
Abstract
Implicit learning of visual contexts facilitates search performance—a phenomenon known as contextual cueing; however, little is known about contextual cueing under situations in which multidimensional regularities exist simultaneously. In everyday vision, different information, such as object identity and location, appears simultaneously and interacts with each other. We tested the hypothesis that, in contextual cueing, when multiple regularities are present, the regularities that are most relevant to our behavioral goals would be prioritized. Previous studies of contextual cueing have commonly used the visual search paradigm. However, this paradigm is not suitable for directing participants’ attention to a particular regularity. Therefore, we developed a new paradigm, the “spatiotemporal contextual cueing paradigm,” and manipulated task-relevant and task-irrelevant regularities. In four experiments, we demonstrated that task-relevant regularities were more responsible for search facilitation than task-irrelevant regularities. This finding suggests our visual behavior is focused on regularities that are relevant to our current goal.
Similar content being viewed by others

Our visual environment consists of highly structured arrangements of objects. Individuals can implicitly learn such regularities, and these regularities lead to efficient processing of visual scenes (Turk-Browne, Jungé, & Scholl, 2005; Chun & Turk-Browne, 2008; Chun, 2000). Research has shown that implicit learning of contexts facilitates search performance, which is a phenomenon referred to as “contextual cueing” (e.g., Chun & Jiang, 1998). However, little is known about contextual cueing under situations in which multiple regularities exist simultaneously, although in everyday vision, different information, such as object identity and location, appears simultaneously and interacts with each other. The current study investigated task dependency in contextual cueing; namely, whether visual attention is guided by all regularities, or preferentially by task-relevant regularities.
Human beings learn regularities in their environments through repeated experience. Previous studies have investigated what humans learn from the environment, and how learned knowledge affects our visual behavior. For example, studies of contextual cueing have demonstrated that people can learn spatial configurations and object identities, and that such acquired knowledge is used as a cue for attending and looking (Chun & Jiang, 1998; Chun & Jiang, 1999). In the latter study, participants were asked to search for a target among distractors as quickly as possible to assess contextual cueing. Reaction times for the target became faster when the same configurations or same sets of objects were presented repeatedly than when different configurations or object sets were presented. Participants in this kind of experiment do not realize that the same pattern is repeated during the search task, so learning occurs without awareness of this manipulation (i.e., implicit learning). Note that certain studies of contextual cueing have distinguished between implicit learning itself and expressions of implicit learning (Jiang & Leung, 2005; Goujon, Didierjean, & Marmèche, 2009). According to Jiang and Leung (2005), contextual cueing is the expression of implicit learning, defined as the facilitation of reaction time by memory-guided attention, and implicit learning could occur even when there is no contextual cueing. The current study focused on the contextual cueing effects, rather than on implicit learning itself, because we were interested in how memory guides our visual attention.
Studies on contextual cueing have demonstrated that memory for regularities of location or identity guide visual attention independently, but, in everyday vision, these different regularities appear simultaneously and interact with each other. For example, in a classroom, we might always see a blackboard, desks, lights, and chairs in the same configuration. In such a situation, there are regularities of object identity and spatial location. However, little is known about how this environment containing multidimensional regularities guides visual attention. Multiple regularities might simultaneously guide our attention, or alternatively our attention might be guided only by regularities that are relevant to our current behavior.
One study focusing on single dimensional multiple regularities has suggested that contextual cueing occurs only for attended objects (Jiang & Chun, 2001). In this latter study, participants were presented with red and green colored objects, and were asked to search for either a red or a green target, such that the target color (say “red”) was attended, whereas the other color (say “green”) was ignored. Under this manipulation, reaction times decreased when the attended objects were presented repeatedly, whereas they did not decrease when the ignored objects were repeatedly presented. This result indicates that selective attention is important for inducing contextual cueing.
Therefore, possibly, attention acts as a filter that determines the multiple regularities that would preferentially induce contextual cueing. Based on this possibility, we can hypothesize that a task in which people are currently involved also modulates contextual cueing for multidimensional regularities, and that task-relevant information is prioritized. However, studies examining this issue have shown inconsistent results, depending on experimental settings. Therefore, strong evidence to support the contention that the task prioritizes relevant information in contextual cueing is lacking. For example, Endo and Takeda (2004) found that contextual cueing occurs only for the location, even when the task is relevant for object identity. They showed that the location was the only learned regularity during visual search, although object identity regularity was also simultaneously presented and the task was to find a target of a certain identity. Their findings suggested that location learning predominates in contextual cueing, regardless of the task. In contrast, Jiang and Song (2005) showed that contextual cueing occurs both for identity and location under situations when identity is as salient as location. They reported that, when participants observed a variety of stimulus shapes, or colors, during learning, they could use not only location regularity, but also object identity regularity as cues for a target. Although this latter study suggested that multidimensional regularities can help deploy visual attention, it remains unclear whether both regularities interact equally with contextual cueing, or whether one of the multiple regularities is prioritized.
Another paradigm, implicit sequence learning, has also suggested that task-relevant information is selectively acquired (Meier, Weiermann, & Cock, 2012). In their study, the authors prepared primary (category: e.g., plant and instrument) and secondary (a specific word regarding the category: e.g., rose and piano) information. Secondary information was presented sequentially, and participants reported the primary information corresponding to the secondary information (when “rose” was presented, “plant” was the correct answer). Both primary and secondary information were regular for certain participants, whereas only the primary information was regular for other participants. Then, authors removed all the regularities in a subsequent test, and they predicted that, if both primary and secondary information were learned during exposure, the participants presented with both primary and secondary regularities would show a larger response disruption compared to participants presented with only the primary regularity. Interestingly, the results showed that the response disruption was not different between the two groups. Therefore, the authors concluded that only task-relevant (primary) information is learned as regular. This finding is important, but since the conclusion is based on the null result that the response disruption did not differ, regardless of the information that was randomized, we need to be careful in concluding that task-irrelevant information did not guide attention in this study. In addition, the study also showed that the location information is learned even when participants responded to stimulus categories (Meier, Weiermann, & Cock, 2012, Experiment 3). This result is consistent with that of Endo and Takeda (2004), showing a location dominance in contextual cueing. Therefore, it remains possible that location information becomes prioritized when memory guides visual attention, regardless of the task.
