
Abstract
IceCube is a neutrino observatory deployed in the glacial ice at the geographic South Pole. The \(\nu _\mu \) energy unfolding described in this paper is based on data taken with IceCube in its 79-string configuration. A sample of muon neutrino charged-current interactions with a purity of 99.5% was selected by means of a multivariate classification process based on machine learning. The subsequent unfolding was performed using the software Truee. The resulting spectrum covers an E\(_\nu \)-range of more than four orders of magnitude from 125 GeV to 3.2 PeV. Compared to the Honda atmospheric neutrino flux model, the energy spectrum shows an excess of more than \(1.9\,\sigma \) in four adjacent bins for neutrino energies \(E_\nu \ge 177.8\,\text {TeV}\). The obtained spectrum is fully compatible with previous measurements of the atmospheric neutrino flux and recent IceCube measurements of a flux of high-energy astrophysical neutrinos.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
The neutrino flux, which can be observed with instruments such as IceCube, has its origin both in cosmic ray air showers (atmospheric neutrinos) [1,2,3] and extraterrestrial sources [4,5,6,7]. These different components can be modeled separately and fitted to data, with the atmospheric component dominating up to energies of approximately \(300\,\text {TeV}\). Such fits, however, require assumptions on the spectral shape. An extraction of the energy spectrum from experimental data is more model-independent, as no assumption on the cosmic ray composition or spectral shape is required. It thus poses an alternative to fitting model parameters and allows a direct comparison to theoretical model predictions.
This paper presents a measurement of the muon neutrino energy spectrum with IceCube during its deployment phase in the 79-string configuration (IC79). The spectrum was obtained from a highly pure sample of neutrino candidates by means of regularized unfolding.
1.1 The IceCube detector
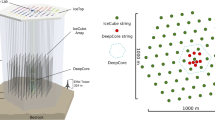
The IceCube detector, located at the geographic South Pole, is a neutrino observatory with an instrumented volume of \(1~\hbox {km}^3\) [8]. It consists of 5160 digital optical modules (DOMs) deployed on 86 strings at depths between \(1450\,\text {m}\) and \(2450\,\text {m}\). The strings are arranged in a hexagonal array, with a string-to-string distance of \(125\,\text {m}\). The 86 strings include the low-energy extension DeepCore [9], which has a string spacing of approximately \(70\,\text {m}\) and a vertical DOM distance of \(7~\text {m}\). It is optimized for low energies and reduces the energy threshold of the entire detector to \(E_{\text {th}}\sim 10\,\text {GeV}\) [9].
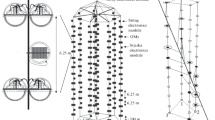
Each DOM consists of a glass sphere of \(35.6\,\text {cm}\) diameter, which houses a \(25~\text {cm}\) Hamamatsu R7081-02 photomultiplier tube (PMT) and a suite of electronics board assemblies. Internal digitizing and time-stamping the photonic signals ensures high accuracy and a wide dynamic range of the DOMs. Packaged digitized data is then transmitted to the IceCube Laboratory (ICL) at the South Pole. Each DOM can operate as a complete and autonomous data acquisition system [8, 10]. The air shower array IceTop complements the detector [11].
As neutrinos cannot be observed directly, they are detected via secondary particles produced in the interactions of neutrinos with nuclei in the ice or the bedrock. These secondary particles induce the emission of Cherenkov light, which is recorded by the DOMs. The majority of the events observed with IceCube are track-like events, which originate from muons propagating through the detector. These muons are either produced in charged current (CC) neutrino-nucleon interactions or in cosmic ray air showers. The second most frequent signature are cascade-like events, originating from CC interactions of \(\nu _{e}\) and \(\nu _{\tau }\), where the second cascade, resulting from the decay of the emerging \(\tau \)-lepton, cannot be experimentally resolved. Cascade-like events further originate from neutral-current (NC) interactions of neutrinos of all flavors within the instrumented volume.
1.2 Atmospheric muon neutrinos
The atmospheric muon neutrino flux is expected to consist of two components distinguished by the lifetime of their hadronic parent particles. Conventional atmospheric muon neutrinos originate from the decay of charged pions and kaons in cosmic ray air showers. Due to their relatively long lifetime (\(\tau \sim 10^{-8}\,\text {s}\) [12]), kaons and pions interact prior to decaying. This results in a flux of approximately \(\frac{\mathrm {d}\Phi }{\mathrm {d}E} \propto E^{-3.7}\).
The second, much rarer component, consisting of prompt atmospheric neutrinos, originates from the decay of charmed particles such as D mesons and \(\Lambda _{\text {c}}^+\) baryons. Due to their short lifetime (\(\tau \sim 10^{-12}\,\text {s}\) [12]), these hadrons decay before interacting. Prompt atmospheric neutrinos inherit the spectral index of the cosmic ray flux directly, resulting in a flux of \(\frac{\mathrm {d}\Phi }{\mathrm {d}E} \propto E^{-2.7}\). The conventional component is the dominant component to the flux of atmospheric neutrinos up to energies of \(E_{\nu } \sim 300\,\text {TeV}\) [13]. The prompt component has not been observed so far and the exact threshold depends strongly on the underlying theoretical model.
