
Abstract
Real-time data streaming fetches live sensory segments of the dataset in the heterogeneous distributed computing environment. This process assembles data chunks at a rapid encapsulation rate through a streaming technique that bundles sensor segments into multiple micro-batches and extracts into a repository, respectively. Recently, the acquisition process is enhanced with an additional feature of exchanging IoT devices’ dataset comprised of two components: (i) sensory data and (ii) metadata. The body of sensory data includes record information, and the metadata part consists of logs, heterogeneous events, and routing path tables to transmit micro-batch streams into the repository. Real-time acquisition procedure uses the Directed Acyclic Graph (DAG) to extract live query outcomes from in-place micro-batches through MapReduce stages and returns a result set. However, few bottlenecks affect the performance during the execution process, such as (i) homogeneous micro-batches formation only, (ii) complexity of dataset diversification, (iii) heterogeneous data tuples processing, and (iv) linear DAG workflow only. As a result, it produces huge processing latency and the additional cost of extracting event-enabled IoT datasets. Thus, the Spark cluster that processes Resilient Distributed Dataset (RDD) in a fast-pace using Random access memory (RAM) defies expected robustness in processing IoT streams in the distributed computing environment. This paper presents an IoT-enabled Directed Acyclic Graph (I-DAG) technique that labels micro-batches at the stage of building a stream event and arranges stream elements with event labels. In the next step, heterogeneous stream events are processed through the I-DAG workflow, which has non-linear DAG operation for extracting queries’ results in a Spark cluster. The performance evaluation shows that I-DAG resolves homogeneous IoT-enabled stream event issues and provides an effective stream event heterogeneous solution for IoT-enabled datasets in spark clusters.
Similar content being viewed by others


Introduction
Real-time streaming empowers an organization to process live data feed generated through an on-line data production system [1]. In the late 90s, an American scientist Peter J. Denning presented a streaming idea to save in-process bits for solving complex calculations much faster than traditional machine processing. This method helps create, process, and observe the data-stream of an instrument and generate a statistical result set [2]. Nowadays, we find several enhanced forms these days such as, live radio, streaming media, HTTP-based adaptive streaming, instant streaming service, HTTP-live streaming, HD streamed video, Full HD (1080p), and streaming 4k content [3]. On the other hand, record-keeping also used a streaming technique to build various data streams management systems such as STREAM, Aurora, TelegraphCQ, and NiagaraCQ [4].
These management systems store data records using a one-time query, long-running query, dataflow query, and query stream; however, it becomes complex for them to manage large-scale dataset queries in a heterogeneous distributed computing environment [5]. Moreover, this complexity also includes the management of an enormous number of indices in non-tabular datasets that ultimately raises the concept of big data management that could handle large-scale datasets [6]. There are several enterprises out in the market that offers big data management systems such as SQLstream [7], TIBCO [8], IBM [9], Striim [10], and Apache software foundation [11]. Among these, Apache group offers several open-source GPLv3 licensed big data stream engines i.e. Flume [12], Spark [13], Storm [14], NiFi [15], Apex [16], Kafka [17], Samza [18], Flink [19], Beam [20] and Ignite [21], that includes various streaming features as shown in Table 1.
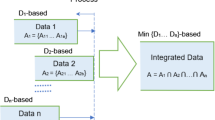
These streaming engines are programmed to handle several forms of data-types, such as structured data, unstructured data, and semi-structured data [22]. These data types are generated through sources that include sensory devices and web-based intelligent portal [23]. Internet of Things (IoT) is a sensory device that consists of an intelligent processor, sensor to detect and store records in its cache storage and an interface to exchange datasets with global networks [24]. This device also generates a continuous flow of data that requires persistent storage to store, and streaming engines categorize its data into three forms, such as unprocessed, processed, and replicas [25]. The unprocessed data is a non-filtered collection that holds an association of tuples with indices only, whereas, the processed data is the extraction of query result onto the unprocessed data. The replica is a block of processed data ready to be exchanged with streaming engines to perform real-time analytics in a distributed computing environment [26], as shown in Fig. 1.

