
Abstract
It has been just over a century since Gestalt psychologists described the factors that contribute to the holistic processing of visually presented stimuli. Recent research indicates that holistic processing may come at a cost; specifically, the perception of holistic forms may reduce the visibility of constituent parts. In the present experiment, we examined change detection and change identification accuracy with Kanizsa rectangle patterns that were arranged to either form a Gestalt whole or not. Results from an experiment with 62 participants support this trade-off in processing holistic forms. Holistic processing improved the detection of change but obstructed its identification. Results are discussed in terms of both their theoretical significance and their application in areas ranging from baggage screening and the detection of changes in radiological images to the systems that are used to generate composite images of perpetrators on the basis of eyewitness reports.
Similar content being viewed by others

It has been over 100 years since Max Werthheimer (1912) observed how two rapidly alternating flashing lights created the illusion of pure movement and published the first paper on the phi phenomenon. What was surprising about phi movement was not that illusory motion could occur, since movies created from successively presented images had already been shown in 1912. Instead, what was surprising was that the two alternating lights could appear to be stationary, with an objectless form moving in such a way as to cover and uncover the two lights. The discovery of motion without form was important in the development of the Gestalt school of psychology (see Steinman, Pizlo, & Pizlo, 2000) and its subsequent principles of grouping (for reviews, see Wagemens, Elder, et al., 2012; Wagemens, Feldman, et al., 2012). One prominent argument of Gestalt psychologists is that a whole is not the same as its distinct parts (Wertheimer, 1923/1938) or perhaps, more accurately, that holistic properties of an object coexist with, but don’t replace, individual constituent features (Garner, 1978). In fact, the whole seems to dominate perception and is extracted rapidly (Larson, Freeman, Ringer, & Loschky, 2013; Rensink & Enns, 1995; Schyns & Oliva, 1994; Thorpe, Fize, & Marlot, 1996) and without the need for conscious processing (Mack, Tang, Tuma, Kahn, & Rock, 1992; Moore & Egeth, 1997). For example, when participants in Moore and Egeth’s experiment had to determine which of two briefly presented and masked lines was longer, their line length discriminations were affected by dots in the background that, if grouped by similarity of color, sometimes formed Ponzo or Müller-Lyer illusions. Importantly, the dots affected the line length judgments even when the displays were presented under conditions of inattention and participants were unaware that the dots were arranged to form these visual patterns.
It is clear that the visual system seeks out meaningful forms (Thorpe et al., 1996) and that meaning, or denotation, can influence the earliest stages of vision (Kahan & Enns, 2013). Most recently, research has also suggested that the perception of a holistic pattern will directly affect the accessibility of its parts (Poljac, de-Wit, & Wagemans, 2012). Poljac et al. suggested that the “silencing” that occurred in Suchow and Alvarez’s (2011) motion silencing study could, in part, be explained by a holistic group disrupting the perception of changes in the constituent parts. In Suchow and Alvarez’s motion silencing demonstrations, each of 100 dots arranged in a circular ring individually and asynchronously changed colors. Although these color changes were easily seen when the dots were stationary, the color changes were quite difficult to see when the dot display was rotated back and forth (hence, motion silencing). According to Poljac et al., motion facilitated the grouping of the dots into a holistic object (grouping by common fate), and it is perception of the whole that contributed to the difficulty participants had in perceiving changes to the individual dots. Poljac et al. tested this by comparing perception of color changes in dots that were arranged to form meaningful versus nonmeaningful patterns. Participants in their study had more difficulty seeing the dots change colors in dynamic displays in which the dots were arranged to form an upright human figure in motion (i.e., biological motion) than with the same figure inverted.
