
Abstract
Background
A scoping review to characterize the literature on the use of conversations in social media as a potential source of data for detecting adverse events (AEs) related to health products.
Methods
Our specific research questions were (1) What social media listening platforms exist to detect adverse events related to health products, and what are their capabilities and characteristics? (2) What is the validity and reliability of data from social media for detecting these adverse events? MEDLINE, EMBASE, Cochrane Library, and relevant websites were searched from inception to May 2016. Any type of document (e.g., manuscripts, reports) that described the use of social media data for detecting health product AEs was included. Two reviewers independently screened citations and full-texts, and one reviewer and one verifier performed data abstraction. Descriptive synthesis was conducted.
Results
After screening 3631 citations and 321 full-texts, 70 unique documents with 7 companion reports available from 2001 to 2016 were included. Forty-six documents (66%) described an automated or semi-automated information extraction system to detect health product AEs from social media conversations (in the developmental phase). Seven pre-existing information extraction systems to mine social media data were identified in eight documents. Nineteen documents compared AEs reported in social media data with validated data and found consistent AE discovery in all except two documents. None of the documents reported the validity and reliability of the overall system, but some reported on the performance of individual steps in processing the data. The validity and reliability results were found for the following steps in the data processing pipeline: data de-identification (n = 1), concept identification (n = 3), concept normalization (n = 2), and relation extraction (n = 8). The methods varied widely, and some approaches yielded better results than others.
Conclusions
Our results suggest that the use of social media conversations for pharmacovigilance is in its infancy. Although social media data has the potential to supplement data from regulatory agency databases; is able to capture less frequently reported AEs; and can identify AEs earlier than official alerts or regulatory changes, the utility and validity of the data source remains under-studied.
Trial registration
Open Science Framework (https://osf.io/kv9hu/).
Similar content being viewed by others


Background
Each year, thousands of people die from an adverse drug reaction, defined as an undesirable health effect that occurs when medication is used as prescribed [1]. Adverse drug reactions can vary from a simple rash to more severe effects, such as heart failure, acute liver injury, arrhythmias, and even death [1]. These events have a significant impact on both patients and the health care system in terms of cost and health service utilization (e.g., frequent visits to physicians and emergency departments, hospitalizations) [2].
Post-marketing adverse drug reaction surveillance in most countries is suboptimal and consists largely of spontaneous reporting. It is estimated that spontaneous reporting systems only capture 1–10% of all adverse drug reactions. For example, one out of every five physicians reports an adverse drug reaction using the Canada Vigilance Database [3].
In order to advance pharmacovigilance (defined as the science and activities related to detection, comprehension and prevention of adverse drug events) [4], monitoring and analysis of data collected from social media sources (i.e., social media listening) is being researched as a potential to supplement traditional drug safety surveillance systems. Three reviews [5,6,7] have been recently published to explore the breadth of evidence on the methods and use of social media data for pharmacovigilance; however, none of the reviews found rigorous evaluations of the reliability and validity of the data.
As this is a rapidly evolving field, we conducted a comprehensive scoping review to assess the utility of social media data for detecting adverse events related to health products, including pharmaceuticals, medical devices, and natural health products.
Methods
Research questions
The specific research questions were:
(1) Which social media listening platforms exist to detect adverse events related to health products, and what are their capabilities and characteristics?
(2) What is the validity and reliability of data from social media for detecting these adverse events?
Study design
We used a scoping review method to map the concepts and types of evidence that exist on pharmacovigilance using social media data [8]. Our approach followed the rigorous scoping review methods manual by the Joanna Briggs Institute [9].
Protocol
The Preferred Reporting Items for Systematic Reviews and Meta-analysis Protocols (PRISMA-P) [10] guideline was used to develop our protocol, which we registered with the Open Science Framework [11] and published in a peer-reviewed journal [12]. The protocol was developed by the research team and approved by members of the Health Canada Health Products and Food Branch, the commissioning agency of this review. Since the full methods have been published in the protocol [12], they are briefly outlined below.
Eligibility criteria
The eligibility criteria were any type of document (e.g., journal article, editorial, book, webpage) that described listening to social media data for detecting adverse events associated with health products (see Additional file 1: Appendix 1). The following interventions were excluded from our review: programs of care, health services, organization of care, as well as public health programs and services. Documents related to the mining of social media data to detect prescription drug misuse and abuse were eligible for inclusion. Social media listening was defined as mining and monitoring of user-generated and crowd-intelligence data from online conversations in blogs, medical forums, and other social networking sites to identify trends and themes of the conversation on a topic (see Additional file 1: Appendix 2). We included documents that reported on at least one of the following outcomes: social media listening approaches, utility of social media data for pharmacovigilance and their performance capabilities, validity and reliability of user-generated data from social media for pharmacovigilance, and author’s perception of utility and challenges of using social media data.
Information sources and search strategy
Comprehensive literature searches were conducted in MEDLINE, EMBASE, and the Cochrane Library by an experienced librarian. The MEDLINE search strategy was peer-reviewed by another librarian using the PRESS checklist [13], which has been published in our protocol [12], and also available in Additional file 1: Appendix 3. In addition, we searched grey literature (i.e., difficult to locate, unpublished documents) sources outlined in Additional file 1: Appendix 4 using the Canadian Agency for Drugs and Technologies in Health guide [14], and scanned the reference lists of relevant reviews [5, 6, 15].
Study selection process
After the team achieved 75% agreement on a pilot-test of 50 random citations, each citation was independently screened by reviewer pairs (WZ, EL, RW, PK, RR, FY, BP) using Synthesi.SR; an online application developed by the Knowledge Translation Program [16]. Potentially relevant full-text documents were obtained and the same process (described above) was followed for full-text screening.
