
Abstract
Reading involves mapping combinations of a learned visual code (letters) onto meaning. Previous studies have shown that when visual word recognition is challenged by visual degradation, one way to mitigate these negative effects is to provide "top–down" contextual support through a written congruent sentence context. Crowding is a naturally occurring visual phenomenon that impairs object recognition and also affects the recognition of written stimuli during reading. Thus, access to a supporting semantic context via a written text is vulnerable to the detrimental impact of crowding on letters and words. Here, we suggest that an auditory sentence context may provide an alternative source of semantic information that is not influenced by crowding, thus providing “top–down” support cross-modally. The goal of the current study was to investigate whether adult readers can cross-modally compensate for crowding in visual word recognition using an auditory sentence context. The results show a significant cross-modal interaction between the congruency of the auditory sentence context and visual crowding, suggesting that interactions can occur across multiple levels of processing and across different modalities to support reading processes. These findings highlight the need for reading models to specify in greater detail how top–down, cross-modal and interactive mechanisms may allow readers to compensate for deficiencies at early stages of visual processing.




Similar content being viewed by others

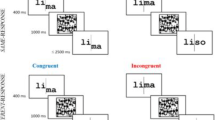

Notes
Two additional reading tasks were carried out using two short excerpts from newspaper articles. However, the texts were poorly matched on several factors, and one text also had some grammatical errors, we do not report any analyses including these texts.
One subject had an accuracy rate of less than 60% in the incongruent sentence condition for words in the LDT-auditory context.
References
Awadh, F. H. R., Phénix, T., Antzaka, A., Lallier, M., Carreiras, M., & Valdois, S. (2016). Cross-language modulation of visual attention span: An Arabic-French-Spanish comparison in skilled adult readers. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2016.00307.
Becker, C. A. (1979). Semantic context and word frequency effects in visual word recognition. Journal of Experimental Psychology: Human Perception and Performance, 5, 252–259. https://doi.org/10.1037/0096-1523.5.2.252.
Becker, C. A. (1980). Semantic context effects in visual word recognition: an analysis of semantic strategies. Memory and Cognition, 8, 493–512. https://doi.org/10.3758/BF03213769.
Becker, C. A., & Killion, T. H. (1977). Interaction of visual and cognitive effects in word recognition. Journal of Experimental Psychology: Human Perception and Performance, 3, 389–401. https://doi.org/10.1037/0096-1523.3.3.389.
Bertoni, S., Franceschini, S., Ronconi, L., Gori, S., & Facoetti, A. (2019). Is excessive visual crowding causally linked to developmental dyslexia? Neuropsychologia, 130, 107–117. https://doi.org/10.1016/j.neuropsychologia.2019.04.018.
Binder, J. R., Desai, R. H., Graves, W. W., & Conant, L. L. (2009). Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. Cerebral Cortex, 19, 2767–2796. https://doi.org/10.1093/cercor/bhp055.
Booth, J. R., Burman, D. D., Meyer, J. R., Gitelman, D. R., Parrish, T. B., & Mesulam, M. M. (2002). Modality independence of word comprehension. Human Brain Mapping, 16, 251–261. https://doi.org/10.1002/hbm.10054.
Bosse, M. L., Tainturier, M. J., & Valdois, S. (2007). Developmental dyslexia: the visual attention span deficit hypothesis. Cognition, 104, 198–230. https://doi.org/10.1016/j.cognition.2006.05.009.
Bouma, H. (1970). Interaction effects in parafoveal letter recognition. Nature, 226, 177–178. https://doi.org/10.1038/226177a0.
Carreiras, M., Armstrong, B. C., Perea, M., & Frost, R. (2014). The what, when, where, and how of visual word recognition. Trends in Cognitive Sciences, 18, 90–98. https://doi.org/10.1016/j.tics.2013.11.005.
Carter, M. D., Hough, M. S., Stuart, A., & Rastatter, M. P. (2011). The effects of inter-stimulus interval and prime modality in a semantic priming task. Aphasiology, 25, 761–773. https://doi.org/10.1080/02687038.2010.539697.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: a dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204–256. https://doi.org/10.1037/0033-295X.108.1.204.
