
Abstract
Background
Environmental exposures are related to the risk of some types of cancer, and children are the most vulnerable group of people. This study seeks to present the methodological approaches used in the papers of our group about risk of childhood cancers in the vicinity of pollution sources (industrial and urban sites). A population-based case–control study of incident childhood cancers in Spain and their relationship with residential proximity to industrial and urban areas was designed. Two methodological approaches using mixed multiple unconditional logistic regression models to estimate odds ratios (ORs) and 95% confidence intervals (95% CIs) were developed: (a) “near vs. far” analysis, where possible excess risks of cancers in children living near (“near”) versus those living far (“far”) from industrial and urban areas were assessed; and (b) “risk gradient” analysis, where the risk gradient in the vicinity of industries was assessed. For each one of the two approaches, three strategies of analysis were implemented: “joint”, “stratified”, and “individualized” analysis. Incident cases were obtained from the Spanish Registry of Childhood Cancer (between 1996 and 2011).
Results
Applying this methodology, associations between proximity (≤ 2 km) to specific industrial and urban zones and risk (OR; 95% CI) of leukemias (1.31; 1.04–1.65 for industrial areas, and 1.28; 1.00–1.53 for urban areas), neuroblastoma (2.12; 1.18–3.83 for both industrial and urban areas), and renal (2.02; 1.16–3.52 for industrial areas) and bone (4.02; 1.73–9.34 for urban areas) tumors have been suggested.
Conclusions
The two methodological approaches were used as a very useful and flexible tool to analyze the excess risk of childhood cancers in the vicinity of industrial and urban areas, which can be extrapolated and generalized to other cancers and chronic diseases, and adapted to other types of pollution sources.
Similar content being viewed by others


Background
Environmental exposures are related to the risk of some types of cancer [1], and children are the most vulnerable group of people because they are far more sensitive than adults to toxic chemicals in the environment [2, 3]. Moreover, the causes of many childhood cancers are largely unknown, so it is necessary epidemiologic research as a tool for identifying associations between proximity to environmental exposures and the frequency of these cancers. In this sense, the biggest population-based case–control study of incident childhood cancer in Spain has been carried out by our group with the purpose of analyzing the risk of various types of cancer in the proximity of environmental exposures (industrial installations, urban areas, road traffic, and agricultural crops) [4,5,6,7,8,9,10,11,12].
This paper seeks: (a) to present the several methodological approaches used in our study, summarizing the main results; and, (b) to describe our experience studying the risk of childhood cancers in the vicinity of some of the pollution point sources, principally industrial and urban sites, with the purpose of establishing some guidelines and encouraging other researchers to apply these methodological tools in their environment-epidemiologic studies, using the publicly-available data from the Pollutant Release and Transfer Registers (PRTRs).
Results
Spanish industrial installations included in the European PRTR (E-PRTR) were taken into account in the paper. A list of industrial groups, together with their E-PRTR categories, and number of industrial installations and amounts (in kg) released by these industrial plants in 2009, by groups of carcinogens [according to the International Agency for Research on Cancer (IARC)] and groups of toxic substances, are shown in Table 1. A list including the specific pollutants released to both air and water, by category of industrial groups, are described in detail in Table 2.
First methodological approach: “Near vs. far” analyses
As a first example of this methodology, the odds ratios (ORs) and their 95% confidence intervals (95% CIs) of the several childhood cancers studied in our papers in relation to the analysis of industrial and urban areas as a whole (analysis 1.a), for industrial distances between 2 and 5 km, are shown in Table 3. Statistically significant excess risks were found in children close to:
-
(a)
industrial facilities for leukemias (OR 1.31; 95% CI 1.04–1.65 at ≤ 2 km, and OR 1.31; 95% CI 1.03–1.67 at ≤ 2.5 km) and renal cancer [with ORs ranged between 1.85 (95% CI 1.07–3.18) at ≤ 5 km and 2.02 (95% CI 1.07–3.18) at ≤ 2 km];
-
(b)
urban areas for leukemias (OR 1.28; 95% CI 1.00–1.53 at ≤ 2 km, OR 1.36; 95% CI 1.02–1.80 at ≤ 2.5 km, and OR 1.66; 95% CI 1.08–2.55 at ≤ 4 km) and bone tumors [with ORs ranged between 4.02 (95% CI 1.73–9.34) at ≤ 2 km and 4.43 (95% CI 1.80–10.92) at ≤ 3 km]; and,
-
(c)
intersection area between industrial and urban sites for renal cancer (with ORs ranged between 1.90 (95% CI 1.00–3.59) at ≤ 5 km and 3.14 (95% CI 1.50–6.58) at ≤ 2 km), neuroblastoma (OR 2.12; 95% CI 1.18–3.83 at ≤ 2 km), and bone tumors [with ORs ranged between 3.66 (95% CI 1.53–8.75) at ≤ 3 km and 3.90 (95% CI 1.48–10.29) at ≤ 2 km].
The ORs of those childhood cancers with statistically significant results and a number of controls and cases ≥ 5, for the “near vs. far” analysis by category of industrial group (analysis 1.b) and an industrial distance of ≤ 2.5 km, are shown in Table 4. The following positive associations between certain cancers and residential proximity to specific industrial groups were found:
-
(a)
‘Production and processing of metals, ‘Galvanization’, ‘Surface treatment of metals and plastic’, ‘Glass and mineral fibers’, and ‘Hazardous waste’ ⇔ leukemias and renal tumors;
-
(b)
‘Organic chemical industry’ and ‘Urban waste-water treatment plants’ ⇔ renal and bone tumors;
-
(c)
‘Pharmaceutical products’ ⇔ leukemias and bone tumors;
-
(d)
‘Surface treatment using organic solvents’ ⇔ leukemias;
-
(e)
‘Ceramic’ and ‘food and beverage sector’ ⇔ renal tumors;
-
(f)
‘Mining’ ⇔ neuroblastoma; and,
-
(g)
‘Cement and lime’ ⇔ bone tumors.