The atmospheric \(\nu _{\mu }\) energy spectrum has been measured by various experiments, including AMANDA [1], Fréjus [14] and ANTARES [15], as well as IceCube in the 40- [2] and 59-string configuration [3].
An additional contribution to the overall flux is expected to arise from a flux of astrophysical neutrinos [16]. This flux has recently been discovered by IceCube [5, 17]. Its sources are still unknown. The spectral index of the astrophysical component is expected to be approximately \(\gamma =2.0\) for the simplest assumption of Fermi acceleration [4]. Recent measurements by IceCube obtained indices between \(\gamma =2.13\pm 0.13\) [18] and \(\gamma =2.50^{+0.08}_{-0.09}\) [7].
A major challenge in the measurement of muon neutrinos is the background of atmospheric muons. Although muons and muon neutrinos are produced at approximately the same rate, the rate of triggering atmospheric muons is \(\sim 10^6\) times higher, due to the small cross sections of neutrino-nucleon interactions.
The application of a Random Forest-based analysis chain for IC59 presented in [3] resulted in a high statistics sample of 66,865 atmospheric neutrino candidates with an estimated background contribution of \(330\pm 200\) background events. Averaging these numbers, one obtains an event rate of \(9.3 \times 10^{-4}\) neutrino candidates per second at an average background event rate of \((3.8\pm 3.4) \times 10^{-6}\) events per second. The separation process presented here is based on the approach presented in [3]. Compared to [3], however, the signal efficiency with respect to the starting level of the analysis was improved from 18.2 to 26.5% at an equally high purity of the final sample of event candidates.
The subsequent unfolding extends the upper end of the muon neutrino energy spectrum by a factor larger than 3 (up to \(3.2\,\text {PeV}\)) in comparison to previous measurements [3]. The obtained spectrum is in good agreement with previous measurements of the atmospheric neutrino flux up to energies of \(E_\nu \approx 130\,\text {TeV}\). For higher energies an excess above an atmospheric only assumption is observed. This excess is consistent with the flux of astrophysical neutrinos observed in other IceCube analyses and can therefore be attributed to a flux of high energy astrophysical neutrinos from unknown sources.
The paper is organized as follows: in the next section the selection of neutrino candidates is presented. Section 3 describes the unfolding of the \(\nu _{\mu }\) energy spectrum and discusses statistical and systematic uncertainties. A discussion of the results is given in Sect. 4. The paper concludes in Sect. 5 with a summary and an outlook.
2 Event selection
In this paper, data taken between the 31st of May 2010 and the 13th of May 2011 are analyzed. After data quality selections, a dataset with a livetime of 319.6 days remains for the analysis. First reconstruction and selection steps are performed at the detection site. Further processing of the data, such as detailed track reconstruction [19] and energy estimation [20], are carried out offline. This analysis used as input a data set consisting of \(\sim 2.58\times 10^{8}\) event candidates, \(\sim 2.39\times 10^{5}\) of which are expected to be neutrinos of atmospheric origin. One thus obtains a signal-to-background ratio of \(\approx 0.93\times 10^{-3}\).
At this level of the analysis, the majority of the event candidates still consists of atmospheric muons, which need to be efficiently rejected. The separation process can be structured in two parts: straight cuts and the application of machine learning algorithms.
Simulated events provide the basis for the machine learning-based part of the event selection as well as for the applied cuts.
Simulated neutrino events were produced using the IceCube neutrino generator NuGen, which is based on updated cross-sections for deep inelastic scattering using the HERA1.5 set of parton distribution functions [21]. The events were simulated according to an assumed cosmic \(E^{-2}\)-spectrum and weighted to neutrino flux models by Honda 2006 [22] and Enberg [13] to account for the conventional and the prompt component of the atmospheric muon neutrino flux. In total, \(\sim 8.3\times 10^{6}\) simulated muon neutrino events were available at the starting level of the analysis. Since the dominant contribution to the neutrino energy spectrum arises from conventional neutrinos up to energies of \(E_{\nu }\approx 300\,\text {TeV}\), the event selection does not depend on the detailed modeling of the prompt component.
The background of atmospheric muons was simulated using the air shower code CORSIKA [23]. The poly-gonato model [24] was used as an input spectrum for primary cosmic rays. In total, \(\sim 1.6\times 10^{6}\) simulated atmospheric muons were available at the starting level of the analysis. This corresponds to approximately 6 days of detector livetime. This shortage of simulated background events was compensated by evaluating the machine learning part of the event selection in a bootstrapping procedure (see Sect. 2.2 for details).
