
Abstract
Cardiovascular diseases are associated with high morbidity and mortality. However, it is still a challenge to diagnose them accurately and efficiently. Electrocardiogram (ECG), a bioelectrical signal of the heart, provides crucial information about the dynamical functions of the heart, playing an important role in cardiac diagnosis. As the QRS complex in ECG is associated with ventricular depolarization, therefore, accurate QRS detection is vital for interpreting ECG features. In this paper, we proposed a real-time, accurate, and effective algorithm for QRS detection. In the algorithm, a proposed preprocessor with a band-pass filter was first applied to remove baseline wander and power-line interference from the signal. After denoising, a method combining K-Nearest Neighbor (KNN) and Particle Swarm Optimization (PSO) was used for accurate QRS detection in ECGs with different morphologies. The proposed algorithm was tested and validated using 48 ECG records from MIT-BIH arrhythmia database (MITDB), achieved a high averaged detection accuracy, sensitivity and positive predictivity of 99.43, 99.69, and 99.72%, respectively, indicating a notable improvement to extant algorithms as reported in literatures.
Similar content being viewed by others
1 Introduction
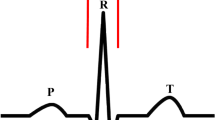
The electrocardiogram (ECG) is one of the major physiological signals generated by the heart. It is the graphical representation of the electrical activity in the heart, providing valuable information for diagnosing cardiac diseases [1, 2]. In the normal condition, the pattern of cardiac electrical propagation is not random, but spreads over the heart in a coordinated manner, resulting in an ordered and measurable change in the spatio-temporal distribution of the body surface potentials, which is reflected by recorded ECGs. A typical ECG tracing is characterized by a recurrent sequence of waves including P, QRS and T waves, corresponding to the depolarization of the atria, ventricles and repolarization of the ventricles respectively. P wave represents the electrical signal marking the initiation of the heartbeat, atrial depolarization that spreads from the sinoatrial node (SAN) towards the atria and the atrioventricular node (AVN) with 0.08-0.11s duration. The QRS complex reflects the combination of three graphical deflections seen on a typical electrocardiogram that marks the depolarization of the ventricles. It is usually the central and most visually obvious part of the ECG trace because of the larger size of ventricles. It corresponds to the depolarization of the right and left ventricles of the human heart with 0.06–0.10 s duration. The Q, R, and S waves occur in rapid succession, do not all appear in all leads, and reflect a single event, and thus are usually considered together. T wave represents the repolarization (or recovery) of the ventricles with a duration of 0.05–0.25 s. Figure 1 shows a typical ECG signal segment from MIT-BIH arrhythmia database (ECG 100 recording).

A typical cardiac cycle (heartbeat) from MIT-BIH arrhythmia database (ECG 100 recording)
The QRS complex is known as the reference waveform for analysis of ECG signals, accurate and reliable detection of which affects the performance of an automatic ECG analyzing algorithm based on heart rate variability (variation in RR intervals) for diagnosing cardiac diseases [3, 4]. In order to detect the QRS complex more accurately, it is vital to identify the exact R-peak locations from the recorded ECG data. Furthermore, accurate delineation of other ECG waves also depends on this. When the location of QRS complex is detected, then other ECG signal components such as P and T waves may be determined by their relative position to QRS complex [5, 6]. However, in practice, ECG records are often corrupted by various types of artefacts and noises [7, 8]. Hence, the de-noising and enhancement of ECG signals are perquisites for accurate ECG analysis.