Data items and data abstraction process
Data were abstracted on document characteristics (e.g., type of document), population characteristics of social media users (e.g., disease), characteristics of social media data (e.g., social media source), characteristics of social media listening approaches (e.g., pre-processing), and performance of the different approaches (e.g., validity and reliability of social media data). After the team pilot-tested the data abstraction form using a random sample of 5 included documents, each document was abstracted by one reviewer (WZ, EL, RW, PK, RR, FY, BP) and verified by a second reviewer (WZ, EL). The data were cleaned by a third reviewer (WZ, EL) and confirmed by the content expert (SJ, GH).
Risk of bias assessment or quality appraisal
Risk of bias or quality appraisal was not conducted, which is consistent with the Joanna Briggs Institute methods manual [9], and those documented in scoping reviews on health-related topics [17].
Synthesis of results
To characterize the health conditions studied, the World Health Organization version of the International Statistical Classification of Diseases and Related Health Problems (10th Revision, ICD-10) was used [18]. The social media system characteristics were described and categorized according to the steps typically involved in a social media data processing pipeline [19]. In addition, the social media systems were classified according to whether they were manual systems (i.e., coded by hand, without computer assistance), experimental/developmental stage systems (i.e., automatic information extraction systems being developed by researchers), or fully developed systems (i.e., automatic information extraction systems that are either commercially available or being used by regulatory agencies).
Descriptive statistics were performed (e.g., frequencies, measures of central tendency) using Excel 2010. Thematic analysis of open-text data was performed by two reviewers (WZ, EL) and verified by a third reviewer (ACT or SJ) to categorize the author perception of utility and challenges of using social media data for pharmacovigilance [20].
Results
Study flow
A total of 3631 citations from electronic databases and grey literature and other sources (e.g., reference scanning) were screened (Fig. 1). Of these, 321 potentially relevant full-text records were screened and 70 unique records with an additional 7 companion reports were included in our scoping review. The full list of included documents and companion reports can be found in Additional file 1: Appendix 5.

Study flow diagram
Document characteristics
The documents were dated between 2001 and 2016 with 78% of the relevant documents being from 2013 onwards (Table 1). The most common document types were journal articles (57%) and conference papers (33%). Most of the corresponding authors were from North America (73%) and Europe (17%). Public sources of funding were the most common (40%). Most of the papers (66%) described an experimental/developmental automated information extraction system to mine data from social media for drug safety surveillance.
Social media data characteristics
The commonly mined sources of social media platforms were Twitter (33%), MedHelp (13%), DailyStrength (11%), and AskaPatient (9%) (Fig. 2). The majority of the documents mined only one social media site to obtain user-generated data (54%) (Table 2). The user types included patients from health forums, such as BreastCancer.org (50%); the general population on micro-blogging sites, such as Twitter (39%); or both (10%). The geographic location of the social media users was seldom reported (17%). When it was reported, the users were from high-income countries as per the World Bank classification [21]. The social media posts were mostly in English (86%), followed by Spanish, French, and multiple languages (3% each). A small fraction (1% each) of posts was written in German and Serbian.

Wordcloud of social media sources mined in the documents
The posts were collected for a median duration of 1.13 years (i.e., the investigators “listened” to social media conversations for this duration), with an interquartile range of 6 months to 7 years. A median of 42,594 posts were included in the documents, with an interquartile range of 4608 to 711,562 posts. A variety of techniques were used to identify relevant social media posts, such as web crawlers or spiders (27%, i.e., an automated program that scans the social media source to identify posts about adverse events), application programming interfaces (APIs) of the host site (20%, i.e., a set of applications, rules, and definitions used to build the data set) and keyword search of social media sites (10%). Four papers (6%) used a combination of the above methods. Other approaches included using browser add-ons to monitor search query activities, using a pre-existing database of social media conversations, and requesting processed database from the social media site system administrators.
Health conditions, types of surveillance, and types of health products
The majority of the documents applied their social media listening approach to the study of a specific health condition (Table 3). According to the ICD-10 classification system, almost half (46%) included patients with health conditions from more than one disease system, 13% included patients with neoplasms, and 11% included patients with mental illness and behavioural disorders. The focus of surveillance was most commonly any adverse event (74%), and the type of health products examined were mostly pharmaceutical drugs (98.6%).
Social media data processing pipeline
A variety of data processing approaches were identified (Additional file 1: Appendix 6):
-
supervised learning (21%, i.e., a machine learning approach that is trained from a set of labeled data that has been coded typically by humans)
-
rule-based learning (9%, i.e., a learning algorithm that allows automatic identification of useful rules, rather than a human needing to apply prior domain knowledge to manually constructed rules and curate a rule set)
-
semi-supervised learning (7%, i.e., a machine learning method that uses both labeled and unlabeled data for training)
-
unsupervised learning (6%, i.e., machine learns patterns in the data without any labels given by humans)
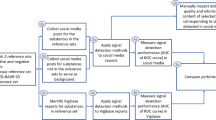
After the social media dataset was created, the following steps were typically used to process the social media data (Fig. 3):
-
1)
pre-processing (e.g., removing punctuations and stop words; breaking text into words, phrases, and symbols or tokens; reducing words to the root; and correcting spelling mistakes)
-
2)
de-identification (e.g., removing identifiable information, such as user names and addresses)
-
3)
de-duplication (e.g., removing duplicate and related posts)
-
4)
concept identification (e.g., identifying adverse drug reactions and other events from a sequence text)
-
5)
concept normalization (e.g., converting colloquial terms to medical terms for drug names, symptoms, history, events, disease)
-
6)
relation extraction (e.g., determining the relationship between the health product and an adverse event)
Different text processing methods were reported for each step, with varying levels of automation.

Steps typically involved in social media data processing flow
Types of social media listening systems
Most of the documents examined an experimental social media listening system that was under development (66%). Seven pre-existing social media listening systems were identified in eight documents (Additional file 1: Appendix 7): MedWatcher Social (US Food and Drug Administration), commercial systems AETracker (IMS health), Visible Intelligence (Cision), BeFree System: Bio-Entity Finder & RElation Extraction (Integrative Bioinformatics group), MeaningCloud (MeaningCloud LLC, Sngular company), Treato (Treato Ltd.), and OpenCalais (Thomson Reuters). An eighth system was identified during the environmental scan, which is known as the Web-RADR Social and is currently under development by European Union regulators. Sixteen documents studied a manual approach, whereby posts were coded manually by humans without any assistance from computers (23%).