2.1 Cuts
Since there is no topological difference between neutrino-induced muons entering the detector and muons from cosmic ray air showers, one has two options: either to select neutrino interactions inside the instrumented volume or to select only neutrino candidates from zenith angles, for which atmospheric muons are stopped by the Earth. This analysis pursues the second approach and, in a first cut, downgoing events (zenith angle \(\theta \le 86^\circ \)) are rejected. The remaining background consists mostly of misreconstructed atmospheric muons, where the separation task is to distinguish between well- and misreconstructed events (see Fig. 1).

A second cut is applied on the reconstructed event velocity \(v_{\mathrm {reco}}\ge 0.1\,\text {c}\), which is obtained from reconstructing the muon track on the basis of the positions \(\mathbf {r}_{i}\), and hit times \(t_i\) of all DOMs giving signals in the event. Ignoring the geometry of the Cherenkov cone and the optical properties of the ice, the reconstruction fits a straight line, parameterized by the time, to the hits. The event velocity \(v_{\mathrm {reco}}\) is assumed to be constant and obtained from minimizing the following \(\chi ^{2}\):
The velocity is expected to be significantly smaller for cascade-like events in comparison to high quality track-like events. This cut therefore selects high quality track-like events, which are required for a reliable reconstruction of the neutrino spectrum in the subsequent unfolding. Furthermore, it reduces the rate of electron neutrinos in the sample.
A third cut is applied on the length of the reconstructed track in the detector \(L_\mathrm {reco}\), which is required to be longer than \(200\,\mathrm {m}\). This cut suppresses events of low energies (\(E_{\nu }\le 100\,\text {GeV}\)) and events that pass near the edge of the detector. The cut favors long tracks, which are reconstructed more accurately.
In total, the three cuts achieve a background rejection of \(81\,\%\) and keep \(71\,\%\) of the neutrino-induced muons with respect to the starting level of the analysis. The cuts further favor well-reconstructed and highly energetic events. The remaining background is significantly harder to reject.
2.2 Machine learning
The separation process is continued with algorithms from the field of machine learning and artificial intelligence. The core of the next steps is a multi-variate classification using a Random Forest (RF) [26]. From the machine learning point of view, this corresponds to a two-class classification process, with neutrino-induced muons being the positive class and atmospheric muons being the negative class. To carry out the machine learning part of the analysis, a class variable was assigned to every simulated event. This class variable was chosen to be 1 for neutrino-induced muons and 0 for atmospheric muons.
As in [3], the RF is preceded by a variable selection and the entire classification process is embedded in multifold validation methods. This allows to control the stability and the optimization of each step of the process separately. Thereafter, recorded events are either classified as neutrino-induced muons or as misreconstructed atmospheric muon events.
To maintain computational feasibility, not all available variables can be used as input to the Random Forest. Following the approach in [3], the input variables are selected using the Minimum Redundancy Maximum Relevance [27] (MRMR) algorithm. To avoid mismatches between experimental data and simulation, variables with a large \(\chi ^{2}\)-disagreement between data and Monte Carlo were discarded from the set of candidate variables. The set of possible input variables was further reduced by removing constant variables and variables with a Pearson correlation \(|\rho |\ge 0.95\). If two variables showed a correlation \(|\rho |\ge 0.95\), only the first one was kept. The MRMR algorithm was then applied to this set of preselected variables. Details on the utilized implementation are presented in [28].
MRMR builds up a variable set in a sequential way. It starts with the variable with the highest correlation to the class variable. In the succeeding iterations, the k-th variable \(V_k\) (\(k>1\)) is selected by taking into account the correlation K of \(V_k\) to the class variable (relevance), as well as the average correlation L of \(V_k\) to all variables \(V_1,\ldots , V_{k-1}\) selected in the preceding iterations (redundancy). The variable with the largest difference \(D=K-L\) is added to the set. The relevance of a variable with respect to the class variable is determined by an F-test, whereas the redundancy between two variables is computed as the absolute value of the Pearson correlation coefficient [28]. This way a set of m variables is built up. A more detailed description of the approach can be found in [3, 27].
In this analysis, \(m=25\) showed a reasonable trade-off between computational feasibility and retaining information in the dataset. The selected variables can be ordered into three different groups: variables to approximate the energy, variables containing geometric properties of the event and variables indicating the reconstruction quality. Since the performance of the Random Forest depends on the agreement between data and simulation, the 25 variables selected by MRMR were manually inspected for disagreement between data and Monte Carlo. No such disagreement was found and the 25 variables were used to train the Random Forest accordingly.
A Random Forest is an ensemble of decision trees. It is trained with simulated events to build a model that can be applied to unclassified events. In the application the j-th tree assigns a label \(x_{i,j}=\{ 0,1 \}\) to the i-th event. Thus, the final classification is achieved by averaging the output of all decision trees in the forest:
In machine learning, \(c_{\mathsf {Signal},i}\) is generally referred to as confidence. To achieve unique trees in the RF, each decision tree is trained on a subset of simulated events. At each node only k randomly chosen variables are used to find the best cut. Before applying the RF to experimental data, the RF is applied to simulated events to evaluate the performance of the classification.
