
Abstract
We build on a one parameter family of weighting schemes arising from \(L^2\)-constrained portfolio optimization problems. The parameter allows to fine tune the trade-off between the volatility and the diversification of the portfolio. We propose two criteria in order to determine two unique portfolios: the first criterion requires that no weights be negative while the second one imposes a target diversification which is median between full concentration and full diversification. Both portfolios are empirically compared to classical benchmarks. The first one behaves very much like other popular Long-Only weighting schemes while the second displays a more aggressive profile, while generating moderate turnover. We also discuss implementation issues, as well as estimation related problems.

Similar content being viewed by others
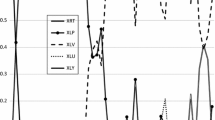

Notes
This is also true for many other Long-Only weighting schemes which allocate non-zero weights to most, if not all, constituents: for instance, the ERC of Maillard et al. (2010), the inverse volatility portfolio, the inverse variance portfolio, among others.
Green and Hollifield (1992), in their article on the diversification of optimal mean-variance portfolios, use the \(L^1\) norm. In this article, diversification is only assessed through the concentration of portfolio weights. Whether it is the best way to assess diversification is clearly out of our scope.
A more technical explanation of this fact is provided in “Appendix A”.
Apart from the S&P500, we have chosen the same universes as in DeMiguel et al. (2009).
These three estimators are not linked by the rotation-equivariant property described in Sect. 4 but are simply well known benchmarks for covariance matrix estimation.
This value can only be reached asymptotically when the leverage goes to infinity, that is, when the magnitude of some positive and negative weights increases to infinity. If the weights are positive, then the minimum value is \(1/N\).
Note that this is not always true, since the lowest turnovers are usually achieved by cap-weighted portfolios which are rather concentrated. However, in the case of norm-constrained portfolios, this is often verified. Indeed, the principal source of turnover is the change in covariance matrix (rather than changes in asset prices). In the remark after the proof of Theorem 1, we argue that tight constraints - and hence strong diversification - lead to a lower sensitivity of weights to variations in the covariance structure.
Given the first half of the proof, it suffices to replace all the values \(\varLambda _{k,k}\) or \(\varLambda _{i,i}\) which are numerators by 1, so that \(\varvec{w'\varSigma w}\) is replaced by \(\varvec{w'I_Nw}=\varvec{w'w}\).
References
Behr, P., Guettler, A., Miebs, F.: On portfolio optimization: imposing the right constraints. J Bank Financ 37(4), 1232–1242 (2013)
Best, M.J., Grauer, R.R.: On the sensitivity of mean-variance-efficient portfolios to changes in asset means: some analytical and computational results. Rev Financ Stud 4(2), 315–342 (1991)
Britten-Jones, M.: The sampling error in estimates of mean-variance efficient portfolio weights. J Financ 54(2), 655–671 (1999)
Chamberlain, G., Rothschild, M.: Arbitrage, factor structure, and mean-variance analysis on large asset markets. Econometrica 51(5), 1281–1304 (1983)
Chopra, V.K., Ziemba, W.T.: The effect of errors in means, variances, and covariances on optimal portfolio choice. J Portf Manag 19(2), 6–11 (1993)
Clarke, R., De Silva, H., Thorley, S.: Minimum-variance portfolio composition. J Portf Manag 37(2), 31 (2011)
DeMiguel, V., Garlappi, L., Nogales, F.J., Uppal, R.: A generalized approach to portfolio optimization: improving performance by constraining portfolio norms. Manag Sci 55(5), 798–812 (2009a)
DeMiguel, V., Garlappi, L., Uppal, R.: Optimal versus naive diversification: how inefficient is the 1/n portfolio strategy? Rev Financ Stud 22(5), 1915–1953 (2009b)
