
Abstract
Dual-task costs can be greatly reduced or even eliminated when both tasks use highly-compatible S-R associations. According to Greenwald (Journal of Experimental Psychology: Human Perception and Performance, 30, 632–636, 2003), this occurs because the appropriate response can be accessed without engaging performance-limiting response selection processes, a proposal consistent with the embodied cognition framework in that it suggests that stimuli can automatically activate motor codes (e.g., Pezzulo et al., New Ideas in Psychology, 31(3), 270-290, 2013). To test this account, we reversed the stimulus-response mappings for one or both tasks so that some participants had to “do the opposite” of what they perceived. In these reversed conditions, stimuli resembled the environmental outcome of the alternative (incorrect) response. Nonetheless, reversed tasks were performed without costs even when paired with an unreversed task. This finding suggests that the separation of the central codes across tasks (e.g., Wickens, 1984) is more critical than the specific S-R relationships; dual-task costs can be avoided when the tasks engage distinct modality-based systems.
Similar content being viewed by others

When we do two things at the same time, performance usually suffers. Such costs are robust and observed even when the two tasks are simple and involve distinct input and output modalities (e.g., Pashler & Johnston, 1989). In a few cases, however, the magnitude of the dual-task cost is small (e.g., Greenwald & Shulman, 1973), although there is debate as to whether dual-task costs are eliminated or just significantly reduced as a result of using highly compatible S-R pairs (e.g., Lien, Proctor & Ruthruff, 2003; Shin & Proctor, 2008; Greenwald, 2003, 2004). Nonetheless, given the pervasiveness of dual-task costs, dramatic reductions with certain S-R pairs are striking and surely offer insight into how stimulus information is used to guide the selection of action.
Single-session experiments resulting in little or no dual-task costs have used tasks with ideomotor (IM) compatible stimulus-response mappings; that is, the stimuli depict some aspect of the sensory consequences of the appropriate response (Greenwald & Shulman, 1973). For example, in Experiment 3 from Halvorson et al. (2013), an auditory-vocal (AV) shadowing task (e.g., if the participants heard the word “dog,” they had to say the word “dog”) was paired with a visual-manual (VM) button-press imitation task (e.g., if the index finger of the hand in the image on the screen was depressed, participants pressed the 1 key with their index fingers). When these two tasks were performed together, there was little evidence of dual-task costs.
Greenwald and Shulman (1973) proposed that IM-compatible tasks eliminate dual-task costs because they allow responses to be selected without engaging the central mechanisms responsible for producing interference. They claimed that, when the sensory cue for the action and its outcome are highly similar, responses are activated automatically. This proposal resonates with theoretical work on response-effect (R-E) compatibility in that it emphasizes the role of bidirectional action representations in response selection (e.g. Pfister, Kiesel, & Melcher, 2010). More broadly, this framework converges with a growing embodied cognition literature whose central claim is that cognitive processes are grounded in the body’s interaction with the environment and operate in a dynamic manner that depends on organism–environment coupling (Barsalou, 1999). According to such accounts, response selection is accomplished by activating the same neural resources and motor codes during perception, mental simulation, and action execution (see Pezzulo, Candidi, Dindo, & Barca, 2013 for a review).
Thus, the embodied cognition account suggests that dual-task costs are eliminated because of the unique relationship between the physical features of the stimulus and environmental consequences of the correct response. That is, correspondence between the stimuli and environmental consequences of the appropriate responses leads to automatic activation of the correct response, thereby minimizing dual-task costs. To explain why both tasks must be IM-compatible for dual-task costs to be very small (e.g., Greenwald & Shulman, 1973; Halvorson et al., 2013), it can be assumed that automatic activation of the responses drive behavior only when the correct response is automatically activated for both tasks. Binding stimuli to correct responses for the arbitrary S-R pairings may require the use of central, domain-general response selection mechanisms which, once engaged, select the responses for both tasks regardless of whether responses are automatically activated for one task.
However, while much of the existing research has focused on whether IM-compatible tasks actually eliminate dual-task costs, only a small set of tasks has been used and little work has attempted to identify the task properties that allow for dramatic reductions in costs. Note that there are at least two other ways to account for the absence of dual-task costs with two IM-compatible tasks. One alternative explanation stems from the fact that the IM-compatible tasks essentially share the same rule: “Do what you perceive.” If participants conceptualize the task in this way, both responses could be selected by choosing to imitate the stimuli. Thus, when the task pairing consisted of two IM-compatible tasks, participants could use one translation rule to produce both responses. In other words, the relationship between the tasks made it so that participants could treat the two responses on dual-task trials as belonging to a single, multi-component task.
