
Abstract
Formal and semantic overlap across languages plays an important role in bilingual language processing systems. In the present study, Japanese (first language; L1)–English (second language; L2) bilinguals rated 193 Japanese–English word pairs, including cognates and noncognates, in terms of phonological and semantic similarity. We show that the degree of cross-linguistic overlap varies, such that words can be more or less “cognate,” in terms of their phonological and semantic overlap. Bilinguals also translated these words in both directions (L1–L2 and L2–L1), providing a measure of translation equivalency. Notably, we reveal for the first time that Japanese–English cognates are “special,” in the sense that they are usually translated using one English term (e.g., コール /kooru/ is always translated as “call”), but the English word is translated into a greater variety of Japanese words. This difference in translation equivalency likely extends to other nonetymologically related, different-script languages in which cognates are all loanwords (e.g., Korean–English). Norming data were also collected for L1 age of acquisition, L1 concreteness, and L2 familiarity, because such information had been unavailable for the item set. Additional information on L1/L2 word frequency, L1/L2 number of senses, and L1/L2 word length and number of syllables is also provided. Finally, correlations and characteristics of the cognate and noncognate items are detailed, so as to provide a complete overview of the lexical and semantic characteristics of the stimuli. This creates a comprehensive bilingual data set for these different-script languages and should be of use in bilingual word recognition and spoken language research.
Similar content being viewed by others

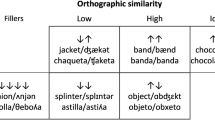
Words within a language can have formal (phonological [P] and orthographic [0]) and/or semantic (S) overlap (e.g., bat/bat [ + P, + 0, – S], tear/tear [ − P, + 0, – S], break/brake [ + P, – 0, – S], couch/sofa [ − P, – 0, + S]). Importantly, research has shown that such overlap can increase activation and speed processing, or create competition and slow processing (Balota, Cortese, Sergent-Marshall, Spieler, & Yap, 2004; Jared, McRae, & Seidenberg, 1990; McClelland & Rumelhart, 1981). Words in different languages can also have such overlap. For example, the English word ball and the Japanese word ボール /booru/ overlap in terms of S, although not all of the senses of English ball are associated with the Japanese word /booru/. This issue of degree of S overlap is a crucial aspect of the present research and is discussed in more depth later. The two words overlap a great deal in P, although there is no O overlap, as the two languages are written in different scripts. Such overlap, or what we will refer to in the present research as cross-linguistic similarity, plays an important role in bilingual language processing (Allen & Conklin, 2013; Dijkstra, Miwa, Brummelhuis, Sappeli, & Baayen, 2010). Moreover, in the present research we show that this overlap is perceived by bilinguals to be continuous in nature.
In the literature on bilingual word processing, words that share both form and meaning are usually referred to as cognates (Dijkstra, 2007). This is because, until recently, most of the research has investigated the processing of European languages (e.g., Catalan, Dutch, English, French, German, Italian, and Spanish). Thus, when words had form and meaning overlap (e.g., English night, French nuit, German nacht), this was in fact due to the modern words having a common historical root (e.g., Latin nocte); therefore, they were cognates. In the case of the Japanese word ボール /booru/ “ball,” it is more appropriately called a loanword/borrowing. However, in this case not the historical origin of such words in a language, but instead their cross-linguistic similarity, influences their processing. Thus, for the purposes of this article, we will refer to any cross-linguistic word pairs that share form and meaning as cognates. Although Japanese–English cognates can easily be identified by simply considering the overlap of form and meaning across languages, a much more precise definition of “cognateness” can be determined by the use of bilingual measures of perceived similarity. This is discussed further in the following sections.
Cognates have been central to psycholinguistic research into bilingual language processing. Traditionally, bilinguals have been referred to by such classic distinctions as “compound” and “additive” by scholars such as Weinreich (1953). However, in the psycholinguistic literature, bilinguals are characterized by their proficiency in both languages. Thus, if a native speaker of Japanese also speaks English as a second language to some degree of proficiency, the speaker can be referred to as bilingual. An important question about bilingual language processing has been whether bilinguals could selectively activate a single language or whether both of their languages are activated nonselectively. In other words, when processing one language, is it possible to turn the other language “off”? Cognates have provided an ideal way to investigate this question, as they had a great deal of formal and S overlap. When bilinguals perform a task such as lexical decision, in which all words are presented in one language, cross-linguistic overlap should only influence processing if language activation is nonselective. That is, if both languages are activated during single-language processing, cognates should facilitate processing. Alternatively, if only a single language is activated during language processing, shared cross-linguistic S–O–P features of cognates should not influence processing relative to words that have no S–O–P overlap.
A considerable amount of research has shown that bilingual word recognition is fundamentally nonselective in nature (e.g., Dijkstra & Van Heuven, 2002; Van Heuven, Dijkstra, & Grainger, 1998; see Dijkstra, 2007, for a review). When bilinguals use a second language, cognates have been shown to speed their responses, relative to matched noncognate controls, in a wide variety of tasks, such as word naming (Schwartz, Kroll, & Diaz, 2007), word translation (Christoffels, de Groot, & Kroll, 2006), and lexical decision (Dijkstra, Grainger, & Van Heuven, 1999). Moreover, similar findings have been found for languages that differ in script (e.g., lexical decision with Hebrew–English, Gollan, Forster, & Frost, 1997; picture naming with Japanese–English, Hoshino & Kroll, 2008; masked priming lexical decision with Japanese–English, Nakayama, Sears, Hino, & Lupker, 2012; or masked priming lexical decision and word naming with Korean–English, Kim & Davis, 2003). Typically, in such studies cognates and noncognates are matched on important characteristics such as frequency, length, phonological onset, and phonological neighborhood size (for naming) or orthographic neighborhood size (for lexical decision).
Although cognates typically speed responses in L2 tasks such as lexical decision, picture naming, and translation, Dijkstra et al. (1999; Dijkstra et al., 2010) showed that in language decision tasks, in which bilinguals had to decide whether the targets were either Dutch or English, cognates were inhibited relative to noncognates.Thus, for tasks in which cross-linguistic similarity is disadvantageous, as in language decision, cognates can actually slow processing.
Even in sentence processing tasks, in which semantic and syntactic constraints may be more likely to induce language-selective processing, cognate facilitation has been observed relative to noncognates (e.g., Schwartz & Kroll, 2006; Van Assche, Drieghe, Duyck, Welvaert, & Hartsuiker, 2011; Van Assche, Duyck, Hartsuiker, & Diependaele, 2009; Van Hell & de Groot, 2008). Although cognate effects are typically more prominent in the L2 than in the L1 for unbalanced bilinguals (i.e., bilinguals who are not equally proficient in both languages, and typically are more proficient in the L1), due to the boosted activation of the more dominant L1, L2 cognate effects have also been observed in the L1 (Duñabeitia, Perea, & Carreiras, 2010; Van Assche et al., 2009). Thus, even when bilinguals are more dominant in an L1, it is still possible to observe cross-linguistic similarity effects in both L1 and L2 processing.