In general, most of the QRS detection algorithm in the past few years consist of two components: the signal processing and decision stages [9]. So far, variant methods for ECG de-noising and R-wave detection have been proposed, including approaches of derivatives [10, 11], digital filters [12–15], wavelet transform(WT) [1, 16–26], artificial neural network (ANN) [27, 28], support vector machine (SVM) [29], k-means [30], empirical mode decomposition (EMD) [31], geometrical matching [32–34], combined threshold method [35, 36], phase space method [37], Hilbert Transform method [38], and mixed approach [39, 40]. Almost all of the methods listed above have some limitations. For most of the existing derivative and digital filter algorithms, QRS complex was determined with an assumption on that ECG signals were free of noise and other waves were eliminated, which were ideal for automatic ECG analysis [11]. In general, in the preprocessing stage, most of the above methods implement different signal processing techniques to strengthen the QRS complex and weaken noises. But the methods applied have some shortcomings resulting from the decision between missing or false detections which depends on the choice of filter bandwidth and moving-window size [12]. The WT method has a problem in the selection of mother wavelet and scales to obtain QRS events, which different scales may determine how much QRS complex energies will be reserved [16]. In wavelet analysis, variant mother wavelets can be used. Generally, a mother wavelet is a function with characteristics of orthogonality, compact support, and symmetry. As more than one mother wavelet with the same properties often exist for the same signal, different analysis results may be obtained by using different mother wavelets. To overcome this, the similarity between signal and mother wavelet are considered in selecting a mother wavelet. For the choice problem of the basis function, EMD-based approach can be better than WT, but the selection of intrinsic mode functions (IMFs) is sensitive to noise, which requires the design of more effective filtering and selection of threshold [31]. The use of ANN and SVM require the training of specific model and adjustment of parameters, which needs massive complicated calculations. Hence, it is difficult to effectively address the balance between QRS enhancement and noise reduction in practice [27–29].
In previous studies, the squaring transformation has been widely used, but it considerably diminishes the magnitude of the candidate R-peaks of various QRS complexes [11]. The Hamilton–Tompkins algorithm proposed by Tompkins in 1986 is one of the most typical QRS detection algorithms and is widely used because of its high accuracy and capability in real-time detection [13]. Later, this algorithm has been improved by adding an automatic adjustment of the primary threshold in order to avoid subjective selection of threshold coefficients, which is called as Tompkins Modified Method II [11]. The performance of the modified method has shown better detection performance, but it is not sensitive to the change of the integral information of QRS, leading to mistakes in the cases of low-amplitude QRS, sudden change of amplitude and high P and T waves. Other methods based on cluster such as K-means have a similar problem and cost enormous computation time because of the need of calculation over the whole sample set, which makes it unrealistic for the real-time detection [30].
In this paper, based on detailed analysis of beat features in ECG, we proposed a simple and novel method with high average accuracy to detect QRS in ECGs with atypically shaped QRS complexes and noises. The method is based on a simple peak-finding logic using the K-Nearest Neighbor (KNN) and Particle Swarm Optimization (PSO). The rest of this paper is organized as follows. In Section 2, the method of four-stage R-peak detection is described in details. In Section 3, the proposed method is evaluated using the MIT-BIH arrhythmia database. Finally, Section 4 concludes our study.
2 Method
The flowchart diagram of the proposed R-peak detection method is shown in Fig. 2. It contains four stages which are digital filtering, enhancement of QRS complex, KNN peak-finding, and PSO parameter selection. In general, in the first stage of the proposed algorithm a bandpass filter was used to remove the noise in ECG signals. In the second stage, a five-point first-order differentiation, absolute and the backward cumulation operation were used to emphasize the QRS complex. This stage plays the most critical role in the proposed algorithm. In the third stage, the proposed peak-finding technique based on the KNN was implemented to identify accurate locations of the local maxima. Finally, PSO was applied to deal with the parameter selection, which maximizes the accuracy rate of R-peaks. Detailed description of each stage in Fig. 2 are presented in the following subsections.

The block diagram of the proposed R-peak detection algorithm
2.1 MIT-BIH arrhythmia database
The annotated ECG records from the MIT-BIH arrhythmia database consists of 48 records, which are used for QRS detection in this study [41]. Including a modified limb lead II and one of the modified chest leads V1, V2, V3, V4, V5, or V6, each record has a 30-min duration and is sampled at 360 Hz (Fs = 360 Hz). The ECG records present a variety of waveforms such as artifacts, complex ventricular, junctional and supraventricular arrhythmias and conduction abnormalities. Each ECG trace is accompanied by an annotation file in which the category of each ECG beat has been identified by expert cardiologists. These labels, referred to as “truth” annotation in this paper, are used to evaluate the performance of our method.
