
Abstract
Background
The percentage of mammographic dense tissue (PD) is an important risk factor for breast cancer, and there is some evidence that texture features may further improve predictive ability. However, relatively little work has assessed or validated textural feature algorithms using raw full field digital mammograms (FFDM).
Method
A case-control study nested within a screening cohort (age 46–73 years) from Manchester UK was used to develop a texture feature risk score (264 cases diagnosed at the same time as mammogram of the contralateral breast, 787 controls) using the least absolute shrinkage and selection operator (LASSO) method for 112 features, and validated in a second case-control study from the same cohort but with cases diagnosed after the index mammogram (317 cases, 931 controls). Predictive ability was assessed using deviance and matched concordance index (mC). The ability to improve risk estimation beyond percent volumetric density (Volpara) was evaluated using conditional logistic regression.
Results
The strongest features identified in the training set were “sum average” based on the grey-level co-occurrence matrix at low image resolutions (original resolution 10.628 pixels per mm; downsized by factors of 16, 32 and 64), which had a better deviance and mC than volumetric PD. In the validation study, the risk score combining the three sum average features achieved a better deviance than volumetric PD (Δχ2 = 10.55 or 6.95 if logarithm PD) and a similar mC to volumetric PD (0.58 and 0.57, respectively). The risk score added independent information to volumetric PD (Δχ2 = 14.38, p = 0.0008).
Conclusion
Textural features based on digital mammograms improve risk assessment beyond volumetric percentage density. The features and risk score developed need further investigation in other settings.
Similar content being viewed by others

Background
Mammographic density is a term used to describe whiter regions of images that reflect the amount of fibroglandular as opposed to fatty tissue in the breast. Mammographic density is a well-established risk factor for breast cancer [1]. One well-studied measure of breast density is the percentage of the breast area that is opaque, often referred to as percent density (PD). In addition to area-based PD, volumetric measures have been developed to make use of the greyscale pixel values, without thresholding. It has been estimated that 16% of all breast cancers and 26% of breast cancers in women aged 55 years or less are attributable to breast density over 50% [2]; women with PD over 75% have been consistently reported to be at a fourfold to sixfold higher risk of developing the disease than women of similar age with little or no dense tissue [3]; and PD has been described as a risk factor that is the most significant after age [4].
While PD is an important risk factor, it is likely that characteristics of the mammogram other than PD may be related to breast cancer. For example, Wolfe’s parenchymal patterns [5] indicate texture characteristics that are not necessarily correlated with PD [6]. Similarly, the American College of Radiology Breast Imaging Reporting and Data System (BI-RADS) classifies density into categories based on not only the amount of density but on descriptors of the distribution, such as “scattered” and “heterogeneously dense” [7]. This suggests that the pattern or texture of dense tissue should be considered while assessing mammograms. In addition, some texture features have been suggested to predict BRCA1/2 carrier status, in contrast with PD [8].
A growing body of literature has considered mammographic texture features and their relationship with breast cancer risk. A recent review paper identified 17 original research articles [9]. These included early work by Manduca et al. [6], who identified texture features based on the grey-level co-occurrence matrix (GLCM) of neighbouring pixels. Kontos et al. [10] looked at a range of texture features with the aim to see how they are associated with PD based on both digital mammography and digital breast tomosynthesis (DBT). With a limited sample size, they identified GLCM features (homogeneity, contrast and energy) that were associated with PD from DBT and, to a lesser extent, digital mammography. Haberle et al. [11] considered five types of texture feature, finding that statistical features based on GLCM were strongly predictive of breast cancer, and that PD did not add information to risk once texture features had been accounted for. Li et al. [3] found that textural features predict breast cancer slightly better than semi-automated percent density. Keller et al. [12] compared risk prediction models using PD along with texture features based on the GLCM, statistical moments and run-length [13], and reported that texture features outperformed PD. However, there is not a great deal of consistency in the textural features identified between studies, so more work in this area is critically important. Nielsen et al. [14] developed a mammographic texture resemblance (MTR) marker based on multi-scale Gaussian features, which was found to have similar prediction performance compared with PD and could further improve the predictive ability when PD and MTR are combined.
While several studies have identified texture features for cancer prediction, many have been based on digitised film [9]. With the introduction of FFDM breast screening, there is a need to assess how best to assess the risk from textural features using digital mammograms. This is important partly because the properties of FFDM images differ from those of digitised films. For example, FFDM have a higher dynamic range than digitised film images [15] resulting in richer grey-level profiles; they also have different noise properties because the inherent granularity of screen-film mammography is not present in FFDM [16].
Very few studies have looked at texture features of original raw FFDM images. An additional issue with digital processed images is that one has to rely on manufacturers’ proprietary processing algorithms before feature extraction, which may result in images from different machines being less comparable. A recent review [9] of texture features for breast cancer risk found just two case-control studies based on raw FFDM including those by Chen et al. [17] and Zheng et al. [18]. There were just 156 cases in these studies (combined), and the case mammograms were from the contralateral (unaffected) breast at breast cancer diagnosis. Thus, overall information on the ability of textural features to predict risk of breast cancer in this context is limited.
