
Abstract
This paper is devoted to test the parametric single-index structure of the underlying model when there are outliers in observations. First, a test that is robust against outliers is suggested. The Hampel’s second-order influence function of the test statistic is proved to be bounded. Second, the test fully uses the dimension reduction structure of the hypothetical model and automatically adapts to alternative models when the null hypothesis is false. Thus, the test can greatly overcome the dimensionality problem and is still omnibus against general alternative models. The performance of the test is demonstrated by both Monte Carlo simulation studies and an application to a real dataset.




Similar content being viewed by others

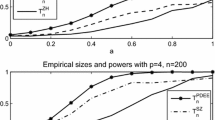

Change history
29 November 2017
Unfortunately, original article has been published without acknowledgement section.
References
Bierens, H. J. (1990). A consistent conditional moment test of functional form. Ecomometrica, 58, 1443–1458.
Bierens, H. J., Ploberger, W. (1997). Asymptotic theory of integrated conditional moment test. Econometrica, 65, 1129–1151.
Escanciano, J. C. (2006a). Goodness-of-fit tests for linear and nonlinear time series models. Journal of the American Statistical Association, 101, 531–541.
Escanciano, J. C. (2006b). A consistent diagnostic test for regression models using projections. Econometric Theory, 22, 1030–1051.
Escanciano, J. C. (2007). Model checks using residual marked empirical processes. Statistica Sinica, 17, 115–138.
Fan, J. Q., Zhang, C., Zhang, J. (2001). Generalized likelihood ratio statistics and the wilks phenomenon. The Annals of Statistics, 29, 153–193.
Feng, L., Zou, C. L., Wang, Z. J., Zhu, L. X. (2015). Robust comparison of regression curves. Test, 24, 185–204.
Fernholz, L. T. (1983). von Mises calculus for statistical functionals. New York: Springer.
González-Manteiga, W., Crujeiras, R. M. (2013). An updated review of goodness-of-fit tests for regression models. Test, 22, 361–411.
Guo, X., Wang, T., Zhu, L. X. (2016). Model checking for parametric single index models: A dimension-reduction model-adaptive approach. Journal of the Royal Statistical Society: Series B, 78, 1013–1035.
Hampel, F. R. (1974). The influence curve and its role in robust estimation. Journal of the American Statistical Association, 69, 383–393.
Härdle, W. (1992). Applied nonparametric regression. Cambridge: Cambridge University Press.
Härdle, W., Mammen, E. (1993). Comparing nonparametric versus parametric regression fits. The Annals of Statistics, 21, 1296–1947.
Heritier, S., Ronchetti, E. (1994). Robust bounded-influence tests in general parametric models. Journal of the American Statistical Association, 89, 897–904.
Horowitz, J. L., Spokoiny, V. G. (2001). An adaptive, rate-optimal test of a parametric meanregression model against a nonparametric alternative. Econometrica, 69, 599–631.
Huber, P. J. (1985). Projection pursuit. The Annals of Statistics, 13, 435–475.
Koul, H. L., Ni, P. P. (2004). Minimum distance regression model checking. Journal of Statistical Planning and Inference, 119, 109–141.
Lavergne, P., Patilea, V. (2008). Breaking the curse of dimensionality in nonparametric testing. Journal of Econometrics, 143, 103–122.
Lavergne, P., Patilea, V. (2012). One for all and all for one: Regression checks with many regressors. Journal of Business & Economic Statistics, 30, 41–52.
Li, K. C. (1991). Sliced inverse regression for dimension reduction. Journal of the American Statistical Association, 86, 316–327.
Markatou, M., Hettmansperger, T. P. (1990). Robust bounded-influence tests in linear models. Journal of American Statistical Association, 85, 187–190.
Markatou, M., Manos, G. (1996). Robust tests in nonlinear regression models. Journal of Statistical Planning and Inference, 55, 205–217.
Maronna, R., Martin, D., Yohai, V. (2006). Robust statistics: Theory and methods. New York: Wiley.
