
Abstract
Background
Health economic models are critical tools to inform reimbursement agencies on health care interventions. Many clinical trials report outcomes using the frequency of an event over a set period of time, for example, the primary efficacy outcome in most clinical trials of migraine prevention is mean change in the frequency of migraine days (MDs) per 28 days (monthly MDs [MMD]) relative to baseline for active treatment versus placebo. Using these cohort-level endpoints in economic models, accounting for variation among patients is challenging. In this analysis, parametric models of change in MMD for migraine preventives were assessed using data from erenumab clinical studies.
Methods
MMD observations from the double-blind phases of two studies of erenumab were used: one in episodic migraine (EM) (NCT02456740) and one in chronic migraine (CM) (NCT02066415). For each trial, two longitudinal regression models were fitted: negative binomial and beta binomial. For a thorough comparison we also present the fitting from the standard multilevel Poisson and the zero inflated negative binomial.
Results
Using the erenumab study data, both the negative binomial and beta-binomial models provided unbiased estimates relative to observed trial data with well-fitting distribution at various time points.
Conclusions
This proposed methodology, which has not been previously applied in migraine, has shown that these models may be suitable for estimating MMD frequency. Modelling MMD using negative binomial and beta-binomial distributions can be advantageous because these models can capture intra- and inter-patient variability so that trial observations can be modelled parametrically for the purposes of economic evaluation of migraine prevention. Such models have implications for use in a wide range of disease areas when assessing repeated measured utility values.
Similar content being viewed by others

Background
Migraine is a common neurological disorder characterised by debilitating, recurrent headaches, often divided into episodic (EM) and chronic (CM) forms based on month headache days (MHD) and monthly migraine days (MMD) (EM, 4–14 MMD and < 15 MHD, or CM, ≥15 MHD and ≥ 8 MMD) [1,2,3]. Migraine pain is typically unilateral, pulsating in quality, of moderate or severe intensity and aggravated by routine physical activity, such as walking or climbing stairs. In addition, diagnosis depends on the presence of associated symptoms of nausea, vomiting, photophobia or phonophobia in various combinations [1, 2, 4]. The burden of migraine is considerable, both in terms of the physical and emotional effects on the individual, and the economic impact of lost productivity and healthcare resource use [5]. It is ranked as the leading cause of neurological disability worldwide and is one of the five leading causes of long-term disability [6, 7].
Preventive treatment intended to reduce the frequency and severity of headaches is an important aspect of management; all patients with CM would benefit from preventative treatment. Among patients with EM, experiencing 4 or more headache days per month is a leading reason for considering preventative therapy [8]. MMD and MHD are counts that have values that include zero as well as positive integers; count data typically have skewed distributions [9]. Reductions in the frequencies of migraine days (MDs) and headache days are key measures of the efficacy of migraine prophylaxis.
Clinical studies typically examine the mean change in MMD frequency; patient-level data are not widely published. However, examining the mean change in MMD frequency across a cohort of patients may not capture the clinically meaningful effects of migraine prevention, such as the improvement in an individual’s ability to perform daily activities or health-related quality of life. Furthermore, examining the mean change in the MMD frequency for a population in clinical studies may not be applicable in the real-world, as treatments may shift the frequency distribution.
A higher frequency of MMD per 28 days is associated with lower health-related quality of life, increased use of medical resources, acute medication use and increased productivity losses, with the impact of each additional MD increasing with overall frequency. As such, the average outcomes across a patient cohort may not be the same as the outcomes of a patient with the average MMD frequency. The frequency distribution of MHD and MMD is important when it comes to modelling the effectiveness and cost-effectiveness of prophylaxis [10]. Previous analyses examining cost-effectiveness models for migraine have approached this issue by defining health states as categorical event frequency (transition from ≥15 MHD to < 15 MHD) or as response status (≥50% reduction in MHD) [10,11,12,13] which may not adequately account for inter-patient variability. These models group together a heterogeneous set of patient outcomes, rendering the models less precise; for example Markov models tend to categorise patients into broad categories, which can be challenging when assessing benefits. In general, categorising count/continuous variables can lead to several problems including loss of information and may also increase the risk of false positives [14]. Furthermore, use of a data-derived ‘optimal’ cutpoint may lead to bias [15]. Migraine is a disease with considerable variability in the frequency, duration and severity of migraine attacks [16]. Therefore, there is a need for an approach that estimates the change in mean frequency of MMD but also the distribution of individual patients by MMD frequency within a cohort at subsequent time points.