The aim of this study was to develop a fully automated texture feature extraction system for raw digital mammograms, and to assess the predictive ability of textural features to stratify risk beyond volumetric PD. Fully automated in the context of this paper refers to a texture feature extraction system, including any pre-processing procedure, which operates without any human intervention.
Methods
Setting and study design
Two case-control studies were designed using women recruited to the Predicting Risk Of breast Cancer At Screening (PROCAS) cohort, in Manchester, UK [19]. The first case-control study was for feature selection (the training set), and cases were women with cancer detected at first screen on entry to PROCAS. Women were matched approximately 3:1 (controls vs cases) by age, body mass index (BMI), hormone replacement therapy (HRT) use and menopausal status. For feature selection the craniocaudal (CC) views of the contralateral breast for cases and the left breast for controls were used [20]. Unaffected breasts were followed up and recorded and cases of bilateral cancer were excluded. The average follow-up time was 3.9 years for cases and 4.9 years for controls.
The second case-control study was used to validate the risk score (the validation set). Each woman had a normal screening mammogram (no cancer detected) on entry to PROCAS, but an interval or screen-detected cancer had arisen subsequently. The mammograms were acquired approximately 3 years prior to diagnosis of breast cancer and were sampled independently from the same cohort as the training set. There is a small overlap of controls between the two datasets (n = 45) representing 2.7% of the total number of controls in both datasets. Again women were matched approximately 3:1 (controls vs cases) by age, BMI, HRT use, menopausal status and year of mammogram at entry. Since the validation was done in a double-blind fashion, case-control status was unknown before validation, so a pre-defined list of which breast was affected in each woman was provided so that the contralateral breast (also CC views) for cases and the same side for controls were used. As with the first study, women with bilateral cancer were excluded. The average follow-up time to date of diagnosis was 3.0 years for cases and the average follow-up time was 4.3 years for controls.
Mammograms
All digital raw (“for processing”) mammograms were acquired using a GE Senographe system. The resolution of the mammograms was 10.628 pixels per mm. Percent volumetric density was assessed using Volpara 1.5.0 (Volpara Health Technologies, Wellington, New Zealand).
Texture features
Texture features were extracted from the whole breast as a single region after windowing. Specifically, the minimum pixel value (whitest area) in the breast region was used as the lower bound of the window, and the value at the 75th percentile of the pixel value range (darker areas) within the breast was taken as the upper bound. The lower and upper bounds of the window were then reset (lower bound to 1 and pixels on or above the upper bounds to 0, which as a result also inverted the image) and the rest of the pixel values were linearly rescaled between 0 and 1.
We generally followed the literature to decide whether a feature was considered for evaluation in the training set. Statistical moments of pixel values from the windowed images were calculated directly in addition to features based on a grey-level co-occurrence matrix (GLCM), neighbourhood grey-tone difference matrix (NGTDM), form and shape of breast boundary, run-length, and grey-level size zone matrix (GLSZM) [3, 6, 10, 11, 13, 20,21,22,23].
Texture features were extracted from images at their original resolution. In addition, since some features (GLCM, NGTDM, run-length and GLSZM) are resolution-sensitive and might be associated with risk differently at different scales, they were extracted at reduced resolutions, by factors of 2, 4, 6, 8, 16, 32 and 64 using bi-cubic interpolation [6].
All texture features were calculated using Matlab (Mathworks, Natick, MA, USA). The Matlab package developed by Vallieres et al. [24] was employed for computing the GLCM, NGTDM, run-length and GLSZM features; and for these features, pixels were grouped equally into 10 grey levels in forming the relevant matrices before computing the texture features. A total number of 327 features were identified to be investigated. The full list of texture features considered and the types of features, downsize factors and univariate goodness-of-fit statistics using the training set are provided in the supplementary file (see Additional file 1).
Statistical analysis
Feature selection and model building
An initial screening was performed to remove features that were correlated with any other feature with absolute Pearson correlation greater than 0.95, where the feature taken forward was randomly selected. This resulted in a total of 112 candidate texture features.
Feature selection was based on the least absolute shrinkage and selection operator (LASSO) method, adjusted for age, BMI and volumetric PD. The tuning parameter that controls the extent of coefficient shrinkage was chosen by cross-validation. The final calibrated model was based on the one standard error rule, where the most parsimonious model with error (deviance in this case) within one standard error of the model with minimum cross-validation error (leave one out) was selected [25]. LASSO feature selection was performed using the implementation by Friedman et al. [26] in the statistical software R [27]. A single risk score based on the LASSO fit was taken forward for validation. In addition, Volpara density grade (VDG), a categorical version of estimated volumetric PD, was also tested to see whether VDG added information to volumetric PD or selected texture features.