After the application of the forest, the vast majority of the simulated background muons (more than 99.9%) is found to be scored with a confidence \(c_{\mathsf {Signal},i}<0.8\). Only 26 simulated atmospheric muons were found to populate the high confidence region (\(c_{\mathsf {Signal}}>0.8\)). Since the analysis relies on a high purity sample of neutrino candidates, the number of remaining background events needs to be estimated as accurately as possible. The confidence distribution is the basis for this estimation and thus has to be obtained as accurately as possible, as well. Due to the few background events found for \(c_{\mathsf {Signal},i}\ge 0.8\) the accuracy of the confidence distribution is statistically limited for this very region. This limitation can be overcome by utilizing a bootstrapping technique [29].
In the bootstrapping, a total of 200 Random Forest models were trained, each built on a randomly chosen sample with 50% of the size of the full sample. Using this technique, each event is scored on average 100 times. By normalizing the resulting confidence distribution for each event, the approximation of the confidence distribution is improved by taking the variance of \(c_{\mathsf {Signal},i}\) into account. Furthermore, it provides statistical uncertainties for the classification. Using this way to control stability and performance, the parameters of the Random Forest were set to \(k=5\) and 200 trees. The forest was trained using 120,000 simulated signal events and 30,000 simulated background events. The resulting confidence distributions for simulated events and experimental data show good compatibility and confirm a stable separation (see Fig. 2). No signs of overtraining were observed in the cross validation.

Confidence distribution for data and simulation. Low confidence values indicate background-like events and high confidence values indicate signal-like events. A cut in the confidence \(\ge \) 0.92 yields a sample with a purity of (99.5 ± 0.3)%
The cut on \(c_{\mathsf {Signal}}\) is a trade-off between background rejection and signal efficiency. Due to the steeply falling spectrum of atmospheric neutrinos and the expected contribution of astrophysical neutrinos, the cut was selected to yield a sufficient number of events in the highest energy bins. For this analysis, a cut at \(c_{\mathsf {Signal}}\ge 0.92\) was chosen (see Fig. 2).
This cut yields a total of 66,885 neutrino candidates in 319.6 days of detector livetime (\(2.26\times 10^{-3}\) neutrino candidates per second). The number of background events surviving to the final level of the analysis was estimated to \(330 \pm 200\) (\((1.10\pm 0.73)\times 10^{-5}\) background events per second), which corresponds to an estimated purity of (99.5 ± 0.3)%. In total, 21 neutrino candidates with a reconstructed muon energy \(E_{\mu ,\mathsf {reco}}\ge 10\,\text {TeV}\) were observed.

Distribution of the reconstructed muon energy. The plot in the top shows the full zenith range, while the three smaller plots show the zenith ranges indicated
A good understanding of the background is mandatory to ensure that the remaining background lies in a region clearly dominated by signal events. To this end, the distributions of the reconstructed muon energy [20] were investigated in different zenith regions (see Fig. 3). In the region from \(\theta = 120^\circ \) to \(\theta = 180^\circ \), no background and a good compatibility between data and simulation is observed. Due to earth absorption [30, 31], no high energy events (\(E_{\mu ,\mathsf {reco}}\gtrsim 13\,\text {TeV}\)) are observed in experimental data in this region. Closer to the horizon (\(\theta = 90^\circ \) to \(\theta = 120^\circ \)), however, a few atmospheric muons are expected at the lowest energies, but this background is more than three orders of magnitude smaller, compared to the expected number of atmospheric neutrinos and therefore negligible. Between \(316\,\text {TeV}\) and \(1\,\text {PeV}\), an excess over the atmospheric-only prediction is observed in reconstructed muon energies.
No simulated background events are found for zenith angles \(86^\circ < \theta \le 90^\circ \). The livetime of experimental data, however, is about a factor of 50 larger than the livetime of the simulated background. From the results obtained on simulation, one therefore concludes that less than 54 atmospheric muon events are expected to enter the sample from this region.
3 Unfolding
As the energy of the incoming neutrino cannot be accessed directly, it needs to be inferred from energy losses of the neutrino induced-muon within the detector. In the energy region of this analysis, most muon tracks are only partially contained in the detector. Furthermore, the conversion of a neutrino of energy \(E_{\nu }\) into a muon of energy \(E_{\mu }\) is a stochastic process. Thus, the challenge is to compute the muon neutrino energy spectrum from the reconstructed energy of the muons.
This type of problem is generally referred to as an inverse problem. It is described by the Fredholm integral equation of the first kind:
where g(y) is the distribution of a measured variable y and f(x) is the distribution of the sought-after variable x. A(y, x) is generally referred to as the response function and gives the probability to measure a certain y given a specific x. The response function includes the physics of neutrino interactions, as well as the propagation of muons through the ice and all smearing effects introduced by the detector. The term b(y) is the distribution of y for any observed background. Due to the high purity (see Sect. 2), b(y) is negligible in this analysis.
