, e.g. see [14, 22]. More recently, the work [6] shows that the ‘infinitely long cycles’ are distributed as a random interlacement process, and we hope to apply our results and techniques in this manuscript to show that the counter terms lead to an interlacement distribution.
We define the probability weights for the bosonic cycle counts in Sect. 1.1, and show in Sect. 1.2 and Appendix A how these weights are obtained from a marked Poisson point process description of the ideal Bose gas with free and Dirichlet boundary conditions. Both sections can be skipped by the reader at first reading. In Sect. 2, we present all our results along with Fig.1 of the phase diagram, and in Sect. 3, we present all our proofs.
1.1 Probability Weights
The ideal Bose gas at thermodynamic equilibrium with inverse temperature \( \beta >0 \) and chemical potential \( \alpha < 0 \) defines the probability weights for the bosonic cycle counts when there is no interaction. The cycle counts themselves are actually random functions of marked point configurations \( \omega \in \Omega \) as we describe in more detail in Sect. 1.2, that is, \( \varvec{\lambda }_\Lambda =\varvec{\lambda }_\Lambda (\omega ) \). For \( x=(x_k)_{k\in {\mathbb {N}}} \in \ell _1({\mathbb {R}}_+) \) with \( |\Lambda |x_k \in {\mathbb {N}}_0\), we denote by \( {{\textsf {Q} }}\) the probability distribution of the reference process, that is, the probability that the bosonic cycle counts are equal to x is given by
where
As shown in [1], the thermodynamic pressure of the ideal Bose gas is given as
The spatial cycle HYL model is given by the Gibbs distribution \( {{\textsf {P} }}_\Lambda \) in \( \Lambda \) defined via its Radon–Nikodym density with respect to the reference process \( {{\textsf {Q} }}_\Lambda \) in \( \Lambda \),
A vital ingredient in our result is the free energy of the ideal Bose gas given as the Legendre–Fenchel transform of the pressure,
and, as the pressure \( p_0(\beta ,\alpha ) \) is differentiable for \( \alpha <0 \) and diverges for \( \alpha >0 \), we obtain the version of the free energy derived in [3].
1.2 Reference Process
We define the underlying marked Poisson point reference process in the following as background information, since our results depend solely on the measure \( {{\textsf {P} }}_\Lambda \) defined above.
The reference process is a marked Poisson point process, see [1, 5]. The space of marks is defined as
where for \(k\in {\mathbb {N}}\), we denote by \({{\mathcal {C}} }_{k,\Lambda }\) the set of continuous functions \(f:[0,k\beta ] \rightarrow {\mathbb {R}}^d\) satisfying \(f(0)=f(k\beta )\in \Lambda \), equipped with the topology of uniform convergence. We call the marks cycles. By \(\ell :E\rightarrow {\mathbb {N}}\), we denote the canonical map defined by \(\ell (f)=k\) if \(f\in {{\mathcal {C}} }_{k, \Lambda }\). We call \(\ell (f)\) the length of \(f\in E\). We consider spatial configurations that consist of a locally finite set \(\xi \subset {\mathbb {R}}^d\) of particles, and to each particle \(x\in \xi \), we attach a mark \(f_x\in E\) satisfying \(f_x(0)=x\). Hence, a configuration is described by the counting measure \( \omega =\sum _{x\in \xi }\delta _{(x,f_x)} \) on \({\mathbb {R}}^d\times E\).
Consider on \({{\mathcal {C}} }_{k,\Lambda }\) the canonical Brownian bridge measure
Here, \(B=(B_t)_{t\in [0,k\beta ]}\) is a Brownian motion in \({\mathbb {R}}^d\) with generator \(\Delta \), starting from x under \({\mathbb {P}}_x\). Then, \( \mu ^{{\scriptscriptstyle {({ k\beta }})}}_{x,y}\) is a regular Borel measure on \({{\mathcal {C}} }_{k,\Lambda }\) with total mass equal to the Gaussian density,
Let \( \omega _{\mathrm{P}} = \sum _{x \in \xi _{ \mathrm P}} \delta _{(x,B_x)} \) be a Poisson point process on \({\mathbb {R}}^d\times E\) with intensity measure equal to \( \nu \), whose projection onto \( {\mathbb {R}}^d\times {{\mathcal {C}} }_{k,\Lambda } \) is equal to
Alternatively, we can conceive \(\omega _{\mathrm{P}}\) as a marked Poisson point process on \({\mathbb {R}}^d\), based on some Poisson point process \(\xi _{\mathrm{P}}\) on \({\mathbb {R}}^d\), and a family \((B_x)_{x\in \xi _{\mathrm{P}}}\) of i.i.d. marks, given \(\xi _{\mathrm{P}}\). The intensity of \(\xi _{\mathrm{P}}\) is \( {\overline{q}}^{{\scriptscriptstyle {({\alpha }})}} \) (1.3). \( {{\textsf {Q} }}\) denotes the distribution of \(\omega _{\mathrm{P}}\) and \({{\textsf {E} }}\) denotes the corresponding expectation. Note that our reference process is a countable superposition of Poisson point processes and, as long as \( {\overline{q}}^{{\scriptscriptstyle {({\alpha }})}} <\infty \) is finite, this reference process is a Poisson point process as well. The bosonic cycle counts are averages of the random number of points in \( \Lambda \) with mark length equal to k, i.e.
and \( \varvec{\lambda }_k(\omega )={{\mathcal {N}} }_k(\omega )/|\Lambda | \).
1.3 Notations
Throughout the whole text when we write \( \Lambda \uparrow {\mathbb {R}}^d \), we mean the limit for a sequence of centred finite-volume boxes with unbounded volume. Furthermore, we write \( f(\lambda )\sim g(\lambda ) \) whenever \( \lim _{\lambda \rightarrow \infty } \frac{f(\lambda )}{g(\lambda )}=1 \).
2 Results
Our main results concern a complete large deviation analysis and pressure representation of the spatial cycle HYL model. Recall that the partition function \( Z_\Lambda (\beta , \alpha ) \) for any Hamiltonian, \( {{{\textsf {H} }}}_\Lambda \), of marked point configurations can be written as an expectation with respect to the reference process. This follows using the Feynman–Kac formula for traces with symmetrised initial and terminal conditions (see [4, 8]).
Proposition 2.1
[1, 5]. Let \(\beta \in (0,\infty )\), \( \alpha <0 \) and \( \Lambda \Subset {\mathbb {R}}^d \). Assume that \({{{\textsf {H} }}}_\Lambda :\Omega \rightarrow {\mathbb {R}}\) is measurable and bounded from below. Then,
where the expectation is with respect to the reference Poisson process.
The Hamiltonian of the spatial cycle HYL model is given in (1.1) as a function of the bosonic cycle counts \( \varvec{\lambda }(\omega ) \in \ell _1({\mathbb {R}}_+) \).
The thermodynamic pressure for the spatial cycle HYL model is
and the ideal Bose gas pressure, \(p_0\left( \beta ,\alpha \right) \), is given by (1.4), see [1]. The limit on the right-hand side of (2.1) is obtained via a large deviation analysis for the pair empirical particle density \( {\varvec{M}}_\Lambda :\Omega \rightarrow {\mathbb {R}}^2 \),
distributed under the measure \( \mu _\Lambda ^{{\scriptscriptstyle {({2}})}}:={{\textsf {P} }}_\Lambda \circ {\varvec{M}}_\Lambda ^{-1} \) with \( {{\textsf {P} }}_\Lambda \) being the distribution of the Gibbsian point process of the spatial cycle HYL model in \( \Lambda \), i.e. \(\frac{\mathrm{d}{{\textsf {P} }}_\Lambda }{\mathrm{d}{{\textsf {Q} }}_\Lambda }=\mathrm{e}^{-\beta {{{\textsf {H} }}}_\Lambda }/{{\textsf {E} }}\left[ \mathrm{e}^{-\beta {{{\textsf {H} }}}_\Lambda }\right] \).