Davis, C. J. (2010). The spatial coding model of visual word identification. Psychological Review, 117, 713–758. https://doi.org/10.1037/a0019738.
Davis, M. H., Ford, M. A., Kherif, F., & Johnsrude, I. S. (2011). Does semantic context benefit speech understanding through “top–down” processes? Evidence from time-resolved sparse fMRI. Journal of Cognitive Neuroscience, 23, 3914–3932. https://doi.org/10.1162/jocn_a_00084.
De Bruin, A., Carreiras, M., & Duñabeitia, J. A. (2017). The BEST dataset of language proficiency. Frontiers in Psychology. https://doi.org/10.3389/fpsyg.2017.00522.
Diependaele, K., Ziegler, J. C., & Grainger, J. (2010). Fast phonology and the bimodal interactive activation model. European Journal of Cognitive Psychology, 22, 764–778. https://doi.org/10.1080/09541440902834782.
Duchon, A., Perea, M., Sebastián-Gallés, N., Martí, A., & Carreiras, M. (2013). EsPal: one-stop shopping for Spanish word properties. Behavior Research Methods, 45, 1246–1258. https://doi.org/10.3758/s13428-013-0326-1.
Fischler, I., & Bloom, D. A. (1979). Automatic and attentional processes in the effects of sentence contexts on word recognition. Journal of Verbal Learning and Verbal Behavior, 18, 1–20. https://doi.org/10.1016/S0022-5371(79)90534-6.
Gori, S., & Facoetti, A. (2015). How the visual aspects can be crucial in reading acquisition: the intriguing case of crowding and developmental dyslexia. Journal of Vision. https://doi.org/10.1167/15.1.8.
Grainger, J., Dufau, S., & Ziegler, J. C. (2016). A vision of reading. Trends in Cognitive Sciences, 20, 171–179. https://doi.org/10.1016/j.tics.2015.12.008.
Grainger, J., & Ferrand, L. (1994). Phonology and orthography in visual word recognition: effects of masked homophone primes. Journal of Memory and Language, 33, 218–233. https://doi.org/10.1006/jmla.1994.1011.
Grainger, J., Tydgat, I., & Isselé, J. (2010). Crowding affects letters and symbols differently. Journal of Experimental Psychology: Human Perception and Performance, 36, 673–688. https://doi.org/10.1037/a0016888.
Guediche, S., Reilly, M., Santiago, C., Laurent, P., & Blumstein, S. E. (2016). An fMRI study investigating effects of conceptually related sentences on the perception of degraded speech. Cortex, 79, 57–74. https://doi.org/10.1016/j.cortex.2016.03.014.
Guediche, S., Zhu, Y., Minicucci, D., & Blumstein, S. (2019). Written sentence context effects on acoustic-phonetic perception: fMRI reveals cross-modal semantic perceptual interactions. Brain and Language, 199, 104698. https://doi.org/10.1016/j.bandl.2019.104698.
Harm, M. W., & Seidenberg, M. S. (2004). Computing the meanings of words in reading: cooperative division of labor between visual and phonological processes. Psychological Review, 111, 662–720. https://doi.org/10.1037/0033-295X.111.3.662.
Holcomb, P. J., & Anderson, J. E. (1993). Cross-modal semantic priming: a time-course analysis using event-related brain potentials. Language and Cognitive Processes, 8, 379–411. https://doi.org/10.1080/01690969308407583.
Jeon, S. T., Hamid, J., Maurer, D., & Lewis, T. L. (2010). Developmental changes during childhood in single-letter acuity and its crowding by surrounding contours. Journal of Experimental Child Psychology, 107, 423–437. https://doi.org/10.1016/j.jecp.2010.05.009.
Kalikow, D. N., Stevens, K. N., & Elliott, L. L. (1977). Development of a test of speech intelligibility in noise using sentence materials with controlled word predictability. The Journal of the Acoustical Society of America., 61, 1337–1351. https://doi.org/10.1121/1.381436.