Several algorithms are available to obtain a solution to Eq. (3). In the analysis presented here, the software Truee [32], which is based on the RUN algorithm [33], was used to extract the spectrum.
Truee allows for the use of up to three input variables and generates a binned distribution \(\mathbf {g}\) from them. Cubic B-splines are used for the discretization of f(x) and accordingly \(\mathbf {f}\) contains the spline coefficients. The response function is transformed into a matrix \(\mathbf {A}\) accordingly and needs to be determined from simulated events. Within Truee, this leads to an equation of the form:
For most practical applications, \(\mathbf {A}\) is ill-conditioned due to the complex mapping between x and y. Therefore, regularization is required to avoid unstable solutions.
In this analysis, three variables were used as input to the unfolding. This is a trade-off between gaining information by using more input variables and the required number of simulated events, which grows drastically with the number of input variables. In this analysis, the reconstructed muon energy \(E_{\text {reco}}\), the reconstructed track length \(L_{\text {reco}}\), and the number of detected unscattered photons \(N_{\text {ph}}\) were used as input to the algorithm. The three variables were mainly chosen due to their good correlation with the neutrino energy. Furthermore, the combination of these specific variables in an unfolding exhibits a positive synergy effect, which was also observed in previous unfoldings [3].
The energy proxy \(E_{\text {reco}}\) is obtained by fitting the expected number of photons via an analytic template. This template scales with the energy of the muon [20]. A different approach, which discards energy losses from track segments with the highest energy loss rates (generally referred to as truncated mean \(E_{\text {trunc}}\)), reconstructs the muon energy more accurately [34]. \(E_{\text {reco}}\), however, was found to yield a better overall performance of the unfolding, especially when combined with \(N_{\text {ph}}\) and \(L_{\text {reco}}\).
The correlation of the individual variables with the energy of the incoming neutrino is depicted in Figs. 4, 5 and 6. All three input variables are strongly correlated with energy and were also used in [3]. The horizontal bands in Fig. 4 arise from the fact that certain track lengths are preferred in the reconstruction, which is due to the integer number of strings and the regularity of the array. A detailed description of Truee and its implemented validation methods can be found in [32], while its application in a spectral measurement is described in [3].

Correlation between the unfolding observable reconstructed track length and the true energy of the neutrino obtained from simulated events. The horizontal structures in this plot stem from the string spacing

Correlation between the unfolding observable number of direct photoelectrons measured and the true energy of the neutrino obtained from simulated events

Correlation between the unfolding observable reconstructed muon energy at the center of the detector and the true energy of the neutrino obtained on simulated events
In spectral measurements with IceCube, systematic uncertainties are dominated by two sources: The first source is associated with the amount of light detected in an event, which is affected by the light detection efficiency of the optical modules and by the muon interaction cross-sections (ionization, pair-production and photonuclear interaction). These two uncertainties cannot be disentangled on experimental data and are therefore combined in a single value associated with the efficiency of the DOMs. The common calibration error on the photomultiplier efficiency is 7.7% [38], whereas the theoretical uncertainty on the muon cross-sections was estimated to 4% in [39]. The second source of systematic uncertainties is associated with the scattering and absorption of photons in the glacial ice at the South Pole [40, 41]. The results of the natural formation of the detection medium are inhomogeneities that are accounted for by systematically changing the scattering and absorption lengths in Monte Carlo simulations.
As the unfolding result is based on simulated events which are used as input to TRUEE, the specific choices (ice-model, DOM efficiency) used in the generation of these events affect the outcome of the spectral measurement. To estimate the impact of changes with respect to the so-called baseline simulation, systematic uncertainties were derived using a bootstrapping procedure. Within this bootstrapping, a number of simulated events corresponding to the number of neutrino candidates on experimental data was drawn at random from a systematic data set.
In total, five systematic sets were available for the analysis at hand. In each of these sets, one property has been varied with respect to the baseline simulation. In one set, the efficiency for all DOMs was increased by 10%, while in a second, the efficiency for all DOMs was decreased by 10%. To account for uncertainties in the description of the ice, three sets of simulated events with different ice models were generated. The first set was produced with a scattering length increased by 10% with respect to the baseline simulation, whereas the second one was produced with an absorption length also increased by 10% with respect to the baseline simulation. In a third set, the effects of scattering and absorption were combined by simultaneously decreasing scattering and absorption length by 7.1%.
Based on these simulated events the energy spectrum was obtained, while using the baseline simulation for the extraction of the response matrix. In a next step, the discrepancy between the unfolding result and the true distribution was computed. This procedure was repeated 1000 times on any of the five systematic data sets and yielded the contribution of the individual sources of uncertainty. The total systematic uncertainty was computed as the sum of squares of the individual contributions. Compared to the statistical uncertainty, the systematic uncertainty is found to be large, except for the last two bins, where both uncertainties are of approximately the same size.
