
Abstract
Background
Pseudouridylation is the most prevalent type of posttranscriptional modification in various stable RNAs of all organisms, which significantly affects many cellular processes that are regulated by RNA. Thus, accurate identification of pseudouridine (Ψ) sites in RNA will be of great benefit for understanding these cellular processes. Due to the low efficiency and high cost of current available experimental methods, it is highly desirable to develop computational methods for accurately and efficiently detecting Ψ sites in RNA sequences. However, the predictive accuracy of existing computational methods is not satisfactory and still needs improvement.
Results
In this study, we developed a new model, PseUI, for Ψ sites identification in three species, which are H. sapiens, S. cerevisiae, and M. musculus. Firstly, five different kinds of features including nucleotide composition (NC), dinucleotide composition (DC), pseudo dinucleotide composition (pseDNC), position-specific nucleotide propensity (PSNP), and position-specific dinucleotide propensity (PSDP) were generated based on RNA segments. Then, a sequential forward feature selection strategy was used to gain an effective feature subset with a compact representation but discriminative prediction power. Based on the selected feature subsets, we built our model by using a support vector machine (SVM). Finally, the generalization of our model was validated by both the jackknife test and independent validation tests on the benchmark datasets. The experimental results showed that our model is more accurate and stable than the previously published models. We have also provided a user-friendly web server for our model at http://zhulab.ahu.edu.cn/PseUI, and a brief instruction for the web server is provided in this paper. By using this instruction, the academic users can conveniently get their desired results without complicated calculations.
Conclusion
In this study, we proposed a new predictor, PseUI, to detect Ψ sites in RNA sequences. It is shown that our model outperformed the existing state-of-art models. It is expected that our model, PseUI, will become a useful tool for accurate identification of RNA Ψ sites.
Similar content being viewed by others


Background
Pseudouridylation, which occurs at the uridine site and is catalyzed by pseudouridine synthase (PUS), has been observed in various RNAs of all organisms [1,2,3,4]. As the most abundant posttranscriptional modification, pseudouridylation plays an important role in the structure, function and metabolism of RNAs [5,6,7,8,9]. Therefore, it is crucial to identify pseudouridylation information for revealing the biological principles.
Although some experimental techniques for identifying Ψ sites have been developed, they are both time-consuming and costly [10,11,12,13]. Facing the exponential-increasing of RNA sequences in the post-genomic era, it is urgent to have an accurate, efficient and low-cost method to identify Ψ sites on RNA segments. Former studies suggest that computational methods or statistical learning methods are promising candidates because of their low cost and reasonable efficiency [14, 15].
Unfortunately, to the best of our knowledge, only two computational methods have been developed to predict Ψ sites in RNAs. Li et al. [15] built a model called PPUS to predict the PUS-specific Ψ sites in H. sapiens and S. cerevisiae. This model employed support vector machine (SVM) as the classifier and used the nucleotides around Ψ as features. Besides this PPUS model, Chen et al. [14] developed another model called iRNA-PseU to identify Ψ sites in H. sapiens, S. cerevisiae, and M. musculus. This model was built by incorporating the chemical properties of nucleotides and their occurrence frequency density distributions into the general form of pseudo nucleotide composition (pseKNC) [14]. Despite the promising results offered by these two computational methods, it is suggested that the performance of computational methods can be further improved by introducing other effective features such as position-specific nucleotide propensity and position-specific dinucleotide propensity [16].
In this study, we have developed a new model, PseUI, for Ψ sites identification from RNA sequences in H. sapiens, S. cerevisiae, and M. musculus. Based on the RNA sequence segment, we first generated five different kinds of features including nucleotide composition (NC), dinucleotide composition (DC), pseudo dinucleotide composition (pseDNC), position-specific nucleotide propensity (PSNP), and position-specific dinucleotide propensity (PSDP). Then, we selected a relevant feature combination by using a sequential forward feature selection strategy [17, 18]. Based on the selected features, our model was built by using a support vector machine (SVM). Finally, the prediction results provided by our models for the three species, H. sapiens, S. cerevisiae, and M. musculus, were compared with iRNA-PseU’s results by using both jackknife tests and independent validation tests on the benchmark datasets, and it is convincing from the result of comparison that our model PseUI can offer more accurate identification of Ψ sites than iRNA-PseU.
To develop a really useful feature-based analysis method for a biological system as reported in a series of recent studies [19,20,21,22,23], one should observe the 5-step rule [24]: (i) construct or select a valid benchmark dataset to train and test the predictor; (ii) formulate the biological sequence samples with an effective mathematical expression that can truly reflect their intrinsic correlation with the target to be predicted; (iii) develop a powerful algorithm (or engine) to operate the prediction; (iv) perform cross-validation and independent tests properly to objectively evaluate the anticipated accuracy of the predictor; and (v) establish a user-friendly web-server for the predictor that is accessible to the public. Below, we are to describe how to deal with these steps one-by- one.
Methods
Benchmark datasets
Three benchmark datasets, H_990, S_628, and M_944, were used for training in this study, where H, S, and M represent for H. sapiens, S. cerevisiae, and M. musculus, respectively, and 990, 628, 944 are the number of examples in each dataset. These three datasets are the same as that were used in Chen et al.’s work [14]. In their work, they downloaded RNA sequences with experimentally validated Ψ sites of H. sapiens, M. musculus and S. cerevisiae from RMBase [25]. In addition, they collected the RNA segments with uridine at the center but not experimentally conformed as Ψ sites from genomes as negative samples. More details about how to construct these datasets can be found in the reference [14].
