
Abstract
A simultaneous measurement of the top-quark, W-boson, and neutrino masses is reported for \(\mathrm{t}\overline{\mathrm{t}} \) events selected in the dilepton final state from a data sample corresponding to an integrated luminosity of 5.0 fb−1 collected by the CMS experiment in pp collisions at \(\sqrt{s}=7 ~\text{TeV} \). The analysis is based on endpoint determinations in kinematic distributions. When the neutrino and W-boson masses are constrained to their world-average values, a top-quark mass value of \(M_{\mathrm{t}}=173.9\pm0.9 ~\text{(stat.)} {}^{+1.7}_{-2.1} ~\text{(syst.)} ~\text{GeV} \) is obtained. When such constraints are not used, the three particle masses are obtained in a simultaneous fit. In this unconstrained mode the study serves as a test of mass determination methods that may be used in beyond standard model physics scenarios where several masses in a decay chain may be unknown and undetected particles lead to underconstrained kinematics.
Similar content being viewed by others


1 Introduction
The determination of the top-quark mass sets a fundamental benchmark for the standard model (SM), and is one of the precision measurements that defines electroweak constraints on possible new physics beyond the SM [1]. With the recent observations [2, 3] of a Higgs boson candidate at a mass of approximately 125 GeV, existing data can now overconstrain the SM. The top quark plays an important role in such constraints because its large mass, appearing quadratically in loop corrections to many SM observables, dominates other contributions. It is also key to the quartic term in the Higgs potential at high energy, and therefore to the question of stability of the electroweak vacuum [4, 5]. For these reasons, precise top-quark mass determinations are essential to characterize and probe the SM. Recent results obtained at the Large Hadron Collider (LHC) for the top-quark mass in \(\mathrm{t}\overline{\mathrm{t}} \) events include those reported by ATLAS [6], M t=174.5±0.6 (stat.)±2.3 (syst.) GeV, and by the Compact Muon Solenoid (CMS) [7], M t=173.49±0.43 (stat.)±0.98 (syst.) GeV, using the semileptonic decay channel of the \(\mathrm {t}\overline{\mathrm{t}}\) pair. The CMS Collaboration has also reported a measurement [8] in the dilepton channel, M t=172.5±0.4 (stat.)±1.5 (syst.) GeV. A recent summary of top-quark mass measurements conducted by the CDF and D0 Collaborations [9] reports a combined result M t=173.18±0.56 (stat.)±0.75 (syst.) GeV.
In parallel with recent measurements of the properties of the top quark at the LHC, there has been a great deal of theoretical progress on methods using endpoints of kinematic variables to measure particle masses with minimal input from simulation. These methods are generally aimed at measuring the masses of new particles, should they be discovered, but can also be applied to measure the masses of standard model particles such as the top quark. Such an application acts as both a test of the methods and a measurement of the top-quark mass utilizing technique very different from those used in previous studies.
Indeed, top-quark pair production provides a good match to these new methods, as dilepton decays of top-quark pairs (\(\mathrm {t}\overline{\mathrm {t}}\to (\mathrm {b}\ell^{+}\nu)(\overline{\mathrm {b}}\ell ^{-}\bar{\nu})\)) provide challenges in mass measurement very similar to the ones that these methods were designed to solve. A key feature of many current theories of physics beyond the standard model is the existence of a candidate for dark matter, such as a weakly interacting massive particle (WIMP). These particles are usually stabilized in a theory by a conserved parity, often introduced ad hoc, under which SM particles are even and new-physics particles are odd. Examples include R-parity in supersymmetry (SUSY) and T-parity in little-Higgs models. One consequence of this parity is that new physics particles must be produced in pairs. Each of the pair-produced particles will then decay to a cascade of SM particles, terminating with the lightest odd-parity particle of the new theory. In such cases, there will be two particles which do not interact with the detector, yielding events where the observable kinematics are underconstrained. Mass measurements in these events are further complicated by the presence of multiple new particles with unknown masses.
The dilepton decays of \(\mathrm{t}\overline{\mathrm {t}}\) events at the LHC offer a rich source of symmetric decay chains terminating in two neutrinos. With their combination of jets, leptons, and undetected particles, these \(\mathrm{t}\overline{\mathrm{t}}\) events bear close kinematic and topological resemblance to new-physics scenarios such as the supersymmetric decay chain illustrated in Fig. 1. This correspondence has motivated [10] the idea to use the abundant \(\mathrm{t}\overline{\mathrm{t}}\) samples of the LHC as a testbed for the new methods and novel observables that have been proposed to handle mass measurement in new-physics events [11]. A simultaneous measurement of the top-quark, W-boson, and neutrino masses in dilepton \(\mathrm{t}\overline{\mathrm{t}}\) decays closely mimics the strategies needed for studies of new physics.
The analysis presented here focuses on the M T2 variable and its variants [11, 12]. These kinematic observables are mass estimators that will be defined in Sect. 4. The goals of this analysis are two-fold: to demonstrate the performance of a new mass measurement technique, and to make a precise measurement of the top-quark mass. To demonstrate the performance of the method, we apply it to the \(\mathrm{t}\overline{\mathrm {t}}\) system assuming no knowledge of the W-boson or neutrino masses. This allows us to measure the masses of all three undetected particles involved in the dilepton decay: the top quark, W boson, and neutrino. This “unconstrained” fit provides a test of the method under conditions similar to what one might expect to find when attempting to measure the masses of new particles. In order to make a precise measurement of the top-quark mass, on the other hand, we assume the world-average values for the W boson and neutrino masses. This “doubly-constrained” fit achieves a precision in the top-quark mass determination similar to that obtained by traditional methods. The M T2 observable has been previously suggested [13] or used [14] in top-quark mass measurements.
In considering any top-quark mass measurement, however, it is critical to confront the fact that deep theoretical problems complicate the interpretation of the measurement. The issues arise because a top quark is a colored object while the W boson and hadronic jet observed in the final state are not. In the transition t→Wb, a single color charge must come from elsewhere to neutralize the final-state b jet, with the inevitable consequence that the observed energy and momentum of the final state differ from that of the original top quark. The resulting difference between measured mass and top-quark mass is therefore at least at the level at which soft color exchanges occur, i.e. ∼Λ QCD [15, 16]. In the current state of the art, a Monte Carlo (MC) generator is normally used to fix a relationship between the experimentally measured mass of the final state and a top-quark mass parameter of the simulation; but model assumptions upon which the simulation of nonperturbative physics depend further limit the precision of such interpretative statements to about 1 GeV [17].
We therefore take care in this measurement to distinguish between the interpretive use of MC simulation described above, which is inherently model dependent, and experimental procedures, which can be made clear and model independent. A distinctive feature of the top-quark mass measurement reported here is its limited dependence on MC simulation. There is no reliance on MC templates [14], and the endpoint method gives a result which is consistent with the kinematic mass in MC without further tuning or correction. For this reason, the measurement outlined here complements the set of conventional top-quark mass measurements, and is applicable to new-physics scenarios where MC simulation is used sparingly.
2 The CMS detector and event reconstruction
The central feature of the CMS apparatus is a superconducting solenoid of 6 m internal diameter, providing a magnetic field of 3.8 T. Inside the superconducting solenoid volume are silicon pixel and strip trackers, a lead tungstate crystal electromagnetic calorimeter, and a brass/scintillator hadron calorimeter. Muons are measured in gas-ionization detectors embedded in the steel flux return yoke. Extensive forward calorimetry complements the coverage provided by the barrel and endcap detectors. A more detailed description of the CMS detector can be found in Ref. [18].
Jets, electrons, muons, and missing transverse momentum are reconstructed using a global event reconstruction technique, also called particle-flow event reconstruction [19, 20]. Hadronic jets are clustered from the reconstructed particles with the infrared and collinear-safe anti-k
T algorithm [21], using a size parameter 0.5. The jet momentum is determined as the vectorial sum of all particle momenta in this jet, and is found in the simulation to be within 5 % to 10 % of the true momentum over the whole transverse momentum (p
T) spectrum and detector acceptance. Jet energy corrections are derived from the simulation, and are confirmed in measurements on data with the energy balance of dijet and photon + jet events [22]. The jet energy resolution amounts typically to 15 % at jet p
T of 10 GeV, 8 % at 100 GeV, and 4 % at 1 TeV. The missing transverse momentum vector is defined by  where the sum is taken over all particle-flow objects in the event; and missing transverse “energy” is given by
where the sum is taken over all particle-flow objects in the event; and missing transverse “energy” is given by  .
.
