
Abstract
In this study, we introduce a primal-dual prediction-correction algorithm framework for convex optimization problems with known saddle-point structure. Our unified frame adds the proximal term with a positive definite weighting matrix. Moreover, different proximal parameters in the frame can derive some existing well-known algorithms and yield a class of new primal-dual schemes. We prove the convergence of the proposed frame from the perspective of proximal point algorithm-like contraction methods and variational inequalities approach. The convergence rate \(O(1/t)\) in the ergodic and nonergodic senses is also given, where t denotes the iteration number.
Similar content being viewed by others

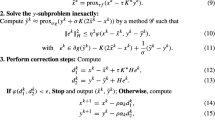
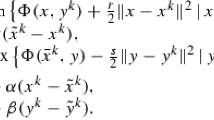
1 Introduction
We consider the following model that arises from various signal and image processing applications:
where B is a continuous linear operator, and \(f_{1}\) and \(f_{2}\) are proper convex lower-semicontinuous functions. We can easily write problem (1) in its primal-dual formulation through Fenchel duality [1]:
where \(X\in R^{N}\) and \(V\in R^{M}\) are two finite-dimensional vector spaces, and \(f_{1}^{*}\) is the convex conjugate function of \(f_{1}\) defined as
As analyzed in [2, 3], the saddle-point problem (2) can be regarded as the primal-dual formulation, and more and more scholars have proposed some primal-dual algorithms. Zhu and Chan [4] proposed the famous primal-dual hybrid gradient (PDHG) algorithm with adaptive stepsize. Though the algorithm is quite fast, the convergence is not proved. He, You, and Yuan [5] showed that PDHG with constant step sizes is indeed convergent if one of the functions of the saddle-point problem is strongly convex. Chambolle and Pock [2] gave a primal-dual algorithm with convergence rate \(O(1/k)\) for the complete class of these problems. They further showed accelerations of the proposed algorithm to yield improved rates on problems with some degree of smoothness. In particular, they showed that the algorithm can achieve the \(O(1/k^{2})\) convergence in problems where the primal or the dual objective is uniformly convex, and the method can show linear convergence, that is, \(O(\varsigma^{k})\) (for some \(\varsigma\in (0,1 )\)), on smooth problems. Bonettini and Ruggiero [6] established the convergence of a general primal-dual method for nonsmooth convex optimization problems and showed that the convergence of the scheme can be considered as an ϵ-subgradient method on the primal formulation of the variational problem when the steplength parameters are a priori selected sequences. He and Yuan [7] did a novel study on these primal-dual algorithms from the perspective of contraction perspective. Their method simplified the existing convergence analysis. Cai, Han, and Xu [8] proposed a new correction strategy for some first-order primal-dual algorithms. Later, He, Desai, and Wang [9] introduced another new primal-dual prediction-correction algorithm for solving a saddle-point optimization problem, which serves as a bridge between the algorithms proposed in [8] and [7]. Recently, Zhang, Zhu, and Wang [10] proposed a simple primal-dual method for total-variation image restoration problems and showed that their iterative scheme has the \(O(1/k)\) convergence rate in the ergodic sense. When we had finished this paper, we found the algorithm proposed in [11], where convergence analysis was similar to our proposed frame. However, the algorithm proposed in [11] is actually a particular case of our unified framework when the precondition matrix in our frame is fixed.
More specifically, the iterative schemes of existing primal-dual algorithms for the problem (2) can be unified as the following procedure:
where \(\gamma,\tau>0\) and \(\theta\in R\). The combination parameter θ is set to zero in the original PDHG algorithm. When \(\theta\in [0,1]\), the primal-dual algorithm proposed in [2] was recovered. He and Yuan [7] showed that the range of the combination parameter θ can be enlarged to \([-1,1]\). Komodakis and Pesquet [12] recently wrote a wonderful overview of recent primal-dual method for solving large-scale optimization problems. So, we refer the reader to [12] for more details.
In some imaging applications, for example, partially parallel magnetic resonance imaging [13], the primal subproblem in (3) may not be easy to solve. Because of this difficulty, it is advisable to use inner iterations to get approximate solutions of the subproblems. In the recent work, several completely decoupled schemes are proposed to avoid subproblem solving, such as primal-dual fixed point algorithm [14–16] and the Uzawa method [17]. Hence, motivated by the works [7, 10, 17], we reconsider the popular iterative scheme (3) and give a primal-dual algorithm framework such that it can be well adopted in different imaging applications.
