
Abstract
Technological advancement of measurement systems has enhanced the accuracy of power quality assessment by using a combination of measured information. This paper proposes a novel approach for estimating power quality based on information fusion technique of Dempster-Shafer (D-S) evidence theory. First, in order to accurately extract transient features regarding power quality indexes, wavelet packet transform and lifting wavelet transform are proposed to detect various disturbance signals’ measurement. By using many kinds of transformed transient indexes and steady state indexes, a novel reliability distribution function is constructed, and synthesized assessment index of power quality is drafted based on information fusion technique of D-S evidence theory. Finally, the simulation results prove that D-S evidence theory is a more effective means for evaluating the power quality.
Similar content being viewed by others

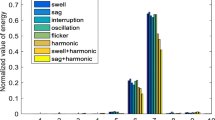
1 Introduction
The power quality (PQ) is one of the most important parameter in power systems: 1) PQ impacts the production process of industry users. The problems in PQ may result in decreasing of operating benefit, life span of equipment and product quality, etc. 2) PQ impacts the security of information system. The problems in PQ may result in the loss of information. 3) PQ is closely related to manufacturing industry of electric equipment. The problems of PQ may impact extension activities of new products or new technology from manufacturing company. The problems of PQ in present electric network are more serious. On one hand, a large number of nonlinear loads, impulsive loads and fluctuant loads, as well as various power electronic equipments and new energy resources are connected into electrical network, so that the electrical network is seriously polluted. On the other hand, up-to-date working of computer systems and automation control systems, etc., depend on better operating environment of electrical network. Therefore, effective power quality assessment is very essential to establish a friendly operating environment of electrical network.
PQ contains a variety of indexes, such as a variation in voltage or current, voltage dips and fluctuations, transient interruptions, harmonic and oscillatory transients caused by a failure or a mal-operation of protection equipments, etc.[1] Users can choose different assessment grades of PQ according to their different demands[2]. Some power quality indexes, especially voltage dips and transient interruptions are considered more and more important for estimating PQ. And how to effectively extract the usable features of transient indexes is a key issue. In the last few years, with respect to the PQ assessment problem, many searches proposed several relevant approaches including the fuzzy mathematic method[3, 4], decision tree assessment[5], expert system[6], support vector machine[7], projection pursuit model[8], etc.
In this paper, considering that PQ contains both transient and steady indexes, in order to extract available transient indexes regarding PQ assessment, we employ wavelet packet transform and lifting wavelet transform to capture transient features, such as initiating time and end time of abnormal signals. Corresponding to different transient indexes and steady indexes, reliability distribution functions are constructed. Based on these reliability distribution functions, synthesized assessment index of power quality is determined based on information fusion technique of D-S evidence theory. Finally, the simulation results prove that D-S evidence theory is a more effective means for evaluating the power quality.
2 PQ assessment indexes
2.1 Composition of PQ assessment system
PQ assessment is a comprehensive problem because it concerns many different indexes. As a result, power quality assessment system consists of many kinds of indexes divided into steady state and transient state. And the composition of PQ assessment system is shown as Fig. 1.

