
Abstract
This paper investigates the dynamics of infectious diseases with a non-exponentially distributed infectious period. This is achieved by considering a multi-stage infection model on networks. Using pairwise approximation with a standard closure, a number of important characteristics of disease dynamics are derived analytically, including the final size of an epidemic and a threshold for epidemic outbreaks, and it is shown how these quantities depend on disease characteristics, as well as the number of disease stages. Stochastic simulations of dynamics on networks are performed and compared to output of pairwise models for several realistic examples of infectious diseases to illustrate the role played by the number of stages in the disease dynamics. These results show that a higher number of disease stages results in faster epidemic outbreaks with a higher peak prevalence and a larger final size of the epidemic. The agreement between the pairwise and simulation models is excellent in the cases we consider.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Mathematical models of infectious diseases are known to provide an invaluable insight into the mechanisms driving disease invasion and spread. In many cases, to obtain the first approximation of the spread of a disease, it is sufficient to use a version of the classical SIR model (Kermack and McKendrick 1927). However, major outbreaks of avian and swine influenza (Ferguson et al. 2006), SARS (Donnelly et al. 2003) and, more recently, Ebola (Chowell and Nishiura 2014) have highlighted the need for a more accurate description of the disease dynamics that would provide predictive power to be used for developing measures for disease control and prevention (Keeling and Rohani 2008).
One of the major simplifying assumptions often used in mathematical models of disease dynamics is the exponential distribution of infectious periods. Effectively, this means that the chance of an individual recovering during any given time period does not depend on the duration of time that individual has already been infected. Whilst such an assumption may provide significant mathematical convenience and be reasonably realistic in some situations, most often it is violated, and this requires the inclusion of the precise distribution of infectious periods in the model (Bailey 1954; Hope-Simpson 1952). There are several methods that can be employed to explicitly include a non-exponential distribution, including a multi-stage approach (Anderson and Watson 1980; Cox and Miller 1965), an integro-differential formulation (Kermack and McKendrick 1927; Hethcote and Tudor 1980; Keeling and Grenfell 1997) and a PDE-based formulation akin to that for age-structured models (Anderson and May 1992). In the multi-stage framework, it is assumed that the infectious stage of a disease is characterised by a number K of distinct stages (Cox and Miller 1965; Lloyd 2000, 2001), with the duration of each stage being an independent exponentially distributed random number. Due to the fact that the sum of independent exponentially distributed random variables obeys a gamma distribution (Durrett 2010), one can replace an exponential distribution with the mean infectious period \(1/\gamma \) by a gamma distribution \(\varGamma (K,1/(K\gamma ))\) that has the same mean infectious period \(1/\gamma \). The so-called linear chain trick (Cox and Miller 1965; MacDonald 1978) then consists in replacing a single infectious stage with K identical exponentially distributed sub-stages, each having a mean period \(1/(K\gamma )\). These multiple stages of infection can be used to represent periods of increased or decreased risk of transmitting the disease (Ma and Earn 2006). The same approach can be extended to models with multiple classes (Keeling and Grenfell 2002; Nguyen and Rohani 2008), as well as non-exponentially distributed latency and temporary immunity periods (Blyuss and Kyrychko 2010; Wearing et al. 2005). Following the methodology of introducing multi-stage of infection to better represent the distribution of infectious periods, we proceed with dividing the infected population into K identical stages \(I_1, I_2, \ldots , I_K\) to create the so-called \(SI^KR\) model (Lloyd 2000), and we denote the total infected population by \(I = \sum _{i=1}^K I_i\). One should note that \(K\gamma \) is now used as the transition rate between successive infectious stages in order to keep the average duration of infection as \(1/\gamma \). With these notations, the \(SI^KR\) model takes the form
where S denotes the proportion of susceptible individuals, R is the proportion of recovered or removed individuals, \(\beta \) is the disease transmission rate taken to be the same for all stages of infection, and the disease is assumed to confer a lifelong immunity. The importance of including not just the mean infectious period, but the actual distribution of infectious periods, as achieved by the system (1) is further highlighted by the inspection of actual values of epidemiological parameters for several real diseases as presented in Table 1. This table illustrates that whilst the transmission rate and the average infectious period may vary between different diseases, in all of these cases the number of stages that has to be included in order to correctly represent the disease dynamics may also be quite high, and this reinforces an earlier observation about the non-exponential nature of infectious period distribution.
Whilst this method of introducing multiple stages of infection is clearly more realistic, the assumption of a homogeneous fully mixed population remains very important, having significant effects on the disease dynamics (Keeling and Rohani 2008). Although this assumption often provides a good approximation that helps reduce complexity of the model, in many cases it is just not realistic and results in erroneous conclusions about the onset and development of epidemic outbreaks (Bansal et al. 2007; Burr and Chowell 2008). To address this issue, networks have been and are being used successfully to model the contact structure of the population to a high degree of detail (Danon et al. 2011; Keeling and Eames 2005). Typically, network models are parameterised with empirical data or synthetic models that can be either purely theoretical, e.g. homogeneous random networks or Erdős–Rényi random graphs, or obey some widely observed network characteristics, such as a particular degree distribution or clustering. However, with added model realism comes complexity, which in the case of epidemic network models can be handled via mean-field models, such as pairwise models (Keeling 1999; House and Keeling 2011) that are able to better account for the explicit nature of network links. As long as such mean-field models provide a good approximation to the explicit stochastic network models, they open up the possibility to analytically compute important quantities such as epidemic threshold and final epidemic size. Thus, the explicit stochastic network simulation model and the pairwise model combine favourably to provide a more accurate model with some degree of analytical tractability.
