
Abstract
Background
Ignoring treatments in prognostic model development or validation can affect the accuracy and transportability of models. We aim to quantify the extent to which the effects of treatment have been addressed in existing prognostic model research and provide recommendations for the handling and reporting of treatment use in future studies.
Methods
We first describe how and when the use of treatments by individuals in a prognostic study can influence the development or validation of a prognostic model. We subsequently conducted a systematic review of the handling and reporting of treatment use in prognostic model studies in cardiovascular medicine. Data on treatment use (e.g. medications, surgeries, lifestyle interventions), the timing of their use, and the handling of such treatment use in the analyses were extracted and summarised.
Results
Three hundred two articles were included in the review. Treatment use was not mentioned in 91 (30%) articles. One hundred forty-six (48%) reported specific information about treatment use in their studies; 78 (26%) provided information about multiple treatments. Three articles (1%) reported changes in medication use (“treatment drop-in”) during follow-up. Seventy-nine articles (26%) excluded treated individuals from their analysis, 80 articles (26%) modelled treatment as an outcome, and of the 155 articles that developed a model, 86 (55%) modelled treatment use, almost exclusively at baseline, as a predictor.
Conclusions
The use of treatments has been partly considered by the majority of CVD prognostic model studies. Detailed accounts including, for example, information on treatment drop-in were rare. Where relevant, the use of treatments should be considered in the analysis of prognostic model studies, particularly when a prognostic model is designed to guide the use of certain treatments and these treatments have been used by the study participants. Future prognostic model studies should clearly report the use of treatments by study participants and consider the potential impact of treatment use on the study findings.
Similar content being viewed by others

Background
An important part of prognostic research is the development and validation of prognostic models or risk scores. These models can be used to make individualised predictions of a person’s absolute risk of developing a specific health outcome [1, 2] and can, for example, be used to inform different aspects of clinical decision-making. A notable example of this is in cardiovascular medicine: if a patient’s risk of a cardiovascular event is predicted to be above a specific probability threshold, lifestyle changes are recommended, with or without initiation of preventative medication [3,4,5].
Concerns have been raised that the use of treatments, such as pharmacological therapy or diet and lifestyle-related interventions, may have an unwanted impact when patient data (e.g. from a cohort or registry) is used to develop or validate a prognostic model [6,7,8]. In order to develop or validate prognostic models that predict an individual’s probability of developing an outcome in the absence of a certain treatment (i.e. their untreated health course), one should ideally include people who have not received that treatment before or during follow-up [1, 6]. In practice, however, such prognostic models are often derived from or validated in data sets where a proportion of the individuals has received that specific treatment. If, for example, treatments were administered in a study according to individuals’ predicted risks (either implicitly or explicitly), a model developed using this data will likely underestimate the risk of the predicted outcome in the absence of treatment and could thus lead to under-treatment when such a model is used in future individuals [8, 9].
In this manuscript, we aim to provide insight into the problems that arise when treatment use is ignored when developing or validating a prognostic model. First, we elaborate on how and when treatment use could negatively impact prognostic modelling. Following this, we provide evidence of the scale of this issue in published studies by means of a systematic literature review of the reporting and handling of treatment use in cardiovascular prognostic model research. We conclude with suggestions for the handling and reporting of treatment use in prognostic model research.
Methods
What do we mean by “treatment” and when is it a problem?
Herein, we use “treatment” to refer to any intervention, medical (e.g. medication, surgery, therapy) or non-medical (e.g. quit smoking or do more exercise), undertaken by an individual that lowers their risk of a certain outcome. We also include in this definition modifications that an individual makes to their behaviour or lifestyle that reduce their risk of a specific outcome. We propose two categories of treatment: “guided” and “background”. The term “guided treatments” refers to treatments that one intends to guide or direct by means of the prognostic model being developed or validated. For example, CVD prediction models are used to guide the prescription of lipid-lowering medication, as well as direct targeted advice about lifestyle changes to high-risk individuals. “Background treatments” refer to any other treatment that an individual receives during a prognostic study. This could, for example, include treatments that are part of routine medical care or changes an individual makes to their lifestyle. Figure 1 outlines the different stages where treatments may be used in a prognostic study.

