
Abstract
Hierarchical Model reduction and Proper Generalized Decomposition both exploit separation of variables to perform a model reduction. After setting the basics, we exemplify these techniques on some standard elliptic problems to highlight pros and cons of the two procedures, both from a methodological and a numerical viewpoint.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
This paper is meant as a first attempt to compare two procedures which share the idea of exploiting separation of variables to perform model reduction, albeit with different purposes. Proper Generalized Decomposition (PGD) is essentially employed as a powerful tool to deal with parametric problems in several fields of application [3, 14, 23]. Parametrized models characterize multi-query contexts, such as parameter optimization, statistical analysis or inverse problems. Here, the computation of the solution for many different parameters demands, in general, a huge computational effort, and this justifies the development of model reduction techniques.
For this purpose, projection-based techniques, such as Proper Orthogonal Decomposition (POD) or Reduced Basis methods, are widely used in the literature [11]. The idea is to project the discrete operators onto a reduced space so that the problem can be solved rapidly in the lower dimensional space. PGD adopts a completely different way to deal with parameters. Here, parameters are considered as new independent variables of the problem, together with the standard space-time ones [5]. Although the dimensionality of the problem is inevitably increased, PGD transforms the computation of the solution for new values of the parameters into a plain evaluation of the reduced solution, with striking computational advantages.
Hierarchical-Model (HiMod) reduction has been proposed to improve one-dimensional (1D) partial differential equation (PDE) solvers for problems defined in domains with a geometrically dominant direction, like slabs or pipes [6, 20]. The main applicative field of interest is hemodynamics, in particular the modeling of blood flow in patient-specific geometries. Purely 1D hemodynamic models completely drop the transverse dynamics, which, however may be locally important (e.g., in the presence of a stenosis or an aneurism). HiMod aims at providing a numerical tool to incorporate the transverse components of the 3D solution into a conceptually 1D solver. To do this, the driving idea is to discretize main and transverse dynamics in a different way. The latter are generally of secondary importance and can be described by few degrees of freedom using a spectral approximation, in combination, for instance, with a finite element (FE) discretization of the mainstream.
The parametric version of HiMod (namely, HiPOD) is a more recent proposal [4, 13]. On the other hand, PGD is not so widely employed in a non-parametric setting, despite its original formulation [12]. Nevertheless, for the sake of comparison, in this paper we consider the non-parametric as well as the parametric versions of both the HiMod and PGD approaches. The goal is to begin a preliminary comparative analysis between the two methodologies, to highlight the respective weaknesses and strengths. The main limit of PGD remains its inability to deal with non-Cartesian geometries without losing the computational benefits arising from the separability of the spatial coordinates. HiMod turns out to be more flexible from a geometric viewpoint. On the other hand, PGD turns out to be extremely effective for parametric problems thanks to the explicit expression of the PGD solution in terms of the parameters, while HiPOD can be classified as a projection-based method with all the associated drawbacks. In perspective, the ultimate goal is to merge HiMod with PGD to emphasize the good features and mitigate the intrinsic limits of the two methods taken alone.
2 The HiMod Approach
Hierarchical Model reduction proved to be an efficient and reliable method to deal with phenomena characterized by dominant dynamics [10]. In general, the computational domain itself exhibits an intrinsic directionality. We assume \(\Omega \subset \mathbb {R}^d\) (d = 2, 3) to coincide with a d-dimensional fiber bundle, \(\Omega = \bigcup _{x \in \Omega _{1D}} \{ x \} \times \gamma _x\), where \(\Omega _{1D}\subset \mathbb {R}\) denotes the supporting fiber aligned with the main stream, while \(\gamma _x \subset \mathbb {R}^{d-1}\) is the transverse fiber at x ∈ Ω 1D, parallel to the transverse dynamics. For the sake of simplicity, we identify Ω1D with a straight segment, (x 0, x 1). We refer to [15, 21] for the case where Ω 1D is curvilinear. From a computational viewpoint, the idea is to exploit a map, \(\Psi :\Omega \rightarrow \hat \Omega \), transforming the physical domain, Ω, into a reference domain, \(\hat \Omega \), and to make explicit computations in \(\hat \Omega \) only. Typically, \(\hat \Omega \) coincides with a rectangle in 2D, with a cylinder with circular section in 3D. To define Ψ, for each x ∈ Ω1D, we introduce the map, \(\psi _x: \gamma _x \rightarrow \hat {\gamma }_{d-1}\), from fiber γ x to the reference transverse fiber, \(\hat {\gamma }_{d-1}\), so that the reference domain coincides with \(\hat {\Omega } = \bigcup _{x \in \Omega _{1D}} \{ x \} \times \hat {\gamma }_{d-1}\). The supporting fiber is preserved by map Ψ, which modifies the lateral boundaries only.
We consider now the (full) problem to be reduced. Due to the comparative purposes of the paper, we focus on a scalar elliptic equation, and, in particular, on the associated weak formulation,
where V ⊆ H 1( Ω), \(a(\cdot , \cdot ): V \times V \rightarrow \mathbb {R}\) is a continuous and coercive bilinear form and \(F(\cdot ): V \rightarrow \mathbb {R}\) is a continuous linear functional. To provide the HiMod formulation for problem (1), we introduce the hierarchical reduced space
for a modal index \(m\in \mathbb {N}^+\), where \(V_{1D}^h \subseteq H^1(\Omega _{1D})\) is a discrete space of dimension N h associated with a partition \(\mathcal {T}_h\) of Ω1D, while \(\{ \varphi _k \}_{k=1}^m\) denotes a modal basis of functions orthogonal with respect to the \(L^2(\hat {\gamma }_{d-1})\)-scalar product. Index m sets the hierarchical level of the HiMod space, being V m ⊂ V m+1, for any m. Concerning \(V_{1D}^h\), we adopt here a standard FE space, although any discrete space can be employed (see, e.g., [21], where an isogeometric discretization is used). Functions in \(V_{1D}^h\) have to include the boundary conditions on \(\{x_0\}\times \gamma _{x_0}\) and \(\{x_1\}\times \gamma _{x_1}\); analogously, the modal functions have to take into account the boundary data along the horizontal sides. In Sect. 4 further comments are provided about the selection of the modal basis and of the modal index m. The HiMod formulation for problem (1) thus reads
To ensure the well-posedness of formulation (3) and the convergence of the HiMod approximation, \(u_m^{\mathrm {HiMod}}\), to the full solution, u, we endow the HiMod space with a conformity and a spectral approximability hypothesis, and we introduce a standard density assumption on the discrete space \(V_{1D}^h\) (see [20] for all the details).