2.2 Suppression of noise and enhancement of QRS complex
In the realistic environments, ECG signals may be corrupted by various kinds of noises, including power line interference, electrode contact noise, motion artifacts, muscle contraction, and baseline drift. On the other hand, large P and T waves may also disturb the QRS detection. In order to reduce noise, the filtering stage is constructed using bandpass filter (10–45 Hz) which accentuates the QRS complex and reduces noise since the frequency domain of available ECG signal is about 10-25 Hz [42]. Then, the filtered signal, f[n] (n denotes sampling points), is differentiated using five-point first-order differentiation to provide information about the slope of the QRS complexes and reduce the influence of the P and T waves [43]. The equation for five-point first-order derivative of the filtered ECG is listed as follows:
where d[n] represents the differentiation signal. The five point first order differentiation is applied to enhance the QRS complex which provides the QRS complex slope information because of the higher amplitude of QRS complex in ECG signals.
The output of the differentiator is a bipolar signal and thus a rectification is applied for the detection of negative R-peaks by simply using absolute value as shown in Eq. (2).
The process of the absolute value can make all the R-peaks positive which deals with the detection of the inverted (negative) R-peaks. In order to further highlight the QRS region, the backward cumulation of Abs(d[n]) is calculated within a window width (Ww) containing 60 sampling points as shown in Eq. (3).
The use of the backward cumulation obtain waveform feature information in addition to the slope of the R-peaks. The backward cumulation window width we selected to use is about 160 ms (because the ECG signal sampling rate is 360 Hz), which is approximately the same width as the widest possible QRS complex to ensure only one QRS complex in each window. For the last 60 sampling points of a ECG signal series, as all of the QRS complex are covered in every window, so we need not to enhance the signal with the backward cumulation algorithm. Results after all the processes are shown in Figs. 4, 5, 6, 7, 8, 9, and 10.
2.3 K-Nearest Neighbor-Based Peak-Finding
K-Nearest Neighbors algorithm (KNN) is a non-parametric method used for classification and regression. It is a type of instance-based learning or lazy learning, where the function is only approximated locally and all computation is deferred until classification [44]. The algorithm output is a class membership. An object is classified by a majority vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
After the noise suppression and enhancement of QRS complex, positive peaks regardless of polarity of QRS complexes can be obtained. The main goal of the next step is to identify R-peaks by implementing the KNN-based peak-finding algorithm, which relies on the use of single-sided threshold [45]. However, it is a challenge to determine such a threshold. After careful evaluation of a large amount of the ECG signals, two classes of QRS characteristics were identified as shown in Fig. 3, which may form a basis for determining the threshold. As it was shown in Fig. 3, in Fig. 3 a, the general features of QRS complex is temporally consistent, presenting as a continuous period of QRS with large or small R-amplitude. It means the closer the ECG signal is to the current detection position, the higher similarity to the next unknown R-peak (calculated by the Eq. (4)). However, in Fig. 3 b, the features of the individual QRS complex alternates, with every one or two low-amplitude QRS complex followed by two high-amplitude QRS complex. It means the minimum amplitude R-peak in the detected R-peaks before, which will have the greatest influence on the next unknown adaptive threshold (calculated by the Eq. (5)).