IoT dataset categorization through Stream Engines
IoT devices also generate several metadata events, i.e., monitoring the temperature of factory devices through smart meters, recording a credit card transaction, and detecting an unwanted object in a surveillance camera [27]. These events are a crucial part of metadata along with logs and routing path information and direct streaming queries to identify data tuples in the repository [28]. By default, streaming through Apache engines involve few steps such as (i) stream sourcing, (ii) stream ingestion, (iii) stream storage, and (iv) stream processing [29]. Stream sourcing represents an IoT device that provides a continuous flow of datasets, and stream ingestion consumes the same sourcing data chunk to queue the tasks inside a streaming engine systematically. The stream storage then formulates a micro-batch, a collection of live data feed having an adequate size s in time t sequentially, and stream processing facilitates the system to execute queries and retrieve a real-time result set [30] as shown in Fig. 2.

Default Directed Acyclic Graph (DAG) workflow in Streaming Engine
The data transformation phase divides micro-batch into four further subtypes, i.e., local generation, file system (HDFS) generation, dataset-to-dataset generation, and cache generation [31]. This transformation process is considered relatively lazy because of having an abstract extraction of datasets without any real action. Thus, stream processing requires a task route mapper, that could redirect dataset extractions per query into the respective repository. For this, the streaming engine uses a built-in feature of a directed acyclic graph (DAG) that extracts micro-batches to respective column fields without directed cycles [32]. DAG workflow consists of n MapReduce stages and transforms micro-batches through a scheduler, which transports dataset through resource allocations using stage functions. By default, a simple DAG consists of Stage0→1 stages, whereas, multi-purpose DAG involves Stage0→n stages to transform stream into a dataset as shown in Fig. 2a and b.
This workflow facilitates live queries’ extraction from a micro-batch; however, it does not recognize the type of IoT data tuples during micro-batch formation. Thus, when processing IoT stream events, it encounters four problems, such as (i) homogeneous micro-batches, (ii) dataset diversification, (iii) heterogeneous data tuples, and (iv) linear DAG workflow issue [33].
This article proposes an IoT-enabled Directed Acyclic Graph (I-DAG) for heterogeneous stream events that minimize the processing discrepancy issue in data transformation. The presented I-DAG enhances workflow operation by reading labeled stream tags in heterogeneous event stream containers and scheduling workflow task processing in a spark cluster. Thus, I-DAG contains additional features of processing IoT tuples and managing the existing DAG properties mentioned below.
The significant contributions of I-DAG are highlighted as:
-
A novel event stream tag manager
-
A novel parser to filter heterogeneous event streams in the stream engine
-
An innovative workflow manager that bypasses the unnecessary tasks queued in stages of MapReduce Operation.
-
Stage0→1 I-DAG workflow
-
Stage0→n I-DAG workflow
-
The remaining paper is organized in the following manner. “Motivation” section discusses the benefits and complications; “IOT-Enabled directed acrylic graph (I-DAG)” section addresses the motivation; “Performance evaluation” section explains the proposed model I-DAG; “Conclusion” section shows experimental evaluation over the spark cluster. “Declaration” section presents the conclusion with future work.
Motivation
I-DAG is an enhancement in the existing workflow of executing event streams in spark clusters. Let us discuss the benefits and complications of a smart meter use case in a smart grid.
Smart meters cope with on-ground streaming that includes continuous submission of record streams for grid analytics. A smart grid evaluates the functional and procedural performance of distribution end units through that stream. It simultaneously observes the performance of smart meters, i.e., stream accuracy, optimal workload management, and proper functioning of components. A smart grid generates a complicated scenario in bi-directional processing, where a system confirms the accuracy of a stream through the functionality of a source object. Thus, a smart grid cannot verify the accuracy of streaming analytics through a transformed dataset only, but also, it must monitor the error accuracy of smart meters. Therefore, it requires a streaming event analyzer that copes with Stage0→n transformations concurrently, and I-DAG provides such features through label-based stream event analytics [34, 35].
Smart meters generate heterogeneous IoT events concurrently through bi-directional streaming that creates asynchronous problems in the smart grid, i.e., outnumbered of metadata than traditional processing and overwhelmed analytical accuracy. Thus, when the I-DAG technique applies, it acquires cache containers to jump few MapReduce tasks that usually a developer skips to include in the programming model [36, 37].
