
Abstract
Bleckley, Durso, Crutchfield, Engle, and Khanna (Psychonomic Bulletin & Review, 10, 884–889, 2003) found that visual attention allocation differed between groups high or low in working memory capacity (WMC). High-span, but not low-span, subjects showed an invalid-cue cost during a letter localization task in which the letter appeared closer to fixation than the cue, but not when the letter appeared farther from fixation than the cue. This suggests that low-spans allocated attention as a spotlight, whereas high-spans allocated their attention to objects. In this study, we tested whether utilizing object-based visual attention is a resource-limited process that is difficult for low-span individuals. In the first experiment, we tested the uses of object versus location-based attention with high and low-span subjects, with half of the subjects completing a demanding secondary load task. Under load, high-spans were no longer able to use object-based visual attention. A second experiment supported the hypothesis that these differences in allocation were due to high-spans using object-based allocation, whereas low-spans used location-based allocation.
Similar content being viewed by others

For some time now, there has been a debate in the literature about the nature of visual attention allocation. Do people allocate their attention to objects or to locations? Several studies have shown that the nature of the task itself can change whether people tend to use an object-based—rather than location-based—allocation of visual attention (Baylis & Driver, 1993; Bleckley, Durso, Crutchfield, Engle, & Khanna, 2003; Egly, Driver, & Rafal, 1994; Vecera & Farah, 1994). Intuitively, this finding makes sense: In some cases, object-based visual attention is a more effective strategy than location-based attention, and in other cases it may not be. But does the nature of the task alone affect the ability to switch from location-based to object-based visual attention, or might individual differences in attention control capabilities associated with working memory capacity (WMC) also account for this ability? That is the question that we ask here.
Two theories of cued visual attention currently dominate the field: location—or spotlight—based and object-based visual attention. A spotlight of attention is just as the name suggests: People focus on a single point and attend to information in a ring around that point, like the light of a flashlight. The highest resolution of attention then comes from information closest to the center of the spotlight of attention, with lower resolution of attention farther from the center (Arrington, Carr, Mayer, & Rao, 2000; LaBerge, 1983; LaBerge & Brown, 1989; Posner, Snyder, & Davidson, 1980). However, others argue that cued visual attention does not work as a spotlight, and is instead based on expectations of the appearance within a shape or object—such as a square or a ring (Bleckley et al., 2003; Egly & Homa, 1984; Jefferies, Enns, & Di Lollo, 2014; Neisser & Becklen, 1975).
Some research has demonstrated that people can switch between object-based and location-based attention when the need arises (Baylis & Driver, 1993; Egly et al., 1994; Vecera & Farah, 1994). More specifically, forming and maintaining the representation of a shape or object is attention-demanding (Luck & Hillyard, 2000). As a result, if subjects do not need to represent stimuli as objects to perform the task, there is no need to encode the stimuli in these relatively high-level—attention-demanding—visual representations (Vecera & Farah, 1994). Similarly, whether attention is allocated to an object or a location can depend on the task demands and the consequences of the coding that follows those demands (Baylis & Driver, 1993). In summary, utilizing an object-based allocation of visual attention might require available cognitive resources—such as working memory capacity.
Working memory capacity and attention control
Complex span working memory tasks such as Daneman and Carpenter’s (1980) reading span and Turner and Engle’s (1989) operation span correlate with higher-order cognition primarily because of executive attention (Engle, Kane, & Tuholski, 1999). We refer to this construct as working memory capacity despite the fact that it really reflects domain-free executive attention. More specifically, our view is that WMC reflects the ability to maintain information when faced with distraction or proactive interference (Engle & Kane, 2004; Kane, Conway, Hambrick, & Engle, 2007; Shipstead & Engle, 2013). In short, WMC is not about how many chunks or units can be maintained, but about the allocation of attention to do the work necessary maintaining information in an active and quickly retrievable state without interference.
Findings from a wide variety of paradigms support the idea that WMC reflects differences in attention. For example, we know that two of the most popular paradigms used for measuring executive control of attention—the antisaccade and flanker paradigms—consistently show a relationship with WMC. That is, high-WMC individuals (henceforth, high-spans) are faster and more accurate than low-WMC individuals (henceforth, low-spans) on the flanker and antisaccade tasks (Kane, Bleckley, Conway, & Engle, 2001; Redick et al., 2012; Unsworth & Spillers, 2010). In addition, high-spans tend to find items in a visual search task filled with distractors faster than low-spans do (Poole & Kane, 2009). Span scores are also correlated with attention performance when combining feature-based and spatial attention (Bengson & Mangun, 2011). And some research suggests that WMC can predict the ability to use flexible attention control (Bleckley et al., 2003).