The timing of treatment use in a prognostic study
Guided treatments
Prognostic models are often used to guide or direct the initiation of certain treatments or interventions. In this case, a prognostic model should estimate the risk of developing a certain outcome if individuals were to remain untreated with this particular treatment (so-called untreated risk prediction) [1, 8, 10]. If this particular, “guided” treatment is given to study participants after the predictors are measured but before the ascertainment of the outcome (henceforth, we refer to this as “treatment drop-in”, see Fig. 1), the chance of treated individuals developing the outcome of interest will be decreased. Crucially, the outcomes measured in the study will no longer represent the untreated outcomes that the model is designed to predict. It follows that models developed using data from individuals who received guided treatments will provide biased underestimates of (untreated) risks in future individuals, if treatment use is ignored [8]. In validation studies, models will incorrectly appear to overestimate risk if applied in individuals that receive the specific guided treatment [8, 11].
Background treatments
Participants in a prognostic study commonly receive risk-lowering treatments during follow-up as a part of routine care. As in the case of guided treatments, if these “background” treatments are effective in lowering the risk of the outcome under prediction, we can expect a reduction in the probability of treated individuals developing the outcome of interest. However, unlike with guided treatments, the outcomes measured in the study still reflect the outcome under prediction. Background treatments should instead be considered to be a part of the case-mix of participants in study. Provided the pattern of treatment use, and the effect of the treatment on the outcome risk, is consistent across populations, differences between model performance in the development cohort new populations should not be due to treatment use. However, background treatment use and effectiveness may vary between settings. For example, a model developed in a setting where everyone received some standard (effective) treatment during follow-up may not be transportable to a different population where that intervention is not available, or a less effective alternative treatment is routinely used. In this case, the predicted probabilities provided by the model in this new population will be too low.
Examples
We illustrate the distinction between different types of treatment with two hypothetical examples, from two different clinical domains.
Example 1:
A model is developed to predict six-month mortality risk in patients with end-stage renal disease (ERD) in the absence of a kidney transplantation. The model will be used to help decide which future patients will receive a kidney transplant. In the development cohort, all patients began risk-lowering haemodialysis after enrolment as a part of routine care, and a subset of patients additionally received a kidney transplant.
Example 2:
A validation study is conducted to evaluate an existing prognostic model for the prediction of five-year CVD risk in the general population. The model is used in practice to decide whether lipid-lowering drugs (statins) will be prescribed. Several individuals in the study were prescribed risk-lowering statins and were recommended to modify their lifestyle based on their predicted CVD risk. In addition, a number of patients took other risk-lowering medications (e.g. aspirin) as a part of routine care.
In both examples, some study participants initiated one or more treatments or interventions after predictor measurements were taken. In example 1, we can consider haemodialysis to be a “background” treatment, as described above, which requires no further consideration for model development. However, the model may need to be recalibrated for settings where haemodialysis is not a part of usual care or where a substantial proportion of patients receive some other type of (e.g. peritoneal) dialysis. In contrast, kidney transplant, a treatment guided by predictions made by the model, could bias model development. The outcomes measured in individuals who received a transplant during follow-up do not reflect our outcome of interest: six-month mortality without kidney transplantation. Not taking this into account in model development will lead to a prediction model that actually underestimates the risk of mortality without transplantation in future patients with ERD.
In example 2, the use of medications such as aspirin can be considered as background treatment that will not affect the validity of the validation study. It mayhowever explain model miscalibration in the validation cohort if the pattern of use or the effectiveness of these treatments is different from those of the development cohort. With regard to lipid-lowering medication, ideally one would validate the model in individuals who have not received lipid-lowering medication during follow-up. As high-risk individuals received statins in the study, their risk of a CVD event in the study is lower than it would have been, had they remained untreated. In this example, lifestyle changes merit separate attention. If the model is used in practice, as with statins, to help target lifestyle advice to high-risk individuals, this treatment should not be ignored in the validation study. However, many individuals may have modified their lifestyles independent of any targeted advice, in which case, lifestyle changes could be viewed as a background treatment.