In this paper we are concurrently relaxing the assumptions of homogeneous random mixing and exponentially distributed infectious periods to generate a multi-stage pairwise model for the spread of epidemics on networks. The paper is organised as follows. The next section contains a brief summary and discussion of earlier results on the properties of the \(SI^KR\) model (1). In Sect. 3, we employ the framework of pairwise approximations to derive a multi-stage infection pairwise model and use this to derive analytical expressions for the probability of transmission of infection along an infected edge in a network, a threshold parameter controlling the onset of epidemic outbreaks and the final size of an epidemic. In Sect. 4, numerical simulations of the pairwise and the full network models are performed using realistic parameter values from Table 1 to investigate the accuracy of pairwise approximation and to illustrate the role played by the number of stages in the multi-stage distribution in the disease dynamics. The paper concludes in Sect. 5 with discussion of results and future outlook.
2 Dynamics of the Well-Mixed Model
As a first step, we consider the \(SI^KR\) model (1), which has an implicit assumption that every member of the population has a sufficient level of contact so that the infection can be passed from any individual to any other. This is a natural extension of the basic SIR model (Kermack and McKendrick 1927), and as such, it has been well studied in a number of papers (Lloyd 2000; Ma and Earn 2006; Driessche and Watmough 2002).
Perhaps, one of the most important and commonly used parameters characterising the severity of epidemics and stability of the disease-free equilibrium is the basic reproduction number \({\mathcal {R}}_0\) defined as the expected number of secondary infections caused by a single typical infectious individual in a wholly susceptible population. The value of \({\mathcal {R}}_0\) is related to the stability of the disease-free equilibrium, and it is an important threshold parameter signifying that an epidemic will spread when \({\mathcal {R}}_0>1\) and die out otherwise.
The basic reproduction number for the system (1) can be found as follows (Hyman et al. 1999; Ma and Earn 2006; Driessche and Watmough 2002)
which depends on the average duration of infection \(1/\gamma \) but is independent of the number of stages in the model. A practically important characteristic of an epidemic outbreak is the final epidemic size (Keeling and Rohani 2008). Since the total population size is closed with no inflow or outflow of individuals, i.e. \(S(t)+I_1(t)+I_2(t)+\cdots +I_K(t)+R(t)=1\), at the end of an outbreak, we have a burnout of the epidemic, i.e. \(I_1=I_2=\cdots =I_K=0\), and hence \(S(\infty )+R(\infty )=1\) and \(R(\infty ) = 1 - S(\infty )\). This results in the following implicit equation for the final size of an epidemic that determines the proportion of individuals not affected by the disease (Anderson and May 1992; Diekmann and Heesterbeek 2000)
which coincides with the final epidemic size in the original SIR model (Kermack and McKendrick 1927). Ma and Earn (2006) have recently discussed various aspects related to the derivation and validity of formula (3), and Andreasen (2011) has studied the effects of population heterogeneity on the size of epidemic. A major implication of the above results is the fact that inclusion of possibly more realistic gamma distribution of infectious periods does not alter the threshold of an epidemic outbreak, nor does it affect the final epidemic size. One should note, however, that when a stochastic version of the \(SI^KR\) model is considered, the number of stages influences the distribution of final epidemic sizes, whilst the average final size remains the same (Black and Ross 2015; House et al. 2013). We see that in Fig. 1 the three curves show that considering multi-stage infectious periods has a significant effect of the dynamics of the epidemic. In order to get a better understanding of the distinction in the dynamics of SIR and \(SI^KR\) models, it is therefore instructive to look at the development of epidemics. In the standard SIR model, an outbreak can only take place if \({\mathcal {R}}_0 >1\), and at the initial stage, the number of infected individuals can be approximated as \(I(t)\approx I(0)\exp (\lambda t)\), where the growth rate is \(\lambda =\gamma ({\mathcal {R}}_0 -1)\). In the case of a multi-stage \(SI^KR\) model, however, the basic reproduction number \({\mathcal {R}}_0\) does not depend on the number of stages; hence, it cannot by itself be used to determine the exponential growth rate during an early stage of an outbreak. For this model, Wearing et al. (2005) have derived the following relation between the basic reproduction number \({\mathcal {R}}_0\) and the initial growth rate \(\lambda \)
Figure 2 illustrates early dynamics of epidemic outbreaks for different numbers of stages; in each case, an exponential curve was fitted, which provides an accurate approximation for the initial growth rate of the infection as determined by Eq. (4). This figure shows the effects of the gamma distribution on the early growth rate, peak prevalence and overall time frame of the disease, and it also suggests that the largest effect of the gamma distribution on the disease dynamics occurs during intermediate stages of disease progression.

A comparison of infection dynamics for a one-, three- and five-stage \(SI^KR\) models with data from Keeling and Rohani (2008). Each curve represents the sum of all \(I_i\) in the model. Adding extra stages causes epidemics to occur earlier and result in a higher peak of epidemic, although \({\mathcal {R}}_0\) and the final size are identical for each curve. The parameter values are \(N = 1000\), \(\beta = 1.66/\)day, \(\gamma = 0.4545/\)day

Proportion of infected individuals during a boarding school influenza outbreak with \(\beta =1.66\)/day and \(\gamma =0.4545\)/day (Keeling and Rohani 2008). In each plot, the solid black line is the numerical solution of the model (1) with an appropriate number of stages, and the dashed line is the exponential growth curve with the rate determined by Eq. (4) shown on a logarithmic scale. a One-stage model with \(\lambda \approx 1.2055\), b two-stage model with \(\lambda \approx 1.4035\), c three-stage model with \(\lambda \approx 1.4762\), d five-stage model with \(\lambda \approx 1.534\). In each case note that in the earliest stages the exponential approximation is virtually identical to the infection curve
Besides the basic reproduction number, final epidemic size and the initial growth rate of an epidemic, another practically important characteristic of epidemic outbreaks is the peak prevalence defined as the maximum number or proportion of infected individuals that can be achieved during an outbreak. In the case of an SIR model, the peak prevalence can be found as follows (Feng 2007; House and Keeling 2011)
Feng (2007) has recently considered an SEIR model with gamma-distributed infectious period and derived an expression for the peak of a weighted average of infectious compartments. This result gives some intuition into how the number of stages affects peak prevalence, but it does not provide a closed form expression for the actual peak prevalence in an \(SI^KR\) model. Numerical results in Fig. 2 suggest that for the same average infectious period, the overall peak prevalence increases with the number of stages included in the model.
