
Little experience is sufficient to show that the traditional machinery of statistical processes is wholly unsuited to the needs of practical research. Not only does it take a cannon to shoot a sparrow, but it misses the sparrow. The elaborate mechanism built on the theory of infinitely large samples is not accurate enough for simple laboratory data.” (R. A. Fisher, 1925).
Abstract
Background
The use of meta-analysis to aggregate multiple studies has increased dramatically over the last 30 years. For meta-analysis of homogeneous data where the effect sizes for the studies contributing to the meta-analysis differ only by statistical error, the Mantel–Haenszel technique has typically been utilized. If homogeneity cannot be assumed or established, the most popular technique is the inverse-variance DerSimonian–Laird technique. However, both of these techniques are based on large sample, asymptotic assumptions and are, at best, an approximation especially when the number of cases observed in any cell of the corresponding contingency tables is small.
Results
This paper develops an exact, non-parametric test based on a maximum likelihood test statistic as an alternative to the asymptotic techniques. Further, the test can be used across a wide range of heterogeneity. Monte Carlo simulations show that for the homogeneous case, the ML-NP-EXACT technique to be generally more powerful than the DerSimonian–Laird inverse-variance technique for realistic, smaller values of disease probability, and across a large range of odds ratios, number of contributing studies, and sample size. Possibly most important, for large values of heterogeneity, the pre-specified level of Type I Error is much better maintained by the ML-NP-EXACT technique relative to the DerSimonian–Laird technique. A fully tested implementation in the R statistical language is freely available from the author.
Conclusions
This research has developed an exact test for the meta-analysis of dichotomous data. The ML-NP-EXACT technique was strongly superior to the DerSimonian–Laird technique in maintaining a pre-specified level of Type I Error. As shown, the DerSimonian–Laird technique demonstrated many large violations of this level. Given the various biases towards finding statistical significance prevalent in epidemiology today, a strong focus on maintaining a pre-specified level of Type I Error would seem critical.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Background
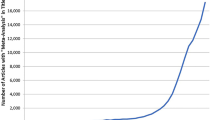
The use of meta-analysis in epidemiological research has been increasing at a very rapid rate. A review of the National Library of Medicine’s online database (“Pub Med”) shows that in 1980 there were only five research articles with the phrase “meta-analysis” in their titles. The number had increased to 92 in 1990, 422 in 2000, and to 9125 in 2014 (see Fig. 1).

Number of articles containing “meta-analysis” in the title by year of publication
While part of this growth may be due to the widespread availability of powerful personal computer software making meta-analysis techniques easier to perform and more feasible to implement, this growth also likely represents a critical epidemiological need to draw meaningful conclusions from an aggregation of studies.
The use of meta-analytic techniques is controversial when the contributing studies are not randomized control trials (“RCT”). Many researchers feel that it is highly misleading to attempt to combine a series of disparate studies [1, 2] while others maintain that, with proper safeguards, meta-analysis allows an extremely useful pooling of smaller studies [3, 4]. A discussion of the appropriateness of meta-analysis is beyond the scope of this paper. Rather, the focus here will be on minimizing unnecessary error in testing the overall statistical significance of a meta-analysis.
Overview of 2 × 2 × k categorical meta-analysis
The “2 × 2 × k” categorical meta-analysis paradigm is probably the most frequently encountered situation in meta-analysis. It consists of a series of k contributing studies each described by a 2 × 2 contingency table. Each cell of the 2 × 2 table contains the number of occurrences of an event (e.g., a disease case) for the particular combination of row and column variables. For the sake of exposition, we can associate the two columns of each table with “Disease Manifestation” versus “No Disease Manifestation” and the two rows with “Exposure” versus “No Exposure.” Table 1 represents the results of one of the k studies
In most meta-analyses, there are typically two distinct components: (1) a statistical test of the overall difference between the “Exposure” and “No Exposure” groups across the k contributing studies, and (2) a method to pool the observed differences between groups across the k studies in order to estimate the true difference (the “Effect Size”).
Many epidemiologists employing meta-analytic techniques have greatly deemphasized the first component in recent years. Borenstein et al. [3] conclude:
“… However, meta-analysis also allows us to move beyond the question of statistical significance, and address questions that are more interesting and also more relevant.” (pp. 11–12).