Although much of the previous research into bilingual processing has defined cognates and noncognates as being dichotomous, a growing number of studies have reported that bilinguals are sensitive to the degree of similarity, above and beyond a simple binary distinction (e.g., Allen & Conklin, 2013; Dijkstra et al., 2010; Van Assche et al., 2011; Van Assche et al., 2009). Using mixed-effects modeling with multiple independent variables, these studies have revealed that continuous measures of cross-linguistic similarity are indeed predictive of bilinguals’ responses in L2 tasks. Most relevant for the present study, Allen and Conklin found that Japanese–English bilinguals responded to English words faster in lexical decision, depending on the degree of P similarity between the English and Japanese words. For example, whereas both bus バス/basu/ and radio ラジオ /rajio/ are cognates and were responded to more quickly than noncognate matched controls, bus was rated as being more phonologically similar to バス /basu/ than radio was to ラジオ /rajio/, and bus was responded to significantly more quickly than radio. This study used mixed-effects modeling with multiple predictors, including word length and word frequency. Because such predictors are correlated with each other and also with P similarity, residualization was used to orthogonalize the predictors prior to model fitting. Collinearity was removed between all correlated variables, and then the residuals of these predictors were used to predict response times (RTs). The orthogonalized predictors showed that length, word frequency, and P similarity accounted for significant, but independent, portions of the variance in RTs. These facilitatory effects of P similarity were observed in L2 English lexical decision and picture naming with Japanese–English bilinguals. In addition, S similarity was shown to be an important predictor of responses to cognates in picture naming, with more semantically similar cognates being responded to more quickly than less semantically similar cognates. In an English lexical-decision experiment, S similarity had a reverse effect, relative to picture naming: Less semantically similar word pairs were responded to faster, due to such items having more senses, which apparently boosted activation of the lexical representation, leading to speeded responses relative to more semantically similar words (which tend to have fewer senses). These results highlighted the importance of task effects in language processing, but they also underscore the importance of continuous measures of cross-linguistic similarity as crucial indicators of bilinguals’ processing performance.
Despite the importance of cross-linguistic measures of word similarity in bilingual language processing research, to our knowledge only one previous study has collected bilingual measures and made them available to researchers. Tokowicz, Kroll, de Groot, and van Hell (2002) conducted a large-scale study on 1,003 word pairs with Dutch–English bilinguals who rated translation equivalents for cross-linguistic O, P, and S similarity. They also elicited translations in order to determine translation equivalency and to assess the number of translations that a word has. Bilinguals translated words in both directions (i.e., from L1 to L2 and from L2 to L1), and this was used to determine whether a word has one or more translations in each language, as the number of translations that a word has has been shown to influence bilingual processing. The number of translations also can provide a metric of the amount of S overlap between words in two languages: If a word that has a number of senses in one language is translated into a single word in the other language, then both words are likely to be used in similar contexts in the two languages. However, if a word in one language has multiple senses that lead to different translations in the other language, that word is likely to be translated into more than one word. Thus, the words will be used in a variety of contexts, and likely will have less complete S overlap. An important implication of this is that when bilinguals translate a word presented in isolation, for many words multiple translations are likely to be given. Therefore, determining a “best” translation for most words is problematic. Providing a number-of-translations measure, on the other hand, provides information about the likelihood that bilinguals will be considering single or multiple translations for any particular word.
For researchers interested in L2 and bilingual language processing, it is critical to have norms for cross-linguistic S similarity in order to control for the influence of the “other” language during language-processing tasks. Moreover, bilingual ratings may be more suitable measures of S overlap than are dictionary measures of the number of meanings/senses in each language, because dictionaries vary greatly in their methods of quantifying meanings/senses, and they also reflect the total number of senses that exist in the language, as opposed to those known by the average bilingual (see Gernsbacher, 1984, for a similar argument).
To our knowledge, currently no measures of cross-linguistic similarity are available for languages other than Dutch–English. The present study thus provides cross-linguistic norming data for Japanese–English translations. Research into Japanese–English bilingual processing is particularly important, not only because relatively little bilingual research has focused on languages that differ in script (in comparison to research on same-script languages), but also because of the importance of English in Japanese society. Compulsory education and tertiary institutions place a strong emphasis on language education, and English is the most widely learned second language in Japan. The Japanese language has many thousands of loanwords borrowed from English that have entered the language since Japan’s ending of its self-imposed isolation in the mid-nineteenth century. Many of these loanwords are in regular and general use; however, the majority are reserved for technical and academic uses. The proportion of loanwords in the 5th edition of the Koujien (1998), a comprehensive Japanese dictionary, is 10.2 %, which equals around 23,000 word entries (Kawaguchi & Tsunoda, 2005; cited in Igarashi, 2008). Moreover, around 90 % of loanwords are borrowed from English (Shinnouchi, 2000). Therefore, a better understanding of how Japanese–English bilinguals process these loanwords/cognates is an important area for research.Footnote 1
The primary goal of the present study was thus to provide a range of cross-linguistic similarity measures of Japanese–English translation equivalents. To this end, ratings were collected to assess P and S similarity. Also, participants were asked to translate words in order to provide estimates of the number of translations and meanings that were known by the bilinguals. A second aim was to collect additional norming data that will be critical for designing experiments to investigate bilingual processing, yet that are not publicly available for all of the Japanese words in this study. Because most studies have focused on high-frequency words (e.g., Yokokawa, 2009, investigated the top 3,000 words in the British National Corpus), there are few measures for many of the cognates that are ubiquitous in the Japanese language, but that tend to be of lower frequency. Thus, information about the perceived age of acquisition (AoA) and concreteness of L1 Japanese words was collected. Concreteness is particularly useful for researchers, as it is typically highly correlated with grammatical class, such that verbs tend to refer to abstract events or actions, whereas nouns often refer to concrete objects as well as to abstract entities. Although grammatical class is problematic as a norming measure, because many words can be read as either verbs or nouns (e.g., call, run, telephone), concreteness can be used as a measure of the intrinsic S properties of the item, which may include both the verbal and nominal uses of items. In addition, we collected bilingual ratings of L2 (English) word familiarity. To create a more complete set of information about Japanese–English cognates that could be useful to researchers, we also provide the following information in the present database: word length, number of English senses (WordNet), number of Japanese senses (Meikyo Japanese Dictionary, 2008 edition), English word frequency (Balota et al., 2007), and Japanese word frequency (Amano & Kondo, 2000). Finally, a set of descriptive statistics is presented, as well as a correlation analysis of the ratings and the collected measures.