Elton, E.J., Gruber, M.J.: Estimating the dependence structure of share prices-implications for portfolio selection. J Financ 28(5), 1203–1232 (1973)
Fan, J., Zhang, J., Yu, K.: Vast portfolio selection with gross-exposure constraints. J Am Stat Assoc 107(498), 592–606 (2012)
Goetzmann, W.N., Kumar, A.: Equity portfolio diversification. Rev Financ 12(3), 433–463 (2008)
Goto, S., Xu, Y.: Improving mean variance optimization through sparse hedging restrictions. J Financ Quant Anal (forthcoming) (2014)
Gotoh, J.-Y., Takeda, A.: On the role of norm constraints in portfolio selection. Comput Manag Sci 8(4), 323–353 (2011)
Green, R.C., Hollifield, B.: When will mean-variance efficient portfolios be well diversified? J Financ 47(5), 1785–1809 (1992)
Hsu, J., Kudoh, H., Yamada, T.: When sell-side analysts meet high-volatility stocks: an alternative explanation for the low-volatility puzzle. J Invest Manag 11(2), 28–46 (2013)
Jagannathan, R., Ma, T.: Risk reduction in large portfolios: why imposing the wrong constraints helps. J Financ 58(4), 1651–1684 (2003)
Jobson, J.D., Korkie, B.: Estimation for markowitz efficient portfolios. J Am Stat Assoc 75(371), 544–554 (1980)
Jorion, P.: International portfolio diversification with estimation risk. J Bus 58(3), 259–78 (1985)
Jorion, P.: Bayesian and capm estimators of the means: implications for portfolio selection. J Bank Financ 15(3), 717–727 (1991)
Klein, R.W., Bawa, V.S.: The effect of estimation risk on optimal portfolio choice. J Financ Econ 3(3), 215–231 (1976)
Kondor, I., Pafka, S., Nagy, G.: Noise sensitivity of portfolio selection under various risk measures. J Bank Financ 31(5), 1545–1573 (2007)
Laloux, L., Cizeau, P., Potters, M., Bouchaud, J.-P.: Random matrix theory and financial correlations. Int J Theor Appl Financ 3(03), 391–397 (2000)
Ledoit, O., Wolf, M.: Improved estimation of the covariance matrix of stock returns with an application to portfolio selection. J Empir Financ 10(5), 603–621 (2003)
Ledoit, O., Wolf, M.: A well-conditioned estimator for large-dimensional covariance matrices. J Multivar Anal 88(2), 365–411 (2004)
Ledoit, O., Wolf, M., et al.: Nonlinear shrinkage estimation of large-dimensional covariance matrices. Ann Stat 40(2), 1024–1060 (2012)
Lin, J.-L.: On the diversity constraints for portfolio optimization. Entropy 15(11), 4607–4621 (2013)
Maillard, S., Teiletche, J., Roncalli, T.: The properties of equally-weighted risk contributions portfolios. J Portf Manag 36(4), 60–70 (2010)
Merton, R.C.: On estimating the expected return on the market: an exploratory investigation. J Financ Econ 8(4), 323–361 (1980)
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: The formal proof of why \(\gamma ^{LO}\) exists and is unique
The main difficulty in (3) is the matrix inversion but it can be handled in the following way. We factorize \(\varvec{\varSigma }\) using its eigendecomposition: \(\varvec{\varSigma =P\varLambda P'}\). Basic algebra then implies
where the inverse matrix is diagonal with values \((\varLambda _{i,i}+\gamma )^{-1}\) for \(i=1,\ldots ,N\). We use the standard notation \(M_{i,j}\) for the elements of the matrix \(\varvec{M}\). Further computations lead to:
Therefore, summing the lines of \(\varvec{Q}\), we see that the weights in (3) are proportional to
Because we are interested in Long-Only portfolios, we require that
Getting rid of the denominators (the inverse parts), this is equivalent to
The function on the l.h.s. of (7) is polynomial in \(\gamma \) with degree \(N-1\). The leading term (in \(\gamma ^{N-1}\)) has coefficient
because \(\varvec{P}\) is orthogonal. This latter expression ensures that as \(\gamma \) increases, all of the weights will progressively become positive. Some of them are already positive, even for \(\gamma =0\), because they correspond to the long positions of \(\varvec{w}_{MV}\).
