
Abstract
Generalizing distributions is an old practice and has ever been considered as precious as many other practical problems in statistics. It simply started with defining different mathematical functional forms, and then induction of location, scale or inequality parameters. The generalization through induction of shape parameter(s) started in 1997, and the last two decades were full of such practices. But to cope with the complex situations under series and parallel structures, the art of mixing discrete and continuous started in 1998. In this article, we present a survey on compounding univariate distributions, their extensions and classes. We review several available compound classes and propose some new ones. The recent trends in the construction of generalized and compounding classes are discussed, and the need for future works are addressed.
Similar content being viewed by others

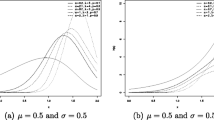
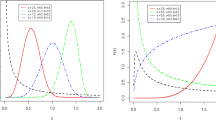
Introduction
The modern era on distribution theory stresses on problem-solving faced by the practitioners and applied researchers and proposes a variety of models so that lifetime data set can be better assessed and investigated in different fields. In other words, there is strong need to introduce useful models for better exploration of the real-life phenomenons. Nowadays, the trends and practices in defining probability models totally differ in comparison to the models suggested before 1997. One main objective for proposing, extending or generalizing (models or their classes) is to explain how the lifetime phenomenon arises in fields like physics, computer science, insurance, public health, medical, engineering, biology, industry, communications, life-testing and many others. For example, the well-known and fundamental distributions such as exponential, Rayleigh, Weibull and gamma are very limited in their characteristics and are unable to show wide flexibility. The number of shape parameters, closed-form expressions of the cumulative distribution function (cdf), forms of the quantile function (qf), density and failure rate shapes, skewness and kurtosis features, entropy measures, estimation of stress reliability \(R=\mathbb {P}(Y<X)\), structural properties, use of advanced mathematical functions and power series, which are available through computing platforms like Mathematica, Maple, Matlab, Python, Ox and R, variety of estimation methods, estimation of parameters in case of censored and uncensored situations, simulation results, coping with data sets having different shapes and goodness-of-fits are some well-established characteristics that a proposed lifetime model may possess.
For complex phenomenons in reliability studies, lifetime testing, human mortality studies, engineering modeling, electronic sciences and biological surveys, the failure rate behavior can be bathtub, upside-down bathtub and other shaped but not usually monotone increasing or decreasing. Thus, in order to cope with both monotonic and non-monotonic failure rate shapes, researchers have introduced several generalizations (or G-classes) which are very flexible to study needful properties of the model and its fitness.
In the last two decades, two main generalization approaches were adopted and practiced, and have also received increased attention.
1.1 First generalization approach (G-classes)
The first approach deals with the shape parameter(s) induction in parent (or baseline) distribution to explore tail properties and to improve goodness-of-fits. Some well-known generalized (or G-) classes are: Marshall-Olkin-G (Marshall and Olkin 1997), exponentiated-G (Gupta et al. 1998), beta-G (Eugene et al. 2002), Kumaraswamy-G (Cordeiro and de-Castro 2011), McDonald-G (Alexander et al. 2012), ZBgamma-G (Zografos and Balakrishnan 2009; Amini et al. 2014), RBgamma-G (Ristić and Balakrishanan 2012; Amini et al. 2014), odd-gamma-G (Torabi and Montazari 2012), Kummer-beta-G (Pescim et al. 2012), beta extended Weibull-G (Cordeiro et al. 2012b), odd exponentiated generalized-G (Cordeiro et al. 2013a), truncated exponential-G (Barreto-Souza and Simas 2013), logistic-G (Torabi and Montazari 2014), gamma extended Weibull-G (Nascimento et al. 2014), odd Weibull-G (Bourguignon et al. 2014a), exponentiated-half-logistic-G (Cordeiro et al. 2014a), Libby-Novick beta-G (Cordeiro et al. 2014b; Ristić et al. 2015), Lomax-G (Cordeiro et al. 2014d), Harris-G (Batsidis and Lemonte 2015; Pinho et al. 2015), modified beta-G (Nadarajah et al. 2014b), odd generalized-exponential-G (Tahir et al. 2015), Kumaraswamy odd log-logistic-G (Alizadeh et al. 2015b), beta odd log-logistic-G (Cordeiro et al. 2016), Kumaraswamy-Marshall-Olkin-G (Alizadeh et al. 2015c), beta-Marshall-Olkin-G (Alizadeh et al. 2015a), Weibull-G (Tahir et al. 2016b), exponentiated-Kumaraswamy-G (da-Silva et al. 2016), ZBgamma-odd-loglogistic-G (Cordeiro et al. 2015a) and Tukey’s g- and h-G (Jiménez et al. 2015). For more details on some well-established G-classes, the reader is referred to Tahir and Nadarajah (2015).
The mathematical properties of the Kumaraswamy-G family were studied by Nadarajah et al. (2012), Hussian (2013), and Cordeiro and Bager (2015). The failure rate and aging properties of the beta-G and ZBgamma-G models were addressed by Triantafyllou and Koutras (2014). The structural properties of the ZBgamma-G and RBgamma-G models were recently investigated by Nadarajah et al. (2015b), and Cordeiro and Bourguignon (2016).
The revolutionary idea in generalization begun with the work of Alzaatreh et al. (2013) who proposed transformed-transformer (T-X) (Weibull-X and gamma-X) family of distributions. This approach was further extended to the exponentiated T-X (Alzaghal et al. 2013), T-X{Y}-quantile based approach (Aljarrah et al. 2014), T-R{Y} (Alzaatreh et al. 2014), T-Weibull{Y} (Almheidat et al. 2015), T-gamma{Y} (Alzaatreh et al. 2016a), T-Cauchy{Y}(Alzaatreh et al. 2016b), Gumbel-X (Al-Aqtash 2013; Al-Aqtash et al. 2014) and logistic-X (Tahir et al. 2016).
After the wide-spread popularity of well-established exponentiated-G, Marshall-Olkin-G, beta-G, Kumaraswamy-G and McDonald-G classes, and T-X family, the transmuted-G class of distributions has received increased attention in the last decade. This class is based on the quadratic rank transmutation map (QRTM) pioneered by Shaw and Buckley (2009) and highlighted by Aryal and Tsokos (2009, 2011).
For any baseline distribution cdf G(x), the cdf of the transmuted-G class (for |η|≤1) is given by
where η is the transmuted (or shape) parameter. For η=0, the above equation reduces to the baseline distribution.
The general properties of the transmuted family were obtained by Bourguignon et al. (2016a) and Das (2015). The transmuted family was further extended as the exponentiated transmuted-G type 1 using the Lehmann alternative type 1 (LA1) class (due to Gupta et al. 1998) by Nofal et al. (2016) and Alizadeh et al. (2016a), the exponentiated transmuted-G type 2 using the Lehmann alternative type 2 (LA2) class (due to Gupta et al. 1998) by Merovci et al. (2016), and the transmuted exponentiated generalized-G by Yousof et al. (2015).
More than fifty transmuted distributions have been reported in the literature, which are complied in chronological order in Table 1; see also Section 8.4.
1.2 Second generalization approach (compounding)
The second approach deals with the compounding of discrete models, namely the geometric, Poisson, logarithmic, binomial, negative-binomial (NB), Conway-Maxwell-Poisson (COMP) and power-series with continuous lifetime models. The basic idea of introducing compound models or families is that a lifetime of a system with N (discrete random variable) components and the positive continuous random variable, say Y i (the lifetime of the ith component), can be denoted by the non-negative random variable Y= min(Y 1,…,Y N ) (the minimum of an unknown number of any continuous random variables) or Z= max(Y 1,…,Y N ) (the maximum of an unknown number of any continuous random variables), based on whether the components are in series or in parallel structure. Some useful references for the readers are Louzada et al. (2012a), Leahu et al. (2013) and Bidram and Alavi (2014).
The objectives of our article are three-fold: Firstly, we present an up-to-date account on the compounded distributions and their generalizations for the readers of modern distribution theory. Secondly, this survey will motivate the researchers to fill the gap and to furnish their work in remaining applied areas. Thirdly, this survey will also be helpful as a tutorial to the beginners of compound modeling art.
The rest of the article is organized as follows. In Section 2, two compound G-classes are reviewed to represent the distributions of the minimum and maximum of an unknown number of continuous random variables having the same parent lifetime distribution. In Section 3, fourteen existing and new compound classes for the minimum constructed from the zero-truncated geometric (ZTG), zero-truncated Poisson (ZTP), logarithmic (Ln), zero-truncated binomial (ZTBi) and zero-truncated negative-binomial (ZTNB) distributions are described. In Section 4, we obtain the dual models for the maximum corresponding to those models discussed in Section 3. Section 5 deals with several compounding models and their extensions, which can be derived under the construction of the minimum and maximum of random variables. Sections 7 and 8 deal with other or different types of compounded models. In Section 8, we present recent trends on compounding of distributions, their G-classes and mixing of compounded and transmuted distributions. The main purpose of Section 9 is to briefly review general inference procedure, crude rate survival models and their inference. The paper is concluded with some remarks in Section 10.
Construction of compound G-classes
Suppose that a system has N subsystems assumed to be independent and identically distributed (i.i.d.) at a given time, where the lifetime of the ith subsystem is denoted by Y i , and that each subsystem is made of α parallel units, so that the system will fail if all the subsystems fail. We note that for a parallel system, the system fails only if all the subsystems fail, but for a series system, the failure of any subsystem will destroy the whole system. Further, suppose that the random variable N follows any discrete distribution with probability mass function (pmf) \(\mathbb {P}(N=n)\) (for n=1,2,…). We consider that the failure times of the components Z i,1,…,Z i,α for the ith subsystem are i.i.d. random variables having a suitable cdf, which is a function of the baseline cdf depending on a parameter vector τ, say T[G(x;τ),α]=G(x;τ)α (for x>0). In the following construction, although α is a positive integer called power or resilience parameter, we can consider that α>0.
If we define Y= min{Y 1,…,Y N }, then the conditional cdf of Y given N is
If we define Z= max{Y 1,…,Y N }, then the conditional (or complementary) cdf of Z given N is
The unconditional cdf of Y follows from Eq. (2) as
The unconditional cdf of Z follows from Eq. (3) as
Many compound G-classes can be constructed from Eqs. (4) and (5) by choosing a discrete model with pmf \(\mathbb {P}(N=n)\). The random variables Y= min{Y 1,…,Y N } and Z= max{Y 1,…,Y N } generate several models that arise in series and parallel systems with identical components and have many industrial and biological applications. For example, the time to the failure of a series system with an unknown number of protected components or the cancer recurrence of an individual after undergoing a certain treatment can be modeled by the generated distribution of Y. In a dual mechanism, the time to the failure of a parallel system with an unknown number of protected components or a disease manifestation, if it occurs only after an unknown number of factors have been active, can be modeled by the generated distribution of Z.
Compound G-classes
In this section, we present 14 compounded models obtained from Eq. (4). In Section 4, we present the corresponding complementary models based on Eq. (5). The list below does not include all compounded models but a large number of them and some new ones. For example, it does not describe the exponentiated-G-Conway-Maxwell Poisson (EGCOMP) class pioneered by Cordeiro et al. (2012a) and its special GCOMP model, among others. For all formulated models, we provide only their cdfs since the corresponding probability density functions (pdfs) can be determined by simple differentiation.
3.1 Exponentiated G-geometric class
If T[G(y;τ);α]=G(y;τ)α and N be a ZTG r.v. with pmf \(\mathbb {P}(N=n)=q\,p^{n-1},\, n=1,2,\dots,\,p\in (0,1)\), where p is the success probability, the cdf of the exponentiated G-geometric (EGG) class can follow as
The EGG class has recently been introduced by Nadarajah et al. (2015a), and can also be called the generalized G-geometric class. For α=1, the EGG class reduces to the G-geometric (GG) class proposed by Alkarni (2012). They investigated some of its general properties.
Remark 1
Swapping p with q in the ZTG pmf with p+q=1, the cdf of an alternative EGG (denoted by EGGA) class is given by
For α=1, the EGGA class reduces to the alternative G-geometric (GGA) class defined by Castellares and Lemonte ( 2016 ).
3.2 Exponentiated Kumaraswamy-G-geometric class (new)
For any baseline cdf G(x) and pdf g(x), Cordeiro and de-Castro (2011) defined the cdf of the Kumaraswamy-G class by K a,b (x;τ)=1−[1−G(x)a]b, where a>0 and b>0 are both shape parameters. Let T[G(y;τ);α]=K a,b (y;τ)α and N be a ZTG r.v. with pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\, n=1,2,\dots \), the cdf of the exponentiated Kumaraswamy-G-geometric (EKGG) class can follow as
For α=1, the EKGG class gives the new Kumaraswamy-G geometric (KGG) family.
3.3 McDonald-G-geometric class (new)
Alexander et al. (2012) defined the cdf of the McDonald-G class by \(\phantom {\dot {i}\!}M_{a,b,c}(x;\tau)=I_{G(x;\tau)^{c}}(a,b)\), where \(\phantom {\dot {i}\!}B(a,b)={\int _{0}^{1}} w^{a-1}\, (1-w)^{b-1}\, dw\), \(\phantom {\dot {i}\!}B_{z}(a,b)={\int _{0}^{z}} w^{a-1}\, (1-w)^{b-1}\, dw\) and I z (a,b)=B z (a,b)/B(a,b) are the beta function, incomplete beta function and incomplete beta function ratio, respectively.
If α=1 and T[G(y;τ)]=M a,b,c (y;τ), and N be a ZTG r.v. with pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\,n=1,2,\dots \), the cdf of the McDonald-G geometric (MGG) class is given by
3.4 Beta-G-geometric class (new)
For any baseline cdf G(x), Eugene et al. (2002) defined the cdf of the beta-G class by
If α=1 and T[G(y;τ]=B a,b (y;τ), and N be a ZTG r.v. with pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\, n=1,2,\dots \), the cdf of the beta-G geometric (BGG) class is given by
3.5 Exponentiated G-Poisson class
If T[G(y;τ);α]=G(y;τ)α and N be a ZTP r.v. with parameter λ defined by the pmf \(\mathbb {P}(N=n)=\lambda ^{n}/[n!\,(\mathrm {e}^{\lambda }-1)],\,n= 1,2,\ldots \), the cdf of the exponentiated G-Poisson (EGP) class can follow as
The EGP class has been studied by Gomes et al. (2015). For α=1, it becomes the G-Poisson (GP) class as defined recently by Tahir et al. (2016a) by the name of the Poisson-X class since it was based on the T-X family.