Method
Participants
One hundred and sixty-six first- and second-year undergraduate university students participated in the present research. The participants were recruited from two Japanese universities: the University of Tokyo and Waseda University. All participants were enrolled in English language courses in one of the two institutions. All recruitment and participation procedures for the studies reported in this article were approved by the ethics committee at the School of English, University of Nottingham. All participants received course credit for taking part, and no participant took part in more than one study. All of the participants were native Japanese speakers who had studied English prior to their university education. In order to qualify for the rating studies, all participants confirmed that they considered themselves native Japanese speakers, who had lived in Japan for the majority of their lives and had received their education in Japan. Thus, L1 proficiency data were not collected, as all participants were at the native-speaker level. Details about the participants, as well as the number of participants in each study, are shown in Table 1. Participants were asked to rate their own perceived English language proficiency in reading, writing, speaking, and listening on a scale of 0–10, with 0 being no ability at all and 10 being native-speaker-level ability. The scores from each component for each participant were averaged in order to calculate an overall proficiency score.
Stimuli and apparatus
A total of 198 words were selected for the study. Our aim was to collect ratings for both concrete and abstract words in order to create a more representative stimulus set that can be used in a variety of tasks, such as picture naming (which typically uses concrete nouns) and comprehension tasks (which may include both concrete and abstract words). Moreover, because bilingual studies often make use of cognates due to their unique characteristics of having both formal and S similarity, approximately half of the words in the database were cognates. Loanwords in Japanese are all written in a separate script, katakana, making it relatively easy to determine “cognate” status. The cognates were all loanwords in Japanese that the authors determined shared obvious P and S similarity with their English translations. It was not necessary to do more than this, as the ratings themselves will show how similar the words are across languages. Five items were removed from analyses because they were not the same grammatical class (e.g., expect (verb) and 期待 /kitai/ (noun) “expectation”). This reduced the total number of items in the final study to 193. The concrete cognate and noncognate items (n = 94; cognate = 48; noncognate = 46) were selected from Nishimoto, Miyawaki, Ueda, Une, and Takahashi’s (2005) picture naming norming study. By selecting items from Nishimoto et al.’s study, which were taken from Snodgrass and Vanderwart’s (1980) picture naming norms in English (also see Szekely et al., 2004), the stimuli are suitable for research in both English and Japanese languages.Footnote 2 Because English loanwords in Japanese are often low-frequency and to ensure that participants would know the items (i.e., that they are lexicalized in Japanese), all of the abstract cognate and noncognate words (n = 99; cognate = 50; noncognate = 49) were selected from a high-frequency word list derived from a 330-million-word Japanese Web corpus (Kilgariff, Rychly, Smrz, & Tugwell, 2004). For the cognates, two professional Japanese–English translators confirmed that the Japanese and English words were translation equivalents, although the translation was not always the most likely translation (e.g., the English word call has many possible translations, with the cognateコール /kooru/ being one of them).
For the similarity rating task, the items were randomized and compiled into lists for P and S ratings. An additional 20 nontranslation filler pairs were added to the S rating task to encourage use of the full scale for similarity ratings. More specifically, because all item pairs are translation equivalents, they would be rated as similar to some degree across languages; in order to get participants to use the completely different end of the scale, non-translation-equivalents (e.g., door–雨 /ame/ “rain” in Japanese) were also included in the S rating task. Fillers were not necessary in the P similarity part of the study, as the use of both cognate and noncognate pairs ensures that the full scale will be utilized. The set of materials and ratings are provided in Appendix A (and in the supplemental materials). The filler items were removed from the analysis and were not used in any of the other tasks reported here. Two groups of participants completed the rating studies, one for concrete items and another for abstract items.
Procedure
All participants completed informed consent forms prior to beginning the experimental procedure. All surveys were administered using the online survey tool (www.surveymonkey.com). Fifteen participants were removed from the tasks due to due to incomplete responses or misunderstanding of the task. The total number of participants included in the tasks is shown in Table 1.
P and S similarity rating
Each item was rated on a 5-point scale ranging from (1 = completely different to 5 = identical). A 5-point scale was used instead of the typical 7-point scale because in a pilot study using a 7-point scale the participants found it difficult to discriminate between some of the levels (i.e., the difference between 5 and 6, or that for 2 and 3). Instructions were provided in Japanese to ensure understanding of the task. A brief explanation and examples were provided at the beginning of each survey. Participants were asked to decide how similar the word pairs sounded on the basis of their intuition and were encouraged to say the words aloud if necessary to help them decide. The examples provided for the P similarity task included band–バンド (/bando/), stress–ストレス (/sutoresu/), bird–鳥 (/tori/), which were rated as similar/very similar (4–5), somewhat similar/similar (3–4) and very different/different (1–2), respectively. For the S similarity-rating task, participants were asked to decide how similar in meaning the words in each pair were. The instructions asked participants to consider differences in senses shared and not shared between the languages, and also differences in use between the two languages. They were told not to use a dictionary, but to complete the task on the basis of their intuition (i.e., their knowledge of the words). The examples provided were triangle–三角 (/sankaku/), fan–扇子 (/sensu/), and clock − 壁 (/kabe/ “wall” in Japanese), which were rated as very similar (5), somewhat similar (3), and very different (1), respectively. Additional explanatory text was included to make clear the basis for the ratings of the examples: The words triangle–三角 have one meaning that is almost identical in both languages, thus having considerable S similarity; fan has a range of meanings in English, whereas 扇子 in Japanese has only one meaning that is similar to that of a (hand-held) fan, therefore they have some S similarity, but also differ in some senses; finally, clock and 壁 do not share word meanings, and therefore these words have no S similarity.
To ensure that all parts of the scale were used, 20 nontranslation equivalents were included in the stimulus list. (All nontranslation equivalents were rated as 1, or completely different, in terms of S similarity). All Chinese characters that may have been unknown to the participants were transcribed in the hiragana phonetic script. Because of the large number of items that required ratings for both P and S similarity, and the likelihood of “survey fatigue,” each participant rated half of the words for each type of similarity, but no participant rated a pair of words for both types of similarity. Each individual item was rated for both P and S similarity by between 16 and 18 different participants.
Number of translations task
Because bidirectional translation data are desirable for bilingual research, two lists were created with half of the items being translated from the L2 to the L1, and the other half being translated from L1 to L2. These lists were counter-balanced across participants and items were presented in random order; each item was only translated once (i.e., either from L2 to L1, or from L1 to L2) by an individual participant. Participants were asked to think of the first translation that comes to mind for each item and to enter that word in the space provided. Instructions were in Japanese and examples were provided in both forward and backward translation tasks; these examples included both cognates and noncognates, and were reversed for each language direction: for instance, L1 to L2, 鳥 (/tori/)–bird, ストレス (/sutoresu/)–stress; and L2 to L1, bird–鳥, stress–ストレス.
Age-of-acquisition rating
Participants were asked to rate Japanese words on a scale of 1–7 indicating the age at which they had learned the words in Japanese: The seven response categories included (1) 0–2 years, (2) 3–4 years, (3) 5–6 years, (4) 7–8 years, (5) 9–10 years, (6) 11–12 years, and (7) 13 years or later. Participants were asked to focus on when they acquired knowledge of the word itself rather than the written form, as this may vary depending on the script (i.e., kana or kanji). Instructions were in Japanese and an example provided for respondents was お母さん (/okaasan/ “mother”) whose meaning would be learned between the ages of 0–2 years, whereas its written form would typically be acquired between 3–6 years, with the kana form preceding the kanji form.