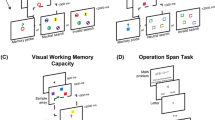
Bleckley and colleagues (2003) asked subjects to complete Egly and Homa’s (1984) selective attention task, in which subjects identify a letter flashed briefly at the center of the screen and then locate the position of a simultaneously presented letter on one of three rings, as is demonstrated in Fig. 1. Prior to the presentation of the letters, subjects are cued to the location of the off-center letter on the inner (close), middle (medium), or outer (distant) ring. Importantly, on a small percentage of critical trials, the cue is invalid. More specifically, subjects might be cued to look on the middle ring, but the letter had actually appeared on the inner ring. Surprisingly, high-spans were less accurate when the letter appeared on the ring inside the cued location than were low-spans, but no difference was apparent between the two groups when the letter appeared on the ring outside the cued location. In other words, when the letter appeared closer to the subjects’ fixation point than expected, high-spans—but not low-spans—became less accurate. So how might we understand this counterintuitive finding?

Examples of modified uncued, validly cued, and invalidly cued trials from the Egly and Homa (1984) selective attention task used in Experiment 1 here. The subjects’ task is first to identify the letter located in the center (here, F) and then to identify the number representing the location of the offset letter (here, 20). Note: The scale of the objects within this figure has been modified for visibility
What Bleckley et al.’s (2003) findings suggest is that high-spans use (generally) more efficient object-based visual attention—focusing their attention onto the ring itself, with the space between one side of the ring and the other left unattended—whereas low-spans use location-based visual attention. As a result, low-spans, who focus their field of attention like a spotlight, are able to more accurately identify the letter appearing inside the cued ring, because their field of attention was already attending to that location. High-spans, on the other hand, focused their attention on the ring itself, and the cued letter that appeared inside that ring was outside their field of attention. Importantly, this finding suggests that high-spans, but not low-spans, flexibly use object-based attention when the need arises. And although this finding demonstrates that high-spans use object-based attention, it does not tell us whether this is because only high-spans choose to use this type of attention, or because low-spans do not have the available cognitive resources to do so.
There are several reasons to believe that WMC can moderate the ability to utilize object-based, rather than location-based, visual attention. We might assume that location-based attention is the more primitive, possibly default, condition and occurs without recourse to executive control (Goodale & Milner, 1992). If object-based attention relies on controlled attention, then some level of executive control may be necessary to bring it about (Milner & Goodale, 1995). In addition, neuroimaging research has demonstrated that many of the brain regions associated with WMC—such as the dorsolateral prefrontal cortex and the inferior parietal cortex—are also associated with cued attentional control processes (Hopfinger, Buonocore, & Mangun, 2000). More to the point, building and maintaining a representation of the cued shape should require executive control resources.
If object-based allocation of attention requires building and maintaining a representation based on the cues, then a secondary task that ties up available cognitive resources would force high-spans to use location-based attention—thereby increasing their accuracy on invalidly cued rings closer to fixation, with little or no effect on low-spans. If this flexible allocation of attention depends relatively little on the available cognitive resources, then the secondary task should not affect the pattern of performance for either group.
Thus, in Experiment 1 we tested high- and low-spans on the Egly and Homa (1984) ring task, with half of each group performing the task under a secondary load and half under no load. The no-load condition constituted a replication of the Bleckley et al. (2003) and Egly and Homa studies. But if high-spans—and not low-spans—were to improve their performance locating letters inside of the invalidly cued ring while under load, then we could conclude that the availability of cognitive resources associated with WMC is important in the ability to utilize an object-based allocation of visual attention. In a second experiment, we used Egly et al.’s (1994) method to more definitively test whether the observed differences in allocation were due to high-spans using object-based attention and low-spans using location-based attention.
Experiment 1
Method
Subjects
A total of 60 adults between the ages of 18 and 40 were recruited on the basis of their performance on the operation–word span task (Turner & Engle, 1989). Subjects received $60 for their participation in the three-day study.