As an example of the “near vs. far” analysis by category of pollutants (carcinogens and toxic substances) (analysis 1.c) for an industrial distance of ≤ 2.5 km, the ORs of leukemias, and renal and bone tumors are shown in Table 5. Statistically significant excess risks of leukemias and bone tumors were found in the environs of facilities releasing substances included in all IARC groups. In the case of bone tumors, the excess risk was only observed near industries releasing Group 1-carcinogens. According to the categorization of ‘Groups of toxic substances’, statistically significant ORs of leukemias, and renal and bone tumors were found in all groups of toxic substances (with the exception of plasticizers for renal tumors, and volatile organic compounds for bone tumors).
Finally, the ORs of those childhood cancers with significant results and a number of controls and cases ≥ 5, for the “near vs. far” analysis by specific pollutant (analysis 1.d) and an industrial distance of ≤ 2.5 km, are shown in Table 6. The highest ORs were found in the environs of industries releasing:
-
(a)
‘Benzo(a)pyrene’ (OR 2.59; 95% CI 1.06–6.16), ‘Indeno(1,2,3-cd)pyrene’ (OR 2.59; 95% CI 1.06–6.16), and ‘Tetrachloromethane’ (OR 2.23; 95% CI 1.35–3.68), for leukemias; and,
-
(b)
‘1,2-Dichloromethane’ (OR 4.24; 95% CI 1.66–10.85), ‘Cobalt and compounds’ (OR 3.73; 95% CI 1.28–10.85), and ‘Polychlorinated biphenyls’ (OR 3.60; 95% CI 1.10–11.76), for renal tumors.
Second methodological approach: “Risk gradient” analyses
As an example of this methodology applied to renal tumors, statistically significant radial effects (rise in OR with increasing proximity to industries, according to concentric rings) in the vicinity of industrial installations, both overall (analysis 2.a) and by industrial group (analysis 2.b), were detected (see Table 7) in all industries as a whole (p-trend = 0.007), and in the following industrial groups: ‘Surface treatment of metals and plastic’ (p-trend = 0.012), ‘Urban and waste-water treatment plants’ (p-trend = 0.034), ‘Food and beverage sector’ (p-trend = 0.040), and ‘Glass and mineral fibers’ (p-trend = 0.046).
Discussion
In the present paper, two different methodological approaches to perform the statistical analyses in the study of risk of childhood cancer in the vicinity of industrial and urban sites have been used by our group. These two approaches are complementary, none is preferable to the other: the “near vs. far” approach is often used as a first step in the study of cancer risk in the environs of pollution sources, whereas the second approach (“risk gradient” analysis) is often used to complement the results obtained in the first approach, giving a more detailed information about the behavior of the risk in different partitions of the “near” zone. Positive results or positive associations found in both approaches support and reinforce the hypothesis of a “real” excess risk in the vicinity of the pollution sources analyzed in the study. However, the main limitation of these methodological approaches is the choice of the radius in the “near vs. far” analysis and the critical categorization in concentric rings in the “risk gradient” analysis, although our industrial distances are in line with the distances used by other authors [13,14,15]. Another limitation is the assumption of the linear trend in the risk in the “risk gradient” analysis, something that might not be true.
In relation to alternative approaches published by other authors, Barbone et al. [16] used an alternative strategy in the definition of “exposure” variable for the “near vs. far” analyses, based on deciles of the distribution of the industrial and urban distances, in a case–control study of air pollution and lung cancer in Trieste (Italy). In that study, there were one urban nucleus and three industrial pollution sources: a shipyard, an iron foundry, and an incinerator. Our group adapted their strategy in a similar case–control study of lung cancer risk and pollution in Asturias (Spain) [17, 18], with 48 industrial facilities, and 4 urban nuclei with numbers of inhabitants ranged between 24,735 and 263,547 inhabitants. However, when the sizes of the towns differ considerably among them, that methodology causes an irregular distribution of cases and controls between the zones around the towns, since all towns have the same radius for the “urban area” and only a few big cities include the majority of cases and controls. Because of this, we consider that our methodology is more appropriate for analyses with many towns and very different size of the towns (see Fig. 2).
The methodology used in the present paper can be extrapolated to other tumors (even in the general population) and/or other countries with a National Registry of Cancer. In fact, the methodology has already been implemented in the ‘MCC-Pollution’ study (included in the ‘MCC-Spain’ project [19]), a population-based multicase–control study that analyzes the risk cancer in tumors of high incidence in the Spanish general population associated with residential proximity to industrial facilities [20]. The diagram of Fig. 1 can also be generalized to other chronic diseases which could be related to environmental risk factors. In general, our results suggest possible associations between residential proximity to specific industrial and urban zones and risk of some childhood cancers, especially leukemias, neuroblastoma, and renal and bone tumors. In relation to industrial sites, this risk was found in children living in the environs of several industrial types and industries releasing specific carcinogens and toxic substances.

Diagram of the case–control study about the association between proximity to industrial and urban areas and childhood cancer risk
This methodology can be applied directly to other hazardous point sources and toxic hotspots, such as e-waste recycling sites and illegal hazardous dumps [21], and it can also be easily adapted when the pollution focus is not a single point (e.g.: industry, urban nucleus) but a line (e.g.: road traffic, motorway, polluted river) [12] or a polygon (e.g.: crops treated with pesticides) [9]. Taking the dispersion of air pollutants into account, the methodology allows the possibility of using information about wind roses (which include the direction and speed of prevailing winds around specific monitoring points) together with the distance to refine the definition of industrial proximity to pollution sources [17].