The HiMod solution can be fully characterized by introducing a basis, \(\{ \theta _l \}_{l=1}^{N_h}\), for the space \(V_{1D}^h\). Actually, each modal coefficient, \(\tilde {u}_k\), of \(u_m^{\mathrm {HiMod}}\) can be expanded in terms of such a basis, so that, we obtain the modal representation
The actual unknowns of problem (3) become the mN h coefficients \(\{ \tilde {u}_{k,l} \}_{k=1, l=1}^{m, N_h}\). With reference to the Poisson problem, − Δu = f, completed with full homogeneous Dirichlet boundary data, the corresponding HiMod formulation, after exploiting (4) in (3) and picking v m(x, y) = θ i(x)φ j(ψ x(y)) with i = 1, …, N h and j = 1, …, m, reduces to the system of mN h 1D equations in the mN h unknowns \(\{ \tilde {u}_{k,l} \}_{k=1, l=1}^{m, N_h}\),
where \(\hat r^{a, b}_{jk}(x)=\int _{\hat \gamma _{d-1} }r^{a, b}_{jk}(x, \hat {\mathbf {y}})|J|\, d\hat {\mathbf {y}}\) with a, b = 0,1, \(J=\mathrm {det}\big ( {\mathcal D}_2^{-1}(x, \psi _x^{-1}(\hat {\mathbf {y}}) )\big )\) with \({\mathcal D}_2={\mathcal D}_2(x, \psi _x^{-1}(\hat {\mathbf {y}}) )=\nabla _{\mathbf {y}}\psi _x\),
with \({\mathcal D}_1={\mathcal D}_1(x, \psi _x^{-1}(\hat {\mathbf {y}}) )=\partial \psi _x/\partial x\), and \(\hat f_j (x)=\int _{\hat \gamma _{d-1} } f(x, \psi _x^{-1}(\hat {\mathbf {y}}) ) \varphi _j(\hat {\mathbf {y}}) |J|\, d \hat {\mathbf {y}}\). Information associated with the transverse dynamics are lumped in the coefficients \(\{ \hat r^{a, b}_{jk} \}\), so that the HiMod system is solved on the supporting fiber, Ω1D. Collecting the HiMod unknowns, by mode, in the vector \({\mathbf {u}}_m^{\mathrm {HiMod}}\in \mathbb {R}^{m N_h}\), such that
we can rewrite the HiMod system in the compact form
where \(A_m^{\mathrm {HiMod}} \in \mathbb {R}^{m N_h \times m N_h}\) and \({\mathbf {f}}_m^{\mathrm {HiMod}} \in \mathbb {R}^{m N_h}\) are the HiMod stiffness matrix and right-hand side, respectively, with \([ {\mathbf {f}}_m^{\mathrm {HiMod}} ]_{ji}=\int _{\Omega _{1D}} \hat f_j (x) \theta _i(x) dx\), and \([A_m^{\mathrm {HiMod}}]_{ji,kl}= \sum _{a,b=0}^1 \int _{\Omega _{1D}} \hat r^{a, b}_{jk}(x) \frac {d^a \theta _l}{dx}(x) \frac {d^b \theta _i}{dx}(x) dx\). According to (5), for each modal index j, between 1 and m, the nodal index, i, takes the values 1, …, N h. Thus, HiMod reduction leads to solve a system of order mN h, independently of the dimension of the full problem (1).
3 The PGD Approach
To perform PGD, we have to introduce on problem (1) a separability hypothesis with respect to both the spatial variables and the data [5, 22]. Thus, domain \(\Omega \subset \mathbb {R}^d\) coincides with the rectangle Ωx × Ωy if d = 2, with the parallelepiped Ωx × Ωy × Ωz (total separability) or with the cylinder Ωx × Ωy (partial separability) if d = 3, for Ωx, Ωy, \(\Omega _z \subset \mathbb {R}\) and \(\Omega _{\mathbf {y}} \subset \mathbb {R}^{2}\), being y = (y, z). In the following, we focus on partial separability, since it is more suited to match HiMod reduction with PGD. Analogously, we assume that the generic problem data, d = d(x, y, z), can be written as d = d x(x)d y(y). The separability is inherited by the PGD space
where \(W^x_h \subseteq H^1(\Omega _x)\) and \(W^{\mathbf {y}}_h \subseteq H^1(\Omega _{\mathbf {y}}; \mathbb {R}^{d-1})\) are discrete spaces, with \(\text{dim}(W^x_h)=N_h^x\) and \(\text{dim}(W^{\mathbf {y}}_h)=N_h^{\mathbf {y}}\), associated with partitions, \(\mathcal {T}_h^x\) and \(\mathcal {T}_h^{\mathbf {y}}\), of Ωx and Ωy, respectively. In general, \(W^x_h\) and \(W^{\mathbf {y}}_h\) are FE spaces, although, a priori, any discretization can be adopted. It turns out that W m is a tensor function space, being \(W_m = W^x_h \otimes W^{\mathbf {y}}_h \subseteq H^1(\Omega _x) \otimes H^1(\Omega _{\mathbf {y}}; \mathbb {R}^{d-1})\).
