
Abstract
Maximum hands-off control is a control mechanism that maximizes the length of the time duration on which the control is exactly zero. Such a control is important for energy-aware control applications, since it can stop actuators for a long duration and hence the control system needs much less fuel or electric power. In this article, we formulate the maximum hands-off control for linear discrete-time plants by sparse optimization based on the ℓ 1 norm. For this optimization problem, we derive an efficient algorithm based on the alternating direction method of multipliers (ADMM). We also give a model predictive control formulation, which leads to a robust control system based on a state feedback mechanism. Simulation results are included to illustrate the effectiveness of the proposed control method.
Similar content being viewed by others

1 Introduction
Sparsity is one of the most important notions in recent signal/image processing [1], machine learning [2], communications engineering [3], and high-dimensional statistics [4]. A wide range of applications is shown in works, such as [5].
Recently, sparsity-promoting techniques have been applied to control problems as stated below. Ohlsson et al. have proposed in [6] sum-of-norms regularization for trajectory generation to obtain a compact representation of the control inputs. In [7], Bhattacharya and Başar have adapted compressive sensing techniques to state estimation under incomplete measurements. The sparsity notion is also applied to networked control for reduction of control data size using model predictive control (MPC) [8–10]. MPC is a very attractive research topic to which sparsity methods are applied; in [11, 12] Gallieri and Maciejowski have proposed ℓ asso-MPC to reduce actuator activity, and in [13] Aguilera et al. have discussed minimization of the number of active actuators subject to closed-loop stability by using the ℓ 0 norm. Sparse MPC is further investigated based on self-triggered control in [14].
Motivated by these researches, the maximum hands-off control has been proposed in [15, 16] for continuous-time systems. This control maximizes the length of the time duration over which the control value is exactly zero. With such control, actuators can be stopped for a long duration, during which the control system requires much less fuel or electric power, emits less toxic gas such as CO2, and generates less noise. Therefore, the control is also called green control [17]. The optimization is described as a finite-horizon L 0-optimal control, which is discontinuous and highly non-convex, and hence difficult to solve in general. In [15, 16], under a simple assumption of normality, the L 0-optimal control is proved to be equivalent to classical L 1-optimal (or fuel optimal) control, which can be described as a convex optimization. The proof of the equivalence theorem is mainly based on the “bang-off-bang” property (i.e., the control takes values ±1 or 0 almost everywhere) of the L 1-optimal control. Moreover, based on the equivalence, the value function in the maximum hands-off control is shown to be continuous and convex in the reachable set [18], which can be used to prove the stability of an MPC-based closed-loop system.
In this paper, we investigate the hands-off control in discrete time for energy-aware green control. The main difference from the continuous-time hands-off control mentioned above is that the discrete-time maximum hands-off control shows in many cases no “bang-off-bang” property. Instead, we use the restricted isometry property (RIP), e.g., [3], for an equivalence theorem between ℓ 0 and ℓ 1.
An associated ℓ 1-optimal control problem can be described via an ℓ 1 optimization problem with linear constraints. This can be equivalently written as a standard linear program, which can be “efficiently” solved by the interior-point method [19]. The efficiency of the interior-point method is true for small or middle-scale problems with offline computation. However, for real-time control applications, problems arise. To improve computational efficiency in the current paper, we adapt the alternating direction method of multipliers (ADMM) to the control problem. ADMM was first introduced in [20] in 1976, and since then, the algorithm has been widely investigated in both theoretical and practical aspects; see the review [21] and the references therein. ADMM has indeed been proved to converge to the exact optimal value under mild conditions, but in some cases it shows quite slow convergence to the optimal value. On the other hand, ADMM often gives very fast convergence to an approximated value ([21], section 3.2). This property is desirable for real-time control application, since the approximation error can often be eliminated by relying upon robustness of the feedback control mechanism. In fact, ADMM has been applied to MPC with a quadratic cost function in [22–24]. In particular, an ADMM algorithm for ℓ 1-regularized MPC has been proposed in [25] without theoretical stability results.
1.1 Contributions
In this paper, we first analyze discrete-time finite-horizon hands-off control, where we give a feasibility condition based on the system controllability, and also develop an equivalence theorem between ℓ 0- and ℓ 1-optimal controls based on the idea of RIP. These are different from the case of continuous-time hands-off control in [16], where the concept of normality for an optimal control problem was adopted. Unfortunately, normality cannot be used in the discrete-time case. RIP is often used to prove equivalence theorems, e.g., [1] in signal processing, and we show in this paper that RIP is also useful for discrete-time hands-off control.