The current study was designed to clarify whether task demands mediate contextual cueing under multidimensional regularities. Addressing this issue requires manipulating task-relevant and task-irrelevant regularities, rather than tasks dominated by one type of regularity. Although visual search is commonly used to study contextual cueing, performance in visual search tasks is dominated more by the location than by other features (Endo & Takeda, 2004, but see Jiang & Song, 2005). This location dominance might stem from the global layout, which is a critical factor for visual search paradigms. Jiang and Wagner (2004) conjectured that global layout information could be more important than individual location information, because global layout is related directly to a set of individual object locations, and location might be more dominant than other features of an object. As discussed above, Endo and Takeda (2004) reported that location was the only learned regularity during visual search, even though other regularities were also presented at the same time. Perhaps location bias in visual search is due to global information, the elimination of which would weaken the dominance of location in information bias. It might be possible to use a serial reaction time (SRT) task to eliminate the location bias stemming from layouts in which stimuli are sequentially presented (Nissen & Bullemer, 1987). In the SRT paradigm, participants are required to respond to each stimulus, and responses are facilitated when the same sequences are presented repeatedly. Although the SRT task is a satisfactory paradigm, it has certain shortcomings for the purpose of our research. The first shortcoming of the SRT task was that it has a strong motor component, because it requires participants to press a key in response to every stimuli, thereby repeating the same sequence of keystrokes (Hoffmann & Koch, 1997). We were interested in finding out about how a task mediates memory-guided visual attention, rather than about learning motor sequences. The second problem of the SRT task was that people sometimes tend to be aware of repeated patterns in the task, which is possibly caused by reliance on only a few stimuli.
To solve these problems, we developed a spatiotemporal contextual cueing paradigm by combining the spatial contextual cueing (Chun & Jiang, 1998; Endo & Takeda, 2004) and the temporal contextual cueing (Olson & Chun, 2001; Mayberry, Livesey, & Dux, 2010) paradigms. In the spatiotemporal contextual cueing paradigm, images are presented sequentially in variable locations, and the task is to find pre-determined targets (say “female face”) and ignore the distractors (say “male face”). Only one item is present during each image, so as to ensure sufficient attention is paid to each item, which is expected to reduce the confounding effects of global layout information on target detection. In contrast to the SRT task, this paradigm does not require responding to every item in a sequence, which allows examining how visual attention is guided by memory during perception, independently of motor learning. Moreover, it also allows the use a variety of locations and stimuli. A number of studies have shown robust contextual cueing effects with respect to location regularity (Chun & Jiang, 1998; Chun & Jiang, 2003; Jiang & Chun, 2001) and object identity regularity (Chun & Jiang, 1999; van Asselen, Sampaio, Pina, & Castelo-Branco, 2011). Therefore, in our experimental paradigm, we manipulated individual object location and identity, as task-relevant and task-irrelevant regularities. Moreover, we used facial identity as a property of object identity, because it is relatively complex and variable. Thus, this paradigm was considered a suitable candidate for investigating interactions between a task and contextual cueing.
In the spatiotemporal contextual cueing paradigm, the type of regularity of concern to participants was determined by the target definition. The paradigm consisted of an identity-related and a location-related task. In the identity-related task, the target was defined by gender (say “female”). In the location-related task, the target was any face that was presented off-center of the placeholder. In the learning phase, a sequence of invariant locations and facial identities was presented repeatedly (invariant sequence), such that those stimuli information were learned as a regularity. In the subsequent test phase, we removed the regularity from the presentation of facial identity, or the location, by randomizing the presentation order of information in the invariant sequence. We tested whether task-relevant regularities showed a larger effect of repetition than task-irrelevant regularities, or if both task-relevant and task-irrelevant regularities contributed equally to spatiotemporal contextual cueing.
Experiment 1
We examined whether the task determined the type of multiple regularity that was prioritized in contextual cueing by employing a spatiotemporal contextual cueing paradigm. In Experiment 1, we tested whether invariant sequences with object identity and location regularities were learned in this paradigm. Participants were asked to find a target face that was the opposite gender to distractor faces among a sequence (if the first item in a sequence was a “male face”, the target was a “female face”), and to report the direction of the target rotation (all faces were rotated 5° to the right or left of the vertical axis). Invariant sequences were presented repeatedly during the learning phase, and both facial identities and the locations of the invariant sequences were randomized to remove regularity in the test phase. If invariant sequences were learned during the learning phase, reaction times should be slower in the test phase in comparison to the last block of the learning phase, because the regularities in the invariant sequences were not available as a cue for response to target in the test phase.
Methods
Participants
Sixteen students attending Kyoto University (five women and 11 men, mean age = 22.4 years) participated in this experiment. The number of participants was determined through several pilot experiments. All participants had normal or corrected-to-normal vision and were naïve concerning the purpose of the experiment. Written informed consent was obtained from all participants prior to participation in the experiment. They received JPN\ 1000 (nearly equal to US $10) per hour for their participation.
Apparatus
Stimulus presentation was controlled by MATLAB (The MathWorks, Inc.; http://uk.mathworks.com/) with Psychtoolbox (Brainard 1997; Pelli 1997; http://psychtoolbox.org/). The visual stimuli were presented on a 19-inch CRT monitor with a resolution of 1280 × 1024 pixels and a refresh rate of 100 Hz. The position of the participant’s head was fixed with a chin rest, and the visual distance of the head from the CRT was 75 cm. Responses were made with a standard keyboard.
Stimuli
Eighty images of Japanese male and female faces were used (40 facial stimuli for each gender, with neutral facial expression). Each face subtended a visual angle of 1.7° at the diameter. Eight, 16, 24, and 32 stimulus locations were placed evenly on the circumferences of four imaginary circles with radii of 2.3°, 4.6°, 6.9°, and 9.2° from the center, respectively (80 possible locations, see Fig. 1). All faces were rotated 5° to the right or to the left of the vertical axis. The directions of facial images were randomly selected in each trial. All facial stimuli were presented against a black background.