To summarise, when treatments are initiated in participants after the moment of prognostication (see Fig. 1), the risk-lowering effects of these treatments may impact on model development or validation. We propose that the intended use and this kind of risk predictions a model aims to provide (i.e. prognosis with or without treatment), as well as the types of treatments (guided or background) used in a data set or study, are key factors that determine how treatments may impact on prognostic model development or validation. For further details on the challenges of treatment use and how to account for them in prognostic model development and validation, see [8] and [11], respectively, and further guidance can be found in Table 1 (see below).
A review of treatment use in published prognostic model studies
To provide insight into the extent to which treatment use has been addressed in the development and validation of prognostic models, we used a previously conducted systematic review of the reporting and analysis of prognostic models for predicting the risk of the future occurrence of CVD outcomes in the general population [12]. A completed PRISMA checklist for this review is found in Additional file 1.
Data sources, search, and study selection
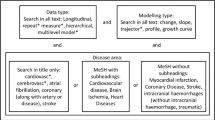
In brief, a search was performed on 1 June 2013 in MEDLINE and EMBASE to identify original research articles reporting the development (derivation of a new model) or external validation (evaluation of an existing model in a new population) of a prognostic model and “incremental value studies”, in which the additional value of a certain predictor or (bio)marker was assessed on top of either an existing risk score or a model consisting of a core set of conventional predictors (e.g. age, sex, smoking, systolic blood pressure, cholesterol, diabetes).
Titles and abstracts were first screened for eligibility, and subsequent full-text screening was conducted. Publications were considered for inclusion if they were original articles that reported cardiovascular risk prognostic modelling in a general population setting. Full details of the search strategy and in-/exclusion criteria can be found in the original review [12].
Data extraction
Directed by the CHARMS checklist [13], a list of key items (Additional file 2) for extraction was derived for the current review by one author (RP) and updated after group consideration (RP, LMP, RHHG, JAAGD, KGMM). As the aim of this review is to provide an overview of research practice and reporting, study quality and risk of bias assessment was not conducted. Independent data extraction was piloted among three authors (RP, JAAGD, RHHG). The remaining data extraction was conducted by one author (RP), and any queries were discussed primarily with one author (JAAGD), and then two other authors (LMP, RHHG) until a consensus was reached.
General study characteristics were extracted for each article, including the study design used to collect data, the start and end dates of participant data collection and the prediction horizons of reported models. Relevant treatments or interventions for cardiovascular disease prevention were defined prior to data extraction and broadly divided into three classes: pharmacological treatments (notably antihypertensive, lipid-lowering and antithrombotic medication), cardiovascular surgical interventions (e.g. coronary revascularization, carotid endarterectomy), and lifestyle interventions. While the term “lifestyle interventions” can refer to changes in a diverse range of modifiable risk factors, we defined this in our review as the reporting of active modifications to exercise, nutritional or smoking habits, as a part of a programme or following physician recommendations. All reported information on treatment use and how it was considered in the analysis was extracted (for full details, see Additional file 2).
Results of the literature review
General characteristics of included articles
The search of the original systematic review identified 9965 unique records, of which 1388 were found to be relevant following title and abstract screening, as previously reported [12]. After full-text screening for eligibility, 302 articles were included for review (Additional file 3). A summary of the article inclusion process is presented in Fig. 2.

A flow diagram of article inclusion and exclusion
The final set of articles includes publications from 102 different journals. Publication dates ranged from 1967 to 2013 and 157 articles (52%) were published from 2009 onwards. Participant data collection ranged from as early as 1948 until 2011. Further details are presented in Table 2.
Reporting and handling of treatment use
Overall, nearly one-third (91 articles, 30%) of the 302 included articles did not report any information about relevant preventative or therapeutic treatments. The reporting of treatments in prognostic modelling articles has increased over time, as illustrated in Fig. 3. Just over half of the articles published up until 2008 (81 articles, 56%) reported information about treatment, whereas from 2009 to June 2013, this increased (130 articles, 83%). Summaries of the reporting and handling of information about treatment use are presented in Tables 3 and 4, respectively.