To calculate discrete-time hands-off control, we then propose to use ADMM, which is widely applied to signal/image processing [21], and we prove by simulation that ADMM is very effective in feedback control since it requires very few iterations. Finally, we prove a stability theorem for hands-off model predictive control, which has been never given in the literature except for the continuous-time case [18].
1.2 Outline
The paper is organized as follows: in Section 2, we formulate the discrete-time maximum hands-off control, and prove the feasibility property and the ℓ 0- ℓ 1 equivalence based on the RIP. In Section 3, we briefly review ADMM, and give the ADMM algorithm for maximum hands-off control. The penalty parameter selection in the optimization is also discussed in this section. Section 4 proposes MPC with maximum hands-off control, and establishes a the stability result. We include simulation results in Section 5, which illustrate the advantages of the proposed method. Section 6 draws concluding remarks.
1.3 Notation
We will use the following notation throughout this paper: \({\mathbb {R}}\) denotes the set of real numbers. For positive integers n and m, \({\mathbb {R}}^{n}\) and \({\mathbb {R}}^{m\times n}\) denote the sets of n-dimensional real vectors and m×n real matrices, respectively. We use boldface lowercase letters, e.g., v, to represent vectors, and upper case letters, e.g., A for matrices. For a positive integer n, 0 n denotes the n-dimensional zero vector, that is, \(\boldsymbol {0}_{n} = [0,\ldots,0]^{\top } \in {\mathbb {R}}^{n}\). If the dimension is clear, the zero vector is simply denoted by 0. The superscript (·)⊤ means the transpose of a vector or a matrix. For a vector \(\boldsymbol {v}=[v_{1},v_{2},\ldots,v_{n}]^{\top }\in {\mathbb {R}}^{n}\), we define the ℓ 1 and ℓ 2 norms, respectively, by
Also, we define the ℓ 0 norm of v as the number of nonzero elements of v and denote it via ∥v∥0. A vector v is called s-sparse if ∥v∥0≤s, and the set of all s-sparse vectors is denoted by \(\Sigma _{s} \triangleq \{\boldsymbol {v}\in {\mathbb {R}}^{\text {N}}: \|\boldsymbol {v}\|_{0}\leq s\}\). For a given \(\boldsymbol {v} \in {\mathbb {R}}^{\text {N}}\), the ℓ 1-distance from v to the set Σ s is defined by
We say a set is non-empty if it contains at least one element. For a non-empty set Ω, the indicator operator for Ω is defined by
2 Discrete-time hands-off control
In this article, we consider discrete-time hands-off control for the following linear time-invariant model:
where \(\boldsymbol {x}[\!k]\in {\mathbb {R}}^{n}\) is the state at time k, \(u[\!k]\in {\mathbb {R}}\) is the discrete-time scalar control input, and \(A\in {\mathbb {R}}^{n\times n}\), \(\boldsymbol {b}\in {\mathbb {R}}^{n}\).
The control (sequence) {u[ 0],u[ 1],…,u[ N−1]} is chosen to drive the state x[ k] from a given initial state x[ 0]=ξ to the origin x[ N]=0 in N steps.
We call such a control feasible, and denote by \({\mathcal {U}}_{\boldsymbol {\xi }}\) the set of all feasible controls. By solving the difference equation in (1) with the boundary conditions, x[ 0]=ξ and x[N]=0, we obtain A N ξ+Φ u=0 with
By this, the feasible control set \({\mathcal {U}}_{\boldsymbol {\xi }}\) is represented by
For the feasible control set \({\mathcal {U}}_{\boldsymbol {\xi }}\), we have the following lemma.
Lemma 1.
Assume that the pair (A,b) is reachable, i.e.,
and N>n. Then \({\mathcal {U}}_{\boldsymbol {\xi }}\) is non-empty for any \(\boldsymbol {\xi }\in {\mathbb {R}}^{n}\).
Proof.