Nowadays, the world is moving towards an unpredictable scale of managing IoT devices and their streaming event analytics. This increment would drastically increase with time, and the demand for resource management would be considered a vital issue that must be managed on a priority basis. At that time, a customized Direct Acyclic Graph for IoT event stream processing would fulfill this demand. This IoT-enabled direct acyclic graph would address future heterogeneous workflow event stream operations in the spark cluster [38].
IOT-Enabled directed acrylic graph (I-DAG)
From a functional perspective, we divide I-DAG into three sub-components:
-
Label-based event streaming
-
Heterogeneous stream transformation
-
IoT-enabled DAG workflow
Label-based event streaming
Let IoT devices events be a sequence of error, backup and information messages with a representation as Ei, Bi and Ii, where each of the message belongs to sensory devices as Devicei in the distributed computing environment as shown in Fig. 3. At each time interval t, streams generated through a function fi holds an array of event messages G[1..(Ei,Bi,Ii)] with G[i]=fi. Therefore, when a new occurrence of event messages arrive, the function representation changes to G[i++] and the individual event message collection at each node could be represented as,

Label-based Heterogeneous Streaming Workflow
Where, G[i++] is a container managing multiple event messages arrival with x≥0.
In order to approximate the inner function elements of G[i++], implicit vectors such as x(E[1..n]), y(B[1..n]) and z(I[1..n]) are added into the stream instruction set with a proportion of (Ei,x)++, (Bi,y)++ and (Ii,z)++ and returns an output approximation as,
Where, Eventm>0 and represents the container of processed heterogeneous event messages.

Lemma-1: \(SE_{o,p,q}=\sum _{n}^{i=1}\left \{ \left (e_{i}\times n_{o}\right), \left (b_{i}\times n_{p}\right), \left (i_{i}\times n_{q}\right)\right \}\)
The individual data segments of Ei, Bi and Ii arrives at nodes No, Np and Nq through an incremental function G[i++] that assembles segments in formation order. This order summarize stream segments in such a way that G[i++] stores SEo,p,q≤0.
Lemma-2: E[s]=PP(ei,bi,ii)
Since, \(SE_{o,p,q}= \sum _{n}^{i=1}\left \{ \left (E_{i}\times N_{o}\right), \left (B_{i}\times N_{p}\right), \left (I_{i}\times N_{q}\right)\right \}\), but, \(\sum _{n}^{i=1}\left \{ \left (E_{i}\times N_{o}\right)\times \left (B_{i}\times N_{p}\right)\times \left (I_{i}\times N_{q}\right)\right \}\neq N_{o,p,q}\times \left (\sum _{n}^{i=1}\left (E_{i},B_{i},I_{i}\right)\right)\). Therefore, the constraints are residing within the (Ei,Bi,Ii,). Moreover, if i=j=k then E[No,p,q]=E[1]=1 and if o≠p≠q, then E[No,p,q] are independent and could be retrieved as, \(E\left [N_{o,p,q}\right ]=\tfrac {1}{2}1+\tfrac {1}{2}\left (-1\right)\). After that, the linearity of expectation could be represented as,
Where E[SEo,p,q] manages the heterogeneous events with independent expectation parameters.
Lemma-3: \(V\left [sE_{o,p,q}\right ]\leq 2E\left [sE_{o,p,q}^{}\right ]^{2}\)
Since,
Lemma-4: average T1 and T2 of SEo,p,q
Let A be the output of algorithm-1, so
and that equals to the,
Therefore, the bound of stream segment could be obtained as,
Thus,
In order to reduce the variance, we apply Chebyshev inequality [40] to \( \sqrt {2}\varepsilon > 1\), we get the output as,
So if B be the average of \(\phantom {\dot {i}\!}A_{i},...,A_{T_{1}T_{2}}\)
Now, by Chebyshev’s inequality, as \(T_{1}T_{2}\geq \frac {16}{\varepsilon ^{2} }\),
we get,
At this point, streaming bound δ could be obtained but since a dependence of \(\frac {1}{\delta }\) is present, therefore, we apply lower bound inequality Hoeffding [41] on H[B]=PP(Ei,Bi,Ii) and get,
Now execute median function Z of T1T2 onto \(B,B_{1},...,B_{T_{1}T_{2}}\phantom {\dot {i}\!}\) and we get,
when,
The stream approximation could be obtained as,
This stream approximation defines the existence of managing heterogeneous parameters in the I-DAG.
