
Abstract
The purpose of this study was to evaluate the dynamics of health and income in contemporary US children and the influence of these dynamics on the age profile of an income–health gradient. Two large cohorts were used to evaluate income gradients in children from 9 months to 5 years and from 6 to 14 years using dynamic specifications of random effects models. An income gradient in parental reports of poor child health was observed in two large cohorts of contemporary US children with ages ranging from infancy to early adolescence. When estimated in separate models both current and averaged income exhibited steepening gradients over the ages of both samples. When estimated jointly only current income exhibited a steepening gradient. While state dependence in health was indicated in dynamic models it did not influence the magnitude or age profile of the income effects. The findings suggested that the age profile of an income–health gradient in the health of US children may depend on whether income is measured as a long-term or short-term variable. Distinguishing these patterns is important for an understanding of how families cope with their children’s health adversities.
Similar content being viewed by others
In what has since served as a benchmark paper for a number of subsequent studies, Case et al. (2002) presented a robust analysis of the relationship between family income and child health in US children and adolescents. Using several nationally-representative datasets, the authors showed a robust negative association between family income and parental reports of poor child health. These findings persisted after controlling for a number of potential confounders: parental education, birthweight, parental health, and health-related behaviors. They also found that the income–health gradient became steeper between early childhood and adolescence. The authors concluded their paper by suggesting a pathway from income to health by which children in lower-income families are subject to higher rates of certain chronic conditions over time and that these conditions are potentially more difficult to manage in environments associated with lower economic status.
Subsequent to the Case et al. (2002) study a number of follow-up papers had been published with similar findings in other US datasets (Case et al. 2007; Chen et al. 2006; Condliffe and Link 2008; Dowd 2007; Murasko 2008) and in samples from other countries including Australia (Khanam et al. 2009; Khanam et al. 2013), Canada (Currie and Stabile 2003), Germany (Reinhold and Jürges 2012), Indonesia (Cameron and Williams 2009), and the United Kingdom (Case et al. 2008; Currie et al. 2007; Kruk 2013; Propper et al. 2007). A key difference in the findings of these studies had been the nature of the age profile in the income–health gradient. Studies using US data found a steepening income–health gradient over childhood and adolescence while those in other countries tended to find a flat association. The exceptions were Currie and Stabile (2003) and Khanam et al. (2009, 2013) who found steepening gradients in Canada and Australia.
For those studies that found a steepening gradient there were differing conclusions as to the mechanisms driving the trend. Currie and Stabile (2003) found a steepening gradient among Canadian children that was suggested to relate to a higher frequency of health shocks (chronic conditions in their study) among lower-income children rather than variations in recovery over time. Condliffe and Link (2008) performed a similar analysis for US children. They found a steepening gradient but their results suggested that lower-income US children exhibited both higher rates of chronic conditions and slower recovery. Murasko (2008) found a steepening gradient in US children but showed that the age-trend was flatter when controlling for baseline health status. Khanam et al. (2009) were also able to control for baseline health in their study of Australian children and continued to find a steepening income gradient in health. However, in a subsequent study that used more data points of their Australian dataset, Khanam et al. (2013) used a more comprehensive dynamic model that controlled for state dependence in health and found no significant association from income to health.Footnote 1
All of these studies used panel data but modeled the dynamic of health in different ways. Currie and Stabile (2003) and Condliffe and Link (2008) evaluated health dynamics through the incidence and persistence of chronic conditions. They did not address the potential dynamics of the outcome health status variable. Murasko (2008) and Khanam et al. (2009) considered the influence of past health states by including controls for baseline health status in their models but did not pursue fully-formed dynamic models (owing perhaps to their having only two data points in their samples). Khanam et al. (2013) was the only study to model the potential for state dependence in health and its implications for the income–health gradient.
The purpose of this study was to evaluate the dynamics of health and income in contemporary US children and the influence of these dynamics on the age profile of an income–health gradient. Two large cohorts were used to evaluate income gradients in children from 9 months to 5 years and from 6 to 14 years. Both cohorts were evaluated over several waves of data allowing for dynamic panel models that evaluated state dependence in health status. This was the first evaluation of health dynamics in contemporary US children over the periods of infancy, childhood, and early adolescence.