Procedure
Working memory capacity
Subjects were screened for working memory capacity by using their scores on an operation–word span task (OSpan) that they had completed in a previous experiment. In the OSpan task, subjects solve a series of simple math problems while they attempt to remember a list of unrelated words given between each math problem (for details, see La Pointe & Engle, 1990). Sixty subjects who scored in the lowest and highest quartiles (30 low-spans, 30 high-spans) were recruited to participate.
Load task
To begin the experiment, all subjects became acquainted with the load task—which was based on the load task used by Moscovitch (1992, 1994) and Kane and Engle (2000). In the load task, subjects repeatedly tapped the fingers of their nondominant hand in a set pattern using a computer keyboard. The tapping pattern was index finger, ring, middle, then pinkie. During three practice trials, the computer gave subjects feedback on their accuracy; if a subject made a mistake, the computer beeped, and the subject restarted the sequence. After practicing the load task, subjects were trained on their primary task.
All 60 subjects performed the tapping task before and after the visual attention task each day. High- and low-spans were randomly assigned to complete or not complete the secondary task. Half of the subjects (15 high-spans and 15 low-spans) performed the finger-tapping task during the visual attention task. As can be seen in Table 1, there were no group (load vs. no load) differences for high-spans [t(29) = 0.44, p = .33] or low-spans [t(29) = 1.78, p = .08] in mean OSpan scores.
Visual attention allocation task
The visual allocation task was based on the methods from Bleckley et al. (2003), with some modifications to accommodate the load task. As in Bleckley et al., stimuli were presented on a monitor, with subjects seated 31¾ inches from the monitor, resulting in the grid subtending 6° of visual angle.
Subjects were instructed to identify a letter flashed briefly at the center of fixation and to locate a letter presented off-center at the same time on one of three concentric octagons (rings), which were separated by 1° of visual angle, as is demonstrated in Fig. 1. The experimental stimuli consisted of a pair of letters, one presented at the center of the grid and the second (displaced) letter presented at one of the 24 vertices of the octagons. The pairs of letters were selected from the set of nine letters used by Egly and Homa (1984; C, O, Q, F, L, T, V, X, and Y). The subjects’ task was first to identify the letter appearing at the center of the grid, and second, to identify the location number where the second—displaced—letter had appeared. Subjects completed one session on each of three consecutive days.
The cue—“close,” “medium,” or “distant”—when present, was presented at the start of each trial for 2,000 ms, and then the grid of three concentric octagons was presented for 2,000 ms. The stimuli were presented, and then a pattern mask covered the screen for 150 ms. The location grid then appeared on the screen with the nine letters above it, remaining until the experimenter keyed in the subject’s spoken response.
On the first day, subjects were trained on the task. They received instructions and practiced the task with ten uncued trials, followed by five validly cued trials, then three invalidly cued trials, and finally 20 trials, some of which were cued and some of which were not. No one performed the tapping task during the orientation. Subjects were then reminded that their primary goal was to correctly identify the center letter, and then to locate the second letter.
These instructions were followed by a block of ten trials with a display time of 50 ms (three screen refreshes). Subjects in the load condition performed the tapping task during the display calibration trials. On the basis of their accuracy in identifying the center letter, the display time was adjusted. If subjects correctly identified the center letter on more than 90 % of the trials, their display times were decreased by one refresh rate (16.67 ms). If subjects were correct on 70 % to 80 % of the trials, their display times remained unchanged. If they were correct on fewer than 70 % of the trials, their display time was increased by one refresh screen. There were 30 of these calibration trials at the beginning of each session.
The experimental trials were presented at the new display duration. After 84 of the 168 trials, the subjects were allowed a brief break. Sessions 2 and 3 each began with the display duration set to the last value from the preceding session. The display duration was calibrated on the basis of each subject’s accuracy in naming the center letter during the 30 practice trials, and the remainder of the session was conducted using that display duration. Those in the load condition tapped during the 30 calibration trials each day, as well as during the experimental blocks.
Each of the three sessions contained 168 trials, 120 of which were cued and 48 of which were uncued. Of the 120 that were cued, 24 were invalidly cued trials: That is, the subject was cued to a ring that would not contain the displaced letter. The presentation order of the three cued conditions (uncued, validly cued, and invalidly cued) was randomized. All three of the rings were equally represented in all cue conditions (uncued, validly cued, and invalidly cued). The pairing of the center and displaced letters, as well as the pairing of the center letter and the location of the displaced letter, was randomly generated.
