
Abstract
The Robin boundary value problem for Laplace’s equation in the elliptic region (which is a forward problem) and its related inverse problem can be used to reconstruct Robin coefficients from measurements on a partial boundary (inverse problem). We present a numerical solution of the forward problem that uses a boundary integral equation method, and we propose a fast solver based on one that reduces the computational complexity to \(\mathcal{O}(N\log (N))\), where N is the size of the data. We compute the solution of the inverse problem using a preconditioned Krylov subspace method where the preconditioner is based on a block matrix decomposition. The structure of the matrix is then exploited to solve the direct problem. Numerical examples are presented to illustrate the effectiveness of the proposed approach.
Similar content being viewed by others

1 Introduction
Laplace’s equation is of particular importance in applied mathematics because it is applicable to a wide range of different physical and mathematical phenomena, including electromagnetism, fluid and solid mechanics, conductivity. It has the special status of being the most straightforward elliptic partial differential equation for the description of all sorts of steady state phenomena. When attached to Robin boundary conditions it is able to handle the spherical geometry of the largest to the smallest structures in the universe [1]. If a domain Ω in \(R^{2}\) is assumed to have a smooth boundary \(\partial \varOmega =\varGamma \), the Robin boundary value problem for Laplace’s equation can be stated as follows:
where ν is an outward-facing unit normal vector on Γ; \(p=p(x)\) is the Robin coefficient, which is non-negative and not identical for \(\varGamma _{1}\subset \varGamma \); and \(g=g(x)\) is a given input function.
However, Laplace’s equation is known to present a number of boundary value problems that can be complex to solve and, when it comes to computation, this can demand significant quantities of computational work. There is therefore an ongoing need to come up with more efficient algorithms to solve these kinds of boundary value problems. This paper addresses such a need.
If p in Eq. (1.1) is given, a unique solution, u, can be determined. This is known as the forward problem. The forward map from p to u has already been discussed in the literature, and a number of its properties has been identified, including uniqueness, continuity with respect to proper norms, differentiability and various forms of stability (see [2,3,4,5,6,7]).
However, a more challenging problem is the inverse problem, which aims to recover the Robin coefficient p from a partial boundary measurement of function u. In other words, how to obtain p by using \(u=u_{0}\) on a part, \(\varGamma _{0}\), of the boundary, where \(\varGamma _{0} \cap \varGamma _{1}=\emptyset \). It is well-known that the inverse problem is currently ill-conditioned, which can cause significant computational difficulties. This issue is of concern because a number of applications seek a solution of the problem, notably various kinds of nondestructive evaluation (NDE) [8].
A lot of research over recent years has been devoted to developing a numerical solution to the inverse problem [9,10,11,12,13]. Lin and Fang transformed the Robin inverse problem into a linear integral equation by introducing a new variable v, then located a way of regularizing v [14]. From this, it was possible to derive a linear least-square-based methods for estimation of the Robin coefficient. Jin solved the Robin inverse problem by using conjugate gradient (CG) methods [15], then analyzing the convergence of different regular terms. Jin and Zou looked at ways of estimating piecewise constant Robin coefficients by using a concave-convex procedure to minimize the Modica–Mortola functional [16]. Chaabane et al. also considered the possibility of estimation of piecewise constant Robin coefficients, in their case by using the Kohn–Vogelius method [17]. Jiang et al. [18] discussed the convergence properties for elliptic and parabolic inverse robin problems.
The solution of an inverse problem usually depends upon a forward solver that is capable of expanding upon the current state to assess whether it can be proved given the current conditions. This makes the speed of forward solver a critical consideration. It is possible to discretize Eq. (1.1) directly by using a finite difference method or a finite element method (see, for instance, [19]) or wavelet method (see, for instance, [20, 21]). Equation (1.1) can also be reformulated as a boundary integral equation. The resulting integral equation can then be discretized by using a boundary element method or numerical quadratures [14, 15, 22, 23]. Out of these, using a boundary integral equation (BIE) appears to the best option because the resulting discrete system is much smaller than it is if one uses the original partial differential equation. This has led to a BIE approach being used by many researchers who take an interest in inverse problems, and we, too, will be adopting this method.
