
Abstract
Accurate quantification of coronary artery calcium provides an opportunity to assess the extent of atherosclerosis disease. Coronary calcification burden has been reported to be associated with cardiovascular risk. Currently, an observer has to identify the coronary calcifications among a set of candidate regions, obtained by thresholding and connected component labeling, by clicking on them. To relieve the observer of such a labor-intensive task, an automated tool is needed that can detect and quantify the coronary calcifications. However, the diverse and heterogeneous nature of the candidate regions poses a significant challenge. In this paper, we investigate a supervised classification-based approach to distinguish the coronary calcifications from all the candidate regions and propose a two-stage, hierarchical classifier for automated coronary calcium detection. At each stage, we learn an ensemble of classifiers where each classifier is a cost-sensitive learner trained on a distinct asymmetrically sampled data subset. We compute the relative location of the calcifications with respect to a heart-centered coordinate system, and also use the neighboring regions of the calcifications to better characterize their properties for discrimination. Our method detected coronary calcifications with an accuracy, sensitivity and specificity of 98.27, 92.07 and 98.62%, respectively, for a testing dataset of non-contrast computed tomography scans from 105 subjects.
Similar content being viewed by others

Introduction
Cardiovascular disease (CVD) is one of the major causes of deaths in the western world. It is responsible for almost one million deaths per year in the United States [1]. Thus, appropriate preventive measures need to be taken to decrease the cardiovascular events. However, preventive measures can be applied only when an accurate risk assessment can be made. Thus, there is an urgent need to develop tools to improve the assessment of the cardiovascular risk.
Recent studies [2–5] have shown that coronary artery calcification (CAC) burden as measured by non-contrast computed tomography (CT) is a significant and independent predictor of atherosclerosis disease and is associated with future coronary events. Therefore, accurate identification and quantification of calcifications in the coronary arteries may allow improved diagnosis and monitoring of progression of atherosclerosis. Moreover, the regional coronary calcium burden is related to the regional dysfunction of the left ventricle [6]. Thus, the quantification of the coronary calcifications provides a measure to assess the risk of coronary artery disease (CAD).
With the advancements in imaging technology, the non-invasive assessment of the coronary arteries and their calcification is feasible. Figure 1 depicts typical candidate regions for the coronary and the aortic calcifications as well as the image noise present in a CT scan. The calcifications are highly dense regions compared to other soft tissues; hence, they appear as bright structures in the CT scans. The coronary calcifications are located in the three main coronary arteries and their sub-branches—the left main/left anterior descending artery (LM/LAD), the left circumflex (LCX), and the right coronary artery (RCA)—that cover different portions of the heart surface area.

CT image of a heart depicting typical candidate regions: coronary calcifications in LAD (a), RCA (b), aorta (c), and image noise (d,e)
The current clinical standard to detect the coronary calcifications is to apply a connected component labeling method using a threshold of 130 Hounsfield units (HU) and a minimum size constraint of three/four pixels (at least 1 mm2) [7]. This thresholding results in candidate regions not only from coronary calcifications but also from non-coronary calcifications, noise artifacts, and metal implants. The coronary calcifications are then identified manually. However, manual annotation is a labor intensive and time-consuming task, especially for longitudinal studies and large-scale screening. Hence, automated computational methods for detecting the coronary calcifications are needed to ease the manual burden as well as to provide means to investigate possible improvements in cardiovascular risk assessment.
To the best of our knowledge, Ukai et al. [8, 9] first proposed a method for coronary calcification detection using some diagnostic rules, and later improved their method by utilizing a neural networks based classification method to discriminate between the coronary calcifications and the artifacts. The method was evaluated on helical CT scans (acquired in mass screening for lung cancer) of subjects with very few coronary calcifications and, thus, is limited in scope. The calcium candidates were obtained using an intensity threshold of 80 HU and size limit of 6 pixels, unlike the current clinical standards [7]. The neural network was trained using six features—size, presence of fat in surrounding region, maximum HU, minimum HU, difference between maximum HU inside the candidate and mean HU outside the candidate, and region number obtained by dividing heart into eight regions. However, the true samples used for training in their study included aortic calcifications and artifacts, that satisfied some intensity contraints, resulting in a contaminated model.
Recently, Isgum et al. [10] proposed a two-stage classification method using the k-nearest neighbor classifier for coronary calcification detection. The CT scans used in this study were originally obtained at high resolution and were later resampled to a lower resolution. The candidate regions with high probability of belonging to the negative class in the first stage of classification were discarded and only the remaining ones were considered for the second stage of classification. For classification, the features used were computed based on the size, shape, location, and appearance of the candidate regions. The appearance-based features were computed at the peak intensity point of each candidate region from image derivatives. The use of region-based features was limited to the mean and the maximum intensity values. Additionally, aorta segmentation was performed to improve the performance of the classifier in separating aortic calcifications from coronary calcifications. However, the segmentation results were not satisfactory since the problem of segmenation is inherently difficult in the absence of any contrast. Furthermore, the classifiers were trained on the unbalanced data owing to the large number of negative candidates; hence, they were biased towards the majority class.