3 Event selection
The data set used for this analysis corresponds to an integrated luminosity of 5.0 fb−1 of proton-proton collisions at \(\sqrt{s}=7 ~\text {TeV} \) recorded by the CMS detector in 2011. We apply an event selection to isolate a dilepton sample that is largely free of backgrounds. We require two well-identified and isolated opposite-sign leptons (electrons or muons) passing dilepton trigger requirements; the minimum p T requirements for the triggers are 17 GeV and 8 GeV for the leading and sub-leading leptons. In addition we require at least two b-tagged jets, subsequently used in the top-quark reconstruction, and missing transverse energy. Here and throughout this paper, we use ℓ (and “lepton”) to denote an electron or muon; the signal decays of interest are t→bℓν. Leptons must satisfy p T>20 GeV and the event is vetoed if the leptons have the same flavor and their dilepton invariant mass is within 15 GeV of the Z boson mass. If three leptons are found, the two highest-p T leptons forming an opposite-sign pair are selected. Jets must satisfy p T>30 GeV after correcting for additive effects of pileup (multiple proton collisions in a single crossing) and multiplicative effects of jet energy scale calibration. Jets are further required to lie within |η|<2.5, where η is the pseudorapidity variable, η≡−ln[tan(θ/2)]. The b-tagging algorithm is the Combined Secondary Vertex (CSV) tagger of Ref. [23], deployed here with an operating point that yields a tagging efficiency of 85 % and mistag rate of 10 %. The mistag rate measures the probability for a light quark or gluon jet to be misidentified as a b jet. In the subsample of events passing all selection requirements of this analysis the b-jet purity is 91 %. Jet masses are required to satisfy a very loose requirement m jet<40 GeV to assure the existence of kinematic solutions and reject poorly reconstructed jets. The missing transverse energy must satisfy \(E_{\mathrm{T}}^{\text{miss}}> 30 ~\text{GeV} \) for e+e− and \(\mathrm{\mu^{+}} \mathrm{\mu ^{-}} \) events and \(E_{\mathrm{T}}^{\text{miss}}>20 ~\text{GeV} \) for \(\mathrm{e} ^{\pm} \mathrm{\mu} ^{\mp}\) events, where Drell–Yan backgrounds are smaller. With the exception of the b-tagging criteria and the b-jet mass requirement, all selection requirements summarized here are discussed in more detail in [24, 25]. The sample of events in data meeting all of the signal selection criteria contains 8700 events.
4 Kinematic variables
The endpoint method of mass extraction is based on several variables that are designed for use in the kinematically complex environment of events with two cascade decays, each ending in an invisible particle. The challenge here is two-fold, combining the complications of a many-body decay with the limitations of an underconstrained system. In a two-body decay A→ B C, the momentum of either daughter in the parent rest frame exhibits a simple and direct relationship to the parent mass. In a three-body decay, A→ B C D, the relationship is less direct, encoded not in a delta function of momentum but in the kinematic boundary of the daughters’ phase space. In general, the parent mass may be determined from the endpoints of the observable daughter momenta in the parent rest frame. To carry out this program, however, the daughter masses must be known and enough of the momenta be measurable or constrained by conservation laws to solve the kinematic equations.
Applying this program to the measurement of the top-quark mass in the decay t→bℓν, one immediately encounters a number of obstacles. At a hadron collider, the \(\mathrm{t}\overline{\mathrm {t}}\) system is produced with unknown center-of-mass energy and has an event-dependent p T-boost due to recoil from the initial-state radiation (ISR). Furthermore, in pp collisions we can apply constraints of momentum conservation only in the two dimensions transverse to the beam direction. Since top quarks are normally produced in pairs, the individual neutrino momenta are indeterminate, adding further complication. These obstacles seem daunting but can be overcome by the use of “designer” kinematic variables M T2 [12] and M CT [26], which, by construction, address precisely these issues. In this paper we use M T2. Because the transverse momentum of the \(\mathrm{t}\overline{\mathrm{t}}\) system varies from event to event, the p T-insensitive version [27, 28], M T2⊥, is particularly useful. To measure the masses of the top-quark, W-boson, and neutrino, we measure the endpoints of three kinematic distributions, μ ℓℓ , μ bb, and M bℓ , as discussed in the following subsections.
4.1 M T2 and subsystem variables
4.1.1 The M T2 observable
The variable M T2 is based on the transverse mass, M T, which was first introduced to measure the W-boson mass in the decay W→ℓν. In this case, M T is defined by
The observable M
T represents the smallest mass the W boson could have and still give rise to the observed transverse momenta \(\mathbf{p}_{\text{T}} ^{\ell}\) and  . The utility of M
T lies in the fact that M
T≤M
W is guaranteed for W bosons with low transverse momentum. For a single W→ℓν decay such a lower limit is only marginally informative, but in an ensemble of events, the maximum value achieved, i.e. the endpoint of the M
T distribution, directly reveals the W boson mass. This observation suggests a “min-max” strategy which is generalized by the invention of M
T2.
. The utility of M
T lies in the fact that M
T≤M
W is guaranteed for W bosons with low transverse momentum. For a single W→ℓν decay such a lower limit is only marginally informative, but in an ensemble of events, the maximum value achieved, i.e. the endpoint of the M
T distribution, directly reveals the W boson mass. This observation suggests a “min-max” strategy which is generalized by the invention of M
T2.
The M
T2 observable is useful for finding the minimum parent mass that is consistent with observed kinematics when two identical decay chains a and b each terminate in a missing particle. Figure 1 shows both a SM and a new physics example. If one knew the two missing transverse momenta separately, a value of M
T could be calculated for either or both of the twin decay chains and the parent mass M would satisfy the relationship \(\max( M_{\mathrm{T}} ^{\text{a}}, M_{\mathrm{T}} ^{\text{b}}) \le M\). In practice the two missing momenta cannot be known separately, and are observable only in the combination  . This compels one to consider all possible partitions of
. This compels one to consider all possible partitions of  into two hypothetical constituents \(\mathbf{p}_{\text{T}} ^{\text{a}}\) and \(\mathbf{p}_{\text{T}} ^{\text{b}}\), evaluating within this ensemble of partitions the minimum parent mass M consistent with the observed event kinematics. With this extension of the M
T concept, the variable is now called M
T2:
into two hypothetical constituents \(\mathbf{p}_{\text{T}} ^{\text{a}}\) and \(\mathbf{p}_{\text{T}} ^{\text{b}}\), evaluating within this ensemble of partitions the minimum parent mass M consistent with the observed event kinematics. With this extension of the M
T concept, the variable is now called M
T2:

As with M T, the endpoint of the M T2 distribution has a quantifiable relationship to the parent mass, and the endpoint of an M T2 distribution is therefore a measure of the unseen parent mass in events with two identical decay chains.

Top-quark pair dilepton decays, with two jets, two leptons, and two unobserved particles (left) exhibit a signature similar to some SUSY modes (right). In the figure, \(\widetilde{u}\), \(\widetilde{\chi}^{\pm}\), \(\widetilde{\nu}\), and \(\widetilde{\chi}^{0} \) denote the u-squark, chargino, sneutrino, and neutralino respectively; an asterisk indicates the antiparticle of the corresponding SUSY particle
The observable M T2 requires some care in its use. The presence of \(E_{\mathrm{T}} =\sqrt{ p_{\mathrm{T}} ^{2}+m^{2}}\) in Eq. (4.1) implies that one must either know (as in the case of W→ℓν) or assume (as in the case of unknown new physics) a value of the mass m of the undetected particle(s). In this paper we will refer to an assumed mass as the “test mass” and distinguish it with a tilde (i.e. \(\widetilde{m}\)); the actual mass of the missing particle, whether known or not, will be referred to as the “true mass”, and written without the tilde. Both the value of M T2 in any event and the value of the endpoint of the M T2 distribution in an ensemble of events are in the end functions of the test mass.
Even when a test mass has been chosen, however, the endpoint of the M T2 distribution may not be unique because it is in general sensitive to transverse momentum P T=|P T| of the underlying two-parent system, which varies from event to event. The sensitivity vanishes if the test mass can be set equal to the true mass, but such an option will not be immediately available in a study of new physics where the true mass is not known.
The P T problem is instead addressed by introducing M T2⊥ [27, 28], which uses only momentum components transverse to the P T boost direction. In this way, M T2⊥ achieves invariance under P T boosts of the underlying two-parent system. The construction of M T2⊥ is identical to that of M T2 except that p T values that appear explicitly or implicitly in Eq. (4.1) are everywhere replaced by p T⊥ values, where p T⊥ is defined to be the component of p T in the direction perpendicular to the P T of the two-parent system. Formally,
where \(\hat{\mathbf{n}}_{\text{T}}= \mathbf{P}_{\text {T}} /| \mathbf{P}_{\text{T}} |\) is the unit vector parallel to the transverse momentum of the two-parent system.
4.1.2 Subsystem variables
A further investigation of M T2 and M T2⊥ reveals the full range of kinematic information contained in multistep decay chains by splitting and grouping the elements of the decay chain in independent ways.
The M T2 variable classifies the particles in an event into three categories: “upstream”, “visible”, and “child”. The child particles are those at the end of the decay chain that are unobservable or simply treated as unobservable; the visible particles are those whose transverse momenta are measured and used in the calculations; and the upstream particles are those from further up the decay chain, including any ISR accompanying the hard collision.