Data
Samples
The early-life sample derived from restricted-use microdata of the Early Childhood Longitudinal Study – Birth Cohort (ECLS-B) supported by the US National Center for Education Statistics (NCES). The target population of the ECLS-B was all children born in the US during 2001 except for those born to mothers younger than 15 years of age, those who died before 9 months, and those who were adopted before 9 months. For a detailed description of the ECLS-B and its sample design, see Snow et al. (2009).
The ECLS-B collected family-level information by direct child assessment and parental interview at approximately 9 months, 24 months, 4 years, and 5 years.Footnote 2 The initial 9-month wave had 10,700 children with parental interviews.Footnote 3 By the 5-year wave this number was 6,950. Observations were pooled across waves to yield an analysis sample N = ∑ 4 t=1 n t where n t was the number of original cohort members with parental response up to wave t = 1, … ,4. Cases were dropped where the biological mother was not the interview respondent (3.4 % of cases) or where income information was missing or imputed (8.8 % of cases). The final pooled sample included 31,750 observations.
The school-aged sample derived from public-use microdata of the Early Childhood Longitudinal Study – Kindergarten Class of 1998–1999 (ECLS-K), also supported by the US NCES. The target population of the ECLS-K was all US children enrolled in kindergarten during the 1998–1999 school year. Information was collected by child assessment and parental interview at kindergarten and the first, third, fifth, and eighth grades. The age range from kindergarten to eighth grade was approximately 6 to 14 years. The ECLS-K pre-dated the ECLS-B and the two datasets are not longitudinally related. No structural cohort effects were evaluated given the small average age difference (approximately 6 years) between the samples. For a detailed description of the ECLS-K and its sample design, see Tourangeau et al. (2009).
The initial kindergarten wave consisted of 21,260 children with parental interviews. By the eighth grade this number was reduced to 11,920. Observations were pooled in the same fashion as the ECLS-B sample with dropped cases for non-mother respondents (9.5 %) and missing/imputed income (13.0 %). The final pooled sample included 48,800 cases.
Variables
Ratings of child health were collected at each wave in both datasets. Health was rated by the respondent to the parental interview on an ordinal scale of excellent, very good, good, fair, or poor. The above criterion of mother-only respondents meant that health status was a maternal report for the analysis sample. The analysis was first performed on a health status indicator that took the value of 1 if the child’s health was rated good, fair, or poor (GFP) and 0 otherwise. About 14 % of the ECLS-B sample and 15 % of the ECLS-K sample were reported in GFP health. A second and more conservative indicator was considered afterwards that took the value of 1 if the child’s health was rated fair or poor (FP) and 0 otherwise. About 3 % of each sample was reported in FP health. These variables were chosen to be consistent with previous studies referenced above (e.g., Case et al. 2002; Currie and Stabile 2003).
Household income was reported by parental response in both datasets. Income was reported as one of thirteen bracketed categories (in US$): <$5,000, $5,001–$10,000, $10,001–$15,000, $15,001–$20,000, $20,001–$25,000, $25,001–$30,000, $30,001–$35,000, $35,001–$40,000, $40,001–$50,000, $50,001–$75,000, $75,001–$100,000, $100,001–$200,000, and >$200,000. A continuous income variable was constructed by taking the midpoints of each category and assigning a value of $300,000 to the top category. Dollar values were adjusted for real values using the US Personal Consumption Expenditure index (base year = 2005). Income was entered into the empirical models in logarithmic form.
Basic demographic control variables used in all models included age in years (calculated as age in months divided by 12), an indicator for whether the child was female, a set of indicators for whether the child was black, Hispanic, Asian, or some other non-white race/ethnicity, the logarithm of household size, an indicator for the presence of a resident mother, mother’s age interacted with the indicator for her presence, an indicator for the presence of a resident father, father’s age interacted with the indicator for his presence, a set of indicators for mother’s and father’s highest attained education (high school diploma, vocational/technical qualification or some college, Bachelor’s degree, or graduate degree, reference = not finished high school) interacted with indicators for their presence. These controls were similar to those used in the Case et al. (2002) study. Indicator sets for birth outcomes were also used in all models. For the ECLS-B sample these included birthweight category (<1,000, 1,000–1,499, 1,500–1,999, 2,000–2,499 g, reference = 2,500 g and over), gestation period (<28, 28–31, 32–37 weeks, reference = 37 weeks and over), whether the child was in neonatal intensive care after birth, and whether the child was placed on a ventilator after birth. For the ECLS-K sample these included birthweight category (<1,500, 1,500–1,999, 2,000–2,499 g, reference = 2,500 g and over) and whether the child was born at <37 weeks gestation. The ECLS-B sample had a higher percentage and greater variability of lower birthweight/gestation children due to oversampling. Table 1 shows the means for all variables.
