
Abstract
Background
Type 2 diabetes mellitus (T2DM), a highly prevalent chronic disease, puts a large burden on individual health and health care systems. Computer simulation models, used to evaluate the clinical and economic effectiveness of various interventions to handle T2DM, have become a well-established tool in diabetes research. Despite the broad consensus about the general importance of validation, especially external validation, as a crucial instrument of assessing and controlling for the quality of these models, there are no systematic reviews comparing such validation of diabetes models. As a result, the main objectives of this systematic review are to identify and appraise the different approaches used for the external validation of existing models covering the development and progression of T2DM.
Methods
We will perform adapted searches by applying respective search strategies to identify suitable studies from 14 electronic databases. Retrieved study records will be included or excluded based on predefined eligibility criteria as defined in this protocol. Among others, a publication filter will exclude studies published before 1995. We will run abstract and full text screenings and then extract data from all selected studies by filling in a predefined data extraction spreadsheet. We will undertake a descriptive, narrative synthesis of findings to address the study objectives. We will pay special attention to aspects of quality of these models in regard to the external validation based upon ISPOR and ADA recommendations as well as Mount Hood Challenge reports. All critical stages within the screening, data extraction and synthesis processes will be conducted by at least two authors. This protocol adheres to PRISMA and PRISMA-P standards.
Discussion
The proposed systematic review will provide a broad overview of the current practice in the external validation of models with respect to T2DM incidence and progression in humans built on simulation techniques.
Systematic review registration
PROSPERO CRD42017069983.
Similar content being viewed by others

Background
Diabetes mellitus (DM), characterised by increased blood glucose concentration, is a major health care challenge: more than 415 million adults (20–79 years old), or 8.8% in the given age group, were living with this chronic condition in 2015 according to the latest estimates of the International Diabetes Federation (IDF). This figure, even by conservative projections, will reach 642 million in 2040 [1]. While there is a spectrum of metabolic disorders under the label ‘diabetes’, the majority of cases (90 to 95% [2]) may be classified as type 2 diabetes mellitus (T2DM).
T2DM is a chronic condition that may often remain undiagnosed over several years. Medical conditions related to T2DM, such as retinopathy, often emerge before the time of the clinical diagnosis of T2DM [3, 4]. Moreover, final stage complications such as blindness, limb amputation, renal failure, stroke or myocardial infraction result in high health care expenditures and loss of healthy life years that put an unstringed burden on a patient’s health and the health care system in general [5].
Computer simulation models are often employed to evaluate the clinical and economic effectiveness of various interventions that are considered for implementation or have already been implemented in a health care system [6,7,8]. Using computer simulation models allows addressing characteristics of different patient populations extensively under multiple independent conditions and treatments. Furthermore, models can simulate health outcomes over periods of more than 5–10 years, which is useful for chronic conditions when considering the long-term clinical and economic impact of different intervention scenarios [9]. Modelling assists clinicians or policy makers in the decision making process by synthesizing the existing evidence base in a transparent way with regard to complexity, variability and uncertainty of health and disease progression [9].
Diabetes modelling is a relatively recent technique in health economic analysis. The first publication of a fully integrated (including the full range of complications) economic model of type 1 diabetes mellitus (T1DM) was published in 1996 [10]. As shown in systematic reviews regarding this topic [11], the first influential work on T2DM modelling was the article ‘Model of Complications of NIDDM: I. Model construction and assumptions’ by Eastman et al. published in 1997 [12]. Now, computer simulation is recognized as a well-established method to harmonize and personalize the abundance of evidence on long-term effects of diabetes, which helps to answer ‘what if’ questions about treatment effects. Researchers intend using the models in the analysis of clinical and cost-effectiveness of different, mostly pharmacological, interventions [11, 13, 14].
Therefore, it is of utmost importance that there is confidence in the models to provide an accurate reflection of disease progression in real life [15, 16]. This is particularly true for chronic diseases such as T2DM, which develop over a long period of time and are associated with significant morbidity and mortality and a substantial burden to the health care system and to society.
