
Abstract
To examine the role of inter-word spaces during reading, we used a gaze-contingent boundary paradigm to manipulate parafoveal preview (i.e., valid vs. invalid preview) in a normal text condition that contained spaces (e.g., “John decided to sell the table”) and in an unsegmented text condition that contained random numbers instead of spaces (e.g.,“John4decided8to5sell9the7table”). Preview effects on mean first-fixation durations were larger for normal than unsegmented text conditions, and survival analyses revealed a delay in the onset of both preview validity and word-frequency effects on first-fixation durations for unsegmented relative to normal text. Taken together with simulations that were conducted using the E-Z Reader model, the present findings indicated that unsegmented text deficits reflect disruptions to both parafoveal processing and lexical processing. We discuss the implications of our results for models of eye-movement control.
Similar content being viewed by others

A salient cross-language difference is that English text contains inter-word spaces, whereas several other writing systems either contain no spaces between words (e.g., Chinese, Japanese, and Thai), or contain less prevalent spaces due to features such as long compound words (e.g., Dutch, Finnish, and German). Interestingly, English readers show substantially slower reading rates when they are presented with unsegmented text in which inter-word spaces are either removed entirely or replaced with “filler” characters such as letters, digits, or bloblike gratings (Malt & Seamon, 1978; McGowan, White, & Paterson, 2014; Morris, Rayner, & Pollatsek, 1990; Perea & Acha, 2009; Pollatsek & Rayner, 1982; Rayner, Fischer, & Pollatsek, 1998; Sheridan, Rayner, & Reingold, 2013; Spragins, Lefton, & Fisher, 1976; Yang & McConkie, 2001). Moreover, relative to normal text, unsegmented text produces longer fixation durations, reduced skipping rates, shorter saccades, and initial landing positions that are shifted closer to the beginning of target words (e.g., Rayner et al., 1998; Sheridan et al., 2013).
One possible explanation for the deficits produced by unsegmented text is that removing spaces disrupts (or delays) word identification (Epelboim, Booth, Ashkenazy, Taleghani, & Steinman, 1997; Morris et al., 1990; Pollatsek & Rayner, 1982; Rayner et al., 1998; but see also Epelboim, Booth, & Steinman, 1994, 1996), either by increasing lateral visual masking (Bouma, 1973; Townsend, Taylor, & Brown, 1971) and/or by increasing word segmentation difficulties by obscuring visual cues about word boundaries and word length (e.g., Li, Rayner, & Cave, 2009). Consistent with this hypothesis, Sheridan et al. (2013) used a survival analysis technique (Reingold, Reichle, Glaholt, & Sheridan, 2012; Reingold & Sheridan, 2014) to show that the earliest discernible influence of word frequency on the distributions of first-fixation durations occurred approximately 20–40 ms later for unsegmented than normal text.
Given that word-frequency effects (i.e., longer fixation times on low- than on high-frequency words; Inhoff & Rayner, 1986; Rayner & Duffy, 1986; see White, 2008 for a review) are considered to be an empirical marker of lexical processing (e.g., Rayner, 1998, 2009; Reingold et al., 2012; Reingold, Yang, & Rayner, 2010), Sheridan et al. (2013) interpreted this delay as evidence that removing spaces slows down lexical processing, and they further hypothesized that this slowing of lexical processing might also be accompanied by a decrease in parafoveal processing efficiency. A key goal of the present study was to empirically test this hypothesis that unsegmented text impairs both lexical processing and parafoveal processing, as well as to conduct an exploratory simulation of the obtained effects within the framework of the E-Z Reader model of eye movement control (Reichle, Pollatsek, Fisher, & Rayner, 1998; Reichle et al., 2012). Accordingly, in addition to manipulating inter-word spacing (normal vs. unsegmented), we used the gaze-contingent invisible boundary paradigm (Rayner, 1975) to compare valid-preview trials, in which target words were available for parafoveal processing, with invalid-preview trials, in which an unrelated letter string occupied the position of the target word and was replaced with the target word during the saccade that crossed an invisible boundary located just to the left of that word. We predicted that there would be smaller as well as temporally delayed effects of preview validity on first-fixation durations in the unsegmented relative to the normal (segmented) condition.