The positive subset of H_990, S_628, and M_944 contains 495, 314, and 472 RNA segments, respectively, and each of these RNA segments has a uridine at the center position that can be pseudouridylated. The negative subset is composed of 495, 314, and 472 RNA segments, respectively, and each of these RNA segments has a uridine at the center position that cannot be pseudouridylated.
We can formulate each RNA segment, denoted as Rξ(U), in these datasets as follow:
where the center U represents ‘uridine’, N-ξ represents the ξ-th upstream nucleotide from the central uridine and N+ξ represents the ξ-th downstream nucleotide.
The RNA samples in both of H_990 and M_944 are all composed of 21 nucleotides, while those in S_628 are composed of 31 nucleotides. Namely, the value of ξ is 10 and the RNA segment length is 2 × 10 + 1 for the datasets H_900 and M_944. The value of ξ is 15 and the RNA segment length is 2 × 15 + 1 for the dataset S_628.
Corresponding to the training datasets, Chen et al. [14] provided two independent testing datasets for H. sapiens and S. cerevisiae, i.e. H_200 and S_200, but not for M. musculus. The detailed sequence information for all the aforementioned datasets is given in Table 1; and the sequences of the five datasets can be found in Additional files 1, 2, 3, 4 and 5.
Feature representation of the RNA samples
One of the key problems in designing a predictor based on machine learning is how to encode an RNA sequence as a feature vector containing highly discriminative information. With the explosive growth of biological sequences in the post-genomic era, one of the most important but also most difficult problems in computational biology is how to represent a biological sequence with a discrete model or a vector, yet still keep considerable sequence-order information or key pattern characteristic. This is because all the existing machine-learning algorithms can only handle vectors with equal lengths for all sequence samples, as elucidated in a comprehensive review [26]. However, a vector defined in a discrete model may completely lose all the sequence-pattern information. To avoid completely losing the sequence-pattern information for proteins, the pseudo amino acid composition [27] or PseAAC [28] was proposed. Encouraged by the success of using PseAAC to represent protein/peptide sequences, the concept of PseKNC (Pseudo K-tuple Nucleotide Composition) [29] was developed for generating various feature vectors to represent DNA/RNA sequences. Particularly, recently a very powerful web-server called Pse-in-One [30] have been established that can be used to generate any desired feature vectors for protein/peptide and DNA/RNA sequences according to the need of users’ studies. In the current study, five types of features, nucleotide composition (NC) feature, dinucleotide composition (DC) feature, pseudo dinucleotide composition (pseDNC) feature, position-specific nucleotide propensity (PSNP) feature, and position-specific dinucleotide propensity (PSDP) feature, were proposed to encode the RNA segments for identifying pseudouridine sites in RNA. Three of them, NC, DC, and pseDNC, can also be generated by Pse-in-One server [30].
Nucleotide composition (NC) and dinucleotide composition (DC) feature
Nucleotide composition, a classic method for the characterization of nucleotide sequences, is widely used in previous studies [31,32,33]. Theoretically, a k-mer nucleotide composition for an RNA sequence is a 4kdimensional vector which is consisted of the frequency of each k-mer types. Thus, we can obtain 4 types of nucleotide frequencies and 16 types of dinucleotide frequencies when k is equal to 1 and 2, respectively. We called these two features as NC and DC, respectively, and a 4-dimensional NC feature vector and a 16-dimensional DC feature vector were generated for an RNA segment.
Pseudo dinucleotide composition (pseDNC) feature
The pseudo oligonucleotide composition, or pseudo K-tuple nucleotide composition (PseKNC) [34,35,36,37], can be used to represent an RNA sequence with a discrete model or vector. This type of pseudo composition can still keep considerable sequence order information, particularly the global or long-range sequence order information, via the physicochemical properties of its constituent oligonucleotides [38]. In this study, we choose the value of K to be 2, namely, using pseudo dinucleotide composition (pseDNC) feature to represent the information of RNA sequences. Three physicochemical properties, free energy, hydrophilicity, and stacking energy, were used to generate features of pseudo dinucleotide composition (pseDNC), which are listed in Table 2.
Position-specific nucleotide propensity (PSNP) and position-specific dinucleotide propensity (PSDP) feature
While position-specific amino acid preferences have been widely used in bioinformatics to predict functional site in biological sequences [39,40,41,42], the position-specific nucleotide preferences were first introduced in Li et al.’s paper [16], which were obtained by calculating the differences of the frequency of nucleotides in specific locations between positive and negative RNA segments.
For position-specific nucleotide propensity (PSNP) feature, according to the equation (1), the RNA segment can be reformulated as:
where Nj(j=1,2,...,2ξ+1) represents the nucleotide at the j-th position of the RNA segment, and can be any one of the 4 nucleotides, i.e., Nj ∈ {A, C, G, U}.
First, we calculated the frequency of occurrence at the j-th position for the 4 types of nucleotides from both the positive and negative samples, respectively. Then, we combined the 4-dimensional positive vectors and the 4-dimendional negative vectors individually. In this way, we obtained two 4× (2ξ + 1) position-specific occurrence frequency matrixes, i.e., Z+ and Z−, where Z+ was obtained from all the positive samples, and Z− was obtained from all the negative samples. Next, we defined the position-specific nucleotide propensity (PSNP) matrixes, denoted as ZPSNP, as below:
As for position-specific dinucleotide propensity (PSDP) feature, according to equation (2), the RNA segment can be rewritten in a dinucleotide form:
where Dj = NjNj + 1(j = 1, 2, …, 2ξ) represents the dinucleotide at the j-th position of the RNA segment, and can be any of 16 types of dinucleotides, i.e., Dj ∈ {AA, AC, AG, …, UU}.