Since N>n, the matrix Φ in (2) can be written as
From the reachability assumption in (4), Φ 2 is nonsingular. Then the following vector
satisfies \(A^{N}\boldsymbol {\xi }+\Phi \tilde {\boldsymbol {u}}=\boldsymbol {0}\), and hence \(\tilde {\boldsymbol {u}}\in {\mathcal {U}}_{\boldsymbol {\xi }}\).
For the feasible control set \({\mathcal {U}}_{\boldsymbol {\xi }}\) in (3), we consider the discrete-time maximum hands-off control (or ℓ 0-optimal control) defined by
where \(\boldsymbol {u}=\bigl [\!u[\!0],u[\!1],\dots,u[\!N-1]\bigr ]^{\top }\), and ∥u∥0 is so-called the ℓ 0 norm of u, which is defined as the number of nonzero elements of u. We call a vector u s-sparse if ∥u∥0≤s. Let Σ s be the set of all s-sparse vectors, that is,
For the ℓ 0 optimization in (7), we have the following observation:
Lemma 2.
Assume that the pair (A,b) is reachable and N>n. Then, we have \({\mathcal {U}}_{\boldsymbol {\xi }} \cap \Sigma _{n} \neq \emptyset \).
Proof.
From the proof of Lemma 1, there exists a feasible control \(\tilde {\boldsymbol {u}}\in {\mathcal {U}}_{\boldsymbol {\xi }}\) that satisfies \(\|\tilde {\boldsymbol {u}}\|_{0} \leq n\); see (6). It follows that \(\tilde {\boldsymbol {u}}\in \Sigma _{n}\) and hence \(\tilde {\boldsymbol {u}}\in {\mathcal {U}}_{\boldsymbol {\xi }}\cap \Sigma _{n}\).
This lemma assures that the solution of the ℓ 0 optimization is at most n-sparse. However, the optimization problem (7) is a combinatorial one, and requires heavy computational burden if n or N is large. This property is undesirable for real-time control systems, and we propose to relax the combinatorial optimization problem to obtain a convex one.
For this purpose, we adopt an ℓ 1 relaxation for (7), that is, we consider the following ℓ 1-optimal control problem:
where \(\|\boldsymbol {u}\|_{1} \triangleq |u[\!0]|+|u[\!1]|+\dots +|u[\!N-1]|\). The resulting optimization can be described as a linear program, and hence we can solve it efficiently by using numerical software such as CVX in MATLAB [26, 27]. Moreover, an accelerated algorithm is derived by the alternating direction method of multipliers (ADMM) [21]; see Section 3.
To justify the use of the ℓ 1 relaxation, we recall the restricted isometry property [1] defined as follows:
Definition 1.
A matrix Φ satisfies the restricted isometry property (RIP for short) of order s if there exists δ s ∈(0,1) such that
holds for all u∈Σ s .
Then, we have the following theorem.
Theorem 1.
Assume that the pair (A,b) is reachable and that N>n. Suppose that the ℓ 0 optimization (7) has a unique s-sparse solution. If the matrix Φ given in (2) satisfies the RIP of order 2s with \(\delta _{2s}<\sqrt {2}-1\), then the solution of the ℓ 1-optimal control problem (7) is equivalent to that of the ℓ 0-optimal control problem (8).
Proof.
Let u ∗ denote the unique s-sparse solution to (7). By ([28], Theorem 1.2) or ([1], Theorem 1.8), the solution to the ℓ 1 optimization (8), which we denote by \(\hat {\boldsymbol {u}}\), obeys
where C 0 is a constant given by
and
Since u ∗ is s-sparse, that is, u ∗∈Σ s , we have σ s (u ∗)=0, and hence \(\hat {\boldsymbol {u}}=\boldsymbol {u}^{\ast }\).
3 Numerical optimization by ADMM
The optimization problem in (8) is convex and can be described as a standard linear program [19]. However, for real-time computation in control such as model predictive control discussed in section 4, a much more efficient algorithm is desired than the standard interior point method for the linear program. For this purpose, we propose to adopt ADMM [20, 21, 29], for the ℓ 1 optimization. Although ADMM generally only achieves very slow convergence to the exact optimal value, it is shown in ([21], Section 3.2) that ADMM often converges to modest accuracy within a few tens of iterations. This property is especially favorable in model predictive control, since the computational error generated by the ADMM algorithm can often be reduced by the feedback control mechanism; see the simulation results in Section 5.