Moreover, we also manipulated the frequency of the target words (high vs. low) and used a survival analysis technique (Reingold et al., 2012; Reingold & Sheridan, 2014) to explore the timing of the earliest onset of both word-frequency effects and preview effects on distributions of first-fixation durations. Specifically, survival curves are calculated by examining the proportion of fixations that have not yet terminated as a function of time: The survival percent for a given time t refers to the percent of fixations with a duration greater than t (i.e., “surviving” fixations are those that were not yet terminated by a saccade). For each individual participant, we examined the earliest point in time in which the survival curves from two conditions (i.e., high vs. low, or valid vs. invalid) first began to show reliable differences (this point in time is called the divergence point), using the individual differences divergence point analysis outlined by Reingold and Sheridan (2014). To the extent that unsegmented text delays the time course of both lexical processing and parafoveal processing, we predicted that word-frequency and preview divergence points would be later in the unsegmented than the normal condition.
Finally, we performed simulations using the E-Z Reader model of eye-movement control (Reichle et al., 1998, 2012) to further explore the two different mechanisms that were hypothesized to cause the empirical unsegmented text deficits (i.e., slower lexical processing and parafoveal preview disruption). More specifically, we examined the effect of varying a key parameter in the model that controls the speed of lexical processing (i.e., α1), using both the default version of the model (Reichle et al., 2012), and a “lesioned” version of the model in which parafoveal preview was disrupted by increasing the amount of time required to complete lexical processing during parafoveal preview. We predicted that both of these mechanisms (i.e., slower lexical processing and preview disruption) would lengthen mean fixation durations, which would mimic the empirical unsegmented text deficits. Furthermore, the simulations also explored the impact of both of these mechanisms on the model’s predicted preview effects (valid vs. invalid) and predicted word-frequency effects (high vs. low) on both mean fixations (see Figs. 1 and 2), and on the distribution of predicted divergence points across subjects (see Fig. 3). Thus, taken together, the empirical study and simulations were designed to test the hypothesis that unsegmented text deficits reflect disruptions to both lexical processing and parafoveal processing.

Empirical and simulated effects of preview (valid, invalid) and text condition (normal, unsegmented) on mean target word fixation-time measures (in ms), for first-fixation duration (panels a, d, g, and j), single-fixation duration (panels b, e, h, and k), and gaze duration (panels c, f, i, and l). The empirical means and standard errors are based on the by-participant analyses. Panels a–c show the empirical means, panels d–f show the Simulation 1 means (i.e., slower lexical processing), Panels g–i show the Simulation 2 means (i.e., disrupted parafoveal processing), and Panels j–l show the Simulation 3 means (i.e., slower lexical processing and disrupted parafoveal processing). See text for further details

Empirical and simulated effects of frequency (high, low) and text condition (normal, unsegmented) on mean target word fixation-time measures (in ms), for first-fixation duration (panels a, d, g, and j), single-fixation duration (panels b, e, h, and k), and gaze duration (panels c, f, i, and l). The empirical means and standard errors are based on the by-participant analyses. Panels a–c show the empirical means, panels d–f show the Simulation 1 means (i.e., slower lexical processing), panels g–i show the Simulation 2 means (i.e., disrupted parafoveal processing), and panels j–l show the Simulation 3 means (i.e., slower lexical processing and disrupted parafoveal processing). See text for further details

The empirical and simulated distributions of preview divergence points (panels a, c, e, and g) and word frequency divergence points (panels b, d, f, and h) for individual participants as a function of text condition (normal, unsegmented). Panels a and b show the empirical analyses, panels c and d show the Simulation 1 analyses (i.e., slower lexical processing), panels e and f show the Simulation 2 analyses (i.e., disrupted parafoveal processing), and panels g and h show the Simulation 3 analyses (i.e., slower lexical processing and disrupted parafoveal processing). See text for further details
Method
Participants
All 56 participants were undergraduate students at the University of Toronto. The participants were all native English speakers and were given either one course credit or $10.00 (Canadian) per hour. All participants had normal or corrected-to-normal vision.
Materials and design
The materials for this experiment were the same as those used by Sheridan et al. (2013). Specifically, the target words consisted of 120 low-frequency (LF) nouns and 120 high-frequency (HF) nouns, which ranged in word length from 5 to 10 letters (M = 6.5). The mean word frequency was 2.5 occurrences per million for the LF targets, and 112.1 occurrences per million for the HF targets, according to the SUBTLex corpus of American English subtitles (Brysbaert & New, 2009). 120 pairs of HF and LF words were then created (matched on word length), and two low-constraint sentence frames were composed for each word pair so that either word could plausibly fit into the sentences. For example, Sentences 1a and 1b were created for the pair of words, table and banjo:
-
1a. John decided to sell the table/banjo in the garage sale.