In this paper, we investigate various factors that can make it feasible to build an automated coronary calcium detection system. Though the coronary calcifications appear as high-density structures in the non-contrast CT scans, it is inherently difficult to identify them automatically. The difficulty arises because of the presence of other similar high-density structures, including the non-coronary calcifications, and the absence of any contrast agent to identify the blood vessels. It is apparent that the choice of features plays an important role in solving this problem. We compute several features based on appearance, shape and size of the calcifications. In addition, we investigate various clues that a human observer uses to manually annotate the coronary calcifications in the CT scans (e.g., expected location of the coronary arteries and surrounding regions of calcifications). Thus, in order to better characterize their properties for discrimination, we additionally compute relative location of the calcifications with respect to a heart-centered coordinate system and region-based features for the candidates and their neighboring regions. To the best of our knowledge, it is the first time that the relevance of the region-based features and the neighborhood region of the calcifications is investigated.
Finally, we have developed a novel two-stage hierarchical classification-based method to detect coronary calcifications in the non-contrast cardiac CT scans Footnote 1. In the current problem of classification, the positive class is composed of the coronary calcifications, while the negative class consists of the aortic calcifications, image noise, and metal implants, if any. In the first stage, we explicitly learn to distinguish the arterial (the coronary and the aortic) calcifications from other highly dense regions present within the heart region. In the second stage, we learn to separate the coronary calcifications from the aortic calcifications. We investigate the possibility of such separation without requiring the segmentation of the aorta in this work. At each stage of the hierarchy, we construct an ensemble of classifiers, trained on different data subsets that are generated using an asymmetric sampling method, to overcome the problem of a highly unbalanced and large data set. The decisions of each individual classifier in the ensemble are combined together to obtain the final decision for that stage. Furthermore, each classifier in the ensemble is designed to accommodate asymmetric penalty costs for different types of errors.
Materials and methods
Data
The heart scans were obtained by electron-beam CT (EBCT) imaging with a slice thickness of 3 mm and an x-y pixel spacing of 0.508–0.586 mm. Scans from 205 subjects with approximately 20–35 image slices per scan were used in our experiments. There were 20 coronary calcifications and 335 negative candidate regions in the heart region per scan on average. We created two mutually exclusive data subsets, D 1 with 100 subjects and D 2 with 105 subjects, for the training and testing phases, respectively.
For training and testing purposes, the arterial calcifications were manually annotated. The manual annotation was performed using a software developed at the Computational Biomedicine Lab, specifically for the purpose of calcium scoring. The vertical range of the heart region was defined from the transverse slice at the top in which the pulmonary artery splits to the transverse slice at the bottom till which the coronary arteries are present. To annotate the coronary calcifications, the observer clicks points along the trajectory of a coronary artery in the transverse slices. Then, the software interpolates these points to build an arterial trajectory, and detects the nearby coronary calcium. It computes the extent of the detected calcifications using the minimum HU constraint of 130 HU and the minimum size constraint of four pixels. The observer is allowed to include coronary calcium not detected by the software and exclude any non-coronary calcium detected by the software. To annotate the aortic calcifications, the observer clicks at any point within a calcified region in the aorta and the software computes its extent using the minimum HU and size constraints.
Feature extraction
In classification-based methods, the representation of the candidate samples (i.e., the features) play the most important role. To uniquely represent the coronary calcifications, it is imperative to investigate their various characteristic properties that can be used to distinguish them apart from other candidate regions. The various types of features that were designed and evaluated are discussed next.
Spatial location
To identify a coronary calcification among the candidate regions, a human observer mostly relies on prior knowledge of the expected location of the coronary arteries relative to the heart. To incorporate such information about the location, two sets of location features are computed:
-
F 1 : absolute location (x, y, z) in the image coordinate system, and
-
F 2 : relative location (x, y, z) in a heart-centered coordinate system.
The heart-centered coordinate system is defined by a unit bounding box around the heart region. The heart region is extracted using a hierarchical approach in which the peripheral structures are detected first and then the heart region is determined using dynamic programming and prior knowledge of anatomical location of the heart.