In general, the child, visible, and upstream objects may actually be collections of objects, and the subsystem observables introduced in Ref. [10] parcel out the kinematic information in as many independent groupings as possible. Figure 2 shows two of the three possible ways of classifying the \(\mathrm{t}\overline{\mathrm{t}}\) daughters for M T2 calculations. The μ ℓℓ variable, known as \(M_{\mathrm{T}2\perp}^{210}\) in Ref. [10], uses the two leptons of the \(\mathrm {t}\overline{\mathrm{t}}\) dilepton decays, treating the neutrinos as lost child particles (which they are), and combining the b jets with all other “upstream” momentum in the event. The μ bb variable, known as \(M_{\mathrm{T}2\perp}^{221}\) in Ref. [10], uses the b jets, and treats the W bosons as lost child particles (ignoring the fact that their charged daughter leptons are in fact observable). It considers only ISR jets as generators of upstream momentum.

A \(\mathrm{t}\overline{\mathrm {t}}\) dilepton decay with the two subsystems for computing μ ℓℓ and μ bb indicated. The “upstream” and “child” objects are enclosed in dashed rectangles, while the visible objects, which enter into the computation, are enclosed in solid rectangles. The μ ℓℓ and μ bb variables used here are identical to \(M_{\mathrm{T}2\perp}^{210} \) and \(M_{\mathrm {T}2\perp}^{221} \) of Ref. [10]
For completeness, we note that a third M T2⊥ subsystem can be constructed by combining the b jet and the lepton as a single visible system. This variable, known as \(M_{\mathrm{T}2\perp }^{220}\) in the nomenclature of Ref. [10], exhibits significant correlation with M bℓ , the invariant mass of the b jet and lepton. A third observable is needed to solve the underlying system of equations, and for this we choose M bℓ .
4.2 Observables used in this analysis
This analysis is based on two M T2⊥ variables, μ ℓℓ and μ bb as described above, and one invariant mass, M bℓ , the invariant mass of a b jet and lepton from the same top-quark decay. These three quantities have been selected from a larger set of possibilities based on the low correlation we observe among them and the generally favorable shapes of the distributions in their endpoint regions. The observables can be summarized by the underlying kinematics from which they are derived, and the endpoint relations which include the top-quark, W-boson, and neutrino masses.
For the μ ℓℓ variable, the shape of the distribution is known analytically [27]. In terms of the value x=μ ℓℓ and its kinematic endpoint x max, the normalized distribution can be written:
where the parameter α is treated as an empirical quantity to be measured. In practice, α∼0.6, and the zero bin of μ ℓℓ histograms will be suppressed to better show the features of the endpoint region. The origin of the delta function is geometric: for massless leptons, μ ℓℓ vanishes when the two lepton p T⊥ vectors lie on opposite sides of the axis defined by the upstream P T vector, and is equal to \(2( p_{\text{T}\perp} ^{\ell^{+}} p_{\text{T}\perp} ^{\ell^{-}})^{1/2}\) otherwise.
For a test mass of the child particle \(\widetilde{m}_{\nu}\), the endpoint is related to the masses via [10, 27]:
In the \(\mathrm{t}\overline{\mathrm{t}}\) case, we set the test mass to \(\widetilde{m}_{\nu} =0\). We then expect the endpoint at \(\mu^{\max}_{{\ell\ell}}= M_{ \mathrm{W} } (1-{ m^{2}_{\nu } }/{ M_{ \mathrm{W} } ^{2}})= M_{ \mathrm{W} } =80.4 ~\text{GeV} \). Note that m ν is the true mass of the child and M W is the true parent mass; these should be viewed as variables in a function for which \(\widetilde{m}_{\nu}\) is a parameter. In a new-physics application, the analogs of M W and m ν are not known; but given Eq. (4.5), the measurement of the endpoint, and an arbitrary choice of child mass \(\widetilde{m}_{\nu}\), one can fix a relationship between the two unknown masses. We emphasize that the equality expressed by Eq. (4.5) holds regardless of the value of the test mass, because the test mass enters into both sides of the equation (see discussion in Sect. 4.1.1). This applies below to Eq. (4.6) also.
In the case of μ bb, the visible particles are the two b jets, the child particles are the charged leptons and neutrinos (combined), and ISR radiation generates the upstream transverse momentum. We take the visible particle masses to be the observed jet masses, which are typically ∼10 GeV. The endpoint is unaffected by nonzero jet masses provided the test mass is set to the true mass, and is affected only at the ±0.1 GeV level over a large range of test masses, \(0< \widetilde {M}_{ \mathrm{W} } < 2 M_{ \mathrm{W} } \). For an assumed child mass \(\widetilde{M}_{ \mathrm{W} } \), the endpoint is given by [10, 27]:
In the \(\mathrm{t}\overline{\mathrm{t}}\) case, we set the test mass to \(\widetilde{M}_{ \mathrm{W} } = M_{ \mathrm{W} } =80.4 ~\text{GeV} \). We then expect the endpoint at \(\mu^{\max}_{{\mathrm {b}\mathrm {b}}}= M_{\mathrm {t}} \). As in the previous case, in a new-physics application where the analogs of M t and M W are not known, the measurement of the endpoint together with an arbitrary choice of the child mass \(\widetilde{M}_{ \mathrm{W} } \) yields a relationship between the two unknown masses.
As noted above, a third variable is needed, and we adopt M bℓ , the invariant mass formed out of jet-lepton pairs emerging from the top-quark decay. Two values of M bℓ can be computed in a \(\mathrm{t}\overline{\mathrm{t}}\) event, one for each top decay. In practice four are calculated because one does not know a priori how to associate the b jets and leptons; we discuss later an algorithm for mitigating the combinatorial effects on the endpoint. The shape of the distribution is known for correct combinations but is not used here since correct combinations cannot be guaranteed (see Sect. 5.3). The endpoint is given by:
where \(E^{\ast}_{ \mathrm{W} }\), \(E^{\ast}_{\mathrm {b}}\), and p ∗ are energies and momenta of the daughters of t→bW in the top-quark rest frame. In these formulae the charged-lepton mass is neglected but the observed b-jet mass m b is finite and varies event-to-event.
We can now summarize the mass measurement strategy. If the masses M t, M W, and m ν were unknown, one would measure the two endpoints and the invariant mass that appear on the left-hand sides of Eqs. (4.5)–(4.7), using arbitrary test mass values for the first two, to obtain three independent equations for the three unknown masses. Then, in principle, one solves for the three masses. In practice, the measurements carry uncertainties and an optimum solution must be determined by a fit. In the case when one or more of the masses is known, a constrained fit can improve the determination of the remaining unknown mass(es).
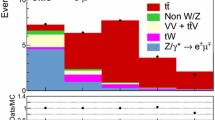
In Fig. 3 we show distributions for the three observables μ ℓℓ , μ bb, and M bℓ . Here and throughout this paper, the zero bin of the μ ℓℓ distribution, corresponding to the delta function of Eq. (4.4), is suppressed to emphasize the kinematically interesting component of the shape. In the μ bb plot shown here, the prominent peak that dominates the figure is an analog of the delta function in μ ℓℓ , its substantial width being due to the variable mass of the jets that enter into the μ bb calculation. As with the μ ℓℓ delta function, the peak arises from events where the axis of the upstream P T falls between the two visible-object p T vectors. In later plots this μ bb peak will be suppressed to better reveal the behavior of the distribution in the endpoint region.

Distributions of the three kinematic distributions μ ℓℓ , μ bb, and M bℓ . Data (\(5.0\mbox{$~\text{fb}^{\text{$-$1}}$}\)) are shown with error bars. MC simulation is overlaid in solid color to illustrate the approximate \(\mathrm{t}\overline{\mathrm{t}}\) signal and background content of the distributions. The backgrounds contained in “Other” are listed in Table 1. The zero-bin of the μ ℓℓ plot is suppressed for clarity. The M bℓ plot contains multiple entries per event (see Sect. 5.3 for details). In all cases, the simulation is normalized to an integrated luminosity of 5.0 fb−1 with next-to-leading-order (NLO) cross sections as described in the text
The agreement between data and MC is generally good, but the comparisons are for illustration only and the analysis and results that follow do not depend strongly on the MC simulation or its agreement with observation.
5 Backgrounds
The two-lepton requirement at the core of the event selection ensures an exceptionally clean sample. Nevertheless a few types of background must be considered, including top-quark decays with τ-lepton daughters, pp→tW events, and sub-percent contributions from other sources.