Concreteness rating
Participants were asked to rate Japanese word items on a scale of 1–7: response categories ranged from very abstract (1) to very concrete (7). Participants were asked to consider whether an item was easily pictured in their mind, making it concrete, or whether it was difficult to picture, in which case it was more abstract. No examples were provided with this task.
L2 familiarity rating
Participants were asked to rate English word items on a scale of 1–7: response categories ranged from very unfamiliar (1) to very familiar (7). Participants were asked to consider how often they use the words in speaking and writing and also in reading and listening. Instructions were in English and examples were provided (signature and abolish are not used every day, whereas book may well be). A clarification was made to consider the words only in English, not loanwords in Japanese (e.g., サッカー /sakkaa/, “soccer”). Because participants were asked to focus on their use of the words, this familiarity survey is similar to a subjective frequency survey (e.g., Gernsbacher, 1984).
Results and discussion
In this section we first describe the cross-linguistic measures (P and S similarity, number of translations), followed by the norming data (AoA, concreteness, L2 familiarity) and finally the additional data that we are including in the data set (L1/L2 frequency, L1/L2 number of senses, L1/L2 word length (number of characters/ number of syllables). The descriptive statistics of all cross-linguistic, norming, and additional data are presented in Table 2. In what follows we make a distinction between cognate and noncognate items (on the basis of both the script used (i.e., katakana for cognates and hiragana/kanji for noncognates) and the obvious P and S similarity between the words) for the purposes of illustrating the characteristics of the stimuli. However, the cross-linguistic similarity ratings provided in this research will allow for more precise measurements of “cognateness” in future empirical Japanese–English bilingual studies. We provide the Bayes factors (using the Jeffrey–Zellner–Siow prior and Cauchy distribution on effect size) for comparisons between means of cognate and noncognate words (Rouder, Speckman, Sun, Morey, & Iverson, 2009). The advantage of using a Bayes factor over a traditional t-test is that the factor represents both the presence and strength of an effect (see Jeffreys, 1961).
P and S similarity
Respondents used all parts of the scale in both the P and S similarity rating tasks (Fig. 1). Cognate items were clearly distinguishable from noncognates on the basis of P ratings, with a Bayes factor that suggests a decisive rejection of the null hypothesis (BF < 0.001). S similarity ratings were skewed to the right side of the scale indicating that items were mainly rated as being highly semantically similar across languages (Fig. 2; note that nontranslation fillers were removed from the analysis). The S ratings showed no difference between cognates and noncognates. This was expected as the primary distinction between cognates and other translation equivalents is that cognates share both form and meaning, whereas noncognate translation equivalents share only meaning. This finding supports those of Tokowicz et al. (2002), who found a similar result for Dutch–English translations, and thus refutes the assumption made by Van Hell and de Groot (1998) that cognates are more likely to share meaning because they share formal features. The present study shows that for languages that differ in script, formal (P) similarity does not make it more likely that words will share a greater amount of S similarity across languages.Footnote 3

Distribution of mean P similarity ratings for all items. The x-axis shows the mean ratings on a 5-point scale, with 1 being completely different and 5 being identical. The y-axis shows the number of translation pairs that fall into each mean rating band

Distribution of mean S similarity ratings for all items (nontranslation filler items were removed from the S similarity task)
Number of translations
Two professional Japanese–English translators determined the accuracy of translations in both directions (L1–L2, L2–L1). Correct translations were then coded for whether they were the expected translation (i.e., that provided by Nishimoto et al., 2005, for concrete items [the picture naming stimuli], or the translation assigned in the initial item selection stage—e.g., ball–ボール—or an alternative translation). The number of distinct meanings provided as translations was also determined and added to the database. (We did not count verb uses of nouns, adjectival uses of nouns, and so on, as different meanings. Also, where meanings were not easily distinguishable, such as in the case of find and locate for 見つける /mitsukeru/ in Japanese, they were treated as the same meaning; thus, our number of meanings measure is somewhat conservative as only distinct meanings were coded as being different). Additional data for the translation task are included in a separate sheet in the database (see the supplemental materials).
Table 2 shows the descriptive statistics for the translation tasks in both directions. As expected, when translating from the L1 into the L2, there were more errors than when translating from the L2 into the L1 (11.5 % vs. 8.4 %). More information on error rates for translations of items in each direction are provided in the supplemental materials for this article. Also, the mean number of translations and the mean number of meanings provided was smaller when translating into the L2 relative to translating into the L1 (mean translations, 1.6 vs. 2.8; mean meanings: 1.2 vs. 1.4). Interestingly, when comparing the number of translations of cognates versus noncognates across the two tasks, one difference emerged: When cognates are translated from Japanese to English, there is usually only one translation (M = 1.1, SD = 0.3), which is the English cognate (e.g., クラス /kurasu/ is translated as class); however, when translating the same cognates from English to Japanese, there is a greater range of translations (M = 3.0, SD = 2.1), which may or may not include the Japanese cognate translation. Furthermore, for concrete items such as television, which have only one translation in Japanese, these are translated using the Japanese cognate form (テレビ /terebi/); however, more abstract words, such as class and other verbs, which can have multiple translations in Japanese, are translated using multiple Japanese words (e.g., クラス /kurasu/, 学級 /gakkyuu/, or 等級 /toukyuu/). The Bayes factor (BF < 0.001) indicates decisive evidence for a difference between the mean numbers of translations for cognates and noncognates in the L1-to-L2 direction, indicating that when bilinguals translate cognates into English, they use significantly fewer translations than when translating noncognates into English. Noncognates had more than one translation on average, regardless of direction (L1 – L2, M = 2.0, SD = 1.3; L2 – L1, M = 2.5, SD = 1.8).
Age of acquisition (AoA)
All parts of the scale were used, although few participants rated learning words in the earliest category (0–2 years). The mean AoA was 3.8, which is between the third and fourth categories (5–6 and 7–8 years; SD = 0.6; Table 2). There was no difference in AoA ratings between cognate and noncognate items. To test the reliability of the ratings, they were compared with Nishimoto et al.’s (2005) Japanese AoA ratings for picture stimuli and with Kuperman, Stadthagen-Gonzalez, and Brysbaert’s (2012) AoA ratings for English words. Only the items that existed in both the present and previous data sets could be subject to this analysis. Because Nishimoto et al.’s ratings focused on picture stimuli, only the concrete items occurred in both data sets. Kuperman et al.’s data set, however, was much larger and covers most of the concrete and abstract words in the present data set. Correlations for the Japanese picture stimulus items were reasonable (r = 0.26, CI = 0.04, 0.46) but stronger for the English word AoA ratings (r = 0.47, CI = 0.35, 0.58). The weaker correlation between our AoA ratings and Nishimoto et al.’s ratings reflects the difference in task requirements. In Nishimoto et al., participants rated the AoA for the concepts depicted in the picture stimuli, whereas our measure reflects the acquisition of word knowledge, which may be acquired later than conceptual knowledge. In sum, the AoA ratings appear most comparable to those collected from English native speakers by Kuperman et al. AoA for words thus appears to have some overlap across languages.