Theorem 2.2
(Large deviation principles and pressure representation). Let \( \beta >0\), \(\alpha <0\), \(\mu \in {\mathbb {R}}\), and \( a>b>0 \). Let \( (m_\Lambda )_{\Lambda \Subset {\mathbb {R}}^d} \) be a sequence with \( m_\Lambda \rightarrow \infty \) and \( \frac{m_\Lambda }{|\Lambda |}\rightarrow \kappa \in [0,\infty ] \) as \( \Lambda \uparrow {\mathbb {R}}^d \), and define \( {\mathbb {K}}(\kappa ):={\mathbb {R}}_+\times \left( \{0\}\cup [\kappa ,\infty )\right) \subset {\mathbb {R}}^2_+\).
Then, the sequence of measures \( (\mu _\Lambda ^{{\scriptscriptstyle {({2}})}})_{\Lambda \Subset {\mathbb {R}}^d} \) satisfies the large deviation principle on \( {\mathbb {R}}^2_+ \) with rate \( \beta |\Lambda | \) and good rate function
where
Remark 2.3
-
(a)
Since \( {\mathbb {R}}_+^2={\mathbb {K}}(0)\supset {\mathbb {K}}(\kappa ) \), we know \( p^{{\scriptscriptstyle {({\kappa }})}}(\beta ,\alpha ,\mu ) \le p^{{\scriptscriptstyle {({0}})}} (\beta ,\alpha ,\mu ) \). This is due to the sequence of counter terms forcing the density in the second component of the pair empirical density to be either zero or greater or equal to \( \kappa \).
-
(b)
The case \(\kappa =\infty \) (i.e. \( m_\Lambda \gg |\Lambda | \)) is different because this condition essentially removes the counter terms in the spatial cycle HYL model. For finite volumes \( |\Lambda | \), the two smallest permitted values of the random variable \( M_\Lambda ^{{\scriptscriptstyle {({2}})}} \) are 0 and \( \frac{m_\Lambda }{|\Lambda |} \). This case then forces all nonzero permitted values of the cycle counts to diverge to infinity, and thus they are naturally unlikely, and the ‘greater than \( m_\Lambda \)’ states are not allowed to support any particle mass. Therefore, the spatial cycle HYL model in this case is essentially equal to the particle mean field model studied for example in [1, 7].
-
(c)
The empirical cycle counts \( (\varvec{\lambda }_\Lambda )_{\Lambda \Subset {\mathbb {R}}^d} \) under the reference process satisfy, for any \( d\ge 1 \) and \( \alpha <0 \), a large deviation principle with rate \( \beta |\Lambda | \) and rate function
$$\begin{aligned} I_0\left( x\right) = {\left\{ \begin{array}{ll} \sum ^\infty _{k=1}x_k\Big (\log \frac{x_k}{q^{{\scriptscriptstyle {({\alpha }})}}_k} - 1\Big ) + p_0(\beta ,\alpha ), &{} \text {for }x\in \ell _1\left( {\mathbb {R}}_+\right) ,\\ +\infty , &{} \text {otherwise}. \end{array}\right. } \end{aligned}$$see [1]. This large deviation analysis require to deal with the lack of continuity of the particle density \( D(x)=\sum _{k\in {\mathbb {N}}} k x_k \) for \( x\in \ell _1({\mathbb {R}}) \), see similar problems in [5]. The splitting into the pair empirical density allows to obtain the upper and lower bounds in our large deviation principles separately with continuous Hamiltonian functions. The large deviation principles in Theorem 2.2 provide more explicit representations of the pressure allowing a more precise phase transition analysis in Theorem 2.5.
\(\square \)
The pressure representations on the right-hand side of (2.3) and their analysis are the key step in revealing the phase transition phenomenon also known as Bose–Einstein condensation.
Corollary 2.4
The right-hand side of (2.3) can, for \( \kappa =0 \), be written as
where \( I_0 \) is the rate function for the ideal Bose gas and \( D(\lambda )=\sum _{k\in {\mathbb {N}}} k \lambda _k \) is the density, see [1].
Proof
The first equality follows from optimising over \( y\ge 0 \), whereas the second can be proved by conditioning on the value of \( D(\lambda ) \). \(\square \)
The analysis of the pressure is related to finding the zeroes of the rate functions. In the following theorem, we identify thus a critical parameter regime for the pressure in terms of the so-called chemical potential \( \mu \in {\mathbb {R}}\). This analysis is followed by showing that the critical parameter is the phase transition point when positive particle density is carried by so-called ‘infinitely’ long cycles, see Theorem 2.11. Recall the critical density of the ideal Bose gas, see [1, 3],
where \( \zeta \) is the Riemann zeta function, \( \zeta \left( \frac{d}{2}\right) =\sum _{k=1}^\infty k^{-\frac{d}{2}} \). For the following results, we define the function \( s_\beta :(0,\infty )\rightarrow {\mathbb {R}}\) by
Here and thereafter, we let \( p^\prime _0(\beta ,s) \) and \( f^\prime _0(\beta ,x) \) denote the s and x partial derivatives, respectively. Note that \(f_0(\beta ,x)=s_\beta (x)x-p_0(\beta ,s_\beta (x))\), \(f^\prime _0(\beta ,x)=s_\beta (x)\), and that \( s_\beta \) is concave everywhere and strictly concave for \( x\le \varrho _{\mathrm{c}}(d) \). Define
along with
and finally the chemical potential for \( \kappa \in (0,\infty ) \),
Denote
Theorem 2.5
(Zeroes of the rate functions). Let \( \beta >0, \alpha <0, \mu \in {\mathbb {R}}\), \( a>b>0 \), and \( \mu _{\mathrm{c}}:= a\varrho _{\mathrm{c}}(d) \). Under the same assumptions on the sequence \( (m_\Lambda )_{\Lambda \Subset {\mathbb {Z}}^d} \) as in Theorem 2.2, the following holds for \( \kappa =0 \), \( \kappa \in (0,\infty ) \), and \( \kappa =\infty \), respectively.
-
(i)
\( \kappa =0 \): There exists a transition chemical potential \( \mu ^*\equiv \mu ^*_0 \in [\mu _{\mathrm{t}},\mu _{\mathrm{c}}] \) such that
$$\begin{aligned} {\mathscr {M}}^{{\scriptscriptstyle {({0}})}}(\mu )= {\left\{ \begin{array}{ll} \{({\tilde{x}}_1,0)\} &{}\hbox { for } \mu <\mu ^*,\\ \{({\tilde{x}}_1,0),({\tilde{x}}_2,\frac{\mu -a{\tilde{x}}_2}{a-b})\} &{} \hbox { for } \mu =\mu ^*,\\ \{({\tilde{x}}_2,\frac{\mu -a{\tilde{x}}_2}{a-b})\} &{} \hbox { for } \mu >\mu ^*\,. \end{array}\right. } \end{aligned}$$If \( \mu ^*=\mu _{\mathrm{c}} \), there is always a unique zero, namely \( ({\tilde{x}}_1,0) \) for \( \mu \le \mu _{\mathrm{c}}\) with \({\tilde{x}}_1(\mu ^*)={\tilde{x}}_2(\mu ^*) \) and \( ({\tilde{x}}_2,\frac{\mu -{\tilde{x}}_2}{a-b}) \) for \( \mu >\mu _{\mathrm{c}} \).
-
(ii)
\( \kappa \in (0,\infty ) \): There exists a transition chemical potential \( \mu ^*_\kappa \), namely \( \mu ^*_\kappa =\mu ^* \) for \( \mu _{\mathrm{r}}\le \mu ^* \) with \( \mu ^*\in [\mu _{\mathrm{t}},\mu _{\mathrm{c}}] \), see (i), and \( \mu ^*_\kappa \in (\mu ^*,\mu _{\mathrm{r}}) \) when \( \mu _{\mathrm{r}}>\mu ^* \), such that
$$\begin{aligned} {\mathscr {M}}^{{\scriptscriptstyle {({\kappa }})}}(\mu )= {\left\{ \begin{array}{ll} \{({\tilde{x}}_1,0)\} &{}\hbox { for } \mu <\mu ^*_\kappa ,\\ \{({\tilde{x}}_1,0),({\tilde{x}}_3,\kappa )\} &{} \hbox { for } \mu =\mu ^*_\kappa \\ \{({\tilde{x}}_3,\kappa )\} &{} \hbox { for } \mu \in (\mu ^*_\kappa ,\mu _{\mathrm{r}}],\\ \{({\tilde{x}}_2,\frac{\mu -a{\tilde{x}}_2}{a-b})\} &{} \hbox { for } \mu \ge \mu _{\mathrm{r}}\,. \end{array}\right. } \end{aligned}$$ -
(iii)
\( \kappa =\infty \): Then \( {\mathscr {M}}^{{\scriptscriptstyle {({\infty }})}}(\mu )=\{({\tilde{x}}_1,0)\} \) for all \( \mu \in {\mathbb {R}}\).