Methods
The empirical models followed the framework used by Contoyannis et al. (2004) to evaluate state dependence in health in a sample of British adults and by Khanam et al. (2013) to evaluate income–health dynamics in a sample of Australian children. A dynamic random effects probit model was defined by:
for t = 2,…,T where h it was an indicator for poor health of child i at time t, h i,t-1 was an indicator for lagged health status, y it was a measure of household real income, x it was a vector of observed non-income variables assumed to associate with health status, α i represented time-invariant unobserved random effects that influence individual health outcomes (e.g., genetic predisposition to disease or parents’ propensity to invest in child health), and v it ∼ N(0, σ 2 v ) was an idiosyncratic disturbance term. Income and the control set x it were assumed strictly exogenous conditional on α i and the random effects were assumed orthogonal to all explanatory variables.Footnote 4
Estimation was performed in the manner suggested by Wooldridge (2005) to address the initial conditions problem of dynamic nonlinear models. The problem is described as when the first observation of the outcome variable is not the true initial value but rather the result of an ongoing stochastic process that determines the outcome variable. In that case the conditional distribution of the initial value would not be known and must be assumed in order to maximize the log-likelihood of the nonlinear model. Wooldridge (2005) suggested a variation of the Mundlak (1978) device by assuming a specification for the random effects that is a linear function of the observed outcome variable at t = 1 and the within-means of the exogenous variables. Thus the random effects associated with Eq. (1) were modeled as:
where h i,1 was an indicator of health status from the first wave of each sample, \( \overline{z}_{i} \) contained within-individual means of the explanatory variables (\( \overline{x}_{i} \) and \( \overline{lny}_{i} \)), and u i ∼ N(0, σ 2 u ) was assumed independent of explanatory variables, initial health, and v it . The variable \( \overline{lny}_{i}\) was interpreted as a measure of permanent income in contrast to the current measure lny it .
The conventional Mundlak (1978) device was reflected in the modeling of α i as a function of \( \overline{z}_{i} \) that allowed for correlation between the random effects and the explanatory variables. Wooldridge (2005) suggested adding the first-period values of the outcome variable (health status) so that after substitution of (2) into (1) the resulting equation became:
which had a conditional likelihood just as a standard random effects model and could be estimated in the conventional manner. Estimated coefficients of any observed time-invariant variables (e.g., sex or race/ethnicity) were linear combinations of their respective components in β and θ.
Estimation of (3) was performed through the “xtprobit” command in Stata/SE 12.1. A limitation of this command is that it did not support sampling weights. Both the ECLS-B and ECLS-K had accompanying sampling weights to adjust for attrition and parental non-response relative to the representativeness of the original cohorts. The potential influence of these sampling weights was evaluated by estimating non-dynamic versions of a random effects linear probability model on Eq. (3) with and without weighting.Footnote 5 The results indicated no substantial differences in the estimated income effects between specifications.
A set of simpler models were estimated to compare with Eq. (3). These took the general form:
Equation (4) was first estimated separately by probit regression for the 9-month ECLS-B wave (t = 1) to establish an income–health gradient at the youngest sampled ages. Three specifications were estimated that differed by income measure. The first specification included the log of current income, lny it . The second specification included the mean of the log of current income, \( {\overline{lny}}_{i} \). The third specification included both measures of income as was done in the dynamic Eq. (3) and could be considered an effective Mundlak (1978) specification for the random effects using only the mean of income. Equation (4) was then estimated separately for the ECLS-B and ECLS-K pooled samples (for t ≥ 2 to support comparability to the dynamic model) as a random effects probit model that included both measures of income. A second specification was estimated with added controls for lagged and initial health status making it comparable to Eq. (3) without the Mundlak (1978) device.