Similarly, following the principle we used to generate the ZPSNP matrix, we can get the 16 × 2ξ position-specific dinucleotide propensity (PSDP) matrix. Both of the PSNP matrix and PSDP matrix can then be used to encode the new samples.
For the features encoded by PSNP and PSDP, we should pay particular attention to the fact that the propensity matrices (ZPSNP/ZPSDP) were only generated from the training samples without the one validation sample when evaluating the model using the jackknife test.
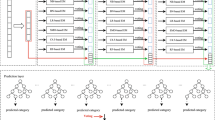
Figure 1 clearly described the jackknife cross validation for features encoded by PSNP/PSDP. The validation process has four steps: (1) Input the dataset (R), e.g., H_990, S_628, or M_944, which is assumed to have n samples. (2) Divide the dataset (R) into n subsets and each subset will contain only one sample. (3) One subset is selected as the validation set, and the rest are used as the training set. The samples of the training set will be used to calculate the frequency of nucleotides at specific locations, and the position specific propensity matrices (ZPSNP/ZPSDP) will be obtained and then used to encode the RNA segments in the training set and the validation set. In such way, the feature matrices RT(PSNP/PSDP) and RV(PSNP/PSDP) can be obtained to represent the statistical information extracted from the training set and the validation set, respectively. A model will be then built by SVM based on the training set, and evaluated on the validation set. The whole process will be repeated for n times and each time a different sample will be selected as the validation set. (4) Count the results from the previous steps and calculate the evaluation parameter, i.e., Sen, Spe, Acc, and MCC, which are described in “Evaluation parameter” section.

Flow charts of the jackknife cross validation for features encoded by PSNP or PSDP
Model construction
Support vector machine
As a popular statistical learning method, SVM has been extensively used to build bioinformatics models [43,44,45,46,47,48,49,50,51,52]. Both of the PPUS and iRNA-PseU models [14, 15] mentioned in the background section were built by using SVM due to its high efficiency and robust output. In this study, we used the Matlab function FITCSVM to build our models. Different kernel functions can be used in SVM training, and we selected the radial basis function in this study. Two parameters c and g were referred for the radial basis function, which were called box constraint and kernel scale in FITCSVM, respectively. Here, we optimized these two parameters based on the jackknife test using a grid search.
In statistical analysis fields, three different validation methods have mostly been used to evaluate the performance of a machine learning model: independent dataset test, subsampling (or K-fold cross-validation) test, and jackknife test [53]. The jackknife test has already proved its effectiveness in many aspects [54, 55]. It is not affected by the random partition of the samples, and the final result is unique. In addition, the training set used by the jackknife test is only one sample less than the initial training set. Therefore, in most cases, the actual model evaluated by the jackknife test is very close to the expected model, which will offer more accurate results. Based on all these advantages, the jackknife test was used to evaluate the performance of our models.
Evaluation parameters
In recent studies, four evaluation parameters, Accuracy (Acc), Sensitivity (Sen), Specificity (Spe), and the Matthews correlation coefficient (MCC) have been frequently used to measure the predictor’s quality [46, 56]. The original formulas of the four parameters, particularly the MCC, are lacking intuitiveness and not easy to understand for most biologists. To make the most readers easy to understand, we here introduced the Chou’s intuitive formulas of the four parameters, as elaborated by the four sub-equations in Eq. 19 of [57], or the four sub-equations in Eq. 14 of [58]. Particularly, the advantages of Chou’s intuitive metrics have been analyzed and concurred by a series of studies published very recently [19, 20, 22, 59, 60]. The Chou’s intuitive metrics are formulated as below:
Where N+ represents the total number of positive RNA samples; N− represents the total number of negative RNA samples; \( {N}_{-}^{+} \) represents the number of positive RNA samples that are incorrectly predicted as negative RNA samples; \( {N}_{+}^{-} \) represents the number of negative RNA samples that are incorrectly predicted as positive RNA samples. In addition, it should be noted that the set of metrics in eq. (5) is only valid for the single-label systems (in which each sample only belongs to one class). For the multi-label systems (in which a sample might belong to several classes), whose existence has become more frequent in system biology [61] and system medicine [20] and biomedicine [60], a completely different set of metrics as defined in [62] is needed.
Feature selection
In this study, we generated five types of features which composed a high dimensional feature vector for each sample. In order to obtain a more compact and effective feature subset, we conducted a sequential forward feature selection (SFS) [17, 18] process on the original features, which is described as follows:
In the first round, the performance metrics of each of the five types of features were calculated based on the jackknife test using a specific prediction engine, respectively. According to Acc or MCC, the best type of feature was selected to enter the next round of calculation. In the second round, the remaining four types of features were added to the type of feature selected by the first round. Similarly, according to Acc or MCC, the best combination of features was selected to enter the next round of calculation. This process continued to run until the Acc or MCC converged. The subset obtained with the highest Acc or MCC value will be regarded as the optimal feature subset.
Results and discussion
Performance of single type of feature
In this section, we evaluated the performance of each type of features using SVM over the rigorous jackknife test, and the feature PSNP was found to be particularly excellent for identifying Ψ sites. The performance of each evaluation index for the three species, i.e., H. sapiens, S. cerevisiae, and M. musculus, were listed in Tables 3, 4, and 5, respectively.