Index m plays the same role as in the HiMod reduction, setting the level of detail for the reduced solution (see Sect. 4 for possible criteria to choose m). PGD exploits the hierarchical structure in W m to build the generic function w m ∈ W m. In particular, w m is computed as
where \(w_k^x\) and \(w_k^{\mathbf {y}}\) are assumed known for k = 1, …, m − 1, so that the enrichment functions, \(w_m^x\) and \(w_m^{\mathbf {y}}\), become the actual unknowns. To provide the PGD formulation for the Poisson problem considered in Sect. 2, we exploit representation (8) for the PGD approximation, \(u^{\mathrm {PGD}}_m\), and we pick the test function as X(x)Y (y), with \(X\in W_h^x\) and \(Y\in W^{\mathbf {y}}_h\). The coupling between the unknowns, \(u_m^x\) and \(u_m^{\mathbf {y}}\), leads to a nonlinear problem, which is tackled by means of the Alternating Direction Strategy (ADS) [5]. The idea is to look for \(u_m^x\) and \(u_m^{\mathbf {y}}\), separately via a fixed point procedure. We introduce an auxiliary index to keep trace of the ADS iterations, so that, at the p-th ADS iteration we compute \(u_m^{x, p}\) and \(u^{\mathbf {y},p}_m\) starting from the previous approximations, \(u_m^{x, g}\) and \(u^{\mathbf {y},g}_m\) for g = 1, …, p − 1, following a two-step procedure. First, we compute \(u_m^{x, p}\) by identifying \(u_m^{\mathbf {y}}\) with \(u^{\mathbf {y},p-1}_m\), and by selecting \(Y(\mathbf {y})=u^{\mathbf {y},p-1}_m\) in the test function. This yields, for any \(X\in W_h^x\),
where the separability of f is exploited (the dependence on the independent variables, x and y, is omitted to simplify notation). Successively, we compute \(u_m^{\mathbf {y}, p}\), after setting \(u_m^x\) to \(u_m^{x,p}\) and choosing function X as to \(u_m^{x,p}\) in the test function, so that we obtain, for any \(Y\in W_h^{\mathbf {y}}\),
The algebraic counterpart of (9) and (10) is obtained by introducing a basis, \( {\mathcal B}_x=\{ \theta _\alpha ^x \}_{\alpha = 1}^{N_h^x}\) and \({\mathcal B}_{\mathbf {y}}=\{ \theta _\beta ^{\mathbf {y}} \}_{\beta = 1}^{N_h^{\mathbf {y}}}\), for the space \(W^x_h\) and \(W^{\mathbf {y}}_h\), respectively, so that \(u_j^q(q)=\sum _{i=1}^{N_h^q} \tilde u_{ji}^q \theta _i^q(q)\), \(u_m^{q,s}(q)=\sum _{i=1}^{N_h^q} \tilde u_{mi}^{q,s} \theta _i^q(q)\), with q = x, y, s = p, p − 1, j = 1, …, m − 1, and, likewise, \(X(x)=\sum _{\alpha =1}^{N_h^x} \tilde x_{\alpha } \theta _\alpha ^x(x)\) and \(Y(\mathbf {y})=\sum _{\beta =1}^{N_h^{\mathbf {y}}} \tilde y_{\beta } \theta _{\beta }^{\mathbf {y}}(\mathbf {y})\). Thanks to these expansions and to the arbitrariness of X and Y , we can rewrite (9) and (10) as
and
respectively, where vectors \({\mathbf {u}}_j^q\), \({\mathbf {u}}_m^{q,s}\in \mathbb {R}^{N_h^q}\) collect the PGD coefficients, being \(\big [ {\mathbf {u}}_j^q \big ]_i=\tilde u_{ji}^q\), \(\big [ {\mathbf {u}}_m^{q,s} \big ]_i=\tilde u_{mi}^{q,s}\) and \(i=1,\ldots , N_h^q\), K x, \(M^x\in \mathbb {R}^{N_h^x\times N_h^x}\) and K y, \(M^{\mathbf {y}}\in \mathbb {R}^{N_h^{\mathbf {y}}\times N_h^{\mathbf {y}}}\) are the stiffness and mass matrices associated with x- and y-variables, with \(\big [ K^x \big ]_{\alpha l}=\int _{\Omega _x} \big ( \theta _\alpha ^x \big )' \big ( \theta _l^x \big )' dx\), \(\big [ K^{\mathbf {y}} \big ]_{\beta s}=\int _{\Omega _{\mathbf {y}}} \big ( \theta _\beta ^{\mathbf {y}} \big )' \big ( \theta _s^{\mathbf {y}} \big )' d{\mathbf {y}}\), \(\big [ M^x \big ]_{\alpha l}=\int _{\Omega _x} \theta _\alpha ^x \theta _l^x dx\), \(\big [ M^{\mathbf {y}} \big ]_{\beta s}=\int _{\Omega _{\mathbf {y}}} \theta _\beta ^{\mathbf {y}} \theta _s^{\mathbf {y}} d{\mathbf {y}}\), and where \({\mathbf {f}}^x\in \mathbb {R}^{N_h^x}\), \({\mathbf {f}}^{\mathbf {y}} \in \mathbb {R}^{N_h^{\mathbf {y}} }\), with \(\big [ {\mathbf {f}}^x\big ]_l=\int _{\Omega _x} f^x \theta _l^x dx\), \(\big [ {\mathbf {f}}^{\mathbf {y}} \big ]_s=\int _{\Omega _{\mathbf {y}}} f^{\mathbf {y}} \theta _s^{\mathbf {y}} d{\mathbf {y}}\), for \(\alpha , l=1, \ldots , N_h^x\), \(\beta , s=1, \ldots , N_h^{\mathbf {y}}\). Systems (11) and (12) are solved at each ADS iteration, so that the computational effort characterizing PGD is the one associated with the solution of two systems of order \(N_h^x\) and \(N_h^{\mathbf {y}}\), respectively, for each ADS iteration. When a certain stopping criterion is met (see the next section for more details), ADS procedure yields vectors \({\mathbf {u}}_m^x\) and \({\mathbf {u}}_m^{\mathbf {y}}\) which identify the enrichment functions \(u_m^x\) and \(u_m^{\mathbf {y}}\).