The zeroes in the previous theorem lead immediately to the following pressure representations We define the sub-critical and the super-critical pressure respectively as
Corollary 2.6
(Pressure representation). For \( \kappa =0 \) we have
and for \( \kappa \in (0,\infty ) \),
and for \( \kappa =\infty \), \( p^{{\scriptscriptstyle {({\infty }})}}(\beta ,\alpha ,\mu )=p_{{\scriptscriptstyle {(\mathrm{sub}})}}(\beta ,\mu ) \) for all \( \mu \in {\mathbb {R}}\).
We have some control over the transition potentials \(\mu ^*_\kappa \), \( \kappa \in [0,\infty ) \), in the following theorem. Denote
Theorem 2.7
For \(d=2\) and all \(\beta >0\),
Otherwise, we describe the high- and low-temperature behaviours.
Low temperature:
High temperature:
Furthermore, for \(\kappa \in \left( 0,+\infty \right) \), we have

Plots of the \(\beta \)-\(\mu \) phase space for \(d\ge 3\). Condensation occurs in region B, and does not in region A. The transition chemical potential resides in the shaded area, and the transition is discontinuous here. For \(d\ge 5\) and \(\beta \ge \beta _{\mathrm{t}}\), the transition is continuous at the boundary. For \(d=1,2\), we have a lower bound for the transition like the one appearing in \(d=3,4\), but no non-trivial upper bound. Like noted by [18], there is a transition at finite \(\mu \) for all \(d\ge 1\)
A second conclusion from our results above is the asymptotic limit for the pair empirical particle density.
Corollary 2.8
(Thermodynamic limit of the pair particle density). For every \( \delta > 0\),
for each unique minimiser (x, y) in Theorem 2.5, that is, when either \( \mu \not =\mu ^* \) in case \( \kappa =0 \), \( \mu \not =\mu ^*_\kappa \) for \( \kappa \in (0,\infty ) \), and for all \( \mu \in {\mathbb {R}}\) when \( \kappa =\infty \).
Remark 2.9
-
(a)
For the mean field model, i.e. for \( b\equiv 0 \), the paper [7] derived similar results for a specific choice of the sequence \( m_\Lambda \), namely \( m_\Lambda \le L^2 \) when \( |\Lambda |=L^d \). This corresponds to \(\kappa =0 \) in our general setting if we have \(d\ge 3\).
-
(b)
Our analysis above shows that at the critical values of the chemical potential, \( \mu =\mu ^* \) for \( \kappa =0 \) and \( \mu =\mu ^*_\kappa \) when \( \kappa \in (0,\infty ) \), we do not have a unique zero. Our large deviation analysis shows that for every \( \delta \)-neighbourhood \( {{\mathcal {U}} }_\delta \) of \( {\mathscr {M}}^{{\scriptscriptstyle {({0}})}}(\mu ^*) \) for \( \kappa =0 \) of \( {\mathscr {M}}^{{\scriptscriptstyle {({\kappa }})}}(\mu ^*_\kappa ) \) when \( \kappa \in (0,\infty ) \), respectively,
$$\begin{aligned} \lim _{\Lambda \uparrow {\mathbb {R}}^d}\,{{\textsf {Q} }}\left( {\varvec{M}}_\Lambda \notin {{\mathcal {U}} }_\delta ^{\mathrm{c}}\right) =0. \end{aligned}$$Denoting \( (x^{{\scriptscriptstyle {({i}})}}_{\mathrm{c}},y^{{\scriptscriptstyle {({i}})}}_{\mathrm{c}}) \), \(i=1,2 \), the zeroes at these critical points, the concentration of measure problem ask whether there are \( \lambda _i\in [0,1], i=1,2 \), such that \( \lambda _1+\lambda _2=1 \) and
$$\begin{aligned} \lim _{\Lambda \uparrow {\mathbb {R}}^d}\,{{\textsf {Q} }}\left( {\varvec{M}}_\Lambda \in B_\delta (x^{{\scriptscriptstyle {({i}})}}_{\mathrm{c}},y^{{\scriptscriptstyle {({i}})}}_{\mathrm{c}})\right) =\lambda _i,\quad i=1,2. \end{aligned}$$This requires finer asymptotic analysis going beyond the large deviation analysis studied here. We devote future work to analyse the fluctuation behaviour of our model, e.g. similar to the analysis in [9] for the ideal Bose gas, as well as the concentration of measure problem at criticality.
\(\square \)
A third observation from our results above is that the expected density of particles in unbounded cycles is related to the expected density of \( M_\Lambda ^{{\scriptscriptstyle {({2}})}} \) denoted
Corollary 2.10
(Density in ‘infinitely long cycles’).
-
(i)
\( \kappa = 0 \),
$$\begin{aligned} \varrho ^{{\scriptscriptstyle {({0}})}}(\mu ) = {\left\{ \begin{array}{ll} 0 &{}\hbox { for }\mu <\mu ^*,\\ \frac{\mu -a{\tilde{x}}_2(\mu )}{a-b} &{} \hbox { for } \mu >\mu ^*\,, \end{array}\right. } \end{aligned}$$and \( \varrho ^{{\scriptscriptstyle {({0}})}}(\mu ) \) is not continuous at \( \mu =\mu ^* \) whenever \( \mu ^*<\mu _{\mathrm{c}} \), whereas \( \varrho ^{{\scriptscriptstyle {({0}})}}(\mu ) \) is continuous at \( \mu =\mu ^* \) with \( {\tilde{x}}_1(\mu ^*)={\tilde{x}}_2(\mu ^*) \) whenever \( \mu ^*=\mu _{\mathrm{c}} \) which is equivalent to
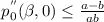 .
. -
(ii)
\(\kappa \in (0,\infty ) \),
$$\begin{aligned} \varrho ^{\scriptscriptstyle {({\kappa }})}(\mu )= {\left\{ \begin{array}{ll} 0 &{} \hbox { for } \mu <\mu ^*_\kappa , \\ \kappa &{} \hbox { for } \mu \in (\mu ^*_\kappa ,\mu _{\mathrm{r}}],\\ \frac{\mu -a{\tilde{x}}_2(\mu )}{a-b} &{} \hbox { for } \mu \ge \mu _{\mathrm{r}}\,, \end{array}\right. } \end{aligned}$$and \( \varrho ^{\scriptscriptstyle {({\kappa }})}(\mu ) \) is continuous at \( \mu =\mu _{\mathrm{r}} \) and discontinuous at \( \mu =\mu ^*_\kappa \).
-
(iii)
\( \kappa =\infty \), then \( \varrho ^{{\scriptscriptstyle {({\infty }})}}(\mu ) =0 \) for \( \mu \in {\mathbb {R}}\).
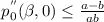 .
.The reader may be tempted to identify the expect density \( \varrho ^{{\scriptscriptstyle {({\kappa }})}}(\mu ) \) as the density of particle in unbounded (‘infinitely long cycles’) cycles which may corresponds to the density of the Bose–Einstein condensate. To answer this conjecture, we first define the condensate density, a definition which goes back to [15], and which is frequently used, e.g. in [18, 23, 24].
For any \( K\in {\mathbb {N}}\) define \(D_K \) as the random particle density of cycles with length greater than K,
Then, the particle density in infinitely long cycles is defined as
Theorem 2.11
(Condensate Density).