5.1 Physics backgrounds
The physics backgrounds consist of \(\mathrm{t}\overline {\mathrm{t}}\) decays that do not conform to the dilepton topology of interest, as well as non-\(\mathrm {t}\overline{\mathrm{t}}\) decays. Table 1 shows the estimation of signal and background events in MC simulation. The MC generators used throughout this study are mc@nlo 3.41 [29] for all \(\mathrm{t}\overline{\mathrm{t}}\) samples, pythia 6.4 [30] for the diboson samples, and MadGraph 5.1.1.0 [31] for all others. The simulated data samples are normalized to 7 TeV NLO cross sections and an integrated luminosity of 5.0 fb−1.
Events in which a top quark decays through a τ lepton (e.g. \(\mathrm {t}\to \mathrm {b}\tau^{+}\nu _{\tau}\to \mathrm {b}\ell^{+}\nu_{\ell }\bar{\nu}_{\tau}\nu_{\tau}\)), constitute about 13 % of the events surviving all selection requirements. From the point of view of event selection, these events are background. The unobserved momentum carried by the extra neutrinos, however, ensures that these events reconstruct to M T2 and M bℓ values below their true values and hence fall below the endpoint of signal events with direct decays to e or \(\mathrm{\mu} \) final states. We therefore include these events among the signal sample. This leaves in principle a small distortion to the kinematic shapes, but the distortion is far from the endpoint and its impact on the mass extraction is negligible.
5.2 Modelling the mistag background
In addition to the backgrounds discussed above, which fall within the bulk the distributions, it is essential also to treat events that lie beyond the nominal signal endpoint. In this analysis, the main source of such events comes from genuine \(\mathrm{t}\overline{\mathrm {t}}\) events where one of the jets not originating from a top-quark decay is mistagged as a b jet. An event in which a light-quark or gluon jet is treated as coming from a top quark can result in events beyond the endpoint in the μ bb and M bℓ distributions, as can be seen in Fig. 4. The measurement of μ ℓℓ , on the other hand, depends primarily on the two leptons and is unaffected by mistags.

Composition of MC event samples, illustrating that signal events with light-quark and gluon jet contamination dominate the region beyond the endpoint. The top and bottom M bℓ distributions contain the same information plotted with different vertical scales. The backgrounds contained in “Other” are listed in Table 1
To determine the shape of the mistag background in μ bb and M bℓ , we select a control sample with one b-tagged jet and one antitagged jet, where the antitagging identifies jets that are more likely to be light-quark or gluon jets than b jets. Antitagging uses the same algorithm as combined secondary vertex algorithm, but selects jets with a low discriminator value to obtain a sample dominated by light-quark and gluon jets. We classify event samples by the b-tag values of the two selected jets, and identify three samples of interest: a signal sample where both jets are b-tagged; a background sample where one jet is b-tagged and the other antitagged; and another background sample where both jets are antitagged. Table 2 shows the composition of these samples as determined in MC simulation. We select the sample consisting of pairs with one tagged and one antitagged jet to be the control sample and use it to determine the shape of the background lying beyond the signal endpoint. It contains a significant fraction of signal events, 27 %, but these all lie below the endpoint and categorizing them as background does not change the endpoint fit.
The control sample is used to generate distributions in μ bb and M bℓ , whose shapes are then characterized with an adaptive kernel density estimation (AKDE) method [32]. The underlying KDE method is a non-parametric shape characterization that uses the actual control sample to estimate the probability distribution function (PDF) for the background by summing event-by-event Gaussian kernels. In the AKDE algorithm, on the other hand, the Gaussian widths depend on the local density of events; empirically this algorithm yields lower bias in the final mass determination than alternative algorithms. Figure 5 shows the performance of the background shape determination; the set of control sample events are taken from MC simulation in order to illustrate the composition of the background and signal.

Background PDF shapes determined by the AKDE method, on MC samples. All events pass the signal selection criteria. Top: M bℓ ; bottom: μ bb. The heavy black curve is the AKDE shape
5.3 Suppressing the combinatorial background
Even if the b-tagging algorithm selected only b jets, there would remain a combinatorics problem in \(\mathrm{t}\overline{\mathrm {t}}\) dilepton events. In the case of the M bℓ distribution the matching problem arises in pairing the b jet to the lepton: for b jets j 1 and j 2, and leptons ℓ + and ℓ −, two pairings are possible: j 1 ℓ +,j 2 ℓ − and j 1 ℓ −,j 2 ℓ +. Four values of M bℓ will thus be available in every event, but only two of them are correct. The two incorrect pairings can (but do not have to) generate values of M bℓ beyond the kinematic endpoint of M bℓ in top-quark decay. To minimize the unwanted background of incorrect pairings while maximizing the chance of retaining the highest values of M bℓ in correct bℓ pairings, which do respect the endpoint, we employ the following algorithm.
Let A and a denote the two M bℓ values calculated from one of the two possible bℓ pairings, and let B and b denote the M bℓ values calculated from the other pairing. Choose the labeling such that a<A and b<B. Without making any assumptions about which pairing is correct, one can order the M bℓ values from smallest to largest; there are six possible orderings. For example the ordering b,B,a,A means that the bB pairing has M bℓ values which are both smaller than the M bℓ values in the aA pairing. In this case, while we do not know which pairing is correct, we can be certain that both M bℓ values of the bB pairing must respect the true endpoint since either (a) bB is a correct pairing, in which case its M bℓ values naturally lie below the endpoint, or (b) aA is the correct pairing, so its M bℓ values lie below the true endpoint, with the bB values falling at yet lower values. Similar arguments apply to each of the other possible orderings.
Table 3 shows the six possibilities. For each mass ordering shown in the left column, the right column shows the mass values that will be selected for use in the M bℓ fit. For any given event only one row of the table applies. For an event falling in one of the first two rows, two values of M bℓ enter in the subsequent fits; for an event falling in the last four rows, three values enter the fits.
This selection algorithm ensures that all masses used in the fits that can be guaranteed to be below the endpoint will be used, while any that could exceed the endpoint because of wrong pairings will be ignored. Note that it does not guarantee that the masses that are used are all from correct bℓ pairings; in practice, however, we find that 83 % of the entries in the fit region are correct bℓ pairings, and that this fraction rises to over 90 % within 10 GeV of the endpoint.
6 Fit strategy
The kinematic observables μ ℓℓ , μ bb, and M bℓ , along with their endpoint relations (Sect. 4.2) and background mitigation techniques (Sects. 5.2, 5.3), are combined in an unbinned event-by-event maximum likelihood fit. The likelihood function is given by a product over all events of individual event likelihoods defined on each of the kinematic variables:
The vector \(\mathbf{M}=( M_{\mathrm {t}} , M_{ \mathrm{W} } , m^{2}_{\nu } )\) contains the mass parameters to be determined by the fit, and each u i comprises the set of transverse momentum vectors, reconstructed object masses, and missing-particle test masses from which the kinematic observables μ ℓℓ , μ bb, and M bℓ of the event i are computed. We fit for \(m^{2}_{\nu}\) rather than m ν because only \(m^{2}_{\nu}\) appears in the endpoint formulae (Eqs. (4.5) and (4.7)); we do not constrain \(m^{2}_{\nu}\) to be positive. As will be described more fully below, only the endpoint region of each variable is used in the fit. If an event i does not fall within the endpoint region of a given variable, the corresponding likelihood component (\(\mathcal{L}_{i}^{ \mu_{{\ell\ell }} }\), \(\mathcal {L}_{i}^{ \mu_{{\mathrm {b}\mathrm {b}}} }\), or \(\mathcal{L}_{i}^{ M_{\mathrm {b}\ell} }\)) defaults to unity.
For each observable x∈{μ ℓℓ ,μ bb,M bℓ }, the likelihood component \({\mathcal{L}}_{i}\) in Eq. (6.1) can be expressed in terms of the value of the observable itself, x i =x(u i ), and its kinematic endpoint, x max=x max(M). Explicit formulae for x max(M) are given in Eqs. (4.5), (4.6), and (4.7); in the first two cases there is additional dependence on the missing-particle test mass. Letting the label a∈{ℓℓ,bb,bℓ} index the three flavors of observables, we can write the signal, background, and resolution shapes as \(S(x|x^{\text{a}}_{\max})\), B a(x), and \(\mathcal{R}^{\text{a}}_{i}(x)\). While the form of the signal shape S(x) is common to all three fits, the background shape B a(x) is specific to each observable and the resolution function \(\mathcal{R}^{\text{a}}_{i}(x)\) is specific to both the observable and the individual event. Then each function \(\mathcal{L}^{\text{a}}_{i}\) appearing on the right-hand side of Eq. (6.1) is given by the general form:
The fit parameter β determines the relative contribution of signal and mistag background.
For the common signal shape \(S(x|x^{\text{a}}_{\max})\) we use an approximation consisting of a kinked-line shape, constructed piecewise from a descending straight line in the region just below the endpoint and a constant zero value above the endpoint. The kinked-line function is defined over a range from x lo to x hi. The generic form is:
The parameter \(\mathcal{N}\) is fixed by normalization. The fidelity of this first-order approximation to the underlying shape depends on both the shape and the value of x lo. The range of the fit, (x lo,x hi), is chosen to minimize the dependence of the fit results on the range, and then the values of x lo and x hi are subsequently varied to estimate the corresponding systematic uncertainties.