In particular, the body region is segmented first using thresholding and morphological operators. Next, the lung is detected within the body region by applying a threshold (−250 HU) and extracting the largest connected-component region from the complement of the thresholded result. The boundary of the extracted lung region may have indentations because of the pulmonary vessels that transport blood between the lung and the heart. Since a part of the lung boundary defines the lateral boundary of the heart, it is important to smooth the jagged boundary resulting from the indentations of pulmonary vessels. To fill the indentations on the lung boundary, a binary morphological closing operation is performed on the extracted lung region [12]. Then, the bones are detected using a threshold and a region growing algorithm because they constraint the heart boundary on anterior and posterior sides. The bone fragments in the first k slices are extracted by applying a threshold (130 HU) outside the convex hull of the lung region. The extracted bone fragments are then provided as input to the 3D region growing algorithm to obtain the complete bone structure.
Since the heart region lies in-between the lung halves that define the heart’s lateral boundary, one could simply compute the convex hull of the lung and then subtract the lung from it to obtain the in-between region. However, such a scheme may miss some portions of the heart on the anterior side and include unnecessary structures on the posterior side. To avoid such situation, the anterior and posterior boundaries are obtained by determining optimal shortest paths between the left and right lung using dynamic programming in each axial slice. Since the spine, sternum and other bone structures constrain the anterior and posterior boundary of the heart, these bone structures guide the dynamic programming method to detect the boundaries. The region between the detected anterior and posterior boundaries, and the lungs is smoothed using morphological operators and extracted as the heart region. Finally, a minimum size cube that contains the complete 3D heart region is computed to define the unit bounding box for the heart-centered coordinate system.
Pixel-based texture features
Texture features have been proven to improve the accuracy of the classification-based methods in different medical image analysis applications. We compute texture features using the Laws texture energy measures [13]. These texture energy measures are computed using convolution kernels generated from one-dimensional convolution kernels of five pixel length characterizing level, edge, spot, wave and ripple patterns. Since the texture features are pixel-based, we selected the maximum HU-density pixel as the representative of the candidate region for pixel-based texture features (F 3 ).
Region-based texture features
Additionally, an observer uses the candidate’s regional properties instead of individual pixel properties to distinguish between the coronary calcification from the rest. Based on this observation, we propose to extract region-based features to better represent a candidate region in addition to the individual pixel features.
Since the coronary arteries mostly span through the pericardial fat after originating from the ascending aorta, except in the distal section when they enter the ventricular wall, the neighboring regions of the coronary calcifications provide significant clues to distinguish the coronary calcifications from the image noise, which mostly has blood in its neighboring region. Hence, the observer also uses appearance clues from the candidate region and its surrounding neighboring region to distinguish the coronary calcification from the rest of the candidate regions. Based on these observations, we extract three set of the region-based features:
-
F 4 : the set of features computed for the candidate calcium region,
-
F 5 : the set of features computed for its neighborhood region, and
-
F 6 : the set of features computed for the combined region of the candidate and its neighborhood.
The neighborhood region is defined as a ribbon-like region of a certain width around the candidate region. Specifically, we compute the mean, standard deviation, skewness, kurtosis, and entropy of the pixel-based Laws texture energy measures [13] for the region of interest. Additionally, we compute the difference of means normalized by the sum of standard deviations of the Laws measures inside and outside the candidate region as a feature for the combined region. We also compute the grey-level co-occurrence matrices (GLCM) proposed by Haralick et al. [14]. The GLCM provides the probability of occurrence of a particular pair of the HU-density at a particular spatial arrangement. Based on the cost statistics, we compute the contrast, correlation, energy, and homogeneity features for four different spatial arrangements.
Additional features
We include object-related features (F 7 ) based on the size, shape, and appearance of the region of interest—area, shape moments, eccentricity, compactness, anisotropy, inertia, and HU density-based first-order statistics (e.g., mean, maximum, minimum, standard deviation, skewness, kurtosis, and entropy), length of major axis, length of minor axis, equivalent radius, mean radial length and so on. To list all features and explain their details is beyond the scope of this paper.
Feature selection
The classification accuracy of a classifier depends largely on the selection of useful features. One of the criterions, often termed as maximum relevance, to find useful features is to select features that are individually highly correlated with the target class distribution. However, the features thus selected may be highly intercorrelated too. When two features are intercorrelated, one of them can be removed without affecting the classification performance to reduce the computational load. Also, individually powerful features may not be so powerful together. Thus, we need to select features which have maximum relevance and minimal redundancy.
The relevance of a feature with respect to a particular outcome or the redundancy between any two features can be characterized in terms of correlation or mutual information. We used a mutual information (MI)-based minimum-redundancy-maximum-relevance (mRMR) feature selection heuristic proposed by Peng et al. [15]. The feature selection is performed in two steps. First, a subset G of N features is selected from the large feature set F such that an mth feature is added incrementally to the currently selected set G m−1 with m − 1 features, if it maximizes the following condition:
where the first term corresponds to the relevance, the second term corresponds to the redundancy, L is the target class, and f i is the ith feature. In the second step, we form P sequential feature subsets in multiples of k features such that G 1*k ⊂ G 2*k ⊂ ... ⊂G p*k and select the feature subset that corresponds to the minimum cross-validation error obtained from a classifier.