Katz, L., & Feldman, L. B. (1983). Relation between pronunciation and recognition of printed words in deep and shallow orthographies. Journal of Experimental Psychology: Learning, Memory, and Cognition, 9, 157–166. https://doi.org/10.1037/0278-7393.9.1.157.
Kleiman, G. M. (1980). Sentence frame contexts and lexical decisions: sentence-acceptability and word-relatedness effects. Memory and Cognition, 8, 336–344. https://doi.org/10.3758/BF03198273.
Lallier, M., Carreiras, M., Tainturier, M. J., Savill, N., & Thierry, G. (2013). Orthographic transparency modulates the grain size of orthographic processing: behavioral and ERP evidence from bilingualism. Brain Research, 1505, 47–60. https://doi.org/10.1016/j.brainres.2013.02.018.
Landerl, K., Wimmer, H., & Frith, U. (1997). The impact of orthographic consistency on dyslexia: a German-English comparison. Cognition, 63, 315–334. https://doi.org/10.1016/S0010-0277(97)00005-X.
Lau, E. F., Phillips, C., & Poeppel, D. (2008). A cortical network for semantics: (de)constructing the N400. Nature Reviews Neuroscience, 9, 920–933. https://doi.org/10.1038/nrn2532.
Lefavrais, P. (1965). Description, définition et mesure de la dyslexie. Utilisation du test “L’Alouette” [Description, definition and measurement of dyslexia. Use of the “Alouette” test]. Revue de Psychologie Appliquée, 15, 33–34.
Lesch, M. F., & Pollatsek, A. (1993). Automatic access of semantic information by phonological codes in visual word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19, 285–294. https://doi.org/10.1037/0278-7393.19.2.285.
Levi, D. M. (2008). Crowding-an essential bottleneck for object recognition: a mini-review. Vision Research, 48, 635–654. https://doi.org/10.1016/j.visres.2007.12.009.
Levy, B. A. (1981). Interactive processes during reading. In A. Lesgold & C. Perfetti (Eds.), Interactive processes in reading (pp. 269–297). Hillsdale: Erlbaum.
Lukatela, G., & Turvey, M. T. (1994). Visual lexical access is initially phonological: I. Evidence from associative priming by words, homophones, and pseudohomophones. Journal of Experimental Psychology: General, 123, 107–128. https://doi.org/10.1037//0096-3445.123.2.107.
McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: Part I. An account of basic findings. Psychological Review, 88, 375–407. https://doi.org/10.1037/0033-295X.88.5.375.
Meyer, D. E., Schvaneveldt, R. W., & Ruddy, M. G. (1975). Loci of contextual effects on visual word-recognition. In P. M. A. Rabbitt & S. Dornic (Eds.), Attention and Performance V (pp. 98–118). London: Academic Press.
Moll, K., & Jones, M. (2013). Naming fluency in dyslexic and nondyslexic readers: differential effects of visual crowding in foveal, parafoveal, and peripheral vision. Quarterly Journal of Experimental Psychology, 66, 2086–2091. https://doi.org/10.1080/17470218.2013.840852.
Montani, V., Facoetti, A., & Zorzi, M. (2015). The effect of decreased interletter spacing on orthographic processing. Psychonomic Bulletin and Review, 22, 824–832. https://doi.org/10.3758/s13423-014-0728-9.
Nation, K., & Snowling, M. J. (1998). Individual differences in contextual facilitation: evidence from dyslexia and poor reading comprehension. Child Development, 69, 996–1011. https://doi.org/10.1111/j.1467-8624.1998.tb06157.x.
Obleser, J., Wise, R. J. S., Dresner, M. A., & Scott, S. K. (2007). Functional integration across brain regions improves speech perception under adverse listening conditions. Journal of Neuroscience, 27, 2283–2289. https://doi.org/10.1523/JNEUROSCI.4663-06.2007.