Heterogeneous stream transformation
The distributed stream elements with probability α(t) are sampled at time t with a computing average of,
and,
In order to perform encapsulation, reservoir sampling is used because it allows adding first k stream elements to the sample having total items t−th with probability \(\frac {k}{t}\). Thus, for every t and i≤t, the sample probability is evaluated as,
and for t+1, the sample probability becomes,
This is mandatory because of the inter-connected heterogeneous IoT tuples that are to be incorporated with the internal of time. The processing of t+1 with i≤t eventually reduces the role of si and returns st+1 as,
The frequency table of stream events uses the event arrival probability Pi,t+1 into Like space saving of count-min sketch to bring an order between transformed heterogeneous stream events as shown in Fig-3. This space saving function provides an approximation fx′ to fx for every x and consumes memory equals to \(O\left (\frac {1}{\Theta }\right)\). Therefore, when a stream vector G[n] is processed with G[i]≥0 for ∀i ε t, it estimates heterogeneous stream G′ of G as,
and,
Where, \(\left | G\right |{~}_{1} =\sum _{i} G\left [i\right ]\) and |G| 1≪streamlength having \(O\left (\frac {1}{\varepsilon ^{2}}ln\frac {2}{\delta }\right)_{HN_{i,i}}\), \(O\left (\frac {1}{\varepsilon ^{2}}ln\frac {2}{\delta }\right)_{BN_{o,p}}\) and \(O\left (\frac {1}{\varepsilon ^{2}}ln\frac {2}{\delta }\right)_{IN_{i,k}}\) memory with \(O\left (ln\frac {n}{\delta }\right)\) update time t.
The heterogeneous events stream \(\sum _{i} G\left [i\right ]\) consists of d independent hash functions h1...hd:[1..n]→[1..w] where, each of the stream element holds memory gp(i) that uses instruction set G[i]+=(Ei,Bi,Ii) having gp(i)+=(Ei,Bi,Ii) for ∀ jε 1..d and the frequency table of heterogeneous events stream could be retrieved as,
This declares that the accessibility of the heterogeneous events stream in enlisted in the I-DAG.
Lemma-5: G′[i]≥g[i]
The minimum count of heterogeneous events stream G[i] remains ≥ 0 for ∀ i with a frequency of update(gp(i)). The stream element having hash function Io,p,q=1 if gp(i)=gp(k)=0 could be retrieved as,
By definition \(A_{o,p}=\sum _{k}H\left [I_{o,p,q}\right ]\times G\left [k\right ]\), the heterogeneous events stream can be represented as,
Now, this stream is well connected and could not be ready independently. Therefore, we apply Markov inequality and pairwise independence as,
if \(w=\frac {2}{\varepsilon }\) then,
for fixed value of i as shown in Figs. 4 and 5. Thus, we observe that the events are synchronized to a central container with independence of accessibility.

Homogeneous IoT Events with Node Representation

Heterogeneous Event Stream Transformation
I-DAG workflow
The events generated through IoT devices with a sequential order of PE[∀ j :Ao,p≥ε|G| 1]are scheduled onto the I-DAG that consists of an identifier LocatorI−DAG which reads events labels \(\left (E_{i}\right)_{N_{o}}=O\left (\frac {1}{\varepsilon ^{2}}ln\frac {2}{\delta }\right)_{HN_{i,i}}\), \(\left (B_{i}\right)_{N_{p}}=O\left (\frac {1}{\varepsilon ^{2}}ln\frac {2}{\delta }\right)_{BN_{o,p}}\) and \(\left (I_{i}\right)_{N_{q}}=O\left (\frac {1}{\varepsilon ^{2}}ln\frac {2}{\delta }\right)_{IN_{i,k}}\) in the source file and shuffle the pointer between n stages as shown in Fig. 6.

IoT-enabled Directed Acyclic Graph (I-DAG) workflow in Streaming Engine
In order to perform stage predictor evaluation, the workflow targets PE[∀ j :Ao,p≥ε|G| 1]: stage(n)→stage(n+1) with LocatorI−DAG: stage(n)→stage(n+1) keeping the error under loss function \(\vartheta :stage\left (n+1\right)\times stage\left (n+1\right)\rightarrow \mathbb {R}\). The predictor error can be obtained as,
This predictor error manages the discrepancies of inter-connection in the I-DAG workflow.