In addition, the receiver operating characteristic (ROC) curves [63] were employed to show the results more clearly. On the ROC curve, the diagonal line from point (0, 0) to (1, 1) corresponds to the random guessing model, and the point (0, 1) corresponds to the ideal model with no positive example wrongly predicted. When comparing models, if the ROC curve of one model is completely enveloped by the curve of the other model, it can be asserted that the latter model is superior to the former in performance. However, it is difficult to judge when the ROC curves of two models cross. In this situation, the area under the ROC curve (AUC) will be used as the more reasonable criteria for comparing model performance, and the lager AUC indicates better performance. The ROC curves of the five types of feature for each species were plotted in Fig. 2, together with the AUC values.

The ROC curves that show the performances of the five type of features for H.sapiens, S.cerevisiae, and M.musculus, respectively
As shown in Fig. 2, the AUC values of PSNP are 0.6569, 0.6441, and 0.7443 for H. sapiens, S. cerevisiae, and M. musculus, respectively. For H. sapiens and M. musculus, the AUC values of PSNP are much higher than those of the other four types of features. For S. cerevisiae, the AUC value of PSNP is only 0.0077 lower than the highest AUC value 0.6518 given by DC. Moreover, the accuracy was improved from 62.10 to 64.49% when PSNP was added in the second round of SFS for S. cerevisiae, which was shown in Table 4. These results all indicate that PSNP offered the best performance among these five types of features and the addition of PSNP provided a great possibility of improving the model performance, which may lay the foundation for our future works.
Feature subsets selected by SFS
For the selection of feature subset with SFS described in the “Feature selection” section, we run three rounds of calculation for the datasets H_990 and M_944, respectively. Finally, the subset that made up of DC and PSNP features was chosen as the optimal feature subset. The results of each round for H. sapiens and M. musculus are shown in Tables 3 and 5, respectively. For both H. sapiens and M. musculus, the best models were built based on the feature subset PSNP+DC.
For the dataset S_628, four rounds of calculation were conducted, and the subset with a combination of DC, pseDNC, and PSNP, was selected as the optimal feature subset. The results of each round are listed in Table 4. The best model of S. cerevisiae is built based on the feature subset DC + PSNP+pseDNC.
Comparison with existing methods
In this section, we compared our model PseUI with the latest model iRNA-PseU [14] by using two validation methods (i.e., the jackknife cross validation and independent tests) to confirm the predictability of our model.
Unfortunately, after a careful study of Chen et al.’s article [14], we found that some of the results reported by the authors were not reasonable. For example, the values of Sen (Sensitivity) and Spe (Specificity) for S. cerevisiae using the jackknife cross validation were 64.65 and 64.33% (see Table 6). However, according to the ROC curve in Chen et al.’s paper [14], the value of “1-Specificity” is estimated to be approximately 0.24, thus the “Specificity” value should be approximately 0.76, when “Sensitivity” is 0.6465. This “specificity” value (0.76) is significantly different from the aforementioned “specificity” value (64.33%). Besides this big discrepancy in “specificity” values, the optimized parameters g and c were not reported in the paper.
To have a more accurate comparison with Chen et al.’s method, we wrote our programs in strict accordance with the description of their paper to re-implement iRNA-PseU. The software LIBSVM-3.22 was used to train the SVM models. To obtain the best performance of the jackknife cross validation, we used a grid search to optimize the SVM parameter g from 2− 15 to 2− 5 and parameter c from 2− 5 to 215 with a step of 2. Finally, the parameters g and c were set at 0.01562 and 2 for H. sapiens, 0.0003 and 32,768 for S. cerevisiae, and 0.00098 and 4 for M. musculus, respectively.
Then, we compared the proposed PseUI with the re-implemented iRNA-PseU (named re-iRNA-PseU) by using the jackknife cross validation. The comparison results for the three training datasets, i.e., H_990, S_628, and M_944, were listed in Table 6, and the ROC curves of PseUI were shown in Fig. 3. As shown in Table 6, both Acc and MCC obtained by PseUI are higher than those obtained by re-iRNA-PseU. For Acc, improvements of 2.32%, 0.95%, and 0.10% were observed for H_990, S_628, and M_944, respectively, and for MCC, improvements of 4 and 2% were observed for H_990 and S_628. In addition, as shown in Fig. 3, the AUC values of PseUI are 0.68 and 0.77, which are 0.03 and 0.02 higher than the corresponding AUC values of re-iRNA-PseU for H. sapiens and M. musculus, respectively. These findings confirmed that the PseUI outperformed the re-iRNA-PseU in both accuracy and stability for identifying Ψ sites. Note that the re-iRNA-PseU is superior to iRNA-PseU according to the evaluation metrics shown in Table 6.

The ROC curves of the best models for H.sapiens, S.cerevisiae, and M.musculus, respectively
Next, we compared our models PseUI with the re-iRNA-PseU on the independent datasets. In this study, independent datasets are only available for the species of H. sapiens and S. cerevisiae (i.e., H_200 and S_200), so the comparison was only conducted on these two datasets. The results were listed in Table 7.
As shown in Table 7, the predictive Accs of H_200 and S_200 are 65.50 and 68.50%, which are similar to the corresponding cross validation Accs on the training datasets. This means that our model is stable and has good generalization ability for predicting Ψ sites. When compared with re-iRNA-PseU, the proposed PseUI model showed improvements of 4 and 8.5% of the Accs values on the two independent test sets, respectively. As for MCC, PseUI outperformed re-iRNA-PseU with improvements of 0.08 and 0.17 for H_200 and S_200, respectively. All these results confirmed that our proposed model PseUI is superior to re-iRNA-PseU.