Concreteness
All parts of the scale were used showing that the stimuli included a variety of concrete and abstract words (M = 4.5, SD = 1.2). There was no difference in concreteness ratings between cognate and noncognate items. Correlations with concreteness and imageability ratings for those items that could be cross-referenced (n = 76) taken from the MRC database (Coltheart, 1981) revealed strong correlations (r = 0.91, CI = 0.86, 0.94, and r = 0.84, CI = 0.76, 0.90, respectively), indicating that the present concreteness ratings collected with Japanese speakers are highly comparable to those collected with English speakers.
English (L2) familiarity
All parts of the scale were used. The Bayes factor (BF < 0.001) for familiarity ratings for cognate and noncognate words provides clear evidence of a difference between the means with the cognate familiarity (M = 4.1, SD = 0.5) being considerably higher than the noncognate familiarity (M = 3.6, SD = 0.6). This shows that English words that are cognate with Japanese were rated as significantly more familiar than those that are noncognate (see Yokokawa, 2009, for a similar finding). To test the reliability of these ratings they were compared with Yokokawa’s L2 familiarity ratings for visually presented English words collected from Japanese learners of English. The correlation was high (r = 0.77, CI = 0.68, 0.84) suggesting that the present ratings are a comparable and reliable resource.
Typically, norming data are collected from monolingual groups for use in monolingual studies. Such data can also be used as measures of one of a bilingual’s languages. However, a bilingual’s language processing system is not simply a combination of two monolingual systems (Grosjean, 1989). Research shows that a bilingual does not process language by accessing one lexicon exclusively depending on the language being used (Dijkstra, 2007). In contrast, nonselective access in language processing by bilinguals suggests that cross-linguistic activation influences performance a great deal in a wide variety of language tasks (Dijkstra, 2007). Here we show that in an L2 rating task, a bilingual’s first language (the nontarget language) can modulate responses, demonstrating cross-linguistic influences in tasks that are not response-speed-dependent (i.e., for which RT is not the primary dependent variable). Thus, when researchers collect L2 norming data, such as familiarity, from bilinguals, they must consider the impact of cross-linguistic influences on such ratings.
Thus, the present L2 word familiarity measure incorporates bilingual participants’ familiarity with both of their languages. Although it is primarily a measure of L2 familiarity, this is clearly influenced by the L1 (as evidenced by the significantly higher familiarity ratings for cognate translations, which share form and meaning with the L1, than for noncognates, which only share meaning). Therefore, it is likely that this measure will be particularly predictive of bilinguals’ responses in word recognition tasks in the L2, at least for the particular sample population (i.e., mid-proficiency Japanese–English bilinguals). Because cross-linguistic influences tend to be more prominent in the weaker language (L2) than the dominant language (L1; Dijkstra & Van Heuven, 2002), the measure may be most predictive in L2 word recognition and or production tasks. Moreover, this bilingual measure of L2 familiarity should be more predictive of word recognition responses for Japanese–English bilinguals than a monolingual measure of English word familiarity.
Additional data for items
Japanese word frequency
Word frequency in Japanese was taken from the Amano and Kondo (2000) database, which consists of word frequencies from all issues of the Asahi Japanese newspaper between 1985–1998 (see Appendix B and the supplemental materials for all additional data for items). The corpus has a total type frequency of 341,771 morphemic units and a total token frequency of 287,792,797 morphemic units (cf. Tamaoka & Makioka, 2009). When Japanese words were used in more than one script (e.g., camel-ラクダ/駱駝 /rakuda/, the frequencies of the word in each script were totaled. When words had more than one reading (e.g., head–頭, in which the Japanese as a stand-alone noun is read /atama/ and when used in a compound it is pronounced /gashira/ or /tou/), frequency of the stand alone noun only was used). Descriptive statistics for raw frequencies are provided in Table 2. We could not provide occurrences per million, as we only had the token count for morphemic units, which overestimates the actual number of “words” (which often have two or more morphemes) in the corpus. Log-transformed frequencies, which increase normality and reduce random variance, are also provided.
The Bayes factor (BF = 0.03) provides strong evidence for a difference between cognate and noncognate log-transformed word frequencies, though there was less evidence for such a difference using the raw frequencies (BF = 0.18). Thus, although our cognates were selected from a high frequency wordlist of katakana loanwords in Japanese, they are still lower in frequency than the noncognates in the present sample. This may partially be due to the fact that cognates tend to have one borrowed meaning (i.e., few senses). This is especially true for borrowed verbs, adjectives, and adverbs, as native words often exist, and the borrowed words fill narrow lexical gaps. The implication of this is that it is difficult for researchers to match cognate and noncognate items in languages in which the cognates are all borrowed words. Therefore, mixed-effects modeling, which can account for multiple continuous variables such as word frequency and number of senses as well as P and S similarity, might be most suitable for analyses with Japanese–English cognates.
English word frequency
Word frequency per million words in English was taken from the SUBTLEX corpus of film and television subtitles (Brysbaert & New, 2009) available from the Elexicon Project (Balota et al., 2007). Log-transformed frequencies, which increase normality and reduce random variance (Baayen, 2008), are also provided (logSUBTLEX). There was no difference in English word frequency or log-transformed frequency for cognate and noncognate items.
In addition to the frequencies from the subtitles corpus (SUBTLEX) for English and the newspaper corpus (Amano & Kondo, 2000) for Japanese, we provide an additional set of corpus frequencies taken from large web-corpora for each language. These two corpora were obtained from the Sketch Engine website (www.sketchengine.co.uk; Kilgariff et al., 2004); the English corpus (UkWaC) contains 1,318,612,719 words, and the Japanese corpus (JpWac) contains 333,246,192 words. The advantage of using these corpora is that they are comparable in terms of their derivation: Both are derived from the Web—specifically, from shopping and commercial websites, blogs, and discussion forums. The log-transformed frequencies are included in Appendix B (and the supplemental materials). The UkWac corpus log frequencies significantly correlate with the SUBTLEX corpus log frequencies (r = 0.78, CI = 0.72, 0.83) and the JpWac log frequencies correlate strongly with the log frequencies from the Japanese newspaper corpus (r = 0.71, CI = 0.63, 0.77). The two Web corpora also correlated (r = 0.70, CI = 0.60, 0.75) to a much higher degree than the English subtitles and Japanese newspaper corpora (r = 0.35, CI = 0.22, 0.47). Thus, whereas within-language corpora correlations are strong for both languages, the Web corpora appear to better correlate across languages, indicating that they are utilizing similar text resources as the basis for the frequencies. Thus, these may also prove to be valuable resources for studies of Japanese–English bilingual language processing. All log-transformed frequencies are provided in Appendix B (and the supplemental materials).
Number of English senses
The total number of senses regardless of class (verb, noun, etc.) was taken from the online version of WordNet (Princeton University, 2010). There was no difference in the numbers of English word senses between cognate and noncognate items.