3 Network Dynamics with Multiple Stages
Inclusion of multiple stages of infection in the \(SI^KR\) model gives a more realistic representation of the infectious period, but the model still has certain limitations due to its underlying assumptions. In the model (1), it is assumed that the disease is not fatal and that transitions between different infected classes, or stages of infection, take place at exactly the same rate \(K\gamma \). Another major assumption behind model (1) is that the population is well mixed, i.e. each individual has equal chances of encountering and transmitting a disease to any other individual in a population. Whilst this may be appropriate in the case of outbreaks in small closed communities, for a large number of communicable diseases, such as SARS, influenza and most sexually transmitted infections, this assumption is a gross simplification of the actual dynamics as it overlooks spatial variability, as well as the complexities of a network structure for infections that are transmitted through direct close contact between individuals (House and Keeling 2011; Keeling and Eames 2005).
Modelling complex contact patterns explicitly via networks has had a profound effect on mathematical epidemiology. This new modelling framework has led to a myriad of models ranging from exact to mean-field and simulation models (Pastor-Satorras et al. 2014; Danon et al. 2011; Keeling and Eames 2005; Newman 2003; Boccaletti et al. 2006). The many degrees of freedom in modelling offered by networks, however, often comes at the price of increasing levels of complexity, where models can be challenging to evaluate analytically and sometimes even numerically. Nevertheless, many valuable paradigm models have been developed which have furthered our understanding of the impact of contact heterogeneity, preferential mixing and clustering on the outbreak threshold and other epidemic descriptors. A particularly useful way of capturing epidemic dynamics on networks is by using the pairwise model (Keeling 1999). This model is based around deriving in a hierarchical way evolution equations for the expected number of nodes, edges, triples and so on. A closure is then employed that curtails the dependence on ever higher-order moments. Its premise is simple and quite intuitive, although it can be also shown rigorously (Taylor et al. 2012) that pairwise models before closure are exact. The basic idea of the model is to recognise that changes at node level depend on the status of the neighbours and thus involves edges, e.g. the rate of change in the number of infectious nodes is proportional to the number of \(S{-}I\) links in the network. Similarly, the number of edges can change due to pair interactions and transitions but also due to interactions induced from outside the edge, e.g. the number of \(S{-}S\) links decrease proportionally to the number of \(S{-}S{-}I\) triples, where infection from the I node destroys the fully susceptible pair. This framework has been used and extended extensively, to asymmetric (Sharkey et al. 2006) and weighted networks (Rattana et al. 2013) for example, and has proved to be a valuable framework.
3.1 Pairwise Model
As a first step in the analysis of dynamics of multi-stage epidemics on networks, we re-formulate the \(SI^KR\) model using the framework of pairwise equations, which allows one to analyse the expected values for the number of nodes and links of each type as a function of time (Keeling 1999; House and Keeling 2011; Taylor et al. 2012). The particular strength of pairwise models lies in their analytical tractability and the fact that they provide a more accurate description than well-mixed ODE models but do not go to the level of full individual-based stochastic simulations (House and Keeling 2011). In this formalism of pairwise models, notations [X], [XY] and [XYZ] are used to denote the expected numbers of individuals in state X, the expected number of links between nodes of type X and Y and the expected number of triples of the form \(X{-}Y{-}Z\), respectively. More precisely, given a “frozen” network with nodes labels X, Y or Z and subscripts indicating nodes i, j and k, then
where \(X, Y, Z \in \{S, I_1, I_2, \ldots , I_K, R\}\), and \(G=(g_{ij})_{i,j=1,2,\dots ,N}\) is the adjacency matrix of the network such that \(g_{ii}=0\), \(g_{ij}=g_{ji}\) and \(g_{ij}=g_{ji}=1\) if nodes i and j are connected and zero otherwise. Moreover, \(X_i\) returns one if node i is in state X and zero otherwise. The average degree of each node is denoted by n and the number of nodes in the network by N. The new pairwise \(SI^KR\) model with a gamma-distributed infectious period can then be written as follows,
where \(\tau =\beta /n\) is the transmission rate per link. Since we consider a closed population, this immediately implies \([S] + \sum _{i=1}^{K}[I_i] + [R] =N\). The system (5) is not closed as additional equations describing the dynamics of triples are needed. To eliminate this dependence on higher moments and close the system, we will use the classical moment closure approximation which assumes that short loops and clusters are excluded from the network and that there is no correlation between nodes with a common neighbour (Keeling 1999).
Applying these closures to the system (5) makes it a self-consistent system of \((2K+2)\) equations.
3.2 The Probability of Transmission Across an Infected Edge
When one considers a stochastic network-based simulation, an important quantity characterising the disease dynamics is the probability \(\tilde{\tau }\) of disease transmission across a given \(S{-}I\) link. In a simple one-stage model, where both infection and recovery are assumed to be distributed exponentially, the probability of no infection event occurring during time t is given by \(p_0(t)=e^{-\tau t}\); hence, \(1 - p_0(t)\) is the probability that infection does take place over the same time period. Averaging this via integration for all possible recovery times yields the probability that the susceptible node becomes infected. In a standard SIR model with exponentially distributed infectious and recovery period, this probability is therefore (Danon et al. 2011; Diekmann et al. 1998)
In the case of an \(SI^KR\) model, the duration of infection is described by the density function of the appropriate gamma distribution
The implication of this fact is the following result for the probability of transmission across an edge.