Web implementation
As demonstrated in a series of recent publications [58, 61, 64,65,66,67,68,69,70,71,72,73,74,75], user-friendly and publicly accessible web-servers or source codes represent the future direction for developing practically more useful analysis methods and computational tools. Actually, many practically useful web-servers have significant impacts on medical science [26], driving medicinal chemistry into an unprecedented revolution [76]. For the convenience of academic users, we did the same and established a user-friendly and publicly accessible web server for PseUI, which is freely accessible at http://zhulab.ahu.edu.cn/PseUI. Users can easily get their desired results without complicated mathematic calculations. The final online PseUI method was trained on H_990, S_628, and M_944, which are composed of 21, 31, and 21 nucleotides, respectively. The detailed procedure to predict Ψ sites by using PseUI method is as follows:
Firstly, a query RNA sequence is submitted and the RNA sequence should be longer than 21 bp for H.sapiens and M.musculus or longer than 31 bp for S.cerevisiae in FASTA format. Secondly, PseUI identifies each uridine site in the query RNA sequence, and a corresponding 21-nt RNA segment for H.sapiens and M.musculus or 31-nt RNA segment for S.cerevisiae is constructed by placing a sliding window centered on the uridine site. Thirdly, according to the reconstructed RNA segment, the vector for the statistical information of the sequence is extracted by the features, and then submitted to the SVM classification engine for prediction. Finally, the users can get the result they desired. Please notice that the reconstructed RNA segment for unequal number of nucleotides around the target uridine is filled with its mirror image [47].
Conclusion
In this study, we proposed a model, PseUI, for accurate and efficient identification of Ψ sites in RNA sequences. We compared our model PseUI with the latest Ψ site identification model iRNA-PseU [14] by using two different methods, jackknife cross validation and independent tests. The results showed that our model is more accurate and stable than iRNA-PseU. In addition, the performances of the five types of features used in this study were systematically evaluated and compared, and the feature of PSNP was found to show the best performance. To facilitate the use of our model, a web server was built at http://zhulab.ahu.edu.cn/PseUI, which allows the academic users to easily use our model to predict the Ψ sites in RNA sequences.
Abbreviations
- DC:
-
Dinucleotide Composition
- NC:
-
Nucleotide Composition
- PSDP:
-
Position-Specific Dinucleotide Preferences
- PSNP:
-
Position-Specific Nucleotide Preferences
- PUS:
-
Pseudouridine Synthase
- SFS:
-
Sequential Forward Selection
- SVM:
-
Support Vector Machine
References
Cantara WA, Crain PF, Rozenski J, Mccloskey JA, Harris KA, Zhang X, Vendeix FA, Fabris D, Agris PF. The RNA modification database, RNAMDB: 2011 update. Nucleic Acids Res. 2011;39(Database issue):D195.
Duninhorkawicz S, Czerwoniec A, Gajda MJ, Feder M, Grosjean H, Bujnicki JM. MODOMICS: a database of RNA modification pathways. Nucleic Acids Res. 2006;34(Database issue):D145.
Behmansmant I, Urban A, Ma X, Yu YT, Motorin Y, Branlant C. The Saccharomyces cerevisiae U2 snRNA:pseudouridine-synthase Pus7p is a novel multisite-multisubstrate RNA:psi-synthase also acting on tRNAs. Rna-a Publication of the Rna Society. 2003;9(11):1371.
Bousquet-Antonelli C, Henry Y, Gélugne JP, Caizergues-Ferrer M, Kiss T. A small nucleolar RNP protein is required for pseudouridylation of eukaryotic ribosomal RNAs. EMBO J. 1997;16(15):4770–6.
Junhui Y, Tao Y. RNA pseudouridylation: new insights into an old modification. Trends Biochem Sci. 2013;38(4):210.
Grosjean H. DNA and RNA modification enzymes: Structure, Mechanism, Function and Evolution. Austin: Landes Biosciences; 2009.
Ofengand J, Fournier MJ: The pseudouridine residues of rRNA: Number, location, biosynthesis, and function. 1998.
Ma X, Zhao X, Yu YT. Pseudouridylation (Ψ) of U2 snRNA in S.Cerevisiae is catalyzed by an RNA-independent mechanism. EMBO J. 2003;22(8):1889.
Newby MI, Greenbaum NL. A conserved pseudouridine modification in eukaryotic U2 snRNA induces a change in branch-site architecture. Rna-a Publication of the Rna Society. 2001;7(6):833–45.
Carlile TM, Rojasduran MF, Zinshteyn B, Shin H, Bartoli KM, Gilbert WV. Pseudouridine profiling reveals regulated mRNA pseudouridylation in yeast and human cells. Nature. 2014;515(7525):143–6.
Lovejoy AF, Riordan DP, Brown PO. Transcriptome-wide mapping of Pseudouridines: Pseudouridine synthases modify specific mRNAs in S. Cerevisiae. PLoS One. 2014;9(10):e110799.
Schwartz S, Bernstein DA, Mumbach MR, Jovanovic M, Herbst RH, Leónricardo BX, Engreitz JM, Guttman M, Satija R, Lander ES. Transcriptome-wide mapping reveals widespread dynamic regulated pseudouridylation of ncRNA and mRNA. Cell. 2014;159(1):148.
Li X, Zhu P, Ma S, Song J, Bai J, Sun F, Yi C. Chemical pulldown reveals dynamic pseudouridylation of the mammalian transcriptome. Nat Chem Biol. 2015;11(8):592.
Wei C, Hua T, Jing Y, Hao L, Chou KC. iRNA-PseU: identifying RNA pseudouridine sites. Mol Ther Nucleic Acids. 2016;5(7):e332.
Li YH, Zhang G, Cui Q. PPUS: a web server to predict PUS-specific pseudouridine sites. Bioinformatics. 2015;31(20):3362–4.