Number of Japanese senses
The total number of senses for Japanese words was taken from MeikyoKokugoJiten (Meikyo Japanese Dictionary, 2008 edition). In four cases, the Japanese loanword was not listed as a single entry (i.e., only as a compound entry) in the selected dictionary; therefore, the number of senses for these items was taken from a second dictionary—Koujien, 6th edition (2008)—in which the items were listed as single entries. Similar to the number of English senses, there was no difference between cognates and noncognates in terms of the number of Japanese senses.
Japanese word length
Japanese word length was calculated as the total number of morae in each word. A mora is the basic phonemic unit in Japanese, roughly corresponding to a syllable. For example, 魚 /sakana/ “fish” is written in kanji (Sino-Japanese characters) and contains three morae, which can be visualized by transcribing the word using the phonetic script, hiragana: さかな, /sa/, /ka/, /na/. On the other hand, カンガルー /kangaruu/ “kangaroo,” is written in katakana, which is used for writing loanwords, and contains five morae in Japanese (/ka/, /n/, /ga/, /ru/, and /u/) , even though the English word contains only three syllables. This exemplifies how the Japanese phonemic system determines the resulting phonetic constitution of the borrowed word, while also briefly illustrating the use of the three scripts of the Japanese language. The Bayes factor (BF = 0.02) provides very strong evidence for a difference in the numbers of morae in cognate and noncognate words, such that the former were longer on average. This is not surprising given that loanwords, which are rephonalized into Japanese from English, tend to be longer than native Japanese words, which typically contain 2–4 morae.
English word length
The number of letters and syllables in each English translation were used as two separate measure of English word length. As expected, the word lengths did not differ for the English translations of cognates and noncognates, whether we looked at the number of letters, or syllables, in each word.
Correlations between ratings and collected measures
S similarity
It is likely that the S similarity is related to other lexical–semantic characteristics, such as concreteness or number of translations. In order to assess whether this is the case, a number of predictors were selected for a correlation analysis with the S similarity measure derived in this study: number of translations (in both directions), number of meanings translated (in both directions), concreteness, number of senses in Japanese and English, and P similarity (Table 3). First, S similarity was strongly negatively correlated with the number of translations measures in the L1 to L2 direction (r = − 0.29, CI = − 0.41, –0.16) and in the L2 to L1 direction (r = − 0.41, CI = − 0.52, –0.29). This shows that as the number of translations increases, S similarity decreases, which is similar to Tokowicz et al.’s (2002) finding for Dutch–English translations. Second, S similarity was negatively correlated with the number of meanings translated in the L1 to L2 direction (r = − 0.20, CI = − 0.33, – 0.06) and less so in the L2 to L1 direction (r = − 0.14, CI = − 0.28, 0.00). Again, the negative correlation shows that words translated with more meanings were rated as less semantically similar across languages. The number of translations measures (L1–L2, L2–L1) were not strongly correlated (r = 0.13, CI = −0.01, 0.27); this was also the case for the number of meanings (r = − 0.09, CI = − 0.23, 0.05). This reflects the fact that the degree of S knowledge varies across languages, with participants having a greater knowledge of S characteristics of words in the L1 relative to the L2. Third, concreteness was highly correlated with S similarity (r = 0.40, CI = 0.27, 0.51), such that the more concrete the words were rated, the more semantically similar across languages they are (this is similar to Tokowicz et al., 2002). Fourth, S similarity was highly negatively correlated with the number of English senses (r = − 0.31, CI = − 0.43, – 0.18) and but much less so with the number of Japanese senses (r = − 0.10, CI = − 0.24, 0.04). The discrepancy may well be due to the different degrees of sense disambiguation in the English and Japanese sources (WordNet vs. Meikyo Japanese Dictionary), the former tending to provide many senses, and the latter tending to be more conservative. Nevertheless, the two measures of number of senses were strongly correlated (r = 0.37, CI = 0.24, 0.49). Taken together, the numbers of translations, meanings, and senses, along with concreteness, appear to be important S characteristics that determine cross-linguistic S similarity.
In addition, the role of P similarity was explored in order to determine whether there was any relationship between it and S similarity; however, the two similarity measures were not strongly correlated (r = − 0.09, CI = − 0.23, 0.05). This supports the finding of Tokowicz et al. (2002) who reported a similar finding for Dutch–English translations. Interestingly, P similarity was highly correlated with number of translations in the L1–L2 direction (r = − 0.43, CI = − 0.54, – 0.31) but much less so with the L2–L1 direction (r = 0.13, CI = − 0.01, 0.27). This shows that more phonologically similar items (i.e., cognates) had fewer translations in the L2 than did phonologically dissimilar items (i.e., noncognates); for example, コール /kooru/ “call” is usually translated into English using the cognate translation only (i.e., call). Finally, P similarity was not correlated with the numbers of meanings in the L2 (r = 0.12, CI = −0.02, 0.26) or in the L1 (r = − 0.11, CI = − 0.25, 0.03), which demonstrates that although fewer different translations were provided for cognates than for noncognates in the L1–L2 direction, the numbers of meanings provided did not differ depending on cognateness or direction of translation.
The present study is the first to report this interesting difference in the numbers of translations for language pairs that do not share etymological origins but are instead loanwords. This characteristic of borrowed words is also likely to be observable in languages pairs such as Korean–English. Thus, when bilinguals translate Korean loanwords into English, they are likely to use a single translation, but this will not be the case when translating from English into Korean. To illustrate, the English word style can be translated into various Korean words: 스타일 /sutail/, 모양 /moyang/, 품격 /pumkyek/, or 문체 /munche/. However, when translating the Korean loanword 스타일 /sutail/, Korean–English bilinguals will use only the English word style. Because the number of translations influences bilingual processing, this feature of loanwords in such languages is thus important for understanding bilingual processing mechanisms.
P similarity and cognates
In most research to date, words have been dichotomized as cognate or noncognate on the basis of the degree of formal and S overlap. However, as we have shown here, words that are typically classed as cognate can vary in terms of their cross-linguistic P overlap. Because formal overlap across languages has been shown to influence processing bilingual tasks, both as a dichotomous “cognate status” variable (Hoshino & Kroll, 2008; Taft, 2002) and as continuous measures of P and/or O overlap (Allen & Conklin, 2013; Dijkstra et al., 2010), it is crucial to investigate the role of overlap in bilingual processing.
As can be seen in Table 4, P similarity was highly correlated with cognate status (r = −0.96, CI = −0.97, –0.95), showing that the two measures are predicting much of the same characteristic. The almost complete correlation between P similarity and cognate status demonstrates just how well P similarity can categorize items as either cognate or noncognate. Importantly, because bilinguals have been shown in this research to be sensitive to the degree of P similarity between translations across languages, as opposed to simply knowing that words are either cognate or noncognate, P similarity is a superior measure of bilinguals’ actual word knowledge and thus should prove to be a more valid measure of bilingual performance in tasks that investigate cross-linguistic processes.