4 HiMod Reduction Versus PGD
Both HiMod reduction and PGD exploit the separation of variables and, according to [5], belong to the a priori approaches, since they do not rely on any solution to the problem at hand. Nevertheless, we can easily itemize features which distinguish the two techniques. The most relevant ones concern the geometry of Ω, the selection of the transverse basis and of the modal index, and the numerical implementation of the two procedures. Pros and cons of the two methods are then here highlighted.
4.1 Domain Geometry
HiMod reduction and PGD advance precise hypotheses on the geometry of the computational domain.
According to the HiMod approach, Ω is expected to coincide with a fiber bundle and to be mapped into the reference domain, \(\hat \Omega \), by a sufficiently regular transformation. Actually, map Ψ is assumed differentiable, while map ψ x is required to be a C 1-diffeomorphism, for all x ∈ Ω1D [20]. These hypotheses introduce some constraints, in particular, on the lateral boundary of Ω which, e.g., cannot exhibit kinks. Additionally, geometries of interest in many applications, such as bifurcations or, more in general, networks are ruled out from the demands on ψ x and Ψ. An approach based on the domain decomposition technique is currently under investigation as a viable way to deal with such geometries. The isogeometric version of HiMod (i.e., the HIgaMod approach) will play a crucial role in view of HiMod simulations for the blood flow modeling in patient-specific geometries [21].
The constraints introduced by PGD on the geometry of Ω are more restrictive. The separability hypothesis leads to consider essentially only Cartesian domains. This considerably reduces the applicability of PGD to practical contexts. Some techniques are available in the literature to overcome this issue. For instance, in [9] a generic domain is embedded into a Cartesian geometry, while in [7] the authors introduce a parametrization map for quadrilateral domains.
Overall, HiMod reduction exhibits a higher geometric flexibility with respect to PGD, in its straightforward formulation. As discussed in Sect. 5, this limitation can be removed when considering a parametric setting.
4.2 Modeling of the Transverse Dynamics
In the HiMod expansion, y-components, φ k(ψ x(y)), are selected before starting the model reduction. This choice, although coherent with an a priori approach, introduces a constraint on the dynamics that can be described, so that hints about the solution trend along the transverse direction can be helpful to select a representative modal basis. In the original proposal of the HiMod procedure, sinusoidal functions are employed according to a Fourier expansion [6, 20]. This turns out to be a reasonable choice when Dirichlet boundary conditions are assigned on the lateral surface, Γlat = {x}× ∂γ x, of Ω. Legendre polynomials, properly modified to include the homogeneous Dirichlet data and orthonormalized, are employed in [20] as an alternative to a trigonometric expansion. Nevertheless, Legendre polynomials require high-order quadrature rules to accurately compute coefficients \(\{ \hat r^{a, b}_{jk} \}\).
In [1], the concept of educated modal basis is introduced to impose generic boundary conditions on Γlat. The idea is to solve an auxiliary Sturm-Liouville eigenvalue problem on the transverse reference fiber \(\hat \gamma _{d-1}\), to build a basis which automatically includes the boundary values on Γlat. The eigenfunctions of the Sturm-Liouville problem provide the modal basis. A first attempt to generalize the educated-HiMod reduction to three-dimensional (3D) cylindrical geometries is performed in [10], where the Navier-Stokes equations are hierarchically reduced to model the blood flow in pipes. This generalization is far from being straightforward due to the employment of polar coordinates. To overcome this issue, we are currently investigating the HIgaMod approach [21], which allows us to define the transverse basis as the Cartesian product of 1D modal functions, independently of the considered geometry.
Additionally, we remark that any modal basis can be precomputed on the transverse reference fiber before performing the HiMod reduction, thanks to the employment of map Ψ. This considerably simplifies computations.
When applying PGD, y-components are unknown as the ones associated with x. This leads to the nonlinear problems (9)–(10), thus loosing any advantage related to a precomputation of the HiMod modal basis. On the other hand, PGD does not constrain the transverse dynamic to follow a prescribed (e.g., sinusoidal) analytical shape as HiMod procedure does. The educated-Himod reduction clearly is out of this comparison, since the modal basis strictly depends on the problem at hand.
Finally, we observe that HiMod modes are orthonormal with respect to the \(L^2(\hat \gamma _{d-1})\)-norm. This property is not ensured by PGD.
Concerning the selection of the modal index m in (2) and (7), as a first attempt, both HiMod reduction and PGD resort to a trial-and-error approach, so that the modal index is gradually increased until a check on the accuracy of the reduced solution is satisfied. For instance, in [6, 20] a qualitative investigation of the contour plot of the HiMod approximation drives the choice of m. Concerning PGD, the check on the relative enrichment
is usually employed, with TOL E a user-defined tolerance [5]. An automatic selection of index m can yield a significant improvement. In [17, 19], an adaptive procedure is proposed for HiMod, based on an a posteriori modeling error analysis. In particular, the estimator in [17] is derived in a goal-oriented setting to control a quantity of interest, and exploits the hierarchical structure (i.e., the inclusion V m ⊂ V m+d, ∀m, \(d\in \mathbb {N}^+\)) typical of a HiMod reduction. A similar modeling error analysis is performed in [2] for PGD, although no adaptive algorithm is here set to automatically pick the reduced model. Paper [19] generalizes the a posteriori analysis in [17] to an unsteady setting, providing the tool to automatically select m together with the partition \(\mathcal {T}_h\) along Ω1D and the time step.
Finally, HiMod allows to tune the modal index along the domain Ω, according to the local complexity of the transverse dynamics. In particular, m can be varied in different areas of Ω or, in the presence of very localized dynamics, in correspondence with specific nodes of the partition \(\mathcal {T}_h\). We refer to these two variants as to piecewise and pointwise HiMod reduction, in contrast to a uniform approach, where the same number of modes is adopted everywhere [16, 18]. This flexibility in the choice of m is currently not available for PGD. Adaptive strategies to select the modal index are available for the three variants of the HiMod procedure [17, 19].