Several ways of assessing and controlling for the quality of these models are in use, in which validation is a crucial part [15,16,17]. According to the recommendations given in the report of the International Society for Pharmacoeconomics and Outcomes Research (ISPOR) Good Research Practice Task Force, validation of models is categorized in three main groups: internal validation, between-model validation, and external validation [18]. The American Diabetes Association (ADA) released guidelines [9] to standardize the description and validation of diabetes models. They defined criteria that, if followed, would build confidence for a model to accurately perform its intended function: the steps that can be taken by model developers to ensure that others can reproduce the results and build confidence that the models are accurate, useful and reliable.
‘External validation’ refers to the ability of the model to accurately predict or replicate the results of studies that were not used to build the model [18, 19]. This ability of replicated external studies is appreciated as a model’s intended purpose [9]. Eddy et al. [19] gave the best practices of a formal process to conduct external validation. They suggested that modellers should make a description of the external validation process and its results available on request. Moreover, they should identify parts of the model that cannot be validated given a lack of suitable sources and describe how the related uncertainty was addressed.
The Mount Hood Challenge meetings are organized to promote validity and reliability in diabetes modelling [16]. The first meeting of health economic simulation modelling groups focusing on diabetes took place in 1999 and challenged only two simulation models [20]. Several of the later meetings were focusing on the external validation of models but only for models developed by researchers attending the meeting [15, 16]. However, the organisers stated that there was still no clear consensus on what precisely model validation means [15]: appropriate statistical approaches should be defined to assess correlation between model and clinical trial outcomes, and limits could be predefined for model accuracy and precision.
Several systematic literature reviews comparing and assessing the quality of diabetes models are available. In 2010, two reviews included DM models published before 2008 and focused on health-economic aspects of diabetes models, specifically, their use for pharmacological treatment evaluations [11, 13]. Three years later, a review by Charokopou et al. updated results by including studies published between 2008 and 2013 [14]. Moreover, a systematic health economic assessment of three models (the US Centers for Disease Control and Prevention (CDC-RTI) Diabetes Cost-effectiveness Model [21], the Quintiles IMS CORE Diabetes Model (CORE) [22], and the Archimedes model [23]) was conducted by Becker et al. in 2011 [24]. In 2016, Henriksson et al. [25] focused on economic models of T1DM and provided an overview of the characteristics and capabilities of available models. Also, Kirsch published a systematic review of Markov models evaluating multicomponent disease management programs for DM in 2015 [26].
In four of six literature reviews (Yi et al. [13], Becker et al. [24], Tarride et al. [11], Charokopou et al. [14]), the authors evaluated whether internal and external validation of the models was reported. Only in one review [24] did the authors appraise the validation approaches by applying the criteria to assess a models’ quality recommended by the panel of the ADA [9]. Becker et al. [24] found that while there were reports on extensive validations for all of the assessed models, results were not directly comparable due to different outcomes, studies or populations used. By focusing on the use of DM models in practice, these reviews may not have identified all published models in the field of T2DM per se and may not have identified all evidence associated with the validation of the identified models.
Despite the broad consensus about the general importance of the validation of models presented in the literature, there are to our knowledge no systematic reviews comparing the practice of validating diabetes models. Such a systematic review might serve to understand, improve and critically appraise current practices, in particular, in the context of the external validation.
The lack of extensive reviews in regards to validation of the models can be explained by the specific challenges faced in the field. The models are diverse in their structure and the underlying assumptions and use of inhomogeneous methods to conduct the validation and to report their results and respective methodology. Furthermore, most of the diabetes models are built on the same data sources (e.g. The United Kingdom Prospective Diabetes Study (UKPDS)) [11, 14, 25], or the availability of data sources is limited.
Study objective and rationale
The main objective of this systematic literature review is to identify and appraise the quality of approaches that are being used for the external validation of existing computer models covering the development and progression of T2DM in human populations.
We will review identified models with regard to the validation efforts to provide an overview of current practices reported in the literature and to find out if these practices are in line with the recommendations given elsewhere [9, 15,16,17].