Lemma 1
For the stochastic \(SI^KR\) model with the period of infection following the gamma distribution (8), the probability of disease transmission across a given \(S{-}I\) link is given by
The proof of this lemma is given in “Appendix 1”.
By rewriting expression (9) in the form
and using the fact that \(e^x = \lim _{n \rightarrow \infty } \left( 1+x/n\right) ^n\), it follows that
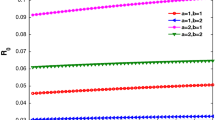
Figure 3 illustrates the dependence of \(\tilde{\tau }\) on the number of stages K, as well as a limiting behaviour as \(K\rightarrow \infty \). This figure illustrates that whilst \(\tilde{\tau }\) is growing with the increasing number of stages K, it eventually saturates at a level determined by Eq. (10). In fact, this saturation at higher K is observed not only in the probability of transmission, but also in the peak prevalence rate, as well as in the early growth rate. When compared to an exponential distribution, it is these substantial changes in \(\tilde{\tau }\) observed for smaller values of K that explain the changes in the profile of the infection curves. As will be shown later, \(\tilde{\tau }\) is a very important quantity that controls various properties of epidemic dynamics, such as the threshold for an outbreak and the final size of an epidemic.

Dependence of the probability of transmission across an \(S{-}I\) edge \(\tilde{\tau }\) on the number of stages K as given by Eq. (9) for different mean infectious periods with \(\tau =0.166\). Crosses, circles and diamonds correspond to integer values of K on each curve
3.3 \({\mathcal {R}}_0\)-Like Threshold Parameter
Unlike epidemic models in well-mixed populations, defining an appropriate \({\mathcal {R}}_0\) for pairwise models is more challenging. This is in part due to the difficulty of identifying the typical infectious individual. In order to derive a value for \({\mathcal {R}}_0\), one needs to consider and correctly account for the correlation between susceptible and infected nodes and measure \({\mathcal {R}}_0\) when this has stabilised, see Keeling (1999) and Eames (2008). Intuitively, this means that the epidemic is allowed to spread in order to become established in the network. This allows for typical infectious individuals to develop and for \({\mathcal {R}}_0\) to be measured. In large networks, this regime can still be considered to be close to or only a small perturbation away from the disease-free steady state.
We now proceed to derive an \({\mathcal {R}}_0\)-like threshold parameter \({\mathcal {R}}\) which can be used to predict when the epidemics occur, by allowing outbreaks only when \({\mathcal {R}} > 1\) (Rattana et al. 2013). To this end, we linearise the model (5) with a classic closure (6) near the disease-free equilibrium which has the form \([S]=N\), \([SS]=nN\), and all other quantities being zero. As in the standard approach, the condition necessary for the initial growth of an epidemic is that the dominant eigenvalue \(\lambda _{\max }\) of the resulting characteristic polynomial is real and positive, and a threshold parameter is obtained as a condition on system parameters that ensure the stability change, i.e. \(\lambda _{\max } = 0\). In the “Appendix 2” it is shown that the characteristic equation for eigenvalues \(\lambda \) of the linearised system near the disease-free steady state for a K-stage model (5) is given by
In “Appendix 2” we prove that the largest eigenvalue \(\lambda \) satisfying this equation goes through zero, i.e. \(\lambda _{\max } = 0\), when
This defines a new \({\mathcal {R}}_0\)-like threshold parameter with \(\tilde{\tau }\) introduced in (9). A closer inspection shows that this parameter \({\mathcal {R}}\) describes the probability of spreading the disease across a given link multiplied by the likely number of susceptible contacts of the individual assuming that they are the earliest people being infected, which perfectly agrees with the standard definition of \({\mathcal {R}}_0\) as the average number of secondary cases produced in a fully susceptible population by a single typical infectious individual. Whilst \({\mathcal {R}}\) does not quantify the early growth rate of an epidemic, through its dependence on \(\tilde{\tau }\) and K, it allows one to better predict epidemic outbreaks in the case of a more realistic gamma distribution of infectious period, where in the case of an exponential distribution with the same mean infectious period. We also note that whilst in the implementation of the classic \(SI^KR\) model there was no effect of changing the number of stages on \({\mathcal {R}}_0\), and this more sophisticated model results in a threshold which implicitly accounts for multi-stage infectious periods.
3.4 The Final Size of an Epidemic
Since the pairwise model (5) is a network representation of an epidemic with lifelong immunity and fixed population size, eventually an epidemic will burn out, leaving some proportion of the population unaffected and still susceptible to the disease. Since \([I_1](\infty )=[I_2](\infty )=\cdots =[I_K](\infty )=0\), the final size of an epidemic is given by the proportion of people in the removed class, i.e. \([R]_{\infty } = N-[S]_{\infty }\). As we saw earlier for the \(SI^KR\) model (1) in a well-mixed population, the final size of a single epidemic does not change with the number of stages. However, the same conclusion no longer holds for the pairwise model (5) with the closure (6), in which case we have the following result.
Theorem 1
For a single epidemic outbreak in a closed population with a vanishingly small starting level of infection, the final size of an epidemic in the pairwise model (5) with the classical closure (6) is given by
where
and \(\tilde{\tau }\) is defined in (9).