4.3 Computational Aspects
From a computational viewpoint, HiMod reduction and PGD lead to completely different procedures. Indeed, for a fixed value of m, we have to solve the only system (6) of order mN h when applying HiMod, in contrast to PGD which demands a multiple solution of systems (11)–(12) of order \(N_h^x\) and \(N_h^{\mathbf {y}}\), respectively because of the fixed point and the enrichment algorithms. Thus, the direct solution of a single system, in general of larger order, is replaced by an iterative solution of several and smaller systems. This heterogeneity makes a computational comparison between PGD and HiMod not so meaningful. We verify the reliability of the HiMod and PGD procedures on a common test case, by choosing in (1) \(V=H^1_0(\Omega )\) with Ω = (0, 5) × (0, 1), a(u, v) =∫Ω[μ∇u ⋅∇v + b ⋅∇u]d Ω for μ = 0.24, b = [−5, 0]T, and F(v) =∫Ω fvd Ω with \(f(x,y) = 50 \big \{\exp \big [ - \big ((x-2.85)/0.075 \big )^2 - \big ( (y - 0.5)/0.075 \big )^2 \big ] + \exp \big [ - \big ((x-3.75)/0.075 \big )^2 - \big ( (y - 0.5)/0.075 \big )^2 \big ] \big \}\). For both the methods, we uniformly subdivide Ω1D into 285 subintervals. We set the PGD discretization along y as well as the PGD and the HiMod index m in order to ensure the same accuracy, TOL, on the reduced approximations with respect to a reference FE solution, computed on a 2500 × 500 structured mesh. In particular, for TOL = 8 ⋅ 10−3, we have to subdivide interval (0, 1) into 20 uniform subintervals, and to set m to 6 and to 9 in the PGD and the HiMod discretization, respectively. Sinusoidal functions are chosen for the HiMod modal basis. The ADS iterations are controlled in terms of the relative increment, as
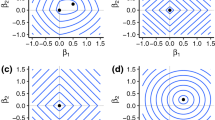
with TOL FP = 10−2. Figure 1 shows the reduced approximations (which are fully comparable with the FE one, here omitted). The contourplots are very similar. The coarse PGD y-discretization justifies the slight roughness of the PGD contourlines.

Qualitative comparison between a HiMod (left) and a PGD (right) approximations
Another distinguishing feature between HiMod and PGD is the domain discretization. Indeed, HiMod requires only the partition \(\mathcal {T}_h\) along Ω1D, independently of the dimension of Ω. No discretization is needed in the y-direction, although we have to carefully select the quadrature nodes to compute coefficients \(\{ \hat r^{a, b}_{jk} \}\). This task becomes particularly challenging when dealing with polar coordinates [10]. With PGD to benefit of the computational advantages associated with a 1D discretization, we are obliged to assume the full separability of Ω; actually, a partial separability demands a 1D partition for Ωx, and a two-dimensional partition of Ωy. As explained in Sect. 5, non-Cartesian domains require a 3D discretization of Ω.
Finally we analyze the interplay between the enrichment and the ADS iterations in the PGD reduction. We investigate the possible relationship between TOL FP in (14) and TOL E in (13), to verify if a small tolerance for the fixed point iteration improves the accuracy of the PGD approximation, thus reducing the number of enrichment steps. To do this, we adopt the same test case used above. Table 1 gathers the number of ADS iterations, #IT FP, the number, m, of enrichment steps, and the CPU timeFootnote 1 (in seconds) demanded by the PGD procedure, for two different values of TOL E and three different choices of TOL FP. In particular, in column #IT FP we specify the number of ADS iterations required by each enrichment step. As expected, there exists a link between the two tolerances, namely, when a higher accuracy constrains the fixed point iteration, a smaller number of enrichment steps is performed to ensure the accuracy TOL E.
5 HiMod Reduction and PGD for Parametrized Problems
The actual potential of PGD becomes more evident when considering a parametric setting, i.e., when problem (1) is replaced by the formulation
with μ a parameter, which may represent any data of the problem, e.g., the coefficients of the considered PDE, the source term, a boundary value or the domain geometry.
The technique adopted by PGD to deal with the parametric dependence in (15) is very effective. Parameter μ is considered as an additional independent variable which varies in a domain Ωμ [5]. Thus, the PGD space (7) changes into the new one
with \(W^{\boldsymbol \mu }_h\) a discretization of the space \(L^2(\Omega _{\boldsymbol \mu }; \mathbb {R}^Q)\), being Q the length of vector μ. Generalizing the enrichment paradigm in (8), at the m-th step of the PGD approach applied to problem (15) we have to compute three unknown functions, \(u_m^x\), \(u_m^{\mathbf {y}}\) and \(u_m^{\boldsymbol \mu }\), by picking the test function as X(x)Y (y)Z(μ), with \(X\in W_h^x\), \(Y\in W^{\mathbf {y}}_h\), \(Z\in W_h^{\boldsymbol \mu }\). Functions \(u_m^x\), \(u_m^{\mathbf {y}}\), \(u_m^{\boldsymbol \mu }\) are computed by ADS, which now coincides with a three-step procedure. Thus, with reference to the Poisson problem, −∇⋅(μ∇u) = f completed with full homogeneous Dirichlet boundary conditions and for μ ≡ μ, we first compute \(u_m^{x, p}\) by identifying \(u_m^{\mathbf {y}}\) and \(u_m^{\boldsymbol \mu }\) with the previous approximations, \(u^{\mathbf {y},p-1}_m\) and \(u_m^{\boldsymbol \mu , p-1}\), respectively and by selecting \(Y(\mathbf {y})Z({\boldsymbol \mu })=u^{\mathbf {y},p-1}_m u^{{\boldsymbol \mu },p-1}_m\) in the test function. This leads to a linear system which generalizes (11), namely
