
Abstract
Defects4J is a large, peer-reviewed, structured dataset of real-world Java bugs. Each bug in Defects4J comes with a test suite and at least one failing test case that triggers the bug. In this paper, we report on an experiment to explore the effectiveness of automatic test-suite based repair on Defects4J. The result of our experiment shows that the considered state-of-the-art repair methods can generate patches for 47 out of 224 bugs. However, those patches are only test-suite adequate, which means that they pass the test suite and may potentially be incorrect beyond the test-suite satisfaction correctness criterion. We have manually analyzed 84 different patches to assess their real correctness. In total, 9 real Java bugs can be correctly repaired with test-suite based repair. This analysis shows that test-suite based repair suffers from under-specified bugs, for which trivial or incorrect patches still pass the test suite. With respect to practical applicability, it takes on average 14.8 minutes to find a patch. The experiment was done on a scientific grid, totaling 17.6 days of computation time. All the repair systems and experimental results are publicly available on Github in order to facilitate future research on automatic repair.






Similar content being viewed by others

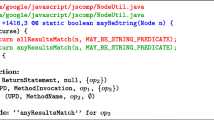

Notes
1 The dataset and the repair system in Kim et al. (2013) are not publicly available.
2 Apache Commons Lang, http://commons.apache.org/lang.
3 JFreeChart, http://jfree.org/jfreechart/.
4 Apache Commons Math, http://commons.apache.org/math.
5 Joda-Time, http://joda.org/joda-time/.
6 Google Closure Compiler, http://code.google.com/closure/compiler/.
7 Bug ID in the bug tracking system of Commons Math is Math-942, http://issues.apache.org/jira/browse/MATH-942.
References
Abreu R, Zoeteweij P, Van Gemund AJ (2007) On the accuracy of spectrum-based fault localization. In: Testing: Academic and Industrial Conference Practice and Research Techniques-MUTATION, 2007. IEEE, pp 89–98
Arcuri A, Yao X (2008) A novel co-evolutionary approach to automatic software bug fixing. In: Proceedings of the IEEE Congress on Evolutionary Computation. doi:10.1109/CEC.2008.4630793, pp 162–168
AstorCode (2016). The github repository of jgenprog and jkali, http://bit.ly/1OLZSAu
Bolze R, Cappello F, Caron E, Daydé M, Desprez F, Jeannot E, Jégou Y, Lanteri S, Leduc J, Melab, N et al (2006) Grid’5000: a large scale and highly reconfigurable experimental grid testbed, vol 20. SAGE Publications, pp 481–494
Cifuentes C, Hoermann C, Keynes N, Li L, Long S, Mealy E, Mounteney M, Scholz B (2009) Begbunch: Benchmarking for c bug detection tools. In: Proceedings of ISSTA. doi:10.1145/1555860.1555866. ACM, New York, pp 16–20
Dallmeier V, Zimmermann T (2007) Extraction of Bug Localization Benchmarks from History. In: Proceedings of the Twenty-second IEEE/ACM International Conference on Automated Software Engineering. doi:10.1145/1321631.1321702, pp 433–436
Debroy V, Wong WE (2010) Using mutation to automatically suggest fixes for faulty programs. In: Third International Conference on Software Testing, Verification and Validation, ICST 2010, Paris, France, April 7-9, 2010. doi:10.1109/ICST.2010.66, pp 65–74
DeMarco F, Xuan J, Berre DL, Monperrus M (2014) Automatic Repair of Buggy If Conditions and Missing Preconditions with smt. In: Proceedings of the 6Th International Workshop on Constraints in Software Testing, Verification, and Analysis. ACM, pp 30–39
Do H, Elbaum S, Rothermel G (2005) Supporting controlled experimentation with testing techniques: an infrastructure and its potential impact. Empir Softw Eng 10(4):405–435
ExperimentalData (2016). The github repository of the experimental data, http://bit.ly/1ON6Vmf
Fry ZP, Landau B, Weimer W (2012) A human study of patch maintainability. In: Proceedings of the 2012 International Symposium on Software Testing and Analysis, pp 177–187
Gopinath D, Khurshid S, Saha D, Chandra S (2014) Data-guided repair of selection statements. In: Proceedings of the 36th International Conference on Software Engineering. ACM, pp 243–253