Nadaraya, E. A. (1964). On estimating regression. Theory of Probability and Its Applications, 10, 186–196.
Schrader, R. M., Hettmansperger, T. P. (1980). Robust analysis of variance based upon a likelihood ratio criterion. Biometrika, 67, 93–101.
Sen, P. K. (1982). On $M$-tests in linear models. Biometrika, 69, 245–248.
Serfling, R. J. (1980). Approximation theorems of mathematical statistics. New York: Wiley.
Stone, C. J. (1980). Optimal rates of convergence for nonparametric estimators. Annals of Statistics, 8, 1348–1360.
Stute, W. (1997). Nonparametric model checks for regression. Annals of Statistics, 25, 613–641.
Stute, W., Zhu, L. X. (2002). Model checks for generalized linear models. Schadinavian Journal of Statistics, 29, 535–545.
Stute, W., González-Manteiga, W., Presedo-Quindimil, M. (1998a). Bootstrap approximations in model checks for regression. Journal of the American Statistical Association, 93, 141–149.
Stute, W., Thies, S., Zhu, L. X. (1998b). Model checks for regression: An innovation process approach. Annals of Statistics, 26, 1916–1934.
Stute, W., Xu, W. L., Zhu, L. X. (2008). Model diagnosis for parametric regression in high dimensional spaces. Biometrika, 95, 1–17.
Van Keilegom, I., Gonzáles-Manteiga, W., Sánchez Sellero, C. (2008). Goodness-of-fit tests in parametric regression based on the estimation of the error distribution. Test, 17, 401–415.
Wang, L., Qu, A. N. (2007). Robust tests in regression models with omnibus alternatives and bounded influence. Journal of the American Statistical Association, 102, 347–358.
Watson, G. S. (1964). Smoothing regression analysis. Sankhyā: The Indian Journal of Statistics, Series A, 26, 359–372.
Whang, Y. J. (2000). Consistent bootstrap tests of parametric regression functions. Journal of Econometrics, 98, 27–46.
Xia, Q., Xu, W. L., Zhu, L. X. (2015). Consistently determining the number of factors in multivariate volatility modelling. Statistica Sinica, 25, 1025–1044.
Xia, Y. C. (2007). A constructive approach to the estimation of dimension reduction directions. Annals of Statistics, 35, 2654–2690.
Zheng, J. X. (1996). A consistent test of functional form via nonparametric estimation techniques. Journal of Econometrics, 75, 263–289.
Zhu, L. P., Wang, T., Zhu, L. X., Ferré, L. (2010). Sufficient dimension reduction through discretization-expectation estimation. Biometrika, 97, 295–304.
Zhu, L. X. (2003). Model checking of dimension-reduction type for regression. Statistica Sinica, 13, 283–296.
Zhu, L. X., An, H. Z. (1992). A test for nonlinearity in regression models. Journal of Mathematics, 4, 391–397. (Chinese).
Zhu, L. X., Li, R. Z. (1998). Dimension-reduction type test for linearity of a stochastic model. Acta Mathematicae Applicatae Sinica, 14, 165–175.
Acknowledgements
The authors thank the Editor, the Associate Editor and referees for their constructive comments and suggestions, which led to the substantial improvement in an early manuscript. The research described herewith was supported by the Fundamental Research Funds for the Central Universities, China Postdoctoral Science Foundation (2016M600951), National Natural Science Foundation of China (11701034, 11671042) and a grant from the University Grants Council of Hong Kong.
Author information
Authors and Affiliations
Corresponding author
Appendix: Proofs of the theorems
Appendix: Proofs of the theorems
The following conditions are required for proving the theorems in Sect. 3.
-
(C1)
The joint probability density function f(z, y) of (Z, Y) is bounded away from 0.