A second explanation holds that IM-compatible tasks avoid dual-task interference because the VM tasks used S-R mappings that relied exclusively on spatial information and the AV task used S-R mappings that relied exclusively on verbal information (Wickens, 1984). Unlike VM tasks in which a verbal label (e.g., a color word like “red”) is used to identify the visual stimulus, the arrow stimuli used by Greenwald and Shulman (1973; see also Lien et al., 2003; Shin & Proctor, 2008; Greenwald, 2003, 2004) and the hand stimuli used by Halvorson et al. (2013) contained spatial information that corresponded to the correct response. Similarly, unlike AV tasks that rely on the pitches of tones, the word and letter stimuli used in IM-compatible tasks contained verbal information that corresponded to the correct response. Such mappings may allow for concurrent processing of the two tasks because the response for the IM-compatible VM task can be selected using only spatial information and the response for the IM-compatible AV task can be selected using only verbal information.
Present study
To test these accounts, we designed tasks that used the same stimuli and responses but altered the SR mappings to form a between-subjects 2 × 2 design. The instructions for each task were either to “imitate” or “do the opposite” (see Fig. 1). For group II, both tasks used imitate instructions and were thus IM-compatible. For group OO, both tasks used the “do the opposite” instructions, so that participants had to choose the manual response not depicted on the screen (of the two possible choices) and/or say the word from the response set that was not presented.

The 2 × 2 design used to measure dual-task interference with 2 opposite tasks (bottom right), 2 IM tasks (top left), and one of each (top right, bottom left). Italicized text indicates the opposite rule. Dashed horizontal lines in the middle of the quadrant indicate the two tasks shared the same rule; a solid line indicates two different rules
In the opposite VM task, the unique relationship between the finger depressed in the image and the finger required for making the correct response (as well as the spatial relationship between the stimulus and the response) is eliminated. Likewise, in the opposite AV task, the correspondence between the stimulus and the correct response is greatly reduced. Hearing “cat” may automatically activate the opposite response “dog”, but certainly not as much as the alternative response “cat”. Thus, the embodied cognition account predicts large dual-task costs for group OO compared to group II.
In contrast, the single-rule account predicts small dual-task costs in both groups because the correct response for both tasks can be selected on dual-task trials by implementing a single rule (group II: “do what you perceive”; group OO: “do the opposite”). Similarly, the spatial-verbal account also predicts small costs across groups II and OO because the opposite rule only changes the particular S-R mappings, not the modality pairings; the opposite VM task relies only on spatial codes to link the stimulus to the response and the opposite AV task relies only on verbal information.
To distinguish between the single-rule and spatial-verbal accounts, groups OI and IO fill the remaining cells in the 2 × 2 design in which one task is IM-compatible and the other uses the opposite mapping. The single-rule account predicts dual-task costs for these groups; these combinations of tasks should prevent consolidation of the S-R pairs into a single task. In contrast, the spatial-verbal account predicts minimal dual-task costs in these groups; regardless of the mappings, the S-R pairs in the VM task can be encoded spatially and should not interfere with the AV task.
We used three block-types to isolate the dual-task costs: homogenous single-task blocks, in which only one task was presented on a given trial, mixed-task blocks (OR blocks), which contained single-task trials from both task sets presented in a random order but never simultaneously, and dual-task blocks in which two responses were required on each trial (AND blocks) (see Halvorson et al., 2013; Tombu & Jolicoeur, 2004). Differences in RT between OR and single-task blocks, which equate to the number of responses (1) made on each trial, measure the increase in cognitive load independently of the number of responses required on a given trial, or the mixing costs. Differences in RT between AND and OR blocks, which equate the number of response alternatives possible on each trial (4), measure the dual-task costs that results from selecting and executing two responses simultaneously compared to one response. Moreover, because strategies can shift the cost from one task to another (Tombu & Jolicoeur, 2004), we analyze the sum of the costs across the two tasks (see also, Halvorson et al., 2013).
Methods
Participants
Ninety-two undergraduates from the University of Iowa were recruited to participate; twelve subjects with an overall accuracy of less than 85 % were eliminated from the analyses resulting in twenty participants in each group (49 female, ages 19–25). Individuals participated in partial fulfillment of an introductory course requirement and reported normal or corrected-to-normal vision and hearing.