The LocatorI−DAGwith an approximated finite heterogeneous event labels can be sampled with SI−DAG=((stage(n)1,stage(n+1)1),...,(stage(n)n,stage(n + 1)n)) through \(\frac {1}{n}\sum _{i=1}^{n}\vartheta \left (P\left [ \forall \ j \ : A_{o,p}\geq \varepsilon \left | G\right |{~}_{1}\right ], stage\left (n+1\right)\right)\). The workflow loss function are categorized into two types: (i) regression and (ii) classification. The regression loss on predictor LocatorI−DAG is expressed as,
and classification loss on predictor LocatorI−DAG is expressed as,
Thus, I-DAG is ready to facilitate the independent heterogeneous IoT entries with prediction locator.
Performance evaluation
I-DAG technique is incorporated into the Spark cluster, having a virtualized distributed environment, as shown in Table 2.

Environment
Spark cluster consists of Intel Xeon processor with a core computation capacity of 8 CPU units, 64 GB RAM and persistent storage media of 2 TB Disk and 1 TB SSD. The remaining partial workers consist of the Intel Core i7 processor having 4 Cores, 16 GB RAM, and persistent storage media of 1 TB Disk along with 500 GB SSD. The virtual environment consists of Virtual Box 5.2 installed at five virtual machines, as mentioned in Table 3.
Experiments
The dataset used to evaluate I-DAG belongs to Amazon Web Service (AWS) public datasets repository [42–47]. It contains a collection of 4500 files storing stream data having a total volume of 8.6 GB.
The experiments performed on the AWS dataset consists of (i) Events labeling, (ii) Labeling error factor, (iii) Joining Heterogeneous Streams, (iv) Heterogeneous dataframes, (v) Workflow Endurance and (vii) Cluster performance.
Metrics of evaluation
I-DAG consists of two performance metrics, i.e., (i) Merging of disjoint streams and (ii) Stages bypass. The disjoint stream merging overlaps the individual element and strengthens connectivity between heterogeneous streams. The stages bypass reduces unnecessary consumption of RAM and a decrease in redundant garbage values that appear as a result of regular stage processing.
Results
This section discusses the experimental results generated through the proposed approach I-DAG tasks processing.
Events labeling
IoT devices generate events of errors, backup, and record information in the form of text data that the stream engine receives for micro-batch transformation. Event labels mark the stream elements with an I-DAG tag sequence having a hash function. This tagging creates an impact of trust, and it no longer requires a pair in a prefix or postfix, and the transformation function uses the same hash to bundle stream elements into the core engine. This labeling function consists of several sub-routines such as (i) data ingest, (ii)element queuing, (iii)stream chunk tagger, (iv) hash element, and (v) element dispatcher. The data_ingest function fetches an enormous number of individual stream elements from several devices and uses Heap memory to enlist the element arrival into stream engine. The element_queuing feature then assign the indices to respective Heap function entries in FCFS (First come First serve) order. The stream_chunk_tagger method assigns a label \(Stream_{E_{i},B_{i},I_{i}}\) to each of the indexed entry and allocates a hash_element value for identifying any particular index in the stream and finally the dispatcher encapsulates the tags and transform the event streams as shown in Table 4.
The tagged events are recognized by the stream engine much effectively than regular heterogeneous events, as shown in Fig. 7.

Heterogeneous Events Processing
Labeling error factor
The error in an event labeling process appears due to improper placement of tag. It occurs during the application of events labeling relies upon several reasons such as (i) improper ingest, (ii) queue out of bound, (iii) abnormal tagging, (iv) inaccuracy in tag, and (v) partial release of an element. During the tag formation process, a stream element could lead to improper ingestion due to concurrent in-takes at the same time. The queue responsible for managing stream may lead to a buffer overflow problem if the tagging time interval increases than the usual timeline. Also, the stream could be released without having a proper index and hash function due to continuous inaccurate tag application. The errors in label-based events, as well as healthy stream formation, can be observed in Fig. 8.

