
Abstract
Background
The survival difference between adherers and non-adherers to placebo in the Coronary Drug Project has been used to support the thesis that adherence adjustment in randomized trials is not generally possible and, therefore, that only intention-to-treat analyses should be trusted. We previously demonstrated that adherence adjustment can be validly conducted in the Coronary Drug Project using a simplistic approach. Here, we re-analyze the data using an approach that takes full advantage of recent methodological developments.
Methods
We used inverse-probability weighted hazards models to estimate the 5-year survival and mortality risk when individuals in the placebo arm of the Coronary Drug Project adhere to at least 80% of the drug continuously or never during the 5-year follow-up period.
Results
Adjustment for post-randomization covariates resulted in 5-year mortality risk difference estimates ranging from − 0.7 (95% confidence intervals (CI), − 12.2, 10.7) to 4.5 (95% CI, − 6.3, 15.3) percentage points.
Conclusions
Our analysis confirms that appropriate adjustment for post-randomization predictors of adherence largely removes the association between adherence to placebo and mortality originally described in this trial.
Trial registration
ClinicalTrials.gov, Identifier: NCT00000482. Registered retrospectively on 27 October 1999.
Similar content being viewed by others


Background
In 1980, an analysis of the Coronary Drug Project (CDP) randomized trial found a greater survival in individuals who adhered to placebo than in those who did not adhere to placebo [1]. Statistical adjustment for multiple prognostic factors could not remove these survival differences. This finding was used to support the thesis that adherence adjustment in randomized trials is not generally possible and, therefore, that only intention-to-treat analyses should be trusted.
In 2016, we reported a re-analysis of the CDP placebo arm that incorporated statistical advances not available in 1980. Our re-analysis showed that most of the survival differences between placebo adherers and non-adherers were actually removed after adjustment for pre- and post-randomization prognostic factors [2]. Specifically, we modified the definition of adherence at missed visits, updated the method of adjustment for baseline predictors of adherence, and added adjustment for post-randomization predictors of adherence via inverse-probability (IP) weighting.
With these changes, the 5-year survival difference between placebo adherers and non-adherers decreased from 10.9 percentage points (95% confidence interval, 7.5, 14.4) to 2.5 percentage points (95% confidence interval, − 2.1, 7.0).
However, our re-analysis did not take full advantage of the recent methodological advances. In an attempt to conduct a re-analysis as comparable as possible to the original 1980 analysis, we used a cumulative incidence model that did not account for the exact time of death during the 5-year period, and a somewhat unintuitive measure of adherence – a binary indicator for cumulative adherence greater than 80% during the entire 5-year period. Although modeling the data this way was useful to demonstrate that methods developed since 1980 can address previously intractable sources of bias, the analytic approach we used is not the recommended one. Here, we demonstrate a better approach which uses a more natural definition of adherence and a survival analysis approach to incorporate time of death.
A brief introduction to the Coronary Drug Project
The CDP was a six-arm double blind, placebo-controlled randomized trial of 8341 men with a history of myocardial infarction (MI) enrolled between 1966 and 1969 [3]. Eligibility criteria for participation in the trial included men aged 30–64 years at entry, with an electrocardiogram-documented MI at least 3 months prior to enrollment, a New York Heart Association functional class of I (no limitation in physical activity) or II (slight limitations only), no prior surgery for coronary artery disease, no anti-coagulant therapy or lipid-influencing therapy use at entry, and no other chronic medical conditions which could affect trial participation. In addition, potential participants were required to complete a 2-month control period during which all individuals were given placebo and only those who adhered to at least 80% were eligible for randomization. Participants were then randomized within study center and by risk group (low risk if one prior MI with no complications; high risk if more than one MI or complications).
Study medications were prescribed as three pills daily at randomization, and dosage was increased to nine pills daily, based on tolerance, over the following 2 months. Adherence was assessed by study clinicians at each visit based on a visual inspection of pill bottles, and recorded as a six-level categorical variable (≥ 80%, 60–79%, 40–59%, 20–39%, 1–19%, none) which was then adjusted for expected dose at that visit [1, 2].