Coronary calcium detection method
For classification-based coronary calcium detection, the negative class (aortic calcifications, image noise, and metal implants, if any) is broader and richer than the positive class (coronary calcifications), introducing complex class compositions. Such complex class composition may increase the complexity of the learner and introduce a significant number of false positives. Moreover, the majority of the candidate regions belong to the image noise and hence, the negative class. Thus, there is large number of candidates and the classes are highly unbalanced in terms of the number of candidates. Training on such unbalanced classes will bias the classifier towards the majority class, and will degrade its performance.
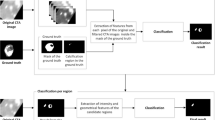
To account for the complex class composition, we divide the problem of detecting coronary calcifications in to two sub-problems: (1) detection of arterial (aorta and coronary arteries) calcifications among all the candidates, and (2) detection of the coronary calcifications among the arterial calcifications. We construct a two-stage hierarchical classifier to solve these two sub-problems (Fig. 2). At the first stage of the hierarchy, a classifier is constructed using the features selected specifically to discriminate the arterial (coronary and aortic) calcifications from the rest of the candidate regions. At the second stage of the hierarchy, another classifier is constructed using the features selected specifically to separate the coronary calcifications from the aortic calcifications. The final decision of the two-stage classifier is a combination of decisions of the individual classifiers of each stage and is given by:
where D 1 and D 2 are the hard-output decisions of the classifiers from the two stages of the hierarchy, respectively.

A schematic of the classification framework for coronary calcium detection
The problem of unbalanced classes persists even in the two-stage hierarchical classification-based approach. At the first stage, the number of arterial calcifications is significantlty lower than the the number of candidates belonging to the image noise. At the second stage, the number of aortic calcifications is very small as compared to the number of coronary calcifications. We address the problem of the unevenness of the positive and negative classes by employing an asymmetric random sampling strategy. In asymmetric random sampling, the candidates are randomly selected from the majority class until the number of the selected candidates is equal to the number of the candidates from the minority class.
However, a single learning agent or classifier trained on an under-sampled data subset assumes that the distribution of candidates in the sampled subset is the same as in the original dataset, which may not be true in practical situations. Thus, some potentially relevant candidates may get eliminated during the sampling process, hampering the performance of the classifier. An ensemble of multiple classifiers that are trained on different independently sampled subsets would improve the accuracy of prediction over a single classifier. Moreover, distortion of data distribution that can be introduced via data sampling will be minimized. Thus, for each stage of the hierarchy, we train individual classifiers whose decisions are combined to obtain the final decision at that stage (Fig. 3). We investigated two combination rules—simple majority voting rule (MVR) and weighted majority rule (WMR)—to combine the decisions of the individual classifiers. In the WMR, the weights are directly related to the competency or accuracy of the classifiers, and are computed as the logarithm of odds of competency, \(\psi_i=log({\frac{A_i}{1-A_i}}),\) where A i is the prior probability for correct classification of ith classifier, computed from the validation set.

Depiction of the construction of an ensemble classifier using multiple classifiers
To further reduce the error of classification, asymmetric penalty cost may be applied to the different types of errors. Support vector machines (SVMs) [16] are capable of incorporating different costs for the positive and the negative classes by modifying their objective function as follows:
where w is a normal vector perpendicular to the separating hyperplane; y i is a label for each ith data sample with +1 for positive outcome and −1 for negative outcome; ξ i is a slack variable allowing soft margins (i.e., training errors for data that may not be completely separable); and C p and C n are the cost parameters for the positive and the negative classes, respectively [17]. However, the specific costs for this problem are not easy to determine. We employ a grid search algorithm in which a classifier determines the optimal costs based on the cross-validation accuracy obtained using three-fold cross-validation. In n-fold cross-validation, the training data is first partitioned into n subsets and then, classifier uses one of the n subsets for validation and the rest n − 1 subsets for training. The cross-validation accuracy is computed by averaging the accuracy of classifier from the n-folds. In grid search method, a discrete grid is constructed in the parameter space and the parameter values at each grid node are evaluated using the n-fold cross-validation method. The parameter values at the node having the highest cross-validation accuracy are finally selected to train the classifier [18].
Training
The candidate regions are extracted from the training CT scans using the minimum size and HU-density constraints. From the training set, we generate four asymmetrically-sampled training subsets for each stage of the hierarchy with equal number of candidates in the positive and negative classes. Next, we compute the features for all the candidate regions. Then, we apply the feature selection method to select the most relevant and non-redundant feature subset for each stage of the hierarchy. The feature subset with highest cross-validation accuracy is selected. Finally, we construct a two-stage classifier using multiple classifiers trained on the selected subsets of features for each stage. We use LIBSVM [19] to train the individual SVMs using a nonlinear Gaussian radial basis kernel function. The width parameter γ, the penalty cost parameter C, and the ratio of asymmetric misclassification costs C p /C n are optimized using a grid search technique and the three-fold cross-validation method.