We will summarise the findings of the studies by each model identified. The information from articles and reports on each model will be aggregated and compared with other models.
Methods
Protocol
This protocol adheres to the Preferred Reporting Items in Systematic Reviews and Meta-analyses (PRISMA) statement [27] and PRISMA for systematic review protocols (PRISMA-P) statement [28, 29]. The PRISMA-P checklist is given in Table 3 in the Appendix. The protocol is registered in the International Prospective Register of Systematic Reviews (PROSPERO) CRD42017069983.
Eligibility criteria
We will include studies reporting and describing the use of a computer simulation model with the characteristics given in Table 1.
We will exclude studies published before 1995 from our review because computer simulation of diabetes is a relatively new concept. Two previous systematic literature reviews [25, 26] also restricted the time frame of their searches to the year 1995: the authors justified the limitation by the fact that the first two relevant publications were published in 1996 [10] and in 1997 [12], respectively.
Information sources
We will search the following literature databases: MEDLINE (via NLM, PubMed), CENTRAL (via Wiley), EMBASE (via Ovid SP), EconLit (via EBSCOhost), Web of Science (via Thomson Reuters), PsycINFO (via Ovid SP), Scopus (via Elsevier) and NHS Economic Evaluation Database (NHS EED) (via Wiley).
To identify potential existing systematic reviews with regard to our research topic, we will also search the Cochrane Database of Systematic Reviews (CDSR) (via Wiley) and the Database of Abstracts of Reviews of Effects (DARE) (via Wiley).
We will also include grey literature databases in our search: ProQuest Dissertations & Theses Database (PQDT) (via ProQuest), System for Information on Grey Literature in Europe (OpenGrey) (via INIST/CNRS), The Directory of Open Access Repositories (OpenDOAR) (via CRC) and CINAHL (via EBSCOhost). In PQDT, the search will be limited to titles only since this database contains very unspecific abstracts. In OpenGrey and OpenDOAR, the results will be limited to the first 100 hits due to the Google Custom Search-based procedure. The grey literature will be concerned to widen the search scope and to capture models that were not highlighted in previous systematic literature reviews.
Besides references identified through databases and systematic reviews, we will include models published in the Mount Hood Challenge meetings proceedings [15, 16].
Search strategy
We composed the ‘primary’ bibliographic search strategy according to MEDLINE search rules, which will be later translated to other database syntaxes. We have applied the search strategy to the relevant references of studies found in the previous literature reviews and/or known in the research field to check for the search strategy’s sensitivity. This primary search strategy has been peer-reviewed using a structured checklist given in the PRESS Peer Review of Electronic Search Strategy: 2015 Guideline Statement [30]. The peer review assessment is given in Additional file 1.
The details of this search strategy are given in Table 2.
Technical tools
The references will be collected and stored in the reference manager Mendeley using its cloud-based platform [31]. The abstract and full text screening will be carried out using the web application Rayyan [32]. During the data extraction, we will fill in Google-doc spreadsheet forms that are stored on Google’s cloud storage [33]. All information will be shared and be made available within the working group. The access will be restricted to a private mode.
Study selection
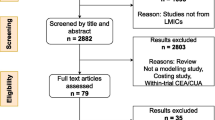
We will select data studies in several steps. First, we will identify all relevant studies by conducting the search in the scientific publication databases listed in the ‘Information sources’ section. We will remove duplicates to reduce the reviewers’ workload associated with the next steps.
Next, we will screen titles and abstracts of all references selected so far. Two tandems of researchers will independently review and include or exclude references guided by the eligibility criteria mentioned above. The title and abstract screening will be piloted first within the tandems independently and then between the tandems to adjust the procedure. Any disagreement and inconsistency in the final decisions will be recorded and resolved in the further discussion among all researchers involved in the screening.
Full text screening will be the final step within our study selection process. Two independent researchers will review full texts of the studies selected in the previous step to collect the final list of studies for data extraction. The decision on inclusion or exclusion will be made on the basis of the eligibility criteria. The full text screening will be piloted first to adjust the procedure. Any apparent discrepancies appearing during the full text screening will be resolved by a third, independent reviewer.