3.6 Exponentiated Kumaraswamy-G-Poisson class (new)
If T[G(y;τ);α]=G(y;τ)α and N be a ZTP r.v. with parameter λ, the cdf of the exponentiated Kumaraswamy-G Poisson (EKGP) class is given by
For α=1, the EKGP class reduces to the Kumaraswamy-G Poisson (KGP) family studied by Ramos et al. (2015).
3.7 McDonald-G-Poisson class (new)
Let α=1 and T[G(y;τ)]=M a,b,c (y;τ) and N be a ZTP r.v. with parameter λ, the cdf of the McDonald-G Poisson (MGP) class can be expressed as
3.8 Beta-G-Poisson class (new)
If α=1 and T[G(y);τ]=B a,b (y;τ) and N be a ZTP r.v. with parameter λ, the cdf of the beta-G Poisson (BGP) class reduces to
3.9 Exponentiated G-logarithmic class (new)
If T[G(y;τ);α]=G(y;τ)α and N be a Ln r.v. with pmf \(\mathbb {P}(N=n)=(1-\phi)^{n}/[-n\,\ln \,\phi ],\,\phi \in (0,1),\, n=1, 2,\dots \), the cdf of the exponentiated G-logarithmic (EGLn) class is given by
by noting that \(\sum _{n=1}^{\infty }\,Q^{n}/n=-\,\ln (1-Q)\).
For α=1, the EGLn class becomes the G-logarithmic (GLn) family introduced by Alkarni (2012).
3.10 Exponentiated Kumaraswamy-G-logarithmic class (new)
If T[G(y;τ);α]=G(y;τ)α and N be a Ln r.v. with pmf \(\mathbb {P}(N=n)=(1-\phi)^{n}/[-n\,\ln \,\phi ],\, \phi \in (0,1),\quad n=1, 2,\dots \), the cdf of the exponentiated Kumaraswamy-G-logarithmic (EKGLn) is given by
For α=1, the EKGLn cdf is identical to the cdf of the new Kumaraswamy-G-logarithmic (KGLn) class.
3.11 McDonald-G-logarithmic class (new)
If T[G(y;τ)]=M a,b,c (y;τ) and N be a Ln r.v. with pmf \(\mathbb {P}(N=n)=(1-\phi)^{n}/[-n\,\ln \,\phi ],\, \phi \in (0,1),\quad n=1, 2,\dots \), the cdf of the McDonald-G-logarithmic (MGLn) class is defined by
3.12 Beta-G-logarithmic class (new)
If α=1 and T[G(y;τ)]=B a,b (y;τ) and N be a Ln r.v. with pmf \(\mathbb {P}(N=n)=(1-\phi)^{n}/[-n\,\ln \,\phi ],\, \phi \in (0,1),\, n=1, 2,\dots \), the cdf of the beta-G-logarithmic (BGLn) class is given by
3.13 Exponentiated G-binomial class (new)
If T[G(y;τ);α]=G(y;τ)α and N be a ZTBi r.v. with pmf given by
the cdf of the exponentiated G-binomial (EGBi) class reduces to
Bakouch et al. (2012b) studied a special case of the EGBi class so-called the exponentiated-exponential binomial (EEBi) model. For α=1, the EGBi class becomes the G-binomial (GBi) class pioneered by Alkarni (2013).
3.14 Exponentiated G-NB class (new)
If T[G(y;τ);α]=G(y;τ)α and N be a ZTNB r.v. with parameter β∈(0,1) as the probability of success and pmf given by
the cdf of the exponentiated G-NB (EGNB) class can follow as
Using the binomial expansion \((1-w)^{-s}-1=\sum _{n=1}^{\infty } \binom {s+n-1}{n}\, w^{n}\), we obtain
For α=1, the EGNB class leads to the G-NB (GNB) class proposed by Percontini et al. (2013b).
Remark 2
-
If we replace the probability of success β by 1−β and the dispersion parameter s by θ in (6), the cdf of an alternate form of the GNB class (denoted by EGNB1) will be
$$\begin{array}{@{}rcl@{}} F_{EGNB1}(y)=1-\frac{\beta^{\theta}}{1-\beta^{\theta}}\, \left\{\left[G(y;\tau)^{\alpha}+(1-\beta)\bar{G}(y;\tau)^{\alpha}\right]^{-\theta}-1\right\}. \end{array} $$(7)For α=1, the EGNB1 class leads to the GNB family discussed by Nadarajah et al. ( 2013b ), who also studied, as a special case of the GNB1 class, the exponential-truncated negative-binomial (ETNB) model.
-
If we express β in terms of the population mean of the distribution in (6), the cdf of an alternate form of the GNB class (denoted by EGNB2) will be
$$\begin{array}{@{}rcl@{}} F_{EGNB2}(y)&=&\frac{1-\left[1+\eta\theta\,G(y;\tau)^{\alpha}\right]^{-\frac{1}{\eta}}}{1-(1+\eta\theta)^{-\frac{1}{\eta}}}. \end{array} $$For α=1, the EGNB2 class leads to the GNB family. Louzada et al. ( 2012b ) studied a special model of this class.
Complementary compound G-classes
Complementary compound models are constructed by considering the maximum of a sequence of i.i.d. random variables which represents the risk time of a system having components in parallel structure. In this section, we generate from Eq. (5) the complementary G-classes of those ones presented in Section 3. Some proposed complementary G-classes are really new ones.
4.1 Complementary exponentiated G-geometric class (new)
If T[G(z;τ);α]=G(z;τ)α and N be a ZTG r.v. with geometric pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\, n=1, 2,\dots \phantom {\dot {i}\!}\), the cdf of the complementary exponentiated G-geometric (CEGG) class reduces to
This equation is also called the complementary generalized G-geometric family. For α=1, the CEGG class becomes the complementary G-geometric (CGG) family.
Remark 3
Swapping p with q in the ZTG pmf with p+q=1, the cdf of an alternative CEGG (CEGGA) class will be
For α=1, the CEGGA class leads to the complementary G-geometric (CGG) family proposed by Castellares and Lemonte ( 2016 ).
4.2 Complementary exponentiated Kumaraswamy-G-geometric class (new)
If α=1, T[G(z;τ)]=K a,b (z;τ) and N be a geometric r.v. with pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\, n=1, 2,\dots \), the cdf of the CEKGG class is given by
For α=1, the CEKGG class leads to the complementary KGG (CKGG) class.
4.3 Complementary McDonald-G-geometric class (new)
If α=1, T[G(z;τ)]=M a,b,c (z;τ) and N be a geometric r.v. with pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\, n=1, 2,\dots \), the cdf of the complementary McDonald-G-geometric (CMGG) class can follow as
4.4 Complementary beta-G-geometric class (new)
If α=1, T[G(z;τ)]=B a,b (z;τ), and N be a geometric r.v. with pmf \(\mathbb {P}(N=n)=q\, p^{n-1},\, n=1, 2,\dots \), the cdf of the complementary beta-G-geometric (CBGG) class is given by
4.5 Complementary exponentiated G-Poisson class (new)
If T[G(z;τ);α]=G(z;τ)α and N be a ZTP r.v. with parameter λ, the cdf of the complementary exponentiated G-Poisson (CEGP) can follow as
For α=1, the CEGP class leads to the complementary G-Poisson (CGP) class.
4.6 Complementary exponentiated Kumaraswamy-G Poisson class (new)
If T[G(z;τ);α]=K a,b (z;τ)α and N be a ZTP r.v. with parameter λ, the cdf of the complementary exponentiated Kumaraswamy-G Poisson (CEKGP) class is given by
For α=1, the CEKGP class reduces to the complementary Kumaraswamy-G Poisson (CKGP) class.
4.7 Complementary McDonald-G Poisson class (new)
If α=1 and T[G(z;τ)]=M a,b,c (z;τ) and N be a ZTP r.v. with parameter λ, the cdf of the complementary McDonald-G Poisson (CMGP) class reduces to
4.8 Complementary beta G-Poisson class (new)
If α=1, T[G(z);τ]=B a,b (z;τ) and N be a ZTP r.v. with parameter λ, the cdf of the complementary beta G-Poisson (CBGP) class is given by
4.9 Complementary exponentiated G-logarithmic class (new)
If T[G(z;τ);α]=G(z;τ)α and N be a Ln r.v. with pmf given by \(\mathbb {P}(N=n)=(1-\phi)^{n}/[-n\,\ln \,\phi ],\quad \phi \in (0,1),\quad n=1, 2,\dots \), the cdf of the complementary exponentiated G-logarithmic (CEGLn) class can be expressed as
by noting that \(\sum _{n=1}^{\infty }\,Q^{n}/n=-\,\ln (1-Q)\). For α=1, the CEGLn class becomes the complementary G-logarithmic (CGLn) class.
4.10 Complementary exponentiated Kumaraswamy-G-logarithmic class (new)
If T[G(z;τ);α]=K a,b (z;τ)α and N be a Ln r.v. with \(\mathbb {P}(N=n)=(1-\phi)^{n}/[-n\,\ln \,\phi ],\,\phi \in (0,1),\,n=1, 2,\dots \), the cdf of the complementary exponentiated Kumaraswamy G-logarithmic of type 1 (CEKGLn1) class is given by
For α=1, the complementary Kumaraswamy-G-logarithmic (CEKGLn) class becomes the complementary G-logarithmic (CGLn) class.
4.11 Complementary McDonald-G-logarithmic class (new)
If α=1, T[G(z;τ)]=M a,b,c (z;τ) and N be a Ln r.v. with pmf \(\mathbb {P}(N=n)=(1-\phi)^{n}/(-n\,\ln \,\phi),\quad \phi \in (0,1),\quad n=1, 2,\dots \), the cdf of the complementary McDonald-G-logarithmic (CMGLn) class can be expressed as
4.12 Complementary beta-G-logarithmic class (new)
If α=1 and T[G(z;τ)]=B a,b (z;τ) and N be a Ln r.v. with pmf \(\mathbb {P}(N=n)=(1-\phi)^{n}/(-n\,\ln \,\phi),\,\phi \in (0,1),\, n=1, 2,\dots \), the cdf of the complementary beta-G-logarithmic (CBGLn) class is given by
4.13 Complementary exponentiated G-binomial class (new)
If T[G(z;τ);α]=G(z;τ)α and N be a ZTBi r.v. with pmf
the cdf of the complementary exponentiated G-binomial (CEGBi) class is given by
For α=1, the CEGBi class becomes the complementary G-binomial (CGBi) class.
4.14 Complementary exponentiated G-NB class (new)
If T[G(z;τ);α]=G(z;τ)α and N be a ZTNB r.v. with parameter β∈(0,1) with pmf
Using the binomial expansion \((1-w)^{-s}-1=\sum _{n=1}^{\infty } \binom {s+n-1}{n}\, w^{n}\), the cdf of the complementary exponentiated G-NB (CEGNB) class reduces to
For α=1, the CEGNB class leads to the new complementary GNB class.
Review of existing compounded models
In this section, we review some available compounded models. In the literature, several authors have reported compounding discrete distributions, namely the ZTG, ZTP, logarithmic, ZTBi, ZTNB, zero-truncated generalized Poisson and zero-truncated power-series, with continuous lifetime models.
5.1 Compounded models based on geometric distribution
For the following models, X denotes the r.v. of the baseline G model.
Exponential-geometric (EG) model. If X∼Exponential(β) have cdf G(x;β)=1− exp(−β x), then the cdf of the EG model pioneered by Adamidis and Loukas (1998) (as the first compounded model in the literature) can be determined from the GG class (Section 3.1 with α=1) as
Adamidis et al. (2005) also defined an extended EG model.
Generalized EG (GEG) model. If X∼Exponential(β), Silva et al. (2010) applied the LA1 class to the EG cdf in the last equation and defined the GEG cdf by
where γ>0 is the power parameter, β>0 and p∈(0,1).
Complementary EG (CEG) model (proposed). If X∼Exponential(β), then the CEG cdf can be determined from the CEGGA class (Section 4.1 with α=1) as
Long-term complementary EG (LCEG) model. If X∼Exponential(β), then Louzada et al. (2012d) proposed another CEG model called the LCEG model, in a latent complementary risk framework, with cdf given by
where β>0 is a scale parameter, θ is a shape parameter and p is the long-term parameter.
Generalized complementary EG (GCEG) model. Bidram and Nadadrajah (2016) applied the LA1 class to the CEGA cdf (given in Section 4.1 with α=1) and obtained the GCEG cdf as
where γ>0 is the power parameter, β>0 and p∈(0,1).
Complementary exponentiated-exponential geometric (CEEG) model. If X∼ExponentiatedExponential(β,α) have cdf G(x;β,α)=[1− exp(−β x)]α, then the cdf of the CEEG model, proposed by Louzada et al. (2014a), can be determined from the alternative CEGG class (Section 4.1 with α=1) as
Exponentiated-CEG (ECEG) model. Yamachi et al. (2013) generalized the CEG model \(F_{CEG}(z; p, \beta, b)=\frac {p(1-\mathrm {e}^{-b\,\beta \,z})}{\mathrm {e}^{-\beta \,z}(1-p)+p}\) introduced by Louzada et al. (2011) by applying the LA1 class and defined the ECEG cdf as
where γ>0 is the power parameter.
Beta-EG (BEG) model. If X∼Exponential(β), the cdf of the BEG model proposed by Bidram (2012) and Nassar and Nada (2012) can follow from the BGG class (Section 3.4) as
where
Exponentiated EG (EEG) model. The cdf of the EEG model defined by Louzada et al. (2014) can be determined from the EGGA class (Section 3.1) as
Ristić and Kundu (2016) proposed the generalized geometric extreme distribution, which is identical to the EEG model given above.