Two typical characteristics of ECG signals. a General change tendency of QRS complex which the overall waveform is small or large in succession. b The change tendency of individual which will appear similar amplitude QRS complex locally
The core idea of KNN algorithm is to find k samples most similar to the unknown sample among the existed samples, which is used for classifying the unknown sample. In this study, the detected K R-peaks were used as samples, which are used to determine an adaptive threshold for detecting the next R-peak. Thus, there are two factors that affect KNN algorithm: (1) how to measure the similarity among samples, which affects the precision of computation; (2) how to find the most similar samples fast, which affects the efficiency of execution. In our study, applying KNN algorithm to the detection of QRS complex, we should predict the threshold of next QRS complex through detected QRS complex. However, the features cannot be extracted from the unknown threshold, so we convert another thought to conduct the computation of similarity and the selection of nearest neighbor according to the two characteristics of QRS complex mentioned above. We regard n detected QRS complex as the reference set of nearest neighbor, calculate the difference of every QRS peak value and the minimum value and the last QRS peak time and every peak time, which is accompanied by the proportionality coefficient and Euler distance as the final similarity vector. Finally, we select K elements according to the similarity obtained above to calculate the next detection threshold of QRS complex. Thus, we proposed KNN algorithm based on time distance and amplitude to dynamically generate threshold base value (Thresbasis) by the two characteristics of QRS complex mentioned above. There are several formulas as the followings:
As mentioned above, how to find the most similar samples fast is another key factor affecting the efficiency of execution of KNN approach. With respect to this problem, the influence of time in similarity calculation has been included in Eq. (4) (RpeakIndex(end) is the last R-peak location before detecting point and RpeakIndex(i) is each detected R-peak location before). The degree of similarity will obviously attenuate to zero when the sample is far away from the R-peak to be detected. In this case, we only calculate K R-peaks near the next detected R-peak. In this study, K was set to 7 based on experimentation experiences. Therefore, this model can decrease amount of calculation and has the capability of real time analysis. Equation (5) calculates the degree of R-peak amplitude similarity in the selected K R-peaks, which Rpeak(i) represents each detected R-peak amplitude before. Equation (6) calculates the degree of similarity of both in time and amplitude as defined by the Eular distance way (α 1 and α 2 are the proportionality coefficient of time and amplitude features). In the Eq. (7), Weight (i) is the weight of each R-peak, which α and θ are the Gaussian coefficient. In this study, θ was set to 1.5 based on experimentation experiences. Thresbasis is the threshold base value and Threshold is the final adaptive threshold multiplied by Thresfrac.
After threshold selection, R peaks are identified as the peaks larger than the threshold. Normally, if the RR interval is 1.5 times larger than average RR, we think a missing R-peak appear because of the low amplitude R-peaks, so the secondary threshold is regarded as lower threshold than the threshold calculated for the first time to detect all the R-peaks, which is applied to detect the missing R-peaks. Finally, we set a refractory period within a 200-ms window. In the refractory period, once a peak is detected, the largest amplitude in the vicinity of each identified peak is removed.
2.4 Particle swarm optimization-based parameter selection
The proposed KNN approach above contains multiple parameters. In order to obtain the best detection results, it is unpractical to adjust the parameters only relying on the traditional experience and observation of ECG waveforms. Thus, we used the automatic optimization choice of parameters by applying PSO.
PSO originally developed by Kennedy et al. is a computational method that optimizes a problem by iteratively improving a candidate solution with regard to a given measure of quality [46, 47]. This method uses a population of candidate solutions, here referred as particles, and moves these particles around in the search-space according to simple mathematical formula of the particle’s position and velocity. Each particle’s movement is influenced by its local best known position and is also guided toward the best-known positions in the search-space. The position of the particle will be updated as better positions are found, which is expected to move the swarm toward the best solutions. The core equations are as followings,
where t represents the number of iterations, v ij ∈[−v max , v min ] represents the movement speed of the particle i on the dimension of j, pbest ij represents the best value of the particle i on the dimension of j. gbest j represents the best value of the global particles on the dimension of j. w and β represent the adjustment weight of the particle movement speed and the rate of change, respectively. C 1 and C 2 represent the weight which control the local and global solution. In our study, we defined a fitness function as Eq. (12),
where TP, FP, and FN represent the true positives (TP), false positives (FP) and false negatives (FN) respectively. Finally, we apply PSO to automatically choose the optimization parameters (Thresfrac, Thresfrac2, α 1, α 2, α) to achieve the maximum value of fitness function.
In this paper, we use particle swarm optimization to choose the optimization parameters. We select the 100-124 ECG recordings as the training data (the sum of the R-peak beats is 45,882) to ensure the five optimal parameters and test all the ECG recordings, which achieved a better result than others. In our study, we have set some initial parameters. The number of particles is 50, The iterations are 100. The PSO updated parameters c 1, c 1 and β are 0.5, 0.5 and 1. The five parameters generated during the iterative process of the algorithm are shown in Table 1. Not difficult to find, gbest and fitness(gbest) tend to be stable after 40 iterations, the values of the five optimization parameters and the detected R-peaks are 0.55, 0.61, 1.16, 2.77, 9.14, and 45,625.