The screening process will be reported accurately and in sufficient detail—including the title and abstract screening and the full text screening—to complete a PRISMA flowchart [27]. The number of the excluded studies (with reasons for exclusion for those excluded from the full text screening step) will be recorded. Tables for ‘Characteristics of excluded studies’ and ‘Characteristics of included studies’ will be provided.
Additional data source selection
During the title/abstract screening, we will collect systematic literature reviews addressing diabetes modelling as a potential reference source of interest.
After the full text screening, we will export the reference list of all publications identified for the data extraction. Moreover, we will check forward citations of these publications by tracking them in different citation databases (Scopus, Web of Science). Also, we will apply PubMed’s ‘related articles’ feature for the same papers to collect the first 20 hits. The restricted number of hits is voluntarily chosen to reduce the workload. All references gathered in this step will be subject to the same steps as described in the ‘Study selection’ section.
All researchers who conducted the eligible studies or built the selected models will be contacted by e-mail for information on unpublished or ongoing studies related to the objectives of the systematic review.
We will send a written request to experts in the field through open and private communication channels (i.e. emails, subscription newsletters and professional boards) to check if a pre-final list of the identified models is complete and sufficient. If some undetected models are mentioned, we will include them in our review.
Data extraction
Two reviewers will independently extract data from all included studies after the full text review by filling in a predefined data extraction spreadsheet. The data extraction spreadsheet was first piloted. The data extraction table is provided in addition to the paper documents (Additional file 2).
Data to be extracted will be arranged into the following categories:
-
1.
Model characteristics;
-
2.
Types of validation involved;
-
3.
External validation: definition, description and use;
-
4.
Data sources used in the external validation: description and use;
-
5.
Results of the external validation: methods and reporting formats;
-
6.
Miscellaneous (conflict of interest and factors not considered).
The data extraction sheet ‘extraction form’ is provided in addition to the paper documents.
Authors of studies included in the full text review that do not provide sufficient information on the external validation in the retrieved articles will be contacted for further information.
Quality appraisal
The data extraction sheet contains questions and categories that are related to the quality appraisal of the validation. These parameters are based on the collaborative ISPOR, the Academy of Managed Care Pharmacy (AMCP) and the National Pharmaceutical Council (NPC) (ISPOR-AMCP-NPC) guidance on assessing the relevance and credibility of modelling studies [17], the ADA Guidelines for Computer Modelling of Diabetes and Its Complications [9], the Mount Hood Challenge reports [15, 16] and other materials discussing the validation of computer models in health care research. In line with our main objective, the assessment of studies will be limited to the credibility section of the questionnaire. If information is not provided, we will assign ‘Not Applicable’, ‘Not Reported,’ ‘Not Enough Information’ or ‘Not Enough Training’ to the corresponding questions/categories.
Data synthesis
Since the models are different and the external validation approaches are largely diverse, we will concise results in a narrative descriptive analysis summarizing the definitions and approaches used in different models: data sources, techniques or methods used. In the end, we will provide a summary of what has been done in the external validation of diabetes models up to now.
Discussion
This protocol describes objectives, methods and steps of an upcoming systematic review that will include studies on external validation of simulation-based computer models designed to represent T2DM incidence and progression in humans. To the best of our knowledge, this contribution to the scientific community is novel since no publications are specially targeting the external validation of T2DM models systematically. The objectives are to identify and define the approaches that are being used for external validation of the T2DM models, appraise the quality of the validation procedures and their reporting and summarize findings to provide a broad overview of the current practice in the field.