Similarly, Higgins and Green [4] rather dismissively state:
“… If review authors decide to present a P value with the results of a meta-analysis, they should report a precise P value, together with the 95% confidence interval” (pp. 371–372).
This study addresses only the first of these two components. A method is developed that attempts to maintain the Type I error (“false alarm rate”) at the desired level but has good power to detect true differences across a large range of event probability, number of contributing studies, sample size and level of heterogeneity.
An argument can be made that maintaining the Type I error at a pre-specified level is more important than the power (1—Type II error rate) to detect true differences between conditions. The framers of modern statistical testing called such errors “Errors of the First Kind” and placed a special emphasis on them. Neyman & Pearson in 1933 stated:
“A new basis has been introduced for choosing among criteria available for testing any given statistical hypothesis, H0, with regard to an alternative Ht. If ϴ1 and ϴ2 are two such possible criteria and if in using them there is the same chance, ε, of rejecting H0 when it is in fact true, we should choose that one of the two which assures the minimum chance of accepting H0 when the true hypothesis is Ht.” [5] [p. 336]
Thus, while Neyman and Pearson supported the effort to choose criteria that yield the greatest power to detect true differences, this effort is secondary to maintaining a pre-specified level of Type I error. Estimating the Effect Size particularly for rare events is well covered in a number of recent studies (see in particular [6, 7]).
“Rare” events and meta-analysis
The probability of occurrence of a disease is often categorized as “rare” although no specific definition exists. As an example, Higgins et al. state that “There is no single risk at which events are classified as ‘rare’” but gives as examples 1 in a 1000 or 1 in a 100 (see [8], p. 520). An obvious related issue is observing zero cases in one or more cells of a contingency table. Table 2 shows the expected cell sizes from various realistic combinations of disease probability and individual study sample size.
If one heuristically defines “rare” as fewer than five expected cases of a disease, Table 2 supports the notion that “rare” events are a focus of many epidemiological studies.
For homogeneous meta-analysis (i.e. where the effect across studies may be assumed to be the same within statistical variation), the two techniques typically used for categorical data are the Mantel–Haenszel and Peto techniques. Both of these techniques rely on the Mantel–Haenszel Chi Square to test for the overall statistical significance. For heterogeneous meta-analyses, the DerSimonian–Laird inverse variance technique (DL) which requires a number of assumptions is typically used [9]. The technique developed in this paper will be compared directly to the DL technique as described below.
The problem in applying large sample asymptotic techniques to meta-analyses involving small numbers of cases will be illustrated in the older and more developed domain of homogeneous meta-analyses. Mantel and Haenszel developed what is probably the most used technique for homogeneous meta-analyses [10]. In applying this technique, Manel and Fleiss showed that a minimum of approximately five cases was required in each of the 4 cells of each of the 2 × 2 tables for each of the k studies comprising the meta-analysis [11]. This is the same requirement typically used without any particular justification for the simple Chi square test. All but one of the combinations of individual study sample size and disease probability shown in Table 2 would yield fewer than five cases per cell leading to violations of the minimum cell size in the asymptotic Mantel–Haenszel (MH) Chi Square test, and thus the test would be potentially flawed.
R. A. Fisher addressed the limitations of using asymptotic large sample methods in 1925 in the preface to the first edition of his well-known “Statistical Methods for Research Workers” [12]:
Little experience is sufficient to show that the traditional machinery of statistical processes is wholly unsuited to the needs of practical research. Not only does it take a cannon to shoot a sparrow, but it misses the sparrow. The elaborate mechanism built on the theory of infinitely large samples is not accurate enough for simple laboratory data. Only by systematically tackling small sample problems on their merits does it seem possible to apply accurate tests to practical data.
The continued use asymptotic tests in situations not suited for their use is unacceptable given the computer power that is now available to all researchers.