The organization of this paper is as follows. In Section 2, we propose the primal-dual-based contraction algorithm framework in prediction-correction fashion. In Section 3, we present convergence analysis. The iteration complexity in the ergodic and nonergodic senses is established in Sections 4 and 5. In Section 6, connections with well-known methods, and some new schemes are discussed. Finally, a conclusion is given.
2 Proposed frame
Problem (2) can be reformulated as the following monotone variational inequality (VI): Find \((x^{*},v^{*})\in X\times V\) such that
where ∂ denotes the subdifferential operator of a convex function. By denoting
the VI (4) can be written as follows (denoted \(\operatorname{VI}(\Omega,F)\)):
Note that the monotonicity of the variational inequality is guaranteed by the convexity of the function \(\partial f_{1}^{*}\) and \(\partial f_{2}\).
Recall that the primal-dual algorithm for (2) presented in [2] (\(\theta=1\)) is
We can easily verify that the iteration \((v_{k+1},x_{k+1})\) generated by (5) can be characterized as follows:
The convergence of iteration (6) was proved in [2] with the condition on the stepsize \(\gamma\tau\|B^{T}B\|<1\). Motivated by the idea in [7], the scheme (6) can be considered as a prediction step. So, in the following, we propose a primal-dual-based contraction method for problem (2). To present new methods in the prediction-correction fashion, we denote the iteration \(\tilde{u}_{k}=(\tilde{v}_{k},\tilde{x}_{k})\) generated by the following primal-dual procedure (7), where the prediction step can be redescribed as
where P is a positive definite matrix to be selected properly in different applications. Then, the new iteration is yielded by correcting \(\tilde{u}_{k}\) via
where \(0<\rho<2\). Similarly to (6), the predictor scheme (7) can also be written in the VI form as follows:
Setting
and using the notation in (4), we have the following compact form of (9):
So, we can prove the convergence of the proposed algorithm in the form of proximal point algorithm [7, 18]. Next, we use this idea to prove that the scheme (7)-(8) converges.
3 Convergence analysis
In this section, we show the convergence of the proposed frame. Convergence results easily follow from proximal point algorithm-like contraction methods [7] and VI approach [19].
Lemma 1
Let B be the given operator, let \(\gamma,\tau>0\), and let Q be defined by (10). Then Q is positive definite if
where \(p>0\) is the minimal eigenvalue of P.
Proof
For any nonzero vectors s and t, we have
where we used the Cauchy-Schwarz inequality. The proof is completed. □
In the following, we give an important inequality for the output of the scheme (7)-(8).
Lemma 2
For iteration sequences \(\{u_{k}\}\) and \(\{ \tilde{u}_{k}\}\), we have
Proof
Since (11) holds for any \(u\in\Omega\), we set \(u=u^{*}\), where \(u^{*}\) is an arbitrary solution, and obtain
Thus (13) leads to
Note that the mapping \(F(u)\) is monotone. We thus have
and also
Replacing \(u^{*}-\tilde{u}_{k}\) by \((u^{*}-u_{k})+(u_{k}-\tilde{u}_{k})\) in (14) and using (15), we get the assertion. □
Lemma 3
The sequence \(\{u_{k}\}\) generated by the proposed scheme (7)-(8) satisfies
Proof
Using (8) and (12), by a simple manipulation we obtain
The assertion is proved. □
The following theorem states that the proposed iterative scheme converges to an optimal primal-dual solution.
Theorem 1
If Q in (10) is positive definite, then any sequence generated by the scheme (7)-(8) converges to a solution of the minimax problem (2).
Proof
From (16) we know that the norm \(\|u_{k}-u^{*}\|_{Q}\) is nonincreasing. We also can get that \(u_{k}\) is bounded and \(\|u_{k}-\tilde{u}_{k}\|_{Q}\rightarrow0\). Inequality (16) implies that the sequence \(\{u_{k}\}\) has at least one cluster point. We denote it by \(u^{\infty}\). Let \(\{u_{k_{j}}\}\) be a subsequence converging to \(u^{\infty}\). Thus we have
Due to the facts (11) and (17), we have
Because \(\{u_{k_{j}}\}\) converges to \(u^{\infty}\), this inequality becomes
Thus, the cluster point \(u^{\infty}\) satisfies the optimality condition of (2). Note that inequality (16) is true for all solution points of \(\operatorname{VI}(\Omega,F)\). Hence we have
and thus the sequence \({u_{k}}\) converges to \(u^{\infty}\). This proof is completed. □
4 Convergence rate in an ergodic sense
In the following, using proximal point algorithm-like contraction methods for convex optimization [19], the convergence rate in the ergodic and nonergodic senses is given. First, we prove a lemma, which is the base for the proofs of the convergence rate in the ergodic sense.