Gu Z, Barr E, Hamilton D, Su Z (2010) Has the bug really been fixed?. In: 2010 ACM/IEEE 32nd International Conference on Software Engineering. doi:10.1145/1806799.1806812, vol 1, pp 55–64
Jha S, Gulwani S, Seshia SA, Tiwari A (2010) Oracle-Guided Component-Based Program Synthesis Proceedings of the International Conference on Software Engineering, vol 1. IEEE, pp 215–224
Jin G, Song L, Zhang W, Lu S, Liblit B (2011) Automated atomicity-violation fixing. In: Proceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation. doi:10.1145/1993498.1993544, pp 389–400
Jones JA, Harrold MJ, Stasko J (2002) Visualization of test information to assist fault localization. In: Proceedings of the 24th international conference on Software engineering. ACM, pp 467–477
Just R, Jalali D, Ernst MD (2014a) Defects4J: A database of existing faults to enable controlled testing studies for Java programs. In: Proceedings of the International Symposium on Software Testing and Analysis (ISSTA), pp 437–440
Just R, Jalali D, Inozemtseva L, Ernst MD, Holmes R, Fraser G (2014) Are Mutants a Valid Substitute for Real Faults in Software Testing. In: 22Nd International Symposium on the Foundations of Software Engineering (FSE)
Kim D, Nam J, Song J, Kim S (2013) Automatic patch generation learned from human-written patches. In: Proceedings of the 2013 International Conference on Software Engineering, pp 802–811
Kong X, Zhang L, Wong WE, Li B (2015) Experience report: How do techniques, programs, and tests impact automated program repair?. In: 2015 IEEE 26th International Symposium on Software Reliability Engineering (ISSRE). IEEE, pp 194–204
Le Goues C, Dewey-Vogt M, Forrest S, Weimer W (2012a) A systematic study of automated program repair: Fixing 55 out of 105 bugs for $8 each. In: 2012 34th International Conference on Software Engineering (ICSE). IEEE, pp 3–13
Le Goues C, Nguyen T, Forrest S, Weimer W (2012b) Genprog: A generic method for automatic software repair. IEEE Trans Softw Eng 38(1):54–72
Le Goues C, Holtschulte N, Smith EK, Brun Y, Devanbu P, Forrest S, Weimer W (2015) The manybugs and introclass benchmarks for automated repair of c programs. In: IEEE Transactions on Software Engineering (TSE). in press
Long F, Rinard M (2015) Staged program repair with condition synthesis. In: Proceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering, ACM, New York, NY, USA, ESEC/FSE, 2015. doi:10.1145/2786805.2786811, pp 166–178
Long F, Rinard M (2016a) An Analysis of the Search Spaces for Generate and Validate Patch Generation Systems. In: Proceedings of the 38th International Conference on Software Engineering, pp 702–713
Long F, Rinard M (2016b) Automatic patch generation by learning correct code. SIGPLAN Not 51(1):298–312. doi:10.1145/2914770.2837617
Long F, Sidiroglou-Douskos S, Rinard MC (2014) Automatic runtime error repair and containment via recovery shepherding. In: ACM SIGPLAN Conference on Programming Language Design and Implementation, PLDI ’14 Edinburgh, June 09 - 11, 2014. doi:10.1145/2594291.2594337, p 26
Lu S, Li Z, Qin F, Tan L, Zhou P, Zhou Y (2005) Bugbench: Benchmarks for evaluating bug detection tools. In: Workshop on the Evaluation of Software Defect Detection Tools
Martinez M, Monperrus M (2015) Mining software repair models for reasoning on the search space of automated program fixing. Empir Softw Eng 20(1):176–205. doi:10.1007/s10664-013-9282-8
Martinez M, Monperrus M (2016) Astor: A program repair library for java (demo). In: Proceedings of the 25th International Symposium on Software Testing and Analysis, ISSTA 2016. doi:10.1145/2931037.2948705. ACM, New York
Martinez M, Weimer W, Monperrus M (2014) Do the fix ingredients already exist? an empirical inquiry into the redundancy assumptions of program repair approaches. In: Proceedings of the 36th International Conference on Software Engineering. doi:10.1145/2591062.2591114, pp 492–495
Mechtaev S, Yi J, Roychoudhury A (2015) Directfix: Looking for simple program repairs. In: Proceedings of the 37th International Conference on Software Engineering. IEEE
Menzies T, Krishna R, Pryor D (2015) The promise repository of empirical software engineering data, http://openscience.us/repo