Validation of risk score and components
The composite risk score and individual texture features identified by LASSO were validated in a two-stage double-blind fashion. A statistical analysis plan was drafted detailing the procedure of data exchange and statistical analysis. After identification of a limited set of textural features and a risk score to investigate further using the training data, CW calculated these features using anonymised mammograms from the validation set, and blind to case-control status. EH ran the initial statistical analysis for these features using the validation set, and then CW was unblinded. The predictive ability of the risk score beyond volumetric PD was tested using conditional logistic regression. Deviance (or likelihood-ratio χ2) and the matched concordance index (mC) [28] were calculated to test and measure prediction performance. Deviance is a likelihood-based statistic and is analogous to the sum of squared residuals. For model comparison, it is common practice to examine the change in deviance (likelihood-ratio χ2) to measure relative model performance. mC is a modification of the concordance index (or area under the receiving operator characteristic curve (AUC)) to matched case-control studies, and measures an average concordance index within matched groups. Some other features that were not selected by LASSO but had previously been identified to be important, and were observed to be univariately significant in the training set (i.e. standard deviation, coarseness and contrast as shown below), were also assessed in the validation case-control study. As biologic phenotypes between screen-detected and interval cancers are different, the effects of texture features or volumetric PD on risk may also differ between them. To explore this, a series of multivariate models were fitted with risk factors that were statistically significant in the univariate models, and an additional interaction term between the image feature and indicator for screen-detected or interval cancer.
Results
Study characteristics
The training case-control study had a total of 264 cases and 787 controls, of which 199 cases were invasive tumors, 63 were ductal carcinoma in situ (DCIS), and two were unknown. The validation case-control study had a total of 317 cases and 931 controls, of which 277 were invasive tumors, 39 were DCIS and one was unknown. The demographic characteristics of the women in the two studies are summarised in Table 1, which shows that age, BMI, and HRT use were well-matched between cases and controls in both studies. As expected, median volumetric PD was greater in cases than controls in both studies. The median 10-year Tyrer-Cuzick score was also greater for cases than controls in both studies. A majority of women had never used HRT and the percentage was slightly higher in the training set (60% for controls and 65% for cases in training set, vs 51% for controls and 52% for cases in validation set; the differences between training and validation sets are significant with p values of 0.0002 and 0.0019, respectively). In both studies around three quarters of women were postmenopausal, and the majority of women were ethnically white.
Texture feature risk score development
Three features were selected from the training set using LASSO (the value of the LASSO tuning parameter = 0.0402) and taken forward for validation in a combined risk score. They were the GLCM feature sum average calculated using images downsized by factors of 16, 32 and 64. Sum average is a feature considered to capture a relationship between radiolucent and radiopaque areas in an image [29]. Table 2 shows the correlation coefficients between the three sum average features, volumetric PD, age, BMI, and other important features identified in the literature including standard deviation (SD), contrast (based on NGTDM), and coarseness calculated at the original image resolution. Coarseness measures the amount of local grey-level variation and contrast measures the amount of difference among all grey levels and the amount of local variation in grey level presented in the image [21]. SD is a histogram-based feature so does not take into account spatial relationships between pixels.
The sum average features at different resolutions were relatively highly and positively correlated (Spearman correlation 0.74–0.88). There were weaker and negative associations between sum average features and age (-0.23 to -0.18) or BMI (-0.35 to -0.23). Volumetric PD was quite strongly and positively correlated with the sum average features (0.54– 0.63).
Table 3 shows the prediction performance of volumetric PD and the three sum average features in a univariate analysis, in addition to some texture features that have previously been identified in the literature and were univariately significant in the training data, and taken forward to be assessed in the validation set as secondary measures.
In the training sample, all three sum average features outperformed the other univariate features in terms of χ2, and achieved a mC that was comparable with PD. Sum average downsized by a factor of 32 achieved the best result in terms of both χ2 and mC (0.61). The performance of PD, SD and contrast was similar, while coarseness was the least predictive in terms of χ2. We also tested the Volpara density grade (VDG), a categorical version of estimated volumetric PD, finding it has a very similar predictive performance compared to volumetric PD (χ2 = 20.19, degrees of freedom = 3). A series of likelihood-ratio tests showed that VDG did not add further information to either volumetric PD (Δχ2 = 3.36, p = 0.3), or LASSO selected texture features such as sum average 16 (Δχ2 = 3.40, p = 0.3).
The risk score taken forward for validation is a weighted linear combination of the three sum average features. The standardized weights (i.e. using z scores where predictors were rescaled by their means and standard deviations before entering the model) were:
where the means of the three features were respectively 0.0555, 0.0559 and 0.0566; the standard deviations were respectively 0.000238, 0.000430 and 0.000775. It can be seen that sum average 64 contributed most to the score (0.066/(0.066 + 0.036 + 0.044) = 45%). In the training set the risk score had a similar mC (0.60) to its sum average components.
Figure 1 shows the mC and its confidence intervals for the sum average features calculated at different resolutions, including those not selected by the LASSO algorithm. Generally mC increased as images were downsized up to a factor of 32, and was approximately flat at downsizing factors between 16 and 128.

Matched concordance index (mC) for sum average at different image downsize factors, with bootstrap 95% confidence intervals (CI)
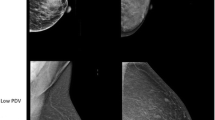
To better understand the feature sum average and risk score, and see how the feature looks visually, example images with low and high values of risk scores but similar volumetric PDs in the training study are presented in Fig. 2.