Outcome results
Utility of social media data for pharmacovigilance
Nineteen documents provided information on the utility of social media data for pharmacovigilance; however, this was not considered to be the primary objective of the documents (Additional file 1: Appendix 8). Most of the documents focused on the detection of adverse events, while one document focused on the timing of adverse event detection [22].
Ten documents compared social media data against spontaneous reports to regulatory agencies to study the difference in the number of adverse events captured, time lag in detecting adverse events or whether the two data sources are correlated [22,23,24,25,26,27,28,29,30,31]. Specifically, 7/10 documents [25,26,27,28,29,30,31] compared the frequency of adverse events detected from social media source(s) versus a regulatory database, and all but one [26] reported consistent results [24,25,26,27,28,29,30]. In 2/10 documents, authors reported a positive correlation between adverse events reported in social media data sources and those reported by regulatory agencies [23, 31]. In one document, timing of adverse event reporting on social media was compared with the timing of the FDA’s official alert or labeling revision time, and adverse events were detected on social media earlier [22].
Six documents compared adverse events reported in social media posts against published data or safety signals known by the authors, [32,33,34,35,36,37,38] (exact sources were not specified) and all found consistent results. One document compared weighted scores of adverse events reported in social media posts with drugs withdrawn from the market and found a positive correlation between higher weighted scores and withdrawn drugs [39]. One document compared the frequency of adverse events reported on social media with those from a large integrated healthcare system database and found that their results were generally consistent, though several less frequently reported adverse events in the medical health records were more commonly reported on social media (e.g., aspirin-induced hypoglycemia was discussed only on social media) [40]. In contrast, one document found that less than 2% of adverse events detected by AETracker (a commercially available platform) were actual events, as confirmed by pharmacovigilance experts [41].
Themes of utility and challenges of social media listening
Several themes emerged from the qualitative analysis of the study authors' discussions of the strengths and limitations of using social media data for pharmacovigilance. In order of prevalence, the utility of social media listening were as follows: provides supplemental data to traditional surveillance systems, captures perceptions about the effects of treatment (including adverse events), and offers an extensive source of publicly available data (Table 4). The three most common challenges were the unstructured nature of the data, complex structure of the text data, and potential lack of representativeness (i.e., posts may not be representative of all those administered health products) (Table 4). Further details can be found in Additional file 1: Appendix 17.
Validity and reliability of analytics used to process social media data
The validity and reliability measures were categorized according to the social media data processing pipeline, as follows:
Pre-processing
Thirty-two documents reported methods for pre-processing (Additional file 1: Appendix 9), and provided information on the software used and accessibility of the tool (e.g., public, proprietary) [23, 26, 32, 34, 35, 42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72]. Validity or reliability of data processed in this step was not reported.
De-identification
Six documents reported methods for de-identification (Additional file 1: Appendix 10), and provided information on the software used and accessibility of the tool [31, 43, 53,54,55,56, 64, 73]. Only one study reported validity/reliability of data processed in this step, which included a precision of 67%, recall of 98%, and F-measure of 80% [43].
De-duplication
Five documents reported methods for de-duplication (Additional file 1: Appendix 11), and provided information on the software used and accessibility of the tool [30, 40, 74,75,76]. Validity or reliability of data processed in this step was not reported.
Concept identification
Forty-five documents reported on automated methods for concept identification for drugs, adverse events, and overall (i.e., drug and adverse events), which were reported using the following approaches: dictionary/lexicon-based (n = 30) [22, 23, 26, 30, 31, 39, 40, 43, 44, 47, 50, 51, 53,54,55,56,57, 59, 63,64,65,66,67,68,69, 72, 74, 75, 77,78,79,80,81,82], supervised classifier (n = 6) [42, 61, 62, 71, 73, 83], mixed lexicon-based/supervised classifier (n = 2) [52, 58], rule-based phrase extraction (n = 2) [34, 35, 84], sentiment analysis (n = 2) [32, 46], statistical approaches (n = 2) [58, 70], or unspecified (n = 1; Additional file 1: Appendix 12) [85]. Three documents reported evaluation results for overall concept identification. In these, supervised classifier approaches were studied and their accuracy for overall concept identification ranged from 78 to 83%, precision ranged from 32 to 78%, recall ranged from 32 to 74%, and F-measure ranged from 42 to 61%. [62, 71, 73] Validity and reliability results for drug and adverse event concepts can be found in Additional file 1: Appendix 14.
Concept normalization – Drug names
Nineteen documents reported on automated methods for concept normalization of drug names and all used a variation of dictionary or lexicon-based approaches (n = 19; Additional file 1: Appendix 13) [22, 30, 43, 47,48,49,50,51, 54,55,56,57,58, 63,64,65,66, 74, 75, 78, 79, 83, 86]. One paper also used a hybrid approach of statistical modeling using conditional random fields and dictionary-based methods [58]. Two documents reported accuracy results for dictionary/lexicon-based approaches, which ranged from 0 to 92% [58, 83]. Using a hybrid approach of statistical methods combined with dictionary-based methods, Metke-Jimenez and colleagues found accuracy results ranging from 75 to 77% [58].
Concept normalization – Medical events
Thirty-four documents reported on automated methods for concept normalization of medical concepts (i.e., adverse events, symptoms, disease), of which 33 documents reported a dictionary/lexicon-based approach [22, 23, 26, 30,31,32, 39, 40, 43,44,45, 48, 50, 51, 53,54,55,56,57,58,59, 61, 63, 64, 66,67,68,69, 71, 72, 74, 75, 77, 81,82,83], and 2 documents also used statistical approaches (Additional file 1: Appendix 14) [58, 70]. Two documents reported accuracy of dictionary/lexicon approaches, which ranged from 3 to 67%. Using a hybrid approach of statistical methods combined with dictionary methods, Metke-Jimenez and colleagues found accuracy results ranging from 33 to 38%.
