
Abstract
Open source software (OSS) is essential for modern society and, while substantial research has been done on individual (typically central) projects, only a limited understanding of the periphery of the entire OSS ecosystem exists. For example, how are the tens of millions of projects in the periphery interconnected through technical dependencies, code sharing, or knowledge flow? To answer such questions we: a) create a very large and frequently updated collection of version control data in the entire FLOSS ecosystems named World of Code (WoC), that can completely cross-reference authors, projects, commits, blobs, dependencies, and history of the FLOSS ecosystems and b) provide capabilities to efficiently correct, augment, query, and analyze that data. Our current WoC implementation is capable of being updated on a monthly basis and contains over 18B Git objects. To evaluate its research potential and to create vignettes for its usage, we employ WoC in conducting several research tasks. In particular, we find that it is capable of supporting trend evaluation, ecosystem measurement, and the determination of package usage. We expect WoC to spur investigation into global properties of OSS development leading to increased resiliency of the entire OSS ecosystem. Our infrastructure facilitates the discovery of key technical dependencies, code flow, and social networks that provide the basis to determine the structure and evolution of the relationships that drive FLOSS activities and innovation.













Similar content being viewed by others
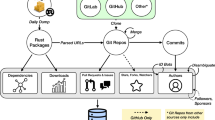

Notes
blackducksoftware.com,fossid.com
CPU: E5-2670, No. node: 36, No. core: 16, Mem size: 256 GB
The exclusion only happens when all the conditions are met: a GitHub project has not been seen in the project list in a previous update, GitHub marked this project as a fork, and all the heads already exist in our database.
“git fetch” downloads only new objects from the remote repository
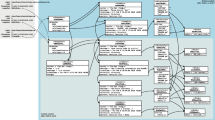
a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data
bidirectional maps between the commit and five objects/attributes and between file and blob
‘File’ in this figure refers to ‘File name’
By file, we refer to the file name (including folder path) in the rest of our paper.
Section 5.2 shows how WoC can also be used to improve them
The size information for Software Heritage, GHTorrent and WoC is directly obtained from their official websites. GHArchive, on the other hand did not provide such detailed information, and we looked into its dataset and checked the author ID field and project ID field.
References
Abadi DJ (2009) Data management in the cloud: limitations and opportunities. IEEE Data Eng Bull 32(1):3–12
Agrawal S, Narasayya V, Yang B (2004) Integrating vertical and horizontal partitioning into automated physical database design. In: Proceedings of the 2004 ACM SIGMOD international conference on management of data. ACM, pp 359–370
Amreen S, Mockus A, Bogart C, Zhang Y, Zaretzki R (2019) Alfaa: active learning fingerprint based anti-aliasing for correcting developer identity errors in version control data. arXiv:1901.03363
Amreen S, Mockus A, Zaretzki R, Bogart C, Zhang Y (2020) ALFAA: Active Learning Fingerprint based Anti-Aliasing for correcting developer identity errors in version control systems. Empir Softw Eng 25(2):1136–1167
Bajracharya S, Ossher J, Lopes C (2014) Sourcerer: an infrastructure for large-scale collection and analysis of open-source code. Sci Comput Program 79:241–259
Bevan J, Whitehead EJ Jr, Kim S, Godfrey M (2005) Facilitating software evolution research with kenyon. ACM SIGSOFT Softw Eng Notes 30(5):177–186
Bird C, Gourley A, Devanbu P, Gertz M, Swaminathan A (2006) Mining email social networks. In: Proceedings of the 2006 international workshop on mining software repositories, MSR ’06. https://doi.org/10.1145/1137983.1138016. ACM, New York, pp 137–143
Bird C, Rigby PC, Barr ET, Hamilton DJ, German DM, Devanbu P (2009) The promises and perils of mining git. In: 6th IEEE international working conference on mining software repositories, 2009. MSR’09. IEEE, pp 1–10