-
(C2)
The density function \(f(B^\top X)\) of \(B^\top X\) on support \(\mathcal {Z}\) exists and has two bounded derivatives and satisfies
$$\begin{aligned} 0<\inf f(z)<\sup f(z)<1. \end{aligned}$$ -
(C3)
The kernel function \({\mathcal {K}}(\cdot )\) is a bounded and symmetric density function with compact support and a continuous derivative and all the moments of \({\mathcal {K}}(\cdot )\) exist.
-
(C4)
The bandwidth satisfies \(nh^2\rightarrow \infty \) under the null (1) and local alternative hypothesis (14); \(nh^{q}\rightarrow \infty \) under the global alternative hypothesis (2).
-
(C5)
There exists an estimator \(\hat{\alpha }\) such that under the null hypothesis, \(\sqrt{n}(\hat{\alpha }-\alpha )=O_p(1)\), where \(\alpha =(\beta ,\theta )\) and under the local alternative sequences, \(\sqrt{n}(\hat{\alpha }-\tilde{\alpha })=O_p(1)\), where \(\alpha \) and \(\tilde{\alpha }\) are both interior points of \(\Theta \), a compact and convex set.
-
(C6)
Denote \(\alpha =(\beta ,\theta )^\top \) and there exists a positive continuous function G(x) such that \(\forall \alpha _1,\alpha _2\), \(|g(x,\alpha _1)-g(x,\alpha _2)|\le G(x)|\alpha _1-\alpha _2|\).
-
(C7)
\({\mathcal {M}}_n(s)\) has the following expansion:
$$\begin{aligned} {\mathcal {M}}_n(s)={\mathcal {M}}(s)+E_n\{\psi (X,Y,s)\}+R_n(s), \end{aligned}$$where \(E_n(\cdot )\) denotes the average over all sample points, \(E\{\psi (X,Y,s)\}=0\) and \(E\{\psi ^2(X,Y,s)\}<\infty \).
-
(C8)
\(\sup _s\parallel R_n(s)\parallel _F=o_p(n^{-1/2})\), where \(\parallel \cdot \parallel _F\) denotes the Frobenius norm of a matrix.
Remark 6
Conditions (C1),(C2),(C5) and (C6) are essentially the same as those in Wang and Qu (2007). These conditions are regular for ensuring the consistency and normality of the parameter estimator. Condition (C3) is standard for nonparametric regression estimation. Condition (C4) is the same as that in Guo et al. (2016). This condition on bandwidth is required to ensure the asymptotic normality of our test statistic. Conditions (C7) and (C8) are for the DEE estimation. Under the linearity condition, SIR-based DEE satisfies conditions (C7) and (C8). These conditions are quite mild and can be satisfied in many practical situations. It is worth mentioning that the second moment condition is not strong here because in DEE, we use the indicator function of Y, rather than the original Y and the target matrix only involves the square of the expectation of the product of X and the indicator of Y. Thus, these conditions only involve the second moment of X.
The following lemmas are used to prove the theorems in Sect. 3. We first give the proof of Lemma 1 in Sect. 2.
Proof of Lemma 1
In the following, we give the proof of the DEE-based estimate and the same conditions in Theorem 4 of Zhu et al. (2010) are adopted.
Under the conditions designed by in Zhu et al. (2010), their Theorem 2 ensures that \({\mathcal {M}}_{n,n}-{\mathcal {M}}=O_p(n^{-1/2})\). Further, the root-n consistency of the eigenvalues of \({\mathcal {M}}_{n,n}\) is retained, that is, \(\hat{\lambda }_i-\lambda _i=O_p(n^{-1/2})\). Note that when \(l\le q\), \(\lambda _l>0\) and for \(l>q\), we have \(\lambda _l=0\). As recommended, \(c=1/\sqrt{nh}\) is used. when \(nh\rightarrow \infty , h\rightarrow 0\), we have \(1/\sqrt{n}=o(c)\) and \(c=o(1)\). For \(1\le l<q\),
When \(l>q\),
Therefore, we can conclude that under the null hypothesis \(H_0\) and under the fixed alternative hypothesis (2), \(\hat{q}= q\) with a probability going to one as \(n\rightarrow \infty \). The proof is concluded. \(\square \)
The proof of Lemma 2 in Sect. 3 is given as follows.