Onifer, W., & Swinney, D. A. (1981). Accessing lexical ambiguities during sentence comprehension: effects of frequency of meaning and contextual bias. Memory and Cognition, 9, 225–236. https://doi.org/10.3758/BF03196957.
Pattamadilok, C., Morais, J., Ventura, P., & Kolinsky, R. (2007). The locus of the orthographic consistency effect in auditory word recognition: further evidence from French. Language and Cognitive Processes, 22, 700–726. https://doi.org/10.1080/01690960601049628.
Patterson, K., & Lambon Ralph, M. A. (2015). The Hub-and-Spoke hypothesis of semantic memory. In G. Hickok & S. L. Small (Eds.), Neurobiology of Language. (pp.765–775). New York: Academic Press. doi:https://doi.org/10.1016/B978-0-12-407794-2.00061-4
Patterson, K., Nestor, P. J., & Rogers, T. T. (2007). Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience, 8, 976–987. https://doi.org/10.1038/nrn2277.
Pelli, D. G., Palomares, M., & Majaj, N. J. (2004). Crowding is unlike ordinary masking: distinguishing feature integration from detection. Journal of Vision, 4, 1136–1169. https://doi.org/10.1167/4.12.12.
Pelli, D. G., & Tillman, K. A. (2008). The uncrowded window of object recognition. Nature Neuroscience, 11, 1129–1135. https://doi.org/10.1038/nn1208-1463b.
Perea, M., & Gomez, P. (2012). Increasing interletter spacing facilitates encoding of words. Psychonomic Bulletin and Review, 19, 332–338. https://doi.org/10.3758/s13423-011-0214-6.
Perfetti, C. A., & Roth, S. (1981). Some of the interactive processes in reading and their role in reading skill. In A. Lesgold & C. Perfetti (Eds.), Interactive Processes in Reading (pp. 269–297). Hillsdale: Erlbaum.
Perry, C., Ziegler, J. C., & Zorzi, M. (2006). Nested incremental modeling in the development of computational theories: the CDP+ model of reading aloud. Psychological Review, 114, 273–315. https://doi.org/10.1037/0033-295X.114.2.273.
Perry, C., Ziegler, J. C., & Zorzi, M. (2010). Beyond single syllables: large-scale modeling of reading aloud with the Connectionist Dual Process (CDP++) model. Cognitive Psychology, 61, 106–151. https://doi.org/10.1016/j.cogpsych.2010.04.001.
Price, C. J. (2012). A review and synthesis of the first 20 years of PET and fMRI studies of heard speech, spoken language and reading. NeuroImage, 62, 816–847. https://doi.org/10.1016/j.neuroimage.2012.04.062.
Rumelhart, D. E., & McClelland, J. L. (1982). An interactive activation model of context effects in letter perception: II. The contextual enhancement effect and some tests and extensions of the model. Psychological Review, 89, 60–94. https://doi.org/10.1037/0033-295X.89.1.60.
Schuberth, R. E., & Eimas, P. D. (1977). Effects of context on the classification of words and nonwords. Journal of Experimental Psychology: Human Perception and Performance, 3, 27–36. https://doi.org/10.1037/0096-1523.3.1.27.
Schuberth, R. E., Spoehr, K. T., & Lane, D. M. (1981). Effects of stimulus and contextual information on the lexical decision process. Memory and Cognition, 9, 68–77. https://doi.org/10.3758/BF03196952.
Seidenberg, M. S., Tanenhaus, M. K., Leiman, J. M., & Bienkowski, M. (1982). Automatic access of the meanings of ambiguous words in context: some limitations of knowledge-based processing. Cognitive Psychology, 14, 489–537. https://doi.org/10.1016/0010-0285(82)90017-2.
Simpson, G. B., Lorsbach, T. C., & Whitehouse, D. (1983). Encoding and contextual components of word recognition in good and poor readers. Journal of Experimental Child Psychology, 35, 161–171. https://doi.org/10.1016/0022-0965(83)90076-0.
Snell, J., van Leipsig, S., Grainger, J., & Meeter, M. (2018). OB1-reader: A model of word recognition and eye movements in text reading. Psychological Review, 125, 969–984. https://doi.org/10.1037/rev0000119.