Heterogeneity versus homogeneity in meta-analyses
The term “heterogeneity” refers to the fact that studies done at different times and by different researchers might be expected to have different treatment effects. The expectation is that a variable of interest may owe its effect, at least in part, to one or more other variables. The meta-analysis researcher, J. P. T. Higgins stated: “Heterogeneity is to be expected in a meta-analysis: it would be surprising if multiple studies, performed by different teams in different places with different methods, all ended up estimating the same underlying parameter.” ([13], p. 1158). While researchers may agree that heterogeneity is to be expected, there is very little agreement on how to quantify this variability. The most obvious and direct candidate is τ2, the assumed variability between studies. However, τ2 is not invariant across study designs and its interpretation may not be intuitive. Alternatives include I2, the ratio of the inter-study variability to the total variability and the Q statistic, which is mathematically related to I2 (see, e.g., [14]).
In the technique described in this paper, heterogeneity will be mathematically manipulated through τ2 and the logit function using the same approach as Bhaumik et al. [15]. Namely,
where B is the Binomial Distribution, N is the Normal Distribution, xic, xit are the observed number of cases in the control and exposure groups respectively of the ith study, pic, pit are the event probabilities in the control and exposure groups respectively of the ith study, nic, nit are the sample sizes in the two groups of the ith study, µ corresponds to the background event probability in the treatment and control groups, \(\theta\) corresponds to the overall Odds Ratio for the Exposure Group relative to the Control Group or the “log of the odds ratio”, \(\tau^{2}\) is a variance corresponding to the heterogeneity or the “heterogeneity parameter”, \(\varepsilon_{i}\) is the deviation in the treatment group of each of the contributing studies due to heterogeneity.
The basic principles of the DerSimonian–Laird (DL) method
As stated above, this research specifically contrasts an exact method for conducting meta-analyses in k 2 × 2 tables with heterogeneity with the most popular approach which was developed by DerSimonian and Laird [9] (DL).
For each contributing study, the DL technique calculates the logarithm of the sample odds ratio and a corresponding estimate of the variance of this measure based on the asymptotic distribution of these logarithms. Adjustments are made for entries in the individual 2 × 2 tables that contain a zero-cell count. Equations 2–5 below capture the core DL approach. In Eq. 2, an estimate of the interstudy variability, \(\tau^{2}\), is first derived from Cochran’s Q statistic and the weights assigned to each of the k contributing studies, \(\omega_{i}\). These weights are equal to the inverse of the square of the standard error of the estimate of the odds ratio, \(\hat{\theta }_{i } ,\) in each of the k contributing studies.
As shown in Eq. 3, a new set of weights, \(\omega_{i}^{{\prime }}\), are then calculated based on the estimated value of \(\hat{\tau }^{2}\) from Eq. 2 and the standard errors of the contributing studies.
These new weights are then used to calculate estimates of both the overall log odds ratio, \(\theta_{DL }\) and its standard error as shown in Eq. 4 and 5.
A test of statistical significance is then based on a large sample normal distribution. The DL technique requires asymptotic assumptions regarding both the Q statistic used to estimate the interstudy variability, \(\tau^{2} ,\) and the normal distribution required to test for statistical significance. A more subtle issue is the possibility of distorting correlations between the individual estimates of the effect size for each contributing study, \(\theta_{i }\), and the individual weights used for each of these contributing effect sizes.
The ML-NP-EXACT: an exact maximum likelihood non-parametric test of 2 × 2 × k dichotomous data
Basic approach
An exact approach to developing a maximum likelihood test of independence for k 2 × 2 tables logically starts by first addressing the simple k = 1 2 × 2 table case. An exact method would use maximum likelihood estimates of the cell counts and associated cell probabilities and then use a “goodness of fit” test sensitive to violations of independence. Agresti and Wackerly [16] argued that “exact conditional tests can be simply formulated by using other criteria for ranking the tables according to the deviation each exhibits from independence.” [pp. 113–114] and go on to mention likelihood ratio statistics.
One such statistic is the G Test “goodness of fit” statistic strongly advocated by Sokal and Rohlf [17] to test for independence between the row and column variables. Sokal and Rohlf cite Kullback and Leibler’s “Divergence” measure which is mathematically identical to the G Test [18]. The probability distribution of the G Test statistic is asymptotically χ2 which would be adequate for tables with large numbers in each of the cells. However, for the case of sparse tables being developed in this paper, this would not be satisfactory. For this simple k = 1 case, Fisher’s Exact Test would be appropriate [19]. Fisher’s Exact Test exploits the fact that if one conditions on any of the marginal totals, the cell frequency of interest will be a sufficient statistic. Then, the associated frequency distribution of the cell frequency of interest may be determined exactly using the hypergeometric distribution. Fisher’s Exact approach has been extended by Thomas [20] and others. Among other advantages, such conditioning eliminates the effect of any nuisance variable identically affecting both exposure categories. Using Table 1 nomenclature, the number of individuals manifesting the disease being studied in the Exposure Group, rk, conditionalized on the total number of individuals manifesting the disease, tk is a sufficient statistic. This approach can be directly extended to 2 × 2 × k designs by again using the G Test “goodness of fit” statistic and testing for conditional independence in each of the k tables comprising the overall meta-analysis.