Selection of the most appropriate model is important when fitting MHD or MMD data [17]. There are several approaches to modelling these data. Reports on modelling MMD frequency in the literature are limited but previous analyses have used Poisson and negative binomial to model headache day frequency [17,18,19,20,21]. Zero-inflated variants of these distributions have also been used to improve goodness-of-fit [17, 22]. The Poisson distribution belongs to the family of discrete probability distributions traditionally used to model count data. In general, the model assumes that the mean and variance of the count data are equal [23]. It is considered appropriate for unrestricted count data [24], and because MMD frequency is a count variable, Poisson distribution may be considered an eligible model. However, its ability to model the variation seen in the patient-level data has proved limited [20, 25] due to insufficient accounting for overdispersion (where a single parameter is insufficient to characterise the mean and variance) [26]. More recently, thanks to Shmueli et al. there has been a resurgence in interest in Conway-Maxwell-Poisson distributions, originally proposed by Conway and Maxwell to handle queuing systems [27, 28]. The main characteristic of these distributions, which are an extension of the Poisson distribution, is the ability to handle both overdispersion and underdispersion. These distributions are limited, however, due to the lack of a hierarchical model to assess repeated measurements and parameterization that is not made directly via the mean of counts, making these distributions not easily comparable to other count regression models. By contrast, the negative binomial distribution, which uses an additional dispersion parameter to represent the additional variation seen in the data, has provided superior fits when modelling migraine populations [17, 20].
A preliminary analysis, based on cross-sections of the data, has indicated that the beta-binomial is an alternative distribution that could be used to model MMD frequency data and has been shown to provide comparable fits to the negative binomial models [25]. The beta-binomial model is commonly used to account for intraclass correlation coefficients (ICC) among dichotomous outcomes in cluster sampling [29]. The use of the beta-binomial model may offer some advantages because the outcome can be restricted to a maximum number of possible successes (i.e. a maximum of 28 MMD per 4-week period).
In order to assess the feasibility of fitting MMD data using negative binomial or beta-binomial models, longitudinal data from two erenumab studies were examined [30, 31]. Erenumab is a fully human monoclonal antibody that specifically binds to and blocks the calcitonin gene-related peptide (CGRP) receptor [32]. Erenumab has been evaluated as a prophylactic treatment for migraine in 2 pivotal clinical trials in patients with EM and CM [30, 31, 33].
To the best of our knowledge, longitudinal negative binomial and beta-binomial regression models that accommodate over-dispersed data have not been used previously in the assessment of MMD frequency. Here, we describe an assessment of these models of the change in MMD frequency, using data from the placebo and erenumab 140 mg arms of two pivotal erenumab clinical trials.
Methods
Models specification
Three longitudinal regression models were evaluated for their ability to estimate the frequency distribution of MMD: multilevel/hierarchical negative binomial regression (with constant dispersion parameter over time), multilevel beta-binomial regression (with constant ICC over time) and the multilevel Poisson model. The distributions in the erenumab cohorts of the studies were estimated and compared to the observed distribution across the double-blind period. Zero-inflated negative binomial models with robust standard errors clustering at patient level (presented in Additional file 1: Table S1 and Additional file 2: Figure S1) were also fitted, but only the non-zero-inflated were considered here because zero-inflated models did not improve the model’s fit, and there was no substantial inflation of zeros due to the eligibility criteria for the study [20].
Negative binomial distribution
The negative binomial distribution is an extension of the Poisson distribution and includes a dispersion parameter (τ) to account for overdispersion in the data. The negative binomial does not have an upper bound (unlike the beta binomial), so it is possible for high mean frequencies to result in predictions above the maximum of 28 MDs per month. The dispersion parameter is estimated based on the mean MD frequency.
The negative binomial probability function [34] is defined as:
Where:
-
P(Y = k) is the probability of a patient experiencing k MDs per 28 days
-
λ is the mean MDs per 28 days
-
τ is the dispersion parameter.
Note that the dispersion parameter estimated by Stata is 1 divided by the dispersion parameter in eq. 1. To ensure that the function sums to unity, the model divides each estimated frequency by the cumulative frequency of the negative binomial at Y = 28 (28 MDs per 28 days).