After Eq. (1.1) has been transformed into a BIE and the discretization scheme set up, it can be found that the structure of the coefficient matrix of the resulting discrete system is the sum of the circulant. This makes it possible for a fast algorithm for matrix-vector products to be developed by using a fast Fourier transform (FFT) approach where only \(\mathcal{O}(N\log (N))\) operations are required instead of the standard \(\mathcal{O}(N^{2})\). In this way, numerical methods for solving the inverse problem can be effectively sped up by using this faster forward solver. Aside from this, we shall be looking at a preconditioner that can exploit the structure of the forward problem matrix. A variant of the symmetric quasi-minimal residual (SQMR) method is employed to accomplish this. SQMR is known to offer significant economy in solving large-scale problems. As the preconditioner is not formed explicitly, we also present an algorithm that can obtain the product of the preconditoner with a given vector.
The paper is organized as follows. In Sect. 2, the Robin inverse problem is transformed into an equivalent BIE. We then derive a fast algorithm for discretization of its linear system by exploiting the special properties of certain relevant kernel functions. In Sect. 3, we look at how the preconditioner used in the Krylov subspace method for the Karush–Kuhn–Tucker (KKT) system might be used to further enhance our approach. In Sect. 4, we conclude with numerical examples to demonstrate the effectiveness of our proposed fast solver for the Robin inverse problem.
2 Fast solution of the forward problem
Let \(\varPhi =\varPhi (x,y)\) be the fundamental solution for Laplace’s equation in \(\mathbb{R}^{2}\). Thus:
We will first introduce a formulation of the BIE for the boundary value problem presented in Eq. (1.1). Using Green’s formula, the solution, u, to Eq. (1.1) in domain Ω can be represented in terms of its boundary value by the following:
where \(ds_{y}\) denotes the arc length differential. After moving x in Ω to the boundary Γ, one can arrive at the following BIE on the boundary Γ:
Hence, solving Eq. (1.1) in Ω can be reduced to solving the above BIE, (2.1), on Γ.
The double-layer and single-layer operators can be defined, respectively, by
and, by denoting \(\mathcal{A}(p)(u)= (\frac{1}{2}\mathcal{I}+ \mathcal{D} )u+\mathcal{S}(pu)\), we can re-write Eq. (2.1) in terms of its operators as follows:
where \(f=\mathcal{S}g\).
Let us now suppose that Ω is an ellipse in \(\mathbb{R}^{2}\). So,
where \(a, b >0\). The usual parametrization for Γ is
The kernels in the integral operators \(\mathcal{D}\) and \(\mathcal{S}\) can be explicitly expressed as follows:
for \(0\leq t\), \(s \leq 1\).
For discretization of the integral equation (2.1) with the given parametrization of Γ, a Nyström method can be applied by using the mid-point quadrature rule. If we partition the interval \([0,1]\) into N uniform subintervals \([(i-1)h,ih]\) (\(i = 1,2,\dots ,N\)) with \(h = 1/N\), then the quadrature points will be \(t_{i} = (i-1/2)h\). With the mid-point quadrature rule, we can denote the matrix representation of the kernels \(K_{d}\) and \(K_{s}\) by D and S, respectively. As \(K_{d}(t,s)\) is smooth, the rectangular rule can be applied to obtain the following discrete representation:
However, because the kernel function \(\mathcal{S}\) is weakly singular at \(s=t\) and \((t,s)=(0,1)\) and \((1,0)\), discretizing \(\int _{0}^{1}K _{s}(t,s)u(s)\,ds\) requires special measures to avoid large errors. By denoting
it is possible to decompose \(K_{s}(t,s)\) as follows:
If we now use a singularity subtraction technique, we get
where \(\delta _{ij}\) is the Kronecker delta.
Let us now denote \(K_{s}=hK_{s}(t_{i},t_{j})\), \(K_{s1}=hK_{s1}(t_{i},t _{j})\), \(K_{s2}=hK_{s2}(t_{i},t_{j})\), \(K_{s3}=K_{s3}(t_{i})\). For a given vector v, the product Sv can then be obtained as follows:
where 1 denotes the vector whose elements are all one and \(a.*b\) denotes element-by-element multiplication of the vectors a and b. For more techniques to deal with the singular integral operators we refer to [24, 25].