Lemma 4
The sequence \(\{u_{k}\}\) is generated by the proposed scheme (7)-(8). Then we have
Proof
Using (8), the right-hand side of (11) can be written as
For the right-hand side of (19), taking
and applying the identity
we obtain
For the last term of the right-hand side of (20), we have
Substituting (20) and (21) into (19), we get
Using the property of the mapping F, we have
Substituting it into (22), the lemma is proved. □
Theorem 2
Let \(\{u_{k}\}\) be the sequence generated by the scheme (7)-(8), and let \(\tilde{u}_{t}\) be defined by
Then, for any integer \(t>0\), we have that \(\tilde{u}_{t}\in\Omega\) and
Proof
By the convexity of Ω it is clear that \(\tilde{u}_{t}\in\Omega\). Summing (18) over \(k=0, 1,\ldots, t\), we have
By the definition of \(\tilde{u}_{t}\), the assertion of the theorem directly follows. □
5 Convergence rate in a nonergodic sense
In this section, we show that a worst-case \(O(1/t)\) convergence rate in a nonergodic sense can also be established for the proposed algorithm frame. We first prove the following lemma.
Lemma 5
Let the sequence \(\{u_{k}\}\) be generated by the proposed scheme (7)-(8). Then we have
Proof
Setting \(u=\tilde{u}_{k+1}\) in (11), we get
Note that (11) is also true for \(k :=k+1\), and we have
Setting \(u=\tilde{u}_{k}\) in this inequality, we obtain
Adding (26) and (27) and using the monotonicity of F, we obtain
Adding the term
to both sides of (28), we have
Substituting \(u_{k}-u_{k+1}=\rho(u_{k}-\tilde{u}_{k})\) into the left-hand side of the inequality, we obtain the lemma. □
Next, we are ready to prove the key inequality of this section.
Lemma 6
Let the sequence \(\{u_{k}\}\) be generated by the proposed scheme (7)-(8). Then we have
Proof
Taking \(a=u_{k}-\tilde{u}_{k}\), \(b=u_{k+1}-\tilde {u}_{k+1}\) in the identity
we have
Since inequality (25) holds, we obtain
The assertion directly follows from this inequality. □
Now, we establish a worst-case \(O(1/t)\) convergence rate in a nonergodic sense.
Theorem 3
Let \(\{u_{k}\}\) be the sequence generated by the scheme (7)-(8). Then, for any integer \(t>0\), we have
Proof
It follows from (16) that
By Lemma 6 the sequence \(\{\|u_{k}-\tilde{u}_{k}\|_{Q}^{2}\}\) is nonincreasing. So, we obtain
6 Connections with existing methods
In this section, we focus on a specific version of problem (1),
which arises in imaging processing, where \(f_{2}(x)=\frac{1}{2}\|Ax-b\|^{2}\) is quadratic. For discrete total-variation regularization, B is the gradient operator, and A is a possibly large and ill-conditioned matrix representing a linear transform. If A is the identity matrix, then problem (1) is the well-known Rudin-Osher-Fatemi denoising model [20]. Because total-variation regularization can preserve sharp discontinuities in an image for removing noise, the above problem has received a lot of attention by most scholars in image processing, including computerized tomography [14] and parallel magnetic resonance imaging [13].
In the following, we establish connections of the proposed frame to the well-known methods for solving (33). There are other types methods designed to solve problem (33). Among them, the split Bregman method proposed by Goldstein and Osher [21] is very popular for imaging applications. This method has been proved to be equivalent to the alternating direction of multiplier method. In [17], based on proximal forward-backward splitting and Bregman iteration, a split inexact Uzawa (SIU) method is proposed to maximally decouple the iterations, so that each iteration is explicit in this algorithm. Also, the authors gave an algorithm based on Bregman operator splitting (BOS) when A is not diagonalizable. Recently, Tian and Yuan [11] proposed a linearized primal-dual method for linear inverse problems with total-variation regularization and showed that this variant yields significant computational benefits. Next, we show that different P in (7) can induce the following well-known methods: the linearized primal-dual method, SIU, BOS, and split Bregman methods and some new primal-dual algorithms with the correction step (8).