Three of the five active treatment arms were discontinued early because of adverse events (low- and high-dose equine estrogen, and dextrothyroxine) [4,5,6], and the other two treatments (clofibrate and niacin) were not found to be effective in reducing mortality [7]. The 5-year cumulative incidence of mortality was 20.9% in the placebo arm, 20.0% in the clofibrate arm, and 21.2% in the niacin arm [7].
Methods
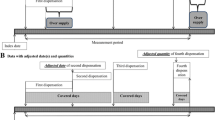
We restricted our analyses to the 2787 men in the placebo arm. Let t be an index for visit, where t = 0 is the baseline visit and t = 14 is the last visit at year 5, with 4-month intervals between each visit. Let A t be an indicator for adherence ≥ 80% to the protocol-specified placebo dose between t and t + 1, Y t an indicator of death between t and t + 1, Ct + 1 an indicator for loss to follow-up defined as three consecutive missed study visits at t + 1, V a set of 39 variables measured at the time of randomization, and L t a set of post-randomization variables measured at each t. The baseline covariates V were adherence during the run-in period, demographics (age, race), lifestyle characteristics (cigarette smoking, physical activity), medical history (risk group, weight, New York Heart Association class, comorbidities, blood pressure), use of non-study medications, laboratory findings, and electrocardiogram findings. All of these variables (except age, race, weight, risk group) were also post-randomization variables L t at each visit t. When an individual missed a study visit, the most recent covariate and adherence values were carried over from the most recent available data, up to three consecutive missed visits. Participants were censored at the expected date of their third consecutive missed study visit.
The choice of 80% as a cut-point for adherence was based on standard practice, as reflected by the use of a run-in period requiring 80% adherence to placebo among all trial participants. Note that, since adherence was assessed as a categorical variable, with the highest category ≥ 80% of prescribed pills taken, higher thresholds were not possible for the binary adherence indicator.
In our primary analysis, we artificially censored individuals when they reported an adherence level that differed from their baseline adherence level, that is, when A t ≠ A0 [8, 9]. We then fit the IP-weighted pooled logistic model for the discrete-time hazards at each time [10]:
where θ0,t is a time-varying intercept modeled as a restricted cubic spline of time (knots at 0, 5, 10, 15 visits), and θ2 is a vector parameter. The time-varying stabilized weights [11] were defined as:
where M t is an indicator for measurement of adherence at visit t (1 if measured, 0 otherwise), and overbars indicate history of the variable. The weight models were fit in the full population before artificial censoring; in a sensitivity analysis, we restricted the fit of the weight models to person-visits with A k = A0 for 0 < k ≤ t.
To estimate the denominator of the weights, we fit the model logit(Pr[M t = 1|\( {A}_0,{\bar{A}}_{t-1},V,{\overline{L}}_t,{C}_t=0 \)]) = α0t + α1A0 + α2At − 1 + α3V + α4Lt − 1 to all person-visits, and the model logit(Pr[A t = 0|\( {A}_0,{\bar{A}}_{t-1},V,{\overline{L}}_t,{C}_t=0 \),M t = 1]) = β0t + β1A0 + β2At − 1 + β3V + β4L t to the person-visits with measured adherence. When adherence was not measured at a visit (M t = 0) but the individual was not yet defined to be lost to follow-up (that is, at the first or second consecutive missed visit), adherence was carried forward from the previous visit and the factor in the denominator of the adherence weight was 1 for that visit.
Similar models that did not include the time-varying covariates were fit to estimate the numerators of the weights. The final weight for each individual at each time was the product of the measurement and adherence weights for that individual up to that time point. As in previous studies, we truncated the estimated IP weights at the 99th percentile to avoid undue influence of outliers. The truncated weight estimates had a mean of 1.00 (SD = 0.29) and a range of 0.02 to 2.55.
We used the parameter estimates from the weighted outcome logistic model to estimate the 5-year survival as previously described [2]. We compared the survival for always vs. never at least 80% adherent, that is, A0 = 0 vs. A0 = 1.