Budde R, Kautz K, Kuhlenkamp K, Züllighoven H (1992) Prototyping. In: Prototyping. Springer, pp 33–46
Chacon S, Straub B (2014) Pro git. Springer Nature, Berlin
Coelho J, Valente MT, Silva LL, Shihab E (2018) Identifying unmaintained projects in github. In: Proceedings of the 12th ACM/IEEE international symposium on empirical software engineering and measurement. ACM
Czerwonka J, Nagappan N, Schulte W, Murphy B (2013) Codemine: building a software development data analytics platform at microsoft. IEEE Softw 30(4):64–71
Dey T, Mockus A (2018a) Are software dependency supply chain metrics useful in predicting change of popularity of npm packages?. In: Proceedings of the 14th international conference on predictive models and data analytics in software engineering. ACM, pp 66–69
Dey T, Mockus A (2018b) Modeling relationship between post-release faults and usage in mobilesoftware. In: Proceedings of the 14th international conference on predictive models and data analytics in software engineering, pp 56–65
Dey T, Mockus A (2020a) A dataset of pull requests and a trained random forest model forpredicting pull request acceptance. https://doi.org/10.5281/zenodo.3858046
Dey T, Mockus A (2020b) Deriving a usage-independent software quality metric. Empir Softw Eng 25(2):1596–1641
Dey T, Mockus A (2020c) Effect of technical and social factors on pull request quality for thenpm ecosystem. In: Proceedings of the 14th ACM/IEEE international symposium on empirical software engineering and measurement (ESEM), pp 1–11
Dey T, Ma Y, Mockus A (2019a) Patterns of effort contribution and demand and user classification based on participation patterns in npm ecosystem. In: Proceedings of the fifteenth international conference on predictive models and data analytics in software engineering, pp 36–45
Dey T, Ma Y, Mockus A (2019b) Patterns of effort contribution and demand and user classification based on participation patterns in npm ecosystem. arXiv:1907.06538
Dey T, Mousavi S, Ponce E, Fry T, Vasilescu B, Filippova A, Mockus A (2020a) A dataset of bot commits. https://doi.org/10.5281/zenodo.3610205
Dey T, Mousavi S, Ponce E, Fry T, Vasilescu B, Filippova A, Mockus A (2020b) Detecting and characterizing bots that commit code. In: Proceedings of the 17th international conference on mining software repositories, pp 209–219
Dey T, Karnauch A, Mockus A (2020c) Representation of developer expertise in open source software. arXiv:2005.10176
Dey T, Vasilescu B, Mockus A (2020d) An exploratory study of bot commits. In: Proceedings of the IEEE/ACM 42nd international conference on software engineering workshops, pp 61–65
Dey T, Vasilescu B, Mockus A (2020e) A mapping between Bot Commit, Projects, Files, and Blobs [Data set]. Zenodo. https://doi.org/10.5281/zenodo.3699665
Di Cosmo R, Zacchiroli S (2017) Software heritage: why and how to preserve software source code. In: iPRES 2017: 14th international conference on digital preservation. Kyoto, Japan. https://www.softwareheritage.org/wp-content/uploads/2020/01/ipres-2017-swh.pdfhttps://hal.archives-ouvertes.fr/hal-01590958
Ducasse S, Gîrba T, Nierstrasz O (2005) Moose: an agile reengineering environment. In: ACM SIGSOFT software engineering notes, vol 30. ACM, pp 99–102
Dyer R (2013) Task fusion: improving utilization of multi-user clusters. In: Proceedings of the 2013 companion publication for conference on Systems, programming, & applications: software for humanity, SPLASH SRC, pp 117–118
Dyer R, Nguyen HA, Rajan H, Nguyen TN (2013) Boa: a language and infrastructure for analyzing ultra-large-scale software repositories. In: Proceedings of the 35th international conference on software engineering, ICSE’13, pp 422–431
Dyer R, Nguyen HA, Rajan H, Nguyen TN (2015a) Boa: An enabling language and infrastructure for ultra-large-scale msr studies. In: The art and science of analyzing software data. Morgan Kaufmann, pp 593–621
Dyer R, Nguyen HA, Rajan H, Nguyen TN (2015b) Boa: ultra-large-scale software repository and source-code mining. ACM Trans Softw Eng Methodol 25(1):7:1–7:34