In the 3-way 2 × 2 × k meta-analysis, one approach is to first test for independence among the two factors (Disease Status and Treatment in the terminology of Table 1) in each of the k strata (e.g. using the Breslow-Day test of interaction [21]). If such a test of interaction supported independence of the two factors, the notion of a Common Odds Ratio (COR) could be entertained. Then the overall COR averaged across the k strata could be tested against the null hypothesis of 1.0 using the Cochran-Mantel–Haenszel test or equivalent.
Alternatively, Yao and Tritchler [22] developed an exact conditional independence test for 2 × 2 × k categorical data. Although they derived an exact null hypothesis frequency distribution, they chose to use the standard Chi Square test statistic:
where k is the number of contributing studies.
The present author programmed their test in the R statistical language based on Yao’s dissertation [23]. Preliminary Monte Carlo simulations showed, however, that this implementation yielded a test with limited power compared to the DL method. With the advantage of the hindsight provided by this simulation, the use of a Chi Square statistic for this exact test is probably suboptimal and is not necessary given their derivation of an exact null hypothesis frequency distribution.
A straightforward utilization of G Test per [17] would thus be:
where k is the number of contributing studies, Oi is the number of observed cases in the Exposure Group of the ith contributing study, Ei is the number of expected cases in the Exposure Group of the ith contributing study assuming conditional independence.
Table 1 which shows the data for a particular one of the k contributing studies will be used to help clarify this approach. There are two sources of cases, cases from the “Exposure” group and cases from the “No Exposure” group. The number of observed cases in the Exposure Group (rk of Table 1) per Eq. 3 is 4. The number of expected cases under Fisher’s conditional independence approach would be the total number of cases of 6 multiplied by the proportion of the overall sample size corresponding to the Exposure Group which in this case would be .5. Thus, the number of expected cases in the Exposure Group would be 6 *.5 = 3 cases.
The approach being developed in this paper attempts to deal with “rare” events including the possibility of no disease events in either the Exposure group or in the No Exposure group. However, when the number of cases in the Exposure Group, Oi, is zero, the \(\ln \frac{{O_{i} }}{{E_{i} }}\) term would not be calculable. Simply eliminating such studies would likely lead to an anti-conservative bias in Type I Error. Thus, the following modified G Test statistic was used and will be referred to as G*:
This transformation permits calculation of the test statistic when the number of cases in one of the two groups equals zero, but where there are a positive number of cases in the other group. This issue and a similar approach of adding a constant to both the number of Observed and Expected cases was more fully explored in a recent Ph.D. dissertation [24].
Two special cases under large heterogeneity
Protocols were developed to handle two special situations under large heterogeneity. The first situation involves the event probabilities in the control and exposure groups respectively of the ith study, pic, pit, as originally presented in Eq. 1 and shown for convenience below:
As shown in Fig. 2 plotted with p as a function of the logit variable, p has a slope of exactly .25 at p = .5 with the slope approaching zero as p approaches both zero and 1.0. In addition, the curve is only symmetric in the logit variable at exactly p =.5.

Plot of event probability, p, as a function of the logit variable
For realistic values of event probability such as .01, positive event probability excursions will be much larger than negative ones for large values of heterogeneity across studies. This problem manifests itself in artificially large violations of the pre-specified level of Type I Error. Therefore, negative values of the test statistic \(G\) which corresponds to observing fewer cases in the Exposure Group than expected were increased in magnitude (made more negative) by multiplying them by a correction factor based on the derivative of p with respect to the logit variable:
As required, the correction factor equals one when p = .5 and becomes appropriately large as p approaches zero. This correction factor was applied when the \(G^{*}\) statistic was negative and when the treatment variance relative to the control variance was greater than or equal to 3.0.