-
(a)
Let \( \beta >0\), \(\alpha <0\), \(\mu \in {\mathbb {R}}\), and \( a>b>0 \). For \(\kappa =0\) and \(\kappa =\infty \),
$$\begin{aligned} \Delta ^{{\scriptscriptstyle {({0}})}}(\mu )=\varrho ^{{\scriptscriptstyle {({0}})}}(\mu ),\qquad \Delta ^{\scriptscriptstyle {({\infty }})}\left( \mu \right) = \Big (\frac{\mu }{a}-\varrho _c\Big )_+. \end{aligned}$$For \(\kappa \in \left( 0,\infty \right) \), there exists \({\hat{\mu }}^*_\kappa \in \left[ \mu ^*_\kappa ,\mu _{\mathrm{r}}\right] \), such that
$$\begin{aligned} \Delta ^{\scriptscriptstyle {({\kappa }})}\left( \mu \right) = {\left\{ \begin{array}{ll} \left( \frac{\mu }{a}-\varrho _c\right) _+ &{}\text {for }\mu < {\hat{\mu }}^*_\kappa \\ \varrho ^{\scriptscriptstyle {({\kappa }})}\left( \mu \right) &{}\text {for }\mu > {\hat{\mu }}^*_\kappa . \end{array}\right. } \end{aligned}$$ -
(b)
Let \( b\uparrow a \) with fixed \(\beta >0\), \( \mu \in {\mathbb {R}}\), \(a>0 \), and \( \kappa \in [0,\infty ) \), then \(\Delta ^{{\scriptscriptstyle {({\kappa }})}}(\mu )\sim \big (\frac{\mu }{a-b}\big )_+\).
-
(c)
Let \( \mu \rightarrow \infty \), with fixed \(\beta >0\), \( \mu \in {\mathbb {R}}\), \(a>b>0 \), and \( \kappa \in [0,\infty ) \), then \(\Delta ^{{\scriptscriptstyle {({\kappa }})}}(\mu )\sim \frac{\mu }{a-b}\).
Remark 2.12
Since \(m_\Lambda > K\) eventually, it follows that \(\Delta ^{\scriptscriptstyle {({\kappa }})}\left( \mu \right) \ge \varrho ^{\scriptscriptstyle {({\kappa }})}\left( \mu \right) \). However, if \(\kappa >0\), we have parameter ranges in which this inequality is strict. This indicates that a positive condensate density is held on cycles whose lengths diverge slower than \(m_\Lambda \), and therefore not directly affected by the counter-term. In the \(\kappa =\infty \) case, \(m_\Lambda \) diverges too quickly to affect any positive density, see Remark 2.3, and we approach the mean field model. The case \( \kappa =\infty \) is special in the sense that the density of ‘infinitely long cycles’ as the zero of the rate function vanishes but the above order parameter does not vanish when \( \mu \ge a\varrho _{\mathrm{c}} \). \(\square \)
3 Proofs
The proof of the main large deviation theorem is in Sect. 3.1, and all remaining proofs about the zeroes of the rate function and the condensate density are in Sect. 3.2.
3.1 Proof of the Large Deviation Principles, Theorem 2.2
To prove the large deviation principle in Theorem 2.2, we adapt and extend the ideas in [23]. Our model is on spatial cycle structures, and thus our method is different as the so-called condensate resides in cycles of unbounded length. For the negative counter-term in the Hamiltonian, the long cycles are the relevant ones, whereas in [23], the energy indices with low values are relevant. Though technically slightly more challenging, our method allows us to investigate the different ways the counter-term scales with the volume—in this way providing insight how the cycle condensate is scaled with the volume. The standard Varadhan Lemma approach for our model does not work directly as, due to the counter term, lower semi-continuity is missing. The general idea is to find lower and upper bounds for the Hamiltonian, and then prove large deviation principles for the two bounds individually. The final step is then to identify the two bounds. The proof for the upper bound is in Sect. 3.1.1 and the one for the lower bound in Sect. 3.1.2.
3.1.1 Large Deviation Upper Bound
We split the proof in two parts. In the first one, we derive the large deviation principle for pair empirical particle density under the reference measure, i.e. with no interaction. In the second step, we will apply Varadhan’s lemma to a lower bound of the Hamiltonian.
Step1: Define the reference measure \( \nu _\Lambda ^{{\scriptscriptstyle {({2}})}}:={{\textsf {Q} }}\circ {\varvec{M}}_\Lambda ^{-1} \).
Lemma 3.1
For any \( \kappa \in [0,\infty ] \) the limiting logarithmic moment generating function for \( (\nu _\Lambda ^{{\scriptscriptstyle {({2}})}})_{\Lambda \Subset {\mathbb {R}}^d} \) is given by
The Legendre–Fenchel transform is
Proof
Given the properties of the weights \( q_k \), we immediately see convergence of the first term on the right-hand side for any value of \( \kappa \in [0,\infty ] \) towards \( p_0(\beta ,\alpha +s) \) for \( (s,t)\in (-\infty ,-\alpha ]\times (-\infty ,-\alpha ] \). Furthermore, for any \( v>0 \),
This gives divergence for \( s>-\alpha \) or \( t>-\alpha \). The Legendre–Fenchel transform is then
\( \varvec{\Lambda }^* \) has been defined for \( (x,y)\in {\mathbb {R}}_+^2 \) as for negative values of the arguments the function value is infinity. \(\square \)
Now, we define
and can easily obtain the large deviation upper bound.
Lemma 3.2
For any closed set \(C\subset {\mathbb {R}}^2\),
Proof
The upper bound for closed sets \( C\subset {\mathbb {R}}^2 \),
follows for example with the Gärtner-Ellis theorem [10, Theorem 2.3.6]. Furthermore, for any \( C\subset \big ({\mathbb {R}}_+^2\big )^{\mathrm{c}} \), we have \( \nu _\Lambda ^{{\scriptscriptstyle {({2}})}}(C)=0 \). We improve this bound for \(\left( x,y\right) \not \in {\mathbb {K}}\left( \kappa \right) \) by noting that the image of \(M^{\scriptscriptstyle {({2}})}_\Lambda \) is \(\big \{0,\frac{m_\Lambda }{|\Lambda |},\frac{m_\Lambda +1}{|\Lambda |},\frac{m_\Lambda +2}{|\Lambda |},\ldots \big \}\). So if \(E\subset \left( 0,\kappa \right) \), then \(\nu ^{\scriptscriptstyle {({2}})}_\Lambda \left( M^{\scriptscriptstyle {({2}})}_\Lambda \in E\right) =0\) for all \(\Lambda \) sufficiently large. \(\square \)
Step 2:
The crucial step is to bound the Hamiltonian in (1.1) from below. We have \({{{\textsf {H} }}}_\Lambda (\omega )\ge |\Lambda |{\mathscr {H}}\circ {\varvec{M}}_\Lambda ^{{\scriptscriptstyle {({2}})}}(\omega )\), where
Lemma 3.3
Let \( C\subset {\mathbb {R}}^2 \) be closed, then
and
Proof
The function \( {\mathscr {H}}\) in (3.2) is continuous and bounded below; thus, the statement is simply a matter of applying Varadhan’s Lemma. Taking \( C={\mathbb {R}}^2 \) gives the bound on the thermodynamic pressure by using the Legendre–Fenchel transform for the pressure. \(\square \)
In Sect. 3.1.2, we obtain the corresponding lower bound on the thermodynamic pressure, i.e. confirming (2.3). Then, Lemma 3.3, in conjunction with the pressure representation in (2.3), gives the large deviation upper bound
3.1.2 Large Deviation Lower Bound
The large deviation lower bound is more delicate as we shall find an upper bound on the energy, that is, the counter term cannot be replaced by the square of the sum of the single terms. In the following steps, we derive a more detailed splitting of the empirical particle density which is the novel step in this type of large deviation proofs. Our splitting is based on properties derived for the pair empirical particle density splitting in Sect. 3.1.1. The rate function \( J_\kappa \), defined in (3.1), is a good rate function which follows from the fact that the origin is in the interior of the domain where the limiting logarithmic moment generating function is finite, see [10, Lemma 2.2.20]. We combine this with the local nature of the large deviation lower bound, that is, we will show that for any \( (x,y)\in {\mathbb {R}}^2 \),
where \( B_\delta ((x,y)) \) is the open ball of radius \( \delta >0 \) around (x, y) . In the first step, we define the detailed splitting which is local as it depends on (x, y) . In the second step, we prove a large deviation lower bound under the reference measure for the new splitting of the empirical particle into a quadruple, and, using the derived upper bound on the energy, the lower bound for the quadruple splitting follows with Varadhan’s Lemma. In a final step, we employ the contraction principle to derive the lower bound in (3.3).