Comparison of mammograms (for presentation purpose processed images are shown) with two of the lowest (a) and highest (b) standardized risk scores. All mammograms have similar volumetric percent density (PD) around 10%. a Mammograms with low risk scores (-1.7 and -1.3, respectively). Volumetric PDs are 10.1% and 10.2%, respectively. b Mammograms with high risk scores (3.2 and 2.0, respectively). Volumetric PDs are 9.9% and 10.0%, respectively
Validation of texture risk score
The regression results using the validation dataset in Table 4 confirmed the predictive power of the texture risk score found in the training dataset. The standardized odds ratio was 1.36 (95% CI 1.20–1.55) with mC 0.58 (95% CI 0.54–0.62), which was broadly comparable with the development analysis using the training set (mC = 0.60). The risk score also achieved a better performance than volumetric PD in terms of deviance (Δχ2 = 10.55), indicating some evidence of preference of risk score relative to the PD [30] (logarithm PD Δχ2 = 6.95), but a similar mC (0.58 compared with 0.57 for PD). A series of likelihood-ratio tests showed that the risk score also added independent predictive information to volumetric PD (Δχ2 = 14.38, p = 0.0008) and Tyrer-Cuzick risk (logarithm transformed, Δχ2 = 22.43, p < 0.0001) and PD and Tyrer-Cuzick combined (Δχ2 = 10.22, p = 0.001). On the other hand, once the risk score was taken into account, PD added little information (Δχ2 = 0.21, p = 0.7).
Looking at individual texture features, only the three sum average features and contrast were statistically significant. Sum average based features also achieved the best fit in terms of deviance compared with other texture features and PD. Additionally, only the sum-average-based features added information to PD (the Δχ2 test statistics were 5.16, 6.46 and 12.56 for sum average using images downsized by factors of 16, 32 and 64, respectively). This confirms that sum average at low resolutions is an independent risk factor. Other texture features did not add further information once the risk score was taken into account.
Modelling results showing the difference between screen-detected and interval cancers for statistically significant features are presented in Table 5. As Table 5 shows, with the exception of contrast, the difference in screen-detected and interval cancers was statistically significant; and texture features and volumetric PD had higher odds ratios for interval than screen-detected cancers. This is likely related to masking of interval cancers from dense breasts, and perhaps also masking due to texture when the density is more dispersed (higher sum average value, c.f. Fig. 2).
Discussion
This study aimed to predict breast cancer risk with various texture features from raw digital mammograms. To achieve this, a number of relevant texture features were extracted and the LASSO model was employed for feature selection. The risk score was validated using a separate set of cases and controls from the same overall cohort.
The original raw mammogram files were pre-processed using a windowing technique. This effectively means that the darkest 25% pixels within the breast (mostly the uncompressed region) were set to be background. This is similar to the method used by Heine et al. [20] for computing standard deviation. They eroded a 25% area from the edge of the breast in scanned film images, as they reported that the region in question could potentially interfere with further feature extraction. The breast edge contains the darkest pixels. In addition to standardizing pixel intensities, another benefit of windowing is that image contrast is enhanced, making image appearance similar to that of film mammograms.
The texture features tested included many of those identified in previous studies, such as standard deviation of the pixel intensity values, NGTDM contrast, coarseness, and GLCM features. We also assessed some novel features that have been less well-studied in the literature, including GLSZM-based features that measure zonal effects and some form-based features such as the diameter of a circle with the same area as the breast region.
The GLCM feature, sum average, at lower image resolutions was selected by LASSO in the training study. Based on its mathematical formulation (see Appendix) and visual assessment of some mammograms, one can show that this feature tends to identify dispersed patterns of density on a mammogram. It was slightly surprising that PD and some previously reported texture features such as standard deviation, contrast and coarseness were not selected, although contrast was significantly and negatively associated with risk in both the training and validation studies, in line with Huo et al. [21]. Other texture features such as standard deviation and coarseness, however, were not significant in the validation study. While it is interesting that only 3 features were selected out of 112 features by the LASSO algorithm, it is worth noting that the features that were not selected by LASSO are not necessarily non-predictive of risk. For example, the feature contrast was shown as predictive in both the training and validation studies. Volumetric PD was not selected by LASSO either. This may be an indication that once some features were used, other features may no longer have added information. This is supported by the likelihood-ratio test that showed that once the risk score is taken into account, volumetric PD adds little information (p = 0.7). In the validation study, the three sum-average-based features achieved the best results among univariate predictors in terms of both deviance and mC. The risk score, a weighted combination of three sum-average-based features, has only obtained similar deviance or mC to its components on univariate analysis, suggesting sum average measured at one image resolution might be adequate. Although the sum average feature has been employed in some previous studies, it has not previously been identified as the strongest texture feature. The reason for different findings might be due to differences in the methods used to compute textural features. Indeed, it is often difficult to determine precisely how a feature was computed in prior publications and so we have been careful to provide a detailed description of the sum average feature used here in the Appendix. A lesser factor for differences might be different feature selection methods. Previous studies have often used stepwise regression for feature selection [6, 8, 11, 12, 21]. However, as pointed out by Hastie et al. [25], stepwise regression often leads to poor results compared to a less greedy method such as LASSO.