A second problem concerns meta-analyses in which there are only a small number of contributing studies. As shown by InHout and colleagues [25], there is a monotonic and large positive effect on Type I Error as the number of contributing studies decreases. This is not a problem of inadequate replications, but one of bias. The author conducted a separate analysis that showed that under large heterogeneity there is a corresponding large probability for a single study to incorrectly skew the overall test statistic towards statistical significance. When the number of contributing studies is large, this tendency is counterbalanced by other studies having correspondingly large excursions in the negative direction.
This problem can be appreciated in Fig. 3.

Plot of probability of a single “skewing” event and its contribution to the overall test statistic as a function of the number of contributing studies
The first curve plotted on the primary vertical axis is the probability of obtaining a single large positive excursion likely due to a high level of heterogeneity in any one of the k contributing studies. The second curve plotted on the secondary vertical axis is simply the first variable divided by the number of studies on the x axis. This second variable is thus proportional to the contribution made by this single study’s large positive excursion to the average test statistic. As the plot of this second variable suggests, the contribution of a single large positive excursion study is monotonically decreasing with increasing number of contributing studies as the effect of averaging begins to be exhibited. The correction algorithm that was used identified those situations when the overall test statistic was greater than the critical value and .75 or more of the test statistic came from a single large positive excursion. When this situation obtained, the contribution of this likely outlier to the overall test statistics was eliminated.
Implementation of the test in the R statistical language
This conditional-independence maximum likelihood exact test was implemented in the R Statistical Language. Each of the k contributing studies has a discrete probability distribution which is a function of the background event probability and odds ratio of that study. The joint probability distribution of the k discrete probability distributions is the convolution of these k distributions which will also be a discrete distribution. Directly performing this convolution would be extremely time consuming even for relatively small values of k. However, it can be readily shown that if each of the k distributions is first transformed into the “frequency domain” using the Fourier Transform, the simple multiplicative product of these k transformations is the Fourier transform of the joint probability distribution. A single inverse Fourier transform then yields the joint probability distribution (see, e.g., [26]). This was the approach used by Yao & Tritchler [22]. The development of the Fast Fourier Transform (FFT) for generation of the Fourier Transform in discrete situations [see, e.g. [27] for a relatively early presentation] such as the categorical meta-analysis presented here permits quickly determining the joint probability distribution using almost any PC-type computer. The program has been extensively tested across a large range of heterogeneity, odds ratios, disease probability, number of contributing studies and sample size.
Monte Carlo simulation of the ML-NP-EXACT and DerSimonian–Laird techniques
Population-based odds ratio simulation
A series of Monte Carlo simulations was conducted to evaluate the ML-NP-EXACT technique and compare it directly to the typically used DerSimonian–Laird Inverse Variance technique [9] for population-based odds ratio scenarios. The simulation was written and executed in “R: A Programming Environment for Data Analysis and Graphics.” [28]. The DerSimonian–Laird results were calculated using the “meta” package in R [29].
Five levels of odds ratio were chosen (1.0, 1.25, 1.5, 1.75, and 2.0) which were crossed with three levels of background event probability (.005, .01, and .05), and three levels of sample size (50,100 and 200) in each arm of each contributing study. Finally, the number of studies entering into each meta-analysis was chosen to be 5, 10, 20, or 40 studies.
In addition, the heterogeneity between the contributing studies, τ2, was evaluated at 0 (homogeneity), .4, and .8. This last value of .8 represents a very large variance among the studies and was partially chosen to be able to compare the results with previous work [15]. To put such a large inter-study variance into some perspective, a background event probability (e.g. disease probability) of .01 would be expected to fluctuate between .0017 and .057, a ratio of 33:1 under a heterogeneity of τ2 = .8.
Finally, the common variability in both the exposure and control groups was chosen to be .5 and an error term, \(\varepsilon_{i} = N\left( {0,.5} \right)_{{}}\) was added to both the logit transformed probabilities of Eq. 1 above per Bhaumik’s [15] desire to “imply that both the control and treatment groups have varying rates of events” (p. 9) allowing direct comparisons to be made to this earlier research. For each simulation, the overall treatment effect was evaluated using both the ML-NP-EXACT and DerSimonian–Laird techniques. All simulation runs were conducted with 2000 replications. A value of .05 was used as the pre-specified level of Type I Error.