Finally, Eq. (3) and the alternate specifications of (4) were estimated with added interaction terms between income measures and age. Equation (3) was estimated with an interaction between income and age and a second interaction between averaged income and averaged age (the latter being included in \( \overline{z}_{i} \)). The age-income interactions were added to evaluate the age profile in any income–health gradients.
Results
Table 2 presents the average marginal effects (AMEs) from the 9-month ECLS-B cross-section probit regression estimated on both health outcomes. AMEs for log-income gave the average percentage change in the probability of a health outcome associated with a doubling of income, where the average was taken over all cases in the sample. AMEs were found using the “margins” post-estimation command in Stata/SE 12.1. When treated separately the AMEs from both current and averaged income were negative and significant, with slightly larger AMEs from averaged income. When entered jointly into the same equation only the AME from averaged income was significant. A doubling of averaged income was associated with a 1.8 % decrease in the probability of GFP health and a 0.7 % decreased probability of FP health.
Table 3 shows the results from the various random effects probit models estimated on GFP health. The ECLS-B pooled sample exhibited the same pattern as the 9-month wave. Current and averaged income exhibited significant AMEs when treated separately (columns (i) and (ii)) but only averaged income was significant when the two measures were entered into the model jointly (column (iii)). A doubling of averaged income was associated with a 2.5 % decrease in the probability of GFP health. In the ECLS-K pooled sample the AMEs from both current and averaged income remained significant when jointly considered. A doubling of average income was associated with a 4.1 % decrease in the probability of GFP health and a doubling of current income was associated with a 0.9 % decreased probability. The AMEs in the ECLS-K sample were larger than those in the ECLS-B sample, suggesting a steepening gradient between the respective age ranges.
The last two columns show the estimated AMEs from the random effects models with lagged and initial health status. Column (iv) shows the AMEs in the model that did not include the Mundlak (1978) specification for random effects and column (v) shows the AMEs from the full dynamic model given by Eq. (3). The AMEs were nearly identical across specifications. For both samples only the AME from averaged income was significant. A doubling of averaged income was associated with a 2.3 % decreased probability of GFP health in the ECLS-B sample and a 3.2 % decreased probability in the ECLS-K sample. The AME in the ECLS-B sample was little changed from the model that did not include lagged health status (column (iii)). The AME in the ECLS-K sample exhibited a modest reduction in magnitude.
State dependence of health was indicated in both samples and was not affected by the modeling of random effects as a function of the means of explanatory variables other than income. AMEs for both lagged and initial health were similar in magnitude across the samples, with modestly larger AMEs from initial health relative to lagged health. Being in GFP health at the initial wave of each sample was associated with a 10–11 % increased probability of being in GFP health at a given time period. A lagged state of GFP health was associated with a 6–7 % increased probability of GFP health at a given time period.
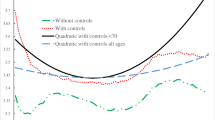
Figure 1 depicts the results of the age-income interaction models. AMEs for income were calculated separately over the integer ages of each sample and then smoothed by locally-weighted regression over the ages of both samples.Footnote 6 The figures show the plotted smoothed AMEs from current and averaged income against age in years for four cases: when estimated in separate (1), when entered jointly (1b), when entered jointly and with controls for lagged/initial health status (1c), and when estimated from the full dynamic model (1d). There were strengthening AMEs over the ages of both samples from current and averaged income when those measures were modeled separately (Fig. 1a). A doubling of either income measure was associated with about 3–4 % lower probabilities of GFP health at the oldest ages of the ECLS-K sample in comparison to the youngest ages of the ECLS-B sample. When both income measures were included in the same model then only current income exhibited a steepening gradient (Fig. 1b). A doubling of current income again exhibited an approximate 3 % differential probability of GFP health at the extremes of the sample ages. The AME from averaged income exhibited a modest strengthening into the younger ages of the ECLS-K sample but returned to its initial magnitude by the oldest ages.

Age-specific average marginal effects from income on good/fair/poor health as estimated from age-interaction models. Solid lines indicate current income, dashed lines indicate averaged income. Average marginal effects (AMEs) given on the vertical axes. a AMEs from separate models for current and averaged income, b AMEs from model with both income measures, c AMEs from model with both income measures and lagged/initial health, d AMEs from full dynamic model
The AME comparison for the models with lagged and initial health status is depicted in Fig. 1c, d. The AME trends were identical between models suggesting no influence from the modeling of correlation between the random effects and explanatory variables. The trends were nearly identical to that exhibited in the models without health dynamics. Current income exhibited a steepening gradient while the AMEs from averaged income exhibit a U-shape. The main difference was that the AME from averaged income trended much closer to zero by the oldest ages of the ECLS-K sample.