The following paragraphs discuss the forms of B a(x) and \({\mathcal{R}}^{\text{a}}(x)\) for each of the three kinematic distributions.
6.1 μ ℓℓ
In the case of μ ℓℓ , the visible particles are the two leptons, which are well measured. The projection of their vectors onto the axis orthogonal to the upstream P T, however, necessarily involves the direction of the upstream P T, which is not nearly as well determined. The resolution function is therefore wholly dominated by the angular uncertainty in P T, and it varies substantially from event to event depending on the particular configuration of jets found in each event. Although jet resolutions are known to have small non-Gaussian tails, their impact on the μ ℓℓ resolution function and the subsequent fit procedure is small and we treat only the Gaussian core. A far more important feature of the resolution arises when the P T direction uncertainty is propagated into the μ ℓℓ variable to derive \({\mathcal{R}}^{{\ell\ell}}_{i}(x)\). In this procedure a sharp Jacobian peak appears wherever the P T smearing can cause μ ℓℓ to pass through a local maximum or minimum value. These peaks depend only on azimuthal angles and occur at any value of μ ℓℓ . The detailed shape of the highly non-Gaussian μ ℓℓ resolution and its convolution with the underlying signal shape, as specified in Eq. (6.2), are handled by exact formulae derived analytically (see the Appendix). The background in the μ ℓℓ distribution is vanishingly small, so we set B ℓℓ(x)=0.
6.2 μ bb
For μ bb, the visible particles are the b jets, and since the resolution smearing of both the b jets and the upstream jets defining P T are large and of comparable magnitudes, the event-by-event resolution is more complicated than in the μ ℓℓ case. As a result, no analytic calculation is possible and we instead determine the μ bb resolution function, \(\mathcal{R}^{{\mathrm {b}\mathrm {b}}}_{i}(x)\), numerically in each event, using the known p T and ϕ resolution functions for the jets. As with the μ ℓℓ resolutions, Jacobian peaks appear in the μ bb resolutions. The mistag background is included by scaling the shape B bb(x) obtained from the AKDE procedure as discussed in Sect. 5.2.
6.3 M bℓ
In the M bℓ case, the theoretical shape S(x) is well-known, but the combinatorics of bℓ matching, together with the method of selecting bℓ pairs from the available choices (see Sect. 5.3), sculpt the distribution to the degree that the theoretical shape is no longer useful. Therefore we use the kinked-line shape of Eq. (6.3) to model the signal near the endpoint. In contrast to the μ ℓℓ and μ bb variables, numerical studies confirm that linearly propagated Gaussian resolutions accurately reflect the smearing \({\mathcal{R}}^{{\mathrm {b}\ell}}_{i}(x)\) of M bℓ , as one expects in this case. The background shape B bℓ(x) is given by the AKDE procedure as discussed in Sect. 5.2.
6.4 Applying the fit to data
The unbinned likelihood fit prescribed in Eqs. (6.1) and (6.2) is performed on the three kinematic distributions using the shapes given for signal S(x|x max), resolution \({\mathcal{R}}_{i}(x)\), and mistag background B(x). Although a simultaneous fit for all three masses is an important goal of this study, it is useful in the context of the \(\mathrm{t}\overline{\mathrm{t}}\) data sample to explore subclasses of the fit in which some masses are constrained to their known values. For this purpose we define: (a) the unconstrained fit, in which all three masses are fit simultaneously; (b) the singly-constrained fit, in which m ν =0 is imposed; and (c) the doubly-constrained fit, in which both m ν =0 and M W=80.4 GeV are imposed [33]. The unconstrained fit is well-suited to testing mass measurement techniques for new physics, while the doubly-constrained fit is optimal for a SM determination of the top-quark mass.
The fit procedure takes advantage of bootstrapping techniques [34]. In particle physics, bootstrapping is typically encountered in situations involving limited MC samples, but it can be profitably applied to a single data sample, as in this analysis. The goal of bootstrapping is to obtain the sampling distribution of a statistic of a particular data set from the data set itself. With the distribution in hand, related quantities such as the mean and variance of the statistic are readily computable.
In order to estimate the sampling distribution of a statistic, we first need to estimate the distribution from which the data set was drawn. The basic assumption of bootstrapping is that the best estimate for this distribution is given by a normalized sum of delta functions, one for each data point. This is the bootstrap distribution. One can estimate the distribution of a statistic of the data by drawing samples from the bootstrap distribution and calculating the statistic on each sample. To simplify the process further we note that, since the bootstrap distribution is composed of a delta function at each data point, sampling from the bootstrap distribution is equivalent to sampling from the observed data.
In this analysis, the fitted top-quark mass is the statistic of interest, and we wish to find its mean and standard deviation. To do so, we conduct the fit 200 times, each time extracting a new sampling of events from the 8700 selected events in the signal region of the full data set. The sampling is done with replacement, which means that each of these bootstrapped pseudo-experiments has the same number of events (N=8700) as the original data set, and any given event may appear in the bootstrap sample more than once. Each bootstrapped sample is fit with the unbinned likelihood method described in the previous subsections. As an illustration, we show in Fig. 6 the distribution of the 200 values of M t that emerges in the case of the doubly-constrained fit; the mean and its standard deviation in this distribution, M t=173.9±0.9 GeV, constitute the final result of the doubly-constrained fit.

Distribution of M t in doubly-constrained fits of 200 pseudo-experiments bootstrapped from the full data set
A key motivation for applying bootstrapping to the data is that the impact of possible fluctuations in the background shape are naturally incorporated. Because the background shape in a given fit is constructed from a control sample with the AKDE method (Sect. 5.2), the possible statistical variation in the shape is most easily accounted for by multiple samplings of the control sample. Thus for each bootstrap sample taken from the signal region of the data, another is taken simultaneously from the set of background control events. Each pseudo-experiment fit therefore has its own background function and the ensemble of all 200 such fits automatically includes background shape uncertainties. (The total background yield is a separate issue, handled by the normalization parameter that floats in each fit.)
A secondary motivation to use bootstrapping on the data sample is that it offers a convenient mechanism to correct for event selection and reconstruction efficiencies [35]. To do so, each event is assigned a sampling weight equal to the inverse of its efficiency, and during the bootstrap process events are selected with probabilities proportional to these weights. A bootstrapped data set therefore looks like efficiency-corrected data, but each event is whole and unweighted.
7 Validation
We test for bias in the above procedures by performing pseudo-experiments on simulated events. Each pseudo-experiment yields a measurement and its uncertainty for M t. From these a pull can be calculated, defined by \(\text{pull} = ({m_{\text{meas}}-m_{\text{gen}}})/{\sigma_{\text{meas}}}\). In this expression m gen is the top-quark mass used in generating events while m meas and σ meas are the fitted mass and its uncertainty, determined for each pseudo-experiment. For an unbiased fit, the pull distribution will be a Gaussian of unit width and zero mean. A non-zero mean indicates the method is biased, while a non-unit width indicates that the uncertainty is over- or under-estimated. We increase the precision with which we determine the pull distribution width by bootstrapping the simulation to generate multiple pseudo-experiments. The results of Ref. [36] are then used to calculate the mean and standard deviation of the pull distribution, along with uncertainties on each, taking into account the correlations between pseudo-experiments introduced by over-sampling.
Figure 7, top, shows the pull distribution for the doubly-constrained fit over 150 pseudo-experiments. Extracting a result from each pseudo-experiment involves the methods discussed in Sect. 6.4, and thus the total number of pseudo-experiments required for the study is 150×200. The measured pull mean is 0.15±0.19 and the pull standard deviation is 0.92±0.06, indicating that the fit is unbiased to the level at which it can be measured with the available simulated data. The slightly low standard deviation suggests that the statistical uncertainty may be overestimated; since the systematic uncertainty is significantly larger than the statistical error, we do not make any correction for this.

(Top) Pull distribution \({(m_{\text{meas}}-m_{\text{gen}})}/{\sigma_{\text{meas}}}\) for the top-quark mass (other masses are fixed) across 150 MC pseudo-experiments. (Bottom) Fit results obtained in MC \(\mathrm{t}\overline{\mathrm{t}}\)-only samples generated with MadGraph for various top-quark masses. The best-fit calibration is shown by the solid line and the line of unit slope is shown in the dashed line. Data points are from doubly-constrained fits. The line of unit slope agrees with the fit results with χ 2/degree of freedom=10.7/9
In an independent test, we perform fits to MC samples generated with various M t values. As the results, shown in Fig. 7, bottom, indicate that there is no significant bias as a function of the top-quark mass, we make no correction.