where \(M^{\boldsymbol \mu }\in \mathbb {R}^{N_h^{\boldsymbol \mu } \times N_h^{\boldsymbol \mu }}\) is the mass matrix associated with the parameter μ, with \(\big [ M^{\boldsymbol \mu } \big ]_{ij}=\int _{\Omega _{\boldsymbol \mu }} \boldsymbol \mu \theta _i^{\boldsymbol \mu } \theta _j^{\boldsymbol \mu } d{\boldsymbol \mu }\) for i, \(j=1,\ldots , N_h^{\boldsymbol \mu }\) and \({\mathcal B}_{\boldsymbol \mu }=\{ \theta _\gamma ^{\boldsymbol \mu } \}_{\gamma = 1}^{N_h^{\boldsymbol \mu }}\) a basis for the space \(W_h^{\boldsymbol \mu }\), \({\mathbf {f}}^{\boldsymbol \mu } \in \mathbb {R}^{N_h^{\boldsymbol \mu } }\) with \(\big [ {\mathbf {f}}^{\boldsymbol \mu }\big ]_l=\int _{\Omega _{\boldsymbol \mu }} f^{\boldsymbol \mu } \theta _l^{\boldsymbol \mu } d{\boldsymbol \mu }\) for \(l=1,\ldots , N_h^{\boldsymbol \mu }\) after assuming the separability f = f x f y f μ for the source term f, and where we employ the same notation as in (11)–(12) to denote vectors \({\mathbf {u}}_w^{\boldsymbol \mu }\), \({\mathbf {u}}_m^{\boldsymbol \mu , s}\), with w = 1, …, m − 1, s = p, p − 1, collecting the PGD coefficients associated with the basis \({\mathcal B}_{\boldsymbol \mu }\). Analogously, \(u_m^{\mathbf {y}, p}\) is computed by solving the generalization of the linear system (12) given by
after setting \(u_m^x=u_m^{x, p}\), \(u_m^{\boldsymbol \mu }=u_m^{\boldsymbol \mu , p-1}\) and \(X(x)Z({\boldsymbol \mu })=u^{x,p}_m u^{{\boldsymbol \mu },p-1}_m\) for the PGD test function. Finally, we have the additional linear system used to compute \(u_m^{\boldsymbol \mu , p}\),
obtained for \(u_m^x=u_m^{x, p}\), \(u_m^{\mathbf {y}}=u_m^{\mathbf {y}, p}\) and by selecting \(X(x)Y(\mathbf {y})=u^{x,p}_m u^{\mathbf {y},p}_m\) for the test function. From a computational viewpoint, at each ADS iteration, we have to solve now three linear systems of order \(N_h^x\), \(N_h^{\mathbf {y}}\), \(N_h^{\boldsymbol \mu }\), respectively.
We investigate the reliability of PGD on problem (15), for \(V=H^1_{\Gamma _{\mathrm {in}}\cup \Gamma _{\mathrm {up}}\cup \Gamma _{\mathrm {down}}} (\Omega )\) with Ω = (0, 3) × (0, 1), Γin = {0}× (0, 1), Γup = (0, 3) ×{1}, Γdown = (0, 3) ×{0}, a(u, v) =∫Ω[μ∇u ⋅∇v + b ⋅∇u]d Ω with b = [2.5, 0]T and μ the parameter to be varied in Ωμ = [1, 5], F(v) =∫Ω fvd Ω with f = 1. The problem is completed with mixed boundary conditions, namely a homogeneous Dirichlet data on Γup ∪ Γdown, the non-homogeneous Dirichlet condition, u = u in with u in = y(1 − y), on Γin and a homogeneous Neumann value on Γout = {3}× (0, 1). We apply the PGD reduction for m = 2, and we uniformly subdivide Ωx, Ωy, Ωμ, being \(N_h^x=150\), \(N_h^{y}=50\), \(N_h^{\mu }=500\). The tolerance in (14) is set to 10−2. Figure 2 compares the PGD approximation for μ = 1 and μ = 2.5 with a reference full solution coinciding with a linear FE approximation computed on a 300 × 100 structured mesh. The qualitative matching between the corresponding solutions is significant. From a quantitative viewpoint, the L 2( Ω)-norm of the relative error associated with the PGD approximation does not vary significantly by increasing m, whereas a slight error reduction is detected by increasing μ.

Qualitative comparison between the reference (left) and the PGD (right) solutions, for μ = 1 (top) and μ = 2.5 (bottom)
The parametric counterpart of the HiMod reduction, known as HiPOD, merges HiMod with POD [4, 13]. HiPOD pursues a different goal with respect to PGD. Indeed, for a new value, μ ∗, of the parameter, PGD provides an approximation for the full solution u(μ ∗), while HiPOD approximates the HiMod solution associated with μ ∗. The offline/online paradigm of POD is followed also by HiPOD. The peculiarity is that the offline step is now performed in the HiMod setting to contain the computational burden typical of this stage and by relying on the good properties of HiMod in terms of reliability-versus-accuracy balance. Thus, we choose P different values, μ = μ i with i = 1, …, P, for parameter μ, and we collect the HiMod approximation for the corresponding problem (15) into the response matrix, \(\mathcal S = \big [ {\mathbf {u}}_m^{\mathrm {HiMod}} (\boldsymbol {\mu }_1), {\mathbf {u}}_m^{\mathrm {HiMod}} (\boldsymbol {\mu }_2), \ldots , {\mathbf {u}}_m^{\mathrm {HiMod}} (\boldsymbol {\mu }_P) \big ]\in \mathbb {R}^{mN_h\times P}\), according to representation (5). Successively, we define the null-average matrix
and we apply the Singular Value Decomposition (SVD) to \(\mathcal V\), so that \(\mathcal V=\Phi \Sigma \Psi ^T\), where \(\Phi \in \mathbb {R}^{(mN_h) \times (mN_h)}\) and \(\Psi \in \mathbb {R}^{P\times P}\) are the unitary matrices of the left- and of the right-singular vectors of \({\mathcal V}\), respectively while \(\Sigma = \text{ diag }(\sigma _1, \dots , \sigma _{\rho }) \in \mathbb {R}^{(mN_h) \times P}\) denotes the pseudo-diagonal matrix of the singular values of \({\mathcal V}\), being σ 1 ≥ σ 2 ≥⋯ ≥ σ ρ ≥ 0 and \(\rho = \min (m N_h, P)\) [8]. The POD basis is identified by the first l left singular vectors, ϕ i, of \(\mathcal V\), so that the reduced POD space is \(V_{\mathrm {POD}}^l= \text{span} \{{\boldsymbol \phi }_1, \dots , {\boldsymbol \phi }_{l}\}\), with \(\dim (V_{\mathrm {POD}}^l)=l\) and l ≪ mN h. In the numerical assessment below, value l coincides with the smallest integer such that \(\sigma _{l}^2< \varepsilon \), with ε a prescribed tolerance.