3.1 Alternating direction method of multipliers (ADMM)
Here, we briefly review the ADMM algorithm. ADMM is an algorithm to solve the following type of optimization:
where \(f:{\mathbb {R}}^{\mu }\mapsto {\mathbb {R}}\cup \{\infty \}\) and \(g:{\mathbb {R}}^{\nu }\mapsto {\mathbb {R}}\cup \{\infty \}\) are closed and proper convex functions, and \(C\in {\mathbb {R}}^{\kappa \times \mu }\), \(D\in {\mathbb {R}}^{\kappa \times \nu }\), \(\boldsymbol {c}\in {\mathbb {R}}^{\kappa }\). For this optimization problem, we define the augmented Lagrangian by
where ρ>0 is called the “penalty parameter” (or the step size; see the third line of the ADMM algorithm below). Then the algorithm of ADMM is described as
where ρ>0, \(\boldsymbol {y}[\!0]\in {\mathbb {R}}^{\mu }\), \(\boldsymbol {z}[\!0]\in {\mathbb {R}}^{\nu }\), and \(\boldsymbol {w}[\!0]\in {\mathbb {R}}^{\kappa }\) are given before the iterations.
Assuming that the unaugmented Lagrangian L 0 (i.e., L ρ with ρ=0) has a saddle point, the ADMM algorithm is known to converge to a solution of the optimization problem (9) ([21], Section 3.2).
3.2 ADMM for ℓ 1-optimal control
Here we derive the ADMM algorithm for the ℓ 1-optimal control (8). The optimization (8) can be described in the standard form in (9) as follows:
where \({\mathcal {I}}_{{\mathcal {U}}_{\boldsymbol {\xi }}}\) is the indicator operator for \({\mathcal {U}}_{\boldsymbol {\xi }}\), that is
Then, the ADMM algorithm for the ℓ 1-optimal control (8) is given by
where Π is the projection operator onto \({\mathcal {U}}_{\boldsymbol {\xi }}\), that is,
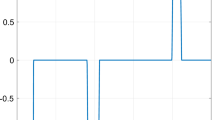
Φ is as in (2), and S 1/ρ is the element-wise soft thresholding operator (see Fig. 1) defined by (for scalars a)

Soft-thresholding operator S 1/ρ (a)
The operator S 1/ρ is also known as the proximity operator for the ℓ 1-norm term in the augmented Lagrangian L ρ . Note that if the pair (A,b) is reachable and N>n, then the matrix Φ is full row rank (see the proof of Lemma 1), and hence the matrix Φ Φ ⊤ is non-singular. Note also that the matrix I−Φ ⊤(Φ Φ ⊤)−1 Φ and the vector Φ ⊤(Φ Φ ⊤)−1 A N ξ in (13) can be computed before the iterations in (12), and hence the computation in (12) is very simple.
3.3 Selection of penalty parameter ρ
To use the ADMM algorithm in (12), we should appropriately determine the penalty parameter (or the step size) ρ. In general, if the penalty parameter is large, then the primal residual y[j]−z[j], or C y[j]+D z[j]−c[j] tends to be small, since it places a large penalty on violations of primal feasibility; see (10). On the other hand, a smaller ρ tends to give a sparser output from the definition of the soft thresholding operator S 1/ρ ; see (14) or Fig. 1. For the selection of ρ, one should rely on trial and error by simulation. One may extend the idea of optimal parameter selection for quadratic problems [24, 30] to the ℓ 1 optimization (8), for which we do not have any optimal parameter selection method. Alternatively, one can adopt the varying penalty parameter ([21], Section 3.4), in which one may use possibly different penalty parameters ρ[j] for each iteration. See also [31, 32].
4 Model predictive control
Based on the finite-horizon ℓ 1-optimal control in (8), we here extend it to infinite-horizon control by adopting a model predictive control strategy. 1
4.1 Control law
The control law is described as follows. At time k (k=0,1,2,…), we observe the state \(\boldsymbol {x}[\!k]\in {\mathbb {R}}^{n}\) of the discrete-time plant (1). For this state, we compute the ℓ 1-optimal control vector
Then, as usual in model predictive control [33, 34], we use the first element \(\hat {u}_{0}[\!k]\) for the control input u[ k], that is, we set
This control law gives an infinite-horizon closed-loop control system characterized by
Since the control vector \(\hat {\boldsymbol {u}}[k]\) is designed to be sparse by the ℓ 1 optimization as discussed above, the first element, \(\hat {u}_{0}[\!k]\), will often be exactly 0, e.g., the vector shown in (6). A numerical simulation in Section 5 illustrates that the control will often be sparse, when using this model predictive control formulation.