To replicate this methodology in other countries, in relation to the location of subjects (cases and controls) and pollution sources (industries and towns), the children’s domiciles (and geographic coordinates) for cases and controls should be provided by the respective National Registry of Childhood Tumors and National Statistics Institute (see Fig. 1), under collaboration agreements, because they are usually very sensitive data (see Availability of data and material section). In the case of the industries, all information about industrial plants, including geographic coordinates is publicly available. In the case of the towns, the geographic coordinates of towns’ centroids are publicly available in the Spanish Census. On the other hand, the tools used in the geocoding strategies for all these elements (cases, controls, industries, and towns) are open access (see Methods section). The methodology used in the paper requires the compulsory use of geographic coordinates to be applied correctly in the different analyses.
Epidemiological studies of childhood cancer in relation to proximity to pollution foci have reached great importance recently [22,23,24,25,26,27], and industrial registers of toxic substances as the E-PRTR provide a tool for the monitoring and surveillance of harmful effects of these industrial pollutants, some of them carcinogenic, on the human health. In this sense, our experience is being positive because our study is providing some epidemiological clues that residing in the vicinity of certain industrial and urban areas may be a risk factor for some types of childhood cancers.
With regard to childhood leukemias and the pollution sources analyzed in our previous papers, our findings about proximity to industrial groups (see Table 4) are consistent with other studies in relation to the excess risk found in the environs of the metal industry (which includes ‘Production and processing of metals’, ‘Galvanization’, and ‘Surface treatment of metals and plastic’) [28, 29] and installations for the manufacture of ‘Glass and mineral fibers’ [28], although other authors did not find associations with proximity to incinerators (‘Hazardous waste’) [15]. In relation to specific carcinogens and groups of pollutants, some authors found a possible increased risk of some types of childhood leukemias in children living within 3 km of industrial dichloromethane releases (OR 1.64; 95% CI 1.15–2.32) [30], very similar to our results for this pollutant at 2.5 km (OR 1.65; 95% CI 1.11–2.45). Other authors have also found associations between benzene exposure and childhood risk of acute lymphocytic leukemia [31,32,33], in line with our results (see Table 6). Finally, our findings about proximity to urban areas (see Table 3), as a proxy of urban pollution, are consistent with other papers [12, 34, 35].
With respect to proximity to environmental exposures and childhood renal tumors, the few studies focused on residential proximity to environmental pollution sources did not find associations in relation to hazardous waste sites [36] or major roadways [27]. However, some authors have found associations between children prenatally exposed to polycyclic aromatic hydrocarbons during the third trimester and risk of Wilms’s tumor (the main histologic type of childhood renal tumors) [37], something that could be related to our findings about this type of pollutant (see Table 6).
Insofar as neuroblastoma and environmental exposures are concerned, Heck et al. [38] did not find associations between exposure to traffic pollution and neuroblastoma. In our study about this cancer, the excess risks found in the urban areas were not statistically significant (see Table 3). However, the same authors found increased risks of neuroblastoma with regard to a higher maternal exposure to chromium and polycyclic aromatic hydrocarbons in a radius of 2.5 km, very similar to the non-statistically excess risks found in our study (data not shown).
In relation to childhood bone tumors and proximity to industrial areas, there are few studies focused on this aspect. Pan et al. [39] found a higher mortality of bone tumors in the environs of petrochemical industries, whereas Wulff et al. [40] found an excess risk of bone cancer near a smelter. Our results about ‘Organic chemical industry’ and ‘Production and processing of metals’ yielded high excess risks (see Table 4). With respect to childhood bone tumors and proximity to urban areas, the majority of the studies existing in the literature found significant excess risks in children living in urban zones [41,42,43], in line with our findings (see Table 3). However, other authors did not find associations between proximity to urban zones and risk of childhood bone cancer [44].
As future perspectives, research is still needed on air pollution, especially in industrial and urban zones, and childhood cancer to guide policies for the reduction of emission of toxic and carcinogenic substances and protection of public health. Direct epidemiologic observation of exposed children for evaluating the magnitude of air pollution and large-scale epidemiologic studies of environmental exposures and childhood cancer are needed [45]. Moreover, surveillance systems for residential and occupational exposures, and clusters of childhood cancers should be implemented to prevent childhood cancer risk [46]. Finally, identification and control of environmental risk factors that may cause cancer in children is the single most effective strategy for cancer prevention [23]. As Nelson et al. [47] say, reducing environmental hazards associated with residential exposures could substantially reduce the human burden of childhood cancer and result in significant annual and lifetime savings.
Conclusions
The methodological approaches used by our group have proved to be very useful and flexible tools to analyze the excess risk of childhood cancers in the vicinity of industrial and urban areas, which can be extrapolated and generalized to other cancers and chronic diseases, and adapted to other types of pollution sources.
Methods
A population-based case–control study of incident childhood cancers in Spain and their relationship with residential proximity to environmental pollution sources, in this case, industrial and urban areas, was designed. The diagram of our study is shown in Fig. 1: the first part depicts the several steps about the study subjects, data collection, and definition of the exposure, whereas the second part represents the strategies of statistical analysis used in our papers [4,5,6,7,8, 10].
Study subjects/data collection/definition of exposure
Step 1 Cases, controls, industries, and towns were selected as follows:
-
(A)
Cases: in our case, incident cases of childhood cancers (0–14 years) were gathered from the Spanish Registry of Childhood Tumors, for Autonomous Regions with 100% coverage between 1996 and 2011: (a) Leukemias, myeloproliferative diseases, and myelodysplastic diseases [code I, according to the International Classification of Diseases for Oncology, 3rd revision (ICCC-3)]; (b) Renal tumors (code VI, ICCC-3); (c) Neuroblastoma and other peripheral nervous cell tumors (code IV, ICCC-3); (d) Malignant bone tumors (code VIII, ICCC-3); (e) Retinoblastoma (code V, ICCC-3); (f) Hepatic tumors (code VII, ICCC-3); (g) Soft tissue and other extraosseous sarcomas (code IX, ICCC-3); (h) Germ cell tumors, trophoblastic tumors, and neoplasms of gonads (code X, ICCC-3); (i) Other malignant epithelial neoplasms and malignant melanomas (code XI, ICCC-3); and, (j) Central nervous system and miscellaneous intracranial and intraspinal neoplasms (code III, ICCC-3) [48].