Table 4 shows the results from the repeated analysis on the second health indicator, FP health. In general the same patterns were observed but with AMEs at much smaller magnitudes (ranging from 0.1 to 0.5 % decreased probabilities associated with a doubling of either income measure). A key difference was that neither income measure exhibited strongly significant associations to FP health in the ECLS-B sample when lagged health was included in the models.
Figure 2 shows the AMEs from the age-income interaction models on FP health for the same cases as described for Fig. 1. Again the same patterns were observed that were present for GFP health. Both current and averaged income exhibit steepening gradients when considered separately and ignoring health dynamics (Fig. 2a). When entered jointly into the models only current income exhibited a steepening gradient (Fig. 2b, c, d). Notably there were negative AMEs from current income only at the older ages of the ECLS-K sample. The AME from averaged income was essentially flat over most of the age range.

Age-specific average marginal effects from income on fair/poor health as estimated from age-interaction models. Solid lines indicate current income, dashed lines indicate averaged income. Average marginal effects (AMEs) given on the vertical axes. a AMEs from separate models for current and averaged income, b AMEs from model with both income measures, c AMEs from model with both income measures and lagged/initial health, d AMEs from full dynamic model
Discussion
The findings of this analysis are summarized as follows. An income gradient in parental reports of poor child health was observed in two large cohorts of contemporary US children with ages ranging from infancy to early adolescence. The gradient was present for current and averaged income with a larger magnitude of association from the latter. When estimated in separate models both current and averaged income exhibited steepening gradients over the ages of both samples. When estimated jointly only current income exhibited a steepening gradient. Average income exhibited a U-shape age profile (GFP health) or a relatively flat age profile (FP health). While state dependence in health was indicated in dynamic models it did not influence the magnitude or age profile of the income effects. Neither does any potential correlation between unobserved heterogeneity and the means of explanatory variables other than income.
The findings support previous work that identifies an income–health gradient that begins in early-life and becomes steeper as children age through adolescence. However, they build on previous work in distinguishing the age profile in current and averaged income. One interpretation of the results is that US children from families in long-term lower-income environments face disadvantages particularly before late-adolescence but that transitory changes to current income become more important as children become older. This could occur if long-term economic conditions exert a stronger influence on the probability of health shocks (e.g., chronic conditions) but short-term income is more relevant for the management of those shocks. Management may be more important for older children if conditions are more severe or if children are exposed to a greater set of possible conditions. Examples would include reproductive disease that manifests during puberty, metabolic disorders that manifest from chronic childhood obesity, or permanent injury resulting from sports participation or risk-taking behaviors. The ECLS-B and ECLS-K data are not sufficient to examine these relationships but they would be consistent with the results of previous work (e.g., Currie and Stabile 2003; Condliffe and Link 2008).
If it is the case that short-term income is more relevant for health management than it would suggest that policies directed toward short-term healthcare access for families with transitory income shocks may alleviate part of health inequality in the US. There has been some evidence of the effectiveness of such policies for unemployment shocks on pregnancy outcomes (Menclova 2013). However, such policies may not be expected to address the effect from the long-term economic environment. It is this effect that is potentially more ambiguous to discernand introduces a caveat to the interpretation of results. As noted in Contoyannis et al. (2004) it is not possible in the models to distinguish a causal effect from the averaged income variable from its correlation with the unobserved effects. Support for a causal interpretation comes from the conditioning on lagged health status and the lack of sensitivity of the AMEs to a set of extended controls (see footnote 4). This would suggest direct mechanisms by which the long-term economic environment may affect health outcomes including its role in housing conditions, access to nutrition, or consistent contact with health providers, all of which may not amenable to short-term intervention (e.g., Chang et al. 2013; Fiese et al. 2013; Kainz et al. 2012). The ECLS-B and ECLS-K data lack sufficient information to test for the influence of these factors. Their influence on the age profile in children’s health is left to future work.