Stanovich, K. E. (1980). Toward an interactive-compensatory model of individual differences in the development of reading fluency. Reading Research Quarterly, 16, 32–71. https://doi.org/10.2307/747348.
Stanovich, K. E. (1984). The interactive-compensatory model of reading: a confluence of developmental, experimental, and educational psychology. Remedial and Special Education, 5(3), 11–19. https://doi.org/10.1177/074193258400500306.
Stanovich, K. E., & West, R. F. (1979). Mechanisms of sentence context effects in reading: automatic activation and conscious attention. Memory and Cognition, 7, 77–85. https://doi.org/10.3758/BF03197588.
Steen-Baker, A. A., Ng, S., Payne, B. R., Anderson, C. J., Federmeier, K. D., & Stine-Morrow, E. A. L. (2017). The effects of context on processing words during sentence reading among adults varying in age and literacy skill. Psychology and Aging, 32, 460–472. https://doi.org/10.1037/pag0000184.
Swinney, D. A. (1979). Lexical access during sentence comprehension: (re)consideration of context effects. Journal of Verbal Learning and Verbal Behaviour, 18, 645–659. https://doi.org/10.1016/S0022-5371(79)90355-4.
Swinney, D. A., Onifer, W., Prather, P., & Hirshkowitz, M. (1979). Semantic facilitation across sensory modalities in the processing of individual words and sentences. Memory and Cognition, 7, 159–165. https://doi.org/10.3758/BF03197534.
Van Orden, G. C. (1987). A ROWS is a ROSE: Spelling, sound, and reading. Memory and Cognition, 15, 181–198. https://doi.org/10.3758/BF03197716.
West, R. F., & Stanovich, K. E. (1978). Automatic contextual facilitation in readers of three ages. Child Development, 49, 717–727. https://doi.org/10.2307/1128240.
Whitney, D., & Levi, D. M. (2011). Visual crowding: a fundamental limit on conscious perception and object recognition. Trends in Cognitive Sciences, 15, 160–168. https://doi.org/10.1016/j.tics.2011.02.005.
Ziegler, J. C., & Ferrand, L. (1998). Orthography shapes the perception of speech: the consistency effect in auditory word recognition. Psychonomic Bulletin and Review, 5, 683–689. https://doi.org/10.3758/BF03208845.
Ziegler, J. C., Ferrand, L., & Montant, M. (2004). Visual phonology: the effects of orthographic consistency on different auditory word recognition tasks. Memory and Cognition, 32, 732–741. https://doi.org/10.3758/BF03195863.
Ziegler, J. C., & Goswami, U. (2005). Reading acquisition, developmental dyslexia, and skilled reading across languages: a psycholinguistic grain size theory. Psychological Bulletin, 131, 3–29. https://doi.org/10.1037/0033-2909.131.1.3.
Zwitserlood, P. (1989). The locus of the effects of sentential-semantic context in spoken-word processing. Cognition, 32, 25–64. https://doi.org/10.1016/0010-0277(89)90013-9.
Acknowledgements
This research is supported by the Basque Government through the BERC 2018-2021 program; the Spanish State Research Agency through BCBL Severo Ochoa excellence accreditation (SEV-2015-0490); the "Programa Estatal de Promoción del Talento y su Empleabilidad en I+D+i" fellowship, reference number: PRE2018-083945" to C.C; funding from European Union's Horizon 2020 Marie Sklodowska-Curie grant agreement No-79954 to S.G.; and the grants from the Spanish Ministry of Science and Innovation, Ramon y Cajal-RYC-2015-1735 and Plan Nacional-RTI2018-096242-B-I0 to M.L.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declared no conflicts of interest regarding authorship and publication of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Clark, C., Guediche, S. & Lallier, M. Compensatory cross-modal effects of sentence context on visual word recognition in adults. Read Writ 34, 2011–2029 (2021). https://doi.org/10.1007/s11145-021-10132-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-021-10132-x