We explored the risk score by visual inspection of mammograms. Those in Fig. 2 are deliberately extreme, but they were chosen to show readers a clear demonstration that mammograms with a high risk score have more dispersed areas of bright pixels; whilst those with a low risk score do not. The example shows that a higher risk score helps to identify more widely dispersed dense patterns. In other words, it might capture an element of dense area that is (implicitly) not necessarily taken into account by volumetric density. As observed in Table 2, there is fairly high correlation between texture features and PD, so some of the effects of PD may be captured by texture features. Considering texture features improve prediction beyond PD, it is possible some spatial patterns of dense tissue may be related to risk in addition to the relative amount of density. This interpretation also follows the mathematical formula for the feature. Downsizing is important because it enables the measure of spatial relationships between pixels at a greater distance, and so better measures wider areas of density. In summary, this feature seems to capture the distribution of dense tissue and our results suggest that mammograms with greater areas of high density are associated with higher risk.
Differences in prediction performance at different resolutions are due to change in patterns for each feature at those resolutions. Some texture features are more consistent than others when the images were re-scaled. For example, the Spearman correlation coefficient for sum average between downsize factors of 1 and 64 is -0.12, indicating weak association; whilst the Spearman correlation coefficient for coarseness between downsize factors of 1 and 64 is 0.78, showing strong correlation. This means some factors such as coarseness are more consistent than others when the images were re-scaled. Texture features such as those based on GLCM typically measure spatial relationships between a pixel and its neighbouring pixels. As the images were downsized, the neighbouring pixels become more distant, thus resulted in changes in feature patterns. Some features, such as coarseness, are relatively robust to such change in neighbourhood definition, while some features change dramatically. This suggests that it is important to consider the impact of image resolution while analysing a certain texture feature. The implication is that a feature that predicts well at a given resolution may not perform well at another resolution. It is thus important to indicate the image resolution when exploring the prediction performance of a feature. This finding has also been observed elsewhere. For example, Haberle et al. [11] reported that a GLCM feature based on the same set of mammograms but at different resolutions have either different (opposite) associations with PD or different associations with cancer risk. Manduca et al. [6] also found that texture features tended to predict risk better when they were extracted at reduced image resolutions. For instance, the AUC of a feature increased from 0.50 to 0.60 when the images were downsized by factors of 2, 4, 8, and 16.
One contribution of our paper is that it shows how to extract a useful textural feature in a fully automated way from digital raw mammograms. Traditionally, studies utilising image texture features for cancer prediction have been based on scanned films, e.g. [6, 21]. Also, there is concern that results from processed (i.e. for presentation) mammograms may not be generalizable since different manufacturers have their own proprietary processing algorithms, making the resulting images and their features potentially not fully comparable between different manufacturers and machines. This paper addresses the above concerns by using the raw FFDM, and has shown which texture features might be important for predicting breast cancer risk, and how the risk model can be improved by downsizing the images. It is anticipated that the method proposed in the paper would better facilitate breast cancer risk prediction by using digital mammograms.
There are several possible ways to expand our study. For example, our image pre-processing method did not consider acquisition parameters, such as compression force, and thickness of the compressed breast and breast edge. It is possible that employing these acquisition parameters may lead to better image pre-processing and ultimately risk prediction. Another very important direction is to externally validate the method on a different population with different characteristics such as ethnicity and parity. In particular, we note that more than 92% of our study population was white, and more than 88% parous. The use of larger and diverse datasets would allow for additional breast cancer risk factors to be adjusted in the model. Also, the mammograms used in our analysis were all acquired from a GE system. It would be interesting to test our method on mammograms produced by other brands of machines. For transferability of our method, digital mammograms from other machines may be re-scaled to the same resolution as in this paper before feature extraction. There is also potential that our method can be adapted for digitised films. It would also be interesting to compare our method to recent advancement in deep learning [31]. Finally, this study focused on the CC view of mammograms. It is possible that texture features that are predictive of cancer risk may be different for mediolateral oblique (MLO) view mammograms. The issue with using MLO view mammograms is how to treat the pectoral muscle in an analysis. One possible approach is to remove the pectoral muscle before feature extraction. This requires an automated pectoral muscle removal algorithm (e.g. [17]) since our ultimate aim is to develop a fully automated risk prediction system. The additional information from the MLO view may assist in better predicting breast cancer risk than using the CC view alone.
Conclusion
This paper has shown that texture features are likely to be useful for predicting breast cancer risk using raw digital mammograms. Important texture features previously identified in the literature and some novel features were tested. The feature selection method LASSO was adopted to finalise the feature set taken forward for validation.
Among various features tested including standard deviation, coarseness, contrast and volumetric PD, we found the GLCM feature sum average at low image resolution was the strongest predictor of breast cancer risk, and added independent information to volumetric PD. An image standardization method was adopted to pre-process the digital raw mammograms before feature extraction, making it likely that our approach would have merit on other mammogram machines. However, while the selected features and calibrated model were internally validated in a separate case-control study from the same cohort with consistent results, our findings and risk algorithm would benefit from further studies to externally validate them.