-
1b. I was told that the table/banjo was made out of expensive wood.
As discussed by Sheridan al. (2013), cloze norming (Taylor, 1953) confirmed that the average predictability was extremely low for these target words, amounting to 1.3 % for the HF target words and 0.1 % for LF target words.
In addition to the word frequency manipulation, on half of the trials (valid preview trials), the sentences appeared normally with one of the target words in the target location. On the other half of the trials (invalid preview trials), a pronounceable non-word (e.g., plart) that was equal in length to the target was initially displayed in the target location. All of the letters in the non-word previews were different from the corresponding letters in both the HF and LF targets.
Finally, in addition to the frequency and preview manipulations, we contrasted a normal text condition with an unsegmented text condition that contained random numbers between 2 and 9 instead of spaces (e.g., John4decided8to5sell9the7table2in3the9garage6sale). Thus, eight experimental conditions resulted from crossing word frequency (high vs. low), parafoveal preview (valid vs. invalid), and text condition (normal vs. unsegmented). All three of these experimental variables were manipulated within participants. Each participant read any given target word or sentence frame only once and the assignment of target words to sentence frames and preview conditions was counterbalanced across participants. Participants read 16 practice sentences followed by 278 sentences (240 experimental and 38 filler) that were presented in a random order.
Apparatus and procedure
Eye movements were measured with an SR Research EyeLink 1000 system with high spatial resolution and a sampling rate of 1,000 Hz. Viewing was binocular, but only the right eye was monitored. A chin rest and forehead rest were used to minimize head movements. Following calibration, gaze-position error was less than 0.5°. The sentences were displayed on a 21-in. ViewSonic monitor with a refresh rate of 150 Hz and a screen resolution of 1,024 × 768 pixels. All letters were lower case (except when capitals were appropriate). The text was presented in black (4.7 cd/m2) on a white background (56 cd/m2). Participants were seated 60 cm from the monitor, and 2.4 characters equaled approximately 1° of visual angle. All sentences were displayed on a single line, and the target words were located near the middle of the sentences. The average number of words in each sentence was 11.2 words (range = 6–16 words). In addition, for the word prior to the target (i.e., word n-1), the average length, frequency, and predictability values were 3.8 letters, 18,923 occurrences per million, and 0.17, respectively. During invalid preview trials, an invisible boundary was defined in the middle of the space between the final letter of the pre-target word and the first letter of the target word. Following the first eye-movement sample with a gaze position to the right of this boundary, a display change was initiated replacing the non-word occupying the target position with either the HF or LF target word. This change was accomplished within an average of 6.4 ms (range = 3–11 ms). No display change occurred in valid preview trials (i.e., the target word was presented in its sentence frame for the entire duration of the trial). Participants were not informed of the occurrence of the display changes. However, prior to the experiment, participants were instructed to read the sentences for comprehension, and they were informed that they would encounter sentences that contained numbers instead of spaces. Trials from the different conditions (i.e., valid vs. invalid, normal vs. unsegmented, HF vs. LF) were randomly intermixed. After reading each sentence, the participants pressed a button to end the trial and proceed to the next sentence. To ensure that participants were reading for comprehension, about 15 % of the sentences (all were filler sentences) were followed by multiple-choice comprehension questions. The average accuracy rate was 96 % in the normal reading condition and 90 % in the unsegmented reading condition, and this difference in accuracy rates across conditions was significant, t(55) = 6.65, p < 0.001.
Results
Our main goal was to test if removing spaces during reading impairs both parafoveal processing and lexical processing. We will first test this hypothesis by examining means and distributions of fixation durations, and we will then report on the findings from an exploratory simulation of unsegmented text deficits using the framework of the E-Z Reader model of eye-movement control (Reichle et al., 1998, 2012).
Mean fixation durations
To examine target word processing, we analyzed the following measures: first-fixation duration (i.e., the duration of the initial first-pass fixation on the target, regardless of the number of subsequent fixations on the target), single-fixation duration (i.e., the first-fixation value for the subset of trials in which there was only one first-pass fixation on the target), and gaze duration (i.e., the sum of all the consecutive first-pass fixations on the target, prior to a saccade to another word). Trials were excluded if the target was skipped during first-pass reading (6.6 % of trials), or if a blink occurred immediately before or after the first-fixation on the target (5.6 % of trials). In the invalid condition, we additionally removed trials in which the invisible boundary was crossed during a fixation (14.9 % of invalid trials).