Dyer R, Rajan H, Nguyen TN (2013) Declarative visitors to ease fine-grained source code mining with full history on billions of AST nodes. In: Proceedings of the 12th international conference on generative programming: concepts & experiences, GPCE, pp 23–32
Eastlake 3rd D, Jones P (2001) Us secure hash algorithm 1 (sha1). Tech. rep
Fry T, Dey T, Karnauch A, Mockus A (2020) A dataset and an approach for identity resolution of 38 million author ids extracted from 2b git commits. In: Proceedings of the 17th international conference on mining software repositories, pp 518–522
German D, Mockus A (2003) Automating the measurement of open source projects. In: Proceedings of the 3rd workshop on open source software engineering. University College Cork Cork Ireland, pp 63–67
Gorton I, Bener AB, Mockus A (2016) Software engineering for big data systems. IEEE Softw 33(2):32–35
Gousios G (2013) The ghtorrent dataset and tool suite. In: Proceedings of the 10th working conference on mining software repositories, MSR ’13. http://dl.acm.org/citation.cfm?id=2487085.2487132. IEEE Press, Piscataway, pp 233–236
Gousios G, Pinzger M, Deursen AV (2014) An exploratory study of the pull-based software development model. In: Proceedings of the 36th international conference on software engineering. ACM, pp 345–355
Gousios G, Spinellis D (2009) Alitheia core: an extensible software quality monitoring platform. In: IEEE 31st international conference on software engineering, 2009. ICSE 2009. IEEE, pp 579–582
Gousios G, Spinellis D (2012) Ghtorrent: Github’s data from a firehose. In: 2012 9th ieee working conference on mining software repositories (msr). IEEE, pp 12–21
Gousios G, Vasilescu B, Serebrenik A, Zaidman A (2014) Lean ghtorrent: Github data on demand. In: Proceedings of the 11th working conference on mining software repositories. ACM, pp 384–387
Gousios G, Zaidman A (2014) A dataset for pull-based development research. In: Proceedings of the 11th working conference on mining software repositories. ACM, pp 368–371
Hackbarth R, Mockus A, Palframan J, Weiss D (2010) Assessing the state of software in a large enterprise. J Empir Softw Eng 10(3):219–249
Howison J, Conklin M, Crowston K (2006) Flossmole: a collaborative repository for floss research data and analyses. Int J Info Technol Web Eng (IJITWE) 1(3):17–26
Hung CS, Dyer R (2020) Boa views: easy modularization and sharing of msr analyses. In: Proceedings of the 17th international conference on mining software repositories, pp 147–157
Kalliamvakou E, Gousios G, Blincoe K, Singer L, German DM, Damian D (2014) The promises and perils of mining github. In: Proceedings of the 11th working conference on mining software repositories, MSR 2014. https://doi.org/10.1145/2597073.2597074. Association for Computing Machinery, New York, pp 92–101
Kim S, Zimmermann T, Kim M, Hassan AE, Mockus A, Gîrba T, Pinzger M, Jr. EJW, Zeller A (2006) Ta-re: an exchange language for mining software repositories. In: ICSE’06 workshop on mining software repositories. http://dl.acm.org/authorize?804411. Shanghai, China, pp 22–25
Le Q, Mikolov T (2014) Distributed representation of sentences and documents. In: Proceedings of the 31st international conference on machine learning. https://cs.stanford.edu/quocle/paragraph_vector.pdf, vol 32. JMLR, Beijing
Leavitt N (2010) Will NoSQL databases live up to their promise? Computer 43(2):12–14. https://doi.org/10.1109/MC.2010.58
Lichter H, Schneider-Hufschmidt M, Zullighoven H (1994) Prototyping in industrial software projects-bridging the gap between theory and practice. IEEE Trans Softw Eng 20(11):825–832
Ma Y, Dey T, Smith JM, Wilder N, Mockus A (2016) Crowdsourcing the discovery of software repositories in an educational environment. PeerJ Preprints 4:e2551v1. https://doi.org/10.7287/peerj.preprints.2551v1
Ma Y, Mockus A, Zaretzki R, Bichescu R, Bradley B (2020) A methodology for analyzing uptake of software technologies among developers. IEEE Transactions on Software Engineering. https://doi.org/10.1109/TSE.2020.2993758
Mockus A (2007) Large-scale code reuse in open source software. In: ICSE’07 intl. workshop on emerging trends in FLOSS research and development. Minneapolis, Minnesota. papers/ossreuse.pdf