The composition of PQ assessment system
2.2 Formulation of PQ assessment indexes
1) Voltage deviation
In power systems, there is voltage variation when the system runs normally. It is denoted by ΔU[9]. The variations of the voltage can serve as a characteristic indication. Here, the relative variations of the voltage act as a characteristic index as
where U is real voltage, and U e is rated voltage.
2) Voltage fluctuation and flicker
Voltage fluctuation represents two extreme values of the voltage, U min and U max as
Voltage flicker usually happens in the load peak, and it belongs to the fluctuation of voltage amplitude.
3) Voltage three-phase unbalance
Using ε U to measure the degree of unbalance in three-phases of voltage, it is given as
where U 2 is root-mean-square value of negative-sequence voltage, and U 1 is root-mean-square value of positive-sequence voltage.
4) Harmonic
According to the rule of public grid harmonics, for alternating current (AC) rated frequency (50 Hz), the voltage total harmonic distortion should be less than 5% of nominal voltage, which is about 0.38kV. Moreover, the rate of odd harmonics should be lower than 4%, and the rate of even harmonics should be lower than 2%. Generally, the percentage of harmonic amplitude is relative to the fundamental amplitude, and it is represented as follows:
where U k represents the root-mean-square value of k-th time harmonic. Then in order to reflect the total harmonic content, the total harmonic distortion is given as
where N is the highest time of the detected harmonic.
5) Voltage sags
Voltage sag means that the root-mean-square value of voltage is dropped to 10% from 90% of the rated voltage amplitude in a short time during 0.5 cycles∼30 cycles, and the voltage amplitude recovers to normal value after 10 ms∼1 min. Voltage sag is denoted as ΔUD. The change of voltage amplitude is usually detected by measuring the root-mean-square value of voltage.
6) Voltage rise
Voltage rise means that the root-mean-square value of voltage rises to 110%–180% of the rated voltage during 0.01s–60s. Voltage rise is denoted as ΔUR.
7) Voltage interruption
If the root-mean-square value of voltage is near to zero, it was called as voltage interruption.
8) Frequency deviation
Frequency deviation is formulated as
where f r is the rated frequency (50Hz) and f is the real frequency (Hz).
9) The reliability of power supply
For reliability of power supply (I R ), generally, it represents the ability of power system to supply power continuously. Taking one year as an example, the reliability of power supply is given as
where I N represents the total failure time of power supply in one year. I T represents the total time of one year.
10) Service indicator
For users, demand-side management (DSM) means the service of electricity commodity. The electricity supplying sectors formulate the model of DSM and recommend energy saving equipment to users, which makes the users change the way of using electricity. In this way, users can reduce the cost of electricity by electricity services.
2.3 Grade standards of PQ assessment indexes
In general, the ranks of PQ assessment indexes are divided into abnormal quality, ordinary quality and high quality[10]. However, these ranks are very general and cannot accurately assess PQ.
In this paper, the ranks of PQ assessment indexes are divided as G = g 1, g 2, g 3, g 4, g 5, where, g 1 is the optimal quality, g 2 is high quality, g 3 is good, g 4 is ordinary, and g 5 is failure. According to the above ranks, based on [11], there is power quality determination of grade standards as shown in Table 1.
3 Feature extraction and PQ transient assessment indexes
3.1 Select an optimal wavelet basis for characterization of power signals
Wavelet transform has found application in numerous signal and image processing tasks. It is well known that the fundamental idea of wavelet transform is to analyze the signal at different scales or resolutions[12]. Wavelets are a class of functions, which are used to localize a given signal in both space and scaling domains. That is called multi-resolution. The application result of wavelet multi-resolution analysis depends on the choice of the wavelet basis[13]. Although wavelet basis is the core of the wavelet transform, but it is not unique. For transient signals in power system, an optimal wavelet basis was obtained by taking into account these properties which are regularity, high vanishing moments, orthogonal, degree of shift variance, time-frequency resolution, linear phase, etc. Daubechies experts have demonstrated that continuous, short support and orthogonal scaling function and wavelet function are not symmetric. There are conflicts between symmetry and orthogonality[14, 15]. In the practical application, according to different signals and different research purposes, the choice of wavelet basis is not identical. So, among the rules, the most important thing is the choice of wavelet basis, wavelet decomposed layers and wavelet coefficients.
3.2 Db4 lifting wavelet transform
Db wavelet is an orthogonal and short support wavelet. It is the most useful wavelet because it has better features to detect the singularity of signal[16, 17]. In db wavelet group, db4 wavelet has the shortest time windows and time resolution compared with other members[18–20]. The Db4 wavelet, which has four wavelet and scaling function coefficients, is the most widely used in practical application. The scaling function and wavelet function coefficients are given as
If the initial data set consists of N values, the scaling function and wavelet function will be applied to calculate N/2 differences, it means that the forward lifting wavelet transform divides the data set being processed into an even half and an odd half[21].
Db4 scaling function a [i] and wavelet function c [i] are shown as
The lifting wavelet transform is divided into three steps: split, predict and update[22]. The decomposition principle of lifting wavelet transform is shown in Fig. 2.

Db4 lifting wavelet transform algorithm
In Fig. 2, firstly, the split step divides the original data into even elements which are stored in the lower half of N element (S 0 to S half–1) and odd elements which are stored in the upper half of the N element (S half to S N–1 ). S [half+j] refers to an odd element and S[j] references an even element. Secondly, update 1 step, as given by (13) is carried out. During the process, the even elements are updated by odd elements in (13). Then, predict step is implemented. During the process, the even elements are left unchanged as input for next step (the predict step), and the odd elements are predicted from the even element by (14). Thirdly, the even elements are updated by new odd elements in (15)[23]. At last, after normalization step, the new even elements and new odd elements are stored in N1 and N2.
Update 1:
where j ∈ [0, half – 1], half = N/2. Predict:
Update 2:
Normalize:
From these formulas, we can get a conclusion: the Db4 lifting wavelet transform has good performance, and it does not take additional space when wavelet transform.
3.3 Determine the best decomposition layer
With the purpose of detecting and extracting power quality disturbances, we must determine the decomposition levels which can divide the signal band correctly. Band division principle is to make the low frequency signal located in the center of the lowest sub-band. Fig. 3 indicates that the decomposition level has an effect on canceling noise of signal. To get better denoising, not only appropriate wavelet function should be selected, but the best decomposition layer and threshold must be determined. The layers of band division can be calculated as
where f s is the sampling frequency and f b is the fundamental frequency. In this paper, f s = 3200 Hz, f b = 50 Hz, we can get m = 4.