Abbreviations
- ADA:
-
The American Diabetes Association
- AMCP:
-
The Academy of Managed Care Pharmacy
- CDC-RTI:
-
The US Centers for Disease Control and Prevention, Research Triangle Institute
- CDSR:
-
The Cochrane Database of Systematic Reviews
- CENTRAL:
-
Cochrane Central Register of Controlled Trials
- CINAHL:
-
Cumulative Index to Nursing and Allied Health Literature
- CORE:
-
The Quintiles IMS CORE Diabetes Model
- CRC:
-
Centre for Research Communications
- DARE:
-
The Database of Abstracts of Reviews of Effects
- DM:
-
Diabetes mellitus
- EMBASE:
-
Excerpta Medica database
- HbA1c:
-
Glycated hemoglobin
- IDF:
-
International Diabetes Federation
- IFG:
-
Impaired fasting glucose
- IGT:
-
Impaired glucose tolerance
- INIST/CNRS:
-
Institut de l’information scientifique et technique/Centre national de la recherche scientifique
- ISPOR:
-
The International Society for Pharmacoeconomics and Outcomes Research
- MEDLINE:
-
Medical Literature Analysis and Retrieval System Online
- NHS EED:
-
NHS Economic Evaluation Database
- NLM:
-
US National Library of Medicine
- NPC:
-
The National Pharmaceutical Council
- OpenDOAR:
-
The Directory of Open Access Repositories
- OpenGrey:
-
System for Information on Gray Literature in Europe
- PQDT:
-
The ProQuest Dissertations & Theses Database
- PRESS:
-
Peer Review of Electronic Search Strategies
- PRISMA:
-
The Preferred Reporting Items in Systematic Reviews and Meta-analyses
- PRISMA-P:
-
The Preferred Reporting Items in Systematic Reviews and Meta-analyses for Protocols
- PROSPERO:
-
The International Prospective Register of Systematic Reviews
- T1DM:
-
Type 1 diabetes mellitus
- T2DM:
-
Type 2 diabetes mellitus
- UKPDS:
-
The United Kingdom Prospective Diabetes Study
References
Ogurtsova K, da Rocha Fernandes JD, Huang Y, Linnenkamp U, Guariguata L, Cho NH, et al. IDF diabetes atlas: global estimates for the prevalence of diabetes for 2015 and 2040. Diabetes Res Clin Pract. 2017;128:40–50.
Deshpande AD, Harris-Hayes M, Schootman M. Epidemiology of diabetes and diabetes-related complications. Phys Ther. 2008;88:1254–64.
The Diabetes Prevention Program Research Group. The prevalence of retinopathy in impaired glucose tolerance and recent-onset diabetes in the diabetes prevention program. Diabet Med. 2007;24:137–44.
Porta M, Curletto G, Cipullo D, Rigault de la Longrais R, Trento M, Passera P, et al. Estimating the delay between onset and diagnosis of type 2 diabetes from the time course of retinopathy prevalence. Diabetes Care. 2014;37:1668–74.
Zhang P, Gregg E. Global economic burden of diabetes and its implications. Lancet Diabetes Endocrinol. 2017;5:404–5.
Marshall DA, Burgos-Liz L, IJzerman MJ, Crown W, Padula WV, Wong PK, et al. Selecting a dynamic simulation modeling method for health care delivery research-part 2: report of the ISPOR Dynamic Simulation Modeling Emerging Good Practices Task Force. Value Health. 2015;18:147–60.
Briggs ADM, Wolstenholme J, Blakely T, Scarborough P. Choosing an epidemiological model structure for the economic evaluation of non-communicable disease public health interventions. Popul Health Metr. 2016;14:17.
Salleh S, Thokala P, Brennan A, Hughes R, Booth A. Simulation modelling in healthcare: an umbrella review of systematic literature reviews. PharmacoEconomics. 2017;35(9):937–49.
American Diabetes Association Consensus Panel. Guidelines for computer modeling of diabetes and its complications. Diabetes Care. 2004;27:2262–5.
Lifetime benefits and costs of intensive therapy as practiced in the diabetes control and complications trial. The Diabetes Control and Complications Trial Research Group. JAMA. 1996;276(17):1409–15. Erratum in: JAMA 1997;278(1):25.
Tarride J-E, Hopkins R, Blackhouse G, Bowen JM, Bischof M, Von Keyserlingk C, et al. A review of methods used in long-term cost-effectiveness models of diabetes mellitus treatment. PharmacoEconomics. 2010;28:255–77.