This regression framework can accommodate differences in MMD frequency and the variation in frequency between patients at different time points. Parameters that accommodate overdispersion were estimated for the negative binomial regression, referred to as the dispersion parameter.
Beta-binomial distribution
The beta-binomial data model is a combined model of the beta and binomial distributions. It is used to model the number of successes (counts) over a number of binomial trials, when the probability of success is a beta distribution with two specific parameters (α and β) [35]. In general, the beta-binomial distribution accounts for the fact that the observed events are not equally distributed across patients and can be used to assess non-linear associations [35]. In the beta-binomial distribution, the count data at each observation timepoint are regarded as a set of 28 binary outcomes (MD or non-MD) grouped by patient. The α and β parameters of the beta-binomial distribution can be calculated from the mean and ICC, which represents the strength of the correlation between days for the same patient, i.e. daily outcomes are likely to be similar for the same patient.
The beta-binomial probability function is specified as follows:
Where:
-
k is the number of MDs
-
P (Y = k) is the probability of patients experiencing τ MDs
-
N is the number of days in the cycle (28 days)
-
B () is the beta function
-
α and β are the parameters of the underlying beta distribution.
The ICC is assumed constant over time and equal to 1 / (1 + α + β).
Erenumab clinical trial data
Table 1 summarises some of the key characteristics of the patients from the two erenumab studies. The patient data used in the modelling analysis were taken from two pivotal clinical trials of erenumab as migraine prophylaxis; one in patients with EM (NCT02456740) [30], the other in patients with CM (NCT02066415) [31]. Patients enrolled in the EM study had 4 to 14 MDs and fewer than 15 headache days per month (28 days) at baseline. Patients in the CM study had 15 or more headache days per month at baseline, of which at least 8 were MDs. Both of these randomised, double-blind studies compared erenumab 70 mg and 140 mg, administered every 28 days by subcutaneous injection, with placebo [30, 31]. Patients received double-blind treatment for 12 weeks (CM study) or 24 weeks (EM study), and efficacy was assessed as the change in mean MMD from baseline. This analysis focuses on the erenumab 140 mg dose only. Patient-level data were obtained for the patients in each study, with the following variables extracted for use in the analysis: subject ID, MMD frequency, visit, and treatment. This approach allows the regression models to estimate both the change in MMD frequency over time and the dispersion parameters required to reproduce the distribution of patient-level MMD frequency.
Goodness of fit of the regression models was assessed by estimating the root mean squared errors (RMSE) across the estimated values compared with trial observations, mean absolute errors (MAE) and visual inspection of the predicted distributions. The models could not be compared via Akaike’s information criteria (AIC) or Bayesian information criterion (BIC) because the beta-binomial model was performed on the augmented dataset.
Predicted MMD values and 95% confidence intervals were calculated with the Delta method. For economic modelling purposes, the mean MMD frequencies were extrapolated beyond the trial observation, up to a maximum of 2 years, after which no further change in MMD frequency was assumed. The models tested were exponential, logistic, log-logistic and Gompertz. Extrapolation was performed using a logistic function, the best-fitting function out of the models tested. Further information on the extrapolations can be found in the supplementary material (Additional file 3: Figure S2).
All analyses were performed using Stata Statistical Software: Release 15.0 (StataCorp LLC, College Station, TX, USA) [36], and the Stata codes to fit the regression models proposed are located in the Additional file 4: Technical appendix.
Results
Patient characteristics
Baseline patient characteristics were similar in the two studies, despite differences in MMD frequency at baseline (patients experienced an average of 8 vs 18 MDs per 28 days for EM and CM respectively) (Table 1). In the EM study, mean age was 40.9 years, and the majority of patients were white (89.1%) and female (85.2%). In the CM study, these figures were similar with a mean age of 42.5 years, 94.2% were white and 82.8% were female.