We conducted a second analysis where, rather than censor individuals who reported a change in adherence, we specified a dose-response function for the effect of adherence on mortality. To do so, we summarized the adherence history Ā t between baseline and visit t by the cumulative average cum(Ā t ) = \( \frac{1}{t+1}\sum \limits_{k=0}^t{A}_k \) (i.e., the proportion of visits during which an individual was adherent to at least 80% of the placebo dose), and then fit the pooled logistic model
where f[·] is a dose-response function and θ1 is a vector parameter.
In separate analyses, we specified more flexible dose-response functions. Specifically, we considered both a quadratic dose-response function θ1f[cum(Ā t )] = θ1,1cum(Ā t ) + θ1,2[cum(Ā t )]2, and a function that allowed for a separate effect of recent adherence θ1,0A t + θ1,1cum(Āt - 1) + θ1,2[cum(Āt - 1)]2. We also considered functions that included product terms with the time parameters.
To compute 95% confidence intervals, we used non-parametric bootstrapping with 500 samples.
SAS 9.4 was used for all analyses and code is provided in the supplementary online materials (see Additional file 1).
Results
Using our primary hazards models with artificial censoring, the estimated 5-year mortality risk difference between adherers and non-adherers in the placebo arm was 0.01 percentage points (95% confidence interval, -12.2, 13.2) after adjusting for post-randomization covariates (Table 1). Estimates based on dose-response hazards models without artificial censoring gave consistent estimates ranging from less than 1 percentage point to approximately 5 percentage points. Using an oversimplified dose-response model (a linear term only for cumulative adherence) resulted in implausible risk estimates (data not shown). The results were robust to other modeling choices, such as the number or placement of knots for the spline of time. As a sensitivity analysis, we also assessed censoring individuals for loss to follow-up at the second missed visit. Results were similar with an estimated 5-year mortality risk difference of 8.8 percentage points (95% CI, − 1.7, 20.7) in the unadjusted analysis and 0.6 percentage points (95% CI, − 8.1, 10.5) after adjusting for post-randomization covariates. When we restricted the fit of the weight models to person-visits with A k = A0 for 0 < k ≤ t, the 5-year mortality risk difference adjusted for post-randomization covariates increased slightly to 3.1 percentage points (95% CI, − 3.1, 9.4).
Discussion
Our analysis confirms that the survival differences between adherers and non-adherers to placebo can be largely adjusted away in the Coronary Drug Project. Adjustment for post-randomization predictors of adherence results in estimated 5-year mortality risk differences comparing adherence and non-adherence to placebo that are approximately null regardless of the analytic approach used. Our previous analysis [2] reached a similar conclusion but, by simply estimating the cumulative mortality at the end of follow-up, ignored the timing of events. In contrast, the current analyses use a survival analysis approach that allows estimation of adjusted survival curves for adherers and non-adherers throughout the follow-up.
We used two methods to compare the survival under continuous high-average adherence vs. low adherence (< 80%). The first method was a relatively inefficient censoring procedure that does not require a dose-response model for the effect of cumulative adherence on mortality. The second method was a theoretically more efficient method that requires a dose-response model and, therefore, will result in bias if the dose-response model is misspecified. We considered a variety of dose-response functions, which made different assumptions about the relationship between adherence and mortality over time. When sufficient data are available, more flexible dose-response functions are generally preferable as they impose fewer a priori constraints. For example, a function that models separately current adherence and prior cumulative adherence (using, say, linear and quadratic terms as in our analysis) requires fewer assumptions than a function that models total cumulative adherence. However, the added flexibility comes at the price of less precise estimates. Unlike in other examples [12], our estimates were not very sensitive to the choice of dose-response model. Further research into dose-response modeling for adherence-adjusted estimates is warranted.
Obtaining a null estimate when comparing adherers and non-adherers in the placebo arm supports the validity of adherence-adjusted effect estimates in randomized trials. However, this comparison relies on the lack of psychobiological effects of placebo on mortality. For other outcomes, such as pain or symptom severity, this assumption may be less reasonable.