Results and discussion
Before addressing our primary research question, we first analyzed accuracy at identifying the noncritical center letter from each trial and accuracy on validly cued, relative to uncued, ring locations. In both cases, a Span × Load interaction would make it difficult to interpret findings for the invalidly cued trials. To address the primary research questions, we then analyzed accuracy on the critical—invalidly cued—trials. For all within-subjects effects, we report the Greenhouse–Geisser degree-of-freedom adjustment for violations of sphericity in both Experiments 1 and 2.
Center letter accuracy
As can be seen in Table 2, there were span differences as well as condition differences in accuracy at identifying the center letter. To check for group interactions, we used a 2 (span: high, low) ×2 (load: tapping, no tapping) ×3 (cue type: uncued, validly cued, invalidly cued) mixed-factor analysis of variance (ANOVA), with span and load as between-subjects variables and cue type as a within-subjects variable. These analyses showed a main effect of span, F(1, 56) = 35.51, MSE = 0.05, p < .01; a marginally significant main effect of load, F(1, 56) = 4.78, MSE = 0.05, p = .05; and a main effect of cue type, F(1.97, 55.08) = 17.89, MSE < 0.01, p < .01. None of the interactions were significant. The display length calibration was effective in setting the overall center-letter accuracy at approximately 90 %. However, the main effect of cue type in center-letter accuracy appears to be driven by the uncued condition. More specifically, accuracy at identifying the center letter was significantly lower in the uncued condition than in either the validly cued condition [t(59) = 5.52, p < .01] or the invalidly cued condition [t(59) = 2.74, p < .01], whereas the invalidly cued and validly cued conditions did not differ significantly [t(59) = 1.61, p = .11]. Apparently, the additional foreperiod provided by the cue allowed the two low-span groups and the high-span group in the load condition to better prepare for the stimulus presentation.
Uncued and validly cued trials
As can be seen in Fig. 2, high-spans were overall more accurate than low-spans on uncued and validly cued trials, and those in the load condition were less accurate than those in the no-load condition. Importantly, though, we found no Span × Load interaction. An ANOVA testing Span and Load as between-subjects factors and Cue Type and Distance as within-subject factors revealed a main effect of span, F(1, 56) = 43.92, p < .01. More to the point, all four groups showed improvement when letters were validly cued, indicating that the cues were being utilized. We also observed a main effect of load, F(1, 56) = 5.71, p = .02. The main effects of cue type and distance were also significant [F(1.97, 55.08) = 26.93, p < .01, and F(1.97, 55.08) = 31.78, p < .01, respectively]. The Load × Distance interaction was marginally significant, showing that those under load had a greater decrease in accuracy for the most distant ring than did those not under load, F(1.97, 55.08) = 3.17, p = .08. Importantly, though, no other interactions were statistically significant.

Uncued and validly cued trials in Experiment 1, by span group, load condition, and ring
Invalidly cued trials
Recall that our primary research question was whether high-spans under load would be better able to recognize an invalidly cued trial appearing inside the cued ring than high-spans not under load. To address this question, we next analyzed trials in which the displaced letter appeared inside or outside the invalidly cued location, and we display these results in Fig. 3. That figure shows three important findings. First, subjects showed poorer performance when under load than when not under load, regardless of their span group. Second, all subjects performed worse on invalidly cued letters that appeared outside the cued location. Third, and of critical importance, the accuracy with letters appearing inside the invalidly cued ring increased for high-spans, but decreased for low-spans, under load—a finding that suggests that high-spans were using object-based visual attention when not under load, causing them to miss the letter location appearing inside the invalidly cued ring. When put under cognitive load, though, they were forced to switch to location-based visual attention, shifting their attention to include the location inside the invalidly cued ring. Low-spans, on the other hand, had no such change in strategy and therefore showed decreased accuracy, reflecting the general decrease in accuracy due to cognitive load.

