
Abstract
We illustrate the usefulness of an Ontology-Based Data Management (OBDM) approach to develop an open information system, allowing for a deep level of interoperability among different databases, and accounting for additional dimensions of data quality compared to the standard dimensions of the OECD (Quality framework and guidelines for OECD statistical activities, OECD Publishing, Paris, 2011) Quality Framework. Recent advances in engineering in computer science provide promising tools to solve some of the crucial issues in data integration for Research and Innovation.


Similar content being viewed by others


Notes
According to OECD (2015), open science refers to “efforts by researchers, governments, research funding agencies or the scientific community itself to make the primary outputs of publicly funded research results—publications and the research data—publicly accessible in digital format with no or minimal restriction as a means for accelerating research; these efforts are in the interest of enhancing transparency and collaboration, and fostering innovation. […] Three main aspects of open science are: open access, open research data, and open collaboration enabled through ICTs. Other aspects of open science—post-publication peer review, open research notebooks, open access to research materials, open source software, citizen science, and research crowdfunding are also part of the architecture of an open science system” (OECD 2015, p. 7).
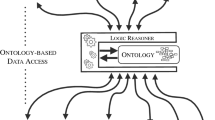
An automated reasoner based on logic is a software which is able to derive logical consequences from a given set of axioms in an automatic way.
SPARQL is a semantic query language for databases.
Sapientia 1.0 was closed on the 22nd of December 2014, and was organized in 14 Modules, including around 350 symbols (concepts, relations and attributes). It has been presented at the Workshop of the 20 February 2015 held at Sapienza University of Rome (see Daraio 2015).
References
Baader, F., Calvanese, D., McGuinness, D., Nardi, D., & Patel-Schneider, P. F. (Eds.). (2007). The description logic handbook: Theory, implementation and applications (2nd ed.). Cambridge: Cambridge University Press.
Baldwin, C. Y., & Clark, K. (2000). Design rules—The power of modularity. Cambridge: MIT Press.
Borgman, C. L. (2015). Big data, little data, no data: Scholarship in the networked world. Cambridge: MIT Press.
Calvanese, D., De Giacomo, G., Lembo, D., Lenzerini, M., Poggi, A., Rodriguez-Muro, M., & Rosati, R. (2009a). Ontologies and databases: The DL-Lite approach. In S. Tessaris, E. Franconi, T. Eiter, C. Gutierrez, S. Handschuh, M.-C. Rousset & R. A. Schmidt (Eds.), Reasoning Web. Semantic Technologies for Information Systems, Lecture Notes in Computer Science (Vol. 5689, pp. 255–356). Berlin: Springer.
Calvanese, D., De Giacomo, G., Lembo, D., Lenzerini, M., & Rosati, R. (2009b). Ontology-based data access and integration. Encyclopedia of database systems. Berlin: Springer.
Calvanese, D., De Giacomo, G., Lembo, D., Lenzerini, M., Poggi, A., Rodriguez-Muro, M., et al. (2011). The Mastro system for ontology-based data access. Semantic Web, 2(1), 43–53.
Civili, C., Console, M., De Giacomo, G., Lembo, D., Lenzerini, M., Lepore, L., & Santarelli, V. (2013). Mastro studio: Managing ontology-based data access applications. Proceedings of the VLDB Endowment, 6(12), 1314–1317.
Console, M., & Lenzerini, M. (2014). Data quality in ontology-based data access: The case of consistency. AAAI, 2014, 1020–1026.
Daraio, C. (Eds.). (2015). Efficiency, effectiveness and impact of research and innovation. In Proceedings of the workshop of the 20 February 2015 DIAG, Sapienza University of Rome, Efesto Edizioni, Rome. ISBN 9788899104306.
Daraio, C., Lenzerini, M., Leporelli, C., Moed, F. H., Naggar, P., Bonaccorsi, A., & Bartolucci, A. (2016). Data integration for research and innovation policy: An ontology-based data management approach. Scientometrics, 106(2), 857–871.