Li GQ, Liu Z, Shen HB, Yu DJ: TargetM6A: identifying N6-methyladenosine sites from RNA sequences via position-specific nucleotide propensities and a support vector machine. IEEE Transactions on Nanobioscience 2016, PP(99):1–1.
Ververidis D, Kotropoulos C. Sequential forward feature selection with low computational cost. In: Signal processing conference, 2005 European; 2010. p. 1–4.
Wang L, Shen C, Hartley R. On the optimality of sequential forward feature selection using class Separability measure. In: International conference on digital image computing techniques and applications; 2012. p. 203–8.
Jia J, Liu Z, Xiao X, Liu B, Chou KC. iPPI-Esml: an ensemble classifier for identifying the interactions of proteins by incorporating their physicochemical properties and wavelet transforms into PseAAC. J Theor Biol. 2015;377:47–56.
Cheng X, Zhao SG, Xiao X, Chou KC. iATC-mISF: a multi-label classifier for predicting the classes of anatomical therapeutic chemicals. Bioinformatics. 2017;33(3):341–6.
Feng P, Ding H, Yang H, Chen W, Lin H, Chou KC. iRNA-PseColl: identifying the occurrence sites of different RNA modifications by incorporating collective effects of nucleotides into PseKNC. Mol Ther Nucleic Acids. 2017;7:155–63.
Liu B, Wang S, Long R, Chou KC. iRSpot-EL: identify recombination spots with an ensemble learning approach. Bioinformatics. 2017;33(1):35–41.
Xu Q, Xiong Y, Dai H, Kumari KM, Xu Q, Ou HY, Wei DQ. PDC-SGB: prediction of effective drug combinations using a stochastic gradient boosting algorithm. J Theor Biol. 2017;417:1–7.
Chou KC. Some remarks on protein attribute prediction and pseudo amino acid composition. J Theor Biol. 2011;273(1):236–47.
Sun WJ, Li JH, Liu S, Wu J, Zhou H, Qu LH, Yang JH. RMBase: a resource for decoding the landscape of RNA modifications from high-throughput sequencing data. Nucleic Acids Res. 2016;44(Database issue):D259–65.
Chou KC. Impacts of bioinformatics to medicinal chemistry. Med Chem. 2015;11(3):218–34.
Chou KC. Prediction of protein cellular attributes using pseudo-amino acid composition. Proteins. 2001;43(3):246–55.
Chou KC. Using amphiphilic pseudo amino acid composition to predict enzyme subfamily classes. Bioinformatics. 2005;21(1):10–9.
Chen W, Lin H, Chou KC. Pseudo nucleotide composition or PseKNC: an effective formulation for analyzing genomic sequences. Mol BioSyst. 2015;11(10):2620–34.
Liu B, Liu F, Wang X, Chen J, Fang L, Chou KC. Pse-in-one: a web server for generating various modes of pseudo components of DNA, RNA, and protein sequences. Nucleic Acids Res. 2015;43(W1):W65–71.
Brayet J, Zehraoui F, Jeansonleh L, Israeli D, Tahi F. Towards a piRNA prediction using multiple kernel fusion and support vector machine. Bioinformatics. 2014;30(17):i364.
Kamil E, Hashim M, Rosni A. Rare k-mer DNA: identification of sequence motifs and prediction of CpG Island and promoter. J Theor Biol. 2015;387:88–100.
Vinje H, Liland KH, Almøy T, Snipen L. Comparing K-mer based methods for improved classification of 16S sequences. BMC Bioinformatics. 2015;16(1):205.
Feng P, Ding H, Chen W, Lin H. Identifying RNA 5-methylcytosine sites via pseudo nucleotide compositions. Mol BioSyst. 2016;12(11):3307.
Feng P, Jiang N, Liu N. Prediction of DNase I hypersensitive sites by using Pseudo nucleotide compositions. Thescientificworldjournal. 2014;2014:11):740506.
Liu B, Fang L, Long R, Lan X, Chou KC. iEnhancer-2L: a two-layer predictor for identifying enhancers and their strength by pseudo k-tuple nucleotide composition. Bioinformatics. 2016;32(3):362.
Chen W, Zhang X, Brooker J, Lin H, Zhang L, Chou KC. PseKNC-general: a cross-platform package for generating various modes of pseudo nucleotide compositions. Bioinformatics. 2015;31(1):119–20.
Chen W, Lei TY, Jin DC, Lin H, Chou KC. PseKNC: a flexible web server for generating pseudo K-tuple nucleotide composition. Anal Biochem. 2014;456(1):53.
Tang YR, Chen YZ, Canchaya CA, Zhang Z. GANNPhos: a new phosphorylation site predictor based on a genetic algorithm integrated neural network. Protein Engineering Design & Selection Peds. 2007;20(8):405–12.
Thangakani AM, Kumar S, Nagarajan R, Velmurugan D, Gromiha MM. GAP: towards almost 100 percent prediction for β-strand-mediated aggregating peptides with distinct morphologies. Bioinformatics. 2014;30(14):1983–90.
Xu Y, Ding YX, Ding J, Wu LY, Deng NY. Phogly–PseAAC: prediction of lysine phosphoglycerylation in proteins incorporating with position-specific propensity. J Theor Biol. 2015;379:10–5.
Chou KC. A vectorized sequence-coupling model for predicting HIV protease cleavage sites in proteins. J Biol Chem. 1993;268(23):16938–48.
Zhu X, Mitchell JC. KFC2: a knowledge-based hot spot prediction method based on interface solvation, atomic density, and plasticity features. Proteins. 2011;79(9):2671–83.