Relation extraction
Thirty-eight documents reported on automated methods for relation extraction, which is used to establish relationships between drugs and adverse events using social media data (Additional file 1: Appendix 15). Methods were classified as rule-based or statistical association mining (n = 16) [22, 31, 34, 35, 40, 43, 47, 51, 60, 67,68,69, 75,76,77, 83, 85], supervised classifier (n = 16) [30, 39, 44, 49, 53,54,55,56,57, 61, 63,64,65,66, 70, 71, 73, 74, 86], dictionary/lexicon based (n = 4) [23, 45, 78,79,80] or sentiment analysis (n = 2) [32, 46]. Eight documents provided validity/reliability data on rule-based or statistical association mining. The precision ranged from 35 to 79%, recall ranged from 6 to 100%, F-measure ranged from 9 to 94%, and area under the curve (AUC) ranged from 0.57 to 0.93. Fifteen documents provided validity and reliability data for the supervised classifier approach and accuracy ranged from 29 to 90%, precision from 20 to 86%, recall from 23 to 100%, F-measure from 32 to 92%, and AUC was 74%. Two documents provided data on the reliability and validity of dictionary/lexicon-based approaches, which ranged from 44 to 83% for precision, 2 to 84% for recall, and 3 to 58% for the F-measure. Validity and reliability of data for this step were not reported for sentiment analysis or semantic matching approaches.
Additional processing steps
Some authors investigated additional processing steps, which included identifying the source of an adverse event report (n = 4; i.e,. personal experience vs. witnessed) [42, 44, 53,54,55,56], and query matching which retrieves and filters the relevant documents to answer a given user query (n = 1; Additional file 1: Appendix 16) [87]. Eight documents analysed user-generated texts in other languages, including Spanish [78,79,80], French [29, 88], German [37], Serbian [51], and multiple languages [45, 77] but only 5 reported their methods [47, 52, 62, 88,89,90]. One document included 53 different languages [77] and another document included English, Spanish, and French [45]. None of the papers described validity or reliability of processing non-English text.
Discussion
Most of the documents included in our scoping review dated from 2013 onwards. We identified seven pre-existing social media platforms, and another platform (Web-RADR Social) that is currently under development by European regulators. Unfortunately, no information on when this social media platform will be completed was provided. The majority of the documents primarily focused on the development of social media listening tools for pharmacovigilance (as opposed to their application), which would be useful for those interested in developing such platforms. In particular, documents authored by Freifeld et al., [74] Karimi et al., [83] and Vinod et al. [19] provide useful information on the development of such platforms.
We identified 19 documents providing some information on the utility of social media. This information was mostly abstracted from the discussion section of the documents, suggesting that the conclusions were highly speculative. Furthermore, most of the included documents only followed social media posts for a median duration of 1 year. A high-quality study that examines utility over a longer timeframe with a broader data frame may provide further useful information to the field.
According to authors’ perceptions, social media can be used to supplement traditional reporting systems, to uncover adverse events less frequently reported in traditional reporting systems, to communicate risk and to generate hypotheses. However, challenges exist, such as difficulties interpreting relationships between the drugs and adverse events (e.g., there are inadequate data to draw causality), potential lack of representativeness between social media users and the general population, and the resource-intensive process of using social media data for pharmacovigilance. Evaluation studies of pharmacovigilance using social media listening are needed to substantiate these perceptions. Future studies should also consider evaluating the performance and utility of integrating social media data with other data sources, such as regulatory databases that collect spontaneous reports, as well as relevant surveillance databases.
Our results have summarized the most common elements involved in the processing of social media data for pharmacovigilance. Across the included documents, the most common steps employed were: 1) pre-processing; 2) de-identification; 3) de-duplication; 4) concept identification; 5) concept normalization; and 6) relation extraction. Validity and reliability findings varied across the different approaches that were used to mine the data, which suggests some may be more effective than others. The heterogeneous nature of the study designs and approaches reported in the documents; however, make it difficult to definitively determine which approaches are more useful than others.
As described in our protocol, we conducted this scoping review to inform members of Health Canada who are currently using our results to plan an evaluation study on utility of social media for detecting health product adverse events. They may also consider a Canadian platform to be developed in the future, depending on the results of their study.
Our results are similar to 3 other reviews on this topic. A recent review by Sarker et al. [7] described the different automatic approaches used to detect and extract adverse drug reactions from social media data for pharmacovigilance purposes in studies published in the last 10 years. Although the authors characterized existing social media listening and analytics platforms, validity and reliability of the user-generated data captured through social media and crowd-sourcing networks were not examined. Golder and colleagues [5] conducted a systematic review on adverse events data in social media. They found that although reports of adverse drug events can be identified through social media, the reliability or validity of this information has not been formally evaluated. Finally, Lardon and colleagues [6] conducted a scoping review on the use of social media for pharmacovigilance. They identified numerous ways to identify adverse drug reaction data, extract data, and verify the quality of information. However, gaps in the field were identified. For example, most studies identifying adverse drug reactions failed to verify the reliability and validity of the data and none of the studies proposed a feasible way to integrate data from social media across more than one site/information source.
The strengths of our scoping review include a comprehensive search of multiple electronic databases and sources for difficult to locate and unpublished studies (or grey literature), as well as the use of the rigorous scoping review methods manual by the Joanna Briggs Institute. In addition, we included researchers with computer science expertise (SJ, GH) to help code automated approaches. In terms of a dissemination plan, we will use a number of strategies, such as: a 1-page policy brief, two stakeholder meetings (i.e., consultation exercises), presentations at an international conference, and publications in open-access journals. Team members will also use their networks to encourage broad dissemination of results.
There are some limitations to our scoping review process. The review was limited to documents written in English to increase its feasibility, given the 5-month timeline. Additionally, due to the large number of documents identified, the data were abstracted by one reviewer and verified by a second reviewer. Lastly, although our literature search was comprehensive, there is always a chance that some social media platforms or data analytics documents were missed. Since this is a rapidly evolving and emerging field, we expect that new documents fulfilling our inclusion criteria will be released in increasing numbers [91, 92], highlighting a potential need to update our review in the near future.