Proof of Lemma 2
From the proof of Theorem 2 in Guo et al. (2016), it is shown that under the local alternative hypothesis, \({\mathcal {M}}_{n,n}-{\mathcal {M}}=O_p(C_n)\). Further, we can get \(\hat{\lambda }_i-\lambda _i=O_p(C_n)\).
Thus, note that \(\lambda _1>0\) and for any \(l > 1\), we have \(\lambda _l = 0\). Consequently, under the condition that \(C_n=o(c)\) and \(c=o(1)\),
Thus, under the local alternative (14), Lemma 1 holds. The proof of Lemma 2 is finished. \(\square \)
Lemma 3
Given Conditions (C1)–(C8) in Appendix, we have
where \({\mathop {\rightarrow }\limits ^{p}}\) represents convergence in probability and
here, \({\mathcal {K}}_h(\cdot )={\mathcal {K}}(\cdot /h)/h^{\hat{q}}\).
Proof of Lemma 3
We first decompose \(V_n-V_n^\star \) as
Since \(e_i=y_i-g(\beta ^\top x_i,\theta )\), we further have \(\hat{e}_i-e_i=g(\beta ^\top x_i,\theta )-g(\hat{\beta }^\top x_i,\hat{\theta })\). Let \(\alpha =(\beta ,\theta )^\top \) and \(L(\hat{\alpha })\) as
Denote \(\Omega =\{\alpha ^\star : \sqrt{n}|\alpha ^\star -\alpha _0|\le \delta \}\) for \(\delta =O(1)\) and \(t(x_i,x_l,\alpha ,\alpha ^\star )=[g(\beta ^\top x_i,\theta )-g({\beta ^\star }^\top x_i,\theta ^\star )]-[g({\beta }^\top x_l,\theta )-g({\beta ^\star }^\top x_l,{\theta ^\star })]\), then
where C is a generic positive constant. From the above derivation, we can obtain that, conditional on \(e_i\), \(I(|e_l-e_i|\le Cn^{-1/2}), l\ne i\) are iid Bernoulli random variables with \(O(n^{-1/2})\)-order success probability. Using Bernstein’s inequality leads to \(P\{\sum _{l=1,l\ne i}^n I(|e_l-e_i|\le Cn^{-1/2})\ge Cn^{1/2}|e_i\}\le \exp (-Cn^{1/2})\). Unconditionally, we still have that
Further,
When \(n\rightarrow \infty \), for a positive constant C, \(n\exp (-Cn^{1/2})\rightarrow 0\). Therefore, \(P\{\max _{1\le i\le n}\sum _{l=1,l\ne i}^n I(|e_l-e_i|\le Cn^{-1/2})< Cn^{1/2}\}=1\). Then,
Combining (20) and (21), we can gain the following useful probability bound
An application of the formula (21) and for the term \(A_1\) in (19), we have
where \(C_1\) is a positive constant. Let \(Z=B^\top X\). As to the term \(A_{11}\), the term
is an U-statistic with the kernel as \(H_n(z_1,z_2)=h^{-\hat{q}}{\mathcal {K}}\{(z_1-z_2)/h\}\). In order to apply the theory for non-degenerate U-statistic (Serfling 1980), \(E[H_n(z_1,z_2)^2]=o(n)\) is needed. It can be verified that
where \(p(\cdot )\) is denoted as the probability density function. With the condition \(nh^{\hat{q}}\rightarrow \infty \), we have \(E[H_n(z_1,z_2)^2]=O(1/h^{\hat{q}})=o(n)\). The condition of Lemma 3.1 of Zheng (1996) is satisfied, and we have \(A_{11}=h^{1/2}E[H_n(z_1,z_2)]+o_p(1)\), where \(E[H_n(z_1,z_2)]=O(1)\). Therefore, we can obtain that \(A_{11}=O_p(h^{1/2})=o_p(1)\). Denote
where \(\tilde{B}\) lies between B and \(\hat{B}\). Then, for the term \(A_{12}\) in (22), we have
Similar to \(A_{11}\), the following term
can be regarded as an U-statistic. It can be similarly shown that the term is the order of \(O_p(h)\). As \(\Vert \hat{B}(\hat{q})-B\Vert _2=O_p(1/\sqrt{n})\) and under the condition \(n\rightarrow \infty , h\rightarrow 0\), we can obtain that \(A_{12}=o_p(1)\). Toward (22), we have
Similarly, we can derive that \(nh^{1/2}|A_i|=o_p(1)\) for \(i=2,3\). Combining with the formula (19), it can be concluded that
which completes the proof of Lemma 3. \(\square \)
In the following, we give the proof of Theorem 1.