Modified EG (MEG) model. Let X∼ModifiedExponential(β,π) or the MO-exponential with cdf G(x;β,π)=1− exp(−β x)/[1−(1−π) exp(−β x)]. The cdf of the modified EG (MEG) distribution given by Bordbar and Nematollah (2016) can follow from the GG class (Section 3.1 with α=1) as
Exponentiated-LL geometric (ELLG) and complementary exponentiated-LL geometric (CELLG) models. If X∼ELL(a,b) has cdf \(G(x;a,b,\alpha)=\frac {\alpha \,b}{a} (x/a)^{-b-1} \left [1+(x/a)^{-b}\right ]^{-\alpha -1}\), then the cdfs of the ELLG and CELLG models proposed by Mendoza et al. (2016) can be determined from the GG and CGG classes described in Sections 3.1 and 4.1 (with α=1), respectively, as
and
Generalized linear failure rate-geometric (GLFRG) model. If X∼LinearExponential(a,b) have cdf G(x;a,b)=1− exp[−(a x+(b/2)x 2)], then the cdf of the GLFRG model proposed by Nadarajah et al. (2014a) can follow from the EGG class (Section 3.1) as
Complementary generalized linear failure rate-geometric (CGLFRG) model. If X∼LinearExponential(a,b) have cdf G(x;a,b)=1− exp[−(a x+(b/2)x 2)], then the CGLFRG cdf defined by Harandi and Alamatsaz (2016) can be determined from the CEGG class (Section 4.1) as
Exponentiated power Lindley-geometric (EPLG) model. If X∼ExpPowerLindley(α,β,θ) introduced by Ashour and Eltehiwy (2015) have cdf \(G(x;\alpha, \beta, \theta)=\left [1-\left (1+\frac {\theta \,x^{\beta }}{\theta +1}\right)\,\mathrm {e}^{-\theta \,x^{\beta }}\right ]^{\alpha }\), the EPLG cdf defined by Alizadeh et al. (2016b) can follow from the GG class (Section 3.1) as
Weibull-geometric (WG) model. If X∼Weibull(a,b) have cdf \(G(x; a,b)=1-\mathrm {e}^{-(b\,x)^{a}}\), then the cdf of the WG model proposed by Barreto-Souza et al. (2011) can be expressed from the GG class (Section 3.1 with α=1) as
Exponentiated Weibull-geometric (EWG) model. If X∼Weibull(a) have cdf \(G(x;a)=1-\mathrm {e}^{-x^{a}}\), then the EWG cdf given by Chung and Kang (2014) can be obtained from the EGG cdf (Section 3.1) as
Beta-Weibull-geometric (BWG) model. If X∼Weibull(a,b) have cdf \(G(x;a,b)=1-\mathrm {e}^{-(b\,x)^{a}}\), then the cdf of the BWG model defined by Bidram et al. (2013) and Cordeiro et al. (2013b) can follow from the BGG cdf (given in Section 3.4) as
where
Complementary exponentiated Weibull-geometric (CEWG) model. If X have Weibull cdf \(G(x;a,b)=1-\mathrm {e}^{-(b\,x)^{a}}\), the cdf of the CEWG model proposed by Mahmoudi and Shiran (2012a) follows from the CEGG class (Section 4.1) as
Complementary Weibull-geometric (CWG) model. If X∼Weibull(a,b) have cdf \(G(x;a,b)=1-\mathrm {e}^{-(b\,x)^{a}}\), the cdf of the CWG model proposed by Tojeiro et al. (2014) follows from the alternative CGG class given in Section 4.1 (α=1) as
Modified Weibull-geometric (MWG) model. If X∼ModifiedWeibull(a,b,δ) introduced by Sarhan and Zaindin (2009) have cdf G(x;a,b,δ)=1− exp[−(a x+b x δ)], then the cdf of the MWG model defined by Wang and Elbatal (2015) can be determined from the GG class (Section 3.1, α=1 and all parameters positive) as
Kummer-beta Weibull-geometric (KBWG) model. Ashour and Wahed (2014) extended the WG model to the KBWG model. The KBWG cdf is given by
where \(K=\frac {\Gamma {(l)}\Gamma {(m)}}{\Gamma {(l+m)}}\, {}_{1}F_{1} (l;l+m;-c)\) and 1 F 1 is the Gauss hyper-geometric function.
Additive Weibull-geometric (AWG) model. If X∼AddiveWeibull(a,b,γ) introduced by Cordeiro et al. (2014c) have cdf \(G(x;a, b, \gamma)= 1-\mathrm {e}^{-(a x+b x^{\gamma })},\quad x, a, b>0\) and γ∈(0,∞)∖{1}, then the cdf of the AWG model defined by Elbatal et al. (2016) can be obtained from the GG class (Section 3.1, α=1) as
Lindley-geometric (LG) model. If X∼Lindley(θ) have cdf \(G(x;\theta)=1-\left (1+\frac {\theta \,x}{\theta +1}\right)\,\mathrm {e}^{-\theta \,x}\) (for x>0, θ>0), then the cdf of the LG model proposed by Zakerzadeh and Mahmoudi (2013) can follow from the GG class (Section 3.1, α=1) as
Exponentiated Lindley-geometric (ELG) model. If X∼Lindley(θ) have cdf \(G(x;\theta)=1-\left (1+\frac {\theta \,x}{\theta +1}\right)\,\mathrm {e}^{-\theta \,x}\) (for x>0, θ>0), then the cdf of the ELG model proposed by Wang (2013) follows from the EGG class (Section 3.1) as
5.2 Compounded models based on Poisson distribution
Exponential-Poisson (EP). If X∼Exponential(β), then the cdf of the EP model proposed by Kuş (2007) can be obtained from the GP class defined in Section 3.5 (with α=1) as
For some structural properties and applications of the EP model, the reader is referred to Kuş (2007) and Cancho et al. (2011a).
Generalized EP (GEP) model. If X∼Exponential(β), Barreto-Souza and Cribari-Neto (2009) obtained the GEP cdf by applying the LA1 class to the EP cdf given in the last equation
where γ>0 is the power parameter, β>0 and p∈(0,1).
Complementary EP (CEP) model. If X∼Exponential(β), the cdf of the CEP model, proposed by Cancho et al. (2011a) and Rezaei and Tahmasbi (2012), can be determined from the CGP class (Section 4.5, α=1) as
Modified EP (MEP) model. If X∼ModifiedExponential(β) or MO-exponential with cdf \(G(x;\beta)=\frac {1-\mathrm {e}^{-\beta \,x}}{1-(1-p)\mathrm {e}^{-\beta \,x}}\), then the cdf of the MEP model, proposed by Preda et al. (2011), can follow from the GP class (Section 3.9, α=1) as
Exponentiated EP (EEP) model. If X∼Exponential(β), then the cdf of the EEP model given by Ristić and Nadarajah (2014) can be obtained from the EGP class defined in Section 3.5 as
Weibull-Poisson (WP) model. If X∼Weibull(a) have cdf \(G(x;a,b)=1-\mathrm {e}^{-bx^{a}}\), then the cdf of the WP model proposed by Lu and Shi (2012) can follow from the GP class (Section 3.5, α=1) as
Hemmati et al. (2011) and Bereta et al. (2011) also obtained the WP or Poisson-Weibull (PW) models from the Weibull cdf G(y;a,b)=1− exp{−(b y)a}. The cdf of their WP model is given by
Beta-Weibull Poisson (BWP) model. If X∼Weibull(a,b) have cdf \(G(x;a,b)=1-\mathrm {e}^{-bx^{a}}\), then the cdf of the BWP model, proposed by Percontini et al. (2013a), can follow from the BGP class defined in Section 3.8 as
where
Complementary modified Weibull-Poisson (CMWP) model. If X∼ModifiedWeibull(a,b,δ) introduced by Sarhan and Zaindin (2009) have cdf G(x;a,b,δ)=1− exp[−(a x+b x δ)], then the cdf of the CMWP model proposed by Ghorbani et al. (2014) can be obtained from the GP class presented in Section 3.5 (with α=1) as
Complementary exponentiated Weibull-Poisson (CEWP) model. If X∼Weibull(a,b) have cdf \(G(x;a,b)=1-\mathrm {e}^{-(bx)^{a}}\), then the cdf of the CEWP model defined by Mahmoudi and Sepahdar (2013) can follow from the EGP class (see Section 3.5) as
Log-logistic generalized Weibull Poisson (LLGWP) model. Let X∼Weibull(a,b) have cdf \(G(x;a,b)=1-\mathrm {e}^{-bx^{a}}\). Oluyede et al. (2016a) first defined the log-logistic generalized Weibull (LLGW) cdf by \(F_{LLGW}=1-\left [1+(x/s)^{c}\right ]^{-1}\, \mathrm {e}^{-bx^{a}}\) from the generalized extended Weibull family G(x;θ,ψ)=1−B(x;ψ) exp{−α H(x;θ)}, where θ and ψ are both vectors, by taking H(x;θ)=x b and B(x;ψ)=1−[1+(x/s)c]. Then, the cdf of the LLGWP model proposed by Oluyede et al. (2016c) can follow from the GP class (Section 3.5, α=1) as
Lai-modified Weibull-Poisson (LaiMWP) model. If X∼ModifiedWeibull(a,b,δ) introduced by Lai et al. (2003) have cdf G(x;a,b,δ)=1− exp(−a x δ ebx),a,b,δ>0, then the cdf of the LaiMWP model proposed by Delgarm and Zadkarami (2015) can be obtained from the GP class (Section 3.5, α=1) as
Exponentiated Lomax-Poisson (ELoP) model. If X∼Lomax(a,b) have cdf G(x;a,b)=1−(1+b x)−a, then the cdf of the ELoP model proposed Ramos et al. (2013) can be determined from the EGP class (Section 3.5) as
Complementary Poisson-Lomax (CPLo) model. Let X∼Lomax(a,b) have cdf G(x;a,b)=1−(1+b x)−a, then the cdf of the CLoP model proposed Al-Zahrani and Sagor (2014) can follow from the CGP class (Section 4.5, α=1) as
Lindley-Poisson (LP) model. Let X∼Lindley(θ) have cdf \(G(x;\theta)=1-\left (1+\frac {\theta \,x}{\theta +1}\right)\, \mathrm {e}^{-\theta \,x},\, x, \theta >0\). The cdf of the LP model introduced by Gui et al. (2014) can be determined from the GP class (Section 3.5, α=1) as
Complementary extended Lindley-Poisson (CExtLP) model. If X∼ExtLindley(θ,δ,β) proposed by Bakouch et al. (2012a) have cdf \(G(x;\theta, \delta, \beta)=1-\left (\frac {1+\theta +\theta \,x}{\theta +1}\right)^{\delta }\, \mathrm {e}^{-(\theta \,x)^{\beta }}\), the cdf of the CExtLP model introduced by Pararai et al. (2015b) can be determined from the CGP class (Section 4.5, α=1) as
Poisson Birnbaum-Saunders (PBS) model. Let X∼BS(a,b) have cdf \(G(x;a,b)=\Phi \left [\left (1/a\right)+\left (\sqrt {x/b}-\sqrt {b/x}\right)\right ],\, x, a, b>0\), then the cdf of the PBS model, proposed by Hashimoto et al. (2014) in terms of long-term survivors, can be obtained from the GP class (Section 3.5, α=1) as
Exponentiated-Burr XII Poisson (EBP) model. Let X∼Burr(c,k,s) have cdf G(x;c,k,s)=1−[1+(x/s)c]−k, x,c,k,s>0, then the cdf of the EBP model introduced by da-Silva et al. (2015b) can be determined from the EGP class (Section 3.5) as
Complementary Burr III Poisson (CB3P) model Let X∼BurrIII(c,k) have cdf G(x;c,k)=(1+x −c)−k, x,c,k>0, then the cdf of the CB3P model defined by Hassan et al. (2015) can follow from the CGP class (Section 4.5, α=1) as
The Burr III distribution is also known as the Dagum distribution (Dagum1977), which is a very well-known model for studying income and wealth inequality data. Oluyede et al. (2016b) have recently introduced and studied the Dagum-Poisson distribution.
Poisson generalized linear failure rate (PGLFR) model. Let X∼GLFR(a,b,α) introduced by Sarhan and Kundu (2009) have cdf G(x;a,b,α)=(1− exp[−a x−(b/2)x 2])α, x,a,b,α>0, then the cdf of the PGLFR model defined by Cordeiro et al. (2015b) can be obtained from the EGP class (Section 3.5) as
Complementary failure rate Poisson (CLFRP) model. Let X∼LFR(a,b,α), then the cdf of the CLFRP model defined by Gitifar et al. (2016) can follow from the CEGP class (Section 4.5, α=1) as
Complementary exponentiated power Lindley-Poisson (CEPLP) model. If X∼ExpPowerLindley(α,β,θ) introduced by Warahena-Liyanage and Pararai (2015b) have cdf \(G(x;\alpha, \beta, \theta)=\left [1-\left (1+\frac {\theta \,x^{\beta }}{\theta +1}\right)\,\mathrm {e}^{-\theta \,x^{\beta }}\right ]^{\alpha }\) (for x>0, α,β,θ>0), then the EPLG cdf defined by Pararai et al. (2016) can follow from the CGP class (Section 4.5) as
5.3 Compounded models based on the logarithmic distribution
The following compounded models have been reported in the literature from the logarithmic discrete model.
Exponential-logarithmic (ELn). If X∼Exponential(β) have cdf G(x;β)=1− exp(−β x), then the cdf of the exponential-logarithmic (ELn) model proposed by Tahmasbi and Rezaei (2008) can be obtained from the GLn class (Section 3.9, α=1) as
Generalized ELn. Pappas et al. (2015) applied the LA1 class to the ELn cdf given in Eq. (8), and obtained the cdf of the generalized ELn (GELn) distribution as
where γ>0 is the power parameter.