Stimuli and apparatus
Stimuli were presented on a 19–inch (c.48-cm) color LCD monitor located approximately 57 cm from the participant. A PC computer using Microsoft Office Visual Basic software was used to present the auditory stimuli (the words “cat” and “dog” lasting 250 ms in duration) through a headset equipped with a microphone. The visual stimuli were color images of a right hand making a key press with either the index or middle finger as if participants were looking down at their own hands (Fig. 1). The images were presented in the center of the screen within a 6.7° × 6.6° neutral colored rectangle, on a black background. Participants made button-press responses on the 1 and 2 keys of the number pad.
Procedure
Each participant completed voice recognition training before being given verbal and written instructions for the AV and VM tasks. Participants were instructed to respond as quickly and accurately as possible and that each task was equally important. The order of events for trials was as follows: a white fixation cross subtending 1.3° × 1.3° visual angle appeared in the center of the screen for 500 ms. Next, the auditory and visual stimuli were presented for 250 ms. In single-task and OR blocks, only one type of stimulus was presented. In OR blocks, each trial had an equally likely chance of being an AV trial or a VM trial. In AND blocks, one of each type of stimulus was presented. After 2000 ms or a response, the next trial started.
Each block consisted of 36 trials and each block type was completed 4 times for a total of 16 total blocks. The block order (AV task alone, VM task alone, OR block, AND block), was the same for all participants. Feedback at the end of each block indicated the percent of correct responses and the average RT for each task.
Group II (Fig. 1, top left) was a replication of Experiment 3 in Halvorson et al. (2013). Participants were instructed to “repeat what you hear” in the AV task (e.g., if you hear “dog,” say “dog”). In the VM task, participants were instructed to “repeat what you see” by making a response based on the depressed finger in the image.
In the group OO (Fig. 1, bottom right,), participants were instructed to “do the opposite” for both tasks. In the AV task, if they heard “cat”, they were instructed to say “dog” and vice versa. In the VM task if the middle finger was depressed in the image on the screen, they were instructed to press the 1 key, and if the index finger was depressed, press the 2 key.
In the group OI (Fig. 1, top right,), participants were instructed to “do the opposite” for the AV task and “repeat what you see” for the VM task. In the group IO (Fig. 1, bottom left), participants were instructed to “repeat what you hear” for the AV task and “do the opposite” for the VM task.
Results
The first of each block type from each group was considered practice and eliminated from the final analyses. Trials where an incorrect response was made on either task or where RTs exceeded 1500 ms or were shorter than 150 ms (2 % of the remaining trials) were also eliminated.
Single-task RTs
A 2 × 2 × 2 ANOVA with task (AV, VM), instruction (imitate, opposite), and task pairing (same, different) as factors was conducted on the single-task RTs for each task (see Table 1). The main effect of task was significant, F(1,152) = 226.91, MSE = 4109.79, p < .001, indicating faster overall RTs in the AV task (365 ms) than the VM task (518 ms). The main effect of instruction was also significant, F(1,152) = 23.94, MSE = 5824.81, p < .001, indicating faster overall RTs for tasks that used the imitate instructions (412 ms) than the opposite instructions (471 ms). Neither the main effect of task pairing nor any interactions were significant, F < 1.