Deployment
In the deployment or testing phase, the candidate regions are extracted using the size and HU-density constraints from the CT scan. The features from the selected feature subsets are computed for the candidate regions and provided as input to the two-stage hierarchical classifier. The classifier then predicts for each candidate region whether it is a coronary calcium region or not.
Family of classifiers
To demonstrate the importance of using an ensemble of multiple classifiers over a single classifier, and a two-stage hierarchical classifier over a single stage classifier, we constructed the following classifiers:
-
L1: single stage, single classifier
-
L2: single stage, ensemble classifier with MVR rule
-
L3: single stage, ensemble classifier with WMR rule
-
L4: two-stage classifier using a single classifier at each stage
-
L5: two-stage classifier using an ensemble classifier with MVR rule at each stage
-
L6: two-stage classifier using an ensemble classifier with WMR rule at each stage
-
L7: two-stage classifier using an ensemble classifier with MVR rule and asymmetric penalty costs at each stage
-
L8: two-stage classifier using an ensemble classifier with WMR rule and asymmetric penalty costs at each stage.
Results
The performance of the classifiers was evaluated in terms of sensitivity, specificity and accuracy based on metrics derived from confusion matrix. These statistical performance measures can be computed in terms of true-positives (TP), true-negatives (TN), false-positives (FP) and false-negatives (FN) as following:
First, we present the results of the feature analysis experiments that were conducted using single stage classifiers to emphasize the choice of the features used. Then, we evaluate the performance of the proposed two-stage hierarchical classifiers and analyze the errors in detail.
Feature analysis
To systematically assess the effectiveness of different types of feature groups to detect the coronary calcium, we constructed various feature sets by combining different types of feature groups incrementally. The various feature sets that were constructed are listed in the Table 1. Each of the feature set was further reduced to a subset of the most relevant and non-redundant features, independently, through the feature selection process. The effectiveness of each feature set was assessed using the single stage classification approach. Thus, three single stage classifiers (i.e., L 1, L 2, and L 3) were applied to detect the coronary calcifications.
Table 2 presents the performance metrics for these. Using the heart-centered coordinate system-based features (F 2 ) instead of the absolute image coordinate system-based features (F 1 ) improved the sensitivity by approximately 7.0 and 1.5% when used independently and in combination with the other features, respectively. Adding object features (F 7 ) to the spatial location features improved the sensitivity and specificity by almost 10.0 and 1.5%, respectively, in feature set S 3 . The pixel-based texture features computed at the peak HU pixel (F 3 ) further improved the sensitivity by 3.5% in feature set S 4 . Addition of the region-based features computed for the candidate region (F 4 ) in feature set S 6 didn’t have significant effect on the prediction of the classifiers. However, addition of the region-based features computed for the combined candidate and neighborhood region (F 6 ) in feature set S 7 improved the sensitivity by almost 5%. Inclusion of all the region-based features in feature set S 5 reduced the sensitivity over the feature set S 7 by almost 2.0, 1.0, and 0.7% for L 1, L 2, and L 3, respectively. Thus, the best performance was obtained for the feature set S 7 comprising of the features F 2 , F 7 , F 3 , and F 6 for all the three classifiers.
Comparison of the classifiers
The two-stage hierarchical classifiers (i.e., L 4, L 5, L 6, L 7 and L 8) were constructed for the two feature sets (S 5 and S 7 ) that provided highest sensitivity and accuracy for the single stage classifiers. The performance metrics of the single stage classifiers and the two-stage hierarchical classifiers are presented in the Tables 2 and 3, respectively. The ensemble-based classifiers exhibited the highest accuracy for both single stage and two-stage classifiers. The MVR rule proved to be the best decision fusion rule for the ensemble-based classifiers in terms of accuracy. Among the ensemble-based classifiers using the MVR rule, the single stage classifiers provided higher sensitivity; however, the two-stage hierarchical classifiers provided higher accuracy.
The feature set S 7 proved to be better than the feature set S 5 for the ensemble-based classifiers in terms of the sensitivity with specificity remaining almost same. Using the asymmetric penalty costs improved the sensitivity by 0.10–0.50% for the two-stage ensemble-based classifiers. Overall, the highest accuracy of 98.27% (sensitivity: 92.07%, specificity: 98.62%) was achieved for the two-stage hierarchical L 7 classifier for the feature set S 7 .