The online phase of HiPOD approximates the HiMod solution to problem (15) for a new value, μ ∗, of the parameter by exploiting the POD basis instead of solving system (6). This is performed via a projection step. After assembling the HiMod stiffness matrix and right-hand side, \(A_m^{\mathrm {HiMod}}({\boldsymbol {\mu }}^*)\) and \({\mathbf {f}}_m^{\mathrm {HiMod}}({\boldsymbol {\mu }}^*)\), associated with the new value of the parameter, we solve the POD system of order l
where \(A_{\mathrm {POD}}({\boldsymbol {\mu }}^*)=(\Phi _{\mathrm {POD}}^l)^T A_m^{\mathrm {HiMod}}({\boldsymbol {\mu }}^*) \, \Phi _{\mathrm {POD}}^l\) and \({\mathbf {f}}_{\mathrm {POD}}({\boldsymbol {\mu }}^*) = (\Phi _{\mathrm {POD}}^l)^T {\mathbf {f}}_m^{\mathrm {HiMod}} ({\boldsymbol {\mu }}^*)\) denote the POD stiffness matrix and right-hand side, respectively with \(\Phi _{\mathrm {POD}}^l=[{\boldsymbol \phi }_1, \ldots , {\boldsymbol \phi }_l]\in \mathbb {R}^{(mN_h) \times l}\) the matrix collecting the POD basis vectors. The HiMod solution is thus approximated by vector \(\Phi _{\mathrm {POD}}^l {\mathbf {u}}_{\mathrm {POD}}({\boldsymbol {\mu }}^*)\in \mathbb {R}^{mN_h}\), i.e., after solving a system of order l instead of mN h. Overall, HiPOD requires to solve P linear systems of order mN h during the offline phase, additionally to a system of order l in the online phase.

Contour plots: comparison between the reference HiMod solution (left) and the HiPOD approximation with l = 1 (right), for μ ∗ = 1 (top) and μ∗ = 2.5 (bottom). Table: relative error between HiMod and HiPOD solutions with respect to the L 2( Ω)-norm
To check the performances of HiPOD, we adopt the test case used above for PGD, for the same values of the parameters, μ ∗ = 1 and μ ∗ = 2.5. The reference solution is the corresponding HiMod approximation computed by using m = 15 sinusoidal functions in the y-direction, and a linear FE discretization along the mainstream based on a uniform subdivision of Ω1D into 50 subintervals. The same HiMod discretization is adopted to build the response matrix. Concerning the HiPOD approximation, we pick P = 100 by uniformly sampling the interval [1, 5], and we select ε = 2.5 ⋅ 10−15. This choice sets the dimension of the POD space to l = 8, so that we have to solve a system of order 8 instead of 750. The contour plots in Fig. 3 qualitatively compare the HiMod solution with the HiPOD approximation for l = 1. The correspondence between the two approximations is good despite a single POD mode is employed (in such a case, system (18) reduces to a scalar equation). We do not provide the HiPOD approximations for l = 8 since they qualitatively coincide with the corresponding HiMod solution. The left panels can be additionally compared with the FE solutions in Fig. 2 to verify the reliability of the HiMod procedure. Finally, the table in Fig. 3 gathers the L 2( Ω)-norm of the relative error between HiMod and HiPOD solutions, for four different POD bases and for three choices of the viscosity (1, 2.5 and the average over a sampling of 30 random values of μ). The error monotonically decreases for larger and larger values of l, independently of the choice for μ. If we compare the values for μ = 1 and for μ = 2.5 (one of the endpoints and the midpoint of the sampling interval, respectively), we notice a higher accuracy (of about one order of magnitude) for the latter choice. This is rather standard in projection-based reduced order modeling [11]. Concerning the computational saving in terms of CPU time, HiPOD method requires on average O(10−3)[s] to be compared with O(10)[s] demanded by HiMod, resulting in a speedup of 104.
Although PGD and HiPOD are not directly comparable due to the different purpose they pursue, we highlight the main pros and cons of the two methods. The explicit dependence of the approximation on the parameters makes PGD an ideal tool to efficiently deal with parametric problems. For any new parameter, a direct evaluation yields the corresponding PGD approximation. On the other hand, HiPOD suffers of the drawbacks typical of the projection-based methods. The main bottleneck is the assembling of the HiMod arrays involved in A POD(μ ∗) and f POD(μ ∗).
When PGD is applied to parametric problems, we recover the possibility to deal with any geometric domain. In such a case, a partial separability is applied to the problem, so that the space independent variables are kept together whereas parameters are separated. This approach clearly looses the computational advantages due to space separability. On the contrary, HiPOD inherits the geometric flexibility of the HiMod reduction, without giving up the spatial dimensional reduction of the problem.
Notes
- 1.
The computations have been run on a Intel Core i5 Dual-Core CPU 2.7 GHz 8 GB RAM MacBook.