In general, it is necessary to choose specific quadrature rules for the Nyström method to be able to discretize the BIEs. Nyström techniques can then be used to build faster algorithms [14]. In our case, we want to exploit the special structure of the matrices D and S to devise a fast algorithm that can solve Eq. (2.1) or (2.2).
From the above operator expression, it can be observed that the discretized matrix D is a Hankel matrix, where \(D_{i,j}\) is an element of D and satisfies \(D_{i,j}=D_{i-1,j+1}\). For a given vector v, we can use a fast algorithm to compute the product of D times vector v with the help of an FFT. Obviously, \(K_{s1}\) is a Toeplitz matrix, which has constant values along its negative-sloping diagonals, whilst \(K_{s2}\) is a Hankel matrix. This enables us to get the product of S with a given vector v by using the FFT.
Generally, the discretized form of the direct problem (2.2) is as follows:
where \(\mathbf{p}=\operatorname{diag}(\mathrm{p})\), which can be solved by using a Gaussian elimination method (GE). However, in this paper we will be using an iterative method to solve the problem. For each iteration, we compute the product of the matrix \(\frac{1}{2}I+D+S \mathbf{p}\) with a given vector x by using the FFT algorithm. For the given vector x:
where \(\mathbf{p}x=\mathbf{p}.*x\).
Note that all of the matrix-vector products involved can be rapidly obtained using FFT method, whereby the computational complexity can be reduced to \(\mathcal{O}(N\log (N))\). This allows for a straightforward solution of the direct problem. As will be seen, the numerical results show that our fast algorithm is superior to the Gaussian elimination (GE) method.
3 The Robin inverse problem and preconditioner
The Robin inverse problem we specifically focus on was that, given \(u = u_{0}\) on \(\varGamma _{0}\), one recover the Robin coefficient p on \(\varGamma _{1}\) with \(\varGamma _{0} \cap \varGamma _{1} = \emptyset \). That is,
A solution to the inverse problem does not depend continuously on the data even if this does exist, because of the ill-conditioned nature of the Robin inverse problem for Laplace’s equation. For this reason, the precess of regularization is required to obtain a relatively smooth solution to a nearby problem [10]. In view of this, the inverse problem can be transformed into the following constrained minimization problem:
where \(\mathcal{R}_{0}\) is restriction operator from Γ to \(\varGamma _{0}\). As for regularization function, we choose the \(H^{1}\) semi-norm of \(p(x)\):
and the regularization parameter \(\alpha >0\) to balance the data fidelity \(\|\mathcal{R}_{0}u-u_{0}\|^{2}_{L^{2}(\varGamma _{0})}\) and regularization terms \(J(p)\).
Various nonlinear programming methods have been developed for constrained optimization. These methods seek a critical point for the Lagrangian function:
where λ is a Lagrangian multiplier. The goal here is to get a solution to the large system of nonlinear equations:
where
To solve these nonlinear equations, we can use a Newtonian method to obtain the following KKT system:
where
with
Therefore, the main computational step in the solution process is the repeated solution of large linear systems in the KKT system. To solve the discretized KKT system expressed in Eq. (3.4), there are two basic approaches—a reduced sequential quadratic programming method (SQP) [26] and a full space method [27]. SQP seems preferable because it significantly reduces the dimensions of the problem. However, the major disadvantage here is that it is necessary to solve the variables for u and the Lagrange multipliers λ at each iteration.
The full space method, by contrast, is able to solves KKT systems in such a way that u, λ and p can be obtained simultaneously. The KKT system expressed in (3.4) is relatively straightforward to solve by using Krylov subspace methods. In this paper, we apply a preconditioned Krylov subspace method directly to the KKT system (3.4), and compute a solution to the inverse problem and to the direct problem simultaneously. The sky step here is choosing an appropriate preconditioner for the fast solver of the above KKT system. Recently, the idea of using indefinite preconditioners for KKT systems has come to the fore [28, 29]. However, although it is no longer necessary for the product of the preconditioner within the KKT system (3.4) to be symmetrical, a symmetrical algorithm still be applied to solve the system. In this paper, we assume the preconditioners are symmetrical but far from being positive definite. This is possible because the matrix \(H_{kkt}\) of the KKT system has similar properties. To this end, we shall be looking at how to use a fast symmetrical quasi-minimal residual algorithm (SQMR) to solve the system. We can find that it is possible to apply a symmetric QMR variant to the solution of the system, although the product of the preconditioner with the KKT system (3.3a)–(3.3c) is no longer symmetric.