Xiong Y, Liu J, Wei DQ. An accurate feature-based method for identifying DNA-binding residues on protein surfaces. Proteins. 2011;79(2):509–17.
Liu Z, Xiao X, Qiu WR, Chou KC. iDNA-methyl: identifying DNA methylation sites via pseudo trinucleotide composition. Anal Biochem. 2015;474:69.
Wei C, Hui D, Feng P, Hao L, Chou KC. iACP: a sequence-based tool for identifying anticancer peptides. Oncotarget. 2016;7(13):16895.
Chen W, Feng P, Ding H, Lin H, Chou KC. iRNA-methyl: identifying N(6)-methyladenosine sites using pseudo nucleotide composition. Anal Biochem. 2015;490:26.
Liu Z, Xiao X, Yu DJ, Jia J, Qiu WR, Chou KC. pRNAm-PC: predicting N(6)-methyladenosine sites in RNA sequences via physical-chemical properties. Anal Biochem. 2015;497:60–7.
Shao J, Dong X, Sau-Na T, Wang Y, Sai-Ming N. Computational identification of protein methylation sites through bi-profile Bayes feature extraction. PLoS One. 2009;4(3):e4920.
Song J, Tan H, Shen H, Mahmood K, Boyd SE, Webb GI, Akutsu T, Whisstock JC. Cascleave: towards more accurate prediction of caspase substrate cleavage sites. Bioinformatics. 2010;26(6):752–60.
Jia C, Liu T, Chang AK, Zhai Y. Prediction of mitochondrial proteins of malaria parasite using bi-profile Bayes feature extraction. Biochimie. 2011;93(4):778.
Wang Y, Zhang Q, Sun MA, Guo D. High-accuracy prediction of bacterial type III secreted effectors based on position-specific amino acid composition profiles. Bioinformatics. 2011;27(6):777.
Chou KC, Zhang CT. Prediction of protein structural classes. Crc Critical Reviews in Biochemistry. 1995;30(4):275–349.
Rodgers JL. The bootstrap, the jackknife, and the randomization test: a sampling taxonomy. Multivar Behav Res. 1999;34(4):441.
Dalgleish LI. Discriminant analysis: statistical inference using the jackknife and bootstrap procedures. Psychol Bull. 1994;116(3):498–508.
Chou KC. Using subsite coupling to predict signal peptides. Protein Eng. 2001;14(2):75.
Xu Y, Shao XJ, Wu LY, Deng NY, Chou KC. iSNO-AAPair: incorporating amino acid pairwise coupling into PseAAC for predicting cysteine S-nitrosylation sites in proteins. PeerJ. 2013;1:e171.
Chen W, Feng PM, Lin H, Chou KC. iRSpot-PseDNC: identify recombination spots with pseudo dinucleotide composition. Nucleic Acids Res. 2013;41(6):e68.
Liu B, Long R, Chou KC. iDHS-EL: identifying DNase I hypersensitive sites by fusing three different modes of pseudo nucleotide composition into an ensemble learning framework. Bioinformatics. 2016;32(16):2411–8.
Qiu WR, Sun BQ, Xiao X, Xu ZC, Chou KC. iPTM-mLys: identifying multiple lysine PTM sites and their different types. Bioinformatics. 2016;32(20):3116–23.
Cheng X, Zhao SG, Lin WZ, Xiao X, Chou KC. pLoc-mAnimal: predict subcellular localization of animal proteins with both single and multiple sites. Bioinformatics. 2017;33(22):3524.
Chou KC. Some remarks on predicting multi-label attributes in molecular biosystems. Mol BioSyst. 2013;9(6):1092–100.
Fawcett T. An introduction to ROC analysis. Pattern Recogn Lett. 2006;27(8):861–74.
Lin H, Deng EZ, Ding H, Chen W, Chou KC. iPro54-PseKNC: a sequence-based predictor for identifying sigma-54 promoters in prokaryote with pseudo k-tuple nucleotide composition. Nucleic Acids Res. 2014;42(21):12961–72.
Wang J, Yang B, Revote J, Leier A, Marquez-Lago TT, Webb G, Song J, Chou KC, Lithgow T. POSSUM: a bioinformatics toolkit for generating numerical sequence feature descriptors based on PSSM profiles. Bioinformatics. 2017;33(17):2756–8.
Song J, Li F, Leier A, Marquez-Lago TT, Akutsu T, Haffari G, Chou KC, Webb GI, Pike RN, Hancock J. PROSPERous: high-throughput prediction of substrate cleavage sites for 90 proteases with improved accuracy. Bioinformatics. 2018;34(4):684–7.
Cheng X, Xiao X, Chou KC. pLoc-mHum: predict subcellular localization of multi-location human proteins via general PseAAC to winnow out the crucial GO information. Bioinformatics. 2018;34(9):1448–56.
Noutahi E, Calderon V, Blanchette M, Lang FB, El-Mabrouk N. CoreTracker: accurate codon reassignment prediction, applied to mitochondrial genomes. Bioinformatics. 2017;33(21):3331–9.
Leclercq M, Diallo AB, Blanchette M. Prediction of human miRNA target genes using computationally reconstructed ancestral mammalian sequences. Nucleic Acids Res. 2017;45(2):556–66.
Cingolani P, Sladek R, Blanchette M. BigDataScript: a scripting language for data pipelines. Bioinformatics. 2015;31(1):10–6.
Qiao Y, Xiong Y, Gao H, Zhu X, Chen P. Protein-protein interface hot spots prediction based on a hybrid feature selection strategy. BMC Bioinformatics. 2018;19(1):14.