Reporting of treatment in CVD prognostic modelling studies over time. Articles were classified as having reported information on treatment if the use of at least one potentially risk-lowering treatment in the study was reported, or if the effect of a treatment on the study findings was discussed. (*) Articles were included up to June 2013; this column only represents treatment reporting during the first half of 2013
Development studies
Of the 124 articles that reported the development of a new prognostic model, baseline information on treatment use was reported in 43 articles (35%). Six articles (5%) reported treatment use during follow-up, two (2%) reported changes in medication use during follow-up, four (3%) described incident surgical procedures (cardiovascular surgeries occurring after the study baseline) and in 11 articles (9%), the timing of treatments was unclear. Two articles reported that information on treatment was not available. Treatment use was most often accounted for in analyses by modelling treatment as a predictor (54 articles, 44%). Twenty articles (15%) excluded treated individuals from the analysis. Changes in treatment use during follow-up were not modelled.
Incremental value studies
In articles that reported the evaluation of the incremental value of a predictor over either a core set of predictors or an existing model, baseline information about treatment use was reported for 74 articles (55%). Changes in medication use were reported in three articles, and surgical procedures that occurred during follow-up were reported in 15 articles (11%). Five articles (4%) reported that information on treatment use was not available. Where incremental value was assessed over a set of core predictors, treatment use was accounted for most often by including treatment as one of the core predictors (48 articles, 59%). Fifty-three articles (39%) excluded treated individuals from analyses. Surgical outcomes were frequently modelled as a part of a composite endpoint (58 articles, 43%).
Validation studies
In studies that externally validated (evaluated) an existing CVD prognostic model, where reported, most information about treatment use was measured at baseline only (55 articles, 37%). No articles reported changes in medication use during follow-up. Four articles reported a lack of available data on treatment use. In addition, five articles (3%) presented information about treatment use in the population in which the model was originally developed, of which two reported differences of more than 10% in the proportion of baseline treatment users between the development study and the validation study. Another five articles (3%) commented on how differences between treatment use in the development and validation populations could have contributed to poor performance of the model upon validation. Medication use was accounted for exclusively by restricting analyses to untreated patients (38 articles, 26%). In addition, 35 articles (24%) accounted for incident surgical procedures by including surgery within the composite endpoint of their study.
Discussion
Findings from the literature review
The use of treatments in prognostic modelling studies has not been widely addressed in cardiovascular preventative medicine. While reporting has improved over the last decade, and the majority of cardiovascular prognostic modelling studies (211 articles, 70%) made at least one reference to treatment use, we found great heterogeneity in the kinds of information and level of detail that have been reported. Only 52% of studies that developed a model reported specific information about the use of risk-lowering treatments, similar to findings from a previous review in the field of cardiovascular medicine [6]. We also confirm that information beyond baseline antihypertensive medication use, information about other treatments, and changes in treatment use during follow-up are frequently not reported. In addition, we found the reporting or discussion of any differences between treatment use in validation studies and their respective development studies was poorer than that observed in an earlier review of external model validation studies, which found that 40% (31/78) of articles under study discussed differences in case-mix [14].
There are several possible explanations for the findings of the review. First, several articles used data collected during the pre-statin era [15], which may explain why the lipid-lowering medications were scarcely reported. However, effective medications such as aspirin and blood pressure-lowering medication have long been available, along with lifestyle interventions and some surgical procedures, which are also relevant to these studies. In addition, many articles reported a low prevalence of statin use at study baseline; in those situations, it may have been assumed that treatment would not have greatly influenced the predicted probabilities. However, treatment use can greatly change over time, as shown by one study validating the AHA/ACC Pooled Cohort Equations [16], which reported increases in antihypertensive medication use and statin use from 59.9 to 82.4% and 9.7 to 63.7%, respectively, over a 10-year follow-up period (1998–2007) [17]. Second, while only nine articles reported that data on treatments were not available in their studies, it might be that more studies were unable to obtain such data, especially follow-up information, as this may be more costly or difficult to collect. Finally, in some studies, treatments may not have been considered by the authors to be relevant to the prognostic question being addressed. One article did not model treatment effects on the grounds that “The prediction of initial CHD [coronary heart disease] events in a free-living population not on medication is emphasized” [18], i.e. the model was designed for use in individuals who are not already on treatment. However, as already discussed, this rationale does not take into account treatment drop-in that may have occurred during the follow-up period of the study.