For each of our measures (first-fixation, single-fixation, gaze duration), we used 2 × 2 × 2 analyses of variance (ANOVAs) that were carried out on the data via both participants (F 1) and items (F 2), with text condition (normal, unsegmented), parafoveal preview (valid, invalid) and word frequency (high, low) as within-subject variables. However, given that there were no significant three-way interactions (all Fs < 3, all ps > 0.1), we next examined the two-way interactions. Consistent with prior work by Reingold et al. (2012), the two-way interaction between word frequency and preview revealed a numerical trend towards smaller frequency effects for invalid than valid preview, and this interaction was strongest for single fixation, which was significant by-items [F 2 (1, 119) = 4.13, p < 0.05] and marginally significant by-participants [F 1 (1, 55) = 2.53, p = 0.117]. The frequency × preview interaction was marginally significant for first-fixation duration (both Fs > 2, both ps < 0.1), but did not approach significance for gaze duration (both Fs < 1). More importantly, given the present paper’s focus on unsegmented text effects, we will focus on reporting the interactions between text condition and preview (see Fig. 1), and between text condition and word frequency (see Fig. 2).
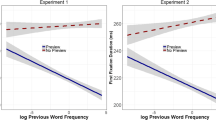
In confirmation of our hypothesis that unsegmented text would disrupt parafoveal processing, the magnitude of the preview effect was smaller for unsegmented than normal text (see Fig. 1, panels a–c), and this text condition × preview interaction was significant for first-fixation duration [F 1 (1, 55) = 5.05, p < 0.05; F 2 (1, 119) = 4.28, p < 0.05], marginally significant for gaze duration [F 1 (1, 55) = 2.79, p = 0.10; F 2 (1, 119) = 2.48, p = 0.12], and non-significant for single fixation (both Fs < 1). Thus, the text condition × preview interaction emerged early (i.e., it was strongest for the first-fixation measure). In contrast, as shown in Fig. 2 (panels a–c), the text condition × frequency interaction was a later effect; in replication of past findings (e.g., Rayner et al., 1998; Sheridan et al., 2013), word-frequency effects were larger for unsegmented than normal text in the case of gaze duration (both Fs > 40, both ps < .001), but not for first-fixation and single-fixation duration (all Fs < 1).
Survival analyses of first-fixation duration
To explore the time-course of the above effects, we also used a survival analysis technique (Reingold et al., 2012; Reingold & Sheridan, 2014). For each subject, this procedure was used to obtain an estimate of the earliest discernible impact of a variable (henceforth referred to as the divergence point) by contrasting the survival curves of first-fixation durations across two experimental conditions using a bootstrap resampling procedure (see Reingold & Sheridan, 2014 for further details, as well as the MATLAB scripts that were used to obtain the divergence point estimates). In the present study, we obtained divergence point estimates for the preview (valid vs. invalid) and word frequency (high vs. low) variables, using the individual differences version of the procedure proposed by Reingold and Sheridan (2014). A small number of subjects had to be excluded because the distributions did not reliably diverge across the two contrasted conditions (we excluded five subjects from the preview analyses and three subjects from the word-frequency analyses).
As shown in Fig. 3 (panels a and b), histograms were created to illustrate the distribution of preview (panel a) and word-frequency (panel b) divergence point estimates across subjects as a function of text condition (normal, unsegmented). Of relevance to our hypothesis that parafoveal processing would be disrupted by unsegmented text, the preview divergence points were significantly later for the unsegmented (M = 155 ms, SD = 43.2 ms) relative to the normal condition (M = 133 ms, SD = 43.9 ms), t(50) = 3.14, p < 0.01. Additionally, in replication of Sheridan et al. (2013; see also Reingold & Sheridan, 2014), the word-frequency divergence points were significantly later for the unsegmented (M = 179 ms, SD = 66.2 ms) relative to the normal condition (M = 143 ms, SD = 46.3 ms), t(52) = 3.45, p < 0.01. In fact, in both panels a and b, a clear shift can be observed such that the distributions of both preview and frequency divergence points are shifted to the right for the unsegmented relative to the normal text conditions, which indicates that the removal of spaces impacted the entire distribution (i.e., both fast and slow divergence points were affected).
Thus, the first-fixation data support our hypothesis that removing spaces produces smaller and temporally delayed preview effects during reading. Building on these findings, the simulations below further explored the link between lexical processing, parafoveal preview, and unsegmented text deficits.