An example of location setting. Placeholders were not presented in actual displays
Figure 2 shows the time course of the stimulus sequence in a trial. Each trial had 9–13 faces, consisting of a pre-filler or pre-filler sequence (two to five faces), an invariant sequence (six faces), a target, and a post-filer. Pre-filler: to make the temporal position of the target unpredictable, a filler face or a filler sequence consisting of two to five faces was presented before the invariant sequence. Faces in filler sequences were the opposite gender to the target face, and were randomly presented in each trial. Thus, the target could appear somewhere between the 8th and the 12th item in a trial sequence. Invariant sequence: Each invariant sequence consisted of six faces of the opposite gender to the target. The faces and locations in invariant sequences were fixed throughout the learning phase, and these sequences were presented repeatedly, such that percipients could learn regularities. There were 16 instances of invariant sequences generated for each participant (8 male sequences and 8 female sequences). Neither facial identities, nor locations were duplicated within a sequence. Target: a target always follows an invariant sequence. Each invariant sequence was associated with a certain target face of the opposite gender. Since there were 16 instances of invariant sequences, 16 different targets were used (half was a combination of a male invariant sequence and a female target, and the other half was a combination of a female invariant sequence and a male target). Post-filler: after the presentation of the target, a random face with the opposite gender to the target was presented.

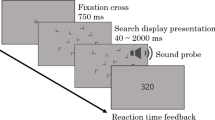
An example of a trial sequence. Image size of faces in the figure is enlarged for illustrative purposes. A fixation cross appeared at the center of the display, and the stimulus sequence was presented 1500 ms after the onset of fixation. Within a sequence, stimulus onset asynchrony was 750 ms, and inter-stimulus interval was 250 ms. After presentation of the fixation cross, either a filler face, or a filler sequence of two to five faces was presented to make the temporal position of the target unpredictable. Then, an invariant sequence was presented, which was followed by the target. After target presentation, another filler face was presented
In the test phase, randomized sequences were presented instead of invariant sequences (see the both random row in Fig. 3). Both locations and facial identities of invariant sequences were randomized. The target faces were identical to those in the learning phase.

Examples of an invariant sequence in the learning phase and randomized sequences in the test phase. Image size of faces in the figure is enlarged for illustrative purposes. During the learning phase, invariant sequences that were invariant in both location and facial identity, were presented repeatedly. In the following test phase, we removed location and/or identity regularities by randomizing the information in invariant sequences. Both locations and identities were randomized in Experiment 1, either identities or locations were randomized in Experiment 2 and later experiments. All faces were rotated 5° either to the right or to the left of the vertical axis. The directions of faces were selected randomly for each trial; therefore, there were no regularities in the direction of faces
Procedure
The task was to find the target, which was the opposite gender to the distractors within a sequence, and to report the direction of the target rotation as accurately and as quickly as possible with a key press. A fixation cross (0.5° × 0.5°) appeared at the center of the display, and the stimulus sequence was presented 1500 ms after the fixation onset. Within a sequence, stimulus onset asynchrony was 750 ms, and inter-stimulus interval was 250 ms. Reaction times were calculated from target onset. Feedback displays and a low-pitched buzz were provided only for incorrect responses.
The experiment began with the 16-trial practice session. This was followed by the 18-block learning phase. During the learning phase, each invariant sequence was presented once in a block; therefore, invariant sequences were presented for a total of 18 times. Each block consisted of 16 trials because 16 invariant sequences were prepared for the current experiment. In the two-block test phase, randomized sequences were presented in place of invariant sequences. Both locations and facial identities of invariant sequences were randomized in the test phase, whereas the target faces were the same as those in the learning phase. There was no distinctive transition to the test phase.
After the test phase, a recognition test was conducted to investigate whether learning was implicit. In the recognition test, participants observed invariant sequences from the learning phase and randomized sequences from the test phase with the exception of the target, and they were required to respond to two kinds of recognition tests on the location of the target and its identity. In the location recognition test, participants were asked to select the target location from among two placeholders: the correct location and one of the other target locations. In the identity recognition test, participants were required to select the target face from among two faces: the correct face and one of the other target faces. Each display remained on the screen until a response was made.
Analyses
Incorrect trials, trials with reaction times shorter than 200 ms, or reaction times longer than three SD in each epoch were discarded recursively as outliers. To increase statistical power, reaction times in the learning phase were collapsed into six epochs of three consecutive blocks, and reaction times in the test phase were collapsed into one epoch.
A repeated-measures analysis of variance (ANOVA) with epoch (1–6) factor was conducted to examine the effect of epochs on reaction times in the learning phase. Decreased reaction times in the learning phase would be accounted not only by leaning effects of invariant sequences, but also by general practice effects (Olson & Chun, 2001). Therefore, we calculated cueing effects as the differences in reaction times between the last epoch of the learning phase (6th epoch) and the test phase. We also conducted a paired t-test between cueing effect and the baseline. Cueing effects were expected to be larger than zero if responses in the test phase were delayed as a result of removing regularity.
Results
The results of reaction times in Experiment 1 are shown in Fig. 4. The ANOVA conducted on reaction times in the leaning phase showed a significant main effect of epoch, F(5, 75) = 9.95, P < .001, η 2p = .399. This result indicates that reaction times decreased in accordance with the epoch. The calculated cueing effects were shown in Fig. 5. A t-test indicated that the cueing effect was significantly larger than zero, t(15) = 2.93, P = .010, d = 1.035, suggesting that reaction times in the test phase were slower than those in the last epoch of the learning phase.

Reaction times in Experiment 1. Error bars Standard error

The results of accuracy are shown in Table 1. Mean accuracy throughout the experiment was 85.5 %. An ANOVA conducted to examine the accuracy in the learning phase showed a significant main effect of epoch, F(5, 75) = 10.08, P < .001, η 2p = .402. This result suggested that the target detection performance improved in accordance with the epoch. Similar to reaction time differences in cueing effects, we calculated the accuracy differences between the last epoch of the learning phase and the test phase. A t-test revealed that difference in accuracy was not significantly different from zero, t(15) = 1.68, P = .114, suggesting that there was no speed–accuracy trade-off.
Mean accuracies for target location in the invariant and randomized sequences in the location recognition test were 53.9 % (SD = 10.2) and 45.7 % (SD = 11.8), respectively. A paired t-test showed no significant difference between these scores, t(15) = 1.64, P = .122. Each accuracy value was compared with chance level of performance (50 %), which indicated no significant differences, invariant sequence: t(15) = 1.54, P = .122, randomized sequence: t(15) = 1.46, P = .166.