Misclassification error analysis
Table 4 presents the misclassification error analysis for the L 1, L 2, and L 7 classifiers. The misclassification error percentage, E 1, was computed as the ratio of the number of misclassifications of a particular candidate to the overall number of misclassfications. The category-wise misclassification error percentage, E 2, was computed as the ratio of the number of misclassified candidate regions in a particular category to the total number of candidate regions in that category. In the negative class, the noise artifacts had the highest misclassification error percentage (E 1), while the ascending aorta calcifications had the highest category-wise misclassification error percentage (E 2). Likewise in the positive class, the right coronary artery calcifications had the highest misclassification error percentage (E 1), while the left main artery calcifications had the highest category-wise misclassification error percentage (E 2). The two-stage classifier L 7 misclassified 50% less aortic calcifications, 4% less image noise, and 7.5% more coronary calcifications than the single stage classifier L 2.
Discussion
Our results demonstrate the feasibility of an automated coronary calcium detection system using a classification-based method. However, the choice of features and the classification approach have played an important role toward calcification detection. Our analysis provides the starting point to automate the coronary calcium detection process by careful choice of the features and the classification approach.
Our results suggest that a heart-centered coordinate system provides a compact representation for the spatial location of the coronary arteries as opposed to the absolute image coordinate system. However, in this paper we have used a simple bounding box-based coordinate system to represent the location of the calcifications. The currently used coordinate system is not compact, nor rotation-invariant, nor patient-invariant. A more compact frame of reference using a local heart-centered coordinate system, as recently proposed by our group [20, 21], which is invariant to translation, scale, and rotation, could further improve the accuracy of the calcification detection system. However, development of a patient-invariant coordinate system may require actual segmentation of the coronary arteries which is a difficult problem owing to the low resolution, anisotropy, and lack of contrast.
Our experiments show that the texture features are able to characterize the coronary calcifications well and the neighborhood region of the coronary calcium plays an important role in distinguishing the coronary calcium from the other candidate regions. Using the combined region—the neighborhood region and the candidate region—to compute the region-based texture features significantly improved the sensitivity of the system over using these regions individually.
Our analysis indicates that the proposed hierarchical classification approach proves to be effective in reducing the false positives from the aorta calcifications and the image noise as compared to the single stage classifiers. Our method achieved sensitivity of 92.07% at the expense of 4.65 false positives per scan. Also, the ensemble of multiple classifiers further reduces the false positives occuring due to the image noise. Nevertheless, there is high percentage of the misclassification errors for the calcifications in the aorta, left main artery and the right coronary artery. This is because of the significant overlap in the relative positions of the ascending aorta near the origin, the left main artery and the proximal region of the right coronary artery in different subjects due to anatomical variations. Further investigation is required into the design of informative features to discriminate between the ascending aorta calcifications and the coronary calcifications near the ostia.
None of the previous studies have attempted to explicitly deal with the issues of unbalanced class priors, and complex class compositions that are the characteristics of the given problem. Such issues have been extensively studied in other applications that have similar requirements. Wu et al. [22] proposed a hierarchical classification scheme to overcome the above mentioned asymmetries in face detection problem. Yan et al. [23] proposed an ensemble of SVMs for predicting rare classes in scene classification. Various techniques for ensemble construction can be categorized mainly in four categories [24]: (1) manipulating the feature space, (2) manipulating the training sets, (3) manipulating the output labels, and (iv) introducing randomness in the learning process. We have utilized the advantages of such hierarchical and ensemble-based techniques in our classification approach to overcome the issues of asymmetry in the given problem.
The current cardiovascular risk scoring methods do not take into account the wealth of information that is available in the non-contrast CT data. Studies indicate that pericardial fat may be a significant cardiovascular risk factor [25]. Other studies have shown that calcification of the thoracic aorta, aortic arch and aortic valve are associated with increased risk of cardiovascular disease [26, 27]. Moreover, a recent study [28] indicated that the spatial distributions of coronary calcifications plays an important role in prediction of cardiovascular heart disease and can be used to improve the current coronary calcium scoring technique. However, there is a dearth of automatic techniques to mine the imaging data for required information. Furthermore, validation in large epidemiological studies is needed to determine which type of information will offer additive predictive value. Our long term goal is to contribute to the development of quantitative methods to assess cumulative risk of vulnerable patients by developing new techniques to mine additional information from the imaging data [29–31]. Toward this goal, we are developing novel robust computational methods for segmentation and classification of various anatomical structures and tissues (e.g., thoracic cavity [32], heart [33], aorta [34, 35], and fat [36]) from non-contrast CT data.
Study limitations
Though our study have demonstrated that a classification-based method can detect coronary calcifications with proper selection of the type of features and classification approach, the findings of this study are limited with respect to the imaging modality of EBCT. With the increased use of multi-detector CT (MDCT) in the routine practice for calcium scoring, it would be interesting to assess the results of our method on MDCT scans. Another major limitation of our study is that the cohort constitutes a higher risk population (i.e., the patients were physician-referred for CHD risk stratification). Currently, our method requires the user to input the start and end slice numbers to define the extent of the heart in transverse slices. However, we are developing methods to automate the detection of the heart extent in the z-axis in order to deploy our method on a larger cohort.