The unfolded flux of atmospheric muon neutrinos, including statistical and systematic uncertainties, is summarized in Table 1. A comparison to previous measurements [1, 3, 6, 15] is depicted in Fig. 7. No significant difference to any of the depicted measurements is observed over the entire energy range.
A comparison to theoretical predictions for the atmospheric neutrino flux is shown in Fig. 8. A clear excess over theoretical predictions is observed for the last four bins which cover an energy range from \(E_\nu = 126\,\text {TeV}\) to \(E_\nu =3.2\,\text {PeV}\). The size of the excess was computed with respect to the Honda 2006 model [22], as well as with respect to fluxes of atmospheric neutrinos predicted using the cosmic ray interaction models SIBYLL-2.1 [42] and QGSJET-II [43] and is found to vary depending on energy and the underlying theoretical model.

The obtained \(\nu _\mu \) spectrum of this analysis compared to the unfolding analyses of AMANDA [1], ANTARES [15] and IceCube-59 [3]. The unfoldings can have slightly different zenith dependent sensitivities. In addition to the unfolding results the best fit and its uncertainties from an IceCube parameter fit [6], evaluated for the zenith dependent sensitivity of this work, are shown

Unfolded \(\nu _\mu \) energy spectrum compared to theoretical calculations. The conventional models Sybill-2.1 and QGSJET-II are used as upper and lower bounds for possible models [35]. Most of the common models such as [36] lie in between those two models over the whole energy range. For the prompt component, the flux from [13] is used. The blue shaded area represents the theoretical uncertainty on the prompt flux as reported in [13]. The pink shaded area depicts the sum of uncertainties arising from the conventional and prompt components, respectively. All predictions are calculated for the primary spectrum proposed in [37] and for the zenith dependent sensitivity shown in Table 2
The largest deviation of \(2.8\,\sigma \) is observed in the 11-th bin (\(E_{\text {Center}}=177.8\,\text {TeV}\)) with respect to an atmospheric neutrino flux computed using QGSJET-II. For atmospheric neutrino fluxes computed using SIBYLL-2.1 and the Honda 2006 model, the largest excess of \(2.4\,\sigma \) is observed for the 13-th bin (\(E_{\text {Center}}=707.9\,\text {TeV}\)). For all three flux models discussed above, the prompt component of the atmospheric flux was modeled according to the ERS model [13]. Uncertainties on the theoretical predictions – indicated by the shaded bands in Fig. 8 – were not taken into account for the calculation of the excess. The size of the excess is found to decrease for the last bin, due to larger statistical and systematic uncertainties. Table 3 summarizes the significance of the excess for the four highest energy bins with respect to selected model calculations. A slight increase of the significances is found when results of recent perturbative QCD calculations [44,45,46] are used to model the prompt component.
Due to the relatively small number of events observed in the four highest energy bins, the observed correlation between those bins is rather large, especially in the case of neighbouring bins. This prohibits an accurate estimation of the spectral index of the diffuse flux of high energy astrophysical neutrinos, as well as its normalization. Furthermore, in such an estimate, two observables would be estimated on the basis of only four data points.
4 Consistency check
A comparison of the unfolded spectrum with theoretical predictions for a purely atmospheric flux shows good compatibility up to energies of \(E_{\nu } \approx 126\,\text {TeV}\) (see Fig. 8). Due to lower maximum energies [1, 15], larger uncertainties and the detector geometry [3], no hints for a non-atmospheric component were observed in previous spectral measurements. Nevertheless, those measurements are in good agreement with the result of this analysis (see Fig. 7).
For energies above \(126\,\text {TeV}\), however, a flattening of the unfolded spectrum is observed. To verify that this flattening is consistent with an astrophysical contribution to the overall spectrum of muon neutrinos, the unfolding result is compared to previous measurements of the astrophysical flux with IceCube.

Comparison of the unfolded data points to previous measurements of the astrophysical neutrino flux with IceCube. The blue shaded area represents the error band on the individual fluxes, which was derived using the 68% CL on the best fit values on \(\gamma _{\text {astro}}\), \(\Phi _{\text {astro}}\) as well as on the contribution of conventional and prompt atmospheric neutrinos. a Comparison of the unfolded overall spectrum of muon neutrinos to a likelihood analysis of 6 years of IceCube data [18]. b Comparison of the unfolded overall flux of muon neutrinos to a combined likelihood analysis of several years of IceCube data [7]
Figure 9 depicts a comparison of the unfolded data points with measurements of the astrophysical flux by IceCube. A comparison of the unfolded data points to a likelihood analysis of muon neutrinos using six years of detector livetime [18] is depicted in Fig. 9a. Figure 9b compares the unfolding result to a combined likelihood analysis of several years of IceCube data [7]. In each of the figures, the blue shaded area represents the uncertainty band of the respective analysis. For each measurement, the uncertainty band was computed using the 68% confidence level errors on the best fit values for \(\gamma _{\text {astro}}\), \(\Phi _{\text {astro}}\) as well as on the contribution of conventional and prompt atmospheric neutrinos. Other IceCube analyses also performed measurements of the astrophysical neutrino flux [6, 47, 48]. We do not, however, explicitly compare those to the unfolding result, as the obtained indices and normalizations are bracketed by the results from [18] (\(\gamma = 2.13 \pm 0.13\)) and [7] (\(\gamma = 2.50\pm 0.09\)).