Step 1: Splitting. Since \( J_\kappa +{\mathscr {H}}\) has compact level sets, there exists \( ({\tilde{x}},{\tilde{x}})\in {\mathbb {K}}(\kappa ) \) such that
Pick now \( (x,y)\in {\mathbb {K}}(\kappa ) \), that is, \( y\in \{0\}\cup [\kappa ,\infty ) \) (for \( (x,y)\notin {\mathbb {K}}(\kappa ) \) we obtain a trivial lower bound). The splitting depends on both (x, y) and \( ({\tilde{x}},{\tilde{y}}) \). Define \( r_\Lambda :=|\Lambda |{\tilde{y}}\vee m_\Lambda \), and then
Define the map
where
the reference measure \( \nu _\Lambda ^{{\scriptscriptstyle {({4}})}}:={{\textsf {Q} }}\circ \varvec{\pi }^{-1} \), and the rate function
where \( \varvec{{{\textsf {K} }}}:={\mathbb {R}}\times {\tilde{y}}{\mathbb {N}}_0\times y{\mathbb {N}}_0\times (\{0\}\cup [\kappa ,\infty )) \).
Step 2: LDP lower bound for the quadruple splitting under the reference measure.
Lemma 3.4
For any open set \( O\subset {\mathbb {R}}^4 \),
Proof
Pick \( (x,y_1,y_2,z)\in \varvec{{{\textsf {K} }}}\) (the other case gives trivial lower bound). The four particle densities \( \varvec{\pi }_i, i=1,\dots ,4 \), are independent, and we derive the lower bound separately for each individual entry. Denote \( \nu _{\Lambda ,i}^{{\scriptscriptstyle {({4}})}}, i=1,\ldots , 4 \), the marginals of \( \nu _\Lambda ^{{\scriptscriptstyle {({4}})}} \), and let \( \varvec{\Lambda }_i \) be the limiting logarithmic moment generating functions for \( \nu _{\Lambda ,i}^{{\scriptscriptstyle {({4}})}} \) whose domains are strictly bounded by \( -\alpha \) and thus each contain a neighbourhood of the origin. The corresponding Legendre–Fenchel transforms are
We now derive for each marginal individual lower bounds.
Marginal \( \varvec{\nu _{\Lambda ,1}^{{\scriptscriptstyle {({4}})}}} \): The function \( \varvec{\Lambda }^*_1 \) is strictly convex on \( [0,\varrho _{\mathrm{c}}) \). For \( x\in [0,\varrho _{\mathrm{c}}) \), we can proceed by standard Gärtner-Ellis-type arguments by tilting the measure. Let \( \eta <0 \) be the unique solution to \( \eta x-p_0(\beta ,\eta )=\sup _{s<0}\{sx-p_0(\beta ,s)\} \), and define the tilted measure by
where \( p_\Lambda (s):=\frac{1}{\beta }\sum _{k< m_\Lambda } q_k\mathrm{e}^{\beta sk} \). Taking the limits, we obtain
Now, using the strict convexity and the Gärtner-Ellis upper bound (see [10, Theorem 2.3.6]), the last term on the right-hand side of (3.1.2) vanishes as \( \nu _{\Lambda ,\eta ,1}^{{\scriptscriptstyle {({4}})}}(B_\delta (x)) \rightarrow 1 \) as \( \Lambda \uparrow {\mathbb {R}}^d \), and
For \( x>\varrho _{\mathrm{c}} \), the function \( \varvec{\Lambda }^*_1 \) is no longer strictly convex, and thus the standard argument fails to show that the last term on the right-hand side of (3.1.2) vanishes. Our new method here is to directly use the Poisson nature of the distribution of the bosonic cycle counts to obtain individual estimates leading to the lower bound (3.5). Let \( x>\varrho _{\mathrm{c}} \). As we cannot exploit the strict convexity of \( \varvec{\Lambda }^*_1 \), we need to estimate the last term on the right-hand side of (3.1.2) directly: pick \( r\in {\mathbb {N}}\), then eventually \( m_\Lambda > r \). Denote \( \varrho _{\mathrm{c}}^\alpha :=\sum _{k\in {\mathbb {N}}}kq_k\mathrm{e}^{\beta \alpha k} \), \( \varrho _{\mathrm{c},r}^\alpha :=\sum _{k< r} kq_k\mathrm{e}^{\beta \alpha k} \), and recall that \( {{\textsf {Q} }}\) is the distribution of the reference Poisson process which is a superposition of independent Poisson processes with parameter \( |\Lambda |q_k\mathrm{e}^{\alpha \beta k}, k\in {\mathbb {N}}\). Then for \( x> \varrho _{\mathrm{c},r}^\alpha \),
Now, the mean and variance of \( |\Lambda |\sum _{k=1}^{r-1}k\varvec{\lambda }_k \) are equal to \( |\Lambda |\varrho _{\mathrm{c},r}^\alpha \), so Chebyshev’s inequality implies that
Independence of the Poisson variables implies that
For the remaining factor, we use Stirling’s formula to get
Combing the individual estimates and taking \( r\rightarrow \infty \) gives
Note that for \( x>\rho _{\mathrm{c}} \) we have, using \( 1-\mathrm{e}^{\beta \alpha k} \le -\alpha k\beta \),
and thus we obtain (3.5) for all \(x\ge 0 \).
Marginal \( \varvec{\nu _{\Lambda ,i}^{{\scriptscriptstyle {({4}})}}, i=2,3} \): If \( {\tilde{y}}=0 \), then
If \( {\tilde{y}}\ge \kappa \), then \( \frac{r_\Lambda }{|\Lambda |}\rightarrow {\tilde{y}} \). Choose \( n\in {\mathbb {N}}_0 \) such that \( y_2=n{\tilde{y}} \). Then,
Precisely, the same argument applies for the case \( i=3 \).
Marginal \( \varvec{\nu _{\Lambda ,4}^{{\scriptscriptstyle {({4}})}}} \): If \( z=0 \), let \( p_\Lambda :=\min \{k\in {\mathbb {N}}:k\ge m_\Lambda ,k\not = r_\Lambda ,s_\Lambda \} \). Then,
If \( z\ge \kappa \), then let \( p_\Lambda :=\min \{k\in {\mathbb {N}}:k\ge z|\Lambda |, k\ge m_\Lambda , k\not = s_\Lambda ,r_\Lambda \} \). In particular, \( p_\Lambda /|\Lambda |\rightarrow z \). Then
We finally obtain for \( (x,y_1,y_2,z)\in \varvec{{{\textsf {K} }}}\),
by combining our marginal estimates above. \(\square \)
Step 3: Upper bound for the energy and LDP lower bound for the quadruple splitting. Define
Then,
Lemma 3.5
Let \( O\subset {\mathbb {R}}^4 \) be open, then
and
Proof
Using (3.6),
Then, noting that \( {\mathscr {K}}\) is continuous, the statement is simply a matter of applying Varadhan’s Lemma. \(\square \)
Step 4: Contraction.