Mean accuracies in the face recognition test for the target face in the invariant and randomized sequences were 54.3 % (SD = 11.1) and 54.3 % (SD = 12.4), respectively. A paired t-test showed no significant difference between these values, t(15) = 0. There were also no significant differences between each accuracy level and chance level of performance, invariant sequence: t(15) = 1.55, P = .143, randomized sequence: t(15) = 1.38, P = .187.
Discussion
We found that responses to the target were impaired when location and identity were randomized in the test phase, suggesting that participants learned the regularities present in the learning phase. Results from the recognition test suggest that this learning did not depend on explicit knowledge of the target information within invariant sequences. These results establish that certain aspects regarding location and identity-based regularities were learned. In subsequent experiments, we sought to more closely examine the contribution of these types of regularities for learning.
Experiment 2
We confirmed that certain aspects of location and identity-based regularities were learned in the spatiotemporal contextual cueing paradigm. Therefore, in Experiment 2, we investigated whether task-relevant regularities were prioritized in contextual cueing, or whether both task-relevant and task-irrelevant regularities contribute equally to contextual cueing. In Experiment 2, similar to Experiment 1, participants were required to find a target face that was the opposite gender to distractor faces, so the task was identity-related. Invariant sequences were presented repeatedly during the learning phase. There were two groups in Experiment 2: identity-random and location-random groups. In the identity-random group, we removed identity regularities in the test phase and examined whether object identities were learned and facilitated response to the target. In the location-random group, we randomized locations of the invariant sequences in the test phase and tested whether locations induced contextual cueing.
Methods
Thirty individuals that did not participate in Experiment 1 were recruited. Half of the participants (eight women and seven men, mean age = 21.4 years) were assigned to the identity-random group, and the remaining half (six women and nine men, mean age = 21.6 years) to the location-random group. The apparatus and stimuli were identical to those in Experiment 1 with the exception that object identities of invariant sequences changed in the test phase for the identity-random group, and locations of the invariant sequences changed in the test phase for the location-random group.
Results
The results of reaction times in Experiment 2 are shown in Fig. 6. An ANOVA conducted to examine the effects of group (identity-random, location-random) and epoch (1–6) factors on reaction times in the learning phase showed a significant main effect of the epoch, F(5, 140) = 36.53, P < .001, η 2p = .566, indicating that reaction times decreased in accordance with the epoch. The main effect of group and the interaction were not significant, group: F(1, 28) = 0.03, P = .864; interaction: F(5, 140) = 0.37, P = .871. Figure 5 shows cueing effects in Experiment 2. The cueing effect was significantly larger than zero for the identity-random group, t(14) = 2.62, P = .020, d = 0.957, but was not different from zero for the location-random group, t(14) = 0.64, P = .535, indicating that the reaction times in the test phase became longer than those in the last epoch of the learning phase when the identity regularity was removed, although this was not the case when the location regularity was removed. Also, the cueing effect in the identity-random group tended to be larger than that in the location-random group, t(28) = 1.98, P = .057, d = 0.724.

Reaction times in Experiment 2. Error bars Standard error
Mean accuracies of responses were 90.0 % in the identity-random group and 89.8 % in the location-random group (as detailed in Table 1). An ANOVA conducted to examine the effect of group and epoch factors on accuracy in the learning phase showed a significant main effect of epoch, F(5, 140) = 16.68, P < .001, η 2p = .373, indicating that accuracy level increased in accordance with epoch. The main effect of group and the interaction were not significant, group: F(1, 28) = 0.02, P = .881; interaction: F(5, 140) = 1.49, P = .198. The accuracy differences between the last epoch of the learning phase and the test phase were not different from zero for either groups, identity-random group: t(14) = 0.14, P = .887, location-random group: t(14) = 0.51, P = .615. Also, there was no difference between the two groups in accuracy difference, t(28) = 0.51, P = .615, indicating that there was no speed–accuracy trade-off.
Mean accuracies for target location within invariant and randomized sequences in the location recognition test were 47.9 % (SD = 13.1) and 53.3 % (SD = 13.5), respectively, in the identity-random group, and 46.7 % (SD = 14.0) and 50.8 % (SD = 9.70), respectively, in the location-random group. Each accuracy value was compared with chance level performance, which indicated no significant differences in the identity-random group, invariant sequence: t(14) = 0.62, P = .547; randomized sequence: t(14) = 0.95, P = .357, or in the location-random group, invariant sequence: t(14) = 0.93, P = .370; randomized sequence: t(14) = 0.33, P = .744.
Mean accuracy in the face recognition test for the target face within invariant and randomized sequences were 52.9 % (SD = 15.3) and 50.4 % (SD = 8.34), respectively, in the identity-random group, and 53.3 % (SD = 8.80) and 45.0 % (SD = 15.5), respectively, in the location-random group. There were no significant differences between accuracy values and chance level performance in the identity-random group, invariant sequence: t(14) = 0.74, P = .472; randomized sequence: t(14) = 0.19, P = .849, or in the location-random group, invariant sequence: t(14) = 1.47, P = .164; randomized sequence: t(14) = 1.25, P = .233.
Discussion
The results showed that responses to the target were impaired when identity was randomized in the test phase of the identity-random group, although responses were not disrupted when location was randomized in the test phase of location-random group. This suggest that participants learned object identity regularities present in the learning phase and used them to predict targets, whereas they did not use location regularities for target detection. Results from the recognition test suggest that this learning did not depend on explicit knowledge of target information within invariant sequences. These results suggest that task-relevant object identities were implicitly learned and facilitated responses to targets when the task was identity-related. Thus, task demands mediated spatiotemporal contextual cueing, and, when repeated, task-relevant regularity had an advantage over task-irrelevant regularity, which supported our prediction.
Experiment 3
The purpose of Experiments 3 was to generalize the finding that task-relevant regularities are prioritized in contextual cueing. We investigated whether locations were used preferentially as contextual cues when the task was location-related. The experimental task was to find a face presented off-center in the placeholder. Invariant sequences were presented repeatedly during the learning phase, and then either locations or identities of the invariant sequences were randomized in the test phase.