MMD frequency modelling
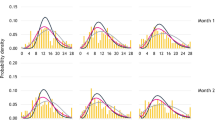
Figure 1 shows the predicted distributions of patients in the two cohorts compared with the study observations at weeks 0, 4, 12 and 24 in the EM study. In the EM study, the predicted distributions for both regression models show a good fit with the actual data at 4, 12 and 24 weeks (Fig. 1). Figure 2 shows the predicted distributions and actual data at weeks 0, 4, 8 and 12 in the CM study. The predicted distributions show a good fit to the actual observations in the EM and CM study; the RMSE estimates were 0.075 and 0.082 for negative binomial regression, 0.102 and 0.081 for beta-binomial regression and 0.142 and 0.152 for Poisson regression for EM and CM studies respectively. The MAE estimates were 0.246 and 0.330 for negative binomial regression, 0.336 and 0.339 for beta-binomial regression, and 0.466 and 0.654 for Poisson regression for EM and CM studies respectively. For negative binomial regression, the dispersion parameter was 0.2397 for the EM study and 0.1323 for the CM study; for the beta-binomial regression, the ICC values were 0.0297 and 0.1370 for the EM and CM studies (Tables 2 and 3).

Estimated and actual MMD distributions in the EM study at weeks 0, 4, 12 and 24

Estimated and actual MMD distributions in the CM study at weeks 0, 4, 8 and 12
For the EM study, the negative binomial mean MMD for weeks 0, 4, 12 and 24 were 8.261, 7.199, 6.434 and 6.421, respectively. For beta-binomial regression, the mean MMD for weeks 0, 4, 12 and 24 were 7.945, 7.080, 6.386 and 6.293, respectively (Table 2). For the CM study, the negative binomial mean MMD for weeks 0, 4, 8 and 12 were 18.111, 15.418, 14.538 and 13.997, respectively. For beta-binomial regression the mean MMD for weeks 0, 4, 8 and 12 were 17.111, 15.843, 15.256 and 14.894, respectively (Table 3).
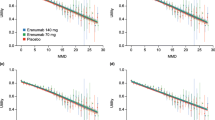
The predicted distributions observed in the CM study appeared a less close fit than for the EM study, which reflects the greater level of variability in the data from the CM study. Figure 3 presents the mean MMD frequencies for placebo predicted by the negative binomial and beta-binomial regression models compared with the observed mean values from patients with EM over the 24-week study period. Figure 4 presents the equivalent data for patients from the 12-week study in CM. In both studies, the modelled data from the two regressions show a closer fit with the observed values, compared with the Poisson reference model.

MMDs over 24 weeks of the EM study: negative binomial and beta-binomial longitudinal regression estimates and observed data. neg, negative. 95% confidence intervals for the negative and beta-binomials indicated by the shaded grey (placebo) and red (erenumab)

MMDs over 12 weeks of the CM study: negative binomial and beta-binomial longitudinal regression estimates and observed data. neg, negative. 95% confidence intervals for the negative and beta-binomials indicated by the shaded grey (placebo) and red (erenumab)
Discussion
This analysis is an assessment of the ability of longitudinal parametric models to capture intra- and inter-patient variability in MMD frequency over time, using data from two erenumab clinical trials as examples. Patients with migraine experience considerable day-to-day variability in the frequency, duration and severity of attacks [16]. This approach was used to estimate patient distribution accurately by the frequency of MMD using mean MMD values for the overall patient population. Modelling MMD with negative binomial and beta-binomial longitudinal regression models can be advantageous because they can accommodate overdispersed data (with a variance larger than the mean) and account for the variation in MMD both within and between individual patients.
The approaches described here allows the distribution of individual patients by MMD to be modelled using only the clinical endpoint of the studies - the mean change from baseline in MMD compared with placebo at a single time point. The beta-binomial regression method allows restriction of the maximum successes (i.e. maximum of 28 MDs), whereas the negative binomial does not. Despite this, the negative binomial showed a better goodness of fit to the MD distributions than beta-binomial. The modelled data from the negative and beta-binomial regressions show a closer fit with the observed values, compared with the Poisson reference model. The zero-inflated negative binomial regressions did not substantially improve the goodness of fit of the predicted distributions. In contrast to clinical trial populations that may have a lower bound of MDs per month, the zero-inflation model may be more useful in a real-world population where a greater proportion of people have zero MDs in a month.
The choice of distributions is important when measuring count data. The Poisson and negative binomial distributions have been used in previous studies to model count data [20, 23, 37] and have also been used to approximate headache day frequency data in published migraine studies [17, 38]. However, these distributions may be inappropriate when event counts are limited by a maximum possible frequency or measuring multimodal distributions. The Poisson and negative binomial distribution have indefinite support for positive integers and, therefore, have the potential to generate inappropriate values, especially with migraine cohorts of higher MD frequency.