3 Results and discussions
The proposed algorithm was tested on the ECG signals taken from the first channel (a modified limb lead II) of the MIT-BIH arrhythmia database. From detection results, we calculated three parameters: true-positive (TP) when a real R-peak is identified correctly, false-negative (FN) when a real R-peak is not detected, and false-positive (FP) when a false R-peak detected as a real R-peak. Also, the true-negative (TN) presents the correctly detected other waves that are needless in this paper, so we have not used the TNs. In order to evaluate the performance of the proposed detection method, the sensitivity (Se) and the positive predictivity (+P) and the detection error rate (DER) were calculated using the following equations, respectively
The overall performance of the method is calculated by the detection accuracy which is defined as follows
The performance evaluation of the proposed method for 47 ECG recordings (except 108 recording) of the MIT-BIH arrhythmia database are summarized in Table 2. For the total of 107,851 beats, the proposed method produced an averaged 99.43% accuracy, with 638 false detections that included 333 false-negative (FN) and 305 false-positive (FP) beats. On the basis of the characteristics of ECG signals of normal, abnormal and different noise levels, the detection precision varied from 96.28 to 100% as shown in Table 2.
ECG recorded in the MIT-BIH arrhythmia database can be grouped into different groups, which contain various conditions. Among them, some ECG recordings such as 104, 105, 200, 203 and 210 include high frequency noise and artifact. Some ECG recordings such as 103, 116, 205, 208, 219, and 228 contain sudden changes of QRS complex waveforms and serious baseline wander. Some ECG recordings such as 201, 208, 223, and 233 exhibit different atrium and ventricular arrhythmia patterns. Some ECG recordings such as 219 and 232 have long time cardiac arrest. Other ECG recordings such as 222 and 106 contain tall P and T waves. For these abnormal ECG recordings, the FPs (ranging from 15 to 272 beats in Table 3) and FNs (ranging from 10 to 705 beats in Table 4) detections are always high by using in all extant algorithms. With the presented algorithm, a significant improvement in the detection of R-peak under various QRS complex waveforms as well as different kinds of noises has been achieved, as shown in Tables 3 and 4 for the effectiveness of the proposed method in terms of the number of FNs and FPs. In this paper, we compare specific records which contain most of various typical arrhythmias in order to prove that our algorithm have ability to detect R-peaks in different ECG recordings with various conditions. The sum of the FPs and FNs (37) are less than other algorithms in Tables 3 and 4. The overall comparison with other algorithms have shown in Table 5.
The ECG signal waveforms recorded in different processing steps are shown in Figs. 4, 5, 6, 7, 8, 9, and 10 showing the performance of the proposed method under various conditions. The TPs are labeled by the red circle compared with the manual annotation, while FPs and FNs are also labeled as black circle. In each figure, (a) to (f) have shown the whole detection procedure clearly.
For ECG with high frequency noise and artifact, most existing methods produced more missing and false detections. However, the presented method illustrates an excellent detection performance as shown in Fig. 4 for ECG recording 200.
The baseline wander and sudden changes are mainly found in record 219 that yields more missing and false detections in most existing methods. The detection performance of the method is shown in Fig. 5.
The numerous long time cardiac arrest in duration are mainly found in record 232 that yields more missing and false detections in most existing methods. The detection performance of the method is shown in Fig. 6.
The tall P waves are mainly found in record 222 that yields more missing and false detections in most existing methods. The detection performance of the method is shown in Fig. 7.
The tall T waves are mainly found in record 106 that yields more false-positive detections in most existing methods. The detection performance of the method is shown in Fig. 8.
The ventricular arrhythmia patterns are mainly found in record 233 that yields more missing and false detections in most existing methods. The detection performance of the method is shown in Fig. 9.
The sudden changes of QRS complex waveforms and serious baseline wander are mainly found in record 103 that yields more missing and false detections in most existing methods. The detection performance of the method is shown in Fig. 10.
Finally, the overall performance of proposed method is compared with some R-peak detection methods. Based on the data shown in Table 5, an average accuracy of 99.43%, a sensitivity of 99.69% and a positive predictivity of 99.72% are obtained for the ECG recordings of the MIT-BIH arrhythmia database, which is significantly better than other detection algorithms. Based on the detection results, we concluded that the simple and effective selection of preprocessing and decision stages can increase the precision rate of detection of R-peaks in ECG recordings with various normal and abnormal waveforms.