Abbreviations
- AUC:
-
Area under the receiver operating characteristic curve
- BI-RADS:
-
Breast Imaging Reporting and Data System
- BMI:
-
Body mass index
- CC:
-
Craniocaudal
- CI:
-
Confidence interval
- DBT:
-
Digital breast tomosynthesis
- DCIS:
-
Ductal carcinoma in situ
- GLCM:
-
Grey-level co-occurrence matrix
- GLSZM:
-
Grey-level size zone matrix
- HRT:
-
Hormone replacement therapy
- LASSO:
-
Least absolute shrinkage and selection operator
- mC:
-
Matched concordance index
- MLO:
-
Mediolateral oblique
- MTR:
-
Mammographic texture resemblance
- NGTDM:
-
Neighbourhood grey-tone difference matrix
- OR:
-
Odds ratio
- PD:
-
Percent density
- PROCAS:
-
Predicting Risk Of breast Cancer At Screening
- SD:
-
Standard deviation
- VDG:
-
Volpara density grade
References
Assi V, Warwick J, Cuzick J, Duffy SW. Clinical and epidemiological issues in mammographic density. Nat Rev Clin Oncol. 2012;9:33–40.
Boyd NF, Martin LJ, Sun LM, Guo H, Chiarelli A, Hislop G, et al. Body size, mammographic density, and breast cancer risk. Cancer Epidemiol Biomarkers Prev. 2006;15:2086–92.
Li J, Szekely L, Eriksson L, Heddson B, Sundbom A, Czene K, et al. High-throughput mammographic-density measurement: a tool for risk prediction of breast cancer. Breast Cancer Res. 2012;14:R114.
Keller BM, Nathan DL, Wang Y, Zheng YJ, Gee JC, Conant EF, et al. Estimation of breast percent density in raw and processed full field digital mammography images via adaptive fuzzy c-means clustering and support vector machine segmentation. Med Phys. 2012;39:4903–17.
Wolfe JN. Breast patterns as an index of risk for developing breast cancer. Am J Roentgenol. 1976;126:1130–9.
Manduca A, Carston MJ, Heine JJ, Scott CG, Pankratz VS, Brandt KR, et al. Texture features from mammographic images and risk of breast cancer. Cancer Epidemiol Biomarkers Prev. 2009;18:837–45.
D’Orsi CJ, Sickles EA, Mendelson EB, Morris EA, et al. ACR BI-RADS atlas. Breast Imaging Reporting and Data System. Reston, VA: American College of Radiology; 2013.
Gierach GL, Li H, Loud JT, Greene MH, Chow CK, Lan L, et al. Relationships between computer-extracted mammographic texture pattern features and BRCA1/2 mutation status: a cross-sectional study. Breast Cancer Res. 2014;16:1–16.
Gastounioti A, Conant EF, Kontos D. Beyond breast density: a review on the advancing role of parenchymal texture analysis in breast cancer risk assessment. Breast Cancer Res. 2016;18:1-12.
Kontos D, Ikejimba LC, Bakic PR, Troxel AB, Conant EF, Maidment ADA. Analysis of parenchymal texture with digital breast tomosynthesis: comparison with digital mammography and implications for cancer risk assessment. Radiology. 2011;261:80–91.
Haberle L, Wagner F, Fasching PA, Jud SM, Heusinger K, Loehberg CR, et al. Characterizing mammographic images by using generic texture features. Breast Cancer Res. 2012;14:1-12.
Keller BM, Chen JB, Conant EF, Kontos D. Breast density and parenchymal texture measures as potential risk factors for estrogen-receptor positive breast cancer. Med Imaging 2014: Computer-Aided Diagnosis. 2014;9035:1-6.
Galloway MM. Texture analysis using gray level run lengths. Comput Graphics Image Process. 1975;4:172–9.
Nielsen M, Vachon CM, Scott CG, Chernoff K, Karemore G, Karssemeijer N, et al. Mammographic texture resemblance generalizes as an independent risk factor for breast cancer. Breast Cancer Res. 2014;16:1-8.
Suryanarayanan S, Karellas A, Vedantham S, Ved H, Baker SP, D'Orsi CJ. Flat-panel digital mammography system: contrast-detail comparison between screen-film radiographs and hard-copy images. Radiology. 2002;225:801–7.
Yaffe MJ. Basic physics of digital mammography. In: Bick U, Diekmann F, editors. Digital mammography. Berlin, Heidelberg: Springer Berlin Heidelberg; 2010. p. 1–11.
Chen X, Moschidis E, Taylor C, Astley S. Breast cancer risk analysis based on a novel segmentation framework for digital mammograms. Med Image Comput Comput Assist Interv. 2014;8673:536–43.
Zheng YJ, Keller BM, Ray S, Wang Y, Conant EF, Gee JC, et al. Parenchymal texture analysis in digital mammography: a fully automated pipeline for breast cancer risk assessment. Med Phys. 2015;42:4149–60.
Evans DGR, Warwick J, Astley SM, Stavrinos P, Sahin S, Ingham S, et al. Assessing individual breast cancer risk within the U.K. National Health Service Breast Screening Program: a new paradigm for cancer prevention. Cancer Prev Res. 2012;5:943–51.