Modelling data as continuous events rather than categorising data has many advantages, including the reduction of bias and more accurately estimating the extent of variation in outcomes between groups [14].This analysis takes the approach of modelling migraine frequency as a continuous outcome and addresses a key limitation of previous modelling approaches which define health states by categorical event frequency or response status. The proposed approach also provides a greater capability to model indirect comparisons than previous models, as the published endpoints of clinical studies (i.e. mean change in MMD) can be used to estimate the distributions of patients, assuming the patient-level variation is similar across cohorts. Using a count-based structure makes indirect comparisons straightforward because data can be linked to study primary endpoints. Estimating the distribution of patients by MMD also allows outcomes linked to MD frequency (such as health-related quality of life or pain medication use) to be quantified directly as a function of frequency. Furthermore, because clinical trials in migraine are commonly placebo-controlled, this approach could be used to parameterise indirect comparison in migraine prevention where patient-level frequency data are not available.
While this approach addresses key limitations of previous approaches, such as defining health states by categorical event frequency or response status, some potential improvements could be made to it. The implementation of a negative binomial regression with upper bound (28 MDs) could be considered and treatment-visit interactions could be included. Additionally, the data are required to fit to the smooth distributions of the model; however, this is not always the case. The predicted distributions observed in the CM study did not fit as well as the EM study owing to the greater spread in distribution in the CM study and may also be due to the differences in the patient populations between the EM and CM cohorts. Therefore, alternative approaches may be required to better model these cohorts.
The method described here has applications in economic evaluations of preventative medication and policy decisions in migraine. The parametric approach proposed can be used to perform extrapolations of treatment effects beyond trial observations. Extrapolation of data is particularly relevant when considering economic evaluations [39] as patient-level data collected within the duration of clinical studies are often too short to assess the long-term relationship between migraine frequency and health status. Further research may consider how such data should be extrapolated into the future, as whilst survival-modelled extrapolation has become well-established and standardised, the parametric approach is relatively novel, and the way in which the data can be best extrapolated is yet to be defined [40]. Furthermore, there is an inherent risk to extrapolation, as the clinical trajectory can be uncertain.
Modelling outcomes as continuous variables rather than health states has advantages when data are limited. Therefore, this approach has implications for use in various disease analyses which have simplified continuous outcomes associated with health states, which may result in loss of information or bias. This approach could be used to evaluate the disease progression of patients with HIV/AIDS, where multistate Markov models based on CD4 cell counts have previously been used [41] or modelling health assessment questionnaire (HAQ) scores in patients with psoriatic arthritis [42].
Conclusions
Modelling MMD with regression models that can accommodate overdispersion in a longitudinal framework is a statistically valid method to estimate the variation in MMD, both within and between individual patients. This approach, which estimates the distribution of patients by MMD, allows outcomes (such as health-related quality of life or pain medication use) to be directly quantified and linked to MD frequency. This has important applications in the evaluation of preventive medications for migraine and beyond.
Abbreviations
- AIC:
-
Akaike’s information criteria
- AIDS:
-
Acquired immunodeficiency syndrome
- BIC:
-
Bayesian information criterion
- CGRP:
-
Calcitonin gene related peptide
- CM:
-
Chronic migraine
- EM:
-
Episodic migraine
- HIV:
-
Human immunodeficiency virus
- ICC:
-
Intraclass correlation coefficients
- MAE:
-
Mean absolute error
- MHD:
-
Monthly headache days
- MMD:
-
Monthly migraine days
- RMSE:
-
Root mean squared errors
References
Katsarava Z, Buse DC, Manack AN, Lipton RB. Defining the differences between episodic migraine and chronic migraine. Curr Pain Headache Rep. 2012;16(1):86–92.
Lipton RB, Silberstein SD. Episodic and chronic migraine headache: breaking down barriers to optimal treatment and prevention. Headache. 2015;55(Suppl 2):103–22 quiz 23-6.
Headache Classification Committee of the International Headache Society (IHS). The International Classification of Headache Disorders, 3rd edition. Cephalalgia. 2018;38(1):1–211.
Headache Classification Committee of the International Headache Society (IHS). The International Classification of Headache Disorders, 3rd edition (beta version). Cephalalgia. 2013;33(9):629–808.
Blumenfeld AM, Varon SF, Wilcox TK, Buse DC, Kawata AK, Manack A, et al. Disability, HRQoL and resource use among chronic and episodic migraineurs: results from the international burden of migraine study (IBMS). Cephalalgia. 2011;31(3):301–15.