6.1 Linearized primal-dual method
The linearized primal-dual method in [11] can be directly induced by setting \(P=I-\tau A^{T}A\) and
We can also easily show that the positive definiteness of the matrices P and Q in (34) is guaranteed if \(\gamma>0\), \(0<\tau<1/\|A^{T}A\| \), \(0<\tau<1/\|A^{T}A+\gamma B^{T}B\|\). In this situation, the scheme (7) can be written as follows:
and the scheme (8) can be expressed as
The idea is also similar to that of [22, 23], which uses the symmetric positive semi-definite matrix instead of the identity matrix in the proximal term. But their methods [22, 23] do not have overrelaxation or correction step. In [24, 25], the authors developed first-order splitting algorithm for solving jointly the primal and dual formulations of large-scale convex minimization problems involving the sum of a smooth function with Lipschitzian gradient, a nonsmooth proximable function, and linear composite functions. Actually, the linearized primal-dual method (35) and (36) is a particular case where a nonsmooth proximable function is missing in [24, 25].
When \(\rho=1\), we can see that there is no correction step, that is, \((x_{k+1},v_{k+1})=(\tilde{x}_{k}, \tilde{v}_{k})\). In the following subsection, we focus on the scheme (7)-(8) with different P and Q when \(\rho=1\), that is,
If \(P=I\), the the CP method is a particular case of (37) as discussed in [7]. We also find that different P in (37) can induce some existing famous algorithms.
6.2 Split inexact Uzawa method
For \(f_{2}(x)=\frac{1}{2}\|Ax-b\|^{2}\), the explicit SIU algorithm can be described as follows:
where \(\gamma>0\), \(0<\tau<1/\|A^{T}A+\gamma B^{T}B\|\), and
Let \(P=I- \tau A^{T}A\) in (37). Then
where \(\gamma>0\), \(0<\tau<1/\|A^{T}A\|\), \(0<\tau<1/\|A^{T}A+\gamma B^{T}B\|\). So, the scheme (37) can be expressed as
Using the relation \(\operatorname{prox}_{\gamma f_{1}^{*}}=(I+\gamma\partial f_{1}^{*})^{-1}\) and changing the order of these equations, the scheme (39) is equivalent to
By the Moreau decomposition (see equation (2.21) in [26]), for all \(v\in R^{M}\) and \(\lambda>0\), we have
Then
By introducing the variable \(d_{k+1}=\operatorname{prox}_{\frac{1}{\gamma }f_{1}}(Bx_{k+1}+\frac{v_{k}}{\gamma})\), the scheme (41) can be further expressed as
Noting that \({v}_{k}=v_{k-1}+\gamma(Bx_{k}-d_{k})\), we have
Substituting (43) into the first equation of (42), the scheme (42) is equivalent to
We can see that the method (44) is equivalent to the SIU. Obviously, the explicit SIU method is a particular case of the proposed frame with \(P=I-\tau A^{T}A\) and \(\rho=1\). If \(\rho\neq1\), then a linearized primal-dual method is presented in Section 6.1. So, the algorithm in [11] can be considered as a relaxed SIU method.
6.3 Bregman operator splitting
The BOS algorithm for solving problem (33) was recently introduced in [17] based on the primal dual formulation of the model. It can be described as
where \(\gamma>0\), \(0<\tau\|A^{T}A\|<1\).
Similarly, let \(P=I-\tau A^{T}A+\tau\gamma B^{T}B\) in (37). Then
where \(\gamma>0\), \(0<\tau<1/\|A^{T}A\|\), \(0<\tau<1/\|A^{T}A-\gamma B^{T}B\|\). The scheme (37) can be expressed as
Using relation (43), we arrive at
Now, we can see that the scheme (47) is the method (45). Clearly, the iterative scheme (45) is a particular case of the frame with \(P=I-\tau A^{T}A+\tau\gamma B^{T}B\) and \(\rho=1\). Also, when \(\rho\neq1\), we can get a new primal-dual method for solving (33) as follows:
In fact, the scheme (48) can be considered as a relaxed BOS algorithm. If \(f_{1}(\cdot)=\|\cdot\|_{1}\), then we can deduce that \((I+\partial f_{1}^{*})^{-1}(v)=\operatorname{proj}(v)\), where proj is the projection operator. If the image satisfies periodic boundary conditions and if we use total-variation regularization, then the matrix \(B^{T}B\) is block circulant; hence, it can be diagonalized by the Fourier transform matrix as noted in [27]. So, the new algorithm (48) can be computed efficiently and does not need the inner iteration to solve the subproblem.