Chen-logarithmic (ChLn). If X∼Chen(γ,β) have cdf \(G(x;\gamma, \beta)=\mathrm {e}^{\gamma (\mathrm {e}^{x^{\beta }}-1)}\phantom {\dot {i}\!}\) introduced by Chen (2000), then the cdf of the Chen-logarithmic (ChLn) model proposed by Pappas et al. (2011) can be determined from the GLn class (Section 3.9 with α=1) as
Complementary exponentiated Weibull-logarithmic (CEWLn) model. Let X∼EW(β,δ,α) have cdf \(G(x; \beta, \delta, \gamma)=\alpha \,\delta \,\beta ^{\delta }\,y^{\delta }\,\mathrm {e}^{-(\beta \,y)^{\delta -1}} [1-\mathrm {e}^{-(\beta \,y)^{\delta }}]^{\alpha -1}\phantom {\dot {i}\!}\), then the cdf of the complementary exponentiated Weibull-logarithmic (CEWLn) model introduced by Mahmoudi et al. (2014) can follow from the cdf of the CGLn class given in Section 4.9 as
where ϕ∈(0,1), α>0 and δ>0 are shape parameters and β>0 is a scale parameter.
Lomax-logarithmic (LxLn) model. Let X∼Lomax(a,b) have cdf G(x;a,b)=(1+b x)−a, then the cdf of the Lomax-logarithmic (LxLn) model given by Al-Zahrani and Sagor (2015) can be obtained from the GLn class given in Section 3.9 with α=1 as
Exponentiated Poisson-logarithmic (EPoLn) model. Let X∼ExpPoisson(θ,β) have cdf \(G(x;a,b)=1-\frac {1-\exp \{-\theta \, \mathrm {e}^{-\beta \,x}\}}{1-\mathrm {e}^{-\theta }}\), then the cdf of the exponentiated Poisson-logarithmic (EPoLn) model given by Fioruci et al. (2016) can follow from the alternative GLn cdf (Section 3.9 with α=1) as
Other compounded models
(i) Extended Weibull power series (EWPS) models. Let T[G(y;τ);α]=1−e−αH(y;τ) be the extended Weibull family, where x>0, α>0 and H(y;τ) is a non-negative monotonically increasing function depending on a parameter vector τ. Much more than twenty known lifetime model cdfs can be expressed in this form. Further, let N be a discrete random variable following a power series (PS) distribution (truncated at zero) with pmf
where a n depends only on n, \(C(\theta) = \sum _{n=1}^{\infty }a_{n} \,\theta ^{n}\) and θ>0 is such that C(θ) is finite. Equation (9) summarizes some power series distributions (truncated at zero) such as the Poisson, logarithmic and geometric distributions, where C(θ) is equal to (eθ−1), − log(1−θ) and θ(1−θ)−1, respectively.
Silva et al. (2013) defined the EWPS cdf obtained under the current set-up from Eq. (4) as
Equation (10) includes as special cases the Weibull power series (WPS) class, which extends the exponential power series (EPS) family. In fact, this class includes much more than 60 (20 × 3) special models, some of them given by Silva et al. (2013) and others yet not investigated. In a similar context, more recently, Silva et al. (2016) defined a family by compounding the generalized gamma (GGa) and power series distributions.
(ii) Complementary extended Weibull power series (CEWPS) models. The CEWPS class follows by taking T[G(y;τ);α]=1−e−αH(y;τ) and the PS distribution for the pmf. So, the cdf of the CEWPS class can be obtained from Eq. (5) as
The CEWPS class can arise in parallel systems with identical components, which appear in many industrial and biological applications.
(iii) Exponential-geometric range (max-min) model (New). Let N be the ZTG r.v. with pmf of type 1 \(\mathbb {P}(N=n)=q\,p^{n-1},\, n=1, 2, \ldots \) and define the range X R = max{Y 1…,Y N |p}− min{Y 1…,Y N |p}. The unconditional cdf of the G-geometric range (R= max− min) can be obtained as
If Y∼E x p(β) have density f Y|β (y)=βe−βy and Z|p∼G e o m e t r i c(p) have pmf \(\mathbb {P}(N=n)=q\,p^{n-1},\,n=0,1, \ldots \), Shahsanaei et al. (2012) proposed the unconditional cdf of the exponential-geometric range (EGR) model as
The EGR distribution is useful for modeling the time between the first failure to the last failure.
(iv) Exponential-generalized Poisson (EGP) model. Let N have the zero truncated generalized Poisson (ZTGP) distribution with parameters λ and α and pmf
Then, Gupta et al. (2014) proposed the EGP cdf given by
where g=−α e−(α+βy) and W(·) is the Lambert W function defined by W(x) eW(x)=x. The above cdf can be derived from the generating function of the ZTGP distribution \(M_{N}^{\ast }(t)=\frac {M_{N}(t)-P(N=0)}{1-P(N=0)}=\frac {1-\mathrm {e}^{-(\lambda /\alpha) [W(g)+\alpha ]}-\mathrm {e}^{-\lambda }}{1-\mathrm {e}^{-\lambda }}\), which is equivalent to the survival function 1−F(t;α,β,λ).
A different approach of compounding
The compounding of some models (continuous with continuous and discrete with discrete) are introduced such as the exponential-Weibull (Cordeiro et al.2014c), generalized exponential-exponential (Popović et al.2015), geometric exponential Poisson (Nadarajah et al.2013a) and additive Weibull (Xie and Lai1995) distributions.
(i) Exponential-Weibull model. Let W and T be independent random variables with exponential and Weibull distributions characterizing two series sub-system lifetimes, whose cdfs are G W (z)=1− exp(−α z) and G T (t)=1− exp(−β t γ), respectively. Here, α>0 and γ>0 are shape parameters and β>0 is a scale parameter. The distribution of the random variable X= min{W,T} is called the exponential-Weibull (EW) distribution, whose cdf is given by
We consider that α>0, β>0 and γ∈(0,∞)∖{1}, which gives identifiability to the model. The mathematical properties of the EW model were investigated by Cordeiro et al. (2014c).
(ii) Generalized exponential-exponential (GEE) model. Gupta and Kundu (1999) introduced the two-parameter generalized exponential (GE) distribution with cdf given by G(x;α,λ)=(1−e−λx)α, where x>0,α>0,λ>0. For a given α, let Y be a random variable with the GE cdf with parameters α>0 and λ>0. Let α be a random variable following an exponential distribution with parameter θ>0. Then, Popović et al. (2015) defined the GEE cdf (for x>0) by
(iii) Exponentiated geometric G-Poisson (EGGP) model (New). If N∼Z T G(p) and M∼Z T P(λ), then the EGGP family can be determined by inserting the EGP cdf (Section 3.9) in the cdf of the EGG class (Section 3.1) as
If α=1 and X∼E x p(β) in the EGGP class above, then it follows the cdf of the geometric exponential Poisson (GEP) defined by Nadarajah et al. (2013a).
(iv) Additive Weibull (AW) model. Suppose a system composed of two interconnected independent series sub-systems that affect the system in a different way, both following the Weibull distribution with proper parameters. Xie and Lai (1995) proposed the AW model based on the simple idea of combining the failure rates of two Weibull distributions: one has a decreasing failure rate and the other one has an increasing failure rate. The cdf of the AW model is given by F(t)=1− exp(−a t b−c t d), where a>0 and c>0 are scale parameters and b>d>0 (or d>b>0) are shape parameters, which gives identifiability to the model. The interpretation of the AW model is evident. A state-of-the-art survey on the AW model can be found in Lemonte et al. (2014).
Recent trends in compounding
There are four very recent trends on compounding of distributions, which have received a great deal of attention.
8.1 First recent trend
Compounding a G-class with discrete model: The first recent trend deals with defining compound classes of lifetime distributions rather than studying a single compound model. In this technique, a non-compound G-family of distributions is compounded with a discrete model to generate a new flexible compounded class. Asgharzadeh et al. (2014) introduced the G-Poisson-Lindley (from discrete Poisson-Lindley) class of distributions by compounding the ZTPL distribution with any other continuous lifetime model. Four special models viz. Weibull Poisson-Lindley, Burr Poisson-Lindley, exponentiated-Weibull Poisson-Lindley and Dagum Poisson-Lindley were investigated. Nadarajah et al. (2015a) proposed the exponentiated G-geometric family, and reported two special models: exponentiated-Weibull geometric and exponentiated-log-logistic geometric. Ramos et al. (2015) introduced the Kumaraswamy-G Poisson family and showed that the special model Kumaraswamy-Weibull Poisson outperforms the competitors Kumaraswamy-Weibull and beta-Weibull models in studying real life data on bladder cancer. Gomes et al. (2015) proposed the exponentiated-G Poisson family and studied two special models, namely the exponentiated-Burr XII Poisson and exponentiated-Weibull Poisson. Two other compound G-classes are the G-Poisson (Alkarni and Oraby2012) and Poisson-X (Tahir et al. 2016a).
8.2 Second recent trend
Combining a continuous model with compound power series class: For the second recent trend on compounding, one continuous lifetime model is compounded with the power series class of distributions truncated at zero. Chahkandi and Gangali (2009) first suggested compounding exponential and power series class, which exhibits decreasing failure rate. The power series class can be used to construct many compounding models with discrete distributions: Poisson, logarithmic, geometric, binomial and negative-binomial. Some well-known compound models defined from the power series class are: Weibull power series (WPS) (Morais and Barreto-Souza2011), complementary generalized-exponential power series (CGEPS) (Mahmoudi and Jafari2012), complementary exponentiated-Weibull power series (CEWPS) (Mahmoudi and Shiran2012b), extended WPS (Silva et al.2013), Kumaraswamy power series (KwPS) (Bidram and Nekouhou2013), complementary exponential power series (CEPS) (Flores et al.2013), Birnbaum-Saunders power series (BSPS) (Bourguignon et al.2014b), complementary WPS (Munteanu2014), complementary Erlang and Erlang power series (CErPS and ErPS) (Leahu et al.2014), complementary extended WPS (Cordeiro and Silva2014), exponentiated extended WPS (Tahmasebi and Jafari2015a), Burr XII power series (BIIPS) (Silva and Cordeiro2015), Lindley power series (LPS) (Warahena-Liyanage and Pararai2015a), linear failure rate power series (LFRPS) (Mahmoudi and Jafari2015), complementary normal power series (CNPS) (Mahmoudi and Mahmoodian2015), complementary generalized Gompertz power series (CGGoPS) (Tahmasebi and Jafari2015b), complementary inverse Weibull power series (CIWPS) (Shafiei et al.2016), complementary generalized modified Weibull (CGMW) (Bagheri et al.2016), complementary exponentiated inverse Weibull power series (CEIWPS) (Hassan et al.2016), generalized gamma power series (GGPS) (Silva et al.2016), Gompertz power series (GoPS) (Jafari and Tahmasebi2016), complementary generalized linear failure rate power series (CGLFR) (Harandi and Alamatsaz2016), and Dagum power series (DaPS) (Oluyede et al.2016b).
8.3 Third recent trend
Combining compound G-class with the non-compound G-class: Here, the cdf of one compound G-class or its special model is inducted into the cdf of a non-compound G-class, thus generating a new flexible G-class. Next, we propose two such classes.
(i) If the cdf of the GP class defined in Section 3.5 with α=1 is inserted into the cdf of Gamma-G class, proposed by Zografos and Balakrishnan (2009), then the cdf of new class (GaGP) is obtained as
where \(\Gamma (a)=\int _{0}^{\infty } t^{a-1}\,\mathrm {e}^{-t}\, dt\) and \(\Gamma {(a,z)}=\int _{z}^{\infty } t^{a-1}\,\mathrm {e}^{-t}\, dt\) are the gamma and upper incomplete gamma functions, respectively, and \(\bar {G}_{GP}(y)=1-G_{GP}(y).\)
One special model of the GaGP class, that is, the gamma-Weibull-Poisson (GaWP) was studied by Percontini et al. (2014), whose cdf is given by
(ii) The cdf of the new Kumaraswamy-GP (KGP) class can be obtained by inducting the cdf of the CGP model given in Section 4.5 with α=1 into the cdf of the Kumaraswamy-G class, pioneered by Cordeiro and de-Castro (2011), as
Pararai et al. (2015a) obtained the cdf of a special KwGP model called the Kumaraswamy Lindley-Poisson (KwLP) distribution.
8.4 Fourth recent trend
Combining transmuted G-class with well-known compound distributions: After receiving increased attention in the last decade, more than 50 transmuted distributions have been reported in the literature. Due to wide acceptability of transmuted G-class, a new trend has now begun by inserting the cdf of the compound G-class or distribution in the transmuted G-class cdf. Some models are given below:
(i) Transmuted Weibull-geometric (TWG). Merovci and Elbatal (2014b) extended the WG model introduced by Barreto-Souza et al. (2011) (given in Section 5) with the transmuted-G family and defined the cdf of the TWG model by
(ii) Exponentiated transmuted-Weibull geometric (ETWG) model. If X∼Weibull(a,b) have cdf \(G(x;a,b)=1-\mathrm {e}^{-(x/b)^{a}}\), Aryal and Tsokos (2011) defined the cdf of the transmuted-Weibull distribution as
The cdf of the ETWG model proposed by Al-Zahrani et al. (2015) can follow from the EGG cdf defined in Section 3.1 as
(iii) Transmuted complementary Weibull-geometric (TCWG) model. Afify et al. (2014) applied the LA1 class to the cdf of the Tojeiro et al.’s CWG model given in Section 5, and obtained the cdf of the TCWG model as
(iv) Transmuted complementary exponentiated Weibull-geometric (TCEWG) model. If X∼ExpWeibull(a,b,α) have cdf \(G(x;\beta)=\left (1-\mathrm {e}^{-(b\,x)^{a}}\right)^{\alpha }\), Saboor et al. (2016) used the CEWG cdf given in Section 5 and obtained the cdf of the TCEWG model as
(v) Transmuted Lindley-geometric (TLG) model. Merovci and Elbatal (2014a) extended the LG model (described in Section 5) by proposing the TLG cdf given by
where η and θ>0 are transmuted and scale parameters, respectively, and p∈(0,1).