A second caveat derives from the use of parental reports of child health. It is not clear on what criteria mothers (or fathers) base their evaluations of their children’s health, whether their criteria is the same in infancy as it is at older ages, or whether the criteria are the same for lower- and higher-income parents. For example, the conceptualization of health in an environment characterized by higher crime, infectious disease, and undernutrition may be different than that in a safer environment. The dynamic models mitigate these variations by conditioning the probability of contemporary health reports on previous reports. However, if parents update their criteria to reflect age-specific health concerns as children age through infancy, childhood, and adolescence, then previous health reports will not fully reflect the new criteria.
It is also noteworthy that income exhibited much stronger associations to GFP health compared to FP health. This could be a reflection of the much lower overall probability of children being rated in fair/poor health relative to good health. It could also be a reflection of income having a stronger association to more modest health problems or that the category of good health is viewed differently by mothers of different income levels (for example, lower-income mothers may be disinclined to rate any aspect of life as “excellent”). There is yet to be a study that fully examines these issues and, more important to the aims of this paper, how they relate to income levels and child age. This places a limitation on the interpretation of this paper’s results.
Conclusion
The balance of evidence from this study and others suggests that the economic environment in which US children develop has an influence on their health outcomes. Previous work has suggested that the economic environment may play a stronger role as children grow older, but the results of this study suggest that the age profile of an income–health gradient in the health of US children may depend on whether income is measured as a long-term or short-term variable. Distinguishing these patterns is important for an understanding of how families cope with their children’s health adversities since the health factors related to short-term and long-term resources are likely different. It is also important for the timing and duration of potential policy interventions.
Notes
The income coefficients in the non-dynamic and dynamic models did not change by much in the Khanam et al. (2013) study. Controlling for health dynamics resulted in higher standard error for the income coefficient.
A follow-up wave was conducted in the fall of 2007 for the subsample of children who did not enter kindergarten in the previous year or were repeating the grade level. This wave is not included in the present analysis because it was not intended to reflect the target population of the original cohort.
A confidentiality agreement on the restricted-use ECLS-B data requires rounding of sample sizes to the nearest 50.
An extended set of controls was also evaluated to support the exogeneity assumption. These included variables related to parental employment, location of residence, prenatal investments, parental involvement at home and school, and parents’ performance in high school. The estimated income associations were unaffected by these controls.
This was done using the “xtmixed” command in Stata/SE 12.1 which can be used to estimate a linear random effects model and allow adjustment for sample weights.
Smoothing of AMEs was done by locally-weighted regression using the “twoway lowess” command in Stata/SE 12.1.
References
Cameron, L., & Williams, J. (2009). Is the relationship between socioeconomic status and health stronger for older children in developing countries? Demography, 46(2), 303–324. doi:10.1353/dem.0.0054.
Case, A., Lee, D., & Paxson, C. (2008). The income gradient in children’s health: A comment on currie, shields and wheatley price. Journal of Health Economics, 27(3), 801–807. doi:10.1016/j.jhealeco.2007.10.005.
Case, A., Lubotsky, D., & Paxson, C. (2002). Economic status and health in childhood: The origins of the gradient. American Economic Review, 92(5), 1308–1334. doi:10.1257/000282802762024520.
Case, A., Paxson, C., & Vogl, T. (2007). Socioeconomic status and health in childhood: A comment on Chen, Martin and Matthews, “Socioeconomic status and health: Do gradients differ within childhood and adolescence?”(62: 9, 2006, 2161–2170). Social Science & Medicine, 64(4), 757. doi:10.1016/j.socscimed.2006.10.025.
Chang, Y., Chatterjee, S., & Kim, J. (2013). Household finance and food insecurity. Journal of Family and Economic Issues. doi:10.1007/s10834-013-9382-z.
Chen, E., Martin, A. D., & Matthews, K. A. (2006). Socioeconomic status and health: Do gradients differ within childhood and adolescence? Social Science & Medicine, 62(2), 2161–2170. doi:10.1016/j.socscimed.2005.08.054.
Condliffe, S., & Link, C. R. (2008). The relationship between economic status and child health: Evidence from the United States. American Economic Review, 98(4), 1605–1618. doi:10.1257/aer.98.4.1605.