The review is, to our knowledge, the first to give an overview of how treatment information has been reported and handled in prognostic model research. While other studies have broadly addressed related methodological issues [14], or have focussed on a single aspect of CVD modelling, such as model development [6], we provide comprehensive coverage of CVD prediction model studies and support this with a conceptual framework describing when and how treatments can affect a prognostic study. However, there are limitations within this study.
First, as the findings presented in the review are based on articles identified through a previously conducted systematic review, we are limited to providing information up to June 2013; more recent trends in cardiovascular prognostic modelling are not presented. Three important developments in the past 4 years include the ACC/AHA Pooled Cohort equations [16], the Globorisk CVD assessment tool [19], and the Qrisk-3 calculator [20], each developed as tools for the prediction of CVD in the general population. Among these three currently implemented CVD risk estimators, there is no clear consensus over how treatments should be taken into account in prognostic models for CVD; treatment use at baseline is modelled differently in each of the prognostic models, and none of the studies accounted for the effects of treatment drop-in. Thus, questions have been raised regarding the validity of these models and their respective validation studies [9, 21], and treatment use remains an issue at present. Furthermore, owing to the large number of included articles (> 100) published from 2009 onwards, our study provides a more up-to-date overview than previous findings [6]. As the CVD domain is a highly active field in prognostic model research, the presented results are likely optimistic for other clinical domains; we speculate that in other clinical domains, treatment use has received less attention. Second, this review focusses on a set of preventative and therapeutic treatments that modify cardiovascular risk, but may not describe all interventions that affect CVD risk. However, a detailed description is presented for the major classes of cardiovascular preventative treatments, particularly those recommended by medical guidelines. Third, as this is a review of reporting, we rely on what the authors decided to mention within the article and we cannot be entirely sure how treatment information has been collected in studies and the extent to which it has been considered by researchers. For example, limited information could be extracted about changes in lifestyle that may have affected prognostic modelling, as this was almost never explicitly reported.
Suggestions for dealing with and reporting treatment use in prognostic model studies
Treatment use can potentially have a great impact on the reported accuracy of developed and validated prognostic models. Our review has identified that information about the use of treatments is often reported with insufficient detail to allow other researchers to evaluate the effect it may have had on the reported study findings, notably the expected predictive accuracy model in future populations. The TRIPOD statement [22, 23] has already made recommendations for the reporting of information on treatment use in prognostic model studies (Item 5c), but these can be strengthened on this aspect. We provide additional recommendations for the design, analysis, and reporting of prognostic model studies, to help improve the way that treatment use, in particular during follow-up, is addressed (Table 4).
Starting with the design of future prognostic studies, we suggest that information should be collected on both treatment use at the study baseline and during follow-up, to record any changes in treatment use over time that may have impacted on the prognosis of study participants. Existing databases should contain information with enough detail to allow researchers to account for treatment use in their analyses, where necessary (see “What do we mean by “treatment” and when is it a problem?” section). We provide initial recommendations on how different kinds of treatments can be taken into account when developing or validating a prediction model. This advice is based on a limited number of simulation studies, and in the absence of further simulations and empirical evidence, researchers must judge which approach will be most valid for their research. We do not provide specific guidance on how to account for complex changes in treatment use in a prognostic study, as more research is needed into the suitability of existing statistical methods. Finally, Table 1 provides, in accordance with the TRIPOD guidelines [23], recommendations for the minimum amount of detail that should be presented in reports of prognostic model studies. We encourage researchers to discuss the potential impact that treatment use in their study could have had on their results, including the expected accuracy of newly developed models.