The Monte Carlo simulation results are shown below in Tables 3, 4 and 5 corresponding to heterogeneity values τ2 of 0, .4, and .8. respectively. The 108 variable combinations with an Odds Ratio of 1.0 (i.e. no treatment effect) are shown in italics for purposes of exposition. The standard deviation as a function of reported power is shown in Fig. 4.

Plot of standard deviation of the simulation as a function of the reported power
There are three general findings from the direct comparison of the ML-NP-EXACT technique with the DL technique.
-
1.
For the homogeneous case of τ2 = 0, the ML-NP-EXACT technique yielded a Type I Error value centered on the pre-specified level of .05 for practically all combinations of event probability, number of contributing studies and sample size as show in Table 3. However, as shown in Table 3, the DL technique consistently returned a Type I Error value well below .05 and correspondingly low levels of power for Odds Ratios greater than 1.0. In order to compare the power for Odds Ratios > 1.0, an upper limit on Type I Error needs to be established. Using a Type I Error level of 7.5%, the ML-NP-EXACT technique demonstrated a larger power in over 73% of the comparisons.
-
2.
For the most heterogeneous τ2 = .8 case and to a lesser degree for τ2 = .4, the DL technique frequently failed to protect the pre-specified Type I Error value of .05 while the ML-NP-EXACT technique was superior. Figures 5 and 6 are the histograms of the 108 Odds Ratio = 1.0 data points for the ML-NP-EXACT and DL techniques respectively. The ML-NP-EXACT Type I Error was centered approximately on the nominal .05 value. The DL technique shows concentrations at very small values of Type I Error and a very wide range of higher values of Type I Error. Using the arbitrary Type I Error limit of 7.5%, there was ten times the number of violations of this level for the DL technique (40) compared to the ML-NP-EXACT technique (4).
Fig. 5 
Histogram of the Type I Error for the ML-NP-EXACT technique
Fig. 6 
Histogram of the Type I Error for the DerSimonian–Laird inverse-variance technique
This inability of the inverse-variance DerSimonian–Laird technique to protect a pre-specified value of Type I Error has been shown in previous studies (See, for example [15, 25]). In the Bhaumik et al. study [15], Fig. 2a shows Type I Error rates up to approximately 15% for the range of µ of -3 to -5 of primary interest in the current study. This same level of violation of the pre-specified level of Type I Error was found in the present simulations.
Finally, three of the four occasions when Type I Error for the ML-NP-EXACT technique exceeded the 7.5% level had just five contributing studies. As discussed earlier, the probability for a single study to incorrectly skew the overall test statistic towards statistical significance increases sharply as the number of contributing studies decreases.
-
3.
As expected, when the DL technique protected the Type I Error, it tended to be more powerful than the ML-NP-EXACT technique for higher values of odds ratio, event probability, number of contributing studies and sample size. These higher values lead to less sparse contingency tables and the increased appropriateness of a large sample asymptotic method such as the DL Inverse Variance technique.


As shown clearly in Tables 3, 4 and 5, the two variables under the experimenter’s direct control, Number of Studies and Sample Size, both had powerful effects on the power for the ML-NP-EXACT technique. Somewhat surprisingly, the heterogeneity variable, τ2, did not largely affect power. However, its inflationary influence on Type I Error needed to first be “tamed.”
Extending the ML-NP-EXACT technique
Unbalanced designs
Additional Monte Carlo testing was done for unbalanced designs (unequal sample sizes in the exposure and no exposure arms of the contributing studies) and meta-analyses with unequal sample sizes across contributing studies. Table 6 shows the sample sizes for the two groups for a typical unbalanced design in which the control sample size is twice the exposure group sample size. The sum of the two sample sizes across the two arms of each study was chosen to be 200. This design allows direct comparison of the simulation results with the balanced designs of Tables 3, 4 and 5.
Table 7 shows the results of the simulation for a heterogeneity value τ2 = 0, Event (“disease”) Probability of .05, and Sample Size (per arm) of 100, at the same five levels of Odds Ratio used above. The simulation run consisted of 2000 replications as in Tables 3, 4 and 5.