Edvinsson L. Headache advances in 2017: a new horizon in migraine therapy. Lancet Neurol. 2018;17(1):5–6.
Disease GBD, Injury I, Prevalence C. Global, regional, and national incidence, prevalence, and years lived with disability for 328 diseases and injuries for 195 countries, 1990-2016: a systematic analysis for the global burden of Disease study 2016. Lancet. 2017;390(10100):1211–59.
Estemalik E, Tepper S. Preventive treatment in migraine and the new US guidelines. Neuropsychiatr Dis Treat. 2013;9:709–20.
Zhou H, Siegel PZ, Barile J, Njai RS, Thompson WW, Kent C, et al. Models for count data with an application to Healthy Days measures: are you driving in screws with a hammer? Prev Chronic Dis. 2014;11:E50 quiz E.
Batty AJ, Hansen RN, Bloudek LM, Varon SF, Hayward EJ, Pennington BW, et al. The cost-effectiveness of onabotulinumtoxinA for the prophylaxis of headache in adults with chronic migraine in the UK. J Med Econ. 2013;16(7):877–87.
Brown JS, Papadopoulos G, Neumann PJ, Friedman M, Miller JD, Menzin J. Cost-effectiveness of topiramate in migraine prevention: results from a pharmacoeconomic model of topiramate treatment. Headache. 2005;45(8):1012–22.
Brown JS, Papadopoulos G, Neumann PJ, Price M, Friedman M, Menzin J. Cost-effectiveness of migraine prevention: the case of topiramate in the UK. Cephalalgia. 2006;26(12):1473–82.
Yu J, Smith KJ, Brixner DI. Cost effectiveness of pharmacotherapy for the prevention of migraine: a Markov model application. CNS Drugs. 2010;24(8):695–712.
Altman DG, Royston P. The cost of dichotomising continuous variables. BMJ. 2006;332(7549):1080.
Royston P, Altman DG, Sauerbrei W. Dichotomizing continuous predictors in multiple regression: a bad idea. Stat Med. 2006;25(1):127–41.
Mannix S, Skalicky A, Buse DC, Desai P, Sapra S, Ortmeier B, et al. Measuring the impact of migraine for evaluating outcomes of preventive treatments for migraine headaches. Health Qual Life Outcomes. 2016;14(1):143.
Houle TT, Turner DP, Houle TA, Smitherman TA, Martin V, Penzien DB, et al. Rounding behavior in the reporting of headache frequency complicates headache chronification research. Headache. 2013;53(6):908–19.
Serrano D, Lipton RB, Scher AI, Reed ML, Stewart WBF, Adams AM, et al. Fluctuations in episodic and chronic migraine status over the course of 1 year: implications for diagnosis, treatment and clinical trial design. J Headache Pain. 2017;18(1):101.
Rinne M, Garam S, Hakkinen A, Ylinen J, Kukkonen-Harjula K, Nikander R. Therapeutic exercise training to reduce chronic headache in working women: Design of a Randomized Controlled Trial. Phys Ther. 2016;96(5):631–40.
Porter JK, Brennan A, Palmer S, Sapra S, Cristino J. Parametric simulation of headache day frequency using a negative binomial distribution: a case study of Erenumab in episodic migraine. Value Health. 2016;19(7):A361.
Russell MB, Kristiansen HA, Saltyte-Benth J, Kvaerner KJ. A cross-sectional population-based survey of migraine and headache in 21,177 Norwegians: the Akershus sleep apnea project. J Headache Pain. 2008;9(6):339–47.
Mann JD, Faurot KR, MacIntosh B, Palsson OS, Suchindran CM, Gaylord SA, et al. A sixteen-week three-armed, randomized, controlled trial investigating clinical and biochemical effects of targeted alterations in dietary linoleic acid and n-3 EPA+DHA in adults with episodic migraine: study protocol. Prostaglandins Leukot Essent Fatty Acids. 2018;128:41–52.
Lee JH, Han G, Fulp WJ, Giuliano AR. Analysis of overdispersed count data: application to the human papillomavirus infection in men (HIM) study. Epidemiol Infect. 2012;140(6):1087–94.