Lemma 3.6
For any open set \( O\subset {\mathbb {R}}^2 \),
and
Proof
Define \( {\hat{\varvec{\pi }}}:{\mathbb {R}}^4\rightarrow {\mathbb {R}}^2, (x,y_1,y_2,z)\mapsto (x,y_1+y_2+z) \), and note that \( {\hat{\varvec{\pi }}} \) is continuous and \( {\varvec{M}}_\Lambda ={\hat{\varvec{\pi }}}\circ \varvec{\pi }\). Then,
and, \(\inf _{{\mathbb {R}}^4}\left\{ J^{{\scriptscriptstyle {({4}})}}_\kappa +{\mathscr {K}}\right\} \ge \inf _{{\mathbb {R}}^2}\left\{ J_\kappa +{\mathscr {H}}\right\} =(J_\kappa +{\mathscr {H}})({\tilde{x}},{\tilde{y}}) \). Using
we derive the lower bound for the pressure in Lemma 3.6, and, with the corresponding upper bound in Lemma 3.3, we obtain (2.3) in Theorem 2.2. To obtain the large deviation lower bound, denoted the rate function per Contraction principle \( {\mathscr {J}}_\kappa (x,y)=\inf _{{\hat{\varvec{\pi }}}^{-1}(x,y)}\{J^{{\scriptscriptstyle {({4}})}}_\kappa +{\mathscr {K}}\}\). Then, for every open set \( O\subset {\mathbb {R}}^2 \), using the lower in Lemma 3.5,
and, finally we derive (3.3),
where we use the particular quadruple splitting in the last step. \(\square \)
3.2 Variational Analysis
Proof of Theorem 2.5
In [23], a related variational principle has been studied. We built on that and extend it to the whole range of the parameter \( \kappa \in [0,\infty ] \) to obtain an improvement on the results in [23]. To obtain the zeroes of the rate function functions \( I^{{\scriptscriptstyle {({\kappa }})}} \), it suffices to minimise
For \(\kappa = +\infty \), we have restricted the y-component to \(y=0\). Therefore, we want to optimise \(F\left( x,0\right) \). We search for stationary points, and find that they satisfy the equation \(s_\beta \left( x\right) = \mu - ax\). Since \(s_\beta \) is non-decreasing and \(s_\beta \left( x\right) \rightarrow -\infty \) as \(x\downarrow 0\), and \(\mu -a x\) is decreasing, there exists a unique stationary point—a minima—given by \({\tilde{x}}_1\).
For \(\kappa = 0\), we first fix \(x\ge 0\) and find an optimal choice of \(y\in {\mathbb {R}}_+\), denoted \({\tilde{y}}\left( x\right) \). This gives \({\tilde{y}}\left( x\right) = \frac{1}{a-b}\left( \mu -ax\right) _+\), and the derivative of \(F_\mu \left( x,{\tilde{y}}\left( x\right) \right) \) is zero precisely when
Now, \(x={\tilde{x}}_1\left( \mu \right) \) is always a solution and gives a local minima for \(\mu \le \mu _c\), whilst \(x={\tilde{x}}_2\left( \mu \right) \) is a solution for \(\mu \ge \mu _t\) and gives a local minima for \(\mu >\mu _t\). These are the only local minima.
Since \({\tilde{x}}_1\left( \mu \right) \ge \frac{\mu }{a}\) and \({\tilde{x}}_2\left( \mu \right) < \frac{\mu }{a}\), and \({\tilde{x}}_1\left( \mu \right) \) is the unique local minimiser for \(\mu =\mu _t\) and \({\tilde{x}}_1\left( \mu \right) \) is the unique local minimiser for \(\mu =\mu _c\),
and
In taking the full \(\mu \)-derivative, we used the fact that \({\tilde{x}}_1\left( \mu \right) \) and \({\tilde{x}}_2\left( \mu \right) \) are stationary points. The inequality comes from \(s_\beta \) being strictly increasing on \(x\le \varrho _c\). This tells us that there exists a \(\mu ^*\in \left[ \mu _t,\mu _c\right] \) such that \({\tilde{x}}_1\left( \mu \right) \) is the minima for \(\mu \le \mu ^*\) and \({\tilde{x}}_2\left( \mu \right) \) is the minima for \(\mu \ge \mu ^*\)—with simultaneous minima at \(\mu =\mu ^*\).
Now, suppose \(\kappa \in \left( 0,+\infty \right) \). If \(\mu \ge \mu _r\) or \(\mu \le \mu ^*\), then at least one global \({\mathbb {R}}^2_+\) minimiser exists in \({\mathbb {K}}\) and we are done. For \(\mu \in \left( \mu ^*,\mu _r\right) \), the quadratic form of F in y tells us that the \({\mathbb {K}}\) minimiser resides on \(y=0\) or \(y=\kappa \). Furthermore, by rearranging terms, we find \(F_\mu \left( x,\kappa \right) = F_{\mu -a\kappa }\left( x,0\right) - \kappa \mu + \frac{a-b}{2}\kappa ^2\). Therefore, \(F_\mu \left( x,\kappa \right) \) is minimised at \(x={\tilde{x}}_1\left( \mu -a\kappa \right) = {\tilde{x}}_3\left( \mu \right) \). Now because \(\left( {\tilde{x}}_1\left( \mu ^*\right) ,0\right) \) is a global \({\mathbb {R}}^2_+\) minimiser at \(\mu =\mu ^*\) and \(\left( {\tilde{x}}_3\left( \mu _r\right) ,\kappa \right) = \left( {\tilde{x}}_2\left( \mu _r\right) ,\kappa \right) \) is a global \({\mathbb {R}}^2_+\) minimiser at \(\mu =\mu _r\),
Furthermore,
since \(s_\beta \) and \({\tilde{x}}_1\) are non-decreasing. Therefore, there exists \(\mu ^*_\kappa \in \left( \mu ^*,\mu _r\right) \) such that \(\left( {\tilde{x}}_1\left( \mu \right) ,0\right) \) is a minimiser over \({\mathbb {K}}\left( \kappa \right) \) for \(\mu \le \mu ^*_\kappa \) and \(\left( {\tilde{x}}_3\left( \mu \right) ,\kappa \right) \) is a minimiser over \({\mathbb {K}}\left( \kappa \right) \) for \(\mu \in \left[ \mu ^*_\kappa ,\mu _r\right] \). \(\square \)
Proof of Corollary 2.6
These representations of the pressure follow from substituting the minimisers from Theorem 2.5 into the pressure expression (2.3) in Theorem 2.2. \(\square \)
Proof of Theorem 2.7
We shall use the notation \(g\left( u,s\right) = \sum ^\infty _{k=1}k^{-s}\mathrm{e}^{u k}\), see (B.1). First note that \(\mu _{\mathrm{t}}=\mu _{\mathrm{c}}\) if and only if the infimum (2.4) is attained at \(s=0\), which happens precisely when \(ap_0''\left( \beta ,0\right) \le \frac{a-b}{b}\). This condition happens if and only if \(d\ge 5\) and \(\beta \ge \beta _{\mathrm{t}}\). In all other cases, there exists \({\bar{\alpha }}<0\) such that
Since \({\bar{\alpha }}\) is a stationary point, it is given as the unique solution to
To deal with \(d=2\), note that from the infinite sum expression for \(g\left( u,s\right) \) that for \(u<0\), we have \(g\left( u,0\right) = \frac{\mathrm{e}^u}{1-\mathrm{e}^u}\), and \(g\left( u,1\right) = -\log \left( 1-\mathrm{e}^u\right) \). We use these to solve for \({\bar{\alpha }}\) and then \(\mu _{\mathrm{t}}\). For the remaining dimensions, we use (3.7) to determine whether \(\beta {\bar{\alpha }}\rightarrow 0\) or \(\beta {\bar{\alpha }}\rightarrow -\infty \). Using \(g\left( u,s\right) \sim \mathrm{e}^u\) as \(u\rightarrow -\infty \) for all real s, and the \(u\uparrow 0\) asymptotic behaviour of \(g\left( u,s\right) \) from Appendix B, we get the asymptotic behaviour of \(\mu _{\mathrm{t}}\left( \beta \right) \).