As the results in Table 7 indicate, the ML-NP-EXACT power in the unbalanced scenario is slightly smaller for all values of Odds Ratio relative to the DerSimonian–Laird method. Type I Error (Odds Ratio = 1.0) was close to the prespecified value of five percent for the ML-NP-EXACT technique and was reasonably close to five percent for the DL technique.
Unequal sample size designs
Table 8 shows the sample sizes for the exposure and control groups for each of the contributing studies for a design with unequal sample size across the contributing studies. This particular design was chosen as a relatively extreme case. As can be seen, the average sample size for both the exposure and control groups was maintained at 100 to allow comparison of the simulation results with the equal sample size scenarios of Tables 3, 4 and 5.
Table 9 shows the results of the simulation for a heterogeneity value τ2 = 0, Event (“disease”) Probability of .05, and Average Sample Size (across both study arms) = 200, at the same five levels of Odds Ratio as used above. The simulation run consisted of 2000 replications as in Tables 3, 4 and 5.
The ML-NP-EXACT power in this unequal sample size condition was slightly superior to the DerSimonian–Laird technique. More importantly, the ML-NP-EXACT was superior at protecting the pre-specified level of Type I Error.
Discussion and conclusions
This research has developed an exact test for the meta-analysis of dichotomous categorical data. The ML-NP-EXACT technique was strongly superior to the DerSimonian–Laird technique in maintaining a pre-specified level of Type I Error. As shown, the DerSimonian–Laird technique demonstrated many large violations of this level. Given the various biases towards finding statistical significance prevalent in epidemiology today, a strong focus on maintaining a pre-specified level of Type I Error would seem critical (see, e.g., [30]). In addition, for the homogeneous case, the new technique is generally more powerful than the typically used large sample asymptotic DerSimonian–Laird inverse-variance technique for realistic, smaller values of disease probability across a large range of odds ratios, number of contributing studies, and sample size. While statistical programs providing exact solutions already exist such as Cytel’s StatXact, they are beyond the means of most practicing statisticians and epidemiologists.
The technique developed here is written in the almost universal statistical language of R and is freely available from the author. As such, it is hoped that other researchers will be able to extend and improve this initial version.
As outlined in this report, the use of meta-analysis in epidemiology is increasing very rapidly and appears to be meeting an important need. However, fortunately, inexpensive and readily available computer power has also increased vastly in the past forty years. For example, task speed as measured in Million Instructions per Second (“MIPS”) has increased from a fraction of a MIP for the IBM 370 mainframe computer in 1972 to thousands of MIPS for an Intel Pentium processor personal computer today [31]. By using the techniques developed here and the computer power available to all researchers today, unnecessary sources of error can be readily eliminated.
References
Shapiro S. Meta-analysis/Shmeta-analysis. Am J Epidemiol. 1994;140(9):771–8.
Shapiro S. Commentary. Oligognostic mega-analysis. Is archie turning in his grave? Maturitas. 2015;81(4):439–41.
Borenstein M, et al. Introduction to meta-analysis. New York: Wiley; 2009.
Higgins JP, Green S, editors. Cochrane handbook for systematic reviews of interventions. Chichester: Wiley-Blackwell; 2008.
Neyman J, Pearson ES. On the problem of the most efficient tests of statistical hypotheses. Philos Trans R Soc Lond Ser A Contain Pap Math Phys Character. 1933;231:289–337.
Bradburn MJ, Deeks JJ, Berlin JA, Localio AR. Much ado about nothing: a comparison of the performance of meta-analytical methods with rare events. Stat Med. 2007;26(1):53–77.
Cai T, Parast L, Ryan L. Meta-analysis for rare events. Stat Med. 2010;29(20):2078–89.
Higgins J, Deeks JJ, Altman DG. Special topics in statistics. In: Higgins J, Green S, editors. Cochrane handbook for systematic reviews of interventions: cochrane book series. Chichester: Wiley; 2008. p. 481–529.
DerSimonian R, Laird N. Meta-analysis in clinical trials. Control Clin Trials. 1986;7(3):177–88.
Mantel N, Haenszel W. Statistical aspects of the analysis of data from retrospective studies of disease. J Natl Cancer Inst. 1959;22(4):719–48.