Yuan Q, Gao J, Wu D, Zhang S, Mamitsuka H, Zhu S. DrugE-rank: improving drug-target interaction prediction of new candidate drugs or targets by ensemble learning to rank. Bioinformatics. 2016;32(12):i18–27.
Sukumar S, Zhu X, Ericksen SS, Mitchell JC. DBSI server: DNA binding site identifier. Bioinformatics. 2016;32(18):2853–5.
Zhu X, Xiong Y, Kihara D. Large-scale binding ligand prediction by improved patch-based method patch-Surfer2.0. Bioinformatics. 2015;31(5):707–13.
Zhu X, Ericksen SS, Mitchell JC. DBSI: DNA-binding site identifier. Nucleic Acids Res. 2013;41(16):e160.
Chou KC. An unprecedented revolution in medicinal chemistry driven by the progress of biological science. Curr Top Med Chem. 2017;17(21):2337–58.
Acknowledgements
The authors thank the editor and two anonymous reviewers for their valuable comments on significantly improving this paper. They also would like to thank Tianle Wu for assistance on manuscript preparation and revision.
Funding
This work was supported by National Natural Science Foundation of China (21403002, 31601074). The fundings had no role in the design of the study and collection, analysis, and interpretation of data and writing the manuscript.
Availability of data and materials
All data generated or analyzed during this study are included in this published article or the Additional files.
Author information
Authors and Affiliations
Contributions
Conceived the study: XZ, YX. Designed the study: JH, XZ. Participate designed the study: YX, TF, BH. Analyzed the data: JH, TF, YX. Website building: ZZ, XZ. Wrote the paper: JH, XZ, YX, BH. All authors read and approved the manuscript.
Corresponding authors
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional files
Additional file 1:
The benchmark dataset H_990 for H.sapiens. The benchmark dataset H_990, S_628, and M_944 is formed by 495, 314 and 472 Ψ-site-containing sequences and 495, 314 and 472 false Ψ-site-containing sequences, respectively. Both H_200 and S_200 are formed by 100 Ψ-site-containing sequences and 100 false Ψ-site-containing sequences, and none of the samples included here occur in the corresponding benchmark datasets. Each of these samples for H.sapiens and M.musculus is 21-bp long with the uridine located at the center, and each of these samples for S.cerevisiae is 31-bp long with the uridine located at the center. None of the sequences included here has ≥60% pairwise sequence identity to any other in a same subset. (DOCX 56 kb)
Additional file 2:
The benchmark dataset S_628 for S.cerevisiae. The benchmark dataset H_990, S_628, and M_944 is formed by 495, 314 and 472 Ψ-site-containing sequences and 495, 314 and 472 false Ψ-site-containing sequences, respectively. Both H_200 and S_200 are formed by 100 Ψ-site-containing sequences and 100 false Ψ-site-containing sequences, and none of the samples included here occur in the corresponding benchmark datasets. Each of these samples for H.sapiens and M.musculus is 21-bp long with the uridine located at the center, and each of these samples for S.cerevisiae is 31-bp long with the uridine located at the center. None of the sequences included here has ≥60% pairwise sequence identity to any other in a same subset. (DOCX 45 kb)
Additional file 3:
The benchmark dataset M_944 for M.musculus. The benchmark dataset H_990, S_628, and M_944 is formed by 495, 314 and 472 Ψ-site-containing sequences and 495, 314 and 472 false Ψ-site-containing sequences, respectively. Both H_200 and S_200 are formed by 100 Ψ-site-containing sequences and 100 false Ψ-site-containing sequences, and none of the samples included here occur in the corresponding benchmark datasets. Each of these samples for H.sapiens and M.musculus is 21-bp long with the uridine located at the center, and each of these samples for S.cerevisiae is 31-bp long with the uridine located at the center. None of the sequences included here has ≥60% pairwise sequence identity to any other in a same subset. (DOCX 54 kb)
Additional file 4:
The independent dataset H_200 for H.sapiens. The benchmark dataset H_990, S_628, and M_944 is formed by 495, 314 and 472 Ψ-site-containing sequences and 495, 314 and 472 false Ψ-site-containing sequences, respectively. Both H_200 and S_200 are formed by 100 Ψ-site-containing sequences and 100 false Ψ-site-containing sequences, and none of the samples included here occur in the corresponding benchmark datasets. Each of these samples for H.sapiens and M.musculus is 21-bp long with the uridine located at the center, and each of these samples for S.cerevisiae is 31-bp long with the uridine located at the center. None of the sequences included here has ≥60% pairwise sequence identity to any other in a same subset. (DOCX 26 kb)
Additional file 5:
The independent dataset S_200 for S.cerevisiae. The benchmark dataset H_990, S_628, and M_944 is formed by 495, 314 and 472 Ψ-site-containing sequences and 495, 314 and 472 false Ψ-site-containing sequences, respectively. Both H_200 and S_200 are formed by 100 Ψ-site-containing sequences and 100 false Ψ-site-containing sequences, and none of the samples included here occur in the corresponding benchmark datasets. Each of these samples for H.sapiens and M.musculus is 21-bp long with the uridine located at the center, and each of these samples for S.cerevisiae is 31-bp long with the uridine located at the center. None of the sequences included here has ≥60% pairwise sequence identity to any other in a same subset. (DOCX 25 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
He, J., Fang, T., Zhang, Z. et al. PseUI: Pseudouridine sites identification based on RNA sequence information. BMC Bioinformatics 19, 306 (2018). https://doi.org/10.1186/s12859-018-2321-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12859-018-2321-0