Also, whereas Japanese log word frequency was highly correlated with P similarity (r = −0.24, CI = −0.37, –0.10), it was not correlated with English log word frequency (r = 0.06, CI = −0.08, 0.20). The same pattern is apparent for cognate status and the two log word frequency measures. This highlights the fact that in Japanese, cognates are typically of lower frequency than noncognates, even though we specifically selected items from a high-frequency word list in Japanese.
Finally, whereas both the number of English letters and English syllables were not correlated with P similarity, the number of mora in Japanese was (r = −0.25, CI = −0.38, –0.11). This highlights the fact that Japanese cognates, which are loanwords from English, tend to have a greater number of mora than native Japanese words (i.e., noncognates).
Conclusions
The goal of this study was to provide cross-linguistic norming data for Japanese–English translation equivalents, which will be a useful resource for researchers of bilingual processing of Japanese and English languages. This is the first study to provide such rich resources for languages that differ in script. The data may be used for norming items for use in production tasks such as picture naming (see also Nishimoto et al., 2005; Szekely et al., 2004), word naming and translation, and also comprehension tasks, such as lexical decision, sentence-context reading studies, and studies using progressive de-masking techniques or the masked priming paradigm (e.g., Nakayama et al., 2012).
In addition, we highlight a number of important features of cross-linguistic similarity for Japanese–English translations. First, we showed that P similarity ratings are varied for translation equivalents and distinguish between cognates and noncognates as well as within the cognates category. Thus, P similarity is more likely to reflect the processing mechanisms of bilinguals than a dichotomous all or nothing categorization of similarity, even though cognate status and P similarity are very highly correlated predictors.
Second, we showed that although S similarity ratings do not differ significantly for cognate and noncognate items (contra the assumptions of Van Hell & de Groot, 1998), the number of translations varies by direction. Specifically, when Japanese loanwords are translated into English, one translation is unanimously preferred. However, when English words that have loanword equivalents in Japanese are translated, bilinguals use not only the Japanese loanwords but other words as well. This interesting feature may well be present in other languages that borrow from English but do not share its etymological origins, such as Korean–English and Chinese–English. Such knowledge is crucial for selecting stimuli for experiments that test theories of bilingual processing and representation.
We also provided measures of standardization that are not freely available for all of the Japanese items in the present study (age of acquisition and concreteness) and bilingual norming data for English word familiarity. In the L2 familiarity study we observed language transfer effects that resulted in English cognates receiving higher familiarity ratings than noncognates, which is likely due to the effect of cross-linguistic similarity. This further stresses the important role of cross-linguistic similarity in offline, as well as online, tasks. Finally, additional information (frequency, number of senses, and word length) was provided. Cognates tend to be lower in L1 frequency and longer in the number of Japanese characters (or morae), whereas these factors are no different for cognates and noncognates in the L2 (English).
To deal with these inherent differences between Japanese cognates and noncognates, bilingual research that uses cognates might benefit from the use of mixed-effects modeling, as this method can account for multiple continuous variables, such as frequency, length, and number of senses, as well as the researchers’ particular variables of interest. All in all, the present data set provides the richest cross-linguistic lexical resource currently available for bilingual studies with different-script languages.
Notes
Some research has also been conducted with English–Japanese bilinguals regarding the learning and use of cognates in Japanese (e.g., Prem, 1991; Tomita, 1991; see Kess & Miyamoto, 2000, for an overview). However, little solid empirical research using English–Japanese bilinguals overlaps with the research discussed in this article, and therefore English–Japanese bilinguals are not discussed further. Moreover, whereas one may assume that perceived cross-linguistic similarity may be comparable for both Japanese–English and English–Japanese bilinguals, no research has put this idea to the test (with any bilinguals), and thus the present data set should be considered as being applicable only to Japanese–English bilinguals.
A reviewer suggested that perhaps no difference appears in the S similarity ratings for cognates and noncognates because of the inclusion of abstract cognates, such as work–/waaku/. However, a comparison of Bayes factors revealed no differences between abstract cognates and noncognates (BF = 6.28) or concrete cognates and noncognates (BF = 5.41), demonstrating that S similarity ratings were not different for items, regardless of their cognate status or concreteness.
References
Allen, D., & Conklin, K. (2013). Cross-linguistic similarity and task demands for Japanese–English bilingual processing. PLOS ONE, 8(8), e72631. doi:10.1371/journal.pone.0072631
Amano, S., & Kondo, T. (2000). Nihongo-no goi-tokusei [Lexical properties of Japanese] (Vol. 7) [CD-ROM]. Tokyo, Japan: Sanseido.
Baayen, R. H. (2008). Analyzing linguistic data: A practical introduction to statistics using R. Cambridge, UK: Cambridge University Press.
Balota, D. A., Cortese, M. J., Sergent-Marshall, S., Spieler, D. H., & Yap, M. J. (2004). Visual word recognition of single-syllable words. Journal of Experimental Psychology: General, 133, 283–316. doi:10.1037/0096-3445.133.2.283
Balota, D. A., Yap, M. J., Cortese, M. J., Hutchison, K. A., Kessler, B., Loftis, B., & Treiman, R. (2007). The English Lexicon Project. Behavior Research Methods, 39, 445–459. doi:10.3758/BF03193014
Brysbaert, M., & New, B. (2009). Moving beyond Kučera and Francis: A critical evaluation of present word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, 41, 977–990. doi:10.3758/BRM.41.4.977
Christoffels, I. K., de Groot, A. M. B., & Kroll, J. F. (2006). Memory and language skills in simultaneous interpreters: The role of expertise and language proficiency. Journal of Memory and Language, 54, 324–345.
Coltheart, M. (1981). The MRC psycholinguistic database. Quarterly Journal of Experimental Psychology, 33A, 497–505. doi:10.1080/14640748108400805
Dijkstra, T. (2007). The multilingual lexicon. In M. G. Gaskell (Ed.), Handbook of psycholinguistics (pp. 251–265). Oxford, UK: Oxford University Press.
Dijkstra, T., Grainger, J., & Van Heuven, W. J. B. (1999). Recognition of cognates and interlingual homographs: The neglected role of phonology. Journal of Memory and Language, 41, 496–518.
Dijkstra, T., Miwa, K., Brummelhuis, B., Sappeli, M., & Baayen, R. H. (2010). How cross-linguistic similarity affects cognate recognition. Journal of Memory and Language, 62, 284–301.
Dijkstra, T., & Van Heuven, W. J. B. (2002). The architecture of the bilingual word recognition system: From identification to decision. Bilingualism: Language and Cognition, 5, 175–197.
Duñabeitia, J. A., Perea, M., & Carreiras, M. (2010). Masked translation priming effects with highly proficient simultaneous bilinguals. Experimental Psychology, 57, 98–107.
Gernsbacher, M. A. (1984). Resolving 20 years of inconsistent interactions between lexical familiarity and orthography, concreteness, and polysemy. Journal of Experimental Psychology: General, 113, 256–281. doi:10.1037/0096-3445.113.2.256
Gollan, T. H., Forster, K. I., & Frost, R. (1997). Translation priming with different scripts: Masked priming with cognates and noncognates in Hebrew–English bilinguals. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23, 1122–1139.