Errors during Heterogeneous Event Processing
Heterogeneous streams join
The tagged stream elements require a join operation to combine like events in the stream engine. This requirement is a must because of the live ingestion of heterogeneous stream feed through enormous IoT devices. The functional aspect of a join operation consists of parsing tagged stream elements adjacent to each other so that streaming ingestion must be within the same range of time along with a conjunctive condition that offers to join elements with similar tagging. This conjunction function correlates element n to n+1 through a forward-feed chain in the data transformation environment. The stream element join is executed through syntax \(Stream_{E_{i}}=join\left (parse\left (Tag_{n},Tag_{n+1}\right)\rightarrow \left (\left |Tag_{n},Tag_{n+1}\right |\right)\right)\) keeping group-by phrase as a priority along with aggregate operators. The heterogeneous streams join of error, backup, and information record events through query operators, as observed through Table 5.
In the same way, the heterogeneous streams join of error, backup, and information record events through diff operator can be observed through Table 6. The comparative effectiveness of the tagged heterogeneous streams joins, as observed through Fig. 9.

Heterogeneous Streams Join Computing Percentile
Heterogeneous data frames
The label-based stream elements stored in a heterogeneous data frame that comprises a table having data structured properties. This data table assigns a sequence of indices to the stream elements that declare as equal length vectors. The frame categorizes into several sub-sections, such as (i) header, (ii) data row, and (iii) cell. The header represents the top line of tabular-structure that manages column names only. The data row depicts the stream element having a prefixed index value, and the cell is the stream element member of the row. The data frame supports event labeling transformation through a prior metadata information set of stream elements. Thus, the tagged stream elements are retrieved in a much more efficient manner than traditional stream elements, as shown in Fig. 10.

Heterogeneous Data Frame Computing Percentile
Workflow endurance
The issues encountered through in-process heterogeneous data streams measures the workflow endurance during stage processing. The IoT-enabled workflow uses data frames to learn about tagged stream elements already enlisted in the data table. Therefore, when a stream joins processes on the source file, the table allows the I-DAG workflow to skip unnecessary steps wherever encountered. This step skipping practice is learned very well through two case studies given as (i) Stage0→1 and (ii) Stage0→n. The Stage0→1 consist of two stages having three operations in total that includes flatMap, Map and Reduce. If the label stream element already processed through the Map functionality, it can jump the control from flatMap to Reduce operation. In the case of Stage0→n, when the compiler parses the source file that consists of a schedule, the control bypasses unscheduled operations in the stages. Thus, it reduces the usage of energy consumption and the computing capacity of a cluster along with skipping functional latency issues. The Stage0→1 and Stage0→n performance could be observed through Tables 7 and 8.
Cluster performance
The parameters measuring cluster performance comprise stage activity that includes map and reduce task processing and the exchange of i/O operations. i-DAG enables a cluster to perform switching in-between stage tasks depending on the source file’s requirement. if the task does not require to produce map values, it bypasses the operation towards the next task, unlike traditional dAG that has to go through each of the individual operation producing i/O latency along with additional operational cost as shown in Fig. 11.

Heterogeneous Event Processing on Spark Cluster
Conclusion
This paper proposes a novel technique that identifies different IoT devices stream events over a graph processing layer in spark cluster. The proposed approach provides a broad analytical perspective of how the stream events are generated, proceeded by their convergence in the heterogeneous form. In the end, the I-DAG workflow processes individual IoT devices’ stream events with a cost-effective mechanism. It reduces graph workload along with decreasing the I/O traffic load in the spark cluster.
Availability of data and materials
The data related to the manuscript is available with the authors and could be produced if required.
References
Gaber M, Zaslavsky A, Krishnaswamy S (2005) Mining data streams: a review. ACM Sigmod Rec 34(2):18–26.
Denning PJ (1990) The science of computing: Saving all the bits. American Sci 78(5):402–405.
Vega M, Perra C, De Turck F, Liotta A (2018) A review of predictive quality of experience management in video streaming services. IEEE Trans Broadcast 64(2):432–445.
de Assuncao M, da Silva Veith A, Buyya R (2018) Distributed data stream processing and edge computing: A survey on resource elasticity and future directions. J Netw Comput Appl 103:1–17.
Krempl G, žliobaite I, Brzeziński D, Hüllermeier E, Last M, Lemaire V, Noack T, Shaker A, Sievi S, Spiliopoulou M, et al. (2014) Open challenges for data stream mining research. ACM SIGKDD explor newsl 16(1):1–10.