Methods
Thirty individuals that did not participate in Experiment 1 or 2 were recruited. Half of the participants (four women and 11 men, mean age = 22.3 years) were assigned to the location-random group, and the remaining half (two women and 13 men, mean age = 21.2 years) was assigned to the identity-random group. The apparatus and stimuli were identical to those in Experiments 1 and 2 except that placeholders (2.0° of visual angles in diameter size) were drawn around each facial image. The target faces were presented off-center (0.3° above or below the center of the placeholder), and the distractor faces were presented at the center of the placeholders. The task was to find a target face that was off-center in the placeholder and to report the direction in which the target face was rotated. Unlike in previous experiments, target faces were the same gender as distractor faces, such that when the target was a female face, the distractors were also female faces. This manipulation was conducted to control for the possibility that participants focused on gender rather than spatial offset (located in the center, or off-center in the placeholder). Invariant sequences were presented repeatedly during the learning phase, and then either locations (location-random group) or identities (identity-random group) of the invariant sequences were randomized in the test phase.
Results
The results of reaction times in Experiment 3 are shown in Fig. 7. An ANOVA with group (location-random, identity-random) and epoch (1–6) factor examining the effect of epoch on reaction times in the learning phase indicated a significant main effect of epoch, F(5, 140) = 43.06, P < .001, η 2p = .606, indicating that reaction times decreased in accordance with epoch. The main effect of group and the interaction was not significant, group: F(1, 28) = 0.30, P = .589; interaction: F(5, 140) = 0.08, P = .995. We investigated the effects of removing regularity by calculating cueing effects as reaction time differences between the last epoch of the learning phase and the test phase (Fig. 5). The cueing effect was significantly larger than zero for the location-random group, t(14) = 2.84, P = .013, d = 1.035, but was not different from zero for the identity-random group, t(14) = 1.23, P = .239, suggesting that response was impaired only when location regularities were removed in the test phase. However, there was no difference between the cueing effect in the identity-random group, or in the location-random group, t(28) = 0.79, P = .438. The lack of differences in the cueing effect indicated that we failed to provide evidence that response was disrupted more in the location-random group than in the identity-random group. This could be due to individual variances, because we conducted a between-participant experiment with respect to the test condition.

Reaction times in Experiment 3. Error bars Standard error
Mean accuracies in the learning and test phases (shown in Table 1) were 88.1 % in the location-random group and 86.8 % in the identity-random group. An ANOVA was conducted to examine the effects of group and epoch factors on accuracy in the learning phase, which indicated a significant main effect of epoch, F(5, 140) = 7.36, P < .001, η 2p = .208, suggesting that accuracy level increased in accordance with epoch. Neither the main effect of group, nor the interaction were significant, group: F(1, 28) = 0.13, P = .712; interaction: F(5, 140) = 1.08, P = .369. The accuracy differences between the last epoch of the learning phase and the test phase were not different from zero for either group, location-random group: t(14) = 0.32, P = .757, identity-random group: t(14) = 1.37, P = .193. Also, there was no difference in accuracy between the two groups, t(28) = 0.91, P = .369, indicating that there was no speed–accuracy trade-off.
In the location recognition test, mean accuracies for target location within the invariant and randomized sequences were 48.8 % (SD = 12.5) and 57.9 % (SD = 11.9), respectively, in the location-random group, and were 50.8 % (SD = 12.2) and 52.1 % (SD = 14.7), respectively, in the identity-random group. Accuracy in each case was compared with chance level, which indicated that accuracy for invariant sequence in the location-random group was not different from chance level, t(14) = 0.39, P = .705, whereas accuracy for randomized sequences was higher than chance level, t(14) = 2.57, P = .022, d = 0.939. However, there were no significant differences in accuracy in the identity-random group: invariant sequence, t(14) = 0.26, P = .796, randomized sequence, t(14) = 0.55, P = .592.
In the face recognition test, mean accuracies for the target face within invariant sequences and randomized sequences were 57.9 % (SD = 9.59) and 50.3 % (SD = 11.5), respectively, in the location-random group, and 50.4 % (SD = 11.9) and 53.3 % (SD = 15.3), respectively, in identity-random group. In the location-random group, accuracy for invariant sequences was higher than chance level, t(14) = 3.20, P < .001, d = 1.17, whereas accuracy for randomized sequence was not different from chance level, t(14) = 0.28, P = .784. There was no significant differences between accuracy values and chance level performance in the identity-random group: invariant sequence, t(14) = 0.14, P = .894, randomized sequence, t(14) = 0.84, P = .413.
Discussion
We found the slowed response in the test phase only when location regularity was removed, and this suggests that locations induced spatiotemporal contextual cueing. There was no difference between the cueing effect for the identity-random and location-random groups, so we failed to provide strong evidence that task-relevant location regularity is prioritized in location-related task. Possibly a between-participant design experiment is not suitable for comparing the effect of regularity removing. In Experiment 4, we employed a within-participant design experiment. Participants could not recognize target locations when they were presented invariant sequences. However, recognition accuracy for the randomized sequences in the location-random group was higher than chance level. This might reflect familiarity with the randomized sequences because these sequences were presented in the test phase, and the recognition test was conducted immediately after the test phase. In the face recognition test, accuracy for the invariant sequences in the location-random group were higher than chance. Even if a task were location-related, participants might learn the association between the invariant sequences and the targets explicitly.
Experiment 4
In Experiment 3, we failed to provide sufficient evidence that location regularity was prioritized in location-related tasks. This might have been because the between-participant design was unsuitable. Therefore, we designed in Experiment 4 having a within-participant design with respect to removing regularity in the test phase, and again investigated whether there was a bias favoring task-relevant regularities compared to task-irrelevant regularities in spatiotemporal contextual cueing. Participants were assigned to either identity-related or location-related task group, and invariant sequences were observed during the learning phase. Then, all participants were presented with both identity-random and location-random sequences in the test phase. If the task prioritized relevant regularity, reaction times in the test phase were expected to be slower when task-relevant regularity was removed, compared to when task-irrelevant regularity was removed.
Methods
Thirty individuals that did not participate in previous experiments were recruited. Half of the participants (four women and 11 men, mean age = 22.7 years) were assigned to the identity-related task, whereas the remaining half (three women and 12 men, mean age = 22.2 years) was assigned to the location-related task.