Accuracy in locating the cued letter: inside, on, and outside the cued ring. High-spans show decreased accuracy at recognizing the location of the offset letter when it appeared inside the cued location in the no-load condition, but not when they were under load
Statistically, a 2 (span) ×2 (load) ×3 (letter location) ANOVA showed a main effect of span, F(1, 56) = 4.45, p = .04, and a main effect of letter location relative to the cue, F(1.97, 55.08) = 17.17, p < .01. The main effect of condition was not significant, F(1, 56) = 0.46, p = .50, reflecting the lack of difference in the low-span performance. However, the two-way Span × Letter Location interaction was statistically significant, F(1.97, 55.08) = 8.56, p < .01, and the Span × Load interaction was marginally significant, F(1, 56) = 3.69, p = .06. The two-way Load × Letter Location interaction was marginally significant, at F(1.97, 55.08) = 2.68, p = .09. The three-way interaction of span, load condition, and letter–cue disparity was significant, F(1.97, 55.08) = 4.35, p = .04. Follow-up t tests showed that high-spans not under load were significantly less accurate at identifying the location of the displaced letter when it appeared inside the invalidly cued ring than were high-spans under load [t(22.27) = 2.70, p = .01], whereas low-spans under load were marginally less accurate with these invalid cues [t(24.48) = 1.79, p = .08].
As predicted, the load task caused differences in the high-WMC group’s ability to locate the second letter. Those performing the load task showed accuracy equivalent to that on validly cued trials when the letter occurred closer to fixation than the cue had indicated (see Fig. 3), but those in the no-load condition showed decreases in accuracy for letters appearing closer to fixation than the invalid cue had indicated. Neither low-span group showed a decline in accuracy when the letter appeared closer to fixation than the cue had indicated, although low-spans under load showed a decline in accuracy as the distance from fixation increased. All groups showed a decline in accuracy when the letter occurred farther from fixation than the cue had indicated.
When we look at accuracy as a function of distance from the invalid cue, high-spans, when not under load, showed a decrease in accuracy for both one and two rings inside the cued ring (the –2 and –1 bars in Fig. 4), suggesting the ring model of allocation that had been seen in Egly and Homa (1984) and Bleckley et al. (2003). However, all other groups—including the high-spans under load—showed no decline in accuracy when the letter occurred inside the invalidly cued ring, suggesting a spotlight-like allocation of attention.

Displaced-letter accuracy in Experiment 1, by span group, load condition, and incorrect cue distance (actual ring – cued ring)
Post-hoc analyses using Dunnett’s L, comparing the invalidly cued trials with the validly cued trials, confirmed that the differences shown by the ANOVA were as predicted. For the high-spans in the no-load condition, performance at both one and two rings inside the cued ring was significantly less accurate than their performance on validly cued trials (see Table 3). However, for all other groups, including the high-spans in the load condition, performance at both one and two rings inside the cued ring was no different from performance on validly cued trials. All groups showed less accurate performance on trials in which the displaced letter occurred farther from fixation than the cue had indicated.
Not surprisingly, both high-spans and low-spans under load performed differently on the displaced-letter localization task than did those who performed that task separately. High-spans under load showed a spotlight of attention similar to that of low-spans not under load. Low-spans under load showed a spotlight also, but their accuracy fell off steeply as the second letter’s distance from the center increased, suggestive of a loss of useful field of view (Williams, 1989). High-spans not under load again showed flexible allocation, as had been seen in Egly and Homa (1984) and Bleckley et al. (2003). These results suggest that the allocation of visual attention can be under executive control and that reducing the resources available reduces the flexibility of that control.
Experiment 2
Although Experiment 1 extended the work of Bleckley et al. (2003), supporting the contention that WMC is predictive of visual attention allocation style, it did not answer the question about the nature of these differences. More specifically, a critic might argue that the Egly and Homa (1984) task makes interpreting the change in accuracy between using object- or location-based visual attention difficult, because the distinction between attention allocation styles is confounded with the distance from the initial fixation point (the center of the ring). To support our claim that the difference between high-WMC and low-WMC individuals’ allocation of attention is due to high-spans using the relatively resource-intensive object-based allocation of attention and low-spans defaulting to the less-demanding location-based allocation, we replicated the original Bleckley et al. (2003) findings using a different paradigm, from Egly et al. (1994). In this paradigm, subjects are cued to a probable target location at the end of one of two congruent rectangles, as is demonstrated in Fig. 5. The target then appears at either the cued location or an invalidly cued location, which is either within the same rectangle or in the other rectangle, but at an equal distance from the cued location. Object-based allocation is displayed when the subject’s response times (RTs) are faster for invalidly cued within-object trials than for invalidly cued between-object trials.

Examples of a validly cued, invalidly cued within-object, and invalidly cued between-object trial, in a paradigm adapted from Egly et al. (1994) and used here in Experiment 2. The subjects’ task is to press a key if the gray square appears within the rectangle, and to do nothing if no gray square appears the there (no-go trials). Note: The scale of objects within this figure has been modified for visibility
Method
Subjects
A total of 43 students at a large southwestern university participated in this study and received partial course credit for their participation. They had been previously screened using the OSpan task and were recruited on the basis of their scores falling in either the upper or the lower quartile. Three of the subjects (two high-spans and one low-span) were dropped from the study for responding to a high percentage of catch trials.