4.2 Stability
We here discuss the stability of the closed-loop system (17) with the model predictive control described above. In fact, we can show the stability of the closed-loop control system by using a standard argument in the stability analysis of model predictive control with a terminal constraint (e.g., ([33], Chapter 6), ([34], Chapter 2), or ([35], Chapter 5)).
The key idea of the stability analysis in model predictive control is to use the value function of the (finite-horizon) optimal control problem as a Lyapunov function. The value function of the ℓ 1-optimal control in (8) is defined by (see (15))
The following lemma shows the convexity, the continuity, and the positive definiteness of the value function V(ξ). These properties are useful to show the value function to be a Lyapunov function (see the proof of Theorem 2 below).
Lemma 3.
Assume that the pair (A,b) is reachable, A is nonsingular, and N>n. Then V(ξ) is a convex, continuous, and positive definite function on \({\mathbb {R}}^{n}\).
Proof.
First, we prove convexity. Fix initial states \(\boldsymbol {\xi },\boldsymbol {\eta }\in {\mathbb {R}}^{n}\) and a scalar λ∈(0,1). From Lemma 1, there exist ℓ 1-optimal controls \(\hat {\boldsymbol {u}}_{\boldsymbol {\xi }}\) and \(\hat {\boldsymbol {u}}_{\boldsymbol {\eta }}\) for ξ and η, respectively. Then the control \(\boldsymbol {\nu }\triangleq \lambda \hat {\boldsymbol {u}}_{\boldsymbol {\xi }} + (1-\lambda)\hat {\boldsymbol {u}}_{\boldsymbol {\eta }}\) is feasible for the initial state \(\boldsymbol {\zeta }\triangleq \lambda \boldsymbol {\xi }+(1-\lambda)\boldsymbol {\eta }\), that is, \( \boldsymbol {\nu } \in {\mathcal {U}}_{\boldsymbol {\zeta }}. \) From the convexity of the ℓ 1 norm, we have
Next, the continuity of V on \({\mathbb {R}}^{n}\) follows from the convexity and the fact that V(ξ)<∞ for any \(\boldsymbol {\xi }\in {\mathbb {R}}^{n}\), due to Lemma 1.
Finally, we prove the positive definiteness of V. It is easily seen that V(ξ)≥0 for any \(\boldsymbol {\xi }\in {\mathbb {R}}^{n}\), and V(0)=0. Assume V(ξ)=0. Then there exists \(\boldsymbol {u}^{\ast }\in {\mathcal {U}}_{\boldsymbol {\xi }}\) such that ∥u ∗∥1=0. This implies u ∗=0 and hence \(\boldsymbol {0}\in {\mathcal {U}}_{\boldsymbol {\xi }}\). Since A is nonsingular, ξ should be 0.
By using the properties proved in Lemma 3, we can show the stability of the closed-loop control system.
Theorem 2.
Suppose that the pair (A,b) is reachable, A is nonsingular, and N>n. Then the closed-loop system with the model predictive control defined by (15) and (16) is stable in the sense of Lyapunov.
Proof.
We here show that the value function (18) is a Lyapunov function of the closed-loop control system. From Lemma 3, we have
-
V(0)=0.
-
V(ξ) is continuous in ξ.
-
V(ξ)>0 for any ξ≠0.
Then, we show V(x[ k+1])≤V(x[ k]) for the state trajectory x[ k], k=0,1,2,…, under the MPC (see (17)). By the assumptions, we have the ℓ 1-optimal control vector \(\hat {\boldsymbol {u}}[\!k]\) as given in (15). From this, define
Since there are no uncertainties in the plant model (1), we see \(\tilde {\boldsymbol {u}}[\!k]\in {\mathcal {U}}(\boldsymbol {x}[\!k+1])\). Then, we have
It follows that V is a Lyapunov function of the closed-loop control system. Therefore, the stability is guaranteed by Lyapunov’s stability theorem.