(vi) Transmuted exponential-Weibulll (TEW) model. Saboor et al. (2015) recently extended the exponentiated-Weibull model originally proposed by Cordeiro et al. (2014c). The TEW cdf is given by
where α>0, β>0 and γ∈(0,∞)∖{1}.
Estimation and inference
9.1 General estimation procedure
Several approaches for parameter estimation were proposed in the literature but the maximum likelihood method is the most commonly employed. The maximum likelihood estimators (MLEs) enjoy desirable properties and can be used when constructing confidence intervals and regions and also in test statistics. The normal approximation for these estimators in large sample distribution theory is easily handled either analytically or numerically. So, we consider the estimation of the unknown parameters for each model discussed in this paper from complete or censored samples by maximum likelihood.
The log-likelihood for the model parameters can be maximized either directly by using the R (optim function), SAS (PROC NLMIXED), Ox program (MaxBFGS sub-routine) or by solving the nonlinear likelihood equations obtained by differentiating the log-likelihood. In the applications, we can also use the AdequacyModel package (version 2.0.0) available in the R programming language. It has been cited very frequently in papers related to new lifetime distributions. The package has been continuously updated and more information can be obtained from http://cran.rstudio.com/web/packages/AdequacyModel/index.html. It is distributed under the terms of the GNU licenses - GNU Project. An important observation is that it is not necessary to define the log-likelihood function but only the pdf and cdf of the model. The package provides some useful goodness-of-fit statistics to assess the quality of the fitted models and compare them, such as the Cramér–von Mises (W ∗) and Anderson-Darling (A ∗) statistics, Akaike information criterion (AIC), consistent Akaike information criterion (CAIC), Bayesian information criterion (BIC), Hannan-Quinn information criterion (HQIC) and Kolmogorov-Smirnov (K-S) test. It is important to emphasize that we can fit several competitive models to a data set and select those which yield best fits by means of the AdequacyModel package.
9.2 Cure fraction survivor models
During the last two decades, the tendency to propose probability models to deal with survival data has increased. This increased interest has lead researchers and medical practitioners to assess correct causes and information of the disease. The survival models which are receiving increased recognition in these days are fractional survivor models. These models have been effectively useful in some situations of clinical, medical or biological studies, where the fractional survival (or survivor fraction) models are useful to study a cure fraction of individuals. These models are also known as cure rate models or long-term survival models. In these models, it is assumed that all units under study are susceptible to an event of interest and will eventually experience it if its follow-up is sufficiently long. However, there are situations for which a fraction of individuals is not expected to experience the event of interest, that is, those individuals are cured or insusceptible. For example, researchers may be interested in analyzing the recurrence of a disease but many individuals may never have an experience or a recurrence, therefore, a cured fraction of the population exist. In other words, the cure rate models cover the situations where the sampling units insusceptible to the occurrence of the event are of interest, and also extend understanding of time-to-event data by allowing the formulation of more accurate and informative conclusions. If the cure fraction of the population is ignored, then the results will match to standard survival analysis. The cure rate models have been used for modeling time-to-event data for cardiac failure and various types of cancers including prostate, breast, leukemia, non-Hodgkin lymphoma and melanoma. That is why, the focus of the researchers is to introduce new, extended or modified distributions which accommodate cure fraction.
In the literature, two formulations of the cure rate models have received increased attention, namely, the mixture cure rate model (Boag1949; Berkson and Gage1952) and promotion time (or accelerated) cure rate model (Yakovlev and Tsodikov1996; Chen et al.1999). Perhaps, the mixture cure rate models has received increased popularity. In mixture model, it is assumed that there is a fraction 1−π 0 of susceptible individuals and, hence, a proportion π 0 of cured individuals. The survivor function for the entire population is
where S 0 denotes the survival function for the non-cured group in the population. So, the flexibility and performance of the population model depends on the choice of S 0. Rodrigues et al. (2009a) unified both formulations considering the negative binomial cure rate model. The proper modeling of cure rate models reported in literature is with covariates, which have been proved very useful in getting improved results for the estimated cure rate. Some selected cure rate models are reported in Table 2. Further detail is beyond the scope of the paper.
9.3 Inference for cure fraction models
Suppose that the time-to-event is not completely observed and may be subject to right censoring. Let C i denote the censoring time. We observe that Y i = min(T i ,C i ) and δ i =I(T i <C i ) is such that δ i =1, if T i is a time-to-event and δ i =0, if it is right censored, i=1,…,n. Let Θ denote the parameter vector of the distribution of the time-to-event. From n pairs of times and censoring indicators D a t a=(y 1,δ 1),…,(y 1,δ 1), the corresponding likelihood function under uninformative censoring is
where f CRM (D a t a,Θ) and F CRM (D a t a,Θ) are the density and cdf of a cure rate model (CRM), respectively.
Maximum likelihood estimation of the parameter vector Θ is carried out through maximization of the log-likelihood function ℓ(D a t a,Θ)= logL(D a t a,Θ). Details for the maximization methods are discussed in Section 9.1. Under suitable regularity conditions, it can be shown that the asymptotic distribution of the maximum likelihood estimator (MLE) \(\widehat {\boldsymbol {\Theta }}\) is normal with mean vector Θ and covariance matrix \(\boldsymbol {\sum }(\widehat {\boldsymbol {\Theta }})\) given by
evaluated at \(\boldsymbol {\Theta }=\widehat {\boldsymbol {\Theta }}\). The required second derivatives are computed numerically.
The EM algorithm (Dempster et al.1977) is also a very popular maximization alternative used to obtain the estimates when the model has missing data. In the literature, Balakrishnan and Pal (2012,2013b,2015a,2015b), Gallardo et al. (2016), Gallardo and Bolfarine (2016) and some others have considered estimation of parameters of cure fraction survival models using the EM algorithm.
Final remarks
The need of compounding was first felt in actuarial science and later researchers of many other fields adopted this approach for lifetime and reliability modeling. We follow the two basic principles (the minimum and the maximum) used in series and parallel structure, and report more than 30 compound G-classes. In this way, the possible available compound G-classes are surveyed and using these basic principles nearly 25 new G-classes are proposed. The purpose of providing a variety of G-classes is to test flexibility of the proposed compound models to cope with the data available in complex situations. The parameters inducted in this way might be helpful in exploring phenomenon generated from real-lifetime data sets. We expect that these G-classes or generated compounded models from them will be an addition to the art of constructing useful probability models. One can imagine its motivation and usefulness in the fields which are not touched earlier. We have also briefly described the latest trends in the development of compounding technique, which portray better exposition of the strategies adopted for the researchers and practitioners. We hope to produce many more new compound G-classes from the function T[G(x;τ);α] but due to space problem we did our best to explore and present the elusive task in most tenable way by mentioning only the cumulative distributions of the classes. The remaining G-classes will appear in another article under the same series. Lastly, we offer more choices to the learners and practitioners of modeling to compare different models and to study pros and cons of old and new G-classes. The possible future projects are: (i) to propose more new compound G-classes of distributions; (ii) to review and develop bivariate compound G-classes; and (iii) to prepare a review and new developments on cure rate survival models.
References
Abdul-Moniem, IB: Transmuted Burr III distribution. J. Statist.–Adv. Theory Applic. 14, 37–47 (2015).
Abdul-Moniem, IB, Seham, M: Transmuted Gompertz distribution. Comput. Appl. Math. J. 1, 88–96 (2015).
Adamidis, K, Dimitrakopoulou, T, Loukas, S: On an extension of the exponential-geometric distribution. Statist. Probab. Lett. 73, 259–269 (2005).
Adamidis, K, Loukas, S: A lifetime distribution with decreasing failure rate. Statist. Probab. Lett. 39, 35–42 (1998).
Afify, AZ, Nofal, ZM, Butt, NS: Transmuted complementary Weibull geometric distribution. Pak. J. Statist. Oper. Res. 10, 435–454 (2014).
Afify, AZ, Hamedani, GG, Ghosh, I, Mead, ME: The transmuted Marshall-Olkin Fréchet distribution: Properties and applications. Int. J. Statist. Probab. 4, 132–148 (2015a).
Afify, AZ, Nofal, ZM, Butt, NS: Exponentiated transmuted generalized Rayleigh distribution: A new four-parameter Rayleigh distribution. Pak. J. Statist. Oper. Res. 11, 115–134 (2015b).
Afify, AZ, Nofal, ZM, Yousof, HM, El-Gebaly, YM, Butt, NS: The transmuted Weibull-Lomax distribution: Properties and application. Pak. J. Statist. Oper. Res. 11, 135–152 (2015c).
Afify, AZ, Yousof, HM, Butt, NS, Hamedani, GG: The transmuted Weibull-Pareto distribution. Pak. J. Statist. 32, 183–206 (2016).
Ahmad, A, Ahmad, SP, Ahmad, A: Transmuted inverse Rayleigh distribution: A generalization of the inverse Rayleigh distribution. Math. Theory Model. 4, 177–185 (2014).
Ahmad, A, Ahmad, SP, Ahmad, A: Characterization and estimation of transmuted Rayleigh distribution. J. Statist. Applic. Probab. 4, 315–321 (2015a).
Ahmad, K, Ahmad, SP, Ahmad, A: Structural properties of transmuted Weibull distribution. J. Mod. Appl. Stat. Methods. 14, 141–158 (2015b).
Al-Aqtash, R: On Generating New Families of Distributions Using the Logit Function. Central Michigan University. Department of Mathematics, Ph.D. thesis (2013).
Al-Aqtash, R, Lee, C, Famoye, F: Gumbel-Weibull distribution: Properties and applications. J. Mod. Appl. Stat. Methods. 13, 201–225 (2014).
Al-Babtain, A, Fattah, AA, Ahmed, AHN: The Kumaraswamy-transmuted exponentiated modified Weibull distribution. Commun. Stat. Simul. Comput (2015). forthcoming.
Alexander, C, Cordeiro, GM, Ortega, EMM, Sarabia, JM: Generalized beta-generated distributions. Comput. Stat. Data Anal. 56, 1880–1897 (2012).
Alizadeh, M, Cordeiro, GM, de-Brito, E, Demétrio, CGB: The beta Marshall-Olkin family of distributions. J. Stat. Dist. Applic. 2, Art, 4 (2015a).
Alizadeh, M, Emadi, M, Doostparast, M, Cordeiro, GM, Ortega, EMM, Pescim, RR: A new family of distributions: the Kumaraswamy odd log-logistic, properties and applications. Hacet. J. Math. Stat. 44, 1491–1512 (2015b).
Alizadeh, M, Tahir, MH, Cordeiro, GM, Mansoor, M, Zubair, M, Hamedani, GG: The Kumaraswamy Marshal-Olkin family of distributions. J. Egyptian Math. Soc. 23, 546–557 (2015c).
Alizadeh, M, Bagheri, SF, Alizadeh, M, Nadarajah, S: A new four-parameter lifetime distribution. J. Appl. Statist. (2016a). doi:http://dx.doi.org/10.1080/02664763.2016.1182137. forthcoming.
Alizadeh, M, Merovci, F, Hamedani, GG: Generalized transmuted family of distributions. Properties and applications. Hacet. J. Math. Stat. (2016b). doi:http://dx.doi.org/10.15672/HJMS.201610915478. forthcoming.
Aljarrah, MA, Lee, C, Famoye, F: On generating T-X family of distributions using quantile functions. J. Stat. Dist. Applic. 1, Art, 2 (2014).
Alkarni, SH: A compound class of geometric and lifetime disributions. Open Statist. Probab. J. 5, 1–5 (2012).
Alkarni, S, Oraby, A: A compound class of Poisson and lifetime disributions. J. Statist. Applic. Probab. 1, 45–51 (2012).
Alkarni, SH: A compound class of truncated binomial lifetime disributions. Open. J. Statist. 3, 305–311 (2013).
Almheidat, M, Famoye, F, Lee, C: Some generalized families of Weibull distribution: Properties and applications. Int. J. Statist. Probab. 4, 18–35 (2015).
Alzaatreh, A, Lee, C, Famoye, F: A new method for generating families of continuous distributions. Metron. 71, 63–79 (2013).
Alzaatreh, A, Lee, C, Famoye, F: T-normal family of distributions: a new approach to generalize the normal distribution. J. Stat. Dist. Applic. 1, Art, 16 (2014).
Alzaatreh, A, Lee, C, Famoye, F: Family of generalized gamma distributions: Properties and applications. Hacet. J. Math. Stat. 45, 869–886 (2016a).
Alzaatreh, A, Lee, C, Famoye, F, Ghosh, I: The generalized Cauchy family of dstributions with applications. J. Stat. Dist. Applic. 3, Art, 12 (2016b).
Alzaghal, A, Famoye, F, Lee, C: Exponentiated T-X family of distributions with some applications. Int. J. Probab. Statist. 2, 31–49 (2013).
Al-Zahrani, B, Fattah, AA, Nadarajah, S, Ahmed, AHN: The exponentiated transmuted Weibull geometric distribution with application in survival analysis. Commun. Stat. Simul. Comput. (2015). forthcoming.
Al-Zahrani, B, Sagor, H: The Poisson-Lomax distribution. Rev. Colombiana Estadíst. 37, 225–245 (2014).
Al-Zahrani, B, Sagor, H: Statistical analysis of Lomax-logarithmic distribution. J. Stat. Comput. Simul. 85, 1883–1901 (2015).
Amini, M, MirMostafaee, SMTK, Ahmadi, J: Log-gamma-generated families of distributions. Statistics. 48, 913–932 (2014).
Aryal, GR: Transmuted log-logistic distribution. J. Statist. Applic. Probab. 2, 11–20 (2013).
Aryal, GR, Tsokos, CP: On the transmuted extreme value distribution with application. Nonlinear Anal. 71, 1401–1407 (2009).
Aryal, GR, Tosokos, CP: Transmuted Weibull distribution: A generalization of Weibull probability distribution. Eur. J. Pure Appl. Math. 4, 89–102 (2011).