Taken together, the extant literature indicates that holistic, meaningful patterns are extracted from the visual environment rapidly and effortlessly and that the whole tends to dominate our perception in a manner that may hinder the processing of constituent features. If Poljac et al.’s (2012) relatively new theoretical position is true and people are shown displays where parts are altered to create changes in a holistic form, then people should easily be able to detect these holistic changes, since the whole, rather than the parts, will be the focus of attention. In addition, if seeing the whole impairs our ability to see the local elements, as Poljac et al. claimed, then this ease for detecting holistic changes should come with a cost at identifying the aspect of the local elements that was modified to create these changes, when the elements are arranged to form a group. Identification of featural-level changes should be easier, though, when the parts are not arranged to form a holistic pattern. The present experiment tests these possibilities.
In the present experiment we used images of Kanizsa (1976) figures (see Fig. 1, top left) and the same stimuli spatially rearranged to form an ungrouped image (see Fig. 1, top right). When the pacman-like portions are pointed inward, all the components of the image are processed holistically, and an illusory square emerges. Kanizsa figures are processed globally by nonhuman primates (Feltner & Kiorpes, 2010), as well as humans (Conci, Töllner, Leszczynski, & Müller, 2011). When the pacman-like portions are pointed outward, the illusion does not occur, and different brainwave patterns occur (Conci et al., 2011). By using these figures, we were able to isolate in the most basic way Gestalt versus feature-based stimuli with the same visual information. We used these holistic (Kanizsa) and featural (ungrouped) images in a change blindness task. Holistic and featural images were changed by either increasing the distance between the dots or increasing the size of the cutouts in the pacman dots. Participants completed either a change detection (i.e., was there a change?) or a change identification (i.e., what type of change?) task.

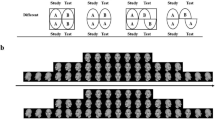
Depiction of the types of image arrangements seen during the first display (holistic or featural) and the second display (holistic with dots further apart or larger cutout, or featural with dots further apart or larger cutout) in the change conditions for both tasks. In the detection task, holistic or featural arrangements shown here in the first display were repeated in the second image in the no-change condition. See the text for details
Method
Participants
Students from two small liberal arts colleges (40 from Bates College and 22 from Bowdoin College) participated for course credit. Thirty-two participants were randomly assigned to the detection task (21 from Bates College and 11 from Bowdoin College), and 30 participants were randomly assigned to the identification task (19 from Bates College and 11 from Bowdoin College). All participants had normal or corrected-to-normal vision.
Materials and procedure
The entire set of images that participants were shown appears in Fig. 1. This limited set of images was repeated, randomly, for each individual, and participants completed 112 trials. For both tasks, half of the pairs of images (56 pairs) were arranged holistically, and the other half (56 pairs) were arranged featurally (see the left- and right-hand sides of Fig. 1). In the detection task, participants (n = 32) decided whether the second of two images was different from the first. Half of the trials of each arrangement type had a change (56 pairs; 28 holistic and 28 featural change pairs), and the other half had no change (56 pairs; 28 holistic and 28 featural no-change pairs). Looking at the top portion of Fig. 1, if the trial did not involve a change, the image in the first display (whether it was arranged holistically or featurally) simply reappeared in the second display. If, on the other hand, there was a change, the image in the second display differed from the image in the first display. There are two ways this could occur for items shown holistically, and two ways this could occur for items shown featurally (see the bottom portion of Fig. 1). Specifically, when there was a change, the dots were moved further apart on half of the trials (14 holistic distance and 14 featural distance changes), and on the other half, the cutout was made larger (14 holistic cutout and 14 featural cutout changes). Responses were made using the “z” and “m” keys for “no” and “yes,” respectively.
In the identification task, participants (n = 30) decided what changed in the second of two images. All 112 trials in this task had a change (i.e., the image shown on the first display never repeated). On half of the trials of each arrangement type, the dots were moved further apart (28 holistic distance and 28 featural distance changes), and on the other half of the trials, the cutout was made larger (28 holistic cutout and 28 featural cutout changes). Responses were made using the “z” and “m” keys for “distance increased” and “cutout size larger,” respectively.