We should note that if we use the first element of the sparse feasible control given in (6), then the MPC generates the all-zero sequence, which obviously does not stabilize any unstable plants. This shows that not all feasible controls necessarily guarantee closed-loop stability. It is also worth noting that continuity of the value function leads to favorable robustness properties of the closed-loop system, see Section 5.
5 Simulation
Here, we document simulation results of the maximum hands-off MPC described in the previous section in comparison with ℓ 2-based quadratic MPC [33]. Let us consider the following continuous-time unstable plant:
with
Note that this plant has the transfer function 1/(s−1)3. We discretize this plant model with sampling period h=0.1 to obtain a discrete-time model as in (1) using MATLAB function c2d(Ac,Bc,h). The obtained matrix and vector are
For the discrete-time plant model, we assume the initial state x[ 0]=[ 1,1,1]⊤ and the horizon length N=30. For the ADMM algorithm in (12), we set the penalty parameter ρ=2, which is chosen by trial and error. We also choose the number of iterations in ADMM as N iter=2, so that the computation in (12) is much faster than the interior-point method (see below for details).
For these parameters, we simulate the maximum hands-off MPC. For comparison, we also simulate the quadratic MPC with the following ℓ 2 optimization
Figure 2 shows the obtained control sequence u[ k] by both MPC formulations.

Maximum hands-off control (solid line) and L 2-optimal control (dashed line)
In this figure, the maximum hands-off control is sufficiently sparse (i.e., there are long time durations on which the control takes zero) while the L 2-optimal control is smoother but not sparse.
The ℓ 2 norm of the resulting state x[ k] is shown in Fig. 3.

The ℓ 2 norm of the state, ∥x[k]∥2, by maximum hands-off control (solid line) and L 2-optimal control (dashed line)
From the figure, the maximum hands-off control achieves significantly faster convergence to zero than the L 2-optimal control.
Since we set the number of iterations N iter to 2 for ADMM, there remains the difference between the exact solution, say \(\hat {\boldsymbol {u}}[\!k]\) of (8) with ξ=x[ k], and the approximated solution, say u ADMM[ k] by ADMM. To elucidate this issue, we describe the control system with ADMM as
where \(\hat {u}[\!k]\) and u ADMM[ k] are the first element of \(\hat {\boldsymbol {u}}[\!k]\) and u ADMM[k], respectively. That is, the ADMM-based control is equivalent to the exact ℓ 1-optimal control with perturbation w[ k], which is caused by the inexact ADMM. Figure 4 illustrates the perturbation w[ k], where the exact solution \(\hat {u}[\!k]\) is obtained by directly solving (8) by CVX in MATLAB based on the primal-dual interior point method [19]. The solution by CVX can be taken as the exact solution since the maximum relative primal-dual gap in the iteration is in this case 1.49×10−8. Figure 4 shows that the perturbation also converges to zero thanks to the stabilizing feedback mechanism (recall that, as shown in Lemma 3, the cost function is continuous, hence the feedback loop can be expected to have favorable robustness properties.)

The ℓ 2 norm of the perturbation w[k] by ADMM with N iter=2
Finally, we compare the number of iterations between ADMM and the interior-point-based CVX. The averaged number of the CVX iterations is 10.7, which is approximately five times larger than that of ADMM, N iter=2. Note that the interior-point-based algorithm needs to solve linear equations at each iteration, and hence computational times may be much longer than those for the ADMM, since the inverse matrix in (13) can be computed offline.
6 Conclusions
In this paper, we have introduced the discrete-time maximum hands-off control that maximizes the length of time duration on which the control is zero. The design is described by an ℓ 0 optimization, which we have proved to be equivalent to convex ℓ 1 optimization using the restricted isometry property. The optimization can be efficiently solved by the alternating direction method of multipliers (ADMM). The extension to model predictive control has been examined and nominal stability has been proved. Simulation results have been shown to illustrate the effectiveness of the proposed method.
6.1 Future work
Here, we show future directions related to the maximum hands-off control. The maximum hands-off control has been proposed in this paper for linear time-invariant systems. It is desired to extend it to time-varying and nonlinear networked control, such as Markovian jump systems as discussed in [36–38], to which “intelligent methods” have been applied in [39, 40]. We believe the sparsity method can be combined with fault detection and reliable control methods, as discussed in [41, 42]. Future work also includes an optimal selection method for the penalty parameter ρ in ADMM which takes into account control performance.