Conclusion
In conclusion, treatment use, if ignored, can raise concerns for the transportability and validity of prognostic models. Our review shows that while the importance of treatments for prognostic prediction has been recognised in many studies, reporting rarely covers all relevant treatments, and changes in treatment have hardly been acknowledged. Furthermore, we found no clear consensus within the published literature over how treatments should be considered in the analyses of prognostic studies. Efforts should be made to collect and report detailed information about treatment use, to allow future researchers and end users of prognostic models to more clearly identify any potential issues that treatment use may have introduced and to understand how a model should be validated and used in practice.
Abbreviations
- CHD:
-
Coronary heart disease
- CVD:
-
Cardiovascular disease
References
Hemingway H, Croft P, Perel P, Hayden JA, Abrams K, Timmis A, et al. Prognosis research strategy (PROGRESS) 1: a framework for researching clinical outcomes. BMJ. 2013;346:e5595.
Steyerberg EW, Moons KG, van der Windt DA, Hayden JA, Perel P, Schroter S, et al. Prognosis Research Strategy (PROGRESS) 3: prognostic model research. PLoS Med. 2013;10(2):e1001381.
Stone NJ, Robinson JG, Lichtenstein AH, Bairey Merz CN, Blum CB, Eckel RH, et al. 2013 ACC/AHA guideline on the treatment of blood cholesterol to reduce atherosclerotic cardiovascular risk in adults: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. Circulation. 2014;129(25 Suppl 2):S1–45.
National Institute for Health and Care Excellence. Lipid modification: cardiovascular risk assessment and the modification of blood lipids for the primary and secondary prevention of cardiovascular disease. NICE Clinical Guideline 181. London. 2014.
Perk J, De Backer G, Gohlke H, Graham I, Reiner Z, Verschuren M, et al. European Guidelines on cardiovascular disease prevention in clinical practice (version 2012). The Fifth Joint Task Force of the European Society of Cardiology and Other Societies on cardiovascular disease prevention in clinical practice (constituted by representatives of nine societies and by invited experts). Eur Heart J. 2012;33(13):1635–701.
Liew SM, Doust J, Glasziou P. Cardiovascular risk scores do not account for the effect of treatment: a review. Heart. 2011;97(9):689–97.
Liew SM, Glasziou P. Risk prediction continue to ignore treatment effects. Br Med J Rapid Responses; 2010;340:c2442. http://www.bmj.com/rapid-response/2011/11/02/risk-prediction-continue-ignore-treatment-effects.
Groenwold RH, Moons KG, Pajouheshnia R, Altman DG, Collins GS, Debray TP, et al. Explicit inclusion of treatment in prognostic modelling was recommended in observational and randomised settings. J Clin Epidemiol. 2016;78:90–100.
Peek N, Sperrin M, Mamas M, Van Staa T, Buchan I. Hari Seldon, QRISK3, and the prediction paradox. BMJ. 2017;357:j2099. http://www.bmj.com/content/357/bmj.j2099/rr-0.
Grobbee DE, Hoes AW. Clinical epidemiology. 2nd ed: Jones & Bartlett Publishers; London 2014.
Pajouheshnia R, Peelen LM, Moons KGM, Reitsma JB, Groenwold RHH. Accounting for treatment use when validating a prognostic model: a simulation study. BMC Med Res Methodol. 2017;17(1):103.
Damen JA, Hooft L, Schuit E, Debray TP, Collins GS, Tzoulaki I, et al. Prediction models for cardiovascular disease risk in the general population: systematic review. BMJ. 2016;353:i2416.
Moons KG, de Groot JA, Bouwmeester W, Vergouwe Y, Mallett S, Altman DG, et al. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: the CHARMS checklist. PLoS Med. 2014;11(10):e1001744.
Collins GS, de Groot JA, Dutton S, Omar O, Shanyinde M, Tajar A, et al. External validation of multivariable prediction models: a systematic review of methodological conduct and reporting. BMC Med Res Methodol. 2014;14:40.