Appendix B: Proof of Proposition 1
For notational ease, we will write \(\varvec{w}\) instead \(\varvec{w}_\gamma \) during the proof.
Using the eigendecomposition \(\varvec{\varSigma =P\varLambda P'}\) and the fact that \(\varvec{P'P=PP'=I_N}\),
We now introduce the following quantity, which will be ubiquitous in the remainder of the proofs:
Straightforward differentiation gives
The denominator is always positive, therefore, the sign of \(\frac{\partial }{\partial \gamma }\varvec{w' \varSigma w}\) is equal to that of
where
Further, we have
and consequently the mapping \(x \mapsto f_{\gamma }(x,y)\) reaches its minimum value (which is zero) at \(x=y\). Therefore, \(\frac{\partial }{\partial \gamma }\varvec{w' \varSigma w} \ge 0\). The derivative can only reach zero if all eigenvalues are equal, which is excluded because \(\varvec{\varSigma }\) is not a multiple if \(\varvec{I_N}\). The derivative of \(\varvec{w' w}\) with respect to \(\gamma \) is dealt with in the same fashionFootnote 10 except that \(f_{\gamma }(x,y)\) must be replaced by
which is always strictly negative for \(x,y,\gamma > 0\) and \(x \ne y\) (which occurs because \(\varvec{\varSigma }\ne \alpha \varvec{I_N}\)). Moreover, it is obvious that \(\frac{\partial }{\partial \gamma }\varvec{w' w} \) bounded for \(x,y>0\) and \(\gamma \ge 0\).
Appendix C: Proof of the lemmas
We start with Lemma 1.
Proof
For the first assertion, if we consider \(\gamma >U\), then we can write \(\varvec{\varSigma }+\gamma \varvec{I_N}=\gamma (\varvec{\varSigma }/\gamma + \varvec{I_N})\). By the definition of \(U\), the largest eigenvalue of \(\varvec{\varSigma }/\gamma \) is strictly smaller than one and hence, the Neumann series of the inverse is given by
We now write \(s_{i,j}^{(2k)}\) for the elements of \((\varvec{\varSigma }/\gamma )^{2k}\). The \(i\)th row sum of \((\varvec{\varSigma }/\gamma )^{2k+1}\) is then given by
In the last inequality, we have used the definition of \(U\) (as well as the symmetry of \(\varvec{\varSigma }\)) and the fact that by the assumption of the lemma, the row sums of even powers of \(\varvec{\varSigma }\) are positive. The inequality shows that all of the row sums of \((\varvec{\varSigma }+\gamma \varvec{I_N})^{-1}\) will be positive, thereby fulfilling the condition in the definition of \(\gamma ^{LO}\) in (4).
We now turn to Lemma 2.
Proof
We use the notations of “Appendix B”, and by replacing \(\varvec{\varSigma }\) by \(\varvec{I_N}\) in the computation of the ex-ante variance, we get
First, we have
while at the same time
Therefore,
where the equality stems from the definition of \(L_k\) and the fact that \(\varvec{P}\) is orthogonal (the sum of all elements of \(\varvec{PP'}\) is equal to \(N\)).
Appendix D: Proof of Proposition 2
We start by looking at the \(L^2\)-norm difference of the two portfolios (3), with common \(\gamma \), but different \(\varvec{\varSigma }^{(i)}\). With the notations of the former proof:
with
Basic computations further yield
where the first inequality stems from the fact that \(x+y+2z \le 2(\max (x,y)+z)\) for \(x,y,z \ge 0\). In the second inequality, we have set \(\eta = {\text {max}}_{i=1,\ldots ,N} \left| \varLambda ^{(2)}_{i,i}-\varLambda ^{(1)}_{i,i}\right| \) and used the identity \(\sum _{k=1}^N L_k=N\).
Moreover,
Combining (8), (10) and (11), we get
Lastly, the simple bounds
and
lead to
for some constant \(c>0\) (which is all the more large that the eigenvalues are dispersed).