Mixing costs
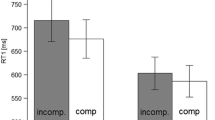
Mixing costs were calculated by subtracting mean RTs in the single-task blocks from mean RTs in the OR blocks and summed across the AV and VM tasks (Fig. 2, white bars). This method allows for the overall cost associated with maintaining two tasks to be calculated as opposed to differences in performance within each task which might reflect participants prioritizing one task over the other (Halvorson et al., 2013; Tombu & Jolicoeur, 2004). A 2 × 2 ANOVA with AV and VM instruction as between-subjects factors was conducted for the sum of the mixing costs across groups. The intercept was significant, F(1,76) = 74.74, p < .001, indicating significant mixing costs across groups. The main effect of AV instruction, F(1,76) = 6.89, MSE = 3157.38, p < .05, revealed larger mixing costs with the imitate instructions (85 ms) compared to the opposite instructions (52 ms). This unexpected finding may reflect the simplicity of the single-task IM-compatible AV condition in which participants simply repeat each word they hear. Neither the main effect of VM instruction, F(1,76) = 1.48, MSE = 2288.38, p = .24, nor the interaction, F(1,76) = 2.89, MSE = 3107.09, p = 011, were significant. In all conditions, t-tests showed that the summed mixing costs was significantly greater than zero, |ts| > 2.75; ps < .05.Footnote 1

Sum of mixing and dual-task costs for the four groups. Error bars indicate the standard error of the mean
Dual-task costs
Dual-task costs were calculated by subtracting mean RTs in the OR blocks from mean RTs in the AND blocks and summed across the AV and VM tasks (black bars, Fig. 2). The dual-task costs for each condition were submitted to a 2 × 2 ANOVA with AV and VM instruction as between-subject factors. The intercept was not significant, F<1, indicating no significant dual-task costs across groups. Neither of the main effects, AV instruction F(1,76) = 3.05, MSE = 5210.01, p = .10, VM instruction, nor the two-way interaction were significant, Fs<1. Follow-up t-tests showed that mean dual-task costs were not significantly different than zero, all |ts|<1 except for group II (–23 ms), where the mean cost was actually marginally less than zero, t(19) = 2.08, p = .05. In other words, when the OR blocks were used as a baseline, there was no evidence that making two responses in the AND blocks slowed RTs for any of the groups. This was true when either or both tasks used opposite mappings. We had sufficient power to detect dual-task costs between 30 and 70 ms, depending on the group. The absence of dual-task costs across groups supports only the spatial-verbal account; in all four groups, the AV and VM tasks required distinct input and output systems and could be coded using exclusively the verbal and spatial systems, respectively.Footnote 2
Accuracy
A 2 × 2 × 2 ANOVA with task (AV, VM), instructions (imitate, opposite), and task pairing (same, different) as within-subject factors was conducted on the accuracy data from the single-task blocks only. There was a significant main effect of task, F(1,152) = 22.23, MSE = .002, p < .001, indicating higher accuracy rates for the VM tasks (97 %) than the AV tasks (93 %) across groups, and a main effect of pairing, F(1,152) = 14.96, MSE = .003, p < .01, indicating higher accuracy when the task pairings used the same instructions (97 %) compared to different instructions (93 %). The main effect of instructions was not significant, F < 1. This suggests that the main effect of instruction observed in the single-task RTs was not likely due to a significant speed–accuracy trade-off. There were no significant interactions.
For the mixing and dual-cost analyses, we submitted the accuracy data (collapsed across task) to a one-way ANOVA with block type as a within-subjects factor for every group. For groups II and OO the main effect of block type was not significant, Fs < 1. For group IO, there was a significant main effect, F(2,38) = 6.91, MSE = .001, p < .01, indicating higher accuracy in OR (97 %), than single task blocks (93 %), t(19) = 3.11, p < .01, and AND blocks (94 %), t(19) = 2.30, p < .05. The main effect was also significant for group IO, F(2,38) = 6.91, MSE = .001, p < .01. Accuracy was highest in OR blocks (96 %) compared to single task blocks (93 %), t(19) = 3.50, p < .01, but not significantly different than AND blocks (95 %), t(19) = 1.65, p = .11. For the groups with different instructions for the two tasks, it is possible that a speed–accuracy trade-off contributed to the longer RTs in the OR blocks; however, it is not likely that this can account for the highly similar pattern of mixing and dual-task costs observed across all four tasks.
Discussion
Across the four groups, no dual-task costs were observed, even though at least one of the tasks used an incompatible mapping in three of the groups. Although mixing costs were consistently observed, these were largest when both tasks were IM-compatible, providing further evidence that the opposite tasks were performed with no greater costs than the IM-compatible tasks. We make no strong claims that the dual-task costs are completely eliminated; rather, we show that they are not large and are unaffected by element-level compatibility when the spatial and verbal codes are segregated by the tasks. Mapping did affect RT, indicating that the opposite mappings were more difficult, but they did not produce greater dual-task costs, demonstrating that costs are not strictly related to the difficulty of the S-R mappings.
The results are inconsistent with the claim that participants avoid dual-task costs with IM-compatible tasks by treating the two tasks as a single task, because no costs were observed when the tasks used conflicting rules. These results are also inconsistent with the claim that participants avoid dual-task costs with IM-compatible tasks by relying on the IM-compatible stimuli to automatically activate the appropriate responses, because the costs were not affected by the mappings. It is possible that activation can be channeled to the opposite response depending on the instruction, but this explanation changes the nature of the activation from an automatic process that simulates the action most relevant to the stimulus to a task-dependent one that uses top–down control.