Stimuli were displayed and responses were recorded using E-Prime v1.2 software (Schneider, Eschman, & Zuccolotto, 2002a, b) on PC computers. The first four trials were practice. On each trial, a black fixation (+) appeared in the center of the screen for 1,000 ms on a white background. The first image was then shown for 500 ms. Kanizsa and ungrouped images were presented in blue on a white background. Each pacman-like dot subtended a visual angle of 2.39°, with a cutout of 0.95°. When the cutouts were facing inward, an illusory rectangle appeared with a width of 2.86°. After this first display, a masking noise pattern was shown for 100 ms. The centered mask consisted of a rectangle of black and white visual noise measuring 78.30° wide by 83.08° high. Then the second image was shown for 500 ms. When there was a change in the second display, either each dot cutout increased to 1.43° or the left and right dots moved 0.48° further from fixation. Both cutout and distance changes resulted in an inner illusory rectangle that increased in width to 3.82° in the holistic condition. After the second image display, a question appeared on the screen (“Did you see a change?” for the detection task and “What changed?” for the identification task) until a response was given. Participants were instructed to respond as accurately as possible. A break was given halfway through the experiment.
Results
Data were analyzed in a 2 (arrangement type: holistic vs. featural) × 2 (task: detection vs. identification) × 2 (participant population: Bates vs. Bowdoin) mixed ANOVA. The dependent variable was accuracy, where chance performance was 50 %. There was a main effect of arrangement type, F(1, 58) = 10.44, p = .002, η 2 partial = .15, observed power = .89. Accuracy rates were higher for the holistic arrangement (M = .81), as compared with the featural arrangement (M = .75). Critically, there was an interaction between arrangement type (holistic vs. featural) and task (detection vs. identification), F(1, 58) = 66.45, p < .001, η 2 partial = .53, observed power = 1.000. This interaction is displayed in Fig. 2. Participants in the detection task were more accurate when stimuli were presented in a holistic arrangement, relative to a featural arrangement, t(31) = 10.52, p < .001, η 2 partial = .78, observed power = 1.000. Participants in the identification task were more accurate when stimuli were presented in a featural arrangement, relative to a holistic arrangement, t(29) = 2.88, p = .007, η 2 partial = .22, observed power = .79. None of the other main effects or interactions were significant.

Proportion correct as a function of task and image arrangement. Error bars represent one standard error of the mean. Chance performance was 50 %. For the change detection task, participants were significantly more accurate for holistic than for featural displays. For the change identification task, participants were significantly more accurate for featural than for holistic displays
Discussion
Change detection accuracy was superior for stimuli processed in a holistic rather than featural manner, whereas change identification accuracy was superior for stimuli processed in a featural rather than holistic manner. The present data add to the established literature indicating that Gestalt grouping principles (Koffka, 1935; Köhler, 1929; Wagemens, Elder, et al., 2012; Wagemens, Feldman, et al., 2012; Wertheimer, 1923/1938) affect object recognition by directly establishing that the way in which stimuli are perceived also affects our ability to detect and identify changes. Our results also point to a trade-off that occurs when stimuli are processed holistically. Although holistic processing appears to benefit change detection over featural processing, our data support the theoretical position that holistic processing has a cost as well (Poljac et al., 2012; Wilford & Wells, 2010). Specifically, holistic processing impairs our ability to see local-level elements, and as such, change identification performance suffers for globally processed stimuli.
Wilford and Wells (2010) have found similar results in a change detection and identification task using images of faces and houses. Change detection performance was superior for images of upright faces, which are processed holistically, than for images of houses, but change identification performance was superior for images of houses than for images of upright faces. Our data add to this by showing that the detection benefit and identification impairment observed when faces are processed generalizes to other globally processed stimuli. This is important because holistic processing and other face-specific effects have been found in nonface stimuli (Gauthier & Tarr, 1997; Wong, Palmeri, & Gauthier, 2009). For example, expertise at identifying dogs (Diamond & Carey, 1986), birds (Gauthier, Skudlarski, Gore, & Anderson, 2000), cars, (Bukach, Phillips, & Gauthier, 2010; Gauthier et al., 2000), and fingerprints (Busey & Vanderkolk, 2005) leads to enhanced global-level processing.