-
(B)
Controls: from among all single live births registered in the Spanish National Statistics Institute [49] for the study period, six controls per case were chosen by simple random sampling, individually matched to cases by autonomous region of residence, sex, and year of birth.
-
(C)
Industries: data on industries were provided from the E-PRTR [50] through the Spanish Ministry for the Ecological Transition [51], for the year 2009.
-
(D)
Towns: urban locations (towns ≥ 75,000 inhabitants, according to the 2001 Spanish Census [52]) were used.
Step 2 The geographic coordinates of cases, controls, industries, and towns were geocoded and validated, as follows:
-
(A)
Geocoding strategy for cases and controls: each child’s last domicile was geocoded using Google Maps JavaScript V3 [53]. The obtained latitude and longitude coordinates were projected into ETRS89/Universal Transverse Mercator (UTM) zone 30N (EPSG:25830) coordinates using QGIS software [54], and subsequently converted into ED50/UTM zone 30 (EPSG:23030) coordinates using the R software [55]. After this, the coordinates were validated and those where the addresses and the coordinates matched were chosen. For this validation process, the inverse method was applied, getting the home addresses of the obtained coordinates and comparing these new addresses (street number and name, postal code, and city/town name) to the original addresses. Lastly, in the final ED50/UTM zone 30 coordinates of the children’s domiciles, the last digit of the pair of coordinates (X, Y) was assigned randomly with the purpose of preserving their confidentiality. With respect to the cases, 87% of their domiciles were successfully validated. The remaining 13% of cases were fairly uniformly distributed through the different autonomous regions and, therefore, we declared that our data were not biased in this sense. In relation to the controls, initially, only 2% of their addresses could not validate. Owing to this small number of failures in the coordinates, we decided to select more controls to replace this small percentage and, finally, we geocoded and validated this last group to end up with six controls with valid coordinates for each case.
-
(B)
Geocoding strategy for industries: the original geographic location of each industrial facility included in the E-PRTR (longitude/latitude projection) was converted into ED50/UTM zone 30 coordinates using the R software [55], and subsequently validated following the methodology used for our group in the validation of the EPER [56], the industrial register to which the E-PRTR replaced in 2007. However, owing to the presence of errors in many of the industrial locations, every single address was thoroughly checked to ensure that the location of the industrial plant was exactly where it should be. The following tools were used: (1) the Spanish Agricultural Plot Geographic Information System (SIGPAC) Viewer [which includes topographic maps showing the names of industrial plants, and orthophotos (digitalized aerial images)] [57]; (2) Google Earth (with the street-view application); (3) the “Yellow pages” web page (which allows for a search of companies and addresses) [58]; (4) the Google Maps server [59]; and (5) the web pages of the industrial companies.
-
(C)
Geocoding strategy for towns: municipal centroids (not polygonal centroids) of towns in which the children resided were used. In Spain, these municipal centroids are located in the centers of the most populated areas, where the main church and/or the town hall tend to be located. Every single municipal centroid was meticulously checked as in the geocoding strategy for industries, using the Google Maps server [59], Google Earth, and the SIGPAC viewer [57].
Step 3 Sociodemographic variables for all children as potential confounders were selected. These variables were provided by the 2001 Spanish Census [52] at a census tract level (for their unavailability at an individual level), and included: (a) percentage of illiteracy; (b) percentage of unemployment; and (c) socioeconomic status (based on the occupation of the head of the family): it ranged from 0.46 to 1.57, where the lower value corresponded to the worst socioeconomic status and the higher values to better socioeconomic status.
Step 4 Euclidean distances between all children and industries (industrial distances) and towns (urban distances) were calculated using the R software [55].
Step 5 Finally, the “exposure” variable (in our case, the proximity to industries, according to several industrial distances ‘d’, and proximity to urban areas, according to the size of the municipality) was determined. Figure 2 shows an example of exposure areas to industrial and urban sites, for an industrial distance of 2.5 km.

Example of exposure areas to industrial and urban zones, for an industrial distance of 2.5 km
Statistical analysis (strategies)
Two methodological approaches using mixed multiple unconditional logistic regression models to estimate ORs were developed, using the R software [55]. For each one of the two approaches, three strategies of analysis (see Fig. 1) were implemented: (a) “Joint” analysis, where the risk of childhood cancer in the vicinity of all industries and towns as a whole was studied; (b) “Stratified” analysis, where the excess risk in the environs of industrial areas was stratified, according to: categories of industrial groups (activities) included in the E-PRTR, categories of pollutants (industries releasing groups of known and suspected carcinogens, and other toxic chemical substances), and by specific pollutant; and (c) “Individualized” analysis, where the excess risk in the environs of individually selected industrial plants was analyzed.
(1) First methodological approach: “near vs. far” analyses.