Proof of Theorem 1
From Lemma 3, we know that the limiting distributions for \(nh^{1/2}V_n\) and \(nh^{1/2}V_n^\star \) are the same. Thus, we just need to derive the asymptotic property of \(nh^{1/2}V_n^\star \). The term \(V_n^\star \) in (18) can be decomposed as
where \({\mathcal {K}}_h(\cdot )={\mathcal {K}}(\cdot /h)/h^{\hat{q}}\).
For the term \(V_{n1}^\star \), it is an U-statistic, since we always assume that the dimension of \(B^\top X\) is fixed in our paper. Under the null hypothesis, \(H(e_i),\,\,i=1,\ldots ,n\) follows a uniform distribution on (0, 1), \(q=1\) and \(\hat{q}\rightarrow 1\). An application of Theorem 1 in Zheng (1996), it is not difficult to derive the asymptotic normality: \(nh^{1/2}V_{n1}^\star \Rightarrow N(0,Var)\), where
with \(Z=B^\top X\).
Denote
where \(\tilde{B}\) lies between \(\hat{B}\) and B. By an application of Taylor expansion yields
Because the kernel \({\mathcal {K}}(\cdot )\) is spherical symmetric, the following term can be considered as an U-statistic:
Further note that
Thus, the above U-statistic is degenerate. Similar as the derivation of \(V_{n1}^\star \), together with \(\Vert \hat{B}(\hat{q})-B\Vert _2=O_p(1/\sqrt{n})\) and \(1/nh^2\rightarrow 0\), we have \(nh^{1/2}V_{n2}^\star =o_p(1)\). Therefore, under the null hypothesis \(H_0\), we can conclude that \(nh^{1/2}V_n^\star \Rightarrow N(0,Var)\). Based on Lemma 3, we have \(nh^{1/2}V_n\Rightarrow N(0,Var)\).
An estimate of Var can be defined as
Since the proof is rather straightforward, we then only give a brief description. Using a similar argument as that for Lemma 3, we can get
The consistency can be derived through U-statistic theory. The proof for Theorem 1 is finished. \(\square \)
The proof for Theorem 2 is given as follows.
Proof of Theorem 2
Under the global alternative \(H_{n}\) in (2), we have \(e_i=m(B^\top x_i)+\varepsilon _i-g(\tilde{\beta }^\top x_i,\tilde{\theta })\). Together with Lemma 3, it can be obtained that \(V_n=V_n^\star +o_p(1)\), where \(V_n^\star \) can be rewritten as
For the term \(V_{n3}^\star \), it is a standard U-statistic with
where \(l(x_\cdot )=[H\{m(B^\top x_\cdot )+\varepsilon _\cdot -g(\tilde{\beta }^\top x_\cdot ,\tilde{\theta })\}-1/2]\). Similar to the proof of (23), when \(nh^{\hat{q}}\rightarrow \infty \), we can derive that \(E[H^2(x_i,x_j)]=o(n)\) and the condition of Lemma 3.1 in Zheng (1996) can be shown to be satisfied. We further calculate
where \(Z=B^\top X\). Therefore, \(V_{n3}^\star =E[l^2(X)^2p(X)]+o_p(1)=:C_2\), here, \(C_2\) is a positive constant.