E-Z Reader simulation
The E-Z Reader model incorporates the assumption that word identification is serial (i.e., one word is processed at a time), as well as the assumption that lexical processing occurs in two stages: an early lexical processing stage (L 1) and a later lexical processing stage (L 2) such that the completion of L 1 triggers the initiation of the programming of a saccade to the next word, and the subsequent completion of L 2 causes attention to shift to the next word. Within this model, the largest influence on the mean duration of L 1 and L 2 (i.e., the speed of lexical processing) is determined by the value of the free parameter α 1 (for detailed descriptions of the model and its parmeters see Pollatsek, Reichle, & Rayner, 2006; Reichle et al., 1998; Reichle, Pollatsek, & Rayner, 2006; Reichle et al., 2012; Reichle, Rayner, & Pollatsek, 2003; Reichle, Warren, & McConnell, 2009; Reichle & Sheridan, 2015; Reichle, 2011). Moreover, the model predicts that a substantial amount of parafoveal processing normally occurs because attention often shifts to the next word prior to the completion of the programming of the saccade to move the eyes to the next word (for a related discussion, see Pollatsek et al., 2006; Schotter, Reichle, & Rayner, 2014; Sheridan & Reichle, 2015). The simulations reported here were completed using the lengths, frequencies, and predictabilities of the pre-target and target words in the present study, and the 48 sentences of the Schilling, Rayner, and Chumbley (1998) corpus as “frames” in which these words were embedded (at sixth word position) as per conventions adopted in previous simulations (e.g., see Reichle et al., 2012). Unless otherwise specified, we used the standard model with its default parameter values (see Reichle et al., 2012), removing trials in which the target was skipped (3.4 % of trials), and using 1,000 statistical subjects per simulation to obtain reliable estimates of the simulated dependent measures.
To explore the mechanisms underlying unsegmented text effects, we simulated the empirical unsegmented text manipulation in three different ways: Simulation 1 slowed down lexical processing, Simulation 2 disrupted parafoveal processing, and Simulation 3 implemented both of these mechanisms simultaneously (i.e., slower lexical processing and disrupted parafoveal processing). To introduce individual differences across the simulated subjects, we generated the normal text condition by randomly sampling the values of the α 1 parameter for each of the 1,000 subjects from a Gaussian distribution with a mean of 104 ms (the default value of the α 1 parameter) and a standard deviation of 25 ms. In Simulation 1, a slower rate of lexical processing was simulated in the unsegmented text condition by increasing the values of α 1 in the normal text condition by 15 %, resulting in a mean α 1 value of approximately 120 ms. In Simulation 2, less efficient parafoveal processing was simulated in the unsegmented text condition by doubling the amount of required time to complete L 1 during parafoveal preview. Finally, in Simulation 3, both of the previously described assumptions were implemented simultaneously (i.e., slower lexical processing and disrupted parafoveal processing).
Similar to the empirical analyses, the simulations were used to examine the hypothesized consequences of all three possible ways of instantiating the disruptive effects of unsegmented text on word frequency (high vs. low) and preview (valid vs. invalid). These analyses were done for both mean fixation durations (Figs. 1 and 2) and the distribution of divergence points across subjects (Fig. 3). Finally, the absence of preview in the invalid preview condition was simulated using the method adopted by Sheridan and Reichle (2015), with the assumption that lexical processing of the target words does not begin until the eyes fixate on or to the right of the blank space preceding the target word.
As shown in Figs. 1 and 2, all three of the simulations were consistent with the empirical finding that unsegmented text produces longer fixation durations than normal text. However, Simulation 3 (i.e., slower lexical processing and disrupted parafoveal processing) was best able to capture the empirical preview effects. As shown in Fig. 1 (panels j–l), Simulation 3 replicated the observed interaction between text condition and preview, with smaller preview effects being evident on fixation durations in the unsegmented than normal text condition. In contrast, Simulation 1 (i.e., slower lexical processing) did not produce this interaction (see Fig. 1, panels d–f), and Simulation 2 (i.e., disruptions to parafoveal processing) failed to produce the observed difference between the normal and unsegmented text conditions during invalid trials (see Fig. 1, panels g–i). Thus, both of the hypothesized mechanisms (i.e., slower lexical processing and disrupted parafoveal processing) are apparently necessary to simulate the complete pattern of observed preview effects.