6.4 Split Bregman
In this subsection, we identify the split Bregman algorithm as a particular case of the proposed algorithm. Firstly, we reformulate model (33) as an equivalent constrained minimization problem
The split Bregman algorithm for solving this constrained problem is as follows:
When \(f_{2}(x)=\frac{1}{2}\|Ax-b\|^{2}\), it can be also described as
where \(\gamma>0\). The difficulty of implementing the scheme (49) is mainly due to that the inverse of the matrix is not easy to obtain. Next, we show that our method can induce the scheme (49).
Let
where \(\tau=1\), \(\gamma>0\). We see that the matrix is not positive. But the scheme (37) with this Q can induce the famous split Bregman algorithm. In this situation, the scheme (37) can be expressed as
Using the relation
the scheme (50) can be further expressed as
The method (51) is the split Bregman scheme (49). So, the split Bregman algorithm can be identified as a particular case of our proposed algorithm framework with \(P=\gamma B^{T}B\) and \(\rho=1\). If \(\rho\neq1\), then, for \(P=\gamma B^{T}B\) and \(\tau=1\), a new primal-dual scheme can be described as follows:
Because the matrix Q is not positive definite, the split Bregman method may be not convergent. This case was also discussed in [16] with the same result. Based on Lemma 1, it suffices to replace the matrix Q by its perturbation in positive definite style. Similarly to [16], we modified the matrix Q as
where α is a positive number, and θ is a number between 0 and 1. Using a similar derivation as before, the modified split Bregman algorithm is
Checking the convergence condition of the theorem, if \(\frac{\alpha}{\gamma}>\|B\|^{2}_{2}\), \(\alpha>0\), and \(\theta\in[0,1)\), we can easily get that the sequence \({x_{k}}\) generated from (54) converges to a solution of problem (33). We remark that when \(\theta=1\), the scheme (54) reduces to the split Bregman method (51). When \(\theta=0\), the scheme (54) is the preconditioned alternating method of multipliers as discussed in [2, 3]. Also, when Q is defined by (53) and \(\rho\neq1\), the new primal-dual method can be expressed as
The other positive definite matrix Q may be chosen as
By a simple manipulation we obtain
According to [28], the eigenvalues of the matrix \(B^{T}B\) all lie in the interval \([0,8)\). So, to guarantee the positive definite of Q, we should set \(\gamma\tau >0\). In fact, the scheme (57) is the third case of Algorithm 2 in [17]. Finally, similarly to the previous subsection, we can also get a new relaxed splitting Bregman algorithm when \(\rho\neq 1\) and Q is given by (56). Then, the new primal-dual algorithm can be reformulated as
7 Conclusions
We proposed a primal-dual-based contraction framework in the prediction-correction fashion. The convergence and convergence rate of the proposed framework are also given. Some well-known algorithms, for example, the linearized primal-dual method, SIU, Bregman operator splitting method, and split Bregman method can be considered as particular cases of our algorithm framework. Some new primal-dual schemes such as (48), (52), (55), and (58) are induced. Finally, how to choose the adaptive parameter ρ is an interesting problem, which will be discussed in a forthcoming work.