3.1 A preconditioned reduced method for the KKT system
In view of the similarity between a preconditioned Krylov subspace approach and a preconditioned reduced approach, we will first of all introduce a reduced Hessian system. In this way, we can eliminate \(\delta _{u}\), then \(\delta _{\lambda }\), and finally solve for \(\delta _{p}\) in (3.4):
where
and
In the Gauss–Newton approximation, second-order information can be dropped by setting \(K = 0\) and \(T = 0\). This produces a symmetric positive-definite matrix:
Thus, we are able to draw upon the classical Gauss–Newton method. In this paper, we will use a preconditioned conjugate gradient (PCG) method to solve Eq. (3.5).
3.2 A preconditioned Krylov subspace method for the KKT system
As the invertible block in \(H_{kkt}\) is only on the cross-diagonal axis, the matrix \(H_{kkt}\) is singular. To find an appropriate preconditioner, we can first of all permute the block rows and columns in matrix \(H_{kkt}\) so that there is an invertible block on the diagonal, and obtain an invertible matrix:
For the permuted matrix H we can obtain a block LU decomposition as follows:
where
Note that H is invertible, such that
with
If we let B be an approximation of \(A^{-1}\) and \(M_{\mathrm{red}}\) be an approximation of \(H^{-1}_{\mathrm{red}}\), we can get the following definitions:
where \(\bar{M} = -\mathcal{R}_{0}BG\). These two matrices, L̂ and Û, are approximations of the matrices \(L^{-1}\) and \(U^{-1}\), respectively. So, if we let
we can obtain an approximate inverse, M, of the permuted KKT matrix H. Furthermore, if B and \(M_{\mathrm{red}}\) are chosen to satisfy a product with a vector that can be rapidly calculated, we can also obtain the product with a vector of the approximate inverse, M, rapidly.
However, we do need not to specify the preconditioner, M, explicitly to able to calculate the product of the matrix with a given vector. In fact, given a vector \(v=[v_{\lambda }^{T}, v_{u}^{T}, v_{p}^{T}]^{T}\), the product \(x = [x^{T}_{u}, x^{T}_{\lambda }, x^{T}_{p}]^{T} = Mv\) can be obtained in six stages:
-
(1)
\(w_{1}=Bv_{\lambda }\);
-
(2)
\(w_{2}=B^{T}(v_{u}-\mathcal{R}_{0}^{T}\mathcal{R}_{0}w_{1})\);
-
(3)
\(w_{3}=v_{p}-G^{T}w_{2}-K^{T}w_{1}\);
-
(4)
\(x_{p}=M_{\mathrm{red}}w_{3}\);
-
(5)
\(x_{u}=w_{1}-BGx_{p}\);
-
(6)
\(x_{\lambda }=B^{T}(v_{u}-\mathcal{R}_{0}^{T}\mathcal{R}_{0}x_{u}-Kx _{p})\).
In this paper, we have chosen \(B = A^{-1}\) because it enables a fast solution of the direct problem. On the basis of this, we can rapidly calculate the first, second and fifth stages. In our algorithm, we need to reorder the components in v and x to get the corresponding preconditioner for (3.4). This reorder ensures that the corresponding preconditioning matrix of (3.4) is symmetrical. Then we can use a preconditioned symmetric QMR algorithm to solve the KKT system.
4 Numerical examples
We will first of all consider a numerical solution of the direct problem.
Example 1
(Fast algorithm of the direct problem)
For this numerical experiment, we assumed that there was an ellipse with the following standard parametrization:
where \(a=1\) and \(b = 0.1\). The two segments \(\varGamma _{0}\) and \(\varGamma _{1}\) were
The function for \(g(t)\) was
The Robin coefficient \(p(t)\) was
For the interval \([0,1]\), we set n equal-length intervals with \(\{t_{i}\}_{i=0}^{n}\) nodes. The tests were carried out by using Matlab. In all of the tests, we first selected \({p}(t)\), then obtained approximate values of the solution, \(u(t)\), at the various grid points by solving the linear system as a the direct problem. For comparison, the tests were also conducted using conventional GE.