Potential excess risks of cancers in children living near (“near”) versus those living far (“far”) from industrial and urban areas were assessed, comparing the ratio between the number of cases and controls in zones close to industrial/urban areas and number of cases and controls in zones far from these pollutant sources (ORnear vs. far), and adjusting by potential confounders. Five “near vs. far” analyses were performed (see Fig. 1):
-
(a)
“Near vs. far” analysis in the proximity of all industrial and urban sites as a whole, for industrial area (only), urban area (only), and intersection between industrial and urban areas:
$$\begin{aligned} & \forall c \in C = \left\{ {childhood\;cancers\;studied} \right\}, \;\;\forall d \in D = \left\{ {industrial\; distances} \right\} \\ & logit = \log \left( {\frac{{P\left( {Y = 1} \right)}}{{1 - P\left( {Y = 1} \right)}}} \right) = \beta_{0} + \beta_{1} IndusUrban_{cid} \\&\quad + \mathop \sum \limits_{j = 2}^{n} \beta_{j} MatchConf_{cij} \\ & Y\;is\; the\; case{-}control \;status \;\left( {1 = case, \;0 = control} \right), \\ & i = 1, \ldots , no.\;of\; children \;with\; tumor\; c, \\ & n = no.\;of\; matching\;factors \;and\; other\; potential \;confounders. \\ \end{aligned}$$Each subject \(i\) was classified into one of the following five categories of the “exposure” variable \((IndusUrban_{cid} )\) for each tumor \(c\) and industrial distance \(d\): (1) residence in the “industrial area − d km (only)”, defined in terms of proximity to industrial facilities, on the basis of the industrial distance \(d\); (2) residence in the “urban area (only)”, taking the areas defined by urban distances, according to the size and spatial characteristics of the municipalities in Spain; (3) residence in the “intersection between industrial and urban areas”; (4) residence in the “intermediate area”, defined as zones forming a “ring” between \(d\) and \(max\left\{ D \right\}\) km around the industries; and, (5) residence within the “reference area”, consisting of zones with children having no industries within \(max\left\{ D \right\}\) km of their residences and far from urban areas (see Fig. 2). A total of \(card\left( D \right)\) independent models were included in this analysis, and all models included matching factors (autonomous region of residence as a random effect, and sex and year of birth as fixed effects) and the potential confounders (\(MatchConf_{cij} )\) previously mentioned (percentages of illiteracy and unemployment, and socioeconomic status).
-
(b)
“Near vs. far” analysis by category of industrial group, stratifying the excess risk found in industrial areas by categories of industrial groups, according to the E-PRTR (see Table 1). The statistical model is analogous to the previous one. In this case, an exposure variable \((IndusGroup_{cikd} )\) for each tumor \(c\) and industrial distance \(d\) was created, in which the subject \(i\) was classified as resident near the specific “industrial group” \(k\) (with \(k\) = 1, …, no. of industrial groups), if the child resided at ≤ \(d\) km from any installation belonging to the industrial group in question, and resident in the reference area, if the child resided at > \(max\left\{ D \right\}\) km from any industry and far from urban areas. A total of \(dim\left( k \right)\) independent models were included in this analysis, and the remaining variables of the models were the same as in the above analysis.
-
(c)
“Near vs. far” analysis by category of pollutants, stratifying the risk near industrial areas by the following categories of pollutants: (a) Groups of known or suspected carcinogens included in the IARC (Group 1—carcinogens to humans, Group 2A—probably carcinogenic to humans, and Group 2B—possibly carcinogenic to humans); and, (b) Groups of toxic substances created by our groups in previous studies [5, 8]: metals, pesticides, polycyclic aromatic chemicals, non-halogenated phenolic chemicals, plasticizers, persistent organic pollutants, volatile organic compounds, solvents, and other. The statistical model is analogous to the first model. An exposure variable for each tumor \(c\) and industrial distance \(d\) (\(SubstanceGroup_{cild} )\) was created, where each subject \(i\) was categorized as resident near industries releasing the specific “group of carcinogenic/toxic substances” \(l\) (with \(l\) = 1, …, no. of groups of carcinogens and toxic substances) or resident in the reference area, analogous to the previous analysis. A total of \(dim\left( l \right)\) independent models were included in this analysis, and the remaining variables of the models were the same as in the first model.
-
(d)
“Near vs. far” analysis by specific pollutant. The statistical model is analogous to the first model. An exposure variable for each model (\(Pollutant_{cimd} )\) was created, where each subject \(i\) was categorized as resident near industries releasing the specific “pollutant” \(m\) (with \(m\) = 1, …, no. of specific industrial pollutants) or resident in the “reference area”, analogous to the previous analyses. A total of \(dim\left( m \right)\) independent models were included in this analysis, and the remaining variables of the models were the same as in the first model.
-
(e)
“Near vs. far” analysis by specific industrial installation, individually. The statistical model is analogous to the first model. An exposure variable for each model (\(Installation_{cifd} )\) was created, where each subject \(i\) was categorized as resident near the specific “industry” \(f\) (with \(f\) = 1, …, no. of industrial installations) or resident in the reference area, analogous to the previous analyses. The remaining variables were the same as in the first model.
(2) Second methodological approach: “Risk gradient” analyses.
To assess the risk gradient in the vicinity of industrial installations (i.e., the rise in OR with increasing proximity to industries, according to concentric rings between 0 km and \(max\left\{ D \right\}\) km), three analyses were performed (see Fig. 1). These analyses were confined to an area of \(10*max\left\{ D \right\}\) km surrounding each installation, and the ORs were estimated using mixed multiple unconditional logistic regression models.