References
Rockafellar, T: Convex Analysis. Princeton University Press, Princeton (1970)
Chambolle, A, Pock, T: A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 40, 120-145 (2011)
Esser, E, Zhang, X, Chan, T: A general framework for a class of first order primal-dual algorithms for convex optimization in imaging science. SIAM J. Imaging Sci. 3, 1015-1046 (2010)
Zhu, M, Chan, T: An efficient primal-dual hybrid gradient algorithm for total variation image restoration. CAM report, 08-34 (2008)
He, B, You, Y, Yuan, X: On the convergence of primal-dual hybrid gradient algorithm. SIAM J. Imaging Sci. 7, 2526-2537 (2014)
Bonettini, S, Ruggiero, V: On the convergence of primal-dual hybrid gradient algorithms for total variation image restoration. J. Math. Imaging Vis. 44, 236-253 (2012)
He, B, Yuan, X: Convergence analysis of primal-dual algorithms for a saddle-point problem: from contraction perspective. SIAM J. Imaging Sci. 5, 119-149 (2012)
Cai, X, Han, D, Xu, L: An improved first-order primal-dual algorithm with a new correction step. J. Glob. Optim. 57(4), 1419-1428 (2013)
He, H, Desai, J, Wang, K: A primal-dual prediction-correction algorithm for saddle point optimization. J. Glob. Optim. 66(3), 573-583 (2016)
Zhang, B, Zhu, Z, Wang, S: A simple primal-dual method for total variation image restoration. J. Vis. Commun. Image Represent. 38, 814-823 (2016)
Tian, WY, Yuan, XM: Linearized primal-dual methods for linear inverse problems with total variation regularization and finite element discretization. Inverse Probl. 32(11), 115011 (2016)
Komodakis, N, Pesquet, J-C: Playing with duality: an overview of recent primal-dual approaches for solving large-scale optimization problems. IEEE Signal Process. Mag. 32(6), 31-54 (2015)
Chen, Y, Hager, WW, Yashtini, M, Ye, X, Zhang, H: Bregman operator splitting with variable stepsize for total variation image reconstruction. Comput. Optim. Appl. 54, 317-342 (2013)
Chen, P, Huang, J, Zhang, X: A primal-dual fixed point algorithm for convex separable minimization with applications to image restoration. Inverse Probl. 29(2), 025011 (2013)
Combettes, PL, Condat, L, Pesquet, J-C, Vu, BC: A forward-backward view of some primal-dual optimization methods in image recovery. In: 2014 IEEE International Conference on Image Processing (ICIP), pp. 4141-4145. IEEE Press, New York (2014)
Li, Q, Shen, L, Xu, Y: Multi-step fixed-point proximity algorithms for solving a class of optimization problems arising from image processing. Adv. Comput. Math. 41(2), 387-422 (2015)
Zhang, X, Burger, M, Osher, S: A unified primal-dual algorithm framework based on Bregman iteration. J. Sci. Comput. 46, 20-46 (2011)
Rockafellar, T: Monotone operators and the proximal point algorithm. SIAM J. Control Optim. 14, 877-898 (1976)
He, B: PPA-like contraction methods for convex optimization: a framework using variational inequality approach. J. Oper. Res. Soc. China 3(4), 391-420 (2015)
Rudin, L, Osher, S, Fatemi, E: Nonlinear total variation based noise removal algorithms. Physica D 60, 259-268 (1992)
Goldstein, T, Osher, S: The split Bregman method for L1-regularized problems. SIAM J. Imaging Sci. 2, 323-343 (2009)
Shefi, R, Teboulle, M: Rate of convergence analysis of decomposition methods based on the proximal method of multipliers for convex minimization. SIAM J. Optim. 24(1), 269-297 (2014)
Xu, M: Proximal alternating directions method for structured variational inequalities. J. Optim. Theory Appl. 134, 107-117 (2007)
Chambolle, A, Pock, T: On the ergodic convergence rates of a first-order primal-dual algorithm. Math. Program. 159(1), 253-287 (2016)
Condat, L: A primal-dual splitting method for convex optimization involving Lipschitzian, proximable and linear composite terms. J. Optim. Theory Appl. 158(2), 460-479 (2013)
Combettes, PL, Wajs, VR: Signal recovery by proximal forward-backward splitting. SIAM J. Multiscale Model. Simul. 4, 168-200 (2005)
Wang, Y, Yang, J, Yin, W, Zhang, Y: A new alternating minimization algorithm for total variation image reconstruction. SIAM J. Imaging Sci. 1(3), 248-272 (2008)
Micchelli, CA, Shen, L, Xu, Y: Proximity algorithms for image models: denoising. Inverse Probl. 27(4), 045009 (2011)
Acknowledgements
This work is supported by the National Natural Science Foundation of China (11361018, 11461015), Guangxi Natural Science Foundation (2014GXNSFFA118001), Guangxi Key Laboratory of Cryptography and Information Security (GCIS201624), and Innovation Project of Guangxi Graduate Education.
Author information
Authors and Affiliations
Contributions
Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Zhang, B., Zhu, Z. A primal-dual algorithm framework for convex saddle-point optimization. J Inequal Appl 2017, 267 (2017). https://doi.org/10.1186/s13660-017-1548-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13660-017-1548-z