Result after performing each stage of the proposed method for the ECG with high frequency noise and artifact (ECG recording 200). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks

Result after performing each stage of the proposed method for the ECG with baseline wander and sudden changes (ECG recording 219). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks

Results after performing each stage of the method for the ECG with numerous long time cardiac arrest in duration (ECG recording 232). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks

Results after performing each stage of the method for the ECG with tall P waves (ECG recording 222). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks

Results after performing each stage of the method for the ECG with tall T waves (ECG recording 106). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks

Result after performing each stage of the method for the ECG with ventricular arrhythmia patterns(ECG recording 233). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks

Result after performing each stage of the method for the ECG with sudden changes of QRS complex waveforms and serious baseline wander (ECG recording 103). a) Original signal. b) Filtering. c) Differentiation. d) Absolute value. e) Backward cumulation. f) Detected peaks
Also, as we mentioned about the proposed detection method, we used K-detected R-peaks to predict the next adaptive threshold, so the new detected R-peaks were incorporated to update the threshold. However, it is unclear if the false positively detected R-peaks may introduce uncertainty to the model, which warrants future studies. However, with the specific data sets of the public MIT-BIH database, our results showed that a small number of false positively detected R-peaks had no effect because of the weights of K-detected R-peaks determined to calculate the adaptive threshold.
4 Conclusions
In this paper, a simple and efficient four-stage method has been proposed for automated detection of R-peaks in an ECG signal. The processing stage is based on a bandpass filter, five-point first-order derivative, absolute value, and the backward cumulation that provides the enhancement processing to the QRS complex of ECG signal. The decision stage is based on KNN and PSO, which is a simple and effective way to detect the location of the R-peaks. The application of time and amplitude similarity with KNN improved the accuracy of adaptive threshold as well as the reduction of computation time. Combining with PSO, the method addressed the problem of manually selecting parameters, which achieved the best result of R-peaks. Experiments showed that combined use of KNN and PSO significantly increases the detection accuracy for ECG recordings with various QRS complex waveforms and may be used for real-time detection. The MIT-BIH arrhythmia database (except 108 recording) has been using for testing the performance of the proposed method, which includes the measurement of the number of false positives, true positives, and false negatives. The overall results are compared with the existing R-peak detection algorithms. The proposed method obtains a high averaged detection accuracy, sensitivity, and positive predictivity of 99.43, 99.69, and 99.72%, respectively. Although the existence of various normal and abnormal QRS complex waveforms and the influences of different noises in the ECG signals, the proposed method also reaches much higher accuracy rate compared with other existing methods.
References
S Saxena, V Kumar, S Hamde, Feature extraction from ecg signals using wavelet transforms for disease diagnostics. Int. J. Syst. Sci. 33:, 1073–1085 (2002).
ED Übeyli, Implementing wavelet transform/mixture of experts network for analysis of electrocardiogram beats. Expert Syst. 25:, 150–162 (2008).
L Schamroth, An introduction to electrocardiography (Oxford Blackwell, 1982).
H Chan, W Chou, S Chen, S Fang, C Liou, Y-S Hwang, Continuous and online analysis of heart rate variability. J. Med. Eng. Technol. 29:, 227–234 (2005).
P Laguna, R Jané, P Caminal, Automatic detection of wave boundaries in multilead ecg signals: Validation with the cse database. Comput. Biomed. Res. 27:, 45–60 (1994).
F Bereksi-Reguig, S Chouakri, Computerised cardiac arrhythmias detection. Automedica. 17:, 41–58 (1998).
L Gargasas, A Janusauskas, A Lukosevicius, A Vainoras, R Ruseckas, S Korsakas, V Miskinis, Development of methods for monitoring of electrocardiograms, impedance cardiograms and seismocardiograms. Stud. Health Technol. Inform. 105:, 131–144 (2004).
Y Wu, RM Rangayyan, Y Zhou, S-C Ng, Filtering electrocardiographic signals using an unbiased and normalized adaptive noise reduction system. Med. Eng. Phys. 31:, 17–26 (2009).