Since many objects, as well as patterned displays (Wilson & Wilkinson, 1998), can be processed holistically, and since expertise leads to improved holistic processing, our data have applied significance. If one is seeking to detect changes between two visual images, as may occur for radiologists who want to determine whether an x-ray has changed from one point in time to another, then detection performance ought to improve with enhanced global-level processing. As such, expertise should facilitate detection performance. In fact, the data indicate that expert radiologists outperform novices (Kok, De Bruin, Robben, & Van Merriënboer, 2012), and this enhancement may reflect improved holistic processing (Kundel, Nodine, Conant, & Weinstein, 2007).
Similarly, since faces are processed holistically, and since seeing the whole impairs accessibility of the parts, our data suggest that eyewitnesses of crimes may more accurately generate composite images of the perpetrator if holistic processing is used in the reconstruction process. Unfortunately, though, many current systems necessitate that eyewitnesses reconstruct a face from its features (e.g., Identikit, Photo-FIT, FACES, and Mac-a-Mug), and it is perhaps for this reason that the images generated using this approach are not as useful as they might otherwise be (Frowd, Bruce, & Hancock, 2008; Kovera, Penrod, Pappas, & Thill, 1997). In other systems, eyewitnesses select features in the context of seeing an entire face (e.g., E-fit and PRO-fit), and to the extent that this increases holistic processing, one might expect superior performance, yet the data do not fully support this being the case (see Davies, van der Willik, & Morrison, 2000). One of the more promising approaches may turn out to be holistic approaches (e.g., EvoFIT; see Frowd, Hancock, & Carson, 2004), where eyewitnesses are given complete faces to choose from (select the face that is most similar to the perpetrator) and then the computer merges these images (or breeds them) in a manner where new faces are generated. Through multiple iterations of selecting and generating photographs, a composite image of the perpetrator is constructed.
However, in applied situations where one wishes to identify aspects of local-level details, as may occur with baggage screeners who are looking for specific contraband items, then performance should be impaired if these parts are arranged in a manner to create a holistic form. For example, if a baggage screener is looking for items that could be combined to create a weapon, identification of these substances might be impaired if they are incorporated into a different holistic shape. It may be at least partially for this reason that baggage screening approaches where contraband items are highlighted prove beneficial (cf. Wiegmann, McCarley, Kramer, & Wickens, 2006). To the extent that contraband items can be highlighted, these items should no longer be grouped to form holistic, and perhaps innocuous, other objects. However, when baggage screeners are looking for a whole object that is presented by itself, rather than being presented as part of a different holistic shape, then holistic processing, which improves with expertise (or practice), should facilitate performance (see McCarley, Kramer, Wickens, Vidoni, & Boot, 2004, for evidence that the ability to recognize target objects in airport security screening improves with practice).
Holistic-level and local-level processing each have costs and benefits, and in order to determine which type of processing should be encouraged in any specific applied situation, one must first determine whether the detection of holistic changes or identification of local-level parts is more important. It has been over 100 years since Gestalt psychologists have described the factors that contribute to holistic processing. We believe that the present data add to this. It is clear that the visual system is biased toward perceiving Gestalt wholes, and although this holistic focus leads to improved change detection, it impedes change identification, a finding that likely has theoretical and applied significance.
References
Bukach, C. M., Phillips, W., & Gauthier, I. (2010). Limits of generalization between categories and implications for theories of category specificity. Attention, Perception, & Psychophysics, 72(7), 1865–1874. doi:10.3758/APP.72.7.1865
Busey, T. A., & Vanderkolk, J. R. (2005). Behavioral and electrophysiological evidence for configural processing in fingerprint experts. Vision Research, 45, 431–448.