Wagner B, Riggs P, Mikulich-Gilbertson S. The importance of distribution-choice in modeling substance use data: a comparison of negative binomial, beta binomial, and zero-inflated distributions. Am J Drug Alcohol Abuse. 2015;41(6):489–97.
JBA P, Palmer S, Sapra S, Shah N, Desai P, Villa G, Lipton RB. Modeling migraine day frequency using the beta-binomial distribution: A case study of erenumab as migraine prophylaxis. Presented at ISPOR 22nd Annual International Meeting, Boston, United States; 2017.
Serrano D, Manack AN, Reed ML, Buse DC, Varon SF, Lipton RB. Cost and predictors of lost productive time in chronic migraine and episodic migraine: results from the American migraine Prevalence and prevention (AMPP) study. Value Health. 2013;16(1):31–8.
Shmueli GM, Minka TP, Kadne JB, Borle S, Boatwright P. A useful distribution for fitting discrete data: revival of the Conway-Maxwell-Poisson distribution. App Statist. 2005;54:127–42.
Conway RM, Maxwell WL. A queuing model with state dependent service rates. J Ind Eng. 1962;12:132–6.
Ahmed MS, Shoukri M. A Bayesian estimator of the Intracluster correlation coefficient from correlated binary responses. J Data Sci. 2010;8:127–37.
Goadsby PJ, Reuter U, Bonner J, Broessner G, Hallstrom Y, Zhang F, et al. Phase 3, randomised, double-blind, placebo-controlled study to evaluate the efficacy and safety of erenumab (amg 334) in migraine prevention: primary results of the strive trial. J Neurol Neurosurg Psychiatry. 2017;88:e1.
Tepper S, Ashina M, Reuter U, Brandes JL, Dolezil D, Silberstein S, et al. Safety and efficacy of erenumab for preventive treatment of chronic migraine: a randomised, double-blind, placebo-controlled phase 2 trial. Lancet Neurol. 2017;16(6):425–34.
Shi L, Lehto SG, Zhu DX, Sun H, Zhang J, Smith BP, et al. Pharmacologic characterization of AMG 334, a potent and selective human monoclonal antibody against the calcitonin gene-related peptide receptor. J Pharmacol Exp Ther. 2016;356(1):223–31.
Sun H, Dodick DW, Silberstein S, Goadsby PJ, Reuter U, Ashina M, et al. Safety and efficacy of AMG 334 for prevention of episodic migraine: a randomised, double-blind, placebo-controlled, phase 2 trial. Lancet Neurol. 2016;15(4):382–90.
Chipeta MG, Ngwira BM, Simoonga C, Kazembe LN. Zero adjusted models with applications to analysing helminths count data. BMC Res Notes. 2014;7:856.
Liu CF, Burgess JF Jr, Manning WG, Maciejewski ML. Beta-binomial regression and bimodal utilization. Health Serv Res. 2013;48(5):1769–78.
StataCorp. 2017. Stata Statistical Software: Release 15. College Station: StataCorp LLC.
Quan HM, Mao X, Wang L. A case study of modeling and exposure-response prediction for count data. J Biopharm Stat. 24(5):1073–90.
Silberstein SD, Hulihan J, Karim MR, Wu SC, Jordan D, Karvois D, et al. Efficacy and tolerability of topiramate 200 mg/d in the prevention of migraine with/without aura in adults: a randomized, placebo-controlled, double-blind, 12-week pilot study. Clin Ther. 2006;28(7):1002–11.
Griffiths A, Paracha N, Davies A, Branscombe N, Cowie MR, Sculpher M. Analyzing health-related quality of life data to estimate parameters for cost-effectiveness models: an example using longitudinal EQ-5D data from the SHIFT randomized controlled trial. Adv Ther. 2017;34(3):753–64.
Latimer NR. Survival analysis for economic evaluations alongside clinical trials - extrapolation with patient-level data. London: NICE Decision Support Unit Technical Support Documents; 2013.
Grover G, Gadpayle AK, Swain PK, Deka B. A multistate Markov model based on CD4 cell count for HIV/AIDS patients on antiretroviral therapy (ART). Int J Stat Med Res. 2013;2:144–51.
Thom HH, Jackson CH, Commenges D, Sharples LD. State selection in Markov models for panel data with application to psoriatic arthritis. Stat Med. 2015;34(16):2456–75.