Procedure
As is demonstrated in Fig. 5, each trial began with a display containing the fixation point and two rectangles. The rectangles occurred either above and below fixation or to the left and right of fixation. The four ends of the rectangles—the possible target locations—occupied the exact same locations in both the horizontal and vertical rectangle conditions.
As in Egly et al. (1994), the fixation point, rectangles, and targets were gray, and the cue was white. Each of the rectangles subtended 1.7° ×11.4° and was centered 4.8° from fixation. The target was a solid square (1.7° ×1.7°), and the cue was three sides of a square also subtending 1.7°, vertically and horizontally, overlapping the end of a rectangle.
The gray fixation display was presented for 1,000 ms, followed by a period of 100 ms during which the cue was superimposed over one end of one of the rectangles. The cue then disappeared, and the fixation display was presented for 200 ms. The target, a gray square (or nothing, on catch trials), was superimposed on the fixation display until the subject responded by pressing the space bar or until 2,000 ms had elapsed, if there was no response. This terminated the trial, and the next trial began after an intertrial interval of 500 ms during which the screen was blank.
The subjects were instructed to press the space bar as quickly as possible after the target appeared and not to respond if no target appeared. If subjects made an anticipatory response (<150 ms) or a false alarm, a 500-ms feedback beep was presented. In addition, subjects were instructed to respond as quickly as possible while minimizing errors.
The order of trials was randomized for each subject. There were eight blocks of 96 trials each, and a break was offered between blocks. Before the experimental blocks, the subjects were given a series of randomly generated practice trials. The practice trials were terminated when the subjects had made 20 consecutive correct responses.
The target was validly cued on 480 (75 %) of the cued trials, and at an uncued end on 160 (25 %) of the cued trials. The critical manipulation on the invalidly cued trials was whether the target appeared in the cued rectangle—at the uncued end—or at the equidistant end of the other rectangle. The target never appeared diagonally from the cue. For each of the two types of invalidly cued trial types, there were ten repetitions for each of the eight cues (2 rectangle orientations ×4 target locations). There were also 128 catch trials, in which the target did not appear.
Results and discussion
To address the question of whether high-spans, but not low-spans, would have slower RTs to invalidly cued trials appearing outside rather than inside the cued object, we calculated each subject’s mean RT at each of the three possible locations: validly cued, invalidly cued inside object, and invalidly cued outside object. These data appear in Fig. 6.

Mean response times by group and trial type for Experiment 2. Validly cued trials are contrasted with those that were invalidly cued within versus between objects. High-spans, but not low-spans, responded faster on invalidly cued trials in which the object appeared within the cued rectangle than when the object appeared outside the cued rectangle
A 3 (trial type: validly cued, within-object, between-object) ×2 (span: high, low) ANOVA showed a main effect of trial type, F(1.75, 66.46) = 65.54, MSE = 256.17, p < .01, with shorter RTs for validly cued trials. No effect of span group emerged, F(1, 38) = 0.51, MSE = 2,206.82, p = .48. However, the interaction between trial type and span group was significant, F(1.75, 66.46) = 4.56, MSE = 256.17, p = .02. Post-hoc comparisons of the cell means showed that in addition to the differences between validly cued trials and invalidly cued trials for each group, the high-spans were significantly faster on the invalidly cued trials in which the target occurred within the cued object than on those trials in which the target occurred in the other object. The same was not true for the low-spans, who exhibited no difference in RTs between the two types of invalidly cued trials.
The results of this experiment support the contention that the differences in allocation shown by Bleckley et al. (2003) and in our Experiment 1 were due to differences in the type of allocation used: High-spans tended to use an object-based allocation of attention, whereas low-spans tended to use a location-based allocation of attention. Importantly, these results further demonstrated that this finding remains when controlling for differences in the distance between the actual and expected target locations.