For \(\mu _{\mathrm{r}}\left( \beta ,\kappa \right) \), note that when restricted to \(\left( 0,\varrho _{\mathrm{c}}\right) \), the function \(s_\beta :\left( 0,\varrho _{\mathrm{c}}\right) \rightarrow \left( -\infty ,0\right) \) is a strictly increasing continuous bijection. Furthermore, we can rewrite
From the definition of \(s_\beta (x)\) for \(x\in (0,\varrho _{\mathrm{c}}]\), we have
\(\square \)
Proof of Corollary 2.8
If \(\left( x,y\right) \) is the unique minimiser of the large deviation rate function \(I^{\scriptscriptstyle {({\kappa }})}\), then for \(\delta >0\), we have \(\inf \left\{ I^{\scriptscriptstyle {({\kappa }})}\left( u,v\right) : \left( u,v\right) \not \in B^\delta \left( x,y\right) \right\} > 0\). Since the complement of the open ball \(B^\delta \left( x,y\right) \) is closed, the large deviation principle tells us that \({{\textsf {Q} }}\left( {\varvec{M}}_\Lambda \not \in B^\delta (x,y)\right) \) decays exponentially. Hence, the required limit holds. \(\square \)
Proof of Corollary 2.10
This follows from applying Corollary 2.8 with the unique minimisers found in Theorem 2.5. \(\square \)
Proof of Theorem 2.11
Our strategy here is to use the large deviation techniques described previously to find \(\lim _{\Lambda \uparrow {\mathbb {R}}^d} {{\textsf {E} }}\left[ D_K\right] \), and then use analytic techniques to take the K-limit.
We begin by introducing the triple empirical particle density \({\varvec{M}}_{\Lambda ,K}:\Omega \rightarrow {\mathbb {R}}^3\), \({\varvec{M}}_{\Lambda ,K}(\omega ):=\left( M_{\Lambda ,K}^{{\scriptscriptstyle {({1}})}},M_{\Lambda ,K}^{{\scriptscriptstyle {({2}})}},M_{\Lambda ,K}^{{\scriptscriptstyle {({3}})}}\right) \) where \(M_{\Lambda ,K}^{{\scriptscriptstyle {({1}})}}=\sum _{k=1}^{K} k\varvec{\lambda }_k\), \(M_{\Lambda ,K}^{{\scriptscriptstyle {({2}})}}=\sum ^{m_\Lambda }_{k=K+1}k\varvec{\lambda }_k\) and \(M_{\Lambda ,K}^{{\scriptscriptstyle {({3}})}}=\sum _{k > m_\Lambda }k\varvec{\lambda }_k\), distributed under the measure \(\mu ^{\scriptscriptstyle {({3}})}_{\Lambda ,K}:={{\textsf {P} }}_\Lambda \circ {\varvec{M}}_{\Lambda ,K}^{-1}\). By repeating the arguments of Theorem 2.2, we can show that \(\left( \mu ^{\scriptscriptstyle {({3}})}_{\Lambda ,K}\right) _{\Lambda \Subset {\mathbb {R}}^d}\) satisfies the large deviation principle on \({\mathbb {R}}^3_+\) with rate \(\beta |\Lambda |\) and good rate function
where \(p_{\kappa ,K}(\beta ,\alpha ,\mu )\) is the appropriate normalisation, \(f^{\scriptscriptstyle {({1}})}_{K}\left( x\right) = \sup _{s\in {\mathbb {R}}}\left\{ sx - \frac{1}{\beta }\sum _{j\le K}q_j\mathrm{e}^{\beta sj}\right\} \) and \(f^{\scriptscriptstyle {({2}})}_K\left( y\right) =\sup _{t\le 0}\left\{ ty - \frac{1}{\beta }\sum _{j>K}q_j\mathrm{e}^{\beta tj}\right\} \). Note that \(f^{\scriptscriptstyle {({1}})}_K\left( x\right) \) is convex, strictly increasing on \(x\ge \varrho _c\) (and decreasing slower than linearly for \(d=1,2\)), and converges pointwise to \(f_0\left( \beta ,x\right) \). Also, \(f^{\scriptscriptstyle {({2}})}_K\left( y\right) \) is convex, constant on \(y\ge \sum _{k>K}kq_k\) and converges pointwise to 0 (converges uniformly for \(d\ge 3\)). From these properties, and since \(\left( x,y,z\right) \mapsto -\mu (x+y+z)+\frac{a}{2}(x+y+z)^2-\frac{b}{2}z^2\) is a constant plus a positive definite quadratic form, we know that there are only finitely many global minimisers and that these are contained in some K-independent compact set. The pointwise convergence translates into uniform convergence on this compact set.
Suppose \(\kappa =\infty \). Then \(I^{\scriptscriptstyle {({\kappa }})}_K\) is finite only if \(z=0\), and therefore, the question reduces to a mean field one. For \(d=1,2\), the minima are eventually in a neighbourhood of the \(\left\{ y=z=0\right\} \) set, and so the condensate vanishes. For \(d\ge 3\), the pointwise limit has a single global minimiser, \(\left( {\tilde{x}}_1,0,0\right) \), for \(\mu \le \mu _c\) and uncountably many for \(\mu >\mu _c\). These minimisers are the convex combinations of \(\left( \frac{\mu }{a},0,0\right) \) and \(\left( \varrho _c,\frac{\mu }{a}-\varrho _c,0\right) \). However, because we know that \(f^{\scriptscriptstyle {({1}})}_K\left( x\right) \) is strictly increasing on \(x\ge \varrho _c\) for all K, we know that the minimisers are eventually in any neighbourhood of \(\left( \varrho _c,\frac{\mu }{a}-\varrho _c,0\right) \).
For finite \(\kappa \), we contract the y and z components to compare with \(I^{\scriptscriptstyle {({\kappa }})}\left( x,y\right) \). After contracting \(\left( x,y,z\right) \mapsto \left( x,y+z\right) \), we get the rate function
This has the pointwise limit
Note \(I^{\scriptscriptstyle {({\kappa }})}\left( x,y\right) \ge J^{\scriptscriptstyle {({\kappa }})}_\infty \left( x,y\right) \ge I^{\scriptscriptstyle {({0}})}\left( x,y\right) \), with equality precisely on \({\mathbb {K}}\left( \kappa \right) \). Therefore if \(I^{\scriptscriptstyle {({0}})}\) has a global minimiser in \({\mathbb {K}}\left( \kappa \right) \), then this is a global minimiser of \(J^{\scriptscriptstyle {({\kappa }})}_\infty \). This proves the \(\kappa = 0\) case, and the \(\kappa \in \left( 0,\infty \right) \) case for \(\mu \le \mu ^*\) or \(\mu \ge \mu _{\mathrm{r}}\).
By fixing x and taking the y-partial derivatives of \(J^{\scriptscriptstyle {({\kappa }})}_\infty \), we find that the optimal choice of y is \(\frac{\mu }{a}-x\) or \(\kappa \) if \(\frac{\mu -ax}{a-b}<\kappa \), and \(\frac{\mu -ax}{a-b}\) otherwise. If \(\mu \ge \mu _{\mathrm{r}}\), then \(y=\frac{\mu -ax}{a-b}\) produces the global minimiser. For \(\mu \in \left( \mu ^*,\mu _{\mathrm{r}}\right) \) we need to compare minimisers along \(y=\frac{\mu }{a}-x\) and \(y=\kappa \). This is a similar process to the comparison of \(y=0\) and \(y=\kappa \) we performed in the proof of Theorem 2.5. Furthermore, because \(J^{\scriptscriptstyle {({\kappa }})}_\infty \left( x,\frac{\mu }{a}-x\right) < J^{\scriptscriptstyle {({\kappa }})}_\infty \left( x,0\right) \), we know that the transition occurs at a higher value of \(\mu \).