Mantel N, Fleiss J. Minimum expected cell size requirements for the Mantel-Haenszel one-degree-of-freedom Chi square test and a related rapid procedure. Am J Epidemiol. 1980;112(1):129–34.
Fisher RA. Statistical methods for research workers. Edinburgh: Oliver and Boyd; 1925.
Higgins JPT. Commentary: heterogeneity in meta-analysis should be expected and appropriately quantified. Int J Epidemiol. 2008;37:1158–60.
Higgins JPT, Thompson SG, Deeks JJ, Altman DG. Measuring inconsistency in meta-analyses. Br Med J. 2003;327(7414):557.
Bhaumik DK, Amatya A, Normand SLT, Greenhouse J, Kaizar E, Neelon B, et al. Meta-analysis of rare binary adverse event data. J Am Stat Assoc. 2012;107(498):555–67.
Agresti A, Wackerly D. Some exact conditional tests of independence for r × c cross-classification tables. Psychometrika. 1977;42(1):111–24.
Sokal RR, Rohlf FJ. Biometry: the principles and practice of statistics in biological research. 3rd ed. New York: WH Freeman; 1994.
Kullback S. Information theory and statistics. Reprint of the 2nd (1968) ed. Mineola: Dover Publications, Inc.; 1997.
Agresti A. A survey of exact inference for contingency tables. Stat Sci. 1992;7(1):131–53.
Thomas DG. Exact and asymptotic methods for the combination of 2 × 2 tables. Comput Biomed Res. 1975;8(5):423–46.
Breslow NE, Day NE. Statistical methods in cancer research, vol. 1. The analysis of case-control studies. 132nd ed. Geneva: Distributed for IARC by WHO; 1980.
Yao Q, Tritchler D. An exact analysis of conditional independence in several 2 × 2 contingency tables. Biometrics. 1993;49(1):233–6.
Yao Q. An exact analysis for several 2 × 2 contingency tables. Dissertation ed, University of Toronto; 1991.
Mcelvenny DM. Meta-analysis of rare diseases in occupational epidemiology. Doctoral dissertation, London School of Hygiene & Tropical Medicine; 2017.
IntHout J, Ioannidis JP, Borm GF. The Hartung-Knapp-Sidik-Jonkman method for random effects meta-analysis is straightforward and considerably outperforms the standard DerSimonian-Laird method. BMC Med Res Methodol. 2014;14(1):25.
Hogg RV, McKean JW, Craig AT. Introduction to mathematical statistics. 6th ed. Upper Saddle River: Prentice Hall; 2004.
Cooley JW, Tukey JW. An algorithm for the machine calculation of complex Fourier series. Math Comput. 1965;19(90):297–301.
The R Project for Statistical Computing. https://www.r-project.org/.
Schwarzer G. Meta: an R package for meta-analysis. R News. 2007;7(3):40–5.
Ioannidis JPA. Why most published research findings are false. PLoS Med. 2005;2(8):e124.
Mollick E. Establishing Moore’s law. IEEE Ann History Comput. 2006;28(3):62–75.
Acknowledgements
Thanks to Dr. David. H. Schwartz of Innovative Science Solutions, LLC for his helpful comments on earlier drafts of this work. Thanks to Dr. Christopher Schmid as Editor in Chief of Research Synthesis Methods who encouraged the author to reach beyond an early submission and solve a much larger and more important problem. Thanks to the anonymous reviewer of this paper. He or she identified a number of areas that needed more development, motivated the author to constantly strive for clearer exposition of the issues, and provided an enormous degree of support.
Lawrence M. Paul: Retired from Lucent Bell Laboratories.
Competing interests
The author declares that he has no competing interests.
Availability of data and materials
The datasets used and/or analyzed during the current study are available from the corresponding author on reasonable request. In addition, the fully tested software to use the ML-NP-EXACT technique written in the R statistical language is freely available from the author on request.
Consent for publication
Not applicable.
Ethics approval and consent to participate
Not applicable.
Funding
No external funding sources were used to support this article.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Paul, L.M. Cannons and sparrows: an exact maximum likelihood non-parametric test for meta-analysis of k 2 × 2 tables. Emerg Themes Epidemiol 15, 9 (2018). https://doi.org/10.1186/s12982-018-0077-7
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12982-018-0077-7