Conclusion
In this paper, we have presented a classification-based method to detect the coronary calcifications from the non-contrast CT scans. We have demonstrated that a two-stage hierarchical classifier using multiple classifiers is more robust, in reducing the false positives keeping a high detection rate than the single stage classifiers. At the first level of the hierarchy, the method discriminates between the arterial (the coronary and the aortic) calcifications and other highly dense regions present within the heart region. At the second level, the method distinguishes the coronary calcifications from the aortic calcifications without requiring explicit segmentation of the aorta. Our results indicate that the neighborhood region of the coronary calcium contains significant clues to distinguish them apart from the other high density structures. Thus, a classification-based method has potential to be used in the calcium scoring softwares to ease the burden of the observers by reducing the manual interaction required and eventually, eliminate them completely.
Notes
Preliminary work on this topic has appeared in [11].
References
National Institutes of Health (2007) Disease statistics. National Heart Lung and Blood Institute, Technical report
Greenland P, LaBree L, Azen S, Doherty T, Detrano R (2004) Coronary artery calcium score combined with Framingham score for risk prediction in asymptomatic individuals. J Am Med Assoc 291(2):210–215
Shaw L, Raggi P, Schisterman E, Berman D, Callister T (2003) Prognostic value of cardiac risk factors and coronary artery calcium screening for all-cause mortality. Radiology 228(3):826–833
Taylor A, Bindeman J, Feuerstein I, Cao F, Brazaitis M, O’Malley P (2005) Coronary calcium independently predicts incident premature coronary heart disease over measured cardiovascular risk factors: mean three-year outcomes in the prospective army coronary calcium (PACC) project. J Am Coll Cardiol 46(5):807–814
Wong ND, Budoff MJ, Pio J, Detrano RC (2002) Coronary calcium and cardiovascular event risk: evaluation by age- and sex-specific quartiles. Am Heart J 143(3):456–459
Edvardsen T, Detrano R, Rosen B, Carr J, Liu K, Lai S, Shea S, Pan L, Bluemke D, Lima J (2006) Coronary artery atherosclerosis is related to reduced regional left ventricular function in individuals without history of clinical cardiovascular disease: the multi-ethnic study of atherosclerosis. Arterioscler Thromb Vasc Biol 26(1):206–211
Rumberger J, Kaufman L (2003) A rosetta stone for coronary calcium risk stratification: agatston, volume, and mass scores in 11,490 individuals. Am J Roentgenol 181(3):743–748
Ukai Y, Niki N, Satoh H, Watanabe S, Ohmatsu H, Eguchi K, Moriyama N (1996) An algorithm for coronary calcification diagnosis based on helical CT images. In: Proceedings of International conference on pattern recognition, vol. 3. Washington, DC, pp 543–547
Ukai Y, Niki N, Satoh H, Watanabe S, Ohmatsu H, Eguchi K, Moriyama N (1998) A coronary calcification diagnosis system based on helical CT images. IEEE Trans Nucl Sci 45(6):3083–3088
Isgum I, Rutten A, Prokop M, van Ginneken B (2007) Detection of coronary calcifications from computed tomography scans for automated risk assessment of coronary artery disease. Med Phys 34(4):1450–1461
Kurkure U, Chittajallu D, Brunner G, Yalamanchili R, Kakadiaris I (2008) Detection of coronary calcifications using supervised hierarchical classification. In: Proceedings of medical image computing and computer-assisted intervention workshop on computer vision for intravascular and intracardiac imaging. New York, NY
Hu S, Hoffman E, Reinhardt J (2001) Automatic lung segmentation for accurate quantitation of volumetric X-ray CT images. IEEE Trans Med Imaging 20(6):490–498
Laws K (1980) Texture image segmentation. Ph.D. dissertation, University of Southern California
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Syst Man Cybern 3:610–621
Peng H, Long F, Ding C (2005) Feature selection based on mutual information: criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell 27(8):1226–1238
Vapnik V (1998) Statistical learning theory. Wiley-Interscience, ISBN 0471030031
Osuna E, Freund R, Girosi F (1997) Support vector machines: training and applications. Massachusetts Institute of Technology, Technical Report AIM-1602, [Online]. Available: http://www.dspace.mit.edu/handle/1721.1/7290
Hsu C, Chang C, Lin C (2003) A practical guide to support vector classification. National Taiwan University, Technical report