As shown in Fig. 2, all three of the simulations replicated the empirical pattern of additive effects of word frequency and text segmentation for the first-fixation and single-fixation measures. However, none of the simulations captured the interaction of larger word frequency effects for unsegmented relative to normal text for gaze durations. To explain this interaction, the model may require a more complex set of assumptions regarding the effects of unsegmented text; for example, that it further interferes with post-lexical processing (see Reichle et al., 2009). Future simulations and empirical studies are thus necessary to further explore the nature of this interaction.
Finally, we estimated survival divergence points for the simulated data using the same procedure used for the empirical data (see Reingold & Sheridan, 2014). As shown in Fig. 3 (panels c–h), all three of the simulations produced distributions of individual participant survival divergence points (see Reingold & Sheridan, 2014) that were qualitatively similar to the empirical results. Specifically, the preview divergence points were significantly later for the unsegmented relative to the normal condition: Simulation 1, normal: M = 144 ms, unsegmented: M = 157 ms; Simulation 2, normal: M = 144 ms, unsegmented: M = 186 ms; Simulation 3, normal: M = 144 ms, unsegmented: M = 187 ms (all ts > 7, all ps < 0.001). And similarly, the word-frequency divergence points were significantly later for the unsegmented relative to the normal condition: Simulation 1, normal: M = 166 ms, unsegmented: M = 178 ms; Simulation 2, normal: M = 166 ms, unsegmented: M = 188 ms; Simulation 3, normal: M = 166 ms, unsegmented: M = 195 ms (all ts > 4, all ps < 0.001). Thus, the simulations provide further support for the hypothesis that removing inter-word spaces slows down the rate of both lexical and parafoveal processing.
Discussion
To clarify the role of spaces during reading, we explored the hypothesis that removing inter-word spaces would interfere with parafoveal processing. As support for this hypothesis, we demonstrated a smaller effect of preview validity on mean first-fixation durations for unsegmented versus normal text. In addition, we manipulated the word frequency (high vs. low) variable that is considered to be a temporal marker of lexical processing (Reingold et al., 2012), and we used a survival analysis technique (Reingold et al., 2012; Reingold & Sheridan, 2014) to determine the onset of both preview and word-frequency effects on distributions of first-fixation durations. Replicating Sheridan et al. (2013), word-frequency effects were delayed for unsegmented relative to normal text, which supports the notion that unsegmented text interferes with word identification (Rayner et al., 1998; Sheridan et al., 2013). Extending this finding, we also showed that unsegmented text delayed the onset of preview effects. Taken together, these results support our hypothesis that unsegmented text produces a delay in the onset of word-frequency and preview effects, as well as a reduction in the magnitude of preview effects.
We also used the E-Z Reader model of eye-movement control (Reichle et al., 2012) to simulate the above empirical effects of unsegmented text on both mean fixation durations and the distribution of divergence points across subjects. Most importantly, simulating the mean effects revealed that two different assumptions – slowing down lexical processing and disrupting parafoveal processing – seemed to be necessary to simulate the empirical finding of smaller preview effects for unsegmented than normal text (see Simulation 3; Fig. 1, panels j–l), and that either assumption on its own was not sufficient (see Simulations 1 and 2; Fig. 1, panels d–i). Moreover, similar to the empirical survival results, the simulated distributions of divergence points (see Fig. 3, panels c–h) revealed that both word-frequency and preview effects were delayed for unsegmented relative to normal text. Thus, taken together with the empirical results, the simulations support our hypothesis that unsegmented text disrupts both lexical processing and parafoveal processing.
Building on the present findings, future work could explore the possibility that unsegmented text deficits also reflect post-lexical integration difficulty. Specifically, although the text condition × frequency interaction on gaze duration (see Fig. 2, panel c) was previously interpreted as reflecting disruptions to lexical processing (Rayner et al., 1998), it seems more likely that this interaction might at least in part reflect post-lexical integration difficulties. This interpretation is supported by the fact that the interaction between text condition and word frequency was not significant for early fixation-duration measures (first-fixation duration and single-fixation duration). In addition, the fact that the E-Z Reader model failed to simulate this interaction using only an assumption about lexical processing (i.e., changes to the value of the α 1 parameter) is also consistent with this interpretation. Future studies could further explore the role of post-lexical integration by combining unsegmented text manipulations with materials that are specifically designed to facilitate or hinder the integration of a word’s meaning within its sentence context (e.g., semantically anomalous words; Rayner, Warren, Juhasz, & Liversedge, 2004). Importantly, however, the present study suggests that a comprehensive account of unsegmented text effects will require some explanation for how the absence of inter-word spaces disrupts both lexical and parafoveal processing.