As to the term \(V_{n4}^\star \), similarly as the term \(V_{n2}^\star \), we have
where,
here, \(\tilde{B}\) lies between B and \(\hat{B}\). Similarly as the derivation of \(V_{n3}^\star \), together with \(\Vert \hat{B}(\hat{q})-B\Vert _2=O_p(1/\sqrt{n})\), when \(nh^{\hat{q}}\rightarrow \infty \), we have \(V_{n4}^\star =O_p(h)\cdot O_p(1/\sqrt{n})\cdot (1/h)=o_p(1)\).
Based on the above analysis, we can derive that \(V_n=C_2+o_p(1)\) and \(nh^{1/2}V_n\Rightarrow \infty \) in probability, which completes the proof of the global alternative situation.
We now consider the situation of local alternative \(H_{1n}\) in (14). Based on Lemma 3, we have \(V_n=V_n^\star +o_p(1)\). In this situation, \(e_i=C_n m(B^\top x_i)+\varepsilon _i\). Therefore, \(V_n^\star \) can be decomposed as
For the term \(V_{n5}^\star \), taking a Taylor expansion of \(H(C_n m(B^\top x_i)+\varepsilon _i)\) around \(C_n=0\), we have
Then, the term \(V_{n5}^\star \) can be decomposed as
Under the local alternative hypothesis, \(\hat{q}\rightarrow 1\) can be obtained. For the term \(D_1\), similarly to the proof of the term \(V_{n1}^\star \) in Theorem 1, we can show that \(nh^{1/2}D_1\Rightarrow N(0,Var)\), where
with \(Z=B^\top X\). As to the term \(D_2\), similarly as the proof of Lemma 3.3b in Zheng (1996), it can be obtained that \(D_2=O_p(1/\sqrt{n})\). When \(C_n=n^{-1/2}h^{-1/4}\), we have \(nh^{1/2}C_nD_2=O_p(h^{1/2})\). Turn to the term \(D_3\), similarly to the proof of \(V_{n3}^\star \) in our Theorem 2, we have \(D_3=E[h^2(\varepsilon )m^2(B^\top X)p(X)]+o_p(1)\). Further, \(nh^{1/2}C_n^2D_3=E[h^2(\varepsilon )m^2(B^\top X)p(X)]+o_p(1)\). Therefore,
where \(\mu =E[h^2(\varepsilon )m^2(B^\top X)p(X)].\)
As to the term \(V_{n6}^\star \), just similarly as the proof of the term \(V_{n2}^\star \) in our Theorem 1, it can be gotten that \(nh^{1/2}V_{n6}^\star =o_p(1)\).
Combining Lemma 3 and the formula (24), under the local alternative, we have \(nh^{1/2}V_n\Rightarrow N(\mu ,Var)\).
The proof of Theorem 2 is finished. \(\square \)
The proof of Theorem 3 is as follows.
Proof of Theorem 3
We first calculate the first-order and second-order influence function of T(F, F) in (16) at the point \((z_0,y_0)\). When \(H_0\) holds, the Hampel’s first-order influence function of T(F, F) in (16) at the point \((z_0,y_0)\) is defined as
where \(T(F,F)=0\) and \(F_t=(1-t)F+t\Delta _{z_0,y_0}\), here, \(\Delta _{z_0,y_0}\) is the point mass function at the point \((z_0,y_0)\). Denote \(L(t)=T(F_t,F_t)=T(F+tU,F+tU)\), where \(U=\Delta _{z_0,y_0}-F\). Thus, we have \(L(0)=0\). From the proof in Appendix, it is not difficult to obtain that \(\frac{\mathrm{d} L(t)}{\mathrm{d}t}|_{t=0}=0\). Therefore, R-DREAM has a degenerate first-order influence function.