8 Systematic uncertainties
The systematic uncertainties are assessed by varying the relevant aspects of the fit and re-evaluating the result. All experimental systematic uncertainties are estimated in data. In the doubly-constrained fit, uncertainties are evaluated for the fitted top-quark mass M t.
The systematic uncertainties related to absolute jet energy scale (JES) are derived from the calibration outlined in Ref. [22]. We evaluate the effects of JES uncertainties in this analysis by performing the analysis two additional times: once with the jet energies increased by one standard deviation of the JES, and once with them decreased by the same amount. Each jet is varied by its own JES uncertainty, which varies with the p T and η values of the jet. In a generic sample of multijet events, selecting jets above 30 GeV, the fractional uncertainty in the JES (averaged over η) ranges from 2.8 % at the low end to 1 % at high p T. The uncertainty is narrowed further by using flavor-specific corrections to b jets. A similar process is carried out for varying the jet energy resolutions by its uncertainties. These variations of jet energy scale and jet energy resolution propagate into uncertainties of \({}^{+1.3}_{-1.8} ~\text{GeV} \) and ±0.5 GeV on the measured top-quark mass, respectively. For the electrons, the absolute energy scale is known to 0.5 % in the barrel region and 1.5 % in the endcap region, while for the muons the uncertainty is 0.2 % throughout the sensitive volume. Varying the lepton energy scale accordingly leads to a systematic uncertainty in M t of \({}^{+0.3}_{-0.4} ~\text{GeV} \).
The choice of fit range in μ bb and M bℓ introduces an uncertainty due to slight deviations from linearity in the descending portion of these distributions. Separately varying the upper and lower ends of the μ bb and M bℓ fit range gives an estimate of ±0.6 GeV for the systematic uncertainty. The uncertainty is mainly driven by dependence on the lower end of the μ bb range. A cross-check study based on the methods of Ref. [37] confirms the estimate.
The AKDE shape which is used to model the mistag background in μ bb and M bℓ is non-parametric and derived from data. For this reason, the AKDE is not subject to biases stemming from assumptions about the underlying background shape or those inherent in MC simulation. However, one could also model the mistag background with a parametric shape, and we use this alternative as a way to estimate the uncertainty due to background modeling. Based on comparisons among the default AKDE background shape and several parametric alternatives, we assign a systematic uncertainty of ±0.5 GeV.
Efficiency can affect the results of this analysis if it varies across the region of the endpoint in one or more of the kinematic plots. The M bℓ observable is sensitive to both b-tagging and lepton efficiency variations, whereas μ bb is only sensitive to uncertainties due to b-tagging efficiency. By varying the b-tagging and lepton selection efficiencies by ±1σ, including their variation with p T, we estimate that the effect of the efficiency uncertainty contributes at most \({}^{+0.1}_{-0.2} ~\text{GeV} \) uncertainty to the measured top-quark mass.
The dependence on pileup is estimated by conducting studies of fit performance and results with data samples that have been separated into low-, medium-, and high-pileup subsamples of equal population; these correspond to 2–5, 6–8, and ≥9 vertices, respectively. The dependence is found to be negligible. In addition, direct examination of the variables μ bb and M bℓ reveals that their correlation with the number of primary vertices is small, with correlation coefficients <43 % and <1 %, respectively.
The sensitivity of the result to uncertainties in QCD calculations is evaluated by generating simulated event samples with varied levels of color-reconnection to beam remnants, renormalization and factorization scale, and jet-parton matching scale. The impact of the variations on M t is dominated by the color reconnection effects, which are estimated by comparing the results of simulations performed with two different MC tunes [38], Perugia2011 and Perugia2011noCR. Factor-of-two variations of renormalization and factorization scale and the jet-parton matching scale translate to negligible (<0.1 GeV) variations in the top-quark mass. Uncertainties in the parton distribution functions and relative fractions of different production mechanisms do not affect this analysis. The overall systematic error attributed to QCD uncertainties is ±0.6 GeV on the value of M t. In quadrature with other systematic uncertainties these simulation-dependent estimates add 0.1 GeV to both the upper and lower systematic uncertainties. This additional contribution reflects theoretical uncertainty in the interpretation of the measurement as a top-quark mass, and unlike other systematic uncertainties in the measurement, is essentially dependent on the reliability of the MC modeling.
For the unconstrained and singly-constrained fits, where the objective is primarily to demonstrate a method, rather than to achieve a precise result, we have limited the investigation of systematic uncertainties to just the evaluation of the jet energy scale and fit range variations, which are known from the doubly-constrained case to be the dominant systematic contributions. Because of this, the systematic uncertainties displayed for these fits are slightly lower than they would be with a fuller treatment of all contributions.
The systematic uncertainties discussed in this section are summarized in Table 4.
9 Results and discussion
The simultaneous fit to the three distributions determines \(m^{2}_{\nu}\), M W, and M t. A complete summary of central values and statistical and systematic uncertainties for all three mass constraints can be found in Table 5. Figure 8 shows the corresponding fits.

Results of simultaneous fits to \(m_{\nu } ^{2}\), M W, and M t. The upper red line is in all cases the full fit, while the green (middle) and blue (lowest) curves are for the signal and background shapes, respectively. While the fit is performed event-by-event for all measured kinematic values, the line shown is an approximate extrapolation of the total fit likelihood function over the entire fit range. Top row: unconstrained fit; Middle row: singly-constrained fit; Bottom row: doubly-constrained fit. The inset shows a zoom of the tail region in M bℓ for the doubly-constrained case to illustrate the level of agreement between the background shape and the data points
We take the doubly-constrained version to be the final result:
In the more general case of the unconstrained measurement, the performance of the endpoint method illustrated here in the \(\mathrm {t}\overline{\mathrm{t}}\) dilepton system suggests the technique will be a viable option for mass measurements in a variety of new-physics scenarios. The precision on M t given by the doubly-constrained fit, for example, is indicative of the precision with which we might determine the masses of new colored particles (like squarks), as a function of the input test mass \(\widetilde{m}_{\nu}\). Of course, as shown in the second column of Table 5, the input mass m ν itself will be determined less precisely. Another plausible scenario is one in which new physics mimics the leptonic decay of the W boson. This can arise in SUSY with R-parity violation and a lepton-number violating term in the superpotential. In this case, the lightest superpartner could be the charged slepton, which decays to a lepton and neutrino, just like the SM W boson. Current bounds from LEP indicate that the slepton must be heavier than 100 GeV. Given the ∼1 GeV precision provided by the singly-constrained fit on the W boson mass, the W boson can easily be discriminated from such an object based on its mass.
It is interesting to note also that in the unconstrained case, one can restrict the range of the neutrino mass (which is treated as an unknown parameter) reasonably well, within approximately 20 GeV, in line with previous expectations [39]. If the \(E_{\mathrm {T}}^{\text{miss}}\) signal is due to SM neutrinos, rather than heavy WIMPs with masses of order 100 GeV, this level of precision is sufficient to distinguish the two cases. If, on the other hand, the \(E_{\mathrm{T}}^{\text{miss}}\) signal is indeed due to heavy WIMPs, one might expect that the precision on the WIMP mass determination will be no worse than what is shown here for the neutrino, assuming comparable levels of signal and background.
10 Conclusions
A new technique of mass extraction has been applied to \(\mathrm{t}\overline{\mathrm{t}}\) dilepton events. Motivated primarily by future application to new-physics scenarios, the technique is based on endpoint measurements of new kinematic variables. The three mass parameters \(m^{2}_{\nu}\), M W, and M t are obtained in a simultaneous fit to three endpoints. In an unconstrained fit to the three masses, the measurement confirms the utility of the techniques proposed for new-physics mass measurements. When \(m^{2}_{\nu}\) and M W are constrained to 0 and 80.4 GeV respectively, we find \(M_{\mathrm {t}} =173.9 \pm0.9 ~\text{(stat.)} {}^{+1.7}_{-2.1} ~\text{(syst.)} ~\text{GeV} \), comparable to other dilepton measurements. This is the first measurement of the top-quark mass with an endpoint method. In addition to providing a novel approach to a traditional problem, it achieves a precision similar to that found in standard methods, and its use lays a foundation for application of similar methods to future studies of new physics.