Asgharzadeh, A, Bakouch, HS, Nadarajah, S, Esmaeili, L: A new family of compound lifetime distributions. Kybernetika. 50, 142–169 (2014).
Ashour, SK, Eltehiwy, MA: Transmuted Lomax distribution. Amer. J. Appl. Math. Statist. 1, 121–127 (2013a).
Ashour, SK, Eltehiwy, MA: Transmuted exponentiated Lomax distribution. Austral. J. Basic Appl. Sci. 7, 658–667 (2013b).
Ashour, SK, Eltehiwy, MA: Transmuted exponentiated modified Weibull distribution. Int. J. Basic Appl. Sci. 2, 258–269 (2013c).
Ashour, SK, Eltehiwy, MA: Exponentiated power Lindley distribution. J. Adv. Res. 6, 895–905 (2015).
Ashour, SK, Wahed, MLA: Kummer beta-Weibull geometric distribution: A new generalizations of beta-Weibull geometric distribution. Int. J. Sci. Basic Appl. Res. 16, 258–273 (2014).
Bagheri, SF, Samani, EB, Ganjali, M: The generalized modified Weibull power series distribution: Theory and applications. Comput. Stat. Data Anal. 94, 136–160 (2016).
Bakouch, HS, Al-Zahrani, BM, Al-Shomrani, AA, Marchi, VAA, Louzada, F: An extended Lindley distribution. J. Korean Stat. Soc. 41, 75–85 (2012a).
Bakouch, HS, Ristić, MM, Asgharzadeh, A, Esmaily, L, Al-Zahrani, BM: An exponentiated exponential binomial distribution with application. Statist. Probab. Lett. 82, 1067–1081 (2012b).
Balakrishnan, N, Pal, S: EM algorithm-based likelihood estimation for some cure rate models. J. Stat. Theory Prac. 6, 698–724 (2012).
Balakrishnan, N, Pal, S: Lognormal lifetimes and likelihood-based inference for flexible cure rate models based on COM-Poisson family. Comput. Stat. Data Anal. 67, 41–67 (2013a).
Balakrishnan, N, Pal, S: Expectation maximization-based likelihood inference for flexible cure rate models with Weibull lifetimes (2013b). doi:http://dx.doi.org/10.1177/0962280213.
Balakrishnan, N, Pal, S: An EM algorithm for the estimation of parameters of a flexible cure rate model with generalized gamma lifetime and model discrimination using likelihood-and information-based methods. Comput. Statist. 30, 151–189 (2015a).
Balakrishnan, N, Pal, S: Likelihood inference for flexible cure rate models with gamma lifetimes. Commun. Stat. Theory Methods. 44, 4007–4048 (2015b).
Barreto-Souza, W, de-Morais, AL, Cordeiro, GM: The Weibull-geometric distribution. J. Stat. Comput. Simul. 81, 645–657 (2011).
Barreto-Souza, B, Cribari-Neto, F: A generalization of the exponential-Poisson distribution. Statist. Probab. Lett. 79, 2493–2500 (2009).
Barreto-Souza, W, Simas, AB: The exp-G family of distributions. Braz. J. Probab. Statist. 27, 84–109 (2013).
Batsidis, A, Lemonte, AJ: On the Harris extended family of distributions. Statistics. 49, 1400–1421 (2015).
Bereta, EMP, Louzanda, F, Franco, MAP: The Poisson-Weibull distribution. Adv. Applic. Statist. 22, 107–118 (2011).
Berkson, J, Gage, RP: Survival curve for cancer patients following treatment. J. Amer. Statist. Assoc. 47, 501–515 (1952).
Bidram, H: The beta exponential-geometric distribution. Commun. Stat. Simul. Comput. 41, 1606–1622 (2012).
Bidram, H, Behboodian, J, Towhidi, M: The beta Weibull-geometric distribution. J. Stat. Comput. Simul. 83, 52–67 (2013).
Bidram, H, Alavi, SM: A note on exponentiated F-geometric distributions. J. Mod. Math. Front. 3, 18–23 (2014).
Bidram, H, Nadadrajah, S: A new lifetime model with decreasing, increasing, bathtub-shaped, and upside-down bathtub-shaped hazard rate function. Statistics. 50, 139–156 (2016).
Bidram, H, Nekouhou, V: Double bounded Kumaraswamy-power series class of distributions. Statist. Oper. Res. Trans. 37, 211–230 (2013).
Boag, JW: Maximum likelihood estimates of the proportion of patients cured by cancer therapy. J. R. Stat. Soc. B 11, 15–53 (1949).
Bordbar, F, Nematollah, AR: The modified exponential-geometric distribution. Commun. Stat. Theory Methods. 45, 173–181 (2016).
Bourguignon, M, Silva, RB, Cordeiro, GM: The Weibull-G family of probability distributions. J. Data Sci. 12, 53–68 (2014a).
Bourguignon, M, Silva, RB, Cordeiro, GM: A new class of fatigue life distributions. J. Stat. Comput. Simul. 84, 2619–2635 (2014b).
Bourguignon, M, Ghosh, I, Cordeiro, GM: General results for the transmuted family of distributions and new models. J. Probab. Statist. Art.ID. 7208425, 21 (2016a).
Bourguignon, M, Leao, J, Leiva, V, Santos-Neto, M: The transmuted Birnbaum-Saunders distribution. REVSTAT (2016b). forthcoming.
Cancho, VG, Louzanda-Neto, F, Barriga, GDC: The Poisson-exponential lifetime distribution. Comput. Stat. Data Anal. 55, 677–686 (2011a).
Cancho, VG, Rodrigues, J, de-Castro, M: A flexible model for survival data with a cure rate: a Bayesian approach. J. Appl. Statist. 38, 57–70 (2011b).
Cancho, VG, Louzada, F, Barriga, GDC: The geometric Birnbaum-Saunders regression model with cure rate. J. Stat. Plann. Infer. 142, 993–1000 (2012).
Cancho, VG, Bandyopadhyay, D, Louzada, F, Yiqi, B: The destructive negarive binomial cure rate model with a latent activation scheme. Stat. Methodol. 13, 48–68 (2013a).
Cancho, VG, Louzada, F, Ortega, EMM: The power series cure rate model: An application to a cutaneous melanoma data. Commun. Stat. Simul. Comput. 42, 586–602 (2013b).
Castellares, F, Lemonte, AJ: On the Marshall-Olkin extended distributions. Commun. Stat. Theory Methods. 45, 4537–4555 (2016).
Chahkandi, M, Gangali, M: On some lifetime distributions with decrasing failure rate. Comput. Stat. Data Anal. 53, 4433–4440 (2009).
Chakraborty, S, Bhati, D: Transmuted geometric distribution with applications in modelling and regression analysis of count data. Statist. Oper. Res. Trans. 40, 153–176 (2016).
Chen, MH, Ibrahim, JG, Sinha, D: A new Bayesian model for survival data with a surviving fraction. J. Amer. Statist. Assoc. 94, 909–919 (1999).
Chen, Z: A new two-parameter lifetime distribution with bathtub shape or increasing failure rate function. Statist. Probab. Lett. 49, 155–161 (2000).
Chung, Y, Kang, Y: The exponentiated Weibull-geometric distribution: Properties and estimations. Commun. Stat. Appl. Methods (Korean). 21, 147–160 (2014).
Cordeiro, GM, Alizadeh, M, Ortega, EMM: The exponentiated half-logistic family of distributions: properties and applications. J. Probab. Statist. Art.ID. 864396, 21 (2014a).
Cordeiro, GM, de-Santana, LH, Ortega, EMM, Pescim, RR: A new family of distributions: Libby-Novick beta. Int. J. Statist. Probab. 3, 63–80 (2014b).
Cordeiro, GM, Ortega, EMM, Lemonte, A: The exponential-Weibull lifetime distribution. J. Stat. Comput. Simul. 84, 2592–2606 (2014c).
Cordeiro, GM, Ortega, EMM, Popović, BV, Pescim, RR: The Lomax generator of distributions: Properties, minification process and regression model. Appl. Math. Comput. 247, 465–486 (2014d).
Cordeiro, GM, Alizadeh, M, Ortega, EMM, Serrano, LHV: The Zografos-Balakrishnan odd log-logistic family of distributions: Properties and applications. Hacet. J. Math. Stat. 45 (2015a). doi:http://dx.doi.org/10.15672/HJMS.20159714145. forthcoming.
Cordeiro, GM, Ortega, EMM, Lemonte, A: The Poisson generalized linear failure rate model. Commun. Stat. Theory Methods. 44, 2037–2058 (2015b).
Cordeiro, GM, Saboor, A, Khan, MN: The transmuted generalized modified Weibull distribution. Filomat (2015c). forthcoming.
Cordeiro, GM, Alizadeh, M, Tahir, MH, Mansoor, M, Bourguignon, M, Hamedani, GG: The beta odd log-logistic generalized family of distributions. Hacet. J. Math. Stat. 45, 1175–1202 (2016). forthcoming.
Cordeiro, GM, Bager, RDSB: Moments for some Kumaraswamy generalized distributions. Commun. Stat. Theory Methods. 44, 2720–2737 (2015).
Cordeiro, GM, Bourguignon, M: New results on the Ristić-Balakrishnan family of distributions. Commun. Stat. Theory Methods. 54, 13–53 (2016).
Cordeiro, GM, de-Castro, M: A new family of generalized distributions. J. Stat. Comput. Simul. 81, 883–893 (2011).
Cordeiro, GM, Cancho, VG, Ortega, EMM, Barriga, GDC: A model with long-term survivors: negative binomial Birnbaum-Saunders. Commun. Stat. Theory Methods. 45, 1370–1387 (2016).
Cordeiro, GM, Ortega, EMM, da-Cunha, DCC: The exponentiated generalized class of distributions. J. Data Sci. 11, 777–803 (2013a).
Cordeiro, GM, Silva, GO, Ortega, EMM: The beta Weibull geometric distribution. Statistics. 47, 817–834 (2013b).
Cordeiro, GM, Rodrigues, J, de-Castro, M: The exponential COM-Poisson distribution. Stat. Papers. 53, 653–664 (2012a).
Cordeiro, GM, Silva, GO, Ortega, EMM: The beta extended Weibull family. J. Probab. Stat. Sci. 10, 15–40 (2012b).
Cordeiro, GM, Silva, RB: The complementary extended Weibull power series class of distributions. Ciênc. Nat. 36, 1–13 (2014).
Dagum, C: A new model of personal income distribution: specification and estimation. Econ. Appl. 30, 413–437 (1977).
Das, KK: On some generalized transmuted distributions. Int. J. Sci. Eng. Res. 6, 1686–1691 (2015).
da-Silva, AL, Rodrigues, J, Silva, G: The beta transmuted Fréchet distribution: Properties and application to survival data (in Portuguese). ForSci. 3, 57–69 (2015a).
da-Silva, RV, Gomes-Silva, F, Ramos, MWA, Cordeiro, GM: The exponentiated Burr XII Poisson distribution with application to lifetime data. Int. J. Statist. Probab. 4, 112–131 (2015b).
da-Silva, RV, Ramos, MWA, Gomes-Silva, F, Cordeiro, GM: The exponentiated Kumaraswamy-G class. J. Egyptian Math. Soc. (2016). forthcoming.
Delgarm, L, Zadkarami, MR: A new generalization of lifetime distributions. Comput. Statist. 30, 1185–1198 (2015).
Dempster, AP, Laird, NM, Rubin, DB: Maximum likelihood from incomplete data via the EM algorithm. J. Roy. Stat. Soc. B 39, 1–38 (1977).
Ebraheim, AEHN: Exponentiated transmuted Weibull distribution: A generalization of the Weibull distribution. Int. J. Math. Comput. Phys. Quantum Eng. 8, 897–905 (2014).
Elbatal, I: Transmuted modified inverse Weibull distribution: A generalization of the modified inverse Weibull probability distribution. Int. J. Math. Arch. 4, 117–129 (2013a).
Elbatal, I: Transmuted generalized inverted exponential distribution. Econ. Qual. Control. 28, 125–133 (2013b).
Elbatal, I, Aryal, G: On the transmuted additive Weibull distribution. Aust. J. Statist. 42, 117–132 (2013).
Elbatal, I, Aryal, G: Transmuted Dagum distribution with applications. Chil. J. Statist. 6, 31–45 (2015).
Elbatal, I, Diab, LS, Alim, NAA: Transmuted generalized linear exponential distribution. Int. J. Computer Appl. 83, 29–37 (2013).
Elbatal, I, Asha, G, Raja, AV: Transmuted exponentiated Fréchet distribution: Properties and applications. J. Statist. Applic. Probab. 3, 379–394 (2014).
Elbatal, I, Elgarhy, M: Transmuted quasi-Lindley distribution: A generalization of the quasi-Lindley distribution. Int. J. Pure Appl. Sci. Technol. 18, 59–70 (2013).
Elbatal, I, Mansour, MM, Ahsanullah, M: The additive Weibull-geometric distribution: Theory and applications. J. Stat. Theory Applic. 15, 125–141 (2016).
Elgarhy, M, Rashed, M, Shawki, AW: Transmuted generalized Lindley distribution. Int. J. Math.– Trends Technol. 29, 145–154 (2016).
Eugene, N, Lee, C, Famoye, F: Beta-normal distribution and its applications. Commun. Stat. Theory Methods. 31, 497–512 (2002).
Fatima, A, Roohi, A: Transmuted exponentiated Pareto-I distribution. Pak. J. Statist. 32, 63–80 (2015).
Fioruci, JA, Yiqi, B, Louzada, F, Cancho, VG: The exponential Poisson logarithmic distribution. Commun. Stat. Theory Methods. 45, 2556–2575 (2016).
Flores, JD, Borges, P, Cancho, VG, Louzada, F: The complementary exponential power series distribution. Braz. J. Probab. Statist. 27, 565–584 (2013).
Gallardo, DI, Bolfarine, H: Two alternative estimation procedures for the negative binomial cure rate model with a latent activation scheme. Statist. Oper. Res. Trans. 40, 31–54 (2016).