7 Endnote
1It is desirable if one can use an infinite-horizon control like an H ∞ control as in e.g. [36]. However, for the maximum hands-off control discussed in this paper, there is no available methods to directly obtain infinite-horizon control, and model predictive control is a convenient way to extend a finite-horizon control to infinite-horizon.
References
YC Eldar, G Kutyniok, Compressed Sensing: Theory and Applications (Cambridge University Press, Cambridge, 2012).
T Hastie, R Tibshirani, M Wainwright, Statistical Learning with Sparsity: The Lasso and Generalizations (CRC Press, Boca Raton, 2015).
K Hayashi, M Nagahara, T Tanaka, A user’s guide to compressed sensing for communications systems. IEICE Trans. Commun.E96-B(3), 685–712 (2013).
C Giraud, Introduction to High-Dimensional Statistics (CRC Press, Boca Raton, 2015).
I Rish, GA Cecchi, A Lozano, A Niculescu-Mizil, Practical Applications of Sparse Modeling (MIT Press, Massachusetts, 2014).
H Ohlsson, F Gustafsson, L Ljung, S Boyd, in 49th IEEE Conference on Decision and Control (CDC). Trajectory generation using sum-of-norms regularization, (2010), pp. 540–545.
S Bhattacharya, T Başar, in Proc. Amer. Contr. Conf. Sparsity based feedback design: a new paradigm in opportunistic sensing, (2011), pp. 3704–3709.
M Nagahara, DE Quevedo, in IFAC 18th World Congress. Sparse representations for packetized predictive networked control, (2011), pp. 84–89.
M Nagahara, DE Quevedo, J Østergaard, Sparse packetized predictive control for networked control over erasure channels. IEEE Trans. Autom. Control. 59(7), 1899–1905 (2014).
H Kong, GC Goodwin, MM Seron, A cost-effective sparse communication strategy for networked linear control systems: an SVD-based approach. Int. J. Robust Nonlinear Control.25(14), 2223–2240 (2015).
M Gallieri, JM Maciejowski, in Proc. Amer. Contr. Conf. ℓ asso. MPC: Smart regulation of over-actuated systems, (2012), pp. 1217–1222.
M Gallieri, JM Maciejowski, in Proc. 2015 European Control Conference (ECC). Model predictive control with prioritised actuators (Linz, 2015), pp. 533–538.
RP Aguilera, RA Delgado, D Dolz, JC Aguero, Quadratic MPC with ℓ 0-input constraint. IFAC World Congr.19(1), 10888–10893 (2014).
E Henriksson, DE Quevedo, EGW Peters, H Sandberg, KH Johansson, Multiple loop self-triggered model predictive control for network scheduling and control. IEEE Trans. Control Syst. Technol.23(6), 2167–2181 (2015).
M Nagahara, DE Quevedo, D Nešić, in 52nd IEEE Conference on Decision and Control (CDC). Maximum hands-off control and L 1 optimality, (2013), pp. 3825–3830.
M Nagahara, DE Quevedo, D Nešić, Maximum hands-off control: a paradigm of control effort minimization. IEEE Trans. Autom. Control. 61(3), 735–747 (2016).
M Nagahara, DE Quevedo, D Nešić, in SICE Control Division Multi Symposium 2014. Hands-off control as green control, (2014). http://arxiv.org/abs/1407.2377. Accessed 23 June 2016.
T Ikeda, M Nagahara, Value function in maximum hands-off control for linear systems. Automatica. 64:, 190–195 (2016).
S Boyd, L Vandenberghe, Convex Optimization (Cambridge University Press, Cambridge, 2004).
D Gabay, B Mercier, A dual algorithm for the solution of nonlinear variational problems via finite elements approximations. Comput. Math. Appl.2:, 17–40 (1976).
S Boyd, N Parikh, E Chu, B Peleato, J Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2011).
B O’Donoghue, G Stathopoulos, S Boyd, A splitting method for optimal control. IEEE Trans. Control Syst. Technol.21(6), 2432–2442 (2013).
JL Jerez, PJ Goulart, S Richter, GA Constantinides, EC Kerrigan, M Morari, Embedded online optimization for model predictive control at megahertz rates. IEEE Trans. Autom. Control. 59(12), 3238–3251 (2014).