References
H. Flächer et al., Revisiting the global electroweak fit of the Standard Model and Beyond with Gfitter. Eur. Phys. J. C 60, 543 (2009). doi:10.1140/epjc/s10052-009-0966-6, arXiv:0811.0009. See also the erratum at doi:10.1140/epjc/s10052-011-1718-y
ATLAS Collaboration, Observation of a new particle in the search for the Standard Model Higgs boson with the ATLAS detector at the LHC. Phys. Lett. B 716, 1 (2012). doi:10.1016/j.physletb.2012.08.020, arXiv:1207.7214
CMS Collaboration, Observation of a new boson at a mass of 125 GeV with the CMS experiment at the LHC. Phys. Lett. B 716, 30 (2012). doi:10.1016/j.physletb.2012.08.021, arXiv:1207.7235
G. Degrassi et al., Higgs mass and vacuum stability in the Standard Model at NNLO. J. High Energy Phys. 08, 098 (2012). doi:10.1007/JHEP08(2012)098, arXiv:1205.6497
S. Alekhin, A. Djouadi, S. Moch, The top quark and Higgs boson masses and the stability of the electroweak vacuum. Phys. Lett. B 716, 214 (2012). doi:10.1016/j.physletb.2012.08.024, arXiv:1207.0980
ATLAS Collaboration, Measurement of the top quark mass with the template method in the \(\mathrm{t}\overline{\mathrm{t}} \to \mathrm{lepton} + \mathrm{jets}\) channel using ATLAS data. Eur. Phys. J. C 72, 2046 (2012). doi:10.1140/epjc/s10052-012-2046-6, arXiv:1203.5755
CMS Collaboration, Measurement of the top-quark mass in \(\mathrm {t}\overline{\mathrm{t}} \) events with lepton+jets final states in pp collisions at \(\sqrt{s}=7\mbox{~TeV}\). J. High Energy Phys. 12, 105 (2012). doi:10.1007/JHEP12(2012)105, arXiv:1209.2319
CMS Collaboration, Measurement of the top-quark mass in \(\mathrm {t}\overline{\mathrm{t}} \) events with dilepton final states in pp collisions at \(\sqrt{s}=7\mbox{ TeV}\). Eur. Phys. J. C 72, 2202 (2012). doi:10.1140/epjc/s10052-012-2202-z, arXiv:1209.2393
CDF and D0 Collaboration, Combination of the top-quark mass measurements from the tevatron collider. Phys. Rev. D 86, 092003 (2012). doi:10.1103/PhysRevD.86.092003, arXiv:1207.1069
M. Burns et al., Using subsystem MT2 for complete mass determinations in decay chains with missing energy at hadron colliders. J. High Energy Phys. 03, 143 (2009). doi:10.1088/1126-6708/2009/03/143, arXiv:0810.5576
A.J. Barr, C.G. Lester, A review of the mass measurement techniques proposed for the Large Hadron Collider. J. Phys. G 37, 123001 (2010). doi:10.1088/0954-3899/37/12/123001, arXiv:1004.2732
C.G. Lester, D.J. Summers, Measuring masses of semi-invisibly decaying particle pairs produced at hadron colliders. Phys. Lett. B 463, 99 (1999). doi:10.1016/S0370-2693(99)00945-4, arXiv:hep-ph/9906349
W.S. Cho et al., Measuring the top quark mass with m(T2) at the LHC. Phys. Rev. D 78, 034019 (2008). doi:10.1103/PhysRevD.78.034019, arXiv:0804.2185
CDF Collaboration, Top quark mass measurement using mT2 in the dilepton channel at CDF. Phys. Rev. D 81, 031102 (2010). doi:10.1103/PhysRevD.81.031102, arXiv:0911.2956
I.I.Y. Bigi et al., Pole mass of the heavy quark: perturbation theory and beyond. Phys. Rev. D 50, 2234 (1994). doi:10.1103/PhysRevD.50.2234, arXiv:hep-ph/9402360
M.C. Smith, S.S. Willenbrock, Top-quark pole mass. Phys. Rev. Lett. 79, 3825 (1997). doi:10.1103/PhysRevLett.79.3825, arXiv:hep-ph/9612329
A.H. Hoang, I.W. Stewart, Top mass measurements from jets and the tevatron top-quark mass. Nucl. Phys. B, Proc. Suppl. 185, 220 (2008). doi:10.1016/j.nuclphysbps.2008.10.028, arXiv:0808.0222
CMS Collaboration, The CMS experiment at the CERN LHC. J. Instrum. 3, S08004 (2008). doi:10.1088/1748-0221/3/08/S08004
CMS Collaboration, Particle–flow event reconstruction in CMS and performance for jets, taus, and \(E_{\mathrm{T}}^{\text{miss}}\). CMS physics analysis summary CMS-PAS-PFT-09-001 (2009). http://cdsweb.cern.ch/record/1194487
CMS Collaboration, Commissioning of the particle-flow event reconstruction with the first LHC collisions recorded in the CMS detector. CMS physics analysis summary CMS-PAS-PFT-10-001 (2010). http://cdsweb.cern.ch/record/1247373
M. Cacciari, G.P. Salam, G. Soyez, The anti-k t jet clustering algorithm. J. High Energy Phys. 04, 063 (2008). doi:10.1088/1126-6708/2008/04/063, arXiv:0802.1189
CMS Collaboration, Determination of jet energy calibration and transverse momentum resolution in CMS. J. Instrum. 6, P11002 (2011). doi:10.1088/1748-0221/6/11/P11002, arXiv:1107.4277
CMS Collaboration, Identification of b-quark jets with the CMS experiment. J. Instrum. 8, P04013 (2012). doi:10.1088/1748-0221/8/04/P04013, arXiv:1211.4462
CMS Collaboration, Measurement of the \(t\bar{t}\) production cross section in the dilepton channel in pp collisions at \(\sqrt{s}=7\mbox{~TeV}\). J. High Energy Phys. 1211, 067 (2012). doi:10.1007/JHEP11(2012)067, arXiv:1208.2671
CMS Collaboration, Measurement of the top-quark mass in \(t\bar{t}\) events with dilepton final states in pp collisions at \(\sqrt{s}=7\mbox{~TeV}\). Eur. Phys. J. C 72, 2202 (2012). doi:10.1140/epjc/s10052-012-2202-z, arXiv:1209.2393
D.R. Tovey, On measuring the masses of pair-produced semi-invisibly decaying particles at hadron colliders. J. High Energy Phys. 04, 034 (2008). doi:10.1088/1126-6708/2008/04/034, arXiv:0802.2879
P. Konar et al., Superpartner mass measurement technique using 1D orthogonal decompositions of the Cambridge transverse mass variable M T2. Phys. Rev. Lett. 105, 051802 (2010). doi:10.1103/PhysRevLett.105.051802, arXiv:0910.3679
K.T. Matchev, M. Park, A general method for determining the masses of semi-invisibly decaying particles at hadron colliders. Phys. Rev. Lett. 107, 061801 (2011). doi:10.1103/PhysRevLett.107.061801, arXiv:0910.1584
S. Frixione, B.R. Webber, Matching NLO QCD computations and parton shower simulations. J. High Energy Phys. 06, 029 (2002). doi:10.1088/1126-6708/2002/06/029, arXiv:hep-ph/0204244
T. Sjöstrand, S. Mrenna, P. Skands, PYTHIA 6.4 physics and manual. J. High Energy Phys. 05 (2006). doi:10.1088/1126-6708/2006/05/026, arXiv:hep-ph/0603175
J. Alwall et al., MadGraph 5: going beyond. J. High Energy Phys. 06, 128 (2011). doi:10.1007/JHEP06(2011)128, arXiv:1106.0522
B.W. Silverman, Density Estimation for Statistics and Data Analysis. Monographs on Statistics and Applied Probability (Chapman and Hall, London, 1986)
J. Beringer et al. (Particle Data Group), Review of particle physics. Phys. Rev. D 86, 010001 (2012). doi:10.1103/PhysRevD.86.010001
B. Efron, R. Tibshirani, An Introduction to the Bootstrap. Monographs on Statistics and Applied Probability (Chapman & Hall, London, 1993)
A.J. Canty, A.C. Davison, Resampling-based variance estimation for labour force surveys. J. R. Stat. Soc. 48, 379 (1999). doi:10.1111/1467-9884.00196
R. Barlow, Application of the bootstrap resampling technique to particle physics experiments. Manchester University Preprint, MAN/HEP/99/4 (1999)
D. Curtin, Mixing it up with M T2: unbiased mass measurements at hadron colliders. Phys. Rev. D 85, 075004 (2012). doi:10.1103/PhysRevD.85.075004, arXiv:1112.1095
P.Z. Skands, Tuning Monte Carlo generators: the Perugia tunes. Phys. Rev. D 82, 074018 (2010). doi:10.1103/PhysRevD.82.074018, arXiv:1005.3457 (Updated 2011 in arXiv:1005.3457v4)
S. Chang, A. de Gouvêa, Neutrino alternatives for missing energy events at colliders. Phys. Rev. D 80, 015008 (2009). doi:10.1103/PhysRevD.80.015008, arXiv:0901.4796
Acknowledgements