Gallardo, DI, Bolfarine, H, Pedroso-de-Lima, AC: An EM algorithm for estimating the destructive weighted Poisson cure rate model. J. Stat. Comput. Simul. 86, 1497–1515 (2016).
Gitifar, N, Rezaei, S, Nadarajah, S: Compound distributions motivated by linear failure rate. Statist. Oper. Res. Trans. 40, 177–200 (2016).
Ghorbani, M, Bagheri, SF, Alizadeh, M: A new lifetime distribution: The modified Weibull Poisson distribution. Int. J. Oper. Res. Dec. Sci. Stud. 1, 28–47 (2014).
Gomes, AE, da-Silva, CQ, Cordeiro, GM: The exponentiated-G Poisson model. Commun. Stat. Theory Methods. 44, 4217–4240 (2015).
Granzotto, DCT, Louzada, F: The transmuted log-logistic distribution: Modeling, inference, and an application to a polled tabapua race time up to first calving data. Commun. Stat. Theory Methods. 43, 3387–3402 (2015).
Gui, W, Zhang, S, Lu, X: The Lindley-Poisson distribution in lifetime analysis and its properties. Hacet. J. Math. Stat. 43, 1063–1077 (2014).
Gupta, RC, Gupta, PI, Gupta, RD: Modeling failure time data by Lehmann alternatives. Commun. Stat. Theory Methods. 27, 887–904 (1998).
Gupta, RD, Kundu, D: Generalized exponential distribution. Austral. N. Z. J. Stat. 41, 173–188 (1999).
Gupta, RC, Wu, Q, Huang, J: Analysis of survival data by an exponential-generalized Poisson distribution. J. Stat. Comput. Simul. 84, 2495–2505 (2014).
Haq, MA, Butt, NS, Usman, RM, Fattah, AA: Transmuted power function distribution. Ghazi Uni. J. Sci. 29, 177–185 (2016).
Harandi, SS, Alamatsaz, MA: A complementary generalized linear failure rate geometric distribution. Commun. Stat. Theory Methods. 45, 2204–2227 (2016).
Hashimoto, EM, Ortega, EMM, Cordeiro, GM, Cancho, VG: The Poisson Birnbaum-Saunders model with long-term survivors. Statistics. 48, 1394–1413 (2014).
Hashimoto, EM, Ortega, EMM, Cordeiro, GM, Cancho, VG: A new long-term survival model with interval-censored data. Sankhyã B 77, 207–239 (2015).
Hassan, AS, Abd-Elfattah, AM, Mokhtar, AH: The complementary Burr III Poisson distribution. Austral. J. Basic Appl. Sci. 9, 219–228 (2015).
Hassan, AS, Abd-Elfattah, AM, Mokhtar, AH: The complementary exponentiated inverted Weibull power series family of distributions and its application. British J. Math. Comput. Sci. 13, 1–20 (2016).
Hemmati, F, Khorram, E, Rezakhah, S: A new three-parameter ageing distribution. J. Stat. Plann. Infer. 141, 2266–2275 (2011).
Hussian, MA: Estimation of P(Y<X) for the class of Kumaraswamy-G distributions. Austral. J. Basic Appl. Sci. 7, 158–169 (2013).
Hussian, MA: Transmuted exponentiated gamma distribution: A generalization of exponentiated gamma probability distribution. Appl. Math. Sci. 27, 1297–1310 (2014).
Iriarte, YA, Astorga, JM: Transmuted Maxwell probability distribution (in Portuguese). Rev. Integr. 32, 211–221 (2014).
Iriarte, YA, Astorga, JM: A version of transmuted generalized Rayleigh distribution (in Portuguese). Rev. Integr. 33, 83–95 (2015).
Jafari, AA, Tahmasebi, S: Gompertz-power series distributions. Commun. Stat. Theory Methods. 45, 3761–3781 (2016).
Jiménez, JA, Arunachalam, V, Serna, GM: A generalization of Tukey’s g-h family of distributions. J. Stat. Theory Applic. 14, 28–44 (2015).
Kannan, N, Kundu, D, Nair, P, Tripathi, RC: The generalized exponential cure rate model with covariates. J. Appl. Statist. 37, 1625–1636 (2010).
Khan, MS, King, R: Transmuted modified Weibull distribution: A generalization of the modified Weibull probability distribution. Eur. J. Pure Appl. Math. 6, 66–88 (2013).
Khan, MS, King, R: A new class of transmuted inverse Weibull distribution for reliability analysis. Amer. J. Math. Manag. Sci. 33, 261–286 (2014a).
Khan, MS, King, R: Transmuted generalized inverse Weibull distribution. J. Appl. Stat. Sci. 20, 213–230 (2014b).
Khan, MS, King, R: Transmuted modified inverse Rayleigh distribution. Aust. J. Statist. 44, 17–29 (2015).
Khan, MS, King, R, Hudson, IL: Characterizations of the transmuted inverse Weibull distribution. ANZIAM J. 55, C197—C217 (2014).
Khan, MS, King, R, Hudson, IL: Transmuted generalized exponential distribution: A generalization of the exponential distribution with applications to survival data. Commun. Stat. Theory Methods (2015a). forthcoming.
Khan, MS, King, R, Hudson, IL: A new three parameter transmuted Chen lifetime distribution with application. J. Appl. Stat. Sci. 21, 239–259 (2015b).
Khan, MS, King, R, Hudson, IL: Transmuted Kumaraswamy distribution. Statist. Transition. 17, 1–28 (2016a).
Khan, MS, King, R, Hudson, IL: Transmuted Weibull distribution: Properties and estimation. Commun. Stat. Theory Methods (2016b). doi:http://dx.doi.org/10.1080/03610926.2015.1100744. forthcoming.
Khan, MS, King, R, Hudson, IL: Transmuted Gompertz distribution: Properties and estimation. Pak. J. Statist. 32, 161–182 (2016c).
Kuş, C: A new lifetime distribution. Comput. Stat. Data Anal. 51, 4497–4509 (2007).
Lai, CD, Xie, M, Murthy, DNP: A modified Weibull distribution. IEEE Trans. Reliab. 52, 33–37 (2003).
Leahu, A, Munteanu, BG, Cataranciuc, S: On the lifetime as the maximum or minimum of the sample with power series distributed size. ROMAI J. 9, 119–128 (2013).
Leahu, A, Munteanu, BG, Cataranciuc, S: Max-Erlang and Min-Erlang power series distributions as two new families of lifetime distribution. Bull. Acad. Ştiinţe. 2, 60–73 (2014).
Lemonte, AJ, Cordeiro, GM, Ortega, EMM: On the Additive Weibull Distribution. Commun. Stat. Theory Methods. 43, 2066–2080 (2014).
Louzada, F, Bereta, EMP, Franco, MAP: On the distribution of the minimum or maximum of a random number of i.i.d. lifetime random variable. Appl. Math. 3, 350–353 (2012a).
Louzada, F, Borges, P, Cancho, V: The exponential negative-binomial distribution: A continuous bridge between under and over dispersion on a lifetime modelling structure. J. Statist. Adv. Theory Applic. 7, 67–83 (2012b).
Louzada, F, Cancho, VG, Barriga, GDC: The Poisson-exponential regression model under different latent activation schemes. Comput. Appl. Math. 31, 617–632 (2012c).
Louzada, F, Cancho, VG, Roman, M, Leite, JG: A new long-term lifetime distribution induced by a latent complementary risk framework. J. Appl. Statist. 39, 2209–2222 (2012d).
Louzada, F, Cancho, VG, Yiqi, B: The log-Weibull-negative-binomial regression model under latent failure causes and presence of randomized schemes. Statistics. 49, 930–949 (2015).
Louzada, F, Granzotto, DCT: The transmuted log-logistic regression model: a new model for time up to first calving of cows. Stat. Papers (2015). doi:http://dx.doi.org/10.1007/s00362-015-0671-5. forthcoming.
Louzada, F, Marchi, V, Carpenter, J: The complementary exponentiated exponential geometric lifetime distribution. J Probab Statist. Art.ID. 502159, 12 (2014a).
Louzada, F, Marchi, V, Romana, M: The exponentiated exponential geometric distribution: a distribution with decreasing, increasing and unimodel failure rate. Statistics. 48, 167–181 (2014).
Louzada, F, Roman, M, Cancho, VG: The complementary exponential geometric distribution: Model, properties, and a comparison with its counterpart. Comput. Stat. Data Anal. 55, 2516–2524 (2011).
Lu, W, Shi, D: A new compounding life distribution: the Weibull Poisson distribution. J. Appl. Statist. 39, 21–38 (2012).
Lucena, SEF, Silva, AHA, Cordeiro, GM: The transmuted generalized gamma distribution: Properties and application. J. Data Sci. 13, 409–420 (2015).
Luguterah, A, Nasiru, S: Transmuted exponential Pareto distribution. Far East. J. Theor. Statist. 50, 31–49 (2015).
Mahmoud, MR, Mandouh, RM: On the transmuted Fréchet distribution. J. Appl. Sci. Res. 9, 5553–5561 (2013).
Mahmoudi, E, Jafari, AA: Generalized exponential–power series distributions. Comput. Stat. Data Anal. 56, 4047–4066 (2012).
Mahmoudi, E, Jafari, AA: The compound class of linear failure rate-power series distributions: Model, properties and applications. Commun. Stat. Simul. Comput. (2015). doi:http://dx.doi.org/10.1080/03610918.2015.1005232. forthcoming.
Mahmoudi, E, Mahmoodian, H: Normal power series class of distributions: Model, properties and applications (2015). arXiv:1510.07180v1 [stat.CO].
Mahmoudi, E, Sepahdar, A: Exponentiated Weibull-Poisson distribution: Model, properties and applications. Math. Comput. Simul. 92, 76–97 (2013).
Mahmoudi, E, Sepahdar, A, Lemonte, AJ: Exponentiated Weibull-logarithmic distribution: Model, properties and applications (2014). arXiv:1402.2564v1 [stat.ME].
Mahmoudi, E, Shiran, M: Exponentiated Weibull-geometric distribution and its applications (2012a). arXiv:1206.4008v1 [stat.CO].
Mahmoudi, E, Shiran, M: Exponentiated Weibull-power series distributions and its applications (2012b). arXiv:1212.5613v1 [stat.CO].
Mansour, MM, Elrazik, EMB, Hamed, MS, Mohamed, SM: A new transmuted additive Weibull distribution: Based on a new method for adding a parameter to a family of distribution. Int. J. Appl. Math. Sci. 8, 31–51 (2015a).
Mansour, MM, Hamed, MS, Mohamed, SM: A new Kumaraswamy transmuted modified Weibull distribution with application. J. Stat. Adv. Theory Applic. 13, 101–133 (2015b).
Mansour, MM, Mohamed, SM: A new generalized of transmuted Lindley distribution. Appl. Math. Sci. 9, 2729–2748 (2015).
Marshall, AW, Olkin, I: A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika. 84, 641–652 (1997).
Martinez, EZ, Achcar, JA, Jácome, AAA, Santos, JS: Mixture and non-mixture cure fraction models based on the generalized modified Weibull distribution with an application to gastric cancer data. Comput. Methods Prog. Biomed. 112, 343–355 (2013).
Mendoza, NVR, Ortega, EMM, Cordeiro, GM: The exponentiated-log-logistic geometric distribution: Dual activation. Commun. Stat. Theory Methods. 45, 3838–3859 (2016).
Merovci, F: Transmuted Rayleigh distribution. Aust. J. Statist. 42, 21–31 (2013a).
Merovci, F: Transmuted exponentiated exponential distribution. Math. Sci. Applic. E-Notes. 1, 112–122 (2013b).
Merovci, F: Transmuted Lindley distribution. Int. J. Open Problems Comput. Math. 6, 63–72 (2013c).
Merovci, F: Transmuted generalized Rayleigh distribution. J. Stat. Applic. Probab. 3, 9–20 (2014).
Merovci, F, Elbatal, I, Ahmed, A: The transmuted generalized inverse Weibull distribution. Aust. J. Statist. 43, 119–131 (2014).
Merovci, F, Alizadeh, M, Hamedani, GG: Another generalized transmuted family of distributions: Properties and applications. Aust. J. Statist. 45, 71–93 (2016).
Merovci, F, Elbatal, I: Transmuted Lindley-geometric distribution and its aplications. J. Stat. Applic. Probab. 3, 77–91 (2014a).
Merovci, F, Elbatal, I: Transmuted Weibull-geometric distribution and its aplications. Sci. Magna. 10, 68–82 (2014b).
Merovci, F, Puka, L: Transmuted Pareto distribution. ProbStat Forum. 7, 1–11 (2014).
Morais, AL, Barreto-Souza, W: A compound class of Weibull and power series distributions. Comput. Stat. Data Anal. 55, 1410–1425 (2011).
Munteanu, BG: The max-Weibull power series distribution. An. Univ. Oradea Fasc. Mat. 21, 133–139 (2014).
Nadarajah, S, Cancho, VG, Ortega, EMM: The geometric exponential Poisson distribution. Stat. Methods Applic. 22, 355–380 (2013a).
Nadarajah, S, Jayakumar, K, Ristić, MM: A new family of lifetime models. J. Stat. Comput. Simul. 83, 1389–1404 (2013b).
Nadarajah, S, Cordeiro, GM, Ortega, EMM: General results for the Kumaraswamy-G distribution. J. Stat. Comput. Simul. 82, 951–979 (2012).
Nadarajah, S, Cordeiro, GM, Ortega, EMM: The exponentiated-G-geometric family of distributions. J. Stat. Comput. Simul. 85, 1634–1650 (2015a).
Nadarajah, S, Cordeiro, GM, Ortega, EMM: The Zografos-Balakrishnan-G family of distributions: Mathematical properties and application. Commun. Stat. Theory Methods. 44, 186–215 (2015b).
Nadarajah, S, Shahsanaei, F, Rezaei, S: A new four-parameter lifetime distribution. J. Stat. Comput. Simul. 84, 248–263 (2014a).
Nadarajah, S, Teimouri, M, Shih, SH: Modified beta distributions. Sankhyã B 76, 19–48 (2014b).