Different wavelet basis and layers by including noise signal
From Fig. 3, the signal processing result shows that noise can be cancelled efficiently by choosing suitable wavelet function and decomposition levels.
3.4 Feature extraction of transient indexes basedonDb4 LWT
When db4 is used in non-stationary signals, we can obtain better analysis result. The voltage sags, voltage rise, and voltage interruption are mainly described by the amplitude and duration of time. So, in this section, with respect to these transient power quality disturbances, we employ db4 wavelet to detect changes of amplitude and time duration. Figs. 3 and 4 display the comparison of other wavelet transforms. Fig. 3 gives the analysis signals of voltage sags including an original signal of the voltage sag and db4 wavelet coefficients based on wavelet transform (WT), wavelet packet transform (WPT) and lifting wavelet transform (LWT), respectively.

Comparison of wavelet transforms for voltage sag
From Fig. 4, it can be seen that the db4 lifting wavelet transform can locate start-stop times of voltage sags more accurately. Similarly, the analysis of voltage interruption and common signal are shown as Figs. 4 and 5.

Comparison of wavelet transforms for voltage interruption
From Figs. 5 and 6, it is also shown that the db4 lifting wavelet transform can detect start-stop times of voltage interruption and common signal more effectively.

Comparison of the wavelet transform for common signals
4 Total probability theorem
The total probability theorem is a theorem of the probability calculus that is useful in solving fusion information problems of probability.
There are some mutually exclusive events, A 1, A 2, ⋯, A n . If Ω is composed of A 1, A 2, ⋯, A n , then
where B is an arbitrary event, and P(B|A j ) is the conditional probability of B given A j .
In this paper, the meaning of A i are the indexes of power quality. P(B i ) means the probability value of A j which belongs to the level g i .
5 Information fusion based on D-S evidence theory
5.1 Construction of recognition framework of power quality assessment
According to the criteria of D-S evidence theory, firstly, a frame of discernment of power quality assessment should be constituted. In this paper, the ranks of PQ assessment indexes are denoted by g 1, g 2, g 3, g 4, g 5 as shown in Table 1. Therefore, the frame of discernment is
The remaining reliability is assigned to the frame of discernment because of each evidence supports a single proposition[24]. With respect to the evidence theory, its cores are made of every subset and the frame of discernment. It is represented by
5.2 Basic probability assignment (BPA) function
The evidence needs a rating credibility by using the basic probability assignment function. In the same frame of discernment, using D-S evidence theory, two evidences can merge to form new evidence. At last, the final assessment decision could be made.
If Φ denotes frame of discernment, when Θ is determined, basic probability distribution function map the frame Θ to [0, 1]. The basic probability distribution function is defined by m : Θ → [0, 1], A ⊆ 6, and m (A) > 0, if
where m (A) is called the basic belief in the distribution function of A, which means the trust of A, and A is a focal element of the basic probability functions.
Due to B ⊆ A ⊂ Θ, as a basic probability function, is a mapping from 2Θ to [0, 1], and A ⊆ Θ, where
where Bel (A) shows the trust level for A. The belief function represents the weight of evidence supporting the likelihood of the hypothesis A[25].
5.3 Structure reliability distribution function
The criteria of constituting reliability distribution function are
-
1)
The characteristic indexes must act as independent variables of the reliability distribution function.
-
2)
The probability assignment of every basic probability function must possess ignorance component.
Based on the above requirements and various assessment indexes, the reliability distribution function is constructed as
where m j (g i ) represents the reliability distribution function of the factor (j) at power quality rank i. N is the total number of indexes. j is the number of the body of evidence (j = 1, 2, 3, ⋯, N), k is a correction factor. w j is the weight coefficient, w j ∈ [0, 1] and \(\sum\nolimits_{j = 1}^N {{w_j} = 1} \). By comparing the priority orders of different stability degree indexes, different weightings will be assigned to basic probability functions. \({\alpha _j} = \max \{ {P_j}({g_i})\}, \, {\alpha _j}\), α j is the maximum probability of j-th index when it is at g i . \({\beta _j} = {w_j}{\alpha _j}/\sum\nolimits_{i = 1}^5 {{P_j}} ({g_i})\) is the maximum relative probability of j-th index when it is at \({g_i}\cdot\gamma = {\alpha _j}{\beta _j}/\sum\nolimits_{j = 1}^N {{\alpha _j}} {\beta _j}\) means the reliability coefficient of the j-th evidence.
where mj (Θ) denotes the basic probability assignment of the uncertainty for the j-th evidence.
5.4 Fusion criteria of D-S evidence
The D-S theory of evidence belongs to decision-level fusion in information fusion. The two evidences are fused by using D-S evidence theory as follows:

where A i , B j ∈ 2Θ, k(k < 1), denotes the conflict degree between both evidences. If the value of k is higher, it indicates that the conflict is bigger among the sources, and the fusion result is available. When k = 1, it means that both of the evidences are completely conflict, in this situation, the fusion result is unavailable[26].
Dempster’s combination rule can be generalized to more than two hypotheses. So, other indexes can be fused by the above fusion criterion as PQ assessment result. Ultimately, we can reach a decision on classification and recognition according to fusion result.
6 Simulation example
We verify the proposed information fusion method to deal with the power quality assessment problem. Table 2 shows the reliability distribution function of indexes of power quality. And the fusion results are shown in Fig. 6.
Firstly, m 1 and m 2 are fused according to the above fusion criteria as
Similarly, the other evidences can be fused by above algorithm step by step.
From Fig. 7, it can be seen that the fusion results based on D-S evidence theory can effectively determine the grade of PQ assessment.

The fusion result of D-S evidence theory
From Fig. 8, it can be seen that the D-S evidence theory information fusion can obtain assessment result better than the total probability theorem as well the supporting degree of the fusion result based on D-S evidence is higher than total probability formula. It is more important that with respect to uncertain problem, the fusion uncertainty based on D-S evidence theory is lower than the other methods.

Comparison of information fusion results under two methods
With the increase of the number of body evidences, the certainty of simulation result improved further. From Fig. 9, the uncertainty has reduced to 0.0004, which is negligible. All this illustrates that D-S theory of evidence is suitable for PQ assessment where there exists massive uncertainty.