Proof
To prove this statement, we extend the methodology developed by Keeling (1999) for one-stage epidemics. We first introduce some new variables and parameters
and
From (5) and the easily derived function
it follows that these new variables satisfy the following system of equations
Since \([I_i](0)=[I_i](\infty )=0\) for any \(i=1,\ldots ,K\), this implies \(F(0)=F(\infty )=0\). Integrating the first equation in (15) gives
where in the last step we have used the fact that \(G(0)=0\) and the relation
derived in “Appendix 3” together with another relation
Substituting these two relations into Eq. (16) and using the fact that \([S](0)=N\) yields
Introducing the fraction of susceptible individuals as \(S_{\infty }=[S]_{\infty }/N\), the above equation can be rewritten as follows,
or alternatively, as another implicit equation for \(S_{\infty }\)
Since \([I]_i(\infty )=0\), introducing \(R_{\infty }=[R]_{\infty }/N\) yields the desired expression for the final size of an epidemic
Using the fact that \(\theta = S^a_{\infty }\), Eq. (19) can be rewritten in the form
where in the last step we have used the relation \(a=(n-1)/n\). This completes the proof. \(\square \)

(Color figure online) Dependence of the final size of an epidemic (12) on the per-link transmission rate \(\tau \) and the number of stages K in the pairwise model (5) with \(\gamma =0.4545\) for different average node degrees. a \(n=2\). b \(n=4\). c \(n=7\). d \(n=10\). e \(n=4\), \(\tau =0.3\) (solid), \(\tau =0.6\) (dashed), \(\tau =0.9\) (dotted). f \(n=10\), \(\tau =0.09\) (solid), \(\tau =0.18\) (dashed), \(\tau =0.27\) (dotted). Circles correspond to integer values of K on each curve. The case \(n=2\) is used solely for illustrative purposes, as the resulting networks would be disconnected and thus inappropriate for direct comparison to results from the pairwise model
We note that our result in Theorem 1 is functionally identical to the result achieved by Keeling (1999), and it generalises the final size equation by replacing \(\tau /(\tau + \gamma )\) with the parameter \(\tilde{\tau }\). In the case \(K=1\) these two values are equivalent, and thus, we have perfect agreement with the existing theory. Equivalent relations have also been derived by Newman (2002) using percolation theory. Those results were later corrected and shown to hold in all cases where the distribution of infectious periods is degenerative (Kenah and Robins 2007). An equivalent relation has been derived for a static configuration network model with an arbitrary degree distribution (Miller 2012). Figure 4 illustrates Theorem 1 by showing how the final size of an epidemic on a network depends on the number of infectious stages and, hence, the shape of the distribution of infectious period, which makes it different from earlier analytical results for a well-mixed population (Ma and Earn 2006). This suggests that inclusion of a more realistic population structure has effect not only on the intermediate disease dynamics, but also on the final proportion of the population that will be affected by the disease. Furthermore, this figure suggests that for the same mean infectious period, the final size of an epidemic is increasing with the increasing number of stages K. One should note that the number of stages K has the largest effect on the final size of an epidemic for sufficiently low values of K, and then, this dependence saturates. As expected, the average node degree n plays an important role, with the minimum value of \(\tau \) or K required for an epidemic outbreak decreasing with increasing n in perfect agreement with an earlier result in Eq. (11). Stochastic simulations (not shown) demonstrate excellent agreement with the results in Fig. 4, especially for denser networks. The conclusions of Theorem 1 highlight the importance of collecting accurate and reliable data about the infectivity profile of a disease for predicting the scale of an outbreak.

Numerical solution of the pairwise \(SI^KR\) model (5) with different average infectious periods and a different number of stages, but the same final size due to identical transmissibility \(\tilde{\tau }\). Parameter values are \(\tau = 0.2\), \(n=10\), \(\gamma = 1\) and \(K=1\) (solid) and \(\tau = 0.2\), \(n=10\), \(\gamma \approx 1.06\) and \(K=3\) (dashed). The solution curves for the overall infected population show a radically different intermediate behaviour, but with \(\tilde{\tau } = 1/6\) in both cases, they have the same final epidemic size
It is worth noting that whilst the final size depends on the distribution of the infectious period, this dependence is not necessarily unique. This means that two different distributions of infected periods can provide the same transmissibility \(\tilde{\tau }\), resulting in the same final epidemic size in accordance with Theorem 1 but having different intermediate dynamics of infection, as illustrated in Fig. 5. The consequence of this observation is that although the epidemic threshold and final epidemic size can both be accurately computed using an estimate for the transmissibility of the disease (Newman 2002), it is not sufficient to correctly predict the dynamics of the infection spreading process over time, which can be done with our model.
4 Impact of a Realistic Infectious Period Distribution: Case Studies
In order to test the accuracy of the pairwise model (5) and to illustrate the role played by the distribution of infectious period, we consider the examples of outbreaks of several diseases mentioned in Table 1 in a population that is initially fully susceptible. We concentrate on two common and fairly simple network structures, namely homogeneous and Erdős–Rényi networks (Newman 2010), with stochastic simulations being performed using a Gillespie algorithm (Gillespie 1977; Chen and Bokka 2005). We restrict our attention to these network types as we have a homogeneous pairwise model and we would not expect it to work well for other networks. Following the derivation of the pairwise model, the per-link transmission rate is taken to be \(\tau =\beta /n\), and we now perform the comparison of an average of 250 stochastic outcomes of serious epidemics on a homogeneous and Erdős–Rényi networks against the results of a pairwise model with gamma-distributed infectious period. To highlight the impact of including a realistic distribution for the infectious period, we compare the results of simulations with realistic values of parameters from Table 1 against those obtained using an exponentially distributed infectious period as assumed in many existing models.

Simulation of a SARS outbreak using data from Table 1 with \(n=10\) and \(N=1000\). Lines correspond to a numerical solution of the pairwise model (5) (\(K=1\) solid line, \(K=3\) dashed line), whilst symbols represent the average of 250 serious outbreaks (\(K=1\) filled circles, \(K=3\) triangles). a Homogeneous network. b Erdős–Rényi random graph
Severe acute respiratory syndrome (SARS) is a viral disease characterised by flu-like symptoms which is primarily spread through close contacts with infected individuals that makes it a perfect candidate for deducing some basic parameters from epidemiological observations. Figure 6 illustrates the comparison of SARS dynamics on homogeneous and Erdős–Rényi networks with a pairwise approximation. One can observe that the effects of including more stages in the disease model on intermediate behaviour are similar to those seen earlier, namely that gamma distribution of infectious period shortens the overall duration of an epidemic and increases peak prevalence. It is also worth noting that, in accordance with Theorem 1, the final size of an epidemic also increases with K.