Grosjean, F. (1989). Neurolinguists, beware: The bilingual is not two monolinguals in one person. Brain and Language, 36, 31–15.
Hoshino, N., & Kroll, J. F. (2008). Cognate effects in picture naming: Does cross-linguistic activation survive a change of script? Cognition, 106, 501–511.
Igarashi, Y. (2008). The changing role of katakana in the Japanese writing system: Processing and pedagogical dimensions for native speakers and foreign learners. Saarbrücken, Germany: VDM Verlag.
Jared, D., McRae, K., & Seidenberg, M. S. (1990). The basis of consistency effects in word naming. Journal of Memory and Language, 29, 687–715.
Jeffreys, H. (1961). Theory of probability. Oxford, UK: Oxford University Press.
Kass, R. E., & Raftery, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90, 773–795. doi:10.1080/01621459.1995.10476572
Kawaguchi, R., & Tsunoda, F. (2005). Nihongo wa darenomonoka [Whom is Japanese for?]. Tokyo, Japan: Yoshikawa Koubunkan.
Kess, J. F., & Miyamoto, T. (2000). The Japanese mental lexicon: Psycholinguistic studies of kana and kanji processing. Baltimore, MD: Benjamins.
Kilgariff, A., Rychly, P., Smrz, P., & Tugwell, D. (2004). The sketch engine. In Proceedings from EURALEX 2004, pp. 105–116. Available at the.sketchengine.co.uk
Kim, J., & Davis, C. (2003). Task effects in masked cross-script translation and priming. Journal of Memory and Language, 49, 484–499.
Koujien Dictionary, 5th edition. (1998). Tokyo, Japan: Iwanami Shoten.
Koujien Dictionary, 6th edition. (2008). Tokyo, Japan: Iwanami Shoten.
Kuperman, V., Stadthagen-Gonzalez, H., & Brysbaert, M. (2012). Age-of-acquisition ratings for 30 thousand English words. Behavior Research Methods, 44, 978–990. doi:10.3758/s13428-012-0210-4
McClelland, J. L., & Rumelhart, D. E. (1981). An interactive activation model of context effects in letter perception: Part 1. An account of basic findings. Psychological Review, 88, 375–407. doi:10.1037/0033-295X.88.5.375
Meikyo Japanese dictionary. (2008). Tokyo, Japan: Taishukan.
Nakayama, M., Sears, C. R., Hino, Y., & Lupker, S. J. (2012). Cross-script phonological priming for Japanese–English bilinguals: Evidence for integrated phonological representations. Language and Cognitive Processes, 27, 1563–1583.
Nishimoto, T., Miyawaki, K., Ueda, T., Une, Y., & Takahashi, M. (2005). Japanese normative set of 359 pictures. Behavior Research Methods, 37, 398–416. doi:10.3758/BF03192709
Prem, M. (1991). Nihongo kyouiku no neck: Gairaigo [Loanwords: the bottleneck in teaching Japanese to foreigners]. Nihongo Kyouiku, 74, 28–33.
Princeton University. (2010). WordNet: A lexical database for English. About WordNet [Web page]. Retrieved from wordnet.princeton.edu
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16, 225–237. doi:10.3758/PBR.16.2.225
Schwartz, A. I., & Kroll, J. F. (2006). Bilingual lexical activation in sentence context. Journal of Memory and Language, 55, 197–212.
Schwartz, A. I., Kroll, J. F., & Diaz, M. (2007). Reading words in Spanish and English: Mapping orthography to phonology in two languages. Language and Cognitive Processes, 22, 106–129.
Shinnouchi, M. (2000). Gendai gairaigo jijoo [The situation concerning contemporary loanwords]. Data and Statistics, 7(510), 8–13.
Snodgrass, J. G., & Vanderwart, M. (1980). A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning and Memory, 6, 174–215. doi:10.1037/0278-7393.6.2.174
Szekely, A., Jacobsen, T., D’Amico, S., Devescovi, A., Andonova, E., Herron, D., & Bates, E. (2004). A new on-line resource for psycholinguistic studies. Journal of Memory and Language, 51, 247–250. doi:10.1016/j.jml.2004.03.002
Taft, M. (2002). Orthographic processing of polysyllabic words by native and nonnative English speakers. Brain and Language, 81, 532–544.
Tamaoka, K., & Makioka, S. (2009). Japanese mental syllabary and effects of mora, syllable, bi-mora and word frequencies on Japanese speech production. Language and Speech, 52, 79–112.
Tokowicz, N., Kroll, J. F., de Groot, A. M. B., & van Hell, J. G. (2002). Number-of-translation norms for Dutch–English translation pairs: A new tool for examining language production. Behavior Research Methods, Instruments, & Computers, 34, 435–451. doi:10.3758/BF03195472
Tomita, T. (1991). Nihongo kyouiku to gairaigo oyobi sono hyouki [Loanwords in teaching Japanese and its orthography]. Nihongogaku [Japanese Linguistics], 10, 37–44.
Van Assche, E., Drieghe, D., Duyck, W., Welvaert, M., & Hartsuiker, R. J. (2011). The influence of semantic constraints on bilingual word recognition during sentence reading. Journal of Memory and Language, 64, 88–107. doi:10.1016/j.jml.2010.08.006
Van Assche, E., Duyck, W., Hartsuiker, R. J., & Diependaele, K. (2009). Does bilingualism change native-language reading? Cognate effects in a sentence context. Psychological Science, 20, 923–927. doi:10.1111/j.1467-9280.2009.02389.x
Van Hell, J. G., & de Groot, A. M. B. (1998). Conceptual representation in bilingual memory: Effects of concreteness and cognate status in word association. Bilingualism: Language and Cognition, 1, 193–211.
Van Hell, J. G., & De Groot, A. M. B. (2008). Sentence context affects lexical decision and word translation. Acta Psychologica, 128, 431–451. doi:10.1016/j.actpsy.2008.03.010
Van Heuven, W. J. B., Dijkstra, T., & Grainger, J. (1998). Orthographic neighborhood effects in bilingual word recognition. Journal of Memory and Language, 39, 458–483.
Weinreich, U. (1953). Languages in contact. The Hague: Mouton.
Yokokawa, H. (2009). Nihonjin eigogakushushano eitangoshimitsudo onseipan: Kyouiku kenyuunotameno dainigengogakudeetabeesu [English word familiarity of Japanese learners of English, Audio Edition: Second language research database for education and research]. Tokyo, Japan: Kuroshio.
Author note
This work was supported in part by a Global Studies grant, Japanese Ministry of Education, Culture, Sports, Science and Technology, to the first author.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(XLSX 196 kb)
Appendices
Appendix A
Appendix B
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Allen, D., Conklin, K. Cross-linguistic similarity norms for Japanese–English translation equivalents. Behav Res 46, 540–563 (2014). https://doi.org/10.3758/s13428-013-0389-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-013-0389-z