The lack of dual-task costs may result from high set-level compatibility, which is identical across all groups. Dual-task costs are typically robust for visual-manual and auditory-vocal task pairings (e.g., Greenwald & Shulman, 1973; Halvorson, et al., 2013; Pashler & Johnston, 1989), but the set-level compatibility in this case could be driven by the correspondence between the hand pictures and manual responses and between the words and vocal responses.Footnote 3 However, while set-level compatibility may be driving the low dual-task costs, for this account to have explanatory power, an independent means of assessing set-level compatibility must be developed.
The proposal that the modality of the information, rather than the specific code, is critical for reducing crosstalk between tasks echoes findings from task-switching studies examining how the pairing of input and output modalities affects switch costs. Stephan and Koch (2010, 2011) concluded that compatible modality pairings (visual-manual and auditory-vocal) showed reduced switch costs compared to incompatible pairings (auditory-manual and visual-vocal) even when there was no dimensional overlap between stimuli and responses. This is consistent with the notion that it is the separation of the tasks when considered together rather than the compatibility of the tasks when considered alone that drives interactions between temporally proximal tasks.
Thus, although the spatial-verbal account runs counter to the traditional explanation of how IM-compatibility reduces dual-task costs, it is consistent with findings from the aforementioned task-switching literature. It is also consistent with crosstalk accounts of dual-task interference that emphasize the importance of the separability of the tasks rather than overlap between stimulus and response features within each task. For example, Wickens, Sandry, and Vidulich (1983) proposed that dual-task interference arises from crosstalk between central codes that are required for S-R translation. When two tasks use similar central codes, the resulting crosstalk is a significant contributor to dual-task costs. Specifically, Wickens (1984) proposed that costs should be minimal when one task uses an exclusively auditory-verbal-vocal mapping and the other uses visual-spatial-manual codes (see also Hazeltine, Ruthruff & Remington, 2006; Janczyk et al., 2014; Navon & Miller, 1987). The present results are consistent with this proposal.
Such modality-based accounts draw obvious parallels to the hugely influential model of working memory (WM) and its distinct domain-specific subsystems (e.g., the visuospatial sketchpad) proposed by Baddeley and colleagues (e.g., Baddeley & Logie, 1999). There is a great deal of evidence that capacity limits for each of these subsystems are not affected by the concurrent activation of information in other subsystems (see, e.g., Cocchinie, Logie, Della Sala, MacPherson, & Baddeley, 2002). Hazeltine and Wifall (2011) offered support for the proposal that dual-task costs might depend on the structure of WM by showing that the pattern of interference depended on the modality of the response in a choice-RT task, even when the modality of the stimulus was kept constant. Given that the mixing costs in the present experiment are no smaller than in similar experiments using arbitrary stimuli, but the dual-task costs are reduced (see Halvorson et al., 2013), it appears that the structure of WM may play its critical role in the selection of the response rather than in the maintenance of the task rules. Thus, the mappings may be stored within procedural memory but the codes may interact as the specific rules are selected.
In sum, the present data do not support claims that IM-compatible tasks eliminate dual-task costs because stimuli automatically activate the appropriate responses. Rather, it appears that when tasks engage distinct, modality-specific mechanisms, two responses can be selected nearly simultaneously with little evidence of interference even with incompatible S-R mappings.
Notes
The mixing costs reported here are indicative of the performance impairments associated with both maintaining multiple task sets and switching between tasks from trial to trial. When these two components are separated by comparing task repeat and task switch trials in the OR blocks to estimate switch costs and comparing task repeat trials in the OR and single-task task trials to estimate the cost of maintaining two sets, the basic finding is that both components contribute roughly equally to the mixing costs. This approach is not particularly revealing as to why the IM-compatible AV task produced larger mixing costs; when paired with the IM-compatible VM task, the increase in mixing cost was mostly in the load component, but when paired with the opposite VM task, the increase was mostly in the switch component.
When task (VM or AV) is added as a third factor to the ANOVA, there is a significant effect of task, F(1,152) = 41.86, MSE = 2918.56, p < .001, indicating that dual-task costs are larger for the AV task (27 ms) than the VM task (–28 ms). This result may stem from a tendency for individuals to try to synchronize their responses under dual-task conditions or to prioritize the slower VM task. Consistent with these interpretations, the task also produced an interaction with the AV instruction, F(1,76) = 8.89, MSE = 2918.56, p < .01, and the VM instruction, F(1,76) = 8.59, MSE = 2918.56, p < .01, indicating greater dual-task RTs on the AV task when it was compatible and smaller dual-task RTs on the VM task when it was compatible. The three-way interaction was not significant, F < 1.