AU Raghunathan, S Di Cairano, in Proc. 21st International Symposium on Mathematical Theory of Networks and Systems. Optimal step-size selection in alternating direction method of multipliers for convex quadratic programs and model predictive control, (2014), pp. 807–814.
M Annergren, A Hansson, B Wahlberg, in Decision and Control (CDC), 2012 IEEE 51st Annual Conference On. An ADMM algorithm for solving ℓ 1 regularized MPC, (2012), pp. 4486–4491.
M Grant, S Boyd, CVX: Matlab software for disciplined convex programming, version 2.1 (2014). http://cvxr.com/cvx. Accessed 23 June 2016.
M Grant, S Boyd, in Recent Advances in Learning and Control, ed. by V Blondel, S Boyd, and H Kimura. Graph implementations for nonsmooth convex programs. Lecture Notes in Control and Information Sciences (SpringerLondon, 2008), pp. 95–110.
EJ Candes, The restricted isometry property and its implications for compressed sensing. Comptes Rendus Mathematique. 346(9-10), 589–592 (2008).
J Eckstein, DP Bertsekas, On the Douglas-Rachford splitting method and proximal point algorithm for maximal monotone operators. Math. Program.55:, 293–318 (1992).
E Ghadimi, A Teixeira, I Shames, M Johansson, Optimal parameter selection for the alternating direction method of multipliers (ADMM): quadratic problems. IEEE Trans. Autom. Control. 60(3), 644–658 (2015).
BS He, H Yang, SL Wang, Alternating direction method with self-adaptive penalty parameters for monotone variational inequalities. J. Optim. Theory Appl.106(2), 337–356 (2000).
SL Wang, LZ Liao, Decomposition method with a variable parameter for a class of monotone variational inequality problems. J. Optim. Theory Appl.109(2), 415–429 (2001).
JM Maciejowski, Predictive Control with Constraints (Prentice-Hall, Essex, 2002).
JB Rawlings, DQ Mayne, Model Predictive Control Theory and Design (Nob Hill Publishing, Madison, 2009).
L Grüne, J Pannek, Nonlinear Model Predictive Control (Springer, London, 2011).
Y Wei, J Qiu, S Fu, Mode-dependent nonrational output feedback control for continuous-time semi-Markovian jump systems with time-varying delay. Nonlinear Anal. Hybrid Syst.16:, 52–71 (2015).
Y Wei, J Qiu, HR Karimi, M Wang, \({\mathcal {H}}_{\infty }\) model reduction for continuous-time Markovian jump systems with incomplete statistics of mode information. Int. J. Syst. Sci.45(7), 1496–1507 (2014).
Y Wei, J Qiu, HR Karimi, M Wang, Filtering design for two-dimensional Markovian jump systems with state-delays and deficient mode information. Inf. Sci.269:, 316–331 (2014).
T Wang, Y Zhang, J Qiu, H Gao, Adaptive fuzzy backstepping control for a class of nonlinear systems with sampled and delayed measurements. IEEE Trans. Fuzzy Syst.23(2), 302–312 (2015).
T Wang, H Gao, J Qiu, A combined adaptive neural network and nonlinear model predictive control for multirate networked industrial process control. IEEE Trans. Neural Netw. Learn. Syst.27(2), 416–425 (2016).
L Li, SX Ding, J Qiu, Y Yang, Y Zhang, Weighted fuzzy observer-based fault detection approach for discrete-time nonlinear systems via piecewise-fuzzy Lyapunov functions. IEEE Trans. Fuzzy Syst. (2016).
J Qiu, SX Ding, H Gao, S Yin, Fuzzy-model-based reliable static output feedback \({\mathcal {H}}_{\infty }\) control of nonlinear hyperbolic PDE systems. IEEE Trans. Fuzzy Syst.24(2), 388–400 (2016).
Acknowledgements
The research of M. Nagahara was supported in part by JSPS KAKENHI Grant Numbers 16H01546, 15K14006, and 15H02668. The research of J. Østergaard was supported by VILLUM FONDEN Young Investigator Programme, Project No. 10095. The authors would like to thank the reviewers for pointing us to references [36–42].
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Nagahara, M., Østergaard, J. & Quevedo, D.E. Discrete-time hands-off control by sparse optimization. EURASIP J. Adv. Signal Process. 2016, 76 (2016). https://doi.org/10.1186/s13634-016-0372-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-016-0372-9