To obtain the second-order influence function of R-DREAM, we first compute
where \(\dot{H}(\cdot )=:\frac{\mathrm{d} H_t(\cdot )}{\mathrm{d}t}|_{t=0}\) and \(H_t(\cdot )\) represents \(H(\cdot )\) under contamination, that is, \(H_t(v)=\int \int _{y\le g(\beta ^\top x(F_t),\theta (F_t))+v}\mathrm{d}F_t(z,y)\). Besides, u(z, y) is the probability density function of U(z, y). Taking \(U=\Delta _{z_0,y_0}-F\) into the formula (25), it is shown that the four terms in (25) converge at the same rate. Further, based on Hampel’s definition, we can obtain the second-order influence function of R-DREAM at the point \((z_0,y_0)\) as follows:
where \(z_0=\beta ^\top x_0\) and \(\dot{H}_{\Delta _{(z_0,y_0)}}(y-g((\beta ^\top x)(F), \theta (F)))\) denotes \(\frac{\mathrm{d}}{\mathrm{d}t}H(y-g((\beta ^\top x)(F_t), \theta (F_t)))|_{t=0,U=\Delta _{(z_0,y_0)}-F}\). The detailed expression of \(\dot{H}_{\Delta _{(z_0,y_0)}}(y-g((\beta ^\top x)(F),\theta (F)))\) can be written as
where \(\alpha =(\beta ,\theta )^\top \) and \(\text{ grad }_{\alpha }\{g((\beta ^\top x)x(F),\theta (F))\}^\top \) represents the gradient of \(g((\beta ^\top x)(F),\theta (F))\) with respect to \(\alpha \). Since the parameter \(\alpha \) comes from a robust fit, we have that \(d\alpha /dt\) is bounded. Together with the conditions (C1) and (C5) in Appendix, it can be shown that \(\dot{H}_{\Delta _{(z_0,y_0)}}(y-g((\beta ^\top x)(F),\theta (F)))\) is also bounded. Further, the second-order influence function \(\mathrm{IF}^{(2)}(z_0,y_0)\) of R-DREAM is bounded in the response direction.
For the purpose of comparison, the first-order and second-order influence functions for the test \(T^\mathrm{GWZ}_n\) in (11) are derived. The first-order influence function is also zero, and the second-order influence function can be derived as
where \(\frac{\mathrm{d}}{\mathrm{d}t}g((\beta ^\top x)(F),\theta (F))=\frac{\mathrm{d}}{\mathrm{d}t}g((\beta ^\top x)(F_t),\theta (F_t))|_{t=0,U=\Delta _{(z_0,y_0)}-F}\). The second-order influence function \(\mathrm{IF}_\mathrm{GWZ}^{(2)}(z_0,y_0)\) in the y-direction is not bounded. \(\square \)
The verification for the formula (25) is as follows.
Verification of (25). Let \(f_t\) and u be the probability density functions of \(F_t\) and U. Recall \(F_t=F+tU\), then \(\mathrm{d}F_t=\mathrm{d}F+t dU\) and \(f_t=f+tu\), we further have
For the first term \(L_1(t)\), we have
Since \(\int [H(y-g(\beta ^\top x(F_t),\theta (F_t)))-1/2]d F(y|z)=0\), we have that
Further,
Similarly, it is not difficult to obtain that \(\frac{\mathrm{d} L_i(t)}{\mathrm{d}t}|_{t=0}=0,~i=2,3,4\) and \( \frac{1}{2}\frac{\mathrm{d}^2L_2(t)}{\mathrm{d}t^2}|_{t=0}~,i=2,3,4\) are equal to other three terms in the formula (25), which completes the proof. \(\square \)
About this article

Cite this article
Niu, C., Zhu, L. A robust adaptive-to-model enhancement test for parametric single-index models. Ann Inst Stat Math 70, 1013–1045 (2018). https://doi.org/10.1007/s10463-017-0626-9
Received:
Revised:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10463-017-0626-9