The asymptotics follow from inspecting the behaviour of \(\varrho ^{\scriptscriptstyle {({\kappa }})}\left( \mu \right) \) in the respective limits. In particular, note that \(\mu _{\mathrm{r}}< \mu _{\mathrm{c}}\) eventually as \(b\uparrow a\). \(\square \)
References
Adams, S., Dickson, M.: Large deviation analysis for classes of interacting Bosonic cycle counts. arXiv:1809.03387 (2018)
Adams, S., Dickson, M.: Limit theorems for statistics of combinatorial structures with two free energy minimiser (in preparation) (2021)
Adams, S.: Large deviations for empirical measures in cycles of integer partitions and their relation to systems of Bosons, analysis and stochastics of growth processes, LMS, pp. 148–172. Oxford University Press, Oxford (2008)
Adams, S., König, W.: Large deviations for many Brownian bridges with symmetrised initial-terminal condition. Probab. Theory Relat. Fields 42(1–2), 79–124 (2008)
Adams, S., Collevecchio, A., König, W.: The free energy of non-dilute many-particle systems. Ann. Prob. 39(2), 683–728 (2011)
Armandáriz, I., Ferrari, P.A., Yuhjtman, S.: Gaussian random permutation and the boson point process. arXiv:1906.11120v1 (2019)
Benfatto, G., Cassandro, M., Merola, I., Presutti, E.: Limit theorems for statistics of combinatorial partitions with applications to mean field Bose gas. J. Math. Phys. 46, 033303 (2005)
Bratteli, O., Robinson, D.W.: Operator algebras and quantum statistical mechanics II, 2nd edn. Springer, Berlin (1997)
Chatterjee, S., Diaconis, P.: Fluctuations of the Bose-Einstein condensate. J. Phys. A Math. Theor. 47(8), 085201 (2014)
Dembo, A., Zeitouni, O.: Large deviations techniques and applications. Springer, Berlin (2009)
Dickson, M.: Interacting Boson Gases and Large Deviation Principles. Ph.D. thesis University of Warwick (2019)
Dorlas, T., Martin, P., Pulé, J.V.: Long cycles in a perturbed mean field model of a boson gas. J. Stat. Phys. 121(3/4), 433–461 (2005)
Feynman, R.P.: Atomic theory of the \( \lambda \) transition in Helium. Phys. Rev. 91, 1291–1301 (1953)
Fichtner, K.-H.: On the position distribution of the ideal Bose gas. Math. Nachr. 151, 59–67 (1991)
Girardeau, M.: Relationship between systems of impenetrable bosons and fermions in one dimension. J. Math. Phys. 1(6), 516–23 (1960)
Gram, J.P.: Tafeln für die Riemannsche Zetafunktion. Skrifter København 8(9), 311–325 (1925)
Huang, K., Yang, C.N., Luttinger, J.M.: Imperfect Bose gas with hard-sphere interaction. Phys. Rev. 105(3), 776 (1957)
Lewis, J.T.: Why do bosons condense?. Statistical Mechanics and Field Theory: Mathematical Aspects, pp. 234–256. Springer, Berlin (1986)
London, R.: On the Bose–Einstein condensation. Phys. Rev. 54, 947–954 (1938)
Robinson, D.W.: The thermodynamic pressure in quantum statistical mechanics. Springer Lecture Notes in Physics, vol. 9. Springer, Berlin (1971)
Sütő, A.: Percolation transition in the Bose gas: II. J. Phys. A: Math. Gen. 35, 6995–7002 (2002)
Ueltschi, D.: Feynman cycles in the Bose gas. J. Math. Phys. 47, 123303 (2006)
van den Berg, M., Lewis, J.T., Pulé, J.V.: The large deviation principle and some models of an interacting boson gas. Commun. Math. Phys. 118, 61–85 (1988)
van den Berg, M., Dorlas, T.C., Lewis, J.T., Pulé, J.V.: The pressure in the Huang–Yang–Luttinger model of an interacting boson gas. Commun. Math. Phys. 128(2), 231–245 (1990)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Christian Maes.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix
Reference Process for Dirichlet Boundary Conditions
For Dirichlet boundary condition, one restricts the Brownian bridges to not leaving the set \(\Lambda \), that is, one replaces \( {{\mathcal {C}} }_{k,\Lambda } \) by the space \( {{\mathcal {C}} }^{{\scriptscriptstyle {(\mathrm{Dir}})}}_{k,\Lambda } \) of continuous functions in \( \Lambda \) with time horizon \( [0,k\beta ] \). Consider the measure
which has total mass \( g_{k\beta }^{{\scriptscriptstyle {(\mathrm{Dir}})}}(x,y)=\mu _{x,y}^{{\scriptscriptstyle {(\mathrm{Dir,k\beta }})}}({{\mathcal {C}} }^{{\scriptscriptstyle {(\mathrm{Dir}})}}_{k,\Lambda }) \). For Dirichlet boundary conditions, (1.3) is replaced by
Note that these weight depends on \( \Lambda \), see [11]. We introduce the Poisson point process \(\omega _{\mathrm{P}} = \sum _{x \in \xi _{ \mathrm P}} \delta _{(x,B_x)}\) on \(\Lambda \times E^{{\scriptscriptstyle {(\mathrm{Dir }})}}\) with intensity measure \( \nu ^{{\scriptscriptstyle {(\mathrm{Dir}})}} \) whose projections on \( \Lambda \times {{\mathcal {C}} }_{k,\Lambda }^{{\scriptscriptstyle {(\mathrm{Dir}})}} \) with \(k\le \left\lfloor \Lambda \right\rfloor \) are equal to \( \nu _k^{{\scriptscriptstyle {(\mathrm{Dir}})}}(\mathrm{d}x,\mathrm{d}f)=\frac{1}{k}\mathrm{Leb}_\Lambda (\mathrm{d}x)\otimes \mu _{x,x}^{{\scriptscriptstyle {({\mathrm{Dir},k\beta }})}}(\mathrm{d}f)\) and are zero on this set for \(k>N\). We do not label \(\omega _{\mathrm{P}}\) nor \(\xi _{ \mathrm P}\) with the boundary condition nor with N; \(\xi _{ \mathrm P}\) is a Poisson process on \(\Lambda \) with intensity measure \({{\overline{q}}}^{{\scriptscriptstyle {(\mathrm{Dir}})}}\) times the restriction \(\mathrm{Leb}_\Lambda \) of the Lebesgue measure to \(\Lambda \). By \({{\textsf {Q} }}^{{\scriptscriptstyle {(\mathrm{Dir}})}}\) and \( {{\textsf {E} }}^{{\scriptscriptstyle {(\mathrm{Dir}})}}\) we denote probability and expectation with respect to this process. Conditionally on \(\xi _{ \mathrm P}\), the lengths of the cycles \(B_x\) with \(x\in \xi _{ \mathrm P}\) are independent and have distribution \((q_k^{{\scriptscriptstyle {(\mathrm{Dir}})}}/{{\overline{q}}}^{{\scriptscriptstyle {(\mathrm{Dir}})}})_{k\in \{1,\dots ,\left\lfloor \Lambda \right\rfloor \}}\); this process has only marks with lengths \(\le \left\lfloor \Lambda \right\rfloor \). A cycle \(B_x\) of length k is distributed according to
The above representations allows us to prove the our large deviation principles as well as the variational analysis for Dirchlet boundary conditions. For details, we refer to [5] where these arguments are presented in detail. The independence of the thermodynamic limit of pressure in Theorem 2.2 follows using either the arguments in [5] or in [8, 20].
Bose Function
The Bose functions are poly-logarithmic functions defined by
and also for \( \alpha =0 \) and \( n>1 \). In the latter case,
which is Riemann zeta function. The behaviour of the Bose functions about \( \alpha =0 \) is given by

At \( \alpha =0 \), \( g(n,\alpha ) \) diverges for \( n\le 1 \), indeed for all n, there is some kind of singularity at \( \alpha =0 \), such as a branch point. For further details, see [16]. The expansions (B.3) are in terms of \( \zeta (n) \), which for \( n\le 1 \) must be found by analytically continuing (B.2). With the asymptotic properties of the zeta function, it can be shown that the k series in (B.3) are convergent for \( |\alpha |<2\pi \). Consequently (B.3) also represents an analytic continuation of \( g(n,\alpha ) \) for \( \alpha <0 \). When \( \alpha \gg 1 \) the series (B.1) itself is rapidly convergent, and as \( \alpha \rightarrow \infty \), \( g(n,\alpha )\sim \mathrm{e}^{-\alpha } \) for all n.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Adams, S., Dickson, M. An Explicit Large Deviation Analysis of the Spatial Cycle Huang–Yang–Luttinger Model. Ann. Henri Poincaré 22, 1535–1560 (2021). https://doi.org/10.1007/s00023-021-01023-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00023-021-01023-6