The second example we consider is smallpox, a viral disease that has been eradicated globally except for two stocks kept in the secure laboratories and being used for further research. Several papers have modelled the effectiveness of smallpox when used as a bio-weapon, as well strategies for its containment during possible outbreaks (Ferguson et al. 2003; Kaplan et al. 2002; Meltzer et al. 2001). Due to a profound impact smallpox has had on a human population over several centuries, an extensive and quite accurate data have been collected about its transmission. Smallpox is spread through a contact with the mucus of an infected individual, which implies that a close contact is essential for a successful disease transmission. In Fig. 7, we show the simulations of smallpox outbreaks on homogeneous and Erdős–Rényi networks using parameter values from Table 1 compared to results of the numerical solution of the corresponding pairwise model (5). The first important observation that the higher severity of epidemics outbreaks as suggested by these data makes the pairwise model more accurate, as expected. The effect of including the realistic distribution of infectious period is more pronounced in this case as compared to the SARS simulations, which can be attributed to the fact that smallpox model includes four stages of infection, whilst the SARS model had only three stages. Despite changes in the intermediate behaviour for smallpox being more pronounced compared to SARS, the final size of an epidemic as given by the pairwise model only increases from 96.34 to 97.89 %, which is consistent with an earlier observation that the effect of increasing the number of stages on the final epidemic size is less noticeable for higher K.

Simulation of a smallpox outbreak using data from Table 1 with \(n=10\) and \(N=1000\). Lines correspond to a numerical solution of the pairwise model (5) (\(K=1\) solid line, \(K=4\) dashed line), whilst symbols represent the average of 250 serious outbreaks (\(K=1\) filled circles, \(K=4\) triangles). a Homogeneous network. b Erdős–Rényi random graph
Figure 8 illustrates the comparison of a pairwise model (5) with the closure (6) and a stochastic simulation on the example of influenza data with different number of stages of infection. Comparison of figures (a) and (b) shows that the heterogeneity introduced by the degree distribution makes the pairwise model less accurate due to the fact that this model only takes into account the mean degree n. This suggests that whilst our model is very helpful for understanding general features of multi-stage disease dynamics on networks, it has to be extended further to deal effectively with wider and more realistic node degree distributions. One should note that the effects of increasing the number of stages on peak prevalence and the duration of epidemics reduce for higher values of K, as can be observed by comparing the minor changes between temporal profiles of the three- and five-stage influenza epidemics presented as shown in Fig. 8.

Simulation of an influenza outbreak using data from Table 1 with \(n=10\) and \(N=1000\). Lines correspond to a numerical solution of the pairwise model (5) (\(K=1\) solid line, \(K=3\) dashed line, \(K=5\) dotted line), whilst symbols represent the average of 250 serious outbreaks (\(K=1\) filled circles, \(K=3\) triangles, \(K=5\) squares). a Homogeneous network. b Erdős–Rényi random graph
5 Discussion
In this paper we have analysed the behaviour of multi-stage infections with particular emphasis on contact networks. Unlike the well-mixed models, for which the number of stages modifies the temporary profile of an outbreak but does not affect the final epidemic size or the condition for disease outbreak, in the case of disease spread on a network, the number of stages, i.e. the precise distribution of infectious period, plays a much more prominent role.
In order to make analytical progress with the analysis of disease dynamics on networks, we have employed the framework of pairwise approximation. This has allowed us to determine the probability of disease transmission across a network edge and to find an \({\mathcal R}_0\)-like threshold that controls the onset of epidemics. We have also derived an analytical expression for the final size of an epidemic, which is in perfect agreement with the final size computed using percolation theory (Newman 2002; Kenah and Robins 2007), and therefore, our findings can be considered exact in the limit of infinite population size. All of these quantities depend not only on the basic disease characteristics, such as the transmission rate and the average infectious period, but also on the distribution of the infectious period as represented by the number of stages in the model. The importance of this result lies in the fact that unlike earlier studies of multi-stage models in well-mixed populations (Anderson and Watson 1980; Ma and Earn 2006), for the same average duration of the infection period, the final epidemic size is not constant but increasing with the number of stages. We also observe that the threshold at which point a major epidemic is expected depends on the number of infectious stages, with epidemics becoming more likely as the number of stages is increased. This dependence emerges due to the higher resolution of our model which allows us to identify new links between model ingredients and disease dynamics. Similar results have been noted in related studies, for example, in models concerned with contact tracing (Eames and Keeling 2003) and models of coupled disease and information transmission on networks (Funk et al. 2009).
Numerical simulations of epidemic outbreak for several different multi-stage infections demonstrate that whilst the pairwise model provides a reasonably good approximation of the network dynamics, the agreement with stochastic simulations is affected by clustering and local network structure that can induce correlations in the dynamics of different nodes, as well as the inhomogeneity in the node degree distribution, as should be expected from the fact that the pairwise closure only depends on the average node degree.
There are several directions in which the approach presented in this paper could be extended. These include the analysis of SIS and SEIR models, as well as inclusion of multiple stages for both the latent and infected classes (Nguyen and Rohani 2008). Whilst inclusion of latent classes may have no effect on the basic reproduction number or the final size distribution in a homogeneous model (Black and Ross 2015; House et al. 2013), whether the same would be true in a network model remains to be seen. Another interesting and important problem would be the consideration of network dynamics for epidemic models with temporary immunity (Blyuss and Kyrychko 2010). Allowing the level of infectiousness of different nodes to vary depending on the stage of infection they belong to would result in even more realistic models of multi-stage diseases on networks. One of the challenging but practically important generalisations of the present framework would be an extension of a pairwise model that would account for heterogeneity in node degree distribution (House and Keeling 2011). This would provide deterministic models potentially amenable to analytical treatment that would more accurately represent stochastic disease dynamics.