Heine JJ, Scott CG, Sellers TA, Brandt KR, Serie DJ, Wu FF, et al. A novel automated mammographic density measure and breast cancer risk. J Natl Cancer Inst. 2012;104:1028–37.
Huo Z, Giger ML, Olopade OI, Wolverton DE, Weber BL, Metz CE, et al. Computerized analysis of digitized mammograms of BRCA1 and BRCA2 gene mutation carriers. Radiology. 2002;225:519–26.
Amadasun M, King R. Textural features corresponding to textural properties. IEEE Trans Syst Man Cybern. 1989;19:1264–74.
Chu A, Sehgal CM, Greenleaf JF. Use of gray value distribution of run lengths for texture analysis. Pattern Recogn Lett. 1990;11:415–9.
Vallieres M, Freeman CR, Skamene SR, El Naqa I. A radiomics model from joint FDG-PET and MRI texture features for the prediction of lung metastases in soft-tissue sarcomas of the extremities. Phys Med Biol. 2015;60:5471–96.
Hastie T, Tibshirani R, Friedman JH. The elements of statistical learning: data mining, inference, and prediction. 2nd ed. New York, NY: Springer; 2009.
Friedman JH, Hastie T, Tibshirani R. Regularization paths for generalized linear models via coordinate descent. J Stat Softw. 2010;33:22.
R Core Team. (2016). R: a language and environment for statistical computing. Available at: https://www.R-project.org/.
Brentnall AR, Cuzick J, Field J, Duffy SW. A concordance index for matched case-control studies with applications in cancer risk. Stat Med. 2015;34:396–405.
Gadelmawla ES, Eladawi AE, Abouelatta B, Elewa IM. Investigation of the cutting conditions in milling operations using image texture features. Proc Inst Mech Eng B J Eng Manuf. 2008;222:1395–404.
Burnham KP, Anderson DR, Huyvaert KP. AIC model selection and multimodel inference in behavioral ecology: some background, observations, and comparisons. Behav Ecol Sociobiol. 2011;65:23–35.
Kallenberg M, Petersen K, Nielsen M, Ng AY, Diao PF, Igel C, et al. Unsupervised deep learning applied to breast density segmentation and mammographic risk scoring. IEEE Trans Med Imaging. 2016;35:1322–31.
Assefa D, Keller H, Menard C, Laperriere N, Ferrari RJ, Yeung I. Robust texture features for response monitoring of glioblastoma multiforme on T1-weighted and T2-FLAIR MR images: a preliminary investigation in terms of identification and segmentation. Med Phys. 2010;37:1722–36.
Acknowledgements
The authors would like to thank the women who agreed to take part in the PROCAS study and other members of the PROCAS group, including the study radiologists, advanced radiographic practitioners and study staff, for recruitment and data collection.
Funding
This research is partially funded by Cancer Research UK (grant number C569/A16891). This work was supported by the National Institute for Health Research (NIHR) under its Programme Grants for Applied Research programme (reference number RP-PG-0707-10031: “Improvement in risk prediction, early detection and prevention of breast cancer”) and the Genesis Prevention Appeal (references GA10-033 and GA13-006). The views expressed are those of the author(s) and not necessarily those of Cancer Research UK, the National Health Service (NHS), the NIHR or the Department of Health.
Availability of data and materials
The datasets used for the current study are available upon reasonable request from the corresponding author.
Author information
Authors and Affiliations
Contributions
CW developed the algorithm to extract the texture features, performed the statistical analysis including feature selection, interpreted the results and drafted the manuscript. AB made substantial contribution to texture feature development and advice on statistical analysis and interpretation and helped to draft the manuscript. EH made substantial contribution to data distribution and model validation and helped to draft the manuscript. DGE conceived the PROCAS study. JC and SA conceived the study, interpreted the results and helped to draft the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The PROCAS study was approved by Central Manchester Research Ethics Committee (reference: 09/H1008/81) and consent was obtained from study participants at the time of screening.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
Univariate modelling results from training dataset. This table shows the univariate modelling results of all candidate texture features considered using training dataset. (DOCX 76 kb)
Appendix
Appendix
Sum average is a statistical texture feature computed from grey-level co-occurrence matrix (GLCM) constructed by considering how often pairs of pixels with specific values and in a specified spatial relationship occur in an image. Sum average is defined as [32]:
where I is the total number of grey levels, and p(i, j) denotes the proportion of a pixel at grey level i in a defined spatial relationship with a pixel at grey level j in the image. p(i, j) is obtained by firstly counting the frequencies of pairs of pixels at different grey levels with a defined spatial relationship (in this study, all eight directions surrounding a pixel were counted), and then normalized so that the sum of the elements of the GLCM is equal to 1. The general forumula includes I 2 to make it comparable between different sizes of GLCMs. In this study, the number of grey levels of 10 was adopted (i.e. I = 10), and the pixels within the breast region was divided into 10 levels in such a way that each level has equal probability. We tested using the number of grey levels other than 10 and the feature pattern changed only marginally - for instance using 5 grey levels the correlation coefficient with sum average using 10 grey levels was 0.97.