Conclusion
Our results suggest that the use of social media is being investigated for drug safety surveillance from an early developmental perspective. Within this context, social media data has the potential to supplement data from regulatory agency databases, capture less frequently reported AEs, and identify AEs earlier than official alerts or regulatory changes. However, the utility, validity and implementation of information extraction systems using social media for pharmacovigilance are under-studied. Further research is required to strengthen and standardize the approaches as well as to ensure that the findings are valid, for the purpose of pharmacovigilance.
Abbreviations
- AE:
-
adverse events
- API:
-
application programming interfaces
- AUC:
-
area under the curve
- FDA:
-
food and drug administration
- ICD:
-
International Statistical Classification of Diseases and Related Health Problems
- PRISMA-P:
-
Preferred Reporting Items for Systematic Reviews and Meta-analysis Protocol
References
Ross CJ, Visscher H, Sistonen J, Brunham LR, Pussegoda K, Loo TT, Rieder MJ, Koren G, Carleton BC, Hayden MR. The Canadian pharmacogenomics network for drug safety: a model for safety pharmacology. Thyroid. 2010;20(7):681–7.
Lazarou J, Pomeranz BH, Corey PN. Incidence of adverse drug reactions in hospitalized patients: a meta-analysis of prospective studies. JAMA. 1998;279(15):1200–5.
Environics Research Group. Adverse Reaction Reporting—Survey with Health Professionals. Ottawa: Health Canada; 2007.
Essential medicines and health products: Pharmacovigilance. http://www.who.int/medicines/areas/quality_safety/safety_efficacy/pharmvigi/en/. Accessed 6 June 2018.
Golder S, Norman G, Loke YK. Systematic review on the prevalence, frequency and comparative value of adverse events data in social media. Br J Clin Pharmacol. 2015;80(4):878–88.
Lardon J, Abdellaoui R, Bellet F, Asfari H, Souvignet J, Texier N, Jaulent MC, Beyens MN, Burgun A, Bousquet C. Adverse drug reaction identification and extraction in social media: a scoping review. J Med Internet Res. 2015;17(7):e171.
Sarker A, Ginn R, Nikfarjam A, O'Connor K, Smith K, Jayaraman S, Upadhaya T, Gonzalez G. Utilizing social media data for pharmacovigilance: a review. J Biomed Inform. 2015;54:202–12.
Arksey H, O'Malley L. Scoping studies: towards a methodological framework. Int J Soc Res Methodol. 2005;8(1):19–32.
Peters MD, Godfrey CM, Khalil H, McInerney P, Parker D, Soares CB. Guidance for conducting systematic scoping reviews. Int J Evid Based Healthc. 2015;13(3):141–6.
Shamseer L, Moher D, Clarke M, Ghersi D, Liberati A, Petticrew M, Shekelle P, Stewart LA, Group P-P. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015: elaboration and explanation. BMJ. 2015;349:g7647.
Utility of social media and crowd-sourced data for pharmacovigilance: A scoping review protocol. https://osf.io/kv9hu/. Accessed 6 June 2018.
Tricco AC, Zarin W, Lillie E, Pham B, Straus SE. Utility of social media and crowd-sourced data for pharmacovigilance: a scoping review protocol. BMJ Open. 2017;7:e013474.
McGowan J, Sampson M, Salzwedel DM, Cogo E, Foerster V, Lefebvre C. PRESS peer review of electronic search strategies: 2015 guideline statement. J Clin Epidemiol. 2016; https://doi.org/10.1016/j.jclinepi.2016.01.021.
Grey Matters: a practical tool for searching health-related grey literature. https://www.cadth.ca/resources/finding-evidence/grey-matters. Accessed 6 June 2018.
Sinnenberg L, Buttenheim AM, Padrez K, Mancheno C, Ungar L, Merchant RM. Twitter as a tool for Health Research: a systematic review. Am J Public Health. 2016;107:e1–8.
Newton D. Synthesi.SR. Toronto: Knowledge Translation Program, St. Michael's Hospital; 2012.
Tricco AC, Lillie E, Zarin W, O'Brien K, Colquhoun H, Kastner M, Levac D, Ng C, Sharpe JP, Wilson K, et al. A scoping review on the conduct and reporting of scoping reviews. BMC Med Res Methodol. 2016;16:15.
Mental and behavioural disorders. In: International Statistical Classification of Diseases and Related Health Problems 10th Revision (ICD-10)-WHO Version for 2016. Geneva: World Health Organization; 2016.
Kumar VD, Tipney HJ. Biomedical literature mining. New York: Springer; 2014.
Hsieh HF, Shannon SE. Three approaches to qualitative content analysis. Qual Health Res. 2005;15(9):1277–88.
World Bank Country and Lending Groups. https://datahelpdesk.worldbank.org/knowledgebase/articles/906519-world-bank-country-and-lending-groups. Accessed 6 June 2018.
Yang CC, Yang H. Exploiting social media with tensor decomposition for pharmacovigilance. In: 2015 IEEE International Conference on Data Mining Workshop (ICDMW): 2015. Washington D.C: IEEE; 2015. p. 188–95.
Freifeld CC, Brownstein JS, Menone CM, Bao W, Filice R, Kass-Hout T, Dasgupta N. Digital drug safety surveillance: monitoring pharmaceutical products in twitter. Drug Saf. 2014;37(5):343–50.
Johnson HK. Nancy: a side effect of social media. What can twitter tell us about adverse drug reactions. In: UKMI 39th professional development seminar: 2013. 2013.
Kmetz J. Pharmaceutical industry special report: adverse event reporting in social media. In: Visible; 2011.
Leaman R, Wojtulewicz L, Sullivan R, Skariah A, Yang J, Gonzalez G. Towards internet-age pharmacovigilance: extracting adverse drug reactions from user posts to health-related social networks. In: Proceedings of the 2010 workshop on biomedical natural language processing: 2010. Upsala: Association for Computational Linguistics; 2010. p. 117–25.