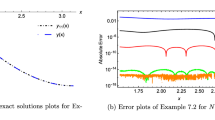
Table 1 shows the results of the fast algorithm for the forward equation when using the discretized matrices. Uniform partitions were set on the parameter domain \([0,1]\) at \(n = 800\). As can be seen from the table, when n exceeded 400, the proposed algorithm was faster than GE, it becoming proportionally faster as n increased.
For the other examples, we will look at the numerical test results for our preconditioned symmetrical quasi-minimal residual method (PSQMR) for the recovery of the Robin coefficients from measurements on \(\varGamma _{0}\). The boundary conditions were the same as those given for the direct problem.
For the approximate inverse \(M_{\mathrm{red}}\), an incomplete LU decomposition was recalled with a threshold \((\operatorname{ILU}(t))\) of \(M^{T}M\).
Example 2
(Comparing of the PCG and PSQMR)
In this example, we compare the PCG for the reduced Hessian system with the PSQMR for the KKT system. The related iterative processes were stopped when the residual was below 10−5.
Table 2 presents iteration counts (‘itns’) for the various values of α because the regular parameters play an important role and need to be quite small. More computations are typically involved in a PCG iteration than in a PSQMR iteration, even though the same types of matrix-vector product are used in both algorithms. We also display flop counts (‘work’) to indicate the total computational work required by each algorithm. The results shown in this table indicate that the number of PSQMR iterations was larger than the number of PCG iteration. However, the overall work when using PSQMR was substantially lower than it was with PCG. This was especially the case when the ILU preconditioner was utilized, because more matrix-vector products were required to arrive at a solution to the forward problem.
Example 3
(Recovery of the Robin coefficient)
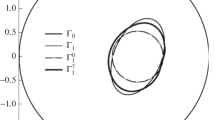
The performance of the two methods was also compared in the elliptic domain. In Fig. 1, the exact p profile generated when using the PSQMR and PCG is plotted together with two reconstructed profiles. For both methods, the regularization parameter α was obtained by employing a discrepancy principle based on our knowledge of noise levels and statistics. The stop criterion was when the norm of the gradient gets below 10−5. It can be seen that under low noise conditions, both method performed well. However, as the noise increased, PCG performed less well, while the PSQMR method remained robust.

Comparison of effectiveness at recovery of the Robin coefficient for PCG and PSQMR
References
Mottin, S.: An analytical solution of the Laplace equation with Robin conditions by applying Legendre transform. Integral Transforms Spec. Funct. 27(4), 289–306 (2016)
Alessandrini, G., Piero, L.D., Rondi, L.: Stable determination of corrosion by a single electrostatic boundary measurement. Inverse Probl. 19(4), 973–984 (2003)
Chaabane, S., Fellah, I., Jaoua, M., Leblond, J.: Logarithmic stability estimates for a Robin coefficient in two-dimensional Laplace inverse problems. Inverse Probl. 20(1), 47–59 (2004)
Chaabane, S., Ferchichi, J., Kunisch, K.: Differentiability of the \({L}^{1}\)-tracking functional linked to the Robin inverse problem. C. R. Math. 337(12), 771–776 (2003)
Sincich, E.: Stability for the determination of unknown boundary and impedance with a Robin boundary condition. SIAM J. Math. Anal. 42(6), 2922–2943 (2010)
Papageorgiou, N.S., Radulescu, V.D., Repovs, D.D.: Asymmetric Robin problems with indefinite potential and concave terms. Adv. Nonlinear Stud. 19, 69–87 (2019)
Papageorgiou, N.S., Scapellato, A.: Nonlinear Robin problems with general potential and crossing reaction. Rend. Lincei Mat. Appl. 30, 1–29 (2019)
Cabib, E., Fasino, D., Sincich, E.: Linearization of a free boundary problem in corrosion detection. J. Math. Anal. Appl. 378(2), 700–709 (2011)