The uncertainty of D-S evidence theory fusion result
7 Conclusions
In this paper, based on various indexes formulated for power quality assessment, we proposed the information fusion technique of D-S evidence theory to precisely assess power quality. Through simulation and comparison, we employ the most effective db4 LWT to decompose transient features of PQ indexes and use WPT to reconstruct signals. Based on multiple indexes extracted, we developed D-S evidence theory to realize the information fusion in order to determine the power quality assessment. Simulation results indicate the proposed D-S evidence method based LWT can effectively determine the grade of PQ assessment.
References
K. R. Krishnanand, S. K. Nayak, B. K. Panigrahi, V. R. Pandi, P. Dash. Classification of power quality disturbances using GA based optimal feature setion. In Proceedings of the 3rd International Conference on Pattern Recognition and Machine Intelligence, Lecture Notes in Computer Science, Springer-Verlag, New Delhi, India, vol. 5909, pp. 561–566, 2009.
S. Kaewarsa, K. Attakitmongcol, W. Krongkitsiri. Wavelet-based intelligent system for recognition of power quality disturbance signals. In Proceedings of the 3rd International Symposium on Neural Networks, Lecture Notes in Computer Science, Springer, Chengdu, China, vol. 3972, pp. 1378–1385, 2006.
A. Kumar, S. K. Choi, L. Goksel. Tolerance allocation of assemblies using fuzzy comprehensive evaluation and decision support process. International Journal of Advanced Manufacturing Technology, vol. 5, no. 1–4, pp. 379–391, 2011.
M. Kowal, J. Korbicz. Fault detection under fuzzy model uncertainty. International Journal of Automation and Computing, vol. 4, no. 2, pp. 117–124, 2003.
H. M. Liu, F. Qu, X. Y. Chen, G. Y. Xue. Comprehensive assessment of power quality based on the model tree. Power Demand Side Management, vol. 10, no. 3, pp. 19–23, 2008. (in Chinese)
O. Leila, E. Noor, B. Ahmad, A. Azuraliza, B. Khairul, N. Maulud. An expert system applied in storm water management plan for construction sites in Malaysia. Expert Systems with Application, vol. 39, no. 3, pp. 3692–3701, 2012.
X. Chen, T. Limchimchol. Monitoring grinding wheel redress-life using support vector machines. International Journal of Automation and Computing, vol. 3, no. 1, pp. 56–62, 2006.
B. H. Fang, Z. H. Cheng, H. P. Liu. Application of projection pursuit model in integrated evaluation of national economy. Operations Research and Management Science, vol. 14, no. 5, pp. 85–88, 2005. (in Chinese)
J. Wiley, S. Ltd. Handbook of Power Quality, Italy: Angelo Baggini University of Bergamo, pp. 631–644, 2008.
L. Chen, Y. H. Xu. Discussion about the methods of evaluating power quality. North China Electric Power University, vol. 24, no. 1, pp. 58–61, 2005. (in Chinese)
L. Zhou, Q. H. Li, F. Zhang. Application of genetic projection pursuit interpolation model on power quality synthetic evaluation. Power System Technology, vol. 31, no. 7, pp. 32–35, 2007. (in Chinese)
W. G. Morsi, M. E. El-Hawary. Wavelet packet transform-based power quality indices for balanced and unbalanced three-phase systems under stationary or nonstationary operating conditions. IEEE Transactions on Power Delivery, vol. 24, no. 4, pp. 2300–2310, 2009.
A. M. Gaouda, M. M. A. Salaam, M. R. Sultan, A. Y. Chikhani. Power quality detection and classification using wavelet multi-resolution signal decomposition. IEEE Transactions on Power Delivery, vol. 14, no. 4, pp. 1469–1476, 1999.
L. H. Wang, S. Y. Yang, R. H. Du. Selection and application of mother wavelet in the analysis of transient signals. China Power, vol. 41, no. 10, pp. 27–29, 2008. (in Chinese)
H. Liu, L. P. Zhai, Y. Gao, W. M. Li, J. F. Zhou. Image compression based on biorthogonal wavelet transform. In Proceedings of IEEE International Symposium on Communications and Information Technology, IEEE, Beijing, China, vol. 1, pp. 598–601, 2005.
X. B. Guo, Q. X. Gao. Research of voltage transient disturbance detection based on wavelet transform. Microcomputer Information, vol. 25, no. 3, pp. 208–209, 2009. (in Chinese)
J. P. Qi, W. F. Yuan. Detection algorithm of transient power quality disturbance based on wavelet transformation. Journal of Shenzhen Institute of Information Technology, vol. 9, no. 1, pp. 69–71, 2011. (in Chinese)
H. Liu, G. H. Liu, Y. Sheng. A novel real time harmonic detection method using fast lifting wavelet transform. Journal of Jiangsu University (Natural Science Edition), vol. 30, no. 3, pp. 288–291, 2009. (in Chinese)
P. K. Parlewar, K. M. Bhurchandi. A 4-quadrant curvelet transform for denoising digital images. International Journal of Automation and Computing, vol. 10, no. 3, pp. 217–226, 2013.
W. Liu. Wideband beamforming for multipath signals based on frequency invariant transformation. International Journal of Computer Applications, vol. 9, no. 4, pp. 420–428, 2012.
W. Sweldens. The lifting scheme: A custom-design construction of biorthogonal wavelets. Applied and Computational Harmonic Analysis, vol. 3, no. 2, pp. 186–200, 1996.
G. Quellec, M. Lamard, G. Cazuguel, B. Cochener, C. Roux. Adaptive non-separable wavelet transform via lifting and its application to content-based image retrieval. IEEE Transactions on Image Processing, vol. 19, no. 1, pp. 25–35, 2010.
S. J. Yuan. Application of db4 wavelet in power network fault detection. Microcomputer Information, vol. 27, vol. 6, pp. 51–52, 2011. (in Chinese)
Q. Q. Jia. Study of earth fault detection for power distribution networks based on D-S evidence theory. China Power, vol. 40, no. 1, pp. 28–31, 2007. (in Chinese)
M. Shoyaib, M. Abdullah-Al-Wadud, O. Chae. A reliable skin detection using Dempster-Shafer theory of evidence. In Proceedings of International Conference on Computational Science and Its Applications, Lecture Notes in Computer Science, Springer, Seoul, Korea, vol. 5593, pp. 764–779, 2009.
K. H. Guo, W. L. Li. Combination rule of D-S evidence theory based on the strategy of cross merging between evidences. Expert Systems with Applications, vol. 38, no. 10, pp. 13360–13366, 2011. (in Chinese)
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by National Natural Science Foundation of China (No. 51177142) and Natural Science Foundation of Hebei Province (No. F2012203063)
Rights and permissions
About this article

Cite this article
Dou, CX., Gui, T., Bi, YF. et al. Assessment of Power Quality Based on D-S Evidence Theory. Int. J. Autom. Comput. 11, 635–643 (2014). https://doi.org/10.1007/s11633-014-0837-y
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11633-014-0837-y