The apparatus and stimuli were similar to those Experiments 1–3; however, unlike in previous experiments, both identity- and location-random sequences appeared in the test phase. There were two blocks in the test phase, with a block containing the same number of identity- and location-random sequences. Each invariant sequence was presented once in each block by randomizing trial-by-trial either identity or location regularity. For example, if a certain invariant sequence was presented as the identity-random sequence in the first test block, then it was presented as the location-random sequence in the second test block. We did not conduct the recognition test in Experiment 4, because in previous experiments we have confirmed that participants could not explicitly discriminate the target within an invariant sequence.
Results
The results of reaction times in Experiment 4 are shown in Fig. 8. An ANOVA examining the effects of task (identity-related, location-related) and epoch (1–6) on reaction times in the learning phase showed a significant main effect of epoch, F(5, 140) = 27.23, P < .001, η 2p = .493, and a marginally significant main effect of task, F(1, 28) = 2.93, P = .098, η 2p = .095. The interaction of task and epoch was not significant, F(5, 140) = 0.08, P = .995. Thus, reaction times decreased in accordance with epoch, and reaction times in the identity-related task tended to be faster than those in the location-related task.

Reaction times for the identity-related task (a) and for the location-related task (b) in Experiment 4. Error bars Standard error. We randomized either the task-relevant regularity (white) or the task-irrelevant regularity (black) in the test phase
To assess the effects of removing regularity, we calculated cueing effects as the difference between the last epoch of the learning phase and the test phase (Fig. 9). An ANOVA conducted to examine the effects of cueing effects with task (identity-related, location-related) and test condition (location random, identity random) revealed a significant interaction of task and test condition, F(1, 28) = 7.47, P = .011, η 2p = .211, but none of the main effects was significant, task: F(1, 28) = 0.01, P = .918; condition: F(1, 28) = 0.33, P = .568. The simple main effect of test condition was significant for cueing effects in the identity-related task, F(1, 14) = 4.99, P = .042, η 2p = .263, and was marginally significant for those in the location-related task, F(1, 14) = 3.57, P = .080, indicating that cueing effects were larger for task-relevant regularity than for task-irrelevant regularity. Moreover, previous experiments showed slower reaction times in the test phase than in the last epoch of the learning phase; therefore, we compared cueing effects for each condition with zero. This indicated that none of the cueing effects showed slower reaction times in the test phase than in the last epoch of the learning phase for the identity-related task in the identity-random condition, t(14) = 0.99, P = .338; or in the location-random condition, t(14) = 1.25, P = .232, or for location-related task in identity-random condition, t(14) = 1.36, P = .197, or in the location-random condition: t(14) = 1.63, P = .126. These findings are discussed below.

Cueing effects as reaction time differences between the last epoch of the learning phase and the test phase for each test condition. Symbols indicate significant differences between conditions (+ P < .10, *P < .05). Error bars Standard error
Mean accuracy in the learning phase was 89.0 % in the identity-related task, and 86.1 % in the location-related task. An ANOVA conducted to examine accuracy in the learning phase showed a main effect of epoch, F(5, 140) = 18.81, P < .001, η 2p = .402. The main effect of task and the interaction were not significant, task: F(1, 28) = 1.63, P = .212; interaction: F(5, 140) = 1.31, P = .264. Similar to cueing effects as reaction time difference, we calculated accuracy differences between the last epoch of the learning phase and the test phase. An ANOVA on accuracy differences with task and test condition factor did not show any main effects or interaction, task: F(1, 28) = 1.48, P = .234; condition: F(1, 28) = 0.14, P = .713; or interaction: F(1, 28) = 0.67, P = .421.
Discussion
The results of Experiment 4 indicated that reaction times delayed more for identity-random sequences than for location-random sequences in the identity-related task, and in contrast, responses were more delayed for location-random sequences than for identity-random sequences in the location-related task. This suggested that spatiotemporal contextual cueing effects were different, depending on the task. Unlike in Experiments 1–3, in Experiment 4, we did not find any differences between the last epoch of the learning phase and the test phase. This could be due to the design of Experiment 4, in which two types of sequences were mixed in the test phase. In the test phases of Experiments 1–3, participants only observed either identity- or location-random sequences, whereas in Experiment 4, they observed both sequences. Therefore, it is possible that responses were partly facilitated by sequences that preserved task-relevant regularity, and this facilitation might have reduced the response delay for sequences in which task-relevant regularity was removed. There was also a possibility that response was not delayed because participants made quick responses by sacrificing accuracy (i.e., speed-accuracy trade-off). However, we did not observe the accuracy differences between the test phase and the last epoch of learning phase, or between the conditions. Although we did not find response delays resulting from removing task-relevant regularity, responses for task-relevant and task-irrelevant regularity were different across tasks, and, therefore, the results of Experiment 4 suggested that task mediated spatiotemporal contextual cueing.
General discussion
The current research was designed to investigate whether the nature of a task determines the type of multidimensional regularity that is prioritized in contextual cueing. To investigate this issue, we developed a spatiotemporal contextual cueing paradigm, and tested whether task-relevant regularities contributed to contextual cueing effects more than did task-irrelevant regularities, or whether both task-relevant and task-irrelevant regularities contributed equally to contextual cueing. Our results indicated that, when object identities were relevant to a task during the initial exposure to a sequence containing both location and identity regularities, participants were impaired in detecting object identities for identity-random sequences, as compared to location-random sequences. Similarly, when object location was task-relevant, reaction times increased more for location-random sequences than for identity-random sequences. Even if both location and object identity were available for predicting the target during the learning phase, task-relevant regularity facilitated performance more than did task-irrelevant regularity.