Medawar C, Herxheimer A, Bell A, Jofre S. Paroxetine, panorama and user reporting of ADRs: consumer intelligence matters in clinical practice and post-marketing drug surveillance. Int J Risk Saf Med. 2002;15(3, 4):161–9.
Discovering Drug Side Effects with Crowdsourcing. https://www.figure-eight.com/discovering-drug-side-effects-with-crowdsourcing/. Accessed 6 June 2018.
Pages A, Bondon-Guitton E, Montastruc JL, Bagheri H. Undesirable effects related to oral antineoplastic drugs: comparison between patients’ internet narratives and a national pharmacovigilance database. Drug Saf. 2014;37(8):629–37.
Powell GE, Seifert HA, Reblin T, Burstein PJ, Blowers J, Menius JA, Painter JL, Thomas M, Pierce CE, Rodriguez HW. Social media listening for routine post-marketing safety surveillance. Drug Saf. 2016;39(5):443–54.
Yom-Tov E, Gabrilovich E. Postmarket drug surveillance without trial costs: discovery of adverse drug reactions through large-scale analysis of web search queries. J Med Internet Res. 2013;15(6):e124.
Akay A, Dragomir A, Erlandsson B-E. Network-based modeling and intelligent data mining of social media for improving care. IEEE J Biomed Health Inform. 2015;19(1):210–8.
Coloma PM, Becker B, Sturkenboom MC, van Mulligen EM, Kors JA. What can social media networks contribute to medicines safety surveillance? In: Pharmacoepidemiol drug Saf: 2015. Hoboken: Wiley; 2015. p. 467–8.
Liu J, Li A, Seneff S. Automatic drug side effect discovery from online patient-submitted reviews: focus on statin drugs. In: Proceedings of first international conference on advances in information mining and management (IMMM): 2011. Barcelona: IMMM; 2011. p. 23–9.
Li YA. Medical data mining: improving information accessibility using online patient drug reviews. Cambridge: Massachusetts Institute of Technology; 2011.
Mao JJ, Chung A, Benton A, Hill S, Ungar L, Leonard CE, Hennessy S, Holmes JH. Online discussion of drug side effects and discontinuation among breast cancer survivors. Pharmacoepidemiol Drug Saf. 2013;22(3):256–62.
Schröder S, Zöllner YF, Schaefer M. Drug related problems with antiparkinsonian agents: consumer internet reports versus published data. Pharmacoepidemiol Drug Saf. 2007;16(10):1161–6.
Sarrazin MSV, Cram P, Mazur A, Ward M, Reisinger HS. Patient perspectives of dabigatran: analysis of online discussion forums. Patient. 2014;7(1):47–54.
Chee BW, Berlin R, Schatz B. Predicting adverse drug events from personal health messages. In: AMIA Annu Symp proc. 2011. Washington DC; 2011. p. 217–26.
Topaz M, Lai K, Dhopeshwarkar N, Seger DL, Sa’adon R, Goss F, Rozenblum R, Zhou L. Clinicians’ reports in electronic health records versus patients’ concerns in social media: a pilot study of adverse drug reactions of aspirin and atorvastatin. Drug Saf. 2016;39(3):241–50.
Nadarajah S. Monitoring adverse events in Pharma’s patient support programs: IMS Health; 2015.
Alvaro N, Conway M, Doan S, Lofi C, Overington J, Collier N. Crowdsourcing twitter annotations to identify first-hand experiences of prescription drug use. J Biomed Inform. 2015;58:280–7.
Benton A, Ungar L, Hill S, Hennessy S, Mao J, Chung A, Leonard CE, Holmes JH. Identifying potential adverse effects using the web: a new approach to medical hypothesis generation. J Biomed Inform. 2011;44(6):989–96.
Bian J, Topaloglu U, Yu F. Towards large-scale twitter mining for drug-related adverse events. In: Proceedings of the 2012 international workshop on smart health and wellbeing. 2012. Maui: ACM; 2012. p. 25–32.
Chary M, Park EH, McKenzie A, Sun J, Manini AF, Genes N. Signs & symptoms of dextromethorphan exposure from YouTube. PLoS One. 2014;9(2):e82452.
Chee BW, Berlin R, Schatz BR. Measuring population health using personal health messages. San Francisco: AMIA; 2009.
Correia RB, Li L, Rocha LM. Monitoring potential drug interactions and reactions via network analysis of instagram user timelines. In: Pacific Symposium on Biocomputing Pacific Symposium on Biocomputing. 2016. Kohala Coast: NIH Public Access; 2016. p. 492.
Elhadad N, Zhang S, Driscoll P, Brody S. Characterizing the sublanguage of online breast cancer forums for medications, symptoms, and emotions. In: Proc AMIA Annual Fall Symposium; Washington DC; 2014.
Ginn R, Pimpalkhute P, Nikfarjam A, Patki A, O’Connor K, Sarker A, Smith K, Gonzalez G. Mining twitter for adverse drug reaction mentions: a corpus and classification benchmark. In: Proceedings of the fourth workshop on building and evaluating resources for health and biomedical text processing. 2014. Reykjavik: Citeseer; 2014.
Gupta S, MacLean DL, Heer J, Manning CD. Induced lexico-syntactic patterns improve information extraction from online medical forums. J Am Med Inform Assoc. 2014;21(5):902–9.
Hadzi-Puric J, Grmusa J. Automatic drug adverse reaction discovery from parenting websites using disproportionality methods. In: Proceedings of the 2012 International Conference on Advances in Social Networks Analysis and Mining (ASONAM 2012). Istanbul: IEEE computer society; 2012. p. 792–7.
Jimeno-Yepes A, MacKinlay A, Han B, Chen Q. Identifying diseases, drugs, and symptoms in twitter. Stud Health Technol Inform. 2014;216:643–7.