Chang C-C, Lin C-J (2001) LIBSVM: a library for support vector machines. Software available at http://www.csie.ntu.edu.tw/
Brunner G, Chittajallu D, Kurkure U, Kakadiaris I (2008) A heart-centered coordinate system for the detection of coronary artery zones in non-contrast computed tomography data. In: Proceedings of medical image computing and computer-assisted intervention workshop on computer vision for intravascular and intracardiac imaging. New York, NY
Brunner G, Chittajallu D, Kurkure U, Kakadiaris I (2010) Toward the automatic detection of coronary artery calcification in non-contrast computed tomography data. Int J Cardiovasc Imaging (in press)
Wu J, Brubaker S, Mullin M, Rehg J (2008) Fast asymmetric learning for cascade face detection. IEEE Trans Pattern Anal Mach Intell 30(3):369–382
Yan S, Li M, Zhang H, Cheng Q (2003) Ranking prior likelihood distributions for bayesian shape localization framework. In: Proceedings of IEEE international conference on computer vision, pp 51–58
Dietterich T (2000) Ensemble methods in machine learning. Lect Notes Comput Sci 1857:1–15 [Online]. Available: http://citeseer.ist.psu.edu/dietterich00ensemble.html
Rosito G, Massaro J, Hoffmann U, Ruberg F, Mahabadi A, Vasan R, O’Donnell C, Fox C (2008) Pericardial fat, visceral abdominal fat, cardiovascular disease risk factors, and vascular calcification in a community-based sample: the Framingham heart study. Circulation 117(5):605–613 [Online]. Available: http://www.circ.ahajournals.org/cgi/content/abstract/117/5/605
Rodondi N, Taylor BC, Bauer DC, Lui LY, Vogt MT, Fink HA, Browner WS, Cummings SR, Ensrud KE (2007) Association between aortic calcification and total and cardiovascular mortality in older women. J Intern Med 261(3):238–244
Witteman JC, Kok FJ, van Saase JL, Valkenburg HA (1986) Aortic calcification as a predictor of cardiovascular mortality. Lancet 2(8516):1120–1122
Brown E, Kronmal R, Bluemke D, Guerci A, Carr J, Goldin J, Detrano R (2008) Coronary calcium coverage score: determination, correlates, and predictive accuracy in the multi-ethnic study of atherosclerosis. Radiology 247:669–675
Kakadiaris I, Kurkure U, Bandekar A, O’Malley S, Naghavi M (2010) Cardiovascular informatics. In: Paragios N, Ayache N, Duncan J (eds) Handbook of biomedical imaging. Springer, Berlin (in press)
Kakadiaris I, Kurkure U, Mendizabal-Ruiz E, Naghavi M (2009) Towards cardiovascular risk stratification using imaging data. In: Proceedings of 31st international conference of the IEEE engineering in medicine and biology society. Minneapolis, MN
Kakadiaris I, Mendizabal-Ruiz E, Kurkure U, Naghavi M (2009) Challenges and opportunities for extracting cardiovascular risk biomarker from imaging data. In: Proceedings of 14th Iberoamerican congress on pattern recognition. Guadalajara, Mexico, 15–18 November, pp 227–235
Chittajallu D, Balanca P, Kakadiaris I (2009) Automatic delineation of the inner thoracic region in non-contrast CT data. In: Proceedings of 31st international conference of the IEEE engineering in medicine and biology society. Minneapolis, MN
Chittajallu D, Brunner G, Kurkure U, Yalamanchili R, Kakadiaris I (2009) Fuzzy-cuts: a knowledge-driven graph-based method for medical image segmentation. In: Proceedings of IEEE computer society conference on computer vision and pattern recognition. Miami Beach, FL
Kurkure U, Avila-Montes O, Kakadiaris I (2008) Automated segmentation of thoracic aorta in non-contrast CT images. In: Proceedings of IEEE international symposium on biomedical imaging: from nano to macro. Paris, France
Avila-Montes O, Kurkure U, Kakadiaris I (2010) Aorta segmentation in non-contrast cardiac CT images using an entropy-based cost function. In: Proceedings of society of photographic instrumentation engineers medical imaging conference. SPIE, San Diego, CA, Feb 13–18 (in press)
Yalamanchili R, Kurkure U, Dey D, Berman D, Kakadiaris I (2010) Knowledge-based quantification of pericardial fat in non-contrast CT data. In: Proceedings of society of photographic instrumentation engineers medical imaging conference. SPIE, San Diego, CA, Feb 13–18 (in press)
Acknowledgments
This work was supported in part by NSF Grants IIS-0431144 and CNS-0521527.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Kurkure, U., Chittajallu, D.R., Brunner, G. et al. A supervised classification-based method for coronary calcium detection in non-contrast CT. Int J Cardiovasc Imaging 26, 817–828 (2010). https://doi.org/10.1007/s10554-010-9607-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10554-010-9607-2