Goadsby PJ, Reuter U, Hallstrom Y, Broessner G, Bonner JH, Zhang F, et al. A controlled trial of Erenumab for episodic migraine. N Engl J Med. 2017;377(22):2123–32.
Acknowledgements
We acknowledge medical writing support by Sinéad Flannery PhD of Oxford PharmaGenesis, Oxford, UK.
Funding
The study was funded by Amgen (Europe) GmbH. Funding for medical writing support was also provided by Amgen (Europe) GmbH. The funding agreement ensured the authors’ independence in designing the study, data collection, interpreting the data, writing and publishing the manuscript.
Availability of data and materials
Qualified researchers may request data from Amgen clinical studies. Complete details are available at the following: http://www.amgen.com/datasharing. The data used in this study were collected from previous Amgen clinical studies.
Author information
Authors and Affiliations
Contributions
GLDT, JP, SS and GV were involved in the conception and design of the study. GLDT, JP and GV collected the individual patient data. GLDT, JP, GV, AB, SP and AJH discussed and agreed on the statistical analysis plan. GLDT and JP ran the statistical analyses and interpreted the results along with RBL, GV and SS. All authors contributed in the manuscript writing. All authors read and approved the manuscript.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
As previously reported, the two trials used in this study were registered with ClinicalTrials.gov, numbers NCT02456740 and NCT02066415 [31, 43]. For each of the study sites the final study protocol was approved by an Institutional Review Board/Independent Ethics Committee (IRB/IEC). The participants provided written informed consent before enrolment.
Consent for publication
Not applicable
Competing interests
JP and GLDT are both Amgen employees.
RBL is the Edwin S. Lowe Professor of Neurology at the Albert Einstein College of Medicine in New York. He receives research support from the NIH: 2PO1 AG003949 (Program Director), 5 U10 NS077308 (PI), 1RO1 AG042595 (Investigator), RO1 NS082432 (Investigator), K23 NS09610 (Mentor), K23AG049466 (Mentor). He also receives support from the Migraine Research Foundation and the National Headache Foundation. He serves on the editorial board of Neurology, is an associate editor of Cephalalgia, and as senior advisor to Headache. He has reviewed for the NIA and NINDS, holds stock options in eNeura Therapeutics and Biohaven Holdings; serves as consultant, advisory board member, or has received honoraria from: American Academy of Neurology, Alder, Allergan, American Headache Society, Amgen, Autonomic Technologies, Avanir, Biohaven, Biovision, Boston Scientific, Dr. Reddy’s, Electrocore, Eli Lilly, eNeura Therapeutics, GlaxoSmithKline, Merck, Pernix, Pfizer, Supernus, Teva, Trigemina, Vector, Vedanta. He receives royalties from Wolff’s Headache, 8th Edition, Oxford Press University, 2009, Wiley and Informa.
AB has research grants from NIHR, PHE, NIH (US), and DH, and receives consulting fees from Amgen, GSK, RTI, TeamDRG.
SP receives consulting fees from Amgen.
SS and GV are employed by Amgen and have stock in Amgen.
AJH was an employee of BresMed Health Solutions when the study was conducted, which received consulting fees from Amgen.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
Table S1. EM and CM regression output for zero-inflated negative binomial. Contains the data for the EM and CM regression output for the zero-inflated negative binomial model. (DOCX 17 kb)
Additional file 2:
Figure S1. Placebo modelling data: MMDs of the EM study (a) and the CM study (b) negative binomial regression, beta binomial regression and zero-inflated negative binomial regression. Contains placebo modelling data of MMDs of the EM and CM study for the regression models. (EPS 2448 kb)
Additional file 3:
Figure S2. Mean MD extrapolations based on regression model predicted means. a) and b) EM regression models c) and d) CM regression models. Parametric extrapolations of mean MMD are based on the predicted means produced by the beta-binomial and negative binomial regression models of both EM and CM. The mean MMD frequency plateaued after approximately 6 months (24 weeks). Fitted values refer to the logistic, exponential and Gompertz functions. (EPS 2384 kb)
Additional file 4:
Implementation of regression models in Stata. The technical appendix contains the Stata codes which were used to fit the regression models. (DOCX 13 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Di Tanna, G.L., Porter, J.K., Lipton, R.B. et al. Migraine day frequency in migraine prevention: longitudinal modelling approaches. BMC Med Res Methodol 19, 20 (2019). https://doi.org/10.1186/s12874-019-0664-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-019-0664-5