Liu X, Liu J, Chen H. Identifying adverse drug events from health social media: a case study on heart disease discussion forums. In: International conference on smart health: 2014. Beijing: Springer; 2014. p. 25–36.
Liu X, Chen H. AZDrugMiner: an information extraction system for mining patient-reported adverse drug events in online patient forums. In: International conference on smart health: 2013. Beijing: Springer; 2013. p. 134–50.
Liu X, Chen H. Identifying adverse drug events from patient social media: a case study for diabetes. IEEE Intell Syst. 2015;30(3):44–51.
Liu X, Chen H. A research framework for pharmacovigilance in health social media: identification and evaluation of patient adverse drug event reports. J Biomed Inform. 2015;58:268–79.
Liu X, Chen H. Identifying adverse drug events from health social media using distant supervision. In: INFORMS Conference on Information Systens and Technology. Philadelphia: INFORMS; 2015.
Metke-Jimenez A, Karimi S. Concept extraction to identify adverse drug reactions in medical forums: a comparison of algorithms. Canberra: CSIRO; 2015. arXiv preprint arXiv:150406936.
Metke-Jimenez A, Karimi S, Paris C. Evaluation of text-processing algorithms for adverse drug event extraction from social media. In: Proceedings of the first international workshop on social media retrieval and analysis. 2014. Queensland: ACM; 2014. p. 15–20.
Nikfarjam A, Gonzalez GH. Pattern mining for extraction of mentions of adverse drug reactions from user comments. In. Austin: AMIA Annual Symposium proceedings; 2011. p. 1019–26.
Nikfarjam A, Sarker A, O’Connor K, Ginn R, Gonzalez G. Pharmacovigilance from social media: mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J Am Med Inform Assoc. 2015;22(3):671–81.
Patki A, Sarker A, Pimpalkhute P, Nikfarjam A, Ginn R, O’Connor K, Smith K, Gonzalez G. Mining adverse drug reaction signals from social media: going beyond extraction. Proceedings of BioLinkSig. 2014;2014:1–8.
Sampathkumar H, Chen X-W, Luo B. Mining adverse drug reactions from online healthcare forums using hidden Markov model. BMC Med Inform Decis Mak. 2014;14(1):1.
Sarker A, Gonzalez G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J Biomed Inform. 2015;53:196–207.
Sarker A, O’Connor K, Ginn R, Scotch M, Smith K, Malone D, Gonzalez G. Social media mining for toxicovigilance: automatic monitoring of prescription medication abuse from twitter. Drug Saf. 2016;39(3):231–40.
Wu H, Fang H, Stanhope S. Exploiting online discussions to discover unrecognized drug side effects. Methods Inf Med. 2013;52(2):152–9.
Yang CC, Jiang L, Yang H, Tang X. Detecting signals of adverse drug reactions from health consumer contributed content in social media. In: Proceedings of ACM SIGKDD Workshop on Health Informatics: 2012. Beijing; 2012.
Yang CC, Yang H, Jiang L, Zhang M. Social media mining for drug safety signal detection. In: Proceedings of the 2012 international workshop on smart health and wellbeing: 2012. Maui HI: ACM; 2012. p. 33–40.
Yang H, Yang CC. Harnessing social media for drug-drug interactions detection. In: Healthcare Informatics (ICHI), 2013 IEEE International Conference on: 2013. Budapest: IEEE; 2013. p. 22–9.
Yang M, Kiang M, Shang W. Filtering big data from social media–building an early warning system for adverse drug reactions. J Biomed Inform. 2015;54:230–40.
Yates A, Goharian N, Frieder O. Extracting adverse drug reactions from forum posts and linking them to drugs. In: Proceedings of the 2013 ACM SIGIR workshop on health search and discovery. 2013. Dublin; 2013.
Wang C, Karimi S. Differences between social media and regulatory databases in adverse drug reaction discovery. In: Proceedings of the first international workshop on social media retrieval and analysis: 2014. Queensland: ACM; 2014. p. 13–4.
Sarker A, Nikfarjam A, Gonzalez G. Social media mining shared task workshop. In: Proceedings of the Pacific Symposium on Biocomputing: 2016. Hawaii; 2016.
Freifeld CC: Digital pharmacovigilance: the medwatcher system for monitoring adverse events through automated processing of internet social media and crowdsourcing. 2014.
White RW, Harpaz R, Shah NH, DuMouchel W, Horvitz E. Toward enhanced pharmacovigilance using patient-generated data on the internet. Clin Pharmacol Ther. 2014;96(2):239.
White RW, Tatonetti NP, Shah NH, Altman RB, Horvitz E. Web-scale pharmacovigilance: listening to signals from the crowd. J Am Med Inform Assoc. 2013;20(3):404–8.
Carbonell P, Mayer MA, Bravo À. Exploring brand-name drug mentions on twitter for pharmacovigilance. Stud Health Technol Inform. 2015;210:55–9.
Segura-Bedmar I, Revert R, Martínez P. Detecting drugs and adverse events from Spanish health social media streams. In: Proceedings of the 5th International Workshop on Health Text Mining and Information Analysis (Louhi)@ EACL. Gothenburg; 2014. p. 106–15.
Segura-Bedmar I, De La Peña S, Martınez P. Extracting drug indications and adverse drug reactions from Spanish health social media. In: Proceedings of BioNLP: 2014; 2014. p. 98–106.
Segura-Bedmar I, Martínez P, Revert R, Moreno-Schneider J. Exploring Spanish health social media for detecting drug effects. BMC Med Inform Decis Mak. 2015;15(2):1.
Whitman CB, Reid MW, Arnold C, Patel H, Ursos L. Sa'adon R, Pourmorady J, Spiegel B: balancing opioid-induced gastrointestinal side effects with pain management: insights from the online community. J Opioid Manag. 2014;11(5):383–91.
Yates A, Goharian N. ADRTrace: Detecting Expected and Unexpected Adverse Drug Reactions from User Reviews on Social Media Sites. In: Serdyukov P, Braslavski P, Kuznetsov SO, Kamps J, Rüger S, Agichtein E, Segalovich I, Yilmaz E, editors. Advances in Information Retrieval: 35th European Conference on IR Research. Berlin, Heidelberg: Springer Berlin Heidelberg; 2013. p. 816–9.