References
Aletti, M.C., Perotto, S., Veneziani, A.: HiMod reduction of advection-diffusion-reaction problems with general boundary conditions. J. Sci. Comput. 76(1), 89–119 (2018)
Ammar, A., Chinesta, F., Diez, P., Huerta, A.: An error estimator for separated representations of highly multidimensional models. Comput. Methods Appl. Mech. Eng. 199(25–28), 1872–1880 (2010)
Ammar, A., Cueto, E., Chinesta, F.: Reduction of the chemical master equation for gene regulatory networks using proper generalized decompositions. Int. J. Numer. Methods Biomed. Eng. 28(9), 960–973 (2012)
Baroli, D., Cova, C.M., Perotto, S., Sala, L., Veneziani, A.: Hi-POD solution of parametrized fluid dynamics problems: Preliminary results. In: Model Reduction of Parametrized Systems. MS&A: Modeling, Simulation and Applications, vol.17, pp. 235–254. Springer, Cham (2017)
Chinesta, F., Keunings, R., Leygue, A.: The Proper Generalized Decomposition for Advanced Numerical Simulations: A Primer. SpringerBriefs in Applied Sciences and Technology. Springer International Publishing, Berlin (2014)
Ern, A., Perotto, S., Veneziani, A.: Hierarchical model reduction for advection-diffusion-reaction problems. In: Numerical Mathematics and Advanced Applications, pp. 703–710. Springer, Berlin (2008)
Ghnatios, C., Ammar, A., Cimetiere, A., Hamdouni, A., Leygue, A., Chinesta, F.: First steps in the space separated representation of models defined in complex domains. In: 11th Biennial Conference on Engineering Systems Design and Analysis, pp. 37–42. Nantes (2012)
Golub, G.H., Van Loan, C.F.: Matrix Computations. Johns Hopkins Studies in the Mathematical Sciences, 4th edn. Johns Hopkins University Press, Baltimore (2013)
González, D., Ammar, A., Chinesta, F., Cueto, E.: Recent advances on the use of separated representations. Internat. J. Numer. Methods Eng. 81(5), 637–659 (2010)
Guzzetti, S., Perotto, S., Veneziani, A.: Hierarchical model reduction for incompressible fluids in pipes. Internat. J. Numer. Methods Eng. 114(5), 469–500 (2018)
Hesthaven, J.S., Rozza, G., Stamm, B.: Certified Reduced Basis Methods for Parametrized Partial Differential Equations. SpringerBriefs in Mathematics. Springer, Cham; BCAM Basque Center for Applied Mathematics, Bilbao (2016)
Ladevèze, P., Passieux, J.-C., Néron, D.: The LATIN multiscale computational method and the proper generalized decomposition. Comput. Methods Appl. Mech. Eng. 199(21–22), 1287–1296 (2010)
Lupo Pasini, M., Perotto, S., Veneziani, A.: HiPOD: Hierarchical model reduction driven by a Proper Orthogonal Decomposition for parametrized advection-diffusion-reaction problems. In preparation
Niroomandi, S., González, D., Alfaro, I., Bordeu, F., Leygue, A., Cueto, E., Chinesta, F.: Real-time simulation of biological soft tissues: a PGD approach. Int. J. Numer. Methods Biomed. Eng. 29(5), 586–600 (2013)
Perotto, S.: Hierarchical model (Hi-Mod) reduction in non-rectilinear domains. In: Domain Decomposition Methods in Science and Engineering XXI. Lecture Notes in Computational Science and Engineering, vol. 98, pp. 477–485. Springer, Cham (2014)
Perotto, S.: A survey of hierarchical model (Hi-Mod) reduction methods for elliptic problems. In: Numerical Simulations of Coupled Problems in Engineering. Computational Methods in Applied Sciences, vol. 33, pp. 217–241. Springer, Cham (2014)
Perotto, S., Veneziani, A.; Coupled model and grid adaptivity in hierarchical reduction of elliptic problems. J. Sci. Comput. 60(3), 505–536 (2014)
Perotto, S., Zilio, A.: Hierarchical model reduction: three different approaches. In: Numerical Mathematics and Advanced Applications 2011, pp. 851–859. Springer, Heidelberg (2013)
Perotto, S., Zilio, A.: Space-time adaptive hierarchical model reduction for parabolic equations. Adv. Model. Simul. Eng. Sci. 2, 25 (2015)
Perotto, S., Ern, A., Veneziani, A.: Hierarchical local model reduction for elliptic problems: a domain decomposition approach. Multiscale Model. Simul. 8(4), 1102–1127 (2010)
Perotto, S., Reali, A., Rusconi, P., Veneziani, A.: HIGAMod: a hierarchical isogeometric approach for model reduction in curved pipes. Comput. Fluids 142, 21–29 (2017)
Pruliere, E., Chinesta, F., Ammar, A.: On the deterministic solution of multidimensional parametric models using the proper generalized decomposition. Math. Comput. Simul. 81(4), 791–810 (2010)
Signorini, M., Zlotnik, S., Díez, P.: Proper generalized decomposition solution of the parameterized Helmholtz problem: application to inverse geophysical problems. Int. J. Numer. Methods Eng. 109(8), 1085–1102 (2017)
Acknowledgements
The authors thank Yves Antonio Brandes Costa Barbosa for his support in the HiMod simulations. This work has been partially funded by GNCS-INdAM 2018 project on “Tecniche di Riduzione di Modello per le Applicazioni Mediche”. F. Ballarin also acknowledges the support by European Union Funding for Research and Innovation, Horizon 2020 Program, in the framework of European Research Council Executive Agency: H2020 ERC Consolidator Grant 2015 AROMA-CFD project 681447 “Advanced Reduced Order Methods with Applications in Computational Fluid Dynamics” (P. I. G. Rozza).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2020 The Author(s)
About this paper

Cite this paper
Perotto, S., Carlino, M.G., Ballarin, F. (2020). Model Reduction by Separation of Variables: A Comparison Between Hierarchical Model Reduction and Proper Generalized Decomposition. In: Sherwin, S.J., Moxey, D., Peiró, J., Vincent, P.E., Schwab, C. (eds) Spectral and High Order Methods for Partial Differential Equations ICOSAHOM 2018. Lecture Notes in Computational Science and Engineering, vol 134. Springer, Cham. https://doi.org/10.1007/978-3-030-39647-3_4
Download citation
DOI: https://doi.org/10.1007/978-3-030-39647-3_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-39646-6
Online ISBN: 978-3-030-39647-3
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)