Conclusion
Adherence-adjusted analyses of randomized controlled trials have been viewed with some skepticism with some authors suggesting that adherence is intractably confounded [1]. However, we have demonstrated that adjustment for post-randomization predictors of adherence can create comparability between adherers and non-adherers when rich data on pre-and post-randomization confounders exist.
Abbreviations
- CDP:
-
Coronary Drug Project
- CI:
-
Confidence interval
- IP:
-
Inverse-probability
References
Coronary Drug Project Research Group. Influence of adherence to treatment and response of cholesterol on mortality in the coronary drug project. N Engl J Med. 1980;303(18):1038–41.
Murray EJ, Hernan MA. Adherence adjustment in the Coronary Drug Project: a call for better per-protocol effect estimates in randomized trials. Clin Trials. 2016;13(4):372–8.
Coronary Drug Project Research Group. The coronary drug project. Design, methods, and baseline results. Circulation. 1973;47(3 Suppl):I1–50.
The Coronary Drug Project. Initial findings leading to modifications of its research protocol. J Am Med Assoc. 1970;214(7):1303–13.
The Coronary Drug Project. Findings leading to further modifications of its protocol with respect to dextrothyroxine. The Coronary Drug Project Research Group. J Am Med Assoc. 1972;220(7):996–1008.
The Coronary Drug Project. Findings leading to discontinuation of the 2.5-mg day estrogen group. The Coronary Drug Project Research Group. JAMA. 1973;226(6):652–7.
Coronary Drug Project Research Group. Clofibrate and niacin in coronary heart disease. JAMA. 1975;231(4):360–81.
Toh S, Hernandez-Diaz S, Logan R, et al. Estimating absolute risks in the presence of nonadherence: an application to a follow-up study with baseline randomization. Epidemiology. 2010;21(4):528–39.
Cain LE, Cole SR. Inverse probability-of-censoring weights for the correction of time-varying noncompliance in the effect of randomized highly active antiretroviral therapy on incident AIDS or death. Stat Med. 2009;28(12):1725–38.
Thompson WA. On the treatment of grouped observations in life studies. Biometrics. 1977;33(3):463–70.
Robins JM, Finkelstein DM. Correcting for noncompliance and dependent censoring in an AIDS Clinical Trial with inverse probability of censoring weighted (IPCW) log-rank tests. Biometrics. 2000;56(3):779–88.
Danaei G, Rodriguez LAG, Cantero OF, et al. Electronic medical records can be used to emulate target trials of sustained treatment strategies. J Clin Epidemiol. 2017; in press
Acknowledgements
We would like to thank Dr. Roger Logan for providing technical assistance.
Funding
This work was supported through a Patient-Centered Outcomes Research Institute (PCORI) Award (ME-1503-28119). All statements in this report, including its findings and conclusions, are solely those of the authors and do not necessarily represent the views of the Patient-Centered Outcomes Research Institute (PCORI), its Board of Governors or Methodology Committee.
Availability of data and materials
A SAS code for all analyses is available in the supplementary online materials. The full CDP dataset has been submitted to the National Heart, Blood, and Lung Institute.
Author information
Authors and Affiliations
Contributions
EM conducted the analysis. EM and MH designed the analysis, and wrote the manuscript. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval
This project was reviewed and exempted by the Harvard T.H. Chan School of Public Health IRB office. No consent was needed from study participants.
Consent for publication
Not applicable
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional file
Additional file 1:
SAS 9.4 code for placebo-arm adherence analysis. A SAS code for all analyses is provided in this file. If you have any questions, comments, or discover an error, please contact Eleanor Murray at emurray@mail.harvard.edu. For the most updated versions of related SAS programs, please visit www.hsph.harvard.edu/causal/. (PDF 316 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Murray, E.J., Hernán, M.A. Improved adherence adjustment in the Coronary Drug Project. Trials 19, 158 (2018). https://doi.org/10.1186/s13063-018-2519-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13063-018-2519-5