Thus, our hypothesis—that task-relevant regularities are prioritized in spatiotemporal contextual cueing— was clearly supported, but the magnitudes of contextual cueing effects were not consistent across the experiments. In Experiments 1–3, when the task-relevant regularities were randomized, reaction times became significantly slower in the test phase than those in the last epoch of learning phase (i.e., contextual cueing effect). However, in Experiment 4, we failed to show a significant difference between the test phase and the last epoch of the learning phase. These inconsistent results can be explained by several factors. One possible factor is speed-accuracy trade-off. We first conjectured that contextual cueing, the response delay in the test phase, was not obtained because participants made quick responses by sacrificing accuracy. However, since there were no accuracy differences, we ruled out this possibility. Another possible factor is different learning rates across experiments. By fitting power functions to the data (see Chun & Jiang, 2003), we found that the learning rates, represented as an exponent of the power function, were smaller in Experiments 3 and 4 than in Experiments 1 and 2 (the functions were Experiment 1: RT = 720 + 139 N–0.67, Experiment 2: RT = 727 + 153 N–0.64, Experiment 3: RT = 1 + 952 N–0.10, identity-related task in Experiment 4: RT = 0 + 836 N–0.07, and location-related task in Experiment 4: RT = 0 + 886 N–0.06). Therefore, it is possible that acquisition of the task-relevant regularities did not complete during the learning phase in Experiments 3 and 4. If learning did not complete, when the task-relevant regularities were preserved in the test phase, response to the task-relevant regularity would be facilitated. Learning rates can be different depending on the task demands (identity-related or location-related) and on participants’ motivations. Considering the fact that most studies in contextual cueing have employed more than 20 repetitions (e.g., 30 times in Chun & Jiang, 1998; 25 times in Endo & Takeda, 2004), perhaps 18 repetitions may not be enough to complete learning in the current experimental setting. Yet, the learning rate cannot fully explain the inconclusive results; response was delayed in Experiment 3, but was not delayed in Experiment 4, whereas both Experiments 3 and 4 showed smaller learning rates than the other experiments. Probably the difference in experimental design between Experiments 3 and 4 can account for the inconsistency between these experiments. Participants observed sequences with only task-relevant regularities randomized in the test phases of Experiments 1-3, while they also observed sequences with task-relevant regularities in Experiment 4. This “mixed design” of the test phase in Experiment 4 might reduce the response delay in trials with task-irrelevant regularities, due to sequential influences from previous trials with task-relevant regularities. It is well known that the performance in the current trial influences the following trial (e.g., Gratton effects, Gratton et al., 1992) Moreover, compared with a block with homogeneous trials, a block with different types of trials tends to increase response variability, leading to a weaker effect size. Together, the combination of differential learning rates and experimental design can account for the lack of contextual cueing effects in Experiment 4. Overall, our findings are consistent with respect to the fact that task-relevant regularity has an advantage over task-irrelevant regularity, thus the weakness in our results is not fatal to our goal.
In the recognition test, participants could not explicitly recognize task-relevant regularities that they used as a contextual cue during the learning phase. Moreover, participants could not discriminate target identities within invariant sequences in the identity-related task (Experiments 1 and 2), and also they could not discriminate target locations in the location-related task (Experiments 3). These results suggest that task-relevant regularities were learned as contextual cues but in an implicit manner.
The results of the current study were consistent with previous findings indicating that, in sequence learning, task-relevant information is learned selectively. Jiménez and Méndez (1999) showed that selective attention to object shapes was necessary for learning the relationship between the current object shape and the next object location in a sequence. Another study by Meier, Weiermann, and Cock (2012) has also shown that task-relevant information is processed preferentially in sequence learning, although this finding is based on the null result, indicating that the response when both task-relevant and task-irrelevant information changed was not different from the response when only task-relevant information changed. The current study clearly demonstrated differences in interactions between task-relevant and task-irrelevant information and memory-guided attention, by using a spatiotemporal contextual cueing paradigm. It is possible that the mechanism of contextual cueing is similar to implicit sequence learning, because both these types of learning rely on utilizing learned regularities in predicting upcoming events.
One important implication of the current study concerns how individuals use redundant regularities to predict upcoming events. When an object has both task-relevant and task-irrelevant regularities, attention might be directed to the regularity that is related to ongoing activity, and therefore task-relevant regularities might be preferentially utilized to anticipate the next event. As a result, humans might give more weight to task-relevant regularities, because memory resources are limited, rather than basing judgements equally on all types of regularities.
The results of the current study, however, do not negate the possibility that both task-relevant and task-irrelevant regularities are learned during exposure to all type of tasks, because the contextual cueing phenomenon reflects memory-guided attention, rather than implicit learning itself. Indeed, Jiang and Leung (2005) demonstrated that contextual cueing occurs only for the attended regularity, although implicit learning itself occurs for both attended and unattended regularities. In their study, participants were presented with black and white colored objects, and were asked to search for a target colored either black or white. Under this manipulation, the target color was attended, whereas the other color was ignored. Results showed that reaction times decreased only when attended colored objects were presented repeatedly, and not when objects in the ignored color were repeatedly presented, suggesting that contextual cueing preferentially occurs for the attended objects. In a subsequent test, they switched object colors, such that previously attended objects were ignored, and previously ignored objects were now attended. Results indicated that previously ignored and now attended objects facilitated performance, whereas previously attended and now ignored context no longer affected reaction times. These findings suggest that expression of implicit learning depends on attending to the context, whereas the implicit learning of the context itself is independent of attention. We were interested in aspects of multidimensional regularities that guide visual attention, and, therefore, we focused on the expression of implicit learning, rather than implicit learning itself. Our results indicated that task-relevant information is prioritized in the expression of implicit learning, which is indexed by spatiotemporal contextual cueing effects. Further studies are needed to examine whether task-irrelevant information is learned, even though such information is not used as target cues, or whether implicit learning does not occur for task-irrelevant information.
We demonstrated that task-relevant regularities are related more closely to spatiotemporal contextual cueing. The remaining question is whether this finding can be generalized to spatial contextual cueing in visual searches. Most studies of contextual cueing have instructed participants to search for a target having a certain identity, such as a target “T” among distractors “L,” and have demonstrated location learning. Moreover, location was the only information learned during visual search in a study that asked participants to find an object with closed contours among outlined objects (Endo & Takeda, 2004). One possible explanation of these findings is that participants attended to location, because global layout information was obtained in the initial stage of the visual search (Treisman & Gormican, 1988). Indeed, we did not find a location dominance when images were presented sequentially. Another possible explanation of these findings is that location information is more salient during visual search than other features (Jiang & Song, 2005). Jiang and Song (2005) suggested that learning could be identity contingent when identity is salient enough even in visual search. Thus, bottom-up information such as saliency might mediate attentional weight in contextual cueing, and under situations in which identity is as salient as location, top-down attention might act as a filter that determines whether identity, or location regularity is prioritized even in visual search. Therefore, if we successfully manipulate the saliency of location, the task might determine which regularities guide our visual attention more strongly in spatial contextual cueing. Another method to generalize our findings to contextual cueing in visual search is by using multiple regularities other than location regularity, such as colors and shapes, as well as categories and subcategories of colors and shapes, or facial identities and facial expressions.