We thank Iring Koch for pointing out this possibility.
References
Baddeley, A. D., & Logie, R. H. (1999). Working memory: The multiple-component model. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 28–61). New York: Cambridge University Press.
Barsalou, L. W. (1999). Perceptual symbols systems. Behavioral and Brain Sciences, 22, 577–660.
Cocchini, G., Logie, R. H., Della Sala, S., MacPherson, S. E., & Baddeley, A. D. (2002). Concurrent performance of two memory tasks: Evidence for domain-specific working memory systems. Memory & Cognition, 30(7), 1086–1095.
Greenwald, A. G. (2003). On doing two things at once: III. Confirmation of perfect timesharing when simultaneous tasks are ideomotor compatible. Journal of Experimental Psychology: Human Perception and Performance, 30, 632–636.
Greenwald, A. G. (2004). On doing two things at once: IV. Necessary and sufficient conditions: Rejoinder to Lien, Proctor, and Ruthruff. Journal of Experimental Psychology: Human Perception and Performance, 30, 632–636.
Greenwald, A. G., & Shulman, H. G. (1973). On doing two things at once: II. Elimination of the psychological refractory period effect. Journal of Experimental Psychology, 101, 70–76.
Halvorson, K. M., Ebner, H., & Hazeltine, E. (2013). Investigating perfect timesharing: The relationship between IM-compatible tasks and dual-task performance. Journal of Experimental Psychology: Human Perception and Performance, 39(2), 413–432.
Hazeltine, E., Ruthruff, E., & Remington, R. W. (2006). The role of input and output modality pairings in dual-task performance: Evidence for content-dependent central interference. Cognitive Psychology, 52, 291–345.
Hazeltine, E., & Wifall, T. (2011). Searching working memory for the source of dual-task costs. Psychological Research, 75(6), 466–475.
Janczyk, M., Pfister, R., Wallmeier, G., & Kunde, W. (2014). Exceptions from the PRP effect? A comparison of prepared and unconditioned reflexes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(3), 776–786.
Lien, M.-C., Proctor, R. W., & Ruthruff, E. (2003). Still no evidence for perfect timesharing with two ideomotor-compatible tasks: A reply to Greenwald (2003). Journal of Experimental Psychology: Human Perception and Performance, 29, 1267–1272.
Navon, D., & Miller, J. (1987). Role of outcome conflict in dual-task interference. Journal of Experimental Psychology: Human Perception and Performance, 13, 435–448.
Pashler, H., & Johnston, J. C. (1989). Chronometric evidence for central postponement in temporally overlapping tasks. Quarterly Journal of Experimental Psychology, 41A, 19–45.
Pezzulo, G., Candidi, M., Dindo, H., & Barca, L. (2013). Action simulation in the human brain: Twelve questions. New Ideas in Psychology, 31(3), 270–290.
Pfister, R., Kiesel, A., & Melcher, T. (2010). Adaptive control of ideomotor effect anticipations. Acta psychologica, 135(3), 316–322.
Shin, Y. K., & Proctor, R. W. (2008). Are spatial responses to visuospatial stimuli and spoken responses to auditory letters ideomotor-compatible tasks? Examination of set-size effects on dual-task interference. Acta Psychologica, 129, 352–364.
Stephan, D. N., & Koch, I. (2010). Central cross-talk in task switching: Evidence from manipulating input-output modality compatibility. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36, 1075–1081.
Stephan, D. N., & Koch, I. (2011). The role of input-output modality compatibility in task switching. Psychological Research, 75(6), 491–498.
Tombu, M., & Jolicœur, P. (2004). Virtually no evidence for virtually perfect time-sharing. Journal of Experimental Psychology: Human Perception and Performance, 30, 795–810.
Wickens, C. D. (1984). Processing resources in attention. In R. Parasuraman & D. R. Davies (Eds.), Varieties of attention (pp. 63–102). Orlando: Academic Press.
Wickens, C. D., Sandry, D. L., & Vidulich, M. (1983). Compatibility and resource competition between modalities of input, central processing, and output. Human Factors: The Journal of the Human Factors and Ergonomics Society, 25, 227–248.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Halvorson, K.M., Hazeltine, E. Do small dual-task costs reflect ideomotor compatibility or the absence of crosstalk?. Psychon Bull Rev 22, 1403–1409 (2015). https://doi.org/10.3758/s13423-015-0813-8
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-015-0813-8