Eastman RC, Javitt JC, Herman WH, Dasbach EJ, Zbrozek AS, Dong F, et al. Model of complications of NIDDM: I. Model construction and assumptions. Diabetes Care. 1997;20:725–34.
Yi Y, Philips Z, Bergman G, Burslem K. Economic models in type 2 diabetes. Curr Med Res Opin. 2010;26:2105–18.
Charokopou M, Sabater FJ, Townsend R, Roudaut M, McEwan P, Verheggen BG. Methods applied in cost-effectiveness models for treatment strategies in type 2 diabetes mellitus and their use in Health Technology Assessments: a systematic review of the literature from 2008 to 2013. Curr Med Res Opin. 2016;32:207–18.
Palmer AJ, Hornberger J, Palmer AJ, Mount Hood Modeling Group, Clarke P, Gray A, et al. Computer modeling of diabetes and its complications: a report on the fifth Mount Hood challenge meeting. Value Health 2013;16:453–454.
The Mount Hood 4 Modeling Group. Computer modeling of diabetes and its complications: a report on the fourth Mount Hood challenge meeting. Diabetes Care. 2007;30:1638–46.
Caro JJ, Eddy DM, Kan H, Kaltz C, Patel B, Eldessouki R, et al. Questionnaire to assess relevance and credibility of modeling studies for informing health care decision making: an ISPOR-AMCP-NPC Good Practice Task Force report. Value Health. 2014;17:174–82.
Weinstein MC, O’Brien B, Hornberger J, Jackson J, Johannesson M, McCabe C, et al. Principles of good practice for decision analytic modeling in health-care evaluation: report of the ISPOR task force on good research practices—modeling studies. Value Health. 2003;6:9–17.
Eddy DM, Hollingworth W, Caro JJ, Tsevat J, McDonald KM, Wong JB. Model transparency and validation: a report of the ISPOR-SMDM Modeling Good Research Practices Task Force-7. Med Decis Mak. 2012;32:733–43.
Brown JB, Palmer AJ, Bisgaard P, Chan W, Pedula K, Russell A. The Mt. Hood challenge: cross-testing two diabetes simulation models. Diabetes Res Clin Pract. 2000;50(Suppl 3):S57–64.
CDC Diabetes Cost-effectiveness Group. Cost-effectiveness of intensive glycemic control, intensified hypertension control, and serum cholesterol level reduction for type 2 diabetes. J Am Med Assoc. 2002;287:2542–51.
Palmer AJ, Roze SS, Lammert M, Valentine WJ, Minshall ME, Nicklasson L, et al. Comparing the long-term cost-effectiveness of repaglinide plus metformin versus nateglinide plus metformin in type 2 diabetes patients with inadequate glycaemic control: an application of the CORE diabetes model in type 2 diabetes. Curr Med Res Opin. 2004;20(Suppl 1):S41–51.
Eddy DM, Schlessinger L, Kahn R. Clinical outcomes and cost-effectiveness of strategies for managing people at high risk for diabetes. Ann Intern Med. 2005;143:251–64.
Becker C, Langer A, Leidl R. The quality of three decision-analytic diabetes models: a systematic health economic assessment. Expert Rev Pharmacoecon Outcomes Res. 2011;11:751–62.
Henriksson M, Jindal R, Sternhufvud C, Bergenheim K, Sörstadius E, Willis M. A systematic review of cost-effectiveness models in type 1 diabetes mellitus. PharmacoEconomics. 2016;34:569–85.
Kirsch F. A systematic review of Markov models evaluating multicomponent disease management programs in diabetes. Expert Rev Pharmacoecon Outcomes Res. 2015;15:961–84.
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gøtzsche PC, Ioannidis JPA, et al. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. PLoS Med. 2009;6:e1000100.
Moher D, Stewart LA, Shekelle P, Ghersi D, Liberati A, Petticrew M, et al. Establishing a new journal for systematic review products. Syst Rev. 2012;1:1.