Wu X, Zhu X, Wu G-Q, Ding W (2013) Data mining with big data. IEEE Trans Knowl Data Eng 26(1):97–107.
Streaming SQL Analytics for Kafka & Kinesis.https://sqlstream.com. Accessed 11 Dec 2019.
Software Inc. TGlobal Leader in Integration and Analytics Software. https://www.tibco.com/. Accessed 11 Dec 2019.
Inc. IComputer hardware company. http://www.ibm.com. Accessed 11 Dec 2019.
striimstream with two i’s for integration and intelligence. https://www.striim.com/. Accessed 11 Dec 2019.
Apache OrgWelcome to The Apache Software Foundation!. https://www.apache.org/. Accessed 11 Dec 2019.
Hoffman S (2013) Apache Flume: Distributed Log Collection for Hadoop. Packt Publishing Ltd, USA.
Zaharia M, Xin R, Wendell P, Das T, Armbrust M, Dave A, Meng X, Rosen J, Venkataraman S, Franklin M, et al. (2016) Apache spark: a unified engine for big data processing. Commun ACM 59(11):56–65.
Jain A, Nalya A (2014) Learning Storm. Packt Publishing Ltd, USA.
Apache nifiWelcome to The Apache Nifi. http://nifi.apache.org. Accessed 11 Dec 2019.
Apache ApexWelcome to The Apache Apex.
Apache KafkaWelcome to The Apache Kafka. http://kafka.apache.org. Accessed 11 Dec 2019.
Apache SamzaWelcome to The Apache Samza. samza.apache.org. Accessed 11 Dec 2019.
Apache FlinkWelcome to The Apache Flink. http://flink.apache.org. Accessed 11 Dec 2019.
Apache BeamWelcome to The Apache Beam. http://beam.apache.org. Accessed 11 Dec 2019.
Apache IgniteWelcome to The Apache Ignite. http://ignite.apache.org. Accessed 11 Dec 2019.
Tatbul N (2010) Streaming data integration: Challenges and opportunities In: 2010 IEEE 26th International Conference on Data Engineering Workshops (ICDEW 2010), 155–158.. IEEE, USA.
Watanabe Y, Yamada S, Kitagawa H, Amagasa T (2007) Integrating a stream processing engine and databases for persistent streaming data management In: International Conference on Database and Expert Systems Applications, 414–423.. Springer, USA.
Atzori L, Iera A, Morabito G (2010) The internet of things: A survey. Comput Netw 54(15):2787–2805.
Vural S, Navaratnam P, Wang N, Wang C, Dong L, Tafazolli R (2014) In-network caching of internet-of-things data In: 2014 IEEE International Conference on Communications (ICC), 3185–3190.. IEEE, USA.
Stonebraker M, Çetintemel U, Zdonik S (2005) The 8 requirements of real-time stream processing. ACM Sigmod Rec 34(4):42–47.
Gaur P, Tahiliani M (2015) Operating systems for iot devices: A critical survey In: 2015 IEEE Region 10 Symposium, 33–36. IEEE.
Kang Y-S, Park I-H, Rhee J, Lee Y-H (2015) Mongodb-based repository design for iot-generated rfid/sensor big data. IEEE Sensors J 16(2):485–497.
Ranjan R (2014) Streaming big data processing in datacenter clouds. IEEE Cloud Comput 1(1):78–83.
Kamburugamuve S, Fox G, Leake D, Qiu J (2013) Survey of distributed stream processing for large stream sources. Grids Ucs Indiana Edu 2:1–16.
Lemon J, Wang Z, Yang Z, Cao P (2004) Stream engine: A new kernel interface for high-performance internet streaming servers In: Web Content Caching and Distribution, 159–170.. Springer, USA.
Liew C, Atkinson M, van Hemert J, Han L (2010) Towards optimising distributed data streaming graphs using parallel streams In: Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, 725–736.. ACM, USA.
Saad A, Park S (2019) Decentralized directed acyclic graph based dlt network In: Proceedings of the International Conference on Omni-Layer Intelligent Systems, 158–163.. ACM, USA.
Qureshi N, Bashir A, Siddiqui I, Abbas A, Choi K, Shin D (2018) A knowledge-based path optimization technique for cognitive nodes in smart grid In: 2018 IEEE Global Communications Conference (GLOBECOM), 1–6.. IEEE, USA.