General discussion
In Experiment 1, high-span performance on the visual task was affected in the predicted manner: When under load, high-spans allocated their attention as a spotlight, similar to the low-span performance in that experiment and in Bleckley et al. (2003). More specifically, we argue that the high-spans in the load condition of Experiment 1 were unable to utilize an object-based allocation of attention, because executive attention was consumed in the tapping task. This change in the pattern of allocation from ring to spotlight supports the Bleckley et al. contention that the differences in performance are related to differences in executive attention. However, it might be argued that high-spans were merely better able to constrain their focus of attention, rather than allocating their attention to objects. However, in Experiment 2, we demonstrated that the difference between high- and low-spans in visual attention holds when using a second paradigm that more explicitly separates object- and location-based visual attention by controlling for target distance. Taken together, these findings support our contention that WMC is involved in the ability to use object-based visual attention.
These findings have important implications for understanding the role of WMC in lower-level visual attention. More specifically, these findings suggest that WMC is not just related to visual attention (Bengson & Mangun, 2011; Bleckley et al., 2003; Kane et al., 2001; Poole & Kane, 2009; Redick et al., 2012; Unsworth & Spillers, 2010), but can affect people’s ability to utilize more controlled processes in visual attention, such as object-based visual attention. These findings are also unique, in the sense that they demonstrate a scenario in which high-spans consistently perform more poorly than low-spans.
Finally, these findings add to the literature on people’s likelihood to switch between location-based and object-based visual attention (Baylis & Driver, 1993; Egly et al., 1994; Vecera & Farah, 1994). More specifically, they extend this literature by demonstrating that when a given situation would benefit from object-based visual attention, only those with the available cognitive resources—such as WMC—will use object-based attention. Moreover, recent research has suggested that people can also attend multiple independent locations at a time (Jefferies et al., 2014). These findings suggest that high- and low-spans should differ in this ability, as well. Of course, whether high- and low-spans differ in their ability to attend multiple independent locations at once is an important one worthy of future research.
References
Arrington, C. M., Carr, T. H., Mayer, A. R., & Rao, S. M. (2000). Neural mechanisms of visual attention: Object-based selection of a region in space. Journal of Cognitive Neuroscience, 12(Suppl. 2), 106–117. doi:10.1162/089892900563975
Baylis, G. C., & Driver, J. (1993). Visual attention and objects: Evidence for hierarchical coding of locations. Journal of Experimental Psychology: Human Perception and Performance, 19, 451–470. doi:10.1037/0096-1523.19.3.451
Bengson, J. J., & Mangun, G. R. (2011). Individual working memory capacity is uniquely correlated with feature-based attention when combined with spatial attention. Attention, Perception, Psychophysics, 73, 86–102.
Bleckley, M. K., Durso, F. T., Crutchfield, J. M., Engle, R. W., & Khanna, M. M. (2003). Individual differences in working memory capacity predict visual attention allocation. Psychonomic Bulletin & Review, 10, 884–889.
Daneman, M., & Carpenter, P. A. (1980). Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior, 19, 450–466. doi:10.1016/S0022-5371(80)90312-6
Egly, R., Driver, J., & Rafal, R. D. (1994). Shifting visual attention between objects and locations: Evidence from normal and parietal lesion subjects. Journal of Experimental Psychology: General, 123, 161–177. doi:10.1037/0096-3445.123.2.161
Egly, R., & Homa, D. (1984). Sensitization of the visual field. Journal of Experimental Psychology: Human Perception and Performance, 10, 778–793. doi:10.1037/0096-1523.10.6.778
Engle, R. W., & Kane, M. J. (2004). Executive attention, working memory capacity, and a two-factor theory of cognitive control. In B. H. Ross (Ed.), The psychology of learning and motivation (Vol. 44, pp. 145–199). San Diego, CA: Elsevier Academic Press.
Engle, R. W., Kane, M. J., & Tuholski, S. W. (1999). Individual differences in working memory capacity and what they tell us about controlled attention, general fluid intelligence and functions of the prefrontal cortex. In A. Miyake & P. Shah (Eds.), Models of working memory: Mechanisms of active maintenance and executive control (pp. 102–134). Cambridge, UK: Cambridge University Press.
Goodale, M. A., & Milner, A. D. (1992). Separate visual pathways for perception and action. Trends in Neurosciences, 15, 20–25. doi:10.1016/0166-2236(92)90344-8
Hopfinger, J. B., Buonocore, M. H., & Mangun, G. R. (2000). The neural mechanisms of top-down attentional control. Nature Neuroscience, 3, 284–291.