It is possible that task demands modulate not only contextual cueing, but also other types of statistical learning. Moreover, additional evidence is needed to conclude that the task modulates statistical learning in a more general sense. For example, it is known that passive exposure to colored object sequences induces object-based statistical learning that binds colors and shape (Turk-Browne et al., 2008). Although the task was not manipulated in the above study, it is possible that task-relevant information would be preferentially learned in statistical learning under similar experimental settings. The findings of this study might be limited by the experimental setting using location and object identity, which are typical regularities used in contextual cueing. Nevertheless, the current study did indicate that the task determines information within an object, which is implicitly learned, at least under certain conditions.
In summary, the current study demonstrated that spatiotemporal contextual cueing occurs preferentially for task-relevant regularities, even when redundant multiple regularities are available. It is suggested that further understanding of interactions between our behavioral goals and implicit learning is critically important, because human behavior is shaped by identifying various useful regularities through attentive processing of visual scenes.
References
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436.
Chun, M. M. (2000). Contextual cueing of visual attention. Trends in Cognitive Science, 4, 170–178. doi:10.1016/S1364-6613(00)01476-5
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36, 28–71. doi:10.1006/cogp.1998.0681
Chun, M. M., & Jiang, Y. (1999). Top-down attentional guidance based on implicit learning of visual covariation. Psychological Science, 10, 360–365. doi:10.1111/1467-9280.00168
Chun, M. M., & Jiang, Y. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 224–234. doi:10.1037/0278-7393.29.2.224
Chun, M. M., & Turk-Browne, N. B. (2008). Associative learning mechanism in vision. In S. J. Luck & A. Hollingworth (Eds.), Visual memory (pp. 209–245). Oxford: Oxford University Press.
Endo, N., & Takeda, Y. (2004). Selective learning of spatial configuration and object identity in visual search. Perception & Psychophysics, 66, 293–302. doi:10.3758/BF03194880
Goujon, A., Didierjean, A., & Marmèche, E. (2009). Semantic contextual cuing and visual attention. Journal of Experimental Psychology: Human Perception and Performance, 35, 50–71. doi:10.1037/0096-1523.35.1.50
Gratton, G., Coles, M. G. H., & Donchin, E. (1992). Optimizing the use of information: Strategic control of activation and responses. Journal of Experimental Psychology: General, 121, 480–506. doi:10.1037/0096-3445.121.4.480
Hoffmann, J., & Koch, I. (1997). Stimulus-response compatibility and sequential learning in the serial reaction time task. Psychological Research, 60, 87–97. doi:10.1007/BF00419682
Jiang, Y., & Chun, M. M. (2001). Selective attention modulates implicit learning. Quarterly Journal of Experimental Psychology, 54A, 1105–1124. doi:10.1080/713756001
Jiang, Y., & Leung, A. W. (2005). Implicit learning of ignored visual context. Psychonomic Bulletin & Review, 12, 100–106. doi:10.1167/4.8.188
Jiang, Y., & Song, J.-H. (2005). Hyperspecificity in visual implicit learning: Learning of spatial layout is contingent on item identity. Journal of Experimental Psychology: Human Perception & Performance, 31, 1439–1448. doi:10.1037/0096-1523.31.6.1439
Jiang, Y., & Wagner, L. C. (2004). What is learned in spatial contextual cuing—configuration or individual locations? Perception & Psychophysics, 66, 454–463.
Jiménez, L., & Méndez, C. (1999). Which attention is needed for implicit sequence learning? Journal of Experimental Psychology: Learning, Memory, and Cognition, 25, 236–259. doi:10.1037//0278-7393.25.1.236
Mayberry, C. R., Livesey, E. J., & Dux, P. E. (2010). Rapid learning of rapid temporal contexts. Psychonomic Bulletin & Review, 17, 417–420. doi:10.3758/PBR.17.3.417
Meier, B., Weiermann, B., & Cock, J. (2012). Only correlated sequences that are actively processed contribute to implicit sequence learning. Acta Psychologica, 141, 86–95. doi:10.1016/j.actpsy.2012.06.009
Nissen, M. J., & Bullemer, P. (1987). Attentional requirements of learning: Evidence from performance measures. Cognitive Psychology, 19, 1–32. doi:10.1016/0010-0285(87)90002-8
Olson, I. R., & Chun, M. M. (2001). Temporal contextual cuing of visual attention. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27, 1299–1313. doi:10.1037/0278-7393.27.5.1299
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Treisman, A., & Gormican, S. (1988). Feature analysis in early vision: Evidence from search asymmetries. Psychological Review, 95, 15–48. doi:10.1037/0033-295X.95.1.15
Turk-Browne, N. B., Isola, P. J., Scholl, B. J., & Treat, T. A. (2008). Multidimensional visual statistical learning. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34, 399–407. doi:10.1037/0278-7393.34.2.399
Turk-Browne, N. B., Jungé, J. A., & Scholl, B. J. (2005). The automaticity of visual statistical learning. Journal of Experimental Psychology: General, 134, 552–564. doi:10.1037/0096-3445.134.4.552
van Asselen, M. V., Sampaio, J., Pina, A., & Castelo-Branco, M. (2011). Object based implicit contextual learning: A study of eye movements. Attention, Perception, & Psychophysics, 73, 297–302. doi:10.3758/s13414-010-0047-9
Acknowledgments
This research was supported by the Japan Society for the Promotion of Science (#21300103, #24240041, #13 J00414). For helpful conversation and comments on drafts of the article, we thank Takemasa Yokoyama and Judith Fan. We also thank Faith Konigbagbe for helpful English editing.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Higuchi, Y., Ueda, Y., Ogawa, H. et al. Task-relevant information is prioritized in spatiotemporal contextual cueing. Atten Percept Psychophys 78, 2397–2410 (2016). https://doi.org/10.3758/s13414-016-1198-0
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1198-0