References
Bouma, H. (1973). Visual interference in the parafoveal recognition of initial and final letters of words. Vision Research, 13(4), 767–82. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/4706350
Brysbaert, M., & New, B. (2009). Moving beyond Kucera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behavior Research Methods, 41(4), 977–990. doi:10.3758/BRM.41.4.977
Epelboim, J., Booth, J. R., Ashkenazy, R., Taleghani, A., & Steinman, R. M. (1997). Fillers and spaces in text: the importance of word recognition during reading. Vision Research, 37(20), 2899–914. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/9415369
Epelboim, J., Booth, J. R., & Steinman, R. M. (1994). Reading unspaced text: implications for theories of reading eye movements. Vision Research, 34(13), 1735–66. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/7941379
Epelboim, J., Booth, J. R., & Steinman, R. M. (1996). Much ado about nothing: The place of space in text. Vision Research, (36), 465–470. Retrieved from http://www.sciencedirect.com/science/article/pii/004269899500131X
Inhoff, A. W., & Rayner, K. (1986). Parafoveal word processing during eye fixations in reading: Effects of word frequency. Perception & Psychophysics, 40(6), 431–439.
Li, X., Rayner, K., & Cave, K. R. (2009). On the segmentation of Chinese words during reading. Cognitive Psychology, 58(4), 525–552. doi:10.1016/j.cogpsych.2009.02.003
Malt, B. C., & Seamon, J. G. (1978). Peripheral and cognitive components of eye guidance in filled-space reading. Perception & Psychophysics, 23(5), 399–402. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/683824
McGowan, V. A., White, S. J., & Paterson, K. B. (2014). The effects of interword spacing on the eye movements of young and older readers. Journal of Cognitive Psychology, 1–13. doi:10.1080/20445911.2014.988157
Morris, R. K., Rayner, K., & Pollatsek, A. (1990). Eye movement guidance in reading: the role of parafoveal letter and space information. Journal of Experimental Psychology: Human Perception and Performance, 16(2), 268–81. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/2142198
Perea, M., & Acha, J. (2009). Space information is important for reading. Vision Research, 49(15), 1994–2000. doi:10.1016/j.visres.2009.05.009
Pollatsek, A., & Rayner, K. (1982). Eye movement control in reading: The role of word boundaries. Journal of Experimental Psychology. Human Perception and Performance, 8(6), 817–833. doi:10.1037//0096-1523.8.6.817
Pollatsek, A., Reichle, E. D., & Rayner, K. (2006). Tests of the E-Z Reader model: exploring the interface between cognition and eye-movement control. Cognitive Psychology, 52(1), 1–56. doi:10.1016/j.cogpsych.2005.06.001
Rayner, K. (1975). The perceptual span and peripheral cues in reading. Cognitive Psychology, 7, 65–81. Retrieved from http://www.sciencedirect.com/science/article/pii/0010028575900055
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124(3), 372–422. Retrieved from http://psycnet.apa.org/psycinfo/1998-11174-004
Rayner, K. (2009). Eye movements and attention in reading, scene perception, and visual search. Quarterly Journal of Experimental Psychology, 62(8), 1457–1506. doi:10.1080/17470210902816461
Rayner, K., & Duffy, S. A. (1986). Lexical complexity and fixation times in reading: Effects of word frequency, verb complexity, and lexical ambiguity. Memory & Cognition, 14(3), 191–201. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/3736392
Rayner, K., Fischer, M. H., & Pollatsek, A. (1998). Unspaced text interferes with both word identification and eye movement control. Vision Research, 38(8), 1129–1144.
Rayner, K., Warren, T., Juhasz, B. J., & Liversedge, S. P. (2004). The effect of plausibility on eye movements in reading. Journal of Experimental Psychology. Learning, Memory, and Cognition, 30(6), 1290–1301.
Reichle, E. D. (2011). Serial attention models of reading. In S. P. Liversedge, I. D. Gilchrist, & S. Everling (Eds.), Oxford Handbook on Eye Movements (pp. 767–786). Oxford: Oxford University Press.
Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105, 125–157. Retrieved from http://psycnet.apa.org/psycinfo/1997-42747-006
Reichle, E. D., Pollatsek, A., & Rayner, K. (2006). E–Z Reader: A cognitive-control, serial-attention model of eye-movement behavior during reading. Cognitive Systems Research, 7(1), 4–22. doi:10.1016/j.cogsys.2005.07.002
Reichle, E. D., Pollatsek, A., & Rayner, K. (2012). Using E-Z Reader to simulate eye movements in nonreading tasks: a unified framework for understanding the eye-mind link. Psychological Review, 119(1), 155–185. doi:10.1037/a0026473
Reichle, E. D., Rayner, K., & Pollatsek, A. (2003). The E-Z reader model of eye-movement control in reading: Comparisons to other models. Behavioral and Brain Sciences, 26(4), 445–76; discussion 477–526. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/15067951
Reichle, E. D., & Sheridan, H. (2015). E-Z Reader: An Overview of the Model and Two Recent Applications. In A. Pollatsek & R. Treiman (Eds.), The Oxford Handbook of Reading (pp. 277–290). Oxford: Oxford University Press.
Reichle, E. D., Warren, T., & McConnell, K. (2009). Using E-Z Reader to model the effects of higher level language processing on eye movements during reading. Psychonomic Bulletin & Review, 16(1), 1–21. doi:10.3758/PBR.16.1.1
Reingold, E. M., Reichle, E. D., Glaholt, M. G., & Sheridan, H. (2012). Direct lexical control of eye movements in reading: Evidence from a survival analysis of fixation durations. Cognitive Psychology, 65, 177–206. doi:10.1016/j.cogpsych.2012.03.00
Reingold, E. M., & Sheridan, H. (2014). Estimating the divergence point: a novel distributional analysis procedure for determining the onset of the influence of experimental variables. Frontiers in Psychology, 5(December), 1–10. doi:10.3389/fpsyg.2014.01432
Reingold, E. M., Yang, J., & Rayner, K. (2010). The time course of word frequency and case alternation effects on fixation times in reading: Evidence for lexical control of eye movements. Journal of Experimental Psychology. Human Perception and Performance, 36(6), 1677–1683. doi:10.1037/a0019959
Schilling, H. E. H., Rayner, K., & Chumbley, J. I. (1998). Comparing naming, lexical decision, and eye fixation times: Word frequency effects and individual differences. Memory & Cognition, 26(6), 1270–1281. doi:10.3758/BF03201199
Schotter, E. R., Reichle, E. D., & Rayner, K. (2014). Rethinking parafoveal processing in reading: Serial-attention models can explain semantic preview benefit and N +2 preview effects. Visual Cognition, 1–25. doi:10.1080/13506285.2013.873508
Sheridan, H., Rayner, K., & Reingold, E. M. (2013). Unsegmented text delays word identification: Evidence from a survival analysis of fixation durations. Visual Cognition, 21, 38–60. doi:10.1080/13506285.2013.767296
Sheridan, H., & Reichle, E. D. (2015). An analysis of the time course of lexical processing during reading. Cognitive Science. doi:10.1111/cogs.12246
Spragins, A. B., Lefton, L. A., & Fisher, D. F. (1976). Eye movements while reading and searching spatially transformed text: A developmental examination. Memory & Cognition, 4(1), 36–42. doi:10.3758/BF03213252
Taylor, W. L. (1953). “Cloze procedure”: a new tool for measuring readability. Journalism Quarterly, 30, 415–433.
Townsend, J. T., Taylor, S. G., & Brown, D. R. (1971). Lateral masking for letters with unlimited viewing time. Perception & Psychophysics, 10(5), 375–378.
White, S. J. (2008). Eye movement control during reading: Effects of word frequency and orthographic familiarity. Journal of Experimental Psychology. Human Perception and Performance, 34(1), 205–223. doi:10.1037/0096-1523.34.1.205
Yang, S.-N., & McConkie, G. W. (2001). Eye movements during reading: A theory of saccade initiation times. Vision Research, 41(25–26), 3567–85. Retrieved from http://www.ncbi.nlm.nih.gov/pubmed/11718796
Author note
The writing of this article was supported by a Postdoctoral Fellowship (PDF) awarded to H.S. from the Natural Sciences and Engineering Research Council of Canada (NSERC) and a grant awarded to E.D.R. from the National Institutes of Health (HD075800).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Sheridan, H., Reichle, E.D. & Reingold, E.M. Why does removing inter-word spaces produce reading deficits? The role of parafoveal processing. Psychon Bull Rev 23, 1543–1552 (2016). https://doi.org/10.3758/s13423-015-0997-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0997-y