Conci, M., Töllner, T., Leszczynski, M., & Müller, H. J. (2011). The time-course of global and local attentional guidance in Kanizsa-figure detection. Neuropsychologia, 49(9), 2456–2464. doi:10.1016/j.neuropsychologia.2011.04.023
Davies, G., van der Willik, P., & Morrison, L. J. (2000). Facial composite production: A comparison of mechanical and computer-driven systems. Journal of Applied Psychology, 85(1), 119–124. doi:10.1037/0021-9010.85.1.119
Diamond, R., & Carey, S. (1986). Why faces are and are not special: An effect of expertise. Journal of Experimental Psychology: General, 115(2), 107–117. doi:10.1037/0096-3445.115.2.107
Feltner, K. A., & Kiorpes, L. (2010). Global visual processing in macaques studied using Kanizsa illusory shapes. Visual Neuroscience, 27(3–4), 131–138. doi:10.1017/S0952523810000088
Frowd, C. D., Bruce, V., & Hancock, P. J. B. (2008). Changing the face of criminal identification. The Psychologist, 21, 670–672.
Frowd, C. D., Hancock, P. B., & Carson, D. (2004). EvoFIT: A holistic, evolutionary facial imaging technique for creating composites. ACM Transactions on Applied Perception, 1(1), 19–39. doi:10.1145/1008722.1008725
Garner, W. R. (1978). Aspects of a stimulus: Features, dimensions, and configurations. In E. Rosch & B. B. Lloyd (Eds.), Cognition and categorization (pp. 99–133). Hillsdale: Erlbaum.
Gauthier, I., Skudlarski, P., Gore, J. C., & Anderson, A. W. (2000). Expertise for cars and birds recruits brain areas involved in face recognition. Nature Neuroscience, 3(2), 191–197. doi:10.1038/72140
Gauthier, I., & Tarr, M. J. (1997). Becoming a 'greeble' expert: Exploring mechanisms for face recognition. Vision Research, 37(12), 1673–1682. doi:10.1016/S0042-6989(96)00286-6
Kahan, T. A., & Enns, J. T. (2013). Long-term memory representations influence perception before edges are assigned to objects. Journal of Experimental Psychology: General. Advance online publication. doi:10.1037/a0033723
Kanizsa, G. (1976, April). Subjective contours. Scientific American, 234, 48–52.
Koffka, K. (1935). Principles of Gestalt psychology. New York: Harcourt, Brace.
Köhler, W. (1929). Gestalt psychology. New York: Liveright.
Kok, E. M., De Bruin, A. H., Robben, S. F., & Van Merriënboer, J. G. (2012). Looking in the same manner but seeing it differently: Bottom‐up and expertise effects in radiology. Applied Cognitive Psychology, 26(6), 854–862. doi:10.1002/acp.2886
Kovera, M., Penrod, S. D., Pappas, C., & Thill, D. L. (1997). Identification of computer-generated facial composites. Journal of Applied Psychology, 82(2), 235–246. doi:10.1037/0021-9010.82.2.235
Kundel, H., Nodine, C., Conant, E., & Weinstein, S. (2007). Holistic component of image perception in mammogram interpretation: Gaze-tracking study. Radiology, 242(2), 396–402.
Larson, A. M., Freeman, T. E., Ringer, R. V., & Loschky, L. C. (2013, November 18). The spatiotemporal dynamics of scene gist recognition. Journal of Experimental Psychology: Human Perception and Performance. Advance online publication. doi:10.1037/a0034986
Mack, A., Tang, B., Tuma, R., Kahn, S., & Rock, I. (1992). Perceptual organization and attention. Cognitive Psychology, 24(4), 475–501. doi:10.1016/0010-0285(92)90016-U
McCarley, J. S., Kramer, A. F., Wickens, C. D., Vidoni, E. D., & Boot, W. R. (2004). Visual skills in airport-security screening. Psychological Science, 15(5), 302–306. doi:10.1111/j.0956-7976.2004.00673.x
Moore, C. M., & Egeth, H. (1997). Perception without attention: Evidence of grouping under conditions of inattention. Journal of Experimental Psychology: Human Perception and Performance, 23(2), 339–352. doi:10.1037/0096-1523.23.2.339
Poljac, E., de-Wit, L., & Wagemans, J. (2012). Perceptual wholes can reduce the conscious accessibility of their parts. Cognition, 123(2), 308–312. doi:10.1016/j.cognition.2012.01.001
Rensink, R. A., & Enns, J. T. (1995). Preemption effects in visual search: Evidence for low-level grouping. Psychological Review, 102(1), 101–130. doi:10.1037/0033-295X.102.1.101
Schneider, W., Eschman, A., & Zuccolotto, A. (2002a). E-Prime reference guide. Pittsburgh: Psychology Software Tools.