Mockus A (2009) Amassing and indexing a large sample of version control systems: towards the census of public source code history. In: 6th IEEE working conference on mining software repositories. papers/amassing.pdf
Mockus A (2014) Engineering big data solutions. In: ICSE’14 FOSE. papers/BigData.pdf
Moniruzzaman A, Hossain SA (2013) Nosql database: new era of databases for big data analytics-classification, characteristics and comparison. arXiv:1307.0191
Munaiah N, Kroh S, Cabrey C, Nagappan M (2017) Curating github for engineered software projects. Empir Softw Eng 22(6):3219–3253
Nexus (2019) Repository. https://www.sonatype.com/nexus-repository-oss. Accessed 02 Jan 2019
Ossher J, Bajracharya S, Linstead E, Baldi P, Lopes C (2009) Sourcererdb: an aggregated repository of statically analyzed and cross-linked open source java projects. In: 6th IEEE international working conference on mining software repositories, 2009. MSR’09. IEEE, pp 183–186
Pietri A, Spinellis D, Zacchiroli S (2019) The software heritage graph dataset: public software development under one roof. In: 2019 IEEE/ACM 16th international conference on mining software repositories (MSR). IEEE, pp 138–142
Qi Z (2007) Fast sha1 implementation. US Patent 7,299,355
Rajan H, Nguyen TN, Dyer R, Nguyen HA (2015) Boa website. http://boa.cs.iastate.edu/
Rosch E (2002) Principles of categorization. In: Levitin DJ (ed) Foundations of cognitive psychology: core readings. MIT Press, pp 251–270
Rozenberg D, Beschastnikh I, Kosmale F, Poser V, Becker H, Palyart M, Murphy GC (2016) Comparing repositories visually with repograms. In: Proceedings of the 13th international conference on mining software repositories. ACM, pp 109–120
Russom P, et al. (2011) Big data analytics. TDWI best practices report, fourth quarter 19(4):1–34
Sayyad Shirabad J, Menzies T (2005) The PROMISE repository of software engineering databases. School of Information Technology and Engineering, University of Ottawa, Canada. http://promise.site.uottawa.ca/SERepository
Spinellis D, Kotti Z, Mockus A (2020) A dataset for github repository deduplication. In: Proceedings of the 17th international conference on mining software repositories, pp 523–527
Tiwari NM, Upadhyaya G, Nguyen HA, Rajan H (2017) Candoia: a platform for building and sharing mining software repositories tools as apps. In: MSR’17: 14th international conference on mining software repositories
Tiwari NM, Upadhyaya G, Rajan H (2016) Candoia: a platform and ecosystem for mining software repositories tools. In: Proceedings of the 38th international conference on software engineering companion. ACM, pp 759–764
Upadhyaya G, Rajan H (2017) On accelerating ultra-large-scale mining. In: Proceedings of the 39th international conference on software engineering: new ideas and emerging results track. IEEE Press, pp 39–42
Upadhyaya G, Rajan H (2018) On accelerating source code analysis at massive scale. IEEE Trans Softw Eng
Wang X, Yin YL, Yu H (2005) Collision search attacks on sha1
Winkler W (1990) String comparator metrics and enhanced decision rules in the fellegi-sunter model of record linkage
Winkler WE (2006) Overview of record linkage and current research directions. Tech. rep. BUREAU OF THE CENSUS
Acknowledgments
This work was supported by the National Science Foundation NSF Awards 1633437, 1901102, and 1925615.
Funding
This work was supported by the National Science Foundation NSF Awards 1633437,1901102, and 1925615.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Yasutaka Kamei and Andy Zaidman
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article belongs to the Topical Collection: Mining Software Repositories (MSR)
Appendices
Appendix A: Source Code for Cmt2ATShow.perl

Appendix B: Source Code for the custom lsort command in tutorial

Rights and permissions
About this article

Cite this article
Ma, Y., Dey, T., Bogart, C. et al. World of code: enabling a research workflow for mining and analyzing the universe of open source VCS data. Empir Software Eng 26, 22 (2021). https://doi.org/10.1007/s10664-020-09905-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s10664-020-09905-9