-
(a)
“Risk gradient” analysis in the proximity of all industries as a whole: for each tumor \(c\) and subject \(i\), a new variable, “\(minimum distance_{ci}\)” was calculated as:
$$\begin{aligned} & {\text{minimum}}\;{\text{distance}}_{\text{ci}} = \hbox{min} \left\{ {{\text{industrial}}\;{\text{distance}}_{\text{cif}} } \right\}_{\text{f}} \\ & i = 1, \ldots , no.\;of \;children \;with\; tumor\; c, \\ & f = 1, \ldots , \;no. \;of\; industrial\; installations, \\ \end{aligned}$$where \(industrial distance_{cif}\) is the distance between child \(i\) and facility \(f\) for each tumor \(c\). This new explanatory variable was categorized in concentric rings (an example of categorization can be: 0 − \(d_{1}\) km, \(d_{1}\) − \(d_{2}\) km, …, \(d_{n - 1}\) − \(d_{n}\) km, and reference: \(d_{n}\) − \(10*max\left\{ D \right\}\) km, being \(D = \left\{ {d_{1} , d_{2} , \ldots ,d_{n - 1} ,d_{n} } \right\}\) the set of the industrial distances). This was included in a first model as a categorical variable to estimate the effect of the respective distances, and in a second model as a continuous variable to ascertain the existence of radial effects (rise in OR with increasing proximity to an installation). The likelihood ratio test was applied to compute the statistical significance of such minimum distance-related effects.
-
(b)
“Risk gradient” analysis by category of industrial group: for each tumor \(c\), subject \(i\), and industrial group \(k\), a total of \({ \dim }\left( k \right)\) new variables “\(minimum \;distance\_industrial \;group_{cik}\)” were calculated as:
$$\begin{aligned} & {\text{minimum }}\;{\text{distance}}\_{\text{industrial }}\;{\text{group}}_{\text{cik}} = \hbox{min} \left\{ {{\text{industrial }}\;{\text{group}}\;{\text{distance}}_{{ {\text{cip}}}} } \right\}_{\text{p}} \\ & i = 1, \ldots , no.\;of\; children\; with\; tumor\; c, \\ & k = 1, \ldots , no.\; of\; industrial \;groups, \\ & p = 1, \ldots , no.\;of\; facilities \;belonging\; to\; industrial\; group\; k, \\ \end{aligned}$$where \(industrial\; group \;distance_{cip}\) is the distance between child \(i\) and facility \(p\) belonging to industrial group \(k\), for each tumor \(c\). These new explanatory variables were categorized in concentric rings as in the previous analysis. These were included in the models as categorical and continuous variables (in separate models as in the previous analysis), and children that had some industry other than the group analyzed within a radius of \(max\left\{ D \right\}\) km of the municipal centroid were excluded.
-
(c)
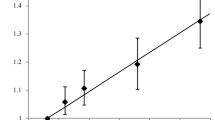
“Risk gradient” analysis specific industrial installation: for each tumor \(c\), subject \(i\), and industrial installation \(f\), a new variable \(industrial\; distance_{cif}\) was calculated as the distance between child \(i\) and facility \(f\) for each tumor \(c\). This new explanatory variable was categorized in concentric rings as in the first analysis and included in the models as both a categorical and a continuous variable (in separate models as in the first “risk gradient” analysis). Figure 3 shows an example of this analysis for a specific industrial installation.
Fig. 3 
Example of the “risk gradient” analysis by specific industrial installation (analysis 2.c)

Availability of data and materials
The data are the geographic coordinates of the address of cases and controls. The authors cannot provide these individual coordinates because they are under protection by the Spanish Organic Law 15/1999 on Protection of Personal Data (LOPD). Privacy, confidentiality, and rights of the cases and controls were ensured by changing the last digits of every coordinate (X, Y) by a random number. Data are from the “Industrial pollution and childhood cancer incidence in Spain” study and authors may be contacted at Carlos III Institute of Health (Madrid, Spain): Dr. Rebeca Ramis, rramis@isciii.es.
Abbreviations
- PRTR:
-
Pollutant Release and Transfer Register
- E-PRTR:
-
European Pollutant Release and Transfer Register
- IARC:
-
International Agency for Research on Cancer
- ORs:
-
odds ratios
- 95% CIs:
-
95% confidence intervals
- ICCC-3:
-
International Classification of Diseases for Oncology, 3rd revision
- UTM:
-
Universal Transverse Mercator
- SIGPAC:
-
Spanish Agricultural Plot Geographic Information System
References
Thun MJ, Linet MS, Cerhan JR, Haiman CA, Schottenfeld D. Cancer epidemiology and prevention. 4th ed. Oxford: Oxford University Press; 2018.
Landrigan PJ, Etzel RA, editors. Textbook of children’s environmental health. Oxford: Oxford University Press; 2014.
Tamburlini G, Ehrenstein OV, Bertollini R. Children’s health and environment: a review of evidence. Copenhagen: European Environment Agency and WHO Regional Office for Europe; 2002.
García-Pérez J, Morales-Piga A, Gómez-Barroso D, Tamayo-Uria I, Pardo Romaguera E, López-Abente G, et al. Risk of bone tumors in children and residential proximity to industrial and urban areas: new findings from a case–control study. Sci Total Environ. 2017;579:1333–42.
García-Pérez J, Morales-Piga A, Gómez J, Gómez-Barroso D, Tamayo-Uria I, Pardo Romaguera E, et al. Association between residential proximity to environmental pollution sources and childhood renal tumors. Environ Res. 2016;147:405–14.
García-Pérez J, Morales-Piga A, Gómez-Barroso D, Tamayo-Uria I, Pardo Romaguera E, López-Abente G, et al. Residential proximity to environmental pollution sources and risk of rare tumors in children. Environ Res. 2016;151:265–74.
García-Pérez J, Morales-Piga A, Gómez-Barroso D, Tamayo-Uria I, Pardo Romaguera E, Fernández-Navarro P, et al. Risk of neuroblastoma and residential proximity to industrial and urban sites: a case–control study. Environ Int. 2016;92–93:269–75.
García-Pérez J, López-Abente G, Gómez-Barroso D, Morales-Piga A, Romaguera EP, Tamayo I, et al. Childhood leukemia and residential proximity to industrial and urban sites. Environ Res. 2015;140:542–53.
Gómez-Barroso D, García-Pérez J, López-Abente G, Tamayo-Uria I, Morales-Piga A, Pardo Romaguera E, et al. Agricultural crop exposure and risk of childhood cancer: new findings from a case–control study in Spain. Int J Health Geogr. 2016;15:18.