B-U Köhler, C Hennig, R Orglmeister, The principles of software qrs detection. Eng. Med. Biol. Mag. IEEE. 21:, 42–57 (2002).
Y-C Yeh, W-J Wang, Qrs complexes detection for ecg signal: The difference operation method. Comput. Methods Prog. Biomed. 91:, 245–254 (2008).
NM Arzeno, Z-D Deng, C-S Poon, Analysis of first-derivative based qrs detection algorithms. IEEE Trans. Biomed. Eng.55:, 478–484 (2008).
J Pan, WJ Tompkins, A real-time qrs detection algorithm. IEEE Trans. Biomed. Eng.BME-32(3), 230–236 (1985).
PS Hamilton, WJ Tompkins, Quantitative investigation of qrs detection rules using the mit/bih arrhythmia database. IEEE Trans. Biomed. Eng.BME-33(12), 1157–1165 (1986).
M Adnane, Z Jiang, S Choi, Development of qrs detection algorithm designed for wearable cardiorespiratory system. Comput. Methods Programs Biomed. 93:, 20–31 (2009).
D Benitez, P Gaydecki, A Zaidi, A Fitzpatrick, The use of the hilbert transform in ecg signal analysis. Comput. Biol. Med. 31:, 399–406 (2001).
J Sahambi, S Tandon, R Bhatt, Using wavelet transforms for ecg characterization. An on-line digital signal processing system. Eng. Med. Biol. Mag. IEEE. 16:, 77–83 (1997).
IR Legarreta, P Addison, N Grubb, G Clegg, C Robertson, K Fox, J Watson, R-wave detection using continuous wavelet modulus maxima. Comput. Cardiol. 2003:, 565–568 (2003).
F Abdelliche, A Charef, in ELECO 2009. International Conference. R-peak detection using a complex fractional wavelet.in Electrical and Electronics Engineering, 2009 (IEEE, Bursa, 2009), pp. II-267-II-270.
M Elgendi, M Jonkman, F De Boer. R wave detection using coiflets wavelets. Bioengineering Conference, 2009 IEEE 35th Annual Northeast (IEEE, Boston, 2009), pp. 1–2.
JP Martínez, R Almeida, S Olmos, AP Rocha, P Laguna, A wavelet-based ecg delineator: Evaluation on standard databases. IEEE Trans. Biomed. Eng.51:, 570–581 (2004).
A Ghaffari, H Golbayani, M Ghasemi, A new mathematical based qrs detector using continuous wavelet transform. Comput. Electr. Eng. 34:, 81–91 (2008).
A Ghaffari, M Homaeinezhad, M Akraminia, M Atarod, M Daevaeiha, A robust wavelet-based multi-lead electrocardiogram delineation algorithm. Med. Eng. Phys. 31:, 1219–1227 (2009).
R Sunkaria, S Saxena, V Kumar, A Singhal, Wavelet based r-peak detection for heart rate variability studies. J. Med. Eng. Technol. 34:, 108–115 (2010).
S Chouakri, F Bereksi-Reguig, A Taleb-Ahmed, Qrs complex detection based on multi wavelet packet decomposition. Appl. Math. Comput. 217:, 9508–9525 (2011).
S Banerjee, R Gupta, M Mitra, Delineation of ecg characteristic features using multiresolution wavelet analysis method. Measurement. 45:, 474–487 (2012).
Z Zidelmal, A Amirou, M Adnane, A Belouchrani, Qrs detection based on wavelet coefficients. Comput. Methods Prog. Biomed. 107:, 490–496 (2012).
G Vijaya, V Kumar, H Verma, Artificial neural network based wave complex detection in electrocardiograms. Int. J. Syst. Sci. 28:, 125–132 (1997).
B Abibullaev, HD Seo, A new qrs detection method using wavelets and artificial neural networks. J. Med. Syst. 35:, 683–691 (2011).
S Mehta, N Lingayat, Svm-based algorithm for recognition of qrs complexes in electrocardiogram. IRBM. 29:, 310–317 (2008).
S Mehta, D Shete, N Lingayat, V Chouhan, K-means algorithm for the detection and delineation of qrs-complexes in electrocardiogram. Irbm. 31:, 48–54 (2010).