Qureshi N, Siddiqui I, Unar M, Uqaili M, Nam C, Shin D, Kim J, Bashir A, Abbas A (2019) An aggregate mapreduce data block placement strategy for wireless iot edge nodes in smart grid. Wirel Pers Commun 106(4):2225–2236.
Siddiqui I, Qureshi N, Shaikh M, Chowdhry B, Abbas A, Bashir A, Lee S-J (2019) Stuck-at fault analytics of iot devices using knowledge-based data processing strategy in smart grid. Wirel Pers Commun 106(4):1969–1983.
Zhu F, Wu W, Zhang Y, Chen X (2019) Privacy-preserving authentication for general directed graphs in industrial IoT. Inf Sci 502:218–228.
Kotilevets I, Ivanova I, Romanov I, Magomedov S, Nikonov V, Pavelev S (2018) Implementation of directed acyclic graph in blockchain network to improve security and speed of transactions. IFAC-PapersOnLine 51(30):693–696.
Deng C, Yang E, Liu T, Tao D (2020) Two-Stream Deep Hashing With Class-Specific Centers for Supervised Image Search. IEEE Trans Neural Netw Learn Syst 31:2189–2201. https://doi.org/10.1109/TNNLS.2019.2929068.
Saw J, Yang M, Mo T (1984) Chebyshev inequality with estimated mean and variance. Am Stat 38(2):130–132.
Duda P, Jaworski M, Pietruczuk L, Rutkowski L (2014) A novel application of hoeffding’s inequality to decision trees construction for data streams In: 2014 International Joint Conference on Neural Networks (IJCNN), 3324–3330.. IEEE, USA.
Qureshi N, Siddiqui I, Abbas A, Bashir A, Choi K, Kim J, Shin D (2019) Dynamic container-based resource management framework of spark ecosystem In: 2019 21st International Conference on Advanced Communication Technology (ICACT), 522–526.. IEEE, USA.
Siddiqui IF, Qureshi NMF, Chowdhry BS, Uqaili MA (2020) Pseudo-Cache-Based IoT Small Files Management Framework in HDFS Cluster. Wirel Personal Commun.
Qureshi NMF, Siddiqui IF, Abbas A, Bashir AK, Nam CS, Chowdhry BS, Uqaili MA (2020) Stream-Based Authentication Strategy Using IoT Sensor Data in Multi-homing Sub-aqueous Big Data Network. Wirel Personal Commun.1–13.
Siddiqui IF, Qureshi NMF, Chowdhry BS, Uqaili MA (2019) Edge-node-aware adaptive data processing framework for smart grid. Wirel Personal Commun 106(1):179–189.
Qureshi NMF, Shin DR, Siddiqui IF, Chowdhry BS (1374) Storage-tag-aware scheduler for hadoop cluster. IEEE Access 5:2–13755.
Qureshi NMF, Shin DR (2016) RDP: A storage-tier-aware Robust Data Placement strategy for Hadoop in a Cloud-based Heterogeneous Environment. TIIS 10(9):4063–4086.
Acknowledgments
This paper was produced with support from the Ministry of Science and ICT’s Broadcasting and Communication Development Fund and may differ from the official opinion of the Ministry of Science and ICT.
Funding
This paper was produced with support from the Ministry of Science and ICT’s Broadcasting and Communication Development Fund and may differ from the official opinion of the Ministry of Science and ICT.
Author information
Authors and Affiliations
Contributions
The authors have contributed in such a manner as: 1st author: He has performed major portions of experiments and have written the manuscript 2nd author: He is responsible to answer the corresponding author queries as well as have performed directed acyclic graph experimentation 3rd author: She is responsible for debugging evaluations in the simulations. 4th author: He is responsible to evaluate the modeling values extracted by the execution of ecosystem. 5th author: He is managing the editing of manuscript in terms of technical as well as written English.
Corresponding author
Ethics declarations
Competing interests
There is not any conflict of interest among the authors related to the content disclosed at the disposal of manuscript and the authors have a mutual consenton all concerned points related to the manuscript.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Koo, J., Faseeh Qureshi, N.M., Siddiqui, I.F. et al. IoT-enabled directed acyclic graph in spark cluster. J Cloud Comp 9, 50 (2020). https://doi.org/10.1186/s13677-020-00195-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13677-020-00195-6