Jefferies, L. N., Enns, J. T., & Di Lollo, V. (2014). The flexible focus: Whether spatial attention is unitary or divided depends on observer goals. Journal of Experimental Psychology: Human Perception and Performance, 40, 465–470. doi:10.1037/a0034734
Kane, M. J., Bleckley, M. K., Conway, A. R. A., & Engle, R. W. (2001). A controlled attention view of working memory capacity. Journal of Experimental Psychology: General, 130, 169–183. doi:10.1037/0096-3445.130.2.169
Kane, M. J., Conway, A. R. A., Hambrick, D. Z., & Engle, R. W. (2007). Variation in working memory capacity as variation in executive attention and control. In A. R. A. Conway, C. Jarrold, M. J. Kane, A. Miyake, & J. N. Towse (Eds.), Variation in working memory (pp. 21–48). Oxford, UK: Oxford University Press.
Kane, M. J., & Engle, R. W. (2000). Working-memory capacity, proactive interference, and divided attention: Limits on long-term memory retrieval. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 336–358. doi:10.1037/0278-7393.26.2.336
La Pointe, L. B., & Engle, R. W. (1990). Simple and complex word spans as measures of working memory capacity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 1118–1133. doi:10.1037/0278-7393.16.6.1118
LaBerge, D. (1983). Spatial extent of attention to letters and words. Journal of Experimental Psychology: Human Perception and Performance, 9, 371–379. doi:10.1037/0096-1523.9.3.371
Laberge, D., & Brown, V. (1989). Theory of attentional operations in shape identification. Psychological Review, 96, 101–124. doi:10.1037/0033-295X.96.1.101
Luck, S. J., & Hillyard, S. A. (2000). The operation of selective attention at multiple stages of processing: Evidence from human and monkey electrophysiology. In M. S. Gazzaniga (Ed.), The new cognitive neurosciences (2nd ed., pp. 687–700). Cambridge, MA: MIT Press.
Milner, A. D., & Goodale, M. A. (1995). The visual brain in action. New York, NY: Oxford University Press.
Moscovitch, M. (1992). A neuropsychological model of memory and consciousness. In L. R. Squire & N. Butters (Eds.), Neuropsychology of memory (2nd ed., pp. 5–22). New York, NY: Guilford Press.
Moscovitch, M. (1994). Cognitive resources and dual-task interference effects at retrieval in normal people: The role of the frontal lobes and medial temporal cortex. Neuropsychology, 8, 524–534.
Neisser, U., & Becklen, R. (1975). Selective looking: Attending to visually specified events. Cognitive Psychology, 7, 480–494. doi:10.1016/0010-0285(75)90019-5
Poole, B. J., & Kane, M. J. (2009). Working memory capacity predicts the executive control of visual search among distractors: The influences of sustained and selective attention. Quarterly Journal of Experimental Psychology, 62, 1430–1454. doi:10.1080/17470210802479329
Posner, M. I., Snyder, C. R., & Davidson, B. J. (1980). Attention and the detection of signals. Journal of Experimental Psychology: General, 109, 160–174. doi:10.1037/0096-3445.109.2.160
Redick, T. S., Broadway, J. M., Meier, M. E., Kuriakose, P. S., Unsworth, N., Kane, M. J., & Engle, R. W. (2012). Measuring working memory capacity with automated complex span tasks. European Journal of Psychological Assessment, 28, 164–171.
Shipstead, Z., & Engle, R. W. (2013). Interference within the focus of attention: Working memory tasks reflect more than temporary maintenance. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 277–289. doi:10.1037/a0028467
Turner, M. L., & Engle, R. W. (1989). Is working memory capacity task dependent? Journal of Memory and Language, 28, 127–154. doi:10.1016/0749-596X(89)90040-5
Unsworth, N., & Spillers, G. J. (2010). Working memory capacity: Attention control, secondary memory, or both? A direct test of the dual-component model. Journal of Memory and Language, 62, 392–406.
Vecera, S. P., & Farah, M. J. (1994). Does visual attention select objects or locations? Journal of Experimental Psychology: General, 123, 146–160. doi:10.1037/0096-3445.123.2.146
Williams, L. J. (1989). Foveal load affects functional field of view. Human Performance, 2, 1–28. doi:10.1207/s15327043hup0201_1
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Bleckley, M.K., Foster, J.L. & Engle, R.W. Working memory capacity accounts for the ability to switch between object-based and location-based allocation of visual attention. Mem Cogn 43, 379–388 (2015). https://doi.org/10.3758/s13421-014-0485-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-014-0485-z