From Fig. 9, one finds that the result of the unfolding agrees well with previous measurements of the astrophysical neutrino flux with IceCube. There is a slight disagreement between the unfolding result and the maximal flux obtained in [7]. This disagreement, however, is only observed for data points below \(\approx 60\) TeV and arises from the fact that a rather large normalization of the conventional atmospheric \(\nu _{\mu }\) flux (\(1.1\pm 0.21\) times Honda 2006) was obtained in [7].
We therefore conclude that the flattening of the muon neutrino energy spectrum at energies above \(\approx 60\) TeV is consistent with an astrophysical flux of neutrinos. Note, however, that due to the rather large uncertainties, the unfolding cannot discriminate between the results obtained in [7, 18].
5 Conclusion
In this paper, an unfolding of the \(\nu _{\mu }\) energy spectrum obtained with IceCube in the 79-string configuration of the detector has been presented. The unfolded spectrum covers an energy range from \(125\,\text {GeV}\) to \(3.2\,\text {PeV}\), thus extending IceCube’s reach in spectral measurements by more than a factor of 3, compared to previous analyses [3].
The unfolding is based on a dataset with a high purity of (99.5 ± 0.3)% at an event rate of \(2.26\times 10^{-3}\) neutrino candidates per second. This is an improvement of the event rate by a factor of 2.43 compared to the previous analysis [3] (\(0.93\times 10^{-3}\) neutrino candidates per second) at an equally high purity of the final sample of neutrino candidates. The improvement is the result of two steps that were altered compared to the previous analysis [3].
Firstly, the quality criteria for tracks were chosen to be less exclusive, which results in a larger number of neutrino candidates available for a further selection with machine learning techniques. This mainly results from the more symmetric shape of the IC-79 detector, when compared to IC-59. Secondly, using a bootstrapping technique, the probability density function of contaminating muon events was estimated more accurately. Therefore, the final cut on the confidence distribution (Fig. 2) was chosen more precisely, which results in a larger number of neutrino candidates at the final analysis level.
The distribution of the reconstructed muon energy in the final sample (Fig. 3) shows an excess of experimental data over the atmospheric prediction for reconstructed muon energies of \(E_\nu > 40\,\text {TeV}\).
The excess at high energies was confirmed in the subsequent unfolding. The unfolded spectrum shows good compatibility with the atmospheric predictions up to neutrino energies of \(\sim 126\,\text {TeV}\) (see Fig. 8). For higher energies the spectrum exceeds an atmospheric only prediction. This excess is compatible with recent measurements of an astrophysical neutrino flux (see Fig. 7 and Sect. 4).
This analysis presents the first observation of an astrophysical muon neutrino flux in a model independent spectral measurement.
References
R. Abbasi et al., Astropart. Phys. 34, 48 (2010)
R. Abbasi et al., Phys. Rev. D 83, 012001 (2011)
M.G. Aartsen et al., Eur. Phys. J. C 75, 116 (2015)
J. Learned, K. Mannheim, Annu. Rev. Nucl. Part. Sci 50, 679 (2000)
M.G. Aartsen et al., Science 342, 1242856 (2013)
M.G. Aartsen et al., Phys. Rev. Lett. 115, 081102 (2015)
M.G. Aartsen et al., Astrophys. J. 809, 98 (2015)
M.G. Aartsen et al., J. Instrum. 12, 03012 (2017)
R. Abbasi et al., Astropart. Phys. 35, 615 (2012)
R. Abbasi et al., Nucl. Instrum. Methods Phys. Res. A 601(3), 294 (2009)
R. Abbasi et al., Nucl. Instrum. Methods Phys. Res. A 700, 188 (2013)
J. Behringer et al. (Particle Data Group), Phys. Rev. D 86 (2012). doi:10.1103/PhysRevD.86.010001
R. Enberg, M.H. Reno, I. Sarcevic, Phys. Rev. D 78, 043005 (2008)
K. Daum et al., Zeitschrift für Physik C Part. Fields 66, 417 (1995)
S. Adrian-Martinez et al., Eur. Phys. J. C 73, 2606 (2013)
J.K. Becker, Phys. Rep. 458, 173 (2008)
M.G. Aartsen et al., Phys. Rev. Lett. 113, 101101 (2014)
M.G. Aartsen et al., ApJ 833, 3 (2016)