European Commission (2010). Communication from the commission to the European parliament, the council, the European economic and social committee and the committee of the regions. A digital agenda for Europe, Brussels. COM(2010)245 final. Available at: http://eur-lex.europa.eu/legalcontent/EN/TXT/PDF/?uri=CELEX:52010DC0245&from=EN. Accessed 19 May 2010.
Floridi, L. (2014). The fourth revolution: How the infosphere is reshaping human reality. Oxford: OUP Oxford.
Hanson, B., Sugden, A., & Alberts, B. (2011). Making data maximally available. Science, 331(6018), 649.
Hilbert, M., & López, P. (2011). The world’s technological capacity to store, communicate, and compute information. Science, 332(6025), 60–65.
Huijboom, N., & Van den Broek, T. (2011). Open data: An international comparison of strategies. European Journal of ePractice, 12(1), 4–16.
Kshetri, N. (2014). Big data's impact on privacy, security and consumer welfare. Telecommunications Policy, 38(11), 1134–1145.
Lenzerini, M. (2002). Data integration: A theoretical perspective. PODS, 2002, 233–246.
Lenzerini, M. (2011). Ontology-based data management. CIKM, 2011, 5–6.
Li, X., & Johnson, J. D. (2002). Evaluate IT investment opportunities using real options theory. Information Resources Management Journal, 15(3), 32–47.
Moed, H. F. (2016). Altmetrics as traces of the computerization of the research process. In C. R. Sugimoto (Ed.), Theories of informetrics and scholarly communication. A Festschrift in honor of Blaise Cronin (pp. 360–371). Berlin: De Gruyter.
National Research Council. (2004). Open access and the public domain in digital data and information for science: Proceedings of an international symposium. Washington, DC: The National Academies Press.
National Research Council. (2012). The case for international sharing of scientific data: A focus on developing countries. Washington, D.C.: National Academies Press.
Nielsen, M. (2012). Reinventing discovery: The new era of networked science. Princeton: Princeton University Press.
OECD. (2011). Quality framework and guidelines for OECD statistical activities. Paris: OECD Publishing.
OECD. (2015). Making open science a reality. OECD science, technology and industry policy papers no. 25. Paris: OECD Publishing. http://dx.doi.org/10.1787/5jrs2f963zs1-en.
Parent, C., & Spaccapietra, S. (2000). Database integration: The key to data interoperability. In M. P. Papazoglou & Z. Zari (Eds.), Advances in object-oriented data modeling (pp. 221–253). Cambridge: The MIT press.
Parnas, D. L. (1972). On the criteria to be used in decomposing systems into modules. Communications of The ACM, 15(12), 1053–1058.
Pinfield, S., Salter, J., Bath, P. A., Hubbard, B., Millington, P., Anders, J. H., & Hussain, A. (2014). Open access repositories worldwide, 2005–2012: Past growth, current characteristics, and future possibilities. Journal of the Association for Information Science and Technology, 65(12), 2404–2421.
Poggi, A., Lembo, D., Calvanese, D., De Giacomo, G., Lenzerini, M., & Rosati, R. (2008). Linking data to ontologies. In S. Spaccapietra (Ed.), Journal on Data Semantics X, Lecture Notes in Computer Science (Vol. 4900, pp. 133–173). Berlin: Springer.
Simon, H. A. (1962). The architecture of complexity. Proceedings of the American Philosophical Society, 106, 467–482.
Tolk, A., Muguira, J. A. (2003). The levels of conceptual interoperability model. In Proceedings of the 2003 fall simulation interoperability workshop (Vol. 7).
Acknowledgments
The helpful and precious comments and suggestions of Henk F. Moed are warmly acknowledged. Research support from the Award Project 2015 No. C26H15XNFS of the Sapienza university of Rome is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Daraio, C., Lenzerini, M., Leporelli, C. et al. The advantages of an Ontology-Based Data Management approach: openness, interoperability and data quality. Scientometrics 108, 441–455 (2016). https://doi.org/10.1007/s11192-016-1913-6
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11192-016-1913-6