Tobert JA. Lovastatin and beyond: the history of the HMG-CoA reductase inhibitors. Nat Rev Drug Discov. 2003;2(7):517–26.
Goff DC Jr, Lloyd-Jones DM, Bennett G, Coady S, D'Agostino RB, Gibbons R, et al. 2013 ACC/AHA guideline on the assessment of cardiovascular risk: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. Circulation. 2014;129(25 Suppl 2):S49–73.
Chia YC, Lim HM, Ching SM. Validation of the pooled cohort risk score in an Asian population—a retrospective cohort study. BMC Cardiovasc Disord. 2014;14:163.
Wilson PW, D'Agostino RB, Levy D, Belanger AM, Silbershatz H, Kannel WB. Prediction of coronary heart disease using risk factor categories. Circulation. 1998;97(18):1837–47.
Hajifathalian K, Ueda P, Lu Y, Woodward M, Ahmadvand A, Aguilar-Salinas CA, et al. A novel risk score to predict cardiovascular disease risk in national populations (Globorisk): a pooled analysis of prospective cohorts and health examination surveys. Lancet Diabetes Endocrinol. 2015;3(5):339–55.
Hippisley-Cox J, Coupland C, Brindle P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ. 2017;357
Muntner P, Safford MM, Cushman M, Howard G. Comment on the reports of over-estimation of ASCVD risk using the 2013 AHA/ACC risk equation. Circulation. 2014;129(2):266–7.
Collins GS, Reitsma JB, Altman DG, Moons KG. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. BMJ. 2015;350:g7594.
Moons KG, Altman DG, Reitsma JB, Ioannidis JP, Macaskill P, Steyerberg EW, et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162(1):W1–W73.
Debray TP, Vergouwe Y, Koffijberg H, Nieboer D, Steyerberg EW, Moons KG. A new framework to enhance the interpretation of external validation studies of clinical prediction models. J Clin Epidemiol. 2015;68(3):279–89.
Riley RD, Ensor J, Snell KIE, Debray TPA, Altman DG, Moons KGM, et al. External validation of clinical prediction models using big datasets from e-health records or IPD meta-analysis: opportunities and challenges. BMJ. 2016;353
Vergouwe Y, Moons KG, Steyerberg EW. External validity of risk models: use of benchmark values to disentangle a case-mix effect from incorrect coefficients. Am J Epidemiol. 2010;172(8):971–80.
Acknowledgments
The authors would like to acknowledge the following people for their contribution to the identification and selection of articles for inclusion in the original systematic review on which this review is based: James Black, Gary Collins, Thomas Debray, Pauline Heus, Lotty Hooft, Camille Lassale, Ewoud Schuit, George Siontis, René Spijker, Ioanna Tzoulaki.
Funding
Rolf Groenwold receives funding from the Netherlands Organisation for Scientific Research (project 917.16.430). Karel G.M. Moons receives funding from the Netherlands Organisation for Scientific Research (project 9120.8004 and 918.10.615). The funding bodies had no role in the design, conduct, or decision to publish this study, and there are no conflicts of interest to declare.
Availability of data and materials
A table of the extracted information from the literature review is available within Additional file 4.
Author information
Authors and Affiliations
Contributions
All authors contributed to the design of the study. JAAGD provided the initial selection of articles for inclusion in the literature review. RP drafted the first versions of the data extraction form and manuscript. RP, JAAGD, and RHHG piloted the data extraction, and RP completed the data extraction. All authors were involved in the drafting of the data extraction form and manuscript and approved the final versions.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
PRISMA statement checklist. (DOC 62 kb)
Additional file 2:
List of items for data extraction. (DOCX 17 kb)
Additional file 3:
List of articles included in the literature review. (DOCX 58 kb)
Additional file 4:
Table of extracted information from the review. (CSV 209 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Pajouheshnia, R., Damen, J.A.A.G., Groenwold, R.H.H. et al. Treatment use in prognostic model research: a systematic review of cardiovascular prognostic studies. Diagn Progn Res 1, 15 (2017). https://doi.org/10.1186/s41512-017-0015-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s41512-017-0015-0