J. Ahrens et al., Nucl. Instrum. Methods Phys. Res. A 524, 169 (2004)
M.G. Aartsen et al., J. Instrum. 9, P03009 (2014)
A. Cooper-Sarkar, P. Mertsch, S. Sarkar, J. High Energy Phys. 8, 42 (2011)
M. Honda et al., Phys. Rev. D 70, 043008 (2004)
D. Heck, J. Knapp, J.N. Capdevielle, G. Schatz, T. Thouw, CORSIKA: a Monte Carlo code to simulate extensive air showers (1998)
J.R. Hoerandel, N.N. Kalmykov, A.I. Pavlov, in Proceedings of International Cosmic Ray Conference 2003, vol. 1 (2003), p. 243
A. Gazizov, M. Kowalski, Comput. Phys. Commun. 172, 203 (2005)
L. Breiman, Mach. Learn. 45, 5 (2001)
C. Ding, H. Peng, J. Bioinform. Comput. Biol. 3, 185 (2005)
B. Schowe, K. Morik, in Ensembles in Machine Learning Applications, ed. by O. Okun, G. Valentini, M. Re (Springer, Berlin, 2011), pp. 75–95
B. Efron, Ann. Stat. 7, 1 (1979)
L. Volkova, G. Zatsepin, Bull. Russ. Acad. Sci. Phys. 38, 151 (1974)
I. Albuquerque, J. Lamoureux, G. Smoot, Astrophys. J. Suppl. 141, 195 (2002)
N. Milke et al., Nucl. Instrum. Methods Phys. Res. A 697, 133 (2013)
V. Blobel, Regularized unfolding for high-energy physics experiments. Technical Note TN361, OPAL (1996)
R. Abbasi et al., Nucl. Instrum. Methods Phys. Res. A 703, 190 (2013)
A. Fedynitch, J. Becker Tjus, P. Desiati, Phys. Rev. D 86, 114024 (2012)
M. Honda, T. Kajita, K. Kasahara, S. Midorikawa, T. Sanuki, Phys. Rev. D 75, 043006 (2007)
T. Gaisser, Astropart. Phys. 35, 801 (2012)
R. Abbasi et al., Nucl. Instrum. Methods Phys. Res. A 618, 139 (2010)
R.P. Kokoulin, Nucl. Phys. B Proc. Suppl. 70, 475 (1999)
M. Ackermann et al., J. Geophys. Res. Atmospheres 111, D13203 (2006)
M.G. Aartsen et al., Nucl. Instrum. Methods Phys. Res. A 711, 73 (2013)
E.-J. Ahn et al., Phys. Rev. D 80(9), 094003 (2009)
S. Ostapchenko, Nucl. Phys. B Proc. Suppl. 151, 143 (2006)
A. Bhattacharya, R. Enberg, M.H. Reno, I. Sarcevic, A. Stasto, J. High Energy Phys. 6, 110 (2015)
M.V. Garzelli, S. Moch, G. Sigl, J. High Energy Phys. 10, 115 (2015)
R. Gauld et al., J. High Energy Phys. 2, 130 (2016)
M.G. Aartsen et al., Phys. Rev. D 91(2), 022001 (2015)
M.G. Aartsen et al., in Proceedings of the 34th International Cosmic Ray Conference (2015). arXiv:1510.05223
Acknowledgements
We acknowledge the support from the following agencies: U.S. National Science Foundation-Office of Polar Programs, U.S. National Science Foundation-Physics Division, University of Wisconsin Alumni Research Foundation, the Grid Laboratory Of Wisconsin (GLOW) grid infrastructure at the University of Wisconsin-Madison, the Open Science Grid (OSG) grid infrastructure; U.S. Department of Energy, and National Energy Research Scientific Computing Center, the Louisiana Optical Network Initiative (LONI) grid computing resources; Natural Sciences and Engineering Research Council of Canada, WestGrid and Compute/Calcul Canada; Swedish Research Council, Swedish Polar Research Secretariat, Swedish National Infrastructure for Computing (SNIC), and Knut and Alice Wallenberg Foundation, Sweden; German Ministry for Education and Research (BMBF), Deutsche Forschungsgemeinschaft (DFG), Helmholtz Alliance for Astroparticle Physics (HAP), Research Department of Plasmas with Complex Interactions (Bochum), Germany; Fund for Scientific Research (FNRS-FWO), FWO Odysseus programme, Flanders Institute to encourage scientific and technological research in industry (IWT), Belgian Federal Science Policy Office (Belspo); University of Oxford, United Kingdom; Marsden Fund, New Zealand; Australian Research Council; Japan Society for Promotion of Science (JSPS); the Swiss National Science Foundation (SNSF), Switzerland; National Research Foundation of Korea (NRF); Villum Fonden, Danish National Research Foundation (DNRF), Denmark
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Aartsen, M.G., Ackermann, M., Adams, J. et al. Measurement of the \(\nu _{\mu }\) energy spectrum with IceCube-79. Eur. Phys. J. C 77, 692 (2017). https://doi.org/10.1140/epjc/s10052-017-5261-3
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-017-5261-3