Karimi S, Metke-Jimenez A, Nguyen A. CADEminer: a system for mining consumer reports on adverse drug side effects. In: Proceedings of the eighth workshop on exploiting semantic annotations in information retrieval: 2015. Melbourne: ACM; 2015. p. 47–50.
Risson V, Saini D, Bonzani I, Huisman A, Olson M. Validation of social media analysis for outcomes research: identification of drivers of switches between oral and injectable therapies for multiple sclerosis. Value Health. 2015;18(7):A729.
Rizo C, Deshpande A, Ing A, Seeman N. A rapid, web-based method for obtaining patient views on effects and side-effects of antidepressants. J Affect Disord. 2011;130(1):290–3.
O’Connor K, Pimpalkhute P, Nikfarjam A, Ginn R, Smith KL, Gonzalez G. Pharmacovigilance on twitter? Mining tweets for adverse drug reactions. In: AMIA Annual Symposium Proceedings: 2014. Washington DC: American Medical Informatics Association; 2014:924.
Cameron D, Sheth AP, Jaykumar N, Thirunarayan K, Anand G, Smith GA. A hybrid approach to finding relevant social media content for complex domain specific information needs. Web Semant Sci Serv Agents World Wide Web. 2014;29:39–52.
Abou Taam M, Rossard C, Cantaloube L, Bouscaren N, Pochard L, Montastruc F, Montastruc J, Bagheri H. Analyze of internet narratives on patient websites before and after benfluorex withdrawal and media coverage. Fundam Clin Pharmacol. 2012;26:79–80.
Hanson CL, Burton SH, Giraud-Carrier C, West JH, Barnes MD, Hansen B. Tweaking and tweeting: exploring twitter for nonmedical use of a psychostimulant drug (Adderall) among college students. J Med Internet Res. 2013;15(4):e62.
Hughes S, Cohen D. Can online consumers contribute to drug knowledge? A mixed-methods comparison of consumer-generated and professionally controlled psychotropic medication information on the internet. J Med Internet Res. 2011;13(3):e53.
Pierce CE, Bouri K, Pamer C, Proestel S, Rodriguez HW, Van Le H, Freifeld CC, Brownstein JS, Walderhaug M, Edwards IR, et al. Evaluation of Facebook and twitter monitoring to detect safety signals for medical products: an analysis of recent FDA safety alerts. Drug Saf. 2017;40(4):317–31.
Duh MS, Cremieux P, Audenrode MV, Vekeman F, Karner P, Zhang H, Greenberg P. Can social media data lead to earlier detection of drug-related adverse events? Pharmacoepidemiol Drug Saf. 2016;25(12):1425–33.
Acknowledgements
We thank Dr. Elise Cogo for developing the literature search, Dr. Jessie McGowan for peer-reviewing the literature search, Ms. Alissa Epworth for performing the database and grey literature searches and all library support. We also thank Ms. Fatemeh Yazdi for helping with some screening and data extraction and Theshani De Silva for formatting the manuscript. Last but not least, we thank Jesmin Antony and Myanca Rodrigues, as well as Health Canada Products and Food Branch, in particular Dr. Laurie Chapman, for their feedback on the manuscript.
Funding
This study was funded by the Canadian Institutes of Health Research Drug Safety and Effectiveness Network (DNM–137713). ACT is funded by a Tier 2 Canada Research Chair in Knowledge Synthesis. SES is funded by a Tier 1 Canada Research Chair in Knowledge Translation.
Availability of data and materials
The datasets used and/or analysed during this study are available from the corresponding author upon reasonable request.
Author information
Authors and Affiliations
Contributions
ACT obtained funding, conceptualized the research, participated in all pilot-tests, provided methods guidance, and drafted the manuscript. WZ coordinated the study, screened citations and articles, abstracted data, cleaned data, coded open-text data, analyzed the data and helped write the manuscript. EL helped coordinate the study, screened citations, abstracted data, cleaned data, coded open-text data, and helped write the manuscript. SJ coded open-text data, verified the data and reviewed the manuscript. PK, RW, RR, and BP screened citations and articles for relevance, abstracted data, and reviewed the manuscript. GH provided content expertise, verified data categorization and reviewed the manuscript. SES obtained funding, helped conceptualize the research, and helped write the manuscript. All authors have critically reviewed the manuscript and provided substantial feedback on the content and interpretation of results, as well as provided final approval for the manuscript to be published. Each author has agreed to be accountable for all aspects of the work.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Since this is a scoping review, ethics approval was not required.
Competing interests
The authors declare that they have no competing interests. The study funder had no input into the study design; in the collection, analysis, and interpretation of data; in the writing of the report; and in the decision to submit the paper for publication.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional file
Additional file 1:
Appendix 1. Description of included and excluded interventions for drug safety surveillance. Appendix 2. Glossary of terms. Appendix 3. Medline search strategy. Appendix 4. Sources for grey literature search. Appendix 5. List of included studies. Appendix 6. Social media data processing pipeline. Appendix 7. Pre-existing social media listening platforms for drug safety surveillance. Appendix 8. Utility of social media data for drug safety surveillance. Appendix 9. Pre-processing methods and results. Appendix 10. De-identification methods and results. Appendix 11. De-duplication methods and results. Appendix 12. Concept identification methods and results. Appendix 13. Drug name normalization methods and results. Appendix 14. Medical event normalization methods and results. Appendix 15. Relation extraction methods and results. Appendix 16. Additional processing methods and results. Appendix 17. Utility and challenges with socila media listening for drug safety surveillance. (DOCX 275 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Tricco, A.C., Zarin, W., Lillie, E. et al. Utility of social media and crowd-intelligence data for pharmacovigilance: a scoping review. BMC Med Inform Decis Mak 18, 38 (2018). https://doi.org/10.1186/s12911-018-0621-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12911-018-0621-y