Ramis R, Tamayo-Uria I, Gómez-Barroso D, López-Abente G, Morales-Piga A, Pardo Romaguera E, et al. Risk factors for central nervous system tumors in children: new findings from a case–control study. PLoS ONE. 2017;12:e0171881.
Ramis R, Gómez-Barroso D, Tamayo I, García-Pérez J, Morales A, Pardo Romaguera E, et al. Spatial analysis of childhood cancer: a case/control study. PLoS ONE. 2015;10:e0127273.
Tamayo-Uria I, Boldo E, García-Pérez J, Gómez-Barroso D, Romaguera EP, Cirach M, et al. Childhood leukaemia risk and residential proximity to busy roads. Environ Int. 2018;121(Pt 1):332–9.
Knox EG. Childhood cancers and atmospheric carcinogens. J Epidemiol Community Health. 2005;59:101–5.
Brender JD, Maantay JA, Chakraborty J. Residential proximity to environmental hazards and adverse health outcomes. Am J Public Health. 2011;101:S37–52.
Reeve NF, Fanshawe TR, Keegan TJ, Stewart AG, Diggle PJ. Spatial analysis of health effects of large industrial incinerators in England, 1998–2008: a study using matched case–control areas. BMJ Open. 2013;3:e001847.
Barbone F, Bovenzi M, Cavallieri F, Stanta G. Air pollution and lung cancer in Trieste, Italy. Am J Epidemiol. 1995;141:1161–9.
Lopez-Cima MF, Garcia-Perez J, Perez-Gomez B, Aragones N, Lopez-Abente G, Pascual T, et al. Lung cancer risk associated with residential proximity to industrial installations: a spatial analysis. Int J Environ Sci Technol. 2013;10:891–902.
López-Cima MF, García-Pérez J, Pérez-Gómez B, Aragonés N, López-Abente G, Tardón A, et al. Lung cancer risk and pollution in an industrial region of Northern Spain: a hospital-based case–control study. Int J Health Geogr. 2011;10:10.
MCC-Spain. Multi-case control study of frequent cancers in Spain. 2019. http://www.mccspain.org/. Accessed 26 Apr 2019.
García-Pérez J, Lope V, Pérez-Gómez B, Molina AJ, Tardón A, Díaz Santos MA, et al. Risk of breast cancer and residential proximity to industrial installations: new findings from a multicase–control study (MCC-Spain). Environ Pollut Barking Essex. 1987;2018(237):559–68.
Fuller R. Hazardous waste and toxic hotspots. In: Landrigan PJ, Wtzel RA, editors. Textbook of children’s environmental health. Oxford: Oxford University Press; 2014. p. 254–61.
Amoon AT, Crespi CM, Ahlbom A, Bhatnagar M, Bray I, Bunch KJ, et al. Proximity to overhead power lines and childhood leukaemia: an international pooled analysis. Br J Cancer. 2018;119:364–73.
Buka I, Osornio A. Environmental carcinogens and childhood cancer. In: Landrigan PJ, Wtzel RA, editors. Textbook od children’s environmental health. Oxford: Oxford University Press; 2014. p. 344–51.
Ortega-García JA, López-Hernández FA, Cárceles-Álvarez A, Fuster-Soler JL, Sotomayor DI, Ramis R. Childhood cancer in small geographical areas and proximity to air-polluting industries. Environ Res. 2017;156:63–73.
Davis J-M, Garb Y. A strong spatial association between e-waste burn sites and childhood lymphoma in the West Bank, Palestine. Int J Cancer. 2019;144:470–5.
Van Maele-Fabry G, Gamet-Payrastre L, Lison D. Residential exposure to pesticides as risk factor for childhood and young adult brain tumors: a systematic review and meta-analysis. Environ Int. 2017;106:69–90.
Kumar S, Lupo P, Pompeii L, Danysh H. Maternal residential proximity to major roadways and pediatric embryonal tumors in offspring. Int J Environ Res Public Health. 2018;15:505.
Knox EG, Gilman EA. Hazard proximities of childhood cancers in Great Britain from 1953–80. J Epidemiol Community Health. 1997;51:151–9.
Knox EG. Leukaemia clusters in childhood: geographical analysis in Britain. J Epidemiol Community Health. 1994;48:369–76.
Park AS, Ritz B, Ling C, Cockburn M, Heck JE. Exposure to ambient dichloromethane in pregnancy and infancy from industrial sources and childhood cancers in California. Int J Hyg Environ Health. 2017;220:1133–40.
Symanski E, Tee Lewis PG, Chen T-Y, Chan W, Lai D, Ma X. Air toxics and early childhood acute lymphocytic leukemia in Texas, a population based case control study. Environ Health Glob Access Sci Source. 2016;15:70.
Raaschou-Nielsen O, Hvidtfeldt UA, Roswall N, Hertel O, Poulsen AH, Sørensen M. Ambient benzene at the residence and risk for subtypes of childhood leukemia, lymphoma and CNS tumor. Int J Cancer. 2018;143:1367–73.
Heck JE, Park AS, Qiu J, Cockburn M, Ritz B. Risk of leukemia in relation to exposure to ambient air toxics in pregnancy and early childhood. Int J Hyg Environ Health. 2014;217:662–8.
Lavigne É, Bélair M-A, Do MT, Stieb DM, Hystad P, van Donkelaar A, et al. Maternal exposure to ambient air pollution and risk of early childhood cancers: a population-based study in Ontario, Canada. Environ Int. 2017;100:139–47.
Malagoli C, Malavolti M, Costanzini S, Fabbri S, Tezzi S, Palazzi G, et al. Increased incidence of childhood leukemia in urban areas: a population-based case–control study. Epidemiol Prev. 2015;39(4 Suppl 1):102–7.