X Hongyan, H Minsong, in Bioinformatics and Biomedical Engineering, 2008. A new qrs detection algorithm based on empirical mode decomposition. ICBBE 2008. The 2nd International Conference on (IEEE, Shanghai, 2008), pp. 693–696.
Y Chen, H Duan, A qrs complex detection algorithm based on mathematical morphology and envelope. Conf. Proc. IEEE. Eng. Med. Biol. Soc.5:, 4654–7 (2005).
F Zhang, Y Lian, Qrs detection based on multiscale mathematical morphology for wearable ecg devices in body area networks. IEEE Trans. Biomed. Circ. Syst. 3:, 220–228 (2009).
KV Suárez, JC Silva, Y Berthoumieu, P Gomis, M Najim, Ecg beat detection using a geometrical matching approach. IEEE Trans. Biomed. Eng.54:, 641–650 (2007).
II Christov, Real time electrocardiogram qrs detection using combined adaptive threshold. Biomed. Eng. Online. 3:, 28 (2004).
S-W Chen, H-C Chen, H-L Chan, A real-time qrs detection method based on moving-averaging incorporating with wavelet denoising. Comput. Methods Prog. Biomed. 82:, 187–195 (2006).
E Plesnik, O Malgina, J Tasič, M Zajc, Detection of the electrocardiogram fiducial points in the phase space using the euclidian distance measure. Med. Eng. Phys. 34:, 524–529 (2012).
D Benitez, P Gaydecki, A Zaidi, A Fitzpatrick, A new qrs detection algorithm based on the hilbert transform. Comput. Cardiol. 2000:, 379–382 (2000).
C Meyer, JF Gavela, M Harris, Combining algorithms in automatic detection of qrs complexes in ecg signals. IEEE Trans. Inf. Technol. Biomed.10:, 468–475 (2006).
H Li, J Tan, Body sensor network based context aware qrs detection. Pervasive Health Conf. Workshops. 2006:, 1–8 (2006).
GB Moody, RG Mark, in Computers in Cardiology 1990. Proceedings. The mit-bih arrhythmia database on cd-rom and software for use with it (IEEE, Chicago, 1990), pp. 185–188.
D Castells-Rufas, J Carrabina, Simple real-time qrs detector with the mamemi filter. Biomed. Signal Process. Control. 21:, 137–145 (2015).
A Ligtenberg, M Kunt, A robust-digital qrs-detection algorithm for arrhythmia monitoring. Comput. Biomed. Res. 16:, 273–286 (1983).
NS Altman, An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 46:, 175–185 (1992).
O Pahlm, L Sörnmo, Software qrs detection in ambulatory monitoring—a review. Med. Biol. Eng. Comput. 22:, 289–297 (1984).
J Kennedy, Particle swarm optimization. Encyclopedia of machine learning (Springer, US, 2011).
Y Shi, R Eberhart, in Evolutionary Computation Proceedings, 1998. IEEE World Congress on Computational Intelligence., The 1998 IEEE International Conference on. A modified particle swarm optimizer. doi:10.1109/ICEC.1998.699146.
Acknowledgements
The work is supported by the National Science Foundation of China (NSFC) under Grant Nos.61572152. (NSFC) under Grant Nos. 61572152, 61571165, and 61601143 (to HZ, KW, and QL), the Science Technology and Innovation Commission of Shenzhen Municipality under Grant Nos. JSGG20160229125049615 and JCYJ20151029173639477 (to HZ), and China Postdoctoral Science Foundation under Grant Nos. 2015M581448 (to QL).
Author information
Authors and Affiliations
Contributions
RH wrote the majority of the text and performed the design and implementation of the algorithm. HZ and QL contributed text to earlier versions of the manuscript and helped with the algorithm. KW and YY commented on and approved the manuscript. NZ and YL initiated the research on the detection of R-peaks. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
He, R., Wang, K., Li, Q. et al. A novel method for the detection of R-peaks in ECG based on K-Nearest Neighbors and Particle Swarm Optimization. EURASIP J. Adv. Signal Process. 2017, 82 (2017). https://doi.org/10.1186/s13634-017-0519-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-017-0519-3