Nascimento, ADC, Bourguignon, M, Zea, LM, Santos-Neto, M, Silva, RB, Cordeiro, GM: The gamma extended Weibull family of distributions. J. Stat. Theory Applic. 13, 1–16 (2014).
Nassar, M, Nada, N: A new generalization of the exponential-geometric distribution. J. Statist. Adv. Theory Applic. 7, 25–48 (2012).
Nofal, Z, Afify, A, Yousof, H, Cordeiro, GM: The generalized transmuted-G family of distributions. Commun. Stat. Theory Methods (2016). doi:http://dx.doi.org/10.1080/03610926.2015.1078478. forthcoming.
Oluyede, BO, Foya, S, Warahena-Liyanage, G, Huang, S: The log-logistic Weibull distribution with applications to lifetime data. Aust. J. Statist. 45, 43–69 (2016a).
Oluyede, BO, Motsewabagale, G, Huang, S, Warahena-Liyanage, G, Rararai, M: The Dagum-Poisson distribution: model, properties and application. Electron. J. Appl. Stat. Anal. 9, 169–197 (2016b).
Oluyede, BO, Warahena-Liyanage, G, Rararai, M: A new compund class of log-logistic Weibull-Poisson distribution: model, properties and application. J. Stat. Comput. Simul. 86, 1363–1391 (2016c).
Ortega, EMM, Cordeiro, GM, Kattan, MW: The negative binomial-beta Weibull regresion model to predict the cure rate of prostrate cancer. J. Appl. Statist. 39, 1191–1210 (2012).
Ortega, EMM, Barriga, GDC, Hashimoto, EM, Cancho, VG, Cordeiro, GM: A new class of survival regression models with cure fraction. J. Data Sci. 12, 107–136 (2014).
Ortega, EMM, Cordeiro, GM, Campelo, AK, Kattan, MW, Cancho, VG: A power series beta Weibull regression model for predicing breast carcinoma. Statist. Med. 34, 1366–1388 (2015).
Owoloko, EA, Oguntunde, PE, Adejumo, AO: Performance rating of the transmuted exponential distribution: an analytical approach. SpringerPlus. 4, 8–18 (2015).
Pal, M, Tiensuwan, M: The beta transmuted Weibull distribution. Aust. J. Statist. 43, 133–149 (2014).
Pappas, V, Adamidis, K, Loukas, S: A three-parameter lifetime distribution. Adv. Applic. Statist. 20, 159–167 (2011).
Pappas, V, Adamidis, K, Loukas, S: A generalization of the exponential-logarithmic distribution. J. Stat. Theory Prac. 9, 122–133 (2015).
Pararai, M, Oluyede, BO, Warahena-Liyanage, G: Kumaraswamy Lindley-Poisson distribution: Theory and applications. Asian. J. Math. Appl. Art. ID. ama0261, 30 (2015a).
Pararai, M, Warahena-Liyanage, G, Oluyede, BO: An extended Lindley Poisson distribution with applications. J. Math. Stat. Sci. 1, 167–198 (2015b).
Pararai, M, Warahena-Liyanage, G, Oluyede, BO: Exponentiated power Lindley Poisson distribution: properties and applications. Commun. Stat. Theory Methods (2016). doi:http://dx.doi.org/10.1080/03610926.2015.1076473. forthcoming.
Pescim, RR, Cordeiro, GM, Demétrio, CGB, Ortega, EMM, Nadarajah, S: The new class of Kummer beta generalized distributions. Statist. Oper. Res. Trans. 36, 153–180 (2012).
Pinho, LGB, Cordeiro, GM, Nobre, JS: On the Harris-G class of distributions: general results and application. Braz. J. Probab. Statist. 29, 813–832 (2015).
Preda, V, Panaitescu, E, Ciumara, R: The modified exponential-Poisson distribution. Proc. Rom. Acad. A12, 22–29 (2011).
Percontini, A, Blas, B, Cordeiro, GM: The beta Weibull Poisson distribution. Chil. J. Statist. 4, 3–26 (2013a).
Percontini, A, Cordeiro, GM, Bourguignon, M: The G-negative binomail family: General properties and applications. Adv. Applic. Statist. 35, 127–160 (2013b).
Percontini, A, Gomes-Silva, FS, Ramos, MWA, Venancio, R, Cordeiro, GM: The gamma Weibull Poisson distribution applied to survival data. Trends Appl. Comput. Math. (TEMA). 15, 165–176 (2014).
Popović, BV, Ristić, MM, Cordeiro, GM: A two parameter distribution obtained by compounding the generalized exponential and exponential distributions. Mediterr. J. Math (2015). doi:http://dx.doi.org/10.1007/s00009-015-0665-5. forthcoming.
Ramos, MWA, Marinho, PRD, Cordeiro, GM, da-Silva, RV, Hamedani, GG: The Kumaraswamy-G Poisson family of distributions. J. Stat. Theory Applic. 14, 222–239 (2015).
Ramos, MWA, Marinho, PRD, da-Silva, RV, Cordeiro, GM: The exponentiated Lomax Poisson distribution with an application to lifetime data. Adv. Applic. Statist. 34, 107–135 (2013).
Rezaei, S, Tahmasbi, R: A new lifetime distribution with increasing failure rate: Exponential truncated Poisson. J. Basic Appl. Sci. Res. 2, 1749–1762 (2012).
Ristić, MM, Balakrishnan, N: The gamma-exponentiated exponential distribution. J. Stat. Comput. Simul. 82, 1191–1206 (2012).
Ristić, MM, Kundu, D: Generalized exponential geometric extreme distribution. J. Stat. Theory Prac. 10, 179–201 (2016).
Ristić, MM, Nadarajah, S: A new lifetime distribution. J. Stat. Comput. Simul. 84, 135–150 (2014).
Ristić, MM, Popvić, BV, Nadarajah, S: Libby and Novick’s generalized beta exponential distribution. J. Stat. Comput. Simul. 85, 740–761 (2015).
Rodrigues, J, Cancho, VG, de-Castro, M, Louzada-Neto, F: On the unification of long-term survival models. Statist. Probab. Lett. 79, 753–759 (2009a).
Rodrigues, J, de-Castro, M, Cancho, VG, Balakrishnan, N: COM-Poisson cure rate survival models and an application to a cutaneous melanoma data. J. Stat. Plann. Infer. 139, 3605–3611 (2009b).
Roman, M, Louzada, F, Cancho, VG, Leite, JG: A new long-term survival distribution for cancer data. J. Data Sci. 10, 241–258 (2012).
Saboor, A, Kamal, M, Ahmad, M: The transmuted exponentiated-Weibull distribution with applications. Pak. J. Statist. 31, 229–250 (2015).
Saboor, A, Elbatal, I, Cordeiro, GM: The transmuted exponentiated Weibull geometric distribution: Theory and applications. Hacet. J. Math. Stat. 45, 973–987 (2016).
Sarhan, AM, Kundu, D: Generalized linear failure rate distribution. Commun. Stat. Theory Methods. 38, 642–660 (2009).
Sarhan, AM, Zaindin, M: Modified Weibull distribution. Appl. Sci. 11, 123–136 (2009).
Shahsanaei, F, Rezaei, S, Pak, A: A new two-parameter lifetime distribution with increasing failure rate. Econ. Qual. Control. 27, 1–17 (2012).
Shafiei, S, Darijani, S, Saboori, H: Inverse Weibull power series distributions: properties and applications. J. Stat. Comput. Simul. 86, 1069–1094 (2016).
Sharma, VK, Singh, SK, Singh, U: A new upside-down bathtub shaped hazard rate model for survival data analysis. Appl. Math. Comput. 239, 242–253 (2014).
Shaw, WT, Buckley, IR: The alchemy of probability distributions: Beyond Gram-Charlier expansions, and a skew-kurtotic-normal distribution from a rank transmutation map (2009). arXiv:0901.0434 [q-fin.ST].
Shahzad, MN, Asghar, Z: Transmuted Dagum distribution: A more flexible and broad shaped hazard function model. Hacet. J. Math. Stat. 45, 227–224 (2016).
Silva, RB, Barreto-Souza, W, Cordeiro, GM: A new distribution with decreasing, increasing and upside-down bathtub failure rate. Comput. Stat. Data Anal. 54, 935–944 (2010).
Silva, RB, Bourguignon, M, Dias, CRB, Cordeiro, GM: The compound class of extended Weibull power series distributions. Comput. Stat. Data Anal. 58, 352–367 (2013).
Silva, RB, Bourguignon, M, Cordeiro, GM: A new compounding family of distributions: The generalized gamma power series distributions. J. Comput. Appl. Math. 303, 119–139 (2016).
Silva, RB, Cordeiro, GM: The Burr XII power series distributions: A new compounding family. Braz. J. Probab. Statist. 29, 565–589 (2015).
Tahir, MH, Cordeiro, GM, Alizadeh, M, Mansoor, M, Zubair, M, Hamedani, GG: The odd generalized exponential family of distributions with applications. J. Stat. Dist. Applic. 2, Art, 1 (2015).
Tahir, MH, Cordeiro, GM, Alzaatreh, A, Mansoor, M, Zubair, M: The Logistic-X family of distributions and its applications. Commun. Stat. Theory Methods. 45, 732–7349 (2016). forthcoming.
Tahir, MH, Nadarajah, S: Parameter induction in continuous univariate distribution: Well-established G families. Ann. Braz. Acad. Sci. 87, 539–568 (2015).
Tahir, MH, Zubair, M, Cordeiro, GM, Alzaatreh, A, Mansoor, M: The Poisson-X family of distributions. J. Stat. Comput. Simul. 86, 2901–2921 (2016a).
Tahir, MH, Zubair, M, Mansoor, M, Cordeiro, GM, Alizadeh, M, Hamedani, GG: A new Weibull-G family of distributions. Hacet. J. Math. Stat. 45, 629–647 (2016b).
Tahmasbi, R, Rezaei, S: A two-parameter lifetime distribution with decreasing failure rate. Comput. Stat. Data Anal. 52, 3889–3901 (2008).
Tahmasebi, S, Jafari, AA: Exponentiated extended Weibull-power series class of distributions. Ciênc. Nat. 37, 183–193 (2015a).
Tahmasebi, S, Jafari, AA: Generalized Gompertz-power series distributions. Hacet. J. Math. Stat. (2015b). doi:http://dx.doi.org/10.15672/HJMS.20158312681. forthcoming.
Tian, Y, Tian, M, Zhu, Q: Transmuted linear exponential distribution: A new generalization of the linear exponential distribution. Commun. Stat. Simul. Comput. 43, 2661–2671 (2014).
Tojeiro, C, Louzada, F, Roman, M, Borges, P: The complementary Weibull geometric distribution. J. Stat. Comput. Simul. 84, 1345–1362 (2014).
Torabi, H, Montazari, NH: The gamma-uniform distribution and its application. Kybernetika. 48, 16–30 (2012).
Torabi, H, Montazari, NH: The logistic-uniform distribution and its application. Commun. Stat. Simul. Comput. 43, 2551–2569 (2014).
Triantafyllou, IS, Koutras, MV: Failure rate and aging properties of generalized beta- and gamma-generated distributions. Commun. Stat. Theory Methods. 43, 4046–4061 (2014).
Vardhan, RV, Balaswamy, S: Transmuted new modified Weibull distribution. Math. Sci. Applic. E-Notes. 4, 125–135 (2016).
Wang, M: A new three-parameter lifetime distribution and associated inference (2013). arXiv:1308.4128v1 [stat.ME].
Wang, M, Elbatal, I: The modified Weibull geometric distribution. Metron. 73, 303–315 (2015).
Warahena-Liyanage, G, Pararai, M: The Lindley power series class of distributions: Model, properties and applications. J. Comput. Model. 5, 35–80 (2015a).
Warahena-Liyanage, G, Pararai, M: A generalized power Lindley Poisson distribution with applications. Asian J. Math. Appl. Art.ID. ama0169, 23 (2015b).
Xie, M, Lai, CD: Reliability analysis using an additive Weibull model with bathtub shaped failure rate function. Reliab. Eng. Syst. Safe. 52, 87–93 (1995).
Yakovlev, AY, Tsodikov, AD: Stochastic Models of Tumor Latency and Their Biostatistical Applications. World Scientific, Singapore (1996).
Yamachi, CY, Romana, M, Louzada, F, Franco, MAP, Cancho, VG: The exponentiated complementary exponential geometric distribution. J. Mod. Math. Front. 2, 78–83 (2013).
Yiqi, B, Russo, CM, Cancho, VG, Louzada, F: Influence diagnostics for the Weibull-negative-binomial regression model with cure rate under latent failure causes. J. Appl. Statist. 43, 1027–1060 (2016).
Yousof, HM, Afify, AZ, Alizadeh, M, Butt, NS, Hamedani, GG, Ali, MM: The transmuted exponentiated generalized-G family of distributions. Pak. J. Statist. Oper. Res. 11, 441–464 (2015).
Yousof, HM, Afify, AZ, Ebraheim, AEHN, Hamedani, GG, Butt, NS: On six-parameter Fréchet distribution: Properties and applications. Pak. J. Statist. Oper. Res. 12, 281–299 (2016).
Zakerzadeh, H, Mahmoudi, E: A new two parameter lifetime distribution: Model and properties (2013). arXiv:1204.4248v1 [stat.CO].
Zografos, K, Balakrishnan, N: On families of beta- and generalized gamma-generated distributions and associated inference. Stat. Methodol. 6, 344–362 (2009).
Acknowledgements
Both authors are very grateful to the Editor-in-Chief Felix Famoye, an associate editor and two referees for their constructive comments which greatly improved the earlier version of our manuscript.
Authors’ contributions
The authors MHT and GMC with the consultation of each other carried out this work and drafted the manuscript together. Both authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Tahir, M.H., Cordeiro, G.M. Compounding of distributions: a survey and new generalized classes. J Stat Distrib App 3, 13 (2016). https://doi.org/10.1186/s40488-016-0052-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40488-016-0052-1