References
Anderson RM, May RM (1992) Infectious diseases of humans: dynamics and control. Oxford University Press, Oxford
Anderson D, Watson R (1980) On the spread of a disease with gamma distributed latent and infectious periods. Biometrika 67:191–198
Andreasen V (2011) The final size of an epidemic and its relation to the basic reproduction number. Bull Math Biol 73:2305–2321
Bailey NTJ (1954) A statistical method of estimating the periods of incubation and infection of an infectious disease. Nature 174:139–140
Bansal S, Grenfell BT, Ancel Meyers L (2007) When individual behaviour matters: homogeneous and network models in epidemiology. J R Soc Interface 4:879–891
Bauch CT, Lloyd-Smith JO, Coffee MP, Galvani AP (2005) Dynamically modeling SARS and other newly emerging respiratory illnesses: past, present, and future. Epidemiology 16:791–801
Black AJ, Ross JV (2015) Computation of epidemic final size distributions. J Theor Biol 367:159–165
Blyuss KB, Kyrychko YN (2010) Stability and bifurcations in an epidemic model with varying immunity period. Bull Math Biol 72:490–505
Boccaletti S, Latora V, Moreno Y, Chavez M, Hwang D-U (2006) Complex networks: structure and dynamics. Phys Rep 424:175–308
Burr TL, Chowell G (2008) Signatures of non-homogeneous mixing in disease outbreaks. Math Comput Model 48:122–140
Cauchemez S, Carrat F, Viboud C, Valleron AJ, Boelle PY (2004) A Bayesian MCMC approach to study transmission of influenza: application to household longitudinal data. Stat Med 23:3469–3487
Chen W-Y, Bokka S (2005) Stochastic modeling of nonlinear epidemiology. J Theor Biol 234:455–470
Chowell G, Nishiura H (2014) Transmission dynamics and control of Ebola virus disease (EVD): a review. BMC Med 12:196
Cox DR, Miller HD (1965) The theory of stochastic processes. Chapman and Hall, London
Danon L, Ford AP, House T et al (2011) Networks and the epidemiology of infectious disease. Interdiscip Perspect Infect Dis 2011:284909
Diekmann O, De Jong MCM, Metz JAJ (1998) A deterministic epidemic model taking account of repeated contacts between the same individuals. J Appl Probab 35:448–462
Diekmann O, Heesterbeek JAP (2000) Mathematical epidemiology of infectious diseases: model building, analysis and interpretation. Wiley, New York
Donnelly CA, Ghani AC, Leung GM, Hedley AJ, Fraser C et al (2003) Epidemiological determinants of spread of causal agent of severe acute respiratory syndrome in Hong Kong. Lancet 361:1761–1766
Durrett R (2010) Probability: theory and examples. CUP, Cambridge
Eames KTD, Keeling MJ (2003) Contact tracing and disease control. Proc R Soc Lond B 270:2565–2571
Eames KTD (2008) Modelling disease spread through random and regular contacts in clustered populations. Theor Popul Biol 73:104–111
Feng Z (2007) Final and peak epidemic sizes for SEIR models with quarantine and isolation. Math Biosci Eng 4:675–686
Ferguson NM, Cummings DAT, Fraser C, Cajka JC, Cooley PC, Burke DS (2006) Strategies for mitigating an influenza pandemic. Nature 442:448–452
Ferguson NM, Keeling MJ, Edmunds WJ, Gani R, Grenfell BT, Anderson RM, Leach S (2003) Planning for smallpox outbreaks. Nature 425:681–685
Funk S, Gilad E, Watkins C, Jansen VA (2009) The spread of awareness and its impact on epidemic outbreaks. Proc Natl Acad Sci USA 106:6872–6877
Gillespie DT (1977) Exact stochastic simulation of coupled chemical reactions. J Phys Chem 81:2340–2361
Hethcote HW, Tudor DW (1980) Integral equation models for endemic infectious diseases. J Math Biol 9:37–47
Hope-Simpson RE (1952) Infectiousness of communicable diseases in the household (measles, chickenpox, and mumps). Lancet 260:549–554
House T, Keeling MJ (2011a) Insights from unifying modern approximations to infections on networks. J R Soc Interface 8:67–73
House T, Keeling MJ (2011b) Epidemic prediction and control in clustered populations. J Theor Biol 272:1–7
House T, Ross JV, Sirl D (2013) How big is an outbreak likely to be? Methods for epidemic final size calculation. Proc R Soc A 469:20120436
Hyman JM, Li J, Stanley EA (1999) The differential infectivity and staged progression models for the transmission of HIV. Math Biosci 155:77–109
Kaplan EH, Craft DK, Wein LM (2002) Emergency response to a smallpox attack: the case for mass vaccination. Proc Natl Acad Sci 99:10935–10940
Keeling MJ (1999) The effects of local spatial structure on epidemiological invasions. Proc R Soc Lond B 266:859–867
Keeling MJ, Eames KTD (2005) Networks and epidemic models. J R Soc Interface 2:295–307
Keeling MJ, Grenfell BT (1997) Disease extinction and community size: modeling the persistence of measles. Science 275:65–67
Keeling MJ, Grenfell BT (2002) Understanding the persistence of measles: reconciling theory, simulation and observation. Proc R Soc B 269:335–343
Keeling MJ, Rohani P (2008) Modeling infectious diseases in humans and animals. Princeton University Press, Princeton
Kenah E, Robins JM (2007) Second look at the spread of epidemics on networks. Phys Rev E 76:036113
Kermack W, McKendrick A (1927) A contribution to the mathematical theory of epidemics. Proc R Soc Lond A 115:700–721
Koplan JP, Azizullah M, Foster SO (1978) Urban hospital and rural village smallpox in Bangladesh. Trop Geogr Med 30:355–358
Lloyd AL (2000) Realistic distributions of infectious periods in epidemic models: changing patterns of persistence and dynamics. Theor Popul Biol 60:59–71
Lloyd AL (2001) Destabilization of epidemic models with the inclusion of realistic distributions of infectious periods. Proc R Soc B 268:985–993
Ma J, Earn DJD (2006) Generality of the final size formula for an epidemic of a newly invading infectious disease. Bull Math Biol 68:679–702
MacDonald N (1978) Time lags in biological models. Springer, Berlin