Schneider, W., Eschman, A., & Zuccolotto, A. (2002b). E-Prime user’s guide. Pittsburgh: Psychology Software Tools.
Schyns, P. G., & Oliva, A. (1994). From blobs to boundary edges: Evidence for time- and spatial-scale-dependent scene recognition. Psychological Science, 5(4), 195–200. doi:10.1111/j.1467-9280.1994.tb00500.x
Steinman, R. M., Pizlo, Z., & Pizlo, F. J. (2000). Phi is not beta, and why Wertheimer's discovery launched the Gestalt revolution. Vision Research, 40, 2257–2264.
Suchow, J. W., & Alvarez, G. A. (2011). Motion silences awareness of visual change. Current Biology, 21(2), 140–143. doi:10.1016/j.cub.2010.12.019
Thorpe, S., Fize, D., & Marlot, C. (1996). Speed of processing in the human visual system. Nature, 381(6582), 520–522. doi:10.1038/381520a0
Wagemans, J., Elder, J. H., Kubovy, M., Palmer, S. E., Peterson, M. A., Singh, M., & von der Heydt, R. (2012a). A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure–ground organization. Psychological Bulletin, 138(6), 1172–1217. doi:10.1037/a0029333
Wagemans, J., Feldman, J., Gepshtein, S., Kimchi, R., Pomerantz, J. R., van der Helm, P. A., & van Leeuwen, C. (2012b). A century of Gestalt psychology in visual perception: II. Conceptual and theoretical foundations. Psychological Bulletin, 138(6), 1218–1252. doi:10.1037/a0029334
Wertheimer, M. (1912). Experimentelle Studien über das Sehen von Bewegung [Experimental studies on the seeing of motion]. Zeitschrift für Psychologie, 61, 161–265.
Wertheimer, M. (1923/1938). Untersuchungen zur Lehre von der Gestalt II. Psychologische Forschung, 4, 301–350. (Excerpts translated into English as 'Laws of organization in perceptual forms' in W.D Ellis (Ed.), A source book of Gestalt psychology. New York: Hartcourt, Brace and Co., and as 'Principle of perceptual organization' in D.C. Beardslee & Michael Wertheimer (Eds.), Readings in Perception, Princeton, NJ: D. Van Nostrand Co., Inc.).
Wiegmann, D., McCarley, J. S., Kramer, A. F., & Wickens, C. D. (2006). Age and automation interact to influence performance of a simulated luggage screening task. Aviation, Space, and Environmental Medicine, 77(8), 825–831.
Wilford, M. M., & Wells, G. L. (2010). Does facial processing prioritize change detection? Change blindness illustrates costs and benefits of holistic processing. Psychological Science, 21, 1611–1615.
Wilson, H. R., & Wilkinson, F. (1998). Detection of global structure in Glass patterns: Implications for form vision. Vision Research, 38, 2933–2947.
Wong, A. C.-N., Palmeri, T. J., & Gauthier, I. (2009). Conditions for face-like expertise with objects: Becoming a Ziggerin expert—but which type? Psychological Science, 20, 1108–1117.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Mathis, K.M., Kahan, T.A. Holistic processing improves change detection but impairs change identification. Psychon Bull Rev 21, 1250–1254 (2014). https://doi.org/10.3758/s13423-014-0614-5
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-014-0614-5