Sum average can be seen as the weighted (by grey levels) sum of GLCM elements. Thus this texture is likely to have higher value if many high grey-level pixels are close to each other.
In addition to sum average, the following GLCM features were tested:
Contrast:
Correlation:
where μ σ are means and standard deviations of corresponding rows and columns of GLCM.
Dissimilarity:
Energy:
Entropy:
Homogeneity:
Variance:
Similar to GLCM, a neighbourhood grey-tone difference matrix (NGTDM) could be constructed, and relevant texture features could be extracted by computing the summary statistics of NGTDM. The NGTDM is a vector (column matrix) constructed by firstly calculating the average grey tone over a neighbourhood centred at, but excluding (k,l):
where (m, n) ≠ (0, 0) (i.e. excluding the (k,l)); f(k,l) is the grey tone of any pixel at (k,l) having grey tone value i; d specifies the neighbourhood size (d = 1 in this case); and W = (2d + 1)2. Then the ith element of the NGTDM is:
where N i is the set of all pixels having grey tone i (exluding the peripheral regions of width d).
Coarseness is defined as:
where ε is a small number (2-52 in this case) to prevent it becoming infinite; p is the probability of occurrence of the corresponding intensity value. Contrast is defined as:
where N g is the total number of different grey levels in the image; n = N-2d.
Coarseness and contrast have been successfully applied for classification of cancer or BRCA1/2 status in the literature, such as Huo et al. [21] and Kontos, et al [10] where these features were described. As with GLCM, the pixels within the breast region were equally divided into 10 levels. In addition to coarseness and contrast, the following NGTDM features were tested:
Busyness:
Complexity:
Strength:
Similar to GLCM and NGTDM, run-length features were extracted from the run-length matrix. Let p(i, j) be the number of runs with pixels of grey level i and run-length j, n r be the total number of runs, and n p be the number of pixels in the region of interest:
Short run emphasis (SRE):
Long run emphasis (LRE):
Grey-level non-uniformity (GLN):
Run length non-uniformity (RLN):
Run percentage (RP):
n r /n p
Low grey-level run emphasis (LGRE):
High grey-level run emphasis (HGRE):
Short run low grey-level emphasis (SRLGE):
Short run high grey-level emphasis (SRHGE):
Long run low grey-level emphasis (LRLGE):
Long run high grey-level emphasis (LRHGE):
Grey-level variance (GLV):
where \( \mu =\frac{1}{I\cdot J}{\sum}_i{\sum}_jp\left(i,j\right)\cdot i \).
Run-length variance (RLV):
where \( \mu =\frac{1}{I\cdot J}{\sum}_i{\sum}_jp\left(i,j\right)\cdot j \).
The GLSZM features are similar to run-length features but the focus is on sizes of zones instead of collinear pixels (i.e. runs). In GLSZM, p(i, j) is defined as the number of zones with pixels of grey level i and area j, and the same formulas for run-length features can be used to compute GLSZM features.
As for shape-based features, convex area measures the number of pixels in the smallest convex polygon that contains the breast; equivalent diameter measures the diameter of a circle with the same area as the breast; extent measures the ratio of pixels in the breast to pixels in the total bounding box; major axis length is the length of the longest diameter of an ellipse that has the same normalized second central moments as the breast region; similarly minor axis length is the length of the minor axis of an ellipse that has the same normalized second central moments as the breast; and solidity is the ratio of breast area and its convex area.
The software implementing the method described in this paper has been made available for the Windows operating system (https://doi.org/10.6084/m9.figshare.4994429.v2). Upon launching the software, a dialogue box would be prompted asking users which mammogram file(s) to examine and where the results are to be saved. The software would then compute the texture features without further user input and save the results in a spreadsheet at the location the user specified.
Differences from density assessment case-control studies: the number of cases and controls differs from a report (submitted elsewhere) that compared density methods using the same women. The reasons are as follows. First, the training case-control study was a subset of one with 317 cases and 952 controls. Three women were excluded due to linkage errors between mammograms and questionnaire data (although they could be subsequently incorporated we decided to present the training data as it was undertaken before validation). We also excluded women with unknown BMI and volumetric PD at the time of analysis (79 and 37 women with missing BMI and PD, respectively). An additional 100 controls were removed during conditional logistic regression because they did not have matched cases as a result of the aforementioned exclusions.
The validation case-control study originally had 338 cases and 1014 controls: 23 women were excluded because of unavailability of mammograms at the time of validation (either no mammograms provided for some women at the given side; or only MLO views were available but no CC views). There were 64 further women removed because the side of cancer (left or right) was unknown; two women were further excluded due to lack of volumetric PD data at the time of validation. A further 15 controls were removed during conditional logistic regression because they had no matched cases as a result of the aforementioned exclusions.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Wang, C., Brentnall, A.R., Cuzick, J. et al. A novel and fully automated mammographic texture analysis for risk prediction: results from two case-control studies. Breast Cancer Res 19, 114 (2017). https://doi.org/10.1186/s13058-017-0906-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13058-017-0906-6