Tsai J, Kaye WE, Bove FJ. Wilms’ tumor and exposures to residential and occupational hazardous chemicals. Int J Hyg Environ Health. 2006;209:57–64.
Shrestha A, Ritz B, Wilhelm M, Qiu J, Cockburn M, Heck JE. Prenatal exposure to air toxics and risk of Wilms’ tumor in 0- to 5-year-old children. J Occup Environ Med. 2014;56:573–8.
Heck JE, Wu J, Lombardi C, Qiu J, Meyers TJ, Wilhelm M, et al. Childhood cancer and traffic-related air pollution exposure in pregnancy and early life. Environ Health Perspect. 2013;121:1385–91.
Pan BJ, Hong YJ, Chang GC, Wang MT, Cinkotai FF, Ko YC. Excess cancer mortality among children and adolescents in residential districts polluted by petrochemical manufacturing plants in Taiwan. J Toxicol Environ Health. 1994;43:117–29.
Wulff M, Högberg U, Sandström A. Cancer incidence for children born in a smelting community. Acta Oncol Stockh Swed. 1996;35:179–83.
Bao P, Zheng Y, Gu K, Wang C, Wu C, Jin F, et al. Trends in childhood cancer incidence and mortality in urban Shanghai, 1973–2005. Pediatr Blood Cancer. 2010;54:1009–13.
Larsson SE, Lorentzon R. The incidence of malignant primary bone tumours in relation to age, sex and site. A study of osteogenic sarcoma, chondrosarcoma and Ewing’s sarcoma diagnosed in Sweden from 1958 to 1968. J Bone Joint Surg Br. 1974;1974(56B):534–40.
Silva JF, Subramanian N. An epidemiologic study of osteogenic sarcoma in Malaysia. Incidence in urban as compared with rural environments and in each of three separate racial groups, 1969–1972. Clin Orthop. 1975;113:119–27.
Thompson JA, Carozza SE, Zhu L. Geographic risk modeling of childhood cancer relative to county-level crops, hazardous air pollutants and population density characteristics in Texas. Environ Health Glob Access Sci Source. 2008;7:45.
Samet JM, Cohen AJ. Air pollution. In: Schottenfeld D, Fraumeni JF, editors. Cancer epidemiology and prevention. 4th ed. Oxford: Oxford University Press; 2018. p. 291–303.
Modonesi C, Oddone E, Panizza C, Gatta G. Childhood cancer and environmental integrity: a commentary and a proposal. Rev Saude Publica. 2017;51:29.
Nelson L, Valle J, King G, Mills PK, Richardson MJ, Roberts EM, et al. Estimating the proportion of childhood cancer cases and costs attributable to the environment in California. Am J Public Health. 2017;107:756–62.
Steliarova-Foucher E, Stiller C, Lacour B, Kaatsch P. International Classification of Childhood Cancer, third edition. Cancer. 2005;103:1457–67.
European Statistical System. Spanish National Statistics Institute (Instituto Nacional de Estadística). 2019. https://www.ine.es/en/welcome.shtml. Accessed 26 Apr 2019.
European Environment Agency (EEA). European Pollutant Release and Transfer Register (E-PRTR). 2019. https://prtr.eea.europa.eu/#/home. Accessed 26 Apr 2019.
Spanish Ministry for the Ecological Transition. Spanish Register of Emissions and Pollutants Sources (PRTR-España). 2019. http://www.en.prtr-es.es/. Accessed 26 Apr 2019.
Spanish National Statistics Institute. Population and housing censuses 2001. Definitive results. 2001. https://www.ine.es/censo/en/inicio.jsp?_IDIOMA=en. Accessed 26 Apr 2019.
Google Maps. Google Maps JavaScript API V3 Reference. 2019. https://developers.google.com/maps/documentation/javascript/reference/. Accessed 26 Apr 2019.
The Open Source Geospatial Foundation (OSGeo). QGIS. 2019. https://www.qgis.org/en/site/index.html. Accessed 26 Apr 2019.
The R Foundation. The Comprehensive R Archive Network. 2019. https://cran.r-project.org/. Accessed 26 Apr 2019.
García-Pérez J, Boldo E, Ramis R, Vidal E, Aragonés N, Pérez-Gómez B, et al. Validation of the geographic position of EPER-Spain industries. Int J Health Geogr. 2008;7:1.
Spanish Ministry of Agriculture, Fisheries and Food. SIGPAC. 2019. http://sigpac.mapa.es/fega/visor/. Accessed 26 Apr 2019.
PA DIGITAL. Yellow Pages (Páginas Amarillas). 2019. https://www.paginasamarillas.es/. Accessed 26 Apr 2019.
Google Maps. Google Maps server. 2019. https://www.google.com/maps. Accessed 26 Apr 2019.
Acknowledgements
Not applicable.
Funding
This study was funded by Carlos III Institute of Health, Spain Grand EPY 1344/16, Spain’s Health Research Fund (Fondo de Investigación Sanitaria—FIS 12/01416), and Scientific Foundation of the Spanish Association Against Cancer, Spain (Fundación Científica de la Asociación Española Contra el Cáncer (AECC)—EVP-1178/14). This article presents independent research. The views expressed are those of the authors and not necessarily those of the Carlos III Institute of Health.
Author information
Authors and Affiliations
Contributions
JG-P and RR conceived and designed the study. JG-P conducted the statistical analyses and wrote the paper. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
García-Pérez, J., Gómez-Barroso, D., Tamayo-Uria, I. et al. Methodological approaches to the study of cancer risk in the vicinity of pollution sources: the experience of a population-based case–control study of childhood cancer. Int J Health Geogr 18, 12 (2019). https://doi.org/10.1186/s12942-019-0176-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12942-019-0176-x