We now consider the functions \(h_{i}(\gamma )=(\varvec{w}^{(i)}_\gamma )'\varvec{w}^{(i)}_\gamma \) for \(i=1,2\). Recall from the proof of Proposition 1, that the derivatives \(h_i'\) are strictly negative. Therefore, the inverse functions \(h^{-1}_i\) are also strictly decreasing and Lipschitz continuous on the interval \((1/N+\varepsilon ,h_i(0))\) for any strictly positive \(\varepsilon \), as is depicted in the right side of Fig. 2.

Graphical illustration of the functions \(h_i\) and their inverses \(h_i^{-1}\)
Since \(\varvec{w}^{(i)}_{\gamma _i}\) both satisfy (2), then
Now, because the \(h^{-1}_i\) are Lipschitz on \((\delta ,h_i(0))\), the first bracket satisfies
while the second, as we have shown in (13) is \(O(\eta /N)\), therefore it must also hold that
for some other constant \(C\) which depends on the maximum absolute values of \((h_i^{-1})'\) on the interval \([\delta ,h_i(0)]\) - note that it is not a priori obvious (or true) that the \(h_i\) are convex. Overall, we therefore expect \(|\gamma ^{(1)}-\gamma ^{(2)}|\) to be smaller for larger values of \(\delta \). When the norm constraint is loose, the \(\gamma ^{(i)}\) will usually be very small and so will their difference.
Appendix E: Proof of Theorem 1
Simplifying the notations of the preceding proof, we will henceforth write \(b_i= b(\varLambda ^{(i)},\gamma ^{(i)})\) (defined in (9)).
where
The denominator of \(X_k\) is bounded from below by
and this constant, given Lemma 2, can be increased so as to be unrelated to the \(\gamma ^{(i)}\).
Moreover, if we recall that \(\eta = {\text {max}}_{i=1,\ldots ,N} \left| \varLambda ^{(2)}_{i,i}-\varLambda ^{(1)}_{i,i}\right| \), the following bound also holds
We now reconnect the pieces. There are 4 terms in the squared numerator in (15):
-
the first one is bounded by a multiple of \(\eta N\)
-
the second one, by Proposition 2 and (12) is \(O(\eta )\)
-
the third one, by (16) is \(O(\eta N)\) like the first one
-
lastly, by (16) and Lemma 2, the fourth one is also \(O(\eta N)\)
Consequently, going back to (14) and plugging \(\sum _{k=1}^N L_k=N\), we get
Remark Instead of looking at the parameters \(\eta \) and \(N\), one may wonder what is the impact of \(\delta \) on \(\epsilon \). It can essentially be measured through the magnitude of the \(\gamma ^{(i)}\). First, by the last remark of the proof of Proposition 2, we expect \(|\gamma ^{(1)}-\gamma ^{(2)}|\) to be a decreasing function of \(\delta \). But this term in (15) is associated with the only term which does not increase with \(N\). Moreover, the terms in \(b_i\) and \(|b_1-b_2|\) are all bounded above and below by functions which decrease \(\gamma ^{(i)}\) and hence increase with \(\delta \) (by Proposition 1). In the end, it is very likely that \((\varvec{w}^{(1)}-\varvec{w}^{(2)})'(\varvec{w}^{(1)}-\varvec{w}^{(2)})\) will be most of the time an increasing function of \(\delta \). This seems logical because as \(\delta \) decreases to \(1/N\), both \(\varvec{w}^{(1)}\) and \(\varvec{w}^{(2)}\) will converge to the equally weighted portfolio. When the constraint is tight, there is not much room for a large differences between \(\varvec{w}^{(1)}\) and \(\varvec{w}^{(2)}\), even if \(\varvec{\varSigma }^{(1)}\) and \(\varvec{\varSigma }^{(2)}\) are very different.
Rights and permissions
About this article

Cite this article
Coqueret, G. Diversified minimum-variance portfolios. Ann Finance 11, 221–241 (2015). https://doi.org/10.1007/s10436-014-0253-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10436-014-0253-x