Shamseer L, Moher D, Clarke M, Ghersi D, Liberati A, Petticrew M, et al. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015: elaboration and explanation. BMJ. 2015;349:g7647.
McGowan J, Sampson M, Salzwedel DM, Cogo E, Foerster V, Lefebvre C. PRESS peer review of electronic search strategies: 2015 guideline statement. J Clin Epidemiol. 2016;75:40–6.
Free Reference Manager. https://www.mendeley.com/. Accessed 14 Aug 2017.
Rayyan, the Systematic Reviews web app. https://rayyan.qcri.org/. Accessed 14 Aug 2017.
Google Docs. https://www.google.com/docs/about/. Accessed 14 Aug 2017.
American diabetes association. Diagnosis and classification of diabetes mellitus. Diabetes Care. 2012;35(Suppl 1):64–71.
Alberti KGMMG, Zimmet PZZ. Definition, diagnosis and classification of diabetes mellitus and its complications. Part 1: diagnosis and classification of diabetes mellitus provisional report of a {WHO} consultation. Diabet Med a J Br Diabet Assoc. 1998;15:539–53.
Acknowledgements
Not applicable.
Funding
This study is funded by the German Federal Ministry for Education and Research (Bundesministerium für Bildung und Forschung, BMBF) and the German Centre for Diabetes Research (Deutsches Zentrum für Diabetesforschung, DZD). The funding bodies played no role in developing the protocol.
Availability of data and materials
Not applicable.
Protocol amendments
If the present protocol is substantially amended after an initiation that may impact on the conduct of the study (including eligibility criteria, study objectives, study design, study procedures and analysis), then this amendment will be agreed upon by all collaborators prior to the implementation and will be documented in a note to a later publication or a report (section ‘Differences between protocol and review’).
Author information
Authors and Affiliations
Contributions
All authors made substantial contributions to the conception and design of the study and reviewed all documents and materials. KO was responsible for the development of the study design as well as the formulation of the study question, the selection criteria and the search terms. TH peer-reviewed and amended the search strategy and the data extraction sheets. KO was responsible for compiling the table and the data extraction spreadsheet. KO drafted the first manuscript, and all the authors contributed to the manuscript revision before the final version. All authors read and approved the final manuscript. KO is the guarantor of the review.
Corresponding author
Ethics declarations
Authors’ information
KO is a modeller and statistician in the Institute for Health Services Research and Health Economics at the German Diabetes Centre, Düsseldorf, Germany.
TLH is currently a research associate with the Research Group for Evidence-based Public Health, BIPS & University Bremen, Bremen, Germany.
UL is a researcher in the Institute for Health Services Research and Health Economics at the German Diabetes Centre, Düsseldorf, Germany.
CMD is, next to his industrial affiliation, a visiting researcher at the Institute for Health Services Research and Health Economics at the Heinrich-Heine-University, Düsseldorf, Germany.
SKL is the group head of the Research Group for Evidence-based Public Health, BIPS & University Bremen, Bremen, Germany.
AX is the head of the Institute for Health Services Research and Health Economics at the German Diabetes Centre in Düsseldorf and the head of the Institute for Health Services Research and Health Economics at the Heinrich-Heine-University, Düsseldorf, Germany.
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
Apart from his academic affiliation, CMD is employed by Bayer Vital GmbH, Leverkusen, Germany. Other authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
Search submission and peer review assessment, the protocol of peer review of the search terms. The file contains the application and the assessment of the search terms written in MEDLINE syntax and designed for the present review. (PDF 463 kb)
Additional file 2:
The data extraction table. The file is an example of a data extraction form that will be used for collecting data in this review. (XLSX 140 kb)
Appendix
Appendix
Details of electronic bibliographic database search strategies
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Ogurtsova, K., Heise, T.L., Linnenkamp, U. et al. External validation of type 2 diabetes computer simulation models: definitions, approaches, implications and room for improvement—a protocol for a systematic review. Syst Rev 6, 267 (2017). https://doi.org/10.1186/s13643-017-0664-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13643-017-0664-7