We congratulate our colleagues in the CERN accelerator departments for the excellent performance of the LHC and thank the technical and administrative staffs at CERN and at other CMS institutes for their contributions to the success of the CMS effort. In addition, we gratefully acknowledge the computing centres and personnel of the Worldwide LHC Computing Grid for delivering so effectively the computing infrastructure essential to our analyses. Finally, we acknowledge the enduring support for the construction and operation of the LHC and the CMS detector provided by the following funding agencies: the Austrian Federal Ministry of Science and Research and the Austrian Science Fund; the Belgian Fonds de la Recherche Scientifique, and Fonds voor Wetenschappelijk Onderzoek; the Brazilian Funding Agencies (CNPq, CAPES, FAPERJ, and FAPESP); the Bulgarian Ministry of Education, Youth and Science; CERN; the Chinese Academy of Sciences, Ministry of Science and Technology, and National Natural Science Foundation of China; the Colombian Funding Agency (COLCIENCIAS); the Croatian Ministry of Science, Education and Sport; the Research Promotion Foundation, Cyprus; the Ministry of Education and Research, Recurrent financing contract SF0690030s09 and European Regional Development Fund, Estonia; the Academy of Finland, Finnish Ministry of Education and Culture, and Helsinki Institute of Physics; the Institut National de Physique Nucléaire et de Physique des Particules/CNRS, and Commissariat à l’Énergie Atomique et aux Énergies Alternatives/CEA, France; the Bundesministerium für Bildung und Forschung, Deutsche Forschungsgemeinschaft, and Helmholtz-Gemeinschaft Deutscher Forschungszentren, Germany; the General Secretariat for Research and Technology, Greece; the National Scientific Research Foundation, and National Office for Research and Technology, Hungary; the Department of Atomic Energy and the Department of Science and Technology, India; the Institute for Studies in Theoretical Physics and Mathematics, Iran; the Science Foundation, Ireland; the Istituto Nazionale di Fisica Nucleare, Italy; the Korean Ministry of Education, Science and Technology and the World Class University program of NRF, Republic of Korea; the Lithuanian Academy of Sciences; the Mexican Funding Agencies (CINVESTAV, CONACYT, SEP, and UASLP-FAI); the Ministry of Science and Innovation, New Zealand; the Pakistan Atomic Energy Commission; the Ministry of Science and Higher Education and the National Science Centre, Poland; the Fundação para a Ciência e a Tecnologia, Portugal; JINR (Armenia, Belarus, Georgia, Ukraine, Uzbekistan); the Ministry of Education and Science of the Russian Federation, the Federal Agency of Atomic Energy of the Russian Federation, Russian Academy of Sciences, and the Russian Foundation for Basic Research; the Ministry of Science and Technological Development of Serbia; the Secretaría de Estado de Investigación, Desarrollo e Innovación and Programa Consolider-Ingenio 2010, Spain; the Swiss Funding Agencies (ETH Board, ETH Zurich, PSI, SNF, UniZH, Canton Zurich, and SER); the National Science Council, Taipei; the Thailand Center of Excellence in Physics, the Institute for the Promotion of Teaching Science and Technology of Thailand and the National Science and Technology Development Agency of Thailand; the Scientific and Technical Research Council of Turkey, and Turkish Atomic Energy Authority; the Science and Technology Facilities Council, UK; the US Department of Energy, and the US National Science Foundation.
Individuals have received support from the Marie-Curie programme and the European Research Council and EPLANET (European Union); the Leventis Foundation; the A.P. Sloan Foundation; the Alexander von Humboldt Foundation; the Belgian Federal Science Policy Office; the Fonds pour la Formation à la Recherche dans l’Industrie et dans l’Agriculture (FRIA-Belgium); the Agentschap voor Innovatie door Wetenschap en Technologie (IWT-Belgium); the Ministry of Education, Youth and Sports (MEYS) of Czech Republic; the Council of Science and Industrial Research, India; the Compagnia di San Paolo (Torino); and the HOMING PLUS programme of Foundation for Polish Science, cofinanced from European Union, Regional Development Fund.
Open Access
This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
Author information
Authors and Affiliations
Consortia
Appendix: Analytical resolution functions for μ ℓℓ
Appendix: Analytical resolution functions for μ ℓℓ
We present the analytical forms of the resolution functions used in the μ ℓℓ fits, together with a brief summary of their derivation.
The leptons used in computing μ ℓℓ are approximately massless and therefore the M T2⊥ variable may be written [27] as
where (p Ti ,ϕ i ) are the transverse coordinates of lepton i∈{1,2} and \({\phi_{\text{US}}}\) is the azimuthal angle of the upstream momentum in the CMS reference frame.
If the upstream P T vector happens to lie between the two lepton vectors p T1 and p T2, so that \(\phi_{1}-{\phi_{\text{US}}}>0\) and \(\phi _{2}-{\phi_{\text{US}}}<0\) (or vice-versa) then the value of μ ℓℓ is identically zero. This is the origin of the delta function in Eq. (4.4). It is convenient to measure \({\phi_{\text{US}}}\) from the midline between the lepton p T vectors rather than from the CMS-defined x axis, and hence we define \({\varPhi}\equiv {\phi_{\text{US}}}-\frac{1}{2}(\phi_{1}+\phi_{2})\). We also define the separation between the two lepton vectors: Δϕ≡ϕ 1−ϕ 2.
Equation (A.1) can now be rewritten as:
To streamline the notation, we have dropped the subscript ℓℓ. (In any case these remarks apply only to calculations on the ℓℓ system.)
The leptonic observables p T1, p T2, ϕ 1, and ϕ 2 are well-measured compared to the direction of the upstream jets, Φ, and thus the resolution of μ(Φ) in a given event depends only on the Φ resolution, with the leptonic observables treated as fixed parameters. The distribution of Φ is well-approximated by a Gaussian form, with σ Φ ≪π; we ignore small non-Gaussian tails.
The functional form given in Eq. (A.2) is maximal at Φ=π/2, falls to zero on either side at \({\varPhi}={\pm}\frac{1}{2}\Delta\phi\), and is exactly zero in the neighboring regions \([0,\frac{\pi}{2}-\frac {1}{2}\Delta\phi]\) and \([\frac{\pi}{2}+\frac{1}{2}\Delta\phi,\pi]\). The function is periodic in Φ with period π, but because of the condition σ Φ ≪π we restrict our attention to the interval 0≤Φ≤π. For the non-zero portion of μ(Φ) there is also an inverse function:
The inverse function Φ(μ) is double-valued as one value of μ maps to two values of Φ located symmetrically on either side of π/2. The maximum value of μ, here denoted μ max, is the largest value μ can take on for the given the lepton momentum vectors; it corresponds to Φ=π/2 where the lepton bisector is orthogonal to the upstream momentum. It should not be confused with the endpoint of the μ distribution, which, in addition to the upstream momentum orientation Φ=π/2, also requires extreme lepton kinematics: p T1 p T2 maximal and Δϕ=0 (leptons collinear).
To map the Gaussian PDF G(Φ|σ Φ ) into a resolution function R 1(μ), we write:
where the sum is over the two branches of the double-valued Φ(μ). The derivatives of Φ(μ) and μ(Φ) have simple analytic forms.
In the region where μ(Φ)=0, R(μ) is a delta function R 0 δ(μ) whose amplitude R 0 is given by the area under G(Φ|σ Φ ) in the angular region between the two leptons, \(R_{0}\equiv\int_{-\Delta\phi/2}^{\Delta\phi/2}G({\varPhi}|\sigma _{{\varPhi}})\,\mathrm {d}{\varPhi}\). Thus the total resolution function is given by
where Θ(μ) is the unit step function transitioning from 0 to 1 at μ=0.
Figure 9 shows two representative cases, showing the range of resolution function behavior from Gaussian to sharply peaked. In the latter case the delta function R 0 δ(μ) is not plotted. In the top panel the Φ is midway between the extremes \({\pm}\frac{1}{2}\Delta\phi\) and π/2 and the σ Φ is relatively narrow; in the bottom panel, Φ is closer to π/2 and has a large value of σ Φ that allows smearing into the \(-\frac{1}{2}\Delta\phi<{\varPhi}<\frac {1}{2}\Delta\phi\) region. The high bin at −45 GeV in the histogram component of the bottom panel contains events in which the resolution smearing of the upstream momentum vector pushed the μ ℓℓ value into the delta function at μ ℓℓ =0. In the analytic form, the corresponding feature would be the delta function R 0 δ(μ); but, as noted above, this has not been explicitly drawn.

Example resolution functions. The panels show two events with different lepton and upstream momentum kinematics, as discussed in the text. The dotted curve is a Gaussian with a σ given by the linearly propagated uncertainties; and the solid curve is the analytic form of the resolution function, given in Eq. (A.4). The histogram is created by numerically propagating resolutions in the underlying parameters
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
The CMS Collaboration., Chatrchyan, S., Khachatryan, V. et al. Measurement of masses in the \(\mathrm{t}\overline{\mathrm{t}}\) system by kinematic endpoints in pp collisions at \(\sqrt{s}=7\ \mathrm{TeV}\) . Eur. Phys. J. C 73, 2494 (2013). https://doi.org/10.1140/epjc/s10052-013-2494-7
Received:
Revised:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-013-2494-7