Monperrus M (2014) A critical review of automatic patch generation learned from human-written patches: essay on the problem statement and the evaluation of automatic software repair. In: Proceedings of the 36th International Conference on Software Engineering. ACM, pp 234–242
Monperrus M (2015) Automatic software repair: a bibliography Tech. Rep. hal-01206501, University of Lille, http://www.monperrus.net/martin/survey-automatic-repair.pdf
Nguyen HDT, Qi D, Roychoudhury A, Chandra S (2013) Semfix: Program repair via semantic analysis Proceedings of the 2013 International Conference on Software Engineering. IEEE Press, pp 772–781
Noor T, Hemmati H (2015) Test case analytics: Mining test case traces to improve risk-driven testing. In: Proceedings of the IEEE 1st International Workshop on Software Analytics. IEEE, pp 13–16
NopolCode (2016) The github repository of nopol, http://bit.ly/1mBlOlx
Pei Y, Furia CA, Nordio M, Wei Y, Meyer B, Zeller A (2014) Automated fixing of programs with contracts. IEEE Trans Software Eng 40(5):427–449. doi:10.1109/TSE.2014.2312918
Qi Y, Mao X, Lei Y (2013) Efficient automated program repair through fault-recorded testing prioritization. In: 2013 IEEE International Conference on Software Maintenance. doi:10.1109/ICSM.2013.29, pp 180–189
Qi Y, Mao X, Lei Y, Dai Z, Wang C (2014) The strength of random search on automated program repair. In: Proceedings of the 36th International Conference on Software Engineering. ACM, pp 254– 265
Qi Z, Long F, Achour S, Rinard M (2015) An analysis of patch plausibility and correctness for generate-and-validate patch generation systems. In: Proceedings of the 2015 International Symposium on Software Testing and Analysis, ISSTA 2015. doi:10.1145/2771783.2771791. ACM, New York
Samimi H, Schäfer M, Artzi S, Millstein TD, Tip F, Hendren LJ (2012) Automated repair of HTML generation errors in PHP applications using string constraint solving. In: Proceedings of the 34th International Conference on Software Engineering. doi:10.1109/ICSE.2012.6227186, pp 277–287
Smith EK, Barr E, Le Goues C, Brun Y (2015) Is the cure worse than the disease? overfitting in automated program repair. In: Proceedings of the 10th Joint Meeting of the European Software Engineering Conference and ACM SIGSOFT Symposium on the Foundations of Software Engineering (ESEC/FSE). doi:10.1145/2786805.2786825, Bergamo
Tan SH, Roychoudhury A (2015) Relifix: Automated repair of software regressions. In: Proceedings of the 37th International Conference on Software Engineering , ICSE ’15. http://dl.acm.org/citation.cfm?id=2818754.2818813, vol 1. IEEE Press, Piscataway, pp 471–482
Tao Y, Kim J, Kim S, Xu C (2014) Automatically generated patches as debugging aids: a human study. In: Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering, pp 64–74
Weimer W, Fry ZP, Forrest S (2013) Leveraging program equivalence for adaptive program repair: Models and first results. In: 2013 IEEE/ACM 28th International Conference on Automated Software Engineering (ASE). IEEE, pp 356–366
Xuan J, Monperrus M (2014) Test case purification for improving fault localization. In: Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE) . ACM
Xuan J, Martinez M, Demarco F, Clément M, Lamelas S, Durieux T, Le Berre D, Monperrus M (2016) Nopol: Automatic Repair of Conditional Statement Bugs in Java Programs. IEEE Trans Softw Eng. https://hal.archives-ouvertes.fr/hal-01285008
Zhong H, Su Z (2015) An empirical study on real bug fixes. In: Proceedings of the 37th International Conference on Software Engineering, vol 1. IEEE Press, pp 913–923
Acknowledgments
This work is partly supported by the National Natural Science Foundation of China (under grant 61502345).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Sunghun Kim
Rights and permissions
About this article

Cite this article
Martinez, M., Durieux, T., Sommerard, R. et al. Automatic repair of real bugs in java: a large-scale experiment on the defects4j dataset. Empir Software Eng 22, 1936–1964 (2017). https://doi.org/10.1007/s10664-016-9470-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-016-9470-4