Contoyannis, P., Jones, A. M., & Rice, N. (2004). The dynamics of health in the British Household Panel Survey. Journal of Applied Econometrics, 19(4), 473–503. Retrieved from http://onlinelibrary.wiley.com.
Currie, A., Shields, M. A., & Price, S. W. (2007). The child health/family income gradient: Evidence from England. Journal of Health Economics, 26(2), 213–232. doi:10.1016/j.jhealeco.2006.08.003.
Currie, J., & Stabile, M. (2003). Socioeconomic status and child health: Why is the relationship stronger for older children? American Economic Review, 93(5), 1813–1823. doi:10.1257/000282803322655563.
Dowd, J. B. (2007). Early childhood origins of the income/health gradient: The role of maternal health behaviors. Social Science & Medicine, 65(6), 1202–1213. doi:10.1016/j.socscimed.2007.05.007.
Fiese, B.H., Koester, B.D., & Waxman, E. (2013). Balancing household needs: The non-food needs of food pantry clients and their implications for program planning. Journal of Family and Economic Issues. doi:10.1007/s10834-013-9381-0.
Kainz, K., Willoughby, M. T., Vernon-Feagans, L., & Burchinal, M. R. (2012). Modeling family economic conditions and young children’s development in rural United States: Implications for poverty research. Journal of Family and Economic Issues, 33(4), 410–420. doi:10.1007/s10834-012-9287-2.
Khanam, R., Nghiem, H. S., & Connelly, L. B. (2009). Child health and the income gradient: Evidence from Australia. Journal of Health Economics, 28(4), 805–817. doi:10.1016/j.jhealeco.2009.05.001.
Khanam, R., Nghiem, H.S., & Connelly, L.B. (2013). What roles do contemporaneous and cumulative incomes play in the income–child health gradient for young children? Evidence from an Australian Panel. Health Economics. doi:10.1002/hec.296.
Kruk, K. E. (2013). Parental income and the dynamics of health inequality in early childhood—evidence from the UK. Health Economics, 22(10), 1199–1214. doi:10.1002/hec.2876.
Menclova, A. K. (2013). The effects of unemployment on prenatal care use and infant health. Journal of Family and Economic Issues, 34(4), 400–420. doi:10.1007/s10834-012-9339-7.
Mundlak, Y. (1978). On the pooling of time series and cross section data. Econometrica, 46(1), 69–85. Retrieved from http://www.jstor.org/stable/1913646.
Murasko, J. E. (2008). An evaluation of the age-profile in the relationship between household income and the health of children in the United States. Journal of Health Economics, 27(6), 1489–1502. doi:10.1016/j.jhealeco.2008.07.
Propper, C., Rigg, J., & Burgess, S. (2007). Child health: Evidence on the roles of family income and maternal mental health from a UK birth cohort. Health Economics, 16(11), 1245–1269. doi:10.1002/hec.1221.
Reinhold, S., & Jürges, H. (2012). Parental income and child health in Germany. Health Economics, 21(5), 562–579. doi:10.1002/hec.1732.
Snow, K., Derecho, A., Wheeless, S., Lennon, J., Rosen, J., Rogers, J., et al. (2009). Early Childhood Longitudinal Study, Birth Cohort (ECLS-B), Kindergarten 2006 and 2007 Data File User’s Manual (2010-010). National Center for Education Statistics, Institute of Education Sciences, U.S: Department of Education. Washington, DC.
Tourangeau, K., Nord, C., Le, T., Sorongon, A.G., & Najarian, M. 2009. Early Childhood Longitudinal Study, Kindergarten Class of 1998–99 (ECLSK), Eighth-Grade Methodology Report (NCES 2009-003). National Center for Education Statistics, Institute of Education Sciences, U.S. Department of Education, Washington, DC. Retrieved from http://nces.ed.gov/pubs2009/2009003.pdf.
Wooldridge, J. M. (2005). Simple solutions to the initial conditions problem in dynamic, nonlinear panel data models with unobserved heterogeneity. Journal of Applied Econometrics, 20(1), 39–54. doi:10.1002/jae.770.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Murasko, J.E. The Age Profile of the Income–Health Gradient: An Evaluation of Two Large Cohorts of Contemporary US Children. J Fam Econ Iss 36, 289–298 (2015). https://doi.org/10.1007/s10834-014-9396-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10834-014-9396-1