Cakoni, F., Kress, R.: Integral equations for inverse problems in corrosion detection from partial Cauchy data. Inverse Probl. Imaging 1(2), 229–245 (2007)
Chaabane, S., Elhechmi, C., Jaoua, M.: A stable recovery method for the Robin inverse problem. Math. Comput. Simul. 66(4), 367–383 (2004)
Fang, W., Lu, M.: A fast collocation method for an inverse boundary value problem. Int. J. Numer. Methods Eng. 59, 1563–1585 (2004)
Fang, W., Zeng, S.: A direct solution of the Robin inverse problem. J. Integral Equ. Appl. 21(4), 545–557 (2009)
Haber, E., Ascher, U.M., Oldenburg, D.: On optimization techniques for solving nonlinear inverse problems. Inverse Probl. 16(5), 1263–1280 (2000)
Lin, F., Fang, W.: A linear integral equation approach to the Robin inverse problem. Inverse Probl. 21(5), 1757–1772 (2005)
Jin, B.: Conjugate gradient method for the Robin inverse problem associated with the Laplace equation. Int. J. Numer. Methods Eng. 71(4), 433–453 (2007)
Jin, B., Zou, J.: Numerical estimation of piecewise constant Robin coefficient. SIAM J. Control Optim. 48(3), 1977–2002 (2009)
Chaabane, S., Feki, I., Mars, N.: Numerical reconstruction of a piecewise constant Robin parameter in the two- or three-dimensional case. Inverse Probl. 28(6), 065016 (2012)
Daijun, J., Hui, F., Zou, J.: Quadratic convergence of Levenberg–Marquardt method for elliptic and parabolic inverse Robin problems. ESAIM: Math. Model. Numer. Anal. 52, 07 (2015)
Jin, B., Zou, J.: Inversion of Robin coefficient by a spectral stochastic finite element approach. J. Comput. Phys. 227(6), 3282–3306 (2008)
Lepik, D.: Solving PDEs with the aid of two-dimensional Haar wavelets. Comput. Math. Appl. 61(7), 1873–1879 (2011)
Guariglia, E., Silvestrov, S.: Fractional-Wavelet Analysis of Positive Definite Distributions and Wavelets on \(\mathcal{D}\)’(\(\mathbb{C}\)), pp. 337–353. Springer, Berlin (2016)
Ma, Y., Lin, F.: Conjugate gradient method for estimation of Robin coefficients. East Asian J. Appl. Math. 4(02), 189–204 (2014)
Ma, Y.: Newton method for estimation of the Robin coefficient. J. Nonlinear Sci. Appl. 08(05), 660–669 (2015)
Ragusa, M.A.: On some trends on regularity results in Morrey spaces. AIP Conf. Proc. 1493(1), 770–777 (2012)
Ragusa, M.A.: Regularity of solutions of divergence form elliptic equations. Proc. Am. Math. Soc. 128(2), 533–540 (2000)
Benzi, M., Golub, G.H., Liesen, J.: Numerical solution of saddle point problems. Acta Numer. 14(2), 1–137 (2005)
Prudencio, E., Byrd, R., Cai, X.: Parallel full space SQP Lagrange–Newton–Krylov–Schwarz algorithms for PDE-constrained optimization problems. SIAM J. Sci. Comput. 27(4), 1305–1328 (2006)
Biros, G., Ghattas, O.: Parallel Lagrange–Newton–Krylov–Schur methods for PDE-constrained optimization. Part I: the Krylov–Schur solver. SIAM J. Sci. Comput. 27, 687–713 (2005)
Stoll, M., Wathen, A.J.: Preconditioning for partial differential equation constrained optimization with control constraints. Numer. Linear Algebra Appl. 19(1), 53–71 (2012)
Acknowledgements
The authors thank the anonymous referees for their valuable comments and suggestions, which improved the quality of the paper.
Availability of data and materials
All data generated or analyzed during this study are included in this published article.
Funding
This work was supported by Guangdong Provincial Department of education innovating strong school project, Grant No. 2016KTSCX085. Parts of this work were supported by the Doctoral Fund of Hanshan Normal University.
Author information
Authors and Affiliations
Contributions
YM conceived of the study, designed the study and collected the data. All authors analyzed the data and were involved in writing the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Qu, D., Ma, YB. The numerical solution of forward and inverse Robin problems for Laplace’s equation. Bound Value Probl 2019, 114 (2019). https://doi.org/10.1186/s13661-019-1229-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13661-019-1229-6