Meltzer MI, Damon I, LeDuc JW, Millar JD (2001) Modeling potential responses to smallpox as a bioterrorist weapon. Emerg Infect Dis 7:959–969
Miller JC (2012) A note on the derivation of epidemic final sizes. Bull Math Biol 74:2125–2141
Newman MEJ (2002) Spread of epidemic disease on networks. Phys Rev E 66:016128
Newman M (2003) The structure and function of complex networks. SIAM Rev 45:167–256
Newman M (2010) Networks: an introduction. Oxford University Press, Oxford
Nguyen HTH, Rohani P (2008) Noise, nonlinearity and seasonality: the epidemics of whooping cough revisited. J R Soc Interface 5:403–413
Pastor-Satorras R, Castellano C, van Mieghem P, Vespignani A (2014) Epidemic processes in complex networks. arXiv preprint arXiv:1408.2701
Rattana P, Blyuss KB, Eames KTD, Kiss IZ (2013) A class of pairwise models for epidemic dynamics on weighted networks. Bull Math Biol 75:466–490
Riley S, Fraser C, Donnelly CA et al (2003) Transmission dynamics of the etiological agent of SARS in Hong Kong: impact of public health interventions. Science 300:1961–1966
Sharkey K, Fernandez C, Morgan K et al (2006) Pair-level approximations to the spatio-temporal dynamics of epidemics on asymmetric contact networks. J Math Biol 53:61–85
Taylor M, Simon PL, Green DM, House T, Kiss IZ (2012) From Markovian to pairwise epidemic models and the performance of moment closure approximations. J Math Biol 64:1021–1042
van den Driessche P, Watmough J (2002) Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission. Math Biosci 180:29–48
Wearing HJ, Rohani P, Keeling MJ (2005) Appropriate models for the management of infectious diseases. PLoS Med 2:e174
Acknowledgments
N. Sherborne acknowledges funding for his PhD studies from the Engineering and Physical Sciences Research Council (EPSRC). The authors would like to thank the anonymous referees for helpful comments and suggestions that have helped to improve the presentation.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1
In this Appendix, we prove an expression (9) for the probability of transmission across a given link. For an arbitrary number of stages and transition/recovery parameter \(K\gamma \), the distribution of the infectious period is gamma distributed, and hence, we consider here the density function originally stated in (8)
Since the probability of infection taking place for a given \(S{-}I\) link during time t is given by \(1-e^{-\tau t}\), the probability of transmission across this link in a K-stage is given by
where the final equality is obtained by noting that the first integral is simply the integral of the gamma distribution function over \(\mathbb {R}^+\), and, hence, is equal to one. Integration by parts yields a recursive relation
which is valid for any integer \(K>1\), and this then implies
Substituting this expression into Eq. (20) yields
Appendix 2
Linearisation of the pairwise model (5) with the closure (6) at the disease-free equilibrium yields the stability condition for eigenvalues \(\lambda \) as a \((2K+2) \times (2K+2)\) matrix. It is useful to first consider it in a block form as follows,
where C is a zero \((K+1) \times (K+1)\) matrix, and the matrix A is lower diagonal, and therefore, its determinant is the product of the diagonal terms. Hence, the characteristic equation can be written as
This matrix can now be reduced to a series of lower diagonal matrices to give the following general form of the characteristic equation
It immediately follows that the above equation has roots of \(\lambda =0\), \(\lambda =-K\gamma \), and the other K roots are determined by the roots of the expression in curly brackets. Since an epidemic outbreak occurs when the disease-free equilibrium becomes unstable, one has to identify conditions on parameters when the stability of the disease-free steady state changes, i.e. where \(\lambda = 0\). Substituting \(\lambda = 0\) into the expression in curly brackets yields
This relation can be recast as
which gives the desired expression of \({\mathcal {R}}=(n-1)\tilde{\tau }\) in Eq. (11).
Appendix 3
To prove relation (17), we consider the time derivatives of the functions \(P_i = \frac{[SI_i]}{[S]^a}\) for \(i=1,2, \ldots , K\), which can be found from the pairwise model (5):
We also remind the reader of the functions G and L and equations for their dynamics
Integrating the equation for \(P_1\) and using the fact that \([SI_1](0)=[SI_1](\infty )=0\) gives
In a similar way, integrating the equation for \(P_2\) yields
which can be rewritten as
Proceeding the same way, one obtains
Going through all stages of infections, we find
On the other hand, integrating equation for G and using \(G(0)=0\) gives
Combining the last two expressions, we obtain
and substituting this result into Eq. (21) gives the final relation (17):
In order to prove relation (18), we examine the ratio [SS] / [S], whose dynamics is governed by the following equation
Separating variables and integrating this equation gives
Rather than computing the integral in the right-hand side of the above equation, we use the first equation of the pairwise model (5), which can be written as
Integrating this equation gives
Using this expression to replace an integral in (23) gives
Substituting \([S]_0=N\) and \([SS]_0=nN\), this formula can be rewritten as
or alternatively,
Multiplying both sides by \([S]_{\infty }\) and using the definition \(a=(n-1)/n\), we obtain
which gives the desired relation (18).
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Sherborne, N., Blyuss, K.B. & Kiss, I.Z. Dynamics of Multi-stage Infections on Networks. Bull Math Biol 77, 1909–1933 (2015). https://doi.org/10.1007/s11538-015-0109-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11538-015-0109-1